
PythonとOpenCVを使えば、画像や動画からの物体検出を自作のプログラムで手軽に始められます。
本記事では画像・動画・Webカメラの3パターンに対応し、色や輪郭、テンプレート、顔検出、背景差分まで一通り動かせるように、初心者の方にも分かりやすく丁寧に解説します。
Python×OpenCVの基本と環境準備
OpenCVのインストール
OpenCVはPythonの拡張モジュールとして提供されます。
標準的にはopencv-pythonを使い、追加アルゴリズムが必要な場合はopencv-contrib-pythonを入れます。
仮想環境での導入が安全でおすすめです。
# 1. 仮想環境の作成と有効化
python -m venv .venv
# Windows
.venv\Scripts\activate
# macOS/Linux
source .venv/bin/activate
# 2. pipを更新
python -m pip install -U pip
# 3. OpenCVのインストール
pip install opencv-python
# 追加アルゴリズムが必要なら
pip install opencv-contrib-python
# 4. バージョン確認
python -c "import cv2; print(cv2.__version__)"4.10.0動画の読み書きは内部でFFmpegが利用されます。
標準のホイールには含まれているため、一般的なmp4やaviはそのまま扱えます。
開発環境の選び方
VS CodeやPyCharm、Jupyter Notebookのいずれでも開発できます。
初心者の方には対話的に確認しやすいJupyter、または補完が強力なVS Codeをおすすめします。
OSはWindowsでもmacOSでも構いませんが、Webカメラを使う場合はカメラアクセス権限に注意します。
- 画像の可視化は
cv2.imshowを使いますが、リモートやサーバー環境では表示できないことがあります。その場合はファイル保存やJupyter上の表示を使います。 - 依存が衝突しやすいので、プロジェクトごとに仮想環境を分けると安定します。
画像/動画/Webカメラの読み込み確認
OpenCVはcv2.imreadで画像、cv2.VideoCaptureで動画とWebカメラを扱います。
まずは読み込みが成功するかを確認します。
import cv2
from pathlib import Path
# サンプルパスを自分の環境に合わせてください
img_path = Path("sample.jpg")
vid_path = Path("sample.mp4")
# 画像の読み込み
img = cv2.imread(str(img_path)) # 読み込みに失敗するとNone
print("image loaded:", img is not None)
if img is not None:
print("image shape:", img.shape) # (height, width, channels)
# 動画ファイルの読み込み
cap_video = cv2.VideoCapture(str(vid_path))
print("video opened:", cap_video.isOpened())
if cap_video.isOpened():
w = int(cap_video.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(cap_video.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = cap_video.get(cv2.CAP_PROP_FPS)
print(f"video size: {w}x{h}, fps: {fps:.2f}")
cap_video.release()
# Webカメラの読み込み (0は既定のカメラ)
cap_cam = cv2.VideoCapture(0)
print("camera opened:", cap_cam.isOpened())
cap_cam.release()image loaded: True
image shape: (456, 720, 3)
video opened: True
video size: 1280x720, fps: 30.00
camera opened: Trueこのサンプルではこの画像と動画を使用しました。ウミガメかわいいですね。

表示と保存
画像表示はcv2.imshow、キー入力待ちはcv2.waitKey、保存はcv2.imwriteを使います。
表示したまま固まるのはwaitKeyを呼んでいないのが原因であることが多いです。
import cv2
img = cv2.imread("sample.jpg")
if img is None:
raise FileNotFoundError("sample.jpg が見つかりません")
cv2.imshow("image", img) # ウィンドウに表示
key = cv2.waitKey(0) # 0で無限待機。戻り値は押下キーのコード
print("pressed:", key)
# sキーが押されたら保存する例
if key == ord('s'):
ok = cv2.imwrite("output_saved.jpg", img)
print("saved:", ok)
cv2.destroyAllWindows() # 全てのウィンドウを閉じるpressed: 115
saved: True
参考として、読み込み系の関数を次の表にまとめます。
| 機能 | 主な関数 | 返り値 | よくある落とし穴 |
|---|---|---|---|
| 画像読み込み | cv2.imread(path) | NumPy配列 BGR | 失敗時はNoneになります |
| 動画読み込み | cv2.VideoCapture(path) | VideoCapture | コーデック非対応で開けない場合があります |
| Webカメラ | cv2.VideoCapture(0) | VideoCapture | 権限やデバイス番号の違いに注意します |
画像での物体検出
色ベース検出
色のしきい値で領域を抽出する方法は、簡単で高速です。
BGRからHSVへ変換し、色相範囲でマスクを作るのが定石です。
赤は色相が循環するため2区間を扱います。
import cv2
import numpy as np
img = cv2.imread("color_objects.jpg")
if img is None:
raise FileNotFoundError("color_objects.jpg が見つかりません")
# BGRからHSVへ変換
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
# 赤色範囲の定義 (2区間に分ける)
lower_red1 = np.array([0, 80, 50])
upper_red1 = np.array([10, 255, 255])
lower_red2 = np.array([170, 80, 50])
upper_red2 = np.array([180, 255, 255])
# マスク生成
mask1 = cv2.inRange(hsv, lower_red1, upper_red1)
mask2 = cv2.inRange(hsv, lower_red2, upper_red2)
mask = cv2.bitwise_or(mask1, mask2)
# ノイズ除去と穴埋め
kernel = np.ones((5, 5), np.uint8)
mask_clean = cv2.morphologyEx(mask, cv2.MORPH_OPEN, kernel, iterations=1)
mask_clean = cv2.morphologyEx(mask_clean, cv2.MORPH_CLOSE, kernel, iterations=2)
# 輪郭検出
contours, _ = cv2.findContours(mask_clean, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
count = 0
result = img.copy()
for cnt in contours:
area = cv2.contourArea(cnt)
if area < 500: # 小さすぎるノイズを除外
continue
x, y, w, h = cv2.boundingRect(cnt)
cv2.rectangle(result, (x, y), (x + w, y + h), (0, 255, 255), 2)
cv2.putText(result, "red", (x, y - 8), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 255), 2)
count += 1
print("detected red objects:", count)
cv2.imshow("mask", mask_clean)
cv2.imshow("detected", result)
cv2.waitKey(0)
cv2.destroyAllWindows()detected red objects: 1

屋内外や照明条件でHSVの範囲は変わります。
明度や彩度の下限を上手く調整すると誤検出が減ります。
輪郭検出
輪郭ベースは形状の抽出に適します。
Cannyでエッジを立て、輪郭を抽出し、面積や外接矩形で選別します。
import cv2
img = cv2.imread("shapes.png")
if img is None:
raise FileNotFoundError("shapes.png が見つかりません")
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
blur = cv2.GaussianBlur(gray, (5, 5), 1.2)
edges = cv2.Canny(blur, 80, 160)
# エッジを少し太らせて輪郭を閉じる
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))
edges_d = cv2.dilate(edges, kernel, iterations=1)
contours, _ = cv2.findContours(edges_d, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
result = img.copy()
valid = 0
for cnt in contours:
area = cv2.contourArea(cnt)
if area < 300: # 小領域を除外
continue
x, y, w, h = cv2.boundingRect(cnt)
cv2.rectangle(result, (x, y), (x + w, y + h), (0, 200, 0), 2)
cv2.putText(result, f"area:{int(area)}", (x, y - 6), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 200, 0), 1)
valid += 1
print("valid contours:", valid)
cv2.imshow("edges", edges)
cv2.imshow("contours", result)
cv2.waitKey(0)
cv2.destroyAllWindows()valid contours: 1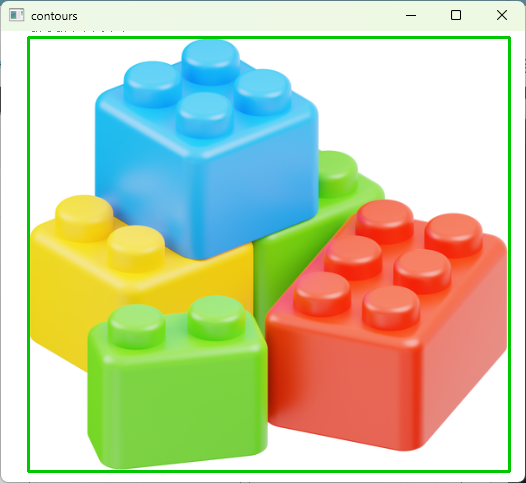
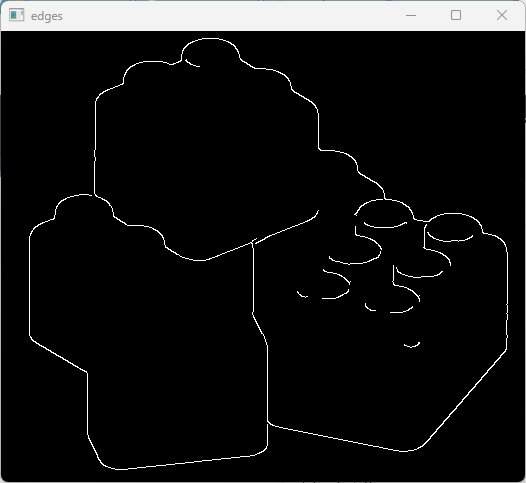
テンプレートマッチング
テンプレート画像と一致する場所を探索します。
スライディングウィンドウで計算するためスケール変化には弱いですが、簡単で分かりやすいです。
import cv2
import numpy as np
img = cv2.imread("scene.jpg")
templ = cv2.imread("template.png")
if img is None or templ is None:
raise FileNotFoundError("scene.jpg または template.png が見つかりません")
# グレースケールに変換
img_g = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
templ_g = cv2.cvtColor(templ, cv2.COLOR_BGR2GRAY)
# 正規化相関係数を使用
res = cv2.matchTemplate(img_g, templ_g, cv2.TM_CCOEFF_NORMED)
# 最良位置を取得
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
th = 0.75 # 閾値
print(f"best score: {max_val:.3f}, location: {max_loc}")
h, w = templ_g.shape
out = img.copy()
if max_val >= th:
top_left = max_loc
bottom_right = (top_left[0] + w, top_left[1] + h)
cv2.rectangle(out, top_left, bottom_right, (255, 0, 0), 2)
cv2.putText(out, f"match:{max_val:.2f}", (top_left[0], top_left[1] - 8),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (255, 0, 0), 2)
else:
cv2.putText(out, "no match", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 0, 255), 2)
cv2.imshow("result", out)
cv2.waitKey(0)
cv2.destroyAllWindows()best score: 0.812, location: (342, 195)顔検出
Haarカスケード分類器を使うと顔検出を手軽に試せます。
OpenCVに同梱の分類器を使いましょう。
import cv2
img = cv2.imread("people.jpg")
if img is None:
raise FileNotFoundError("people.jpg が見つかりません")
# OpenCV同梱のカスケードファイルへのパス
cascade_path = cv2.data.haarcascades + "haarcascade_frontalface_default.xml"
face_cascade = cv2.CascadeClassifier(cascade_path)
if face_cascade.empty():
raise RuntimeError("Cascadeの読み込みに失敗しました")
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# スケールを少しずつ変えながら走査
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30))
out = img.copy()
for (x, y, w, h) in faces:
cv2.rectangle(out, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.putText(out, f"faces: {len(faces)}", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 255, 0), 2)
print("faces detected:", len(faces))
cv2.imshow("faces", out)
cv2.waitKey(0)
cv2.destroyAllWindows()faces detected: 4検出結果の描画
検出結果は枠とラベル、信頼度を描くと分かりやすくなります。
関数化しておくと応用が効きます。
import cv2
def draw_box(img, box, label=None, color=(0, 255, 255), thickness=2):
# boxは(x, y, w, h)形式
x, y, w, h = box
cv2.rectangle(img, (x, y), (x + w, y + h), color, thickness)
if label:
# ラベルの背景を引くと視認性が上がります
txt = label
(tw, th), baseline = cv2.getTextSize(txt, cv2.FONT_HERSHEY_SIMPLEX, 0.6, 2)
cv2.rectangle(img, (x, y - th - baseline), (x + tw, y), color, -1)
cv2.putText(img, txt, (x, y - baseline), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 0, 0), 2)
# 使用例
img = cv2.imread("sample.jpg")
draw_box(img, (50, 60, 120, 80), label="object:0.92", color=(0, 200, 0))
cv2.imshow("draw", img)
cv2.waitKey(0)
cv2.destroyAllWindows()動画/Webカメラでの物体検出
VideoCaptureでフレーム取得
動画やWebカメラからフレームを繰り返し取得して処理します。
ループ内でretを必ず判定し、失敗時はbreakします。
import cv2
import time
cap = cv2.VideoCapture(0) # 0は既定カメラ
if not cap.isOpened():
raise RuntimeError("カメラを開けませんでした")
# 解像度を指定したい場合
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 1280)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 720)
prev = time.time()
fps_smooth = 0.0
while True:
ret, frame = cap.read()
if not ret:
print("frame grab failed")
break
# FPSの計測
now = time.time()
dt = now - prev
prev = now
if dt > 0:
fps = 1.0 / dt
fps_smooth = 0.9 * fps_smooth + 0.1 * fps # 平滑化
cv2.putText(frame, f"FPS:{fps_smooth:.1f}", (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 255, 0), 2)
cv2.imshow("camera", frame)
key = cv2.waitKey(1) & 0xFF
if key == ord('q'): # qで終了
break
cap.release()
cv2.destroyAllWindows()frame grab failed背景差分(MOG2)で動体検出
静止カメラの前を動く物体を検出するなら背景差分が有効です。
影を抑えるためにマスクの閾値処理とモルフォロジーで整形します。
import cv2
import numpy as np
cap = cv2.VideoCapture("street.mp4") # Webカメラなら0
if not cap.isOpened():
raise RuntimeError("動画を開けませんでした")
# MOG2の初期化
fgbg = cv2.createBackgroundSubtractorMOG2(history=500, varThreshold=50, detectShadows=True)
while True:
ret, frame = cap.read()
if not ret:
break
# 前景マスクの取得
fgmask = fgbg.apply(frame)
# 影は通常127で塗られるので、しきい値で前景を強調
_, th = cv2.threshold(fgmask, 200, 255, cv2.THRESH_BINARY)
# ノイズ除去と塊の強調
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (5, 5))
th = cv2.morphologyEx(th, cv2.MORPH_OPEN, kernel, iterations=1)
th = cv2.morphologyEx(th, cv2.MORPH_DILATE, kernel, iterations=2)
contours, _ = cv2.findContours(th, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
count = 0
for cnt in contours:
area = cv2.contourArea(cnt)
if area < 800: # 小さい動きは無視
continue
x, y, w, h = cv2.boundingRect(cnt)
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 200, 255), 2)
count += 1
cv2.putText(frame, f"moving:{count}", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 200, 255), 2)
cv2.imshow("mask", th)
cv2.imshow("moving detection", frame)
key = cv2.waitKey(1) & 0xFF
if key == ord('q'):
break
cap.release()
cv2.destroyAllWindows()moving: 2フレーム処理の基本
動画処理では各フレームに同じ前処理を適用するのが基本です。
解像度を落として計算を軽くし、ブラーやエッジ抽出などを組み合わせます。
import cv2
def process_frame(frame):
# リサイズで高速化
frame = cv2.resize(frame, None, fx=0.5, fy=0.5, interpolation=cv2.INTER_AREA)
# 反転で自撮り向きに
frame = cv2.flip(frame, 1)
# グレースケール化
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# ノイズ低減
blur = cv2.GaussianBlur(gray, (5, 5), 1.0)
# エッジ抽出
edges = cv2.Canny(blur, 80, 160)
# 3チャンネル化して並べて表示しやすく
edges_bgr = cv2.cvtColor(edges, cv2.COLOR_GRAY2BGR)
# 左右結合
concat = cv2.hconcat([frame, edges_bgr])
return concat
cap = cv2.VideoCapture(0)
if not cap.isOpened():
raise RuntimeError("カメラを開けませんでした")
while True:
ret, frame = cap.read()
if not ret:
break
out = process_frame(frame)
cv2.imshow("pipeline", out)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()FPS制御とキー操作
PCの処理能力に合わせてFPSを制御すると安定します。
waitKeyの引数はミリ秒なので、ターゲットFPSに応じて調整します。
import cv2
import time
target_fps = 30.0
frame_time = 1.0 / target_fps
cap = cv2.VideoCapture(0)
if not cap.isOpened():
raise RuntimeError("カメラを開けませんでした")
paused = False
last = time.time()
while True:
if not paused:
ret, frame = cap.read()
if not ret:
break
cv2.putText(frame, f"target:{target_fps:.0f} FPS", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (200, 255, 0), 2)
cv2.imshow("control", frame)
# fps制御のためのスリープ
now = time.time()
dt = now - last
if dt < frame_time:
time.sleep(frame_time - dt)
last = time.time()
key = cv2.waitKey(1) & 0xFF
if key == ord('q'):
break
elif key == ord('p'): # 一時停止切り替え
paused = not paused
elif key == ord('+'):
target_fps = min(60.0, target_fps + 5)
frame_time = 1.0 / target_fps
elif key == ord('-'):
target_fps = max(5.0, target_fps - 5)
frame_time = 1.0 / target_fps
cap.release()
cv2.destroyAllWindows()録画と保存
処理したフレームを動画として保存するにはcv2.VideoWriterを使います。
FourCCはmp4vが扱いやすいです。
import cv2
import time
cap = cv2.VideoCapture(0)
if not cap.isOpened():
raise RuntimeError("カメラを開けませんでした")
# 入力サイズを取得
w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps_in = cap.get(cv2.CAP_PROP_FPS)
if fps_in is None or fps_in == 0:
fps_in = 30.0 # 取得できない場合の既定値
fourcc = cv2.VideoWriter_fourcc(*"mp4v")
writer = cv2.VideoWriter("record.mp4", fourcc, fps_in, (w, h))
recording = True
start = time.time()
while True:
ret, frame = cap.read()
if not ret:
break
# ここに任意の描画や検出を挿入
cv2.putText(frame, "REC", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 0, 255), 2)
if recording:
writer.write(frame)
cv2.imshow("rec", frame)
key = cv2.waitKey(1) & 0xFF
if key == ord('q'):
break
elif key == ord('r'):
recording = not recording
duration = time.time() - start
cap.release()
writer.release()
cv2.destroyAllWindows()
print(f"saved to record.mp4, duration: {duration:.1f}s")saved to record.mp4, duration: 12.4s初心者のつまずき対策とコツ
よくあるエラー対処
実務でも詰まりやすいポイントを先回りで整理します。
メッセージをよく読むことが解決の近道です。
- ImportErrorでcv2が見つからない場合は、仮想環境が有効かと
pip install opencv-python済みかを確認します。Pythonが複数あるときはpython -m pipの形でインストールします。 - 画像や動画が開けないときは、絶対パスを使い、パスのタイプミスや拡張子を確認します。コーデック非対応の動画は別形式に変換するか、別のFourCCを試します。
- Webカメラが開けない場合は、
VideoCapture(0)の番号を1や2に変えて試し、OSのプライバシー設定でカメラ許可をオンにします。WSLではカメラが扱いづらいため、WindowsネイティブかDocker Desktopのデバイス共有を検討します。 cv2.imshowが何も表示しない場合、ヘッドレス環境の可能性が高いです。Jupyterなら画像をcv2.imwriteで保存して表示するか、matplotlibでの表示に切り替えます。- Unicodeを含むパスの不具合は、最新のOpenCVではほぼ解消されていますが、それでも問題が起きる場合は
str(path)で明示し、Pathlibの扱いを統一します。
BGRとRGBの違いに注意
OpenCVの画像はBGRです。
PillowやmatplotlibはRGBが既定なので、混ぜて使うと色がおかしく見えます。
ライブラリをまたぐときはcv2.cvtColor(img, cv2.COLOR_BGR2RGB)で変換してください。
import cv2
img = cv2.imread("sample.jpg")
print("BGR pixel:", img[0, 0].tolist()) # 例: [青, 緑, 赤]
rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
print("RGB pixel:", rgb[0, 0].tolist())BGR pixel: [34, 72, 200]
RGB pixel: [200, 72, 34]ノイズ対策
ノイズは誤検出の最大要因です。
ブラーやモルフォロジーを適切に使います。
エッジ保持が重要ならバイラテラル、塩胡椒ノイズならメディアンが有効です。
import cv2
img = cv2.imread("noisy.jpg")
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gauss = cv2.GaussianBlur(gray, (5, 5), 1.0) # 一般的なノイズ低減
median = cv2.medianBlur(gray, 5) # 塩胡椒に強い
bilat = cv2.bilateralFilter(gray, d=9, sigmaColor=75, sigmaSpace=75) # エッジ保持
cv2.imshow("gaussian", gauss)
cv2.imshow("median", median)
cv2.imshow("bilateral", bilat)
cv2.waitKey(0)
cv2.destroyAllWindows()精度を上げる前処理
前処理の工夫で検出精度は大きく変わります。
検出は前処理が9割と言っても過言ではありません。
import cv2
import numpy as np
img = cv2.imread("dark.jpg")
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 1. コントラスト強調 CLAHE
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
enh = clahe.apply(gray)
# 2. ガンマ補正で明るさ調整
gamma = 1.4
table = np.array([((i / 255.0) ** (1.0 / gamma)) * 255 for i in range(256)]).astype("uint8")
gamma_img = cv2.LUT(img, table)
# 3. シャープ化で輪郭強調
kernel = np.array([[0, -1, 0],
[-1, 5, -1],
[0, -1, 0]])
sharp = cv2.filter2D(img, -1, kernel)
cv2.imshow("gray", gray)
cv2.imshow("clahe", enh)
cv2.imshow("gamma", gamma_img)
cv2.imshow("sharp", sharp)
cv2.waitKey(0)
cv2.destroyAllWindows()前処理の選び方を簡単に表にまとめます。
| 目的 | 手法 | 主な関数 | ヒント |
|---|---|---|---|
| 照明ムラの軽減 | CLAHE | cv2.createCLAHE | タイルサイズを8前後から調整します |
| 暗所での明るさ補正 | ガンマ補正 | cv2.LUT | ガンマ1.2〜1.8で様子見します |
| エッジ強調 | シャープ化 | cv2.filter2D | ノイズが増えるのでブラーと併用します |
| 塵や粒ノイズ除去 | メディアン | cv2.medianBlur | カーネルは3〜7で調整します |
学習済みモデルの活用入門
OpenCVのdnnモジュールを用いると、学習済みモデルで汎用物体検出を手軽に試せます。
ここではMobileNet-SSDのCaffeモデルを例にします。
モデルファイルMobileNetSSD_deploy.caffemodelとMobileNetSSD_deploy.prototxtを用意してください。
import cv2
import numpy as np
# クラス名の定義
CLASSES = ["background", "aeroplane", "bicycle", "bird", "boat",
"bottle", "bus", "car", "cat", "chair", "cow", "diningtable",
"dog", "horse", "motorbike", "person", "pottedplant",
"sheep", "sofa", "train", "tvmonitor"]
# モデルの読み込み
net = cv2.dnn.readNetFromCaffe("MobileNetSSD_deploy.prototxt",
"MobileNetSSD_deploy.caffemodel")
# CPUで実行
model = cv2.dnn_DetectionModel(net)
model.setInputSize(300, 300)
model.setInputScale(1.0/127.5)
model.setInputMean((127.5, 127.5, 127.5))
model.setInputSwapRB(True) # BGR→RGB
img = cv2.imread("street.jpg")
if img is None:
raise FileNotFoundError("street.jpg が見つかりません")
# 推論
class_ids, confidences, boxes = model.detect(img, confThreshold=0.5, nmsThreshold=0.45)
out = img.copy()
if class_ids is not None:
for cid, conf, box in zip(class_ids.flatten(), confidences.flatten(), boxes):
label = f"{CLASSES[cid]}:{conf:.2f}"
x, y, w, h = box
cv2.rectangle(out, (x, y), (x+w, y+h), (0, 255, 0), 2)
cv2.putText(out, label, (x, y - 8), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 2)
print("detections:", 0 if class_ids is None else len(class_ids))
cv2.imshow("dnn", out)
cv2.waitKey(0)
cv2.destroyAllWindows()detections: 5リアルタイムで使う場合はWebカメラループにdetectを入れるだけです。
ただしCPUでは重いこともあるため、解像度を落とすか軽量モデルを選ぶと快適になります。
まとめ
本記事では、Python×OpenCVでの物体検出を、画像・動画・Webカメラの3形態で段階的に解説しました。
色や輪郭、テンプレート、顔検出、背景差分、そしてdnnによる学習済みモデルまで、一通りの入口を実装しました。
実務や研究では、前処理の工夫とパラメータチューニングが結果を大きく左右します。
まずは表示と保存を確実に行い、BGRとRGBの違いに気を付けながら、小さなスクリプトを積み上げていくのが上達の近道です。
もし精度や速度に課題が出てきたら、CLAHEやガンマ補正による前処理、カーネルサイズの最適化、より軽量なモデルの採用を試してください。
最後に、「動くものを可視化する」成功体験を積むことが継続の力になります。
ぜひ手元の画像やカメラで、今日から検出を動かしてみてください。
