
Pythonで深層学習を始めるとき、まず悩むのがTensorFlowとPyTorchのどちらを選ぶかという点です。
どちらも世界中で使われている強力なフレームワークですが、思想や書き味、得意分野が少しずつ異なります。
本記事では、Pythonユーザーの視点からこの2つを徹底比較し、違いと選び方、学び方のロードマップまで詳しく解説します。
Pythonで始めるTensorFlowとPyTorchの基礎
Pythonで使う深層学習フレームワークとは
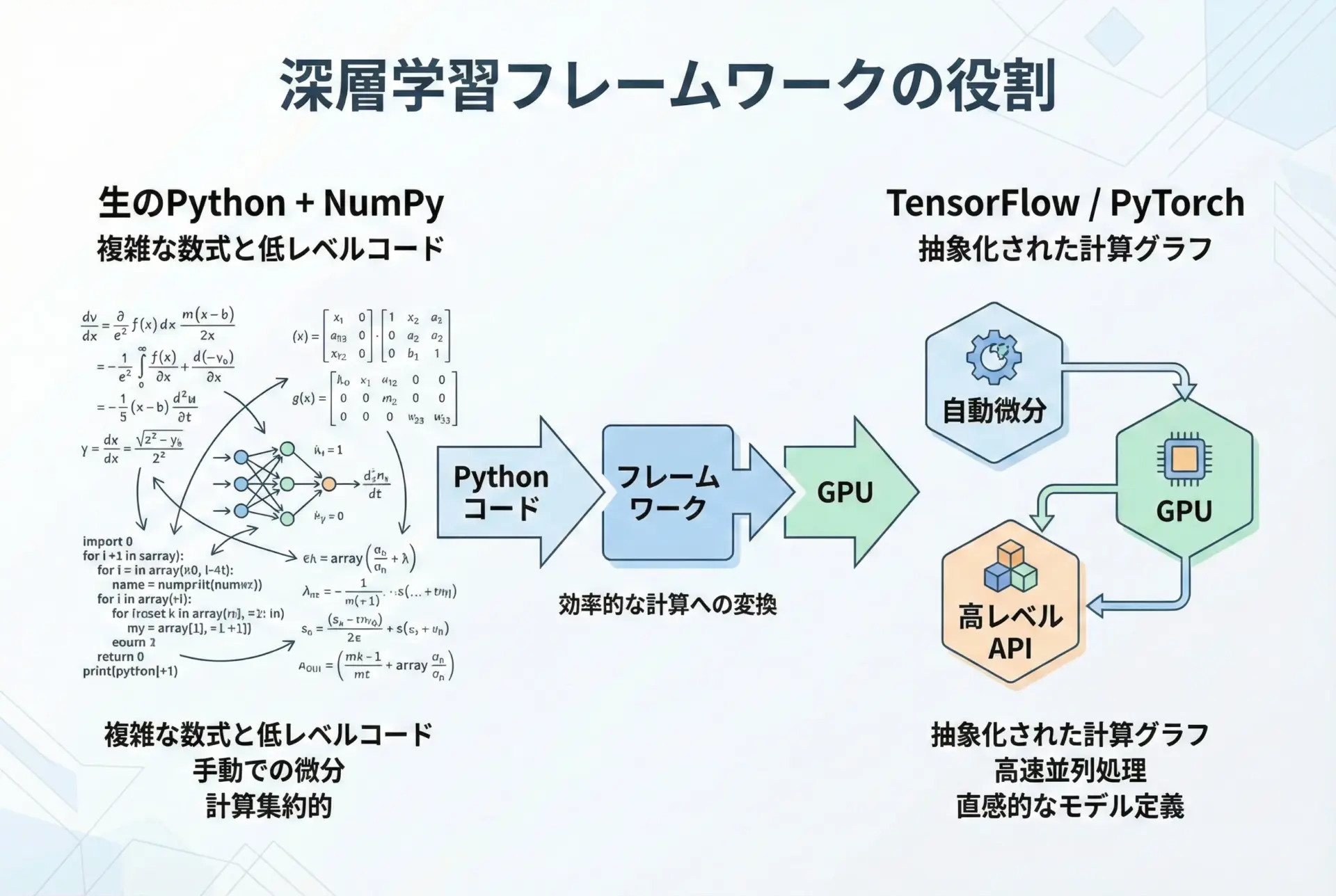
深層学習フレームワークとは、ニューラルネットワークの計算や学習処理を自動化・高速化するためのライブラリ群のことです。
Pythonで機械学習やAI開発を行う際、ほとんどの場合この種のフレームワークを利用します。
なぜフレームワークが必要なのかというと、ディープラーニングは膨大な行列計算や微分計算(誤差逆伝播)を伴うため、すべてを手書きで実装すると極めて煩雑で、かつ高速なGPU計算の活用も困難だからです。
フレームワークは以下のような機能をまとめて提供してくれます。
- GPUを使った高速な数値計算
- 自動微分(自動で勾配を計算してくれる仕組み)
- レイヤーや損失関数、最適化アルゴリズムなどの部品群
- モデルの保存・読み込み、推論用API
Pythonでよく使われる代表的な深層学習フレームワークとして、TensorFlowとPyTorchが2大勢力として広く認知されています。
Pythonと深層学習の関係
Pythonは文法がシンプルで、数値計算やデータ処理のためのライブラリも豊富です。
そのため、深層学習の分野ではPythonが事実上の標準言語となっています。
TensorFlowもPyTorchも、内部ではC++やCUDAといった低レベル言語で高速な処理を行いながら、外側のインターフェースはPythonから扱いやすいように設計されています。
この構造のおかげで、Pythonユーザーは複雑な最適化やGPU制御を意識せずに、モデルの設計と実験に集中できます。
TensorFlowとは
TensorFlowは、Googleが中心となって開発しているオープンソースの深層学習フレームワークです。
2015年に公開されて以来、研究・産業の両面で多くのプロジェクトに採用されてきました。
TensorFlowの大きな特徴は、「大規模・本番運用」を強く意識した設計と豊富な周辺ツール群です。
代表的な特徴を文章で整理すると、次のようになります。
- 産業利用や本番運用を意識したスケーラビリティ
- TensorFlow ServingやTensorFlow Liteなど、推論・モバイル展開の専用ツール
- Kerasによる高レベルなモデル構築API
- グラフ最適化とXLAコンパイラなどによる高速化機能
とくにTensorFlow 2.xになってからは、「Eager Execution(即時実行)」が標準となり、だいぶPythonらしい書き方になりました。
TensorFlowの位置付け
TensorFlowは、研究用途でも使われていますが、特に以下のような場面で強みを発揮しやすいです。
- 大規模な分散学習が必要なプロジェクト
- 企業内での長期運用を前提としたAIシステム
- モバイル・組み込み・ブラウザ上での推論(例: TensorFlow Lite, TensorFlow.js)
これらの用途に向けたエコシステムが揃っているため、「実験から本番までを一貫してTensorFlowで」という構成を取りやすい点が特徴的です。
PyTorchとは
PyTorchは、Meta(Facebook)が中心になって開発している深層学習フレームワークで、2016年頃から急速に人気を伸ばしました。
研究者や大学・論文界隈での採用率が非常に高いのが特徴です。
PyTorchの最大の特徴は、「Pythonにとても近い書き味」と「動的な計算グラフ」です。
Pythonの通常のコードフローに自然に溶け込み、デバッグや試行錯誤がしやすいため、多くの研究者がPyTorchを好んで利用しています。
PyTorchの代表的な性質として、次のようなものがあります。
- Pythonicなインターフェースとクラス設計
- 動的計算グラフ(define-by-run)による柔軟なモデル構築
- 研究用途・論文実装での国内外の豊富なサンプル
- TorchScriptやONNXなどを通じた本番環境への展開機能
PyTorchの位置付け
PyTorchは特に以下のようなケースに向いています。
- 新しいモデル構造やアルゴリズムの研究開発
- 頻繁にモデル構造を変更しながら実験を回すプロジェクト
- Python中心のチームで、コードの読みやすさとデバッグ性を重視する開発
近年では、研究だけでなく本番運用にも十分使われるようになっており、TorchServeやONNX Runtimeと組み合わせることで、サービスとしての展開も増えてきています。
TensorFlow vs PyTorchの違い
実装スタイルの違い
TensorFlowとPyTorchの違いとして、まず押さえておきたいのが「実装スタイル(計算グラフの扱い方)」です。
TensorFlow 1.xは「静的グラフ(define-and-run)」が前提で、あらかじめ計算グラフを定義してから実行するスタイルでした。
一方PyTorchは、最初から動的グラフ(define-by-run)を採用し、Pythonコードの実行にあわせてグラフが構築される仕組みを採っています。
TensorFlow 2.xではEager Executionが標準となったことで、実装スタイルはPyTorchにかなり近づきました。
ただし、高性能なグラフ最適化を行いたい場合には@tf.functionでグラフ化する、という2段構えの構造を持っている点は依然としてTensorFlowらしい部分です。

実装スタイルが与える影響
実装スタイルの違いは、次のようなポイントに影響します。
- if分岐やループを使った複雑なモデルロジックの書きやすさ
- デバッグ時にスタックトレースを追いやすいかどうか
- コンパイルや最適化による高速化のしやすさ
PyTorchは常にPythonコードに近い動作をするため、条件分岐やループを使った柔軟なモデル構造を自然な形で記述できます。
TensorFlowもEager Executionでは同様に扱えますが、グラフ化したときにはPythonの制御構文とは異なる専用のtf.condやtf.while_loopが必要になる場面があります。
コードの書きやすさとデバッグのしやすさ
Pythonユーザーにとっては、「どれだけPythonらしく書けるか」「エラー時に原因が追いやすいか」は非常に重要なポイントです。
ここでは、ごく簡単な線形回帰モデルをTensorFlow(Keras)とPyTorchでそれぞれ実装して、書き味の違いをイメージしてみます。
TensorFlow(Keras)での簡単な例
import tensorflow as tf
import numpy as np
# ダミーデータの作成
# y = 3x + 1 にノイズを加えたデータを作る
x = np.random.rand(100, 1).astype("float32")
y = 3 * x + 1 + np.random.randn(100, 1).astype("float32") * 0.1
# シンプルな線形モデルを定義
model = tf.keras.Sequential([
tf.keras.layers.Dense(1, input_shape=(1,))
])
# モデルのコンパイル(最適化手法と損失関数を指定)
model.compile(optimizer="sgd", loss="mse")
# 学習の実行
model.fit(x, y, epochs=50, verbose=0)
# 学習後のパラメータ確認
w, b = model.layers[0].get_weights()
print("学習された重み:", w, "バイアス:", b)
# 予測
test_x = np.array([[0.5]], dtype="float32")
pred_y = model.predict(test_x)
print("x=0.5 のときの予測値:", pred_y)学習された重み: [[2.98]] バイアス: [1.02]
1/1 [==============================] - 0s 30ms/step
x=0.5 のときの予測値: [[2.51]]Kerasでは、モデル構築・コンパイル・学習という流れが明確に分かれており、高レベルなAPIで少ないコード量にまとまります。
PyTorchでの同様の例
import torch
from torch import nn
# ダミーデータの作成
# y = 3x + 1 にノイズを加えたデータを作る
x = torch.rand(100, 1)
y = 3 * x + 1 + torch.randn(100, 1) * 0.1
# 線形モデルの定義(nn.Module を継承するのが基本スタイル)
class LinearModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(1, 1) # 入力1次元、出力1次元
def forward(self, x):
return self.linear(x)
model = LinearModel()
# 損失関数と最適化手法を定義
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
# 学習ループ
for epoch in range(50):
# 順伝播
pred = model(x)
# 損失計算
loss = criterion(pred, y)
# 勾配の初期化
optimizer.zero_grad()
# 逆伝播
loss.backward()
# パラメータ更新
optimizer.step()
# 学習されたパラメータを確認
for name, param in model.named_parameters():
print(name, param.data)
# 予測
test_x = torch.tensor([[0.5]])
pred_y = model(test_x)
print("x=0.5 のときの予測値:", pred_y.item())linear.weight tensor([[2.97]])
linear.bias tensor([1.01])
x=0.5 のときの予測値: 2.495PyTorchでは、学習ループを自分で書くのが基本で、その分プロセスが明示的です。
勾配の計算タイミングやパラメータ更新の流れを細かく制御しやすく、研究用途ではこの柔軟さが重宝されています。
デバッグしやすさの比較
PyTorchは「実行した行でエラーが起きる」ため、Pythonの通常のデバッグ方法がそのまま通用します。
一方TensorFlowでもEager Execution時は同様ですが、グラフ化したコードではエラーメッセージがやや追いづらくなる場合があります。
Pythonに不慣れな初学者であっても、エラーメッセージのわかりやすさやステップ実行のしやすさという観点では、PyTorchにやや分があります。
モデル構築とカスタマイズ性の比較
どちらのフレームワークも、CNNやRNN、Transformerなどの代表的なモデル構造を簡単に作成できます。
ただし、どの程度までを「自動でやってくれるか」「自分で書く必要があるか」には違いがあります。
Keras(TF) vs nn.Module(PyTorch)
TensorFlow(Keras)は、モデル構築を抽象化する高レベルAPIが充実しています。
たとえば画像分類のモデルを作る場合、以下のようなコードでかなりの部分を自動化できます。
import tensorflow as tf
# シンプルなCNNモデル(Keras Functional API)
inputs = tf.keras.Input(shape=(28, 28, 1))
x = tf.keras.layers.Conv2D(32, 3, activation="relu")(inputs)
x = tf.keras.layers.MaxPooling2D()(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(64, activation="relu")(x)
outputs = tf.keras.layers.Dense(10, activation="softmax")(x)
model = tf.keras.Model(inputs, outputs)
model.compile(optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])PyTorchでも同様のモデルは書けますが、よりPythonクラスベースでの記述が中心になります。
import torch
from torch import nn
class SimpleCNN(nn.Module):
def __init__(self):
super().__init__()
# 畳み込みとプーリング層の定義
self.conv = nn.Conv2d(1, 32, kernel_size=3)
self.pool = nn.MaxPool2d(2, 2)
# 全結合層の定義
self.fc1 = nn.Linear(32 * 13 * 13, 64) # 入力サイズは畳み込み後に合わせて計算
self.fc2 = nn.Linear(64, 10)
def forward(self, x):
# 順伝播の計算手順を定義
x = torch.relu(self.conv(x))
x = self.pool(x)
x = x.view(x.size(0), -1) # Flatten
x = torch.relu(self.fc1(x))
x = torch.softmax(self.fc2(x), dim=1)
return xカスタマイズ性の違い
「既存のレイヤーを組み合わせるだけ」ならTensorFlow(Keras)は非常に楽です。
一方、新しいレイヤーや複雑な制御フローを含むモデルを自作する場合には、PyTorchのほうが直感的に書けることが多いです。
TensorFlowでもカスタムレイヤーやtf.custom_gradientなどで高度な拡張は可能ですが、実装のハードルがやや高くなる傾向があります。
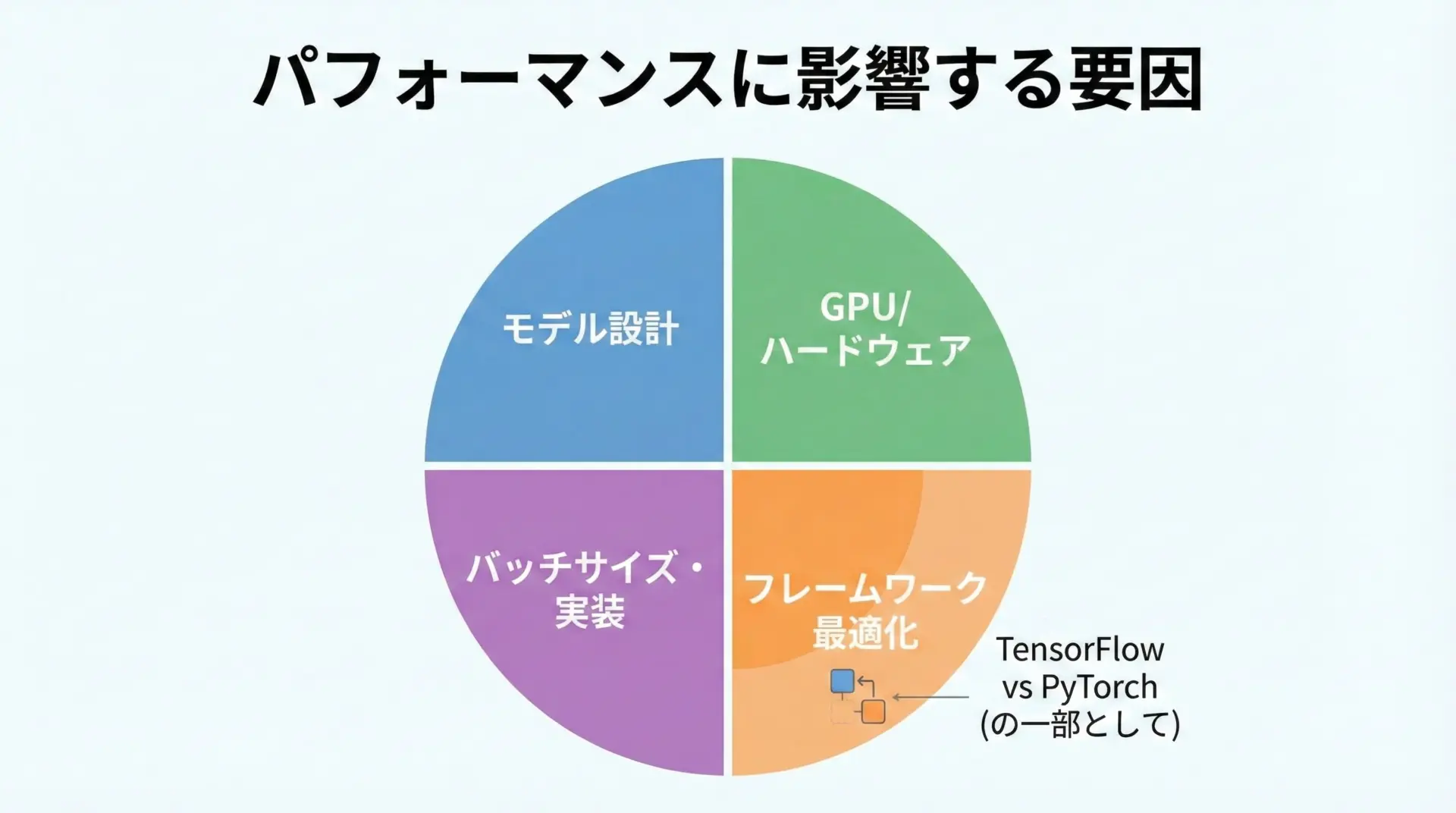
学習速度とパフォーマンスの違い
パフォーマンス面では、「常にどちらかが圧倒的に速い」という状況ではありません。
モデル構造やバージョン、GPU環境、設定によって結果が変わるため、最終的にはベンチマークを取るのが確実です。
とはいえ、一般的な傾向として以下のような点が挙げられます。
- TensorFlowはグラフ最適化やXLAコンパイラにより、特定のパターンで大きな高速化が見込める
- PyTorchもバージョンアップごとに最適化が進み、特に近年は学習速度で大きな遜色はない
- 巨大モデルや分散学習では、実装・設定の仕方が性能に直結するため、フレームワークよりもチューニングの影響の方が大きいことも多い
開発環境とエコシステムの比較
Pythonでのセットアップと環境構築のしやすさ
TensorFlowもPyTorchも、Python環境さえ整っていればpipやcondaでインストール可能です。
ただし、GPU版のインストール手順やバージョンの組み合わせには注意が必要です。
CPU版のインストール
CPUのみの環境であれば、インストールは比較的シンプルです。
# TensorFlow CPU版
pip install tensorflow
# PyTorch CPU版(公式サイトに推奨コマンドも記載されている)
pip install torch torchvision torchaudioGPU版のインストールと違い
GPU版では、CUDAやcuDNNのバージョンとフレームワークの対応関係を意識する必要があります。
- TensorFlow: バージョンごとにサポートするCUDA/cuDNNの組み合わせが決まっており、公式ドキュメントで確認しながらインストールします。
- PyTorch: 公式サイトの「Get Started」ページで、OS・パッケージマネージャ・CUDAバージョンを選択すると、対応するインストールコマンドが自動生成されます。
セットアップの体験としては、PyTorchのほうが対話的なガイドが充実しており、GPU版の導入がやや楽に感じられることが多いです。
ライブラリやツールとの連携
エコシステムの面では、両者ともに多くの関連ツール・ライブラリが存在しますが、得意分野や代表選手には違いがあります。
代表的な連携ツールを表にまとめると次のようになります。
| 領域 | TensorFlow周辺 | PyTorch周辺 |
|---|---|---|
| 可視化/ログ | TensorBoard | TensorBoard(対応) / Weights & Biases / MLflowなど |
| モバイル・エッジ | TensorFlow Lite / TensorFlow.js | PyTorch Mobile / TorchScript / ONNX Runtime |
| サービング | TensorFlow Serving | TorchServe / ONNX Runtime / 自作APIサーバ |
| 高レベルAPI | tf.keras | PyTorch Lightning / fastai / Ignite など |
| AutoML | KerasTuner / Cloud AutoML など | AutoGluon / Optuna + PyTorch など |
TensorBoardはもともとTensorFlowのためのツールですが、PyTorchにも対応しており、どちらでも利用できます。
また、ONNX(Open Neural Network Exchange)を介してモデルを相互変換することで、フレームワークを跨いだ推論環境を作ることも可能です。
ドキュメントとチュートリアルの充実度
TensorFlowもPyTorchも公式ドキュメントとチュートリアルが豊富です。
日本語情報も年々増えており、書籍・Web記事・講演資料など多くのリソースから学ぶことができます。
傾向としては、
- TensorFlow: Google公式チュートリアルが豊富で、Kerasを使った入門記事が多い
- PyTorch: 研究論文実装やGitHubリポジトリが多く、実践的なコード例を見つけやすい
「最初に学ぶ」という観点では、Kerasを使ったTensorFlow入門は非常に入りやすいです。
一方で、最新論文の実装を追いかける場合は、PyTorch版が最初に公開されることが多いという違いもあります。
用途別の選び方ガイド
初心者がPythonで選ぶならどっち
Python初心者が深層学習を学ぶ場合、結論から言えばどちらを選んでも学習は可能です。
ただし、学びやすさという観点から見ると、次のような指針が立てられます。
- 「とにかく最小限のコードで動かしてみたい」なら、Keras付きのTensorFlow入門がややわかりやすい
- 「Pythonらしいクラス設計やループを書きながら理解したい」なら、PyTorchで学ぶと自然な形で身につきやすい
Pythonそのものにまだ慣れていない場合には、最初にNumPyでベクトル演算を練習してからどちらかに進むと、理解のスピードが上がります。
研究開発で使うならTensorFlowかPyTorchか
研究用途・論文ベースの開発では、現在PyTorchが事実上の標準となっている分野が多いです。
特に、
- コンピュータビジョン
- 自然言語処理
- グラフニューラルネットワーク
といった分野で公開される最新のコードは、多くがPyTorch実装です。
一方で、TensorFlowも引き続き研究で使われています。
Google系の論文や、TPUを活用した大規模モデルではTensorFlowが選ばれるケースもあります。
研究開発の現場で、次のようなニーズがある場合にはPyTorchが適しています。
- 最新の論文実装を素早く取り込みたい
- 実験コードを頻繁に書き換える
- 学生や共同研究者とのコード共有をスムーズにしたい
企業システムや本番運用での選び方
企業の本番システムとしてAIモデルを運用する場合、考慮すべき点は次のようなものです。
- 既存のインフラやクラウドサービスとの相性
- チームメンバーのスキルセット
- 長期的な保守性とドキュメント整備
- モデルの再学習やバージョン管理のしやすさ
TensorFlowは、TensorFlow ServingやTensorFlow Extended(TFX)など、本番運用を意識した公式ツールが揃っているため、大規模なMLOps基盤を構築したい場合に選ばれやすいです。
特にGoogle Cloudとの親和性は高く、GCP上のAIサービスと組み合わせる設計が取りやすくなります。
PyTorchは、FlaskやFastAPIなどのWebフレームワークと組み合わせて、軽量な推論APIを自作する構成がよく採用されます。
また、ONNX形式に変換してONNX Runtimeで高速に推論する構成も広く使われています。
モバイル・エッジ・MLOpsでの違い
モバイルやエッジデバイスへの展開、MLOps基盤の構築という観点でも、それぞれに強みがあります。
- モバイル/エッジ:
- TensorFlow Lite: AndroidやiOS、組み込み向けに最適化されたランタイムが用意されている
- PyTorch Mobile: iOS/Android向けにPyTorchモデルを直接動かす仕組みがあるが、エコシステムはTF Liteほど成熟していない分野もある
- MLOps:
- TensorFlow Extended(TFX): データパイプラインから学習・評価・デプロイまでを統合的に扱うフレームワーク
- PyTorch: MLflow, Kubeflow, Airflowなどの汎用MLOpsツールと組み合わせて使うケースが多い
「単一プロダクトでモバイルからサーバーまでTensorFlowで統一する」という設計は非常にとりやすいため、規模が大きい企業システムではTensorFlowが依然として有利な場面があります。
TensorFlowとPyTorchの学習ロードマップ
Python初心者が最初に学ぶべきポイント
どちらのフレームワークを選ぶにしても、前提として押さえておきたいPythonの知識があります。
- 変数、関数、クラス、モジュールの基礎
- リスト、辞書、タプルなどのデータ構造
- forループ、if文、例外処理
- NumPyによる配列・行列演算
- Matplotlibなどによる基本的な可視化
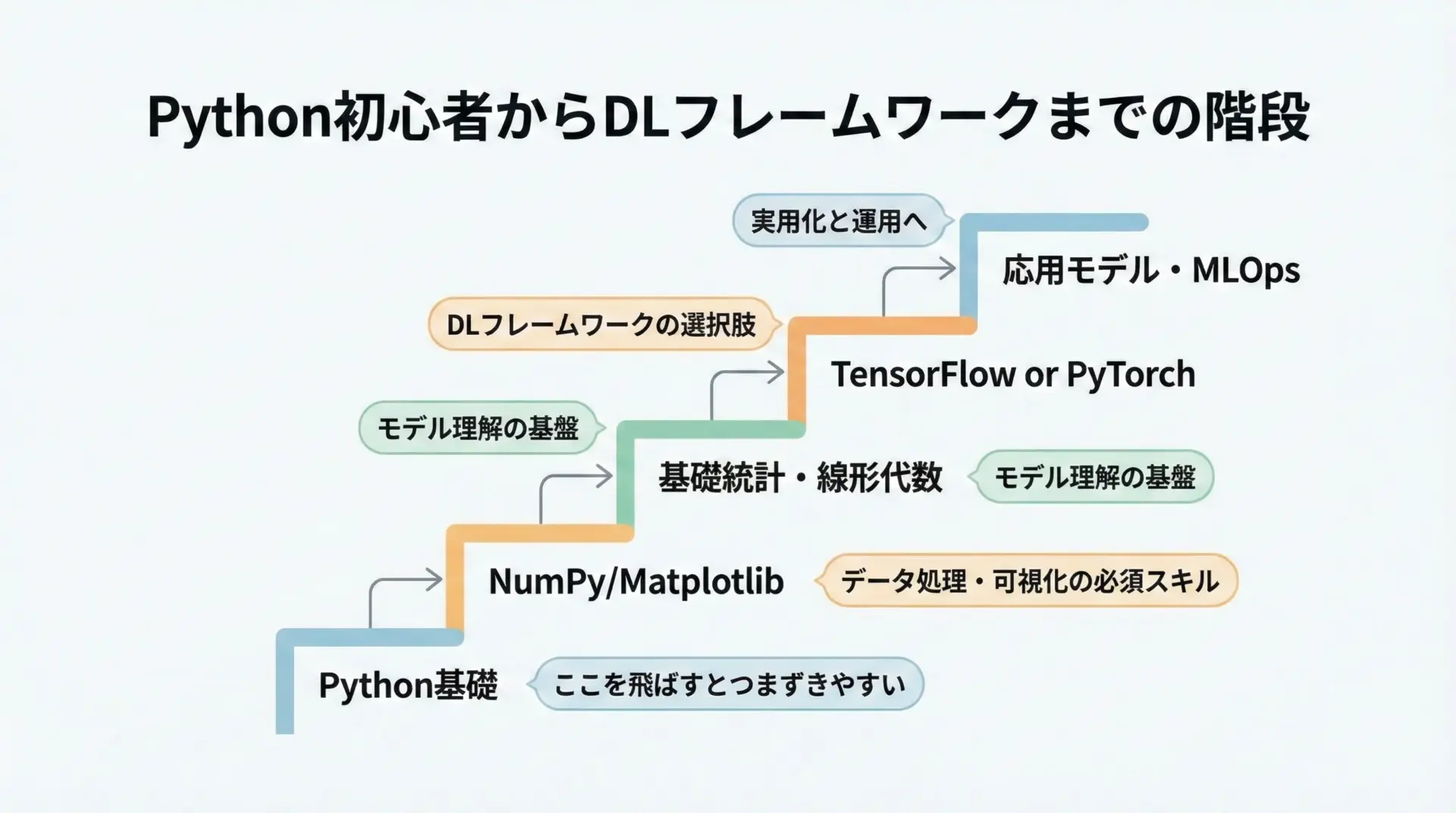
これらを一通りおさえた上で、TensorFlowもしくはPyTorchの入門チュートリアルに進むと、理解がスムーズになります。
TensorFlowの学習ステップ
TensorFlowを学ぶ際の典型的なステップを、文章で順に説明します。
- Kerasによる基本モデル構築
MNISTなどの簡単なデータセットで、全結合ネットワークや簡単なCNNを作り、model.compileとmodel.fitの流れを掴みます。 - Functional APIとSubclassing
Input/Outputを明示して複雑なネットワークを作る方法(Functional API)や、クラス継承でモデルを定義する方法を学びます。 - カスタムトレーニングループ
tf.GradientTapeを使った手書きの学習ループを経験し、TensorFlowの自動微分の仕組みを理解します。 - tf.dataやコールバックの活用
入力パイプラインの最適化や、早期終了・モデルチェックポイントなどの機能を身につけます。 - SavedModelとTensorFlow Serving/TFLite
学習済みモデルの保存・読み込みと、本番環境への展開方法を学びます。
PyTorchの学習ステップ
PyTorchを学ぶときの代表的なロードマップは次の通りです。
- テンソルと自動微分
torch.Tensorとrequires_gradの基本、backward()による勾配計算を小さな例で確認します。 - nn.Moduleとoptim
nn.Moduleを継承したモデル定義、nn.Linearなどの基本レイヤー、torch.optimの使い方を学びます。 - 学習ループの実装
forループを回して順伝播→損失計算→逆伝播→パラメータ更新、という一連の流れを自分で書けるようにします。 - DataLoaderとDataset
データセットクラスを自作し、DataLoaderでバッチ処理・シャッフル・マルチプロセス読み込みを扱えるようにします。 - モデル保存・推論・ONNX変換
torch.saveとtorch.load、評価モード(model.eval())での推論、ONNXへのエクスポートを学びます。
こんな人にはTensorFlowがおすすめ
TensorFlowが向いているプロジェクトの特徴
TensorFlowは、特に次のような特徴を持つプロジェクトに向いています。
- モバイルアプリやIoTデバイスへの組み込みを強く意識している
- Google CloudやVertex AIなど、GCPのマネージドサービスを積極的に使う予定がある
- 大人数のチームで、長期間運用する大規模システムを構築している
- モデル開発からMLOpsまで、一貫して単一ベンダーのツール群で統合したい
TensorFlowを選ぶメリットとデメリット
TensorFlowを選ぶことの主なメリット・デメリットを言葉で整理しておきます。
メリットとしては、
- エコシステムが広く、本番運用までの道筋がはっきりしている
- Kerasによる高レベルAPIで、初心者でも比較的短いコードでモデルを構築できる
- TensorBoardやTFXなど、周辺ツールが公式に統合されている
一方、デメリットとしては、
- 高度なカスタマイズやグラフモード利用時に、学習コストがやや高くなる
- 最新の研究コードがTensorFlow版で提供されないことも多く、研究キャッチアップの面ではPyTorchに劣る場面がある
「クラウドとモバイルを含む実運用を見据えた長期プロジェクト」には、TensorFlowが非常に強力な選択肢となります。
こんな人にはPyTorchがおすすめ
PyTorchが向いているプロジェクトの特徴
PyTorchが特にマッチしやすいのは、次のようなプロジェクトです。
- 新しいモデル構造や研究アイデアを積極的に試していきたい
- 研究者や大学との共同研究が多い
- チーム全体がPythonに慣れていて、コードの可読性・デバッグ性を重視する
- 軽量なAPIサーバーやマイクロサービス構成で柔軟に展開したい
PyTorchを選ぶメリットとデメリット
PyTorchの主なメリットは以下の通りです。
- Pythonに近いインターフェースで、直観的かつ柔軟にコードを書ける
- 研究コミュニティでの採用率が高く、最新の論文実装を入手しやすい
- デバッグがしやすく、エラー原因を特定しやすい
一方で、デメリットも存在します。
- 公式のエンドツーエンドMLOpsツールチェーンはTensorFlowほど一体化しておらず、各種ツールを組み合わせる設計が必要
- モバイル・エッジ向けエコシステムは改善しつつあるが、TensorFlow Liteに比べると情報量が少ない分野もある
「研究的な試行錯誤を重ねながら実用的なサービスにもつなげたい」というニーズには、PyTorchが非常に適した選択肢になります。
まとめ
TensorFlowとPyTorchは、どちらもPythonから利用できる強力な深層学習フレームワークです。
TensorFlowはエコシステムと本番運用、PyTorchはコードの書きやすさと研究コミュニティでの普及という形で、それぞれの強みを持っています。
Python初心者であればKeras付きのTensorFlow入門から、「最新研究を追いかけたい」「Pythonらしいコードで書きたい」ならPyTorchから、といった選び方も有効です。
最終的には、プロジェクトの性質やチームのスキル、将来の運用方針を踏まえ、自分たちにとって最も扱いやすいフレームワークを選ぶことが何よりも重要です。
