
データ分析や機械学習をPythonで行うなら、まずマスターしたいのがpandasです。
pandasは表形式データを効率よく扱えるライブラリで、Excelのような操作をコードで再現できます。
本記事では、「pandasとは?」という基礎から、前処理・集計・可視化・実践的な分析例までを一通りカバーします。
初心者の方でも実行しながら学べるよう、サンプルコードと図解を交えて丁寧に解説していきます。
pandasとは?Pythonによるデータ分析の定番ライブラリ
pandasの特徴とできること

pandasは、Pythonでデータ分析を行う際の事実上の標準ライブラリです。
表形式データを扱うための便利な機能が一通りそろっているため、業務データ分析から研究、機械学習の前処理まで幅広く使われています。
pandasでできる主なことを整理すると、次のようになります。
- CSVやExcel、SQLデータベースなどからデータを読み込み、表形式のデータとして扱えること
- 行・列の抽出や並び替え、条件抽出など、Excelで行うような操作をコードで表現できること
- 欠損値処理や型変換などのデータクリーニングを効率よく行えること
- 集計やグルーピング、ピボットテーブルによる多次元集計を、数行のコードで実現できること
- 時系列データのリサンプリングや移動平均など、時間に関する分析を簡便に行えること
- MatplotlibやSeabornなどの可視化ライブラリと連携し、グラフ描画をスムーズに行えること
特に、pandasのDataFrameは「プログラムで扱えるExcelシート」のような存在です。
複雑な集計やデータ加工を自動化できるため、手作業のExcel分析に限界を感じている方にとって、大きな武器となります。
NumPyとの違いと連携

pandasは、内部的にはNumPyの配列を活用して実装されています。
そのため、「NumPyの上に構築された、表データ操作に特化したライブラリ」と考えると理解しやすいです。
NumPyとpandasの主な違いを表で整理します。
| 項目 | NumPy | pandas |
|---|---|---|
| 主なデータ構造 | ndarray(多次元配列) | Series・DataFrame |
| データのラベル | 基本的にインデックスのみ(0,1,2,…) | 行・列にラベル(名前)を持てる |
| 主な用途 | 数値計算・線形代数・配列操作 | 表形式データ操作・集計・前処理 |
| 欠損値の扱い | 基本は自前で管理 | NaNを標準的に扱える |
| 学習の優先度 | 数値計算中心なら必須 | データ分析中心なら必須 |
実務では、「表形式のデータを扱うときはpandas」「数値計算や行列演算はNumPy」というように使い分けることが多いです。
また、pandasのSeriesやDataFrameの内部データはNumPy配列であるため、.values属性を使ってNumPy配列として取り出し、NumPyの関数に渡すこともよくあります。
pandasの基本準備とインストール方法
pandasのインストール
pandasを使うには、まずPython環境にインストールする必要があります。
もっとも簡単なのはpipを使う方法です。
# pandasのインストール
pip install pandas
# すでにインストール済みの場合、最新版にアップグレード
pip install -U pandasAnacondaディストリビューションを利用している場合は、最初からpandasが含まれていることが多いです。
その場合は、バージョンを確認して必要であれば更新します。
# バージョン確認
python -c "import pandas as pd; print(pd.__version__)"Pythonでのpandasインポート方法
pandasをPythonコード内で利用する際は、慣例としてpdという短い名前でインポートします。
import pandas as pd
# バージョンを表示して、インポートできているか確認
print(pd.__version__)2.2.2上記のようにバージョンが表示されれば、準備は完了です。
このimport pandas as pdはpandasを使うコードの冒頭で必ず記述すると考えてよいです。
pandasのデータ構造(Series・DataFrame)入門
Seriesとは?一次元データの基本操作
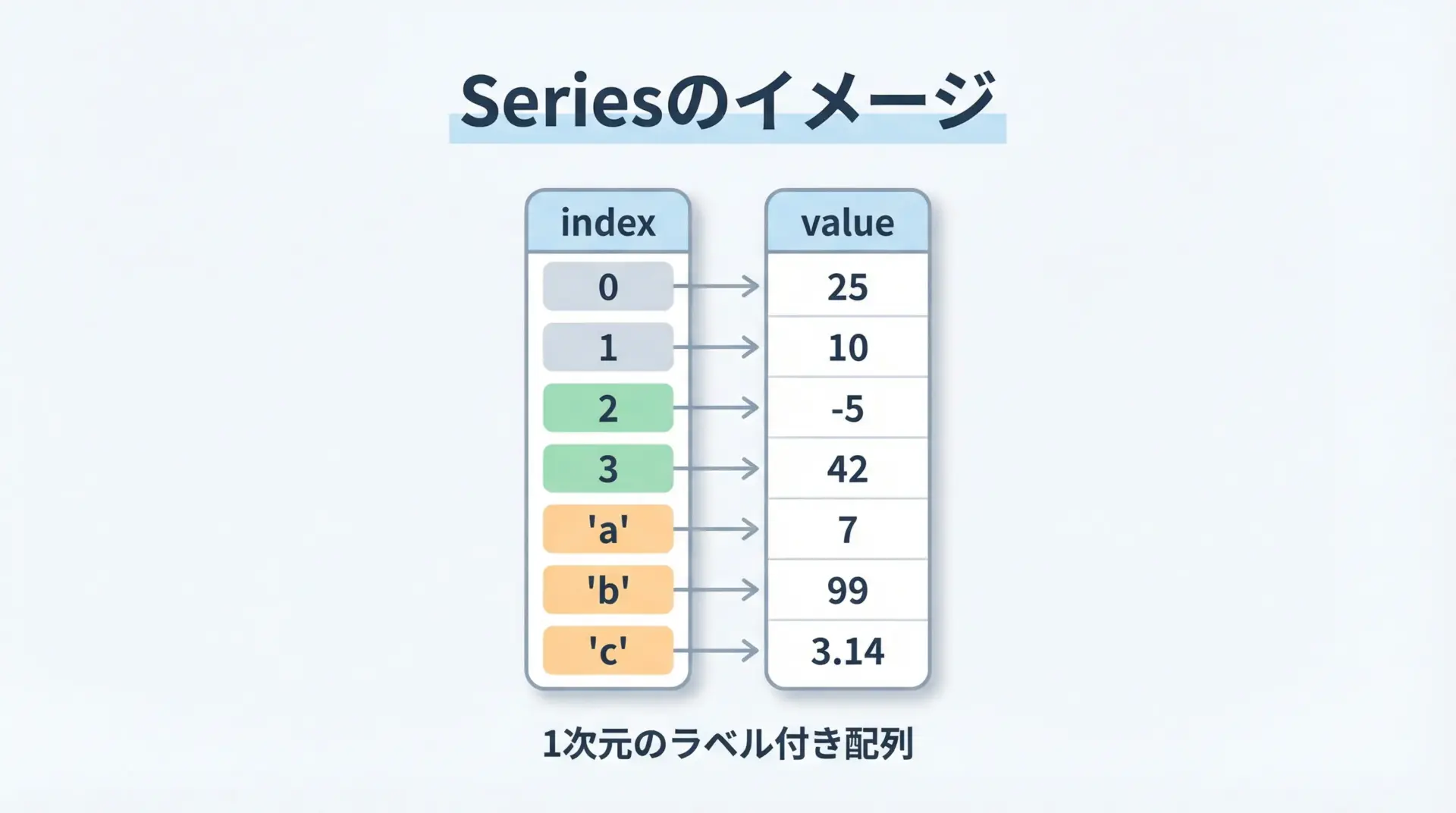
Seriesは「ラベル付きの1次元配列」です。
NumPyの1次元配列に、要素ごとの名前(index)が付いたものだとイメージすると分かりやすいです。
まずは簡単なSeriesを作成してみます。
import pandas as pd
# リストからSeriesを作成
s = pd.Series([10, 20, 30], index=["A", "B", "C"])
print("Series本体:")
print(s)
print("\nvalues(値の部分):", s.values)
print("index(インデックス):", s.index)Series本体:
A 10
B 20
C 30
dtype: int64
values(値の部分): [10 20 30]
index(インデックス): Index(['A', 'B', 'C'], dtype='object')Seriesは、インデックスを指定して要素を参照できます。
print(s["A"]) # ラベルで参照
print(s[0]) # 位置で参照10
10このように、Seriesは「名前付きの縦ベクトル」として、統計量や単一列の操作などに使われます。
DataFrameとは?表形式データの基本操作
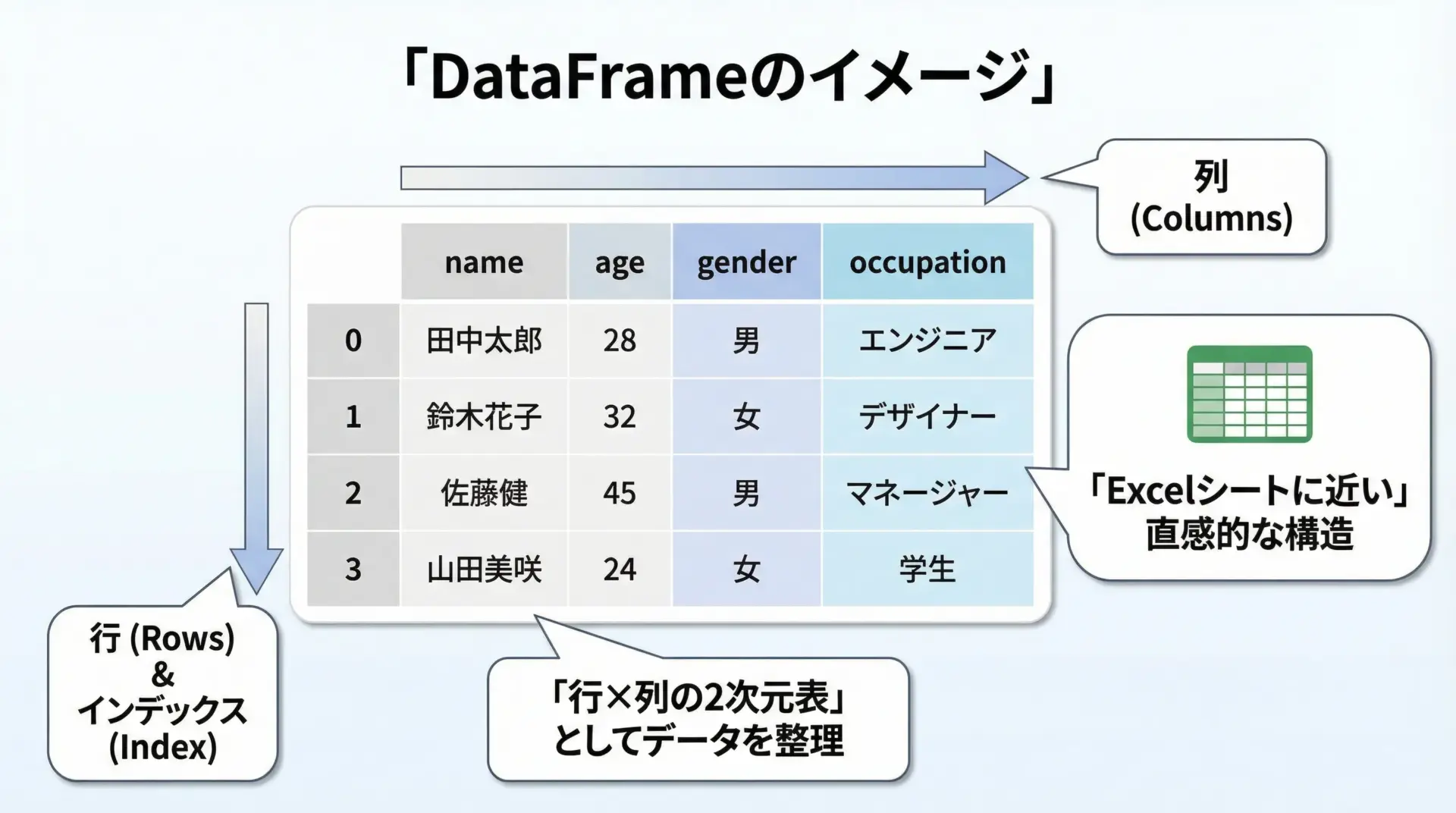
DataFrameは「行と列を持つ2次元の表形式データ」です。
Excelのシートのようなものと考えてください。
簡単なDataFrameを手動で作成してみます。
import pandas as pd
# 辞書からDataFrameを作成
data = {
"name": ["Alice", "Bob", "Charlie"],
"age": [25, 30, 35],
"city": ["Tokyo", "Osaka", "Nagoya"],
}
df = pd.DataFrame(data)
print(df)
print("\n列名:", df.columns)
print("インデックス:", df.index) name age city
0 Alice 25 Tokyo
1 Bob 30 Osaka
2 Charlie 35 Nagoya
列名: Index(['name', 'age', 'city'], dtype='object')
インデックス: RangeIndex(start=0, stop=3, step=1)DataFrameは、行・列どちらの方向にもラベルを持つため、「どの列の、どの行のデータか」を明示的に扱えるのが大きな特徴です。
データの読み込みと書き出し
CSVファイルをpandasで読み込む
実務で最もよく使うのが、read_csvによるCSVファイルの読み込みです。
import pandas as pd
# CSVファイルの読み込み
df = pd.read_csv("sales.csv") # 同じフォルダにsales.csvがある想定
# 先頭5行を表示
print(df.head()) order_id customer product amount date
0 1 Alice A 1200 2024-01-01
1 2 Bob B 3000 2024-01-02
2 3 Charlie A 1500 2024-01-02
3 4 Alice C 5000 2024-01-03
4 5 Bob A 2000 2024-01-03文字コードや区切り文字などを指定したい場合は、引数で調整します。
# 代表的なオプション指定例
df = pd.read_csv(
"sales.csv",
encoding="utf-8", # 文字コード(cp932などに変更することもある)
sep=",", # 区切り文字(タブ区切りなら"\t")
header=0, # 何行目をヘッダ行とみなすか
)Excelファイル読み込み・書き出し
Excelファイルも簡単に読み書きできます。
import pandas as pd
# Excelファイルから読み込み
df = pd.read_excel("sales.xlsx", sheet_name="Sheet1")
print(df.head()) order_id customer product amount date
0 1 Alice A 1200 2024-01-01
1 2 Bob B 3000 2024-01-02
2 3 Charlie A 1500 2024-01-02
3 4 Alice C 5000 2024-01-03
4 5 Bob A 2000 2024-01-03書き出しはto_excelを使います。
# DataFrameをExcelに出力
df.to_excel("sales_output.xlsx", sheet_name="result", index=False)index=Falseとすることで、行インデックスをExcelに書き出さないようにできます。
JSON・SQLなど他形式との連携
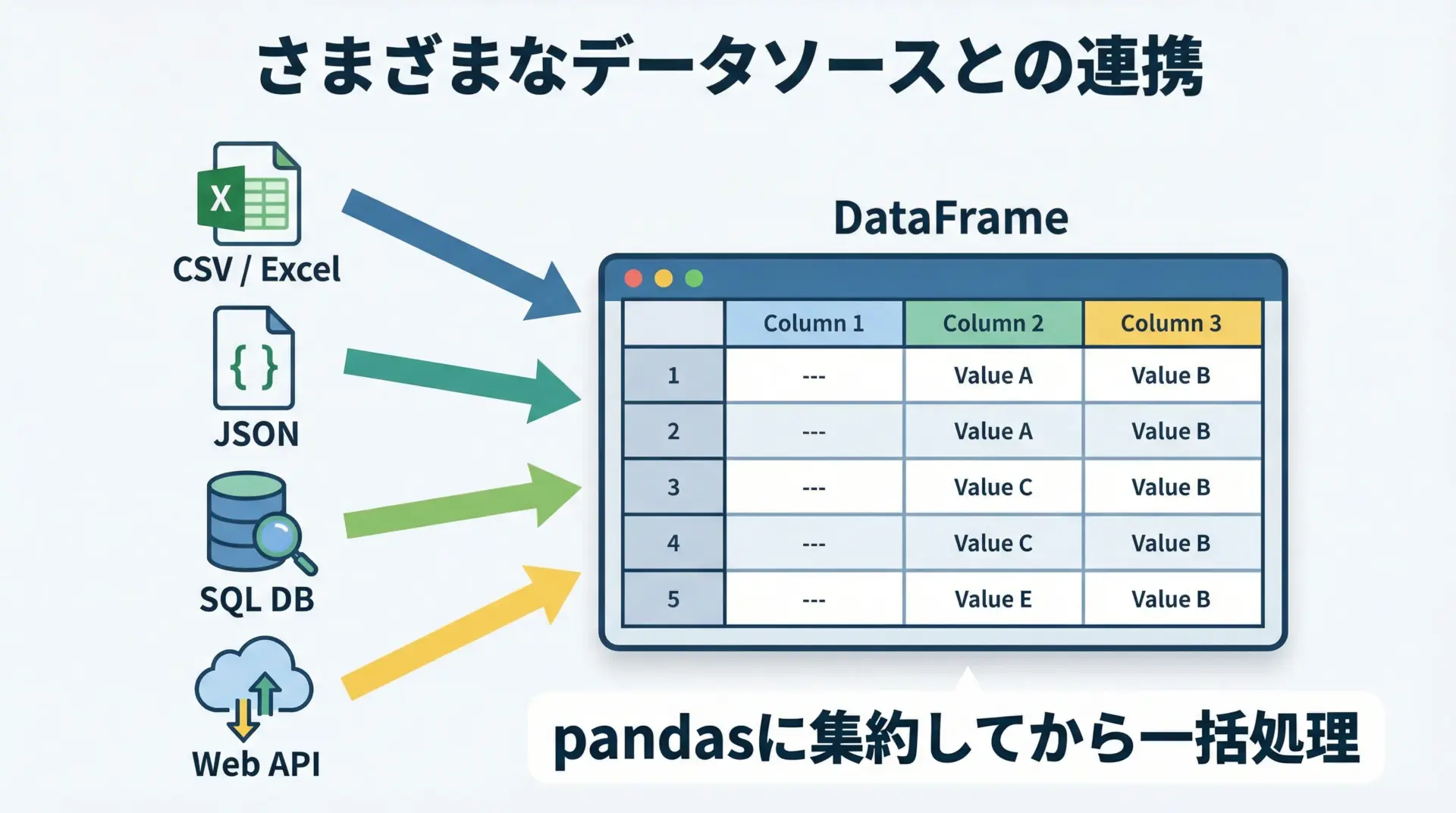
pandasは多くのデータ形式と連携できます。
代表的なものをコードで示します。
import pandas as pd
import sqlite3
# JSONの読み込み
df_json = pd.read_json("data.json")
# SQLデータベースからの読み込み
conn = sqlite3.connect("mydb.sqlite")
# SQLクエリでデータ取得
df_sql = pd.read_sql_query("SELECT * FROM sales", conn)
# DataFrameをSQLテーブルとして保存
df_sql.to_sql("sales_backup", conn, if_exists="replace", index=False)
conn.close()このように、さまざまなソースからデータをpandasに取り込んでから、共通の操作で処理できるのが大きな利点です。
DataFrameの基本操作とアクセス方法
行・列の選択

列の選択は、[]や.locを使います。
import pandas as pd
df = pd.DataFrame(
{
"name": ["Alice", "Bob", "Charlie"],
"age": [25, 30, 35],
"city": ["Tokyo", "Osaka", "Nagoya"],
}
)
# 列の選択
age_col = df["age"] # Seriesとして取得
subset_cols = df[["name", "age"]] # 複数列の選択はリストで
print(age_col)
print("\n---")
print(subset_cols)0 25
1 30
2 35
Name: age, dtype: int64
---
name age
0 Alice 25
1 Bob 30
2 Charlie 35行の選択には.locや.ilocを使います。
# loc: ラベルベースのアクセス
print(df.loc[0]) # インデックスラベル0の行
print(df.loc[0:1, ["name"]]) # 行0〜1の"name"列
# iloc: 位置ベースのアクセス
print(df.iloc[0]) # 0番目の行
print(df.iloc[0:2, 0:2]) # 0〜1行、0〜1列name Alice
age 25
city Tokyo
Name: 0, dtype: object
name
0 Alice
1 Bob
name Alice
age 25
city Tokyo
Name: 0, dtype: object
name age
0 Alice 25
1 Bob 30「ラベルならloc、位置ならiloc」と覚えておくと混乱しにくいです。
列の追加・削除・名前変更
列の追加は、df["新しい列名"] = ...という代入で行います。
import pandas as pd
df = pd.DataFrame(
{
"price": [100, 200, 300],
"quantity": [1, 3, 2],
}
)
# 新しい列 total を追加
df["total"] = df["price"] * df["quantity"]
print(df) price quantity total
0 100 1 100
1 200 3 600
2 300 2 600列の削除にはdropを使います。
# 列の削除(axis=1 または columns引数)
df_dropped = df.drop(columns=["quantity"])
print(df_dropped) price total
0 100 100
1 200 600
2 300 600列名を変更するにはrenameを使用します。
df_renamed = df.rename(columns={"price": "unit_price", "quantity": "qty"})
print(df_renamed) unit_price qty total
0 100 1 100
1 200 3 600
2 300 2 600インデックス操作とリセット
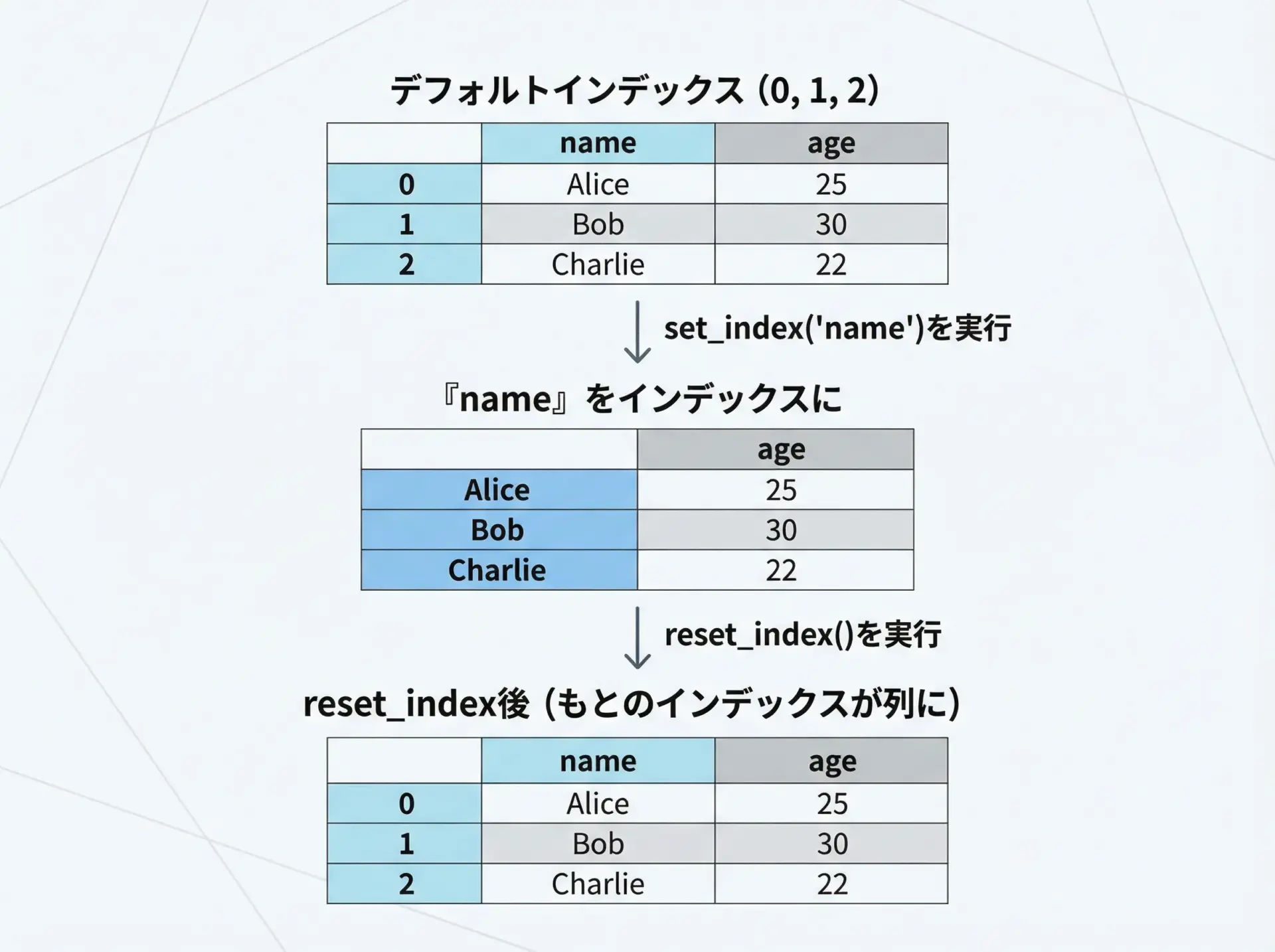
インデックスは行を識別するラベルです。
特定の列をインデックスとして使うと便利な場面が多くあります。
import pandas as pd
df = pd.DataFrame(
{
"id": [101, 102, 103],
"name": ["Alice", "Bob", "Charlie"],
"score": [80, 90, 85],
}
)
# name列をインデックスとして設定
df_indexed = df.set_index("name")
print(df_indexed) id score
name
Alice 101 80
Bob 102 90
Charlie 103 85インデックスを元に戻したい場合はreset_indexを使います。
df_reset = df_indexed.reset_index()
print(df_reset) name id score
0 Alice 101 80
1 Bob 102 90
2 Charlie 103 85インデックスは結合や時系列処理でも重要な役割を果たすため、基本的な操作に慣れておくことが大切です。
データの前処理とクリーニング
欠損値処理

現実のデータには、しばしば欠損値(データが存在しない箇所)が含まれます。
pandasではNaNとして扱われ、欠損値の検出・削除・補完を行う機能が豊富です。
import pandas as pd
import numpy as np
df = pd.DataFrame(
{
"name": ["Alice", "Bob", "Charlie"],
"age": [25, np.nan, 35],
"score": [80, 90, np.nan],
}
)
print("元のDataFrame:")
print(df)
# 欠損の有無を確認
print("\n欠損値の有無:")
print(df.isna())
# 行ごと削除(dropna)
print("\n欠損値を含む行を削除:")
print(df.dropna())
# 平均値で補完(fillna)
age_mean = df["age"].mean()
score_mean = df["score"].mean()
df_filled = df.fillna({"age": age_mean, "score": score_mean})
print("\n平均値で補完したDataFrame:")
print(df_filled)元のDataFrame:
name age score
0 Alice 25.0 80.0
1 Bob NaN 90.0
2 Charlie 35.0 NaN
欠損値の有無:
name age score
0 False False False
1 False True False
2 False False True
欠損値を含む行を削除:
name age score
0 Alice 25.0 80.0
平均値で補完したDataFrame:
name age score
0 Alice 25.0 80.0
1 Bob 30.0 90.0
2 Charlie 35.0 85.0このように、「削除する」か「統計量や指定値で埋める」かをデータの性質に応じて選びます。
型変換と日付データの扱い
データを正しく扱うには、型を確認し、必要に応じて変換することが重要です。
特に日付は、文字列のままでは時系列処理ができないため、datetime型への変換が必須になります。
import pandas as pd
df = pd.DataFrame(
{
"date": ["2024-01-01", "2024-01-02", "2024-01-03"],
"amount": ["1000", "2000", "1500"], # 文字列として読み込まれた金額
}
)
print("元のdtypes:")
print(df.dtypes)
# 日付型に変換
df["date"] = pd.to_datetime(df["date"])
# 数値型に変換
df["amount"] = df["amount"].astype(int)
print("\n変換後のdtypes:")
print(df.dtypes)元のdtypes:
date object
amount object
dtype: object
変換後のdtypes:
date datetime64[ns]
amount int64
dtype: object型が正しくないと、計算や比較が思わぬ結果になるため、読み込み直後にdf.dtypesで確認する習慣をつけておくと安心です。
重複データの確認と削除

データ収集の過程で、同じ行が重複してしまうことがあります。
pandasには重複検出・削除のためのduplicatedとdrop_duplicatesが用意されています。
import pandas as pd
df = pd.DataFrame(
{
"id": [1, 2, 2, 3],
"name": ["Alice", "Bob", "Bob", "Charlie"],
}
)
print("元のDataFrame:")
print(df)
# 重複の有無を確認(最初の出現をFalse、重複分をTrueとする)
print("\nduplicated():")
print(df.duplicated())
# 完全に同じ行を削除
df_unique = df.drop_duplicates()
print("\n重複行を削除:")
print(df_unique)
# 特定の列だけを基準に重複判定
df_unique_name = df.drop_duplicates(subset=["name"])
print("\nname列を基準に重複削除:")
print(df_unique_name)元のDataFrame:
id name
0 1 Alice
1 2 Bob
2 2 Bob
3 3 Charlie
duplicated():
0 False
1 False
2 True
3 False
dtype: bool
重複行を削除:
id name
0 1 Alice
1 2 Bob
3 3 Charlie
name列を基準に重複削除:
id name
0 1 Alice
1 2 Bob
3 3 Charlieどの列を基準に重複とみなすかは、分析の目的に応じて慎重に決める必要があります。
データ集計とグルーピング
groupbyによる集計処理

groupbyは、カテゴリごとにデータをグループ分けし、集計するための中核的な機能です。
import pandas as pd
df = pd.DataFrame(
{
"customer": ["Alice", "Bob", "Alice", "Bob", "Charlie"],
"amount": [1000, 2000, 1500, 3000, 4000],
}
)
print("元のデータ:")
print(df)
# customerごとにamountの合計を計算
grouped = df.groupby("customer")["amount"].sum()
print("\n顧客別の合計金額:")
print(grouped)元のデータ:
customer amount
0 Alice 1000
1 Bob 2000
2 Alice 1500
3 Bob 3000
4 Charlie 4000
顧客別の合計金額:
customer
Alice 2500
Bob 5000
Charlie 4000
Name: amount, dtype: int64集約関数(sum・mean・countなど)の使い方
groupbyと組み合わせて、sum、mean、countなど、さまざまな集約を同時に行うこともできます。
import pandas as pd
df = pd.DataFrame(
{
"customer": ["Alice", "Bob", "Alice", "Bob", "Charlie"],
"amount": [1000, 2000, 1500, 3000, 4000],
"items": [1, 2, 1, 3, 4],
}
)
# 顧客ごとに、合計・平均・件数を計算
agg_df = df.groupby("customer").agg(
total_amount=("amount", "sum"),
mean_amount=("amount", "mean"),
order_count=("amount", "count"),
total_items=("items", "sum"),
)
print(agg_df) total_amount mean_amount order_count total_items
customer
Alice 2500 1250.0 2 2
Bob 5000 2500.0 2 5
Charlie 4000 4000.0 1 4aggを使うと、複数の列・複数の集約関数を1度に指定できるため、実務のレポート作成でも非常に重宝します。
ピボットテーブル(pivot_table)で多次元集計

pivot_tableは、Excelのピボットテーブルと同様の多次元集計を行うための関数です。
import pandas as pd
df = pd.DataFrame(
{
"date": ["2024-01-01", "2024-01-01", "2024-01-02", "2024-01-02"],
"product": ["A", "B", "A", "B"],
"region": ["East", "East", "West", "West"],
"amount": [1000, 2000, 1500, 3000],
}
)
# 商品×地域ごとの売上合計
pivot = pd.pivot_table(
df,
index="product",
columns="region",
values="amount",
aggfunc="sum",
)
print(pivot)region East West
product
A 1000 1500
B 2000 3000縦長の明細データを、分析しやすいクロス集計表に変換できるため、売上分析などで非常に有用です。
データの結合・結合
※見出しに「結合・結合」とありますが、内容としては結合(マージ)の解説を行います。
concatでの縦結合・横結合
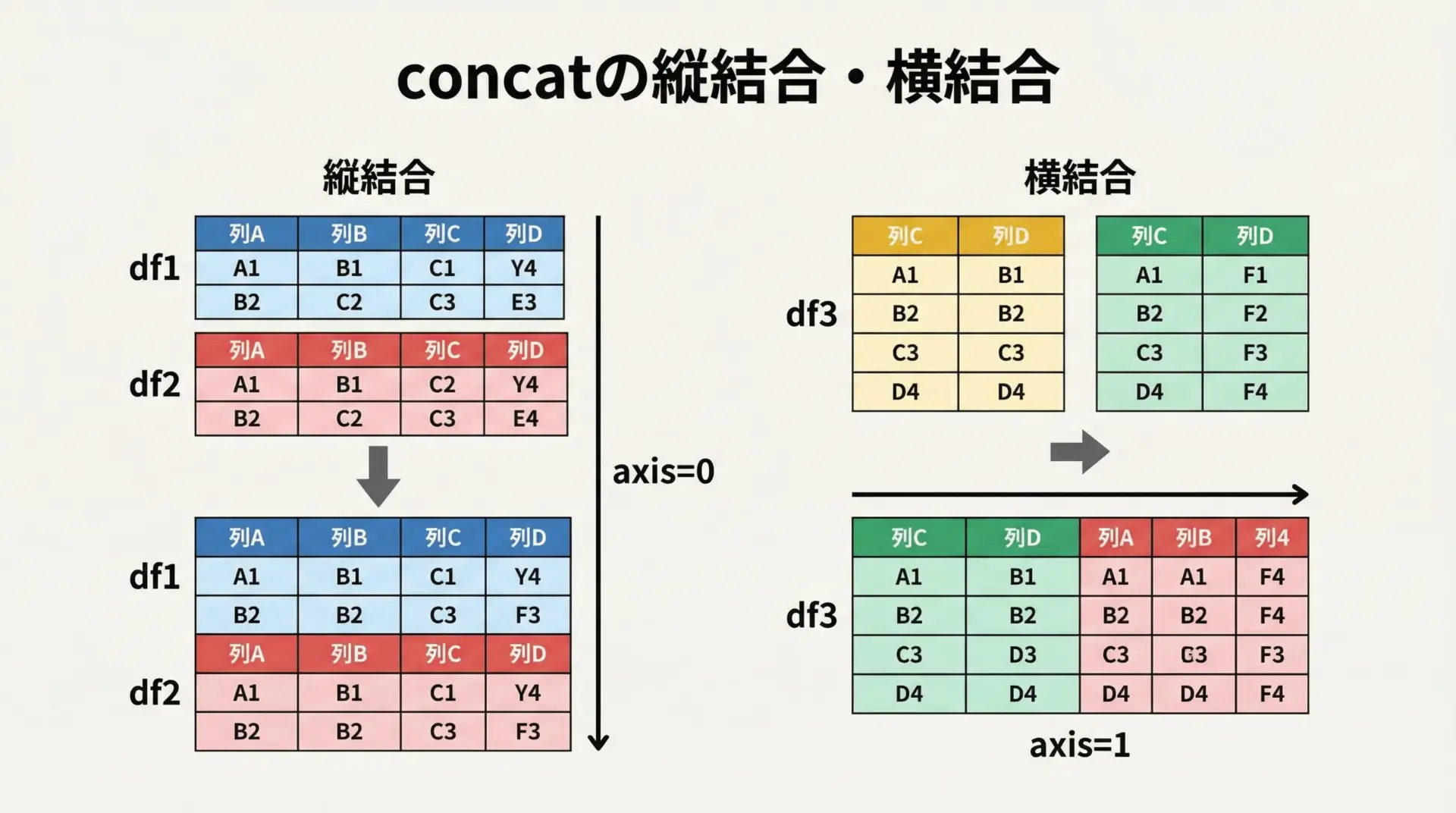
concatは、DataFrame同士を縦または横に連結するための関数です。
import pandas as pd
df1 = pd.DataFrame({"id": [1, 2], "value": ["A", "B"]})
df2 = pd.DataFrame({"id": [3, 4], "value": ["C", "D"]})
# 縦結合(axis=0)
df_vert = pd.concat([df1, df2], axis=0, ignore_index=True)
print("縦結合:")
print(df_vert)縦結合:
id value
0 1 A
1 2 B
2 3 C
3 4 D横方向に列を増やしたい場合は、axis=1を指定します。
df_left = pd.DataFrame({"id": [1, 2], "value1": ["A", "B"]})
df_right = pd.DataFrame({"id": [1, 2], "value2": ["X", "Y"]})
# インデックスを揃えた上で横結合
df_horiz = pd.concat([df_left.set_index("id"), df_right.set_index("id")], axis=1)
print("横結合:")
print(df_horiz)横結合:
value1 value2
id
1 A X
2 B Yconcatは「単純に上下または左右に並べる」操作と理解すると良いです。
mergeでのキー結合
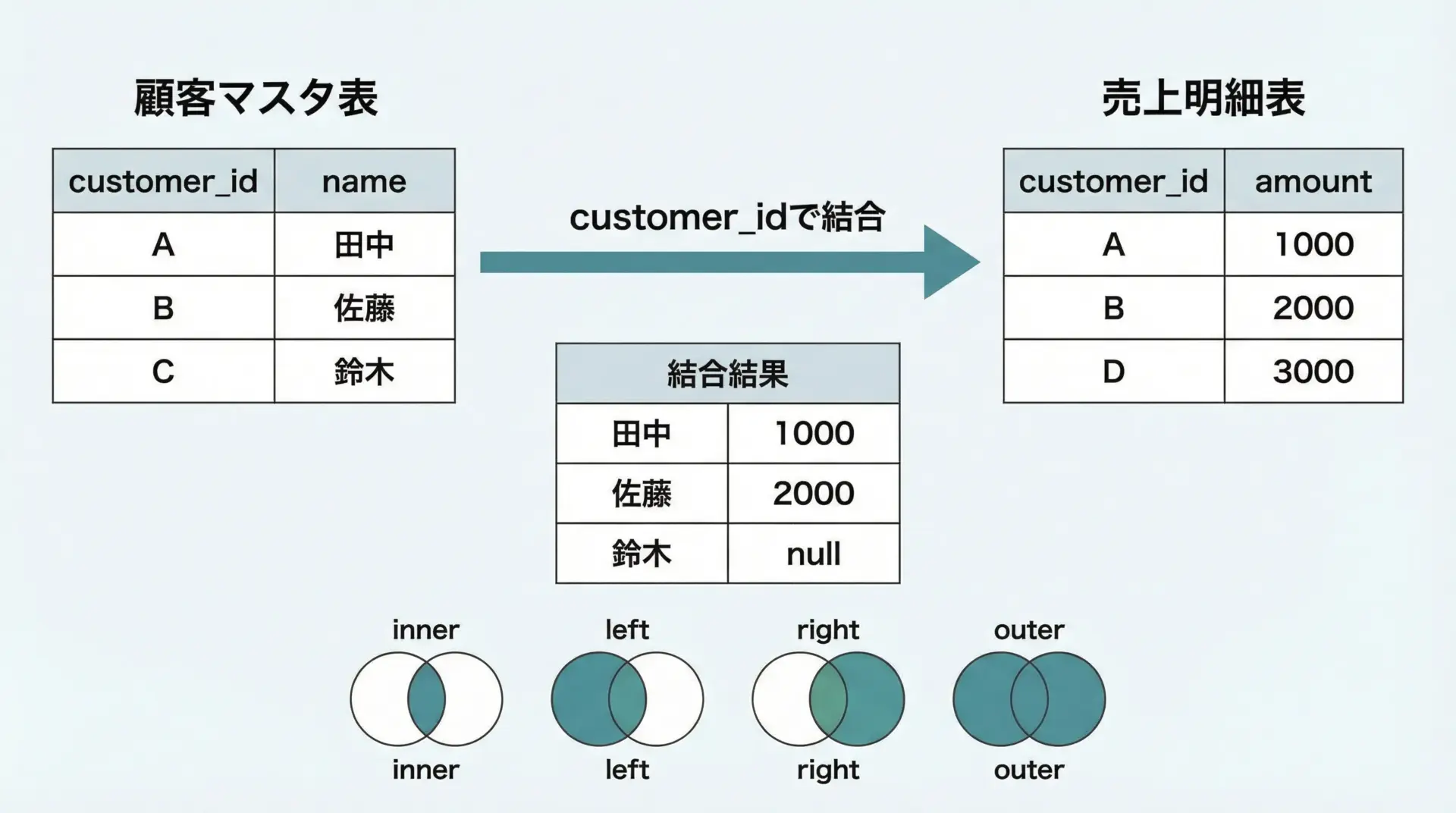
mergeは、SQLのJOINと同様に、共通のキーを使ってDataFrame同士を結合するための関数です。
import pandas as pd
customers = pd.DataFrame(
{
"customer_id": [1, 2, 3],
"name": ["Alice", "Bob", "Charlie"],
}
)
orders = pd.DataFrame(
{
"order_id": [101, 102, 103],
"customer_id": [1, 2, 2],
"amount": [1000, 2000, 1500],
}
)
# customer_idをキーとして結合
merged = pd.merge(customers, orders, on="customer_id", how="inner")
print(merged) customer_id name order_id amount
0 1 Alice 101 1000
1 2 Bob 102 2000
2 2 Bob 103 1500how引数で結合方法を指定できます。
inner: 両方に存在するキーのみ(共通部分)left: 左側のDataFrameを基準に結合right: 右側を基準outer: 両方の全キーを含む(和集合)
# 左外部結合の例
merged_left = pd.merge(customers, orders, on="customer_id", how="left")
print(merged_left) customer_id name order_id amount
0 1 Alice 101.0 1000.0
1 2 Bob 102.0 2000.0
2 2 Bob 103.0 1500.0
3 3 Charlie NaN NaNjoinによるインデックスベースの結合
joinは、インデックスをキーとして結合する場合に便利です。
import pandas as pd
df1 = pd.DataFrame({"value1": [10, 20, 30]}, index=["A", "B", "C"])
df2 = pd.DataFrame({"value2": [100, 200, 300]}, index=["A", "B", "D"])
joined = df1.join(df2, how="left") # 左外部結合
print(joined) value1 value2
A 10 100.0
B 20 200.0
C 30 NaNキーが列にある場合はmerge、キーがインデックスにある場合はjoin、という使い分けが基本です。
並び替え・フィルタリング・条件抽出
sort_values・sort_indexでの並び替え

データを見やすくするために、並び替えはよく使います。
import pandas as pd
df = pd.DataFrame(
{
"name": ["Charlie", "Alice", "Bob"],
"age": [35, 25, 30],
}
)
# ageで昇順にソート
sorted_age = df.sort_values(by="age")
# nameで降順にソート
sorted_name_desc = df.sort_values(by="name", ascending=False)
print("age昇順:")
print(sorted_age)
print("\nname降順:")
print(sorted_name_desc)age昇順:
name age
1 Alice 25
2 Bob 30
0 Charlie 35
name降順:
name age
0 Charlie 35
2 Bob 30
1 Alice 25インデックスで並び替える場合はsort_indexを使います。
df_indexed = df.set_index("name")
print(df_indexed.sort_index()) age
name
Alice 25
Bob 30
Charlie 35条件式による行の抽出
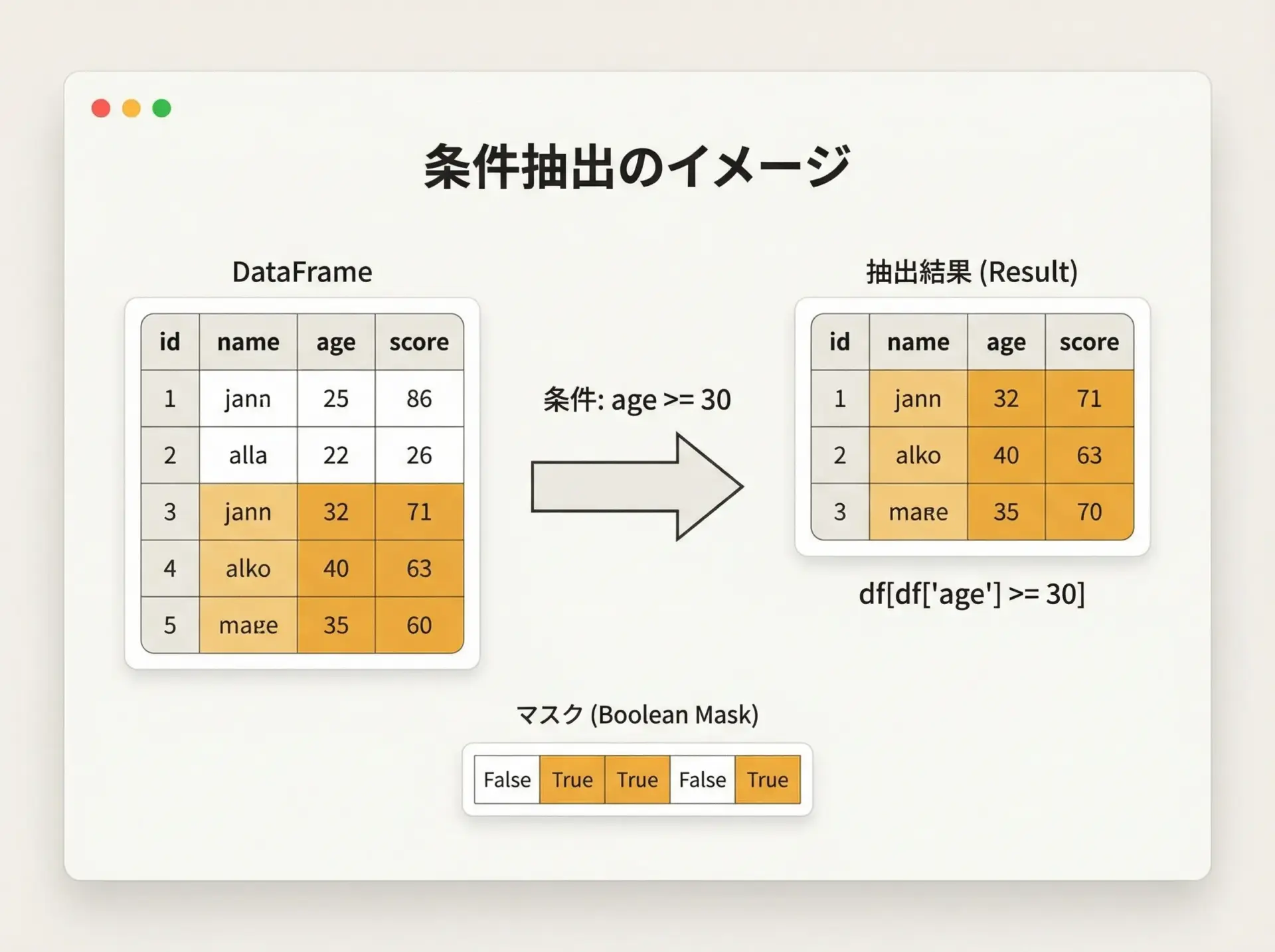
条件でフィルタリングする基本形はdf[条件式]です。
import pandas as pd
df = pd.DataFrame(
{
"name": ["Alice", "Bob", "Charlie"],
"age": [25, 30, 35],
"city": ["Tokyo", "Osaka", "Tokyo"],
}
)
# ageが30以上
cond1 = df["age"] >= 30
result1 = df[cond1]
# ageが30以上 かつ cityがTokyo
cond2 = (df["age"] >= 30) & (df["city"] == "Tokyo")
result2 = df[cond2]
print("age >= 30:")
print(result1)
print("\nage >= 30 & city == 'Tokyo':")
print(result2)age >= 30:
name age city
1 Bob 30 Osaka
2 Charlie 35 Tokyo
age >= 30 & city == 'Tokyo':
name age city
2 Charlie 35 Tokyo論理演算子には&や|を使用し、括弧で条件を囲む必要がある点に注意してください。
queryで可読性の高い条件指定
queryメソッドを使うと、SQL風の文字列で条件を書けるため、可読性が向上します。
import pandas as pd
df = pd.DataFrame(
{
"name": ["Alice", "Bob", "Charlie"],
"age": [25, 30, 35],
"city": ["Tokyo", "Osaka", "Tokyo"],
}
)
# queryで条件抽出
result = df.query("age >= 30 and city == 'Tokyo'")
print(result) name age city
2 Charlie 35 Tokyo列名を変数名のようにそのまま書けるため、複雑な条件では特に読みやすくなります。
pandasによる時系列データ分析
日付型インデックスとリサンプリング
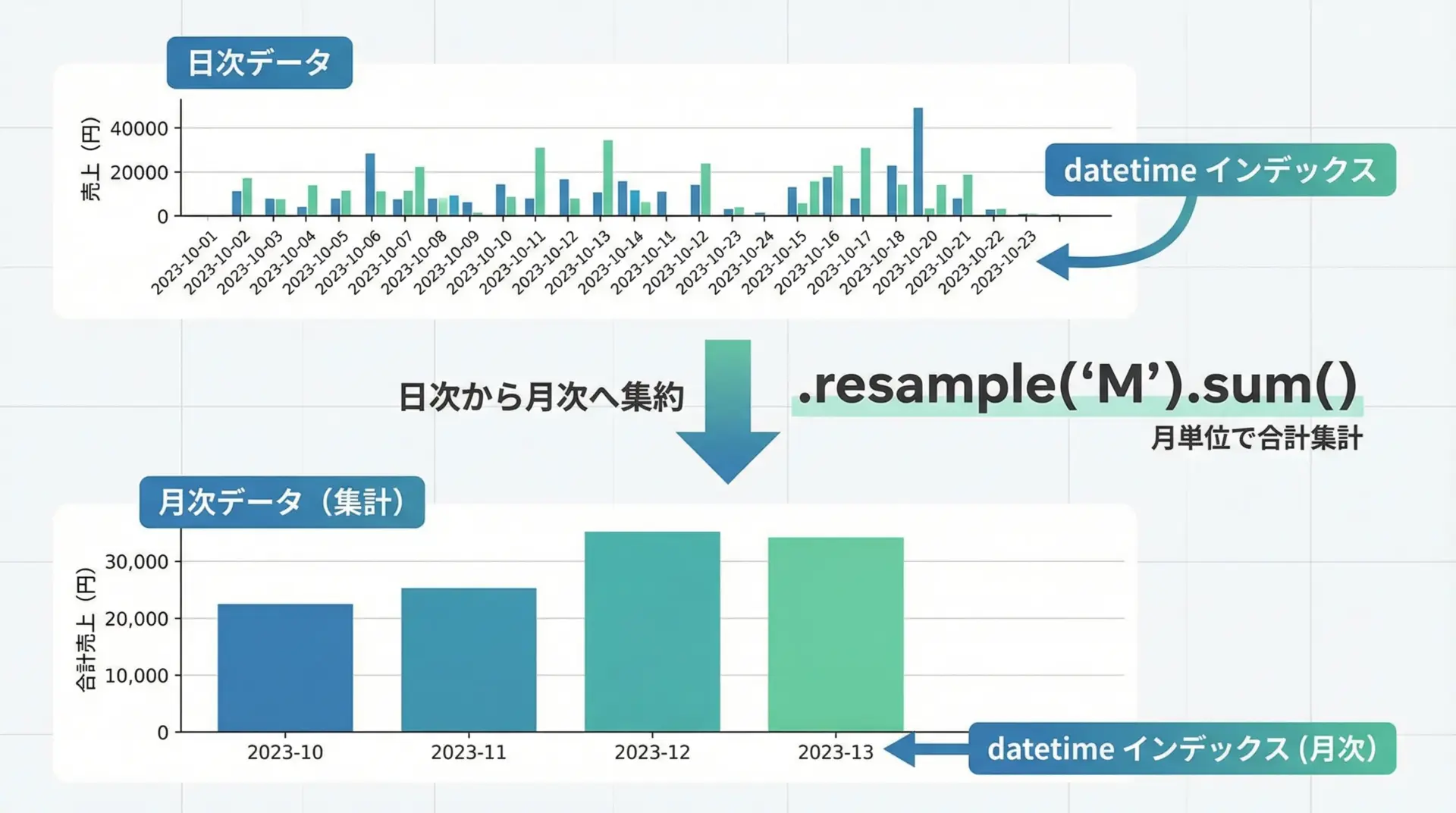
時系列データ分析では、日付をインデックスに設定し、頻度を変換(リサンプリング)する操作が基本となります。
import pandas as pd
# 日次データを作成
df = pd.DataFrame(
{
"date": pd.date_range("2024-01-01", periods=10, freq="D"),
"sales": [100, 120, 80, 90, 110, 130, 150, 170, 160, 140],
}
)
# 日付をインデックスに設定
df = df.set_index("date")
print("日次データ:")
print(df.head())
# 月次にリサンプリングして合計を計算
monthly = df.resample("M").sum()
print("\n月次合計:")
print(monthly)日次データ:
sales
date
2024-01-01 100
2024-01-02 120
2024-01-03 80
2024-01-04 90
2024-01-05 110
月次合計:
sales
date
2024-01-31 1250resample("M")は月次、"W"は週次、"D"は日次など、頻度を表す文字列を指定します。
ローリング集計(rolling)と移動平均
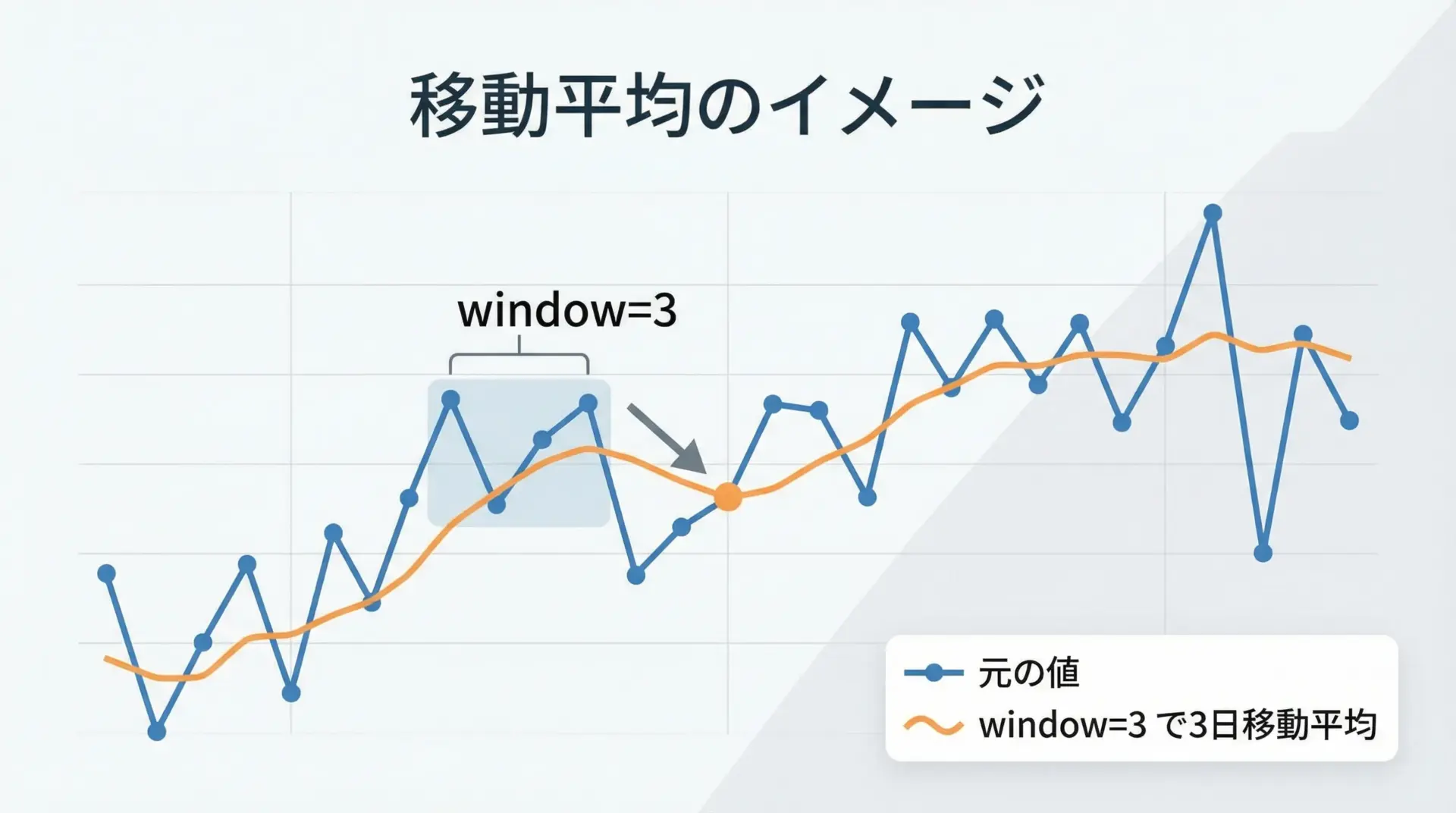
時系列データのノイズをならしたり、トレンドを把握するのに便利なのが移動平均です。
pandasではrollingメソッドを使います。
import pandas as pd
df = pd.DataFrame(
{
"date": pd.date_range("2024-01-01", periods=7, freq="D"),
"sales": [100, 120, 80, 90, 110, 130, 150],
}
).set_index("date")
# 3日移動平均
df["sales_ma3"] = df["sales"].rolling(window=3).mean()
print(df) sales sales_ma3
date
2024-01-01 100 NaN
2024-01-02 120 NaN
2024-01-03 80 100.000000
2024-01-04 90 96.666667
2024-01-05 110 93.333333
2024-01-06 130 110.000000
2024-01-07 150 130.000000最初の数行は、十分なデータ点が揃っていないためNaNになる点も、rollingの特徴です。
時系列シフト(shift・lag)の活用
shiftは、時系列を前後にずらすことで、前日比や前月比などを計算する際に有用です。
import pandas as pd
df = pd.DataFrame(
{
"date": pd.date_range("2024-01-01", periods=5, freq="D"),
"sales": [100, 120, 90, 110, 130],
}
).set_index("date")
# 1日前の売上を追加
df["sales_prev"] = df["sales"].shift(1)
# 前日比(差分)
df["diff"] = df["sales"] - df["sales_prev"]
print(df) sales sales_prev diff
date
2024-01-01 100 NaN NaN
2024-01-02 120 100.0 20.0
2024-01-03 90 120.0 -30.0
2024-01-04 110 90.0 20.0
2024-01-05 130 110.0 20.0shift(-1)とすると、未来方向へのシフト(翌日との比較など)も可能です。
pandasと可視化
DataFrame・Seriesのplotでグラフ描画
pandasは、Matplotlibと連携して簡単なグラフを1行のコードで描画できます。
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame(
{
"date": pd.date_range("2024-01-01", periods=5, freq="D"),
"sales": [100, 120, 90, 110, 130],
}
).set_index("date")
# Seriesのplot
df["sales"].plot(title="Daily Sales")
plt.xlabel("Date")
plt.ylabel("Sales")
plt.tight_layout()
plt.show()このコードを実行すると、日付を横軸、売上を縦軸にした折れ線グラフが表示されます。
折れ線・棒・ヒストグラムの基本グラフ
グラフの種類はkind引数で切り替えられます。
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame(
{
"category": ["A", "B", "C"],
"value": [10, 20, 15],
}
)
# 棒グラフ
df.plot(kind="bar", x="category", y="value", title="Bar Chart")
plt.tight_layout()
plt.show()数値データの分布を見るには、ヒストグラムが役に立ちます。
import pandas as pd
import matplotlib.pyplot as plt
s = pd.Series([10, 12, 10, 15, 13, 12, 11, 14])
# ヒストグラム
s.plot(kind="hist", bins=5, title="Histogram")
plt.xlabel("Value")
plt.tight_layout()
plt.show()グラフ表示のカスタマイズ

pandasのplotはMatplotlibのラッパーなので、Matplotlibの機能を使って細かいカスタマイズが可能です。
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame(
{
"date": pd.date_range("2024-01-01", periods=5, freq="D"),
"sales": [100, 120, 90, 110, 130],
"cost": [60, 70, 50, 65, 80],
}
).set_index("date")
ax = df[["sales", "cost"]].plot(
kind="line",
title="Sales & Cost Over Time",
figsize=(6, 4),
marker="o",
)
ax.set_xlabel("Date")
ax.set_ylabel("Amount")
ax.legend(loc="upper left")
plt.grid(True)
plt.tight_layout()
plt.show()このように、タイトル・軸ラベル・凡例・グリッドなど、見やすいグラフにするための要素を柔軟に設定できます。
pandasデータ分析の実践例
売上データ分析の実例

ここまでの内容を組み合わせて、簡単な売上データ分析を行ってみます。
import pandas as pd
# 1. データ読み込み
df = pd.DataFrame(
{
"order_id": [1, 2, 3, 4, 5, 6],
"date": [
"2024-01-01",
"2024-01-01",
"2024-01-02",
"2024-01-02",
"2024-01-03",
"2024-01-03",
],
"customer": ["Alice", "Bob", "Alice", "Charlie", "Bob", "Alice"],
"product": ["A", "A", "B", "A", "B", "B"],
"amount": [1000, 2000, 1500, 3000, 2500, 1800],
}
)
# 2. 型変換(日付)
df["date"] = pd.to_datetime(df["date"])
# 3-1. 顧客別売上合計
customer_sales = df.groupby("customer")["amount"].sum().sort_values(ascending=False)
# 3-2. 商品×日付のピボット(売上合計)
product_daily = pd.pivot_table(
df,
index="date",
columns="product",
values="amount",
aggfunc="sum",
)
print("顧客別売上合計:")
print(customer_sales)
print("\n商品×日付の売上:")
print(product_daily)顧客別売上合計:
customer
Alice 4300
Bob 4500
Charlie 3000
Name: amount, dtype: int64
商品×日付の売上:
product A B
date
2024-01-01 3000.0 NaN
2024-01-02 3000.0 1500.0
2024-01-03 NaN 4300.0この結果から、「Bobが最も売上が高い顧客」「商品Aは1〜2日に集中、商品Bは3日に集中して売れている」といったインサイトが読み取れます。
アクセスログ分析の実例
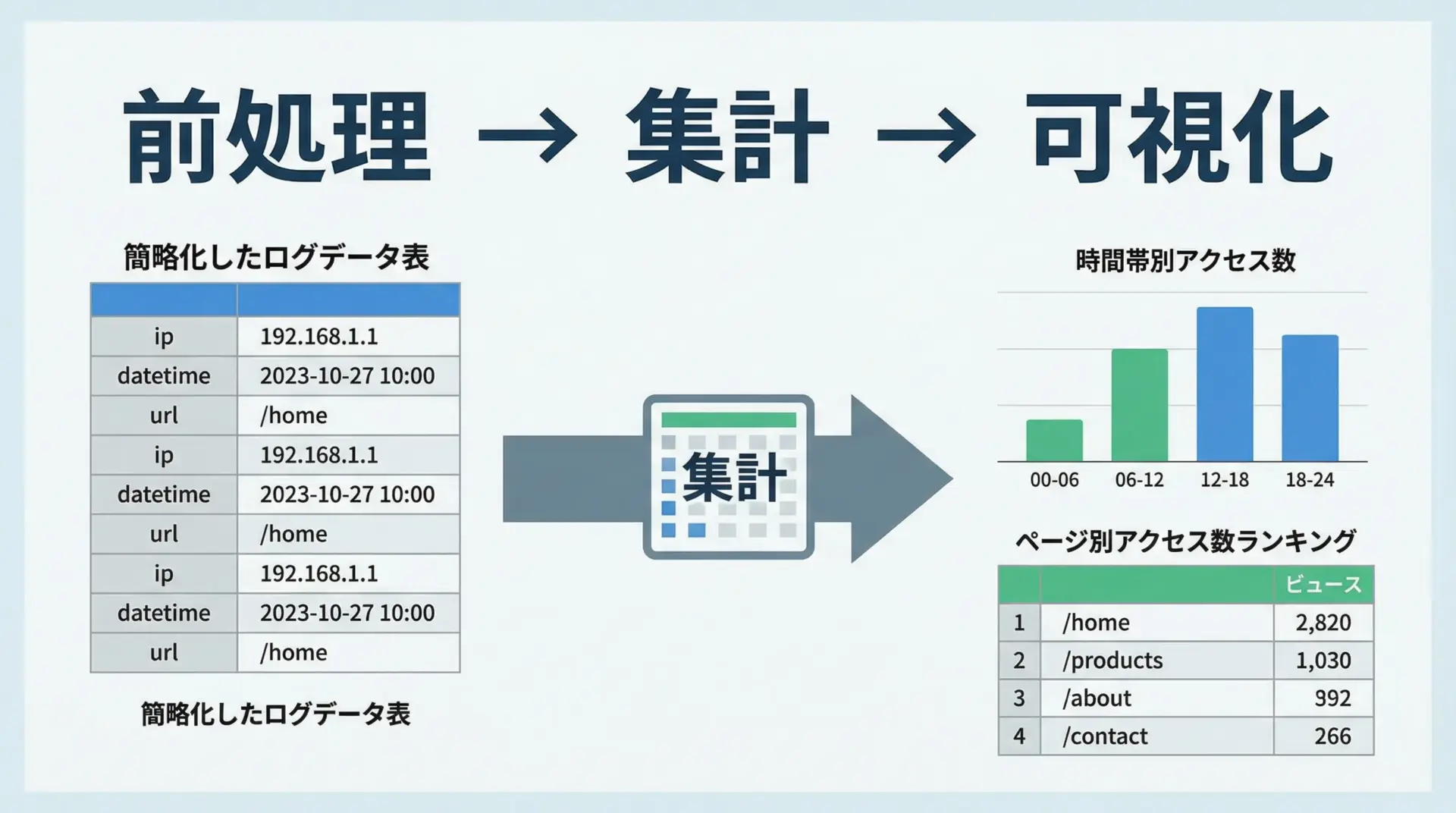
次に、Webアクセスログ風のデータを使った分析例を示します。
import pandas as pd
# サンプルのアクセスログデータ
df = pd.DataFrame(
{
"ip": [
"10.0.0.1",
"10.0.0.2",
"10.0.0.1",
"10.0.0.3",
"10.0.0.2",
"10.0.0.1",
],
"datetime": [
"2024-01-01 09:15",
"2024-01-01 09:20",
"2024-01-01 10:05",
"2024-01-01 10:10",
"2024-01-01 11:00",
"2024-01-01 11:30",
],
"url": ["/", "/products", "/", "/contact", "/products", "/"],
}
)
# 日時をdatetime型に変換し、インデックスに設定
df["datetime"] = pd.to_datetime(df["datetime"])
df = df.set_index("datetime")
# 1. 時間帯別アクセス数(1時間ごと)
hourly = df["ip"].resample("H").count()
# 2. URL別アクセス数ランキング
url_counts = df["url"].value_counts()
print("時間帯別アクセス数:")
print(hourly)
print("\nURL別アクセス数:")
print(url_counts)時間帯別アクセス数:
datetime
2024-01-01 09:00:00 2
2024-01-01 10:00:00 2
2024-01-01 11:00:00 2
Freq: H, Name: ip, dtype: int64
URL別アクセス数:
url
/ 3
/products 2
/contact 1
Name: count, dtype: int64このように、pandasを使えば、ログデータから「どの時間帯にアクセスが集中しているか」「どのページがよく見られているか」を素早く把握できます。
グラフ描画と組み合わせれば、ダッシュボード的な可視化も可能です。
まとめ
pandasは、Pythonによるデータ分析において「表形式データ操作の中心」となるライブラリです。
本記事では、Series・DataFrameといった基本構造から、読み込み・前処理・集計・結合・時系列処理・可視化、そして実践的な分析例までを一通り紹介しました。
実務でpandasを使いこなすには、ここで扱った機能を自分のデータで何度も試し、パターンとして体に覚えさせることが重要です。
ぜひ、身近なCSVやログファイルを題材に、pandasでの分析を実際に手を動かして体験してみてください。
