
Pythonで入力チェックやデータ整形を行うとき、if文だらけのコードになって困った経験はありませんか。
Pydanticは、型ヒントと宣言的な記述だけで、強力なバリデーションとデータ変換を実現できるライブラリです。
本記事では、基礎から実務レベルの活用法、Pydantic v2対応まで、段階的に理解できるよう詳しく解説します。
Python×Pydanticでできるバリデーションとは
Pydanticとは
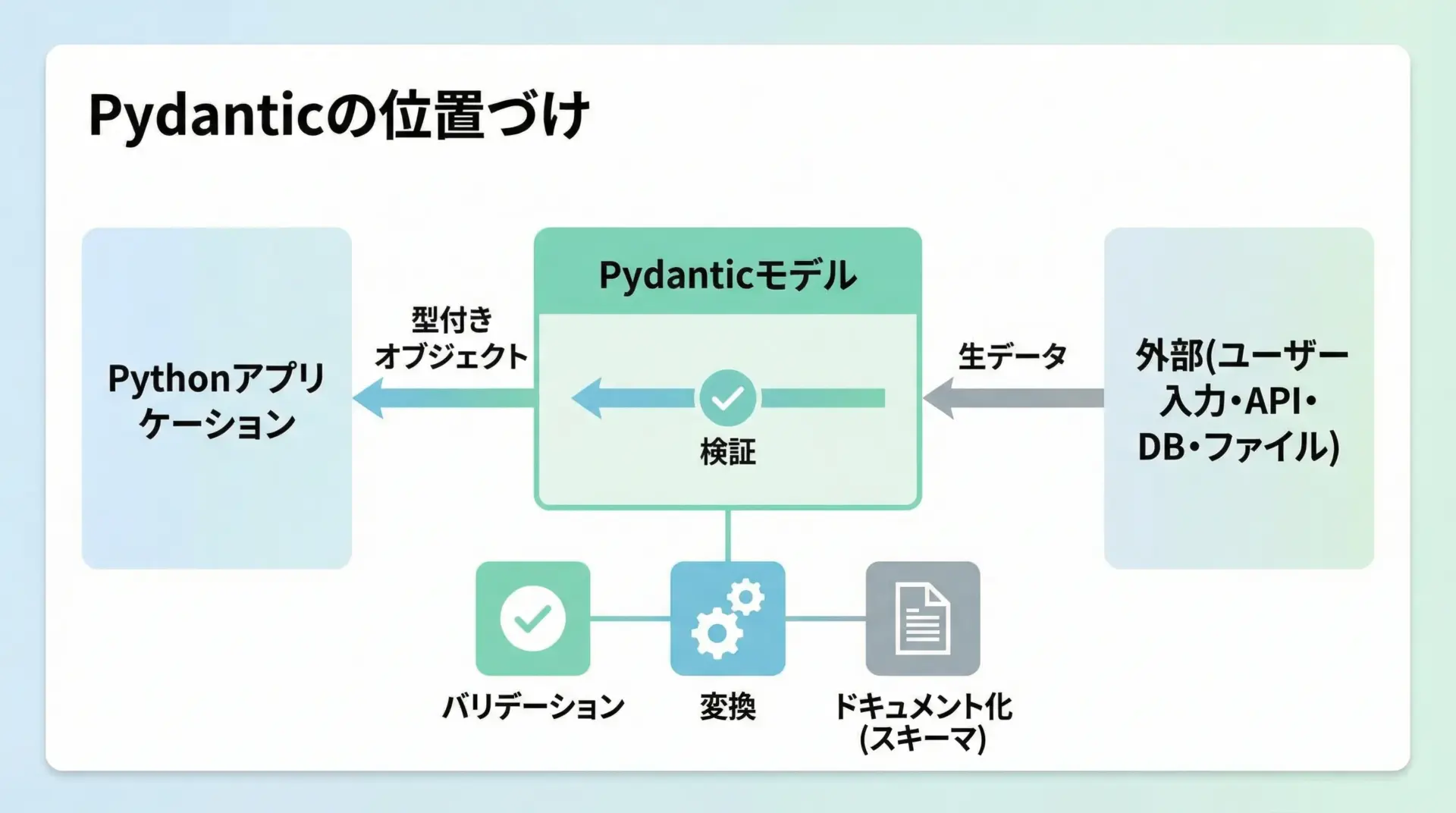
Pydanticとは、Pythonの型ヒントを活用してデータのバリデーション(検証)と変換を行うライブラリです。
フォーム入力やAPIリクエストなどから受け取った信頼できない生データを、安全で扱いやすいオブジェクトに変換してくれます。
Pydanticの特徴として、次の点が挙げられます。
Pydanticは宣言的にルールを書くだけで、煩雑なif文やtry/exceptを大幅に減らせるため、テスト容易性と可読性が向上します。
型ヒントとPydanticの関係
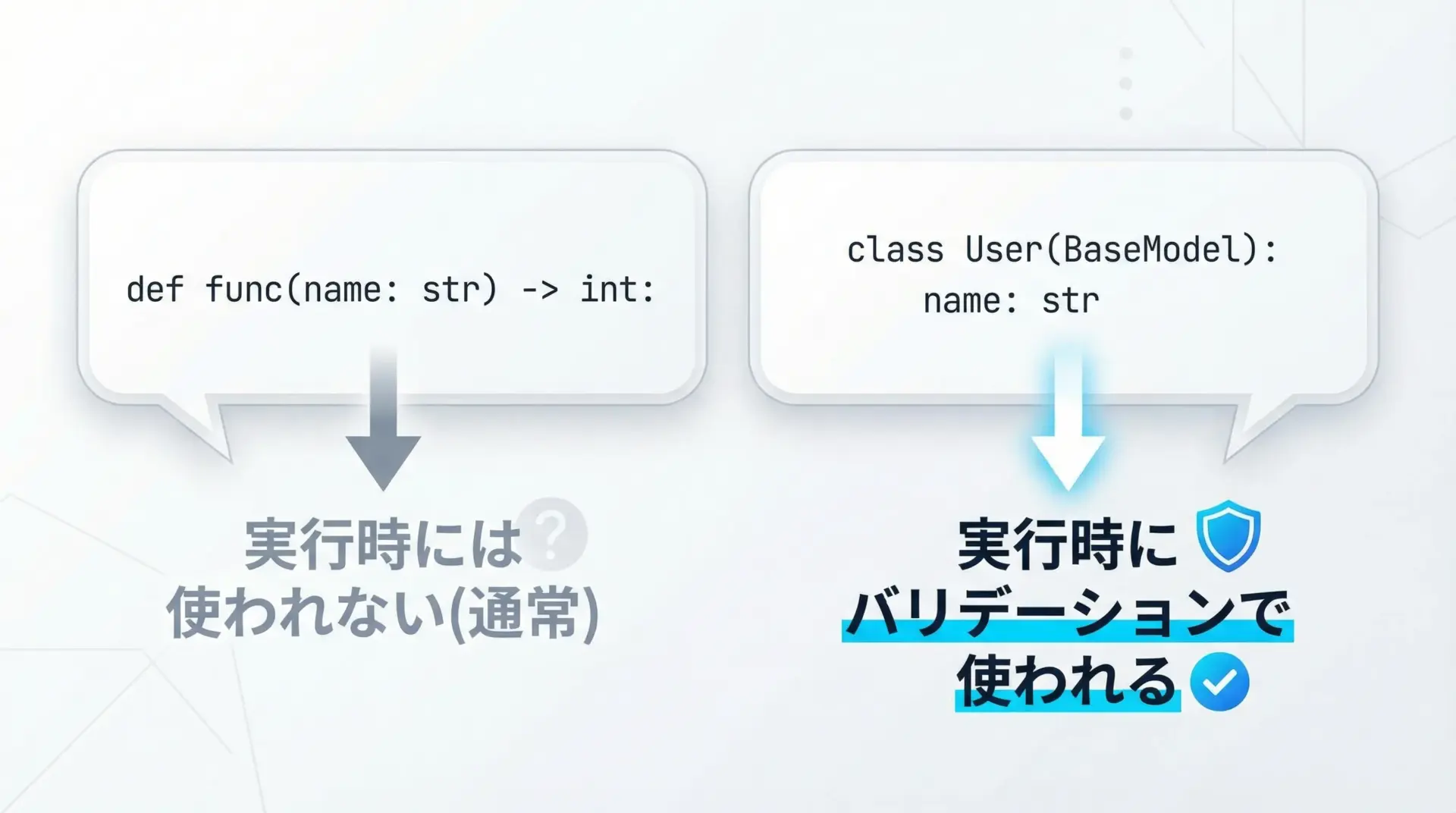
Pythonの型ヒントは通常、静的解析ツール(mypyなど)やエディタ補完のために使われ、実行時には無視されます。
一方、Pydanticでは型ヒントを実行時にも活用し、値のチェックと変換に利用します。
例えばname: strと書かれたフィールドに整数を渡すと、Pydanticは可能な限り変換を試み、それでも不可能ならValidationErrorを発生させます。
このように、型ヒントがコードの自動バリデーション仕様書として機能する点が、Pydanticの大きな魅力です。
フレームワーク(Django/FastAPIなど)との違い
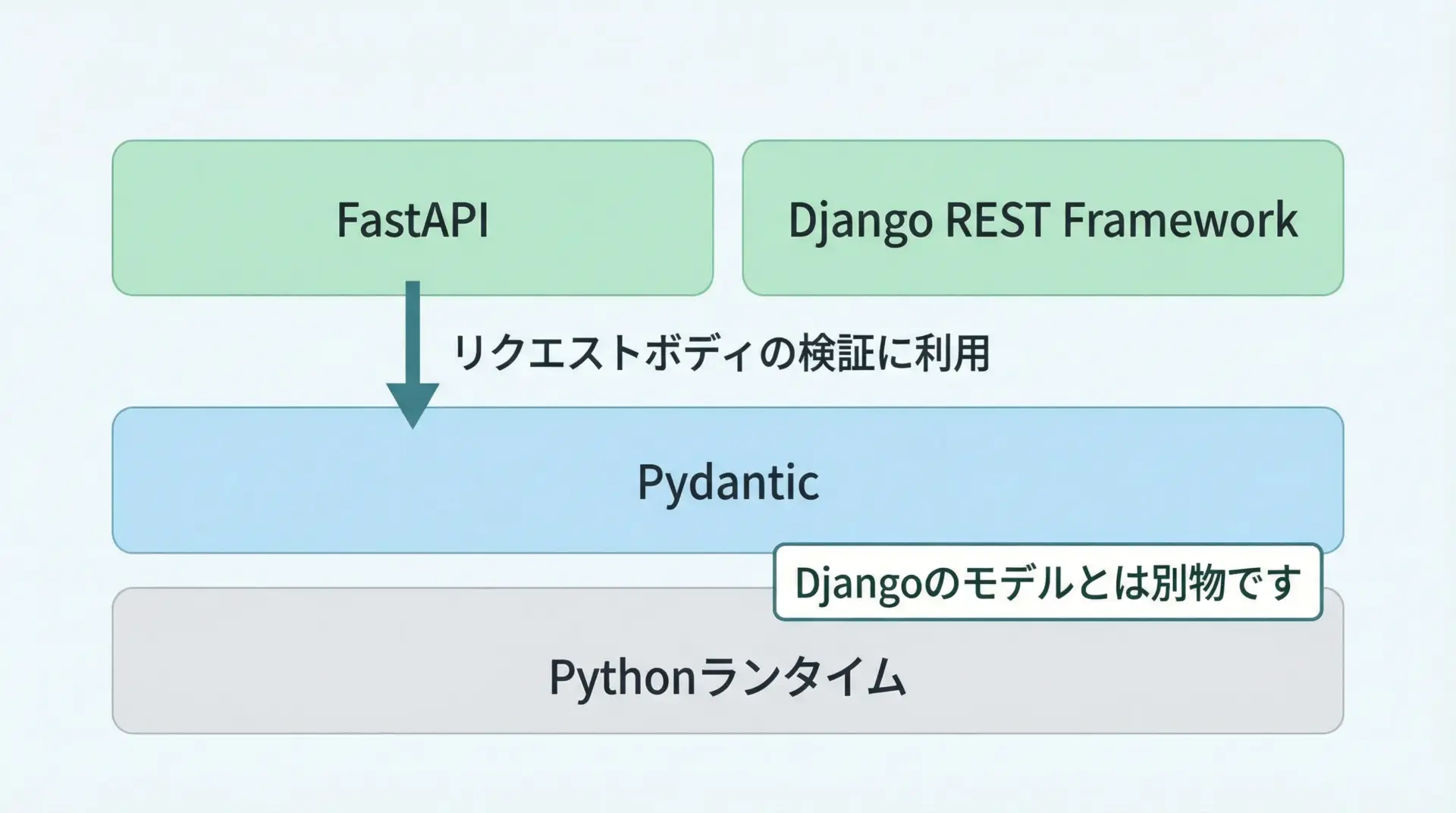
PydanticはWebフレームワークではなく、純粋なデータバリデーションライブラリです。
DjangoやFastAPIとは層が異なります。
FastAPIはリクエスト/レスポンスボディの検証にPydanticを標準採用していますが、Djangoのフォームやモデルバリデーションとは独立しています。
そのため、次のような使い方が可能です。
- Djangoアプリ内で外部APIレスポンスの検証だけにPydanticを使う
- バッチ処理やETLでCSVやJSONの入力チェックに使う
- CLIツールで設定ファイル(TOML/JSON)をPydanticモデルで読み込む
このようにフレームワーク非依存で、どの環境でも同じ記法でバリデーションを統一できる点が強みです。
基本の使い方とモデル定義
BaseModelで始めるPydanticモデル定義
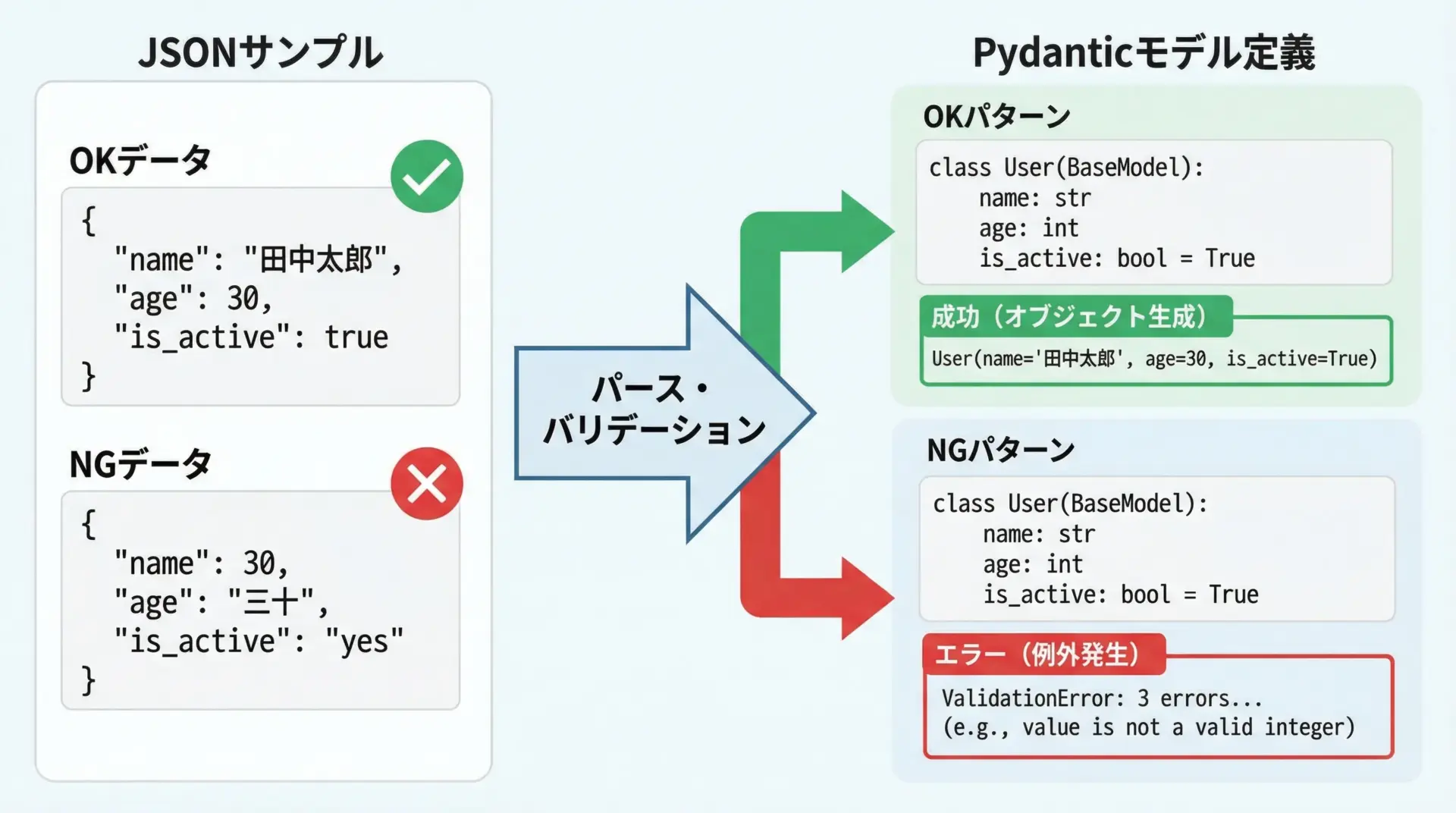
まずはPydantic v2をインストールします。
pip install pydantic基本となるのはBaseModelを継承したクラスです。
# sample_basic_model.py
from pydantic import BaseModel
# ユーザー情報を表すPydanticモデル
class User(BaseModel):
# 型ヒントに基づき、Pydanticが自動でバリデーションを行う
id: int
name: str
is_active: bool
def main():
# 正しいデータ: すべての型が期待通り
user = User(id=1, name="Alice", is_active=True)
print("OK:", user)
# 一部の型が異なるデータ: Pydanticが型変換を試みる
user2 = User(id="2", name="Bob", is_active="true")
print("Converted:", user2)
# 明らかにおかしいデータ(エラーになる例)
try:
User(id="abc", name=123, is_active="yes")
except Exception as e:
print("Error:", repr(e))
if __name__ == "__main__":
main()OK: id=1 name='Alice' is_active=True
Converted: id=2 name='Bob' is_active=True
Error: ValidationError(model='User', errors=...)BaseModelを継承したクラスの属性に型注釈を書くだけで、インスタンス生成時に自動バリデーションが行われます。
型アノテーションによる自動バリデーション

Pydanticは、型アノテーションに基づいて次のような処理を行います。
- 可能ならば自動変換(例: “1” → 1、”true” → True)
- 変換不可能な場合は
ValidationErrorを投げる - ネストしたモデルやリストなども再帰的に検証する
簡単な例を見てみます。
# sample_auto_validation.py
from pydantic import BaseModel
from typing import List
class Item(BaseModel):
id: int
tags: List[str]
def main():
# 文字列の数値を渡しても自動でintに変換される
item = Item(id="10", tags=[1, "python", True])
print(item) # tags も str に変換される
if __name__ == "__main__":
main()id=10 tags=['1', 'python', 'True']このように「受け取ったデータをどう扱いたいか」だけを型で宣言すれば、細かな型変換やチェックはPydanticが肩代わりしてくれます。
必須項目と任意項目(Optional)の扱い方
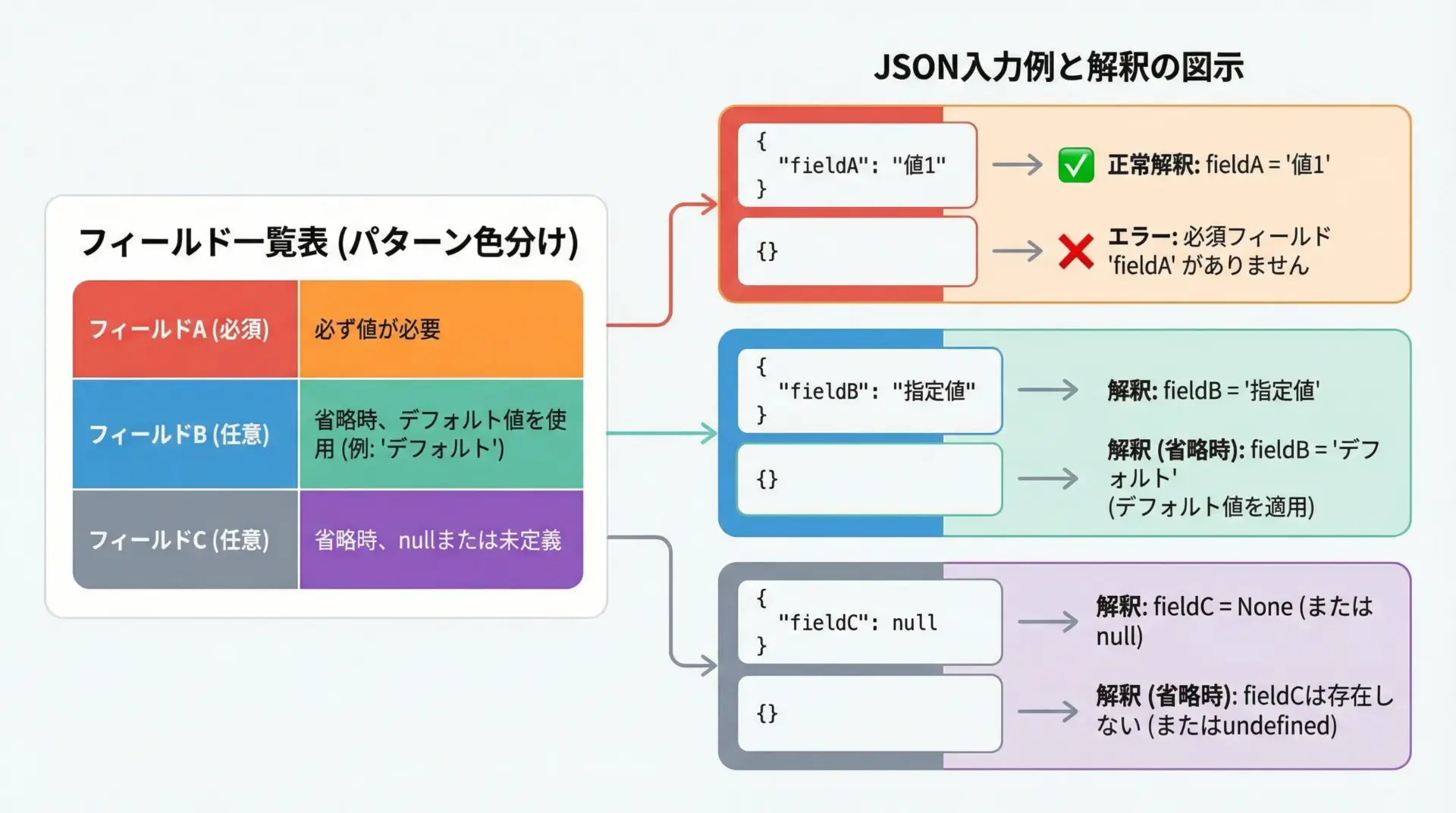
Pydanticでは、フィールド定義の書き方によって必須/任意を表現します。
代表的なパターンは次のようになります。
- 単純な型注釈のみ: 必須項目
- デフォルト値を持つフィールド: 任意(指定がなければデフォルト)
Optional[T]やT | None: Noneも許可
# sample_optional.py
from pydantic import BaseModel
from typing import Optional
class Profile(BaseModel):
# 必須項目
username: str
# デフォルト値あり(任意)
age: int = 0
# Noneを許可する任意項目
nickname: Optional[str] = None
# Python3.10以降のUnion構文でもOK
bio: str | None = None
def main():
# username は必須なので省略するとエラー
try:
Profile()
except Exception as e:
print("Missing username:", repr(e))
# 任意項目を省略するとデフォルト値が適用される
p = Profile(username="alice")
print(p)
if __name__ == "__main__":
main()Missing username: ValidationError(model='Profile', errors=...)
username='alice' age=0 nickname=None bio=Noneビジネス要件に応じて「必須か」「省略可能か」「NULL許可か」を明確に分けて定義することで、データ仕様をコードで正確に表現できます。
代表的な型とバリデーションルール
文字列(String)・数値(int/float)のチェック

Pydanticは基本型に対しても便利な制約機能を提供します。
v2ではpydantic.types配下などの型付きヘルパを使うのが一般的です。
# sample_basic_types.py
from pydantic import BaseModel, Field
class Product(BaseModel):
name: str
price: float = Field(gt=0, description="0より大きい価格")
stock: int = Field(ge=0, description="在庫は0以上")
def main():
ok = Product(name="Book", price=1200, stock=10)
print("OK:", ok)
# 価格が0以下だとエラー
try:
Product(name="Free", price=0, stock=5)
except Exception as e:
print("Invalid price:", repr(e))
if __name__ == "__main__":
main()OK: name='Book' price=1200.0 stock=10
Invalid price: ValidationError(model='Product', errors=...)Fieldを使うことで、同じ型でも値の範囲などの詳細な制約を付与できます。
日付(datetime)・UUIDなどの標準型
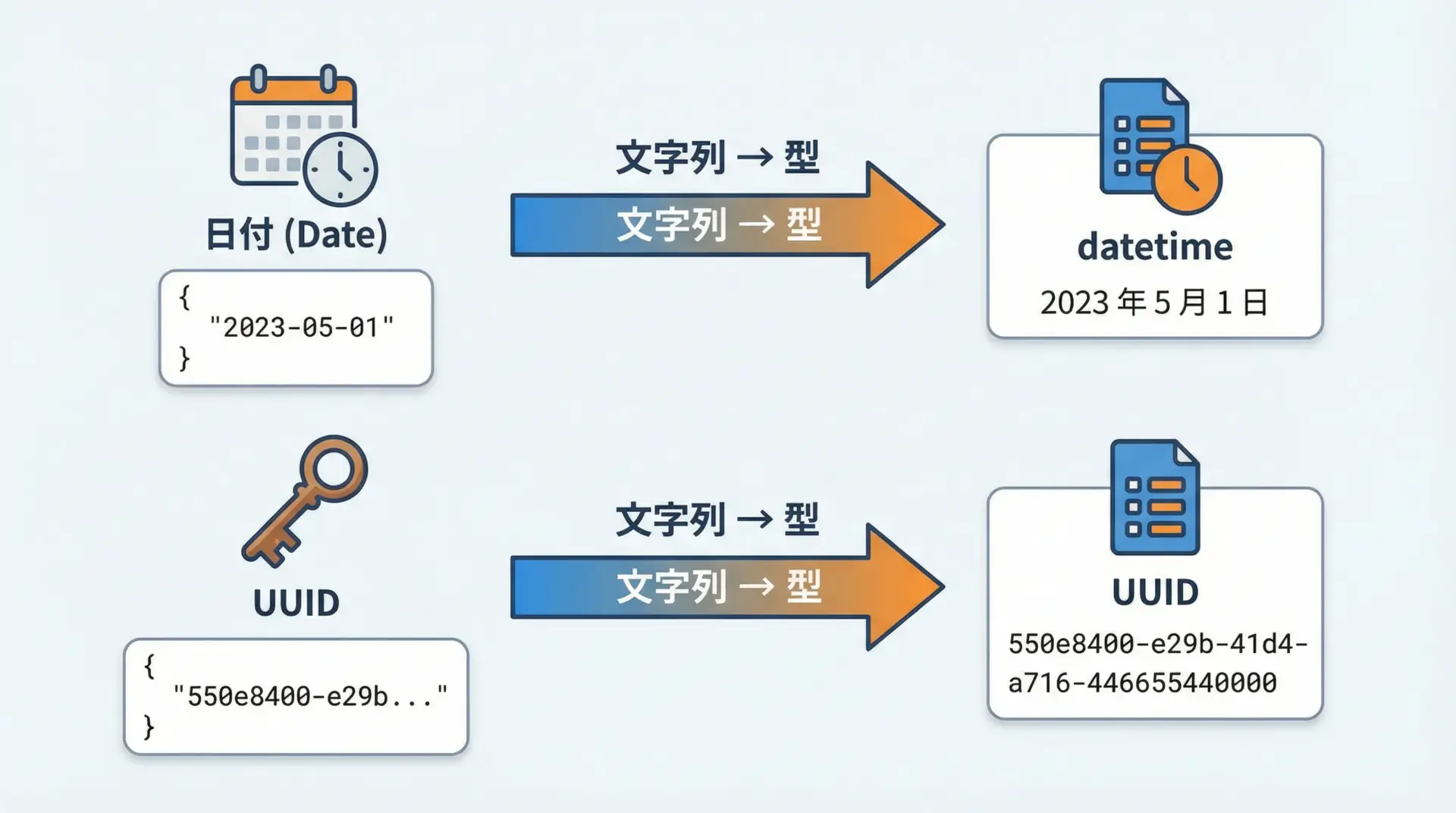
日時やUUIDは、標準ライブラリの型をそのまま使えます。
# sample_datetime_uuid.py
from pydantic import BaseModel
from datetime import datetime, date
from uuid import UUID
class Event(BaseModel):
id: UUID
name: str
start_at: datetime
closed_on: date | None = None
def main():
e = Event(
id="550e8400-e29b-41d4-a716-446655440000", # 文字列でもOK
name="Webinar",
start_at="2024-01-01T10:00:00",
)
print(e)
print("start_at type:", type(e.start_at))
if __name__ == "__main__":
main()id=UUID('550e8400-e29b-41d4-a716-446655440000') name='Webinar' start_at=datetime.datetime(2024, 1, 1, 10, 0) closed_on=None
start_at type: <class 'datetime.datetime'>ISO8601形式の文字列をdatetimeに変換してくれるため、APIなどで扱う日付の安全性と利便性が高まります。
List・Dictなどコレクション型の制約
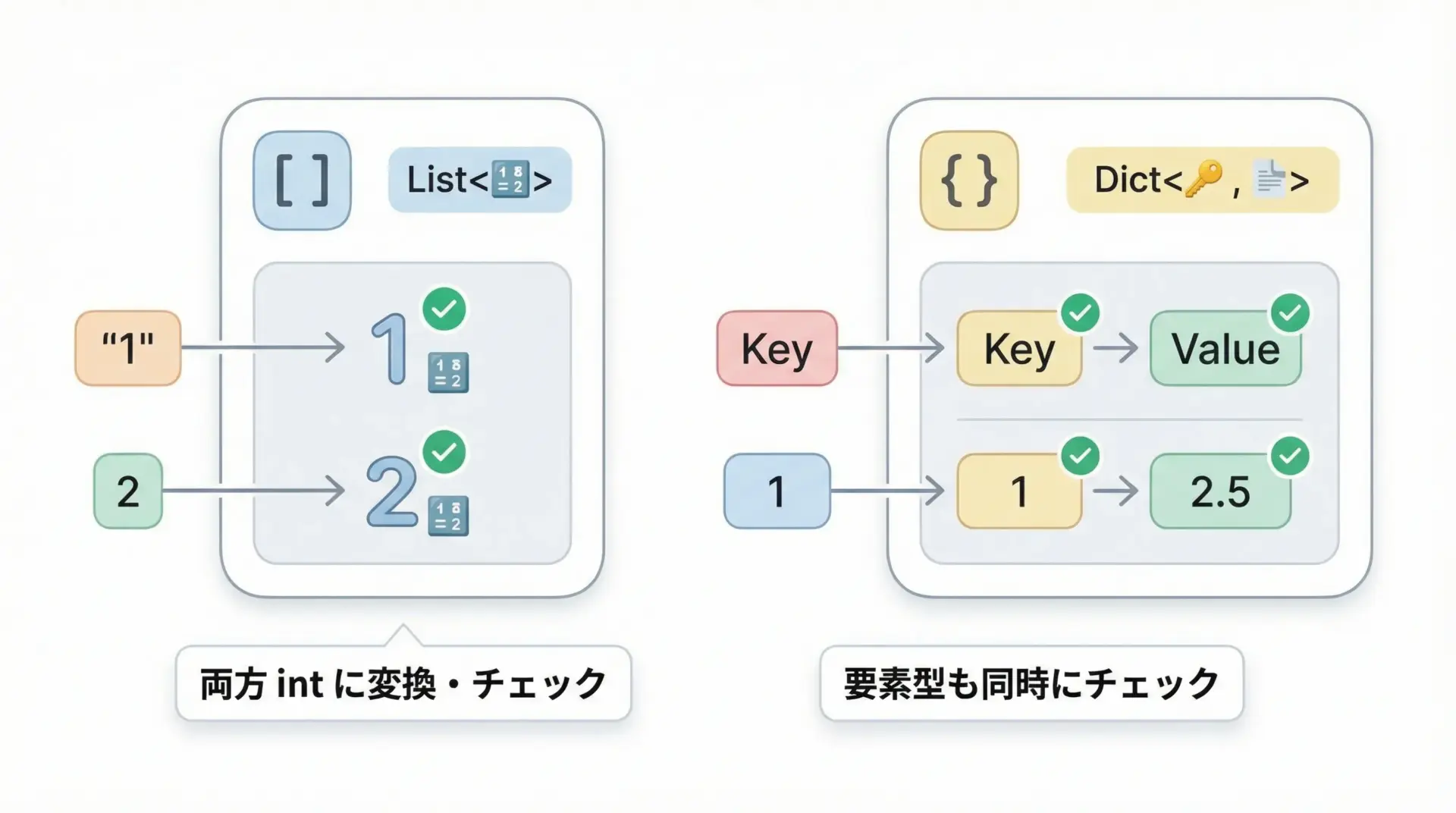
リストや辞書など複数要素を持つコレクションも、要素型を指定することで中身まで検証できます。
# sample_collections.py
from pydantic import BaseModel, Field
from typing import List, Dict
class Order(BaseModel):
# 商品IDのリスト(空リスト禁止・最大100件)
item_ids: List[int] = Field(min_length=1, max_length=100)
# 商品ID → 個数 のマッピング
quantities: Dict[int, int]
def main():
order = Order(
item_ids=["1", 2, 3], # 文字列もintに変換される
quantities={"1": "2", 2: 3},
)
print(order)
print("quantities keys:", list(order.quantities.keys()))
# 空リストはエラー
try:
Order(item_ids=[], quantities={})
except Exception as e:
print("Empty item_ids:", repr(e))
if __name__ == "__main__":
main()item_ids=[1, 2, 3] quantities={1: 2, 2: 3}
quantities keys: [1, 2]
Empty item_ids: ValidationError(model='Order', errors=...)コレクションのサイズ制約(min_length/max_length)や、要素の型チェックが自動で行われるため、配列の検証ロジックも簡潔に書けます。
実務で使えるバリデーションパターン
メールアドレス・URL・正規表現チェック
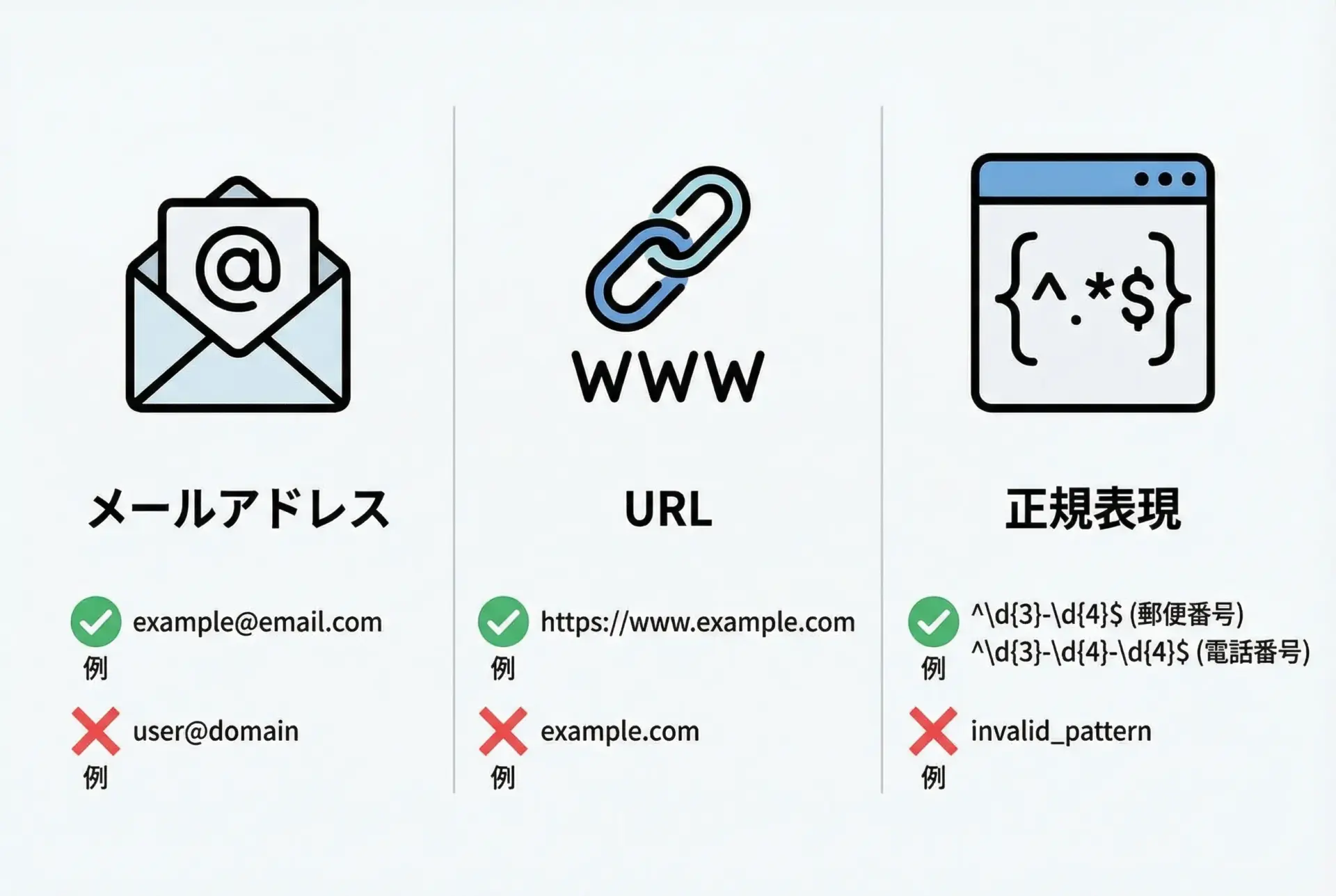
PydanticはメールアドレスやURLなど、よく使うフォーマット用の型を提供しています。
# sample_email_url_regex.py
from pydantic import BaseModel, EmailStr, AnyUrl, Field
class Contact(BaseModel):
email: EmailStr
website: AnyUrl | None = None
# 日本の郵便番号(例: 123-4567)を正規表現でチェック
zipcode: str = Field(pattern=r"^\d{3}-\d{4}$")
def main():
c = Contact(
email="user@example.com",
website="https://example.com/path?x=1",
zipcode="123-4567",
)
print("OK:", c)
# 不正なメールアドレス
try:
Contact(
email="invalid-email",
website="not-a-url",
zipcode="1234567",
)
except Exception as e:
print("Invalid contact:", repr(e))
if __name__ == "__main__":
main()OK: email='user@example.com' website=AnyUrl('https://example.com/path?x=1', ...) zipcode='123-4567'
Invalid contact: ValidationError(model='Contact', errors=...)フォーマットごとの専用型(EmailStr・AnyUrlなど)を使うと、自前で正規表現を書く必要が減り、信頼性も高まります。
範囲チェック
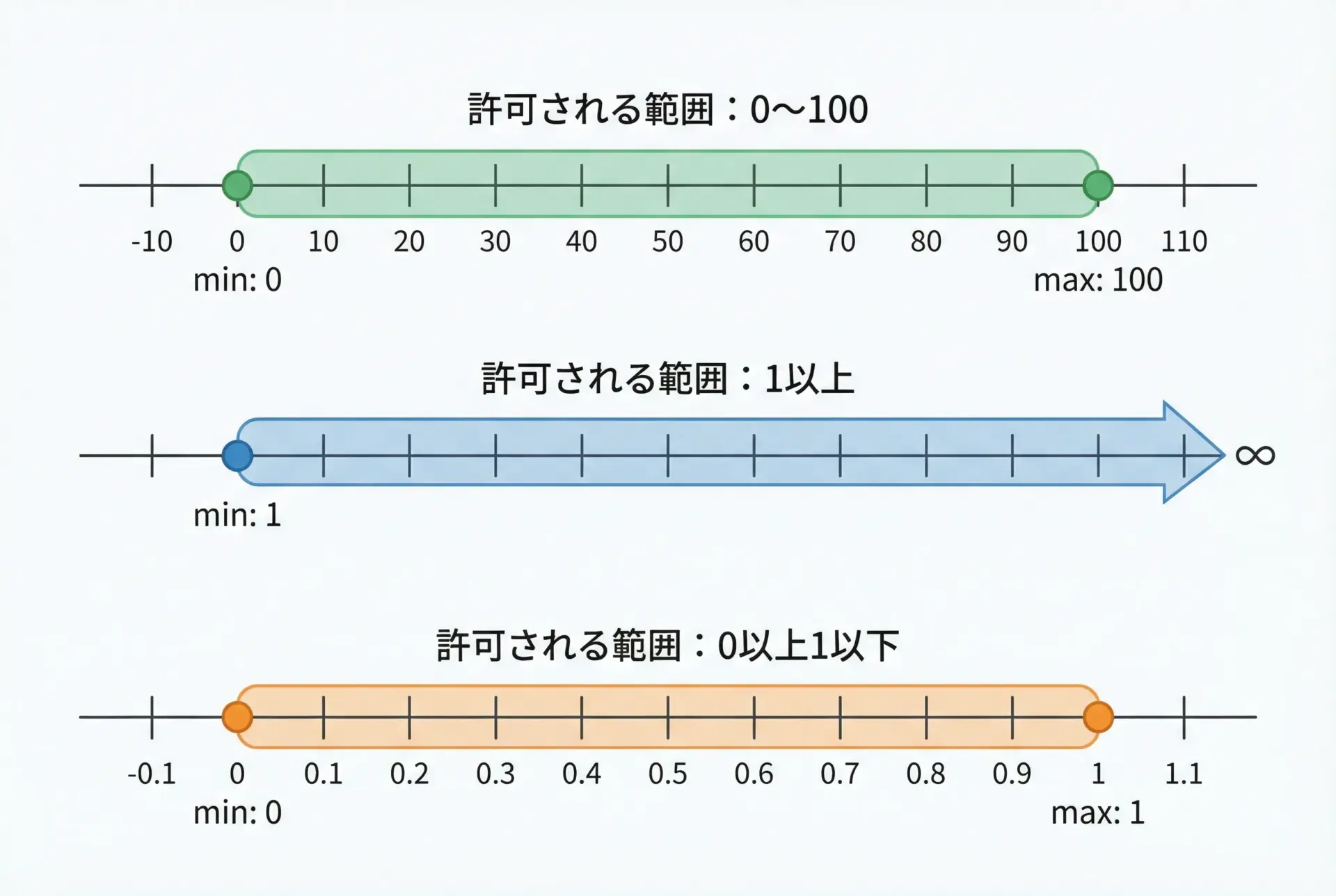
Fieldの引数を使うと、数値や日付などに範囲制約を簡単に付けられます。
# sample_range.py
from pydantic import BaseModel, Field
from datetime import date
class Score(BaseModel):
value: int = Field(ge=0, le=100) # 0〜100点
# 今日以降の日付のみ許可
exam_date: date = Field(ge=date.today())
def main():
s = Score(value=80, exam_date=str(date.today()))
print("OK:", s)
try:
Score(value=120, exam_date="2000-01-01")
except Exception as e:
print("Out of range:", repr(e))
if __name__ == "__main__":
main()OK: value=80 exam_date=datetime.date(20XX, X, X)
Out of range: ValidationError(model='Score', errors=...)gt/ge/lt/le(より大きい/以上/未満/以下)を組み合わせることで、ビジネスロジックに沿った細かい制約を定義できます。
文字数制限・列挙型(Choice)の定義

文字列の長さ制限や、特定の値のみを許可する列挙型は、実務で頻出です。
# sample_length_enum.py
from pydantic import BaseModel, Field
from enum import Enum
class Status(str, Enum):
DRAFT = "draft"
PUBLISHED = "published"
ARCHIVED = "archived"
class Article(BaseModel):
title: str = Field(min_length=3, max_length=100)
body: str = Field(min_length=1)
status: Status = Status.DRAFT
def main():
a = Article(
title="Pydantic入門",
body="本文...",
status="published", # 文字列でもEnumに変換される
)
print("OK:", a)
try:
Article(title="NG", body="", status="unknown")
except Exception as e:
print("Invalid article:", repr(e))
if __name__ == "__main__":
main()OK: title='Pydantic入門' body='本文...' status=<Status.PUBLISHED: 'published'>
Invalid article: ValidationError(model='Article', errors=...)Enumを使うことで、選択肢をコード上で明示でき、IDE補完やリファクタリングの恩恵も受けられます。
カスタムバリデーションの書き方
Pydantic v2では、@field_validatorや@model_validatorでカスタムバリデーションを記述します。
フィールド単位のカスタムバリデータ
# sample_field_validator.py
from pydantic import BaseModel, field_validator
class User(BaseModel):
username: str
password: str
# password フィールドに対するカスタムバリデーション
@field_validator("password")
@classmethod
def password_strength(cls, v: str) -> str:
# 8文字以上・英数字混在をチェックする簡易例
if len(v) < 8:
raise ValueError("password must be at least 8 characters")
if v.isdigit() or v.isalpha():
raise ValueError("password must contain both letters and digits")
return v
def main():
u = User(username="alice", password="abc12345")
print("OK:", u)
try:
User(username="bob", password="short")
except Exception as e:
print("Weak password:", repr(e))
if __name__ == "__main__":
main()OK: username='alice' password='abc12345'
Weak password: ValidationError(model='User', errors=...)フィールド単位のバリデータは、その項目だけで完結するチェックに向いています。
モデル全体の整合性チェック
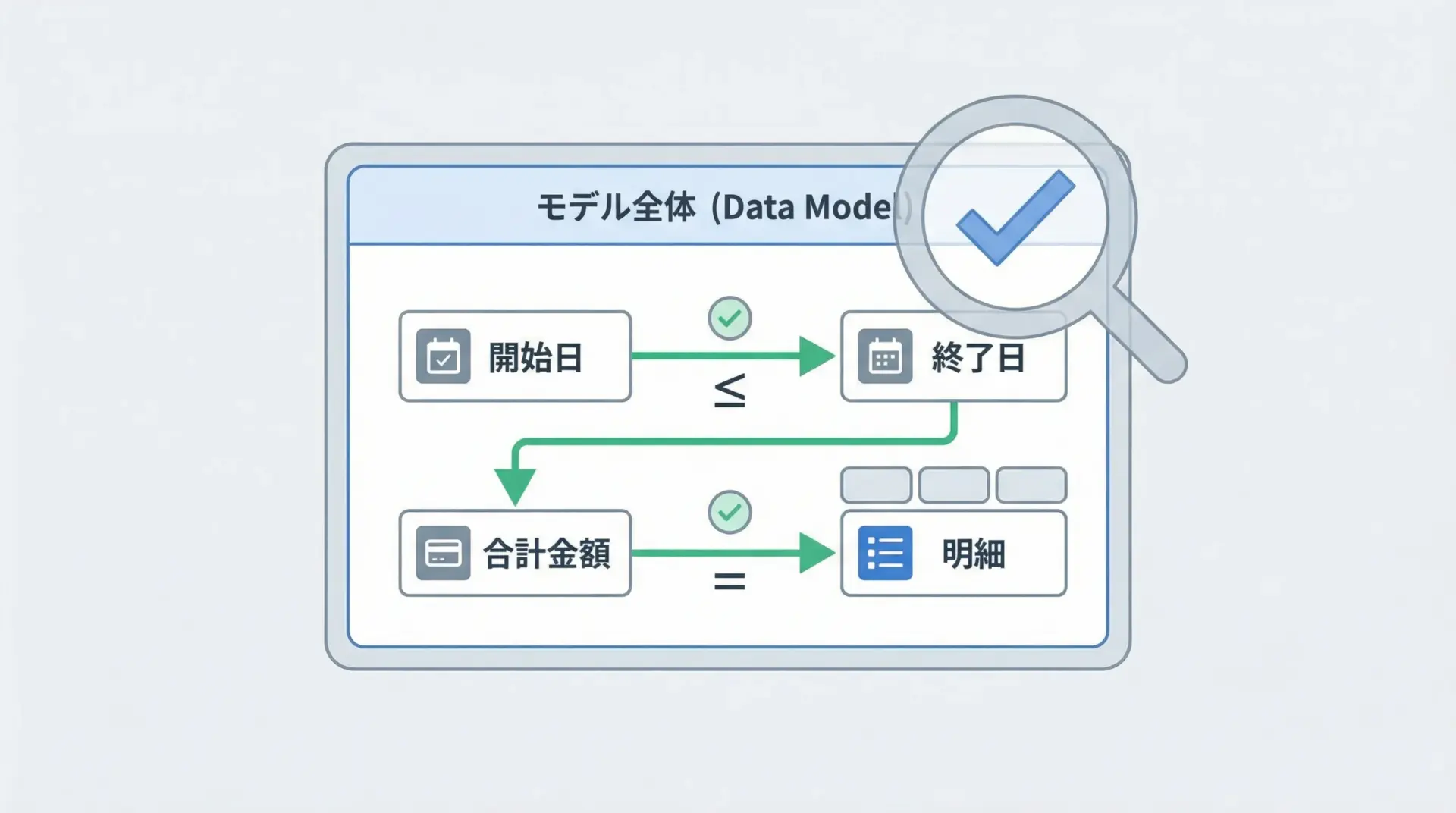
モデル全体を見て整合性を確認したい場合には@model_validatorを使います。
# sample_model_validator.py
from pydantic import BaseModel, model_validator
from datetime import date
class Period(BaseModel):
start: date
end: date
@model_validator(mode="after")
def check_order(self) -> "Period":
# afterモード: すべてのフィールドバリデーション後に呼ばれる
if self.start > self.end:
raise ValueError("start must be before or equal to end")
return self
def main():
p = Period(start="2024-01-01", end="2024-01-31")
print("OK:", p)
try:
Period(start="2024-02-01", end="2024-01-31")
except Exception as e:
print("Invalid period:", repr(e))
if __name__ == "__main__":
main()OK: start=datetime.date(2024, 1, 1) end=datetime.date(2024, 1, 31)
Invalid period: ValidationError(model='Period', errors=...)モデルバリデータは複数フィールドをまたぐチェックに必須であり、ビジネスルールの中核を実装するのに適しています。
複数フィールドにまたがる業務ルールの実装
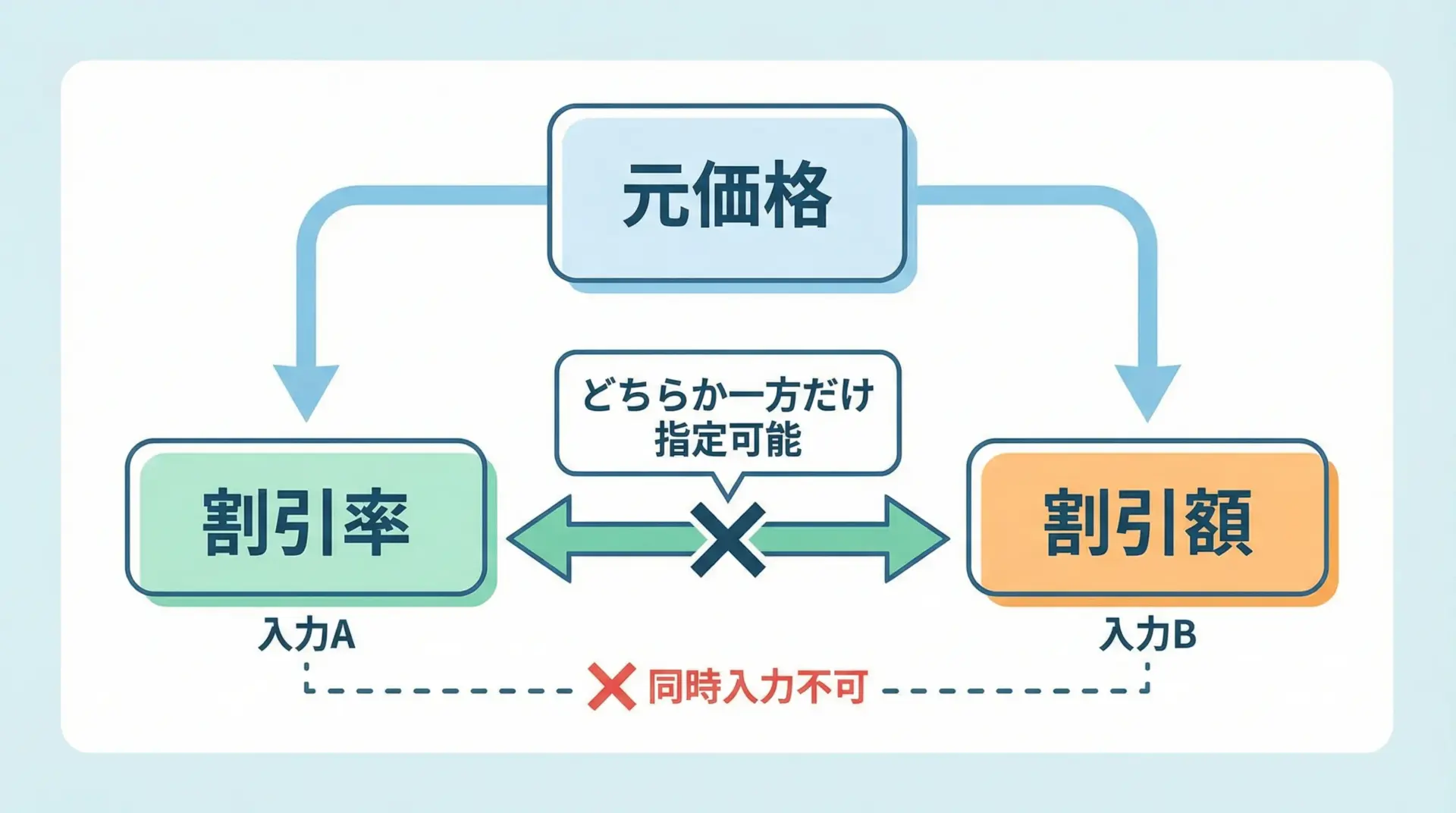
複数のフィールドの組み合わせに意味があるケースでは、モデルバリデータを使って業務ルールを表現します。
# sample_business_rules.py
from pydantic import BaseModel, model_validator, Field
from typing import Optional
class Discount(BaseModel):
price: int = Field(ge=0)
# 割引率か割引額のどちらか一方だけ指定
percent: Optional[int] = Field(default=None, ge=0, le=100)
amount: Optional[int] = Field(default=None, ge=0)
@model_validator(mode="after")
def check_rule(self) -> "Discount":
if self.percent is None and self.amount is None:
raise ValueError("either percent or amount is required")
if self.percent is not None and self.amount is not None:
raise ValueError("percent and amount cannot both be set")
# 合理性チェック(例: 割引額は価格を超えない)
if self.amount is not None and self.amount > self.price:
raise ValueError("amount cannot exceed price")
return self
def main():
d1 = Discount(price=1000, percent=20)
d2 = Discount(price=1000, amount=500)
print("OK1:", d1)
print("OK2:", d2)
try:
Discount(price=1000)
except Exception as e:
print("Missing discount:", repr(e))
if __name__ == "__main__":
main()OK1: price=1000 percent=20 amount=None
OK2: price=1000 percent=None amount=500
Missing discount: ValidationError(model='Discount', errors=...)「どちらか一方だけ」「両方必須」「条件付き必須」など複雑なパターンも、このように宣言的に表現できます。
ネスト・再利用可能なモデル設計
ネストしたPydanticモデルで構造化データを表現
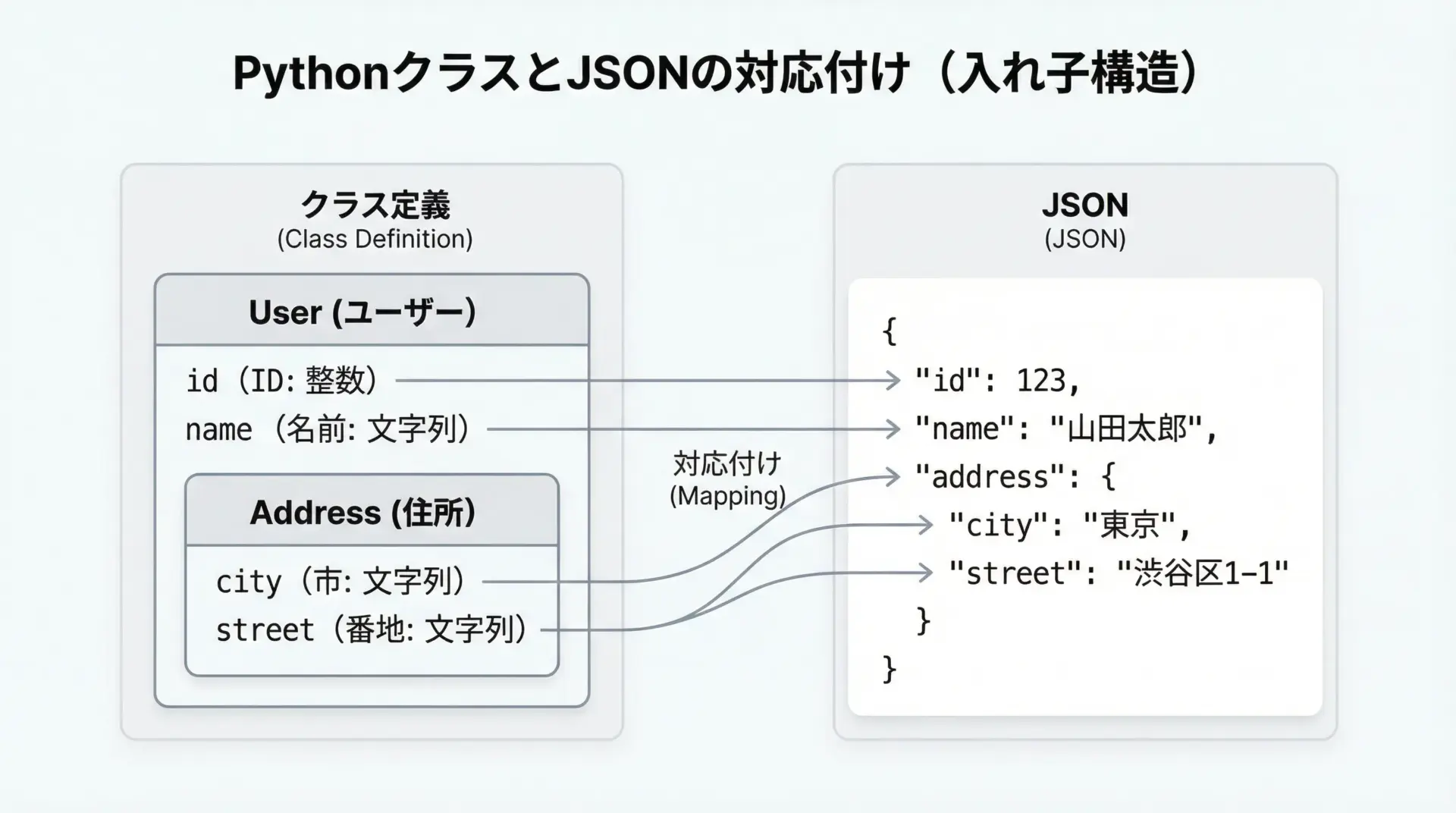
ネストされた構造をそのままクラスで表現すると、JSONなどの構造化データを分かりやすく扱えます。
# sample_nested_models.py
from pydantic import BaseModel
from typing import List
class Address(BaseModel):
city: str
street: str
zip: str
class User(BaseModel):
id: int
name: str
addresses: List[Address]
def main():
data = {
"id": 1,
"name": "Alice",
"addresses": [
{"city": "Tokyo", "street": "1-2-3", "zip": "100-0001"},
{"city": "Osaka", "street": "4-5-6", "zip": "530-0001"},
],
}
user = User(**data)
print(user)
print("First city:", user.addresses[0].city)
if __name__ == "__main__":
main()id=1 name='Alice' addresses=[Address(city='Tokyo', street='1-2-3', zip='100-0001'), Address(city='Osaka', street='4-5-6', zip='530-0001')]
First city: Tokyoネスト構造をそのままモデルにすることで、ドキュメントとしても自己説明的になり、保守性が高まります。
共通スキーマの切り出しと再利用
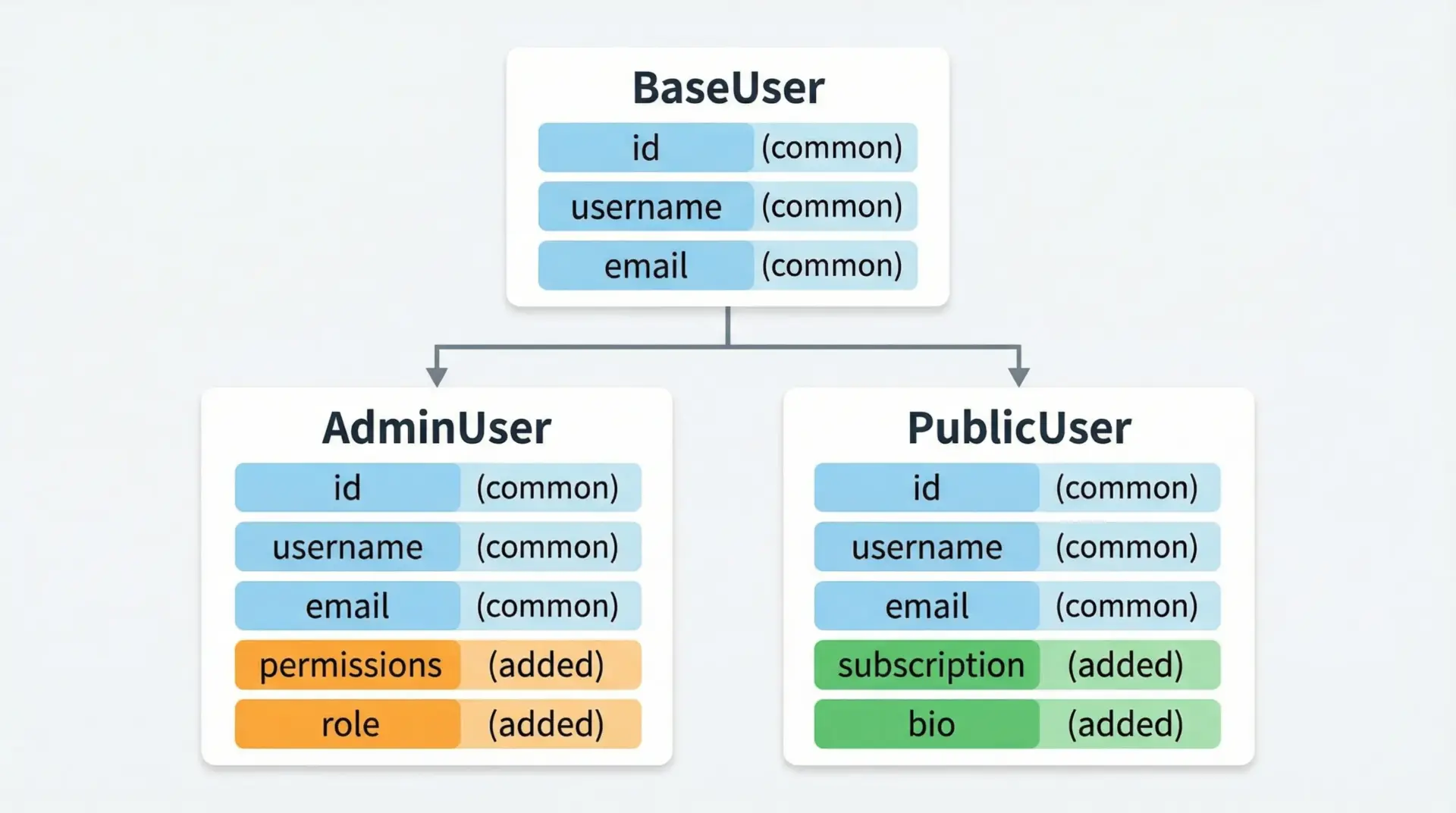
同じフィールド構造を複数の場面で使い回したい場合は、ベースモデルを定義して継承するのが有効です。
# sample_reuse_models.py
from pydantic import BaseModel
class UserBase(BaseModel):
id: int
name: str
email: str
class UserPublic(UserBase):
# 公開向け: メールは隠すなど
pass
class UserInternal(UserBase):
# 社内向け: is_admin フィールドを追加
is_admin: bool = False
def main():
internal = UserInternal(id=1, name="Alice", email="a@example.com", is_admin=True)
public = UserPublic(id=1, name="Alice", email="a@example.com")
print("Internal:", internal)
print("Public:", public)
if __name__ == "__main__":
main()Internal: id=1 name='Alice' email='a@example.com' is_admin=True
Public: id=1 name='Alice' email='a@example.com'再利用可能なベースモデルを定義しておくと、仕様変更時に1カ所の修正で全体を揃えやすくなります。
大規模プロジェクトでのモデル分割アプローチ
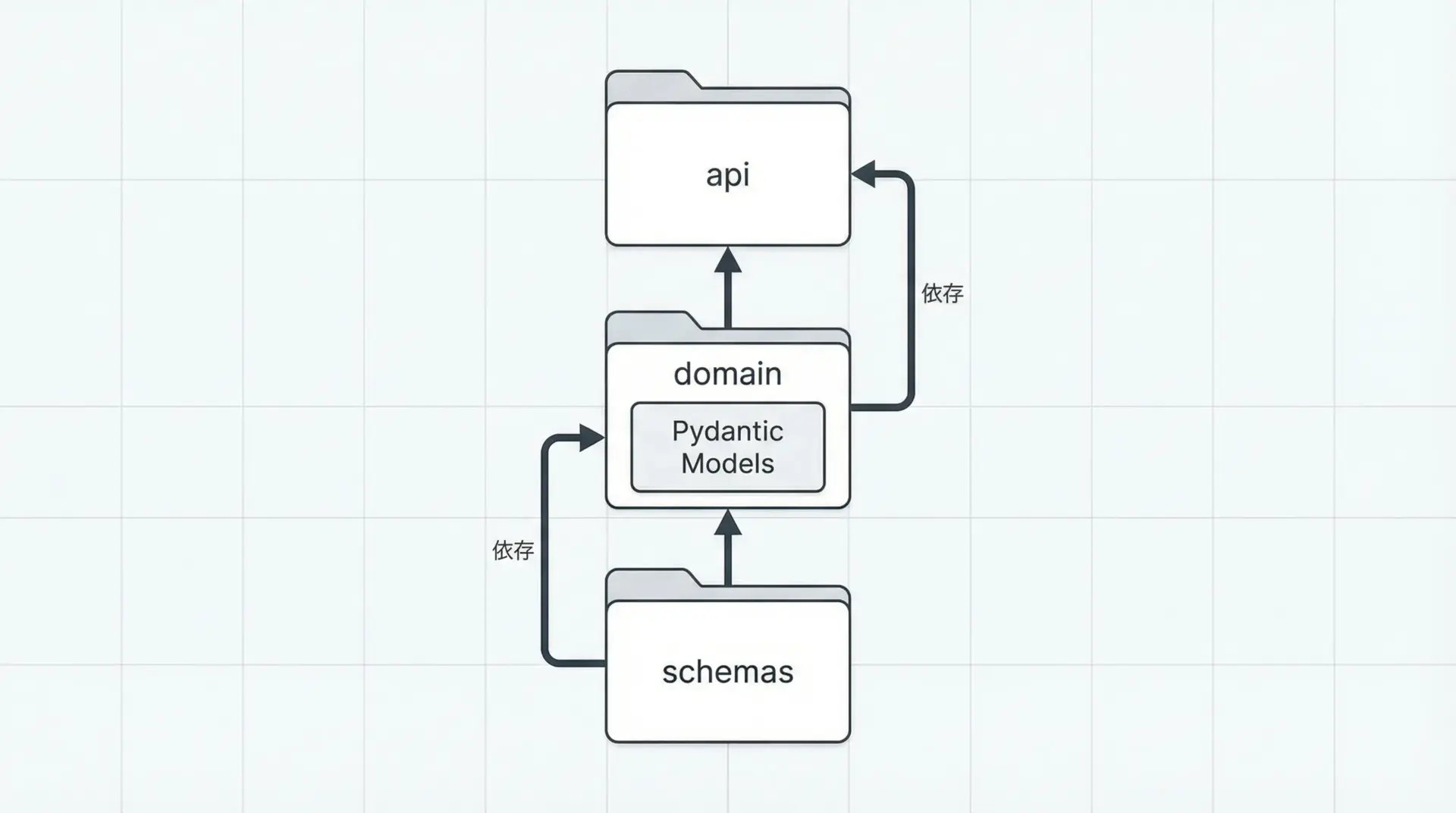
大規模プロジェクトでは、1つのファイルに全モデルを書いてしまうと管理が難しくなります。
一般的には、次のような分割が行われます。
- ドメインごとにディレクトリを分ける(user, order, productなど)
- API入出力用のスキーマと内部ロジック用のモデルを分離する
- 共通の型・Mixin・バリデータを
schemas/common.pyなどにまとめる
「変更頻度」や「利用範囲」に応じてモデルをグルーピングすると、将来の拡張や移行が容易になります。
エラーメッセージと例外処理
ValidationErrorの構造とログ出力

Pydanticのバリデーション失敗時にはValidationErrorが発生し、詳細な情報を持っています。
# sample_validation_error.py
from pydantic import BaseModel, ValidationError, Field
class User(BaseModel):
name: str = Field(min_length=3)
age: int = Field(ge=0)
def main():
try:
User(name="Al", age=-1)
except ValidationError as e:
print("raw:", repr(e))
print("errors():", e.errors())
print("json():", e.json())
if __name__ == "__main__":
main()raw: ValidationError(model='User', errors=...)
errors(): [{'type': 'string_too_short', 'loc': ('name',), 'msg': 'String should have at least 3 characters', ...}, {'type': 'greater_than_equal', 'loc': ('age',), 'msg': 'Input should be greater than or equal to 0', ...}]
json(): [{"type": "string_too_short", "loc": ["name"], "msg": "String should have at least 3 characters", ...}, ...]loc・msg・typeを使って、ログ出力やユーザー向けエラー生成を柔軟に行える点が重要です。
ユーザー向けエラーメッセージの整形
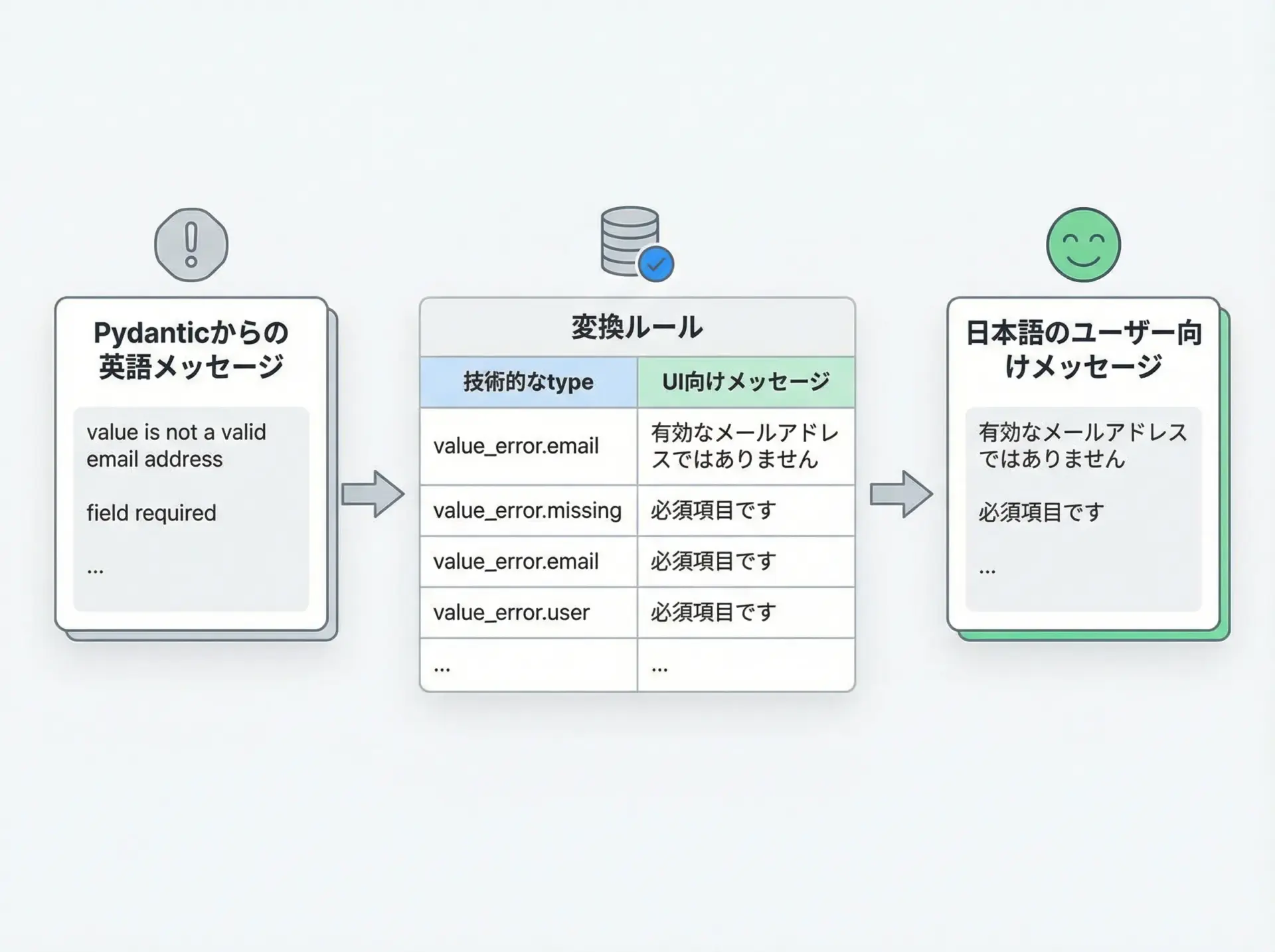
Webフォームなどでは、Pydanticの英語メッセージをそのまま表示するのではなく、フィールド名と日本語文言に整形することが多いです。
# sample_error_messages.py
from pydantic import BaseModel, ValidationError, Field
FIELD_LABELS = {
("name",): "氏名",
("age",): "年齢",
}
class User(BaseModel):
name: str = Field(min_length=3)
age: int = Field(ge=0)
def to_user_messages(e: ValidationError) -> list[str]:
messages = []
for err in e.errors():
loc = tuple(err["loc"])
label = FIELD_LABELS.get(loc, ".".join(map(str, loc)))
msg = err["msg"]
messages.append(f"{label}: {msg}")
return messages
def main():
try:
User(name="Al", age=-1)
except ValidationError as e:
for m in to_user_messages(e):
print(m)
if __name__ == "__main__":
main()氏名: String should have at least 3 characters
年齢: Input should be greater than or equal to 0ValidationErrorから構造化された情報を取り出し、UIレベルの文言に変換するレイヤーを用意しておくと、後から多言語化や文言調整がしやすくなります。
APIレスポンスとしてのエラー設計
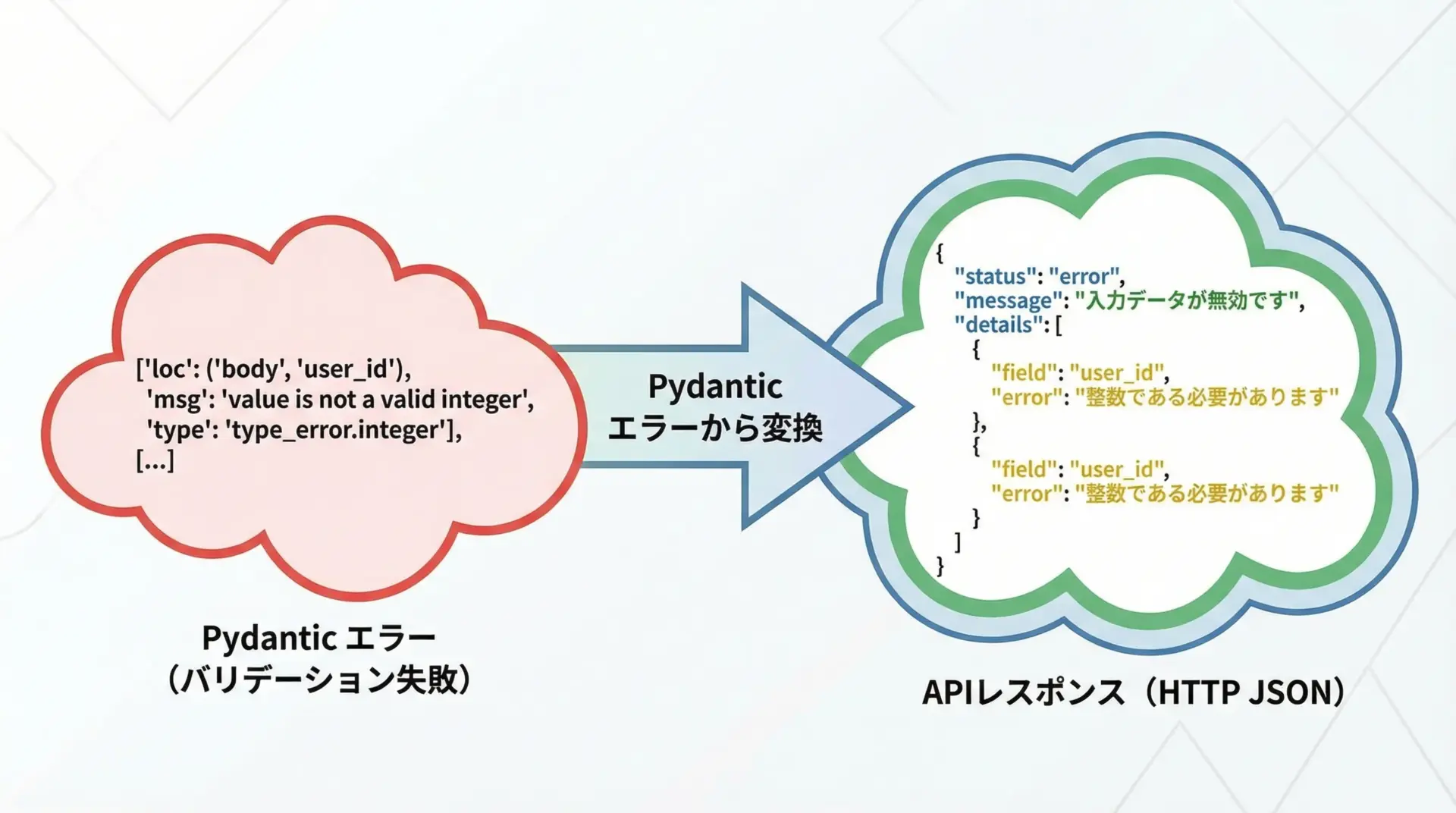
APIでは、ValidationErrorを適切なJSONレスポンスに変換するのが定石です。
例えば次のような形式がよく使われます。
{
"message": "入力値が不正です",
"errors": [
{"field": "name", "message": "必須項目です"},
{"field": "age", "message": "0以上で入力してください"}
]
}FastAPIを利用している場合、Pydanticのエラーは自動的に400レスポンスとして変換されますが、自前のフレームワークでもValidationError.errors()をベースに同様の構造を実装できます。
JSONシリアライズとスキーマ生成
dict・JSONへの変換と活用方法
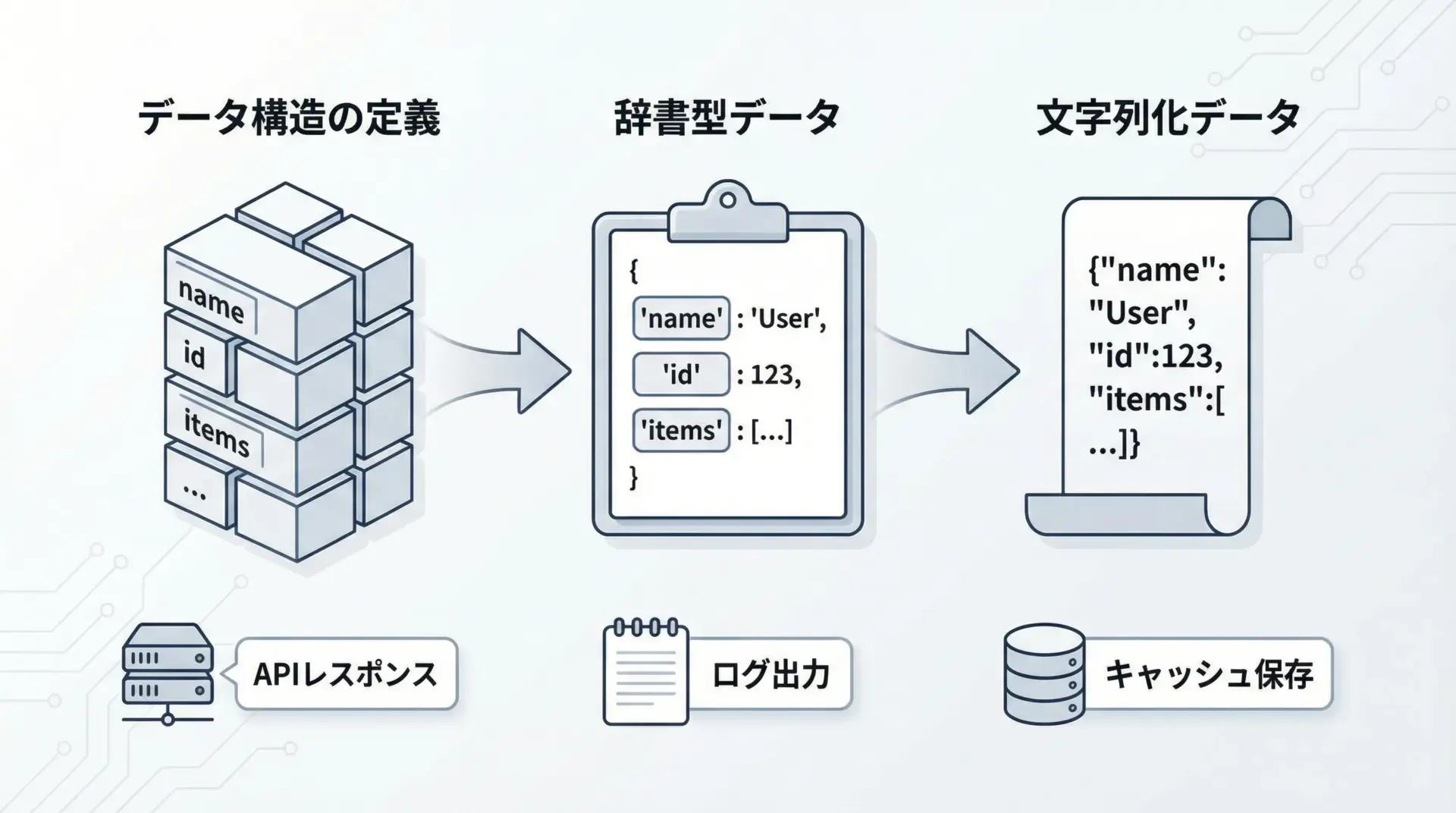
Pydanticモデルはmodel_dump()やmodel_dump_json()で辞書・JSONに変換できます(v2)。
# sample_serialize.py
from pydantic import BaseModel
from datetime import datetime
class LogEntry(BaseModel):
level: str
message: str
created_at: datetime
def main():
log = LogEntry(level="INFO", message="Started", created_at=datetime.now())
# dictに変換
as_dict = log.model_dump()
print("dict:", as_dict)
# JSON文字列に変換
as_json = log.model_dump_json()
print("json:", as_json)
if __name__ == "__main__":
main()dict: {'level': 'INFO', 'message': 'Started', 'created_at': datetime.datetime(...)}
json: {"level":"INFO","message":"Started","created_at":"20XX-..."}モデル → dict/JSON の変換ロジックを1カ所に集約できるため、APIやログ出力が一貫した形式になります。
JSON Schemaの自動生成と仕様共有
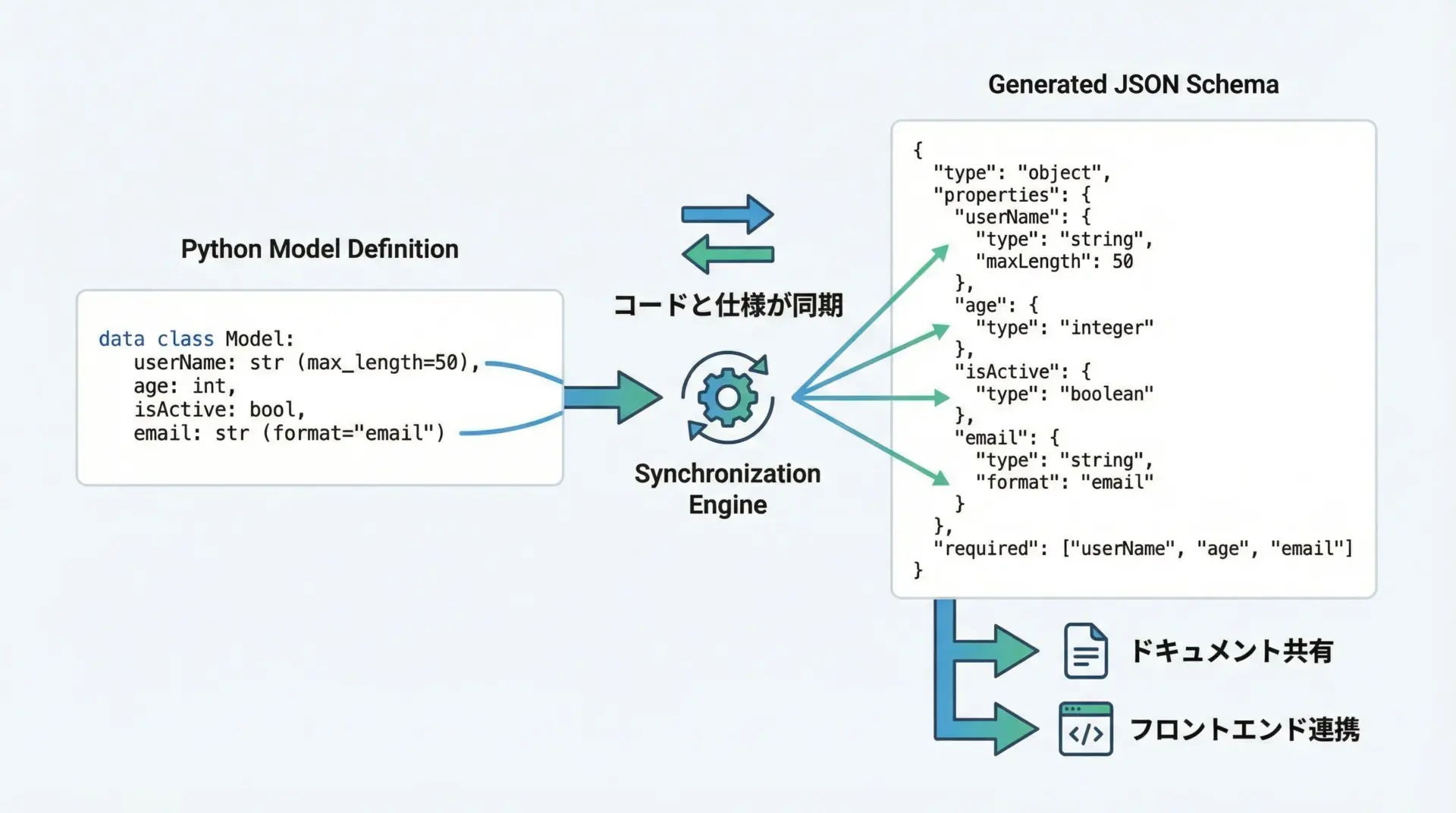
PydanticはモデルからJSON Schemaを自動生成できます。
v2ではmodel_json_schema()を利用します。
# sample_json_schema.py
from pydantic import BaseModel, Field
class User(BaseModel):
id: int = Field(description="ユーザーID")
name: str = Field(min_length=1, description="氏名")
age: int | None = Field(default=None, ge=0, description="年齢")
def main():
schema = User.model_json_schema()
print(schema)
if __name__ == "__main__":
main(){'title': 'User', 'type': 'object', 'properties': {...}, 'required': ['id', 'name'], ...}生成されたSchemaをフロントエンドチームや他システムと共有することで、コードベースの仕様書として活用できます。
OpenAPIとの連携
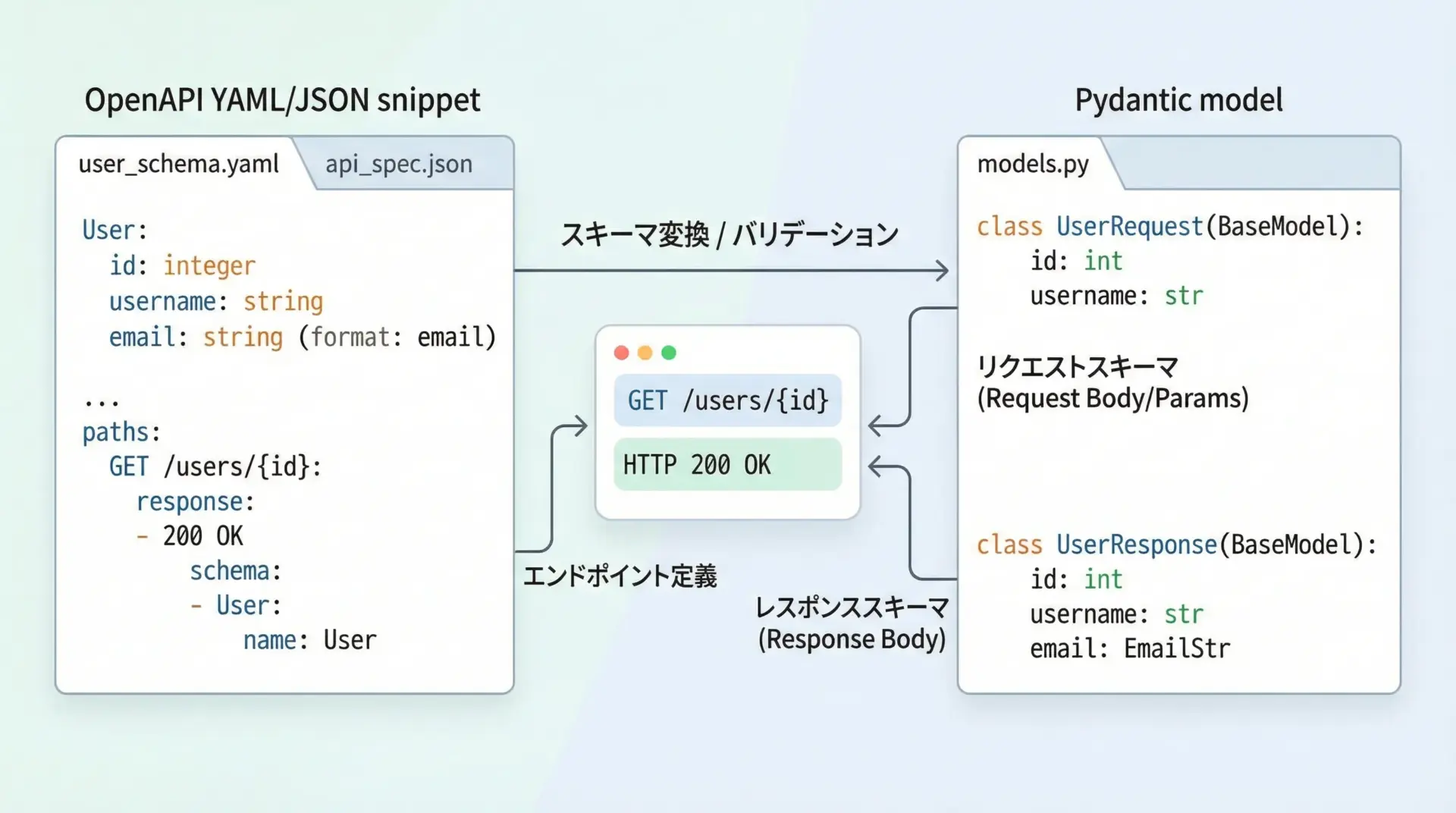
FastAPIでは、Pydanticモデルをエンドポイントの型として定義するだけで、OpenAPI(Swagger)仕様を自動生成してくれます。
自作フレームワークの場合でも、model_json_schema()を使ってOpenAPIのcomponents.schemasに組み込むことが可能です。
「Pydanticモデル = OpenAPIスキーマのソース」という設計にしておくと、API仕様の更新漏れを防ぎやすくなります。
Pydantic v2の新機能と移行ポイント
v1からv2への主な変更点
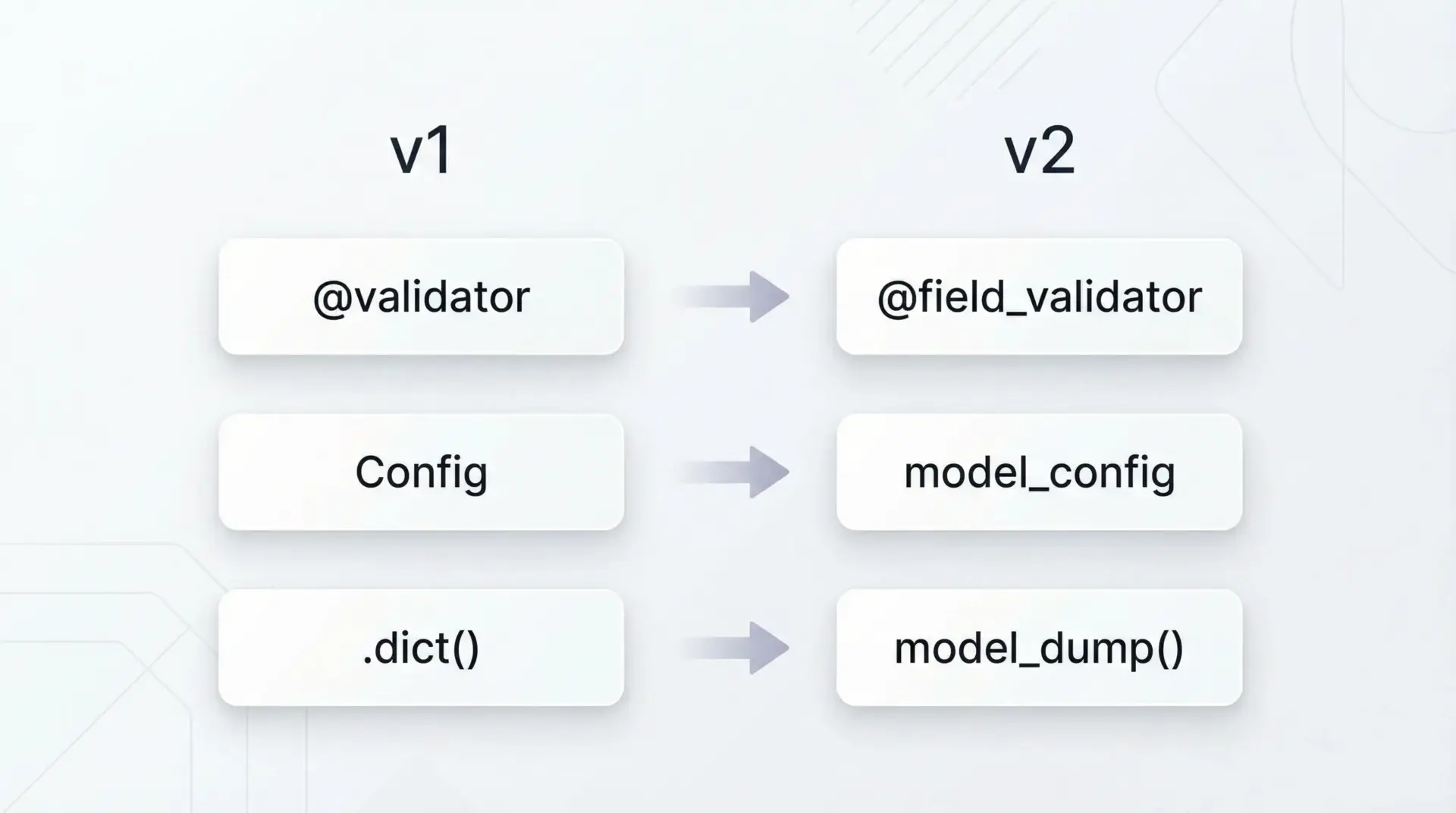
Pydantic v2では内部実装が大きく刷新され、パフォーマンス向上とAPIの整理が行われました。
主な変更点として次のようなものがあります。
@validator→@field_validator/@model_validatorに分離Configクラス →model_config属性に変更.dict()→.model_dump().json()→.model_dump_json()
v1のコードをそのまま動かすと動作しない箇所が出てくるため、公式ドキュメントの移行ガイドを参照しながら段階的に対応する必要があります。
モデル設定とバリデーションAPIの違い
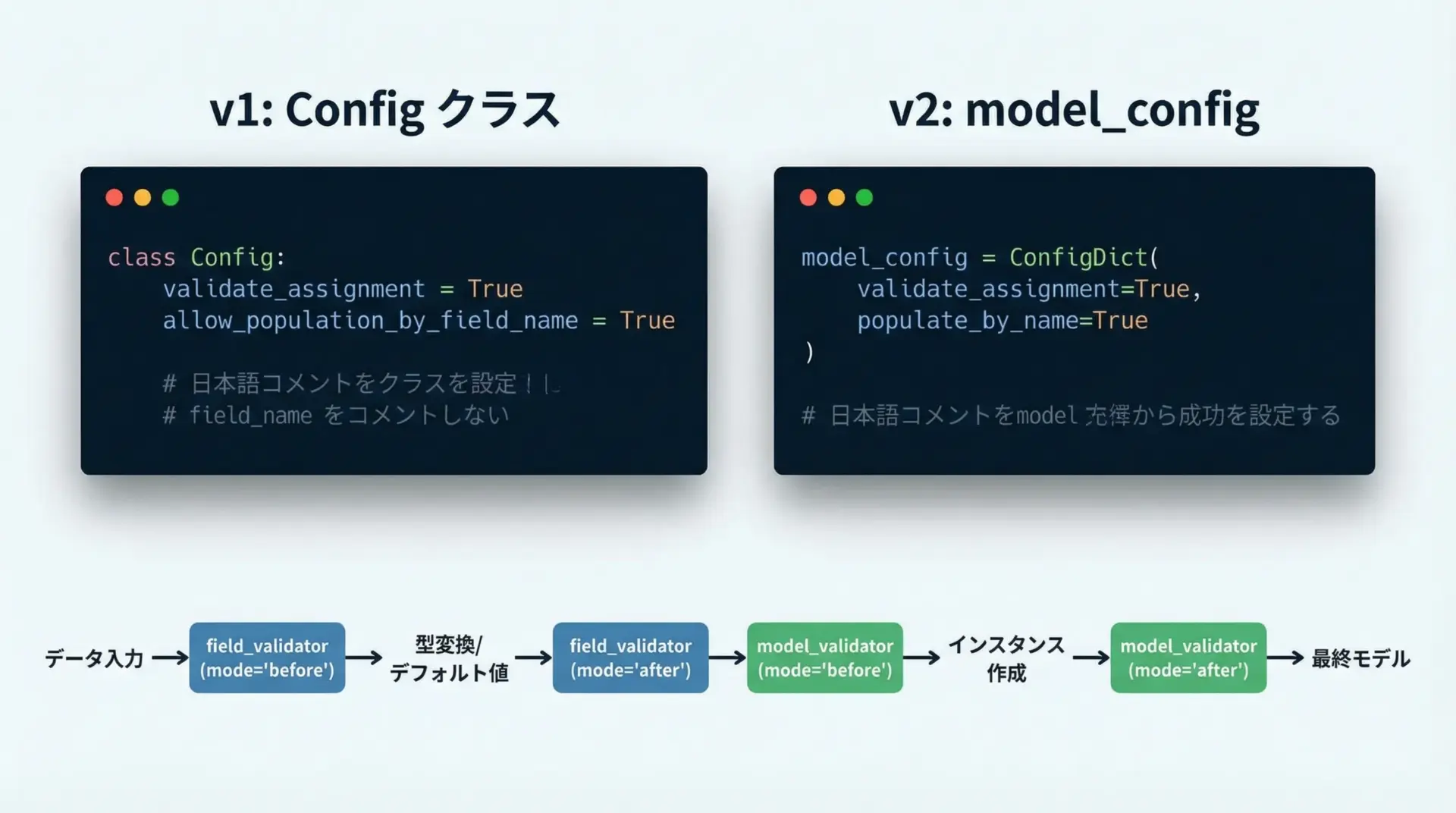
v2では、モデル設定はmodel_configというクラス属性で指定します。
# sample_model_config_v2.py
from pydantic import BaseModel, ConfigDict
class User(BaseModel):
model_config = ConfigDict(
str_strip_whitespace=True, # 文字列の前後空白を自動除去
extra="ignore", # 定義されていないフィールドは無視
)
name: str
age: int
def main():
u = User(name=" Alice ", age="20", unknown="ignored")
print(u)
if __name__ == "__main__":
main()name='Alice' age=20またバリデーションAPIも整理されました。
v1の@validatorは、v2では目的別に@field_validatorと@model_validatorに分かれています。
「どのタイミングで」「何を検証するか」を明示的に書けるようになった点がポイントです。
既存コードを安全に移行するコツ
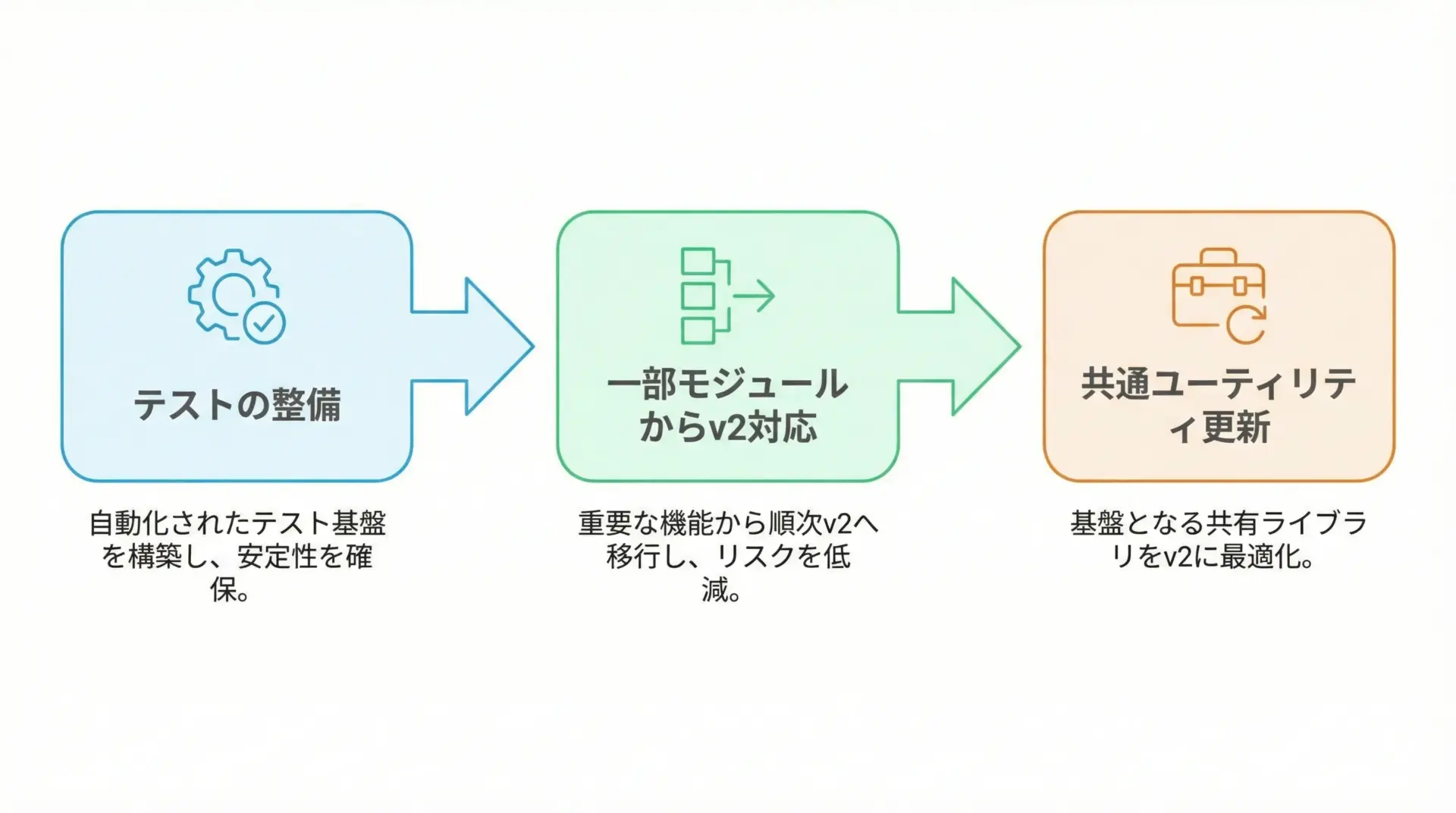
v1からv2への移行では、いきなり全体を書き換えるのではなく、次のようなステップで進めると安全です。
- 既存のバリデーションロジックに対するテストを充実させる
- よく使われる共通モデル・ユーティリティを優先してv2記法に置き換える
.dict()や.json()など、メソッド名の違いに対する対応を一括で行う- 最後に、細かい挙動差(エラーメッセージ・変換ルール)を確認する
自動テストが整っているほど移行は容易になるため、バリデーションを導入する際にはテスト戦略もセットで考えることが重要です。
Python×Pydanticバリデーションの実践Tips
開発初期から型とPydanticを導入するメリット
プロジェクトの初期段階から、Pythonの型ヒントとPydanticを導入しておくと、次のようなメリットがあります。
- データ仕様がコードで明文化され、メンバー間の認識ずれが減る
- 仕様変更時にどこを修正すべきか分かりやすい
- API仕様やフォーム仕様のドキュメントを自動生成しやすい
「とりあえず辞書で実装」ではなく、「Pydanticモデルでデータを表現」する習慣を付けると、長期的な開発効率が大きく変わります。
テストコードでバリデーションを担保する方法
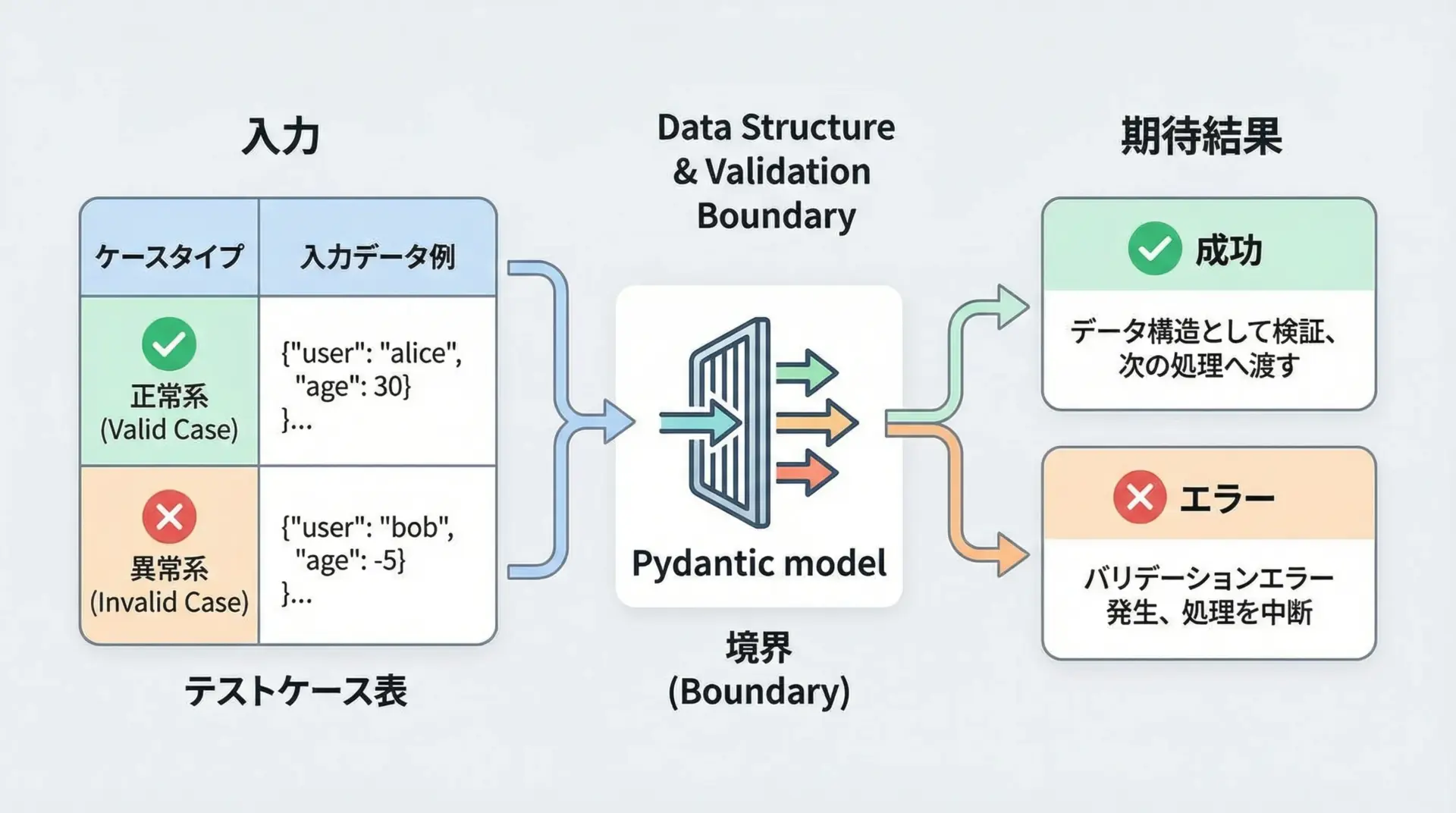
Pydanticモデル自体はロジックをほとんど持ちませんが、バリデーション仕様をテストで保証することが大切です。
例えばpytestを使って、代表的な入力パターンを検証できます。
# test_user_model.py
import pytest
from pydantic import ValidationError
from pydantic import BaseModel, Field
class User(BaseModel):
name: str = Field(min_length=3)
age: int = Field(ge=0)
def test_valid_user():
u = User(name="Alice", age=20)
assert u.name == "Alice"
def test_invalid_name():
with pytest.raises(ValidationError):
User(name="Al", age=20)
def test_negative_age():
with pytest.raises(ValidationError):
User(name="Alice", age=-1)このように、バリデーション仕様そのものをユニットテストで固定しておけば、将来のリファクタリングやPydanticのバージョンアップ時でも安心です。
よくあるアンチパターンと回避策
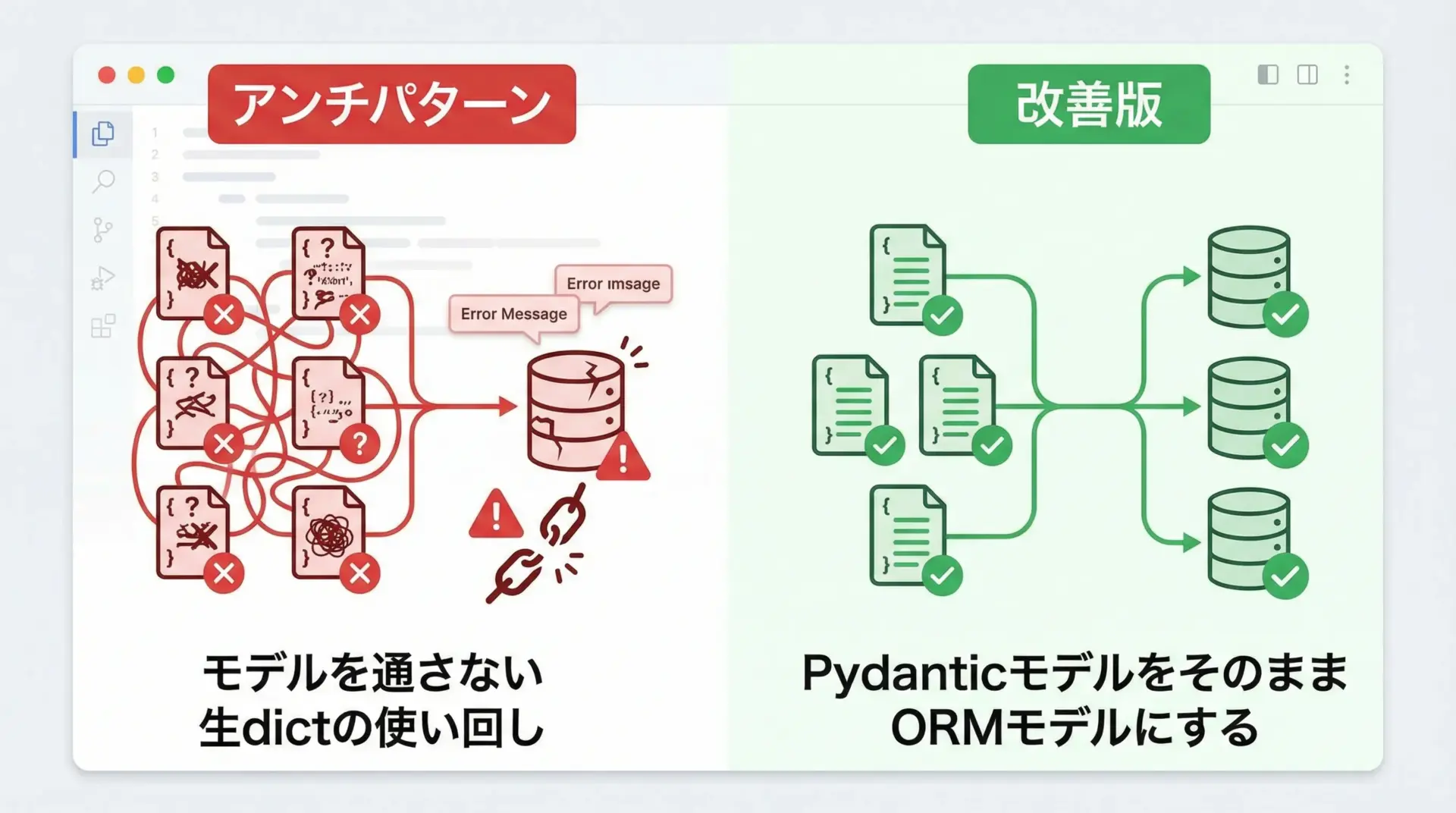
Pydantic利用時のよくあるアンチパターンと、その回避策を簡単にまとめます。
アンチパターンの例と対策:
- Pydanticを導入しているのに、一部の処理で生のdictを直接操作してしまう
→ データの入口・出口は必ずPydanticモデルを通すように統一する - ORMモデル(Djangoモデルなど)とPydanticモデルを1つのクラスで兼用しようとする
→ 永続化用モデルとバリデーション用スキーマは役割を分け、変換関数を明示的に用意する - Pydanticモデルにビジネスロジックを詰め込み過ぎる
→ モデルはあくまで「データとバリデーション」に集中させ、処理はサービス層など別レイヤに切り出す
責務を意識したモデル設計を行うことで、Pydanticは長期運用でも扱いやすい基盤となります。
まとめ
Pydanticは、Pythonの型ヒントを活用して宣言的かつ強力なバリデーションを実現するライブラリです。
BaseModelによる基本定義から、メール・URL・範囲・列挙型・カスタムバリデータ・ネスト構造・JSON Schema生成、そしてv2での新しいAPIまで、データ周りの課題を幅広くカバーできます。
フレームワークに依存せず使えるため、Webアプリ・バッチ・ツールなどあらゆる場面で「まずPydanticモデルを定義する」という設計習慣を取り入れると、仕様の明確化とバグ削減に大きく貢献します。
