Pythonでデータベースを扱うとき、SQL文を毎回手書きするのは負担になりがちです。
SQLAlchemyは、Pythonのクラスやオブジェクトでデータベースを直感的に操作できる強力なライブラリです。
本記事では、インストールからモデル定義、CRUD、リレーション、トランザクション管理まで、実務ですぐ使えるレベルを目標に、図解とサンプルコードで丁寧に解説します。
SQLAlchemyとは?Pythonで使えるORMの基礎
SQLAlchemyの特徴とメリット
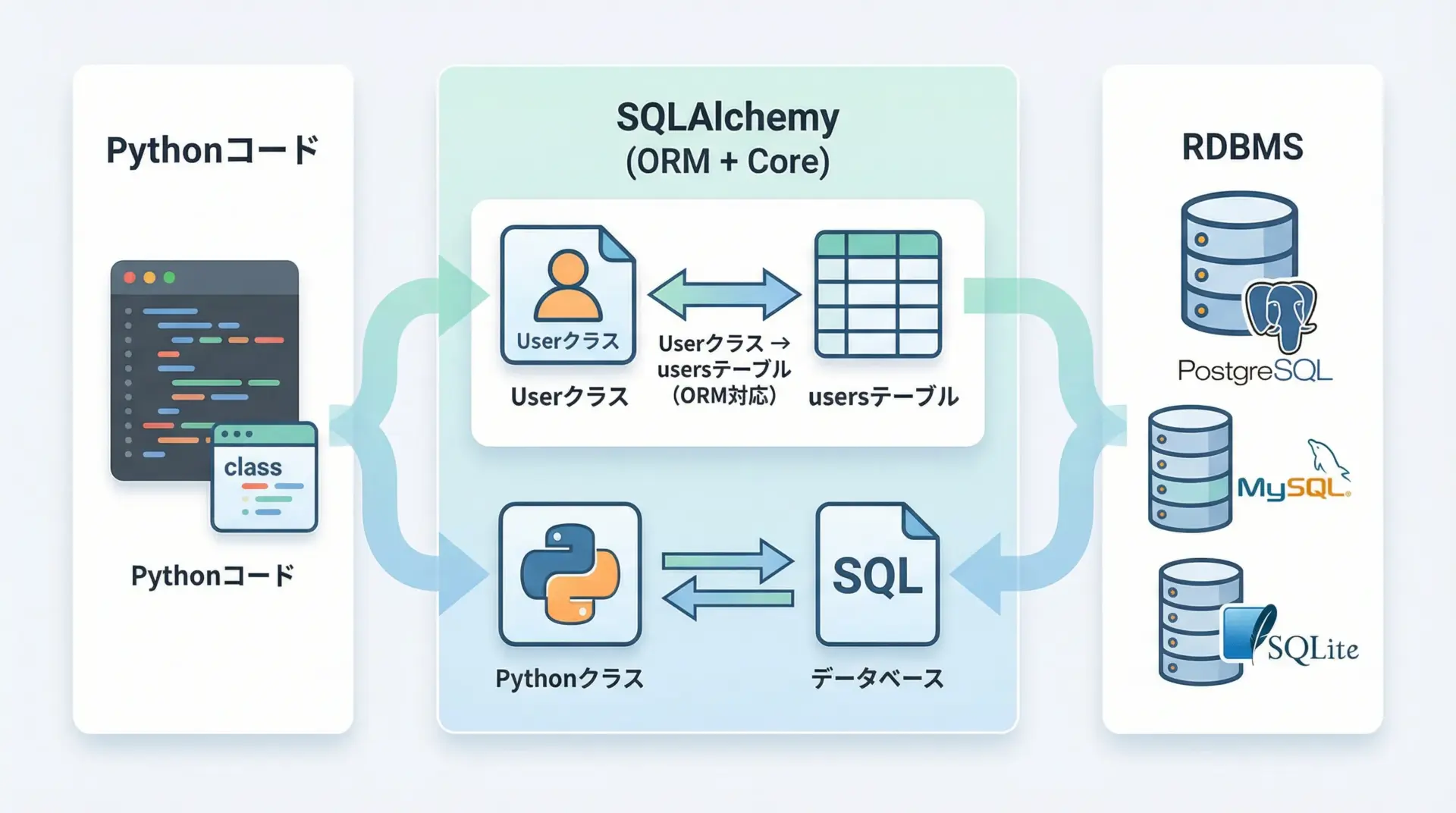
SQLAlchemyは、Pythonでリレーショナルデータベース(RDB)を扱うためのライブラリです。
ORM(Object Relational Mapper)としての機能と、SQLを構造的に組み立てるCoreとしての機能の両方を備えていることが大きな特徴です。
代表的なメリットを、文章で整理してみます。
まず、SQLAlchemyを使うと、データベースのテーブルをPythonクラスとして表現できます。
たとえばUserクラスのインスタンスがusersテーブルの1行に対応するような形です。
そのため、行を追加する処理は「オブジェクトを作ってセッションに追加する」という自然な書き方になります。
また、対応しているデータベースエンジンが多いことも重要です。
SQLite、PostgreSQL、MySQL、MariaDB、Oracleなど、主要なRDBMSに対応しており、接続URLを変えるだけで異なるDBに接続しやすいという利点があります。
SQLAlchemyは、ORMとしての抽象度の高さだけでなく、SQLを意識した細かなチューニングや、高度なクエリ構築にも対応しています。
ORMを使いながらも、「必要なときには生SQLに近い制御ができる」柔軟性があるため、小規模アプリから大規模な業務システムまで幅広く使われています。
SQLAlchemy ORMとCoreの違い
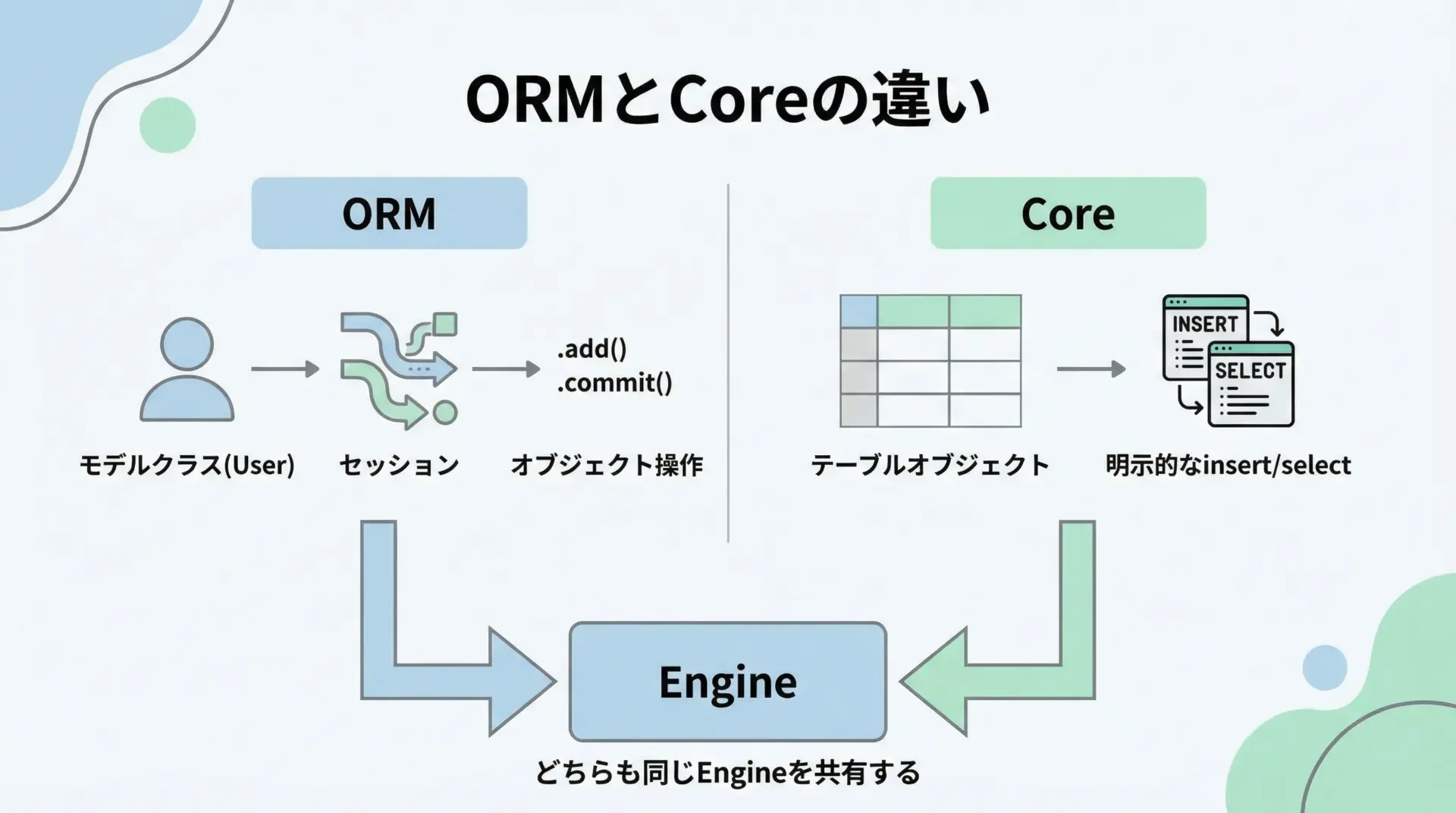
SQLAlchemyには、大きく分けてORM(高レベルAPI)とCore(低レベルAPI)の2つの使い方があります。
両方とも同じEngine(接続)の上に成り立っていますが、書き方と抽象度が異なります。
ORMは、Pythonクラスをテーブルに対応させて操作する方法です。
たとえば、ユーザーの取得はsession.query(User).filter(User.id == 1)のように、クラスと属性を使ってクエリを組み立てます。
オブジェクト指向の書き味が強く、アプリケーションコードからはSQL文をあまり意識しません。
一方、CoreはTableやselect()などのオブジェクトを組み合わせて、構造化されたSQLビルダーとして使うイメージです。
よりSQLに近く、insert(users).values(name="Alice")のようにテーブルオブジェクトを明示的に操作します。
ORMを使わないスクリプトや一時的処理、細かな最適化が必要な場面などで活躍します。
本記事では、実務でよく使うORMを中心に解説しつつ、必要に応じてCoreの書き方にも触れていきます。
SQLAlchemyのインストールと初期設定
pipでのインストール手順
まずはSQLAlchemy本体をインストールします。
ここでは最も簡単なSQLiteを対象に進めます。
# 仮想環境の作成(任意)
python -m venv venv
source venv/bin/activate # Windowsなら: venv\Scripts\activate
# SQLAlchemy本体のインストール
pip install sqlalchemy
# ORM+SQLiteで試すなら、ドライバは標準のsqlite3でOK
# PostgreSQLなどを使う場合は、例えば:
# pip install psycopg2-binaryインストール後、Pythonインタプリタで簡単にインポートできるか確認すると安心です。
python -c "import sqlalchemy; print(sqlalchemy.__version__)"データベース接続(Engine)の作成
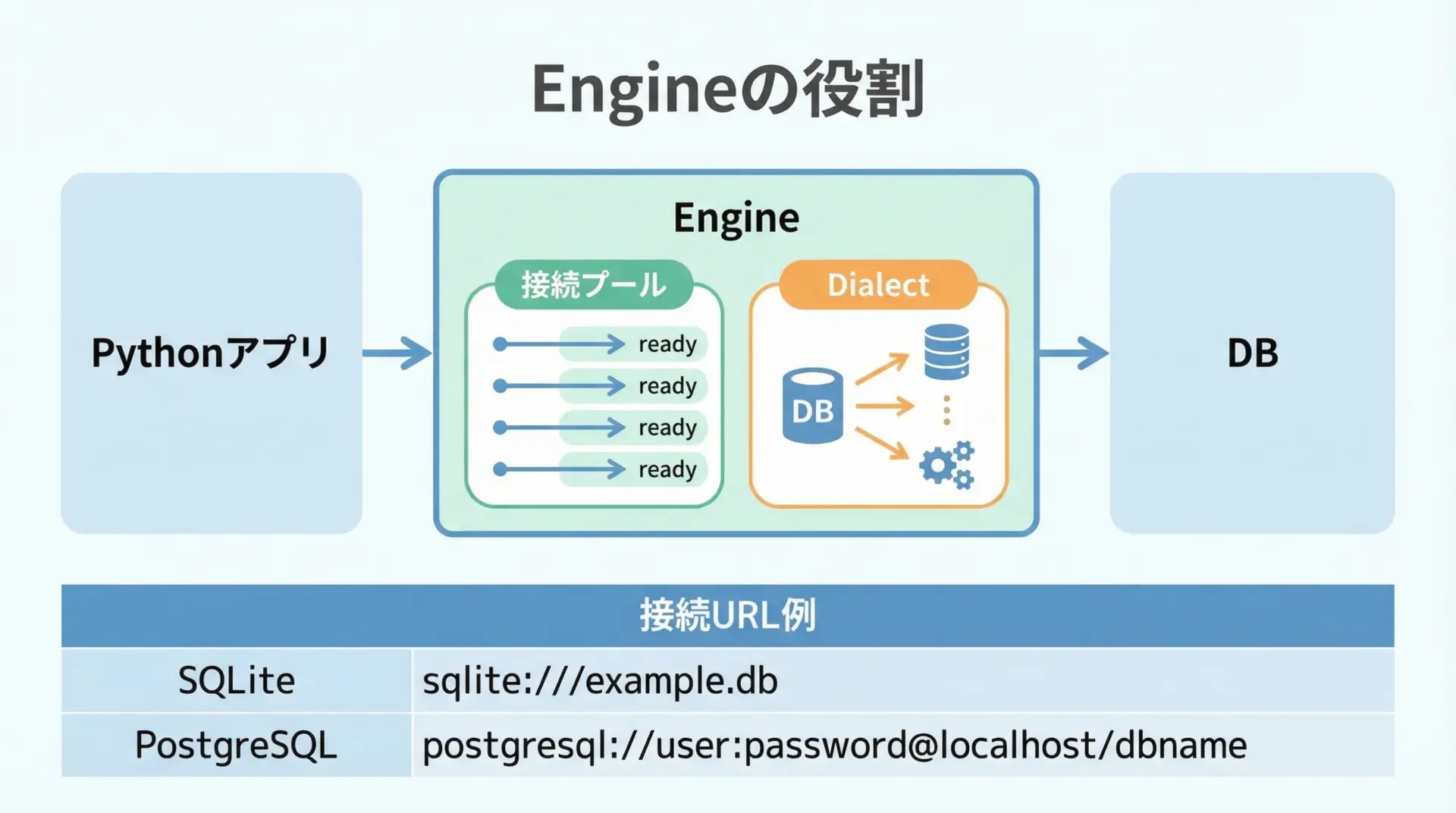
SQLAlchemyでは、Engineがデータベースへの入り口となります。
Engineは接続情報(URL)を持ち、接続プールの管理も担います。
接続URLの例は次のようになります。
| データベース | 接続URLの例 |
|---|---|
| SQLite(ファイル) | sqlite:///example.db |
| SQLite(メモリ) | sqlite:///:memory: |
| PostgreSQL | postgresql+psycopg2://user:pass@localhost:5432/mydb |
| MySQL | mysql+pymysql://user:pass@localhost:3306/mydb |
基本的なEngine作成コードは次の通りです。
# engine_example.py
from sqlalchemy import create_engine
# SQLiteファイルに接続するEngineを作成
# echo=True にすると、実行されるSQLがコンソールに表示される
engine = create_engine("sqlite:///example.db", echo=True, future=True)
# Engineオブジェクトを確認するだけ
print(engine)# 実行例 (python engine_example.py)
Engine(sqlite:///example.db)ここで接続URLの形式を覚えておくことが重要です。
DB種別やユーザー名、パスワード、ホスト名などはこの文字列で指定します。
セッション(Session)の基本設定
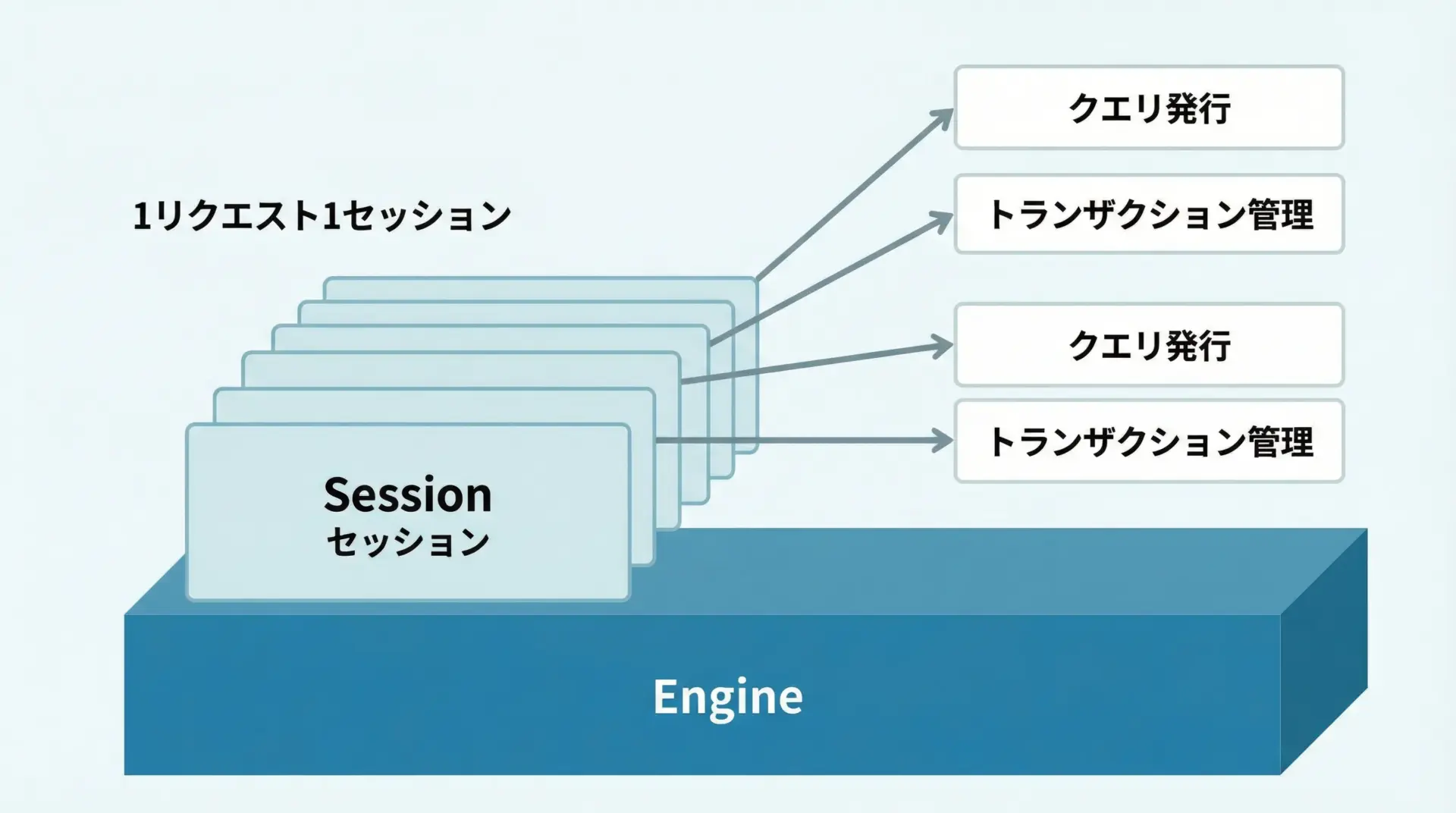
ORMを使う場合、Sessionがクエリ実行やトランザクションの基本単位になります。
Sessionは、Engineを元に作成するファクトリから生成します。
# session_example.py
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
# Engineを先に作成
engine = create_engine("sqlite:///example.db", echo=True, future=True)
# Sessionを作るためのクラス(Session factory)を定義
SessionLocal = sessionmaker(
bind=engine,
autoflush=False, # 自動フラッシュを無効化(明示的に扱う方が初心者向け)
autocommit=False, # 明示的なcommitを前提にする
future=True,
)
# 実際にSessionインスタンスを1つ作ってみる
def main():
db = SessionLocal()
try:
print(db)
# ここでクエリなどを実行していく
finally:
db.close()
if __name__ == "__main__":
main()# 実行例 (python session_example.py)
<sqlalchemy.orm.session.Session object at 0x...>実アプリケーションでは、1リクエスト(あるいは1処理単位)につき1つのSessionを使い、処理の最後に必ず閉じるというパターンが基本になります。
SQLAlchemyでのモデル定義入門
Baseクラスとモデルクラスの作り方
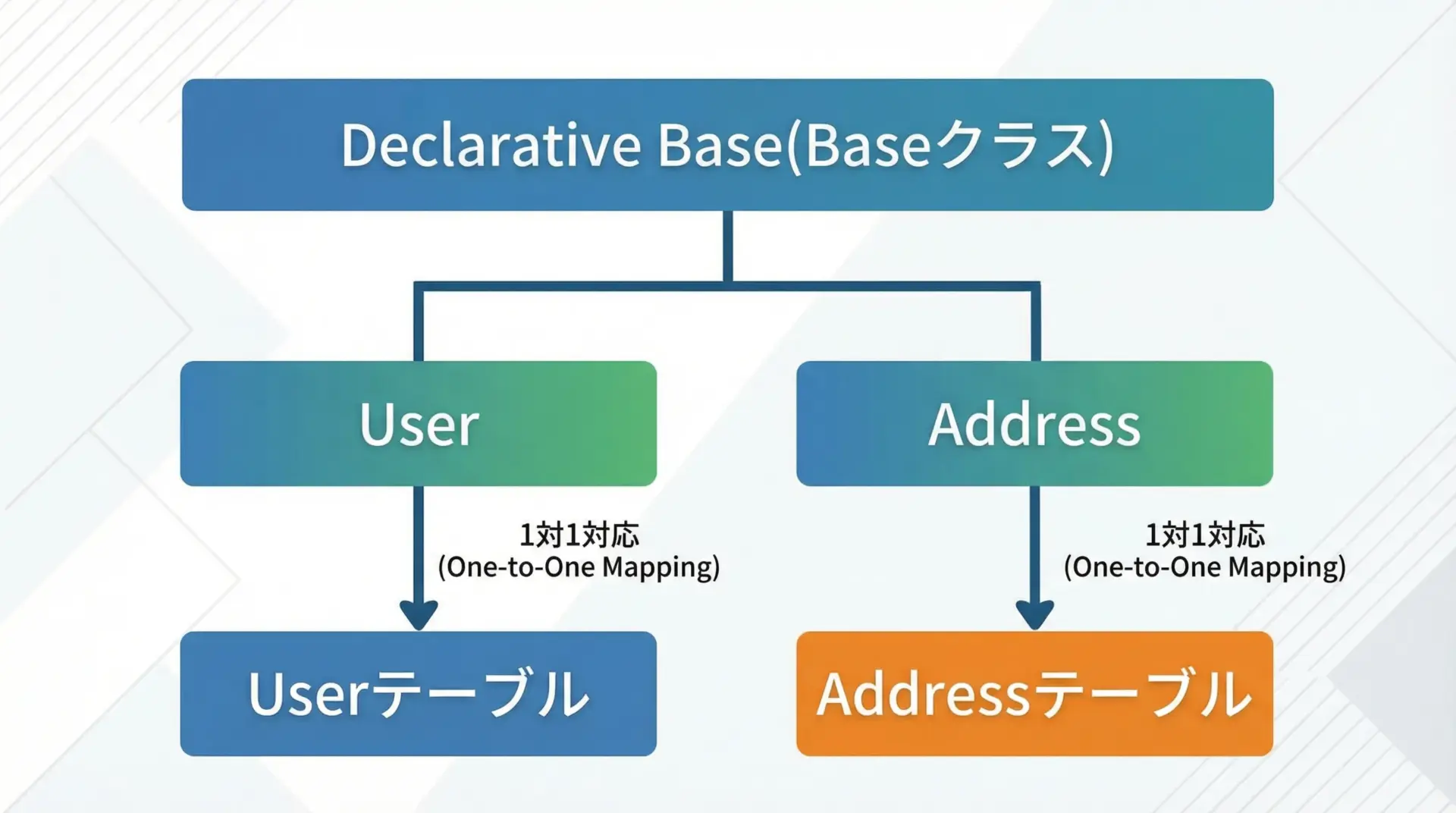
ORMでテーブルを扱うには、Declarative Base(基底クラス)を作り、そのサブクラスとしてモデルクラスを定義します。
これにより、クラス定義から自動的にテーブル情報が組み立てられます。
# models_base.py
from sqlalchemy.orm import declarative_base
# Declarative Base を作成
Base = declarative_base()このBaseを継承したクラスが、テーブルに対応するモデルクラスになります。
テーブル名・カラム定義・主キーの指定

ここでは、ユーザー情報を保持するusersテーブルを例にします。
クラス名は慣例的に単数形(User)、テーブル名は複数形(users)とするケースが多いです。
# models_user.py
from sqlalchemy import Column, Integer, String
from sqlalchemy.orm import declarative_base
Base = declarative_base()
class User(Base):
__tablename__ = "users" # 対応するテーブル名
# 主キー。primary_key=Trueを必ずどれか1つ以上のカラムに指定する
id = Column(Integer, primary_key=True, index=True)
# ユーザー名。長さ制限付きの文字列
name = Column(String(50), nullable=False)
# メールアドレス。一意制約を付けるケースが多い
email = Column(String(255), unique=True, nullable=False)
def __repr__(self) -> str:
return f"User(id={self.id}, name={self.name!r}, email={self.email!r})"ここで主キー(primary_key)は必須です。
主キーを定義しないと、ORMが行を一意に識別できず、多くの操作でエラーになります。
データ型(Column)と制約
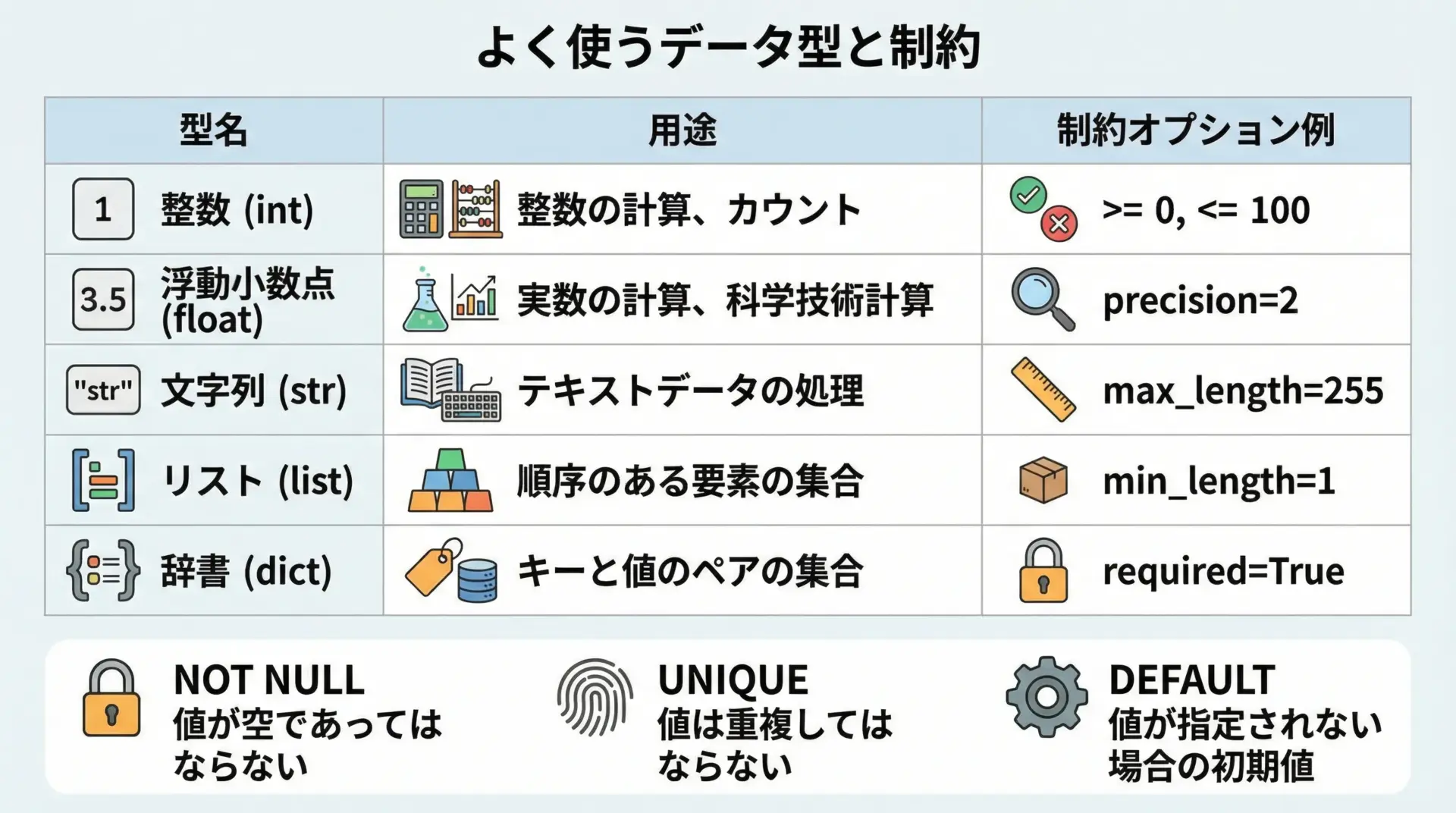
SQLAlchemyのColumnは、データ型と制約をまとめて指定します。
よく使う型とオプションを表に整理します。
| 型名 | 説明 | 例 |
|---|---|---|
Integer | 整数 | ID、カウントなど |
String(length) | 可変長文字列 | 名前、タイトルなど |
Text | 長文テキスト | 本文、コメントなど |
Boolean | 真偽値 | フラグ、状態など |
DateTime | 日時 | 作成日時、更新日時など |
ForeignKey | 外部キー | リレーション用 |
Columnの主な制約オプションは次のようなものがあります。
nullable=False… NOT NULL制約unique=True… UNIQUE制約index=True… インデックス作成default=value… デフォルト値
サンプルとして、タイムスタンプやフラグを持つテーブルを定義してみます。
# models_article.py
from datetime import datetime
from sqlalchemy import Column, Integer, String, Text, Boolean, DateTime
from sqlalchemy.orm import declarative_base
Base = declarative_base()
class Article(Base):
__tablename__ = "articles"
id = Column(Integer, primary_key=True)
title = Column(String(200), nullable=False, index=True)
body = Column(Text, nullable=False)
is_published = Column(Boolean, nullable=False, default=False)
created_at = Column(
DateTime,
nullable=False,
default=datetime.utcnow, # 関数自体を渡す(呼び出さない)
)ここでデフォルト値に関数を渡すときは、()を付けずに関数オブジェクト自体を指定する点に注意します。
付けてしまうと、モジュール読み込み時の値で固定されてしまいます。
リレーション(Relationship)の定義方法
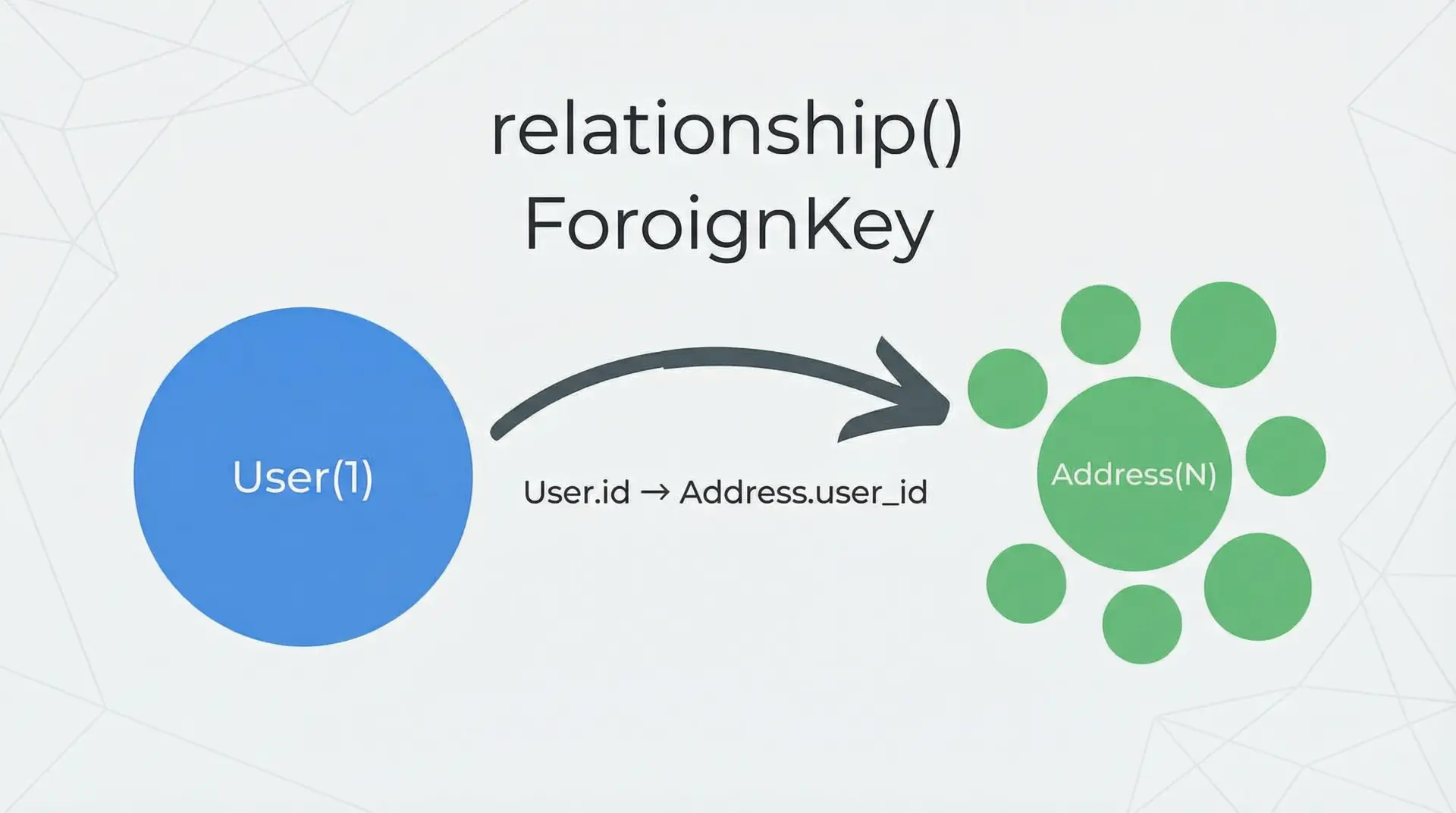
リレーションを表すには、ForeignKeyとrelationshipをセットで定義します。
ここでは、1人のユーザーが複数の住所(Address)を持つ、一対多の例を示します。
# models_relationship.py
from sqlalchemy import Column, Integer, String, ForeignKey
from sqlalchemy.orm import declarative_base, relationship
Base = declarative_base()
class User(Base):
__tablename__ = "users"
id = Column(Integer, primary_key=True)
name = Column(String(50), nullable=False)
# Addressとの一対多。back_populatesで双方向リンクを張る
addresses = relationship("Address", back_populates="user")
class Address(Base):
__tablename__ = "addresses"
id = Column(Integer, primary_key=True)
email = Column(String(255), nullable=False)
user_id = Column(Integer, ForeignKey("users.id"), nullable=False)
# User側との対応を定義
user = relationship("User", back_populates="addresses")ForeignKeyで物理的な結合条件(user_id → users.id)を定義し、relationshipでPython側のオブジェクト同士のリンクを定義するという分担になっていることを理解しておくと、複雑なリレーションも整理しやすくなります。
SQLAlchemyで最速CRUD操作
ここからは、ORMを使った典型的なCRUD操作を一気に体験します。
Create(登録)の基本 insertの書き方
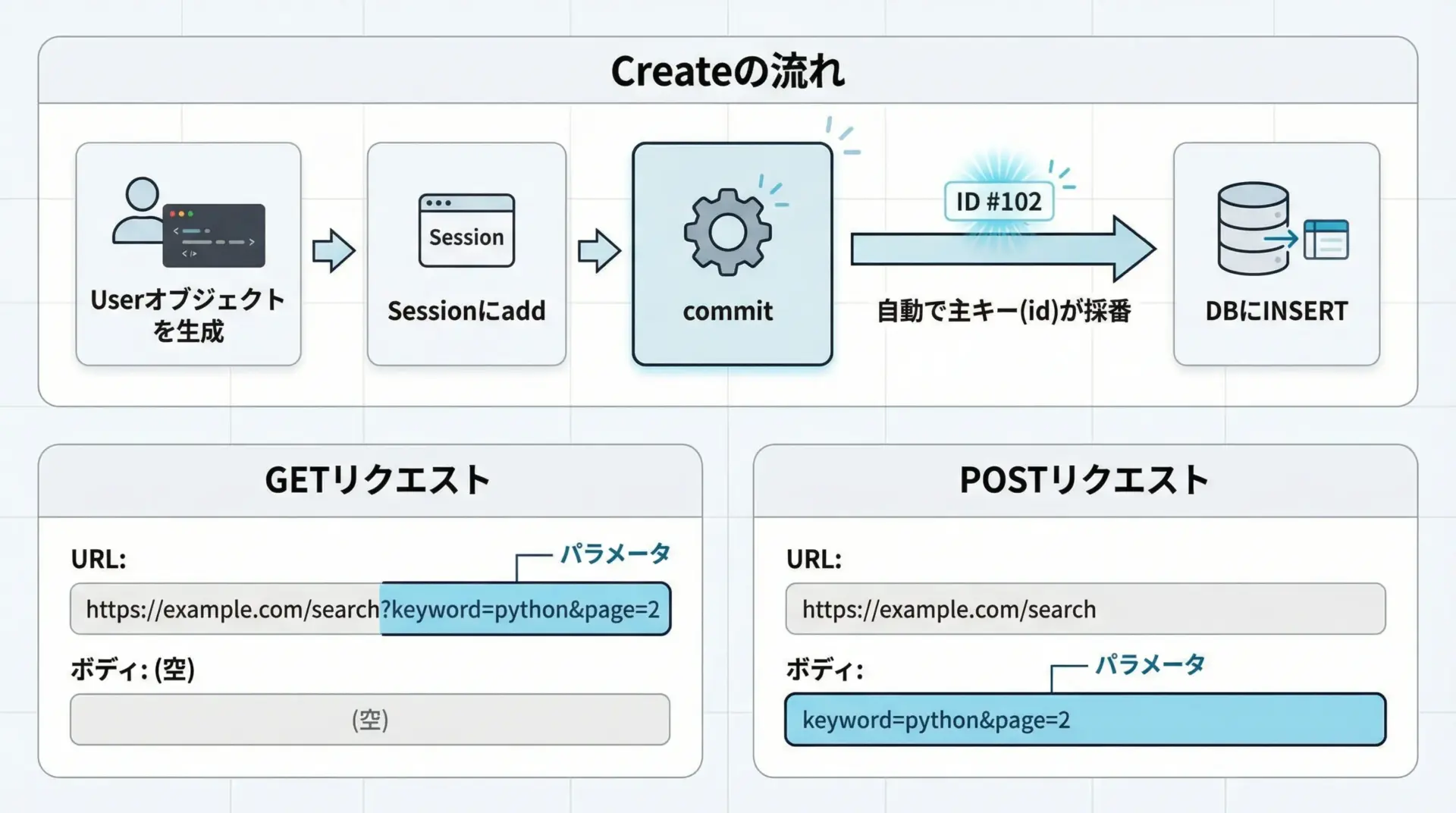
まずは単純なユーザー登録を行います。
モデル定義とEngine、Sessionを1ファイルにまとめた最小構成の例です。
# crud_create.py
from sqlalchemy import Column, Integer, String, create_engine
from sqlalchemy.orm import declarative_base, sessionmaker
# Base定義
Base = declarative_base()
# モデル定義
class User(Base):
__tablename__ = "users"
id = Column(Integer, primary_key=True, index=True)
name = Column(String(50), nullable=False)
email = Column(String(255), unique=True, nullable=False)
def __repr__(self):
return f"User(id={self.id}, name={self.name!r}, email={self.email!r})"
# Engine & Session factory
engine = create_engine("sqlite:///example.db", echo=True, future=True)
SessionLocal = sessionmaker(bind=engine, autoflush=False, autocommit=False, future=True)
# テーブルを作成(存在しない場合のみ)
Base.metadata.create_all(bind=engine)
def create_user(name: str, email: str) -> None:
db = SessionLocal()
try:
# Userオブジェクトを作成
user = User(name=name, email=email)
# セッションに追加
db.add(user)
# トランザクションを確定
db.commit()
# commit後にidが自動的に反映される
db.refresh(user) # DBから最新状態を再取得
print("Created:", user)
except Exception as e:
db.rollback()
raise
finally:
db.close()
if __name__ == "__main__":
create_user("Alice", "alice@example.com")
create_user("Bob", "bob@example.com")# 実行例 (python crud_create.py の一部ログ)
...
INSERT INTO users (name, email) VALUES (?, ?)
[generated in 0.00016s] ('Alice', 'alice@example.com')
...
Created: User(id=1, name='Alice', email='alice@example.com')
Created: User(id=2, name='Bob', email='bob@example.com')オブジェクトを作ってSessionにaddし、commitで確定という流れを覚えておくと、他のモデルでも同じパターンで書けます。
Read(取得)の基本 select・filterの使い方
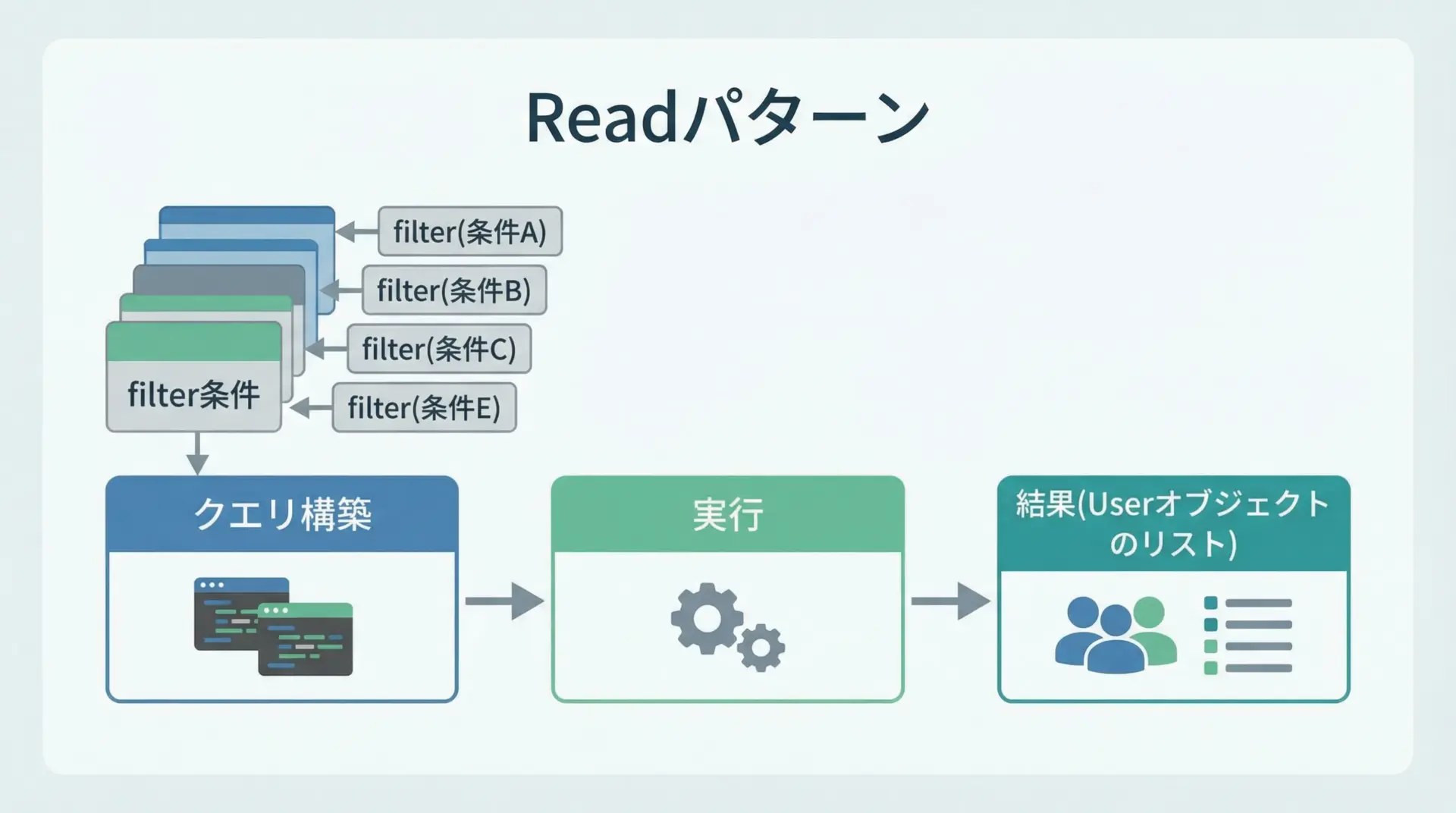
SQLAlchemy 2.x向けのモダンなselect()構文で、複数パターンの取得を示します。
# crud_read.py
from sqlalchemy import create_engine, select
from sqlalchemy.orm import sessionmaker
from crud_create import Base, User # 先ほどの定義を再利用
engine = create_engine("sqlite:///example.db", echo=True, future=True)
SessionLocal = sessionmaker(bind=engine, autoflush=False, autocommit=False, future=True)
def get_user_by_id(user_id: int) -> User | None:
db = SessionLocal()
try:
stmt = select(User).where(User.id == user_id)
result = db.execute(stmt)
# scalars()でUserオブジェクトのストリームを取得し、first()で1件取り出す
user = result.scalars().first()
return user
finally:
db.close()
def get_users_by_name(name: str) -> list[User]:
db = SessionLocal()
try:
stmt = select(User).where(User.name == name)
result = db.execute(stmt)
users = result.scalars().all()
return users
finally:
db.close()
def get_all_users() -> list[User]:
db = SessionLocal()
try:
stmt = select(User)
result = db.execute(stmt)
return result.scalars().all()
finally:
db.close()
if __name__ == "__main__":
print("User id=1:", get_user_by_id(1))
print("Users name='Alice':", get_users_by_name("Alice"))
print("All users:", get_all_users())# 実行例 (python crud_read.py の一部ログ)
SELECT users.id, users.name, users.email
FROM users
WHERE users.id = ?
[generated in 0.00012s] (1,)
User id=1: User(id=1, name='Alice', email='alice@example.com')
...
All users: [User(id=1, ...), User(id=2, ...)]select(User).where(条件) → db.execute() → result.scalars().all()/first()という流れが基本です。
Update(更新)の基本 更新クエリの書き方
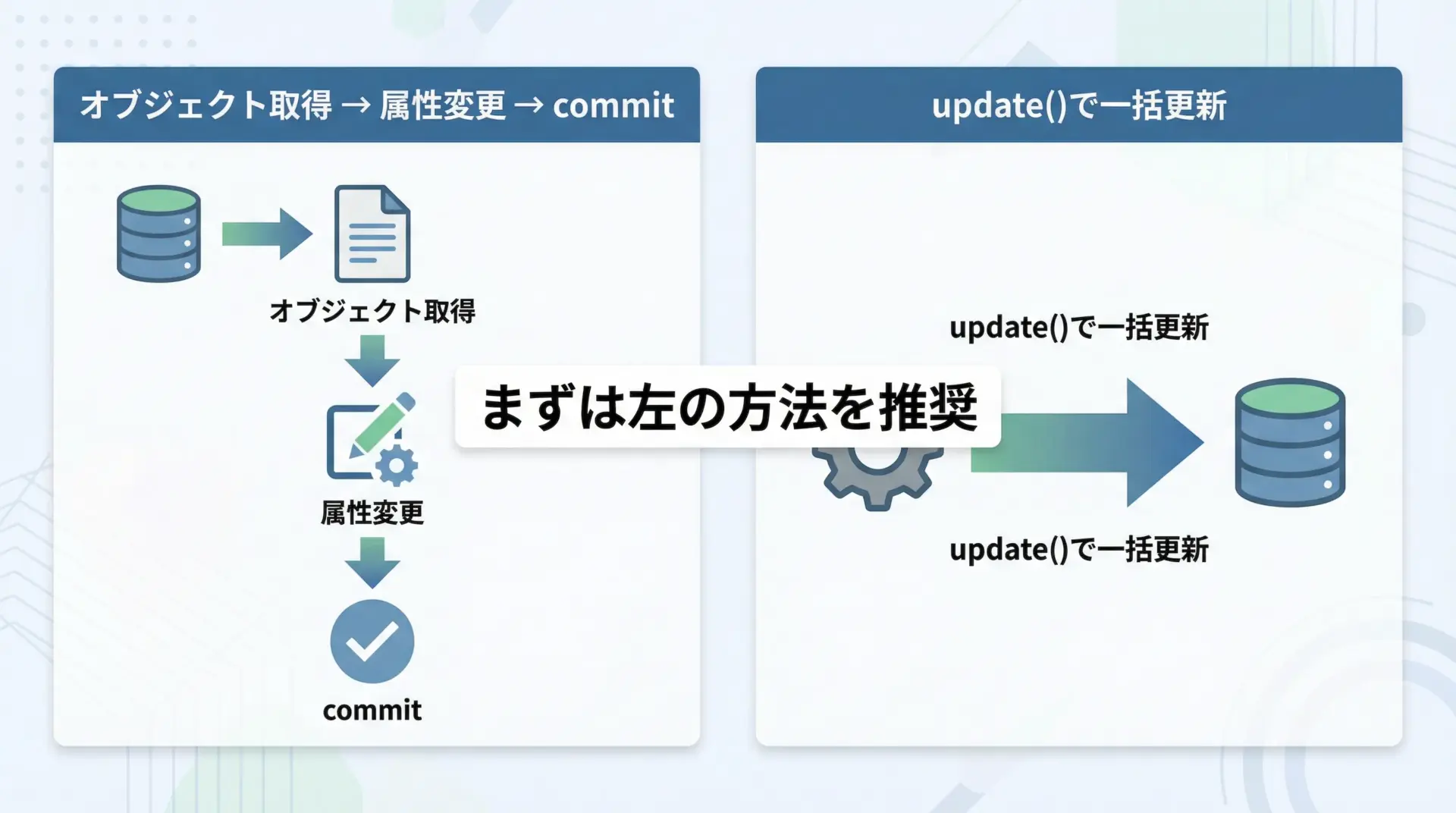
ORMでは、一度オブジェクトを取得してから属性を書き換える方法が最も分かりやすいです。
# crud_update.py
from sqlalchemy import create_engine, select
from sqlalchemy.orm import sessionmaker
from crud_create import Base, User
engine = create_engine("sqlite:///example.db", echo=True, future=True)
SessionLocal = sessionmaker(bind=engine, autoflush=False, autocommit=False, future=True)
def update_user_email(user_id: int, new_email: str) -> None:
db = SessionLocal()
try:
stmt = select(User).where(User.id == user_id)
user = db.execute(stmt).scalars().first()
if user is None:
print("User not found")
return
# 属性を書き換える
user.email = new_email
# commitでUPDATEが発行される
db.commit()
print("Updated:", user)
except Exception:
db.rollback()
raise
finally:
db.close()
if __name__ == "__main__":
update_user_email(1, "alice.updated@example.com")# 実行例の一部
UPDATE users SET email=? WHERE users.id = ?
[generated in 0.00016s] ('alice.updated@example.com', 1)
Updated: User(id=1, name='Alice', email='alice.updated@example.com')多数の行を一括更新したい場合は、Coreのupdate()を直接使うこともできますが、オブジェクト側には自動反映されないため、初学者にはオブジェクト経由の方法をおすすめします。
Delete(削除)の基本 削除クエリの書き方
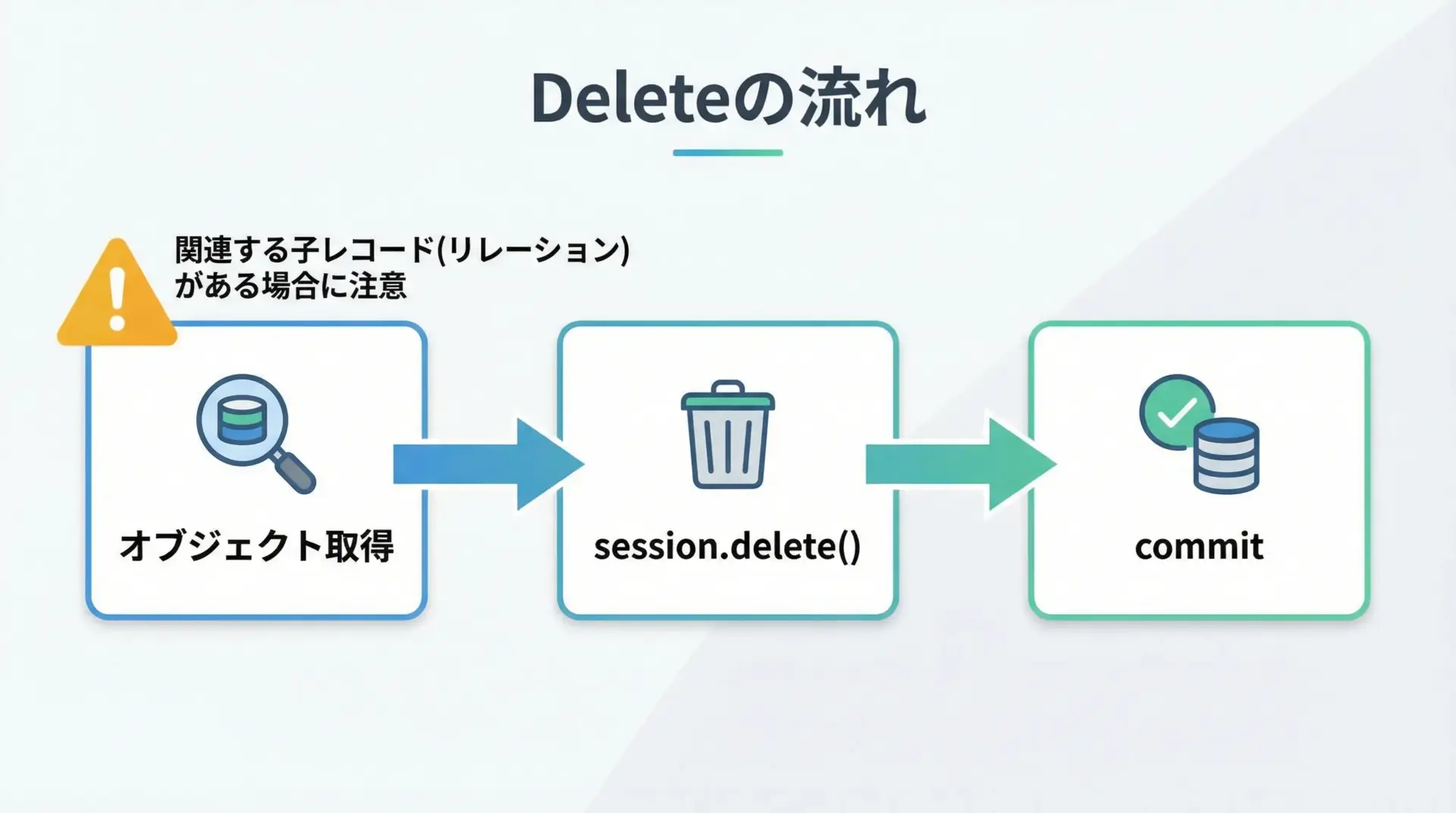
削除も、まずオブジェクトを取得してからsession.delete()する形が分かりやすいです。
# crud_delete.py
from sqlalchemy import create_engine, select
from sqlalchemy.orm import sessionmaker
from crud_create import Base, User
engine = create_engine("sqlite:///example.db", echo=True, future=True)
SessionLocal = sessionmaker(bind=engine, autoflush=False, autocommit=False, future=True)
def delete_user(user_id: int) -> None:
db = SessionLocal()
try:
stmt = select(User).where(User.id == user_id)
user = db.execute(stmt).scalars().first()
if user is None:
print("User not found")
return
db.delete(user)
db.commit()
print(f"Deleted user id={user_id}")
except Exception:
db.rollback()
raise
finally:
db.close()
if __name__ == "__main__":
delete_user(2)# 実行例の一部
DELETE FROM users WHERE users.id = ?
[generated in 0.00011s] (2,)
Deleted user id=2delete()対象のレコードに外部キーで紐づく行がある場合、DB側の制約やcascade設定に注意が必要です。
後半のリレーション設計の章で触れます。
SQLAlchemyのクエリ実行とトランザクション管理
セッションを使ったクエリ実行フロー
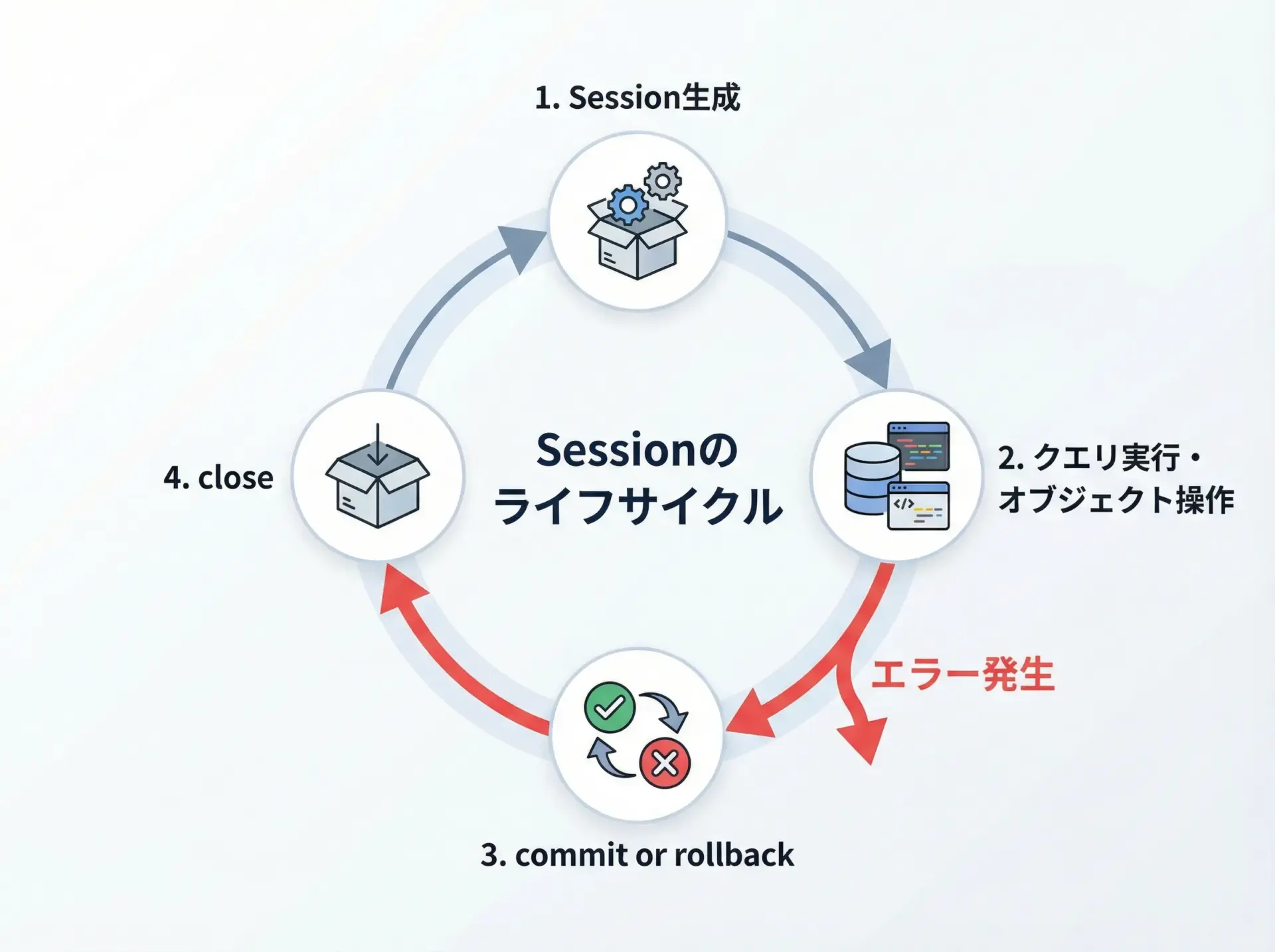
Sessionを使った一般的なフローは、次の4段階に整理できます。
- Sessionを生成する
- クエリを実行したりオブジェクトを操作する
- 正常ならcommit、例外が出たらrollback
- 最後に必ずclose
このパターンを関数化しておくと、アプリケーション全体で統一しやすくなります。
コミット・ロールバックの基本
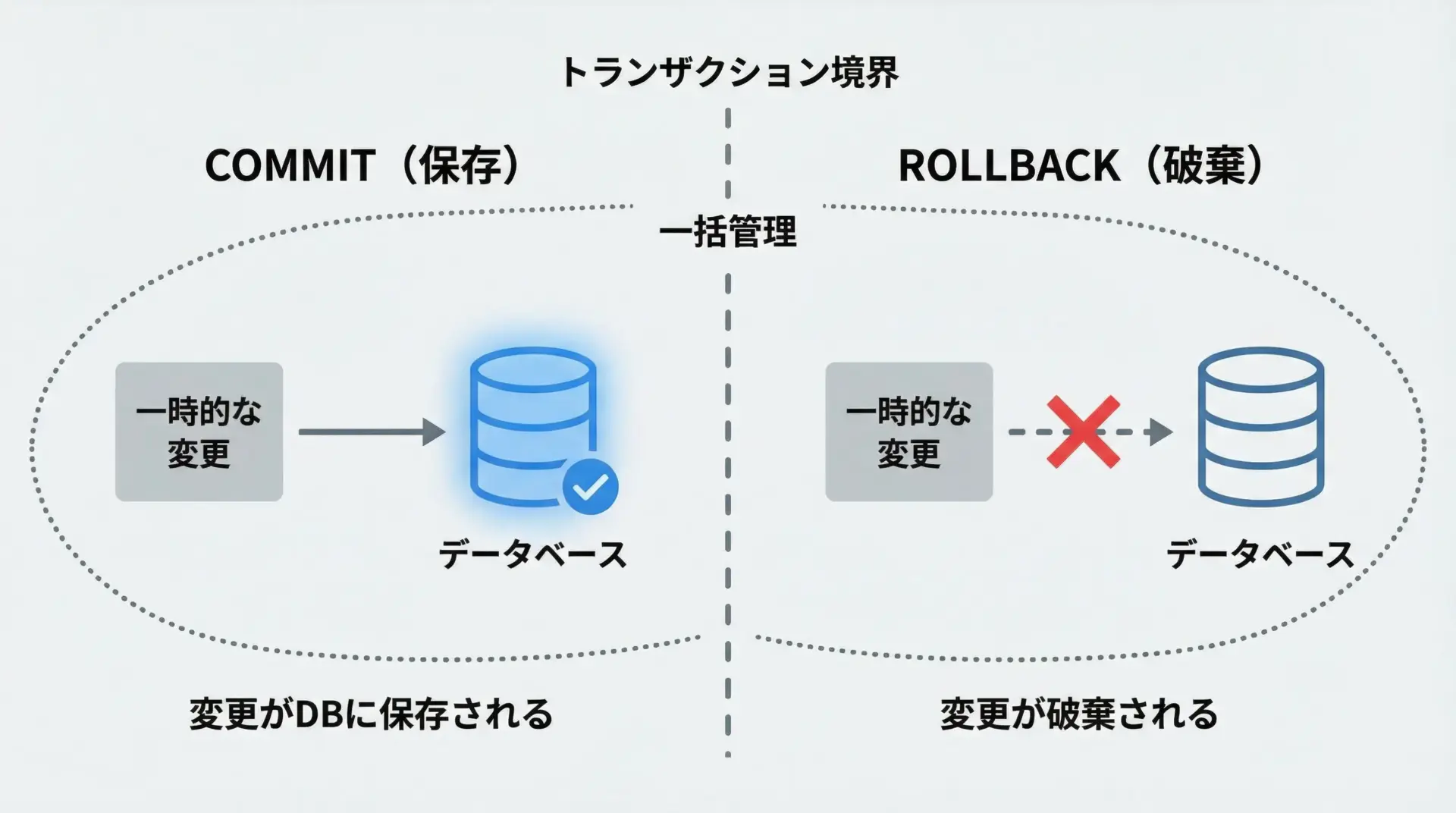
commitは、セッション内で行った変更(INSERT/UPDATE/DELETE)をデータベースに確定させます。
rollbackは、最後のcommit以降の変更をすべて取り消す操作です。
# transaction_basic.py
from sqlalchemy import Column, Integer, String, create_engine
from sqlalchemy.orm import declarative_base, sessionmaker
Base = declarative_base()
class Item(Base):
__tablename__ = "items"
id = Column(Integer, primary_key=True)
name = Column(String(50), nullable=False)
engine = create_engine("sqlite:///tx_example.db", echo=True, future=True)
SessionLocal = sessionmaker(bind=engine, autoflush=False, autocommit=False, future=True)
Base.metadata.create_all(bind=engine)
def demo_commit_and_rollback():
db = SessionLocal()
try:
item1 = Item(name="Committed item")
db.add(item1)
# ここでcommitするとitem1はDBに保存される
db.commit()
item2 = Item(name="Rolled back item")
db.add(item2)
# 例外が起きたと仮定してrollback
raise RuntimeError("Something went wrong!")
except Exception as e:
print("Error:", e)
db.rollback()
finally:
db.close()
if __name__ == "__main__":
demo_commit_and_rollback()# 実行後、DBには"Committed item"だけが残り、"Rolled back item"は存在しないこのように、commitの単位がトランザクションの単位になります。
重要な一連の操作は、1トランザクションの中にまとめるように設計します。
with構文で安全にトランザクション管理
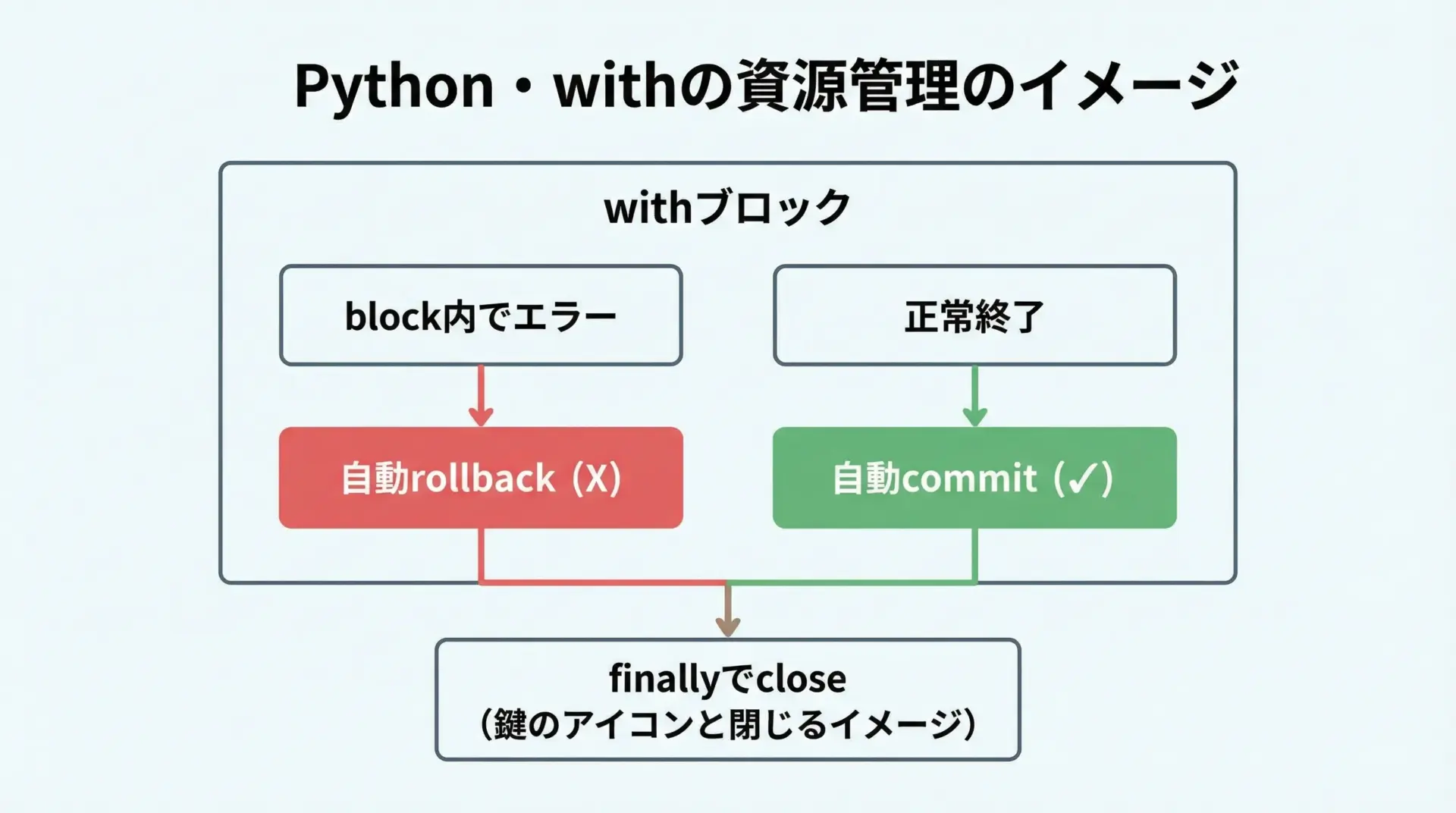
SQLAlchemy 1.4以降では、with構文を使ってSessionを扱うことができます。
これにより、commit/rollback/closeが自動的に行われ、安全性が高まります。
# transaction_with.py
from sqlalchemy import Column, Integer, String, create_engine
from sqlalchemy.orm import declarative_base, sessionmaker
Base = declarative_base()
class Log(Base):
__tablename__ = "logs"
id = Column(Integer, primary_key=True)
message = Column(String(100), nullable=False)
engine = create_engine("sqlite:///tx_with.db", echo=True, future=True)
SessionLocal = sessionmaker(bind=engine, autoflush=False, autocommit=False, future=True)
Base.metadata.create_all(bind=engine)
def write_log_safely(message: str):
# with構文でSessionを管理
with SessionLocal() as db:
log = Log(message=message)
db.add(log)
# withブロックを正常に抜けると、自動的にcommitされる
# 例外が発生した場合はrollbackされる
if __name__ == "__main__":
write_log_safely("Hello transaction with 'with'!")# 実行後、logsテーブルに1行追加されるwith構文を標準スタイルとして採用すると、抜け漏れによるトランザクションの取り扱いミスを防ぎやすくなります。
SQLAlchemyでの実践的なモデル設計
一対多・多対多のリレーション設計
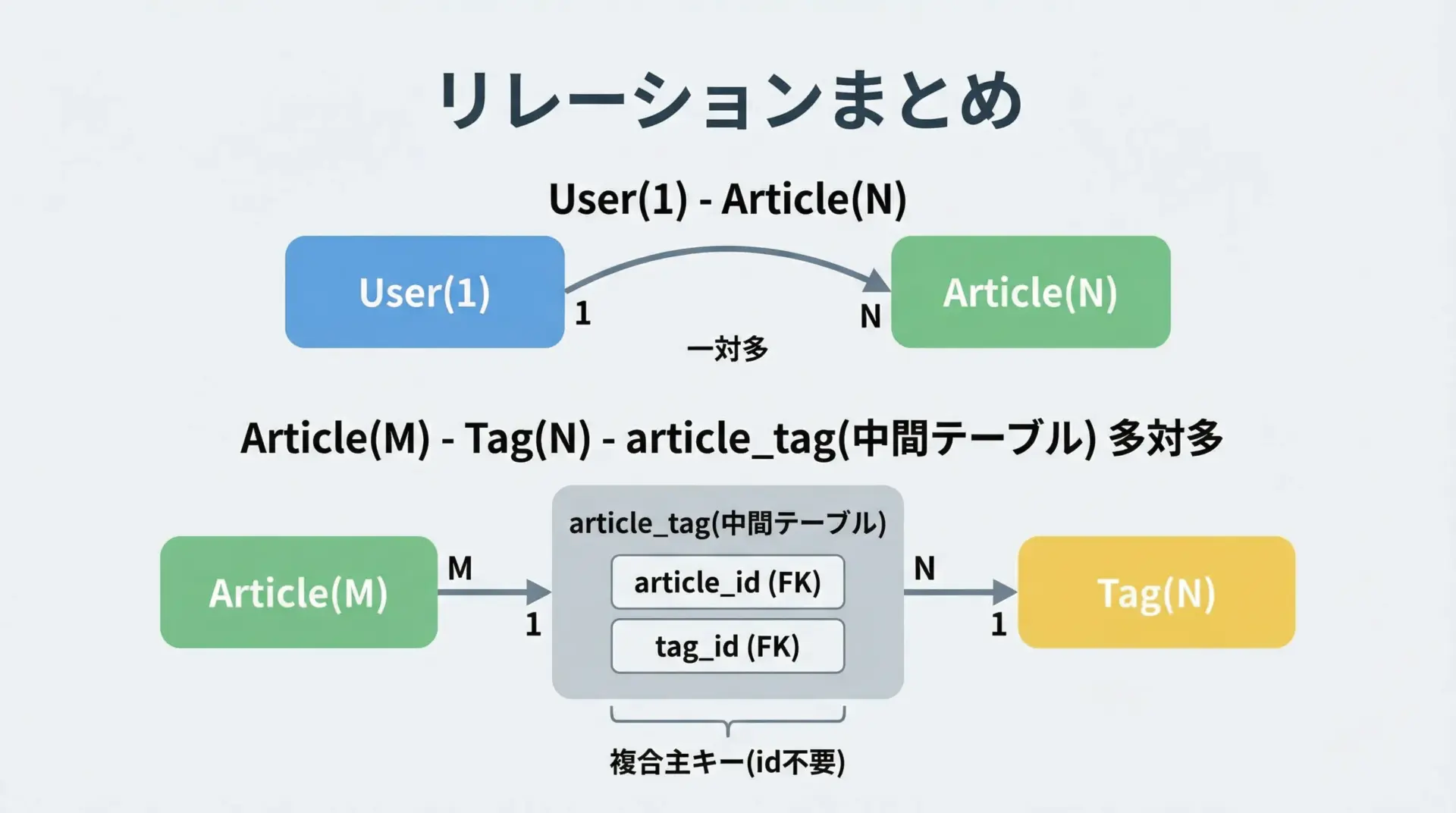
まずは一対多のもう少し実践的なサンプルを示します。
# models_relations_practice.py
from sqlalchemy import (
Column, Integer, String, Text, ForeignKey, Table, create_engine
)
from sqlalchemy.orm import declarative_base, relationship, sessionmaker
Base = declarative_base()
# 中間テーブル(多対多用)の定義
article_tag = Table(
"article_tag",
Base.metadata,
Column("article_id", ForeignKey("articles.id"), primary_key=True),
Column("tag_id", ForeignKey("tags.id"), primary_key=True),
)
class User(Base):
__tablename__ = "users"
id = Column(Integer, primary_key=True)
name = Column(String(50), nullable=False)
articles = relationship("Article", back_populates="author")
class Article(Base):
__tablename__ = "articles"
id = Column(Integer, primary_key=True)
title = Column(String(200), nullable=False)
body = Column(Text, nullable=False)
author_id = Column(Integer, ForeignKey("users.id"), nullable=False)
author = relationship("User", back_populates="articles")
tags = relationship("Tag", secondary=article_tag, back_populates="articles")
class Tag(Base):
__tablename__ = "tags"
id = Column(Integer, primary_key=True)
name = Column(String(50), nullable=False, unique=True)
articles = relationship("Article", secondary=article_tag, back_populates="tags")# relations_demo.py
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from models_relations_practice import Base, User, Article, Tag
engine = create_engine("sqlite:///relation_example.db", echo=True, future=True)
SessionLocal = sessionmaker(bind=engine, autoflush=False, autocommit=False, future=True)
Base.metadata.create_all(bind=engine)
def create_sample_data():
with SessionLocal() as db:
user = User(name="Author A")
tag_python = Tag(name="Python")
tag_orm = Tag(name="ORM")
article = Article(
title="SQLAlchemy入門",
body="SQLAlchemyの基本を解説します。",
author=user, # Userオブジェクトを直接渡す
tags=[tag_python, tag_orm], # 多対多の関連付け
)
db.add(article)
db.commit()
def query_relations():
with SessionLocal() as db:
author = db.query(User).filter_by(name="Author A").first()
print("Author:", author.name)
for article in author.articles:
print("Article:", article.title)
print(" Tags:", [t.name for t in article.tags])
if __name__ == "__main__":
create_sample_data()
query_relations()# 実行例の出力(一部)
Author: Author A
Article: SQLAlchemy入門
Tags: ['Python', 'ORM']secondary引数に中間テーブルを指定することで、多対多の関連が簡潔に書けることを押さえておくと、実際のモデル設計にも応用しやすくなります。
モデルクラスの分割とモジュール構成
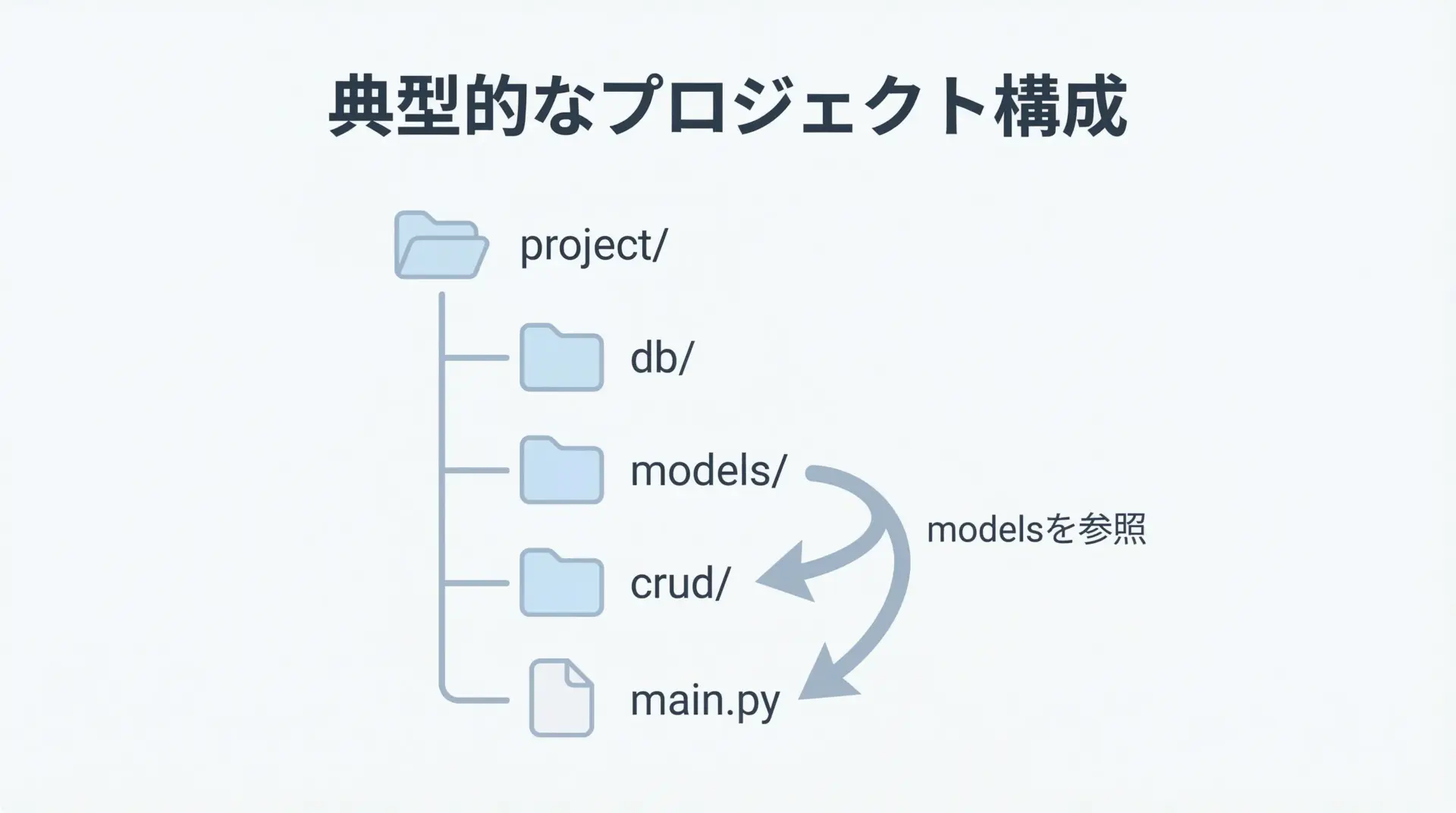
実務では、1ファイルにすべてを書くのではなく、責務ごとにモジュールを分割します。
シンプルな構成例を文章で示します。
db/base.py… Engine、SessionLocal、Baseの定義models/user.py… Userモデルmodels/article.py… Articleモデルcrud/user.py… Userに関するCRUD処理main.py… エントリーポイント
たとえば、db/base.pyは次のようになります。
# db/base.py
from sqlalchemy import create_engine
from sqlalchemy.orm import declarative_base, sessionmaker
DATABASE_URL = "sqlite:///app.db"
engine = create_engine(DATABASE_URL, echo=False, future=True)
SessionLocal = sessionmaker(bind=engine, autoflush=False, autocommit=False, future=True)
Base = declarative_base()モデルはこのBaseをimportして継承し、CRUDコードではSessionLocalを使う構成にすると、循環参照を避けつつ整理しやすくなります。
マイグレーションツール(Alembic)との連携
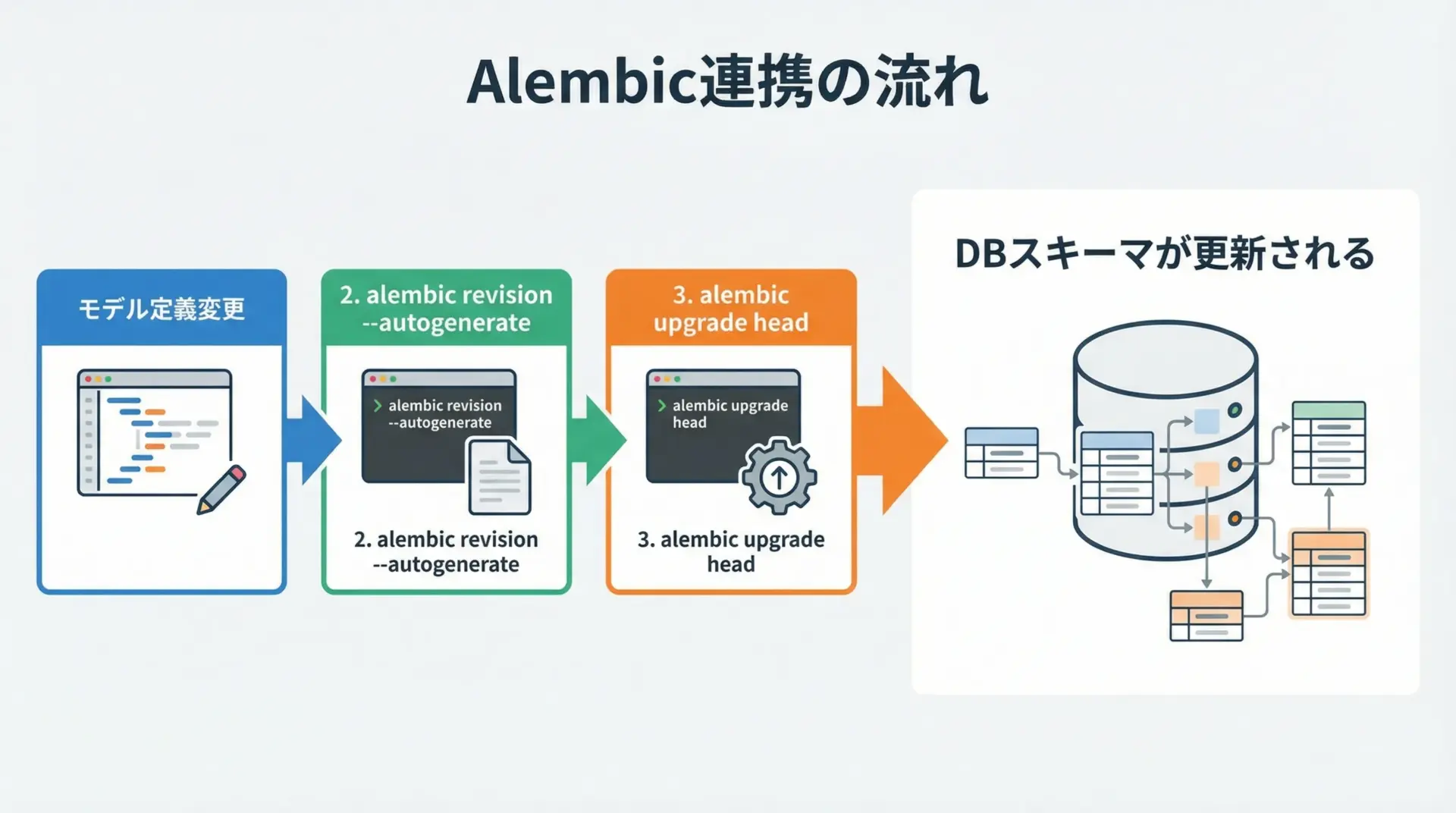
本番運用を意識するなら、Alembicによるマイグレーションはほぼ必須です。
AlembicはSQLAlchemy公式のマイグレーションツールで、モデル定義の変更からDDLを自動生成し、バージョン管理できます。
基本的な導入手順は次の通りです。
# Alembicのインストール
pip install alembic
# 初期化(現在のディレクトリにalembic/が作成される)
alembic init alembicその後、alembic.iniのDB接続URLと、alembic/env.py内でtarget_metadataにBase.metadataを設定することで、モデル定義からマイグレーションスクリプトを自動生成できるようになります。
# モデル変更に応じて新しいマイグレーションファイルを作る
alembic revision --autogenerate -m "create user and article tables"
# マイグレーションをDBに適用
alembic upgrade head詳細なAlembicの使い方は別記事の分量になりますが、「モデルを修正 → Alembicで差分生成 → 適用」というサイクルを回すイメージを持っておくと良いでしょう。
SQLAlchemy入門でつまずきやすいポイント
よくあるエラーとその対処法
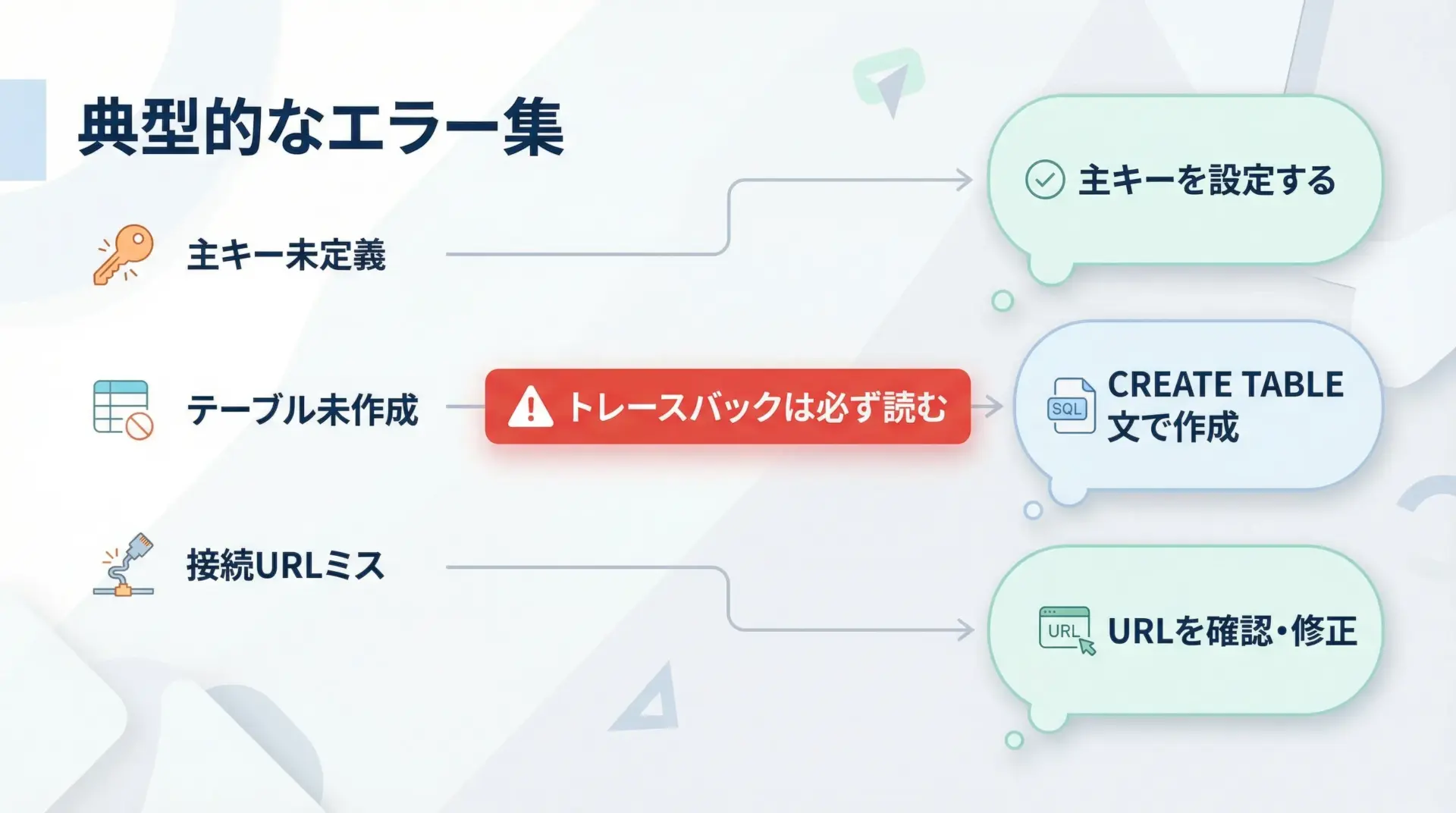
SQLAlchemy入門で特につまずきやすいエラーを、状況別に整理します。
1つ目は主キー未定義です。
モデルにprimary_key=Trueなカラムがないと、INSERT時などにエラーになります。
この場合は、少なくとも1つのカラムにprimary_key=Trueを付けることで解決します。
2つ目はテーブル未作成です。
モデルを定義しただけではDBにテーブルは作られません。
ORMだけを使う入門段階では、Base.metadata.create_all(bind=engine)を忘れずに呼び出す必要があります。
3つ目は接続URLミスやドライバ未インストールです。
特にPostgreSQLやMySQLを使う場合、psycopg2やpymysqlなどのドライバが入っていないと接続時にエラーになります。
また、URLのスキームがpostgresql+psycopg2://のように正しいかも確認が必要です。
エラーが出たときは、トレースバックを上から順に読み、「最初の原因」と「最後のメッセージ」をセットで見る癖をつけると、自己解決できるケースが増えていきます。
パフォーマンスに関わる注意点
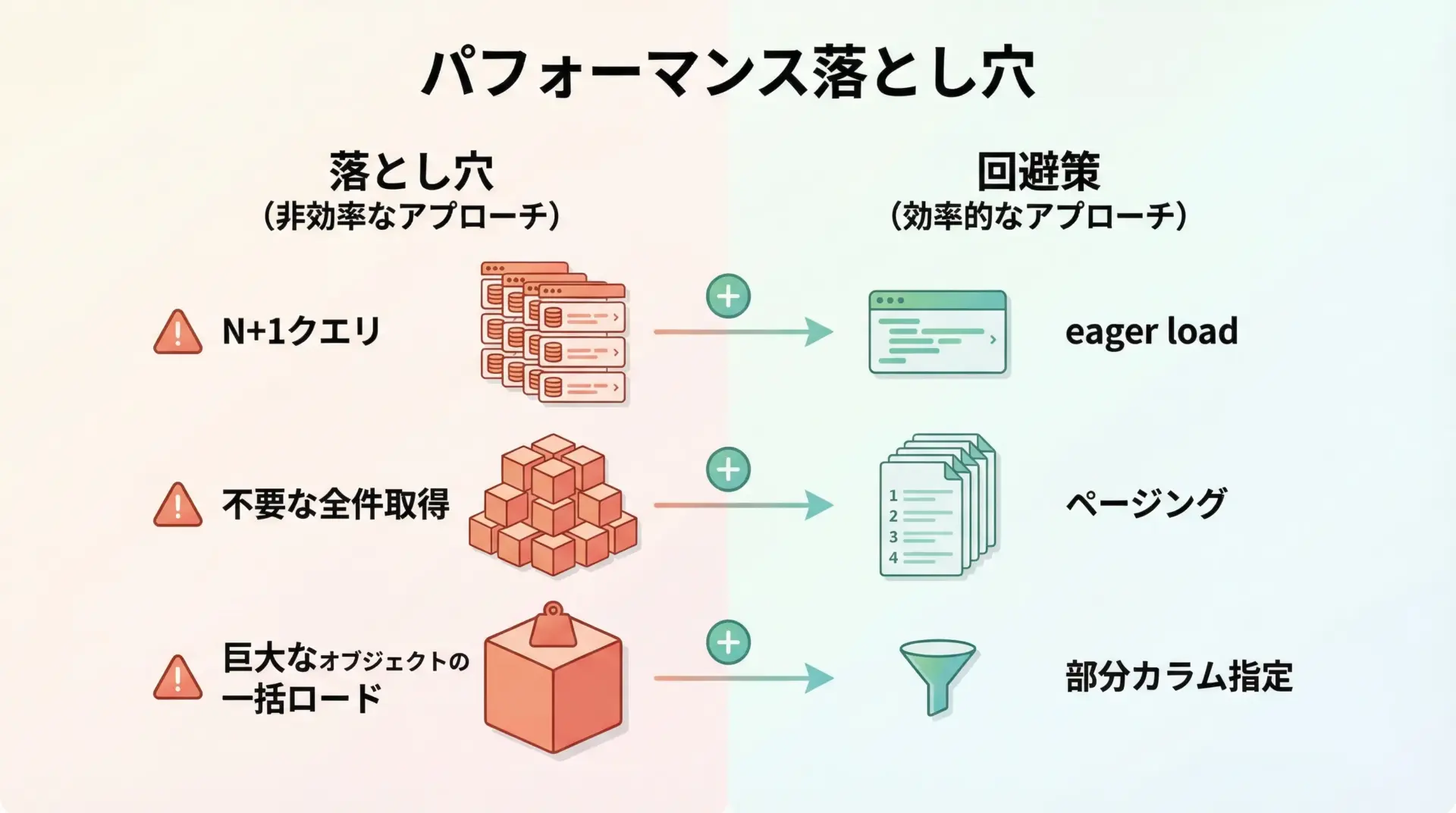
SQLAlchemyは強力ですが、使い方によってはパフォーマンスが悪化することがあります。
代表的な注意ポイントを挙げます。
まずN+1クエリ問題です。
たとえば、ユーザーの一覧を取得し、ループ内でuser.articlesに触れると、ユーザー数+1回のクエリが発行されてしまうことがあります。
これを避けるには、joinedloadなどを使って事前に関連をまとめて取得する必要があります。
次に不要な全件取得です。
.all()は便利ですが、対象件数が多いとメモリを圧迫し、レスポンスも遅くなります。
実運用では、limit()やページングを使い、.all()連発を避ける設計が重要です。
また、不要なカラムまで含めた巨大なオブジェクトの一括ロードも負荷につながります。
必要に応じてselect(User.id, User.name)のように部分的なカラムだけを取得したり、load_onlyを使うと、転送量を抑えられます。
SQLAlchemyで生SQLを使う場合のコツ
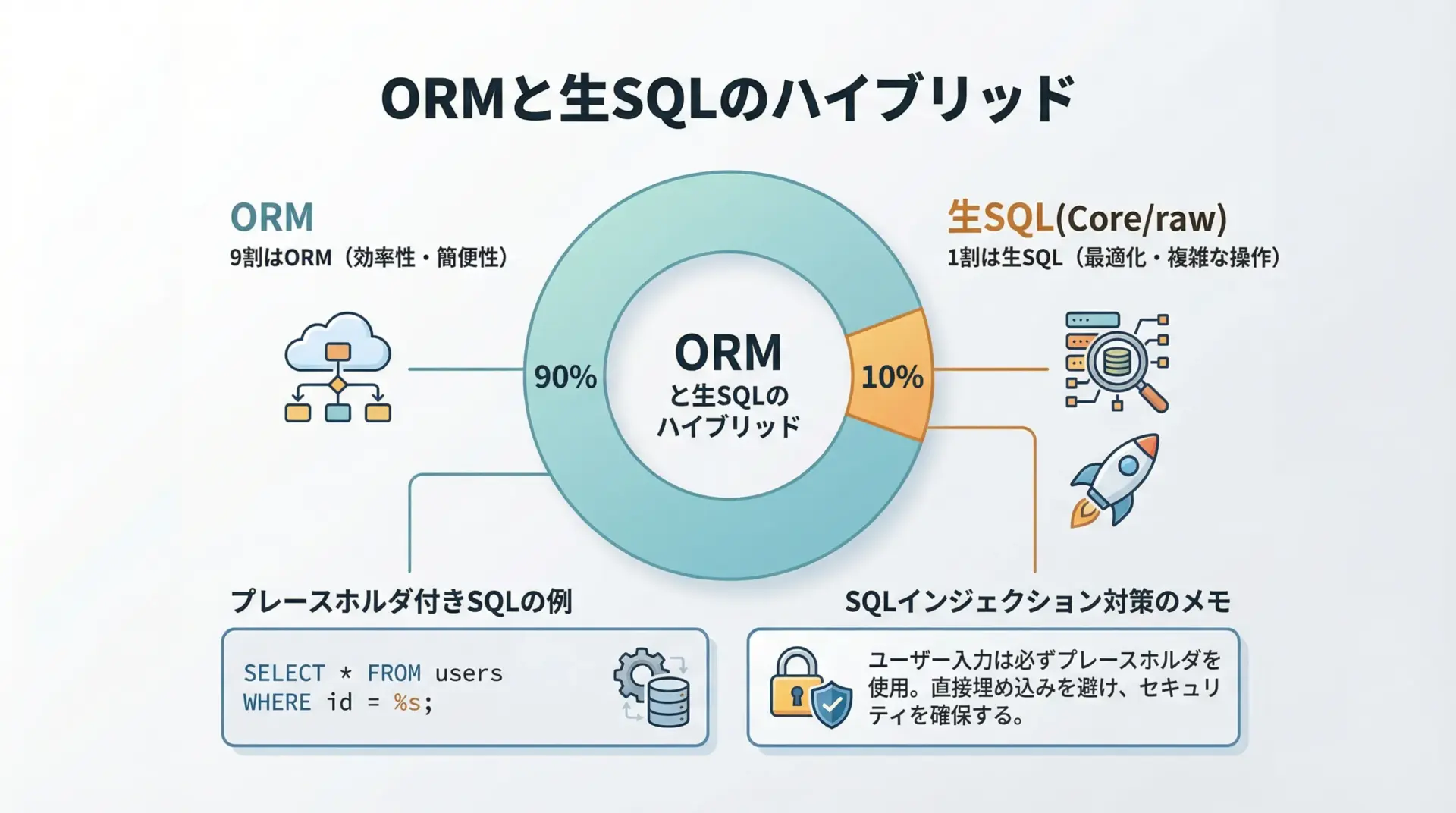
SQLAlchemyを使っていても、どうしても生SQLを書きたい場面は出てきます。
例えば、DB固有の関数や複雑なチューニングが必要なクエリなどです。
ORMのSessionから生SQLを実行する方法の一例です。
# raw_sql_example.py
from sqlalchemy import create_engine, text
from sqlalchemy.orm import sessionmaker
engine = create_engine("sqlite:///example.db", echo=True, future=True)
SessionLocal = sessionmaker(bind=engine, autoflush=False, autocommit=False, future=True)
def get_user_count():
with SessionLocal() as db:
# :name のようなプレースホルダを使い、パラメータを別渡しにする
sql = text("SELECT COUNT(*) FROM users WHERE name = :name")
result = db.execute(sql, {"name": "Alice"})
count = result.scalar_one()
return count
if __name__ == "__main__":
print("Alice count:", get_user_count())# 実行例の一部
SELECT COUNT(*) FROM users WHERE name = ?
[generated in 0.00010s] ('Alice',)
Alice count: 1text()と名前付きプレースホルダ(例: :name)を使い、パラメータは辞書で渡すことで、SQLインジェクションのリスクを避けつつ生SQLを扱えます。
基本スタンスとしては、通常のCRUDやリレーション操作はORMで書き、特殊な箇所だけ生SQLやCoreを併用するとバランスが取りやすくなります。
まとめ
この記事では、SQLAlchemyの基礎から実践的な使い方まで、一通りの流れを解説しました。
EngineとSessionの役割を押さえ、Baseとモデルクラスを定義し、CRUD操作とトランザクション管理のパターンを身につけることで、多くのWebアプリやスクリプトでそのまま応用できるはずです。
まずはSQLiteと簡単なモデルで手を動かし、慣れてきたらリレーション、多対多、Alembicとの連携、生SQLとのハイブリッド運用などへ範囲を広げていくと、自然とSQLAlchemyを使いこなせるようになります。
