
Pythonのコードを書いていると、「この処理はどれくらい時間がかかっているのか」「別の書き方のほうが速いのか」と気になる場面が多くあります。
本記事では、Python標準ライブラリだけで実行時間を正しく計測する方法を丁寧に解説します。
timeモジュールとtimeitモジュールの基本から、それぞれの使い分け方、実務でのベストプラクティスまでを順番に押さえていきます。
Pythonで実行時間を計測する目的
実行時間計測が必要になるケース
実行時間の計測は「なんとなく速くしたい」ためではなく、「どこにどれだけ時間がかかっているかを可視化するため」に行います。
まずは、どのような場面で計測が必要になるのかを整理しておきます。
処理時間を把握したい典型的なシチュエーション
Pythonで実行時間の計測が必要になる代表的なケースとして、次のようなものがあります。
1つ目は、大量データを扱うバッチ処理やスクレイピングなど、完了までに数分~数時間かかるスクリプトです。
こうした処理では、「全体でどれくらいかかるのか」「ボトルネックになっている部分はどこか」を知ることが、設計や運用を考えるうえで重要になります。
2つ目は、WebアプリケーションやAPIサーバーのように、レスポンス時間がユーザー体験に直結するケースです。
1リクエストあたりは数百ミリ秒以下でも、複数の関数呼び出しが積み重なると、全体のレスポンスが大きく遅れてしまうことがあります。
このとき、どの処理が遅いのかを明確にするために実行時間の計測が必要になります。
3つ目は、アルゴリズムや実装方法を比較したいときです。
例えば、同じ処理をforループとリスト内包表記で書き分けたり、標準ライブラリと外部ライブラリを比較したりするとき、定量的な指標として実行時間を比較することで、どの選択肢を採用すべきか判断しやすくなります。
最後に、運用中のシステムの監視やSLA(Service Level Agreement)を守るために、定期的に処理時間を測定し、劣化していないか確認するという用途もあります。
ベンチマークとパフォーマンスチューニングの基本
実行時間計測は、パフォーマンスチューニングの起点になる作業です。
ただし、やみくもに最適化するのではなく、いくつかの基本的な考え方を押さえておく必要があります。
ベンチマークとプロファイリングの違い
ベンチマークとは、ある特定の処理に対して、決められた条件で性能(実行時間など)を測定し、比較することです。
例えば、「この関数を10000回実行したときに何秒かかるか」を測定する、といった使い方が該当します。
処理の一部分だけを切り出して性能を測るときにはベンチマークが適しています。
一方、プロファイリングは、プログラム全体の中で「どの関数がどれだけ時間を使っているか」を詳細に記録する手法です。
PythonではcProfileなどのプロファイラが用意されていますが、本記事の主役はtimeとtimeitなので、まずは「部分的なベンチマーク」がテーマになります。
パフォーマンスチューニングの基本ステップ
パフォーマンス改善を行う際の基本的な流れは次のようになります。
- 現状の性能を測る(ベースライン計測)
- ボトルネックの候補を特定する
- 改善案を1つずつ試し、そのたびに計測する
- 効果があった変更だけを採用する
このとき「計測 → 変更 → 再計測」を小さな単位で繰り返すことが重要です。
感覚だけで「この書き方の方が速そう」と判断すると、かえって遅くなってしまうこともあるからです。
timeモジュールによる実行時間の計測
Pythonのtimeモジュールは、現在時刻の取得やスリープ処理など、時間に関する基本的な機能を提供します。
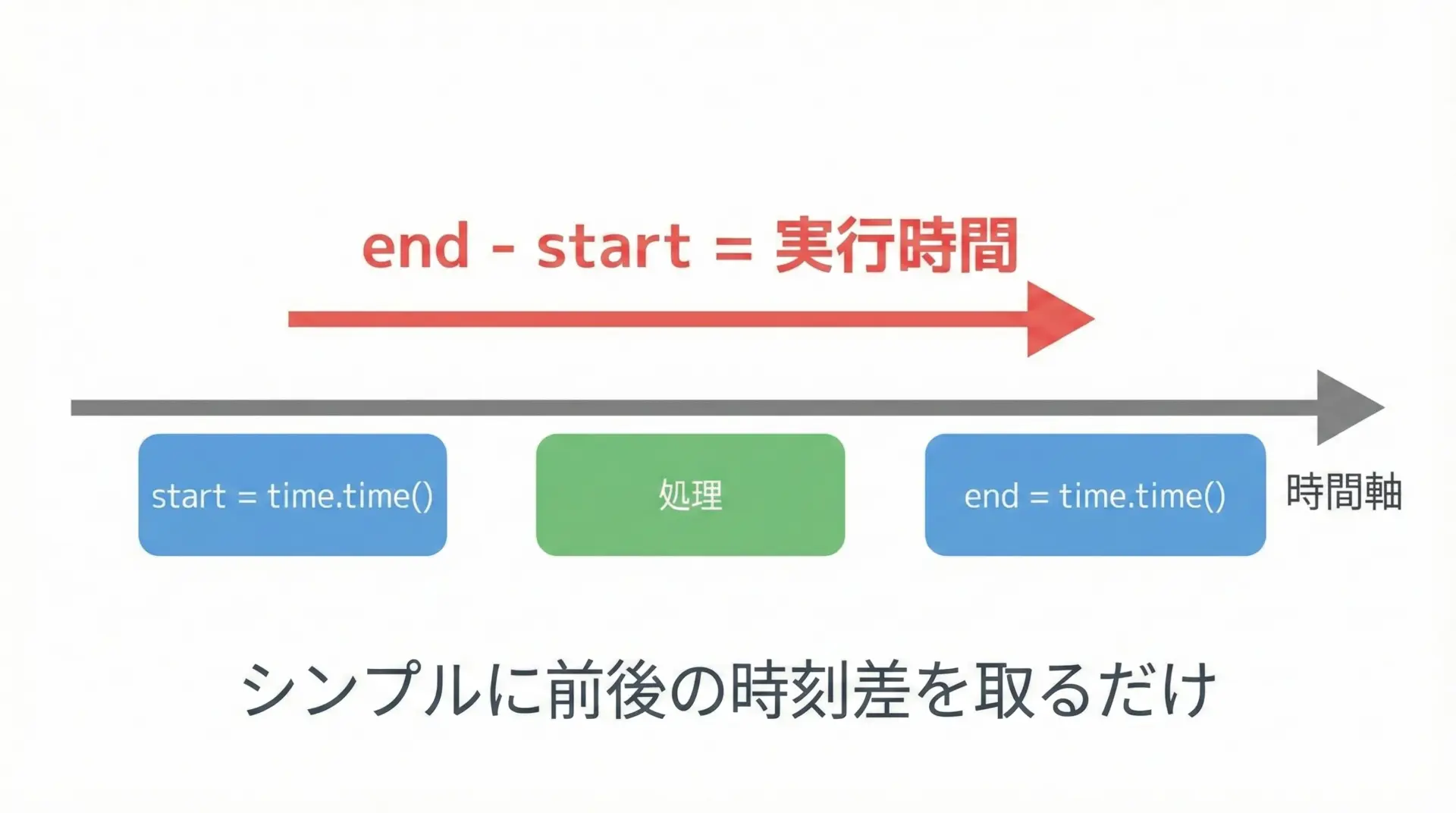
シンプルに「開始時刻と終了時刻の差」を取るだけであれば、timeモジュールで十分です。
time.time()でのシンプルな処理時間計測
最も単純な計測方法は、処理の前後でtime.time()を呼び、その差を取る方法です。
これはUNIXエポック(1970-01-01 00:00:00 UTC)からの経過秒数を返す関数で、扱いやすさが特徴です。
基本的な計測コード
次のコードは、リスト内包表記で0から999,999までの整数を2倍にする処理の実行時間をtime.time()で測定する例です。
import time
# 測定したい処理を関数にしておくと再利用しやすい
def heavy_task():
# 0~999,999 までの数値を2倍にしたリストを生成
data = [i * 2 for i in range(1_000_000)]
return data
def main():
# 開始時刻を取得
start = time.time()
# 計測対象の処理を実行
result = heavy_task()
# 終了時刻を取得
end = time.time()
# 経過時間(秒)を計算
elapsed = end - start
# 結果表示
print(f"要素数: {len(result)}")
print(f"処理時間: {elapsed:.6f} 秒")
if __name__ == "__main__":
main()要素数: 1000000
処理時間: 0.082345 秒この方法は非常にわかりやすく、スクリプト全体の処理時間をざっくり測る用途に適しています。
一方で、後述するtime.perf_counter()に比べて精度や安定性の面で劣る場合があります。
time.perf_counter()による高精度な計測
より高精度な計測が必要な場合にはtime.perf_counter()を使います。
これは「システム全体で最も高精度なモノトニックタイマー」を返す関数で、システムの時計の変更(時刻合わせなど)の影響を受けにくいという特徴があります。

perf_counter()を使った計測例
書き方自体はtime.time()とほとんど同じです。
import time
def heavy_task():
data = [i * 2 for i in range(1_000_000)]
return data
def main():
# 高精度な開始時刻を取得
start = time.perf_counter()
result = heavy_task()
# 高精度な終了時刻を取得
end = time.perf_counter()
# 経過時間(秒)を計算
elapsed = end - start
print(f"要素数: {len(result)}")
print(f"処理時間: {elapsed:.6f} 秒")
if __name__ == "__main__":
main()要素数: 1000000
処理時間: 0.079812 秒実行時間の計測において、現在のPython公式ドキュメントが推奨しているのはperf_counter()です。
特に短い処理(ミリ秒以下)を測る場合には、time()よりperf_counter()を選ぶとよいです。
time.sleep()を使ったサンプルコード
timeモジュールにはtime.sleep()という「指定秒数だけ処理を停止する」関数もあります。
この関数は、意図的に待ち時間を作り、計測のサンプルやテストに利用することができます。
sleepを利用したデモコード
次のコードは、1.5秒だけ待機する処理の実行時間をperf_counter()で測った例です。
import time
def wait_task():
# 1.5秒だけ待機する
time.sleep(1.5)
def main():
start = time.perf_counter()
wait_task()
end = time.perf_counter()
elapsed = end - start
print(f"指定した待ち時間: 1.5 秒")
print(f"実測された待ち時間: {elapsed:.3f} 秒")
if __name__ == "__main__":
main()指定した待ち時間: 1.5 秒
実測された待ち時間: 1.503 秒実際にはOSのスケジューラなどの影響で、指定した値と完全に同じにはなりませんが、おおむね近い値が得られます。
timeモジュールで計測する際の注意点
timeモジュールは手軽な一方で、いくつか注意するべきポイントがあります。
正確なベンチマークを行いたい場合には、このあたりを意識しておくとよいです。
システム負荷や他プロセスの影響を受ける
Pythonの実行時間は、CPUの空き状況や他のプロセスの負荷などに大きく左右されます。
同じコードを同じマシンで実行しても、毎回完全に同じ時間が出るわけではありません。
そのため、1回だけ計測して「この実装は0.01秒、あの実装は0.009秒なので後者が速い」と断言するのは危険です。
より信頼性の高い比較をしたい場合には、複数回計測して平均値や中央値を取るなどの工夫が必要です。
このあたりを自動的に行ってくれるのが、後述するtimeitモジュールです。
計測対象を関数に切り出す
timeモジュールでコードの一部だけを測定したいときは、計測対象を関数に切り出しておくと後からの比較や再利用がしやすくなります。
スクリプトの中にstart = time.perf_counter()とend = time.perf_counter()が散在していると、どの部分を測っているのか把握しづらくなってしまうからです。
ウォームアップ(初回実行のオーバーヘッド)
Pythonでは、モジュールのインポートや関数の初回実行時に、内部でキャッシュが作られるなどして時間が余計にかかることがあります。
このため、本当に知りたいのが「安定した状態での平均的な実行時間」であれば、最初に何度かダミー実行しておくのが安全です。
これもtimeitが自動で面倒を見てくれる部分です。
timeitモジュールの使い方
精度の高いベンチマークを行うための標準ツールがtimeitモジュールです。
複数回の実行、ウォームアップ、最小値の取得など、ベンチマークに必要な処理をいい感じにラップしてくれます。
timeitの基本構文と実行方法
timeitには、大きく分けて次の3つの使い方があります。
- コマンドラインツールとして使う
- Pythonスクリプト内から
timeit.timeit()などを使う - Jupyter Notebookで
%timeitマジックとして使う
ここでは順番に見ていきます。
コマンドラインからtimeitを使う
Pythonがインストールされていれば、ターミナル(コマンドプロンプト)からpython -m timeitを実行するだけで簡単なベンチマークができます。
リスト内包表記のベンチマーク例
例えば、0~999,999までの2乗のリストを作る処理について、1回あたりの実行時間を計測してみます。
python -m timeit "squares = [i*i for i in range(1_000_000)]"10 loops, best of 5: 38.2 msec per loopこの結果は、「このステートメントを1回実行するのに平均して約38.2ミリ秒かかった。10回ずつ5セット試し、その中の最も良い(速い)セットの平均値が38.2ミリ秒だった」という意味です。
複数行のコードを測りたい場合
複数行のコードを直接コマンドラインで書くのは読みにくくなりがちです。
その場合は、セミコロンでつなぐか、あるいはtimeitの-sオプション(後述)を使います。
Pythonコード内からtimeit.timeit()を使う
より柔軟にベンチマークを行いたい場合は、Pythonコード内からtimeitモジュールをインポートして使います。
timeit.timeit()の基本
timeit.timeit()関数は、指定したステートメントをnumber回繰り返し、その合計時間を返します。
import timeit
code = """
squares = [i*i for i in range(1_000_000)]
"""
# codeを100回実行し、その合計時間(秒)を取得
total_time = timeit.timeit(stmt=code, number=100)
print(f"合計時間: {total_time:.3f} 秒")
print(f"1回あたりの平均時間: {total_time / 100:.6f} 秒")合計時間: 3.812 秒
1回あたりの平均時間: 0.038120 秒ここでは、文字列として渡したcodeを100回実行し、そのトータルの実行時間を計測しています。
関数オブジェクトを直接渡す方法
1つのステートメント文字列で書きづらい処理であれば、関数を定義してそれを呼ぶクロージャを渡す方法もあります。
import timeit
def make_squares():
return [i*i for i in range(1_000_000)]
# 文字列ではなく「呼び出し可能オブジェクト」を渡すことも可能
total_time = timeit.timeit(stmt=make_squares, number=100)
print(f"合計時間: {total_time:.3f} 秒")
print(f"1回あたりの平均時間: {total_time / 100:.6f} 秒")合計時間: 3.745 秒
1回あたりの平均時間: 0.037450 秒この書き方のほうが、複雑な処理を測る場合でも読みやすく、エディタの支援も受けやすいです。
setup引数で事前処理を指定する方法
ベンチマークしたい処理の前に、変数定義やインポートなどの準備が必要なことが多くあります。
その場合はsetup引数を用いて、事前に一度だけ実行されるコードを指定します。
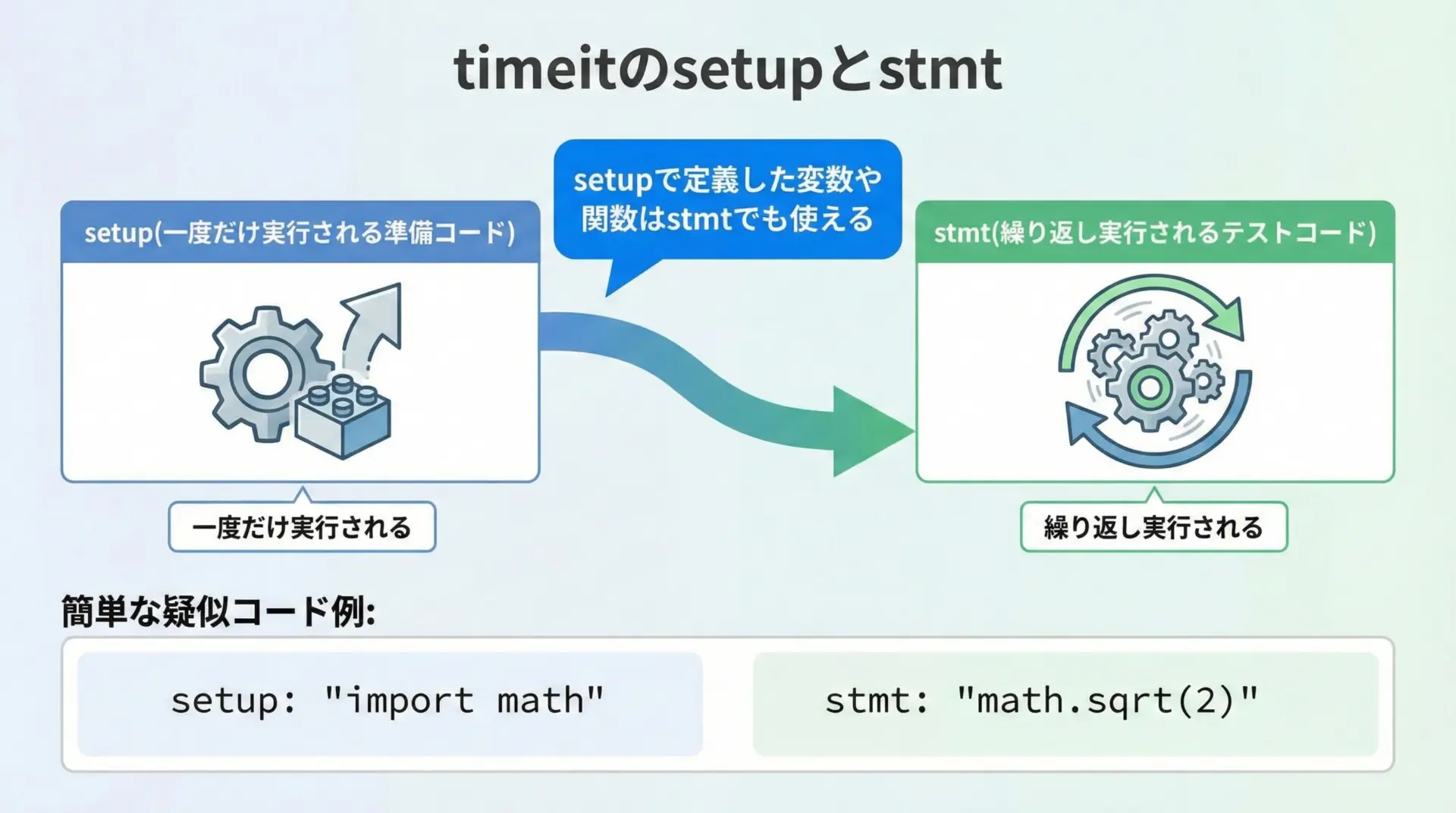
setupとstmtの組み合わせ例
辞書の検索速度を測る場合を考えてみます。
import timeit
setup_code = """
import random
data = {i: i*i for i in range(1_000_0)} # 1万要素の辞書
keys = list(data.keys())
"""
stmt_code = """
key = random.choice(keys)
value = data[key]
"""
# 辞書からランダムに要素を取り出す処理を10000回実行
total_time = timeit.timeit(stmt=stmt_code, setup=setup_code, number=10_000)
print(f"合計時間: {total_time:.4f} 秒")
print(f"1回あたりの平均時間: {total_time / 10_000:.8f} 秒")合計時間: 0.0152 秒
1回あたりの平均時間: 0.00000152 秒ここではsetup_code内で辞書やキーリストを用意し、その状態を使ってstmt_code内で実際の検索処理を繰り返し実行しています。
numberとrepeatで繰り返し回数を調整する
timeitでは「何回実行するか」「そのセットを何回繰り返すか」を柔軟に指定できます。
number引数: 1セットあたりの実行回数
number引数は、1セットでステートメントを何回実行するかを指定します。
デフォルトは1_000_000回ですが、処理が重い場合にはもっと小さい値にする必要があります。
import timeit
code = "sum(range(100))"
for n in (1, 10, 100, 1000, 10_000):
total = timeit.timeit(stmt=code, number=n)
print(f"number={n:6d} のとき: 合計時間 = {total:.6f} 秒, 1回あたり ≒ {total/n:.8f} 秒")number= 1 のとき: 合計時間 = 0.000003 秒, 1回あたり ≒ 0.00000300 秒
number= 10 のとき: 合計時間 = 0.000028 秒, 1回あたり ≒ 0.00000280 秒
number= 100 のとき: 合計時間 = 0.000245 秒, 1回あたり ≒ 0.00000245 秒
number= 1000 のとき: 合計時間 = 0.002410 秒, 1回あたり ≒ 0.00000241 秒
number= 10000 のとき: 合計時間 = 0.023700 秒, 1回あたり ≒ 0.00000237 秒処理が十分に軽い場合は、多めに実行して平均的な時間を出したほうがブレが小さくなります。
repeat関数: セットを複数回繰り返す
OSの状態などによるブレを減らしたい場合にはtimeit.repeat()を使うと便利です。
これはtimeit()をrepeat回繰り返し、その結果のリストを返します。
import timeit
import statistics
code = "sum(range(100))"
times = timeit.repeat(stmt=code, number=10_000, repeat=5)
print("各セットの合計時間:", times)
print(f"最小: {min(times):.6f} 秒")
print(f"最大: {max(times):.6f} 秒")
print(f"平均: {statistics.mean(times):.6f} 秒")
print(f"中央値: {statistics.median(times):.6f} 秒")各セットの合計時間: [0.0213, 0.0209, 0.0211, 0.0208, 0.0210]
最小: 0.020800 秒
最大: 0.021300 秒
平均: 0.021020 秒
中央値: 0.021000 秒timeitのコマンドライン版では、-n(number)と-r(repeat)オプションで同様の制御ができます。
# 1セットあたり 10000 回、セット数 5 回
python -m timeit -n 10000 -r 5 "sum(range(100))"Jupyter Notebookでの%timeitマジックの活用
データ分析や機械学習の現場では、Jupyter Notebookを使うことが多くなっています。
この環境では、IPython拡張として%timeitマジックコマンドが利用できます。
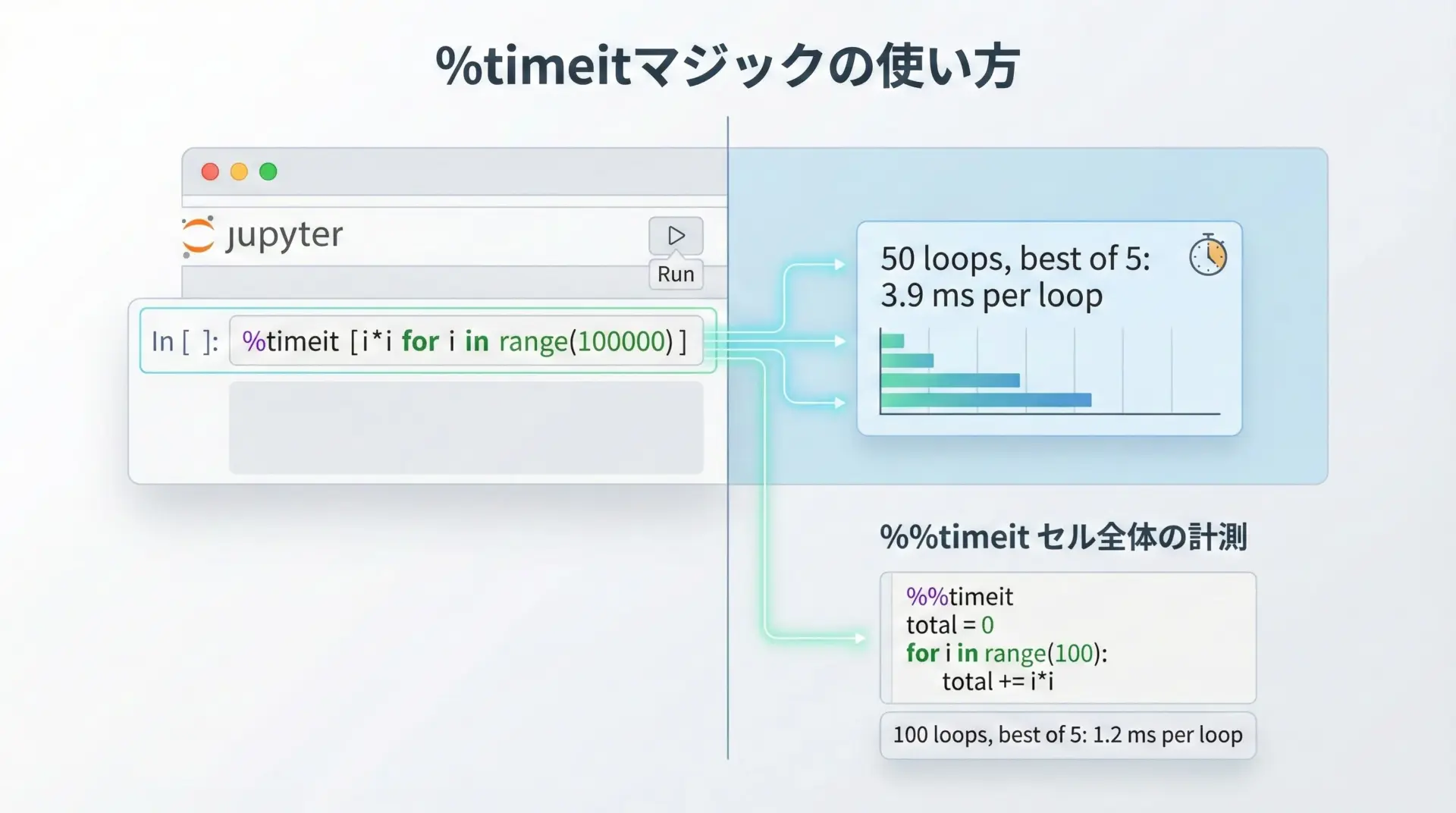
1行のコードに対して%timeitを使う
1行のPythonコードであれば、先頭に%timeitを付けるだけでベンチマークできます。
%timeit [i*i for i in range(1_000_000)]10 loops, best of 5: 39.5 ms per loop複数行のコードには%%timeitを使う
セル全体をベンチマークしたい場合は、セルマジック%%timeitを使います。
%%timeit
data = []
for i in range(1_000_000):
data.append(i*i)10 loops, best of 5: 52.3 ms per loopNotebook環境では%timeitが最も手軽かつ強力な計測手段なので、ちょっとした実装比較を行う際には積極的に活用すると効率的です。
timeとtimeitの使い分け
ここまで、timeモジュールとtimeitモジュールを別々に見てきました。
この章ではそれぞれの特徴を整理し、どのような場面でどちらを使うべきかをまとめます。
timeとtimeitの違い
まずは、両者の違いを表に整理します。
| 観点 | timeモジュール | timeitモジュール |
|---|---|---|
| 主な用途 | 実運用コードの処理時間計測、ログ出力 | ベンチマーク、実装比較 |
| 計測方法 | 前後の時刻差を自分で取る | 繰り返し実行と統計を自動処理 |
| 精度・安定性 | 実装次第。1回計測だとブレが大きい | デフォルトで複数回実行し、最小値を取る |
| 設定の手間 | 非常に少ない | stmt/setup/number などを指定する必要あり |
| 実行環境 | 本番/テスト問わずどこでも | ベンチマーク用(本番では通常使わない) |
「本番コードに組み込むかどうか」という観点で見ると、timeは常用、timeitはスポット的な分析用、という役割分担になります。
実行時間のばらつきとtimeitのメリット
Pythonの実行時間はさまざまな要因で変動します。
OSのスケジューリング、CPUのターボブーストの有無、バックグラウンドで動いている他プロセスなど、プログラマから見えない要因が多く存在します。
単発計測の問題点
time.perf_counter()を1回だけ呼んで差分を取るだけでは、たまたま遅いタイミングを引いてしまうことがあります。
その状態で「この実装は遅い」と判断すると、誤った結論に至ってしまうことになります。
timeitが行っている工夫
timeitはこの問題を軽減するために、次のような工夫を行っています。
- ステートメントを複数回実行して、合計時間を測定する
- そのセットを何度か繰り返し、最も短い(=最もノイズが少ない)結果を採用する
- 実行回数
numberを自動調整し、計測にかかる時間が適切なレンジになるようにする(コマンドライン実行時)
このため、特定の処理の「平均的な速さ」を知りたい場合には、timeitのほうが適していると言えます。
実運用コードの計測に向くのはどちらか
実運用中のアプリケーションでは、次のようなポイントが重要になります。
- ログに処理時間を出力しておきたい
- 実際にユーザーが利用している環境での体感速度に近い値を知りたい
- 本番環境に余計なオーバーヘッドを増やしたくない
これらを満たすには、timeモジュール(特にperf_counter())を使うのが現実的です。
timeitはベンチマークに特化しているため、本番の処理経路に組み込むと余計な繰り返し実行が発生してしまい、用途に合いません。
一方で、開発・検証環境において実装の候補を比較する場合には、timeitのほうが手軽で信頼性の高い結果を得られます。
ケース別のおすすめ計測方法とベストプラクティス
最後に、典型的なシナリオごとにどの方法を使うべきか、ベストプラクティスをまとめます。
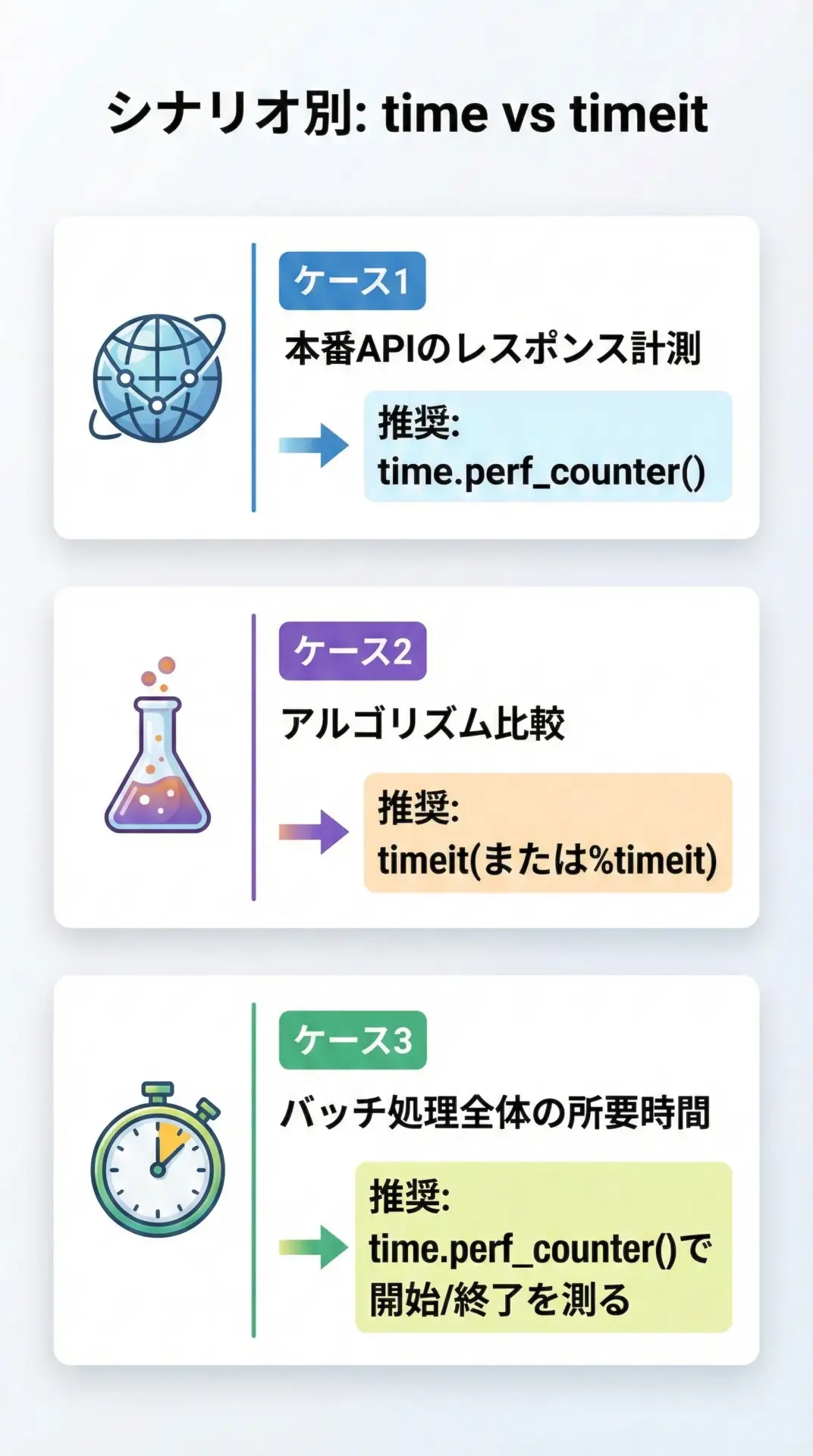
ケース1: Web APIやバッチ処理の本番計測
Web APIのリクエスト処理時間や、バッチ処理の全体時間を計測したいときは、次のようにperf_counter()を埋め込むのが典型的です。
import time
def handle_request(request):
start = time.perf_counter()
# 実際の処理
response = do_something(request)
end = time.perf_counter()
elapsed_ms = (end - start) * 1000 # ミリ秒に変換
# ログに記録する
print(f"Request {request.id}: {elapsed_ms:.2f} ms")
return responseこのように本番コードへの計測は軽量であることが最優先なので、timeモジュールを使います。
ケース2: 実装候補の比較・チューニング
ある処理を別の書き方に変えたときの差を比較したい場合は、timeitを使ったベンチマークが適しています。
import timeit
setup_code = """
data = list(range(1_000_000))
"""
stmt_list_comp = """
result = [x * 2 for x in data]
"""
stmt_map = """
result = list(map(lambda x: x * 2, data))
"""
time_list_comp = timeit.timeit(stmt=stmt_list_comp, setup=setup_code, number=10)
time_map = timeit.timeit(stmt=stmt_map, setup=setup_code, number=10)
print(f"リスト内包表記: {time_list_comp:.3f} 秒")
print(f"map + lambda: {time_map:.3f} 秒")リスト内包表記: 0.820 秒
map + lambda: 0.950 秒このような形で候補を並べてtimeitで定量比較し、「速い実装」を選ぶのが効果的です。
ケース3: 開発中にざっくり感覚を掴みたい場合
開発中に「この処理、ちょっと重い気がするな」と感じたとき、ざっくりとした所要時間を知りたいだけなら、timeモジュールでも十分です。
より詳しく知りたくなった段階でtimeitに切り替える、という2段構えにすると無理がありません。
例えば、次のように区間ごとの処理時間を出すと、ざっくりとしたボトルネックが見えます。
import time
start_total = time.perf_counter()
# 区間1
t1 = time.perf_counter()
load_data()
t2 = time.perf_counter()
print(f"データ読み込み: {t2 - t1:.3f} 秒")
# 区間2
t3 = time.perf_counter()
process_data()
t4 = time.perf_counter()
print(f"データ処理: {t4 - t3:.3f} 秒")
end_total = time.perf_counter()
print(f"合計処理時間: {end_total - start_total:.3f} 秒")「まずtimeで全体の構造を掴み、その後timeitで細かい実装差を詰める」という使い分けが、現場では実用的です。
まとめ
Pythonで実行時間を計測する方法として、本記事ではtimeモジュールとtimeitモジュールの使い方と使い分けを解説しました。
timeは本番コードやバッチ処理の所要時間を手軽に測るための道具であり、特にtime.perf_counter()は高精度な経過時間計測に適しています。
一方、timeitは繰り返し実行や統計処理を自動で行うベンチマーク専用ツールで、アルゴリズムの比較や書き方の違いを検証する際に大きな力を発揮します。
状況に応じて、ざっくりとした全体時間はtimeで、細かな性能比較はtimeitで、という形で使い分けることで、効率的かつ再現性の高いパフォーマンスチューニングが実現できます。
