
Pythonで処理の待機や間隔調整をしたいときに頻繁に登場するのがtime.sleepです。
シンプルな関数ですが、使い方を間違えると処理が止まりすぎたり、アプリ全体が固まったように見えることもあります。
この記事では、初心者の方でも理解しやすいように、基本から実践的な使い方、注意点や代替手段まで順番に詳しく解説します。
Pythonのtime.sleepとは
time.sleepの基本的な役割と特徴
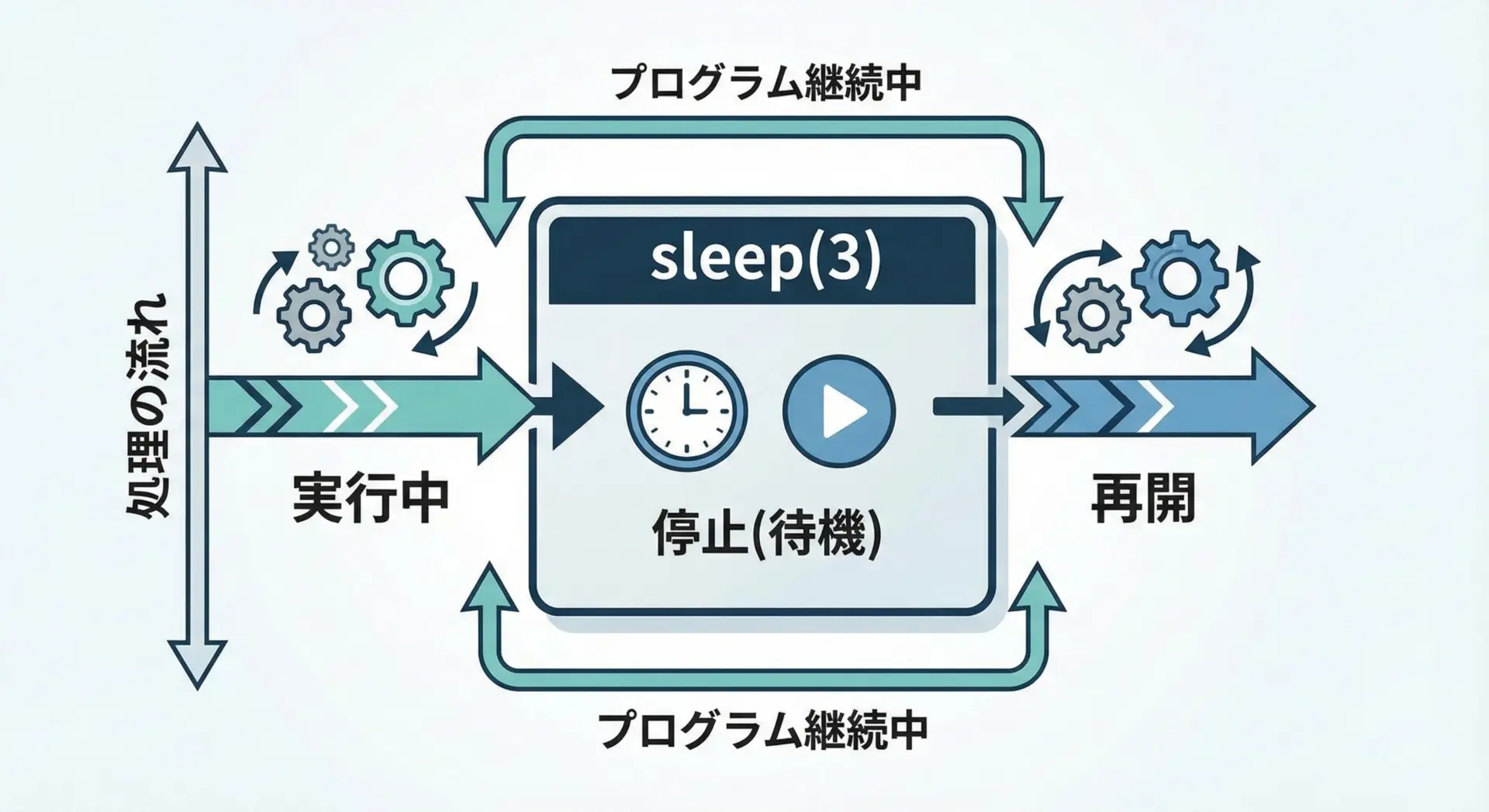
Pythonのtime.sleep関数は、プログラムの実行を指定した秒数だけ一時停止させるための機能です。
標準ライブラリのtimeモジュールに含まれており、インストール不要でどの環境でもすぐに利用できます。
役割をまとめると次のようになります。
- 指定した秒数だけ現在のスレッドの実行を止める
- 引数は
float型も指定できるため、小数点以下の秒数(ミリ秒レベル)の待機も可能 - 戻り値は
Noneで、何かを返すためではなく「待つこと」が目的の関数
たとえばtime.sleep(2)と書くと、その行で2秒間処理が完全に止まり、その後に次の行の処理が実行されます。
time.sleepが使われる主なシーンと注意点

time.sleepはとてもシンプルな関数ですが、現場ではさまざまな用途で使われます。
代表的なシーンとして、次のようなものがあります。
- ループ処理で、一定間隔ごとに処理を実行したいとき
- Web APIやスクレイピングで、アクセス間隔をあけてサーバへの負荷やアクセス制限を回避したいとき
- ログや
print出力を、ゆっくり順番に見せたいとき - デモプログラムやチュートリアルで、処理の進み方をわかりやすく見せたいとき
一方で、time.sleepにはいくつかの注意点があります。
- 待機中はそのスレッドが完全にブロックされるため、GUIやWebアプリのメインスレッドで使うと、画面が固まったように見えます
- 長い秒数を指定しすぎると、デバッグや開発効率が大きく低下します
- テストコードで無計画に使うと、テスト全体が遅くなる原因になります
このように、「処理を止めたい場所でだけ、適切な秒数を指定する」ことがtime.sleep活用のポイントになります。
time.sleepの正しい書き方
timeモジュールのインポート方法と書き方
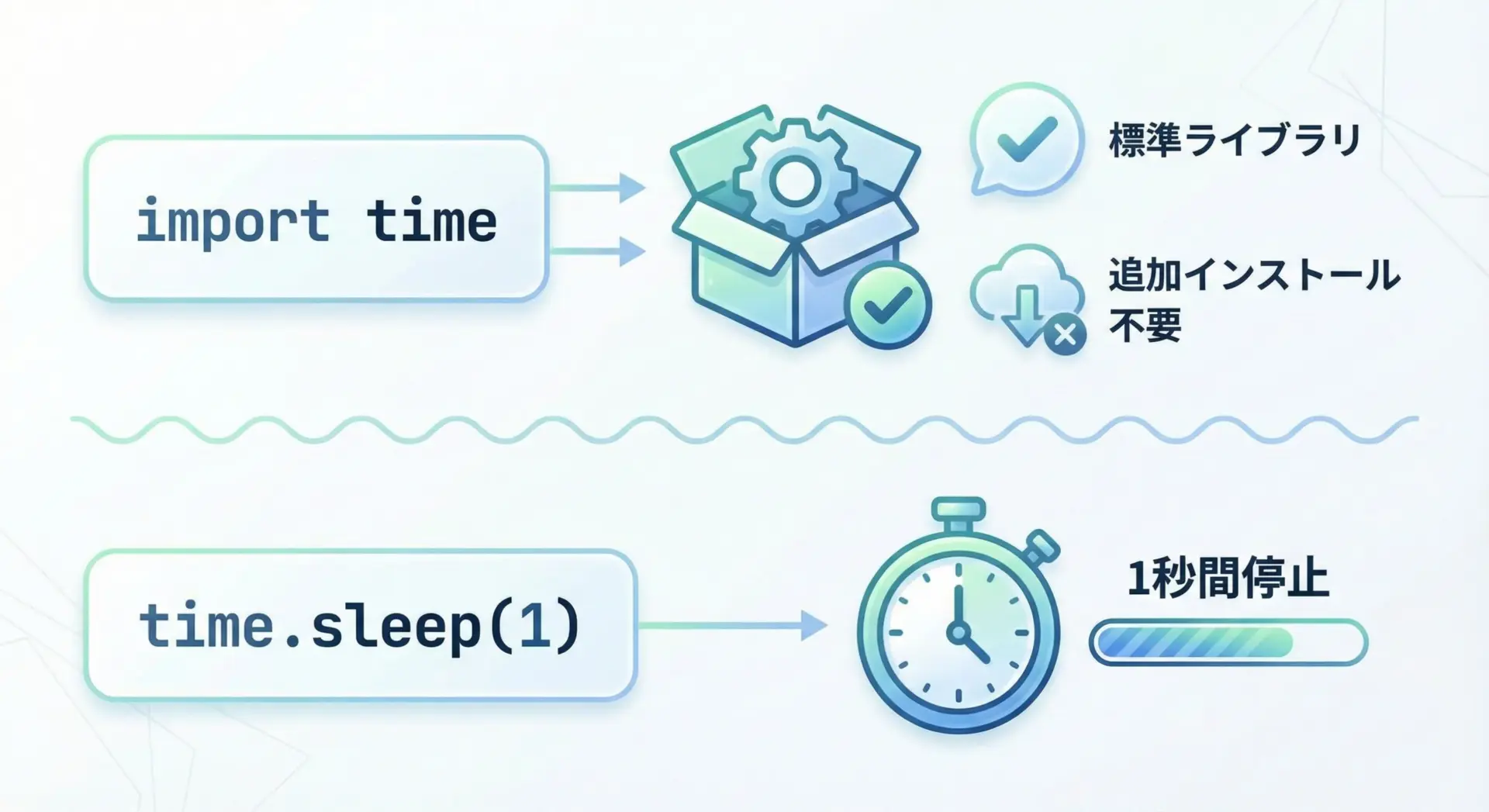
time.sleepを使うには、まずtimeモジュールをインポートする必要があります。
最もシンプルな書き方は次のとおりです。
import time # timeモジュールをインポート
time.sleep(1) # 1秒待機する一般的なインポート方法としては、次の2パターンがよく使われます。
import time
# -> time.sleep(1) のように、time. をつけて呼び出す
from time import sleep
# -> sleep(1) のように、time. を省略して呼び出せる規模の大きなコードや他のtime系関数も使う場合は、名前空間が明確になるimport timeの形を使うほうが読みやすくなります。
一方で、サンプルコードや短いスクリプトではfrom time import sleepもよく使われます。
time.sleepの秒数指定
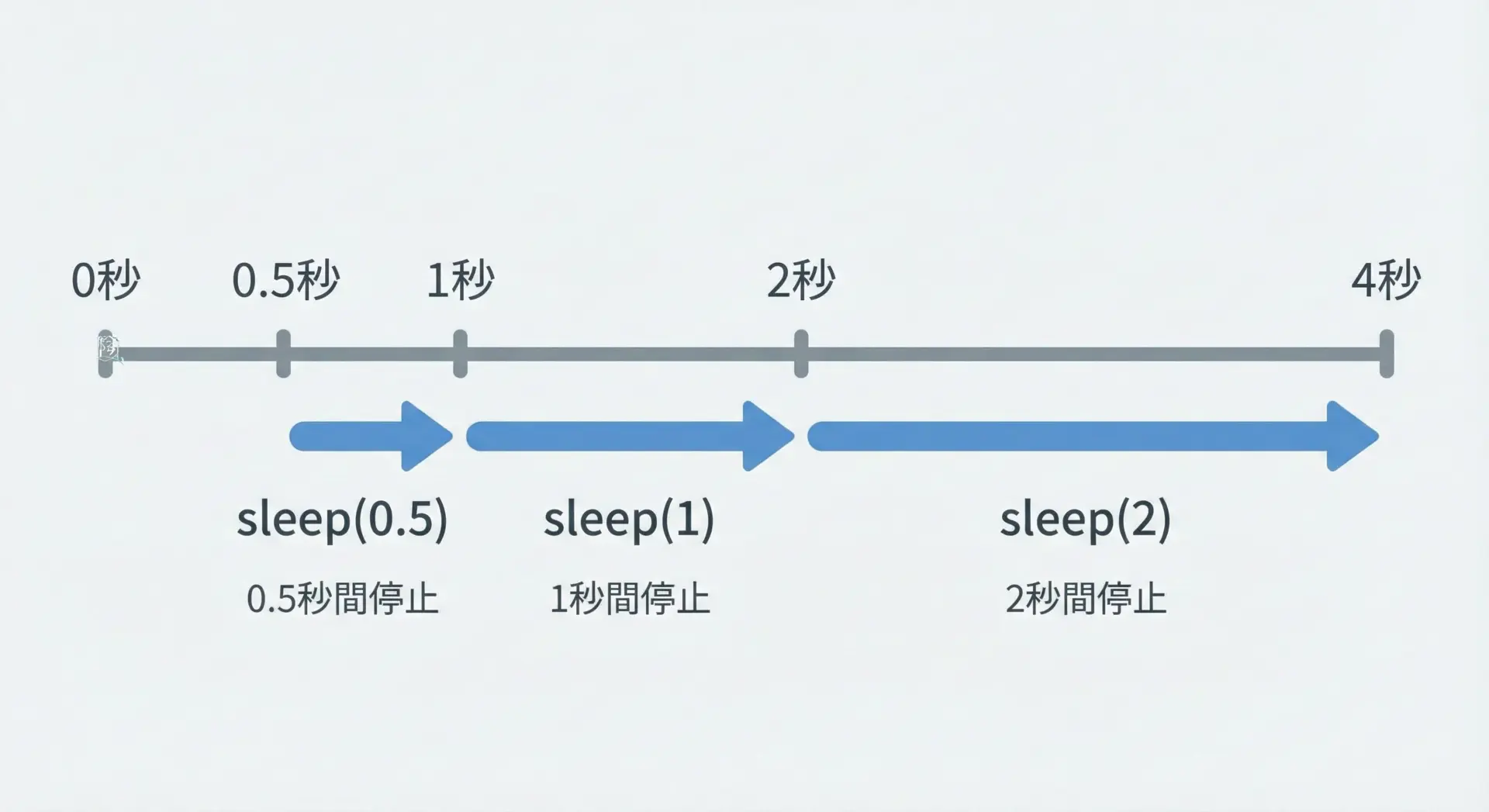
time.sleepの引数には、待機したい秒数をintあるいはfloatで指定します。
- 整数: 秒単位で待機 (
time.sleep(3)→ 3秒待機) - 浮動小数点数: 小数秒単位で待機 (
time.sleep(0.1)→ 0.1秒待機)
たとえば以下のように使います。
import time
time.sleep(1) # 1秒待機
time.sleep(2.5) # 2.5秒待機OSや環境によっては、指定した時間よりわずかに長くなることがありますが、指定した値より極端に短くなることはありません。
そのため、ミリ秒レベルの厳密さが必要なリアルタイム処理には不向きですが、人間が待てる程度の処理間隔をあける用途には十分です。
サンプルコードで見るtime.sleepの基本動作
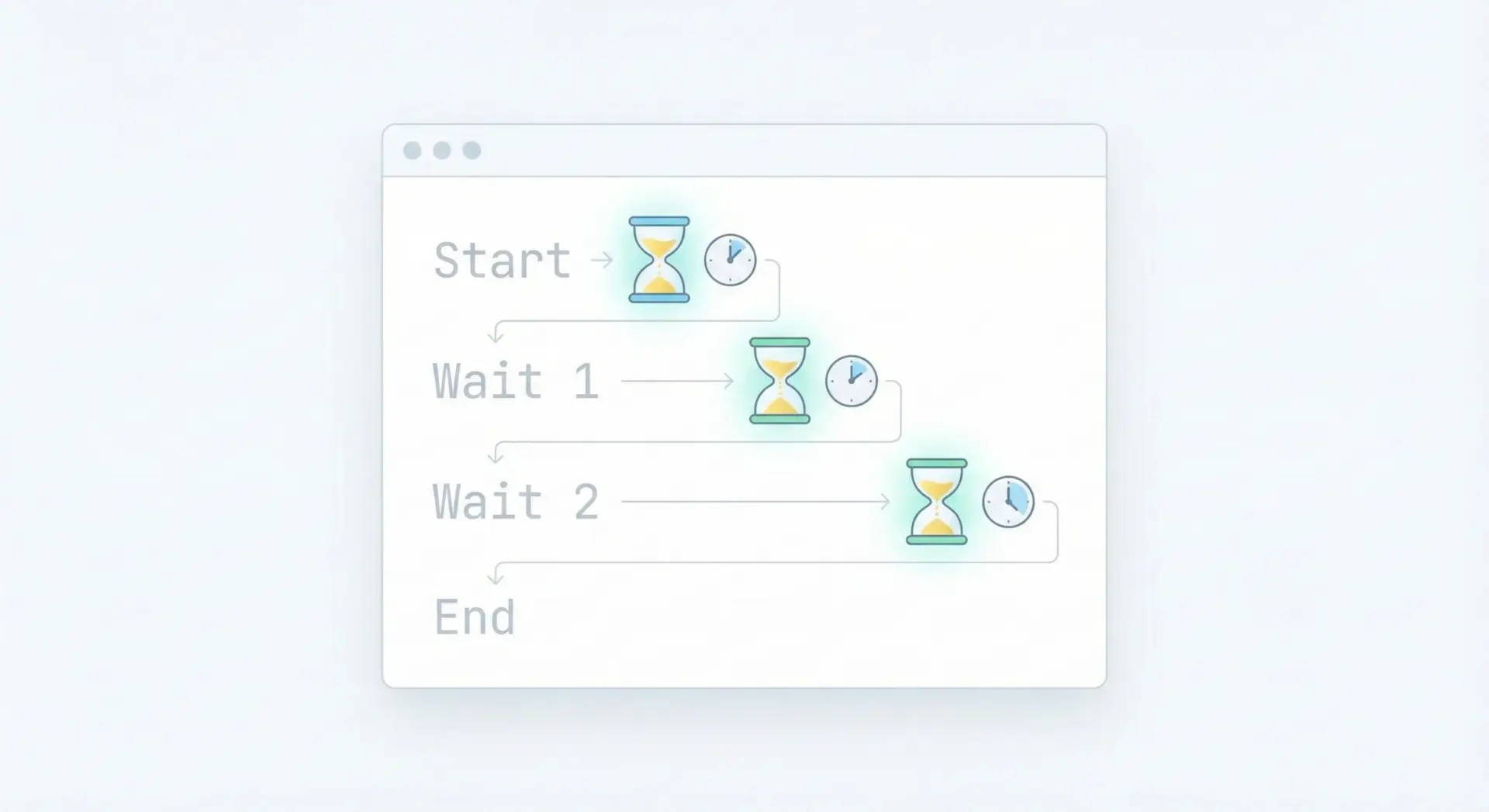
以下は、time.sleepの基本的な動作を確認できるシンプルなサンプルです。
import time # timeモジュールを読み込む
print("処理を開始します")
# 1秒待機
time.sleep(1)
print("1秒経過しました")
# 2秒待機
time.sleep(2)
print("さらに2秒経過しました")
print("処理を終了します")このコードを実行すると、メッセージの表示のあいだに、指定した秒数だけ待機が入ります。
実行結果のイメージは次のようになります。
処理を開始します
(1秒待機)
1秒経過しました
(2秒待機)
さらに2秒経過しました
処理を終了しますこの例のように、sleepを挟むことで、ユーザーに「時間の経過」を視覚的に伝えることができます。
実践で使えるtime.sleepの活用パターン
ループ処理でのtime.sleepの使い方
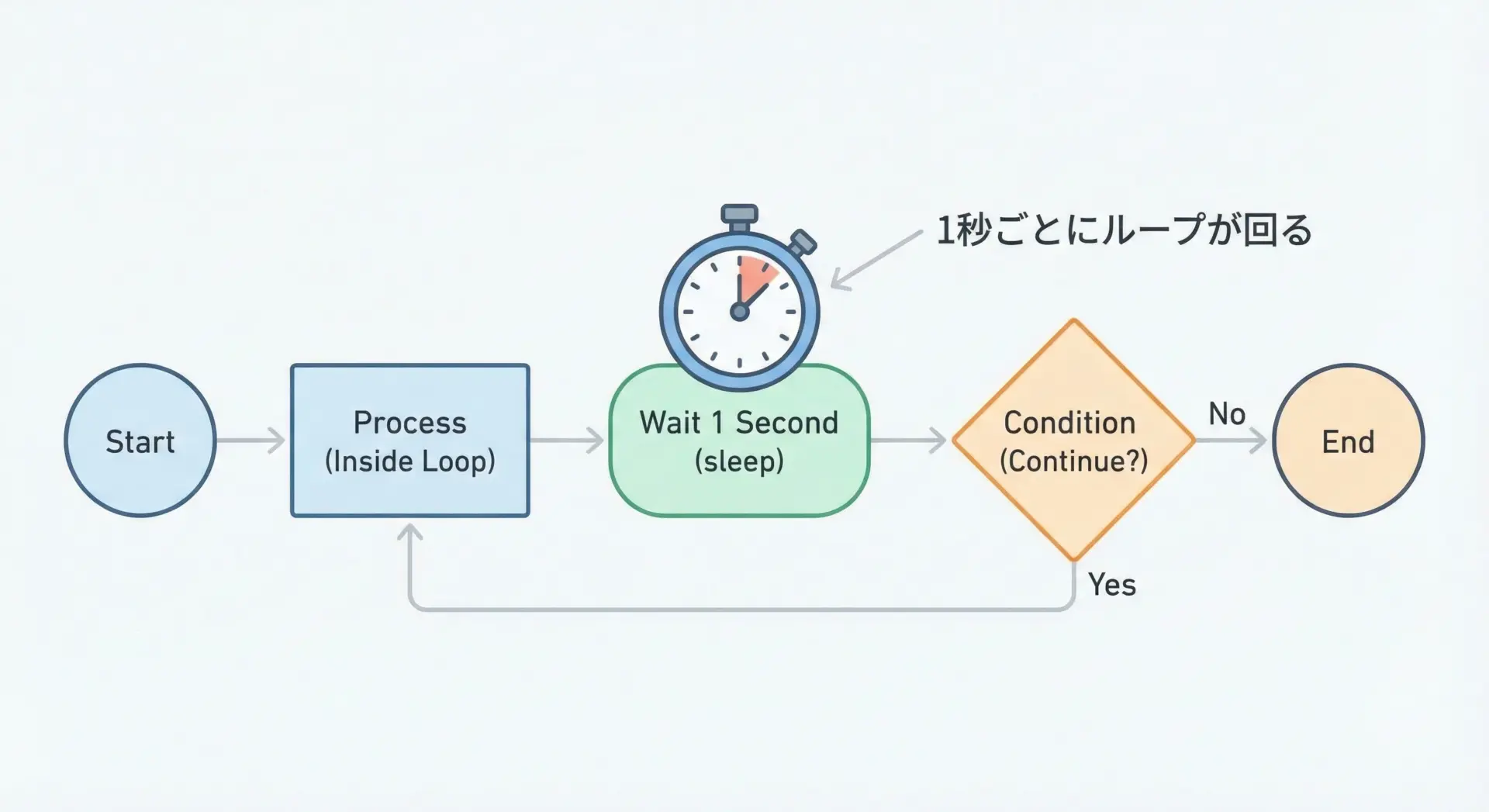
ループ処理とtime.sleepを組み合わせると、一定間隔ごとに処理を実行するプログラムを簡単に作ることができます。
import time
for i in range(5):
print(f"{i + 1}回目の処理です")
time.sleep(1) # 各ループの間で1秒待機出力結果のイメージは次のとおりです。
1回目の処理です
(1秒待機)
2回目の処理です
(1秒待機)
3回目の処理です
(1秒待機)
4回目の処理です
(1秒待機)
5回目の処理ですこのように、監視ツールや定期チェック処理など、一定周期で処理を繰り返したい場合によく使われます。
ただし、次のような点に注意が必要です。
- sleepをどこに置くかで挙動が変わる (ループの先頭か末尾か)
- 長すぎる待機時間はユーザー体験を悪化させる
- GUIやWebのメインスレッドでのループ+sleepはフリーズの原因になる
必要に応じて、time.time()などを組み合わせて「厳密に1秒ごとに実行されるように補正する」といった実装もありますが、初心者のうちは単純なループ+sleepで挙動を理解すると良いです。
APIアクセスやスクレイピングでのtime.sleepの使い方
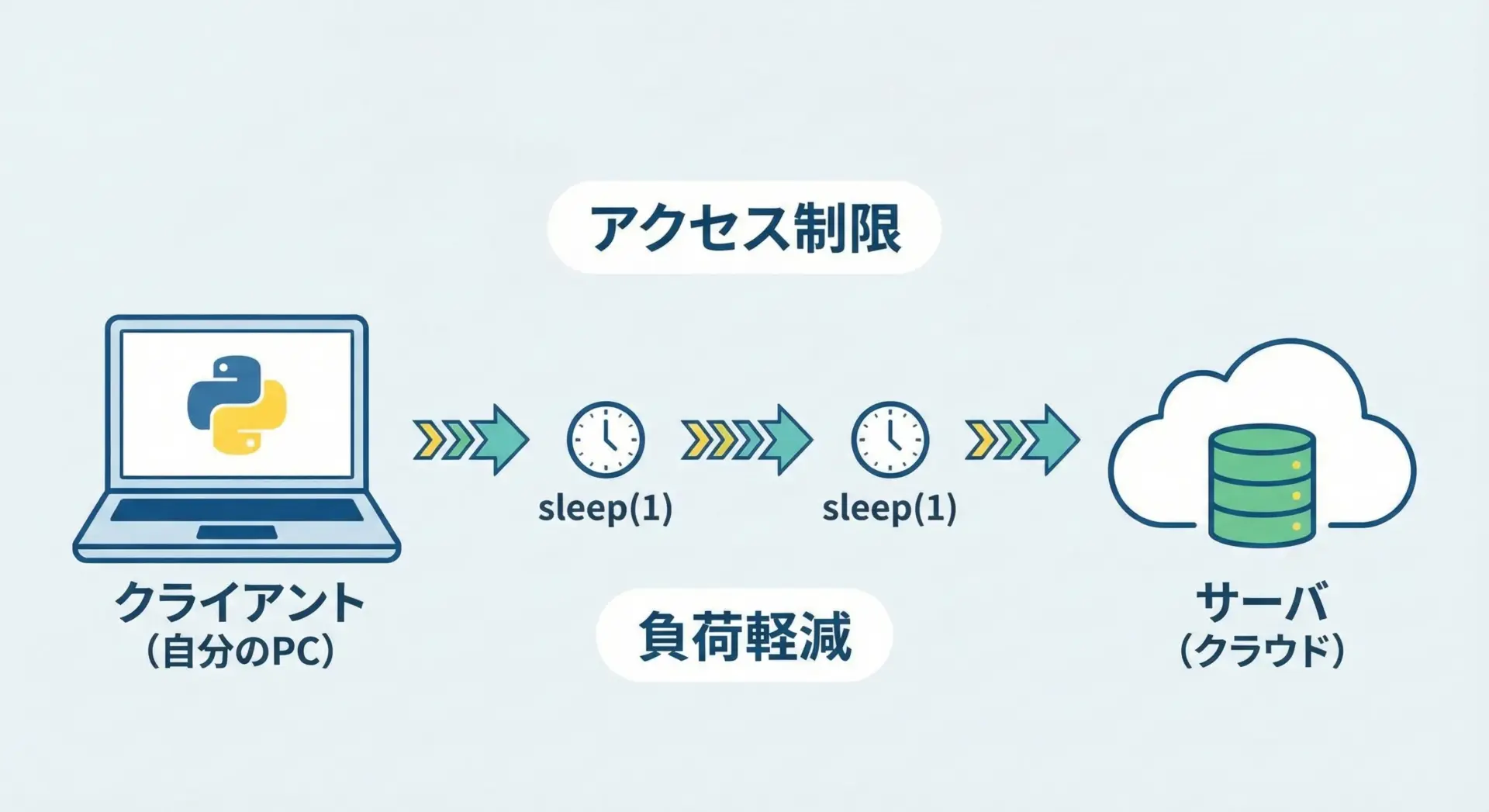
Web APIやスクレイピングでは、短時間に大量のリクエストを送ると、アクセス制限されたりサーバに負荷をかけてしまうことがあります。
そのため、1リクエストごとに少し待機を入れるのが一般的です。
import time
import requests # 例として requests を使用
urls = [
"https://example.com/page1",
"https://example.com/page2",
"https://example.com/page3",
]
for url in urls:
response = requests.get(url)
print(f"{url} のステータスコード: {response.status_code}")
# 1秒待機してから次のリクエストを送る
time.sleep(1)このように待機を入れることで、サーバ側にも自分のプログラムにも優しいアクセスになります。
また、APIによっては「1秒に何回まで」といったレート制限が明記されていることもあるため、その条件に合わせてtime.sleepの秒数を調整します。
ただし、サービスの利用規約やrobots.txtを必ず確認することが大切です。
time.sleepを入れていれば何をしても良いわけではありません。
print出力やログ表示を間隔を空けて行う方法
学習用スクリプトやデモでは、print出力を時間差で表示すると、処理の流れがとても理解しやすくなります。
import time
from datetime import datetime
for i in range(3):
now = datetime.now().strftime("%H:%M:%S")
print(f"[{now}] ログメッセージ {i + 1}")
time.sleep(1.5) # 1.5秒ごとにログを出力実行すると、次のように1.5秒おきにログが表示されます。
[12:00:01] ログメッセージ 1
(1.5秒待機)
[12:00:02] ログメッセージ 2
(1.5秒待機)
[12:00:04] ログメッセージ 3このパターンは、進捗表示や簡単なアニメーション表示にも応用できます。
例えば、ロード中を演出する「…」アニメーションなども、sleepを使って簡単に実装できます。
import time
print("処理中", end="", flush=True)
for _ in range(3):
time.sleep(0.5)
print(".", end="", flush=True)
print("\n完了しました")time.sleepを関数内で使うときのポイント
time.sleepは、関数の内部でももちろん使用できます。
ただし、関数が呼び出されるたびに待機時間が発生するため、設計次第では全体の処理時間が大きく膨らむことがあります。
次の例では、処理の一部分を関数化し、その中で待機を行っています。
import time
def do_task(task_name: str, wait_sec: float) -> None:
"""タスク名と待機秒数を受け取って、処理の前後にメッセージを出力する関数"""
print(f"{task_name} を開始します")
time.sleep(wait_sec) # 指定秒数だけ待機
print(f"{task_name} が完了しました")
do_task("データの保存", 1.0)
do_task("レポートの生成", 2.0)実行イメージは次のとおりです。
データの保存 を開始します
(1.0秒待機)
データの保存 が完了しました
レポートの生成 を開始します
(2.0秒待機)
レポートの生成 が完了しました関数内でsleepを使う際のポイントは、次のようになります。
- 待機時間を引数で受け取るようにしておくと、後から調整しやすいです
- ビジネスロジックの中に固定値でsleepを書き込まないほうが、テストや性能調整が楽になります
- 長時間のsleepを行う関数は、処理時間が長いことをドキュメントやコメントで明示すると親切です
time.sleep使用時の注意点と代替手段
time.sleepが遅い・重いと感じるときの原因
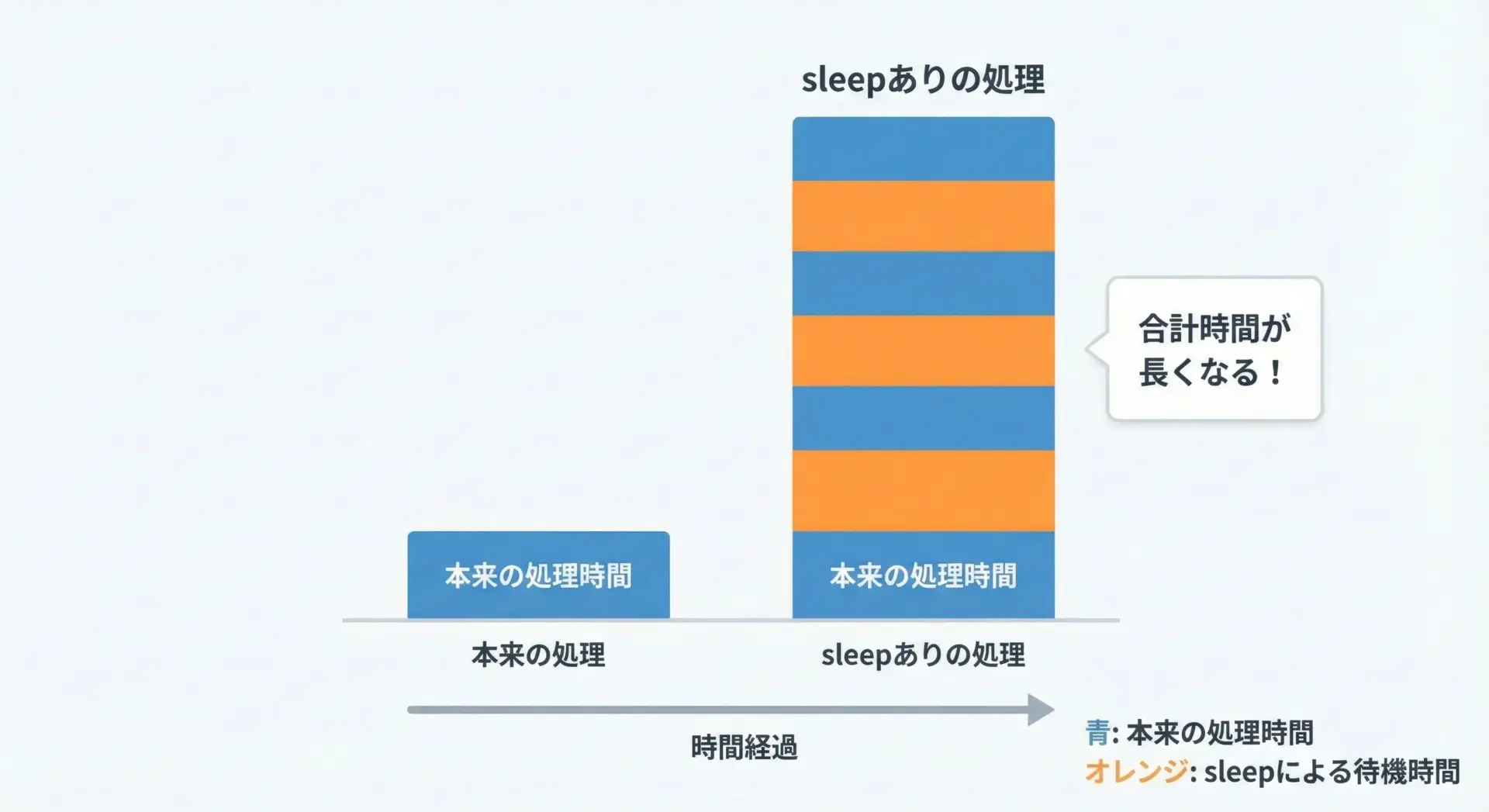
time.sleep自体はとても単純な処理で、CPU負荷もほとんどありません。
しかし、「プログラム全体の実行が遅い」「重い」と感じる場合、その原因は次のような点にあります。
- ループ内でのsleepが何度も繰り返されている
- 必要以上に長い秒数を指定している
- 複数箇所でsleepしており、合計時間が無駄に長くなっている
例えば、1秒のsleepを100回ループの中で行うと、それだけで最低でも100秒かかります。
処理が遅いと感じたときには、grepやエディタの検索機能でsleepを探し、どこでどれだけ待機しているかを確認してみると良いです。
また、開発中はsleep(5)など大きめの値で試していても、本番用にはsleep(0.5)やsleep(1)程度に見直すことを忘れないようにしましょう。
GUIやWebアプリでtime.sleepを避けるべき理由
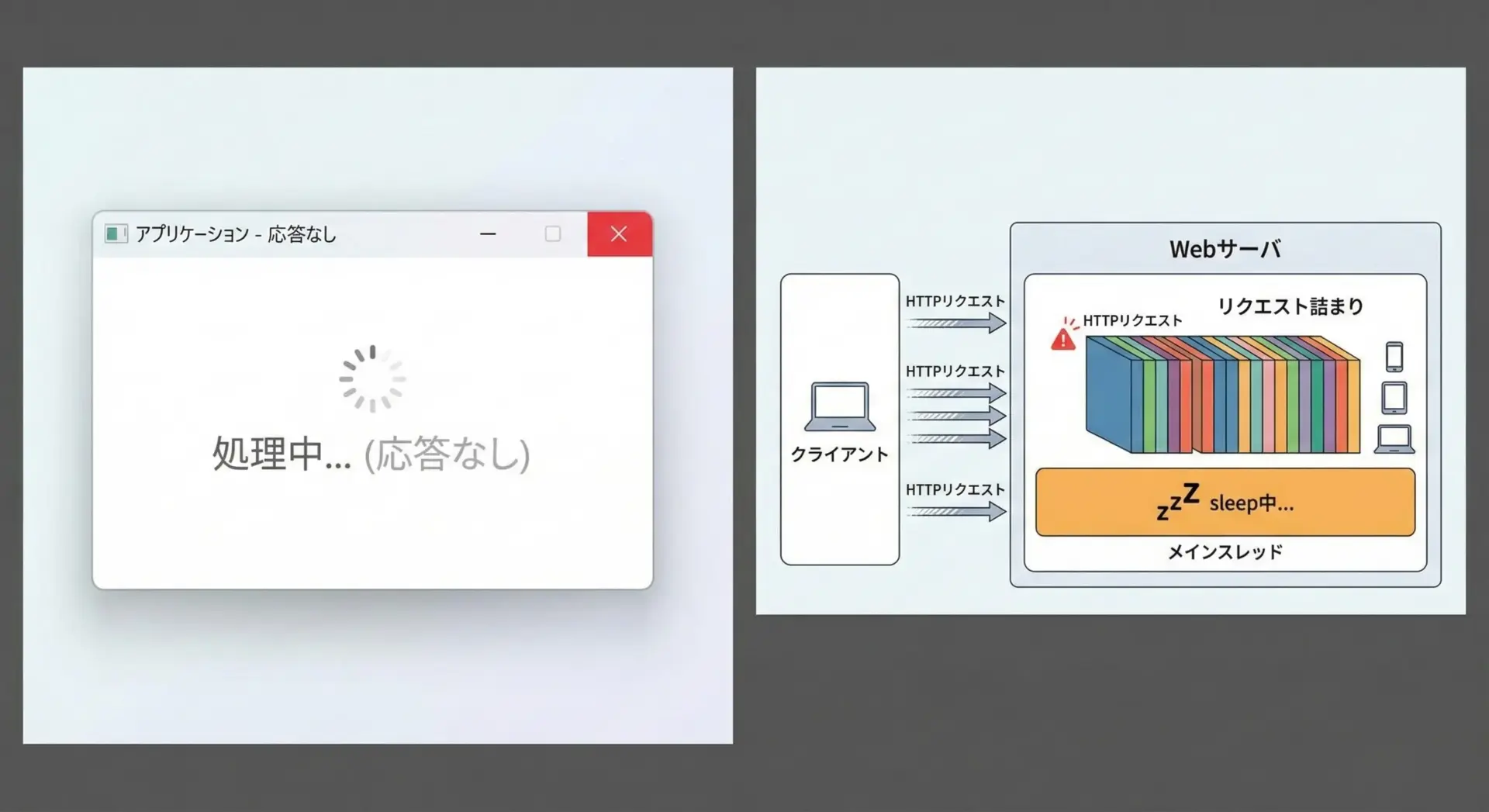
デスクトップアプリ(PyQt、Tkinterなど)やWebアプリ(Flask、Djangoなど)では、メインスレッドでのtime.sleepを原則として避けるべきです。
理由は、待機中に他の処理もすべて止まってしまうからです。
GUIアプリの場合、メインスレッドでsleepすると次のような問題が起こります。
- ウィンドウが「フリーズ」したように見える
- ボタンが押せない、画面が再描画されない
- OSによっては「応答なし」と表示される
Webアプリの場合も同様で、1つのリクエスト処理がsleepしているあいだ、同じプロセス内の他の処理が詰まることがあります。
特にシングルスレッドで動いている開発サーバでは顕著です。
こうした場面では、次のような代替方法を検討します。
- GUIではタイマー機能(例: Tkinterの
after、QtのQTimer)を使う - Webでは非同期処理やバックグラウンドジョブ(Celery、RQなど)を使う
- 処理を別スレッドや別プロセスに切り出して、メインスレッドをブロックしないようにする
非同期処理での代替(Asyncioのsleep)の概要
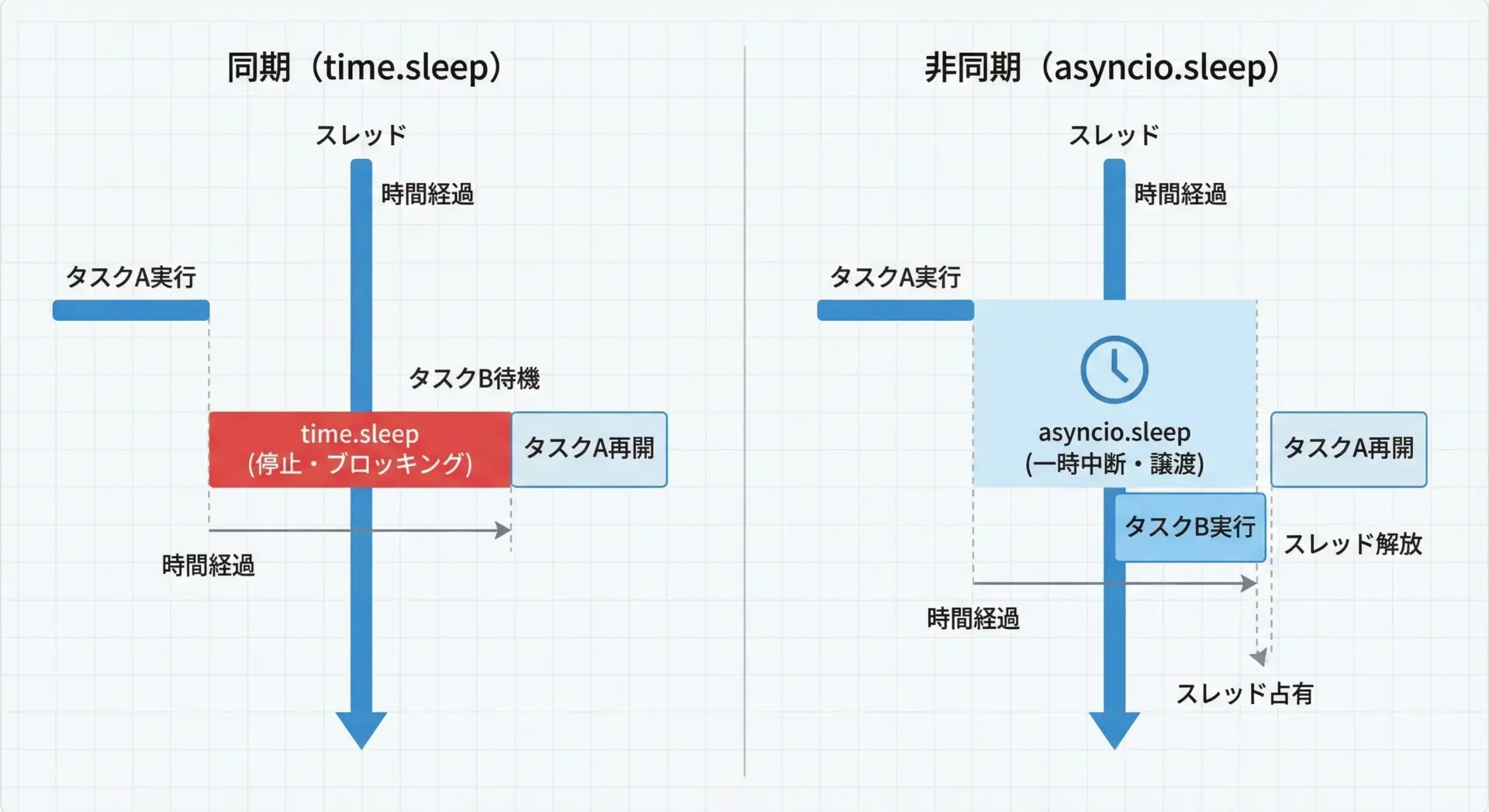
Pythonには、非同期処理用のsleepとしてasyncio.sleepという関数があります。
これはtime.sleepとは異なり、イベントループをブロックせずに待機できるのが特徴です。
簡単な例を見てみます。
import asyncio
async def task(name: str, delay: float):
print(f"{name}: 開始")
await asyncio.sleep(delay) # 非同期に待機
print(f"{name}: {delay}秒後に再開")
async def main():
# 2つのタスクを同時に実行
await asyncio.gather(
task("タスク1", 1),
task("タスク2", 2),
)
asyncio.run(main())実行イメージは次のようになります。
タスク1: 開始
タスク2: 開始
(1秒経過)
タスク1: 1秒後に再開
(さらに1秒経過)
タスク2: 2秒後に再開ポイントは、タスク1が1秒待機しているあいだに、タスク2側の処理も進められることです。
これにより、同じスレッドでも効率よく複数の待機処理を扱えるため、多数のネットワークI/Oなどを扱う場面で威力を発揮します。
通常のtime.sleepは同期処理用であり、async def関数内で使うとイベントループをブロックしてしまうため、非同期コードではasyncio.sleepを使うことが重要です。
テストコードでのtime.sleepの注意点とコツ
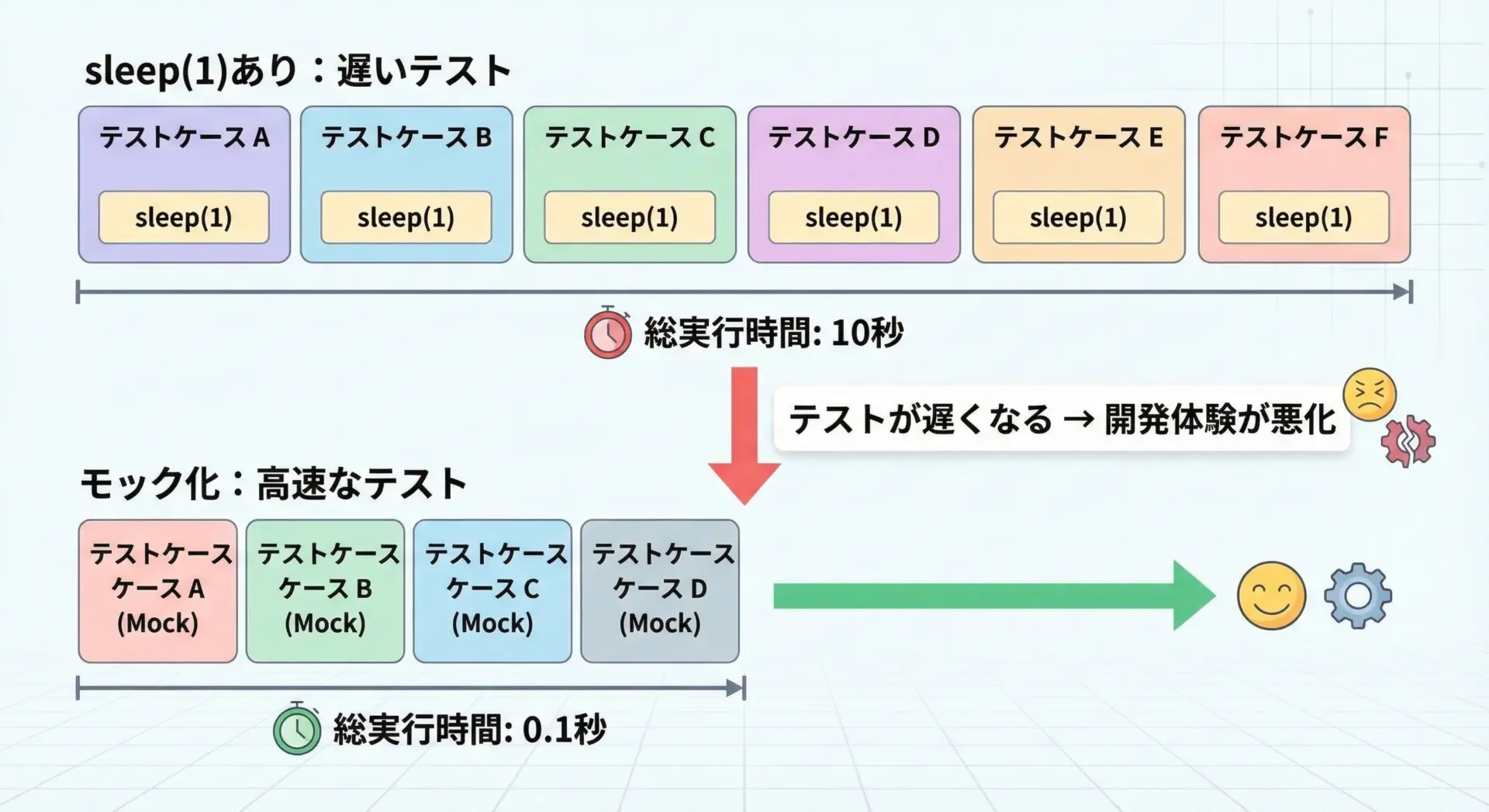
テストコードの中でtime.sleepを使うと、テスト実行時間が長くなりがちです。
例えば、10個のテストでそれぞれ1秒のsleepをしていると、それだけで10秒かかってしまいます。
テストでsleepを使う場面としては、次のようなケースが多いです。
- 非同期処理やバックグラウンド処理の完了を待つ
- ファイル書き込みや外部サービス連携の結果を待つ
- 時間経過による状態変化を確認したい
しかし、できるだけ実際の待機を行わずにテストできるように工夫することが重要です。
代表的なコツは次のとおりです。
- sleepを直接呼ぶのではなく、「待機関数」を自作してそこをモック化する
- 時刻取得(
time.time()やdatetime.now())をラップして、テスト時には任意の時刻を返す - 非同期処理では、
asyncioのテストサポート機能を活用し、sleepを実行せずに進める
簡単な例として、待機処理を関数にまとめておき、テストでは「待機しない版」に差し替える方法を示します。
import time
def wait(sec: float) -> None:
"""本番用の待機関数(実際にsleepする)"""
time.sleep(sec)
def process(wait_func=wait) -> None:
"""待機処理を外から受け取る関数"""
print("処理開始")
wait_func(1.0) # 実際の処理では1秒待つ想定
print("処理終了")テストではwait_funcとして「何もしない関数」を渡すことで、sleepせずに処理を確認できます。
def no_wait(sec: float) -> None:
"""テスト用の待機関数(何もしない)"""
pass
# テストではsleepせずに動作だけ確認できる
process(wait_func=no_wait)このように設計しておくと、本番コードの挙動を保ちつつ、テストだけ高速化することができます。
まとめ
time.sleepは、Pythonで処理を一時停止させるもっとも基本的な手段です。
ループ処理の間隔調整や、APIアクセスの間隔制御、ログ出力の演出など、シンプルながら多くの場面で役立ちます。
一方で、GUIやWebアプリのメインスレッド、テストコード、非同期処理などでは、そのまま使うとフリーズや性能低下を招くことがあります。
この記事で紹介したasyncio.sleepやタイマー機能、モックによる置き換えなども選択肢に入れながら、目的に合った「待機」の方法を選べるようになれば、より洗練されたPythonプログラムを書けるようになります。
