
Pythonは動的型付けの柔軟さが魅力ですが、規模が大きくなるほど型まわりのバグや可読性の低下が問題になりがちです。
そこで役立つのが静的型チェッカーmypyです。
本記事では、mypyとは何かという基礎から導入・設定方法、実践的な型注釈テクニック、チーム開発への組み込み方までを、図解とサンプルコードを交えながら丁寧に解説します。
mypyとは何か
静的型チェックと動的型付けの違い

Pythonは動的型付け(dynamic typing)の言語です。
つまり、変数に型を宣言しなくても、その場でどのようなオブジェクトでも代入して実行できます。
その代わり、型の不整合によるエラーは実行時に初めて発覚します。
これに対して静的型チェック(static type checking)は、プログラムを実行する前に、ソースコードだけから型の整合性を検査する仕組みです。
CやJavaのような静的型付け言語ではコンパイル時に行われますが、Pythonではmypyのような外部ツールを使って同様のことを実現します。
Pythonでは次のような流れになります。
1つ目は素のPythonだけで開発する流れです。
プログラムを書き、すぐ実行し、実行中にTypeErrorが出たらその都度直すという形になります。
短いスクリプトならよいのですが、大きなコードベースではテスト対象から漏れたパスに型バグが潜みやすくなります。
2つ目はmypyを導入した開発スタイルです。
コードを書いたあと、mypyで型チェックを行い、実行する前に「あり得ない型の組み合わせ」を検出します。
エラーを修正してから実行することで、実行時エラーの多くを未然に防ぐことができます。
mypyを使うメリットとデメリット

mypyを導入する最大のメリットは、型に起因するバグの早期発見と可読性・保守性の向上です。
具体的には次のような効果があります。
まず、関数の引数や戻り値に型を明示することで、コードを読むだけでデータの流れが理解しやすくなります。
特にチーム開発では、ドキュメント代わりに型注釈を参照できるため、新規メンバーのキャッチアップにも役立ちます。
さらにIDEやエディタの補完精度が向上するという副次的なメリットもあります。
mypyが前提とする型注釈は、PyCharmやVS Codeなどのエディタが理解しやすい形式なので、自動補完・リファクタリング支援が強化されます。
一方でデメリットも存在します。
型注釈を書く手間が増えるため、初期段階では開発スピードが一時的に落ちたように感じるかもしれません。
また、Pythonはもともと動的な言語であるため、すべてのコードに完全な型を付けるのは難しい場面もあります。
外部ライブラリに型情報がない場合や、高度に動的なメタプログラミングを行っている箇所では、mypyがうまく追い付けないこともあります。
重要なのは、mypyを「完璧に通す」ことよりも「致命的な型バグを減らす」ことを目的にするという姿勢です。
プロジェクトの段階やメンバーの熟練度に応じて、どこまで厳密に見るかを調整していく運用が現実的です。
mypyと型ヒント(typing)の関係
mypyは標準ライブラリのtypingモジュールを前提として設計されています。
関数や変数に付ける型注釈は、Python 3.5以降で導入された標準的な文法であり、mypyに特化した独自記法ではありません。
たとえば次のようなコードは、純粋にPythonとしても正しいし、mypyも理解できる共通フォーマットです。
from typing import List
def total(values: List[int]) -> int:
return sum(values)ここで使っているList[int]や関数注釈は、「型ヒント」あるいは「型アノテーション」と呼ばれます。
Pythonそのものはこれらの型ヒントを実行時の型チェックには使いません。
実行時には、あくまでコメントに近いメタ情報として扱われます。
しかし、mypyはこの型ヒントを静的解析の材料として利用します。
つまり、型ヒントは「書式」、mypyは「それを検査するエンジン」という関係になっています。
このため、型ヒントを正しく理解することは、mypyを活用するうえで欠かせない前提知識になります。
mypy以外のPython静的解析ツールとの違い

Pythonの静的解析ツールはmypyだけではありません。
目的に応じてさまざまなツールが存在しますが、mypyはその中でも「型チェック専門」のツールです。
代表的なツールとの違いを簡単に整理すると次のようになります。
| ツール名 | 主な役割 | 型チェックの範囲 |
|---|---|---|
| mypy | 型チェック専用 | 非常に厳密、設定豊富 |
| pyright | 高速な型チェッカー | TypeScript由来、VS Code連携が強い |
| pylint | コード品質・スタイル | 型は一部推論レベル |
| flake8 | スタイル・簡易バグ検出 | 型はほぼ扱わない |
| ruff | 高速リンター | 将来的に型サポート拡張中 |
mypyとよく比較されるのがMicrosoft製のpyrightです。
どちらも静的型チェックを主目的とし、typingベースの型注釈を理解しますが、mypyは歴史が長く、Pythonコミュニティでの採用実績が多い点が特徴です。
一方、pyrightは非常に高速で、VS CodeのPython拡張機能の型チェックエンジンとしても使われています。
pylintやflake8、ruffは、主にコーディングスタイルやバグパターン検出を担うツールであり、型チェック機能は限定的か、まだ発展途上であることが多いです。
このため、mypyを「型」、ruffなどを「スタイル」として併用する構成がよく採用されます。
mypyの導入方法と基本設定
mypyのインストール方法
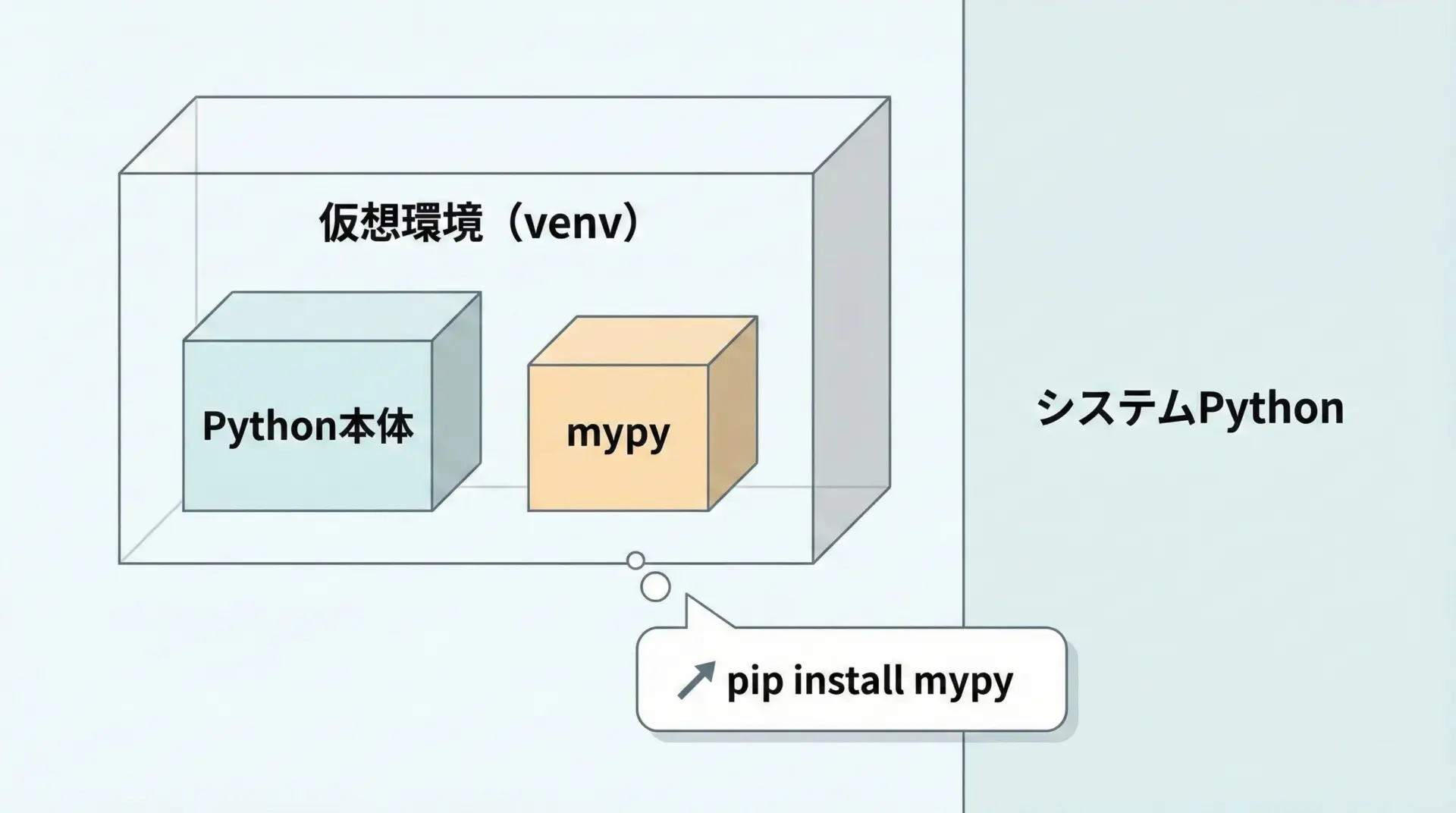
mypyはPythonパッケージとして配布されているため、通常はpipでインストールします。
プロジェクトごとの依存関係をきれいに管理するために、仮想環境(venvやpoetryなど)の中にインストールすることをおすすめします。
一般的な仮想環境での導入手順は次のようになります。
# 仮想環境の作成と有効化 (例: venv)
python -m venv .venv
source .venv/bin/activate # Windowsなら .venv\Scripts\activate
# mypyのインストール
pip install mypyインストールが終わったら、バージョンを確認して動作をチェックします。
mypy --versionこれでバージョン番号が表示されればインストールは完了です。
mypy 1.11.0最小構成でのmypy実行方法
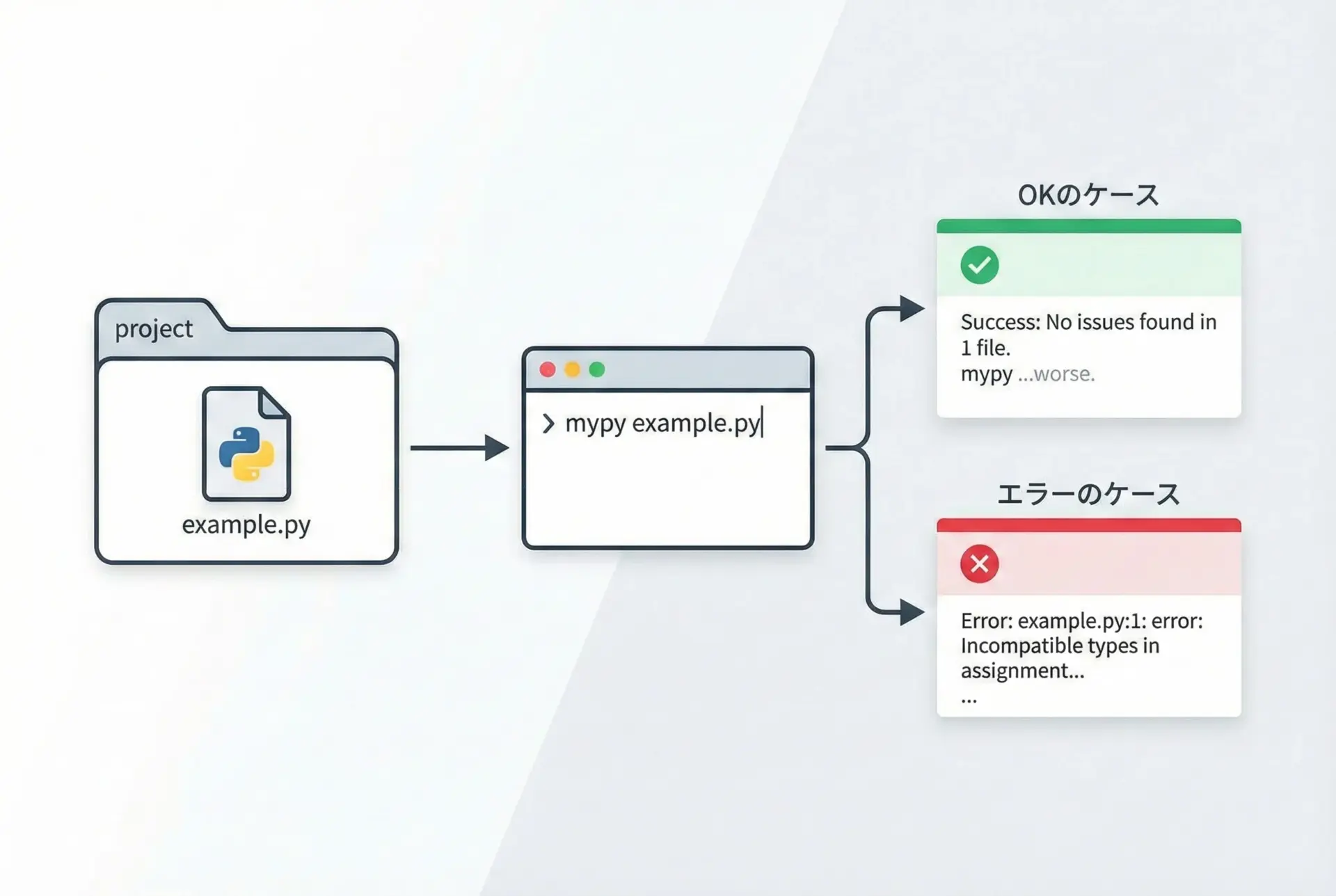
mypyの基本的な使い方は非常にシンプルで、「対象のPythonファイルに対してmypyコマンドを実行する」だけです。
まずは、型エラーが発生する簡単なサンプルコードを用意します。
# example.py
def greet(name: str) -> str:
# nameはstr型と宣言している
return "Hello, " + name
def main() -> None:
# ここで意図的にintを渡してみる
greet(123)
if __name__ == "__main__":
main()このファイルに対してmypyを実行してみます。
mypy example.pyexample.py:9: error: Argument 1 to "greet" has incompatible type "int"; expected "str"
Found 1 error in 1 file (checked 1 source file)ここでmypyは、greet関数の引数nameがstrだと宣言されているにもかかわらず、実際にはintが渡されていることを指摘しています。
Pythonをそのまま実行すると、実行時にTypeErrorが起きるコードですが、mypyを通すことで事前に検出できました。
修正してみましょう。
# example_fixed.py
def greet(name: str) -> str:
return "Hello, " + name
def main() -> None:
greet("Alice") # 正しいstrを渡す
if __name__ == "__main__":
main()mypy example_fixed.pySuccess: no issues found in 1 source fileこのように、mypyは小さなスクリプトに対しても手軽に型チェックを行うことができます。
mypy.iniとpyproject.tomlでの設定方法
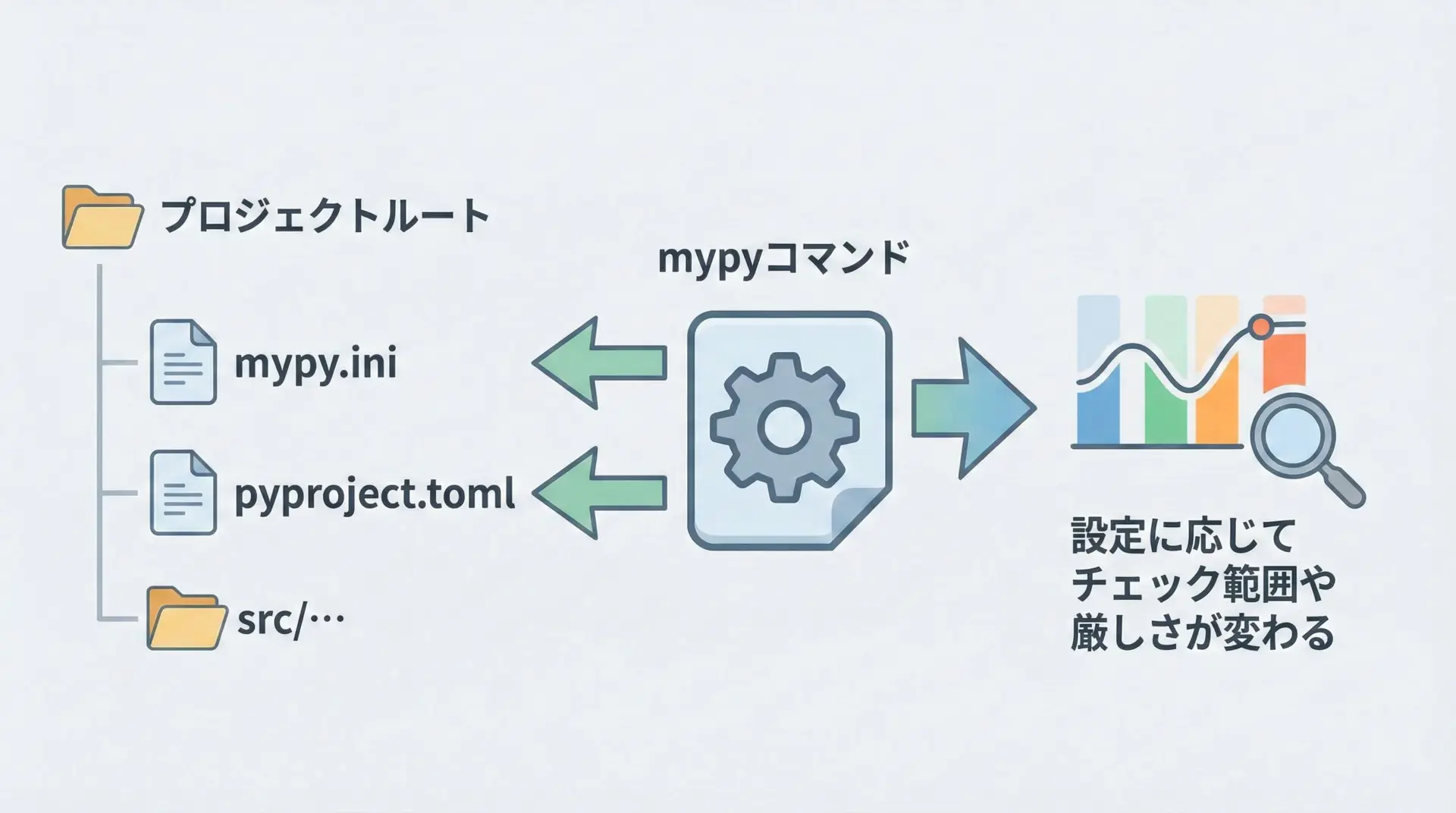
プロジェクトが大きくなってくると、コマンドラインオプションだけでなく設定ファイルでmypyの挙動を管理したくなります。
mypyは次の2つの形式の設定ファイルをサポートしています。
1つは従来からあるmypy.ini(またはsetup.cfg)形式です。
もう1つは近年主流になりつつあるpyproject.toml形式です。
代表的なmypy.iniの例を見てみましょう。
# mypy.ini
[mypy]
python_version = 3.11
# プロジェクトルートから見たソースコードディレクトリ
mypy_path = src
# デフォルトで警告を厳しめにする例
warn_unused_configs = True
disallow_untyped_defs = True
strict_optional = True
# 特定パッケージだけ設定を緩める例
[mypy-third_party_lib.*]
ignore_missing_imports = Trueコマンドラインでmypyを実行すると、デフォルトでこのmypy.iniが読み込まれ、[mypy]セクションの設定が反映されます。
同様の内容をpyproject.tomlに記述することもできます。
最近は依存関係管理も含めてpyproject.tomlに統合するプロジェクトが増えています。
# pyproject.toml
[tool.mypy]
python_version = "3.11"
mypy_path = "src"
warn_unused_configs = true
disallow_untyped_defs = true
strict_optional = true
[[tool.mypy.overrides]]
module = "third_party_lib.*"
ignore_missing_imports = trueどちらの形式を選ぶかはプロジェクト次第ですが、既にpyproject.tomlを使っている場合はそこにまとめると管理がしやすくなります。
タイプチェックモード(strictオプションなど)の選び方

mypyはオプションによってチェックの厳しさをかなり細かく調整できます。
その中でも代表的なのが--strictオプションです。
これは「かなり厳しめの設定一式」をまとめて有効にするショートカットで、以下のような個別オプションが一括でオンになります。
disallow_untyped_defs(型注釈のない関数定義を禁止)warn_return_any(戻り値Anyへの警告)no_implicit_optional(デフォルト引数Noneによる暗黙Optional禁止)- など多数
導入初期から--strictをオンにすると、既存コードが多い場合にはエラーの洪水が発生しがちです。
そのため、多くのチームでは次のような段階的アプローチを取ります。
- まずはデフォルト設定(あるいは少し緩い設定)で全体を通す
- 特に重要なモジュールに限定して
disallow_untyped_defsをオンにする - 徐々に
--strictに近づくよう、個別オプションを追加していく
設定ファイルでは次のように書けます。
# mypy.ini (段階的に厳しくしていく例)
[mypy]
python_version = 3.11
# まずは比較的緩め
warn_unused_configs = True
ignore_missing_imports = True
# 重要ディレクトリだけ厳しくする
[mypy-myapp.core.*]
disallow_untyped_defs = True
[mypy-myapp.domain.*]
disallow_untyped_defs = True
warn_return_any = Trueこのように、「どの範囲を」「どの段階で」厳しくするかを計画的に決めることで、現実的な導入が可能になります。
プロジェクト単位でのmypy設定のベストプラクティス
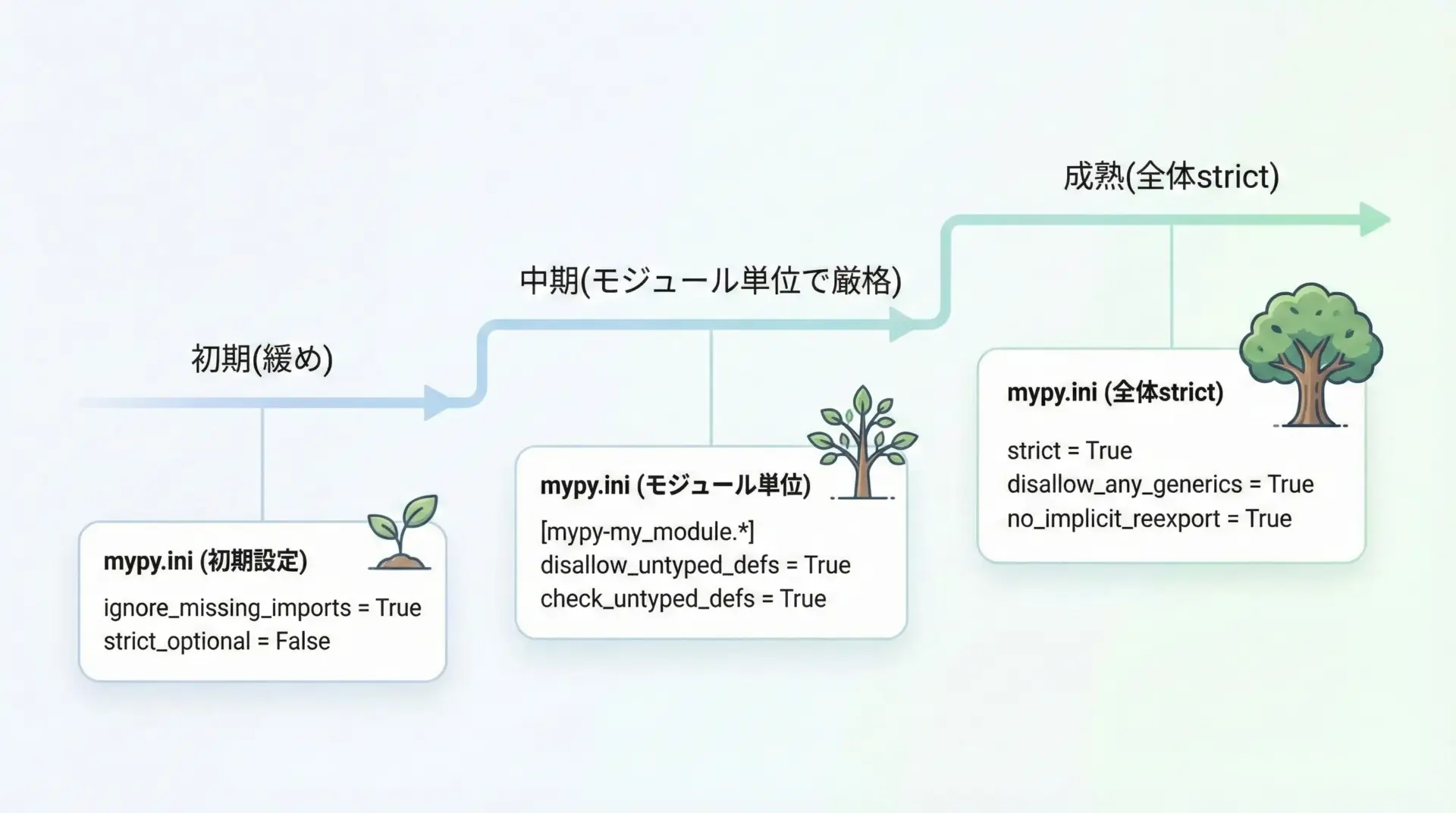
プロジェクト全体でmypyを運用する際には、次のようなポイントを押さえておくとスムーズです。
まず、設定ファイルをリポジトリルートにコミットし、全員が同じ設定でチェックすることが重要です。
個々の開発環境がバラバラのオプションでmypyを走らせていると、ローカルでは通るのにCIで落ちる、といった齟齬が頻発します。
また、ディレクトリごとに設定を変える機能([mypy-xxx.*]セクションやoverrides)を活用し、新しいコードほど厳しく、古いコードは徐々に厳しくという方針を持つと、移行が格段に楽になります。
代表的なベストプラクティスを簡単に整理すると次のようになります。
| 項目 | おすすめ方針 |
|---|---|
| 設定ファイルの場所 | リポジトリルートに<mypy.ini>か<pyproject.toml> |
| 厳しさ | 最初は控えめ、重要モジュールから順にstrict寄り |
| 外部ライブラリ | ignore_missing_imports = Trueをピンポイントに適用 |
| 無視の仕方 | コード側の# type: ignoreは最小限に |
| CI連携 | 同じ設定ファイルを用い、mypyを必ず通すフローに |
プロジェクトポリシーとして「新規コードは必ず型付きで書く」と決めておくと、設定との整合性がとれ、徐々に全体が型安全な状態に近づいていきます。
Pythonコードへの型注釈とmypyの実践活用
基本的な型注釈(int,str,listなど)とmypyチェック
まずは基本的な型注釈から押さえます。
Pythonの組み込み型intやstr、リストや辞書などに対して、どのように型を付けるかを見ていきます。
# basic_types.py
from typing import List, Dict
def add(a: int, b: int) -> int:
"""2つの整数を足し合わせる"""
return a + b
def greet(name: str) -> str:
"""名前付きの挨拶文を返す"""
return f"Hello, {name}"
def average(values: List[float]) -> float:
"""浮動小数点数のリストの平均値を返す"""
return sum(values) / len(values)
def count_by_length(words: List[str]) -> Dict[int, int]:
"""単語の長さごとに出現回数を数える"""
counts: Dict[int, int] = {}
for w in words:
length = len(w)
counts[length] = counts.get(length, 0) + 1
return counts
def main() -> None:
# 正しい呼び出し
print(add(1, 2))
print(greet("Alice"))
# あえて誤った型を渡してみる
print(add("1", "2")) # 型注釈上はNG
if __name__ == "__main__":
main()このファイルをmypyにかけるとどうなるか確認します。
mypy basic_types.pybasic_types.py:27: error: Argument 1 to "add" has incompatible type "str"; expected "int"
basic_types.py:27: error: Argument 2 to "add" has incompatible type "str"; expected "int"
Found 2 errors in 1 file (checked 1 source file)実行自体はPythonの動的型付けにより通ってしまいますが、mypyは関数シグネチャと実際の呼び出しの型の不整合を静的に検出してくれます。
ここでのポイントは、変数にも明示的な型を付けられるということです。
上記コードのcounts: Dict[int, int]のように書くことで、mypyが辞書のキーと値の型を認識し、誤った代入を検出できます。
Union(Optional)やLiteralなど複合型の使い方
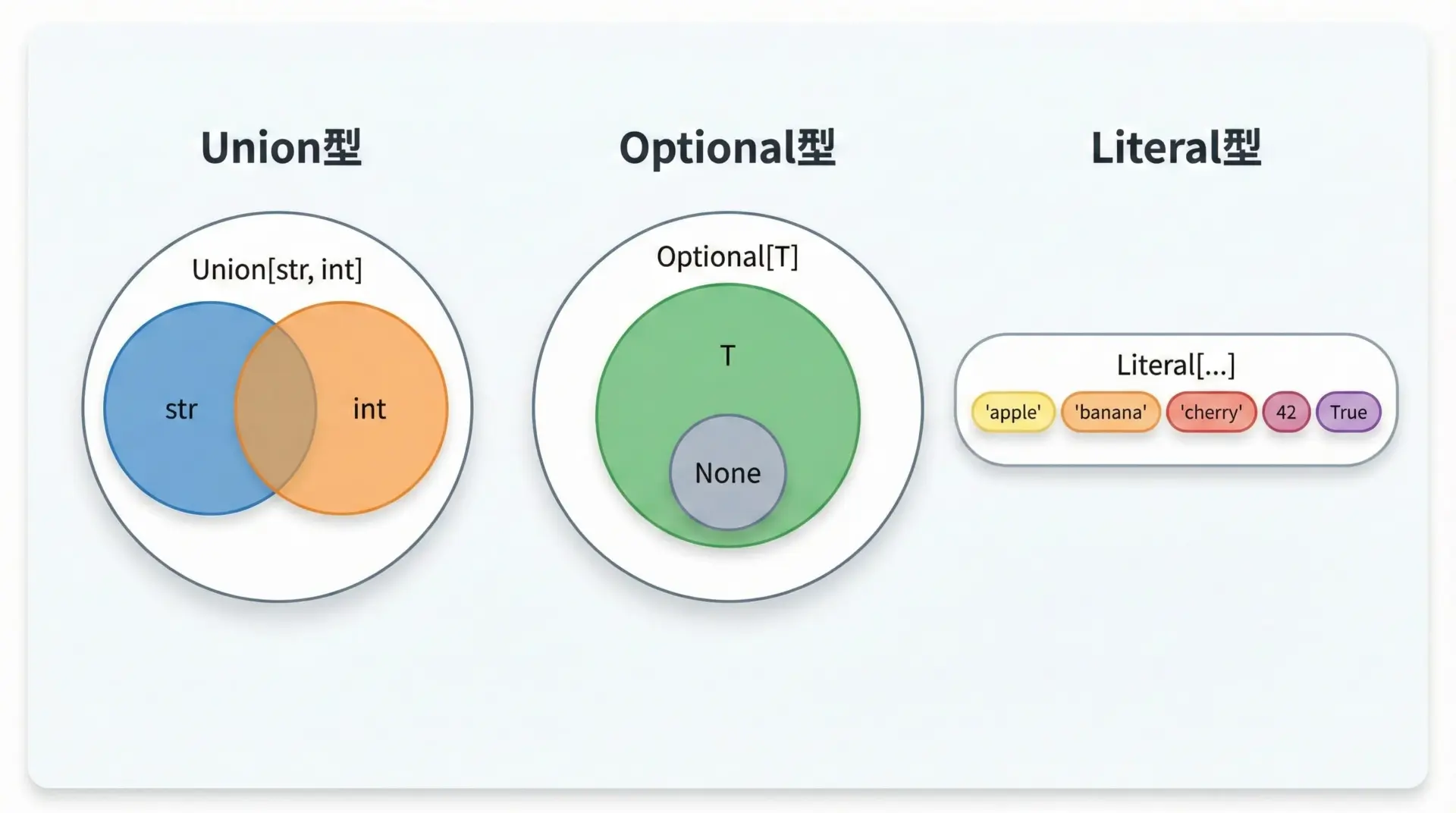
実際のアプリケーションでは、「値が2種類以上の型を取り得る」ケースがよくあります。
そのような場合に使うのがUnionやOptionalです。
また、文字列や数値の具体的な値に基づいて分岐したい場合にはLiteralが便利です。
# unions_and_literals.py
from typing import Union, Optional, Literal
# Python 3.10以降なら Union[int, str] の代わりに int | str と書ける
def to_str(value: Union[int, float, str]) -> str:
"""int/float/strのいずれかを安全に文字列化する"""
return str(value)
def find_user_name(user_id: int) -> Optional[str]:
"""
ユーザーIDから名前を検索する。
見つからなければNoneを返す。
"""
fake_db = {1: "Alice", 2: "Bob"}
return fake_db.get(user_id)
def handle_status(status: Literal["success", "error", "pending"]) -> str:
"""
ステータス文字列に応じてメッセージを返す。
許可される値は success / error / pending のみ。
"""
if status == "success":
return "完了しました"
if status == "error":
return "エラーが発生しました"
if status == "pending":
return "処理中です"
# Literalを使うと、ここには到達しないとmypyが推論できる
raise AssertionError("Unreachable")
def main() -> None:
print(to_str(10))
print(to_str(3.14))
print(to_str("hello"))
name = find_user_name(3)
# nameは Optional[str] なので、そのままstrとして扱うとmypyが警告する
if name is not None:
print(name.upper())
# Literalにない値を渡すと型エラー
handle_status("unknown") # ここはmypyエラー
if __name__ == "__main__":
main()mypy unions_and_literals.pyunions_and_literals.py:39: error: Argument 1 to "handle_status" has incompatible type "Literal['unknown']"; expected "Literal['success', 'error', 'pending']"
Found 1 error in 1 file (checked 1 source file)ここでの重要なポイントは、Optional[T]は「T または None」の略であるということです。
したがってOptional[str]をそのままstrとして扱うと、Noneである可能性を無視していることになり、mypyが警告を出します。
if文でNoneチェックを行うことで、mypyはそのブロック内でstrとして扱えると推論できるようになります。
またLiteralを使うと、「この引数は特定の文字列リテラルか、数値リテラルしか受け付けない」といった制約を型として表現でき、マジックストリングのtypoなどを防ぎやすくなります。
TypedDict,Protocolによる構造的サブタイピング
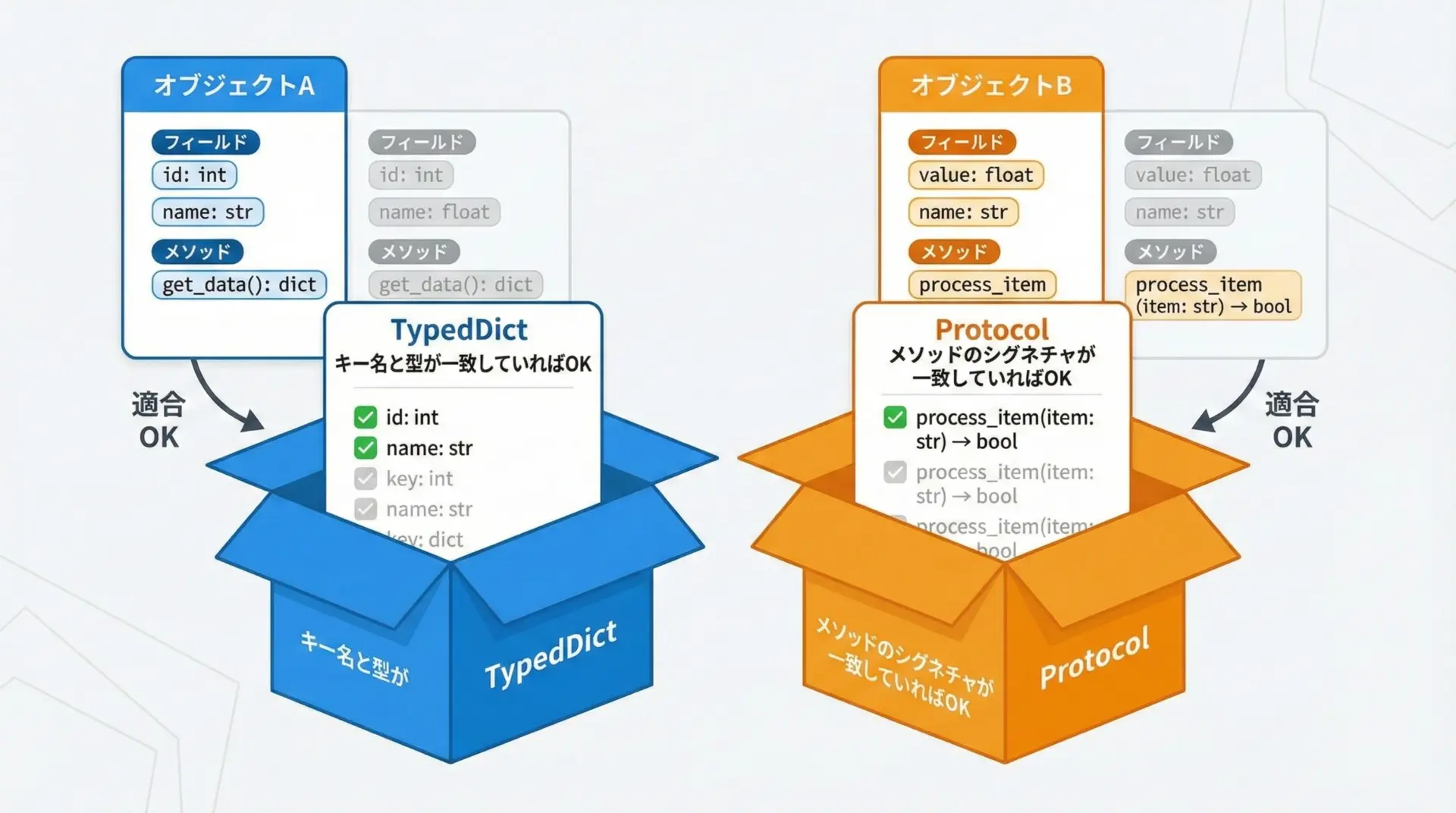
PythonではJSONのような辞書を多用しますが、dictだけではキーと値の型が曖昧になりがちです。
そこで役立つのがTypedDictです。
また、クラスの「構造」に基づいて互換性を判定するProtocolもmypyの強力な機能の1つです。
# typed_dict_and_protocol.py
from typing import TypedDict, Protocol, List
class User(TypedDict):
id: int
name: str
email: str
is_active: bool
def send_email(user: User, message: str) -> None:
"""User型の辞書に基づいてメールを送信する関数(という想定)"""
# 実際の送信処理は省略
print(f"Sending to {user['email']}: {message}")
# Protocolを使って「ファイルっぽいもの」のインターフェースを定義
class SupportsWrite(Protocol):
def write(self, s: str) -> int:
...
def write_lines(writer: SupportsWrite, lines: List[str]) -> None:
"""write(str)を持つオブジェクトなら何でも書き込める"""
for line in lines:
writer.write(line + "\n")
def main() -> None:
user1: User = {
"id": 1,
"name": "Alice",
"email": "alice@example.com",
"is_active": True,
}
# キー不足や型違いはmypyが検出
user2: User = {
"id": "x", # intのはずがstr -> mypyエラー
"name": "Bob",
"email": "bob@example.com",
"is_active": True,
}
send_email(user1, "ようこそ!")
# ファイルオブジェクトはwrite(str)を持つのでSupportsWriteとして扱える
with open("out.txt", "w", encoding="utf-8") as f:
write_lines(f, ["line1", "line2"])
if __name__ == "__main__":
main()mypy typed_dict_and_protocol.pytyped_dict_and_protocol.py:31: error: Incompatible types (expression has type "str", TypedDict item "id" has type "int")
Found 1 error in 1 file (checked 1 source file)TypedDictを使うと、辞書形式のデータ構造に対しても「キーと値の型」の契約を明示できます。
特に外部APIレスポンスや設定オブジェクトなどに有効です。
Protocolは構造的サブタイピングの仕組みで、「このメソッドを持っているならOK」といった柔軟なインターフェース定義を可能にします。
上記のSupportsWriteのように、実際にどのクラスであっても、write(str) -> intを持っていれば受け入れるというポリモーフィズムを型レベルで表現できます。
ジェネリクス(Generic)とコレクション型の型安全

リストや辞書といったコレクション型だけでなく、自作クラスにもGenericを用いてジェネリクスを導入できます。
これにより、「特定の型だけを保持するコンテナ」を型安全に表現できます。
# generics_example.py
from typing import Generic, TypeVar, List, Optional
T = TypeVar("T") # ジェネリック型パラメータ
class Stack(Generic[T]):
"""ジェネリックなスタック実装"""
def __init__(self) -> None:
self._items: List[T] = []
def push(self, item: T) -> None:
self._items.append(item)
def pop(self) -> T:
# 実用コードでは空チェックが必要だが、例では簡略化
return self._items.pop()
def peek(self) -> Optional[T]:
if self._items:
return self._items[-1]
return None
def main() -> None:
int_stack = Stack[int]()
int_stack.push(1)
int_stack.push(2)
top_int = int_stack.pop() # Tはintとして扱われる
str_stack = Stack[str]()
str_stack.push("hello")
top_str = str_stack.peek()
# 型に反する操作はmypyが検出
int_stack.push("not int") # mypyエラー
if __name__ == "__main__":
main()mypy generics_example.pygenerics_example.py:35: error: Argument 1 to "push" of "Stack" has incompatible type "str"; expected "int"
Found 1 error in 1 file (checked 1 source file)一度ジェネリッククラスを定義しておけば、さまざまな型に対して再利用できるため、ライブラリ設計やドメインモデルの構築にも役立ちます。
標準ライブラリのlist[T]やdict[K, V]なども同様のジェネリクスとして定義されていると考えるとイメージしやすいでしょう。
非同期処理(async/await)とmypyの型チェック
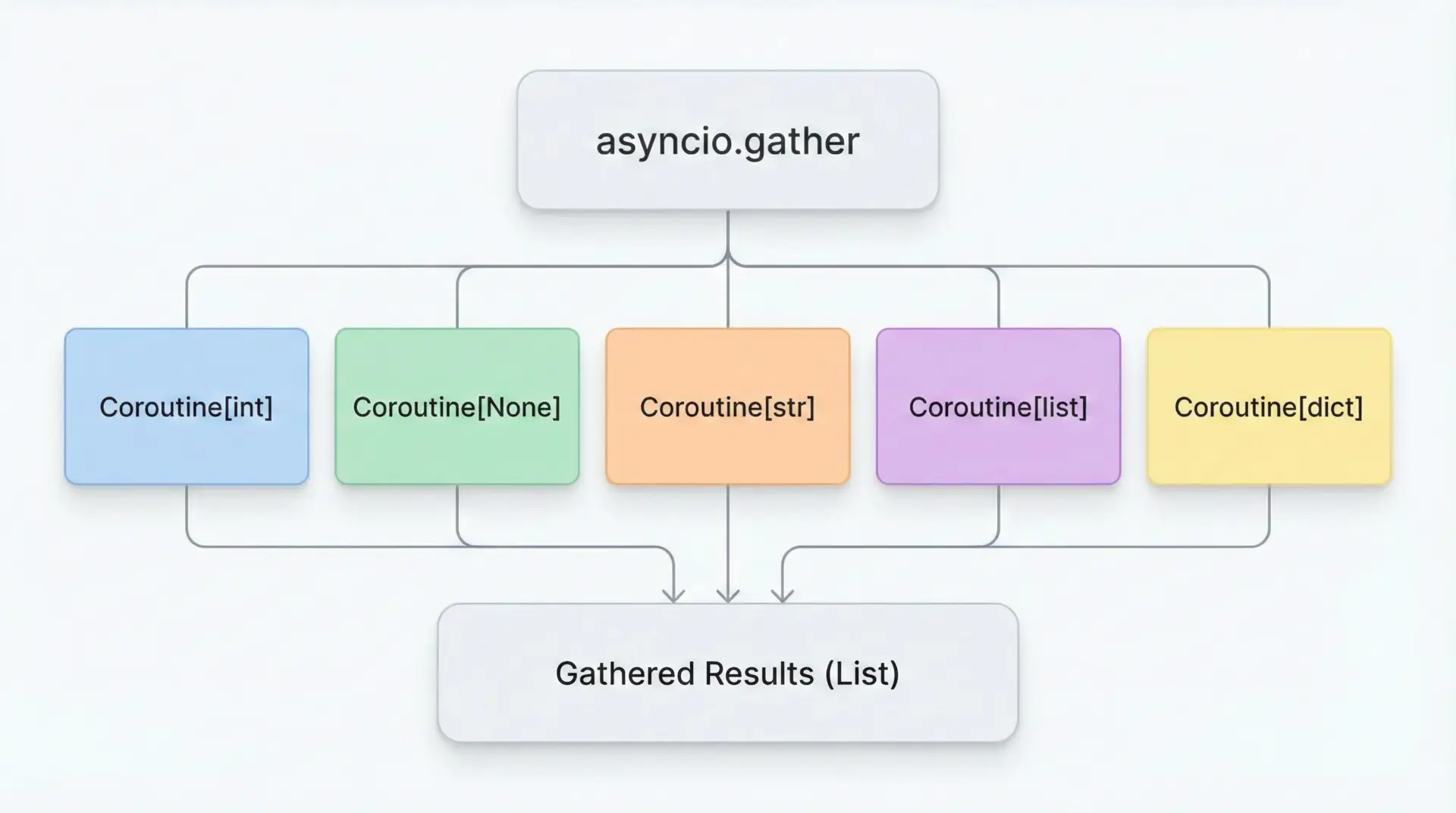
Pythonのasync/await構文も、mypyで型チェックすることができます。
非同期関数はasync defで定義し、戻り値は「コルーチンが最終的に返す型」を記述します。
# async_example.py
from __future__ import annotations
import asyncio
from typing import List
async def fetch_data(n: int) -> int:
"""擬似的にn秒待ってからnを返す非同期関数"""
await asyncio.sleep(n)
return n
async def fetch_all(ns: List[int]) -> List[int]:
"""複数のfetch_dataを並列実行し、結果リストを返す"""
tasks = [fetch_data(n) for n in ns]
results = await asyncio.gather(*tasks)
return list(results)
async def main() -> None:
result = await fetch_data(1)
print(result)
all_results = await fetch_all([1, 2, 3])
print(all_results)
# 間違った引数型
await fetch_data("1") # mypyエラー
if __name__ == "__main__":
asyncio.run(main())mypy async_example.pyasync_example.py:24: error: Argument 1 to "fetch_data" has incompatible type "Literal['1']"; expected "int"
Found 1 error in 1 file (checked 1 source file)ここでのポイントは、非同期関数の戻り値の型は「await後の型」を書くということです。
たとえばasync def fetch_data(...) -> intと書いた場合、mypyはfetch_dataがCoroutine[Any, Any, int]を返し、それをawaitするとintが得られると推論します。
既存コードベースに段階的に型を導入する方法
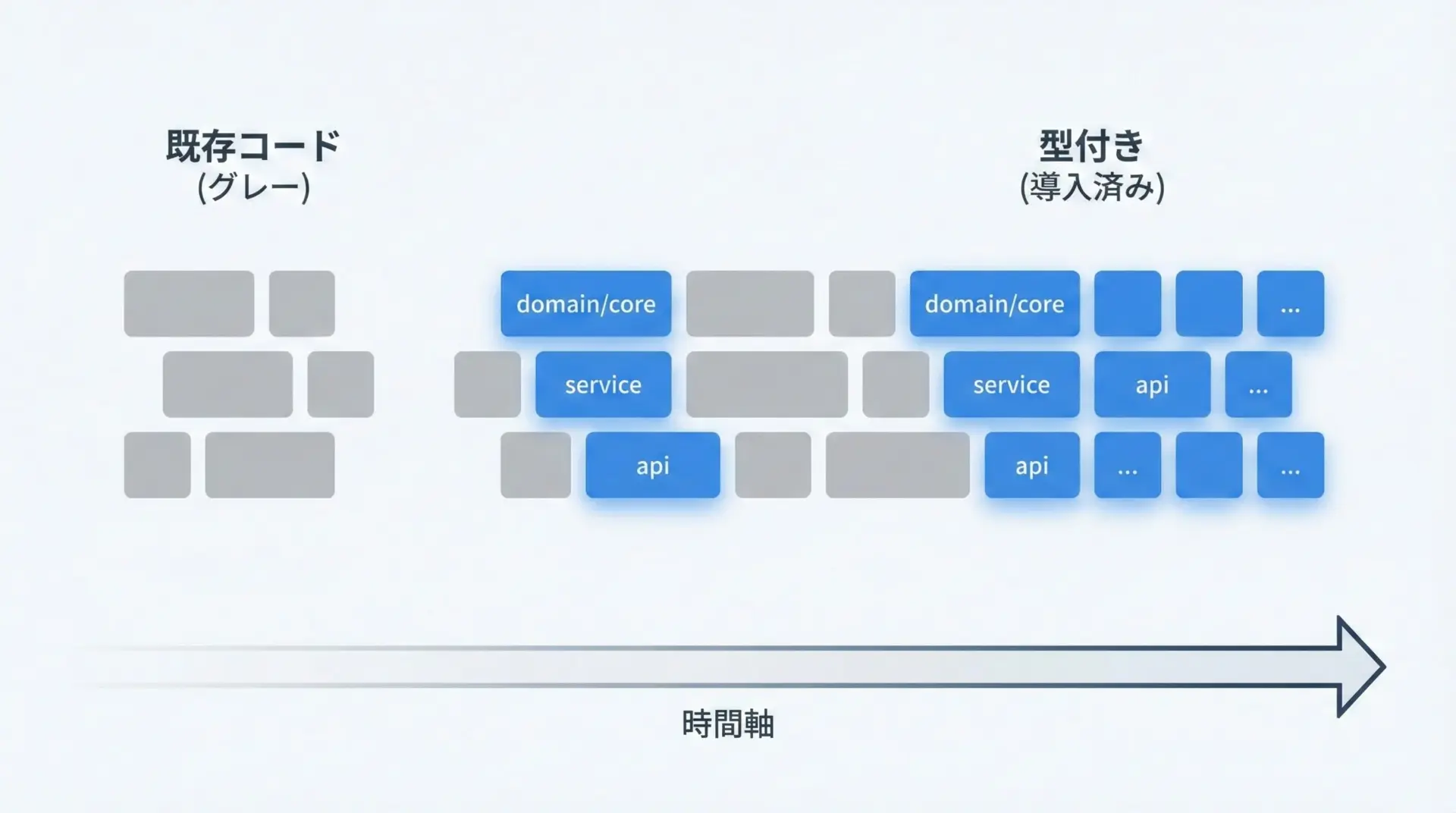
既存の大規模コードベースにいきなり完全な型注釈を付けるのは現実的ではありません。
そこで有効なのが段階的型付け(gradual typing)の考え方です。
具体的なステップとしては、次のような方針が有効です。
まず、最も重要なビジネスロジック層や、外部との境界(API I/Oなど)から型を付け始めます。
これらの箇所はバグの影響が大きく、また仕様が比較的はっきりしていることが多いため、型を定義しやすい場所でもあります。
次に、新規に追加するコードや大きく修正する箇所には、必ず型を付けるというルールを導入します。
これにより、時間が経つほど型付きコードの割合が増えていきます。
mypy側ではdisallow_untyped_defsをサブパッケージ単位で徐々に広げていくのが定番です。
例えば、myapp.domainから始め、次にmyapp.serviceへ、といった具合です。
また、どうしても型を付けづらい箇所には、一時的に# type: ignoreコメントを付けてmypyに無視させる方法もありますが、安易な乱用は避け、後で解消する前提で局所的に使うことが大切です。
型エラーの読み方と典型的なmypyエラーの対処法
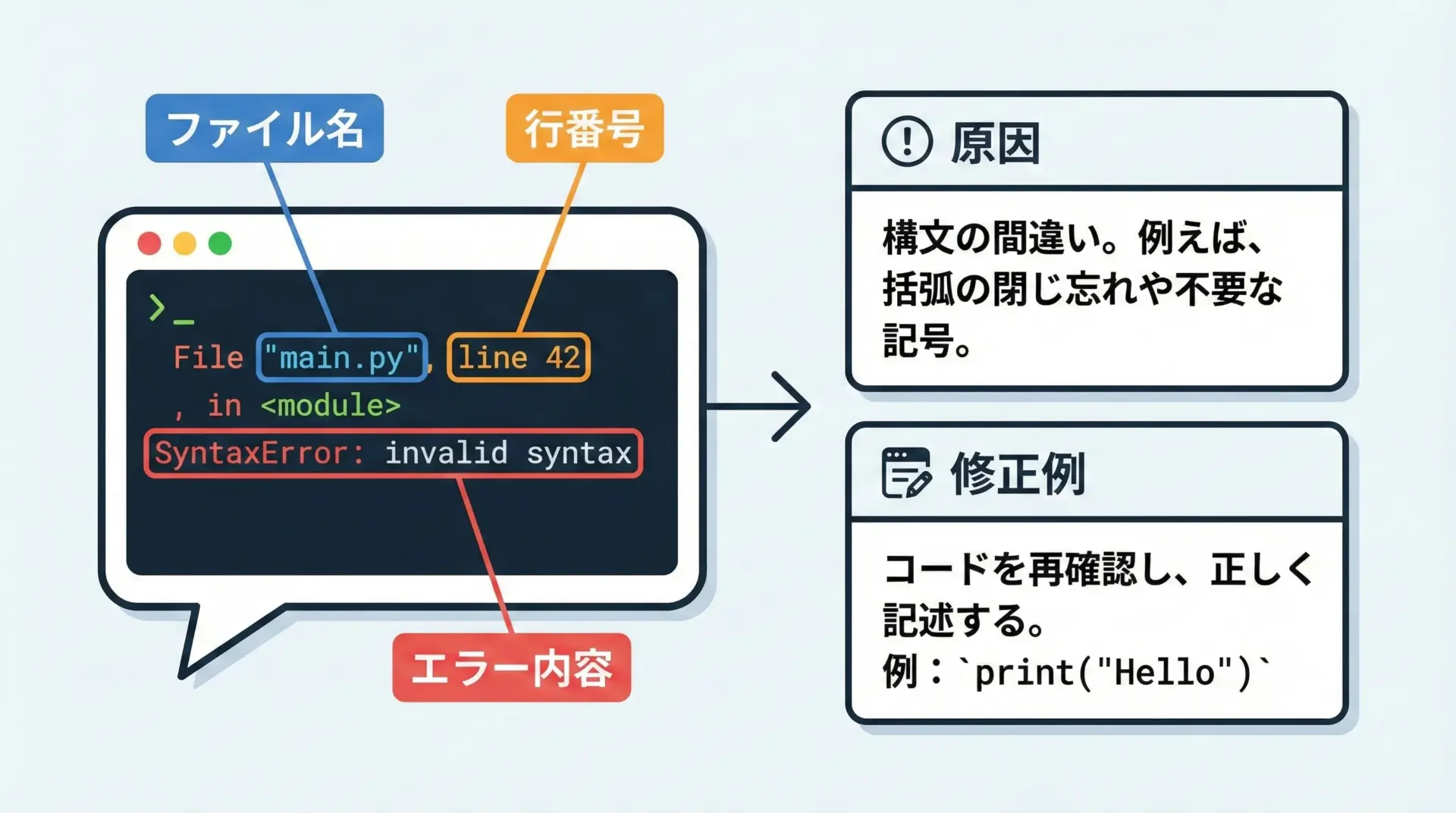
mypyのエラーメッセージは慣れるまでは読みづらく感じるかもしれませんが、フォーマットは一貫しているので、パターンを覚えると効率よく対応できるようになります。
一般的な形式は次のとおりです。
file.py:行番号: error: メッセージ [エラーコード(省略可)]典型的なエラー例と対処法をいくつか見てみましょう。
1つ目は型不一致です。
example.py:10: error: Argument 1 to "greet" has incompatible type "int"; expected "str"これは、greet関数の第1引数にintが渡されているが、定義上はstrを期待しているという意味です。
対処としては、呼び出し側の引数を修正するか、関数定義の型注釈が仕様に合っているかを見直します。
2つ目は未注釈関数の禁止(disallow_untyped_defs有効時)です。
service.py:20: error: Function is missing a type annotation for one or more argumentsこの場合は、該当関数に引数や戻り値の型を追加する必要があります。
3つ目はAnyの流出です。
logic.py:42: error: Returning Any from function declared to return "int"これは関数の戻り値がAnyとして推論されてしまっており、それがintとして宣言された戻り値と矛盾していることを示します。
原因としては、型情報のない外部関数からの戻り値をそのまま返している、などが考えられます。
対処としては、外部関数の返り値に型を付けるか、明示的なキャストで型を絞り込むなどの手があります。
エラーが多すぎて困るときは、エラーの種類を分類し、同じパターンを一括で直すのが効率的です。
また、--show-error-codesオプションを有効にすると、エラーごとにコードが付与され、特定の種類のエラーだけを抑制することも可能になります。
チーム開発でのmypy運用と自動化
CIでのmypy自動実行
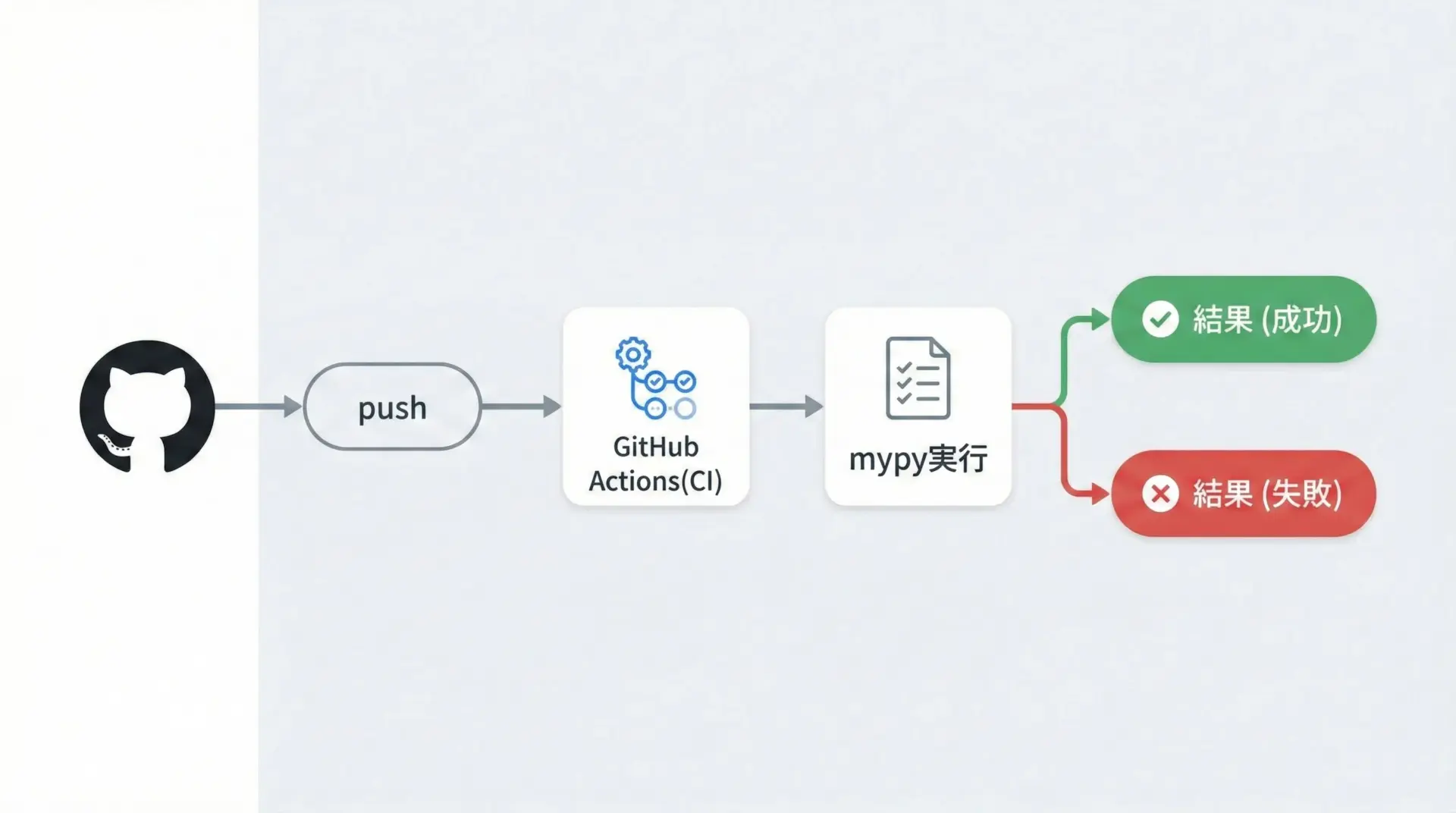
チーム開発では、ローカルだけでなくCI上でも必ずmypyを実行することで、型安全性を一定以上に保ちやすくなります。
ここではGitHub Actionsを例に、シンプルなmypyジョブの設定例を示します。
# .github/workflows/mypy.yml
name: mypy
on:
push:
branches: [ main ]
pull_request:
branches: [ main ]
jobs:
typecheck:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: "3.11"
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
# mypyをrequirementsに含めるか、ここで個別にインストール
pip install mypy
- name: Run mypy
run: |
mypy .このように設定しておけば、mainブランチへのpushやプルリクエスト時に自動的にmypyが実行され、型エラーがあればCIが失敗します。
「mypyが通らない変更はマージしない」というルールを徹底することで、徐々に型の品質を引き上げられます。
pre-commitフックでのmypy運用
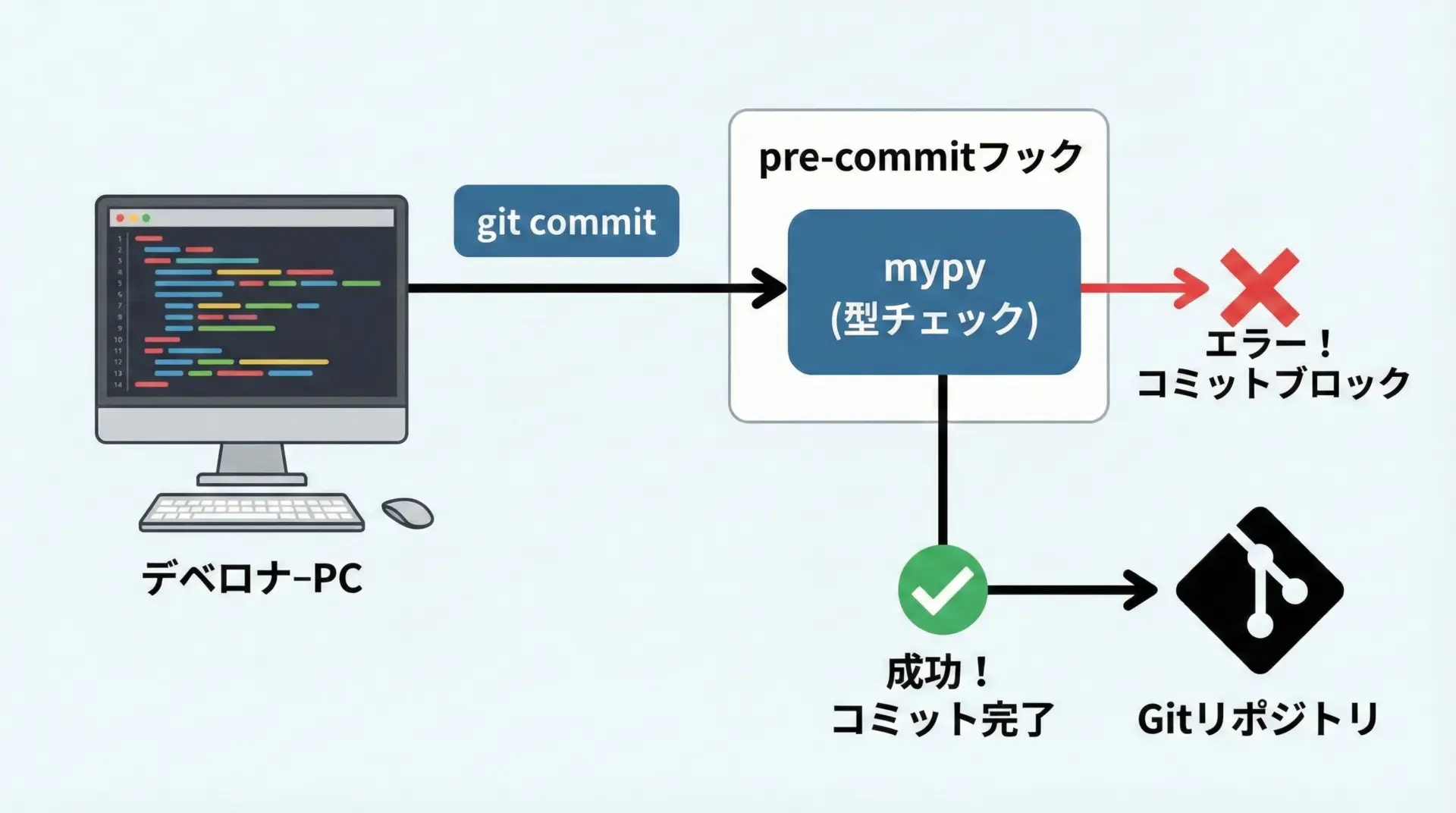
CIだけに頼ると、プッシュしてから初めて型エラーに気づくということが起きがちです。
そこで便利なのがpre-commitフレームワークを使ったローカルフックです。
代表的な設定は次のようになります。
# .pre-commit-config.yaml
repos:
- repo: https://github.com/pre-commit/mirrors-mypy
rev: v1.11.0 # 利用するmypyのバージョン
hooks:
- id: mypy
args: ["--config-file", "mypy.ini"]
additional_dependencies:
- types-requests # 必要なtype stubを追加このファイルを配置したら、次のコマンドでフックをインストールします。
pip install pre-commit
pre-commit installこれでgit commitのたびに自動的にmypyが走るようになり、型エラーを含む変更がコミットされるのを防げます。
プロジェクトの規模によっては、対象ファイルを変更ファイルだけに絞るなどの工夫も有効です。
mypyとテスト(Pytest)の役割分担
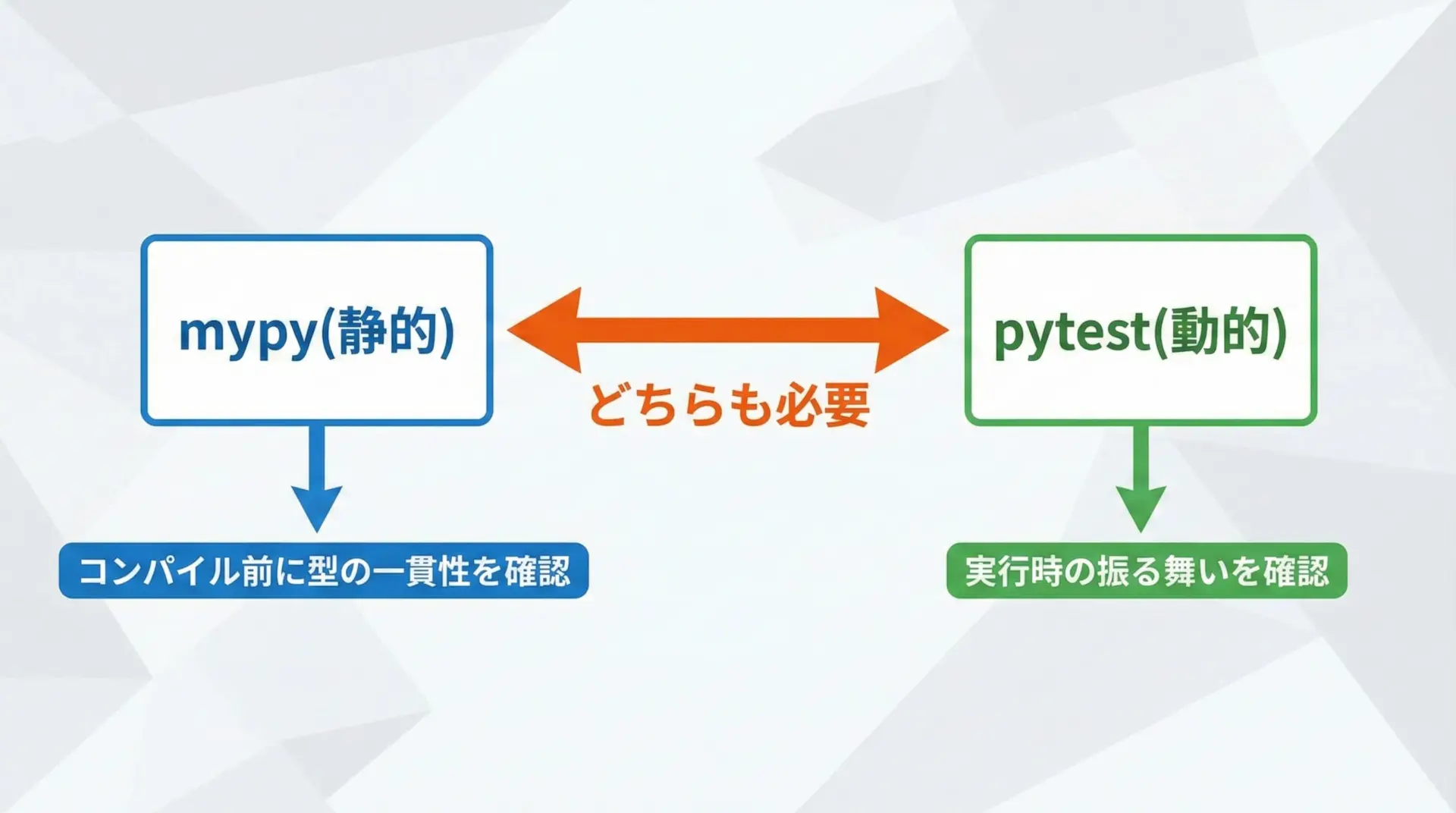
mypyとPytestは、どちらも品質向上のためのツールですが、役割は明確に異なります。
mypyは型の一貫性を静的に検査するツールであり、「この関数は文字列を返すと宣言しているのに、実際には整数を返していないか」といった問題を検出します。
ただし、ビジネスロジックの正しさまでは保証しません。
一方、Pytestは実際にコードを実行して期待通りの結果になるかを検証します。
境界ケースの挙動や、外部サービスとの統合など、mypyではカバーできない領域を担います。
理想的には、mypyで「型のレベルのバグ」をつぶし、Pytestで「振る舞いのレベルのバグ」をつぶすという役割分担を意識します。
型がしっかりしているとテストコードの記述もシンプルになり、テストデータの準備が楽になるという相乗効果もあります。
大規模プロジェクトでの型カバレッジ向上戦略
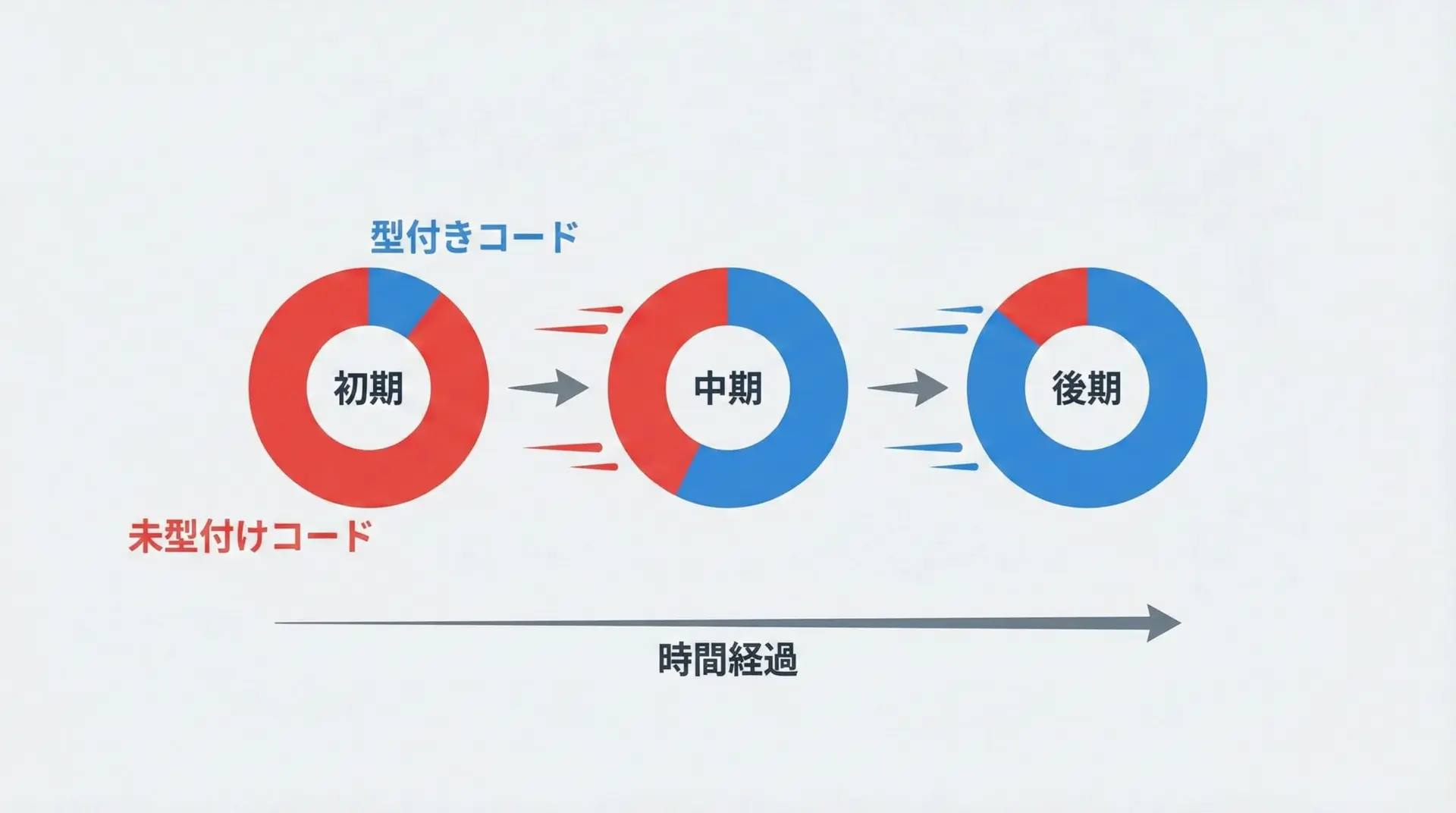
大規模プロジェクトでは、どれだけのコードが型でカバーされているかを意識することが重要です。
この割合を「型カバレッジ」と呼ぶことがあります。
mypy自体にはテストカバレッジのような数値レポート機能はありませんが、外部ツールや簡単なスクリプトを使って型注釈の有無を測定することは可能です。
また、CIで--disallow-untyped-defsを特定ディレクトリにだけ適用するなどして、カバレッジを少しずつ広げていくのも有効です。
戦略としては次のようなステップが考えられます。
まず、現状の型注釈状況を可視化します。
どのモジュールに型が付いていて、どこが未対応なのかを一覧にするだけでも、優先順位付けがしやすくなります。
次に、ビジネスクリティカルなモジュールや、変更頻度の高いモジュールから優先的に型を充実させていきます。
これらのモジュールはバグの影響範囲も広く、型による安全性の恩恵が大きいためです。
最後に、新規コードへは原則として完全な型注釈を要求し、「古いコードは触るときに型を付ける」方針を徹底することで、時間とともに全体の型カバレッジが自然と上がっていきます。
型スタイルガイドの整備とレビュー体制の作り方

mypyをチームで活用するには、「どのように型を書くか」というスタイルをある程度統一しておく必要があります。
そうしないと、メンバーごとに書き方がバラバラになり、かえって読みづらいコードになってしまうこともあります。
型スタイルガイドの内容としては、例えば次のような項目があります。
- 関数には原則としてすべて型注釈を付けるか、ユーティリティ関数などの例外を認めるか
- Optionalの使い方 (できるだけNoneを避けるのか、どこまで許容するのか)
- Anyの扱い (禁止か、局所的に許可するか、その場合のルールはどうするか)
- カスタム型エイリアスやNewTypeの命名規則
- 複雑な
UnionやTypedDictの分解方針
さらに、コードレビューのチェックリストに「型の妥当性」「mypyで警告が出ていないか」といった項目を含めることで、型品質の低下を防げます。
特にAnyの乱用はmypyの効果を大きく損なうため、「どの範囲までAnyを認めるか」をチームで合意しておくとよいでしょう。
例えば「外部ライブラリの境界ではやむを得ずAnyを使ってもよいが、ドメイン層では禁止」といった線引きが考えられます。
まとめ
mypyは、動的型付けであるPythonに静的な型安全性とドキュメント性をもたらしてくれる強力なツールです。
本記事では、mypyの基本概念から導入・設定方法、型注釈の実践的な書き方、既存コードへの段階的な適用、そしてチーム開発での運用ノウハウまでを一通り紹介しました。
いきなり完璧を目指す必要はありません。
まずは重要なモジュールから型を導入し、CIやpre-commitに組み込んで少しずつ厳しさを上げていくことで、無理なく「壊れにくく読みやすいPythonコードベース」へと育てていくことができます。
