
Pythonで日本語を扱っていると、突然UnicodeEncodeErrorやcp932、asciiと書かれたエラーに遭遇することがあります。
原因が分からないまま試行錯誤するよりも、仕組みを理解しておくと安定して日本語を扱えるようになります。
本記事では、cp932・asciiのUnicodeEncodeErrorを根本から理解し、一括で直す方法を、実行例付きで詳しく解説します。
PythonのUnicodeEncodeErrorとは
UnicodeEncodeErrorの意味と発生タイミング
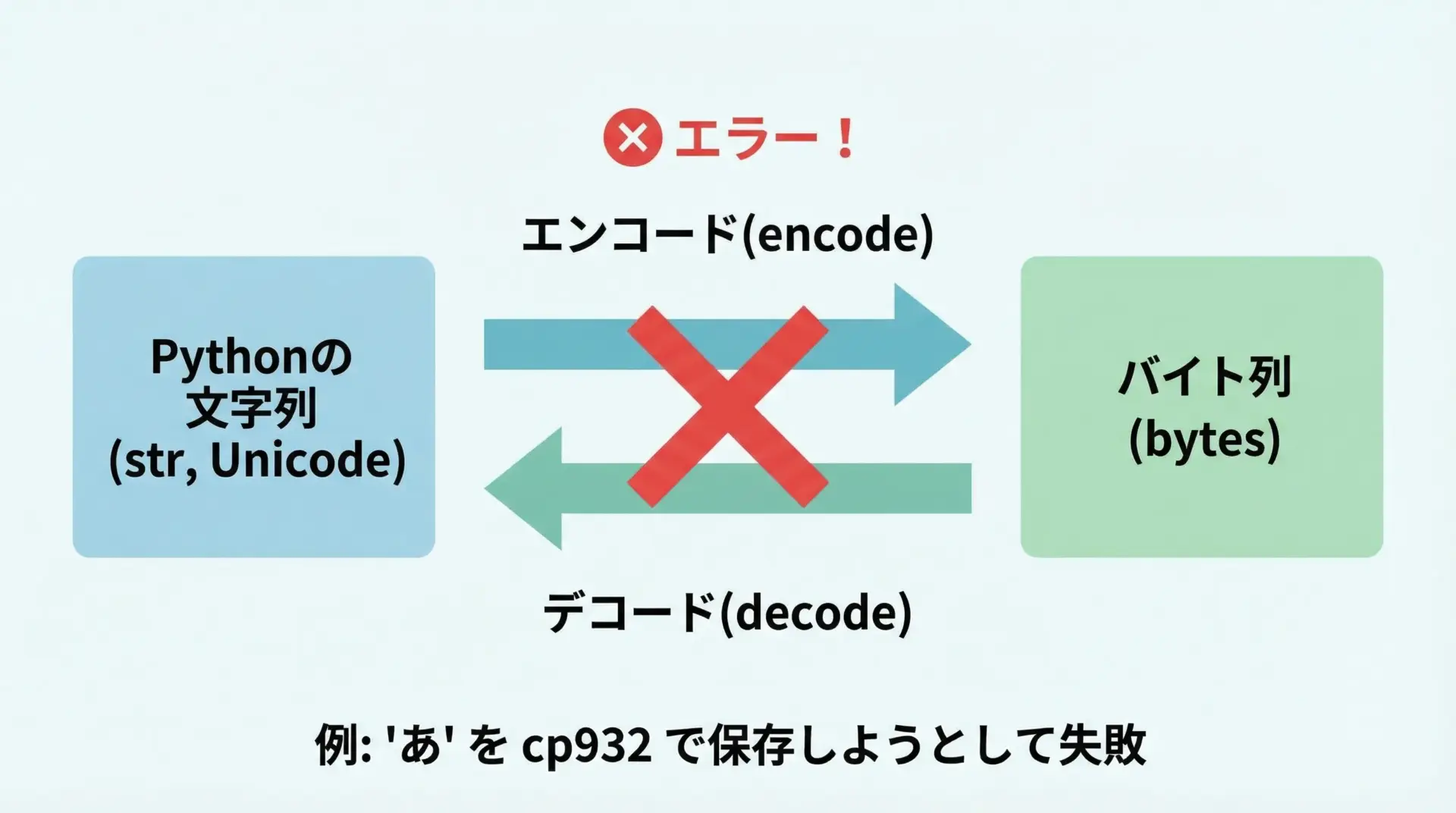
UnicodeEncodeErrorは、Pythonが文字列(str)を特定の文字コードでバイト列(bytes)に変換しようとしたとき、その文字コードでは表現できない文字が含まれている場合に発生するエラーです。
Pythonでは、テキストデータは内部的にはUnicode文字列として扱われますが、次のようなタイミングで「エンコード(文字列→バイト列)」が行われます。
- ファイルへ書き込むとき(エンコーディングを指定したopen)
- コンソール(標準出力)に表示するとき
- ネットワーク送信時、ライブラリ内部処理など
このとき、例えば"こんにちは"をcp932で出力しようとしたが、cp932では対応していない絵文字が含まれている、といった場合にUnicodeEncodeErrorになります。
cp932・asciiでよく出るエラーメッセージ例
Pythonでよく見かけるエラーメッセージの例を見ておきます。
代表的なのは次の2パターンです。
cp932での例(Windows日本語環境)
UnicodeEncodeError: 'cp932' codec can't encode character '\u1f600' in position 0: illegal multibyte sequenceasciiでの例
UnicodeEncodeError: 'ascii' codec can't encode character '\u3042' in position 0: ordinal not in range(128)どちらも'xxx' codec can't encode characterという形になっており、
'cp932'や'ascii'が使われた文字コード(エンコーディング)\u3042などがエンコードしようとして失敗した文字
を表します。
UnicodeDecodeErrorとの違い
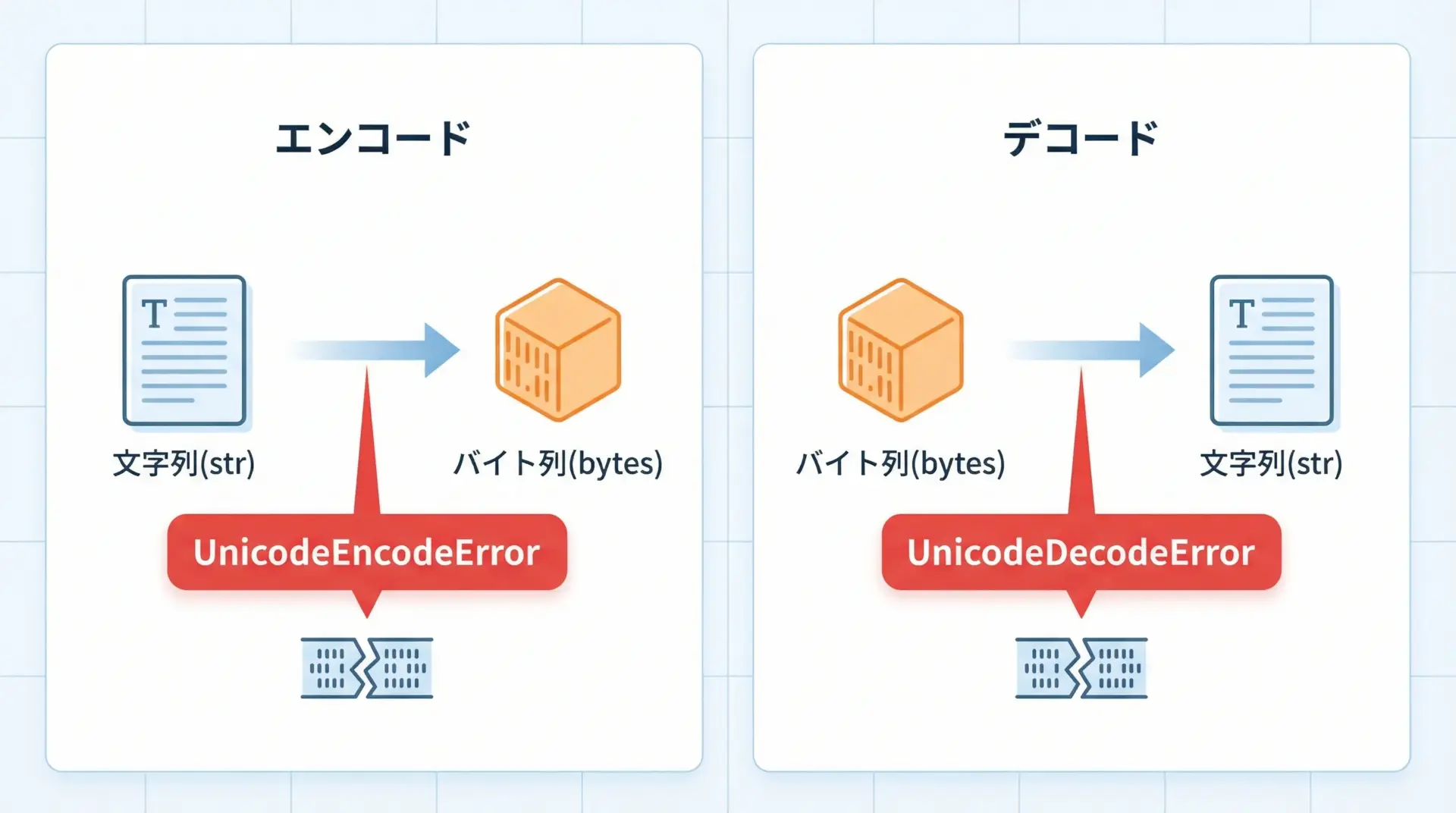
似たエラーにUnicodeDecodeErrorがあります。
2つの違いは次の通りです。
- UnicodeEncodeError
- 方向: 文字列(str) → バイト列(bytes)
- 内容: 「この文字コードでは表現できない文字が含まれている」
- UnicodeDecodeError
- 方向: バイト列(bytes) → 文字列(str)
- 内容: 「このバイト列は、その文字コードとしては不正(読めない)」
つまりEncodeErrorは「出力側の問題」、DecodeErrorは「入力側の問題」と覚えておくと整理しやすいです。
cp932エラー(Python)の原因と対処
cp932とは何か
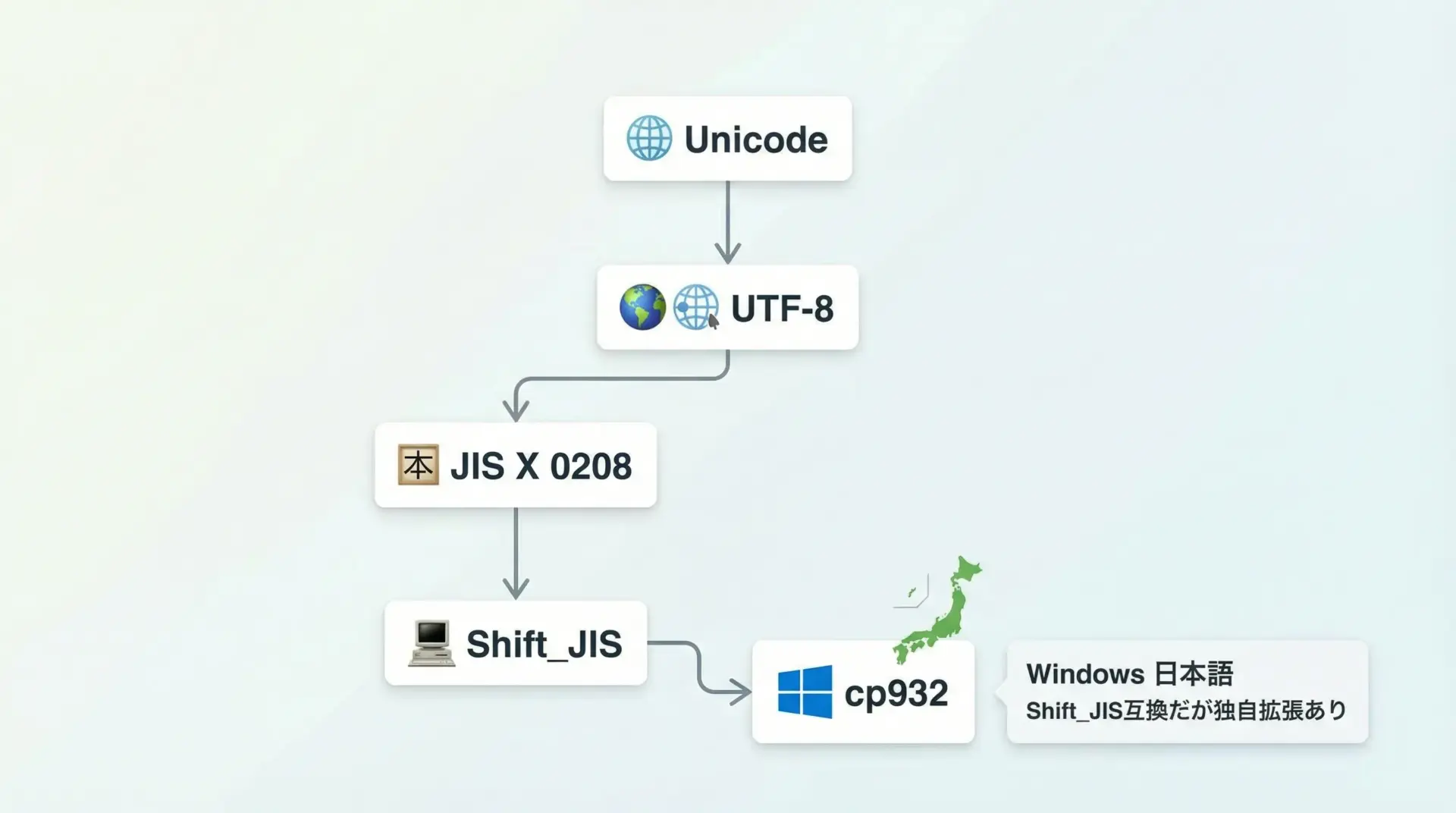
cp932は、Windowsの日本語環境で歴史的に使われているShift_JIS互換の文字コードです。
Microsoft独自の拡張が入っており、一般的なShift_JISと完全一致ではありません。
Windowsの日本語コンソールや、一部の古いテキストファイルでは今でもcp932が標準として使われているため、Pythonで日本語を扱うときのエラーの元になりがちです。
表として特徴を整理します。
| 項目 | cp932 | utf-8 |
|---|---|---|
| 主な利用環境 | Windows日本語コンソール、古いWindowsアプリ | Web、Linux、macOS、最新ツール全般 |
| 表現できる文字 | 多くの日本語だが絵文字などに弱い | Unicodeのほぼ全て(制限ほぼなし) |
| 互換性 | Shift_JISと近いが完全一致ではない | 世界標準、他OSと互換性が高い |
| Pythonでの推奨度 | 新規開発には非推奨 | 新規開発では標準的に推奨 |
新規開発では基本的にutf-8を使うのが安全ですが、既存環境やWindowsコンソールとの兼ね合いでcp932が関わってくる場面が今も多くあります。
cp932で文字化け・UnicodeEncodeErrorが出る典型パターン
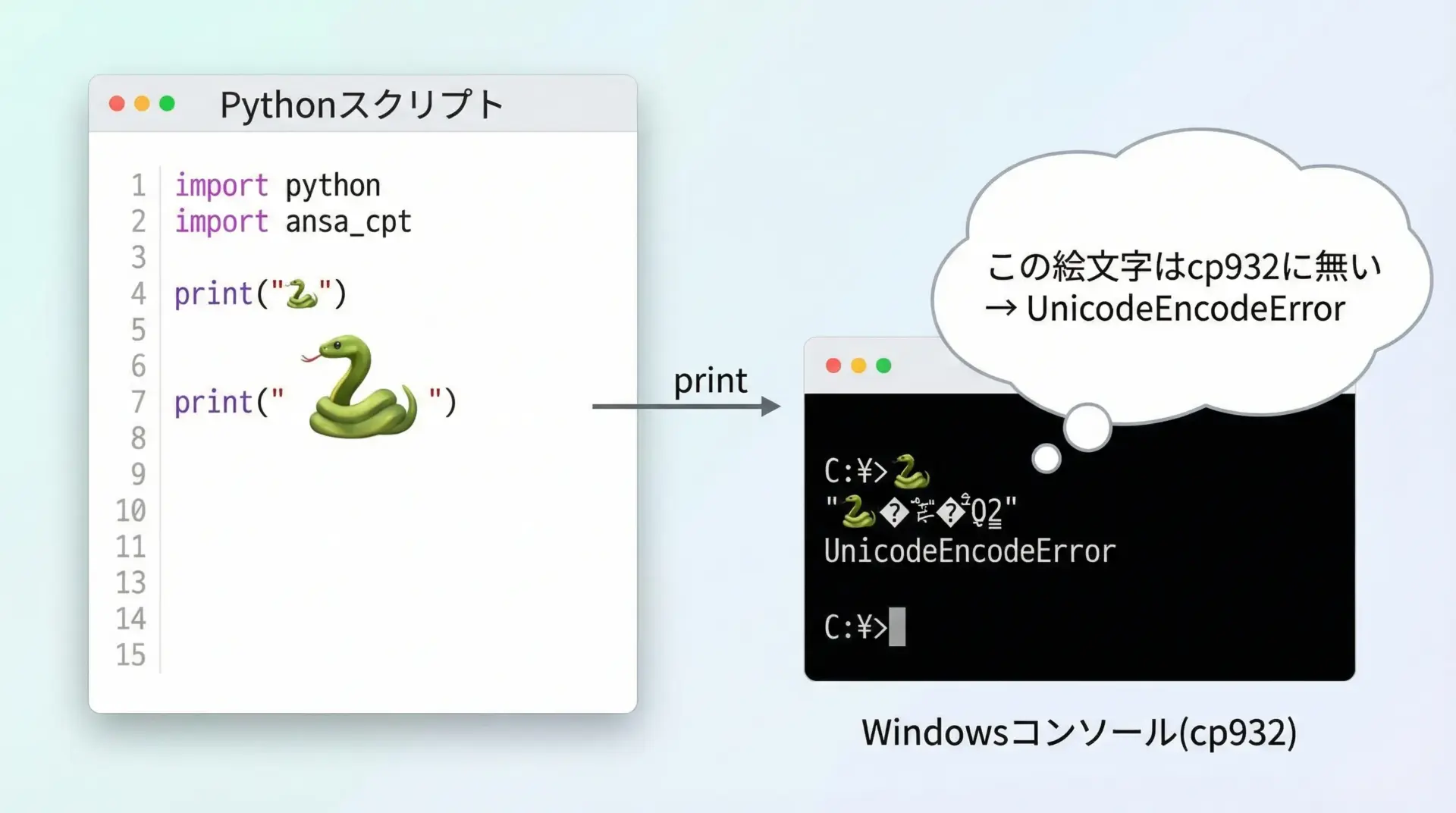
典型的なパターンは、cp932では表現できない文字(絵文字・一部の記号・特殊文字など)を出力しようとしたときです。
例として、Windowsの日本語コンソールで次のようなコードを実行してみます。
# cp932環境で絵文字を表示しようとする例
text = "にっこり絵文字: 😀" # 😀 は多くのcp932環境では表現できない
print(text) # ここでUnicodeEncodeErrorが起こる可能性があるcp932では😀(U+1F600)が定義されていないため、コンソールに出力しようとすると、次のようなエラーになることがあります。
UnicodeEncodeError: 'cp932' codec can't encode character '\U0001f600' in position 7: illegal multibyte sequenceこのように、Pythonの文字列としては問題なく扱えても、「cp932で表示・保存する」というところで初めてエラーが顕在化します。
printやログ出力でcp932エラーになる理由

print関数やログ出力(logging)は、内部的には<sys.stdout>や<sys.stderr>というストリームに対する書き込みです。
Windows日本語環境では、これらのストリームのエンコーディングがデフォルトでcp932になっていることが多く、次のような流れになります。
- Python内部: Unicode文字列(
str)として日本語や絵文字を保持 - printやlogging: それを
sys.stdoutに書き込もうとする - sys.stdout: 自分のエンコーディング(cp932)でエンコードしてからコンソールへ送る
- cp932で表現できない文字がある → UnicodeEncodeError
つまり、printは悪くなく、「stdoutがcp932であること」と「文字にcp932未対応のものが含まれていること」が原因です。
cp932エラーの一括回避

cp932エラーを「都度なんとかする」のではなく、一括で回避する戦略を持っておくと便利です。
代表的な方法は次のとおりです。
- WindowsコンソールをUTF-8モードにする
- 後述の「Windows環境をutf-8モードにしてcp932問題を根本解決する」で詳しく説明します。
- これが最も根本的かつ今後の互換性にも優れた方法です。
- Python側でstdoutのエンコーディングをUTF-8に再設定する
sys.stdout.reconfigure(encoding="utf-8")を使う方法で、後ほど具体例を出します。
- どうしてもcp932で出さないといけないが、一部文字だけ落とす・置き換える
encode("cp932", errors="replace")やerrors="ignore"を使う応急処置的な方法です。
asciiエラー(Python)の原因と対処
ascii codec can’t encode…エラーが出る仕組み
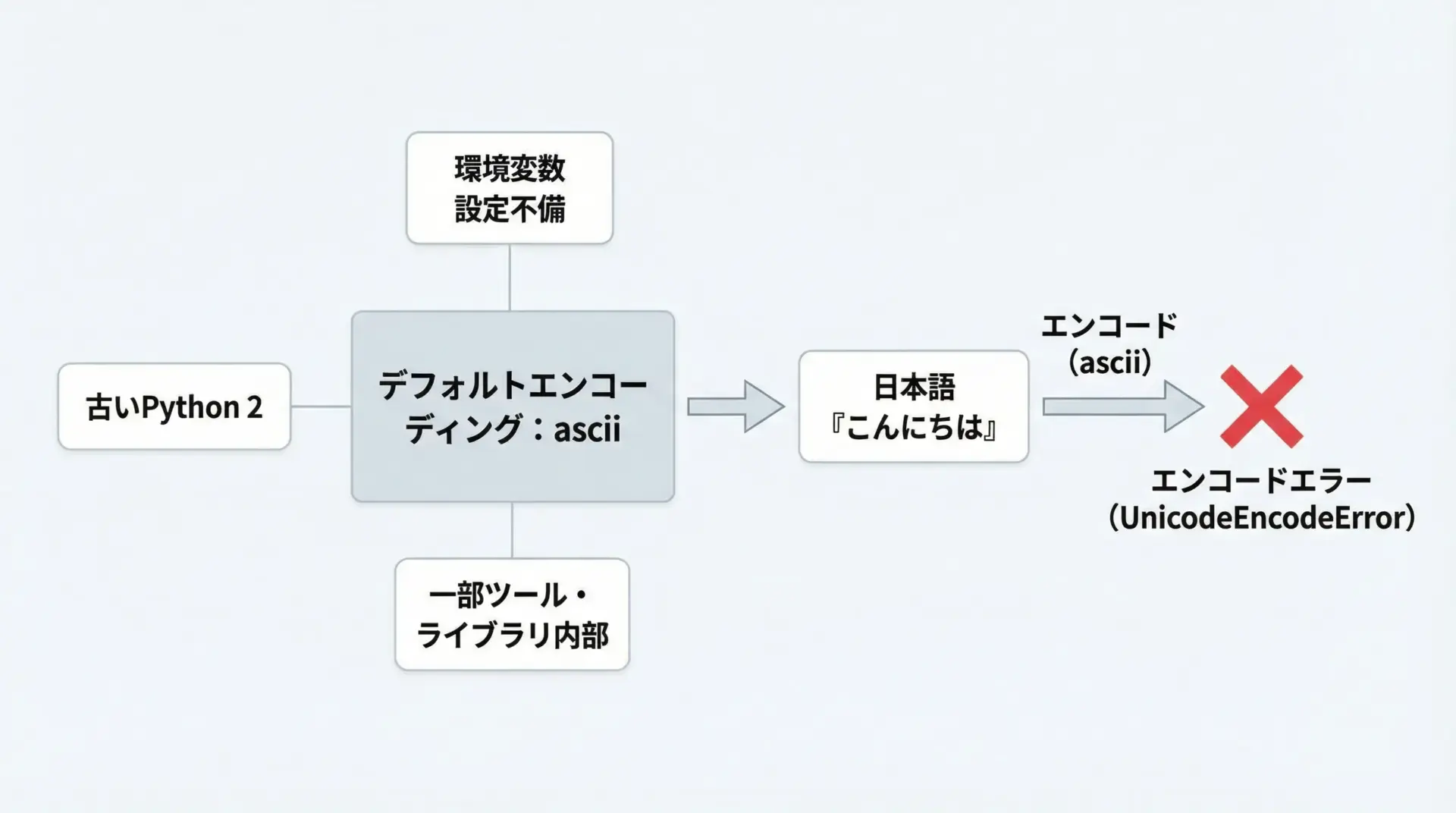
UnicodeEncodeError: 'ascii' codec can't encode character ... というエラーは、どこかで「デフォルトエンコーディング」がasciiになっており、その状態で日本語をエンコードしようとしたときに発生します。
asciiは0〜127の英数字と一部記号しか扱えないため、日本語や全角記号は1文字も表現できません。
そのため、たとえば"あ"をasciiでエンコードしようとすると、必ずUnicodeEncodeErrorになります。
デフォルトエンコーディングがasciiになるケース
Python 3では、通常のスクリプト実行においてデフォルトエンコーディングがasciiになることはほとんどありません。
しかし、次のようなケースでasciiが顔を出すことがあります。
- 一部の外部ライブラリや古いコードが、
sys.getdefaultencoding()を直接使ったり、独自にascii前提でエンコードしている - Python 2系のコードやドキュメントを参考にして、そのまま利用してしまった
- 特殊な環境(組み込み系・古いツール)でPythonがビルドされていて、デフォルトがasciiになっている
Python 3の通常環境では、sys.getdefaultencoding()はたいてい"utf-8"になっています。
もしasciiになっているようであれば、環境やバージョンの見直しを優先的に検討すべきです。
ソースコード内の日本語文字列でasciiエラーが出る場合

ソースコード内の日本語文字列でasciiエラーが出る典型パターンは、ソースファイルのエンコーディング宣言が誤っているケースです。
Pythonファイルの先頭に次のような宣言があるとします。
# -*- coding: ascii -*-
message = "こんにちは" # asciiでは扱えない日本語
print(message)このようにcoding: asciiと宣言しているにも関わらず、日本語リテラルを書いた場合、Pythonがソースコードを読み込む段階で問題が起きます。
対処としては、ソースコード自体の文字コードをutf-8で保存し、宣言をutf-8(または省略)にすることです。
# -*- coding: utf-8 -*-
message = "こんにちは"
print(message)Python 3では、ソースファイルのデフォルトエンコーディングはutf-8なので、特に理由がなければ宣言を省略しても構いません。
ファイル入出力でasciiエラーが出る場合の直し方
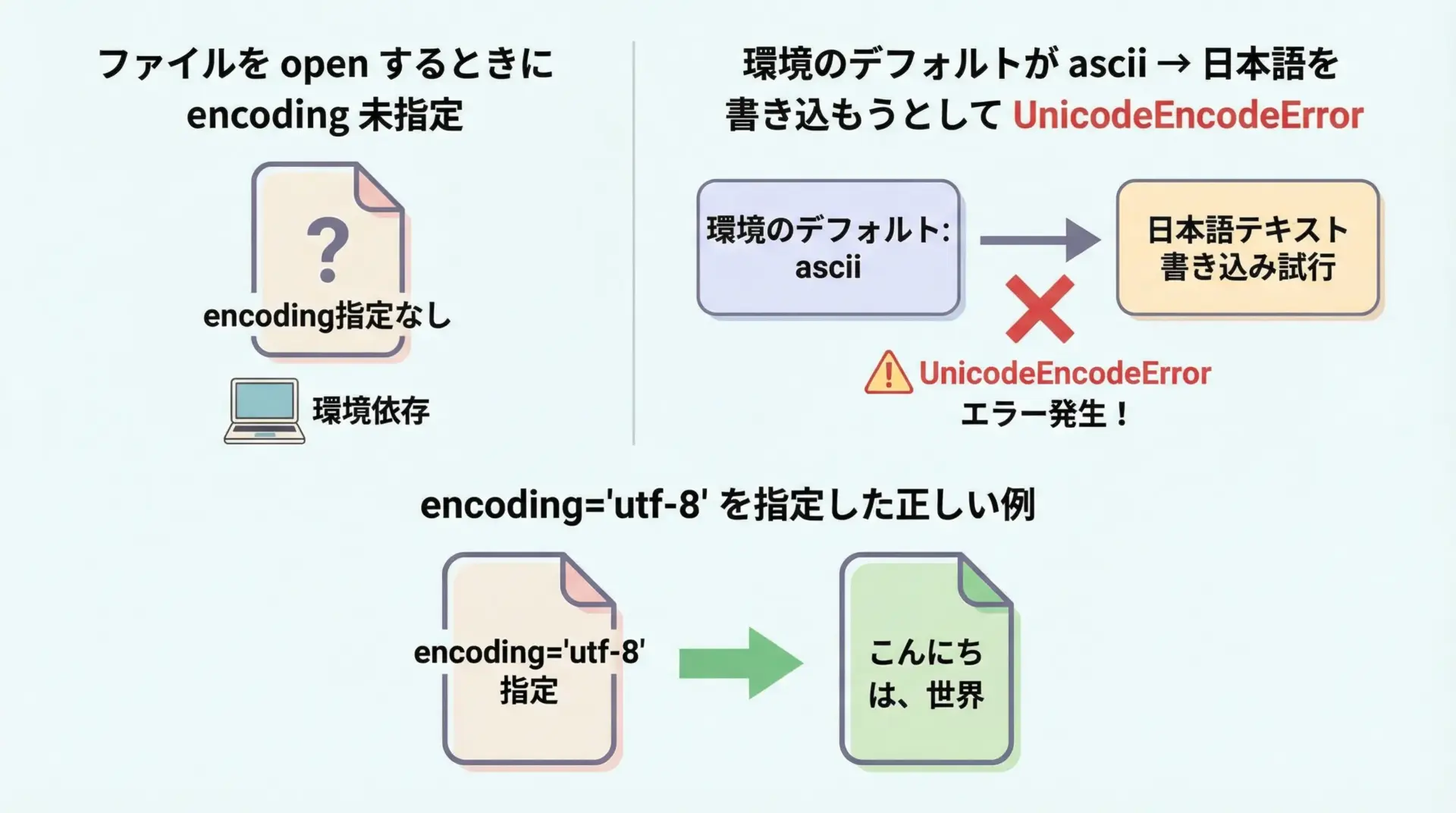
ファイル入出力でasciiエラーが出る典型例を見ておきます。
# 環境のデフォルトエンコーディングがasciiだった場合の例
text = "こんにちは"
with open("hello.txt", "w") as f: # encoding を指定していない
f.write(text) # ここで 'ascii' codec can't encode... になる可能性この場合、open関数が環境のデフォルトエンコーディング(ascii)を使おうとしているため、日本語を書き込もうとするとUnicodeEncodeErrorになります。
直し方はただ1つ、エンコーディングを明示することです。
text = "こんにちは"
# utf-8 でファイルを書き込む(推奨)
with open("hello.txt", "w", encoding="utf-8") as f:
f.write(text)このようにencoding="utf-8"を指定しておけば、環境に依存せずに日本語を正しく扱えるようになります。
UnicodeEncodeErrorの具体的な直し方
ここからは、実際のコードを交えながら、cp932・asciiに起因するUnicodeEncodeErrorをどう「直す」のかを具体的に説明します。
ファイル出力時のエンコーディング指定で解決する
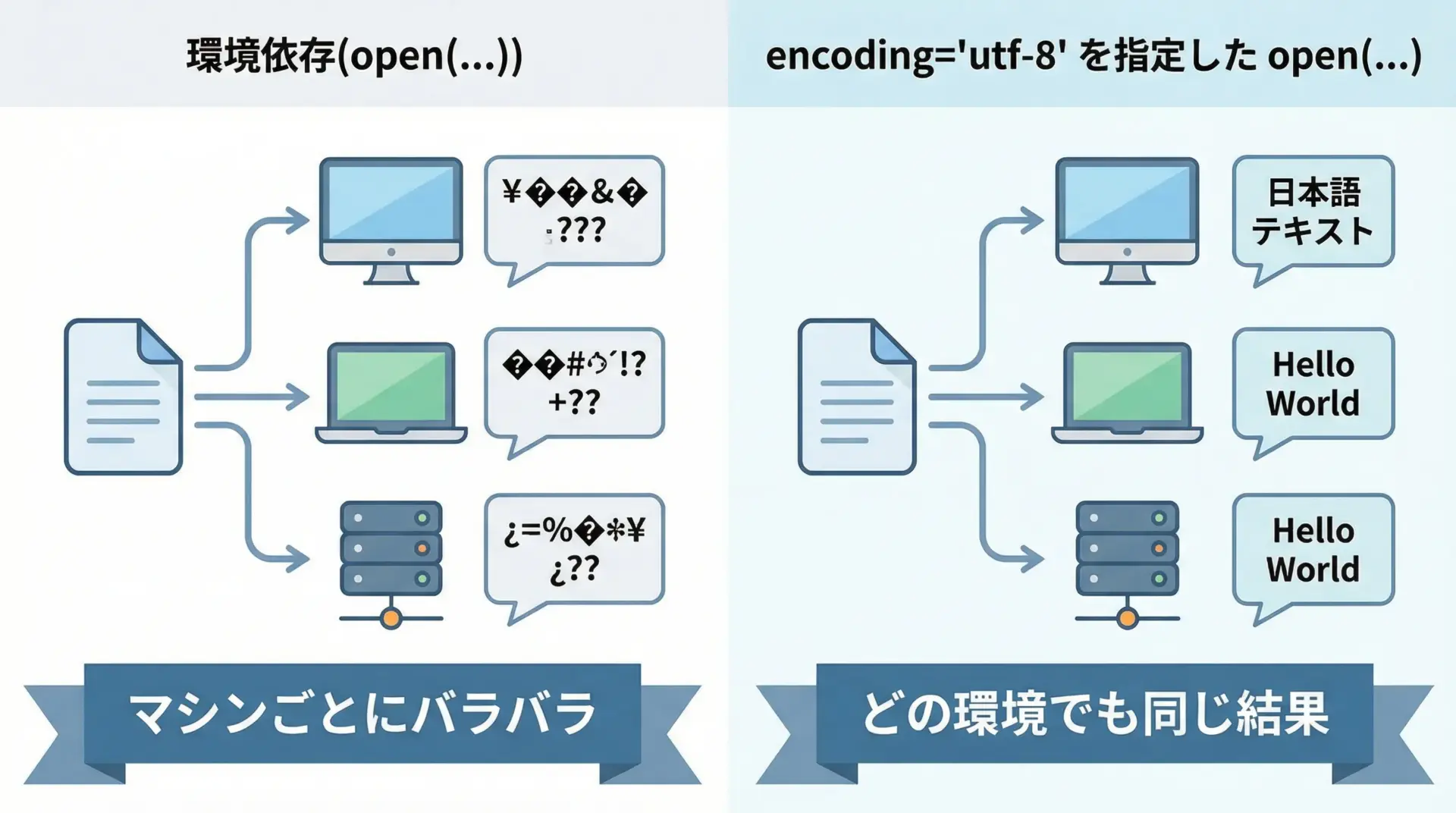
ファイルへの出力でUnicodeEncodeErrorが出る場合、最優先で確認するべきなのがopenのencoding指定です。
悪い例: encodingを指定していない
# 悪い例: encodingを指定していないため、環境依存になる
data = "Pythonで日本語を書き込みます。"
# encoding 引数なし → 環境のデフォルト(cp932, ascii など)に依存
with open("output.txt", "w") as f:
f.write(data)環境によってはこれで問題ないこともありますが、将来別の環境で動かしたときに突然エラーや文字化けが発生します。
良い例: encoding=”utf-8″ を明示する
# 良い例: 文字コードを明示的に指定する
data = "Pythonで日本語を書き込みます。"
# utf-8 で保存することを明示
with open("output_utf8.txt", "w", encoding="utf-8") as f:
f.write(data)出力結果(ファイルの中身をcatしたと仮定):
Pythonで日本語を書き込みます。このように常にencodingを明示することが、cp932・ascii問題を回避する最も基本的なテクニックです。
標準入出力(コンソール)のエンコーディングを確認・変更する
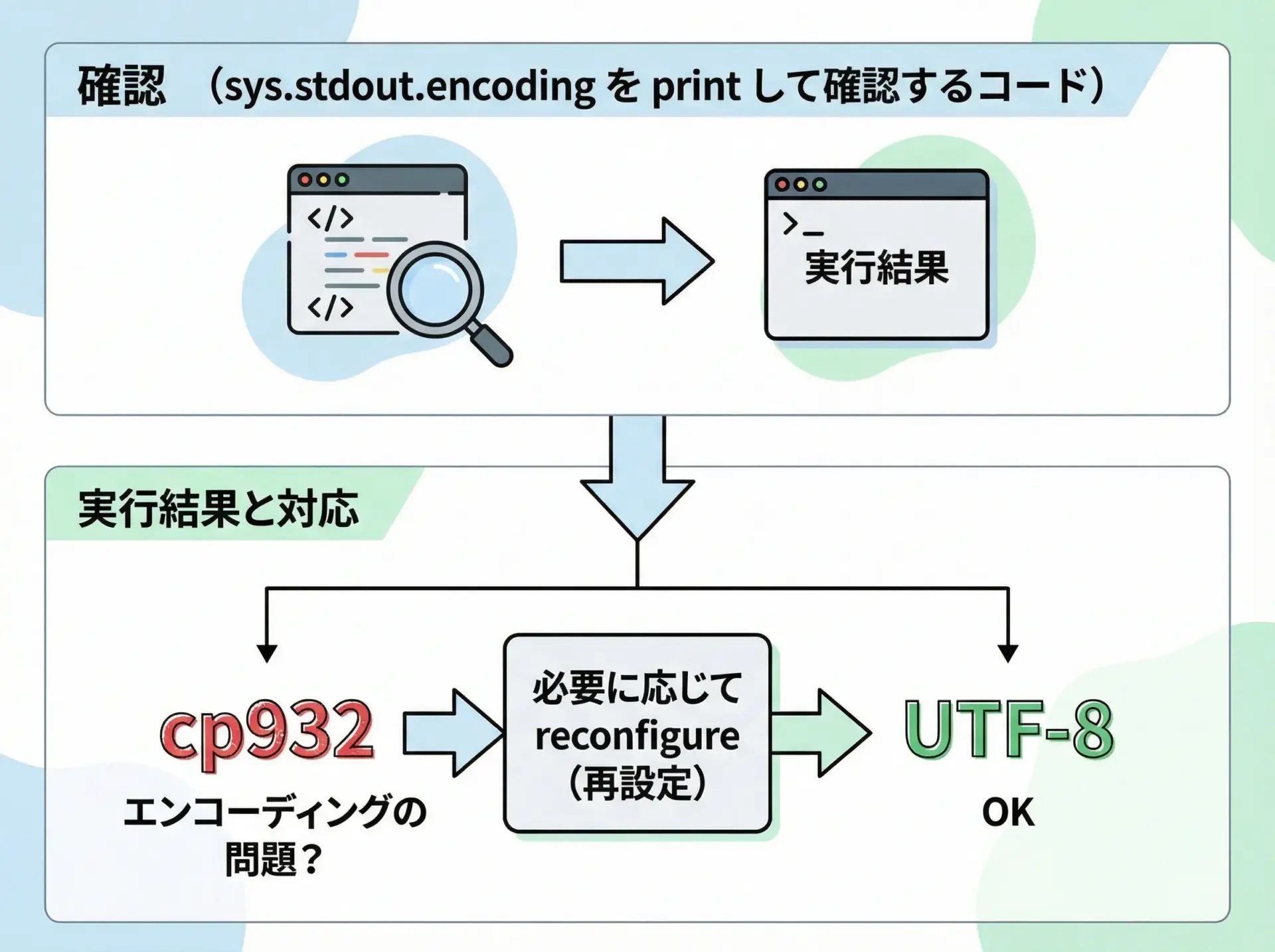
まずは今、自分のPythonがどのエンコーディングで標準出力しているかを確認します。
import sys
print(sys.stdout.encoding) # 現在の標準出力エンコーディングを表示cp932あるいは:
UTF-8ここがcp932になっている場合、絵文字や一部の記号を出力しようとしてUnicodeEncodeErrorが出る可能性があります。
一時的に標準出力エンコーディングを変更する例
Python 3.7以降では、sys.stdout.reconfigureを使ってエンコーディングを変更できます(次のセクションで詳述します)。
import sys
print("変更前:", sys.stdout.encoding)
# 標準出力をUTF-8で再設定
sys.stdout.reconfigure(encoding="utf-8")
print("変更後:", sys.stdout.encoding)
print("にっこり絵文字: 😀") # UTF-8対応ターミナルなら表示可能想定される実行結果:
変更前: cp932
変更後: utf-8
にっこり絵文字: 😀ターミナル自体がUTF-8に対応している必要はありますが、多くのモダンな環境では問題なく表示できます。
sys.stdout.reconfigureでUnicodeEncodeErrorを回避する
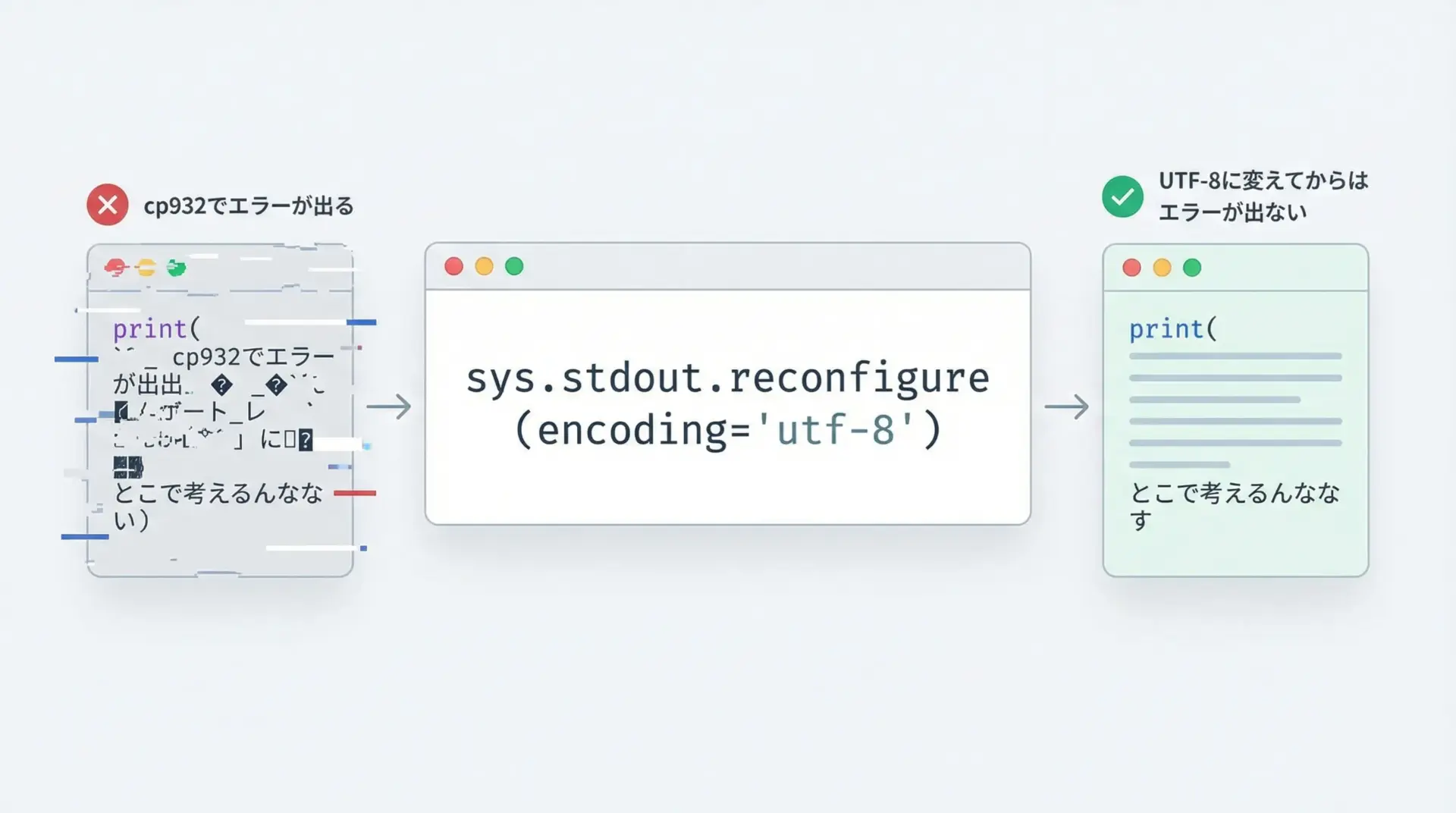
sys.stdout.reconfigureは、すでに開いている標準出力ストリームの設定を変更するためのメソッドです。
これを使うと、スクリプトの途中からUTF-8出力に切り替えることができます。
cp932環境での例
import sys
print("現在の標準出力エンコーディング:", sys.stdout.encoding)
# cp932環境で絵文字を出力してみる
try:
print("にっこり絵文字: 😀") # cp932 では UnicodeEncodeError になることがある
except UnicodeEncodeError as e:
print("エラー発生:", e)
# UTF-8 に再構成
sys.stdout.reconfigure(encoding="utf-8")
print("変更後の標準出力エンコーディング:", sys.stdout.encoding)
# 再度絵文字を出力
print("にっこり絵文字(UTF-8): 😀")想定される実行結果:
現在の標準出力エンコーディング: cp932
エラー発生: 'cp932' codec can't encode character '\U0001f600' in position 7: illegal multibyte sequence
変更後の標準出力エンコーディング: utf-8
にっこり絵文字(UTF-8): 😀このように、cp932のままだとエラーになる出力を、UTF-8に切り替えることで回避できます。
open関数でencoding=utf-8を明示してcp932・ascii問題を防ぐ
ファイル入出力でのトラブルを未然に防ぐには、open関数に必ずencoding="utf-8"を付けるのが基本方針です。
読み込み: 日本語テキストファイルを読む
# utf-8のテキストファイルを読み込む例
file_path = "input_utf8.txt"
with open(file_path, "r", encoding="utf-8") as f:
content = f.read()
print("読み込んだ内容:")
print(content)読み込んだ内容:
これはUTF-8で保存された日本語テキストです。書き込み: ログやレポートを保存する
# utf-8でファイルに書き込む例
log_message = "処理が正常に完了しました。"
with open("log.txt", "w", encoding="utf-8") as f:
f.write(log_message + "\n")このように読み込みでも書き込みでも、常にencodingを明示しておくと、cp932やasciiに引きずられることがありません。
str.encodeやbytes.decodeの正しい使い分け

PythonのUnicode関連で混乱しがちなのがencodeとdecodeの方向です。
これを正しく理解しておくと、エラーの原因が見抜きやすくなります。
- str.encode(encoding)
- 方向: 文字列(str) → バイト列(bytes)
- 「この文字列を、指定した文字コードでバイト列に変換する」
- bytes.decode(encoding)
- 方向: バイト列(bytes) → 文字列(str)
- 「このバイト列を、指定した文字コードとして解釈し、文字列に変換する」
正しい使い方の例
# 正しい encode / decode の例
text = "あいう" # Python内部ではUnicode文字列
# UTF-8でencodeしてバイト列に変換
b = text.encode("utf-8")
print("UTF-8のバイト列:", b)
# utf-8としてdecodeして再び文字列に戻す
restored = b.decode("utf-8")
print("復元した文字列:", restored)想定される実行結果:
UTF-8のバイト列: b'\xe3\x81\x82\xe3\x81\x84\xe3\x81\x86'
復元した文字列: あいう間違った使い方によるエラー例
# 間違った例: bytesに対して再度encodeしようとする
b = "あ".encode("utf-8")
try:
b2 = b.encode("utf-8") # bytesオブジェクトにはencodeはない
except AttributeError as e:
print("エラー:", e)エラー: 'bytes' object has no attribute 'encode'また、エンコーディングの食い違いも典型的なミスです。
# cp932でエンコードしたものを、utf-8としてデコードしようとする誤り
text = "テスト"
b_cp932 = text.encode("cp932") # cp932でバイト列にする
try:
wrong = b_cp932.decode("utf-8") # 間違った文字コードでデコード
except UnicodeDecodeError as e:
print("デコードエラー:", e)ここではDecodeErrorですが、エンコードとデコードの両方で「同じ文字コードを使う」のが鉄則です。
Windows環境をutf-8モードにしてcp932問題を根本解決する
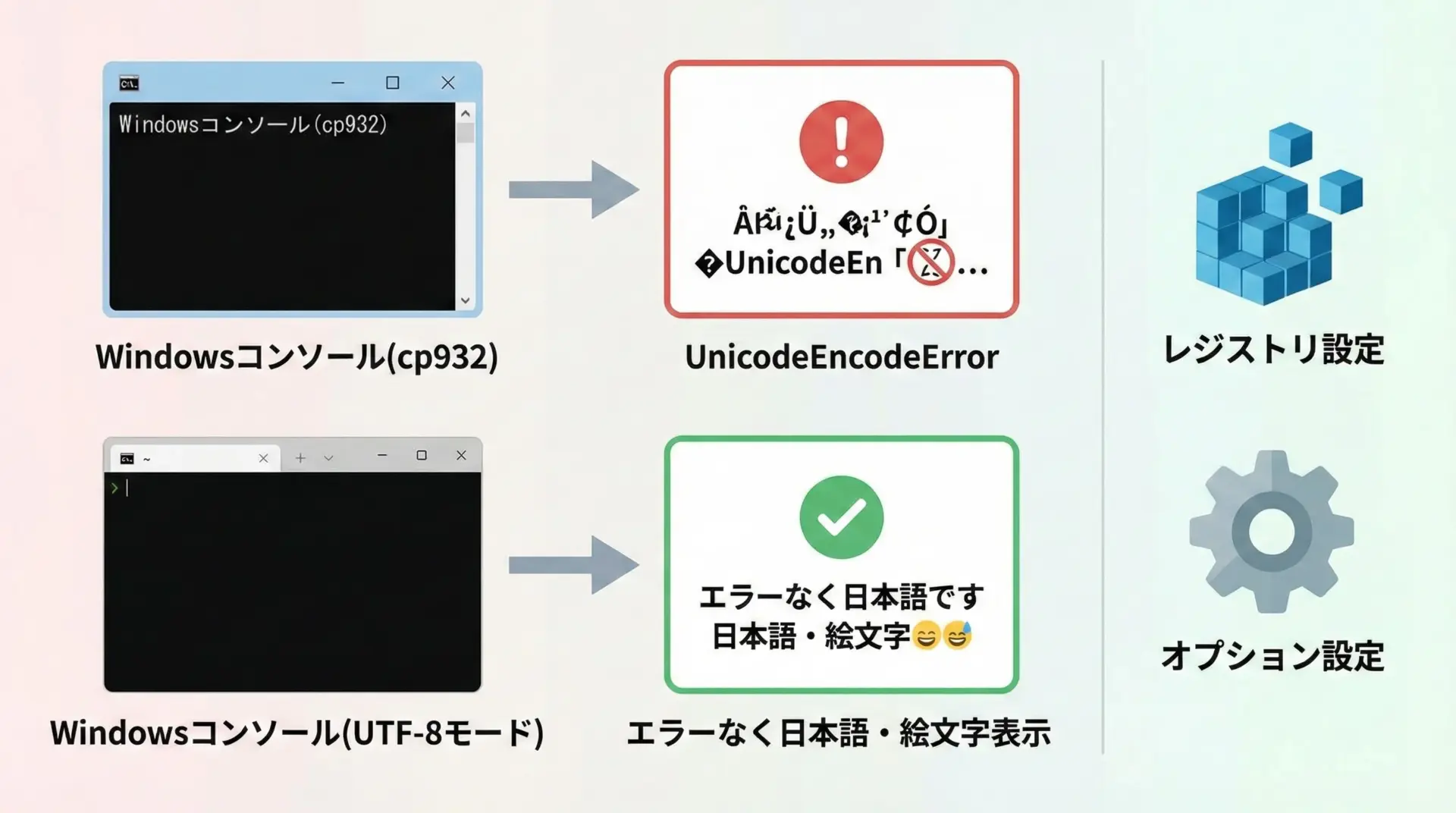
最後に、根本的にcp932問題を減らす方法として、Windows自体をUTF-8モードに近づける手段を紹介します。
1. コンソールのコードページをUTF-8に変更する
Windowsのコマンドプロンプトで、一時的にUTF-8に切り替えるにはchcpコマンドを使います。
chcp 65001この状態でPythonを実行すると、コンソールのエンコーディングがUTF-8になります。
ただし、環境によっては文字化けや表示不具合が出る場合もあるため、実際のプロジェクトで使う前に十分なテストが必要です。
2. Windows 10以降の「ベータ版の世界対応言語サポート」を使う
Windows 10以降では、「ローカル言語設定」でUTF-8ベースのグローバル言語サポートを有効にするオプションがあります。
手順の概要(実際の文言はOSバージョンによって変わる可能性があります)。
- 設定アプリを開く
- 「時刻と言語」→「言語と地域」(または類似の項目)
- 「関連設定」から「管理用の言語の設定」を開く
- 「ベータ: Unicode UTF-8 を使用したグローバル言語サポートを提供」にチェックを入れる
- 再起動
これにより、多くのレガシーアプリケーションがUTF-8モードで動作するようになり、cp932依存が減少します。
ただし、古いアプリとの互換性に影響する場合もあるため、業務環境では慎重な検証が必要です。
3. Windows Terminal や VS Code のターミナルを利用する
よりモダンな方法として、Windows TerminalやVS Codeの統合ターミナルなど、UTF-8対応がしっかりしているターミナルを使うのも有効です。
これらのターミナルでは、初めからUTF-8が前提になっていることが多く、cp932前提のコマンドプロンプトよりもUnicode関連のトラブルが少ないです。
まとめ
UnicodeEncodeErrorは、Pythonの文字列を特定の文字コードでエンコードするとき、その文字コードに存在しない文字を含んでいると発生するエラーです。
Windowsではcp932、特殊な環境ではasciiが原因になることが多く、printやファイル出力、ログ出力で頻繁に表面化します。
対策の基本は、openでencoding=”utf-8″を常に指定することと、標準入出力のエンコーディングを確認し、必要に応じてUTF-8へ切り替えることです。
さらに、Windows環境自体をUTF-8モードに近づけることで、cp932に由来する問題を大幅に減らせます。
この記事で紹介したポイントを押さえておけば、cp932・asciiのUnicodeEncodeErrorに悩まされる場面は大きく減るはずです。
