
Pythonで文字列を扱うとき、必ずと言ってよいほど登場するのがlen関数です。
シンプルに見える関数ですが、実は日本語や絵文字、バイト数との違いなど、知っておかないとハマりやすいポイントがいくつもあります。
本記事では、文字列の長さをlenで取得する基本から、全パターンと注意点、実用的なテクニックまでを体系的に解説します。
Pythonのlenとは
len関数で文字列の長さを取得する基本
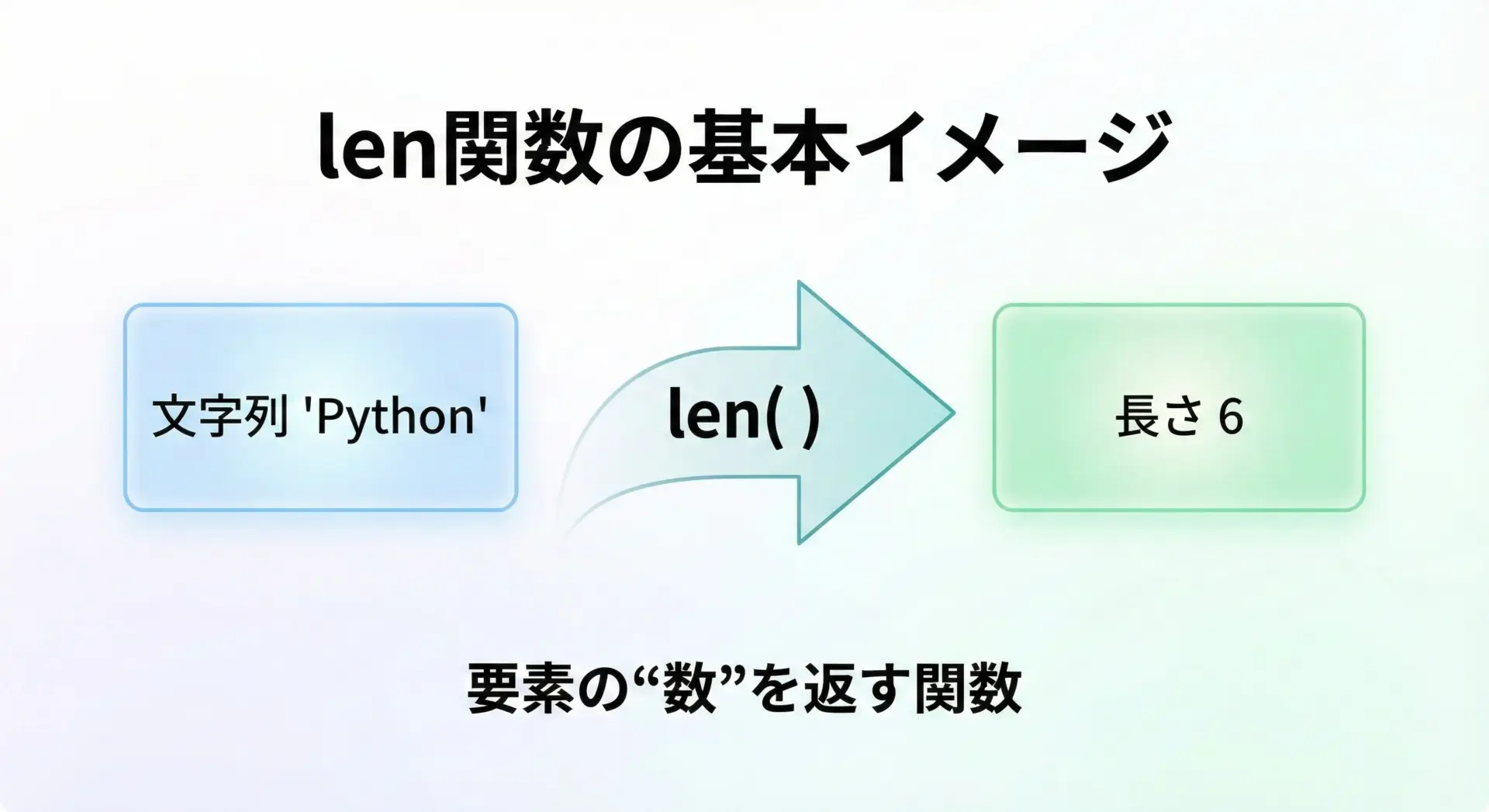
Pythonのlen関数は、オブジェクトに含まれる「要素の数」を返す関数です。
文字列の場合は「文字の数」、リストなら「要素の数」といった具合に、そのオブジェクトが持つ要素の個数を返します。
文字列に対する最も基本的な使い方は次のようになります。
# 文字列の長さをlenで取得する基本例
text = "Python"
length = len(text) # 文字数を数える
print(length) # 6 と表示される6このように、len("Python")の結果は6です。
半角英数字は1文字につき長さ1と数えられます。
Pythonにおける「長さ」とは何を数えるか
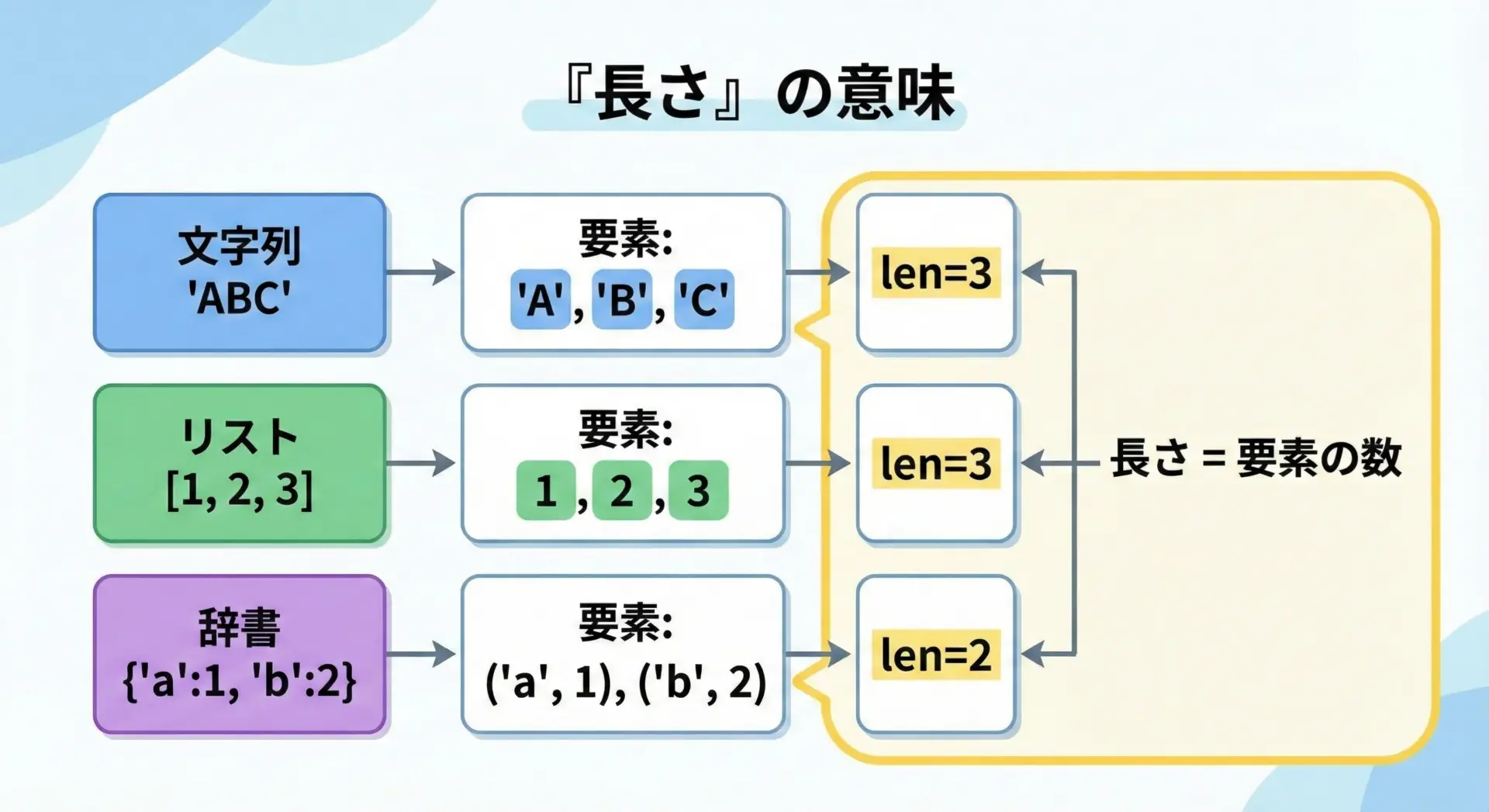
Pythonでlenが返す「長さ」は、そのオブジェクトが持っている要素の数です。
文字列であれば「文字単位」、リストであれば「要素単位」、辞書であれば「キーの数」といった単位で数えられます。
この点を押さえておくと、文字列だけでなく、さまざまなオブジェクトにlenを自然に使い回すことができます。
「長さ = 人間が直感的に数える“個数”」と考えるとイメージしやすいです。
lenが使える主なデータ型
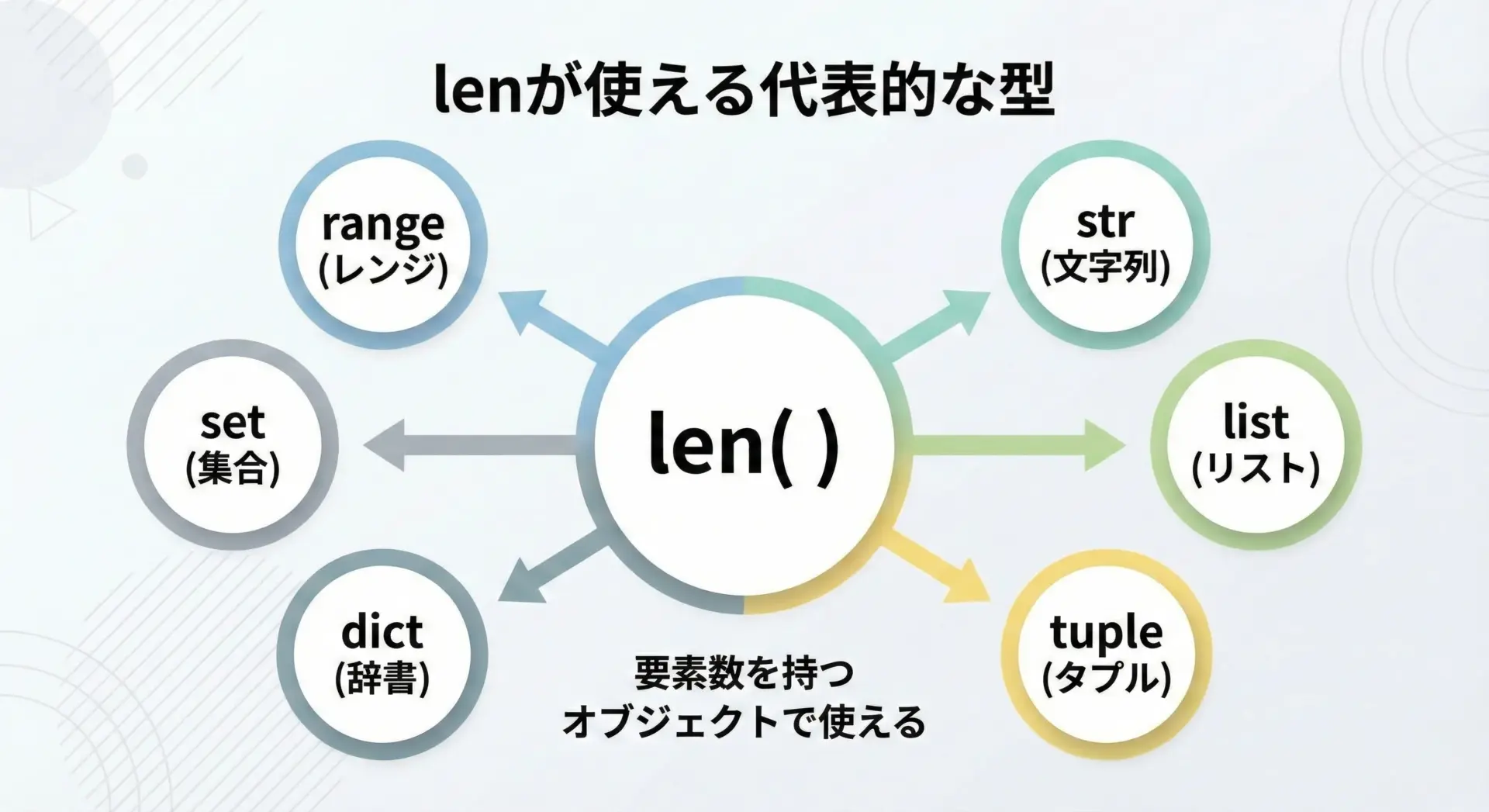
lenは文字列だけの専用関数ではありません。
次のような、「要素の集まり」を表すオブジェクトに対して使うことができます。
代表的なデータ型と、lenが意味するものは次の通りです。
| 型 | 例 | lenが返す値 |
|---|---|---|
str 文字列 | "abc" | 文字数(コードポイント数) |
list リスト | [1, 2, 3] | 要素の個数 |
tuple タプル | (1, 2) | 要素の個数 |
dict 辞書 | {"a": 1, "b": 2} | キーの個数 |
set 集合 | {1, 2, 3} | 要素の個数(重複なし) |
range | range(5) | 生成される整数の個数 |
文字列については「文字数 = len」と覚えておけば基本的には大丈夫ですが、マルチバイト文字や絵文字などの場合は少しだけ注意が必要です。
これについては後半で詳しく説明します。
文字列のlenの基本パターン
文字列のlenの基本的な使い方
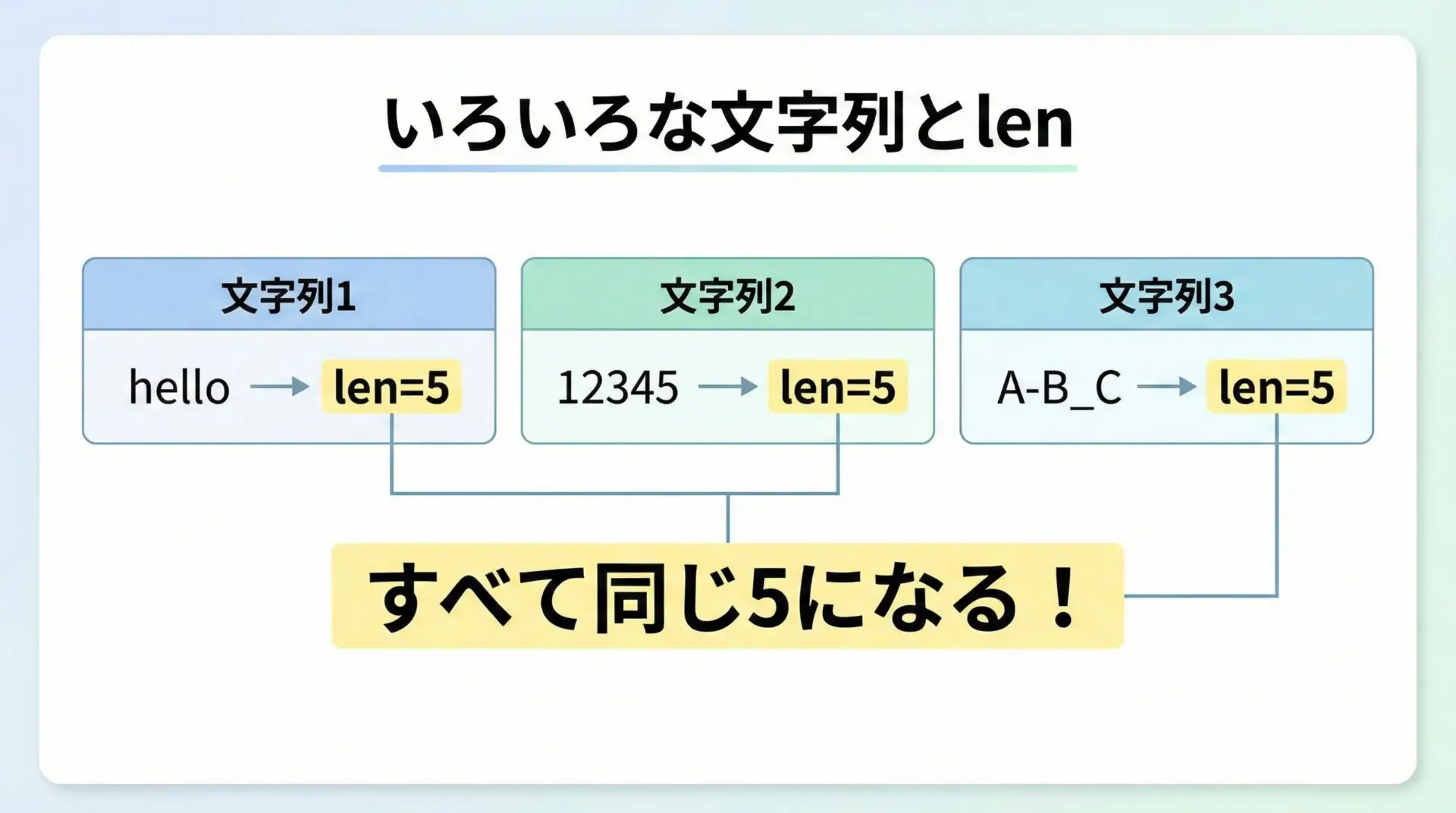
文字列に対するlenの使い方はとてもシンプルです。
文字列をそのまま渡すか、文字列を保持した変数を渡すだけです。
# 文字列の長さを直接取得する例
print(len("hello")) # 5
print(len("12345")) # 5
print(len("A-B_C")) # 55
5
5半角英数字や記号は、基本的に1文字 = 長さ1として数えられます。
Pythonでは、スペースや記号も「文字」としてカウントされる点も意識しておくとよいです。
変数の文字列長をlenで取得する
実際のコードでは、文字列リテラルに直接lenを使う場面よりも、変数に入っている文字列の長さを測るケースのほうが多いです。
# 変数に格納された文字列の長さを取得する例
name = "Alice"
message = "こんにちは"
name_len = len(name)
message_len = len(message)
print("nameの長さ:", name_len)
print("messageの長さ:", message_len)nameの長さ: 5
messageの長さ: 5英語名"Alice"も、日本語の"こんにちは"もlenは5になります。
日本語は見た目上「全角」ですが、Pythonの文字列では「1文字」として扱われることが分かります。
空文字列とスペースのlenの違い
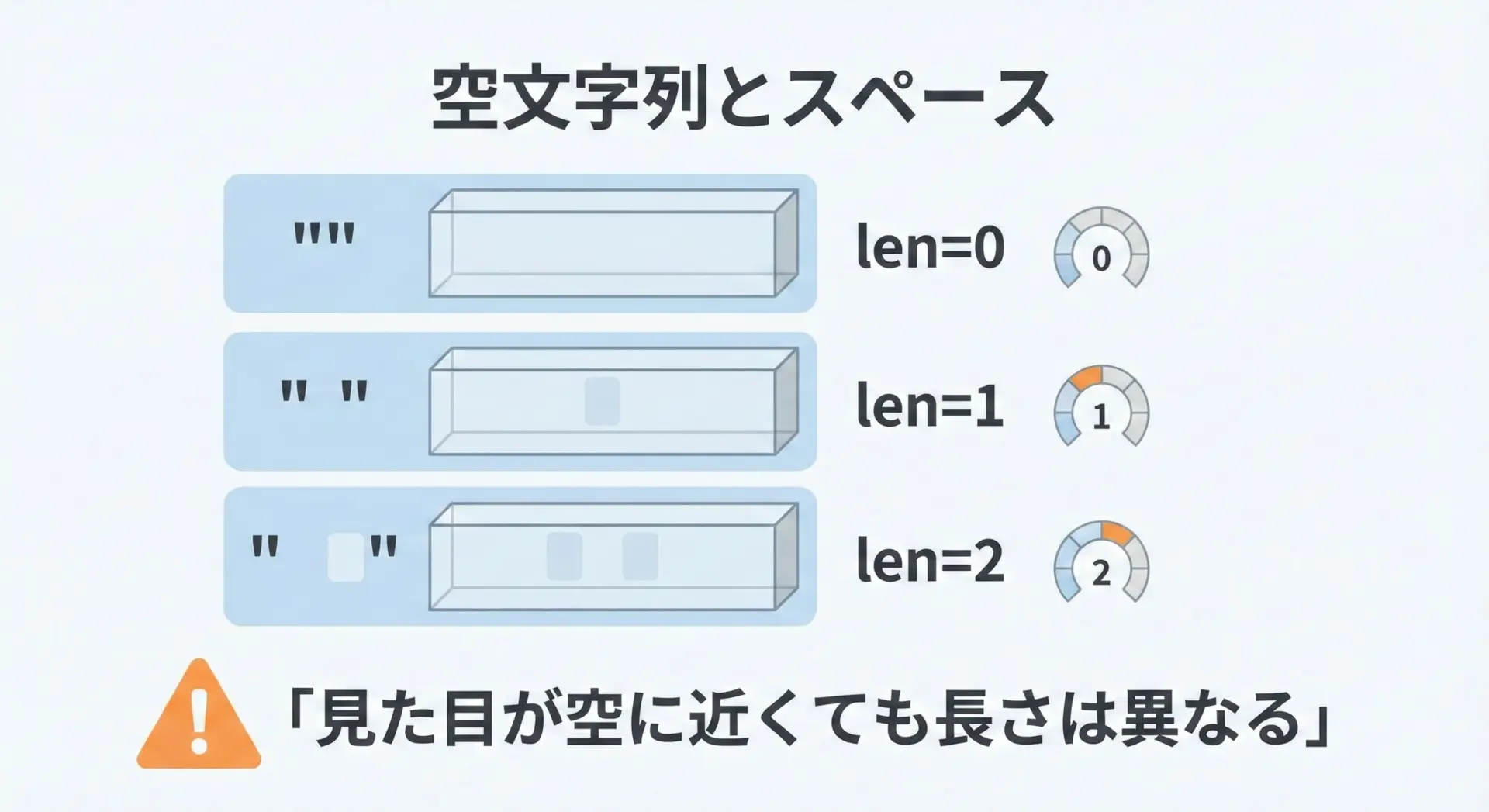
空文字列とスペース付きの文字列は、lenの結果がまったく異なります。
入力チェックやバリデーションでは、この違いが重要になります。
# 空文字列とスペースのlenの違い
empty = "" # 何もない
space = " " # 半角スペース1つ
spaces = " " # 半角スペース2つ
print("empty の長さ:", len(empty))
print("space の長さ:", len(space))
print("spacesの長さ:", len(spaces))empty の長さ: 0
space の長さ: 1
spacesの長さ: 2「ユーザーが何も入力していない」のか「スペースだけ入力したのか」を区別したい場合、lenで見分けることができます。
逆に、スペースだけの入力も空とみなしたい場合は、strip()などと組み合わせる必要があります。
# スペースだけの入力を「空」とみなす例
user_input = " " # スペース3つ
print(len(user_input)) # 3
print(len(user_input.strip())) # 0 (前後の空白を削除)3
0日本語(全角)文字列のlenと文字数
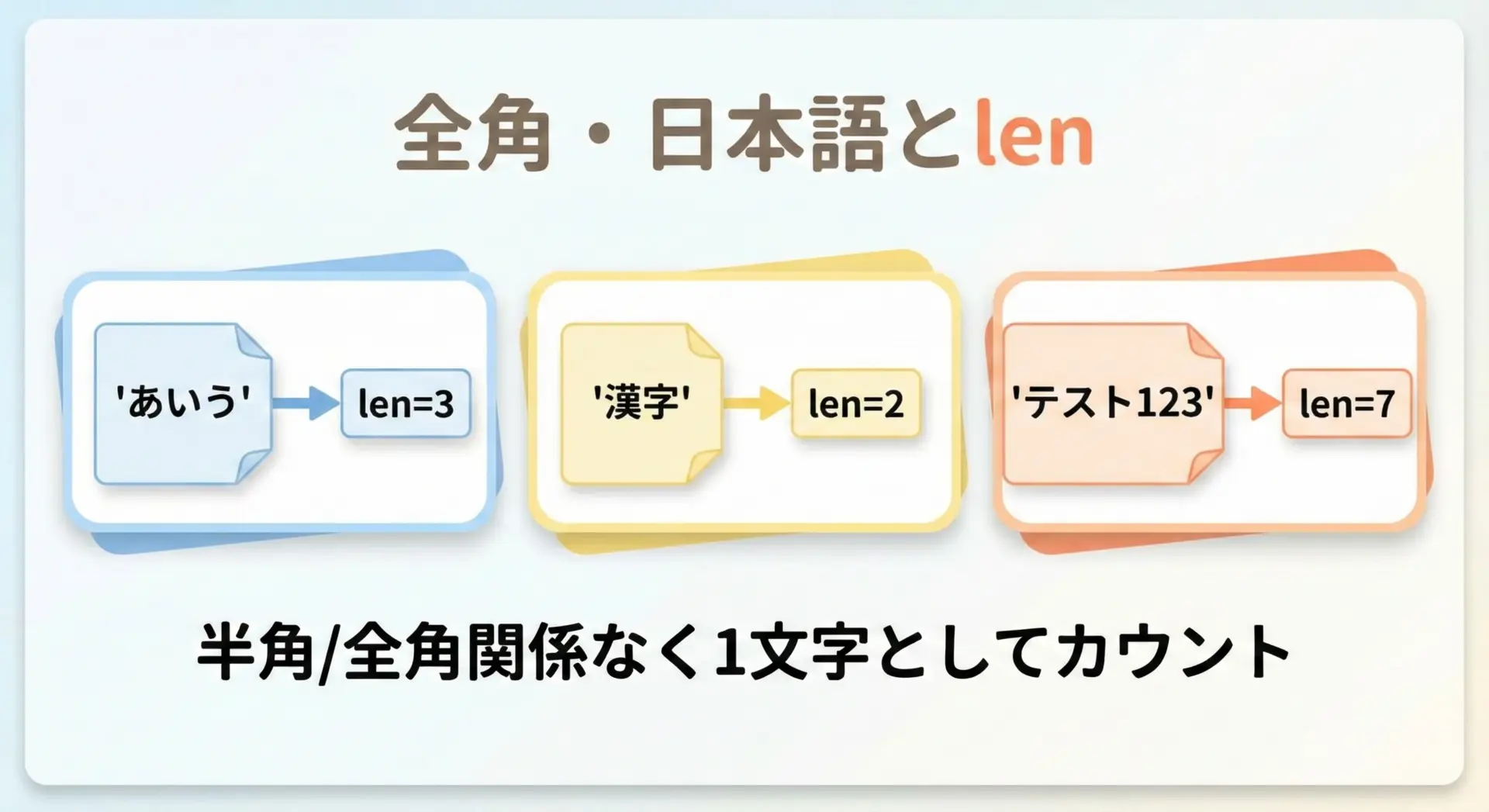
Python3の文字列は、内部的にUnicodeで管理されています。
そのため、日本語や全角文字も、1文字として数えられます。
# 日本語(全角)文字列のlen
text1 = "あいう"
text2 = "漢字"
text3 = "テスト123"
print(len(text1)) # 3
print(len(text2)) # 2
print(len(text3)) # 7 ("テ","ス","ト","1","2","3" で7文字)3
2
7このように、文字数をカウントする目的であれば、多くの場面でlenをそのまま使って問題ありません。
ただし、後述する絵文字や一部の特殊文字では「見た目の1文字」とlenの値が一致しない場合があります。
改行やタブを含む文字列のlen
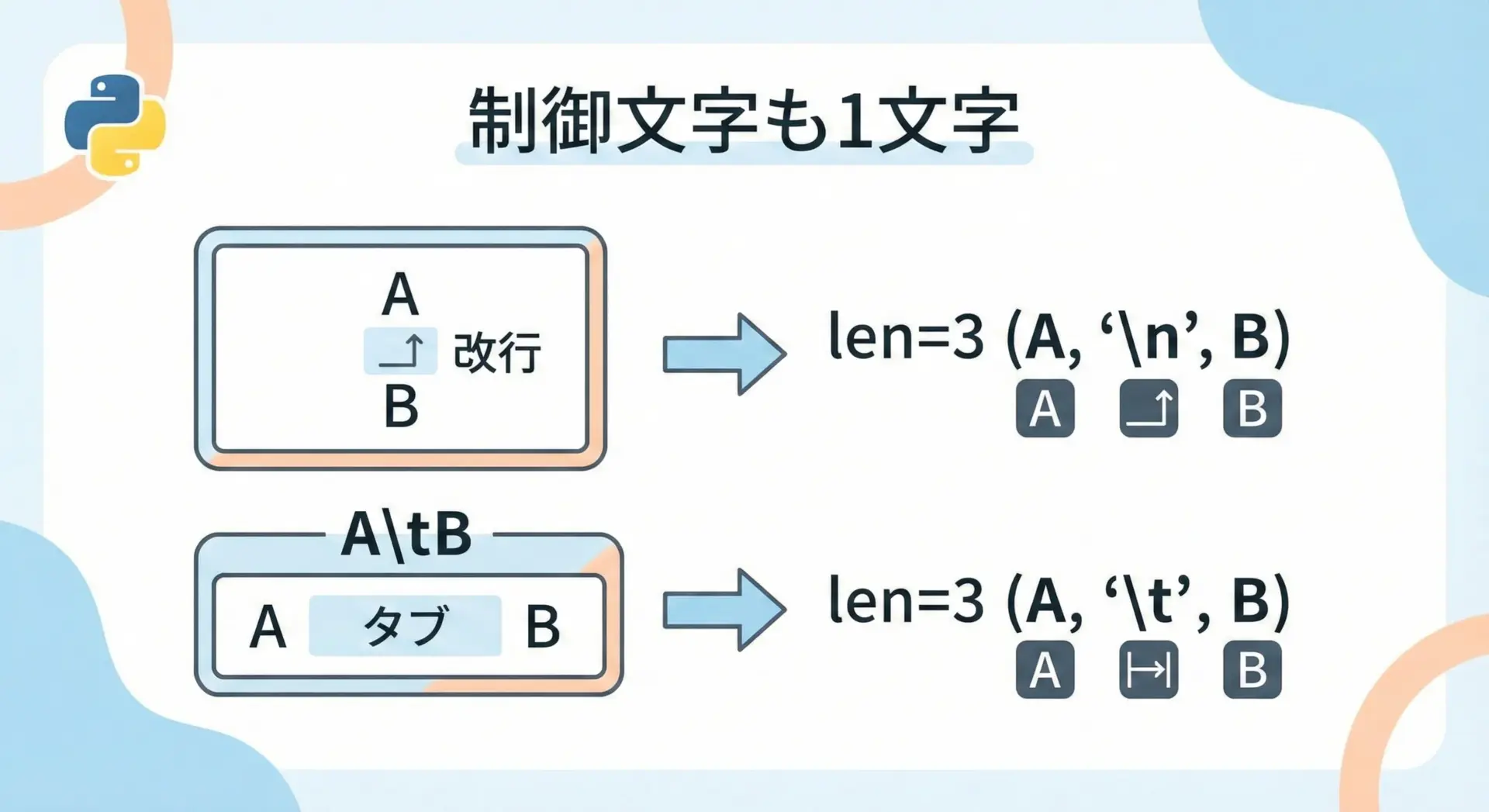
文字列には、改行(\n)やタブ(\t)などの制御文字を含めることができます。
これらも1文字としてカウントされます。
# 改行やタブを含む文字列のlen
text_newline = "A\nB" # A, 改行, B
text_tab = "A\tB" # A, タブ, B
print(repr(text_newline), "の長さ:", len(text_newline))
print(repr(text_tab), "の長さ:", len(text_tab))'A\nB' の長さ: 3
'A\tB' の長さ: 3ここではreprを使って、\nや\tを見える形で表示しています。
画面上では2行に見えても、中身としては「3文字」であることに注意しましょう。
len使用時の注意点と落とし穴
lenとバイト数の違い
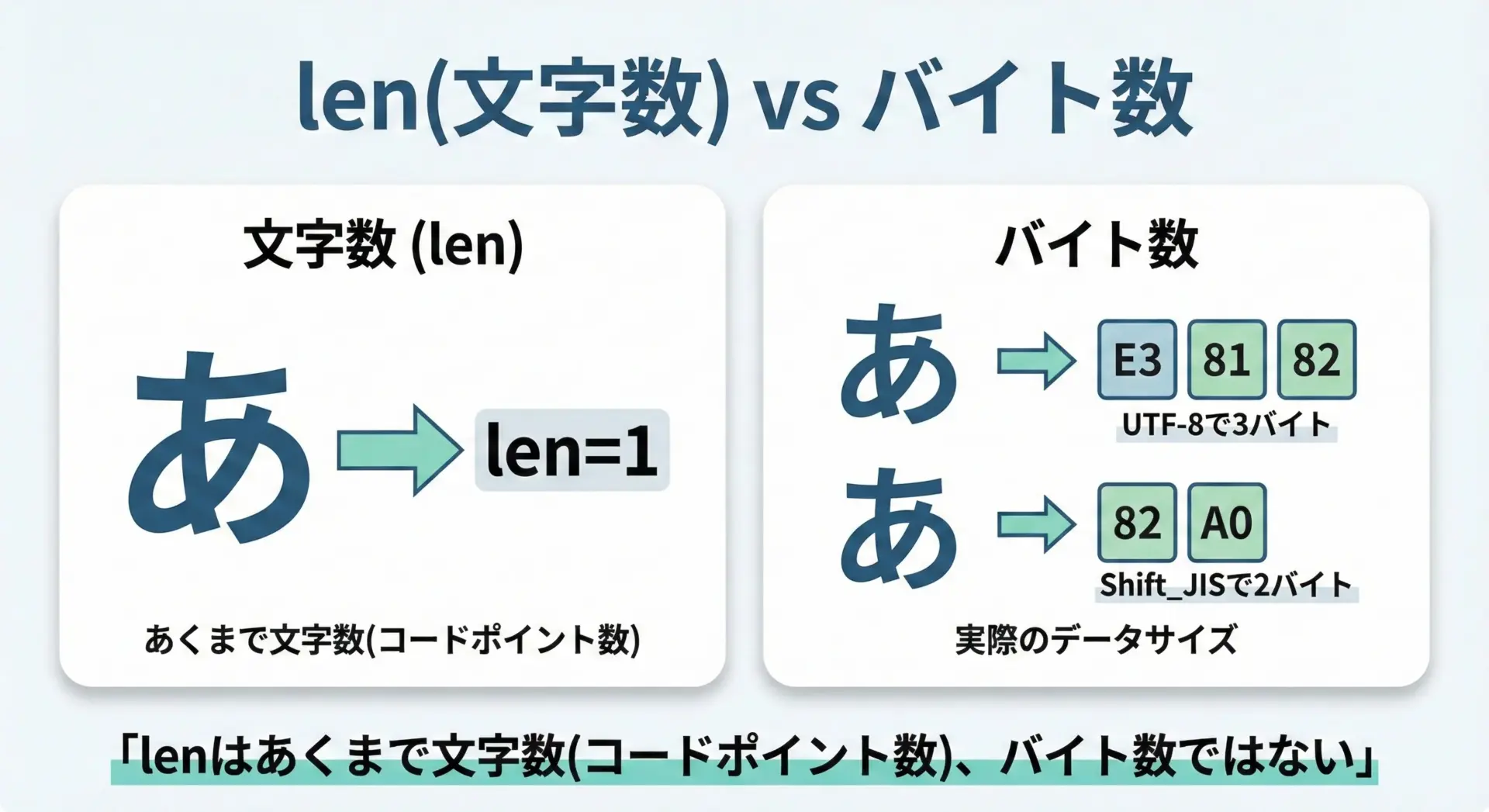
lenは「文字数」を返すのであって、「バイト数」を返すわけではありません。
日本語を扱うとき、この違いが非常に重要になります。
# lenとバイト数の違いを確認する例
text = "あ"
print("len(text):", len(text)) # 1
print("UTF-8のバイト数:", len(text.encode("utf-8"))) # 3
print("Shift_JISのバイト数:", len(text.encode("shift_jis"))) # 2len(text): 1
UTF-8のバイト数: 3
Shift_JISのバイト数: 2画面上の文字数制限(「10文字まで」など)であればlenで十分ですが、データベースやファイルフォーマットで「バイト数」で制限されている場合はlenでは足りません。
その場合は、上記のようにencode()でバイト列に変換してからlenを使う必要があります。
絵文字・サロゲートペアとlenの挙動
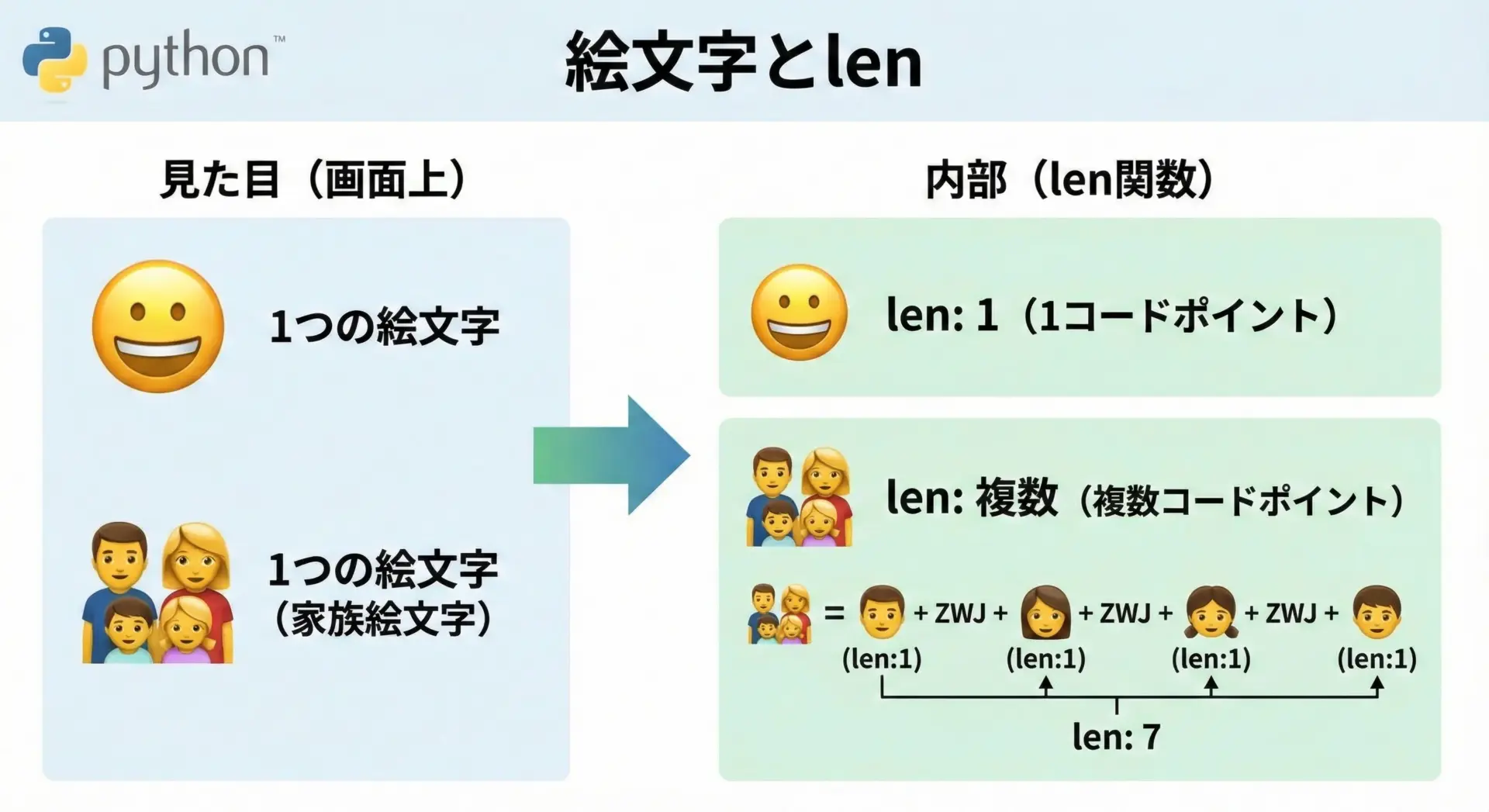
Unicodeでは、1つの見た目の絵文字が、内部的には複数のコードポイントから構成されていることがあります。
Pythonのlenは「コードポイントの数」を数えるので、見た目の文字数とlenの値が一致しないケースが生じます。
# 絵文字のlenを確認する例
smile = "😀" # シンプルな顔の絵文字
family = "👨👩👧👦" # 家族の絵文字 (複数の絵文字の組み合わせ)
print(smile, "のlen:", len(smile))
print(family, "のlen:", len(family))😀 のlen: 1
👨👩👧👦 のlen: 7画面上は「家族」の絵文字1つに見えますが、lenは7を返しています。
これは、複数の人物絵文字と特殊な結合文字(ゼロ幅ジョインナーなど)が組み合わさって1つの見た目になっているためです。
「見た目の文字数」を正確に数えたい場合、lenだけでは不十分です。
正確にグラフェム(表示上の1文字)を数える必要があり、その場合はregexライブラリやunicodedataでは対応しきれないことが多く、python-ucmicroなどの外部ライブラリを検討する必要があります。
UTF-8などエンコーディングとlenの関係
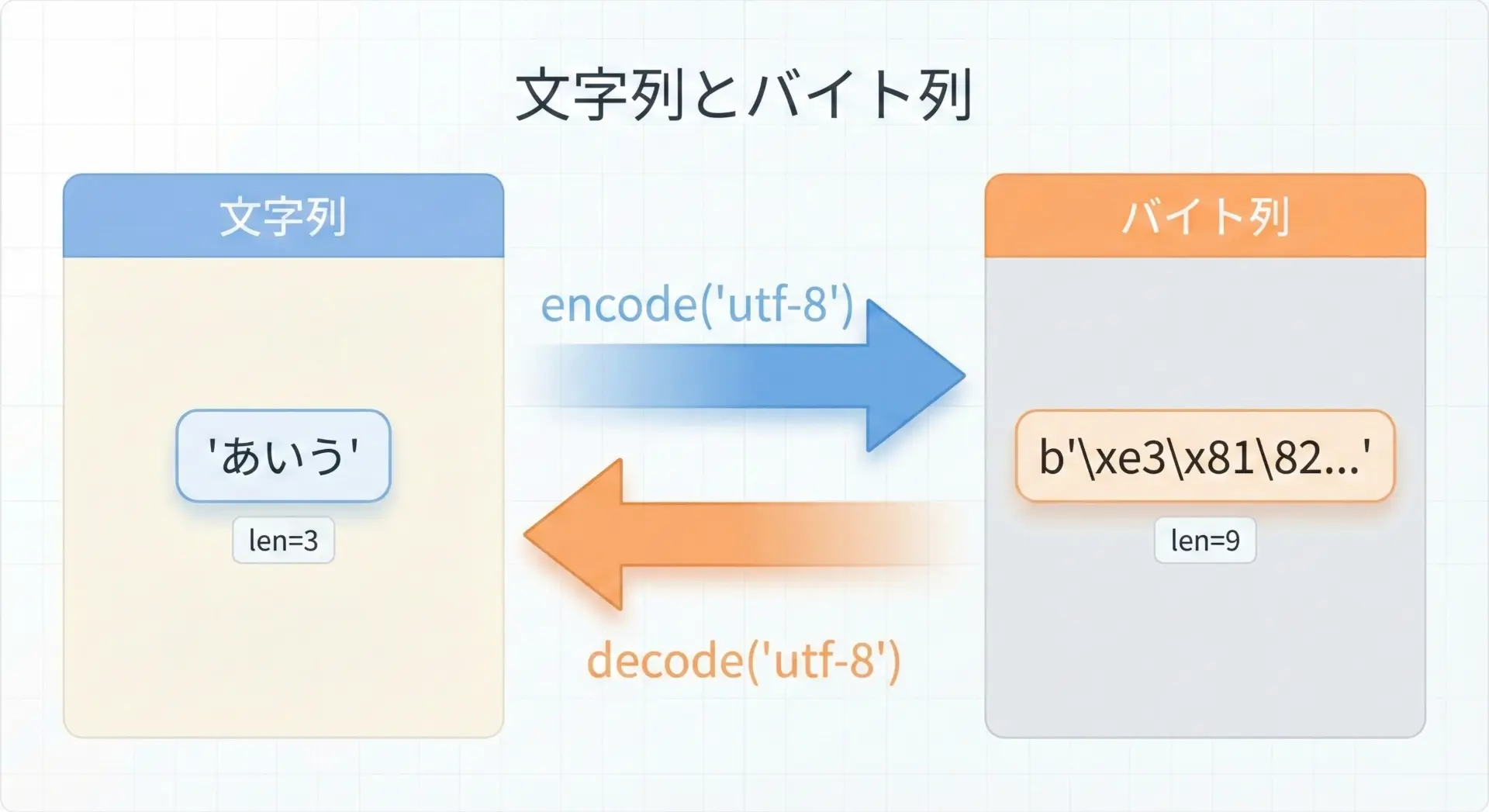
Python3では、文字列(str)とバイト列(bytes)は別物です。
lenは、どちらに対しても使えますが、意味が異なります。
# 文字列とバイト列でのlenの違い
text = "あいう" # 3文字
bytes_utf8 = text.encode("utf-8") # UTF-8でエンコード
print("文字列のlen:", len(text)) # 3
print("バイト列のlen:", len(bytes_utf8)) # 9 (各文字3バイト)
print("バイト列表現:", bytes_utf8)文字列のlen: 3
バイト列のlen: 9
バイト列表現: b'\xe3\x81\x82\xe3\x81\x84\xe3\x81\x86'文字列に対するlenは「文字数」、バイト列に対するlenは「バイト数」です。
どちらを扱っているのかを明確に意識することが、文字化けや長さ制限のバグを防ぐポイントになります。
lenでエラーになるケースの例

lenは、「長さの概念があるオブジェクト」にだけ使える関数です。
数値やNoneなど、要素の個数という概念を持たないものに対して使うと、エラーになります。
# lenでエラーになる例
number = 123
nothing = None
# print(len(number)) # TypeError: object of type 'int' has no len()
# print(len(nothing)) # TypeError: object of type 'NoneType' has no len()上記のprintをコメントアウト解除して実行すると、TypeErrorが発生します。
「lenで数値をケタ数として数える」ことはできない点に注意してください。
数値の桁数を知りたい場合は、次のように文字列に変換してからlenを使います。
# 数値の桁数をlenで求める正しい方法
number = 12345
digits = len(str(number))
print("桁数:", digits)桁数: 5lenが使えないオブジェクトで長さを取得する方法
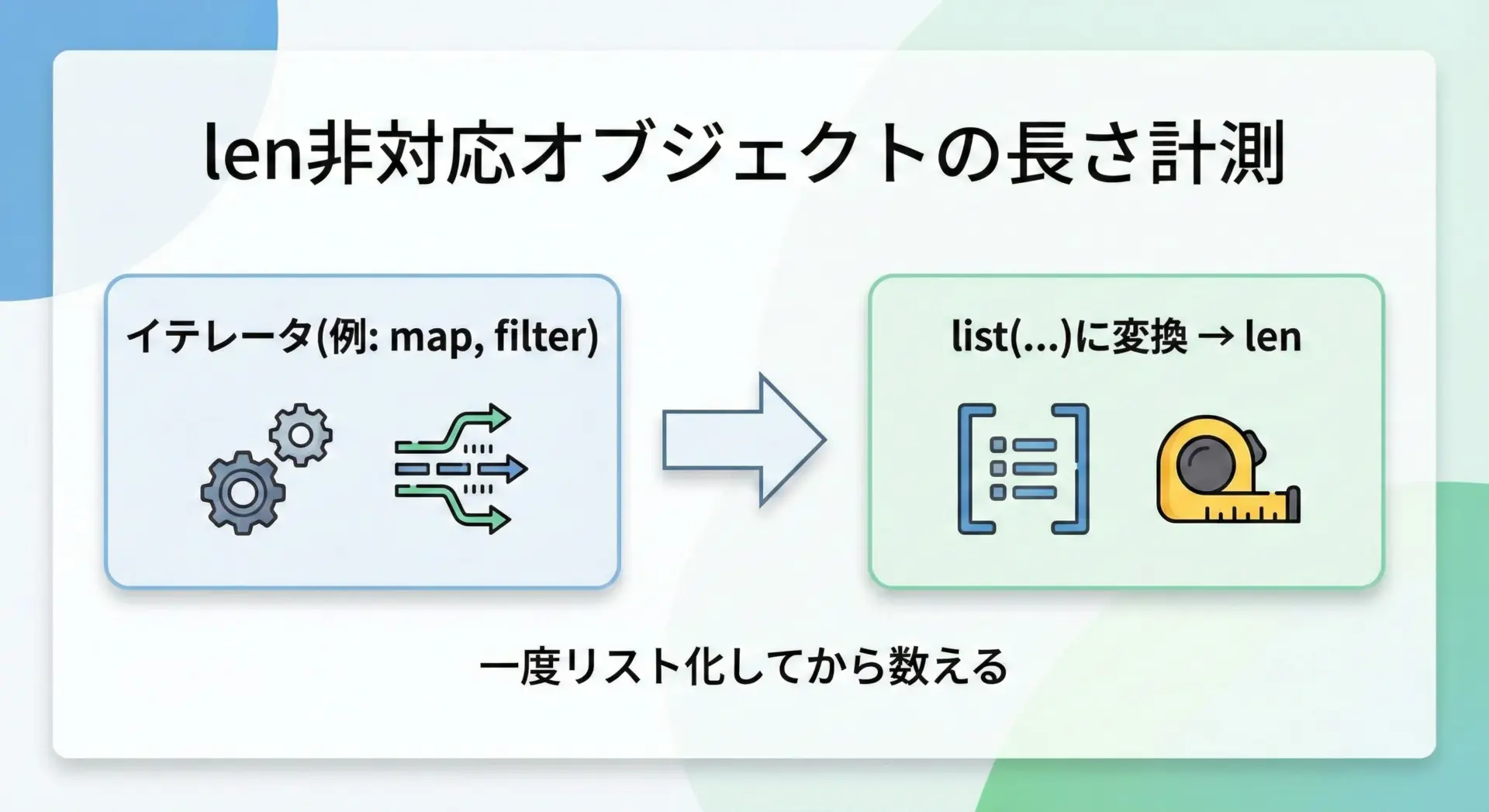
一部のオブジェクトは、そのままではlenが使えません。
例えば、mapオブジェクトやジェネレータなど、遅延評価されるイテレータです。
# lenが直接使えないオブジェクトの例 (map)
nums = [1, 2, 3, 4]
mapped = map(lambda x: x * 2, nums)
# print(len(mapped)) # TypeError: object of type 'map' has no len()
# 一度リストに変換してからlenを使う
mapped_list = list(mapped)
print("要素数:", len(mapped_list))要素数: 4このような場合、一度リストやタプルなどの「長さを持つ型」に変換してからlenを使うのが一般的です。
ただし、ジェネレータなどは一度展開すると再利用できなくなるので、lenを取ることが本当に必要かを検討することも大切です。
lenを使った実用テクニック
文字数制限(バリデーション)へのlenの活用
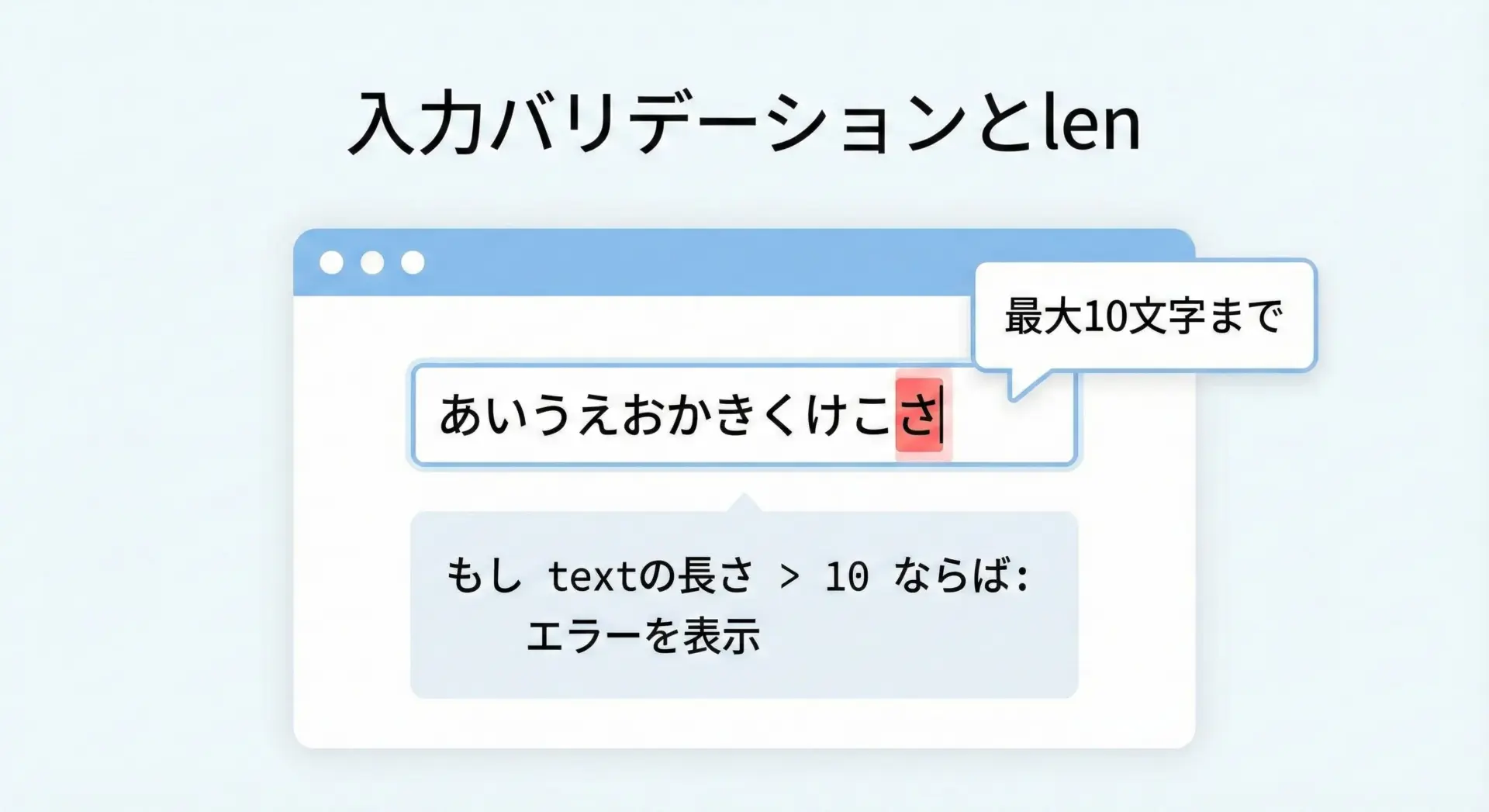
フォーム入力などで、「最大◯文字まで」という文字数制限を設けたい場合、lenはそのまま使えます。
# 文字数制限(最大10文字)の簡単なバリデーション例
def validate_username(name):
max_length = 10
if len(name) == 0:
return False, "名前を入力してください"
if len(name) > max_length:
return False, f"{max_length}文字以内で入力してください"
return True, "OK"
# 動作確認
for test in ["", "山田太郎", "とてもとても長い名前"]:
is_valid, message = validate_username(test)
print(repr(test), "→", is_valid, message)'' → False 名前を入力してください
'山田太郎' → True OK
'とてもとても長い名前' → False 10文字以内で入力してください日本語を含む一般的なテキスト入力のバリデーションであれば、lenで十分なことが多いです。
ただし、前述のように絵文字や結合文字が多用されるケース(ニックネームなど)では、「見た目の文字数」とのズレに注意が必要です。
文字列の長さで条件分岐する
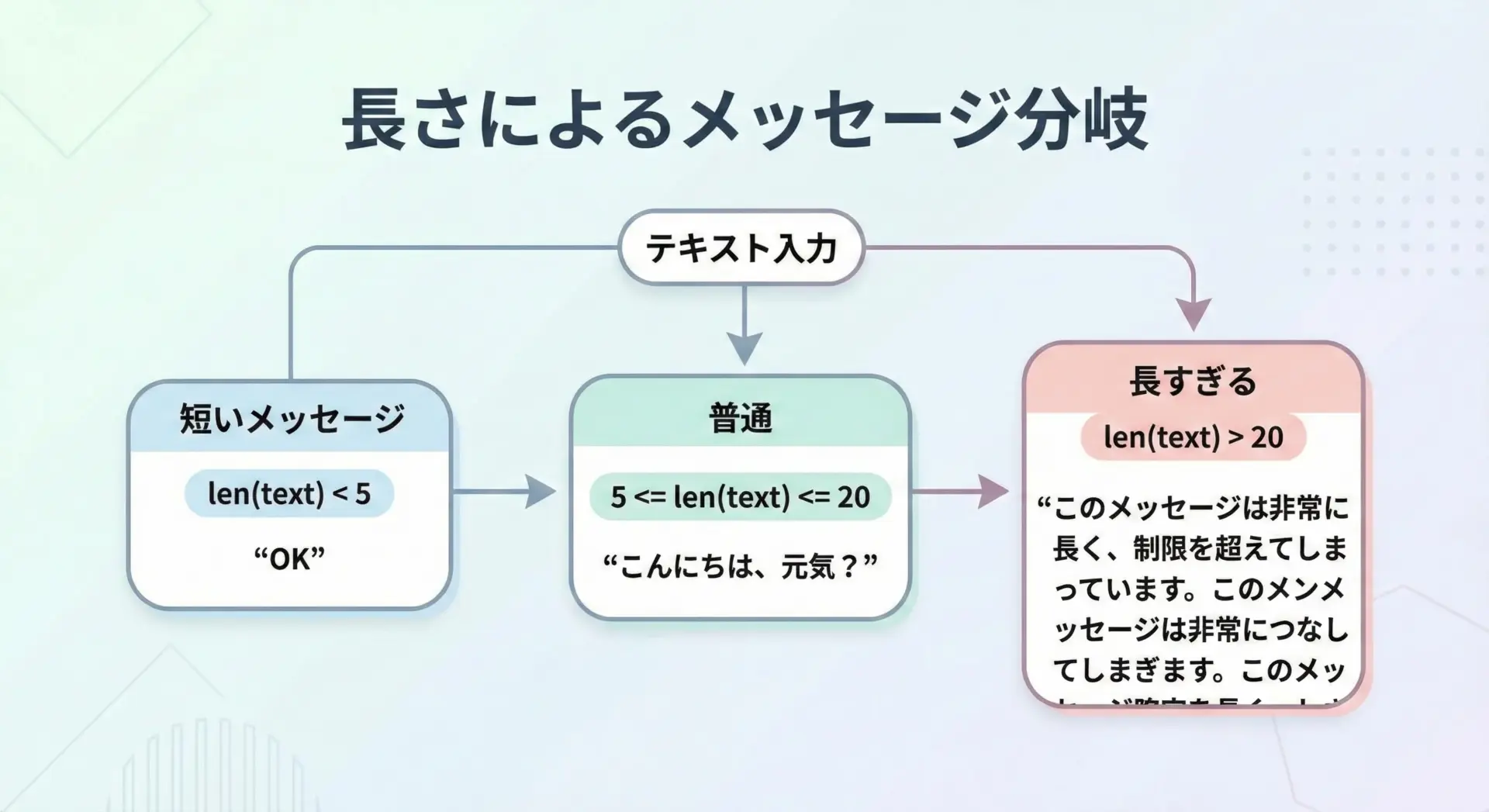
lenを使って、文字列の長さによって処理を変えるのもよくあるパターンです。
# 文字列の長さで条件分岐する例
def comment_length_check(comment):
length = len(comment)
if length == 0:
return "コメントが空です"
elif length < 5:
return "コメントが短すぎます"
elif length > 100:
return "コメントが長すぎます"
else:
return "コメントの長さは適切です"
tests = ["", "OK", "ちょうどよい長さのコメントです", "あ" * 120]
for t in tests:
print(repr(t), "→", comment_length_check(t))'' → コメントが空です
'OK' → コメントが短すぎます
'ちょうどよい長さのコメントです' → コメントの長さは適切です
'ああああああああああああああああああああああああああああああああああああああああああああああああああああああああああああああ' → コメントが長すぎますこのように、lenの結果を変数に一度入れてから使うと、可読性が高まり、何度もlenを呼び出す無駄も避けられます。
内包表記とlenを組み合わせた文字列処理
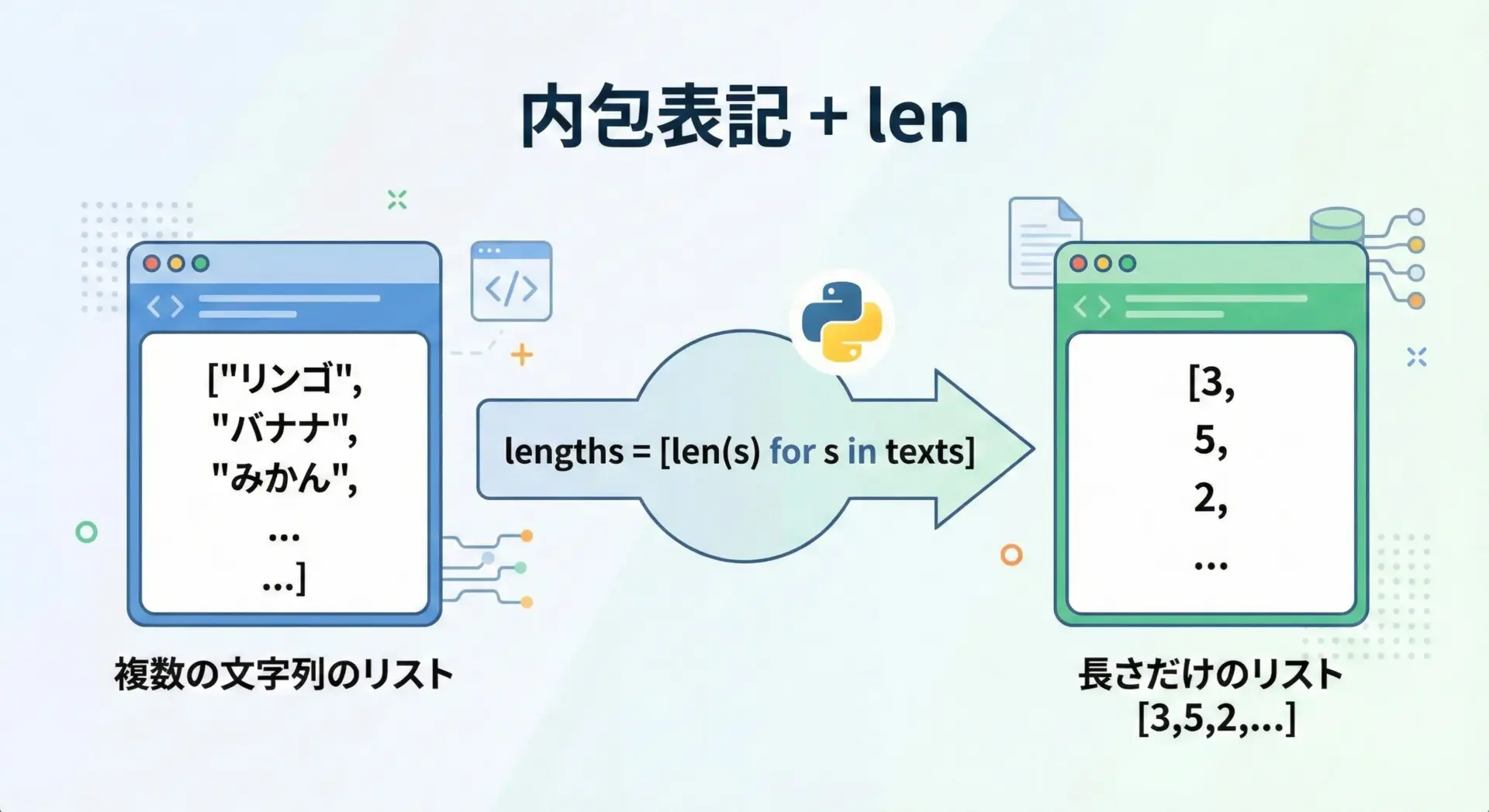
複数の文字列をまとめて処理する際、内包表記とlenを組み合わせると、短く読みやすいコードになります。
# 内包表記で文字列リストの長さだけを取り出す例
texts = ["Python", "あいう", "", "Hello, world!"]
lengths = [len(s) for s in texts]
print("元のリスト:", texts)
print("長さのリスト:", lengths)元のリスト: ['Python', 'あいう', '', 'Hello, world!']
長さのリスト: [6, 3, 0, 13]さらに、特定の長さ以上の文字列だけを抽出するような処理も簡単に書けます。
# 長さが5以上の文字列だけを抽出する例
texts = ["dog", "elephant", "cat", "giraffe", "lion"]
long_texts = [s for s in texts if len(s) >= 5]
print("元のリスト:", texts)
print("5文字以上:", long_texts)元のリスト: ['dog', 'elephant', 'cat', 'giraffe', 'lion']
5文字以上: ['elephant', 'giraffe']このように、lenはフィルタリングや統計処理の条件としても非常に便利です。
Pythonのlenの計算量

Python(特に一般的なCPython実装)では、lenは「O(1)」、つまり要素数に依存しない定数時間で返るように最適化されています。
これは、文字列やリストなどが「長さ」を内部的に持っているためです。
# lenの計算量イメージ (簡易ベンチマーク)
import time
def measure_len(n):
s = "a" * n
start = time.time()
for _ in range(100000):
_ = len(s)
end = time.time()
return end - start
for n in [10, 1000, 100000]:
elapsed = measure_len(n)
print(f"長さ{n}の文字列に対するlen×100000回: {elapsed:.6f}秒")(実行環境により結果は変わりますが、nが増えても時間はほとんど変わらないことが確認できます。)
この性質のおかげで、lenをループの中で何度も呼び出しても大きな負荷にはなりません。
ただし、コードの読みやすさの観点から、前述のようにlength = len(s)と一度変数に入れておく書き方も引き続き有用です。
まとめ
Pythonのlenは、文字列をはじめとするさまざまなオブジェクトの「要素数」を即座に取得できる基本関数です。
空文字列やスペース、日本語や改行・タブなどの扱いを押さえれば、多くの場面で直感的に使えます。
一方で、バイト数との違いや絵文字などの特殊なケースでは、lenの値が「見た目の文字数」とずれる点に注意が必要です。
入力バリデーションや条件分岐、内包表記との組み合わせなど、日常的な文字列処理でlenをうまく活用しつつ、必要に応じてエンコードや外部ライブラリと組み合わせることが、堅牢な文字列処理への近道です。
