
Pythonのtry exceptは、エラーでプログラムを止めずに安全に処理を続けるための中核機能です。
しかし「とりあえず全部exceptで握りつぶす」といった書き方をしてしまうと、バグの温床になってしまいます。
本記事では、よく使うエラー処理パターンと落とし穴、そして実務で役立つベストプラクティスを、図解とサンプルコード付きで詳しく解説します。
Pythonのtry exceptの基本構文と動き
try exceptの基本構文
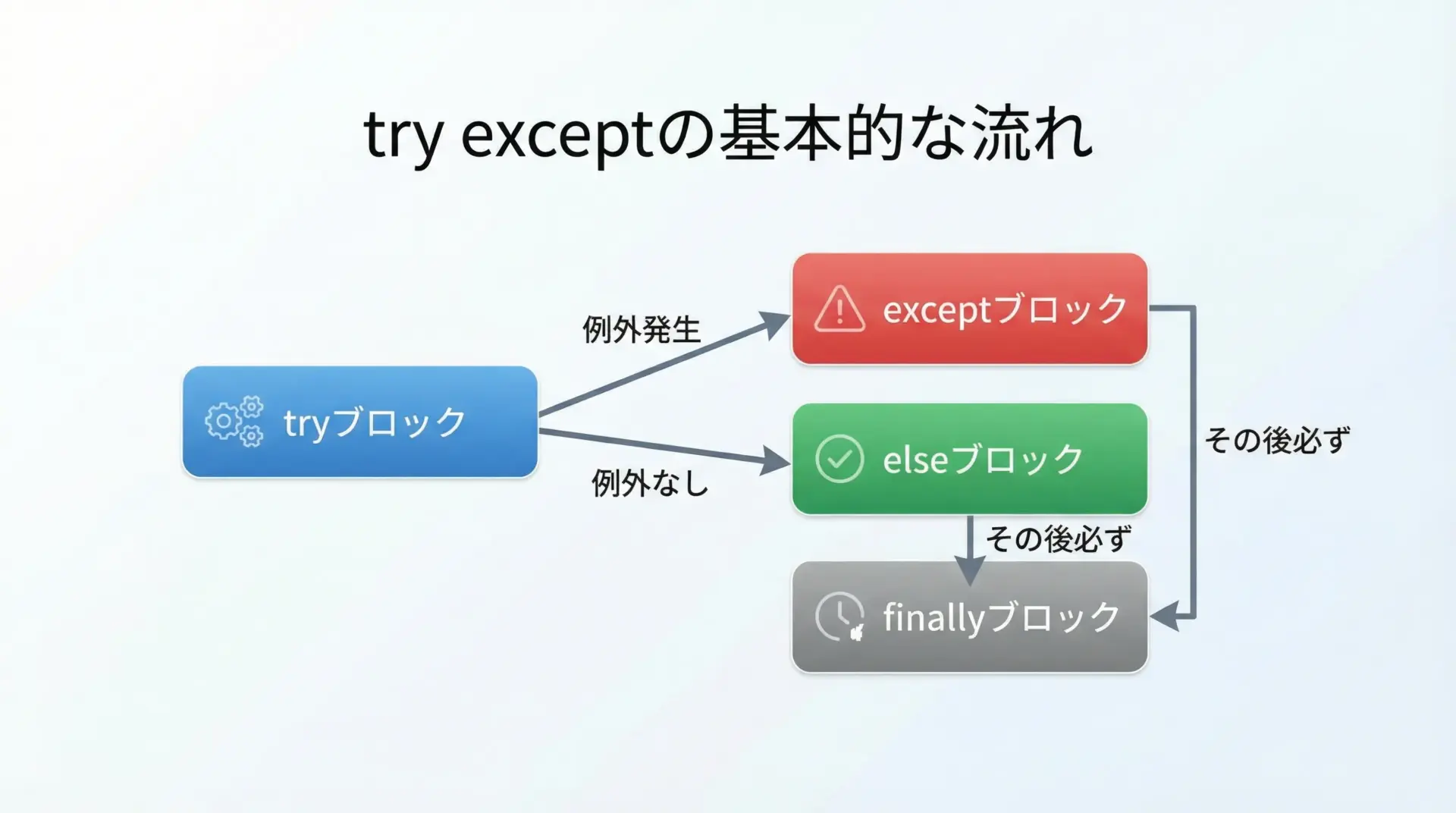
Pythonのtry exceptは、例外(エラー)が発生しそうな処理を囲み、発生したときだけ代わりの処理を行う仕組みです。
最も基本的な構文は次のようになります。
# 基本的なtry except構文の例
try:
# 例外(エラー)が起きるかもしれない処理
x = int(input("整数を入力してください: "))
result = 10 / x
print("計算結果:", result)
except ZeroDivisionError:
# 0で割ったときのエラー処理
print("0で割ることはできません")
except ValueError:
# 整数に変換できない入力のエラー処理
print("整数を入力してください")
# ここはエラーの有無に関わらず実行される
print("プログラム終了")この例では、ユーザーの入力を整数に変換し、10をその値で割る処理をtryに書いています。
入力が不正な場合や0が入力された場合は、対応するexceptが実行され、それ以外の場合は通常通り処理が進みます。
exceptで補足できる例外クラス一覧
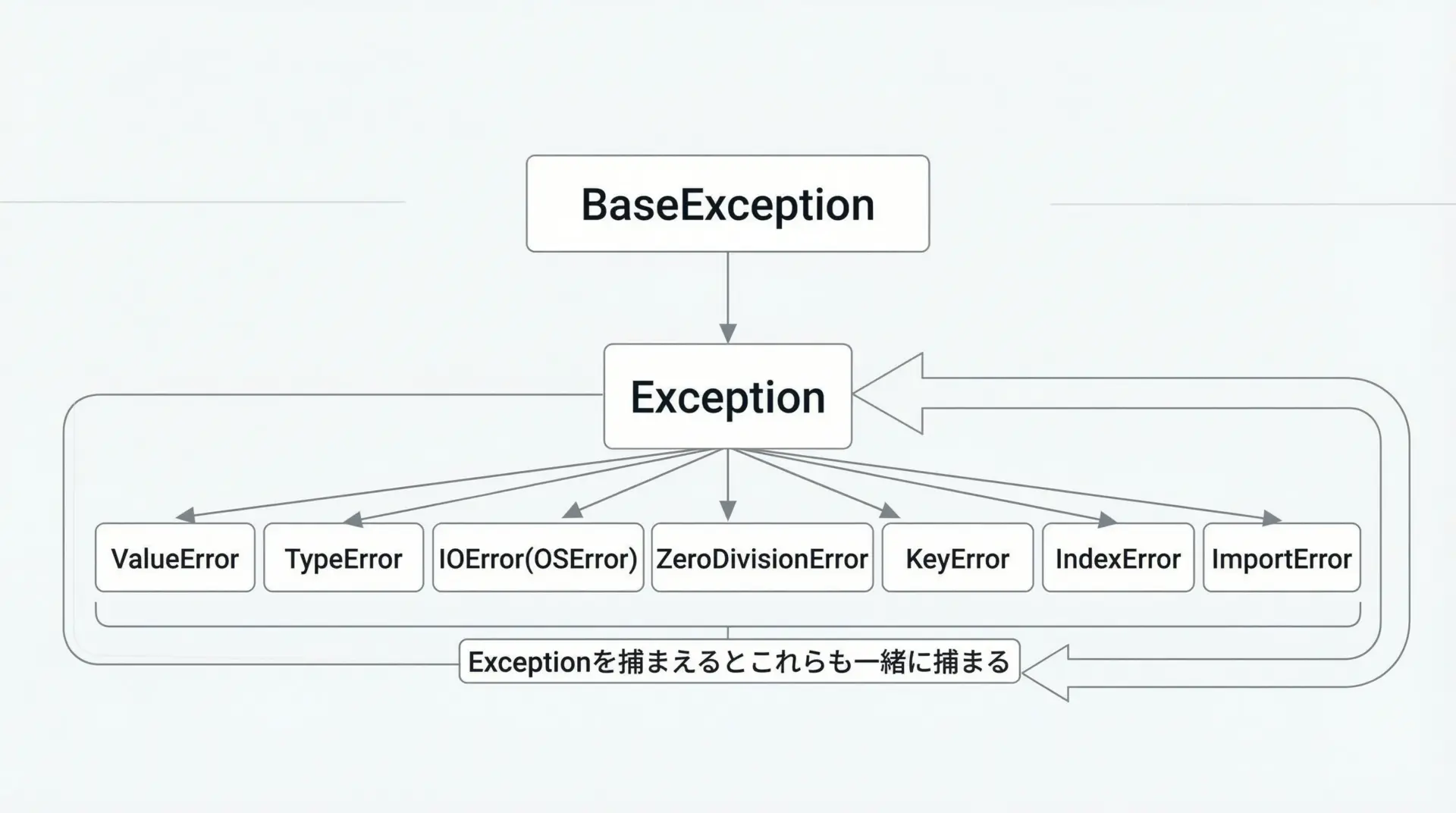
Pythonには多数の例外クラスがありますが、多くのアプリケーションではExceptionクラスとそのサブクラスを扱うことが中心になります。
代表的な標準例外を表にまとめます。
| 例外クラス | 主な発生状況 |
|---|---|
| ValueError | 値の型は正しいが、値そのものが不正なとき |
| TypeError | 型が合わない演算・関数呼び出しをしたとき |
| ZeroDivisionError | 0で割り算をしたとき |
| IndexError | 範囲外のインデックスにアクセスしたとき |
| KeyError | 辞書に存在しないキーを参照したとき |
| FileNotFoundError | 存在しないファイルを開こうとしたとき |
| PermissionError | 権限が足りないファイル操作などをしたとき |
| OSError | OSレベルの入出力やシステムエラー全般 |
| TimeoutError | 処理がタイムアウトしたとき |
| ImportError | モジュールのインポートに失敗したとき |
| RuntimeError | その他の実行時エラー全般 |
実際のコードで複数の例外を意識するには、次のような例が分かりやすいです。
# さまざまな例外クラスを意図的に発生させる例
def cause_exceptions():
# ValueError: intに変換できない文字列
int("abc")
# TypeError: 整数と文字列を足そうとする
1 + "2"
# IndexError: 存在しないインデックスにアクセス
lst = [1, 2, 3]
lst[5]
# KeyError: 存在しないキーにアクセス
d = {"a": 1}
d["b"]
# 実行してみると、最初のValueErrorで処理が止まります
try:
cause_exceptions()
except Exception as e:
print("何らかの例外が発生しました:", type(e).__name__, e)実務では、自分のコードで起こりうる例外を把握したうえで、それぞれ適切にハンドリングすることが大切です。
elseとfinallyの役割と使い分け
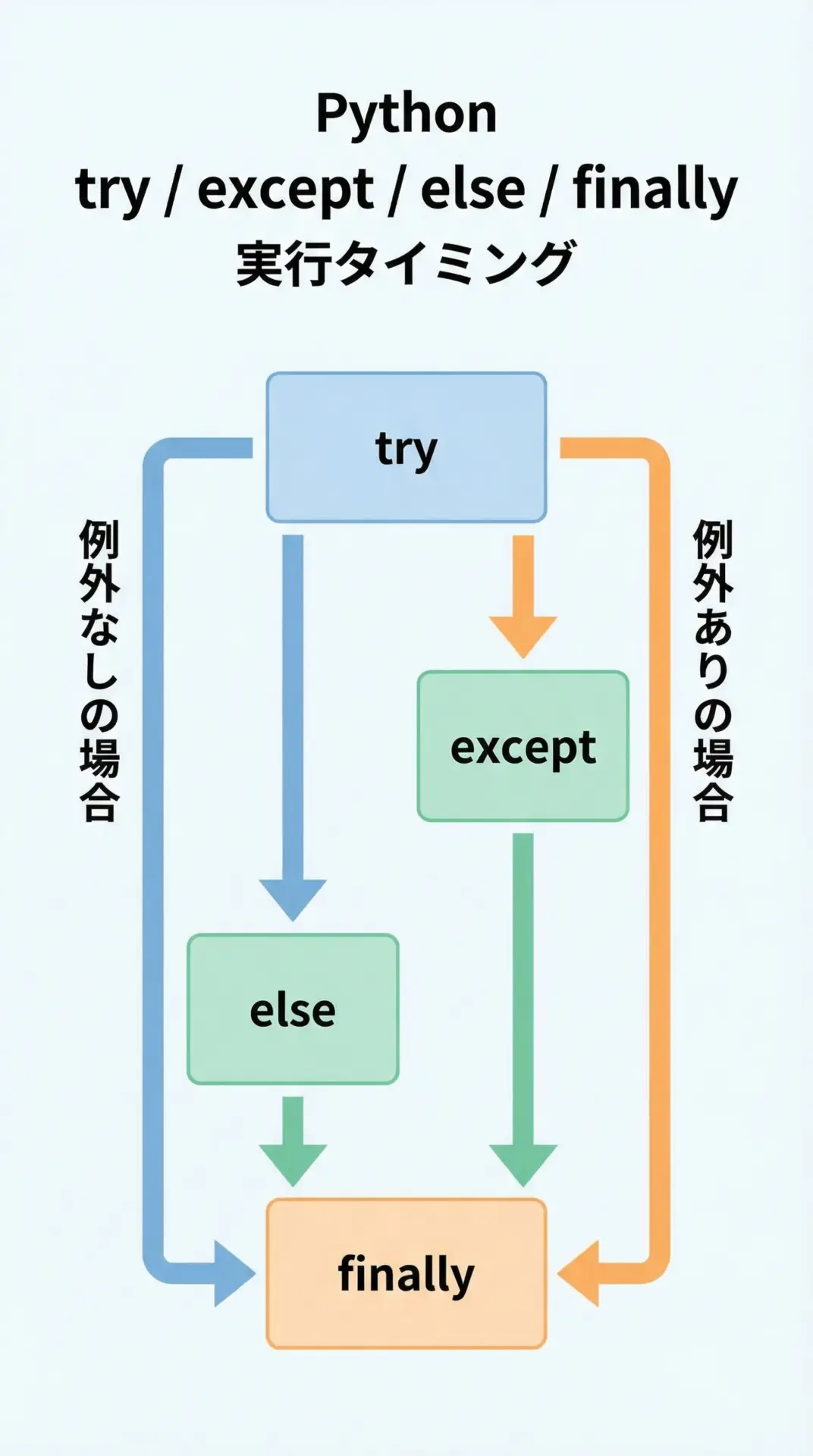
try exceptにはelseとfinallyという2つのオプションブロックがあります。
役割は次のように整理できます。
| ブロック | 実行タイミング | 主な用途 |
|---|---|---|
| try | 例外が出るかもしれないメイン処理 | 危険な処理をまとめて書く |
| except | tryで例外が発生したとき | エラーの補足・ログ出力・代替処理 |
| else | tryで例外が発生しなかったとき | 正常終了後だけ実行したい処理 |
| finally | 例外の有無にかかわらず最後に必ず実行される | リソース解放・後処理 |
次の例で、動きの違いを確認してみます。
# elseとfinallyの動きを確認する例
def divide(a, b):
try:
print("try: 計算を開始します")
result = a / b
except ZeroDivisionError:
print("except: 0では割れません")
else:
# 例外が発生しなかったときだけ実行される
print("else: 正常に計算できました。結果:", result)
finally:
# 例外の有無にかかわらず必ず実行される
print("finally: 後処理を行います")
print("------ 1回目 (正常) ------")
divide(10, 2)
print("------ 2回目 (0で割る) ------")
divide(10, 0)------ 1回目 (正常) ------
try: 計算を開始します
else: 正常に計算できました。結果: 5.0
finally: 後処理を行います
------ 2回目 (0で割る) ------
try: 計算を開始します
except: 0では割れません
finally: 後処理を行いますelseは「エラーが起きなかったときだけ後続処理をしたい」場合に有用で、finallyは「ファイルを閉じる」「ロックを解放する」といった後始末を確実に実行したいときに使います。
Pythonのエラー処理が必要になる典型ケース
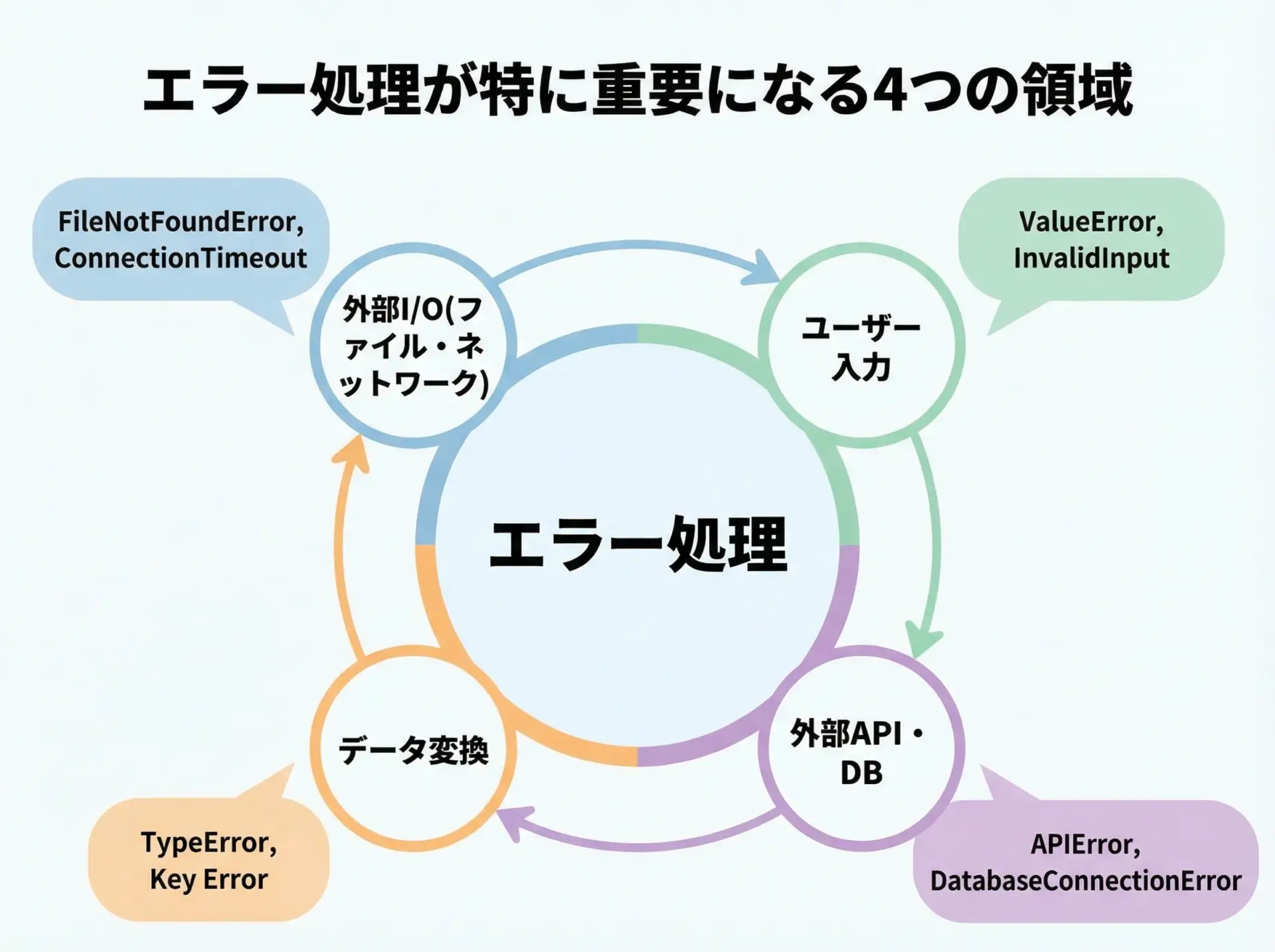
エラー処理が特に重要になるのは、次のようなケースです。
- 外部リソースとのやり取り
ファイル操作、ネットワーク通信、データベース接続などは、環境やネットワーク状況に大きく依存します。ファイルが存在しない、接続先に到達できない、タイムアウトしたといった事態は日常茶飯事です。 - ユーザー入力の処理
コンソール入力やWebフォームの値など、ユーザーが自由に入力できる情報は、常に不正なパターンが混ざる前提で扱うべきです。 - データ変換やパース
文字列から整数に変換したり、JSONやCSVを読み込んだりする処理では、不正形式や欠損値が混ざることがあります。 - 外部APIやライブラリの利用
サードパーティAPI、クラウドサービス、ドライバなどは、仕様変更や一時的な障害で例外を投げることがあります。
これらの場面では、例外を「起きるもの」として前提にした設計が重要になります。
try exceptでよくある書き方パターン
代表的なtry exceptパターン
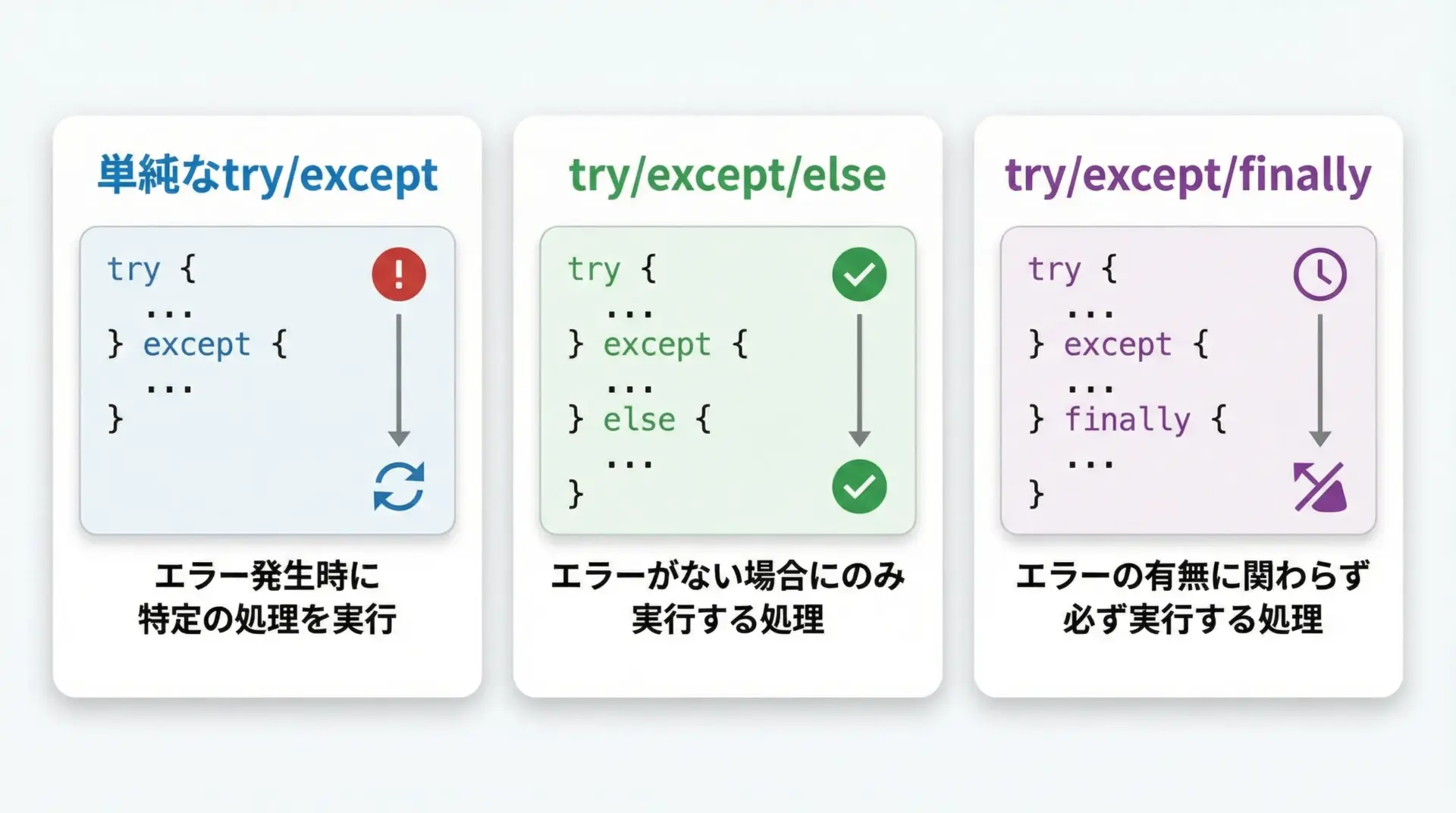
よく使われるパターンを3つに整理してみます。
単純なtry/exceptだけのパターン
最もシンプルな形で、特定の例外を捕まえて代替処理を行いたいときに使います。
# 単純なtry/exceptパターンの例
def read_int():
s = input("整数を入力してください: ")
try:
value = int(s)
except ValueError:
# 不正な入力だった場合のフォールバック
print("整数ではないため、0を返します")
value = 0
return value
num = read_int()
print("読み取った整数:", num)try/except/elseパターン
tryの中をできるだけ「危険な処理」のみにして、後続処理をelse側に分離するパターンです。
# try/except/elseパターンの例
def load_config(path):
try:
# ファイルを開く(ここで例外が起きる可能性が高い)
f = open(path, "r", encoding="utf-8")
except FileNotFoundError:
print("設定ファイルが見つかりません:", path)
return {}
else:
# ファイルが正常に開けたときだけ実行される処理
with f:
import json
return json.load(f)
config = load_config("config.json")
print("設定:", config)try/except/finallyパターン
必ず実行したい後処理があるときに使うパターンです。
ファイルやロックの解放などに用います。
# try/except/finallyパターンの例
def write_log(path, text):
f = None
try:
f = open(path, "a", encoding="utf-8")
f.write(text + "\n")
except OSError as e:
print("ログの書き込みに失敗しました:", e)
finally:
# ファイルオブジェクトが存在する場合のみ閉じる
if f is not None:
f.close()
write_log("app.log", "アプリケーションを開始しました")ネットワーク処理のエラー処理パターン
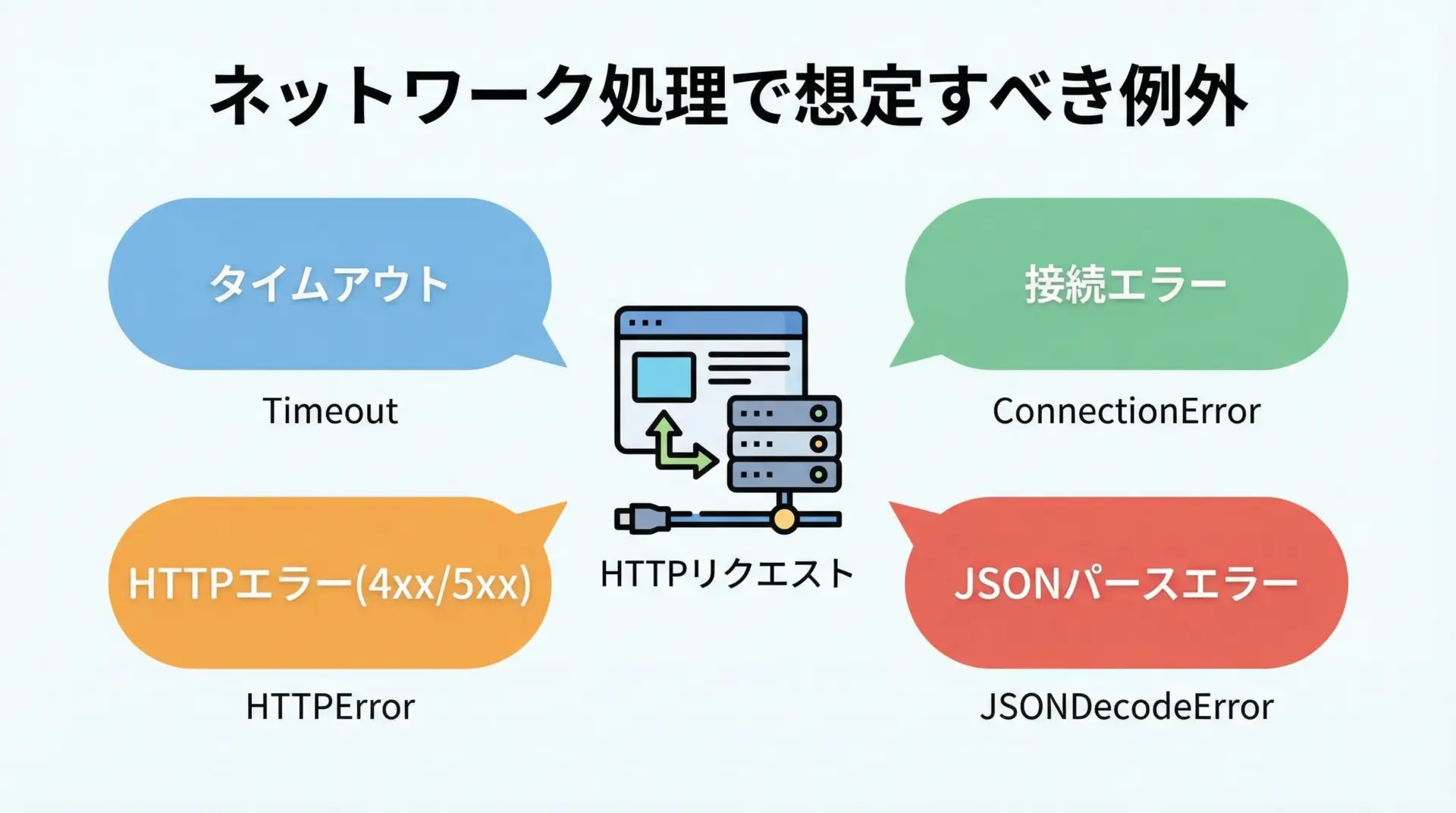
ネットワーク処理では、タイムアウトや一時的な障害が頻発します。
ここではrequestsライブラリを例に、外部APIを叩くときの典型的なパターンを示します。
import requests
def fetch_json(url, timeout=5.0):
try:
# タイムアウト付きでGETリクエストを送信
response = requests.get(url, timeout=timeout)
# HTTPステータスコードが4xx/5xxなら例外を発生させる
response.raise_for_status()
# JSONとして解析
return response.json()
except requests.exceptions.Timeout:
print("タイムアウトしました:", url)
return None
except requests.exceptions.ConnectionError:
print("接続エラーが発生しました:", url)
return None
except requests.exceptions.HTTPError as e:
# ステータスコードによってメッセージを変えるなども可能
print("HTTPエラー:", e.response.status_code, e)
return None
except ValueError:
# response.json() でJSONデコードに失敗した場合
print("レスポンスをJSONとして解析できませんでした")
return None
data = fetch_json("https://api.example.com/data")
print("取得データ:", data)ポイントは、「再試行すべき一時的なエラー」と「ユーザーへのエラーメッセージで終わる恒久的なエラー」を区別することです。
実際のシステムでは、タイムアウト時に数回リトライするなどの戦略を組み合わせます。
データ変換(ValueError・TypeError)のハンドリングパターン
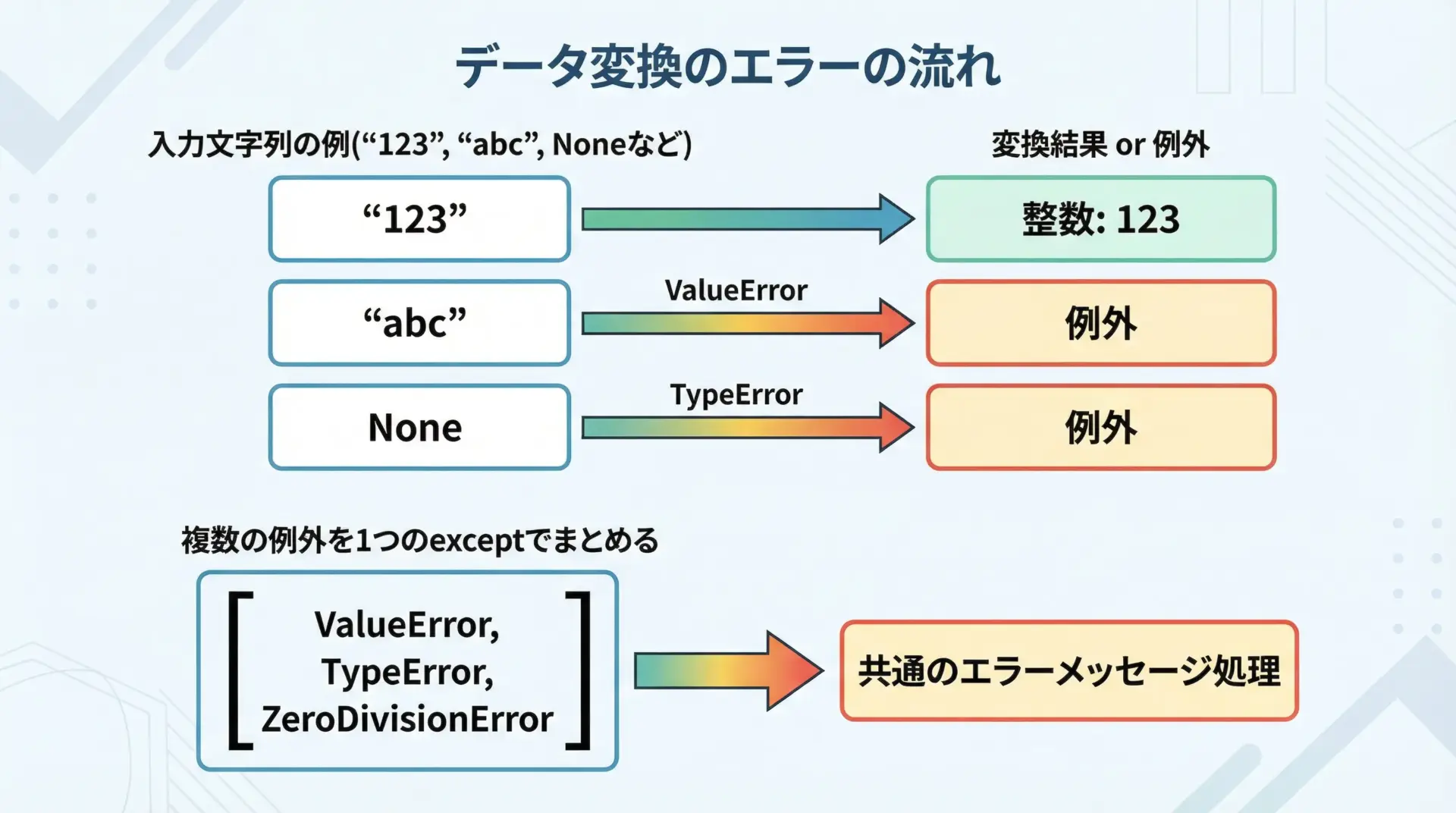
ユーザー入力や外部データを型変換するときにはValueErrorやTypeErrorがよく発生します。
変換用の小さな関数を用意して一箇所でハンドリングすると、コード全体がすっきりします。
# 安全な整数変換関数の例
def to_int(value, default=0):
"""
与えられた値をintに変換します。
変換できない場合はdefaultを返します。
"""
try:
return int(value)
except (ValueError, TypeError):
# ValueError: "abc" のような文字列
# TypeError: None やリストなど、int()できない型
return default
print(to_int("123")) # 123
print(to_int("abc")) # 0 (default)
print(to_int(None)) # 0 (default)
print(to_int(3.14)) # 3このように変換ロジックを関数化し、そこで例外を吸収して意味のあるデフォルト値に変換しておくと、呼び出し側ではtry exceptを書かずに済みます。
複数の例外を1つのexceptでまとめて処理する方法

同じような扱いをしたい例外は、タプルでまとめて1つのexceptに書くことができます。
# 複数の例外をひとまとめに処理する例
data = {"num": "100"}
try:
# 存在しないキーでKeyErrorの可能性
raw = data["value"]
# 不正な文字列でValueErrorの可能性
num = int(raw)
print("結果:", num)
except (KeyError, ValueError, TypeError) as e:
# どの例外でも同じメッセージとフォールバックを行う
print("データが不正なため、0として扱います")
print("詳細な例外クラス:", type(e).__name__)
num = 0
print("最終的な値:", num)「どの例外も同じ扱いで問題ないか」を考えたうえでまとめるようにすると、読みやすさと安全性を両立できます。
カスタム例外クラスを使ったエラー処理パターン

大規模なアプリケーションでは、独自の例外クラスを定義して「アプリ固有のエラー」を明確に区別することがよくあります。
# カスタム例外クラスの定義と利用例
class AppError(Exception):
"""アプリケーション共通の例外の基底クラス"""
pass
class ConfigError(AppError):
"""設定ファイルに関するエラー"""
pass
class ValidationError(AppError):
"""入力値検証に関するエラー"""
pass
def load_config(path):
import json
try:
with open(path, "r", encoding="utf-8") as f:
return json.load(f)
except FileNotFoundError:
# より意味のあるAppError系の例外として包み直す
raise ConfigError(f"設定ファイルが見つかりません: {path}")
except json.JSONDecodeError as e:
raise ConfigError(f"設定ファイルが不正なJSONです: {e}") from e
def process_user_input(name, age_str):
if not name:
raise ValidationError("名前は必須です")
try:
age = int(age_str)
except ValueError as e:
raise ValidationError("年齢は整数で指定してください") from e
if age < 0:
raise ValidationError("年齢は0以上である必要があります")
return {"name": name, "age": age}
def main():
try:
config = load_config("config.json")
print("設定:", config)
user = process_user_input("Taro", "20")
print("ユーザー:", user)
except ValidationError as e:
print("入力エラー:", e)
except ConfigError as e:
print("設定エラー:", e)
except AppError as e:
# その他のアプリ固有エラー
print("アプリケーションエラー:", e)
if __name__ == "__main__":
main()このようにアプリ独自の例外階層を持っておくと、上位のレイヤーではAppErrorだけを捕まえて処理できるため、責務の分離やテストのしやすさにつながります。
try exceptで陥りがちな落とし穴
exceptだけで例外クラスを指定しない危険性

例外クラスを指定しないexcept:は、原則として避けるべきです。
次のようなコードは危険です。
# 悪い例: 例外クラスを指定していないexcept
try:
# 何らかの処理
do_something()
except:
# 何が起きてもここに来てしまう
print("エラーが発生しましたが、無視して続行します")この書き方だとKeyboardInterruptやSystemExitといった「プログラムを止めるための例外」まで捕まえてしまう可能性があります。
その結果、ユーザーがCtrl+Cで止めようとしても止まらない、といった状況になりかねません。
少なくともexcept Exception:のように書き、何を捕まえているのかを明示することが重要です。
# まだマシな例: Exceptionを明示的に指定
try:
do_something()
except Exception as e:
print("予期せぬエラー:", type(e).__name__, e)
# 必要に応じてログを出力したり、再送出したりする
# raiseExceptionを広く捕まえ過ぎる問題

except Exception:で何でも捕まえるパターンも、乱用するとバグを隠す原因になります。
# 問題になりがちな広すぎるexceptの例
def calculate_discount(price, rate):
try:
return price * rate
except Exception:
# どんなエラーでも一律0割引にしてしまう
return 0
print(calculate_discount("1000", 0.1)) # 本来はTypeErrorここでは"1000"という文字列を掛け算しているため、本来はTypeErrorが起きてバグに気づくべきです。
しかし、広すぎるexceptがあると、バグを検知できなくなり、静かにおかしな結果を返すことになります。
対策としては、次のような方針が有効です。
- 業務的に想定される例外だけを個別に捕まえる
- 本当に最後の砦として
except Exceptionを使う場合は、raiseで再送出したり、プログラムを安全に終了させたりするだけに留める
passだけの空のexceptがバグを隠す理由
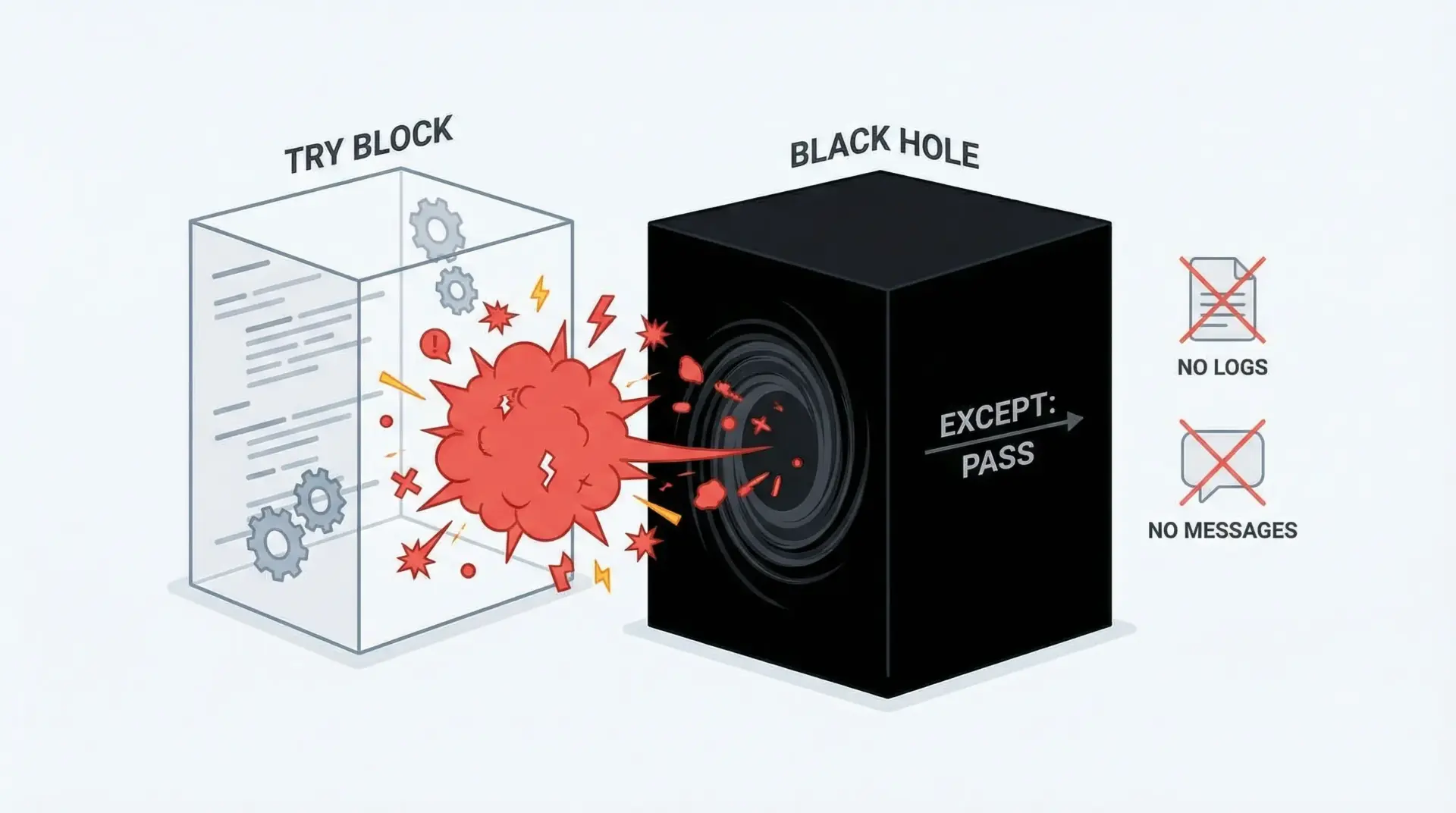
特に危険なのが、except:やexcept Exception:の中でpassだけを書いてしまうパターンです。
# 最悪の例: 例外を完全に握りつぶす
try:
risky_operation()
except Exception:
pass # 何もせずに黙って無視このようなコードは、本来なら気づくべきバグを完全に隠してしまい、あとで原因不明の不具合につながります。
最低限、ログ出力かエラーメッセージの表示を行うべきです。
import logging
logger = logging.getLogger(__name__)
try:
risky_operation()
except Exception:
logger.exception("risky_operationで予期せぬエラーが発生しました")
# 必要なら再送出も検討
# raise例外情報(traceback)を失うログの取り方
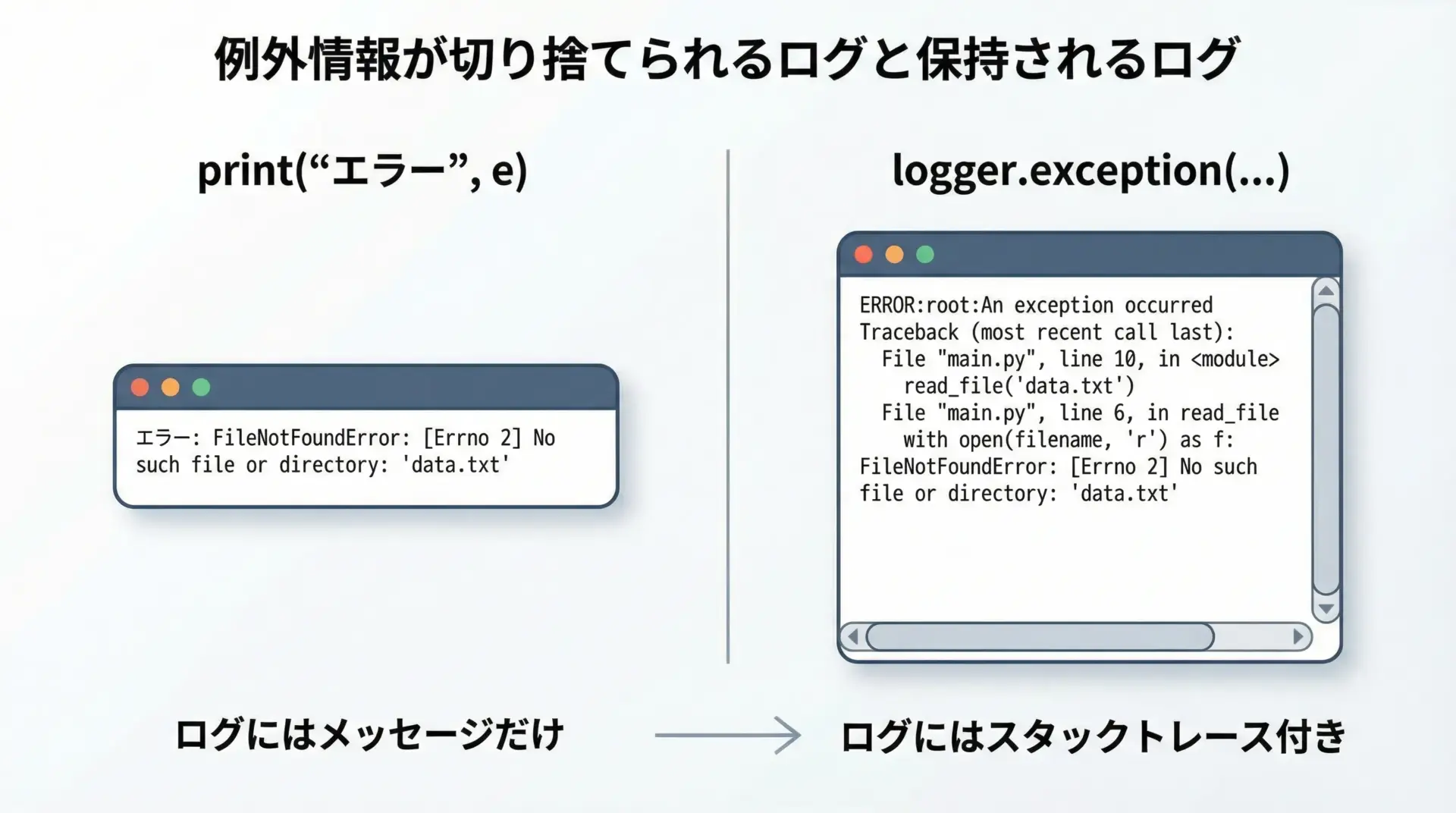
例外をログに出しているつもりでも、スタックトレースを残していないと、原因調査が極めて困難になります。
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def bad_logging():
try:
1 / 0
except ZeroDivisionError as e:
# 悪い例: 例外メッセージだけでスタックトレースが残らない
logger.error("エラーが発生しました: %s", e)
def good_logging():
try:
1 / 0
except ZeroDivisionError:
# 良い例: logger.exception() は自動的にスタックトレースを含める
logger.exception("エラーが発生しました")
bad_logging()
good_logging()ERROR:__main__:エラーが発生しました: division by zero
ERROR:__main__:エラーが発生しました
Traceback (most recent call last):
File "example.py", line XX, in good_logging
1 / 0
ZeroDivisionError: division by zero原因調査にはスタックトレースが不可欠なので、logging.exceptionやlogger.error(..., exc_info=True)を活用しましょう。
ネストし過ぎたtry except構造のアンチパターン
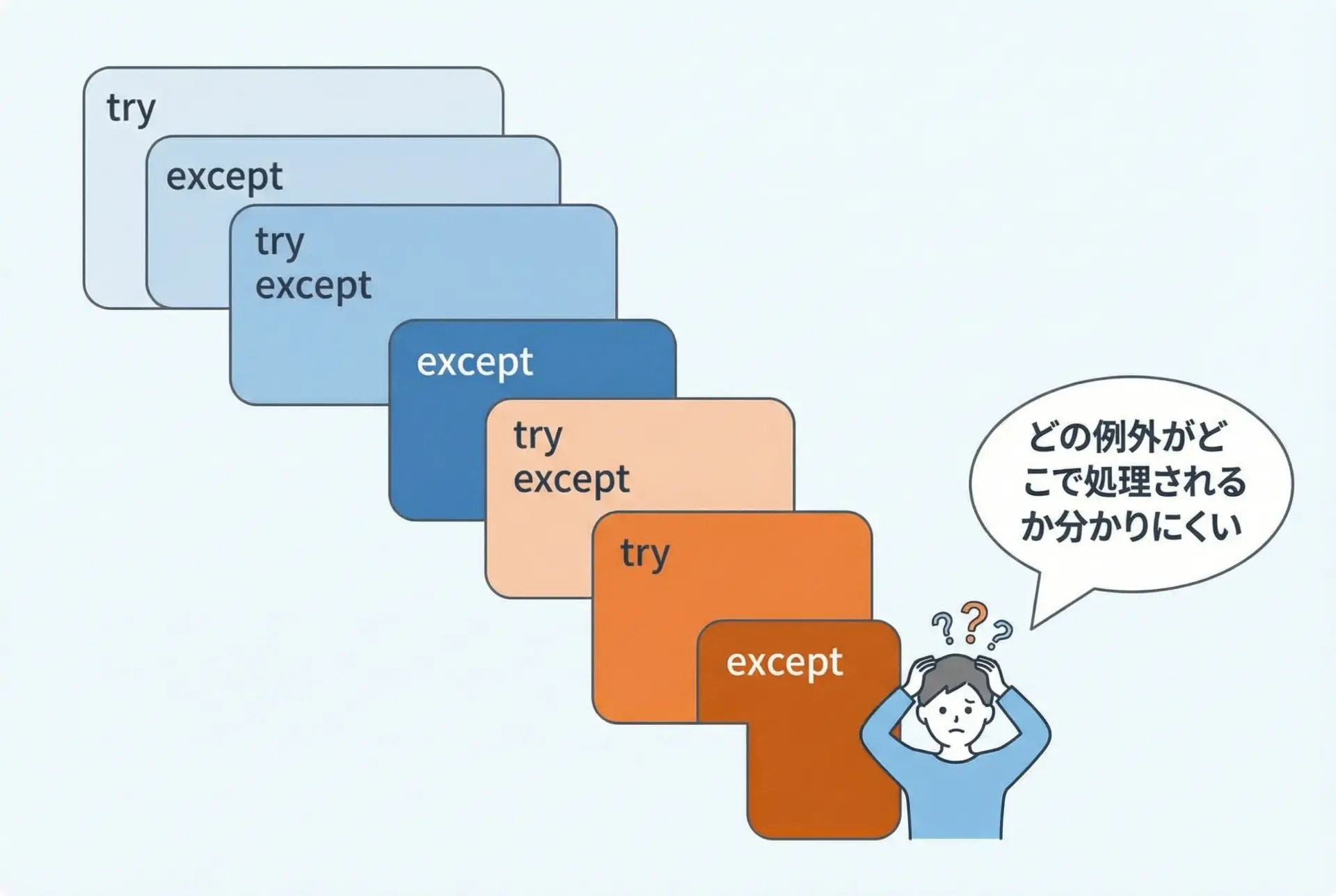
多くの処理で例外が発生しうるからといって、try exceptを深くネストさせるとコードが読めなくなります。
# 悪い例: ネストしすぎたtry/except構造
try:
connect_db()
try:
user = load_user()
try:
update_user(user)
except UpdateError as e:
print("更新エラー:", e)
except LoadError as e:
print("読み込みエラー:", e)
except ConnectionError as e:
print("接続エラー:", e)このようなコードは、どこでどの例外が捕まるのか一目で分からず、保守が非常に困難です。
対策としては、処理を小さな関数に分割し、それぞれの関数の中で局所的にtry exceptを書くことです。
# 良い例: 関数に分割し、try/exceptをフラットにする
def connect_and_load():
connect_db()
return load_user()
def update_user_safely(user):
try:
update_user(user)
except UpdateError as e:
print("更新エラー:", e)
def main():
try:
user = connect_and_load()
except ConnectionError as e:
print("接続エラー:", e)
return
except LoadError as e:
print("読み込みエラー:", e)
return
update_user_safely(user)
main()リソース解放をtry exceptだけで行うリスク
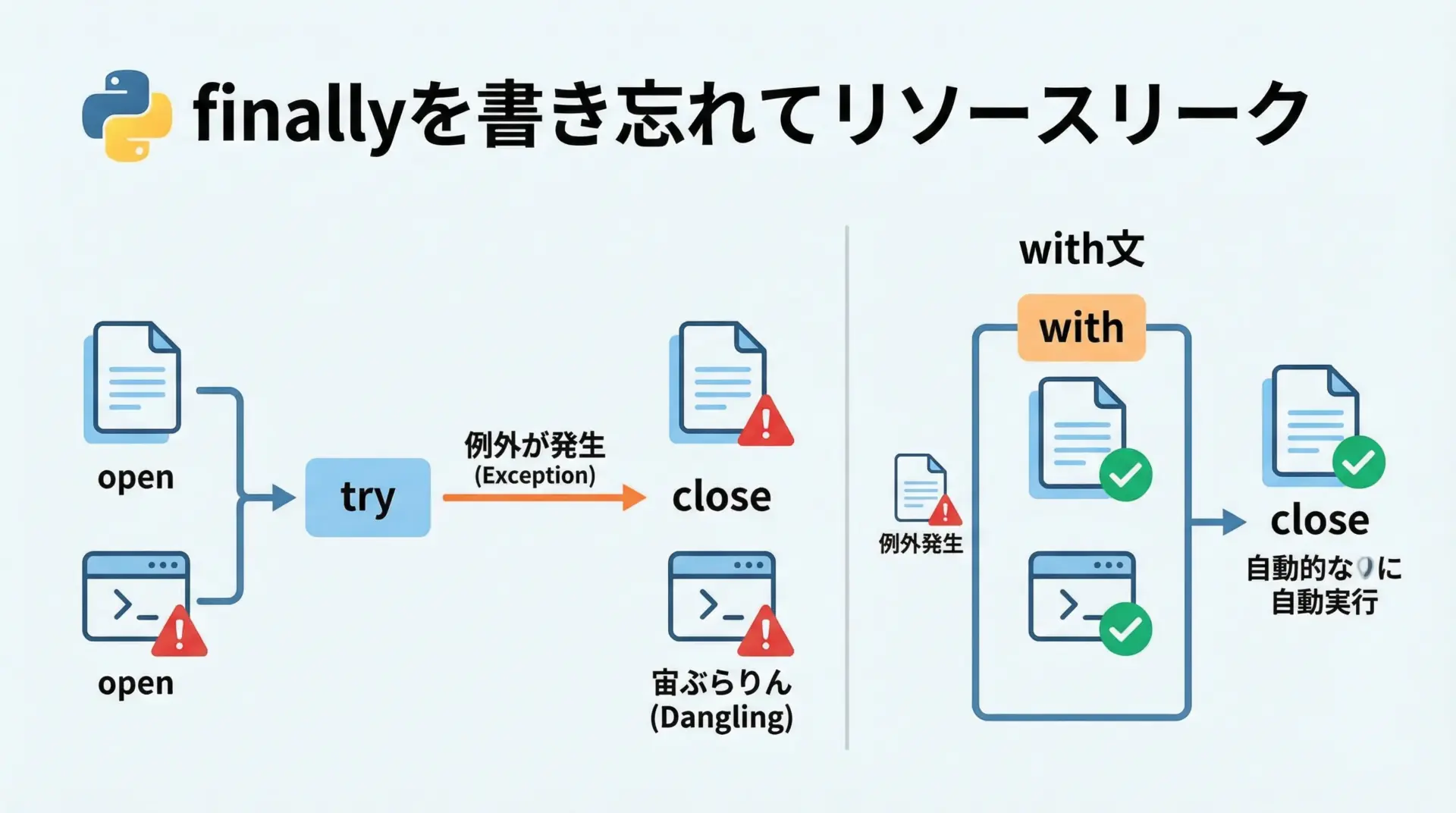
ファイルやソケットなどのリソースを扱うとき、例外が発生しても確実に解放する必要があります。
try exceptだけで後処理をしていると、パスによっては解放されない危険があります。
# 悪い例: 例外時にファイルが閉じられない可能性がある
def write_file(path, text):
f = open(path, "w", encoding="utf-8")
try:
f.write(text)
risky_operation() # ここで例外が出るかもしれない
except Exception as e:
print("エラー:", e)
# f.close() を書き忘れるとファイルが開きっぱなしに確実に解放するには、finallyかwith文を使うべきです。
withについては後の章で詳しく扱いますが、finallyを使うなら次のように書きます。
# 良い例: finallyで確実にファイルを閉じる
def write_file_safely(path, text):
f = open(path, "w", encoding="utf-8")
try:
f.write(text)
risky_operation()
except Exception as e:
print("エラー:", e)
# 必要に応じて再送出など
# raise
finally:
f.close()エラー処理のベストプラクティス
例外クラスの粒度を設計する考え方
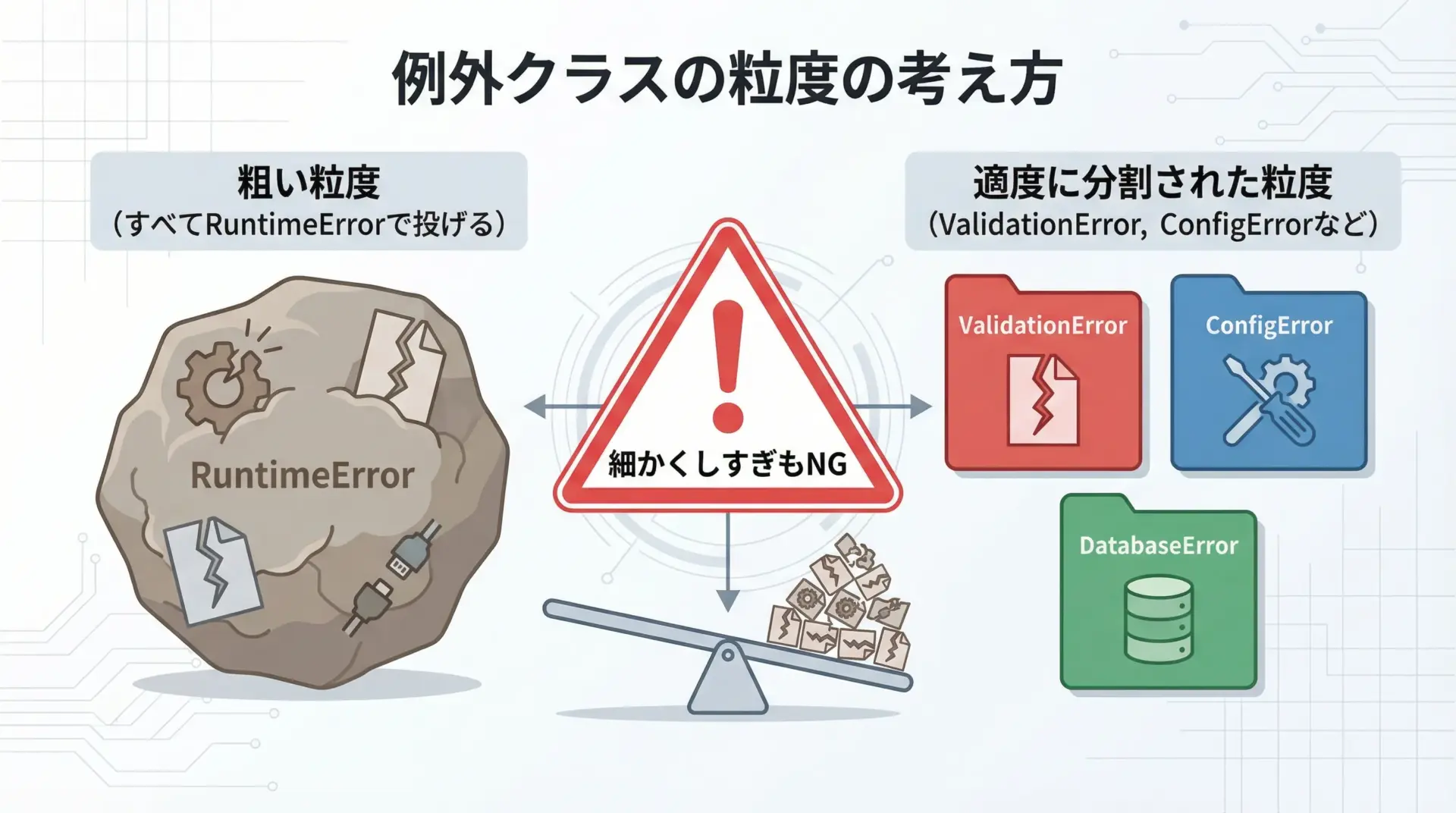
エラー処理を設計するうえで、例外クラスをどのくらい細かく分けるかは重要なテーマです。
考え方の一例として、次の3階層を意識すると整理しやすくなります。
- フレームワーク・共通層の例外(例:
AppError) - 機能ごとの抽象的な例外(例:
ConfigError,ValidationError) - さらに具体的な状況に応じたサブクラス(必要に応じて)
細かく分けすぎると、どの例外を捕まえればよいか分かりにくくなるため、「ハンドリングの仕方が明確に異なるものだけを別クラスにする」、という基準を持つと設計しやすくなります。
例外を再送出(raise)する場面と注意点
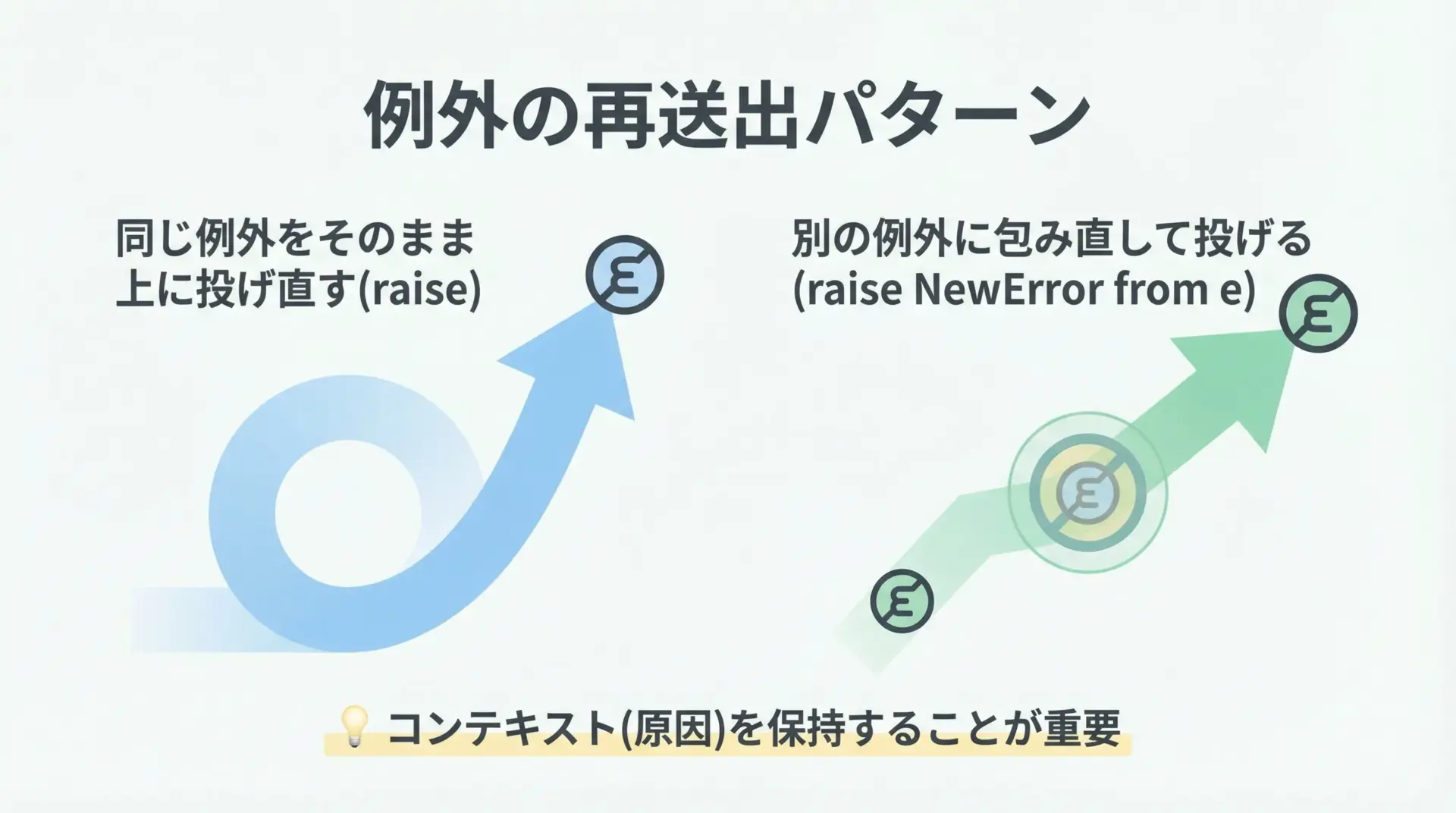
下位の関数で例外を捕まえたあと、その場では完全に処理できない場合、上位に再送出することがあります。
同じ例外をそのまま再送出
def inner():
try:
dangerous()
except SpecificError as e:
log_error(e)
# ログだけ残して、同じ例外を上へ投げ直す
raise
def outer():
try:
inner()
except SpecificError:
handle_error()このようにraiseだけを書くと、元のスタックトレースを保ったまま再送出できます。
別の例外に包み直す(例外チェーン)
class ServiceError(Exception):
pass
def call_service():
try:
low_level_call()
except TimeoutError as e:
# より抽象的な例外に包み直す
raise ServiceError("サービス呼び出しがタイムアウトしました") from efrom eを付けることで、例外チェーンとして「もともとの原因」も一緒にスタックトレースに残すことができます。
これを省略すると、原因が分かりにくくなるため注意が必要です。
with文(context manager)でtry exceptを簡潔にする

リソース管理に関するtry/finallyパターンを簡潔に書くための仕組みが、with文(コンテキストマネージャ)です。
ファイル操作の例を見てみます。
# with文がない場合
f = open("data.txt", "r", encoding="utf-8")
try:
data = f.read()
finally:
f.close()これと同等の処理を、with文を使うと次のように書けます。
# with文を使った場合
with open("data.txt", "r", encoding="utf-8") as f:
data = f.read()with文では、ブロックを抜けるときに自動的に__exit__が呼ばれ、リソースの解放などを行ってくれます。
このとき例外が発生していても、__exit__は必ず実行されます。
さらに、自作のコンテキストマネージャを作ることで、共通のtry except処理を隠蔽することも可能です。
import contextlib
import logging
logger = logging.getLogger(__name__)
@contextlib.contextmanager
def log_exceptions(msg):
"""
ブロック内で発生した例外をログに残し、再送出するコンテキストマネージャ
"""
try:
yield
except Exception:
logger.exception(msg)
raise # 例外は握りつぶさずにそのまま再送出
def process():
with log_exceptions("process中にエラーが発生しました"):
risky_operation()
another_risky_operation()このように、with文を使うとリソース解放や共通のエラー処理ロジックを見通しよく表現できます。
ログ出力(logging)とtry exceptの組み合わせ方
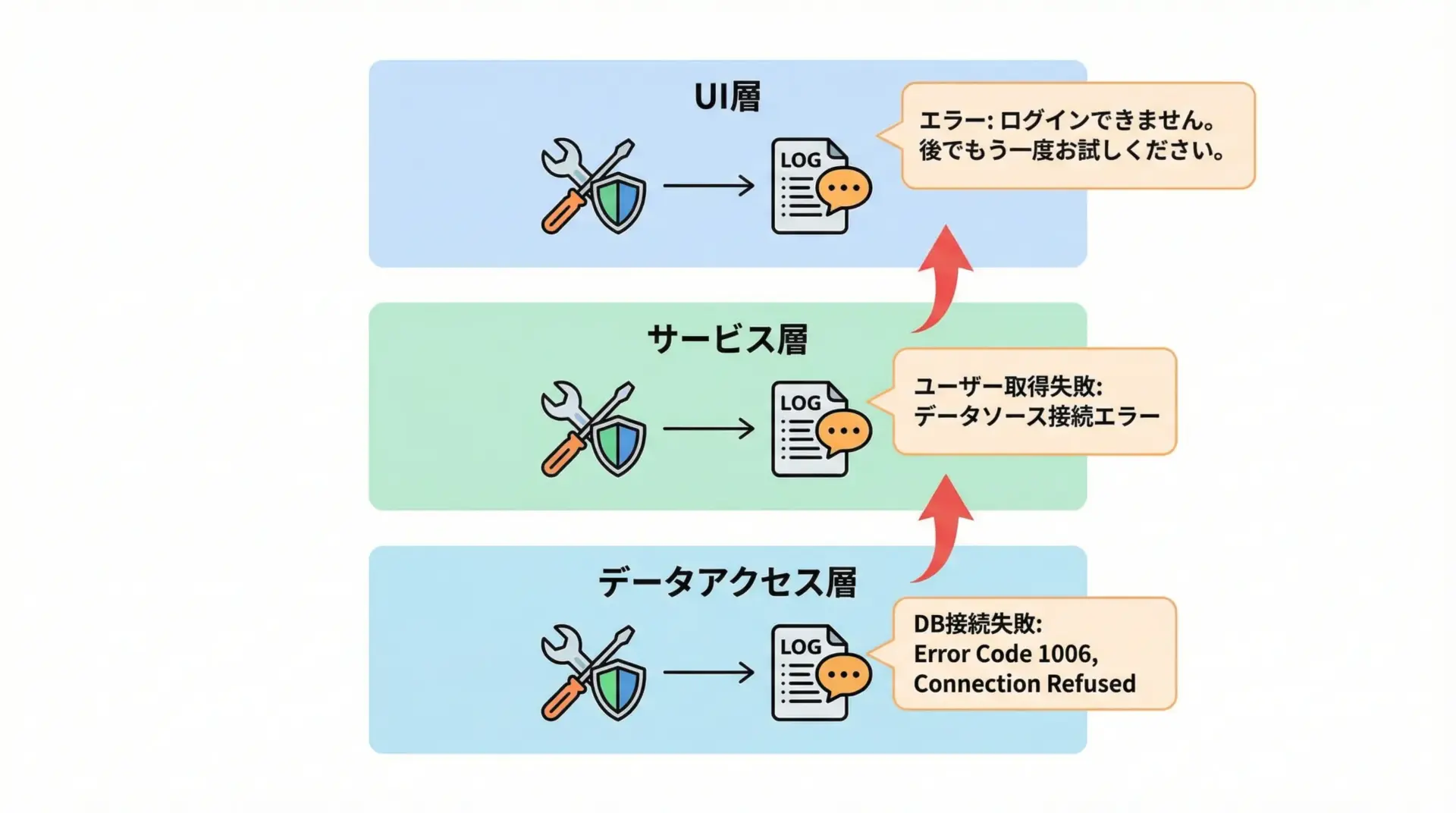
実運用を考えると、try exceptとロギングはセットで設計する必要があります。
基本的なパターンは次のようになります。
import logging
logger = logging.getLogger(__name__)
def low_level():
try:
risky_io()
except OSError:
# 下位層では詳細なログを残す
logger.exception("IOエラーが発生しました")
raise # 上位層へ再送出
def service():
try:
low_level()
except OSError as e:
# 必要に応じて業務例外に変換
raise ServiceError("サービス処理中にエラーが発生しました") from e
def controller():
try:
service()
except ServiceError as e:
# ユーザー向けに分かりやすいメッセージを表示しつつ、ログも残す
logger.error("リクエスト処理に失敗しました: %s", e)
print("しばらくしてから再度お試しください")このように「どのレイヤーでどの程度詳細なログを残すか」をあらかじめ決めておくと、重複ログや不足ログを防ぎやすくなります。
ユニットテストで例外処理を検証するポイント
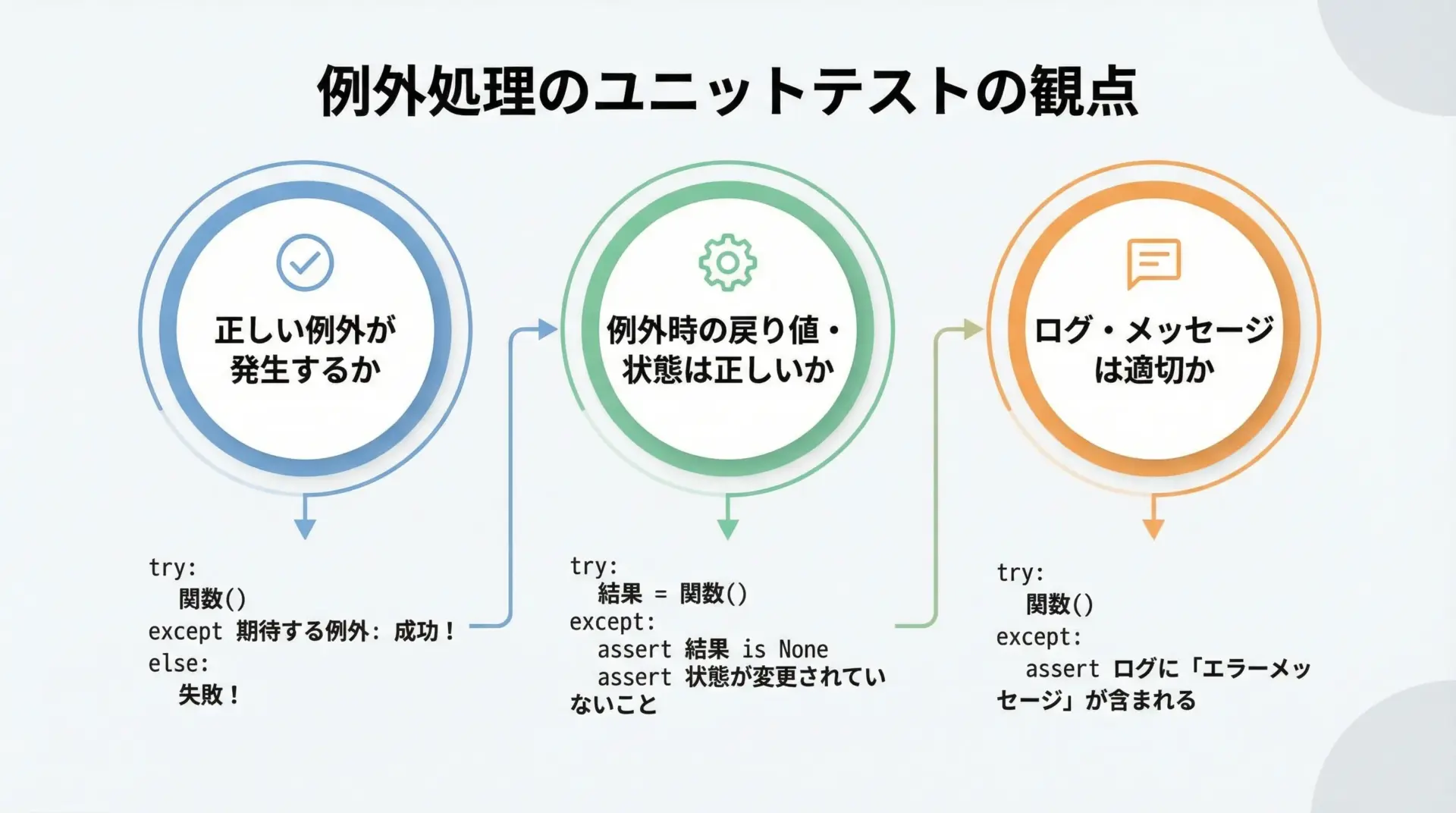
エラー処理はバグの温床になりやすいため、ユニットテストで例外の発生も含めて確認することが重要です。
ここでは標準ライブラリunittestを使った例を示します。
# my_module.py
def divide(a, b):
if b == 0:
raise ValueError("bは0以外である必要があります")
return a / b# test_my_module.py
import unittest
from my_module import divide
class TestDivide(unittest.TestCase):
def test_divide_normal(self):
self.assertEqual(divide(10, 2), 5)
def test_divide_zero_raises(self):
# ValueErrorが発生することを確認
with self.assertRaises(ValueError) as cm:
divide(10, 0)
# 例外メッセージの内容も確認可能
self.assertIn("0以外", str(cm.exception))
if __name__ == "__main__":
unittest.main()..
----------------------------------------------------------------------
Ran 2 tests in 0.001s
OKテストでは、次の点を意識するとよいです。
- 想定通りの例外クラスが発生しているか
- 例外メッセージが分かりやすく、必要な情報を含んでいるか
- 例外発生後の状態(戻り値や副作用)が設計どおりになっているか
このように例外も「仕様の一部」としてテストで明示することで、将来のリファクタリング時に誤って挙動を変えてしまうことを防げます。
まとめ
Pythonのtry exceptは、単にエラーを潰すためではなく、「どのレイヤーで何を責任を持って処理するか」を明確にするための仕組みです。
基本構文にelseやfinally、with文やカスタム例外を組み合わせることで、読みやすく堅牢なエラー処理を実現できます。
一方で、例外クラスを指定しないexceptやpassだけのハンドラ、広すぎるException捕捉は、バグを隠す危険なパターンです。
ログ出力やユニットテストも含めて、「失敗することを前提に設計する」視点でtry exceptを使いこなしていきましょう。
