
Pythonでの改行は、画面表示だけでなくファイル入出力やOS間の互換性にも大きく関わる重要なテーマです。
本記事では、文字列中の改行文字\nと、ファイル操作で登場するnewline引数の違いを軸に、基礎から実務で役立つトラブル防止テクニックまで体系的に解説します。
Windows・Mac・Linuxの違いも押さえながら、今日から迷わず改行を扱えるようになりましょう。
Pythonの改行とnewlineの基本
改行コードとは

コンピュータの世界でいう改行は、画面上で行が変わることと、内部的に使われる「改行コード」という2つの意味を持ちます。
人間から見ると同じように行が折り返されていても、ファイルの中では次のようなバイト列で表現されています。
代表的な改行コードは次の3種類です。
- LF(Line Feed):
\n、16進数で0x0A。Unix系(OS X以降のmacOSを含む)の標準 - CRLF(Carriage Return + Line Feed):
\r\n、0x0D 0x0A。Windowsの標準 - CR(Carriage Return):
\r、0x0D。古いMac OSで使われていた形式
この違いは主にテキストファイルの中身に影響し、OS間でファイルをやりとりする際にトラブルの原因になります。
Pythonは基本的に「どのOSでも同じコードで扱えるようにする」ため、標準ライブラリ側で改行コードの差を吸収する仕組みを持っています。
Pythonにおける改行文字\nの意味
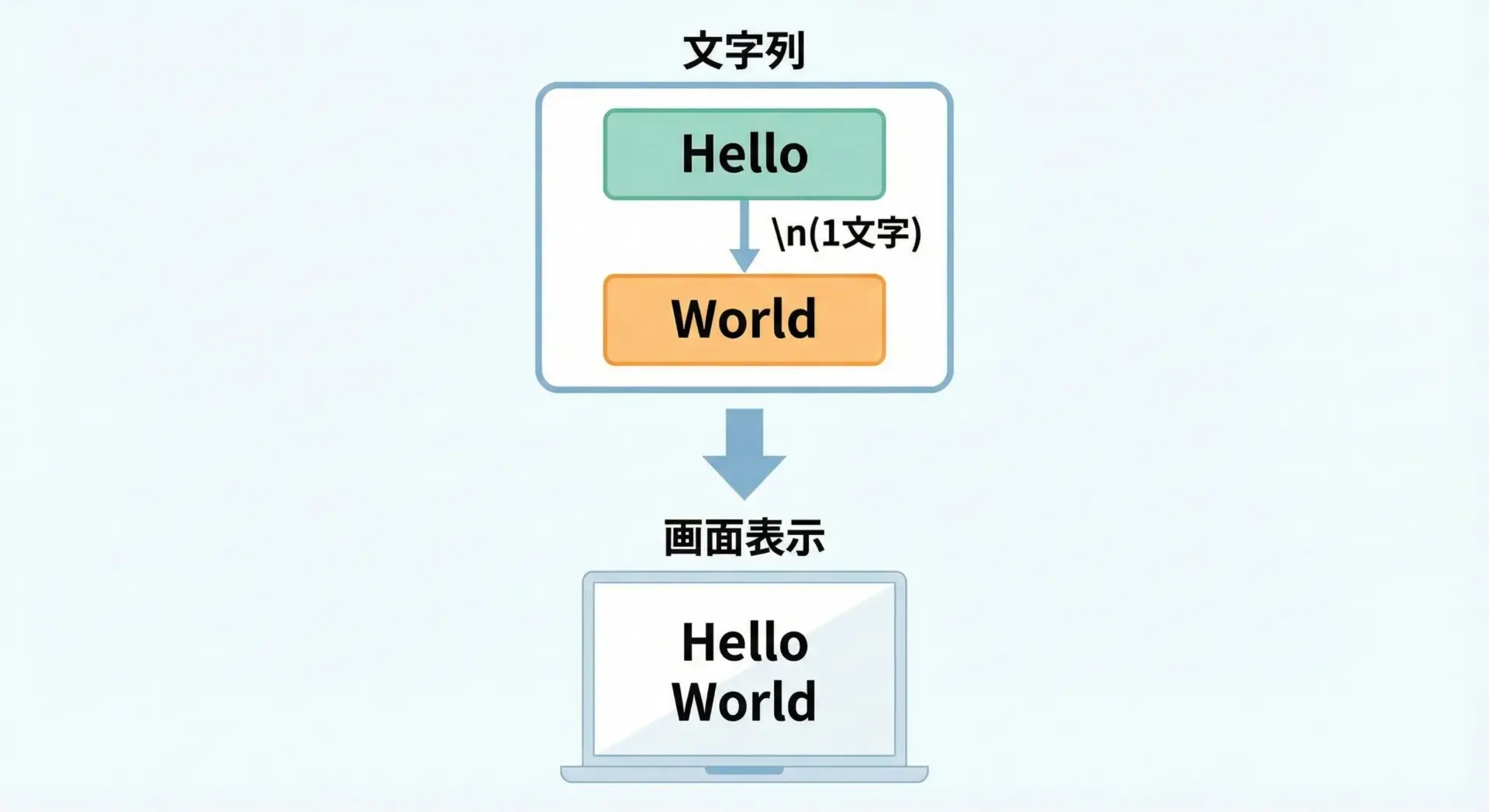
Pythonの文字列中に書く\nは、1文字の特殊な制御文字であり、文字列を表示したときに行を折り返す役割を持ちます。
重要なのは、「2文字のバックスラッシュとn」ではなく、「1つの改行文字」として扱われる点です。
次のコードで確認してみます。
text = "Hello\nWorld"
print(text) # 実際の表示
print("長さ:", len(text)) # 文字数の確認
print("repr:", repr(text)) # 内部表現の確認Hello
World
長さ: 11
repr: 'Hello\nWorld'この結果から分かるポイントは次の通りです。
- 表示は2行に分かれていますが、
len(text)は11で、\nも1文字としてカウントされていること reprで見ると'Hello\nWorld'と表示され、内部的には改行文字であるにもかかわらず、プログラマに分かりやすいように\n表記で表されていること
このように、Pythonの\nはあくまで「文字列中の1文字」であり、OSの種類にかかわらず同じ意味を持つと考えておくと理解しやすくなります。
文字列リテラルと改行

Pythonでは、ソースコード中に文字列をリテラルとして書くとき、改行を表す方法がいくつかあります。
代表的なパターンを整理しておきます。
| リテラルの書き方 | 文字列の実体 | 説明 |
|---|---|---|
"Hello\nWorld" | Hello(改行)World | バックスラッシュ+nで改行文字を表現 |
"Hello\nWorld" | Hello\nWorld | 実際の2文字\とnを含む |
"Hello""World" | HelloWorld | 隣接する文字列リテラルの結合(改行なし) |
"Hello\World" | HelloWorld | バックスラッシュで行継続(改行なし) |
"""HelloWorld""" | Hello(改行)World | 三重クォート内の改行はそのまま改行文字になる |
次のサンプルで、実際にどのような文字列になっているかを確認してみます。
s1 = "Hello\nWorld"
s2 = "Hello\\nWorld"
s3 = "Hello" "World" # 隣接リテラル
s4 = "Hello\
World" # バックスラッシュで行継続
s5 = """Hello
World""" # 三重クォート
for i, s in enumerate([s1, s2, s3, s4, s5], start=1):
print(f"s{i}:", repr(s))s1: 'Hello\nWorld'
s2: 'Hello\\nWorld'
s3: 'HelloWorld'
s4: 'HelloWorld'
s5: 'Hello\nWorld'「見た目のソースコード上の改行」と「文字列に含まれる改行文字」は一致しないことがある点がポイントです。
特に三重クォートでは、意図せず先頭や末尾に余計な改行が入ることがあるため、後半で具体的な対処法も紹介します。
Pythonでの\nの使い方と挙動
printと\nの関係
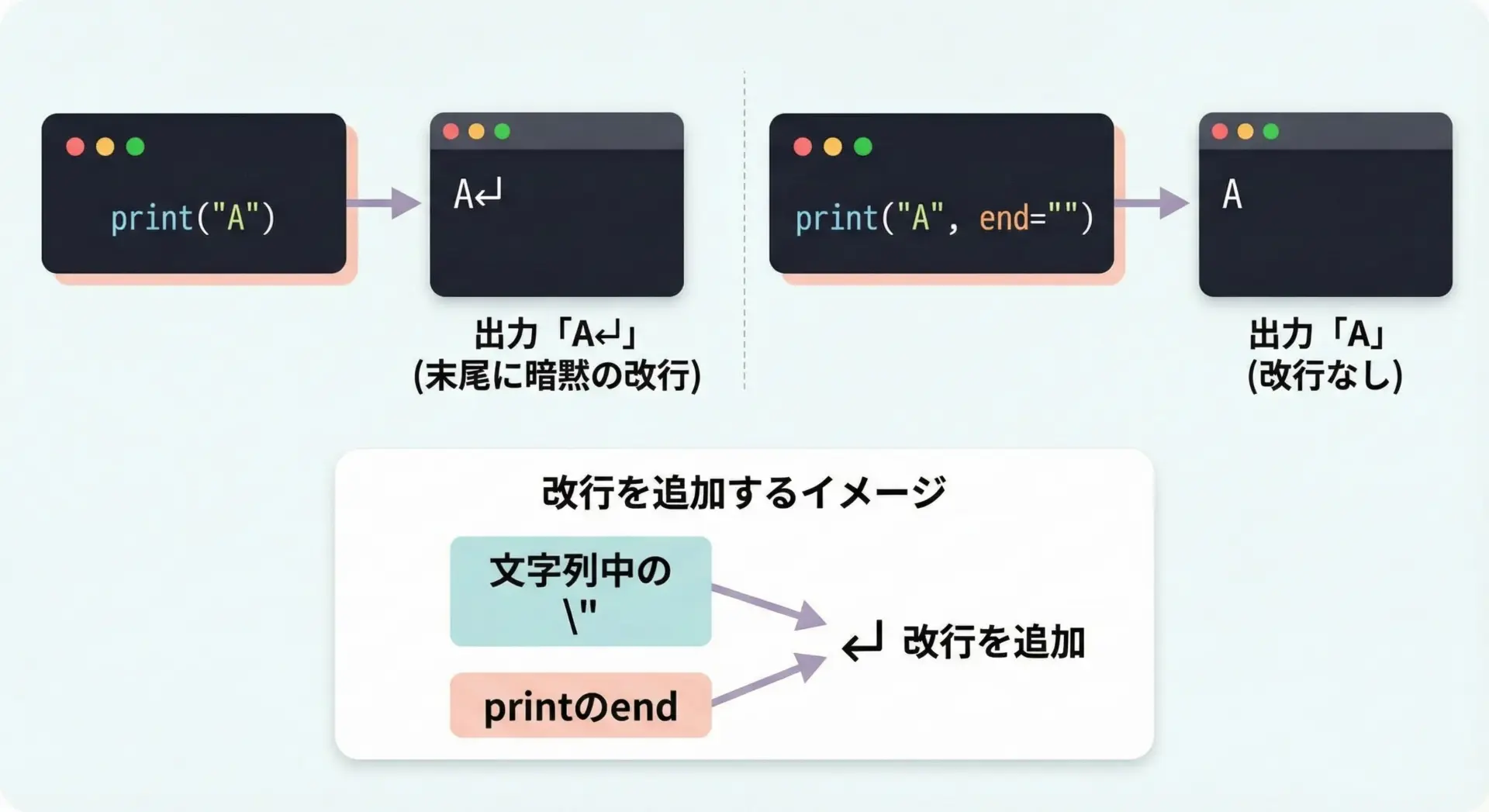
Pythonのprint関数は、デフォルトで行末に自動的に改行を付加します。
これが\nと組み合わさると、二重改行の原因になることがあります。
次のコードで挙動を比較してみます。
# デフォルト(改行あり)
print("Hello")
print("World")
# endを空文字にして改行なし
print("Hello", end="")
print("World")
# 文字列中に\nを含める
print("Hello\nWorld")
print("Hello\nWorld", end="") # 最後に改行を付けないHello
World
HelloWorld
Hello
World
Hello
World解説すると次のようになります。
- 最初の2行: 各
printの末尾に1つずつ改行が入るので、2行の出力になる - 3〜4行目: 1つ目の
printで改行なし、2つ目のprintで続けて出力するため、同じ行に「HelloWorld」と出る - 5行目: 文字列中の
\nで1つ、printの自動改行でさらに1つ、合計2つの改行が入り、最後に空行が1つできる - 6行目: 文字列中の
\nのみが効き、2行表示で終わる
見た目の改行が多いと感じたら、「文字列中の\n」と「printのend」両方を確認する癖を付けると、トラブルを早く発見できます。
複数行文字列と三重クォートでの改行

複数行のメッセージやテンプレートを扱うとき、Pythonでは三重クォート(トリプルクォート)がよく使われます。
例えば次のようなコードです。
message = """
Hello, Python.
This is a multi-line string.
"""
print(repr(message))
print("--- 実際の表示 ---")
print(message)'\nHello, Python.\nThis is a multi-line string.\n'
--- 実際の表示 ---
Hello, Python.
This is a multi-line string.先頭と末尾に改行が入っていることに注意してください。
三重クォートでは、クォートのすぐ後ろの改行や、閉じクォートの直前の改行も文字列に含まれるためです。
余計な改行を避けたいときは、いくつかのテクニックがあります。
先頭の改行を避ける書き方
message = """Hello, Python.
This is a multi-line string."""
print(repr(message))'Hello, Python.\nThis is a multi-line string.'開きクォートの直後に文字を書き始めることで、先頭の改行をなくせます。
textwrap.dedentでインデントと共に整形
コードの可読性のためにインデントしたい場合はtextwrap.dedentが便利です。
import textwrap
message = textwrap.dedent("""\
Hello, Python.
This is a multi-line string.
Indent will be cleaned.
""")
print(repr(message))
print("--- 実際の表示 ---")
print(message)'Hello, Python.\nThis is a multi-line string.\nIndent will be cleaned.\n'
--- 実際の表示 ---
Hello, Python.
This is a multi-line string.
Indent will be cleaned.先頭の"""\のようにバックスラッシュを併用すると、先頭の改行を含めずに複数行文字列を作れます。
これは実務でもよく使われるパターンです。
f文字列・formatでの改行の入れ方
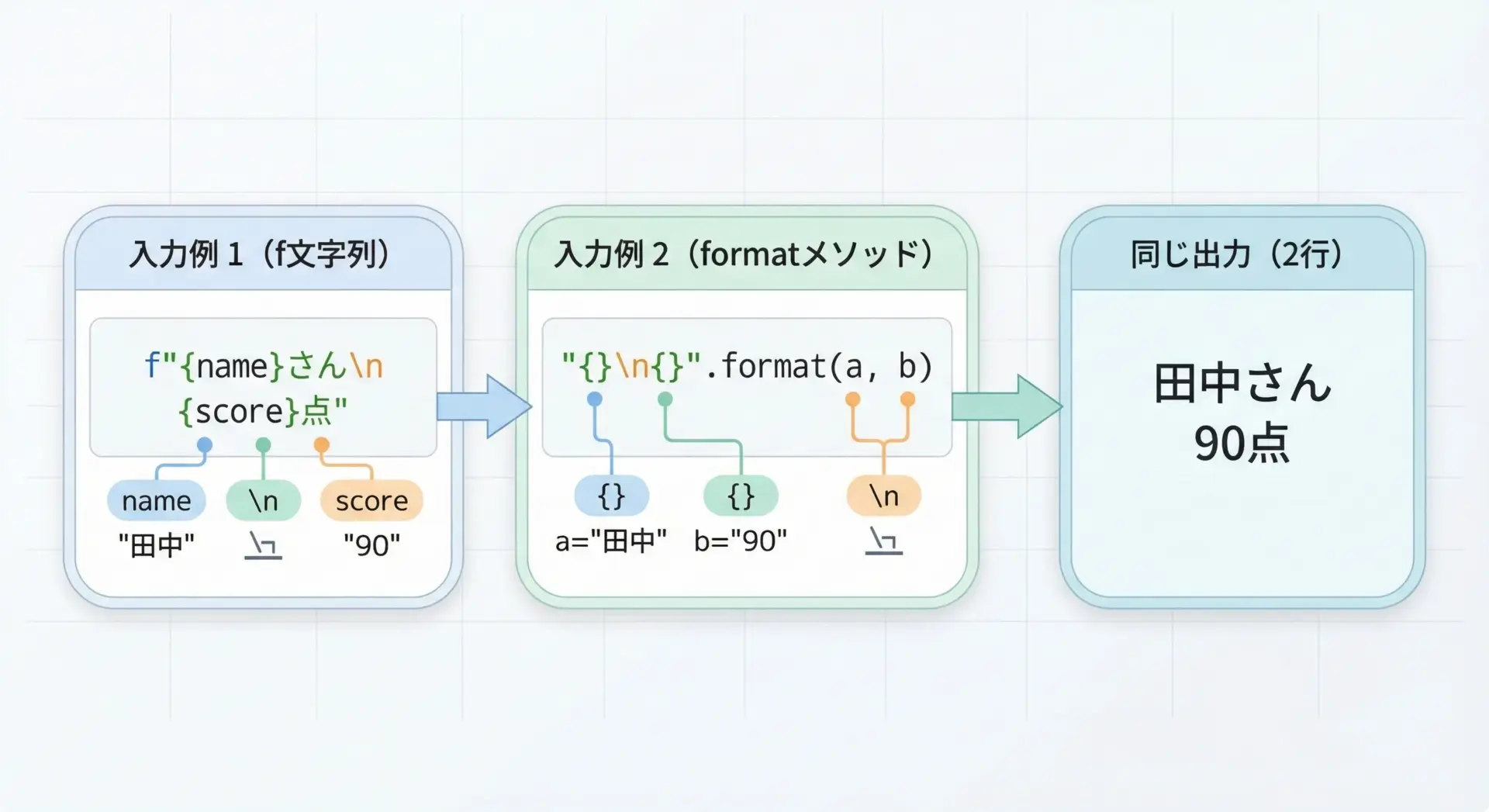
f文字列やstr.formatでも、改行の扱い方は基本的に同じです。
\nを文字列として含めるか、joinを使うか、用途に応じて選びます。
f文字列で改行を入れる
name = "Alice"
score = 95
message = f"{name}さん\nスコア: {score}点"
print(message)Aliceさん
スコア: 95点f文字列は式展開に便利ですが、\n自体は通常の文字列と同じように扱われます。
formatメソッドで改行を入れる
name = "Bob"
score = 88
message = "{}さん\nスコア: {}点".format(name, score)
print(message)Bobさん
スコア: 88点joinで複数行を組み立てる
式が増えて複雑になる場合は、joinで「行のリスト」を改行で結合する書き方が読みやすくなります。
name = "Carol"
score = 77
lines = [
f"{name}さん",
f"スコア: {score}点",
"おつかれさまでした。",
]
message = "\n".join(lines)
print(message)Carolさん
スコア: 77点
おつかれさまでした。このパターンはテンプレート性が高く、あとから行を追加・削除しやすいため、レポート出力やログ生成などでよく使われます。
newline引数とファイル入出力の改行制御
open関数のnewlineパラメータの役割
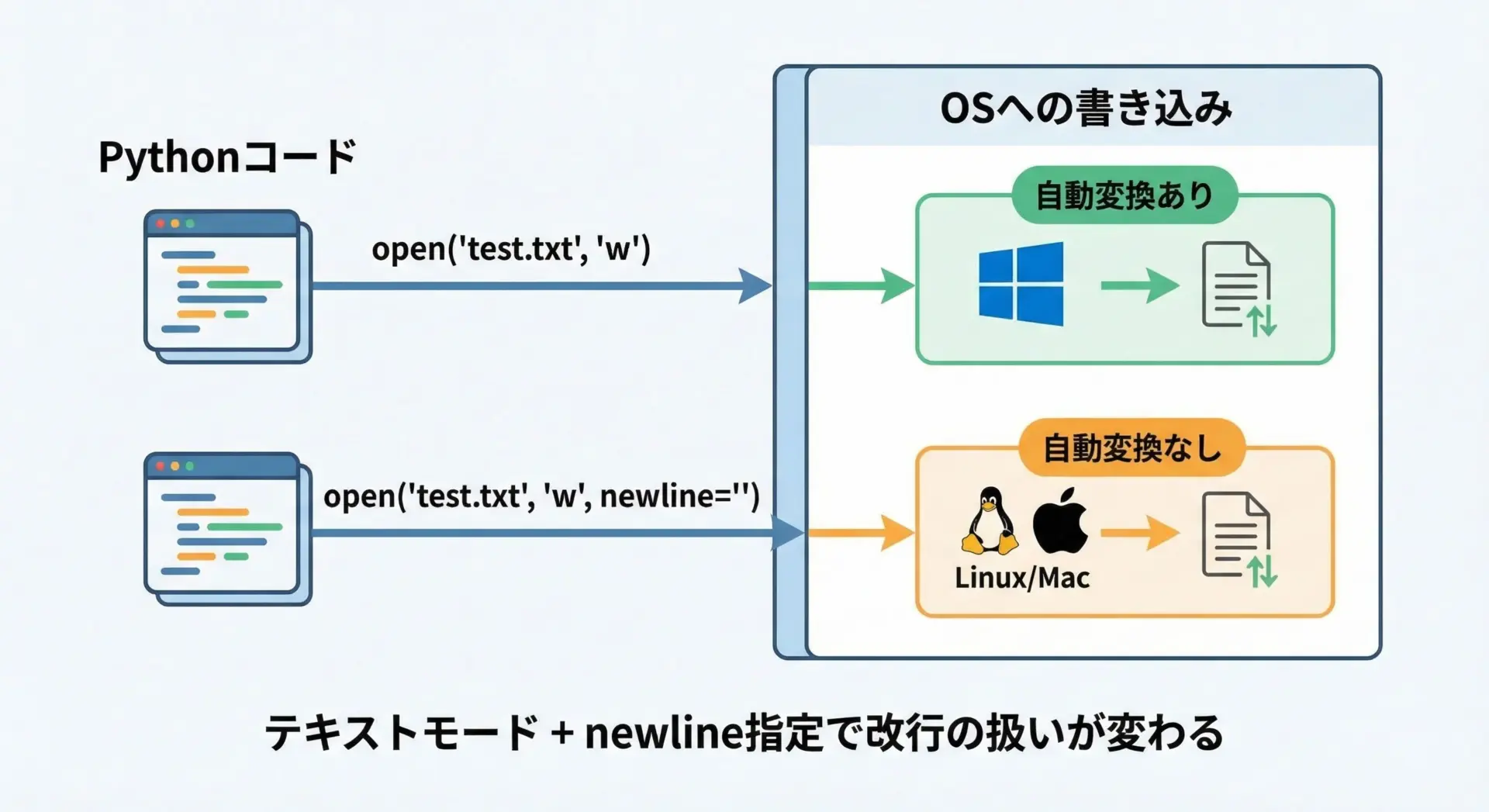
Pythonでファイルを開くopen関数には、newlineという少し分かりにくい引数があります。
これはテキストモードでの改行コードの自動変換をどう扱うかを指定するものです。
基本形は次のようになります。
# デフォルト(テキストモード、newline=None)
f = open("example.txt", mode="w", encoding="utf-8")
# newlineを明示的に指定
f = open("example.txt", mode="w", encoding="utf-8", newline="\n")newlineに指定できる代表的な値と意味は次の通りです。
| newlineの値 | 読み込み時 | 書き込み時 | 用途のイメージ |
|---|---|---|---|
| None(デフォルト) | どの改行でも\nに変換 | \nをOS標準の改行に変換 | 一般的なテキスト処理 |
| “”(空文字) | 変換しない(生のまま) | 変換しない(生のまま) | 改行コードをそのまま扱いたい場合 |
| “\n” | \r, \r\nも\nとして読み込む | \nをそのまま書き込む | OSに依存しないLF固定ファイルを書きたい場合 |
| “\r\n” | 同様に正規化されるが、分割方法に影響 | \nを書き込むと\r\nに変換 | 明示的にCRLFで書きたい場合(主にWindows向け) |
デフォルトのnewline=Noneでは、PythonがOSごとの違いを吸収してくれるため、特別な理由がなければこれを使うのが安全です。
一方で、CSVなど一部のライブラリではnewline=""の指定が推奨されており、これを知らないと改行トラブルの原因になります(後述します)。
テキストモードとバイナリモードでの改行の違い
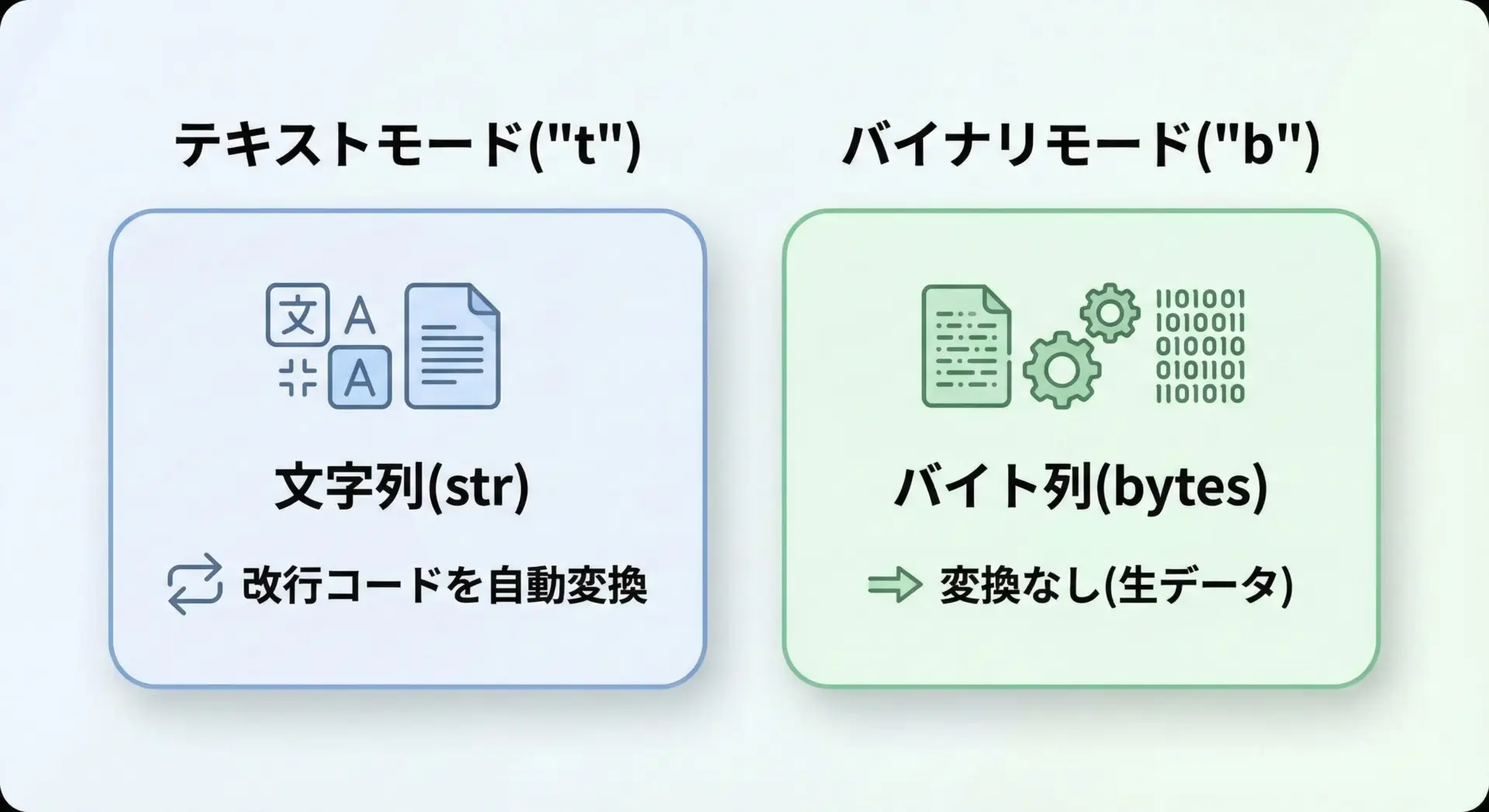
テキストモードとバイナリモードでは、改行の扱いが根本的に異なります。
- テキストモード(
"r","w"など):str型をやりとりし、改行コードをPythonが自動的に処理する - バイナリモード(
"rb","wb"):bytes型をやりとりし、改行も含めて一切変換しない
簡単な比較例を見てみます。
# テキストモードで書き込み & 読み込み
with open("text_mode.txt", "w", encoding="utf-8") as f:
f.write("A\nB\n")
with open("text_mode.txt", "rb") as f:
data_text = f.read()
print("テキストモードで保存された生データ:", data_text)
# バイナリモードで書き込み & 読み込み
with open("binary_mode.txt", "wb") as f:
f.write(b"A\nB\n")
with open("binary_mode.txt", "rb") as f:
data_bin = f.read()
print("バイナリモードで保存された生データ:", data_bin)テキストモードで保存された生データ: b'A\nB\n' (※Unix系の場合の一例)
バイナリモードで保存された生データ: b'A\nB\n'Unix系ではどちらもb"A\nB\n"になりますが、Windowsではテキストモードの場合にb"A\r\nB\r\n"のように自動変換されます。
そのため、バイナリモードを使う場合は、改行コードも含めて自分で完全に管理する必要があることを覚えておくとよいです。
Windows・Mac・Linuxでの改行コード差異とnewline設定

OSごとの標準的な改行コードは次のようになっています。
| OS | 標準的な改行コード | Pythonテキストモードでの内部表現 |
|---|---|---|
| Linux | LF(\n) | \n |
| macOS(OS X以降) | LF(\n) | \n |
| Windows | CRLF(\r\n) | \nとして扱う |
Pythonはテキストモードとnewline=Noneの組み合わせのとき、読み込み時にどの改行コードでも\nに統一し、書き込み時にはOSの標準改行に変換します。
OSの違いを意識してコントロールしたい場合、次のような方針が実務ではよく採用されます。
- ソースコード中: どのOSでも
\nで記述する - テキストファイル出力: 通常は
newline=NoneでOS依存に任せる - プラットフォーム非依存なテキスト(例えば設定ファイルや一部ログなど):
newline="\n"を指定して常にLFで保存する
例として、常にLF改行でファイルを書き出したい場合は次のようにします。
text = "line1\nline2\nline3\n"
# 常にLF改行で保存
with open("lf_only.txt", "w", encoding="utf-8", newline="\n") as f:
f.write(text)このようにすれば、Windows上で実行してもファイルの中身は\nだけになります。
CSVファイルでの改行問題
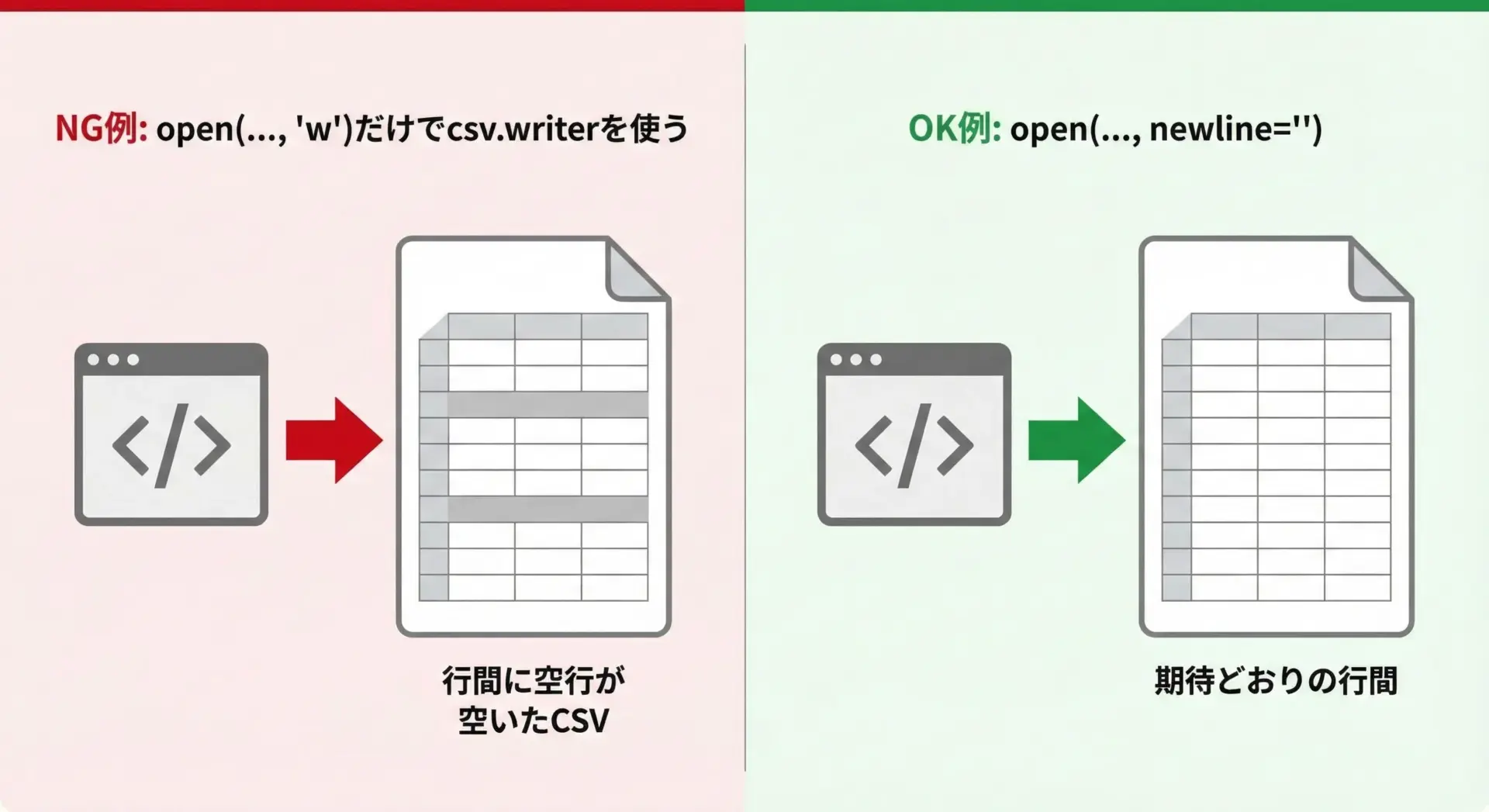
PythonのcsvモジュールをWindowsで使うと、行間に1行ずつ空行が挟まるという有名なトラブルがあります。
これはテキストモードの改行変換と、csv.writer内部の改行処理が二重に働くためです。
典型的なNGパターンは次のようなコードです。
import csv
rows = [
["id", "name"],
[1, "Alice"],
[2, "Bob"],
]
# Windowsで行間に空行が入るNG例
with open("ng.csv", "w", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerows(rows)この場合、Windowsでは各行の末尾が\r\n\r\nのようになり、Excelなどで開くと空行が挿入されたように見えます。
正しい対処法は、openのnewlineに空文字を指定することです。
import csv
rows = [
["id", "name"],
[1, "Alice"],
[2, "Bob"],
]
# 推奨パターン: newline="" を指定
with open("ok.csv", "w", encoding="utf-8", newline="") as f:
writer = csv.writer(f)
writer.writerows(rows)これにより、Python側では改行変換を行わず、csv.writer内部のロジックに任せることができ、OSを問わず安定した結果になります。
実務でCSVを書き出す場合、「newline=""を付ける」のは必須の習慣として覚えておきましょう。
改行トラブル防止テクニック
意図しない二重改行・改行欠けを防ぐ方法
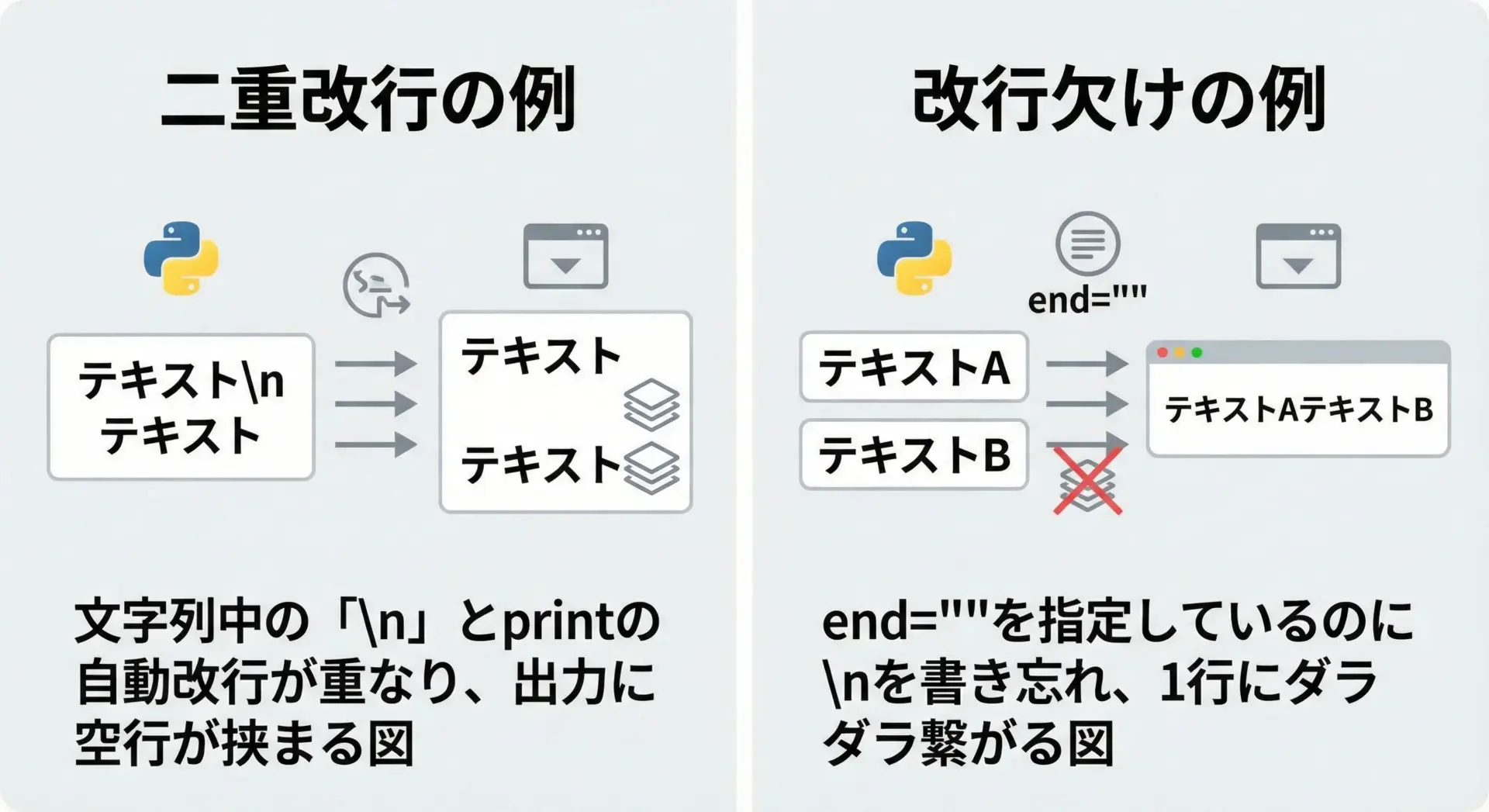
改行トラブルの中でも頻出なのが、「二重改行」と「改行し忘れ」です。
原因と対策を整理しておくと、デバッグ時間を大きく削減できます。
二重改行の典型例と対策
# 二重改行が発生する例
print("line1\n")
print("line2\n")line1
line2各行末に\nを含めているのに、printがさらに改行を追加するため、空行ができてしまいます。
対策は次のいずれかです。
- 文字列中の末尾改行を削る
print("line1")
print("line2")printのendを調整する
print("line1\n", end="")
print("line2\n", end="")「改行を誰が担当するか」を決めておくと、コード全体がすっきりします。
例えば「printには末尾改行を任せるので、文字列中には末尾\nを書かない」といったルールです。
改行欠けを防ぐためのチェックポイント
ログ出力や進捗表示などで、改行を明示的に制御したい場合もあります。
# 改行されずに1行に続いてしまう例
for i in range(3):
print(f"step {i}", end="")step 0step 1step 2このような場合は、endや\nの付け方をコーディング規約で揃えておくと安心です。
例えば次のようにまとめておくとよいでしょう。
- 通常のログ: 改行は
printのendに任せる - 進捗バー:
end=""で同じ行を上書きし、完了時にだけprint()で改行を入れる
改行コードの混在を検知・統一するテクニック
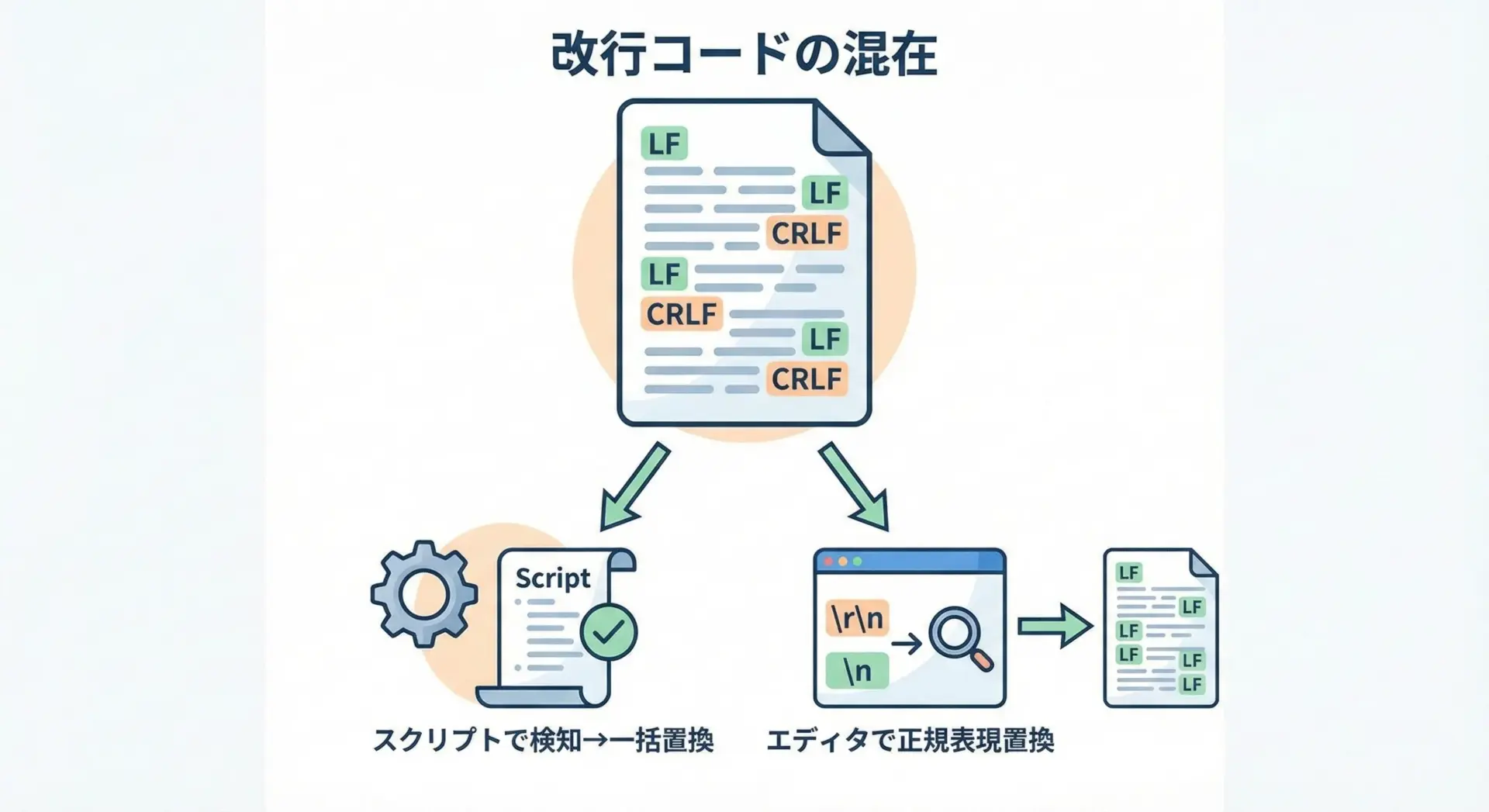
他人から受け取ったファイルや、古い環境からコピーされたデータでは、改行コードが混在していることがあります。
これは差分ツールや一部ツールで問題を引き起こします。
Pythonを使って混在を検知し、統一する簡単なスクリプトを見てみます。
from pathlib import Path
def detect_newlines(path: Path) -> None:
data = path.read_bytes()
crlf = data.count(b"\r\n")
lf = data.count(b"\n") - crlf # CRLF分を引く
cr = data.count(b"\r") - crlf # CRLF分を引く
print(f"ファイル: {path}")
print(f" LF (\\n): {lf}")
print(f" CRLF (\\r\\n): {crlf}")
print(f" CR (\\r): {cr}")
def normalize_to_lf(src: Path, dst: Path | None = None) -> None:
if dst is None:
dst = src
data = src.read_bytes()
# まず CRLF を LF に
data = data.replace(b"\r\n", b"\n")
# 残った CR を LF に
data = data.replace(b"\r", b"\n")
dst.write_bytes(data)
# 使用例
path = Path("mixed_newlines.txt")
detect_newlines(path)
normalize_to_lf(path) # 上書きでLFに統一
detect_newlines(path)ファイル: mixed_newlines.txt
LF (\n): 5
CRLF (\r\n): 3
CR (\r): 1
ファイル: mixed_newlines.txt
LF (\n): 9
CRLF (\r\n): 0
CR (\r): 0このように、一度バイナリとして読み込み、replaceで逐次置換するのが確実です。
特にGitの管理下にないログや外部データなどは、この方法で事前に整形しておくと安全です。
Git設定とエディタ設定で改行トラブルを回避

改行トラブルはコード上だけでなく、Gitやエディタの設定にも深く関係します。
特にWindowsとUnix系の混在環境では、次のポイントを押さえておくことが重要です。
Gitのcore.autocrlf設定
Gitにはcore.autocrlfという設定があり、チェックアウト/コミット時の改行変換を制御します。
- Windowsでのよくある設定:
git config --global core.autocrlf true- チェックアウト時: LF → CRLF
- コミット時: CRLF → LF
- Unix系での設定:
core.autocrlf falseが一般的
プロジェクトとしては、リポジトリ内のテキストファイルをLFで統一し、開発環境ごとの変換はGitに任せる運用が多いです。
さらに、.gitattributesで個別の拡張子ごとに改行ポリシーを指定できます。
# .gitattributes の例
# 一般的なテキストファイルは自動判定
* text=auto
# ソースコードはLFに統一
*.py text eol=lf
*.sh text eol=lf
# バイナリファイルは変換しない
*.png binary
*.jpg binaryエディタの改行設定
エディタ側でも、新規ファイルのデフォルト改行コードを指定できます。
実務では、次のような方針が無難です。
- プロジェクトでLFを標準と決める
- エディタの設定もLFに統一する
- 既存のCRLFファイルを開いた場合は、変更するかどうかをプロジェクトルールに従って判断する
VS Codeの例では、右下のステータスバーから「LF」「CRLF」を切り替えられます。
また、「ファイル保存時に自動でLFに変換」する設定を有効にしておくと、混在防止に役立ちます。
実務で役立つ改行・newlineのベストプラクティス
ここまでの内容を踏まえ、実務で特に役立つポイントをまとめておきます。
1つ目は、「画面表示の改行」と「ファイル保存の改行」を分けて考えることです。
画面表示ではprintのendを基本とし、文字列中の末尾\nは避ける。
ファイル保存ではopenのnewlineを意識して、目的に応じてNone、""、"\n"を使い分けるようにします。
2つ目は、CSVや外部ツールと連携する形式では、そのツールの期待する改行仕様を確認することです。
Pythonのcsvモジュールでnewline=""を指定するのはその代表例です。
3つ目は、プロジェクト全体でLFを標準にし、Gitとエディタの設定も合わせることです。
これによりOS差異の多くは解消されます。
どうしてもCRLFが必要なファイル(例えば一部のWindows専用ツール向け設定ファイルなど)は、.gitattributesなどで個別に指定します。
4つ目は、複数行の文字列はjoinやtextwrap.dedentを活用して、余計な改行やインデントが入り込まないようにすることです。
テスト時にはreprで内部表現を確認するのも有効です。
最後に、「挙動が怪しい」と感じたときには、バイナリで開いて実際のバイト列を確認することをおすすめします。
Pythonはそのための機能を一通り提供しており、正しく使えば改行に振り回されることは大きく減らせます。
まとめ
Pythonの改行は、文字列中の\nと、ファイル操作でのnewline引数の2層構造で理解すると整理しやすくなります。
画面表示ではprintのendと\nの重複に注意し、ファイル入出力ではテキストモードとバイナリモード、そしてnewlineの設定を意識することが重要です。
特にCSVのnewline=""指定や、Git・エディタでLF統一を行うだけでも、多くのトラブルは未然に防げます。
本記事のポイントを押さえておけば、OSをまたいだ開発でも改行まわりで悩む場面は大きく減るはずです。
