
Pythonでの文字列結合や繰り返しは、ログ生成やレポート出力、ファイル名生成など、あらゆる場面で登場します。
本記事では、実務ですぐ使えるサンプルに重点を置きながら、結合の基本からパフォーマンスを意識した書き方までを丁寧に解説します。
Pythonを仕事で使う際に、そのままコピペして応用できるレベルを目指します。
Pythonの文字列結合の基本
+演算子でのシンプルな文字列結合
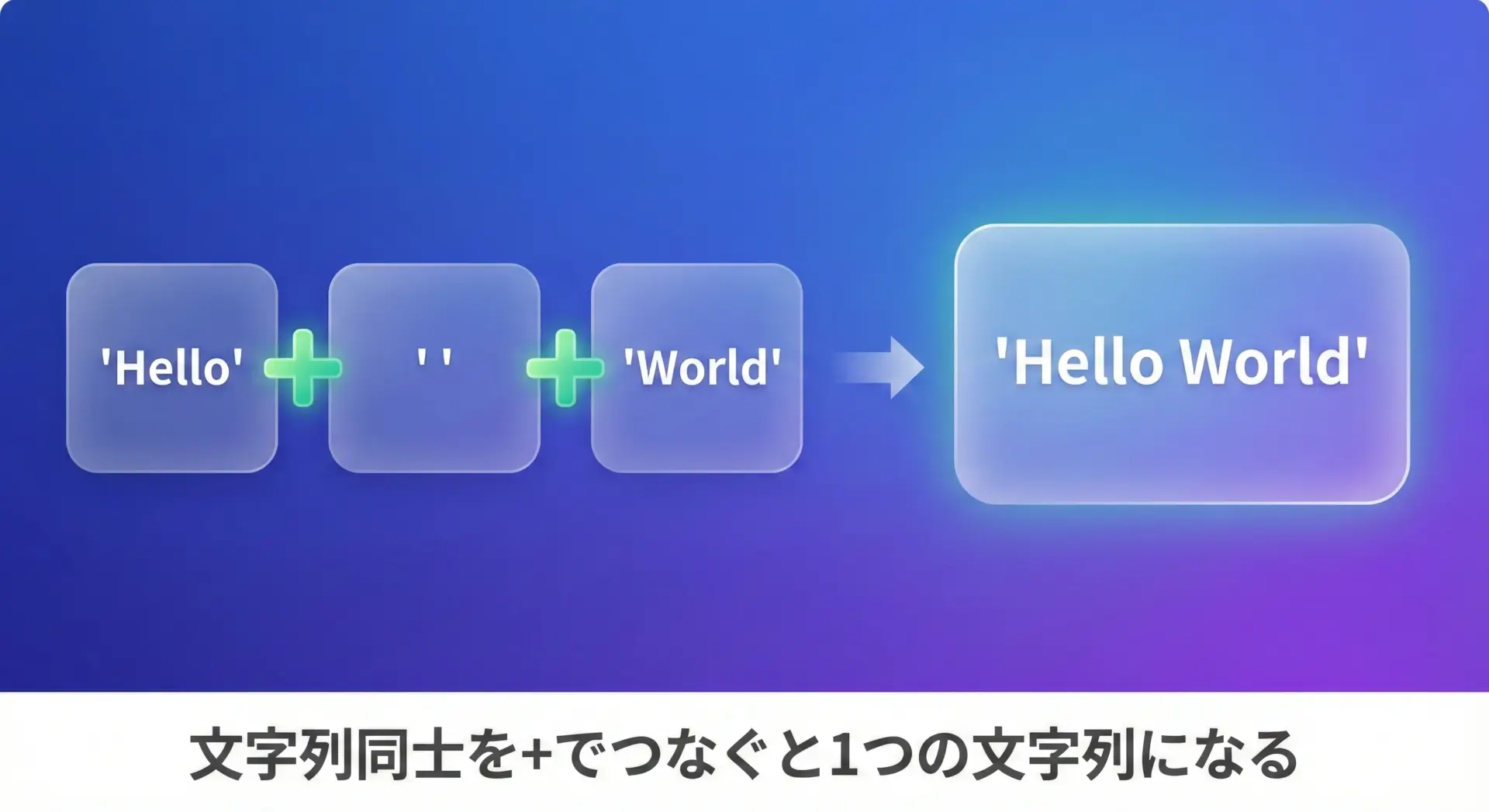
+演算子の基本
Pythonでは、文字列同士を+でつなぐだけで簡単に結合できます。
もっとも直感的でわかりやすい方法です。
# シンプルな文字列結合の例
first_name = "Taro"
last_name = "Yamada"
# + 演算子で結合
full_name = first_name + " " + last_name
print(full_name) # Taro Yamada と表示されるTaro Yamada短い文字列を少数回だけ結合する場合は、この+演算子を使うのがもっとも読みやすく、実務でも日常的に使われます。
+演算子使用時の注意点
Pythonでは、文字列型と数値型をそのまま+で結合することはできません。
数値を含めたい場合は文字列に変換する必要があります。
age = 30
# str() で文字列に変換してから結合する
message = "Age: " + str(age)
print(message)Age: 30数値のまま “Age: ” + age と書くと TypeError になります。
このエラーは頻出なので覚えておくとデバッグが楽になります。
複数要素を””.joinで効率的に結合
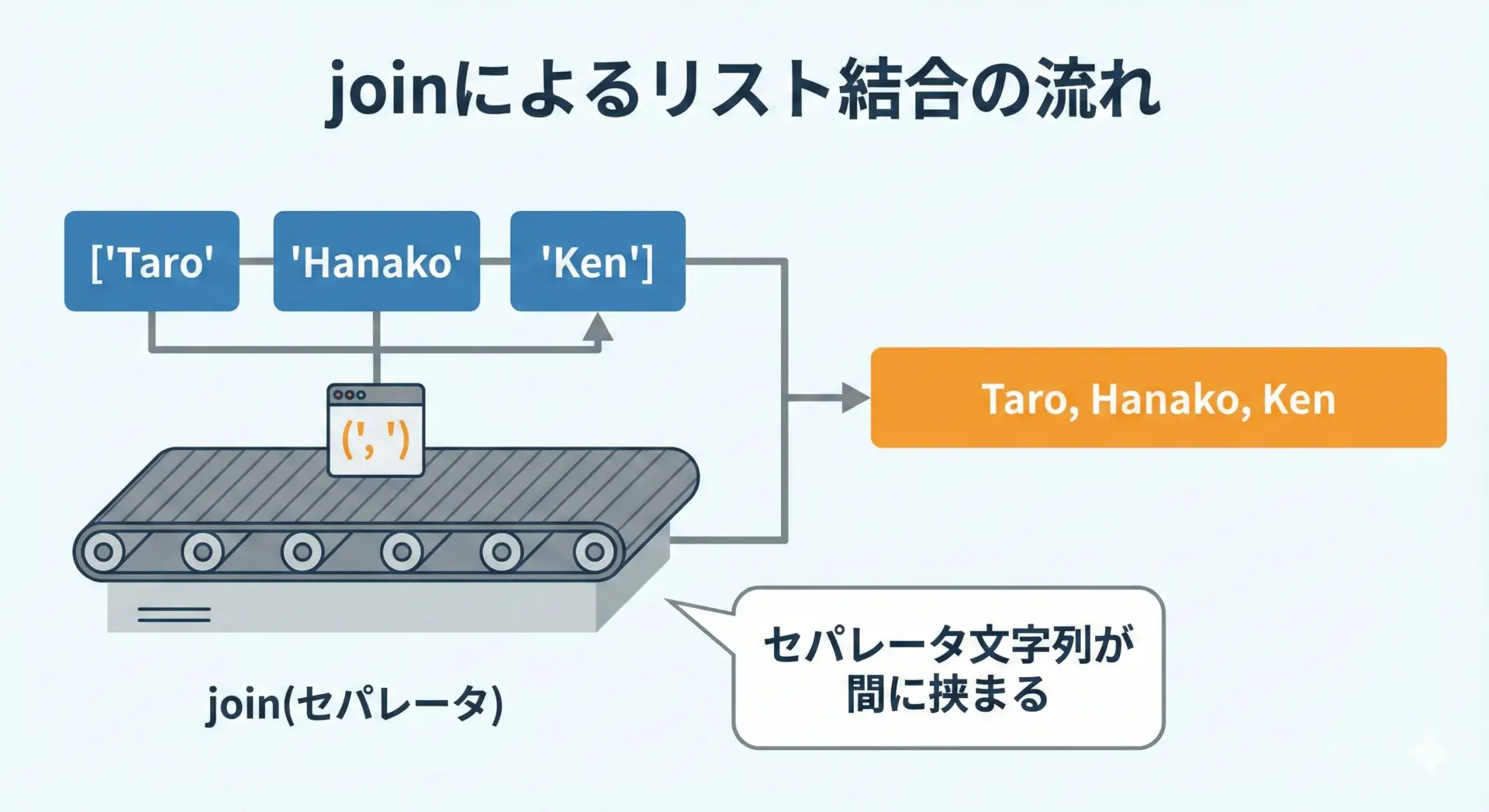
joinの基本イメージ
たくさんの要素をまとめて結合するときは、str.join()を使うと効率的です。
特にリストやタプルのような反復可能オブジェクトを結合する場合に威力を発揮します。
# join でリスト内の文字列を結合する例
names = ["Taro", "Hanako", "Ken"]
# ", " を区切り文字として結合
csv_line = ", ".join(names)
print(csv_line)Taro, Hanako, Ken“区切り文字列”.join(シーケンス)の形で使うのがポイントです。
区切り文字に何を使うかで用途が変わります。
代表的な区切り文字の使い分け
用途によって区切り文字を変えることで、そのまま実務で使える文字列が生成できます。
| 用途 | 区切り文字例 | 出力例 |
|---|---|---|
| CSV行 | "," | "1,2,3" |
| スペース区切りのログ | " " | "INFO 2025-01-01 start" |
| パス風の結合 | "/" | "api/v1/users" |
| 複数行テキスト | "\n" | 複数行の文字列 |
f文字列(f-string)で変数を埋め込んで結合
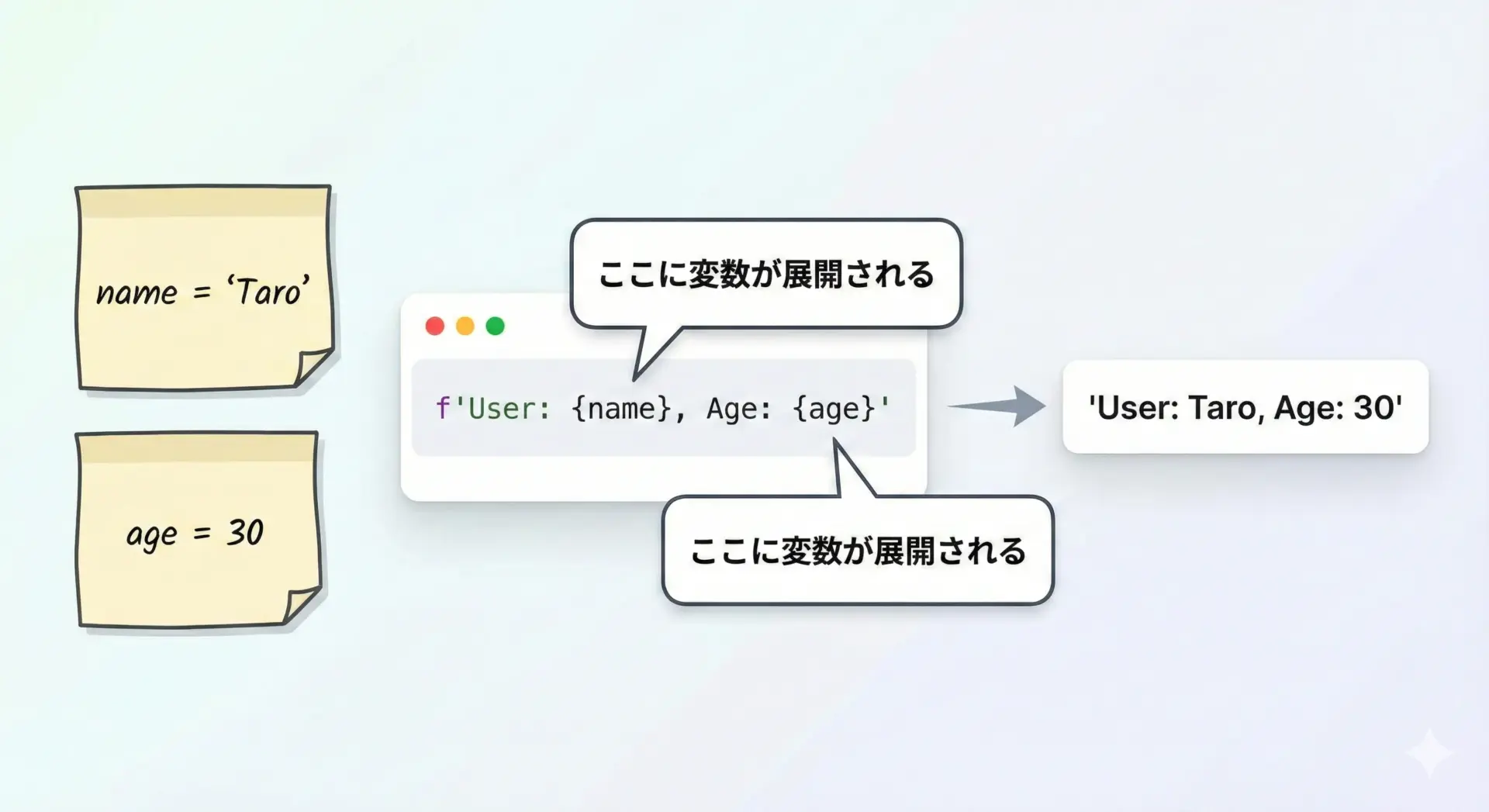
f文字列の書き方
Python 3.6以降では、f文字列(f-string)によって、{ }の中に変数や式を直接書いて文字列に埋め込めます。
可読性が高く、実務での利用頻度も非常に高いです。
# f文字列での文字列結合と変数埋め込み
name = "Taro"
age = 30
# f の後にクォート、{} の中に変数名を記述
message = f"User: {name}, Age: {age}"
print(message)User: Taro, Age: 30f文字列で計算式や書式指定も可能
f文字列の中では簡単な式もそのまま書けるため、ログやレポート生成に向いています。
price = 1200
tax_rate = 0.1
# 税込価格を計算しながら埋め込む
message = f"税抜: {price}円 / 税込: {int(price * (1 + tax_rate))}円"
print(message)税抜: 1200円 / 税込: 1320円数値フォーマットも:以降に指定できます。
score = 0.98765
# 小数点以下2桁で表示
msg = f"正答率: {score:.2%}" # パーセント表示
print(msg)正答率: 98.76%format関数で柔軟な文字列結合を行う

formatメソッドの基本
str.format()は、プレースホルダを柔軟に指定できる文字列フォーマット手法です。
f文字列登場以前から使われており、今でもテンプレート文字列として保管しやすい点から、実務で利用されます。
# format メソッドの基本例
template = "User: {name}, Age: {age}"
message = template.format(name="Taro", age=30)
print(message)User: Taro, Age: 30位置引数を使うこともできます。
template = "X: {0}, Y: {1}"
message = template.format(10, 20)
print(message)X: 10, Y: 20formatとf文字列の使い分け
実務では次のように使い分けると便利です。
- コード内で直書きする短いメッセージ → f文字列
- 外部ファイルや設定として保管したいテンプレート → format
テンプレートを別ファイルやDBに保存するケースでは、"{name}"形式の方が扱いやすいことが多いです。
実務で使う文字列結合パターン集
CSV形式の文字列を結合して生成するサンプル
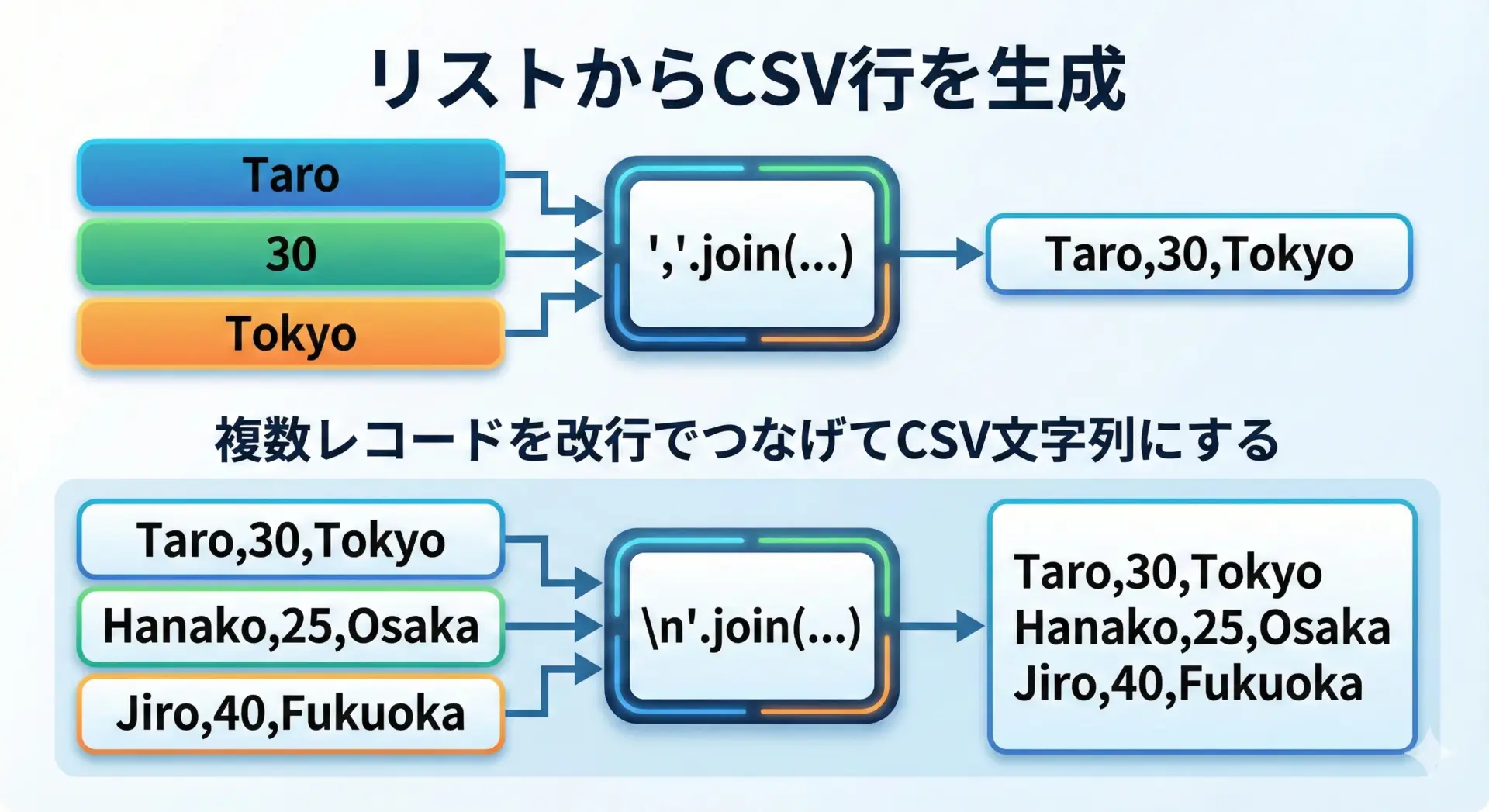
1行分のCSVを生成する
CSVでは、1行がカンマ区切りの文字列です。
Pythonでは",".join()で簡単に作れます。
# 1行分のCSVを結合で生成する例
row = ["Taro", "30", "Tokyo"]
csv_line = ",".join(row)
print(csv_line)Taro,30,Tokyo数値が混ざる場合は、文字列への変換も同時に行います。
# 数値を含むリストからCSV行を生成
row = ["Taro", 30, "Tokyo"]
# map(str, row) ですべて文字列に変換してから join
csv_line = ",".join(map(str, row))
print(csv_line)Taro,30,Tokyo複数行のCSV文字列をまとめて生成する
実務では、行のリストから<u>複数行のCSV文字列</u>をまとめて作る場面が多いです。
# 複数レコードからCSV形式の文字列を生成する例
rows = [
["name", "age", "city"], # ヘッダ
["Taro", 30, "Tokyo"],
["Hanako", 25, "Osaka"],
]
lines = []
for row in rows:
# 各行をCSV形式に変換
line = ",".join(map(str, row))
lines.append(line)
# 行同士を改行で結合して、1つの文字列にする
csv_text = "\n".join(lines)
print(csv_text)name,age,city
Taro,30,Tokyo
Hanako,25,Osakaこのパターンは、ログのバッチ出力や簡易レポートなどでよく使われます。
ファイルパスやURLパスを安全に結合する方法
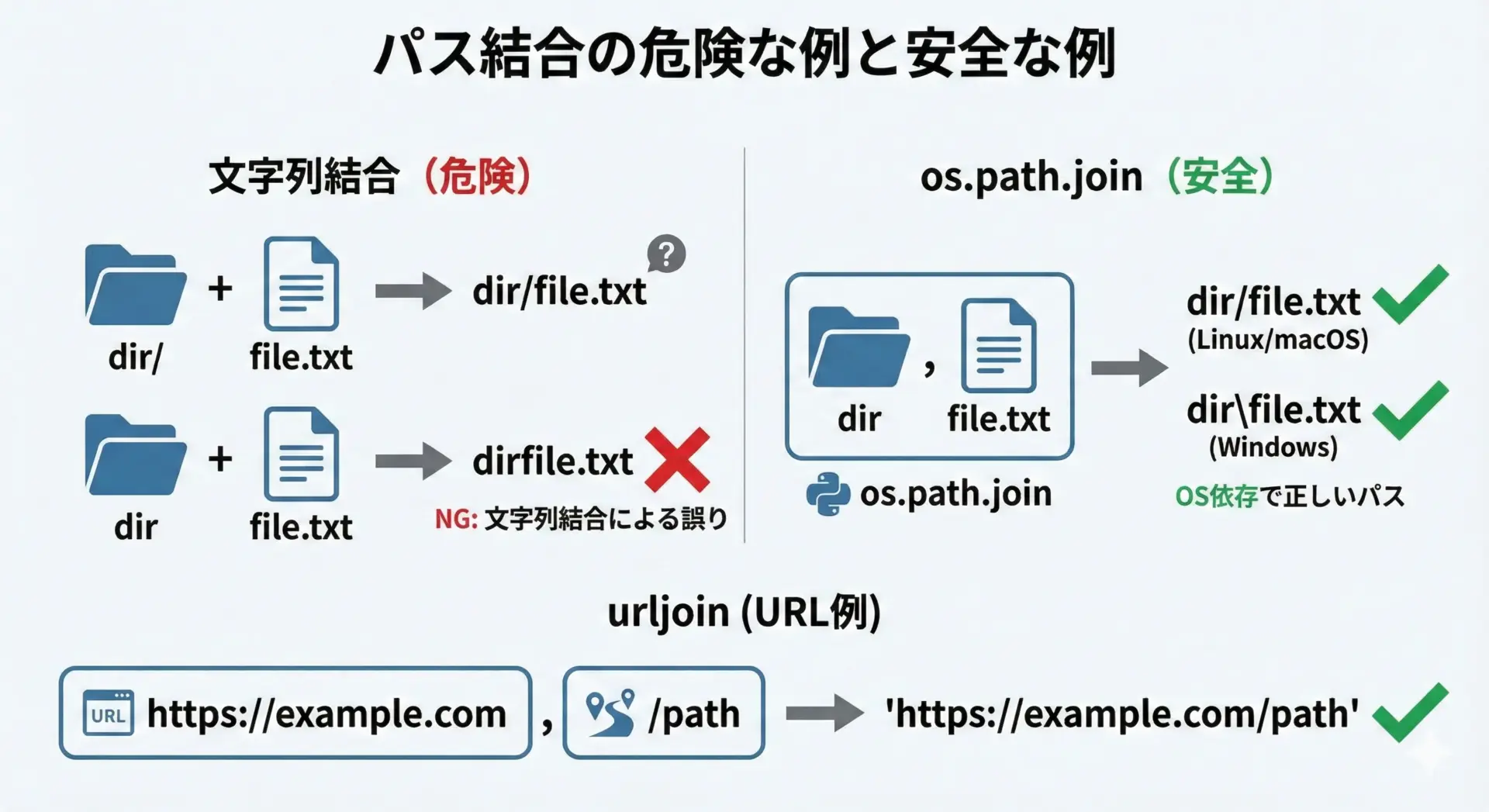
ファイルパスの結合は+より専用関数を使う
ファイルパスを+で結合すると、スラッシュの有無やOS依存の区切り文字問題でバグになりやすいです。
必ず専用の関数を使う習慣をつけましょう。
import os
# 危険な書き方 (例)
base = "/home/user"
filename = "data.txt"
# こう書くと "/home/userdata.txt" になってしまう
bad_path = base + filename
print("bad:", bad_path)
# 安全な書き方
good_path = os.path.join(base, filename)
print("good:", good_path)bad: /home/userdata.txt
good: /home/user/data.txtos.path.join()は、Windowsなら\、LinuxやmacOSなら/と、OSに応じた区切り文字を自動で使ってくれます。
Python 3.4以降なら、pathlibを使うとより直感的です。
from pathlib import Path
base = Path("/home/user")
filename = "data.txt"
path = base / filename # /演算子で結合できる
print(path)/home/user/data.txtURLパスの結合はurllib.parse.urljoinを使う
URLも+で雑に結合すると、スラッシュの数が合わずにおかしなURLになりがちです。
from urllib.parse import urljoin
base_url = "https://example.com/api/"
path = "v1/users"
full_url = urljoin(base_url, path)
print(full_url)https://example.com/api/v1/usersベースURL側に末尾スラッシュがない場合も、urljoinがいい感じに調整してくれます。
ログメッセージを動的に組み立てるサンプル
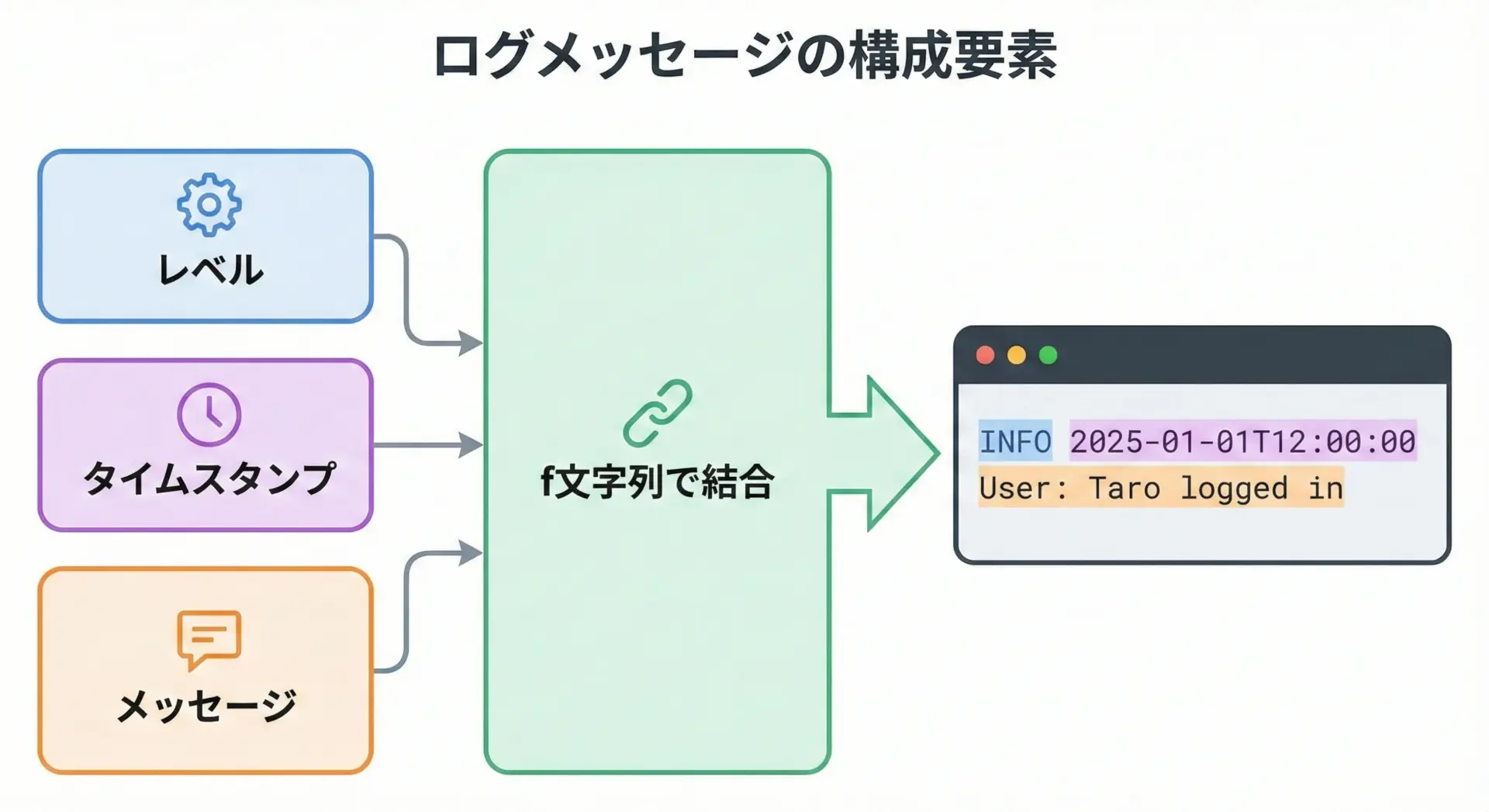
f文字列でログを整形する
ログメッセージは、複数の情報を読みやすく1行にまとめる必要があります。
f文字列を使うとシンプルに書けます。
from datetime import datetime
level = "INFO"
user = "Taro"
action = "login"
timestamp = datetime.now().isoformat(timespec="seconds")
log_message = f"{level} {timestamp} user={user} action={action}"
print(log_message)INFO 2025-12-14T10:30:45 user=Taro action=loginjoinで多くのフィールドを扱う場合
フィールドが増えてくると、joinとの組み合わせで整理すると見通しが良くなります。
from datetime import datetime
level = "INFO"
user = "Taro"
action = "login"
ip = "192.168.1.10"
timestamp = datetime.now().isoformat(timespec="seconds")
parts = [
level,
timestamp,
f"user={user}",
f"action={action}",
f"ip={ip}",
]
log_message = " ".join(parts)
print(log_message)INFO 2025-12-14T10:30:45 user=Taro action=login ip=192.168.1.10「生の値」と「key=value形式」を混在させるパターンは実務のログでよく使われます。
辞書やリストからレポート用文字列を結合する
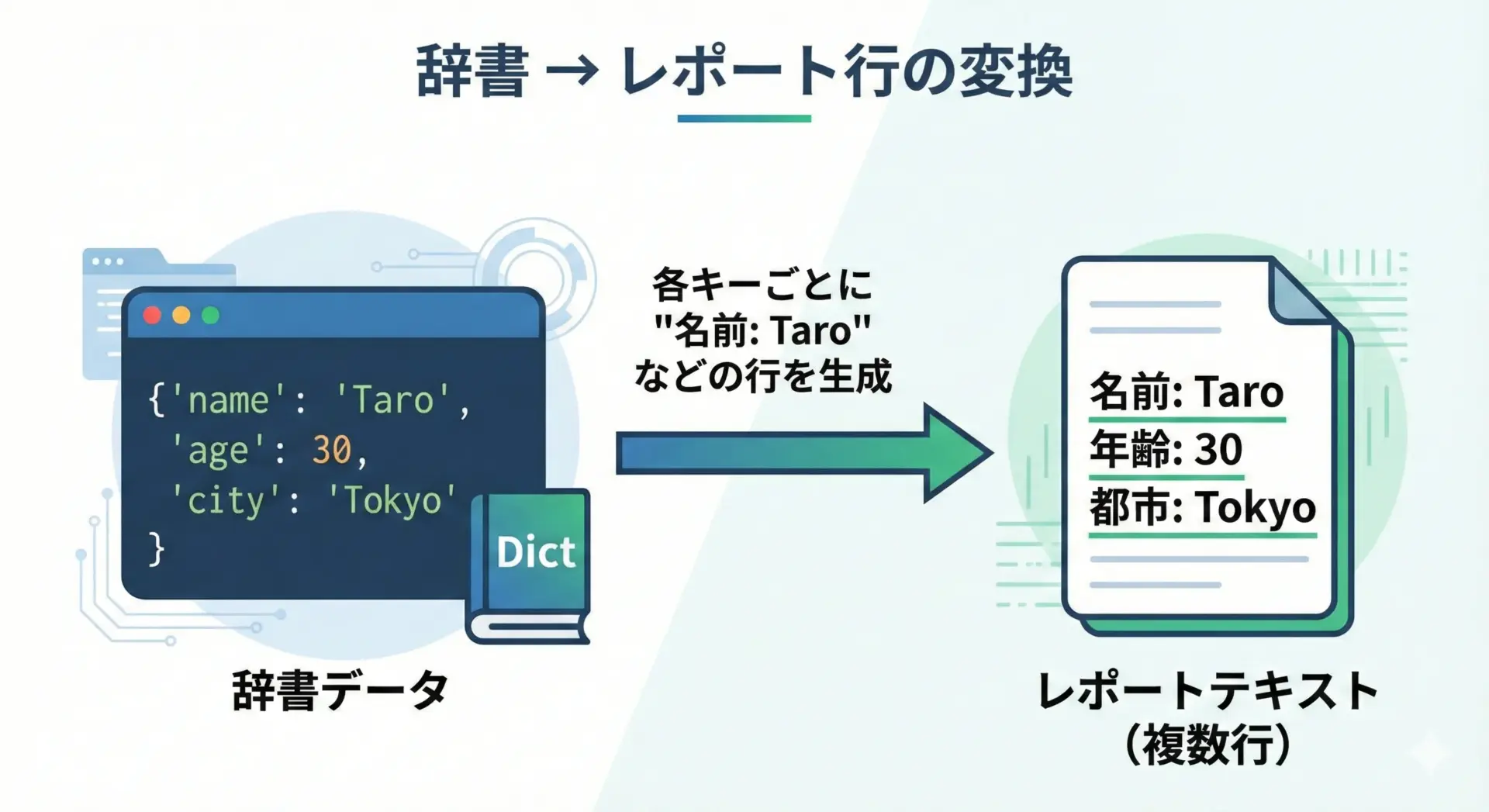
辞書から単票レポートを作る
APIレスポンスやDB取得結果など、辞書データから見やすいレポートを作るパターンです。
# 辞書からレポート用の文字列を生成する例
user = {
"name": "Taro",
"age": 30,
"city": "Tokyo",
}
lines = [
f"名前: {user['name']}",
f"年齢: {user['age']}",
f"都市: {user['city']}",
]
report = "\n".join(lines)
print(report)名前: Taro
年齢: 30
都市: Tokyoリストから表形式のレポートを作る
複数レコードのリストから、簡易的な表を文字列で作ることも多いです。
# 複数ユーザーの簡単な表を文字列で生成
users = [
{"name": "Taro", "age": 30, "city": "Tokyo"},
{"name": "Hanako", "age": 25, "city": "Osaka"},
]
# ヘッダ行
lines = ["name,age,city"]
for u in users:
line = ",".join([u["name"], str(u["age"]), u["city"]])
lines.append(line)
table_text = "\n".join(lines)
print(table_text)name,age,city
Taro,30,Tokyo
Hanako,25,Osakaこのような「ヘッダ + 行のjoin」パターンは、CSVやTSV形式のレポート生成で定番です。
改行やタブを含む複数行文字列を結合するテクニック
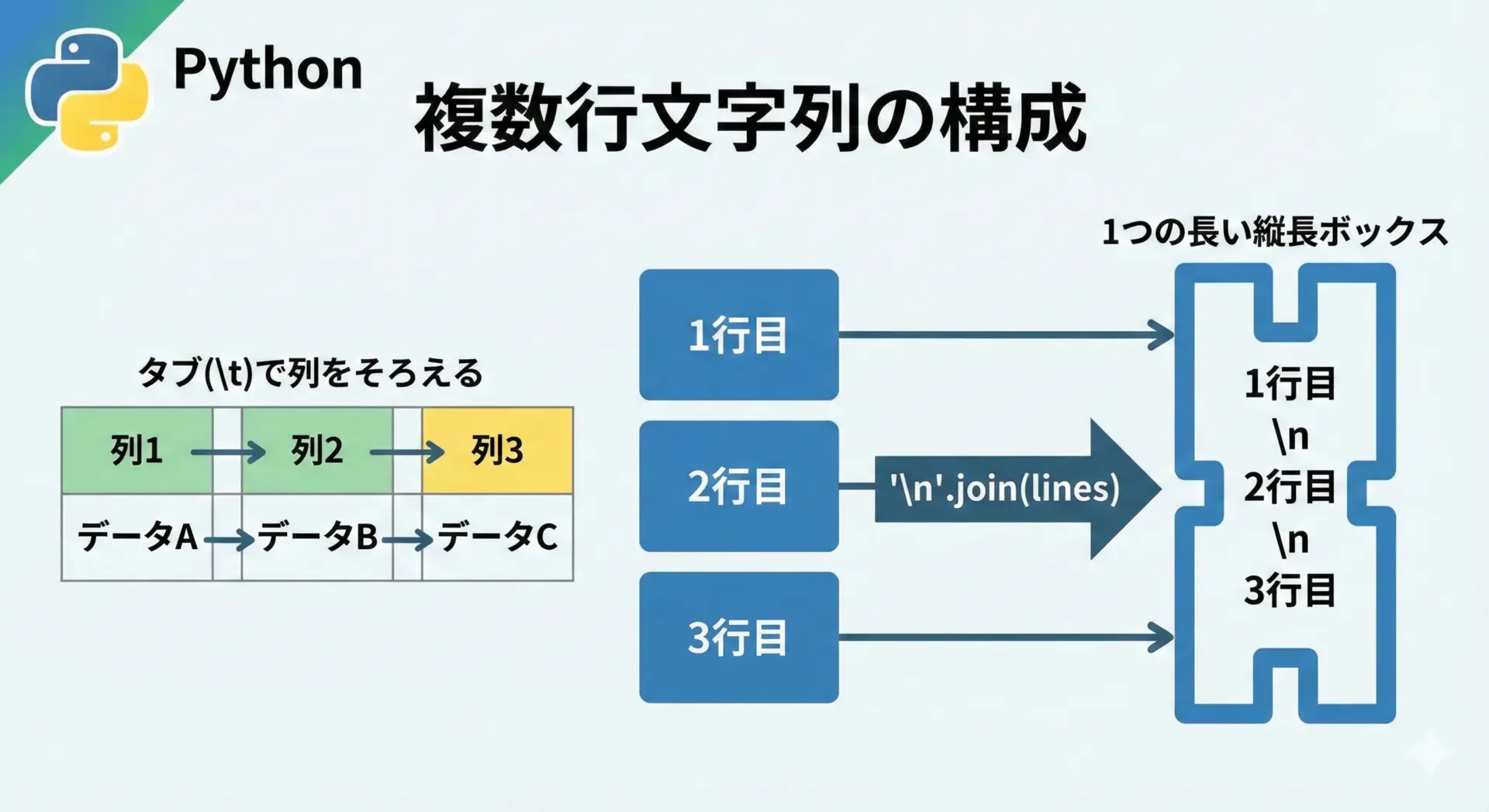
\nや\tを使った制御文字
Pythonでは、改行には"\n"、タブには"\t"といった制御文字を使います。
これらを組み合わせて、複数行のテキストをきれいに整形します。
# 複数行を改行文字で結合する例
lines = [
"1行目のテキスト",
"2行目のテキスト",
"3行目のテキスト",
]
text = "\n".join(lines)
print(text)1行目のテキスト
2行目のテキスト
3行目のテキストタブを使って簡易表を作ることもできます。
# タブ区切りで列を揃えたテキストを生成
rows = [
["name", "age", "city"],
["Taro", "30", "Tokyo"],
["Hanako", "25", "Osaka"],
]
lines = []
for row in rows:
line = "\t".join(row)
lines.append(line)
text = "\n".join(lines)
print(text)name age city
Taro 30 Tokyo
Hanako 25 Osakaテキストファイルとして保存するときも、このようにjoinを使うと扱いやすくなります。
Pythonの文字列繰り返しの基本と応用
*演算子で文字列を繰り返す基本文法
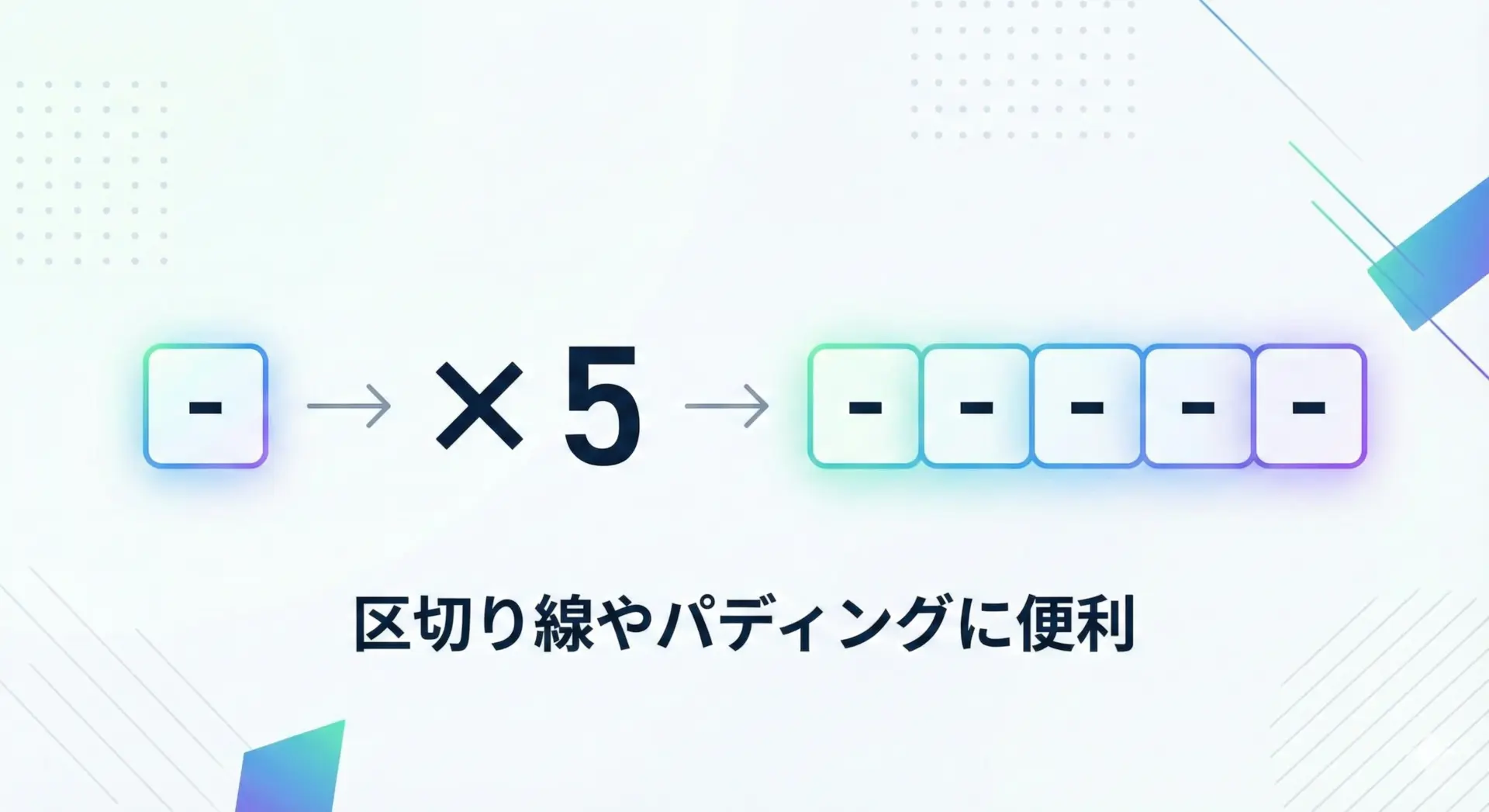
*演算子による繰り返し
Pythonでは、文字列に整数を*で掛けることで、指定回数だけ繰り返した文字列を生成できます。
# 文字列を繰り返す基本
line = "-" * 10
print(line)----------罫線や余白の生成など、シンプルな用途によく使われます。
区切り付きの繰り返しパターンを作る
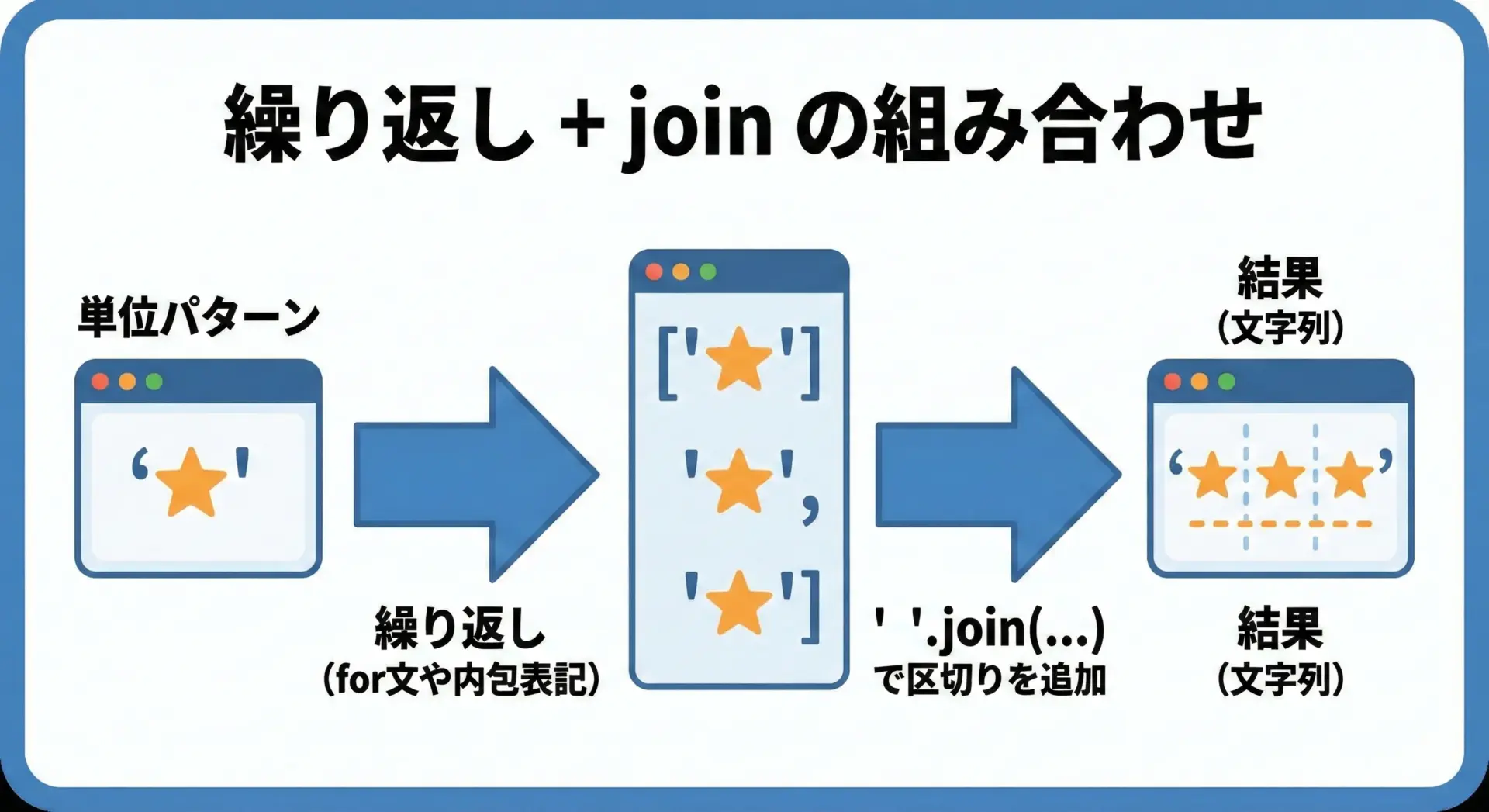
joinと組み合わせたパターン生成
例えば、“* * * * *”のように、区切り付きで繰り返したい場合は、joinと組み合わせるときれいに書けます。
# 区切り付きの繰り返しパターン
unit = "*"
count = 5
# unit を count 回並べたリストを作り、" " で結合
pattern = " ".join([unit] * count)
print(pattern)* * * * *単位要素に文字列を指定し、それを[unit] * countで増やし、最後にjoinで結合するパターンは覚えておくと便利です。
表や罫線を繰り返し文字列で生成する
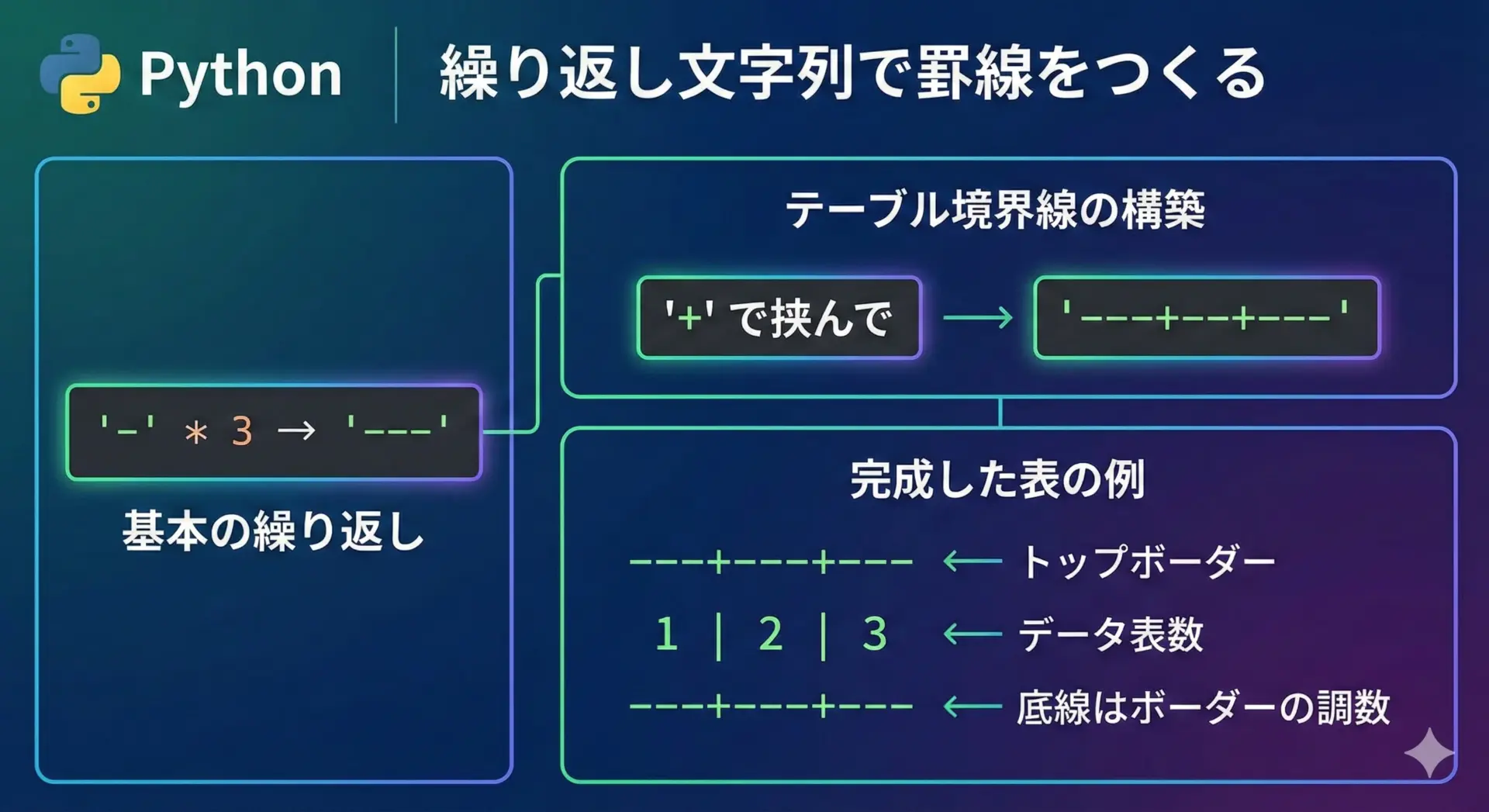
罫線やテーブル枠の生成
簡易的な表やメニューをCLIで出力したいときに、繰り返し文字列はとても役立ちます。
# 罫線付きの簡単な表を出力する例
cols = 3
col_width = 5
# 各列の横幅分 "-" を並べ、それを "+" で区切った境界線
border = "+".join(["-" * col_width] * cols)
# データ行も適当に用意
row = ["A", "B", "C"]
# 各セルの中身を中央寄せで整形
line = "|".join([f"{cell:^{col_width}}" for cell in row])
print(border)
print(line)
print(border)-----+-----+-----
A | B | C
-----+-----+-----「単位パターンを * で増やす → join でつなぐ」という発想は、表形式のCLIツールを書くときに多用されます。
プレースホルダ付きテンプレートを繰り返し適用する
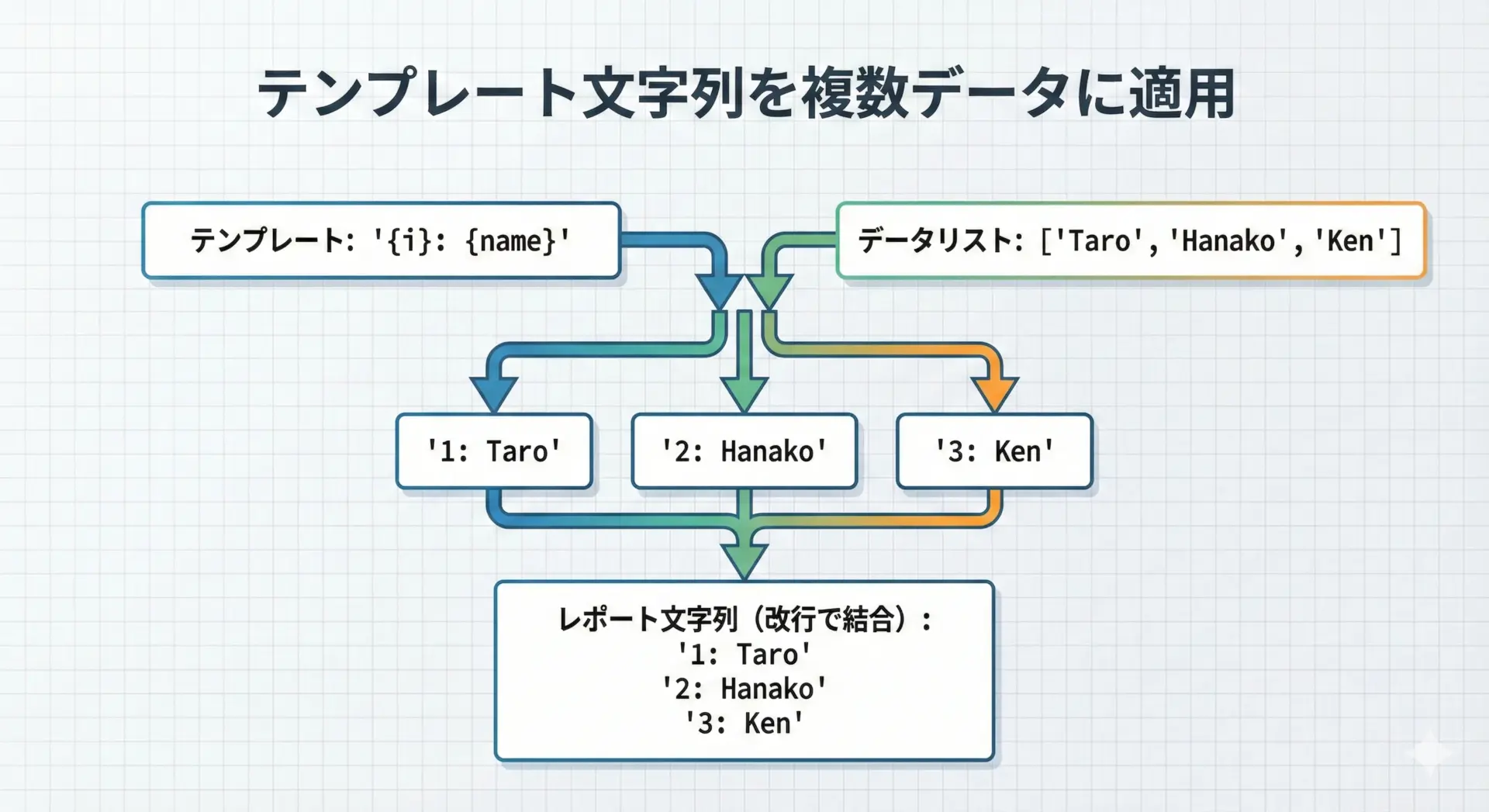
formatテンプレートをループで使う
同じ形式の行を、複数のデータに対して繰り返し生成するのもよくあるパターンです。
# テンプレート文字列を繰り返し適用してリスト表示を作る例
names = ["Taro", "Hanako", "Ken"]
template = "{index}. 名前: {name}"
lines = []
for i, name in enumerate(names, start=1):
line = template.format(index=i, name=name)
lines.append(line)
result = "\n".join(lines)
print(result)1. 名前: Taro
2. 名前: Hanako
3. 名前: Ken同じテンプレートを「データ件数分だけ繰り返し適用 → 改行で結合」という流れは、メール本文や通知文の生成でも重宝します。
実務で役立つ文字列結合&繰り返しテクニック
大量データの文字列結合でパフォーマンスを確保する
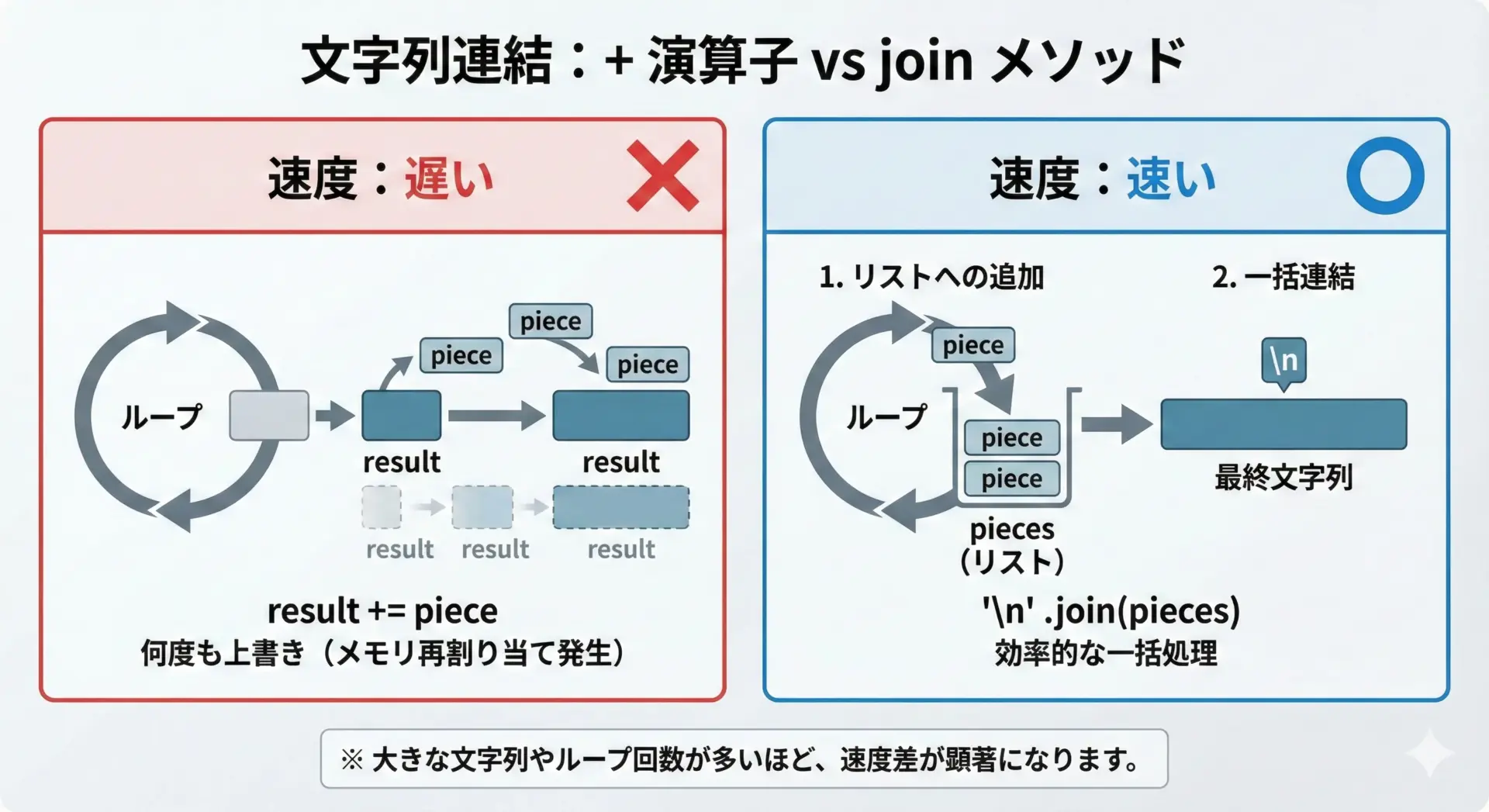
ループ内の+連結は避ける
Pythonの文字列はイミュータブル(不変)なので、+で連結するたびに新しい文字列が作られます。
大量の繰り返しでは非効率です。
# 悪い例: ループの中で += し続ける
items = [str(i) for i in range(10000)]
result = ""
for item in items:
result += item + "\n" # 毎回新しい文字列が作られてしまうこのような場合は、まずリストに貯めてから最後にjoinします。
# 良い例: リストに貯めてから join する
items = [str(i) for i in range(10000)]
lines = []
for item in items:
lines.append(item)
result = "\n".join(lines)データ件数が多いときほど、join方式にするだけで速度とメモリ使用量が大きく改善されます。
リスト内包表記とjoinでスマートに文字列生成
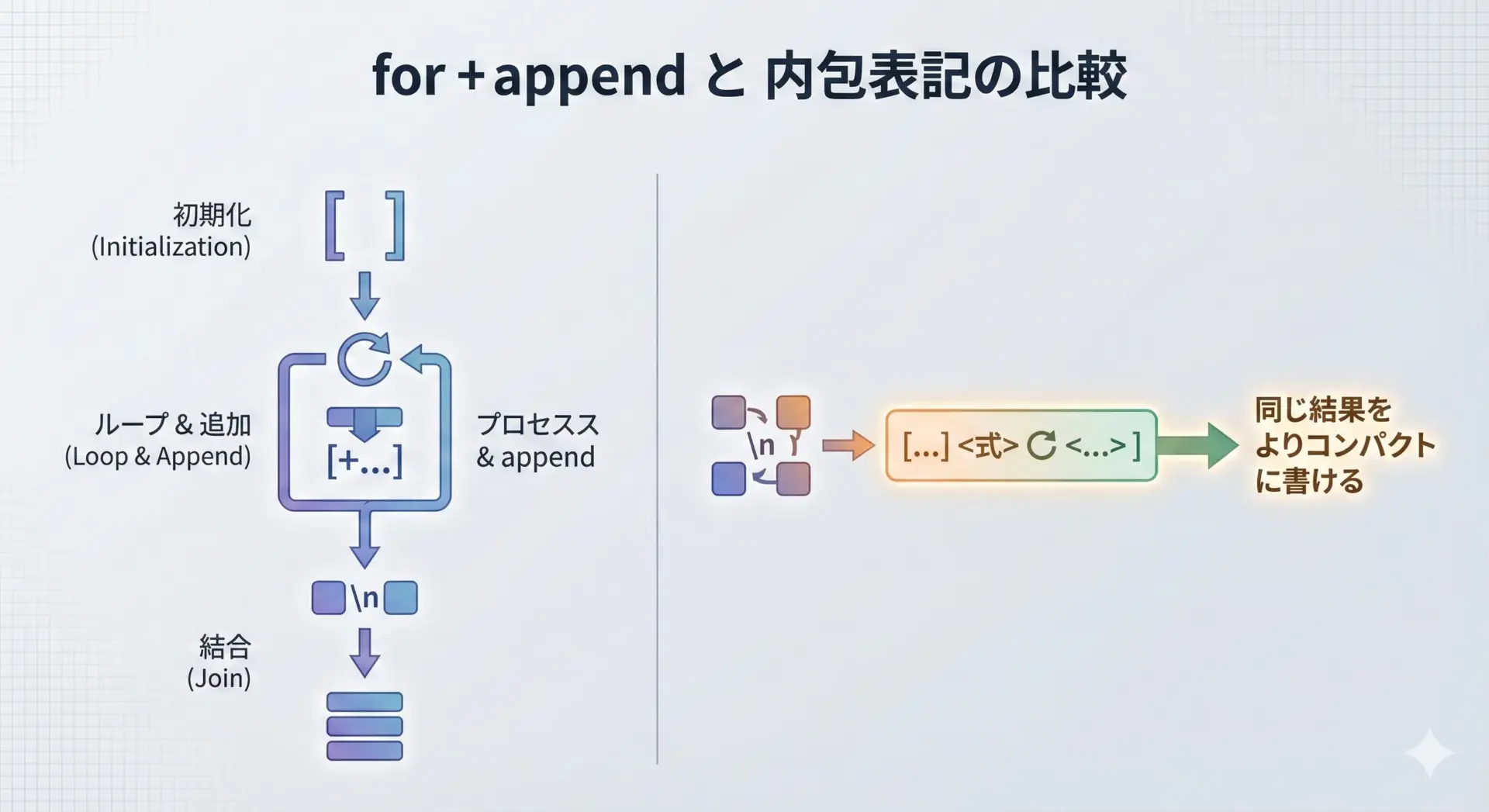
内包表記を使った1行生成
リスト内包表記やジェネレータ式とjoinを組み合わせると、変換と結合をまとめて書けるので、実務コードがすっきりします。
# リスト内包表記と join で番号付きリストを生成
names = ["Taro", "Hanako", "Ken"]
text = "\n".join(
f"{i}. {name}"
for i, name in enumerate(names, start=1)
)
print(text)1. Taro
2. Hanako
3. Ken内包表記が長くなりすぎる場合は、カッコで改行しながら書くと読みやすくなります。
条件付きで文字列を結合・繰り返しする書き方
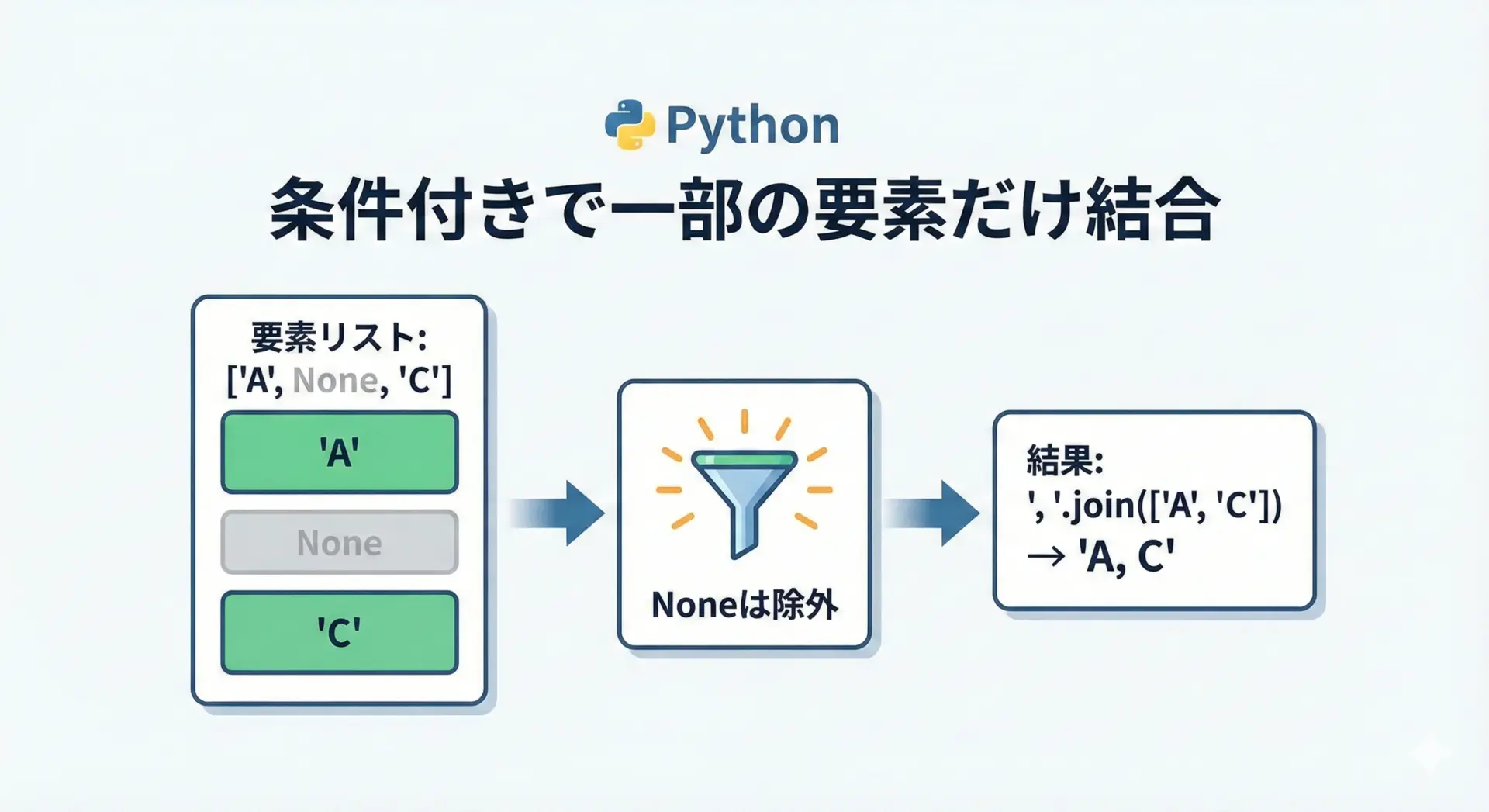
Noneや空文字を飛ばして結合する
オプション項目が入る場合、存在するものだけ結合したいことがあります。
# None や空文字を除外して結合する例
first = "Taro"
middle = None
last = "Yamada"
parts = [first, middle, last]
# 真偽値コンテキストで False (None, 空文字など) なものを除外
filtered = [p for p in parts if p]
full_name = " ".join(filtered)
print(full_name)Taro Yamada条件に応じて特定の文字列だけ繰り返すこともあります。
# 条件付きで警告マーカーを繰り返す例
is_warning = True
marker = "!" * 3 if is_warning else ""
message = f"{marker} データが不足しています {marker}"
print(message)!!! データが不足しています !!!日本語文字列の結合と繰り返しで気をつけるポイント
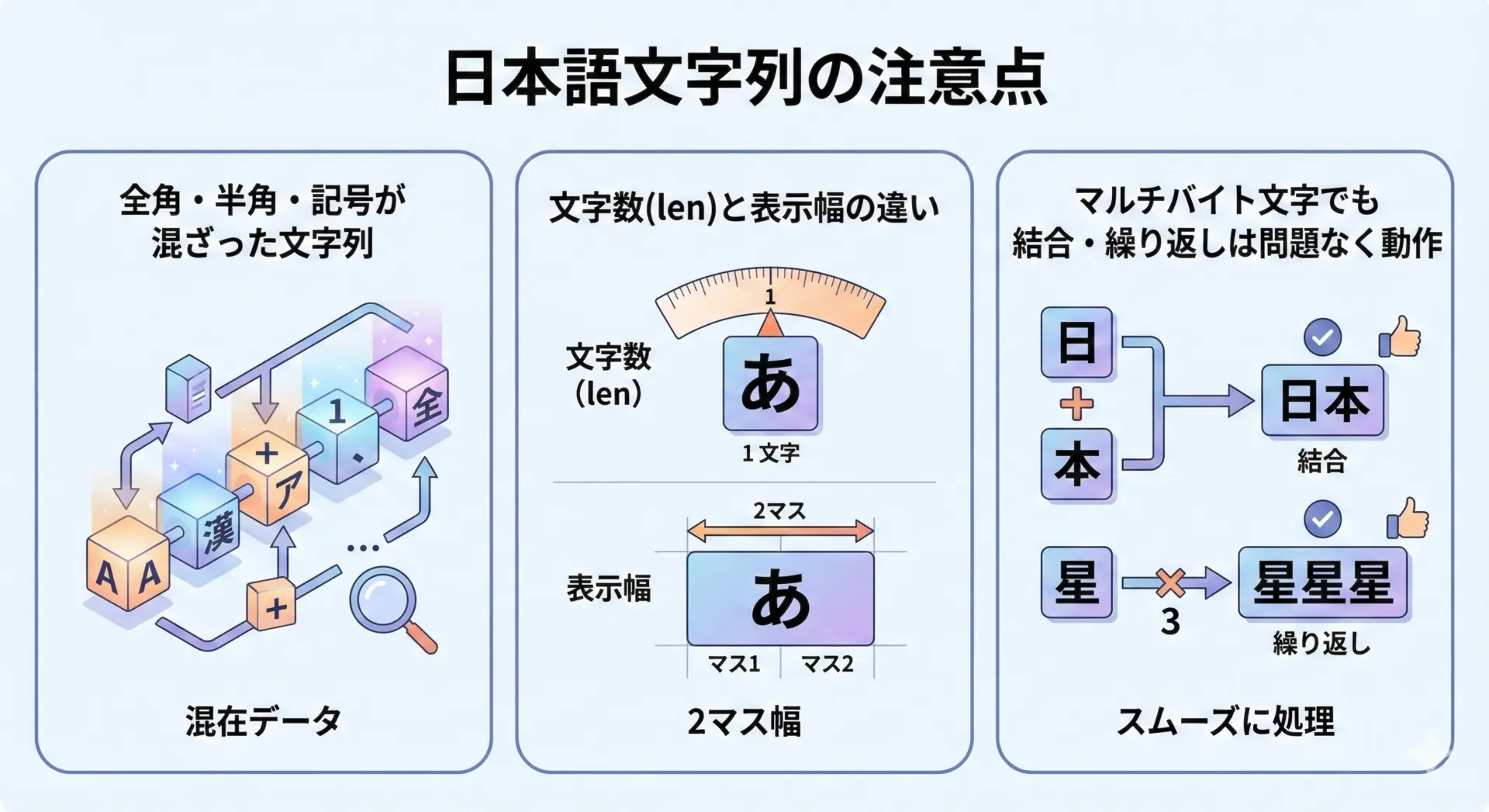
エンコーディングと結合
Python 3では文字列は基本的にUnicodeとして扱われるため、日本語を含む文字列も+やjoinで問題なく結合できます。
# 日本語文字列の結合例
first = "山田"
last = "太郎"
full = first + " " + last
print(full)山田 太郎ただし、ファイル出力やシステム連携時には文字コード(UTF-8など)に注意が必要です。
特にWindows環境では、コンソールのエンコーディングによって文字化けが起きることがあります。
日本語と表示幅の問題
日本語は1文字が2桁分の幅で表示されることが多いため、「文字数」と「表示幅」が一致しない点に注意します。
単純にlen()だけで桁数を揃えようとすると、見た目がずれることがあります。
# 日本語と英数字が混ざると len と見た目の幅がずれる例
s1 = "ABC"
s2 = "あい"
print(len(s1), len(s2)) # 3 と 2 が表示される3 2見た目の列揃えが重要な場合(ログ、表形式出力など)は、wcwidthライブラリなどを使って表示幅を計算するか、あえて日本語を使わず英数字だけで表現する、といった運用上の工夫が必要になることもあります。
まとめ
Pythonの文字列結合と繰り返しは、+演算子やjoin、f文字列、formatを組み合わせることで、実務レベルのログ、CSV、レポート、テーブル出力まで幅広く対応できます。
大量データではjoinによる効率的な結合を心がけ、パスやURLには専用の関数を使うことで安全性も高まります。
ここで紹介したパターンをベースに、自分のプロジェクトに合わせてテンプレートやヘルパー関数を整備していけば、文字列生成まわりのコードは格段に読みやすく、保守しやすくなります。
