
Pythonで複雑な処理を書いていると、気付けばfor文が3重4重と深くなり、どこで何をしているのか分かりにくくなってしまいます。
この記事では、標準ライブラリのitertoolsを使って多重ループを安全かつ効率よく平坦化する実践パターンを詳しく解説します。
二重ループから三重以上のネスト、条件付きループやbreakを含むケースまで、具体的なレシピ形式で整理していきます。
Pythonの多重ループ問題とは
ネストが深いfor文が抱える課題
コードが「右側に伸びていく」問題
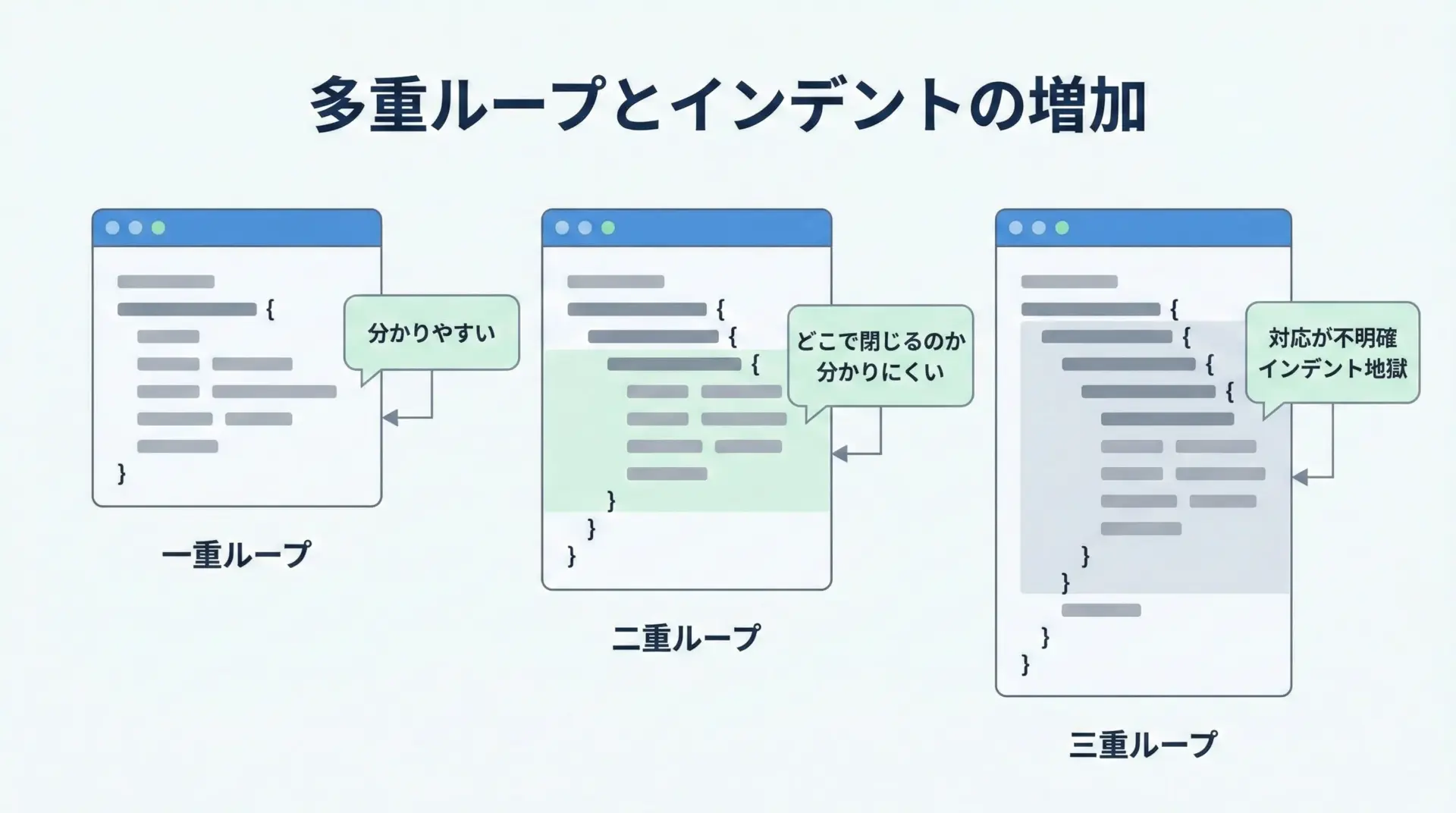
多重ループは、単純な処理なら直感的に書ける一方で、ネストが深くなるほどコードが右側にどんどん押し出されていくという問題があります。
インデントが増えると、どのブロックがどこに対応しているかを目で追うのが難しくなります。
典型的な多重ループの例として、2つのリストの全組み合わせを探索するコードを見てみます。
# 2つのリストの全ての組み合わせを走査する典型的な二重ループ
xs = [1, 2, 3]
ys = [10, 20, 30]
for x in xs:
for y in ys:
# xとyのペアに対して何らかの処理を行う
print(x, y)単純な二重ループならまだ読みやすいですが、これが3重4重と増えていくと、次のような課題が生じます。
- どのforに対応するbreakやcontinueなのか一目で分からない
- 条件分岐
ifが途中に挟まると、処理の流れがさらに追いにくくなる - 少し仕様変更するだけで、複数のネストレベルに手を入れる必要が出てくる
ビジネスロジックとループ構造が混ざる
もう1つ大きな問題が、ビジネスロジックとループ構造が密結合してしまうことです。
ループの中にさらにループ、その中に条件分岐や一時変数の計算が入り込み、次第に「何をやっているコードなのか」よりも「どうループを回しているのか」の方が目立ってしまいます。
パフォーマンスと可読性の低下ポイント
多重ループがパフォーマンスに与える影響
単純な話として、二重ループはO(n×m)、三重ループはO(n×m×k)の計算量になります。
これはitertoolsを使っても計算量自体は変わりませんが、余計な中間リストを作らないことでメモリ効率を改善し、全体としてのパフォーマンスを向上できるケースがあります。
例えば、次のように二重ループの結果を一度リストにためてから処理すると、その分のメモリが必要になります。
# 全組み合わせを一度リストにためてから処理する非効率な例
xs = range(1000)
ys = range(1000)
pairs = []
for x in xs:
for y in ys:
pairs.append((x, y))
# ここでpairsを処理する
for x, y in pairs:
passxsとysが大きくなると、pairsリストのサイズも爆発的に増えます。
これは大規模データに対しては致命的になり得ます。
可読性・保守性が落ちるタイミング
多重ループの可読性が一気に落ちるのは、次のような瞬間です。
- ループ内にさらに
ifやbreakが入り、処理パターンが増えたとき - ループの途中で早期returnしたり、例外を投げたりしているとき
- 1つのループブロックが画面からはみ出すほど長くなったとき
このような状態になると、レビューする側は「ループ構造の正しさ」と「ビジネスロジックの正しさ」を同時に追わなければならず、バグの温床になりやすくなります。
itertoolsが多重ループ解消に向く理由
イテレータで「流れ」を表現する
itertoolsは「イテレータを生成・変換するためのツールセット」です。
ループそのものを書き連ねる代わりに、「どのようなイテレータの流れを作るか」を宣言的に記述できます。
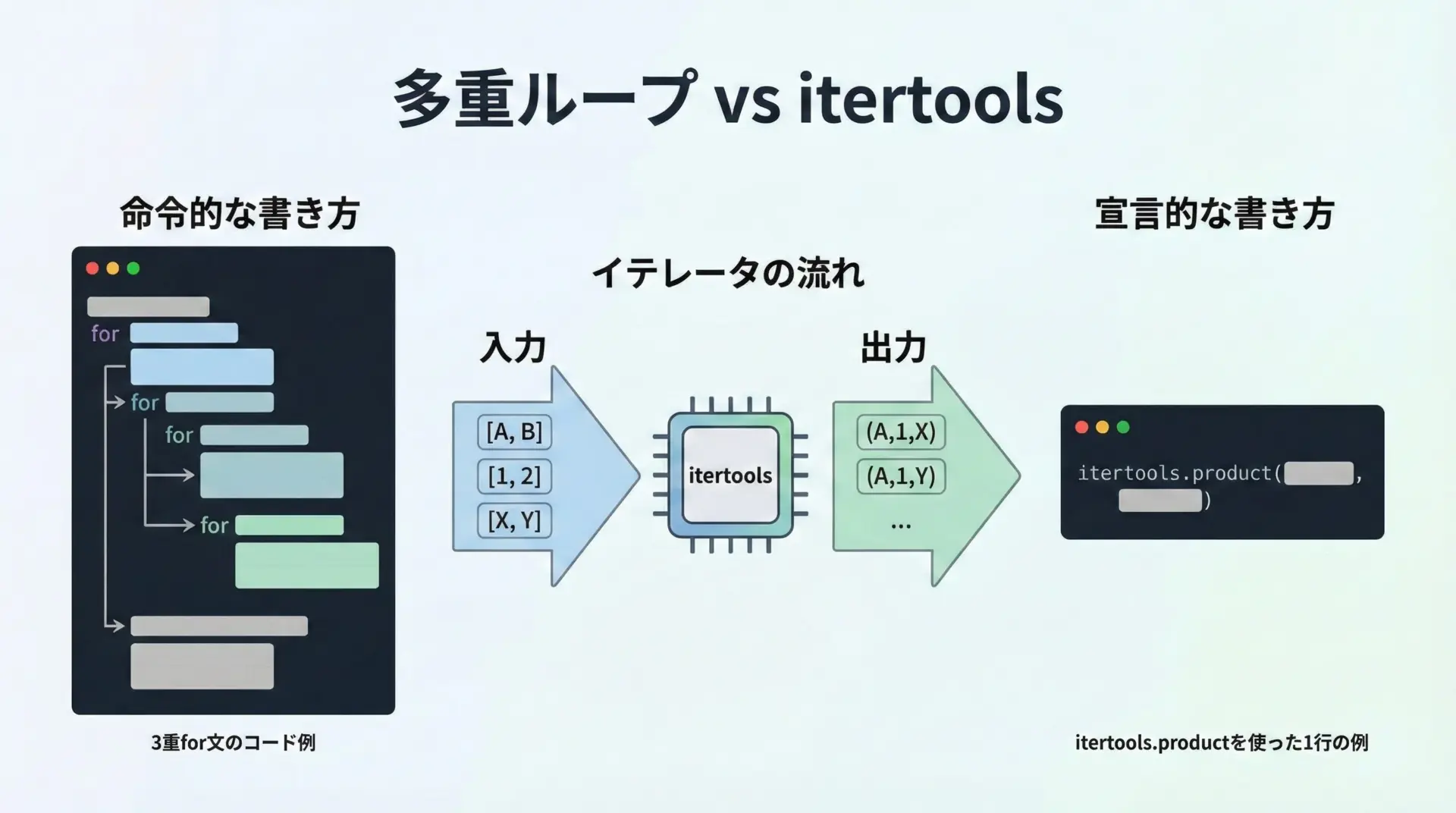
例えば、2つのリストの直積を明示的な二重ループで書く代わりに、itertools.productで「直積」という概念を1つのオブジェクトとして表現できます。
import itertools
xs = [1, 2, 3]
ys = [10, 20, 30]
for x, y in itertools.product(xs, ys):
print(x, y)このように記述すると、以下のメリットがあります。
- 「これは2つのイテラブルの直積を取っている」という意図がひと目で分かる
- ループ構造自体が1つの関数呼び出しに隠蔽され、ビジネスロジックに集中しやすい
- itertools自体が遅延評価するため、必要な分だけ要素を生成できる
itertoolsでネストを平坦化する基本テクニック
itertools.productで多重ループを1行に統合
productの基本構文と動作
itertools.productは、複数のイテラブルの直積を生成する関数です。
数学でいうデカルト積に相当します。
import itertools
xs = [1, 2]
ys = ["a", "b"]
for x, y in itertools.product(xs, ys):
print(x, y)1 a
1 b
2 a
2 b従来の二重ループを、1つのfor文に統合できていることが分かります。
repeat引数による同じイテラブルの多重ループ
productにはrepeat引数があり、同じイテラブルを繰り返し直積に使う場合に便利です。
import itertools
digits = [0, 1]
# digitsを3回使って直積を取る(0/1の3桁の全組み合わせ)
for a, b, c in itertools.product(digits, repeat=3):
print(a, b, c)このように、三重以上のループも「何重ループなのか」が明示的になります。
単純にforを3つ並べるよりも、構造がはっきり見える書き方です。
itertools.chainで複数イテラブルをフラットに結合
chainの基本的な役割
itertools.chainは、複数のイテラブルを順番に連結したかのように扱えるイテレータを生成します。
これにより、「まずリストAをループ、その後リストBをループ」のような構造を1つのループにまとめられます。
import itertools
a = [1, 2, 3]
b = [10, 20, 30]
for x in itertools.chain(a, b):
print(x)1
2
3
10
20
30従来であれば、次のように2つのfor文を書くところを、chainで平坦化できます。
# 従来の書き方
for x in a:
print(x)
for x in b:
print(x)chain.from_iterableで二重リストをフラット化
ネストしたリスト構造を1段フラットにする
chain.from_iterableは、「イテラブルのイテラブル」をフラットにし、1つのイテレータとして扱えるようにします。
例えばリストのリストを1次元にする場合に便利です。
import itertools
matrix = [
[1, 2, 3],
[4, 5],
[6]
]
for x in itertools.chain.from_iterable(matrix):
print(x)1
2
3
4
5
6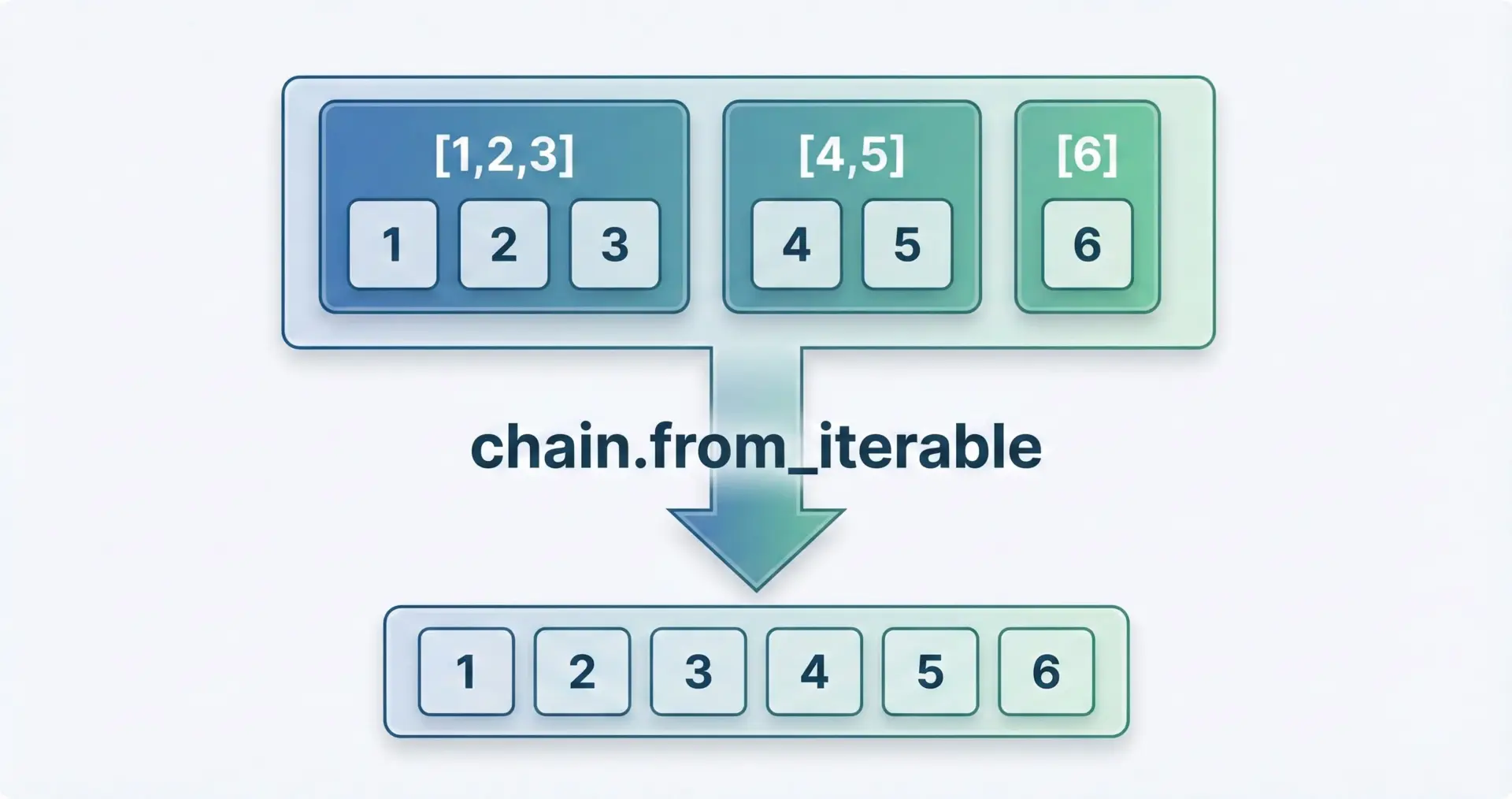
これにより、ネスト構造に対して二重ループを回すかわりに、1つのフラットなストリームとして処理できるようになります。
combinations・permutationsで入れ子ループを排除
combinationsで「組み合わせ」を明示する
itertools.combinationsは、元のイテラブルから要素を重複なしで選び出す組み合わせを生成する関数です。
import itertools
items = ["A", "B", "C"]
for pair in itertools.combinations(items, 2):
print(pair)('A', 'B')
('A', 'C')
('B', 'C')これを入れ子ループで書くと、次のようになります。
items = ["A", "B", "C"]
for i in range(len(items)):
for j in range(i + 1, len(items)):
print(items[i], items[j])combinationsを使うと、「組み合わせ列挙」という意図がそのままコードになるため、ネスト構造が大幅に簡素化されます。
permutationsで「順列」を表現する
itertools.permutationsは、順序を考慮した順列を生成します。
import itertools
items = ["A", "B", "C"]
for perm in itertools.permutations(items, 2):
print(perm)('A', 'B')
('A', 'C')
('B', 'A')
('B', 'C')
('C', 'A')
('C', 'B')本来であれば、二重ループの中で「同じ要素を選ばないようにする」ための条件分岐を入れたりと、ロジックが入り組みがちですが、permutationsならそのロジックを1行で表現できます。
repeat・cycleと組み合わせたループ簡略化
repeatで同じ値を何度も使う多重ループを短縮
itertools.repeatは、同じ値を何度も返すイテレータを作ります。
productと組み合わせると、一部の軸が固定された直積を簡単に表現できます。
import itertools
xs = [1, 2, 3]
# yは常に10として、xsとのペアを作る例
for x, y in itertools.product(xs, itertools.repeat(10)):
print(x, y)1 10
2 10
3 10従来はループの外で固定値を扱うなどの工夫が必要でしたが、repeatを使うと「固定値を含んだ直積」がシンプルに表現できます。
cycleでパターンを繰り返しながらループする
itertools.cycleは、与えられたイテラブルを無限に繰り返すイテレータです。
例えば、要素に対して交互にフラグを付けたい場合などに使えます。
import itertools
items = ["A", "B", "C", "D"]
flags = itertools.cycle(["even", "odd"])
for item, flag in zip(items, flags):
print(item, flag)A even
B odd
C even
D odd多重ループの代わりに、「別の軸をイテレータとして合成する」発想を取ることで、ループ構造を平坦化できる場合があります。
パターン別・多重ループ解消レシピ
二重ループ(二重for文)をproductで置き換えるパターン
素朴な二重ループからの書き換え
ここでは、ごく一般的な二重ループをproductで書き換える例を見ていきます。
# 元の二重ループコード
xs = [1, 2, 3]
ys = [10, 20, 30]
for x in xs:
for y in ys:
print(x, y)これをitertools.productを使って書き換えると、次のようになります。
import itertools
xs = [1, 2, 3]
ys = [10, 20, 30]
for x, y in itertools.product(xs, ys):
print(x, y)処理内容は変わりませんが、forが1つ減るだけでネストの深さが1段浅くなるため、インデントも減り、後から条件や処理を追加するときの負担も軽くなります。
条件付き二重ループのときの注意
例えば「xとyの和が偶数のときだけ処理する」という条件がある場合も、product版ではループ構造と条件が明確に分かれます。
import itertools
xs = [1, 2, 3]
ys = [10, 20, 30]
for x, y in itertools.product(xs, ys):
if (x + y) % 2 == 0:
print(x, y)元の二重ループと比べて、forのネストの中にifが埋もれにくいというメリットがあります。
三重以上のループをproductで平坦化するパターン
3重ループを1本のforにする
3重ループになると、ネストの深さが一気に増え、保守性が大きく下がります。
# 元の三重ループ
as_ = [1, 2]
bs = [10, 20]
cs = [100, 200]
for a in as_:
for b in bs:
for c in cs:
print(a, b, c)これをproductにまとめると、次のように書けます。
import itertools
as_ = [1, 2]
bs = [10, 20]
cs = [100, 200]
for a, b, c in itertools.product(as_, bs, cs):
print(a, b, c)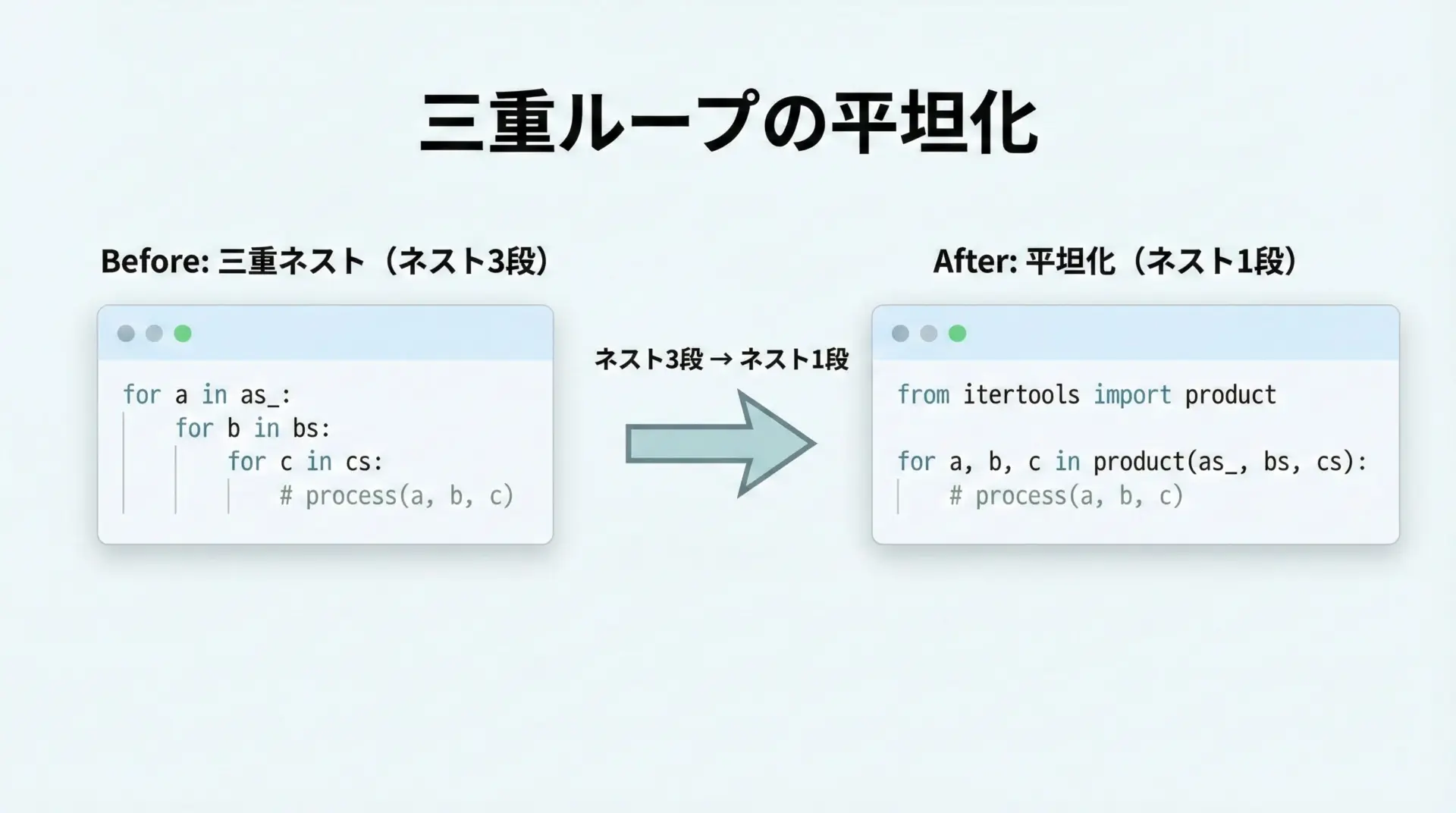
このようにループ数が増えるほど、productで統合したときの見通しの良さの効果が大きくなります。
repeatを使ったパターン化された多重ループ
同じシーケンスを何度も使うケースではrepeat引数が役立ちます。
import itertools
digits = range(3) # 0, 1, 2
# 3桁の全パターンを列挙
for a, b, c in itertools.product(digits, repeat=3):
print(a, b, c)0 0 0
0 0 1
0 0 2
...
2 2 2「何桁か」だけをrepeatで指定するため、コードから意図を読み取りやすくなります。
ネストしたリスト構造をchainでフラット化するパターン
二重ループで展開していた処理を1ループに統合
例えば、複数の行を持つデータ構造をループし、その中の要素を処理するコードがあるとします。
rows = [
[1, 2, 3],
[4, 5],
[6]
]
for row in rows:
for value in row:
print(value)これをchain.from_iterableで書き換えると、二重ループが1つのループになります。
import itertools
rows = [
[1, 2, 3],
[4, 5],
[6]
]
for value in itertools.chain.from_iterable(rows):
print(value)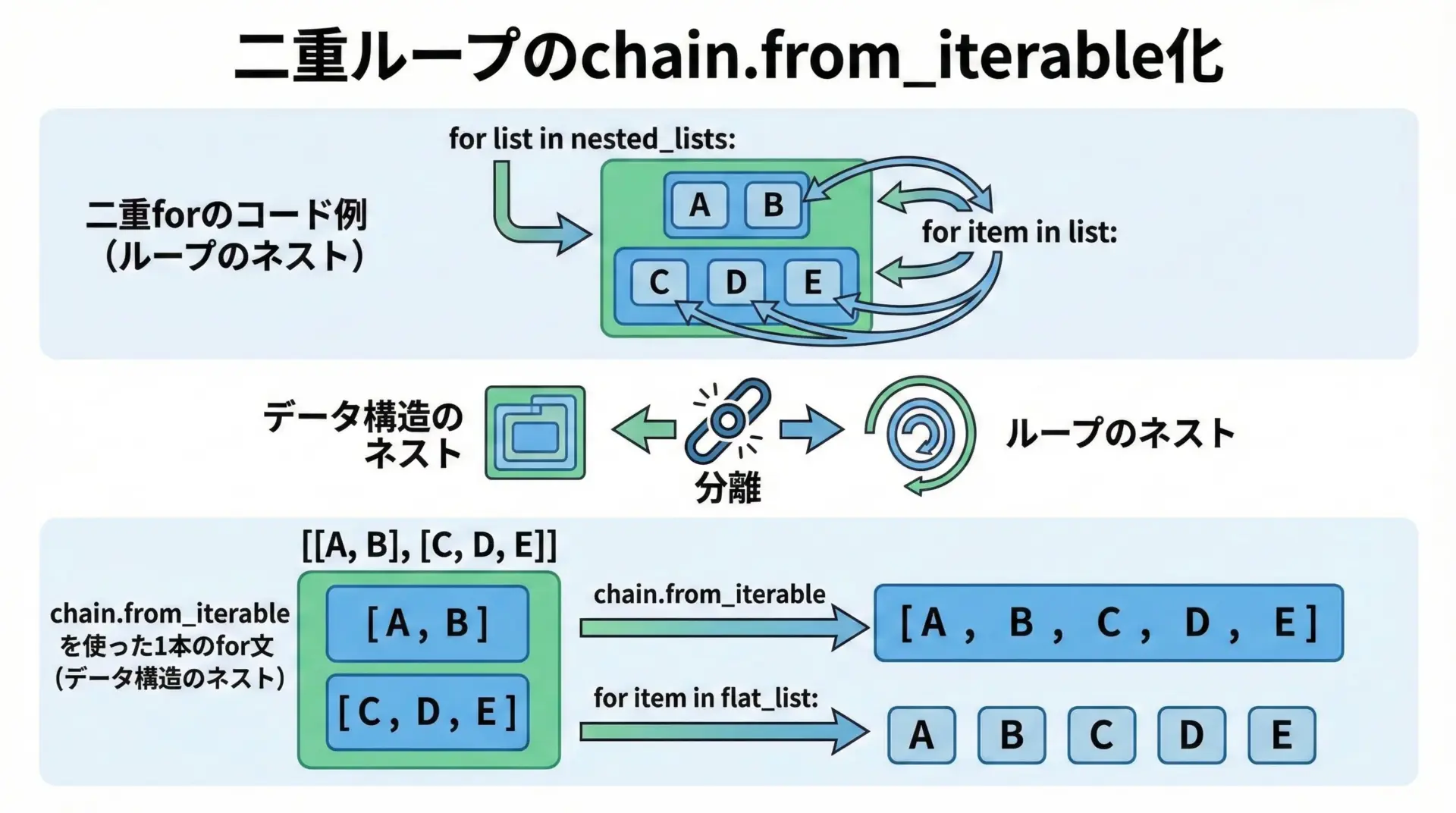
ポイントは、「ネストしたデータ構造をflattenする役割をchainに任せる」ことで、ビジネスロジック側のループが単純化される点です。
条件付きネストループを内包表記+itertoolsで書き直すパターン
条件付き二重ループの平坦化
例えば、2つのシーケンスから条件付きでペアを抽出したい場合を考えます。
xs = [1, 2, 3]
ys = [10, 20, 30]
results = []
for x in xs:
for y in ys:
if (x + y) % 2 == 0:
results.append((x, y))これをproductとリスト内包表記で書き換えると、処理の流れがかなり分かりやすくなります。
import itertools
xs = [1, 2, 3]
ys = [10, 20, 30]
results = [
(x, y)
for x, y in itertools.product(xs, ys)
if (x + y) % 2 == 0
]
print(results)[(1, 11), (1, 29), ...] # 実際は条件に応じたペアのみ「組み合わせ生成」と「条件フィルタリング」を明確に分離できるため、後からどちらかを変更する際にも影響範囲が読み取りやすくなります。
chainと内包表記の組み合わせ
ネストしたリストから、条件を満たす要素だけを集めたい場合も、chainと内包表記を組み合わせると平坦な書き方になります。
import itertools
rows = [
[1, 2, 3],
[4, 5],
[6]
]
# 偶数だけを抽出
evens = [x for x in itertools.chain.from_iterable(rows) if x % 2 == 0]
print(evens)[2, 4, 6]元の二重ループを書き下すと条件が散らばりがちですが、chainを使うとまずフラットにしてから条件で絞るという分かりやすい構図になります。
入れ子ループ+breakをitertoolsで表現するパターン
外側まで抜けるbreakの分かりにくさ
多重ループでbreakを使うと、「どのループから抜けるのか」が読み手には分かりにくくなります。
また、breakした瞬間に「今までのイテレーションはどう扱うのか」といった境界条件のバグも生まれやすくなります。
xs = [1, 2, 3]
ys = [10, 20, 30]
found = None
for x in xs:
for y in ys:
if x + y > 25:
found = (x, y)
break # 内側ループだけ抜ける
if found is not None:
break # 外側ループも抜ける
print(found)このようなコードはロジックが読みにくく、テストしづらいです。
product+ジェネレータ式で「最初の一致」を探す
このパターンは、itertools.productとジェネレータ式、そしてnextを組み合わせるとすっきり書けます。
import itertools
xs = [1, 2, 3]
ys = [10, 20, 30]
# 条件に合う最初のペアを見つける
gen = (
(x, y)
for x, y in itertools.product(xs, ys)
if x + y > 25
)
found = next(gen, None) # 見つからなければNone
print(found)(1, 30)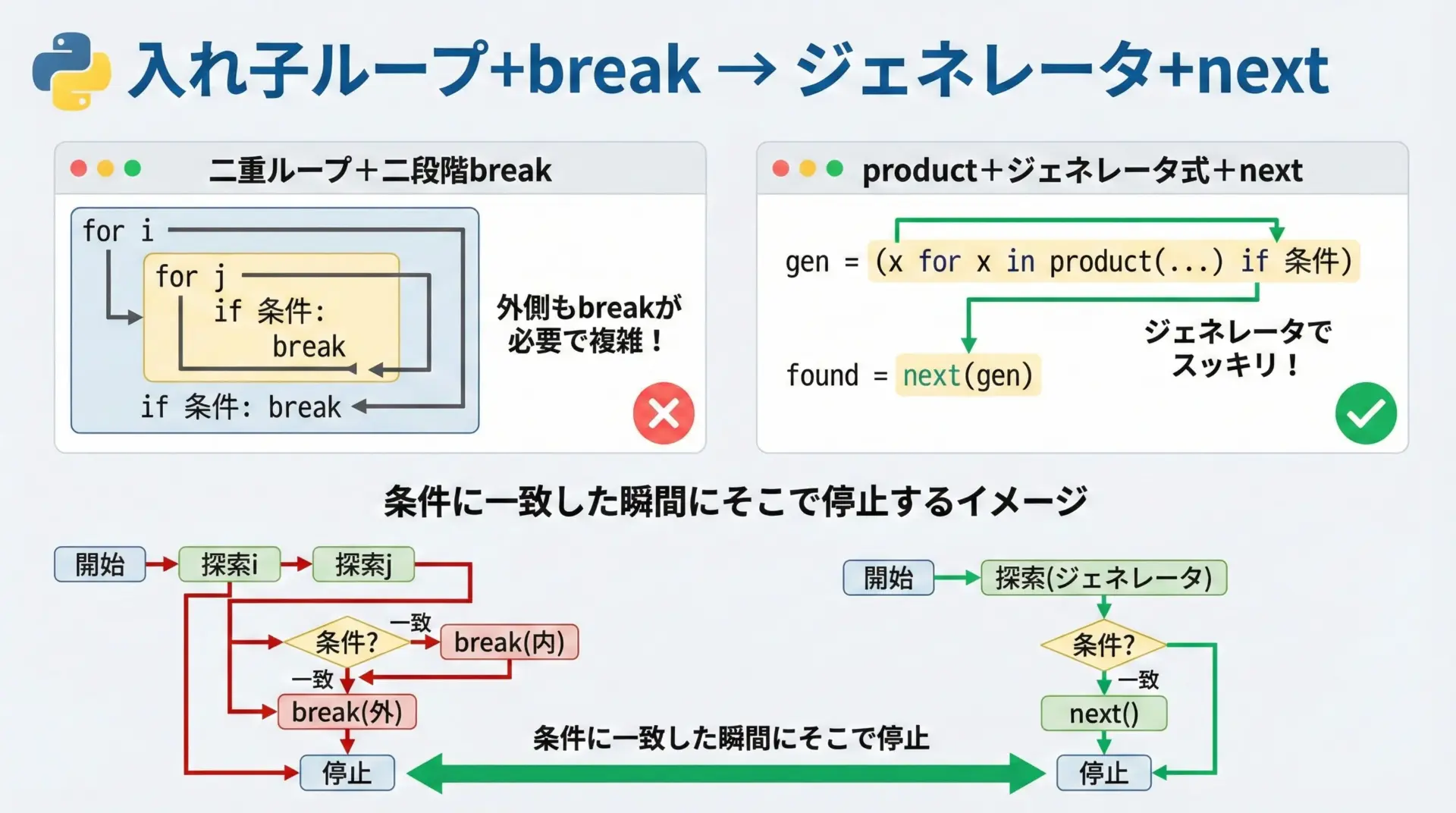
「最初に条件を満たす要素を1つだけ取得する」という意図が、nextの呼び出しに明示され、breakの位置関係を追う必要がなくなります。
大量データの多重ループを遅延評価で高速化するパターン
中間リストを作らないことの重要性
大規模データに対して多重ループを行う場合、途中でリストを構築してしまうと、その分のメモリをすべて占有することになります。
これはメモリ不足やGCのオーバーヘッドにつながり、結果的にパフォーマンス低下を招きます。
itertoolsはイテレータベースで動作するため、必要になったときだけ要素を1つずつ生成する遅延評価を基本としています。
product+isliceで部分的に処理する
例えば、膨大な組み合わせのうち先頭の一部だけを処理したいケースを考えます。
import itertools
xs = range(1000000)
ys = range(1000000)
# 先頭100個の組み合わせだけを処理したい
for x, y in itertools.islice(itertools.product(xs, ys), 100):
# 何らかの処理
passここではproduct(xs, ys)で実際に生成されるのは、isliceで必要になった分だけです。
巨大なリストを作る必要はありません。
chain.from_iterableでフラット化しつつストリーミング処理
大量のファイル行やチャンクされたデータを処理する場合も、chainを活かしてストリーミングに処理できます。
import itertools
def read_chunks():
# 実際にはファイルやネットワークから少しずつ読み込むイメージ
yield [1, 2, 3]
yield [4, 5, 6]
yield [7, 8, 9]
for value in itertools.chain.from_iterable(read_chunks()):
# 各valueをその場で処理し、中間リストを保持しない
print(value)1
2
3
4
5
6
7
8
9「チャンク(塊)ごとに読み込みつつ、中身は1つずつ処理する」構図になり、大量データでもメモリ使用量を抑えられます。
コードのリファクタリング実践
典型的な多重ループコードをitertoolsでリライト
例: スコア表から条件に合うペアを抽出する
次のような、三重ループを含むコードを考えます。
# 元コード: ユーザー、商品の組み合わせごとにスコアを調べる
users = ["Alice", "Bob"]
items = ["Book", "Pen", "Notebook"]
scores = {
("Alice", "Book"): 80,
("Alice", "Pen"): 50,
("Alice", "Notebook"): 90,
("Bob", "Book"): 70,
("Bob", "Pen"): 40,
("Bob", "Notebook"): 85,
}
result = []
for user in users:
for item in items:
score = scores.get((user, item), 0)
if score >= 80:
result.append((user, item, score))
print(result)[('Alice', 'Book', 80), ('Alice', 'Notebook', 90), ('Bob', 'Notebook', 85)]これをitertools.productと内包表記でリライトしてみます。
import itertools
users = ["Alice", "Bob"]
items = ["Book", "Pen", "Notebook"]
scores = {
("Alice", "Book"): 80,
("Alice", "Pen"): 50,
("Alice", "Notebook"): 90,
("Bob", "Book"): 70,
("Bob", "Pen"): 40,
("Bob", "Notebook"): 85,
}
result = [
(user, item, scores[(user, item)])
for user, item in itertools.product(users, items)
if scores.get((user, item), 0) >= 80
]
print(result)[('Alice', 'Book', 80), ('Alice', 'Notebook', 90), ('Bob', 'Notebook', 85)]
ループ構造をproductにまとめることで、「全組み合わせを列挙 → 条件でフィルタ → タプルを構築」という3段階が視覚的にもはっきり分かるようになります。
可読性とメンテナンス性を比較するポイント
比較すべき観点
多重ループからitertoolsに書き換えるときは、次の観点で可読性とメンテナンス性を評価するとよいです。
- 意図の明確さ
「直積」「組み合わせ」「フラット化」といった操作が、コードから一目で読み取れるか。 - インデントの深さ
インデントレベルが減ることで、ループに条件や処理を追加・削除しやすくなっているか。 - 変更時の影響範囲
対象となるイテラブルを追加・削除したとき、どの部分を書き換えればよいかが明快か。 - テストのしやすさ
ジェネレータやイテレータの流れを、単体テストで分割して確認しやすい構造になっているか。
itertoolsにしない方が読みやすいケースもある
一方で、必ずしもすべての多重ループをitertoolsに置き換える必要はありません。
例えば、非常に単純な二重ループで、読む人がPython初心者である場合などは、あえて素朴なfor文を残した方が理解しやすい場合もあります。
「itertoolsを使うことで抽象度が上がりすぎていないか」を常に確認しつつ、チームのスキルやプロジェクトの性質に合わせて採用を判断することが重要です。
itertoolsを使う際の注意点とアンチパターン
無理に1行に詰め込まない
itertoolsや内包表記を組み合わせると、複雑な処理を1行で書きたくなってしまいます。
しかし、可読性を犠牲にしてまで1行にまとめるのはアンチパターンです。
# 悪い例: あまりに詰め込みすぎた1行
result = list(map(lambda x: x * 2, filter(lambda x: x % 2 == 0, itertools.chain.from_iterable(data))))このようなコードは、分割した方が格段に読みやすくなります。
import itertools
flattened = itertools.chain.from_iterable(data)
evens = (x for x in flattened if x % 2 == 0)
result = [x * 2 for x in evens]「イテレータの流れを段階に分けて書く」ことで、デバッグや変更が容易になります。
イテレータは「一度きり」であることに注意
itertoolsが返すイテレータは、一度消費すると再利用できません。
次のようなコードはバグの元になります。
import itertools
xs = [1, 2, 3]
ys = [10, 20, 30]
pairs = itertools.product(xs, ys)
# 1回目のループ
for p in pairs:
print(p)
# 2回目のループ(何も出力されない)
for p in pairs:
print(p)イテレータは使い捨てであることを意識し、必要ならlist()で明示的にリスト化する、あるいはイテレータを生成する処理を関数として切り出して再度呼び出す、といった工夫が必要です。
過剰なネストを別の形で再現してしまわない
itertoolsを使っても、ジェネレータ式や内包表記をネストしすぎると、結局読みづらくなってしまいます。
# 悪い例: 内包表記の中に内包表記、その中にproduct
result = [
f(x, y, z)
for x, y in itertools.product(xs, ys)
for z in zs
if condition(x, y, z)
]このような場合は、途中のステップを名前付きの変数や関数に切り出すことで、意図を分かりやすく表現した方がよいです。
まとめ
多重ループは、処理を素直に書き下すには便利ですが、ネストが深くなるほど可読性・保守性・パフォーマンス面で問題を抱えやすくなります。
この記事で紹介したように、itertools.productやchain、combinations、permutations、repeat、cycleといったツールを活用すると、ループ構造を1本に平坦化しつつ、意図を明確に表現することができます。
特に、大量データを扱う場面では、遅延評価によるメモリ効率の改善も大きなメリットになります。
ただし、無理に1行に詰め込んだり、チームの経験値を超える抽象化を行うと逆効果です。
「ネストを浅くしつつ、処理の流れを素直に追えるコード」を目指して、itertoolsを適切に取り入れていくことが、長く使えるPythonコードへの近道になります。
