
Pythonの文字列はとても使いやすい一方で、内部的な仕組みを誤解しているとパフォーマンスの低下や思わぬバグにつながります。
本記事では、Pythonの文字列が「イミュータブル(変更不可)」であるとは具体的にどういうことなのか、そして実務でどのように意識すればよいのかを、初心者の方にもわかりやすく丁寧に解説していきます。
Pythonの文字列とイミュータブルとは
Pythonの文字列(string)とは
Pythonにおける文字列は、テキストデータを扱うための基本的なデータ型です。
シングルクォートまたはダブルクォートで囲んだものが文字列となります。
text1 = "Hello"
text2 = 'Python'Pythonの文字列は、内部的にはUnicodeで表現されており、日本語や絵文字なども統一的に扱うことができます。
ここで押さえておきたいのは、Pythonの文字列は「オブジェクト」であり、変数はそのオブジェクトへの参照を持っているだけという点です。
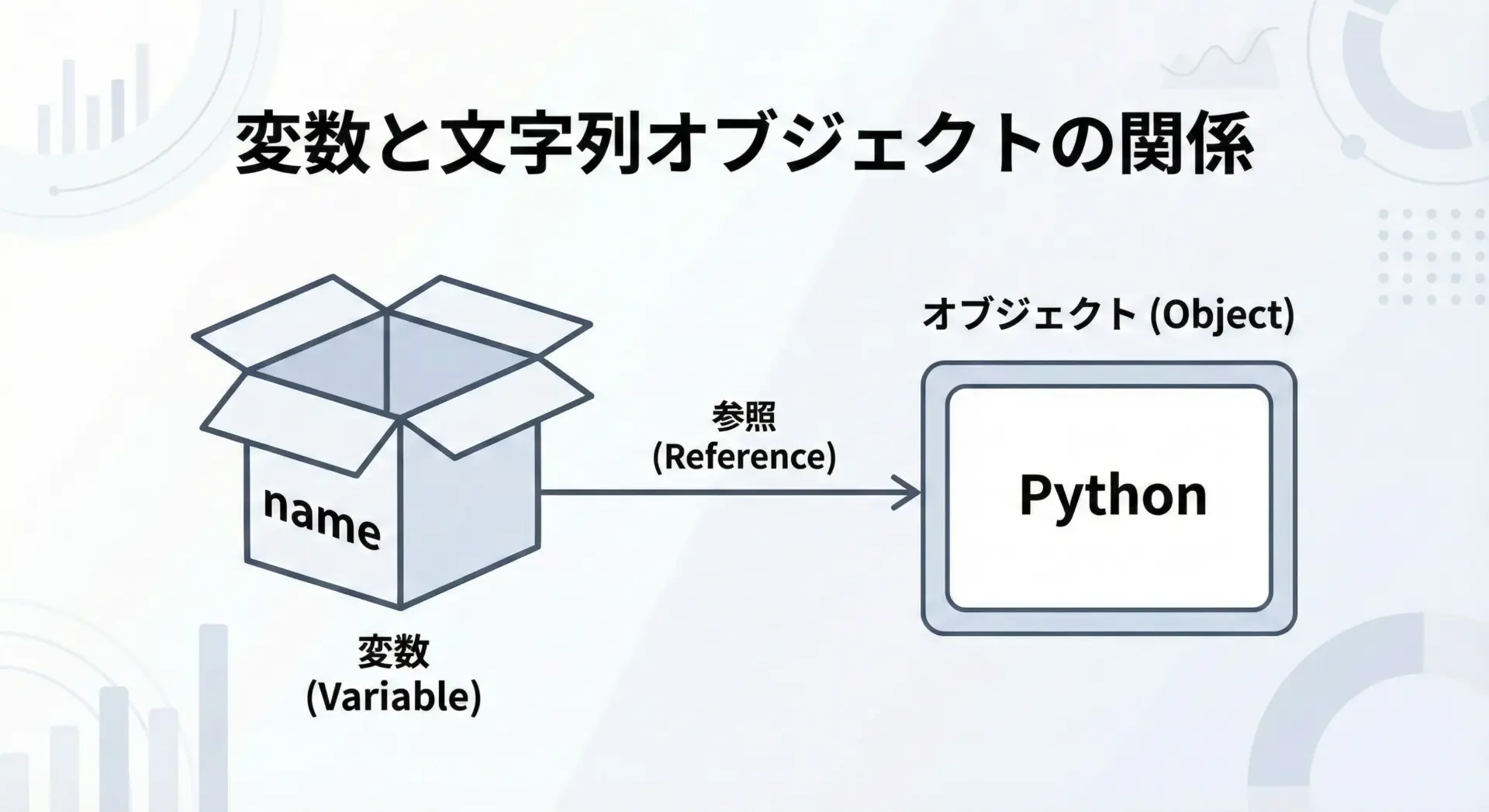
このように、変数は文字列そのものを「持っている」のではなく、文字列オブジェクトを「指している」だけです。
そのため、同じ文字列を別の変数に代入しても、内部的には同じオブジェクトを共有している場合があります。
イミュータブル(変更不可)型とは
イミュータブル(immutable)とは、一度作成されたオブジェクトの中身を変更できない性質を指します。
Pythonにはいくつかのイミュータブル型がありますが、代表的なものとして次のような型が挙げられます。
- 文字列型(str)
- 数値型(int, float など)
- タプル型(tuple)
- フロzenset型(frozenset)
イミュータブルであるということは、例えば文字列について次のような動作を意味します。
text = "Hello"
# text[0] = "h" # これはエラーになるこのコードは実行するとエラーになります。
文字列の個々の文字を直接書き換えることはできないからです。

このように、イミュータブルなオブジェクトは中身がロックされているイメージを持つと理解しやすくなります。
ミュータブル型との違い
イミュータブルの対義語がミュータブル(mutable)です。
ミュータブル型は、中身を後から変更できるオブジェクトです。
Pythonでは次のような型が代表的なミュータブル型です。
- リスト(list)
- 辞書(dict)
- 集合(set)
- 多くのユーザー定義クラスのインスタンス
文字列とリストを比較すると、違いがわかりやすくなります。
text = "Hello"
numbers = [1, 2, 3]
# 文字列の1文字を書き換えようとするとエラー
# text[0] = "h" # TypeError
# リストの1要素は書き換え可能
numbers[0] = 10
print(numbers) # [10, 2, 3]リストはミュータブルなので、同じリストオブジェクトの中身を書き換えることができます。
一方で、文字列はイミュータブルなので、内容を変更したい場合は新しい文字列オブジェクトを作成する必要があります。
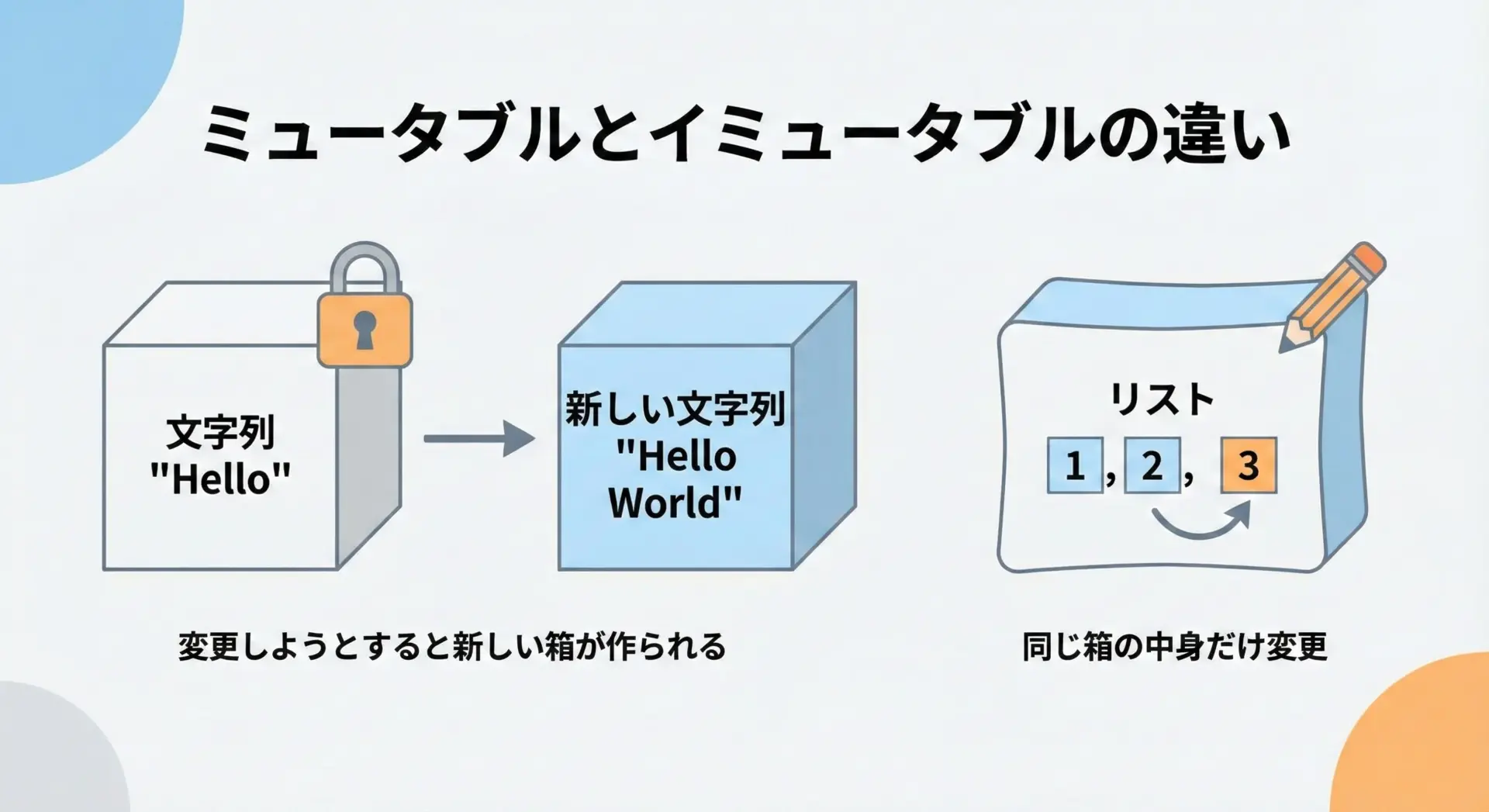
この違いを理解しておくと、後述する「なぜ文字列はイミュータブルなのか」「パフォーマンスにどう影響するか」といった話がぐっと理解しやすくなります。
文字列がイミュータブルである理由
なぜPythonのstrはイミュータブルなのか
Pythonの設計では、文字列をイミュータブルにすることで、多くのメリットを得ています。
代表的な理由は次の通りです。
1つ目は安全性です。
ある関数に文字列を渡したとき、その関数が渡された文字列を勝手に書き換えると、呼び出し元の変数の中身まで変わってしまいます。
イミュータブルであれば、関数が受け取った文字列を勝手に変更することはできず、意図しない副作用が起こりにくくなります。
2つ目はメモリ共有のしやすさです。
イミュータブルなオブジェクトは内容が変わらないので、同じ内容の文字列を複数の場所で共有しても安全です。
a = "Python"
b = "Python"
print(a is b) # 実装によっては True になることが多い実装依存ではありますが、Pythonは同じ文字列リテラルを1つのオブジェクトとして再利用する最適化を行うことがあります。
オブジェクトがイミュータブルであれば、このような最適化を安心して行えます。
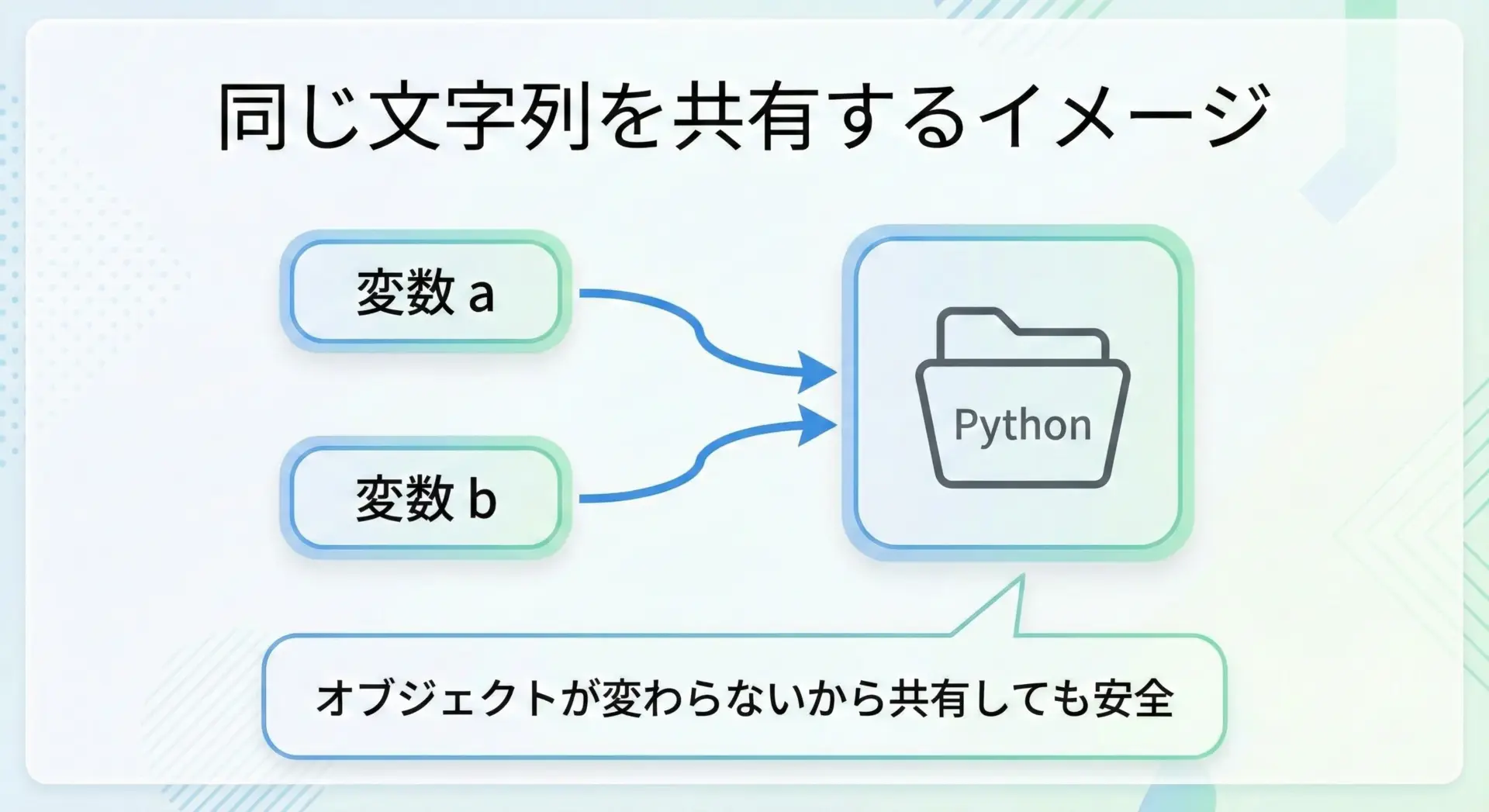
このように、イミュータブルであることは、メモリ効率とプログラムの安全性の両方を高める設計につながっています。
セキュリティとバグ防止のメリット
イミュータブルな文字列は、セキュリティやバグ防止の観点からも重要な役割を果たします。
例えば、環境変数や設定値などの「変わってはいけない情報」を文字列として扱う場面を考えてみます。
もし文字列がミュータブルであれば、意図せずその中身が書き換えられてしまい、セキュリティホールにつながる可能性があります。
また、次のようなケースを考えてみます。
def add_suffix(text, suffix):
# もしtextがミュータブルだったら、中身を書き換える実装もできてしまう
# ここではイメージとしてコメントで表現します
# text.append(suffix) # 仮のイメージ
# 現実のPythonではtextはstrなので、新しい文字列を返す
return text + suffix
name = "Alice"
new_name = add_suffix(name, "さん")
print(name) # "Alice" のまま
print(new_name) # "Aliceさん"このように、関数が引数として受け取った文字列を勝手に書き換えられないという性質は、予期しないバグを防ぐうえで非常に重要です。
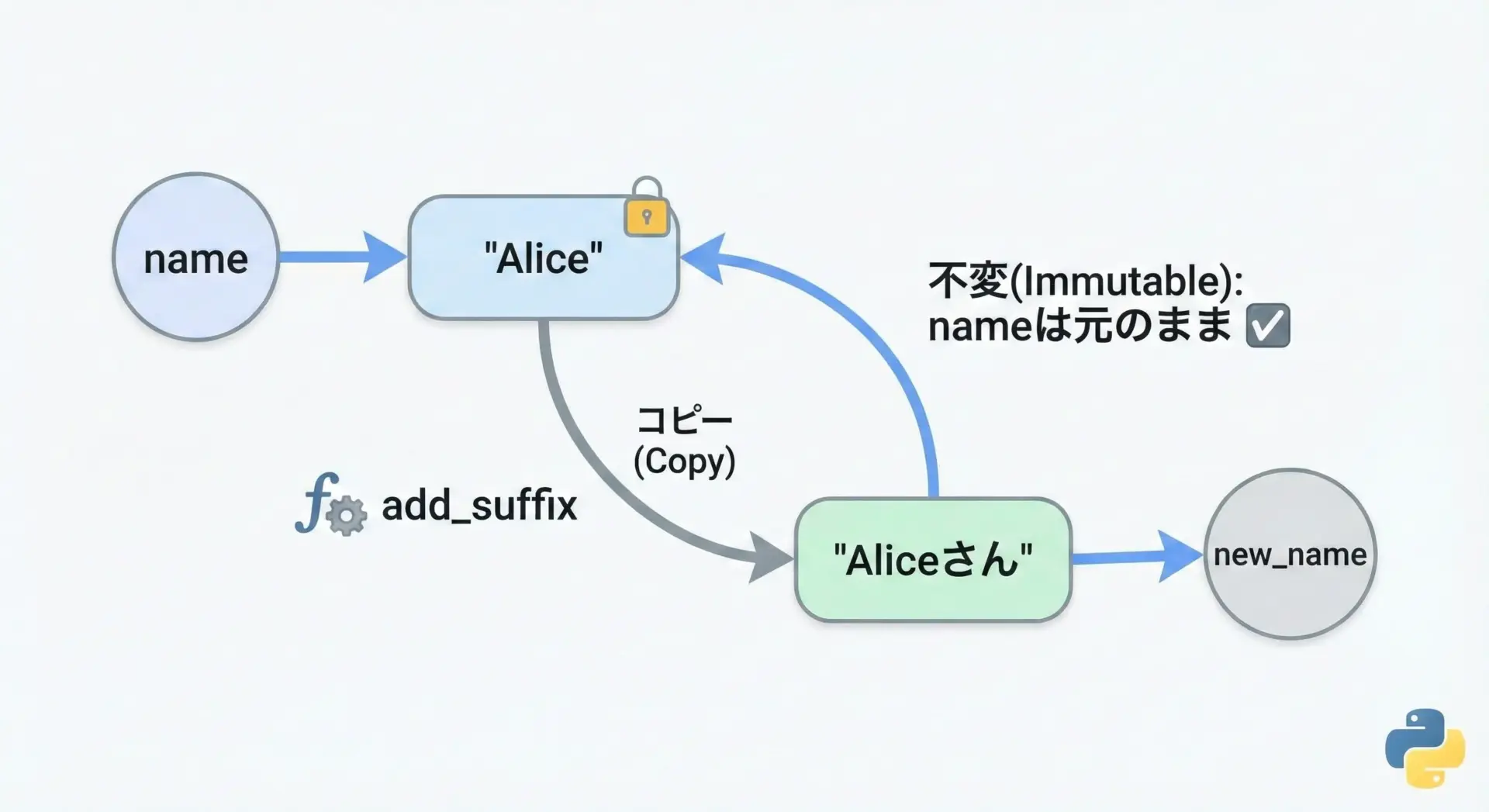
「渡した文字列は勝手に書き換えられない」という安心感は、大規模なプログラムや他人が書いたライブラリを使う場合にこそ、効果を発揮します。
ハッシュ化と辞書(dict)キーに使える理由
Pythonでは、辞書(dict)のキーや集合(set)の要素として使う値は、ハッシュ可能(hashable)である必要があります。
ハッシュ可能であるとは、簡単にいえばオブジェクトの内容に基づいて一意に近い値(ハッシュ値)を計算でき、その値が変化しないということです。
文字列はイミュータブルで中身が変わらないので、その内容から計算されるハッシュ値も変わりません。
したがって、辞書のキーとして安全に利用できます。
prices = {
"apple": 120,
"banana": 80,
}
print(prices["apple"]) # 120もし文字列がミュータブルで、中身が後から変わってしまうとどうなるでしょうか。
辞書の内部ではキーのハッシュ値を使ってデータを管理しているため、途中でキーの内容が変わると、本来あるはずの要素が見つからなくなるといった深刻な問題が発生します。
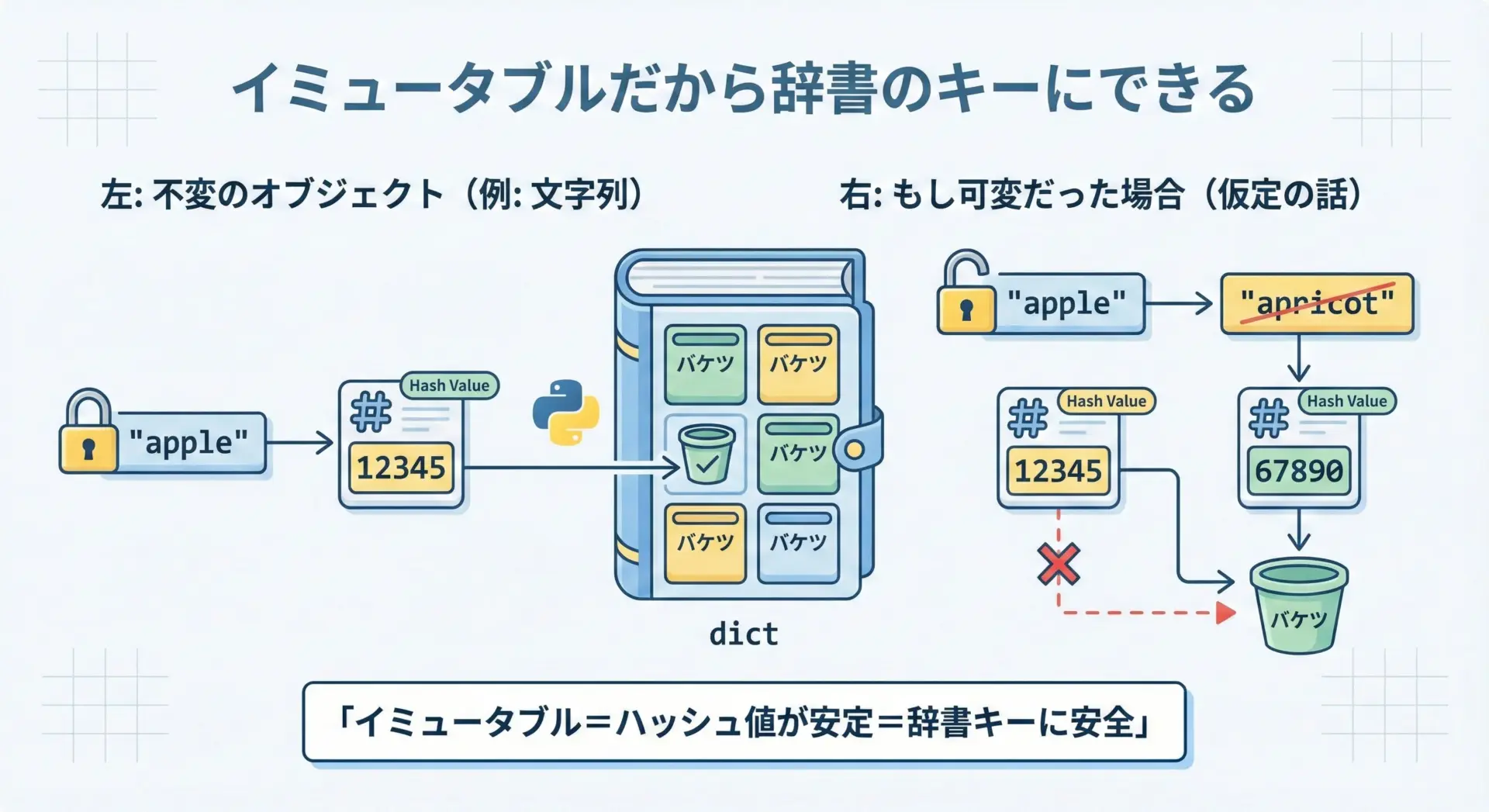
このように、文字列がイミュータブルであることは、辞書や集合といった重要なデータ構造を支える基盤になっています。
イミュータブルな文字列操作の基本
文字列の連結と新しいオブジェクト生成
Pythonで文字列を連結するには+演算子をよく使います。
このとき、元の文字列が書き換えられるのではなく、新しい文字列オブジェクトが作られることがポイントです。
s1 = "Hello"
s2 = "World"
s3 = s1 + " " + s2
print(s1) # "Hello" (元のまま)
print(s2) # "World" (元のまま)
print(s3) # "Hello World"このコードでは、s1とs2は一切変更されず、"Hello World"という新しい文字列オブジェクトが作られ、それをs3が指すようになります。
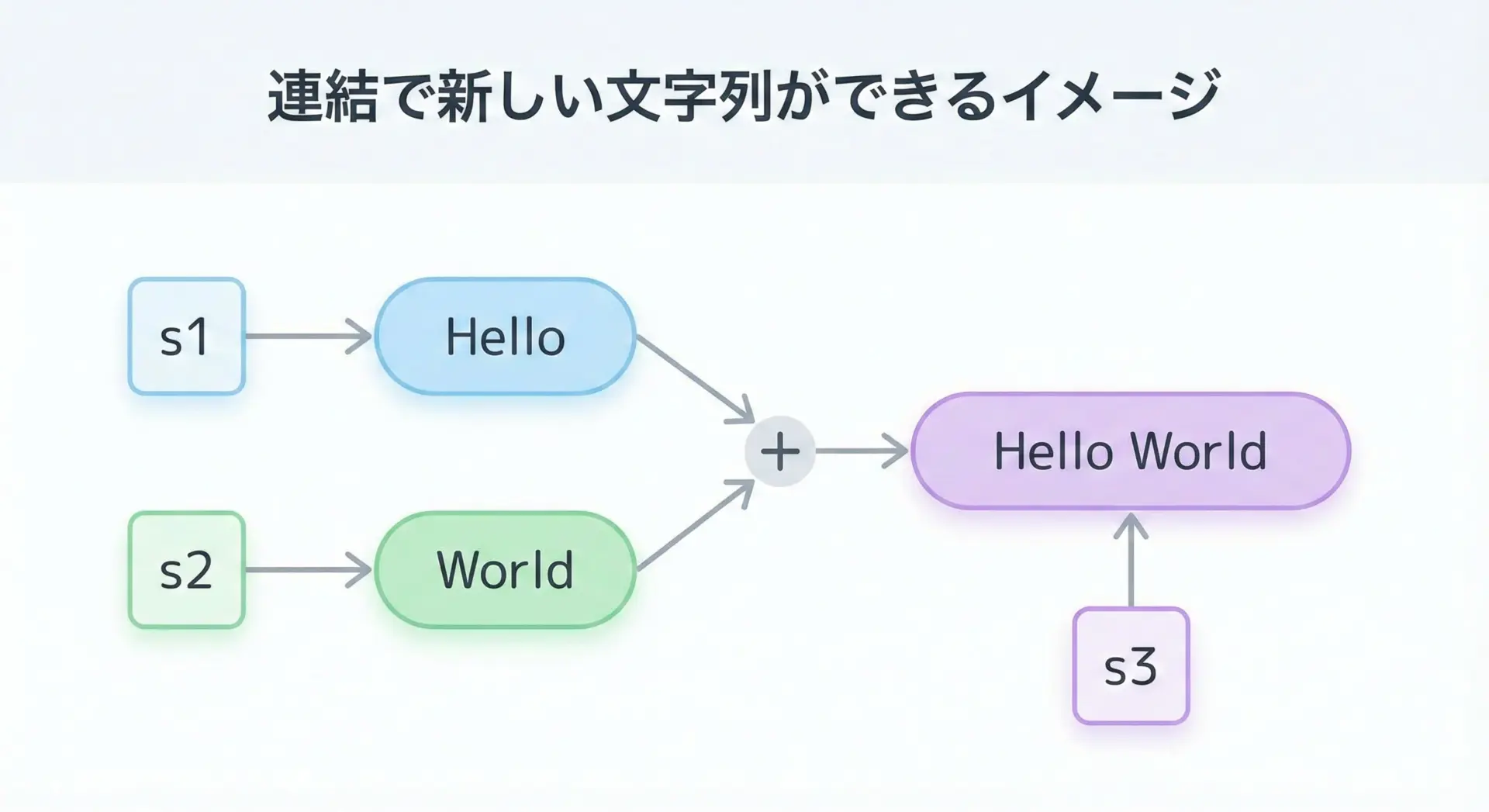
「文字列は書き換えるのではなく、常に新しく作っている」というイメージを、この連結の例でまず押さえておくとよいでしょう。
スライスで部分文字列を作る仕組み
Pythonでは、文字列の一部を取り出すスライス記法がよく使われます。
スライスもまた新しい文字列オブジェクトを返します。
text = "Python string"
part = text[0:6] # 0文字目から5文字目まで("Python")
rest = text[7:] # 7文字目以降("string")
print(part) # "Python"
print(rest) # "string"
print(text) # "Python string" (元の文字列はそのまま)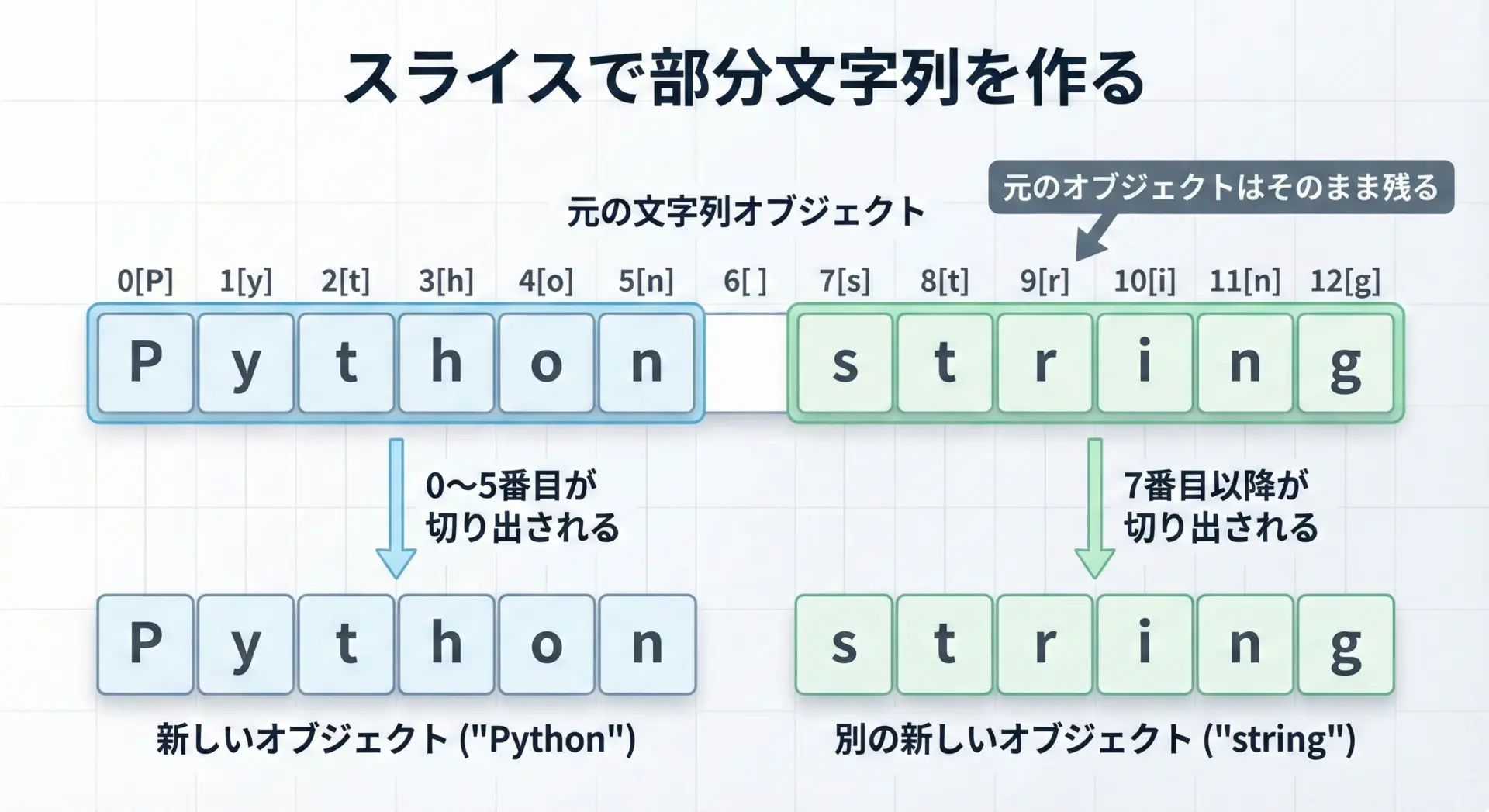
Pythonの実装レベルでは、スライス時に効率化のための工夫がされていることもありますが、プログラマー視点では「新しい文字列が返ってくる」と考えておけば十分です。
replace・upperなどメソッドが新しい文字列を返す理由
文字列にはreplaceやupperなど、多くの便利なメソッドが用意されています。
これらのメソッドもすべて新しい文字列を返し、元の文字列は変更しません。
text = "hello world"
upper_text = text.upper()
replaced_text = text.replace("world", "Python")
print(text) # "hello world"
print(upper_text) # "HELLO WORLD"
print(replaced_text) # "hello Python"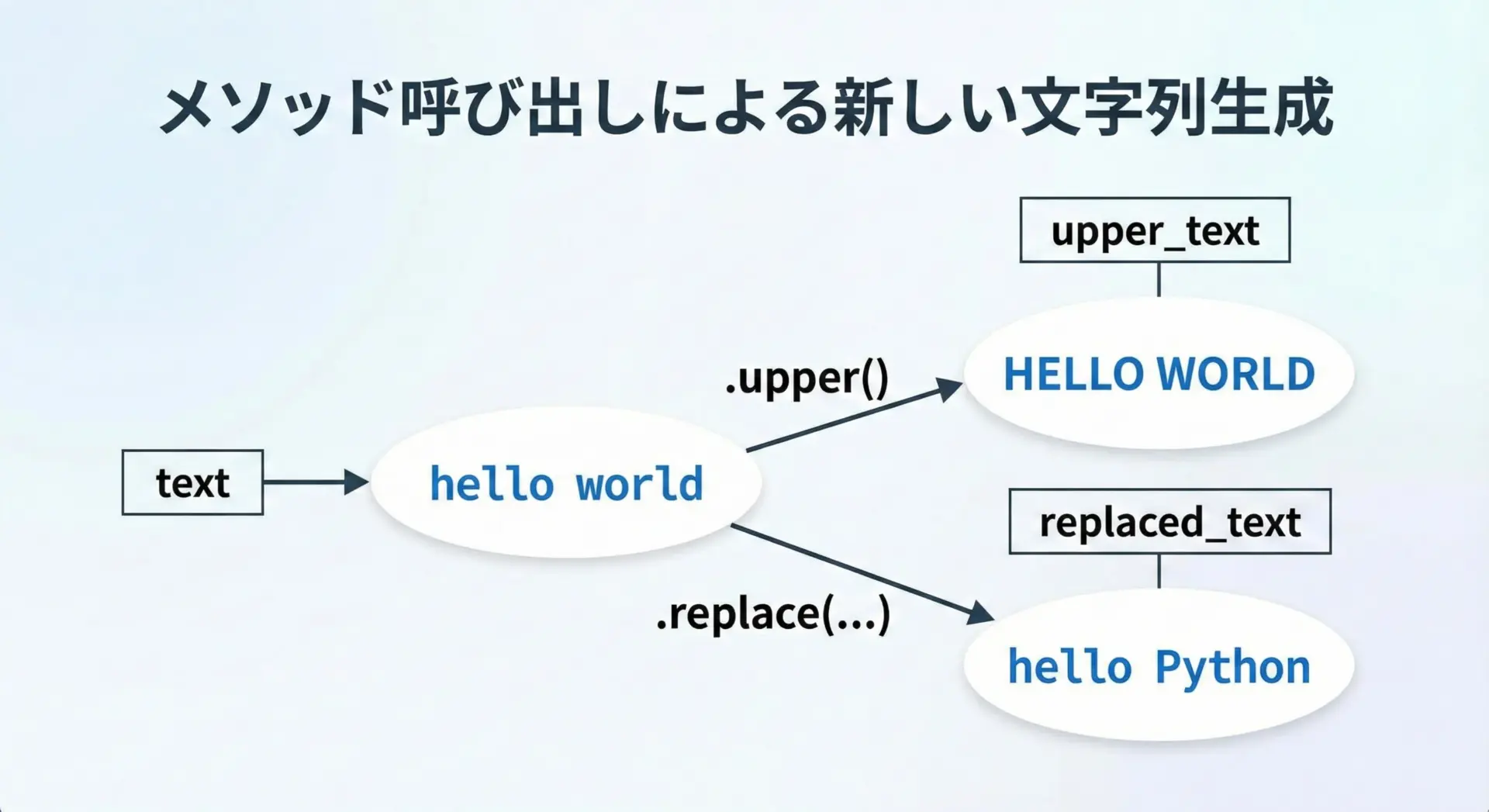
メソッド名に!(破壊的変更を示す記号)がつく言語もありますが、Pythonの文字列メソッドは原則として破壊的変更を行いません。
これはすべて、文字列がイミュータブルであるという設計を守るためです。
大量連結はjoinを使うべき理由
文字列の連結は+で簡単にできますが、ループで何度も+を使うとパフォーマンスが悪くなることがあります。
なぜなら、連結のたびに新しい文字列オブジェクトが作られ、古いものは破棄されるからです。
次の2つの例を見比べてみます。
# よくない例: ループ内で何度も+連結する
result = ""
for i in range(5):
result += str(i)
print(result) # "01234"# よい例: リストに要素を集めてからjoinで連結する
parts = []
for i in range(5):
parts.append(str(i))
result = "".join(parts)
print(result) # "01234"1つ目の例では、ループが回るたびにresultに新しい文字列が作られ、それまでのオブジェクトは不要になります。
これを何百回、何千回と繰り返すと、無駄なオブジェクトが大量に作られてしまい、速度が低下します。
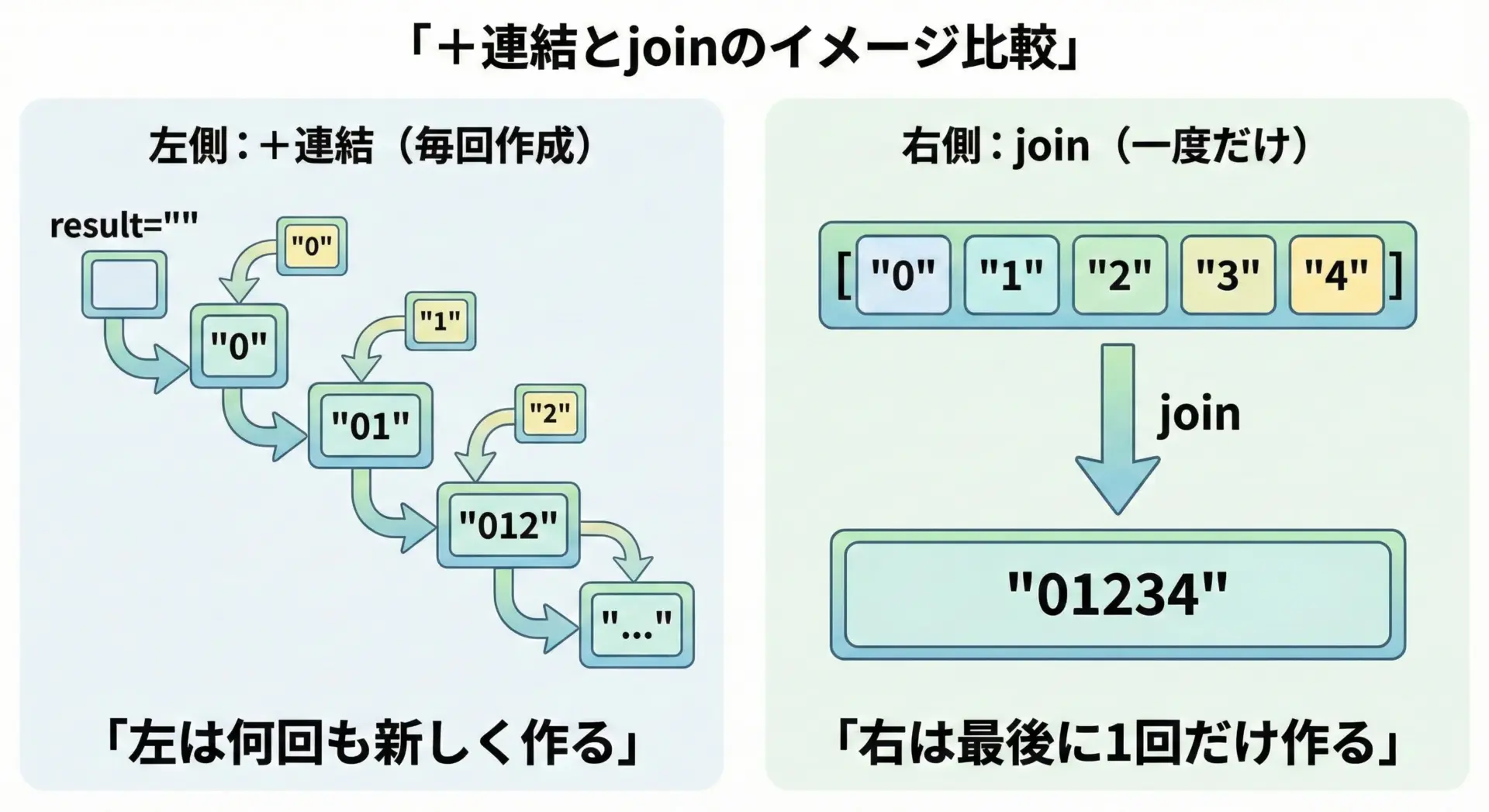
大量の文字列連結が必要な場合はstr.join()を使う、というのはPythonの重要なコーディングパターンです。
Python初心者が押さえるべき実践ポイント
文字列を「書き換える」のではなく「作り直す」と考える
ここまでの内容を実務で活かすためには、「文字列を変更する」という発想をやめて、「文字列を作り直す」と考えることが大切です。
text = "Hello"
# 「書き換える」というより「別の文字列を作り、それをtextに再代入している」
text = text + " World"
print(text) # "Hello World"このコードでは、元の"Hello"が直接書き換えられたわけではなく、"Hello World"という新しいオブジェクトをtextが指すようになっただけです。
変数が「どのオブジェクトを指すか」が変わっていると理解してください。
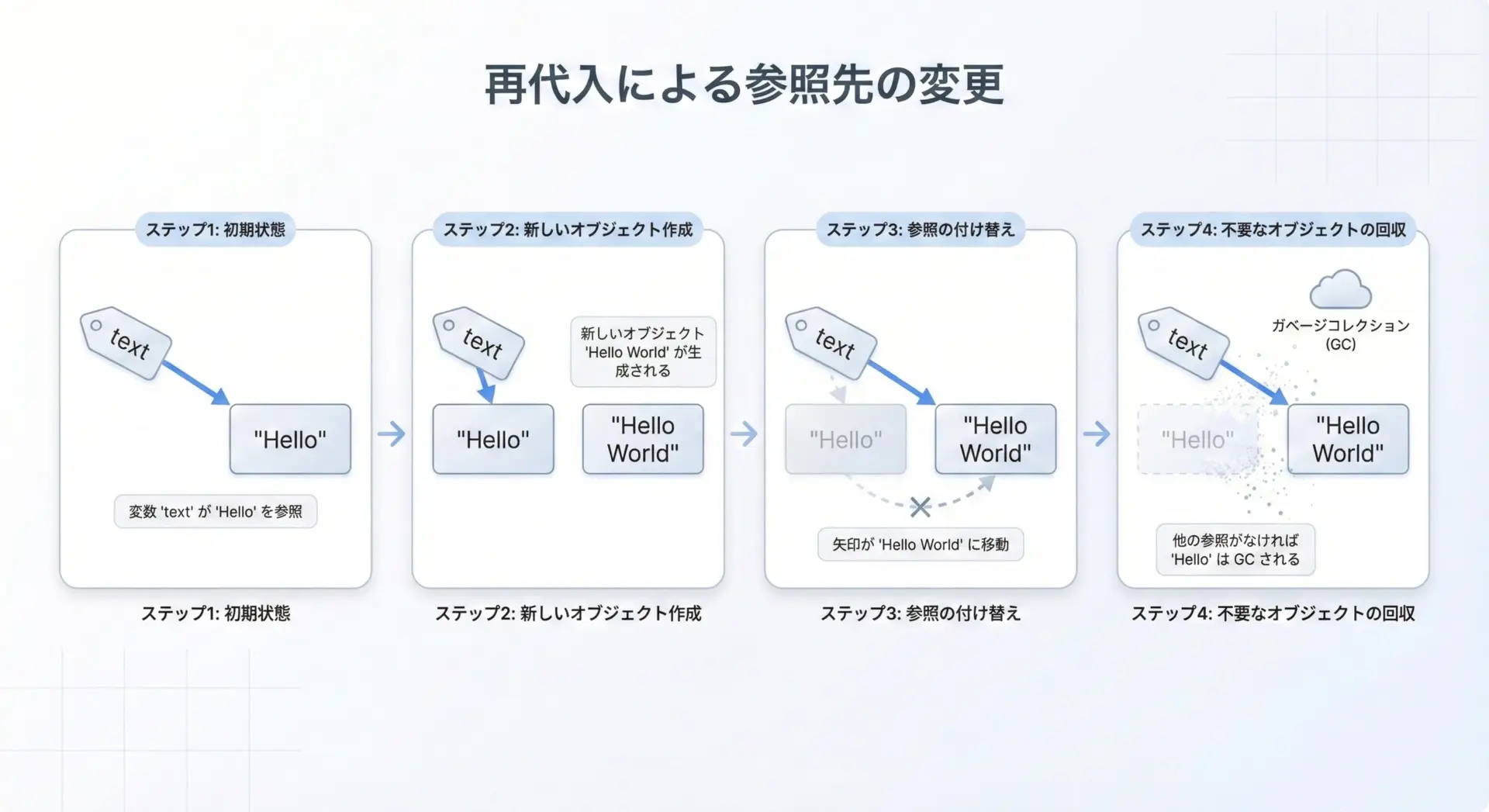
この考え方を身につけると、イミュータブルなオブジェクト全般の扱い方にも自然と慣れていきます。
ループ内での文字列連結の注意点
先ほども触れたように、ループの中で+=を使って文字列を連結すると、毎回新しいオブジェクトが作られてしまいます。
短い回数であれば問題になりませんが、回数が多くなると処理時間が目に見えて遅くなることがあります。
次のコードは、あえて非効率な書き方と効率的な書き方を並べたものです。
import time
# 非効率な方法
start = time.time()
s = ""
for i in range(10000):
s += "a"
end = time.time()
print("+= での連結:", end - start, "秒")
# 効率的な方法
start = time.time()
parts = []
for i in range(10000):
parts.append("a")
s = "".join(parts)
end = time.time()
print("join での連結:", end - start, "秒")実行環境によって結果は異なりますが、通常はjoinを使ったほうが明らかに高速になります。
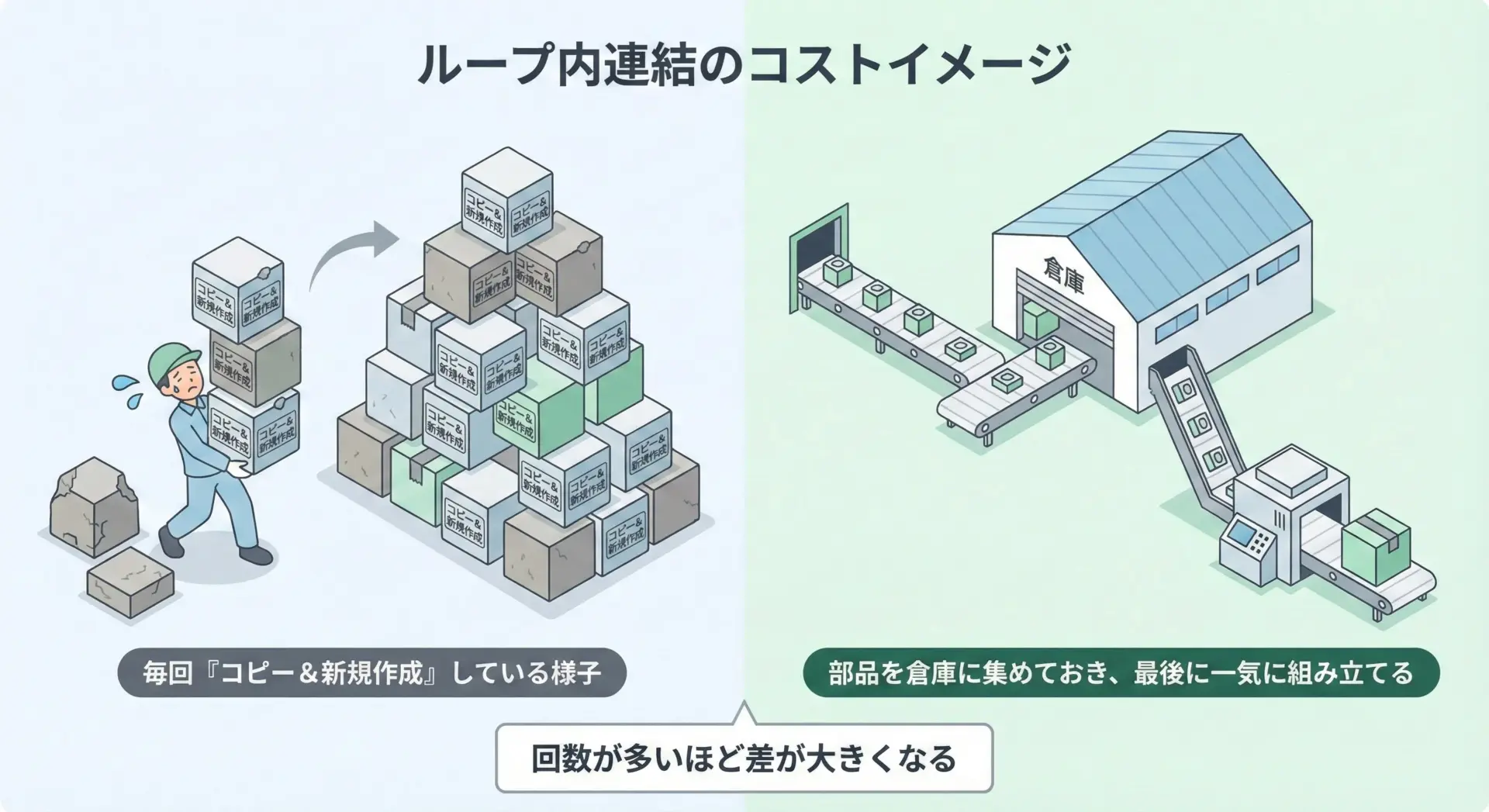
「少しの回数なら気にしなくてよいが、たくさん連結するならjoin」という感覚を早めに身につけると、無駄な遅さを避けられます。
リストで組み立てて最後に文字列へ変換するテクニック
実務で文字列を組み立てる際には、一度リストにパーツを集めてからjoinでまとめるというパターンがよく使われます。
これは、ループ内連結の問題を避けつつ、コードも読みやすくなる便利なテクニックです。
lines = []
lines.append("名前: Alice")
lines.append("年齢: 20")
lines.append("職業: エンジニア")
# 改行(\n)で連結して1つの文字列にする
profile = "\n".join(lines)
print(profile)名前: Alice
年齢: 20
職業: エンジニア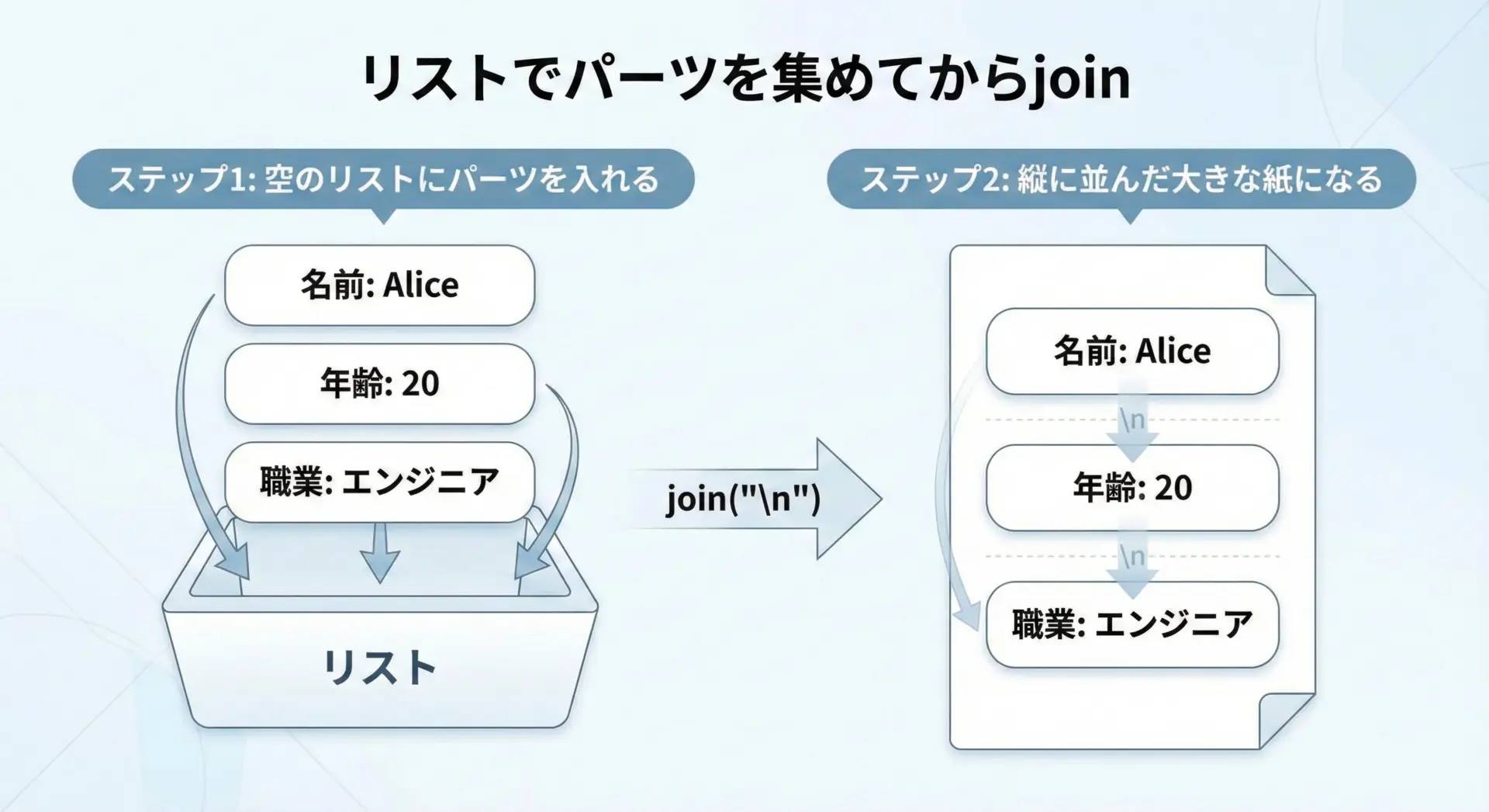
この方法はログの生成やレポートの作成、SQL文の組み立てなど、さまざまな場面で役立ちます。
「ループで文字列を作るときには、まずリストを使えないか検討する」という習慣を付けておくとよいでしょう。
まとめ
Pythonの文字列はイミュータブルであり、「書き換える」のではなく「常に新しい文字列を作っている」という点が本質です。
この性質のおかげで、辞書のキーとして安全に使えたり、複数の場所で同じ文字列を共有できたりと、多くのメリットが得られます。
その一方で、ループ内での+連結のように無駄なオブジェクト生成を引き起こす書き方には注意が必要です。
文字列操作では「イミュータブルだからこそ、どう組み立てるか」を意識し、リスト+joinなどのパターンを活用することで、読みやすく効率的なコードを書けるようになります。
