
Pythonでファイル操作を行うとき、うっかりファイルを閉じ忘れてしまった経験はないでしょうか。
with構文(コンテキストマネージャ)を使えば、そうしたミスを防ぎながら、読み書き処理をすっきりと書くことができます。
本記事では、with構文による安全なファイル操作の書き方を、具体例と図解を交えて丁寧に解説していきます。
with構文とは何か
Pythonのwith構文(コンテキストマネージャ)の基本
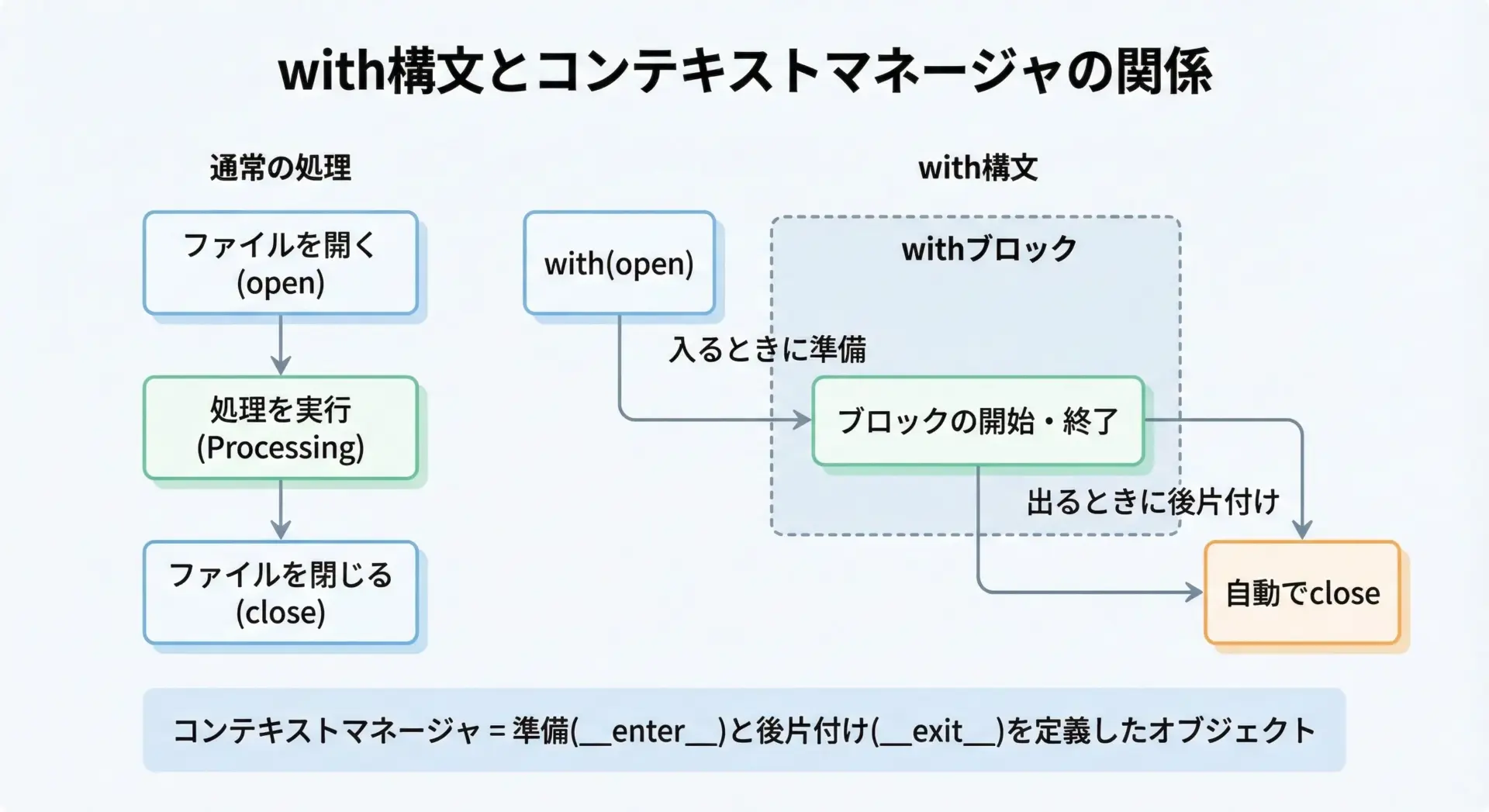
Pythonのwith構文は、リソースの準備と後片付けを自動化するための構文です。
ファイルやネットワーク接続など、開いたら必ず閉じなければならないものを扱う場面で特に威力を発揮します。
Pythonでは、このように書きます。
# with構文の基本形
with expression as variable:
# ここに処理を書く
...ここでのexpressionはコンテキストマネージャと呼ばれるオブジェクトを返します。
コンテキストマネージャは、内部的に__enter__と__exit__という2つの特別なメソッドを持っています。
__enter__はwithブロックに入るときに呼ばれ、返り値がasの右側の変数に代入されます。__exit__はwithブロックを抜けるときに呼ばれ、後片付け(ファイルを閉じるなど)を行います。
ファイルオブジェクトも、このコンテキストマネージャの仕組みを実装しているため、with open(...)という書き方が可能になっています。
with構文を使うメリット

with構文を使う最大のメリットは、リソース解放漏れを防げることです。
ファイル操作に限らず、データベース接続やロックなどでも同様ですが、特にファイルは頻繁に登場するため、with構文を標準的な書き方として身につけておくことが重要です。
主なメリットを文章で整理すると、次のようになります。
まず、ファイルを開いたら必ず閉じるというパターンを、人間の記述ミスに頼らずに言語仕様として保証してくれます。
通常のopenとcloseの書き方では、処理の途中で例外が発生したときにclose()が実行されない危険がありますが、with構文であれば例外が起きても__exit__が必ず呼ばれるため、ファイルは自動的に閉じられます。
また、コードが簡潔で読みやすくなる点も実務では重要です。
openとcloseを離れた場所に書く必要がなくなり、「このブロックの中だけファイルを使う」という範囲が目で見て明確になります。
チームでコードを共有するときにも、with構文が使われていると「リソース管理がしっかりしている」と判断しやすくなります。
with構文による安全なファイル操作の基本
openとwith構文を組み合わせたファイル読み込み

Pythonでテキストファイルを読む最も基本的な書き方は、次のようになります。
# sample_read_basic.py
# ファイルを開いて、中身をすべて読み込む例
file_path = "example.txt"
# with構文を使った安全なファイル読み込み
with open(file_path, mode="r", encoding="utf-8") as f:
# ファイル全体を1つの文字列として読み込む
content = f.read()
# この時点でファイルは自動的にcloseされている
print(content)# 実行結果の一例 (example.txt の中身に依存します)
Hello, world!
これはexample.txtの内容です。ここで重要なのは、withブロックを抜けた瞬間にファイルが自動的に閉じられることです。
print(content)はwithブロックの外側にありますが、すでにfは使えなくなっている一方で、読み取ったcontentはメモリ上に残っているため、安心して参照できます。
with構文でのファイル書き込みとモード指定
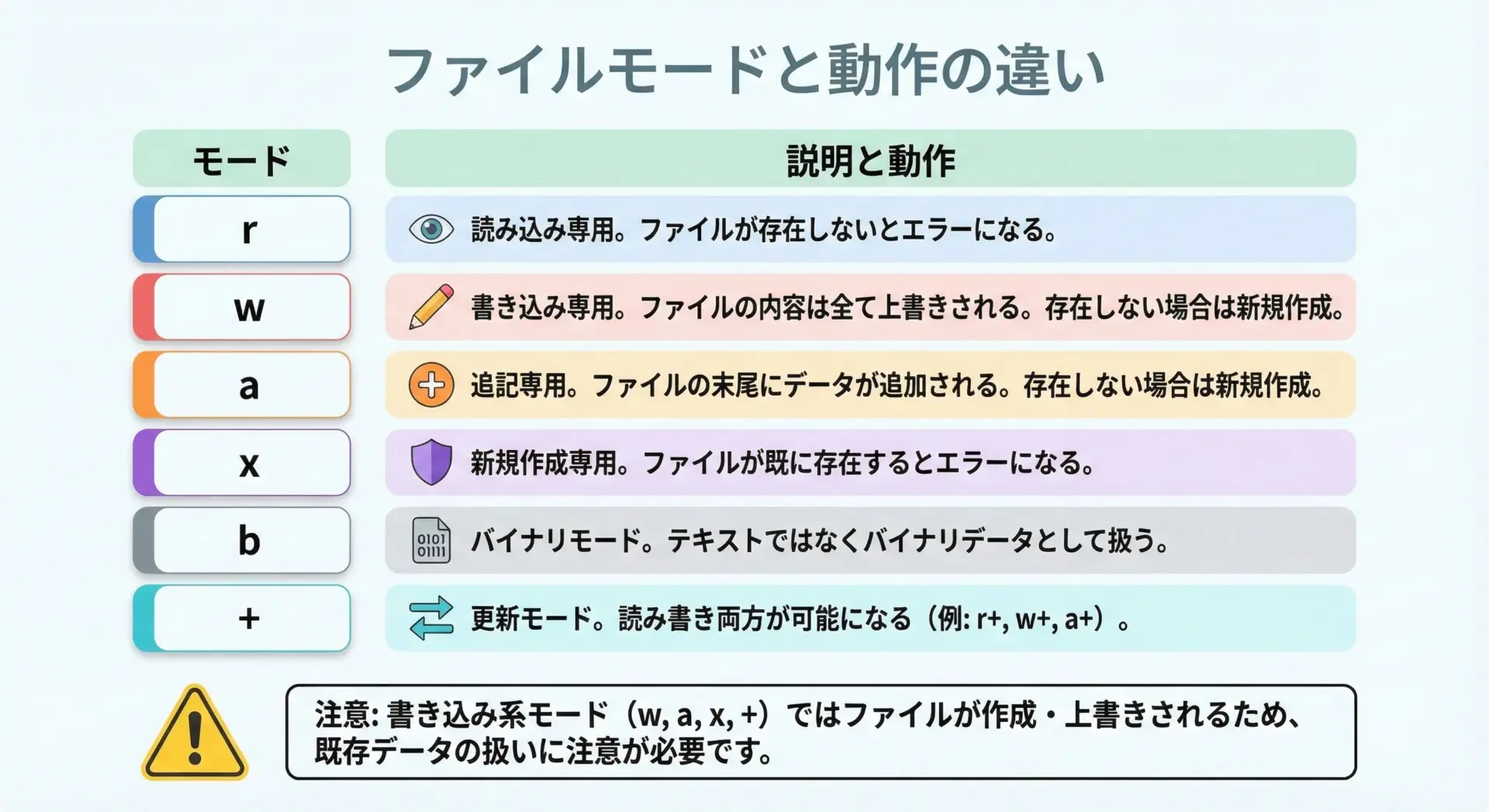
ファイルの書き込みも、with構文とopenを組み合わせて行います。
ここでは代表的なモードを表に整理しておきます。
| モード | 説明 |
|---|---|
"r" | 読み込み専用(デフォルト)。ファイルが存在しないとエラー。 |
"w" | 書き込み専用。既存ファイルは上書きされる。無ければ作成。 |
"a" | 追記モード。末尾に書き足す。無ければ作成。 |
"x" | 新規作成モード。既に存在するとエラー。 |
"b" | バイナリモード(他のモードと併用して使う)。 |
"+" | 読み書き両用モード(他のモードと併用)。 |
テキストを書き込む基本的な例を示します。
# sample_write_basic.py
file_path = "output.txt"
# "w"モードで開くと、既にファイルがあれば中身を消してから書き込みます
with open(file_path, mode="w", encoding="utf-8") as f:
f.write("1行目のテキストです。\n")
f.write("2行目のテキストです。\n")
# "a"モードで開くと、既存の内容を残したまま末尾に追記します
with open(file_path, mode="a", encoding="utf-8") as f:
f.write("3行目を追記します。\n")
# 書き込みが終わった後に読み込んで確認
with open(file_path, mode="r", encoding="utf-8") as f:
print(f.read())1行目のテキストです。
2行目のテキストです。
3行目を追記します。ここでは書き込みのたびにwithブロックを分けている点に注目してください。
ブロックごとに「ここまでで一旦きちんと閉じる」という区切りになるため、処理が複雑な場合でもリソースの状態を把握しやすくなります。
例外発生時でも自動でcloseされる仕組み
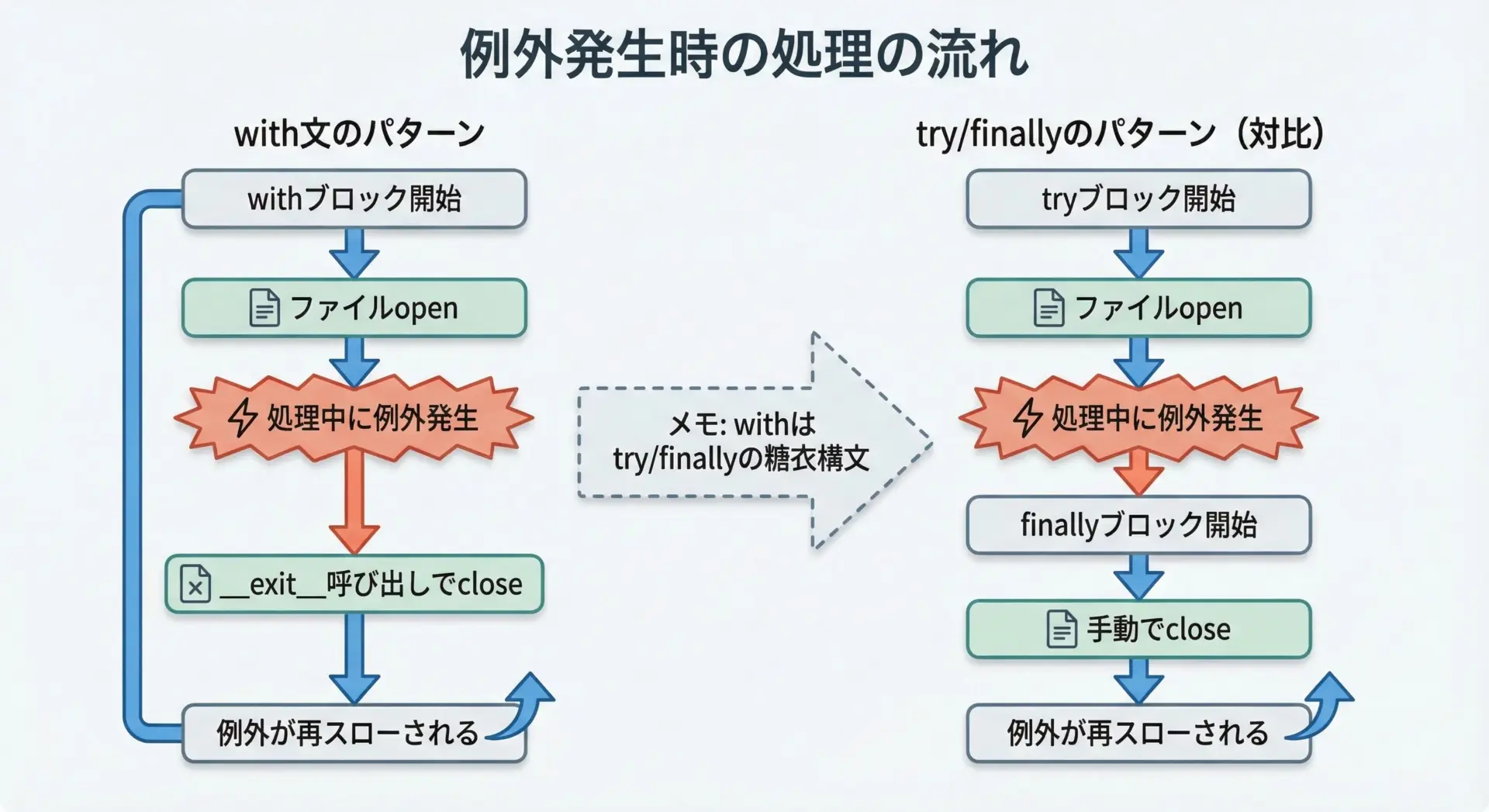
with構文の大きな安心材料は、途中で例外が起きても必ずファイルが閉じられることです。
次のサンプルで挙動を確認してみます。
# sample_exception_auto_close.py
file_path = "error_demo.txt"
# まずファイルを作成しておく
with open(file_path, mode="w", encoding="utf-8") as f:
f.write("エラー発生テスト用のファイルです。\n")
try:
with open(file_path, mode="r", encoding="utf-8") as f:
print("読み込んだ1行目:", f.readline().strip())
# わざとゼロ除算エラーを発生させる
x = 1 / 0
print("この行は実行されません")
except ZeroDivisionError:
print("ゼロ除算エラーを捕捉しました。")
# withブロックを抜けた後でも、ファイルが閉じられているかは
# 実際には f.closed 属性で確認できます。
with open(file_path, mode="r", encoding="utf-8") as f:
print("最後にもう一度読み込み:", f.readline().strip())読み込んだ1行目: エラー発生テスト用のファイルです。
ゼロ除算エラーを捕捉しました。
最後にもう一度読み込み: エラー発生テスト用のファイルです。上のコードでは、withブロックの中でゼロ除算エラーが発生し、その瞬間に__exit__が呼び出されてファイルが閉じられます。
その後、例外は外側のexceptで捕捉されています。
つまり、try/finallyでclose()を呼び出すのと同等の安全性を、より簡潔な構文で実現していると言えます。
よくあるファイル操作パターンとwith構文
テキストファイルの行単位読み込み
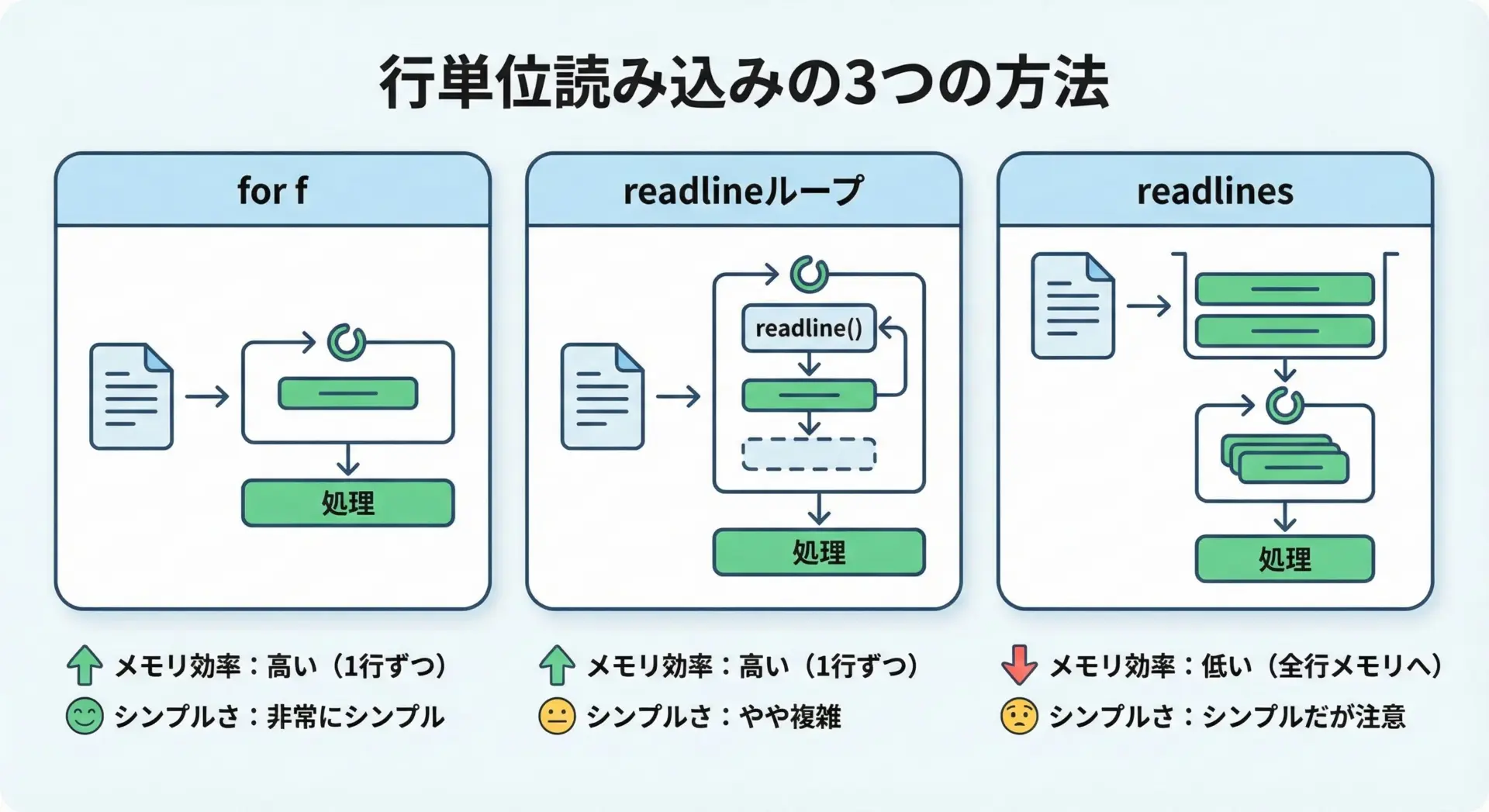
テキストファイルを扱う場面では、1行ずつ処理したいことがよくあります。
with構文を使うことで、どの方法でも安全に行単位の読み込みが可能です。
もっともPython的で分かりやすいのは、ファイルオブジェクト自体を反復可能オブジェクトとして扱う方法です。
# sample_read_lines.py
file_path = "lines_demo.txt"
# デモ用のファイルを作成
with open(file_path, mode="w", encoding="utf-8") as f:
for i in range(1, 6):
f.write(f"{i}行目のテキストです。\n")
# 1行ずつループで処理する方法
with open(file_path, mode="r", encoding="utf-8") as f:
for line in f:
# 行末の改行を取り除いてから表示
print(line.strip())1行目のテキストです。
2行目のテキストです。
3行目のテキストです。
4行目のテキストです。
5行目のテキストです。この方法の利点は、ファイルを順に読み進めるだけなのでメモリ効率がよいことです。
大きなログファイルなどでも、1行ずつ処理できるため、メモリ不足の心配がほとんどありません。
もちろん、readline()メソッドを使って自前でループを書いたり、readlines()でリストとしてまとめて読み込んだりすることもできますが、基本的にはfor line in fという書き方を覚えておくとよいでしょう。
バイナリファイルの読み書きとwith構文

画像ファイルやPDF、音声ファイルなどはバイナリデータとして扱う必要があります。
この場合、openのモードに"b"を付けて"rb"や"wb"と指定します。
次のサンプルでは、ファイルをそのままコピーする処理をwith構文で実装しています。
# sample_binary_copy.py
source_path = "source.bin"
dest_path = "copy.bin"
# デモ用に、適当なバイナリデータを書き込んだファイルを作成
with open(source_path, mode="wb") as src:
# bytesリテラル(b"...")をそのまま書き込む
src.write(b"\x00\x01\x02\x03Hello Binary World!\n")
# バイナリファイルをコピーする処理
with open(source_path, mode="rb") as src, open(dest_path, mode="wb") as dst:
# 全体を一度に読み込んで書き込むシンプルな例
data = src.read()
dst.write(data)
print("コピー完了")コピー完了バイナリモードではencoding引数は指定しません。
その代わり、データはbytes型として扱われる点に注意してください。
テキストとして利用したい場合は、data.decode("utf-8")のようにして明示的にデコードします。
複数ファイルを同時に扱うwith構文の書き方
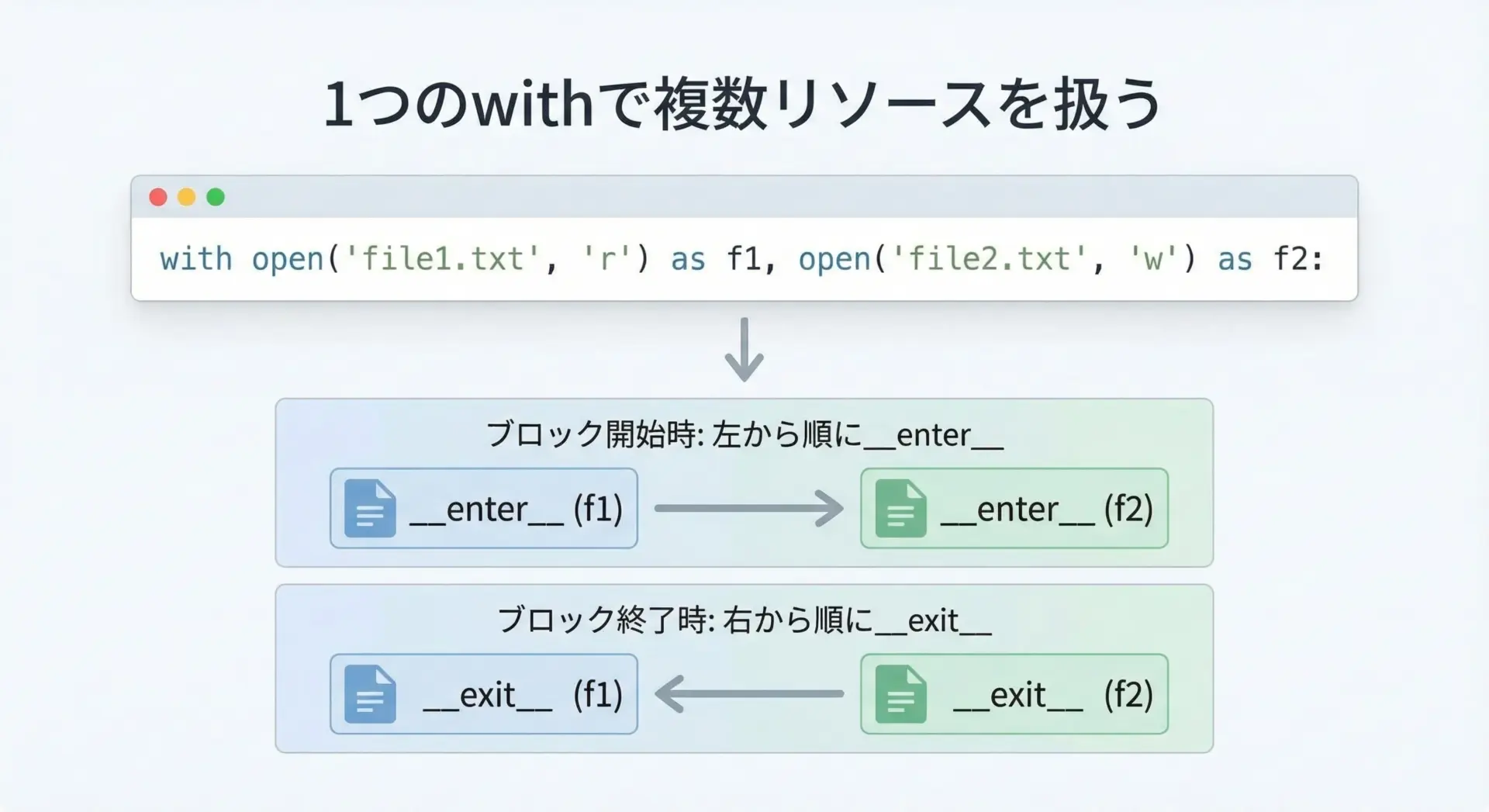
with構文は、1行で複数のリソースを扱うことができます。
ファイルコピー処理の例ですでに少し使いましたが、もう少し分かりやすい形で示してみます。
# sample_multiple_files.py
source_path = "input.txt"
dest_path = "output.txt"
# 入力ファイルを準備
with open(source_path, mode="w", encoding="utf-8") as f:
f.write("複数ファイルwith構文のテストです。\n")
# 1つのwithで2つのファイルを扱う
with open(source_path, mode="r", encoding="utf-8") as src, \
open(dest_path, mode="w", encoding="utf-8") as dst:
for line in src:
dst.write("コピー: " + line)
print("複数ファイルを使ったコピーが完了しました。")複数ファイルを使ったコピーが完了しました。この書き方では、ブロックの開始時に左から順にファイルが開かれ、ブロックの終了時には右から順に閉じられるというルールがあります。
どちらのファイルも、withブロックを抜けた時点で確実に閉じられるため、リソース漏れの心配はありません。
Pythonのスタイルガイド(PEP 8)では、複数行にまたがる場合には上の例のように行末にバックスラッシュを使うか、丸括弧で全体を囲む書き方が推奨されています。
ネストしたwith構文とカンマ区切りの違い

複数のファイルを扱う場合、次の2つの書き方は基本的には同じ意味になります。
# ネストしたwith構文の例
with open("a.txt") as fa:
with open("b.txt") as fb:
# fa, fb の両方を使う処理
...
# カンマ区切りで1行にまとめた例
with open("a.txt") as fa, open("b.txt") as fb:
# fa, fb の両方を使う処理
...どちらもブロックの中ではfaとfbの両方が使え、ブロックを抜けると順に閉じられます。
ただし、例外処理やリソースごとの独立性をどう設計したいかによって、使い分ける意味が出てきます。
例えば、a.txtは必須だけれどb.txtはあれば使う、といった状況では、a.txtのwithブロックの中にb.txtのwithを書き、b.txt側のopenだけ個別にtry/exceptする方が自然な場合があります。
一方で、単に「2つのファイルを同時に開いて、同じ単位で閉じたい」というだけなら、カンマ区切りでフラットに書く方が読みやすくなります。
with構文を使う際の注意点と応用
encoding指定やエラー処理(try except)との組み合わせ

テキストファイルを扱うときは、encoding(文字コード)の指定が重要です。
Python 3ではOSや環境ごとのデフォルトエンコーディングがありますが、特に日本語を扱う場合はencoding="utf-8"を明示的に指定することを強くおすすめします。
また、with構文とtry/exceptは一緒に使うことが多い組み合わせです。
典型的なパターンを示します。
# sample_encoding_and_error.py
file_path = "maybe_exists.txt"
try:
with open(file_path, mode="r", encoding="utf-8") as f:
content = f.read()
except FileNotFoundError:
print(f"ファイルが見つかりません: {file_path}")
except UnicodeDecodeError:
print("UTF-8としてデコードできない文字が含まれています。")
else:
# 例外が発生しなかった場合のみ実行される
print("ファイルの内容:")
print(content)ファイルが見つかりません: maybe_exists.txtここでは、構造化されたエラー処理を意識することがポイントです。
withブロックはあくまで「開く」「閉じる」の責務を担い、エラー時の振る舞い(ログを出すか、再試行するか、ユーザにメッセージを出すかなど)はtry/except側で決める、という役割分担を意識すると、複雑な処理でも整理しやすくなります。
コンテキストマネージャを自作してリソース管理を自動化

with構文はファイル専用ではなく、あらゆる「開く/閉じる」タイプの処理に利用できます。
自分でコンテキストマネージャを定義することで、任意のリソース管理を自動化できます。
まずは、クラスで__enter__と__exit__を実装する基本形の例です。
# sample_custom_context.py
class TagWriter:
"""簡易的なHTMLタグの前後を自動で出力するコンテキストマネージャ"""
def __init__(self, tag_name, file):
self.tag_name = tag_name
self.file = file
def __enter__(self):
# withブロックに入るときに開始タグを書き込む
self.file.write(f"<{self.tag_name}>\n")
# as で受け取るオブジェクトとして self を返す
return self
def __exit__(self, exc_type, exc_value, traceback):
# withブロックを出るときに終了タグを書き込む
self.file.write(f"</{self.tag_name}>\n")
# ここで True を返すと例外を握りつぶすが、基本は False でよい
return False
output_path = "tags_demo.html"
with open(output_path, mode="w", encoding="utf-8") as f:
with TagWriter("html", f):
with TagWriter("body", f):
f.write(" <p>コンテキストマネージャのデモです。</p>\n")
print("HTMLファイルを生成しました。")HTMLファイルを生成しました。この例では、ファイルの開閉に加えて、HTMLタグの前後処理をコンテキストマネージャに任せています。
実際には、データベース接続やロック取得・解放、時間計測(処理前後のタイムスタンプ取得)など、さまざまな用途に応用できます。
さらに簡便な方法として、標準ライブラリのcontextlibモジュールにある@contextmanagerデコレータを使う手もあります。
関数ベースでコンテキストマネージャを定義できるため、軽量な用途に向いています。
# sample_contextlib.py
from contextlib import contextmanager
import time
@contextmanager
def elapsed_time(label):
"""処理時間を計測して表示するコンテキストマネージャ"""
start = time.time()
try:
# withブロックに入るとき
yield
finally:
# withブロックを抜けるとき(例外の有無にかかわらず実行)
end = time.time()
print(f"{label}: {end - start:.4f}秒")
# 利用例
with elapsed_time("ループ処理"):
total = 0
for i in range(1000000):
total += i
print("計算が終わりました。")ループ処理: 0.0XXX秒
計算が終わりました。このように、「開始処理」「終了処理」がワンセットになっている操作であれば、with構文とコンテキストマネージャを組み合わせて、自動化・安全化することができます。
既存コードのopen closeをwith構文にリファクタリングするコツ

最後に、既存コードでopen()とclose()を直接呼んでいる部分を、with構文にリファクタリングする際のポイントを整理します。
典型的なbefore/afterを見てみましょう。
# before: 直接 open と close を使っているコード
file_path = "data.txt"
f = open(file_path, mode="r", encoding="utf-8")
try:
content = f.read()
# ここで複雑な処理がいろいろ行われる…
finally:
f.close()# after: with構文を使ってリファクタリングしたコード
file_path = "data.txt"
with open(file_path, mode="r", encoding="utf-8") as f:
content = f.read()
# ここで複雑な処理がいろいろ行われる…リファクタリングのコツは、「ファイルを使う範囲」をしっかり把握することです。
具体的には、次の観点を意識します。
まず、ファイルオブジェクトfが参照されている最初と最後の位置を見つけ、その範囲をwithブロックで囲む形に書き換えます。
このとき、withブロックを抜けた後にfを使っているコードが残っていないかに注意してください。
もしあれば、その処理をブロック内に移すか、ファイルから読み取ったデータだけを変数に保持しておき、ブロック外ではその変数を使うようにします。
次に、例外処理の責務を整理します。
もともとtry/finallyでcloseしていた部分はwithに置き換えられますが、exceptでエラーをハンドリングしていた部分は、必要であればwithブロックの外側に残す必要があります。
つまり、「リソースの後片付け」はwith、「エラー時の動作」はtry/except、と役割を分離するイメージです。
最後に、大規模なコードでは、段階的な置き換えを心がけることが大切です。
一度にすべてを書き換えるのではなく、テストしやすい単位(関数ごとやモジュールごと)に区切り、各ステップで動作確認を行いながらwith構文へ移行すると、安全にリファクタリングが進められます。
まとめ
with構文は、Pythonにおける安全で読みやすいファイル操作の標準的な書き方です。
コンテキストマネージャの仕組みにより、ファイルのクローズを自動化し、例外発生時でもリソース漏れを防いでくれます。
テキストやバイナリの読み書き、複数ファイルの同時操作、encoding指定や例外処理との組み合わせなど、日常的なパターンのほとんどはwith構文でシンプルに表現できます。
さらに、自作のコンテキストマネージャを使えば、ファイル操作以外のリソース管理も自動化でき、コードの品質と保守性を大きく向上させられます。
