
Pythonのfor文は、最初にきちんと理解しておくと、その後のプログラミングがとても楽になります。
本記事では、Pythonのfor文ループの基本から、range・enumerate・zipといった実用的なテクニックまで、図解とサンプルコードで丁寧に解説します。
初心者の方でも、読み終えるころには「Pythonのループは怖くない」と感じられることを目指します。
Pythonのfor文とは
for文ループの基本構文と処理の流れ
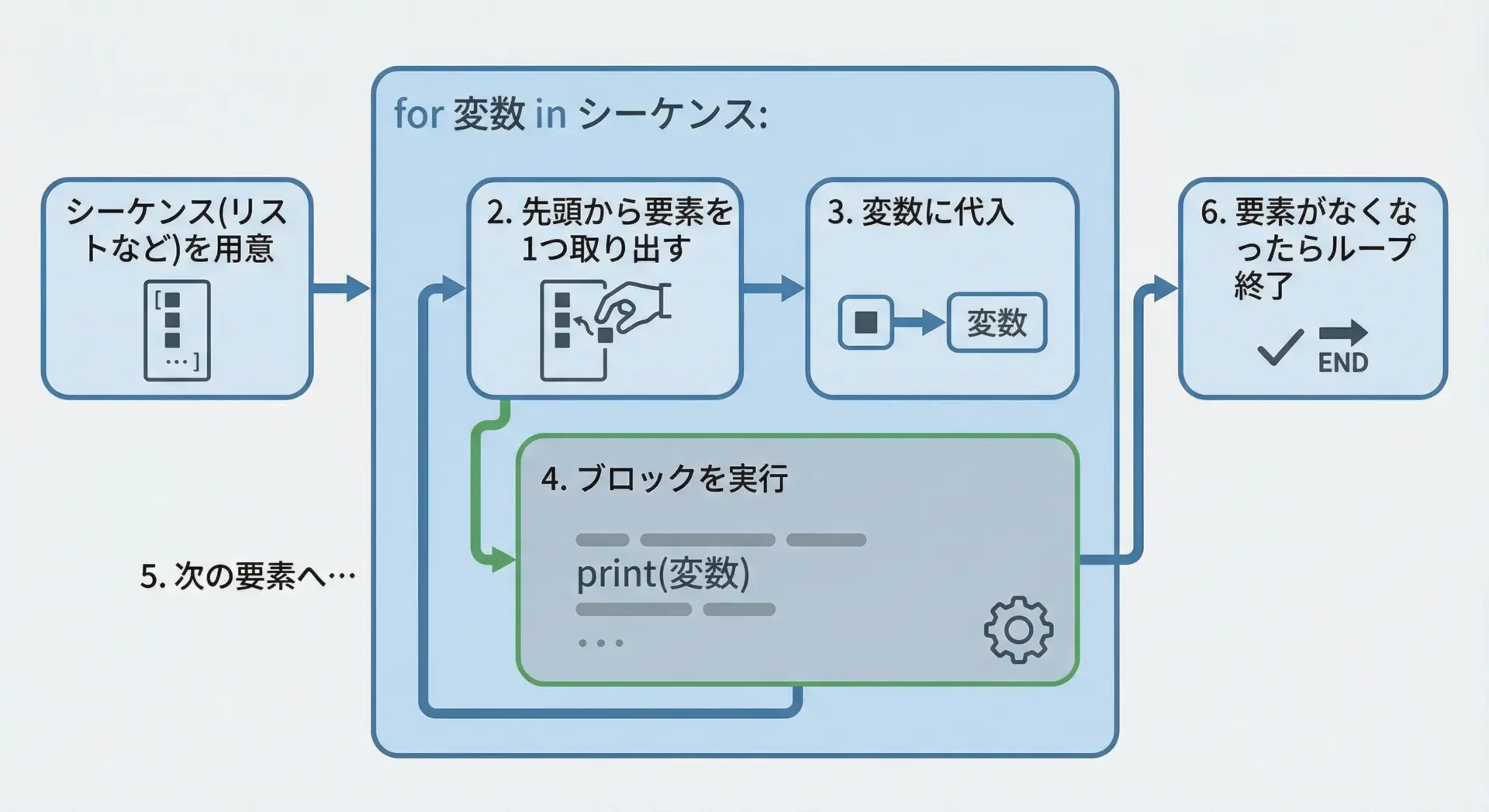
Pythonのfor文は、「繰り返し可能なオブジェクト(イテラブル)から要素を1つずつ取り出しながら、同じ処理を繰り返す構文」です。
典型的な基本構文は次のようになります。
# fruitsの中身を順番に取り出して表示する基本的なfor文の例
fruits = ["apple", "banana", "orange"]
for fruit in fruits: # for 変数 in シーケンス:
print(fruit) # インデントされた部分が、繰り返し実行されるブロックapple
banana
orangeこのときの処理の流れは次のようになります。
- リスト
fruitsから、先頭の要素"apple"が取り出され、変数fruitに代入されます。 - インデントされた
print(fruit)が実行され、画面にappleが表示されます。 - 次に
"banana"がfruitに代入され、同じ処理が行われます。 - 要素がなくなるまで、同じ流れが繰り返されます。
- すべての要素を処理し終わったところで、for文を抜けて次の処理に進みます。
Pythonのfor文は「回数」ではなく「要素」に着目している点が、他の言語(CやJavaなど)と比べたときの大きな特徴です。
while文との違いとfor文を使う場面
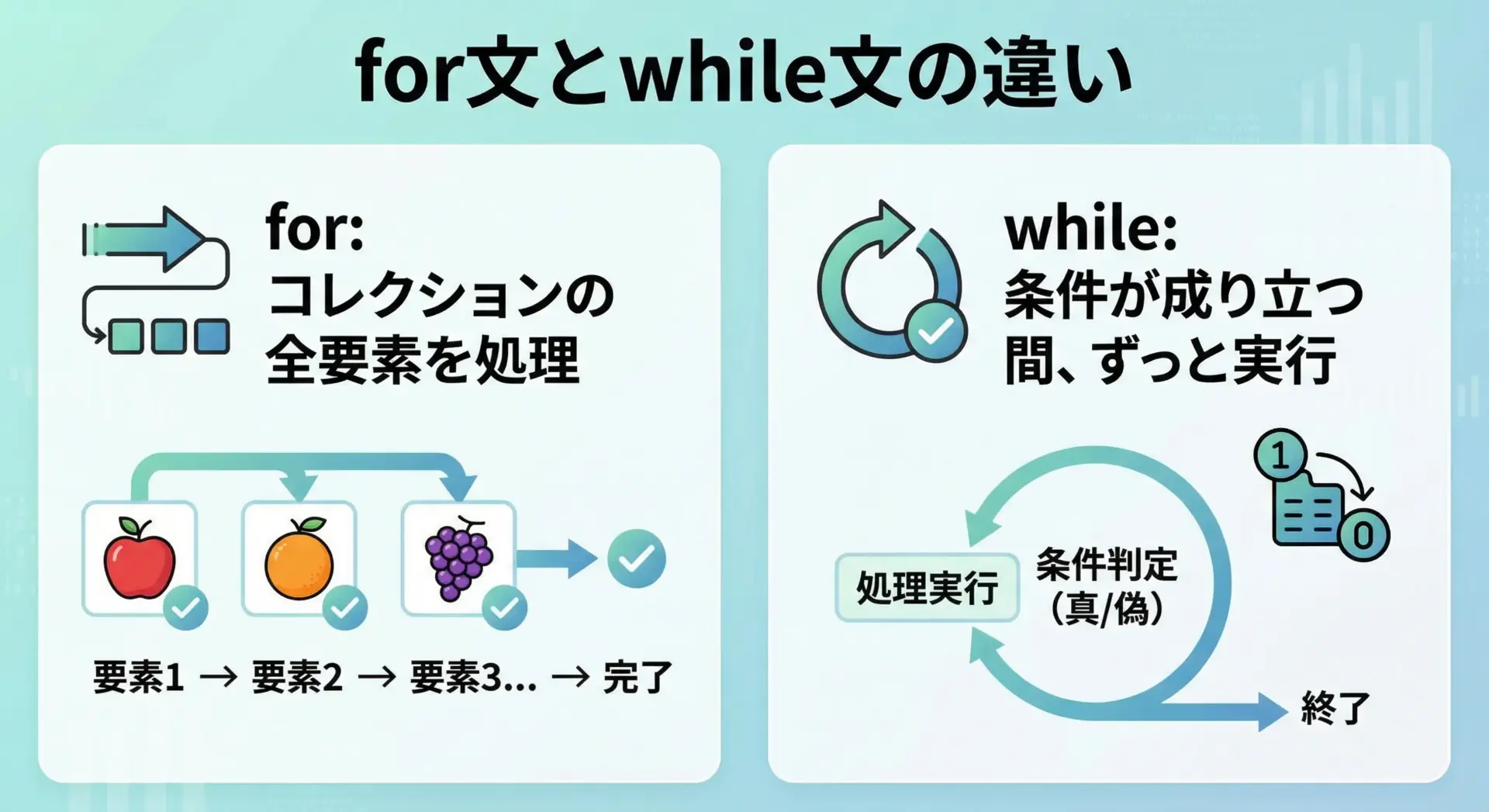
Pythonにはwhile文もありますが、用途が少し異なります。
- for文
イテラブル(リスト、タプル、文字列、rangeなど)の全要素を1回ずつ処理したいときに向いています。 - while文
「ある条件が満たされているあいだ、ずっと処理を続けたい」といった条件ベースの繰り返しに向いています。
例を見比べてみます。
# for文でリストの全要素を処理する例
numbers = [1, 2, 3, 4, 5]
for n in numbers:
print(n)# while文で「条件がTrueの間」処理を繰り返す例
count = 1
while count <= 5: # 条件が成り立つ間だけ繰り返す
print(count)
count += 1 # 条件がいつかFalseになるように更新するどちらも1〜5までを表示しますが、for文は「何回繰り返すか(= 要素数)が明確な場合」、while文は「いつ終わるかは条件次第」という違いがあります。
Pythonでは、リストや文字列を単純に順番に処理する場合、原則としてfor文を使うのが読みやすく安全です。
Pythonのfor文でよくある書き方ミス

Pythonのfor文では、構文のルールがいくつかあります。
初心者の方がよくつまずく例を挙げます。
コロン:の付け忘れ
# NG例: コロンを忘れている
numbers = [1, 2, 3]
for n in numbers # SyntaxError になる
print(n)この場合、Pythonはブロックの始まりを判断できずSyntaxErrorになります。
正しくは次のように書きます。
# OK例
numbers = [1, 2, 3]
for n in numbers: # 行末にコロンを忘れずに
print(n)インデント(字下げ)をしない
# NG例: インデントがない
numbers = [1, 2, 3]
for n in numbers:
print(n) # インデントがないのでエラーになるPythonはインデントでブロックを表現する言語です。
for文の本体は、必ずスペース4つ(あるいはタブ1つ)で字下げします。
# OK例: インデントを入れてforのブロックを表現する
numbers = [1, 2, 3]
for n in numbers:
print(n)使っていない変数名をそのまま書く
ループ変数を全く使わないのに、そのまま中途半端な変数名を付けてしまうケースもよくあります。
Pythonでは、使わない変数名には_(アンダースコア)を使う慣習があります。
# 10回だけ同じ処理をしたいが、ループ変数は使わない例
# NG例: 使わないのに変数iを定義してしまう
for i in range(10):
print("Hello")
# OK例: 使わない変数は _ にする
for _ in range(10):
print("Hello")このような小さな約束を守ることで、コードの意図が伝わりやすくなります。
range関数でシンプルな繰り返し
rangeの基本
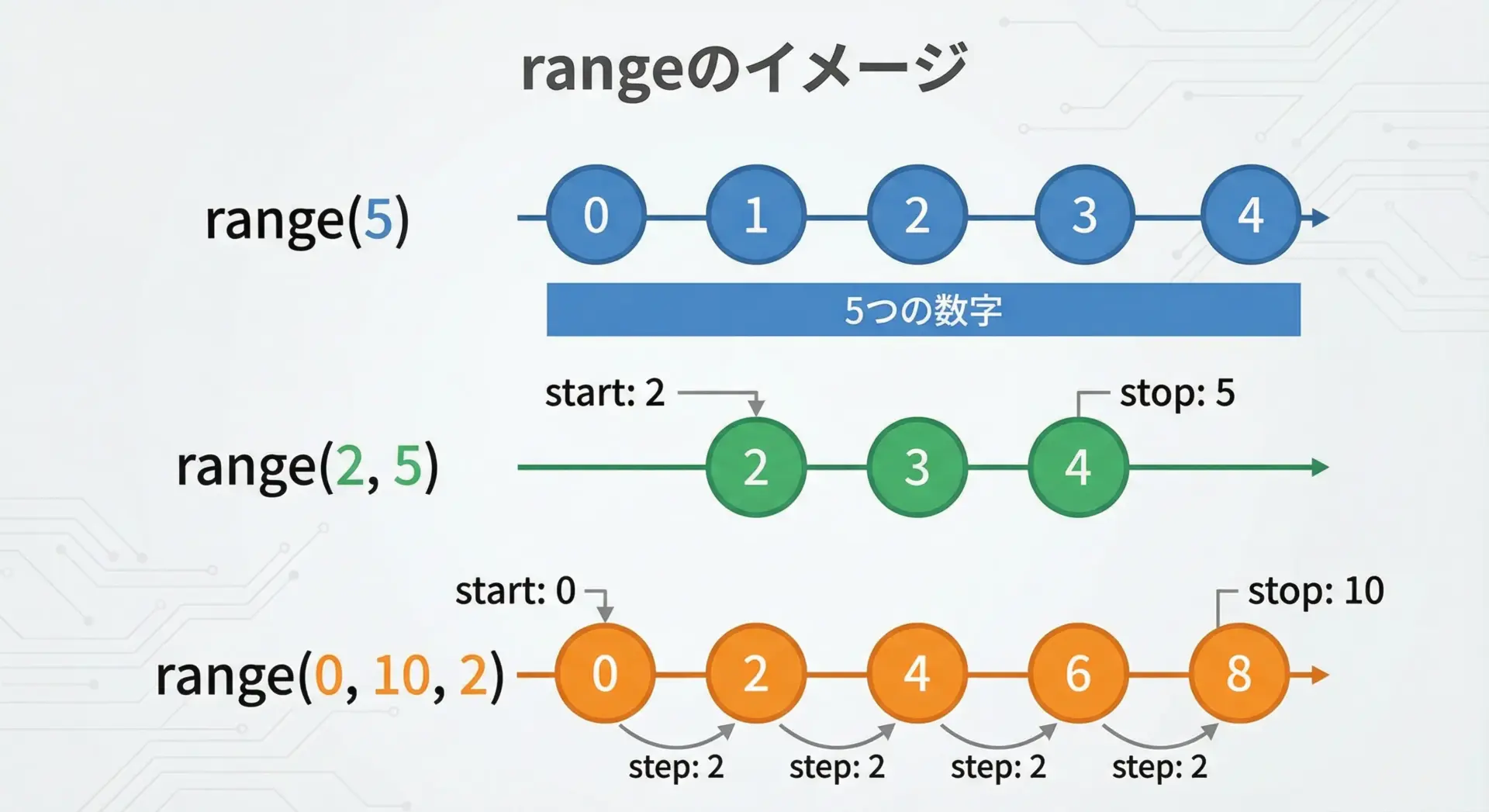
range関数は、一定間隔で並ぶ整数の「連番」を作るための組み込み関数です。
for文と非常に相性がよく、回数ベースのループやインデックス付きのループで頻繁に登場します。
基本的な使い方は次の3パターンです。
range(stop)
0 からstop - 1までの整数を生成します。range(start, stop)startからstop - 1までの整数を生成します。range(start, stop, step)startからstop - 1まで、stepずつ増減させた整数を生成します。
# rangeの基本的な動きを確認する例
print(list(range(5))) # 0〜4 を生成
print(list(range(2, 5))) # 2〜4 を生成
print(list(range(0, 10, 2))) # 0, 2, 4, 6, 8 を生成[0, 1, 2, 3, 4]
[2, 3, 4]
[0, 2, 4, 6, 8]range自体は「リスト」ではなく「rangeオブジェクト」です。
しかしfor文ではそのまま使えるため、普段はあまり意識しなくても問題ありません。
rangeを使ったインデックス付きループ
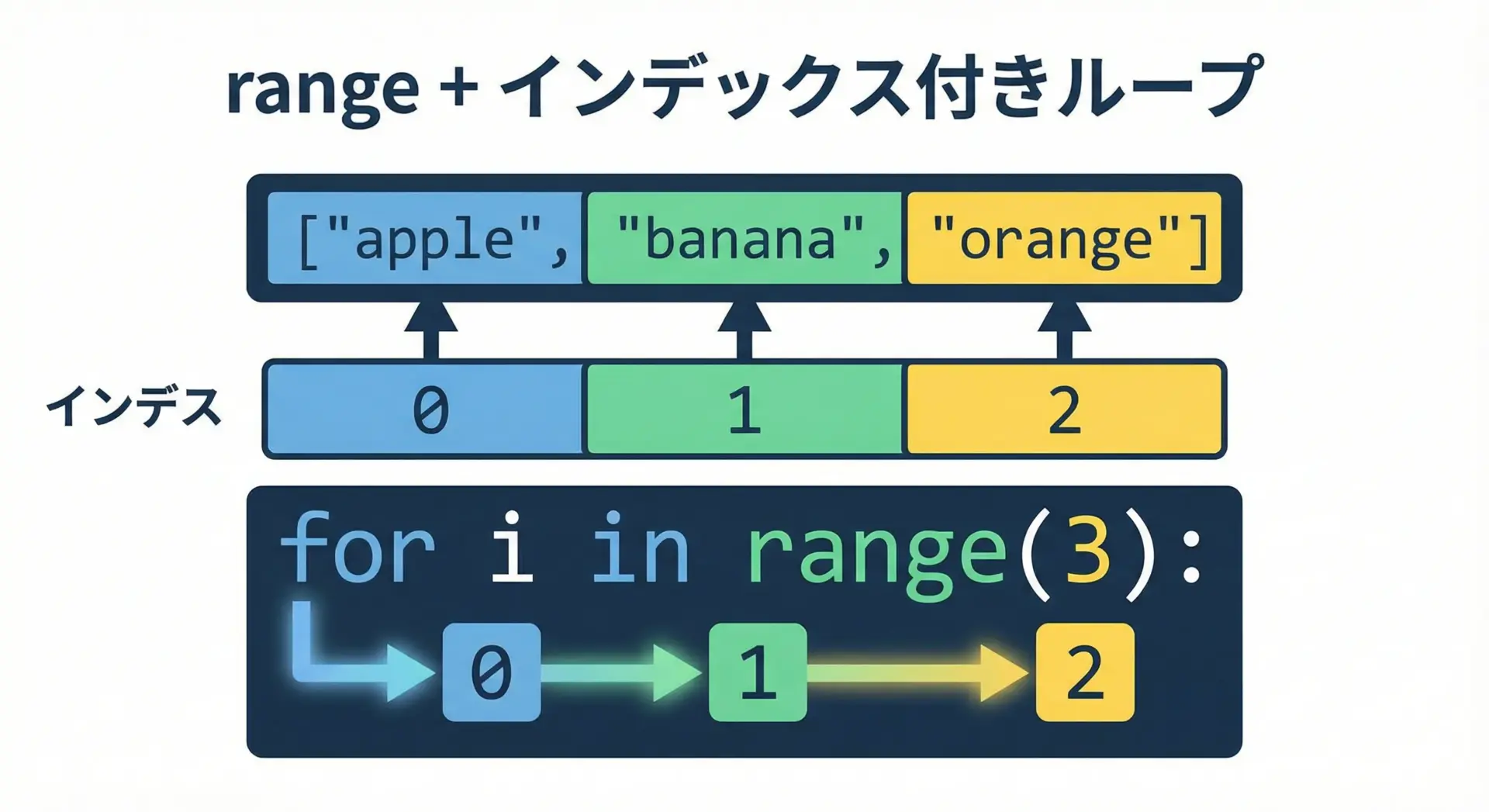
リストの「位置(インデックス)」を使って処理したい場合、rangeを使ったインデックス付きループがよく使われます。
# rangeを使って、インデックスと要素を両方扱う例
fruits = ["apple", "banana", "orange"]
for i in range(len(fruits)): # 0, 1, 2 が順に入る
fruit = fruits[i] # インデックスで要素を取り出す
print(i, fruit)0 apple
1 banana
2 orangeこのパターンはよく見かけますが、インデックスと要素を同時に扱うだけなら、後述のenumerateの方がPythonらしく、読みやすいです。
ただし、「インデックスを使ってリストを書き換える」「一部だけスキップする」といった場合には、rangeが便利です。
rangeとlenを組み合わせたリストの走査
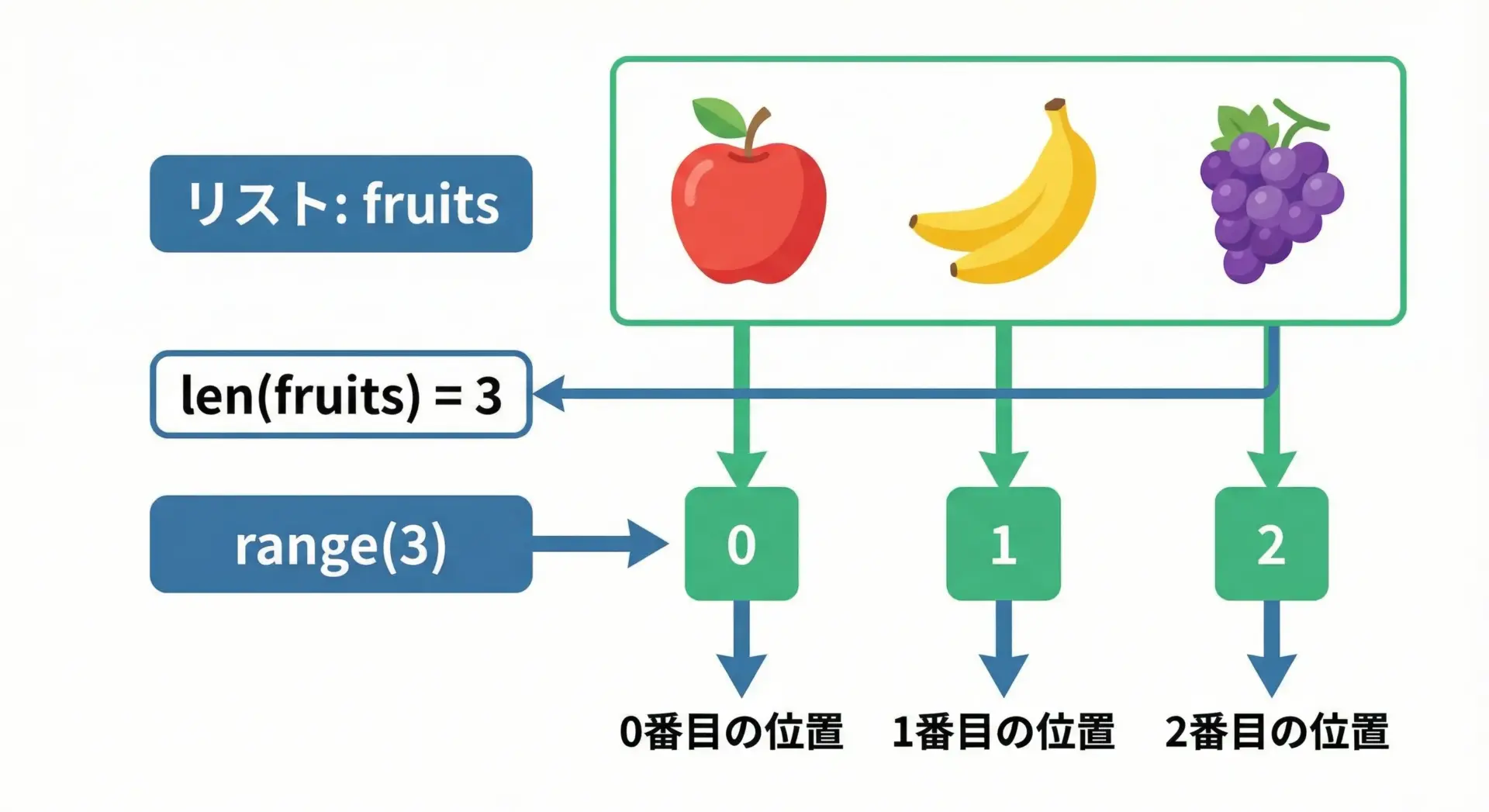
len関数は、リストなどの「長さ(要素数)」を返します。
range(len(…))という組み合わせは、インデックスを0から最後の要素まで順番に回すときの定番パターンです。
# range(len(リスト)) でインデックスを回しながら要素を処理する例
scores = [70, 85, 90]
for i in range(len(scores)): # i は 0, 1, 2
scores[i] += 5 # 得点を +5 点する
print(f"{i}番目のスコア: {scores[i]}")0番目のスコア: 75
1番目のスコア: 90
2番目のスコア: 95このように、「リストを書き換える」「インデックスを何かに使う」といった用途では、range(len(...))が役に立ちます。
rangeで逆順ループ・スキップ付きループ
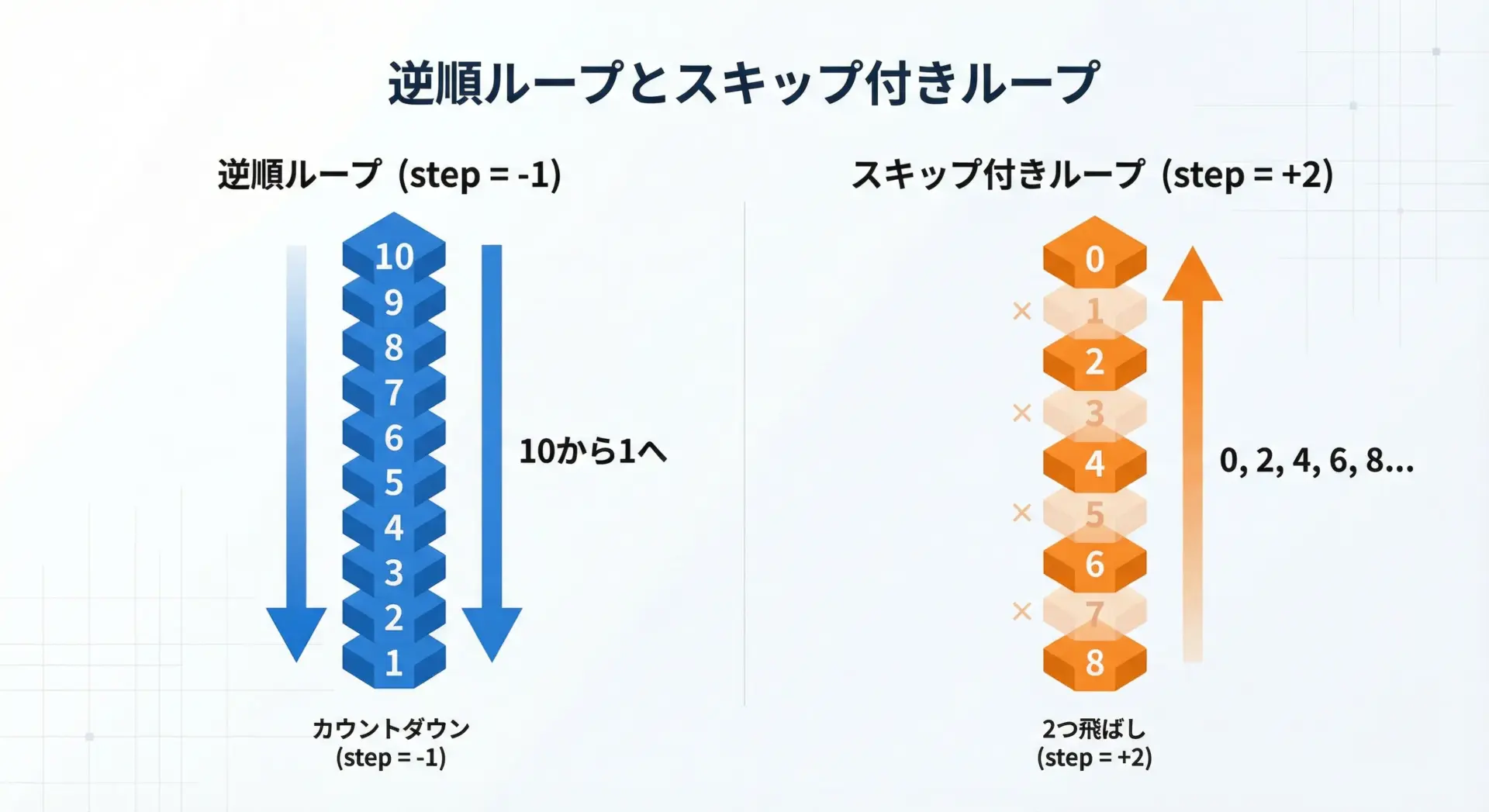
rangeのstep引数を使うと、逆順ループやスキップ付きループが簡単に書けます。
逆順ループの例
# 10から1までカウントダウンする逆順ループ
for n in range(10, 0, -1): # start=10, stop=0(含まない), step=-1
print(n, end=" ")
print() # 改行用10 9 8 7 6 5 4 3 2 1ここでrange(10, 0, -1)は、10, 9, 8, ..., 1を生成します。
stopの値は「含まれない」点を忘れないようにしてください。
スキップ付きループの例
# 0〜10までの偶数だけを処理するスキップ付きループ
for n in range(0, 11, 2): # 0から10まで2刻み
print(n, end=" ")
print()0 2 4 6 8 10このように、step を上手く使うことで、処理したい番号だけを効率良くループさせることができます。
enumerateでインデックスと要素を同時に扱う
enumerateの基本構文と戻り値
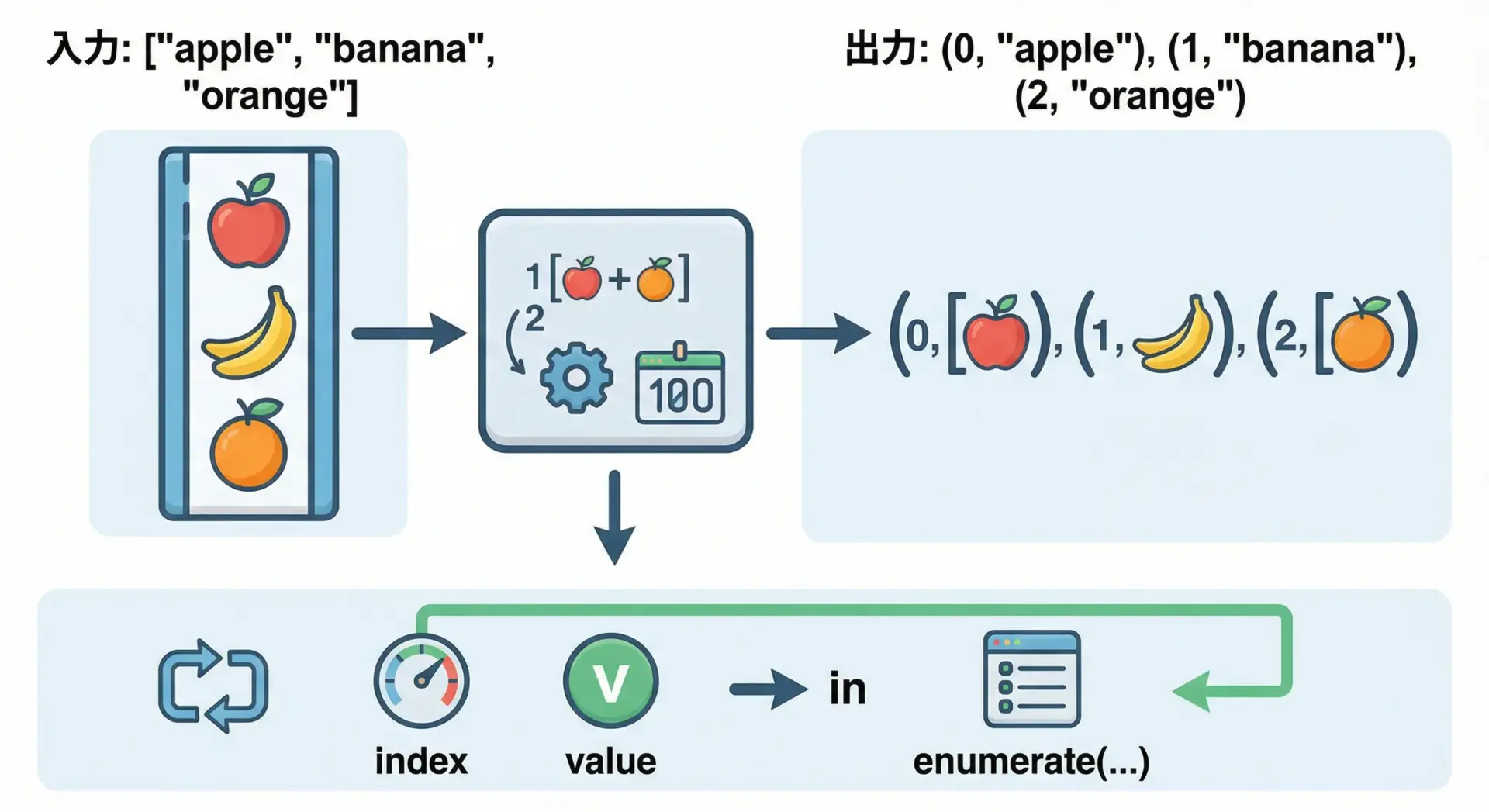
enumerateは、シーケンスをループするときに「インデックス」と「要素」を同時に取り出すための組み込み関数です。
基本構文は次のようになります。
# enumerateの基本構文
for index, value in enumerate(iterable, start=0):
# index と value を使った処理
...iterable
リストやタプル、文字列など、繰り返し可能なオブジェクトstart(省略可)
インデックスの開始値(デフォルトは0)
実際の動作を確認してみます。
# enumerateが返す値を確認する例
fruits = ["apple", "banana", "orange"]
for pair in enumerate(fruits):
print(pair) # (インデックス, 要素) のタプルになっている(0, 'apple')
(1, 'banana')
(2, 'orange')1つのループで「順番」と「中身」の両方が必要な場面では、enumerateが最もPythonらしい書き方になります。
enumerateで書き換える典型的なfor文
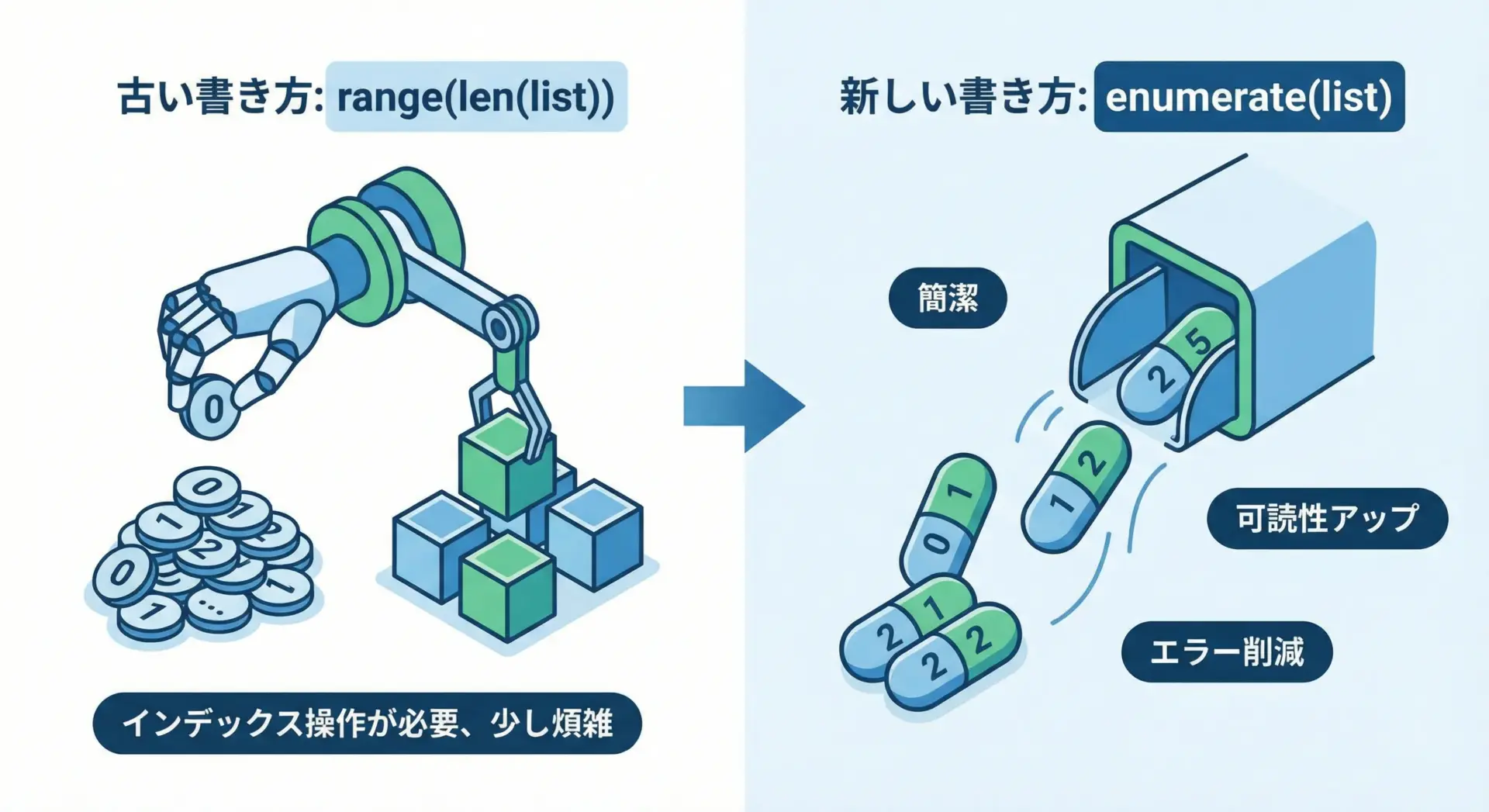
range(len(...))で書かれたループは、ほとんどの場合、enumerateで書き換えることができます。
# NGではないが、あまりPythonらしくない書き方
fruits = ["apple", "banana", "orange"]
for i in range(len(fruits)):
fruit = fruits[i]
print(i, fruit)これをenumerateを使って書き換えると、次のようになります。
# Pythonらしい書き方: enumerateを使う
fruits = ["apple", "banana", "orange"]
for i, fruit in enumerate(fruits): # i: インデックス, fruit: 要素
print(i, fruit)実行結果(どちらも同じ):
0 apple
1 banana
2 orangeインデックスと要素を両方使うだけなら、enumerateを使うのが推奨されるスタイルです。
コードの意図が分かりやすく、バグも生まれにくくなります。
enumerateのstart引数でインデックスを調整
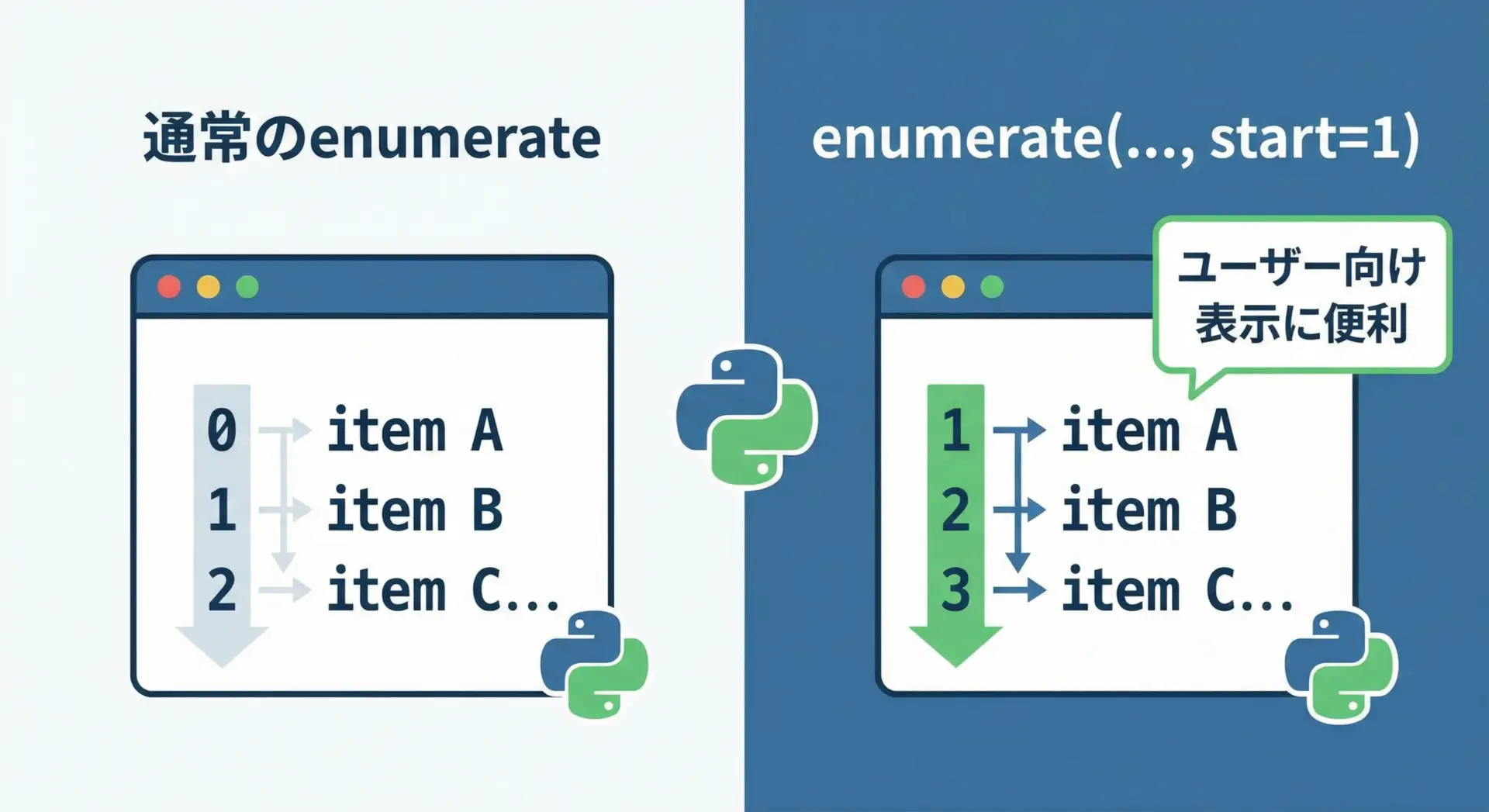
enumerateの第2引数startを指定すると、インデックスの開始値を任意の数に変更できます。
人間に見せる「番号」を付けたいときなどに便利です。
# インデックスを1から始めたい場合の例
fruits = ["apple", "banana", "orange"]
for i, fruit in enumerate(fruits, start=1): # 1, 2, 3... となる
print(f"{i}番目の果物は {fruit} です")1番目の果物は apple です
2番目の果物は banana です
3番目の果物は orange ですユーザーに「1番目」「2番目」と表示したい場面で、i + 1と毎回書く代わりに、start=1を使うとコードがすっきりします。
enumerateを使うメリットと注意点
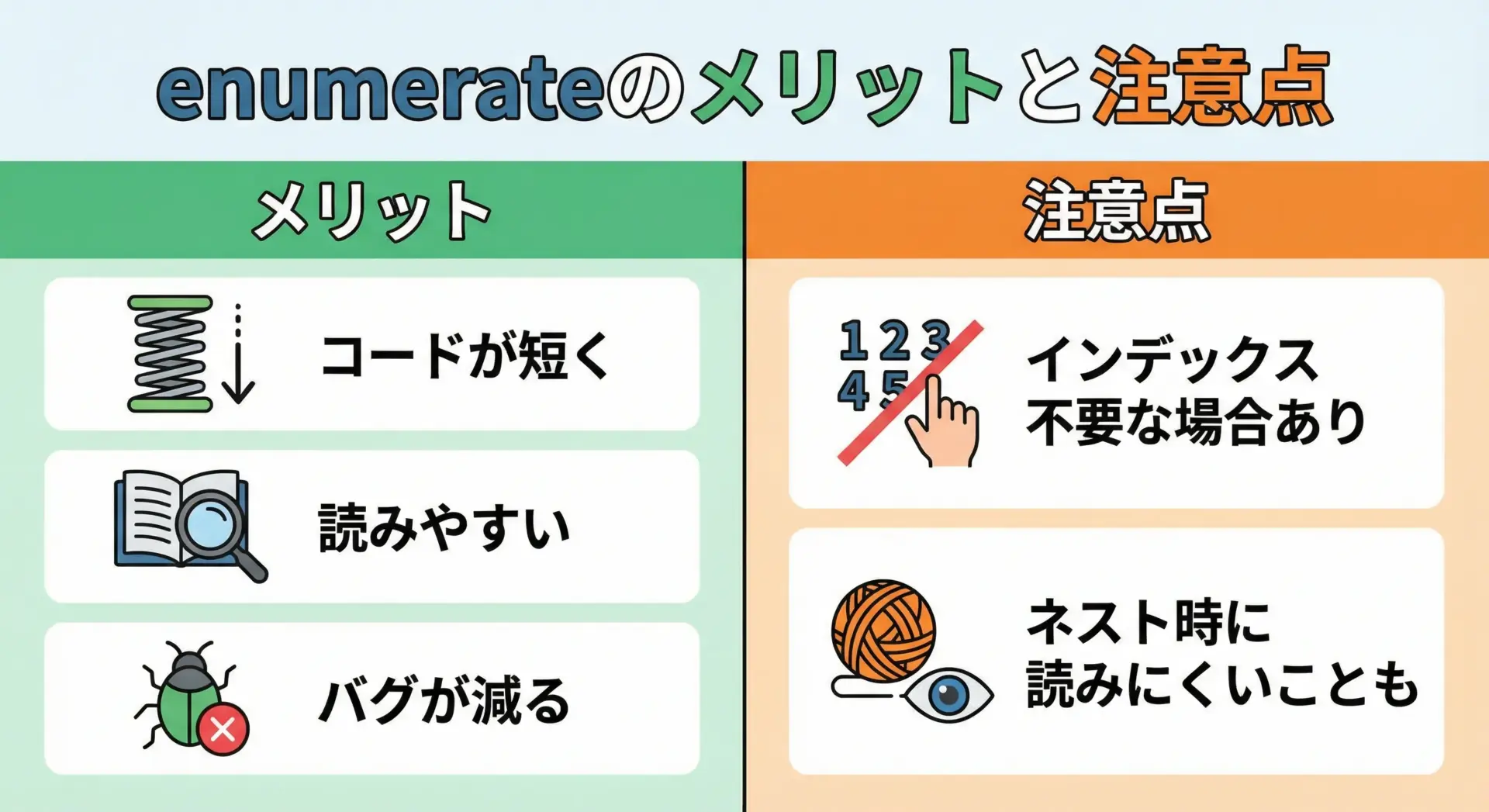
enumerateを使う主なメリットは次の通りです。
- コードが短くなる
range(len(...))を書く必要がなくなります。 - バグを減らせる
インデックス計算のミス(+1や-1の付け忘れなど)が減ります。 - コードの意図が読みやすい
「インデックスと要素を同時に扱う」ことが明確になります。
一方で、注意しておきたい点もあります。
- 本当にインデックスが必要なときにだけ使う
インデックスを全く使わず、要素だけを扱うのであれば、for x in items:のように、単純なfor文で十分です。 - ネストが深いと読みづらくなることがある
入れ子になったループで、i, j, kのようにインデックスが増えてくると、かえって分かりづらくなることがあります。その場合は、処理を関数に分けるなど、構造を整理するとよいです。
「インデックスが欲しいときにだけenumerateを使う」という意識でいれば、コードは自然と読みやすく整理されていきます。
zipで複数のリストを同時にループ
zipの基本
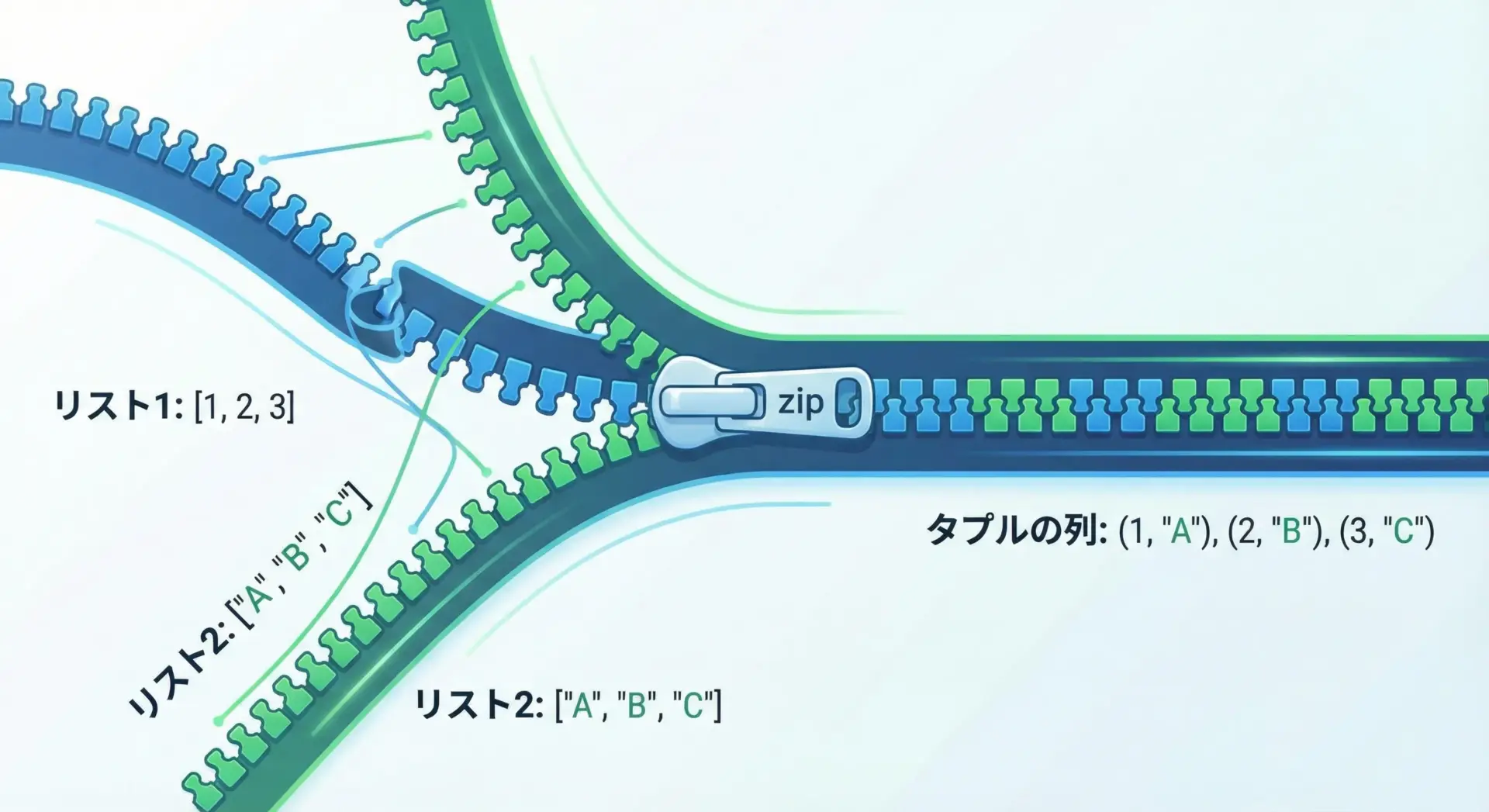
zipは、複数のイテラブル(リストなど)を「同じインデックス同士」でまとめて扱うための組み込み関数です。
そのイメージは、まさに「ファスナー(zip)で噛み合わせる」ようなものです。
基本構文は次の通りです。
# zipの基本構文
for values in zip(iterable1, iterable2, ...):
# values には (要素1, 要素2, ...) のタプルが入る
...簡単な例を見てみます。
# 2つのリストをzipで組み合わせる例
numbers = [1, 2, 3]
letters = ["A", "B", "C"]
for pair in zip(numbers, letters):
print(pair) # (number, letter) のタプル(1, 'A')
(2, 'B')
(3, 'C')同じ長さのリストを、位置ごとにセットにして処理したいときに、とても役立つ関数です。
zipとfor文で2つ以上のリストを一括処理
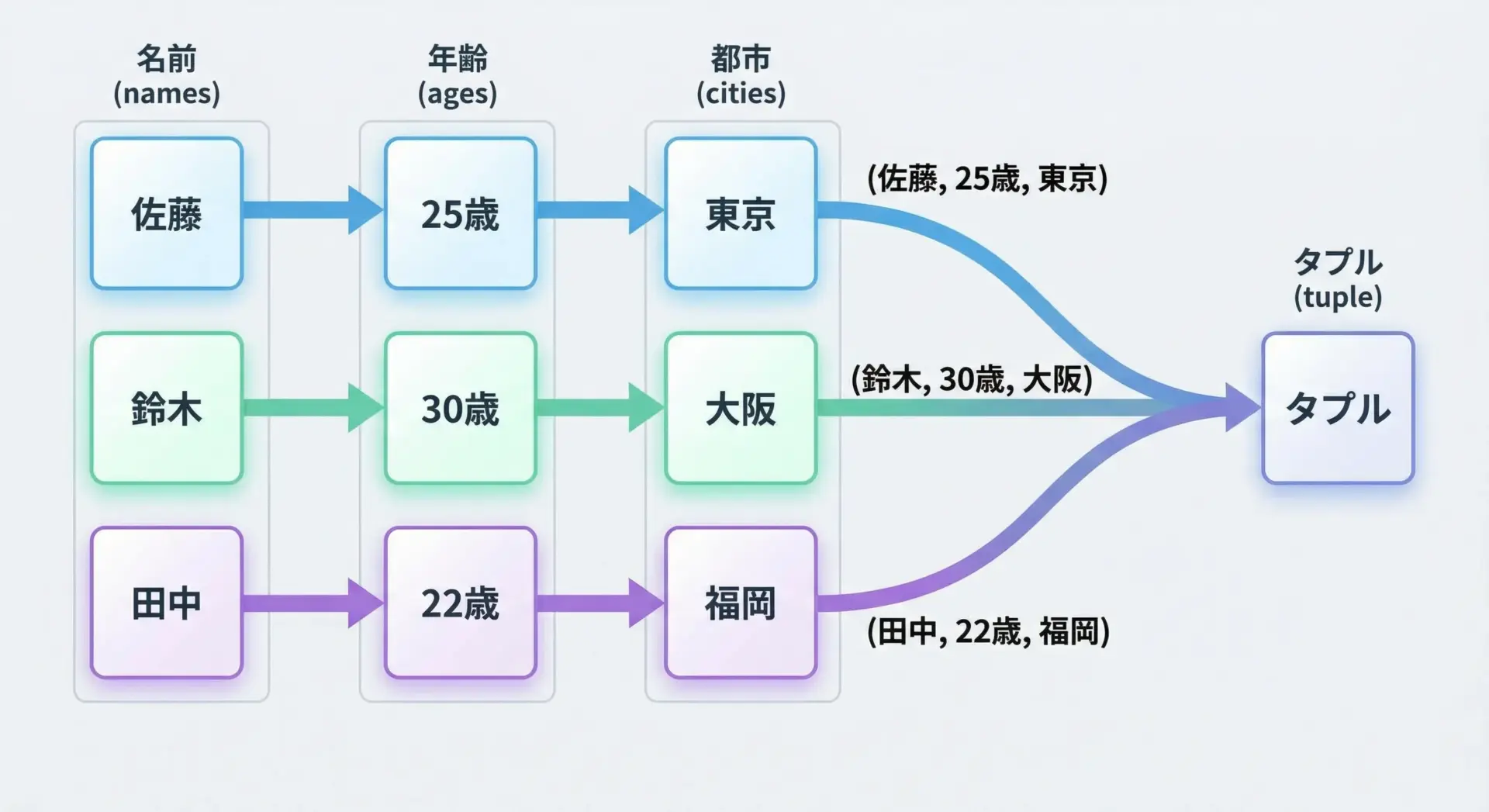
zipの結果はタプルなので、for文の中で複数の変数に同時に展開できます。
2つでも3つでも同様です。
# 2つのリストを同時にループして表示する例
names = ["Alice", "Bob", "Charlie"]
ages = [24, 30, 18]
for name, age in zip(names, ages): # (name, age) に展開される
print(f"{name} さんは {age} 歳です")Alice さんは 24 歳です
Bob さんは 30 歳です
Charlie さんは 18 歳です3つ以上のリストでも同じです。
# 3つのリストを同時に処理する例
names = ["Alice", "Bob", "Charlie"]
ages = [24, 30, 18]
cities = ["Tokyo", "Osaka", "Nagoya"]
for name, age, city in zip(names, ages, cities):
print(f"{name} さん({age}歳) は {city} 在住です")Alice さん(24歳) は Tokyo 在住です
Bob さん(30歳) は Osaka 在住です
Charlie さん(18歳) は Nagoya 在住ですこのように、複数のリストを連携させた処理が、非常に読みやすく書けるようになります。
zipとenumerateを組み合わせたパターン
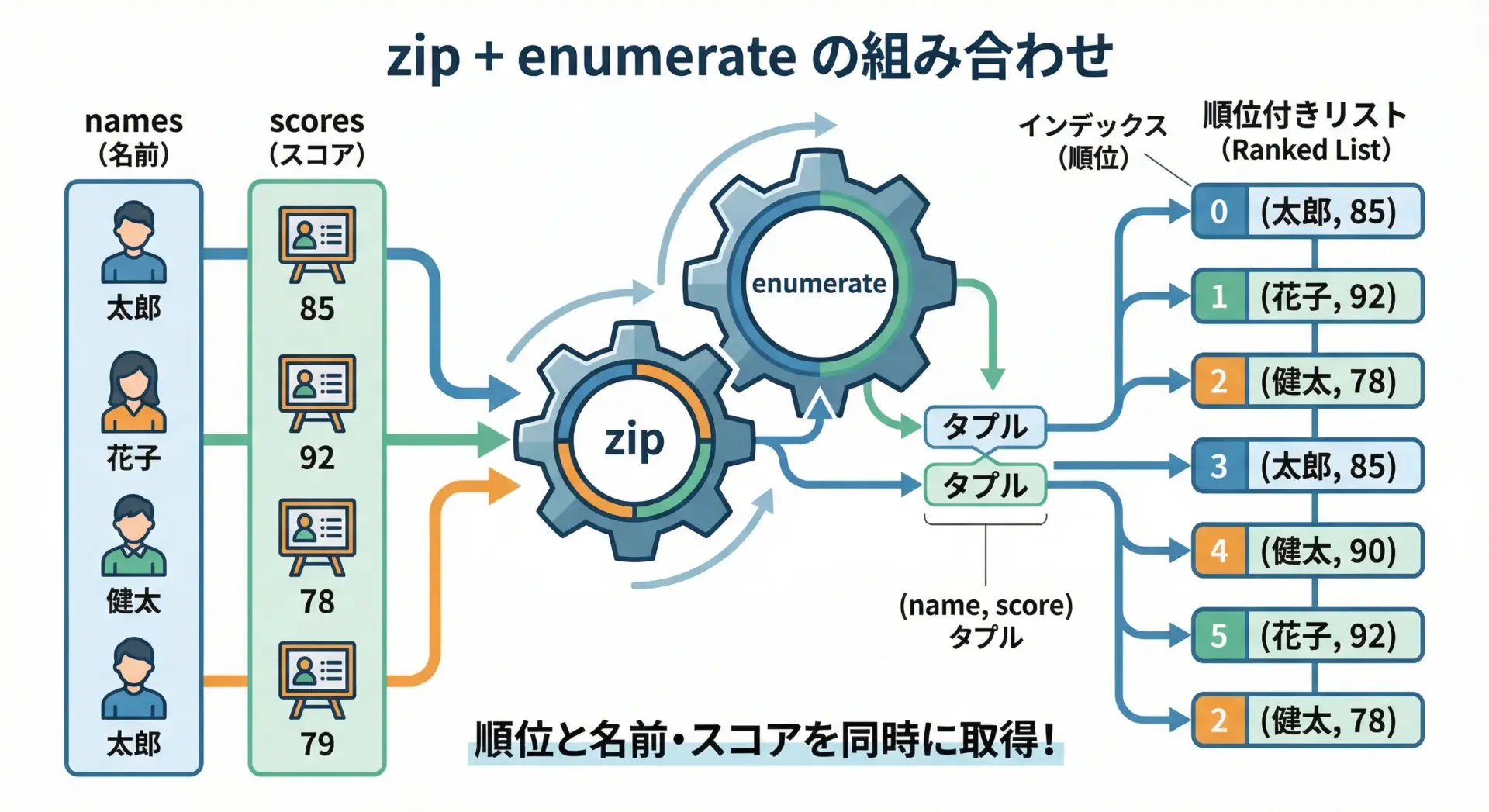
zipとenumerateは同時に使うこともできます。
「複数のリストをまとめて処理しつつ、その順番(インデックス)も使いたい」ときに便利です。
# zipとenumerateを組み合わせて、順位付きで表示する例
names = ["Alice", "Bob", "Charlie"]
scores = [95, 80, 88]
for rank, (name, score) in enumerate(zip(names, scores), start=1):
# rank: 1, 2, 3...
# (name, score): zipでまとめられたタプル
print(f"{rank}位: {name} さん (スコア: {score})")1位: Alice さん (スコア: 95)
2位: Bob さん (スコア: 80)
3位: Charlie さん (スコア: 88)ここでは、enumerate(zip(...), start=1)とすることで、「順位」と「名前+スコア」を同時に扱っていることが分かります。
zipでリストの長さが違う場合の挙動
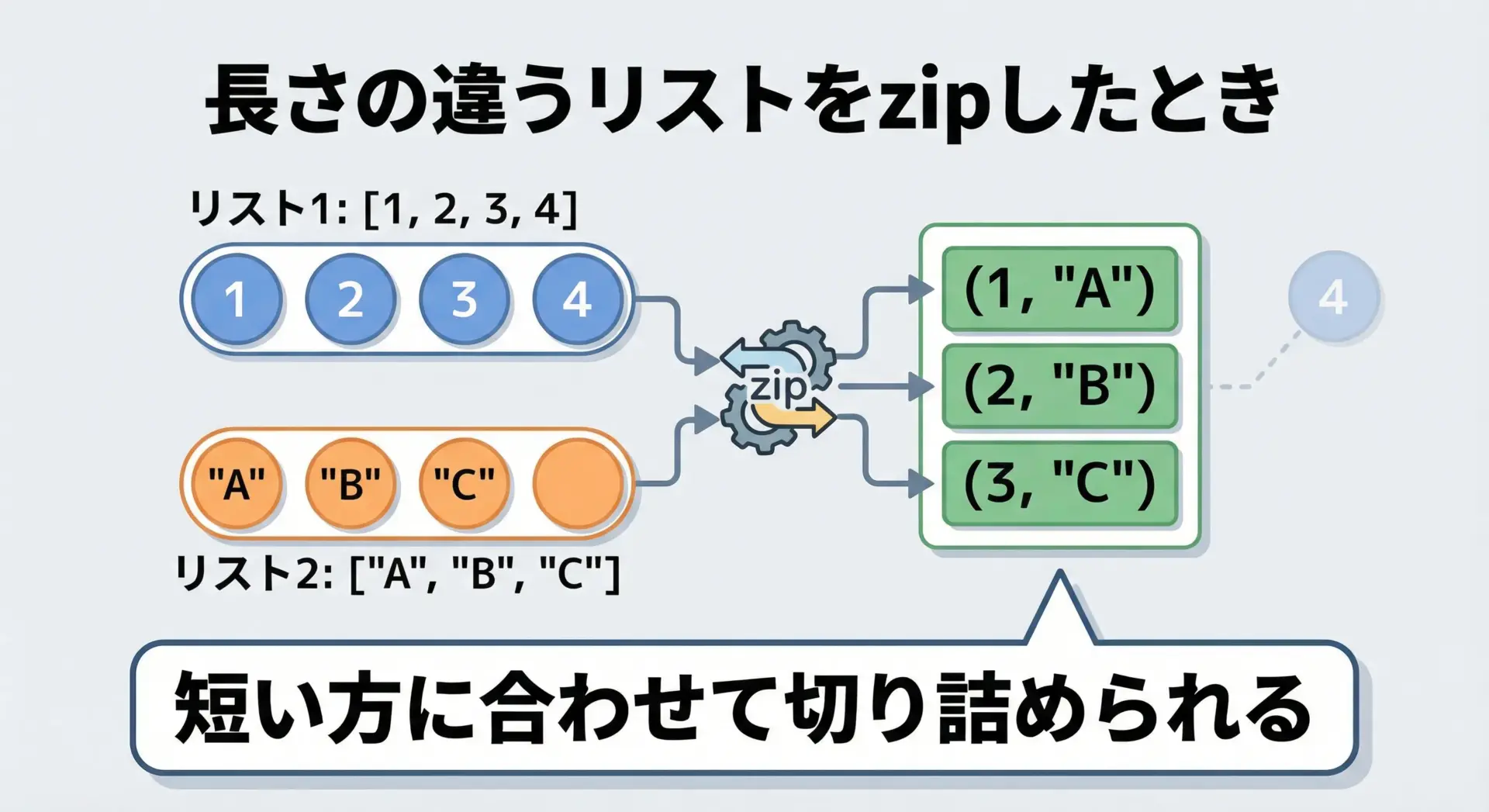
zipに渡すリストの長さが異なる場合、最も短いリストの長さに揃えてループが終了します。
余った要素は無視されます。
# 長さの違うリストをzipしたときの挙動を確認する例
numbers = [1, 2, 3, 4]
letters = ["A", "B", "C"]
for n, ch in zip(numbers, letters):
print(n, ch)1 A
2 B
3 C4番目の4は、対応する文字がないため、組み合わせが作れず捨てられます。
「足りない分を何かで埋めてでも、すべて処理したい」といった場合には、標準ライブラリitertoolsモジュールにあるzip_longestが使えます。
# zip_longest を使って、長さの違うリストを最後まで処理する例
from itertools import zip_longest
numbers = [1, 2, 3, 4]
letters = ["A", "B", "C"]
for n, ch in zip_longest(numbers, letters, fillvalue="-"):
print(n, ch)1 A
2 B
3 C
4 -このように、デフォルトのzipは「短い方に合わせて切り捨てる」動作であることを覚えておくと、意図しないデータの取りこぼしを防げます。
まとめ
Pythonのfor文は、「イテラブルから1要素ずつ取り出して処理する」という考え方を理解すれば、とてもシンプルです。
本記事では、基本のfor文から、回数指定のrange、インデックス付きのenumerate、複数リストを同時に扱うzipまでを解説しました。
これらを組み合わせることで、複雑そうな処理も短く読みやすく書けるようになります。
まずは小さなリストや数字で試しながら、少しずつ自分のコードに取り入れていくと良いです。
