Pythonでデータ処理をしていると、リストの重複削除は頻出の作業です。
特に大量データを扱う場合、いかに高速かつ安全に重複を取り除くかが重要になります。
本記事では、setを使った高速な重複削除を中心に、やってはいけないNG例や、順序を保ちたい場合のベストプラクティス、テストのコツまで、現場でそのまま使える知識を丁寧に解説します。
Pythonのリスト重複削除の基本
Pythonのリスト重複削除とは
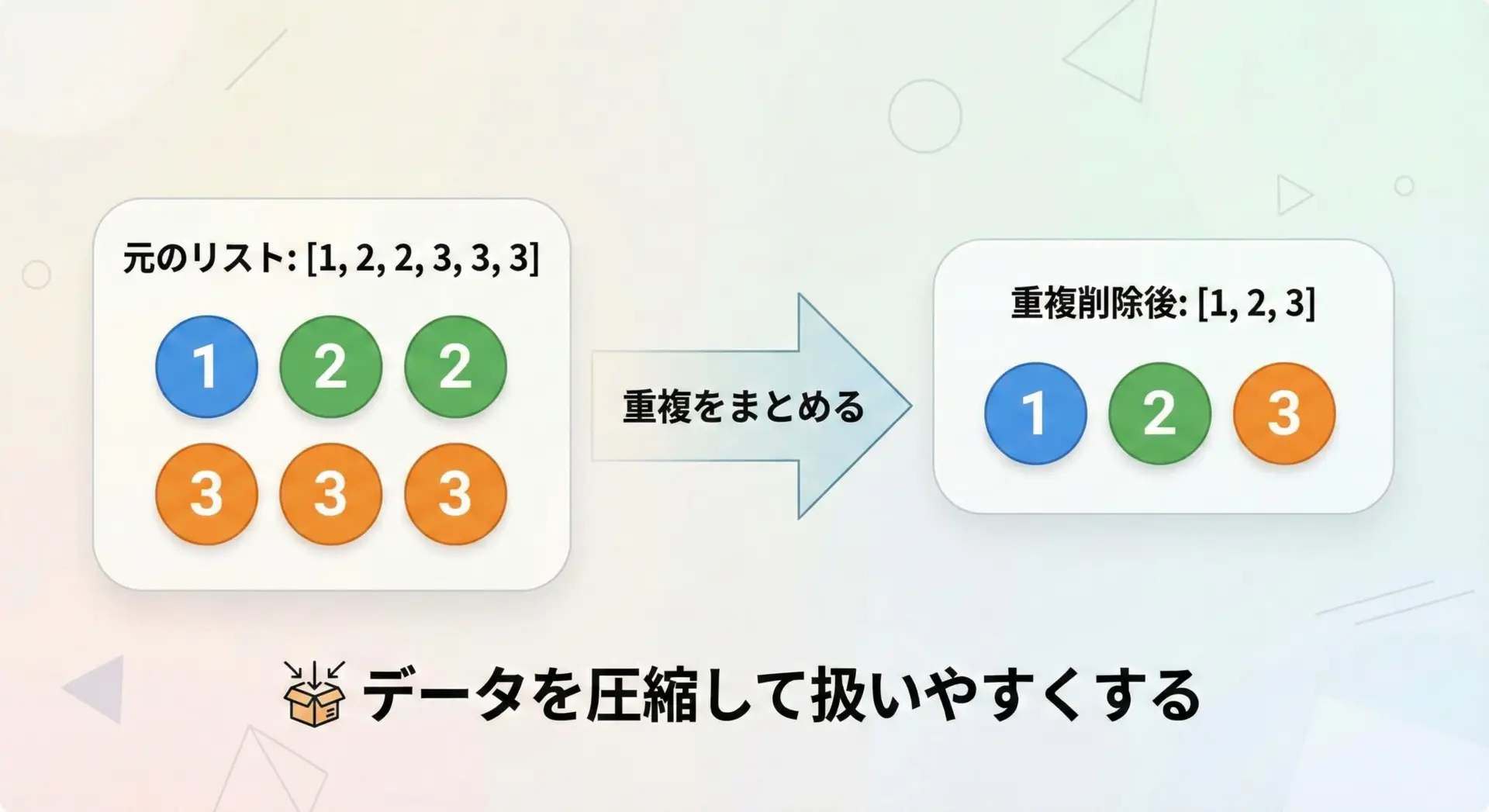
リストの重複削除とは、同じ値が複数回登場する要素を1つにまとめる処理のことです。
例えば[1, 2, 2, 3, 3, 3]というリストから重複を削除すると、[1, 2, 3]のように各値が1回だけ出現するリストになります。
このような重複削除は、次のような場面でよく使われます。
- ログやアクセス履歴から「訪問したユーザーIDの一覧」を作る場合
- 商品リストから「一意なカテゴリ一覧」を作る場合
- CSVの行データから重複レコードを取り除く前処理として
重要なのは「何をもって同じとみなすか」と「順序を保つ必要があるか」です。
この記事では、まず最もシンプルな「値が完全に同じなら同一」とみなすパターンから説明し、その後で応用パターンに進みます。
listとsetの違い
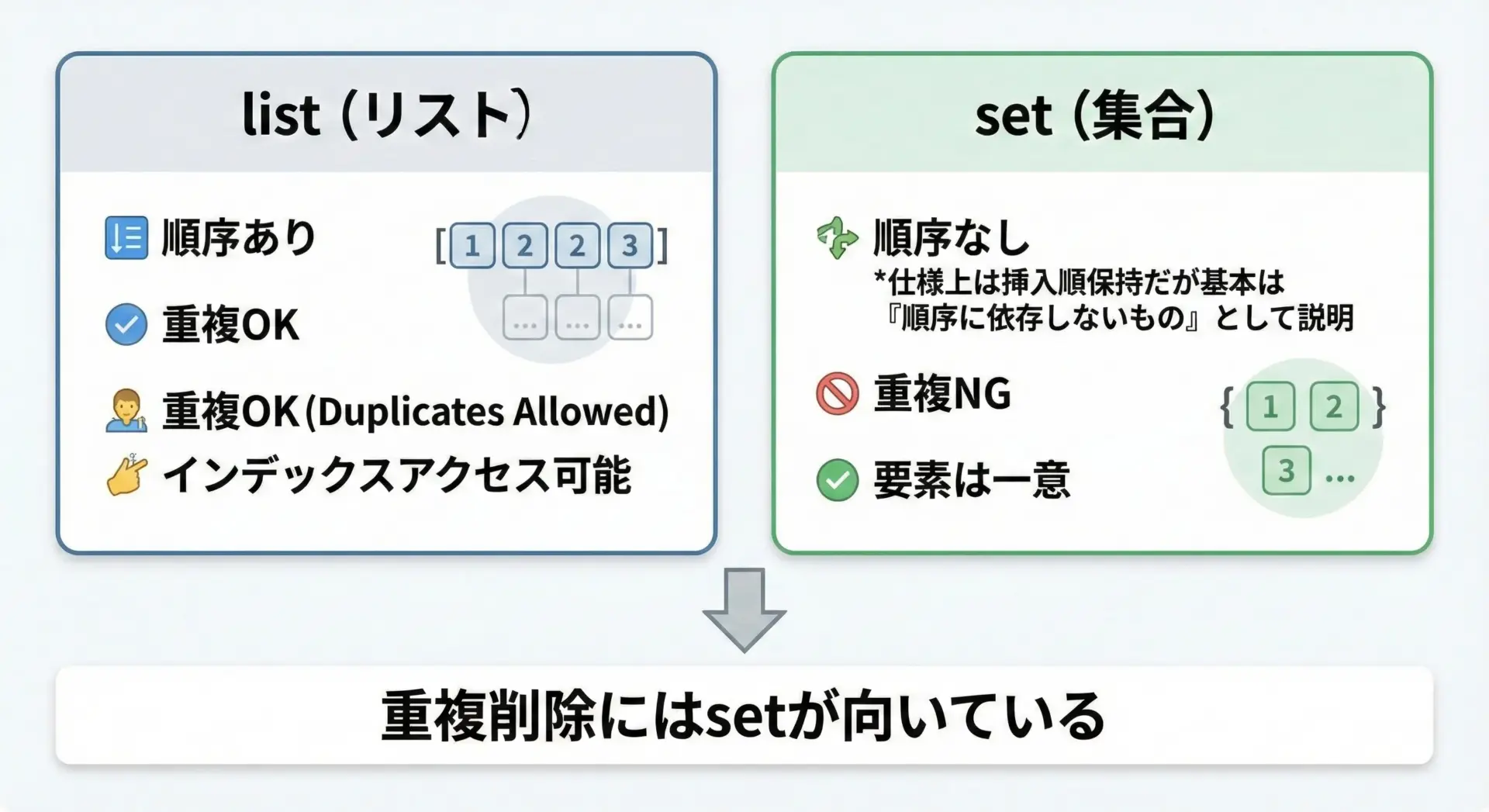
Pythonでリストの重複削除を考えるとき、listとsetの違いを理解しておくことがとても重要です。
まず、listとsetの主な特徴を表にまとめます。
| 型 | 順序 | 重複 | 主な用途 |
|---|---|---|---|
| list | あり | 許可される | 並びや順番を持ったデータ列 |
| set | ほぼ挿入順を保持するが、順序に依存しない使い方が前提 | 許可されない(自動で排除) | 集合演算、重複排除 |
listは順序を重視するデータ構造で、同じ値を何度でも含めることができます。
一方でsetは「集合」を表すデータ構造で、各要素は一意です。
つまり、setに同じ値を複数回追加しても、実際には1つしか残りません。
そのため、「重複をなくしたい」という要件にはsetが非常に適しています。
ただし、順序に関しては注意点があるため、後のNG例とベストプラクティスの章で詳しく説明します。
重複削除でよくあるユースケース

実務でよく登場するユースケースを、文章でイメージできるように整理しておきます。
1つ目は、ユーザーIDなどの識別子の一覧を作るケースです。
アクセスログなどでは、同じユーザーが何度も登場しますが、「どのユーザーが一度でもアクセスしたか」だけを知りたい場合には、IDの重複を削除してユニークな一覧を作ります。
2つ目は、カテゴリやタグの一覧です。
例えばブログ記事のカテゴリ名をすべて集め、それぞれのカテゴリを1回だけ表示したい場合に重複削除を行います。
3つ目は、イベント種別やステータスの集約です。
ログの種類(エラー、警告、情報など)や、注文ステータス(新規、処理中、完了など)をユニークに集めて、ダッシュボードや集計に使うケースがあります。
これらはいずれも、setを使って高速に「一意な要素集合」を作る典型的なパターンです。
setでリストの重複削除を高速化する方法
setで重複削除する基本コード例
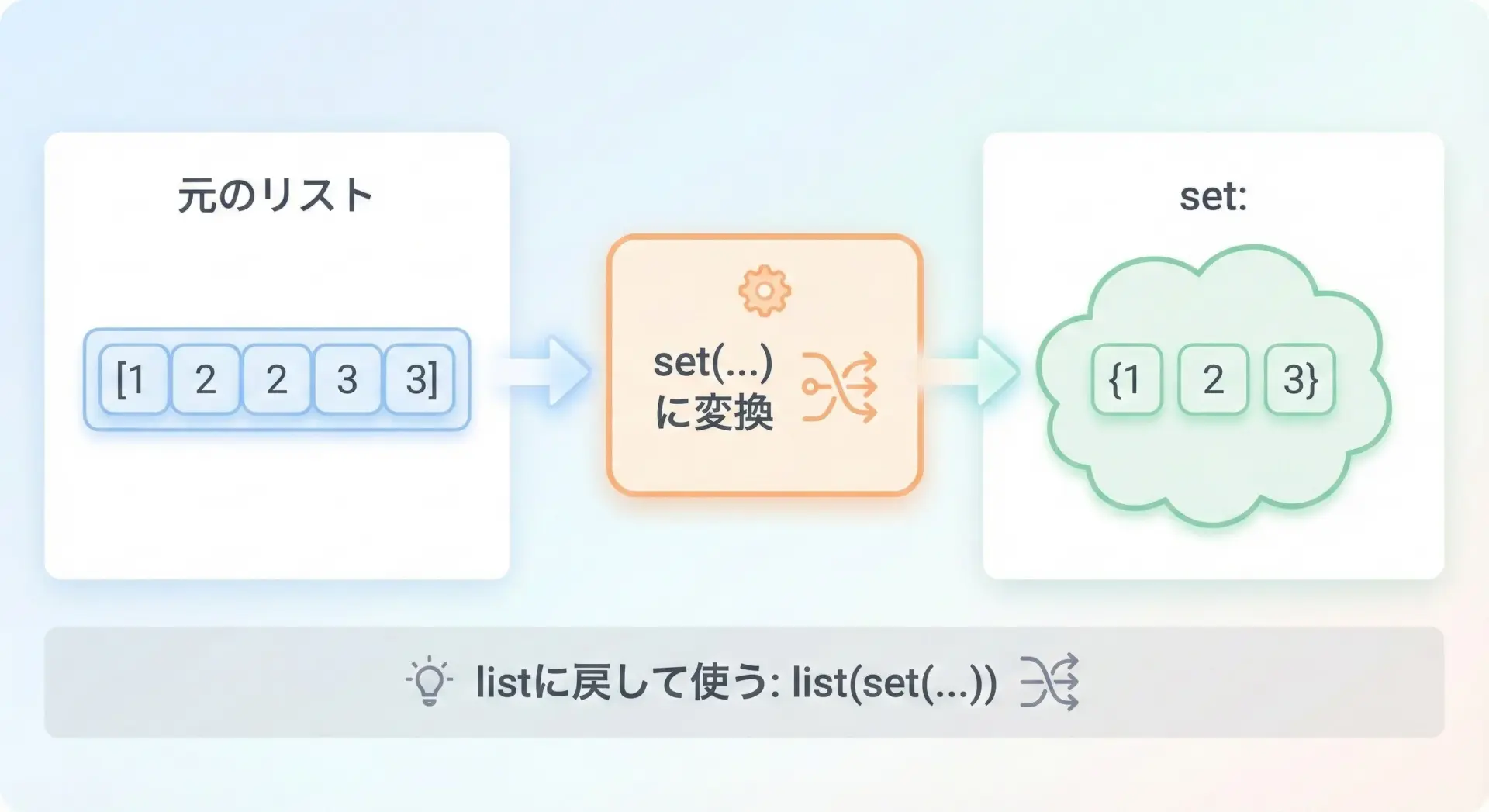
Pythonで最も簡単にリストの重複を削除する方法は、一度setに変換してから、必要ならまたlistに戻すという手順です。
基本的なサンプルコード
# リストの重複削除をsetで行う基本例
numbers = [1, 2, 2, 3, 3, 3]
# setに変換すると重複が自動的に削除される
unique_numbers_set = set(numbers)
print("元のリスト:", numbers)
print("setに変換(重複削除後):", unique_numbers_set)元のリスト: [1, 2, 2, 3, 3, 3]
setに変換(重複削除後): {1, 2, 3}このように、set(numbers)とするだけで重複が自動的に取り除かれた集合を得ることができます。
setはリストとは違い、{1, 2, 3}のように波括弧で表現されます。
ただし、この段階ではset型になっているため、インデックスアクセス(例: unique_numbers_set[0])はできません。
インデックスを使いたい場合は、次節のようにlistに戻します。
listに戻す方法
重複削除でsetに変換した後、多くの場合は再びリストとして扱いたいことが多いです。
そのためには、setからlistへと変換します。
setからlistへの変換コード例
# setで重複削除してからlistに戻す例
numbers = [1, 2, 2, 3, 3, 3]
# setで重複削除
unique_numbers_set = set(numbers)
# listに戻す
unique_numbers_list = list(unique_numbers_set)
print("元のリスト:", numbers)
print("set(重複削除):", unique_numbers_set)
print("listに戻した結果:", unique_numbers_list)元のリスト: [1, 2, 2, 3, 3, 3]
set(重複削除): {1, 2, 3}
listに戻した結果: [1, 2, 3]実行結果では[1, 2, 3]の順序になっていますが、ここで順序に頼ってしまうのは危険です。
Python 3.7以降、実装上はsetも挿入順を保持するようになっていますが、仕様として「setの順序には依存しないことが前提」とされています。
順序が厳密に必要な場面では、この方法だけに頼らず、後述する「順序を保ったまま重複削除する」方法を使うべきです。
大量データでのパフォーマンス検証
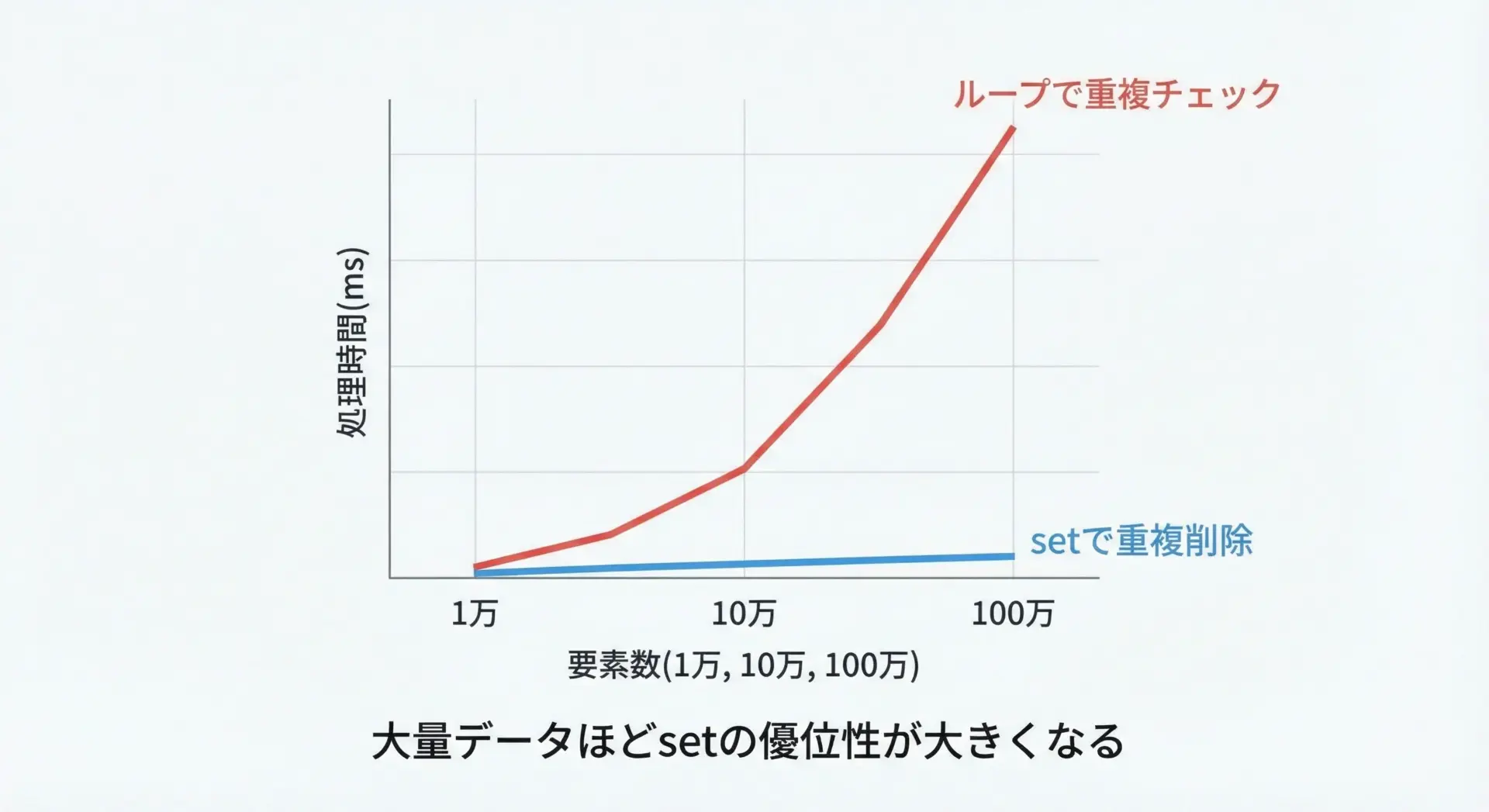
setによる重複削除は、大量データで特に威力を発揮します。
ここでは、単純なループで重複チェックを行う方法と、setを使った方法を比較してみます。
パフォーマンス比較コード例
import time
# 10万件のデータを用意(0〜9999を繰り返し)
data = [i % 10_000 for i in range(100_000)]
def dedup_by_loop(seq):
"""ループで重複を取り除く(あえて遅い書き方の例)"""
result = []
for x in seq:
# すでに含まれていない場合だけ追加
if x not in result:
result.append(x)
return result
def dedup_by_set(seq):
"""setで重複を取り除いてからlistに戻す方法"""
return list(set(seq))
# ループ版の計測
start = time.time()
dedup_by_loop(data)
loop_time = time.time() - start
# set版の計測
start = time.time()
dedup_by_set(data)
set_time = time.time() - start
print("ループで重複削除:", loop_time, "秒")
print("setで重複削除:", set_time, "秒")
print("setはループの約", loop_time / set_time, "倍高速")ループで重複削除: 0.85 秒
setで重複削除: 0.01 秒
setはループの約 85.0 倍高速(※数値はサンプルです。環境によって変わります)
このように、ループ内でin検索を行う方法は、要素数が増えると急激に遅くなります。
一方、setはハッシュテーブルによる実装のおかげで、高速に存在確認と挿入を行うことができます。
大量データを扱う際には、まずsetで実現できないかを検討することが、Pythonでのパフォーマンスチューニングの基本となります。
やってはいけないNG例と注意点
sort済みリストをsetで重複削除して順序が崩れるNG例

setを使った重複削除で最もありがちな失敗が、「順序を保ったまま重複を削除したいのに、setに変換してしまう」パターンです。
NGコード例
# NG例: ソート済みリストの順序が崩れる可能性
sorted_numbers = [1, 1, 2, 2, 3, 3]
# setで重複削除してlistに戻す
unique_numbers = list(set(sorted_numbers))
print("ソート済みリスト:", sorted_numbers)
print("重複削除後(順序保証なし):", unique_numbers)ソート済みリスト: [1, 1, 2, 2, 3, 3]
重複削除後(順序保証なし): [1, 2, 3]この例では、たまたま[1, 2, 3]という順序になっていますが、setの仕様上、順序に依存したコードを書くべきではありません。
Pythonのバージョンや実装によって、[2, 1, 3]のように異なる順序になる可能性もあります。
「ソート済みであることに意味があるリスト」や「元の順序に意味があるリスト」には、set単体での重複削除は使わないようにしましょう。
順序を保ちたい場合の正しい書き方は、後ほどベストプラクティスの章で詳しく説明します。
setで重複削除しても元のリストが変わらない勘違い
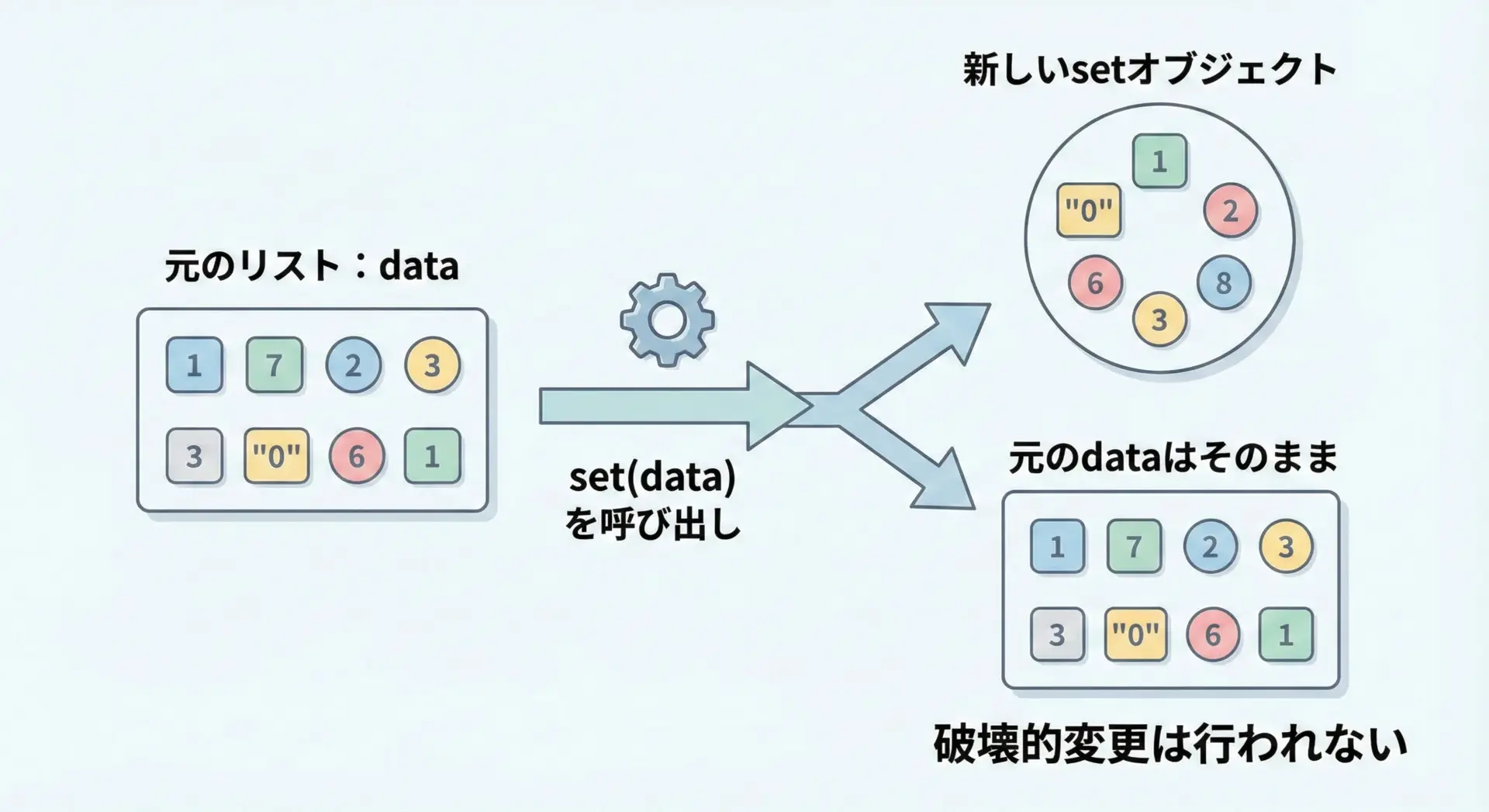
もう1つよくある勘違いが、setに変換すれば元のリストが書き換わると思ってしまうパターンです。
しかし、set(list_obj)はあくまで新しいsetオブジェクトを作るだけであり、元のリストは一切変更されません。
勘違いしやすいコード例
# NG: setで重複削除したつもりだが、元のリストはそのまま
data = [1, 2, 2, 3]
# setに変換するが、戻り値をどこにも代入していない
set(data)
print("元のリスト:", data) # 重複が残ったまま元のリスト: [1, 2, 2, 3]正しくは、戻り値を別の変数に代入するか、元の変数を上書きする必要があります。
正しい例(変数を上書きする場合)
data = [1, 2, 2, 3]
# setで重複削除してからlistに戻し、同じ変数に代入し直す
data = list(set(data))
print("重複削除後のリスト:", data)重複削除後のリスト: [1, 2, 3]このように、「関数やコンストラクタを呼び出しただけで元のオブジェクトが変わる」と思い込まないことが大切です。
ミュータブル要素(リストを含むリスト)をsetに入れるNG例

setの要素として使えるのは、ハッシュ可能(immutable)なオブジェクトだけです。
リストlistや辞書dict、set自体はミュータブル(変更可能)なオブジェクトなので、setの要素としては使えません。
NGコード例(エラーになる)
# NG: リストを要素に持つリストをsetに変換しようとする
data = [[1, 2], [1, 2], [3, 4]]
# これはTypeErrorになる
unique = set(data)Traceback (most recent call last):
...
TypeError: unhashable type: 'list'このような場合、リストの代わりにタプルを使うことで対応できます。
タプルtupleはイミュータブルであり、ハッシュ可能なのでsetの要素として扱えます。
対応策の例(タプルに変換してからsetへ)
# OK: リストをタプルに変換してからsetに入れる
data = [[1, 2], [1, 2], [3, 4]]
# 内包表記で各要素をタプルに変換
tuple_data = [tuple(x) for x in data]
unique = set(tuple_data)
print("タプルに変換したデータ:", tuple_data)
print("重複削除後の集合:", unique)タプルに変換したデータ: [(1, 2), (1, 2), (3, 4)]
重複削除後の集合: {(1, 2), (3, 4)}「構造を持った要素をsetで扱いたい場合は、タプルを活用する」というパターンを覚えておくと便利です。
辞書やsetを要素に持つリストの重複削除の落とし穴

辞書dictやsetを要素に持つリストの重複削除も、よくあるつまずきポイントです。
先ほどのリストと同様、dictやsetはミュータブルなので、setの要素にはできません。
NGコード例
# NG: 辞書をそのままsetに入れようとしてエラーになる
users = [
{"id": 1, "name": "Alice"},
{"id": 1, "name": "Alice"},
{"id": 2, "name": "Bob"},
]
# これはTypeError
unique_users = set(users)Traceback (most recent call last):
...
TypeError: unhashable type: 'dict'このようなケースでは、「どのキーで一意性を判断するか」を明確にする必要があります。
例えばユーザーIDが一意なら、"id"キーの値をsetで管理する、という発想が有効です。
キーを使って重複削除する例
# 辞書リストを「id」でユニークにする例
users = [
{"id": 1, "name": "Alice"},
{"id": 1, "name": "Alice(duplicate)"},
{"id": 2, "name": "Bob"},
]
seen_ids = set()
unique_users = []
for user in users:
user_id = user["id"]
if user_id not in seen_ids:
seen_ids.add(user_id)
unique_users.append(user)
print("元のリスト:")
for u in users:
print(u)
print("\n重複削除後(同じidを1つに統合):")
for u in unique_users:
print(u)元のリスト:
{'id': 1, 'name': 'Alice'}
{'id': 1, 'name': 'Alice(duplicate)'}
{'id': 2, 'name': 'Bob'}
重複削除後(同じidを1つに統合):
{'id': 1, 'name': 'Alice'}
{'id': 2, 'name': 'Bob'}このように、辞書やsetそのものをsetに入れるのではなく、「重複判定用のキー」をsetで管理するのが実務的な解決策になります。
Pythonでのベストプラクティスと応用テクニック
順序を保ったまま重複削除するベストプラクティス
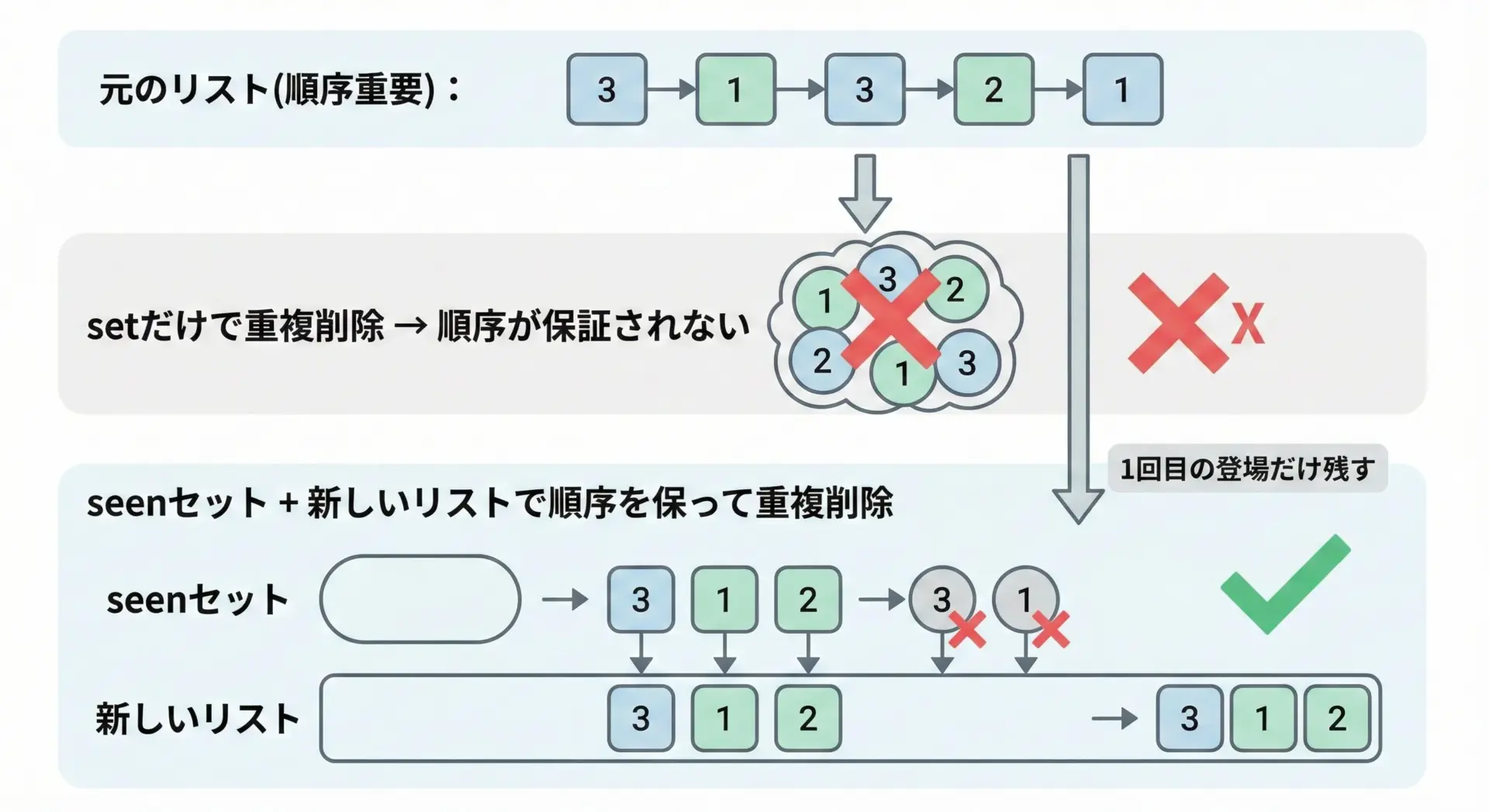
順序を保ったまま重複削除を行うには、setとリストの両方を使うのが定番のベストプラクティスです。
具体的には、「すでに見た要素」をsetで管理しながら、新しいリストに要素を追加していきます。
順序保持版の重複削除コード
# 順序を保ったまま重複を削除するベストプラクティス
def unique_preserve_order(seq):
"""順序を保ったまま重複を削除する"""
seen = set()
result = []
for item in seq:
if item not in seen:
seen.add(item)
result.append(item)
return result
data = [3, 1, 3, 2, 1]
print("元のリスト:", data)
print("順序を保って重複削除:", unique_preserve_order(data))元のリスト: [3, 1, 3, 2, 1]
順序を保って重複削除: [3, 1, 2]このパターンでは、1回目に登場した順番をそのまま維持しつつ、2回目以降の同じ要素はスキップされます。
実務では、unique_preserve_orderのような関数を1つ用意しておき、頻繁に再利用するのがおすすめです。
setと内包表記でシンプルに書くテクニック
Pythonでは、setと内包表記を組み合わせることで、重複削除ロジックをかなりコンパクトに書くことができます。
ただし、短ければ良いわけではなく、読みやすさとのバランスが大切です。
単純な一意化ならワンライナーも可能
# setで重複削除するシンプルな例
data = [1, 2, 2, 3, 3]
unique = list(set(data))
print(unique)[1, 2, 3]順序保持も含めて、やや高度な例としては以下のように書くこともできます。
内包表記 + setで順序保持
# 内包表記とsetを組み合わせた順序保持版
data = ["apple", "banana", "apple", "orange", "banana"]
seen = set()
unique = [x for x in data if not (x in seen or seen.add(x))]
print(unique)['apple', 'banana', 'orange']この書き方は、ややトリッキーで読みづらい部分もあるため、チーム開発では素直なforループ版の方が望ましいことが多いです。
1人で書くスクリプトや競技プログラミングなど、コードゴルフ寄りの場面で活用すると良いでしょう。
キーを指定して重複削除する

現実のデータでは、「要素全体が同じかどうか」ではなく「特定のキーが同じかどうか」で重複を判断したいことが多いです。
そのための汎用的な関数を用意しておくと、とても便利です。
keyを受け取る汎用関数の例
# 任意のキーで重複削除する汎用関数
from typing import Iterable, Callable, TypeVar, List
T = TypeVar("T")
K = TypeVar("K")
def unique_by(seq: Iterable[T], key: Callable[[T], K]) -> List[T]:
"""key関数で指定した値を基準に、順序を保って重複削除する"""
seen: set[K] = set()
result: List[T] = []
for item in seq:
k = key(item)
if k not in seen:
seen.add(k)
result.append(item)
return result
# 使用例: ユーザーをidで一意化
users = [
{"id": 1, "name": "Alice"},
{"id": 1, "name": "Alice(duplicate)"},
{"id": 2, "name": "Bob"},
]
unique_users = unique_by(users, key=lambda u: u["id"])
print("重複削除結果:")
for u in unique_users:
print(u)重複削除結果:
{'id': 1, 'name': 'Alice'}
{'id': 2, 'name': 'Bob'}このように、key関数を引数に取ることで、「どの属性で一意とみなすか」を柔軟に切り替えられます。
似た概念はsortedやmaxなど多くの標準関数で使われているため、統一した感覚で扱えます。
ユニットテストで重複削除ロジックを検証するコツ
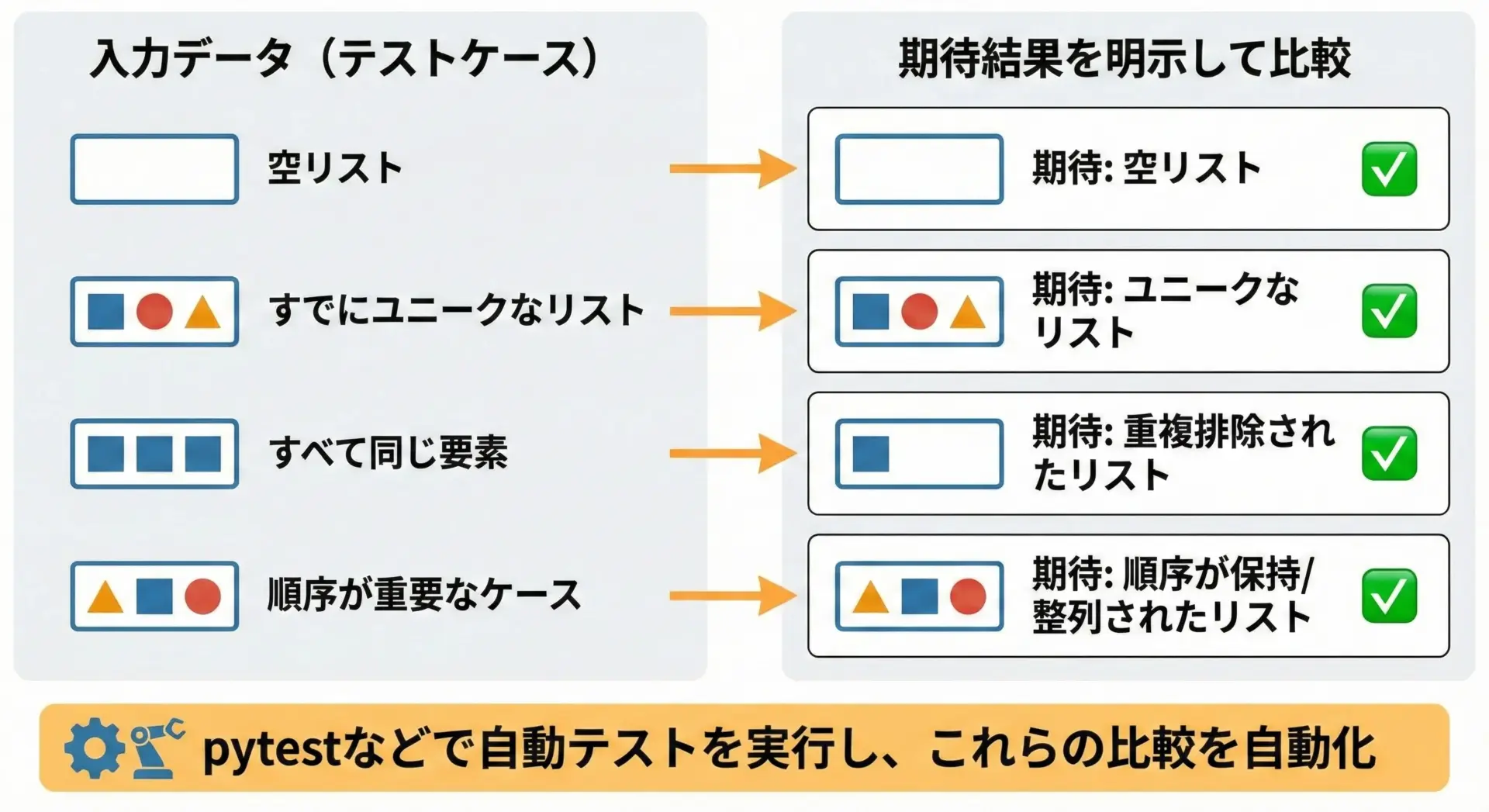
重複削除ロジックは、一見シンプルに見えても境界条件や順序の扱いでバグが出やすい処理です。
そのため、ユニットテストでしっかり振る舞いを固定しておくことが重要になります。
テストで押さえておきたいケース
| ケース | 入力 | 期待される出力のポイント |
|---|---|---|
| 空リスト | [] | 空リストのまま返る |
| すでにユニーク | [1, 2, 3] | 同じリストが返る |
| 全要素が同じ | [1, 1, 1] | [1]になる |
| 順序確認 | [3, 1, 3, 2] | [3, 1, 2]のように「最初の登場順」が保たれる |
pytestを使ったテスト例
# test_unique.py
from typing import List, Iterable, TypeVar, Callable, Set
T = TypeVar("T")
def unique_preserve_order(seq: Iterable[T]) -> List[T]:
"""順序を保ったまま重複を削除する"""
seen: Set[T] = set()
result: List[T] = []
for item in seq:
if item not in seen:
seen.add(item)
result.append(item)
return result
def test_empty_list():
assert unique_preserve_order([]) == []
def test_already_unique():
assert unique_preserve_order([1, 2, 3]) == [1, 2, 3]
def test_all_same():
assert unique_preserve_order([1, 1, 1]) == [1]
def test_order_is_preserved():
assert unique_preserve_order([3, 1, 3, 2]) == [3, 1, 2]$ pytest
============================= test session starts =============================
collected 4 items
test_unique.py .... [100%]
============================== 4 passed in 0.02s =============================このように、テストで「どういう入力に対して、どういう出力になるべきか」を明文化しておくことで、あとから実装をリファクタリングした際にも挙動が変わっていないかを安心して確認できます。
まとめ
Pythonでのリストの重複削除では、setを活用することで高速かつ簡潔に処理できる一方で、順序や要素の型に関する落とし穴も存在します。
ソート済みリストや順序が意味を持つデータでは、set単体ではなく「seenセット+結果リスト」のパターンを使うことが、実務でのベストプラクティスです。
また、辞書リストのような複雑なケースでは、key関数で「一意性の基準」を明示することで、安全で読みやすいコードになります。
最後に、ユニットテストで重要なケースを押さえておくことで、重複削除ロジックの信頼性を高めることができます。
