
Pythonの多重継承とMixinは、コードの再利用性と拡張性を高める一方で、設計を誤ると可読性や保守性を大きく損ないます。
本記事では、Python特有のMRO(Method Resolution Order)の仕組みを押さえつつ、実務で安全かつ効果的に使うためのベストプラクティス10選と、よく使うMixinサンプルを詳しく解説します。
DjangoやFlaskといった実例にも触れながら、現場でそのまま使える知識を身につけていきます。
- Pythonの多重継承とMixinの基礎
- Pythonの多重継承・Mixin設計のベストプラクティス10選
- ベストプラクティス1: Mixinは明確な単一責務に絞る
- ベストプラクティス2: Mixin名に役割を明示する
- ベストプラクティス3: Mixinクラスは状態(state)を極力持たない
- ベストプラクティス4: Mixinでは他クラスの実装に強く依存しない
- ベストプラクティス5: 多重継承はダイヤモンド継承を避けてシンプルに
- ベストプラクティス6: super()とMROを前提にメソッドチェーンを設計する
- ベストプラクティス7: ABC(抽象基底クラス)とMixinを組み合わせて使う
- ベストプラクティス8: Mixinをユーティリティ関数と比較して選択する
- ベストプラクティス9: DjangoやFlaskのMixinパターンから学ぶ
- ベストプラクティス10: 型ヒントとmypyで多重継承の安全性を高める
- 実務で使えるPython Mixinサンプル集
- Python多重継承・Mixin導入時のアンチパターンと注意点
- まとめ
Pythonの多重継承とMixinの基礎
多重継承とは何か
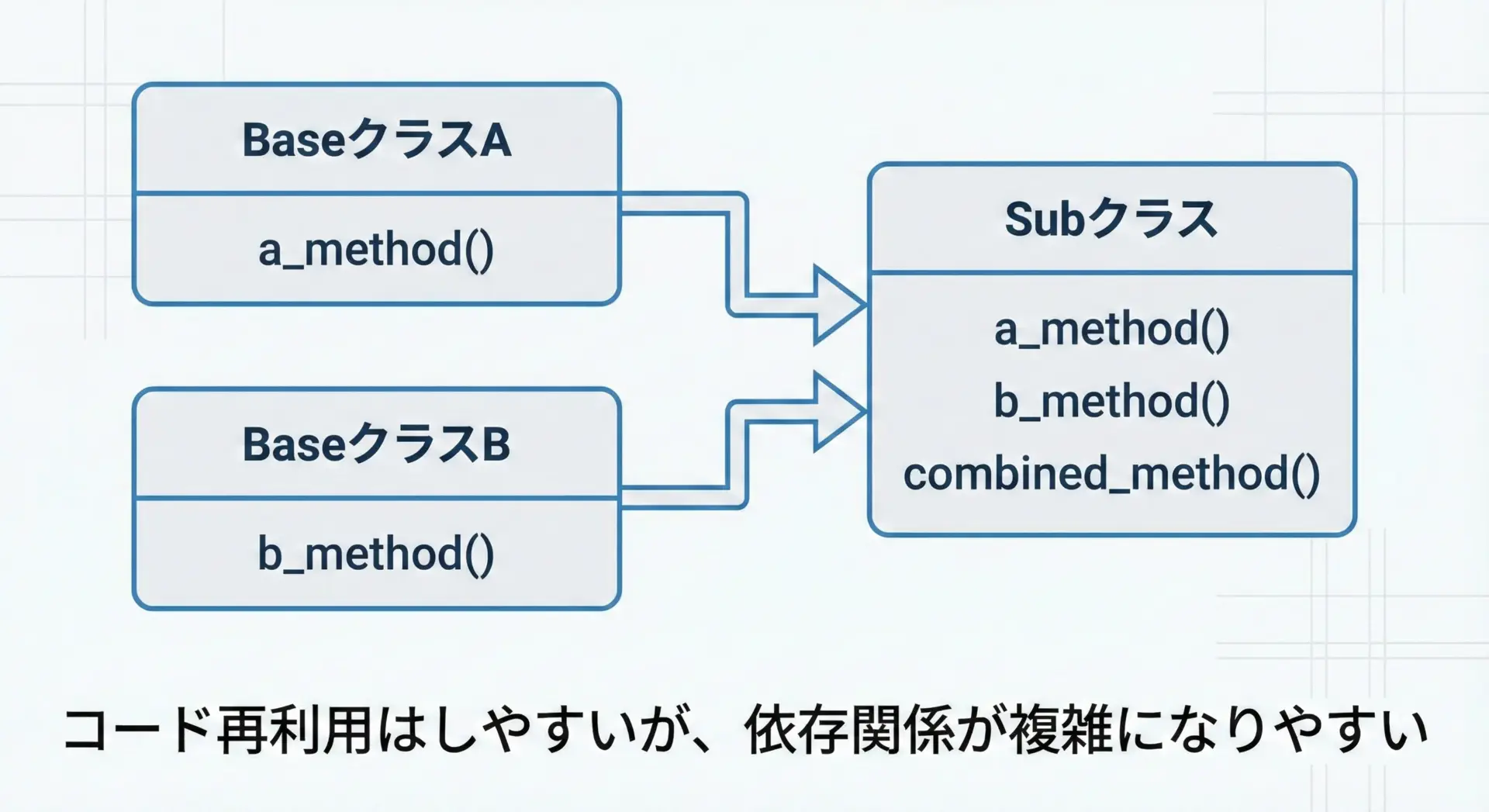
多重継承とは、1つのクラスが複数の親クラスを同時に継承することを指します。
Pythonでは、クラス定義時にカンマ区切りで複数の親クラスを指定することで実現できます。
多重継承の主目的は、複数のクラスに分散している振る舞い(メソッド)を1つのクラスで再利用することです。
ただし、構造が複雑になると、どのクラスのメソッドが実行されるかが分かりづらくなるため、設計には注意が必要です。
Pythonにおける多重継承の基本例
class A:
def greet(self) -> None:
# Aクラス特有の挨拶
print("Hello from A")
class B:
def farewell(self) -> None:
# Bクラス特有のお別れメッセージ
print("Goodbye from B")
class C(A, B):
# AとBの両方を継承したクラス
def intro(self) -> None:
print("I am C")
c = C()
c.greet() # Aクラス由来のメソッド
c.farewell() # Bクラス由来のメソッド
c.intro() # C自身のメソッドHello from A
Goodbye from B
I am Cこのように、クラスCはAとBのメソッドをまとめて利用できますが、クラスが増えるほど関係性が分かりづらくなっていきます。
Mixinとは何か
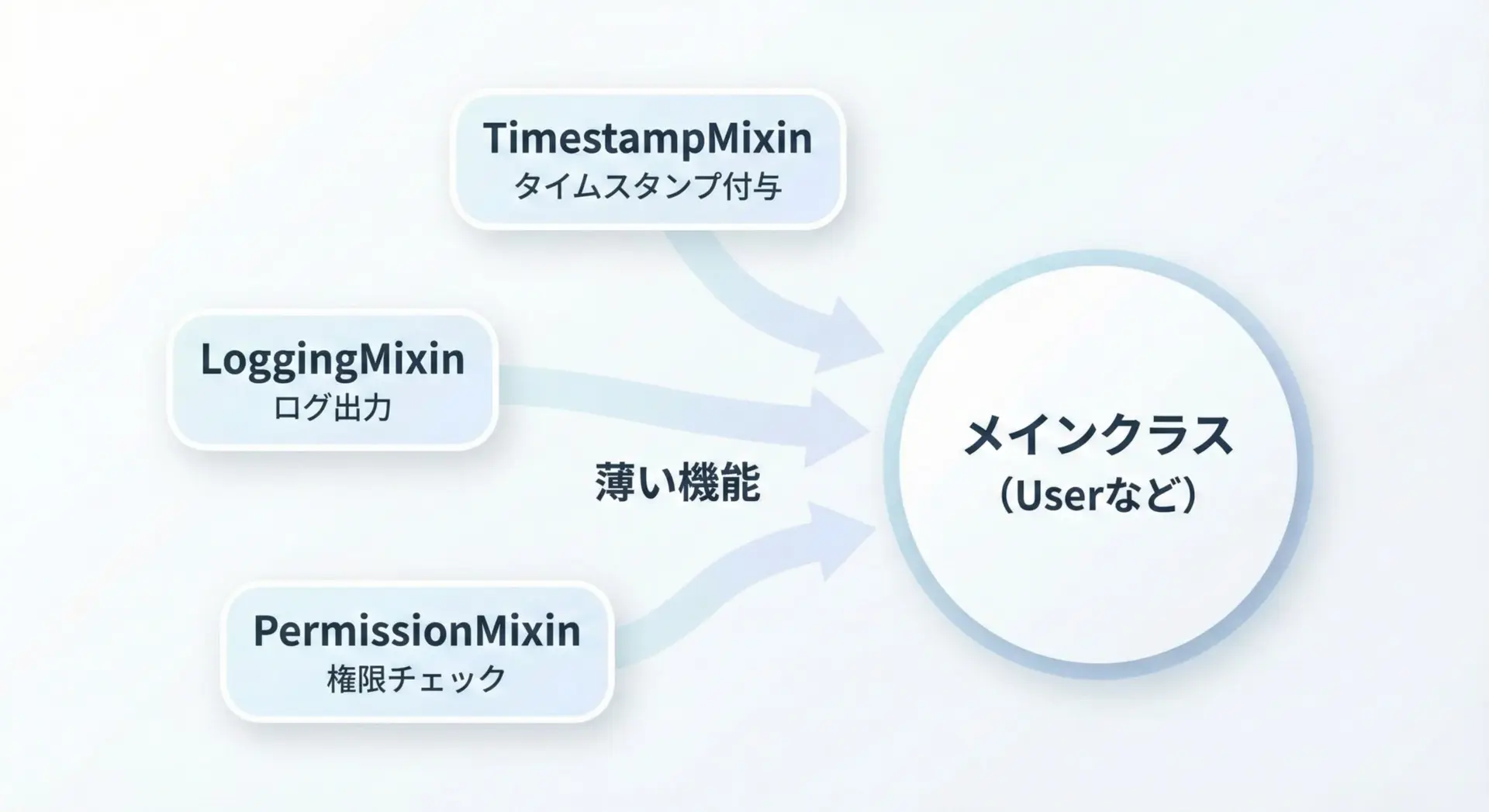
Mixinは、多重継承を用いて特定の機能(振る舞い)だけを別クラスとして切り出し、必要なクラスに「後付け」するための設計パターンです。
一般に、Mixinクラス単体では完全な概念を表さず、他のクラスと組み合わさって初めて意味を持ちます。
Mixinの主な特徴として、次のような点があります。
- 単一の小さな役割(ログ、権限、キャッシュなど)に特化する
- インスタンス変数などの状態をあまり持たない
- 名前に
Mixinを含め、用途を明確にする
Mixin的なクラスの簡単な例
class LoggingMixin:
# ログ出力専用のMixin
def log(self, message: str) -> None:
print(f"[LOG] {message}")
class Service(LoggingMixin):
def process(self) -> None:
self.log("Start processing")
print("Doing main work...")
self.log("End processing")
service = Service()
service.process()[LOG] Start processing
Doing main work...
[LOG] End processingLoggingMixinは、ログ出力という1つの責務に特化しており、任意のクラスに継承して使用できます。
PythonのMRO(Method Resolution Order)の仕組み

多重継承を安全に使うには、PythonのMRO(Method Resolution Order)を理解することが欠かせません。
MROとは、インスタンスからメソッドや属性を探索する際に、どの順番でクラスをたどるかを定めた規則です。
Python 3の新スタイルクラス(通常のクラス定義)では、C3線形化アルゴリズムに基づいたMROが採用されています。
これにより、ダイヤモンド継承のような複雑な関係でも、矛盾のない一意の探索順が決まります。
MROの挙動を確認するコード例
class A:
def hello(self) -> None:
print("A.hello")
class B(A):
def hello(self) -> None:
print("B.hello")
super().hello() # 次のクラスへ委譲
class C(A):
def hello(self) -> None:
print("C.hello")
super().hello()
class D(B, C):
pass
d = D()
d.hello()
# 実際のMROを確認
print(D.mro())B.hello
C.hello
A.hello
[<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]この例では、クラスDのMROは[D, B, C, A, object]となっています。
super()は、このMRO順に基づいて次のクラスのメソッドを呼び出します。
MROを意識した設計を行うことで、多重継承におけるメソッドの衝突や予期せぬ上書きを防げます。
多重継承とMixinを使うべきケース・避けるべきケース
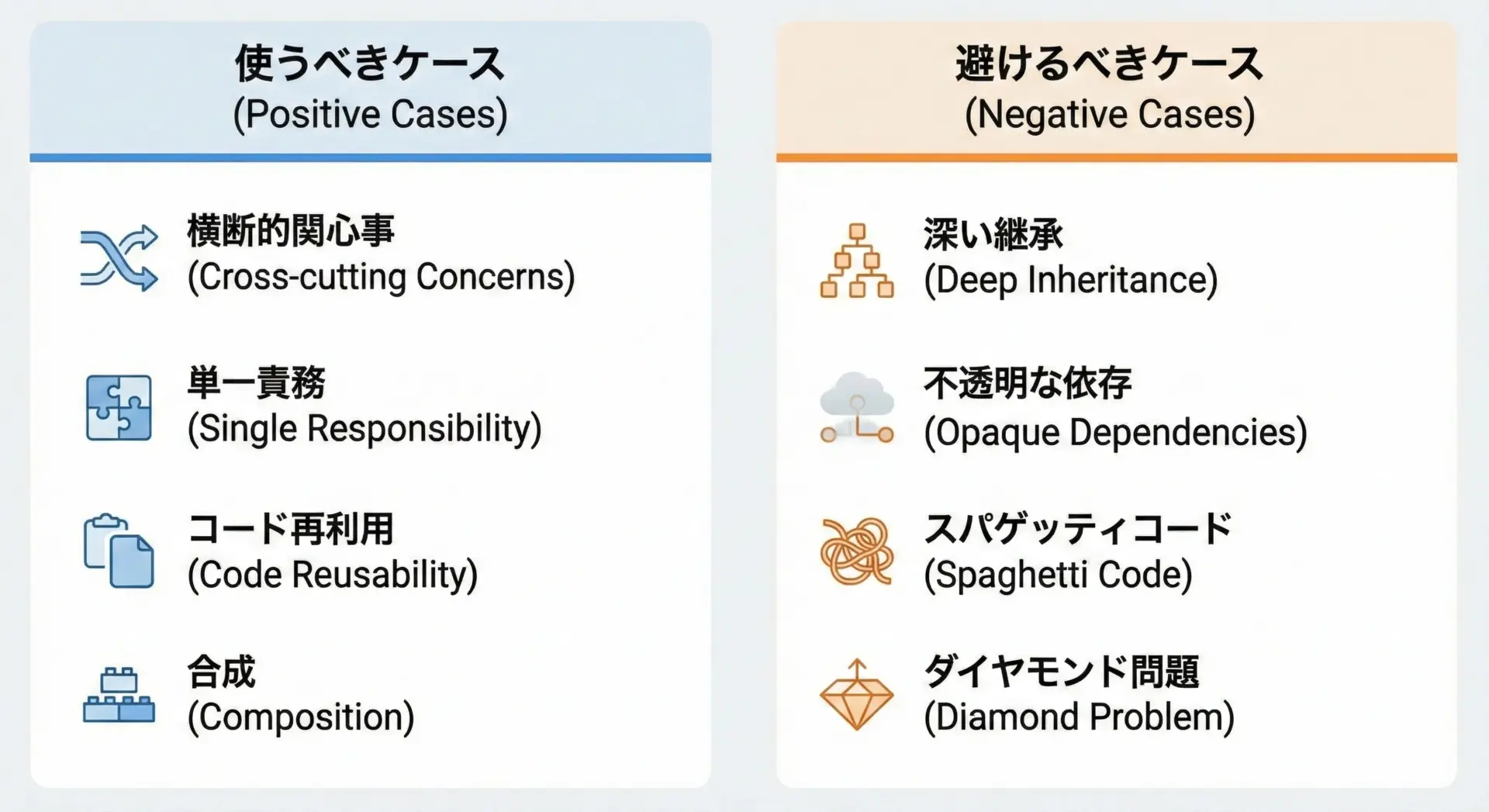
多重継承とMixinはとても強力ですが、万能ではありません。
「どのような場面で使い、どのような場面では避けるべきか」を明確にしておくことが重要です。
使うべき代表的なケースとしては、次のようなものがあります。
- ログ出力、権限チェック、キャッシュ、リトライ機構など、複数クラスに共通する横断的な機能
- Webフレームワーク(Djangoなど)のViewクラスに、認証・ページネーション・JSONレスポンスなどを組み合わせるとき
- 既存のクラス階層に後付けで軽量な機能を共有したいとき
一方で、避けるべきケースもはっきり存在します。
- 業務ドメインの中心となる概念を多重継承で複雑に組み合わせるような設計
- Mixinが状態や内部実装に強く依存しており、単体では再利用できない場合
- 継承階層が深くなり、クラスを追わないと挙動がわからない場合
継承は強い依存関係を生みます。
まずはコンポジション(オブジェクトの委譲)やユーティリティ関数で解決できないかを検討し、それでもなお再利用性と一貫性の面から継承が妥当な場合にだけ、多重継承やMixinの採用を検討するのが安全です。
Pythonの多重継承・Mixin設計のベストプラクティス10選
ベストプラクティス1: Mixinは明確な単一責務に絞る
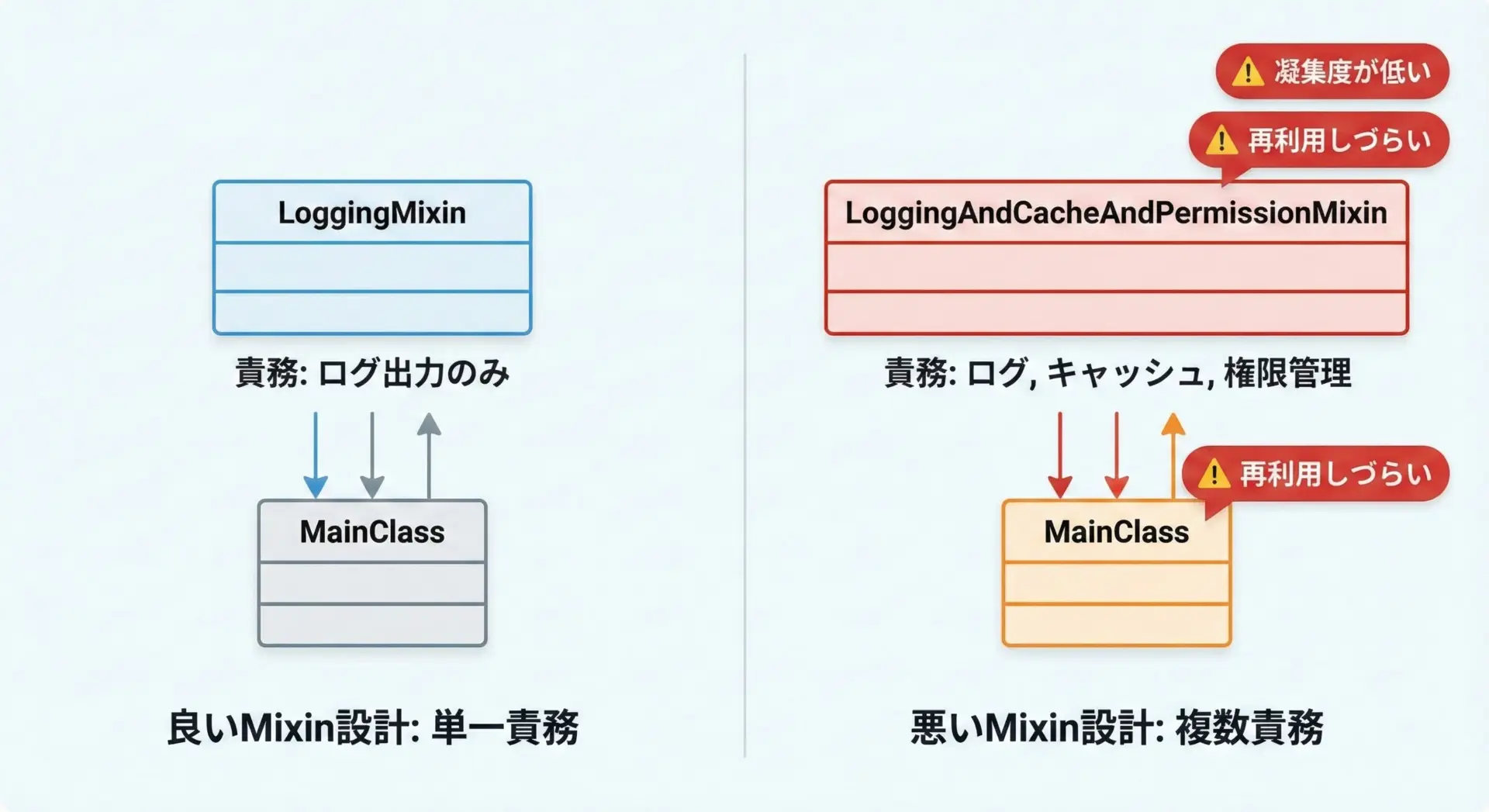
Mixinは1つの明確な責務に絞ることが最も重要な原則です。
1つのMixinにさまざまな機能を詰め込みすぎると、再利用性が落ち、依存関係も不透明になります。
単一責務に絞った良い例
class LoggingMixin:
"""ログ出力だけを担当するMixin"""
def log_info(self, message: str) -> None:
print(f"[INFO] {message}")
def log_error(self, message: str) -> None:
print(f"[ERROR] {message}")責務を詰め込みすぎた悪い例
class LoggingCachePermissionMixin:
"""責務を詰め込みすぎたアンチパターン例"""
def log(self, message: str) -> None:
print(f"[LOG] {message}")
def get_from_cache(self, key: str) -> str | None:
# 擬似的なキャッシュ取得処理
return None
def has_permission(self, user: str, action: str) -> bool:
# 擬似的な権限チェック
return Trueこのようなクラスは、どこに導入しても影響範囲が読みづらく、テストもしにくくなります。
ベストプラクティス2: Mixin名に役割を明示する

Mixinは再利用される前提なので、名前だけで役割が分かるようにすることが重要です。
一般的には、クラス名の末尾にMixinを付け、先頭に役割を表す名詞や動詞句を置きます。
例えば、次のような命名だと意図が伝わりやすくなります。
- LoggingMixin
- PermissionRequiredMixin
- CacheableMixin
- SerializerMixin
逆に、UtilMixinやCommonMixinのような抽象的な名前は、責務があいまいになりがちです。
ベストプラクティス3: Mixinクラスは状態(state)を極力持たない

Mixinは、可能な限りステートレス(状態を持たない)に設計することで、安全かつ再利用しやすくなります。
状態を持つと、他クラスの__init__との衝突や、初期化順序の問題が発生しやすくなります。
状態を持たない良い例
class StrReprMixin:
"""__str__と__repr__の共通実装を提供するMixin"""
def __str__(self) -> str:
return f"{self.__class__.__name__}({self.__dict__})"
__repr__ = __str__状態を持ってしまっている危険な例
class CounterMixin:
"""状態を持つ危険なMixinの例"""
def __init__(self) -> None:
# どのタイミングで初期化されるかが不透明
self._counter = 0
def increment(self) -> None:
self._counter += 1このようなMixinを複数組み合わせると、__init__の競合や初期化漏れが起こりやすくなります。
止むを得ず状態を持つ場合は、super().__init__()を前提にした設計を行うか、初期化用のメソッドを分けるなど注意が必要です。
ベストプラクティス4: Mixinでは他クラスの実装に強く依存しない
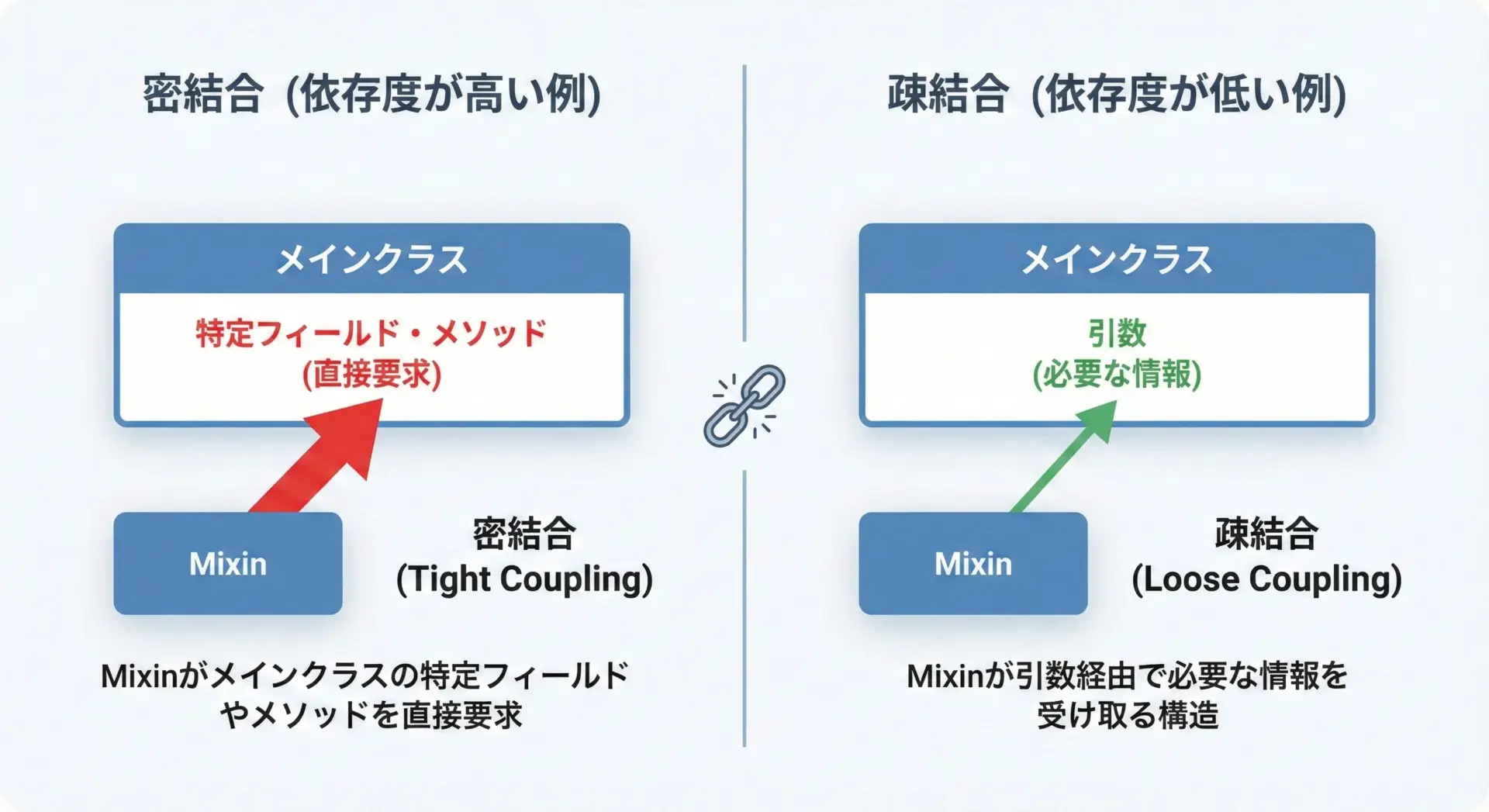
Mixinが他クラスの内部実装に強く依存すると、再利用が難しくなり、変更に弱い設計になります。
できる限り疎結合に保ち、明示的なインターフェースだけに依存することが理想です。
内部実装に強く依存している悪い例
class DangerousPermissionMixin:
"""self.userやself.roleに依存している危険な例"""
def has_admin_permission(self) -> bool:
# user属性とrole属性がある前提で実装されている
return self.user.is_active and self.role == "admin"このMixinは、userやroleという属性が存在しないクラスには簡単に適用できません。
依存をインターフェースに限定した良い例
class PermissionCheckMixin:
"""ユーザ情報を引数で受け取ることで依存を小さくした例"""
def has_permission(self, user: "User", required_role: str) -> bool:
# userオブジェクトの公開インターフェースにだけ依存
return user.is_active and required_role in user.rolesこのように、外部から必要な情報を渡す形にすることで、Mixinの汎用性が高まります。
ベストプラクティス5: 多重継承はダイヤモンド継承を避けてシンプルに
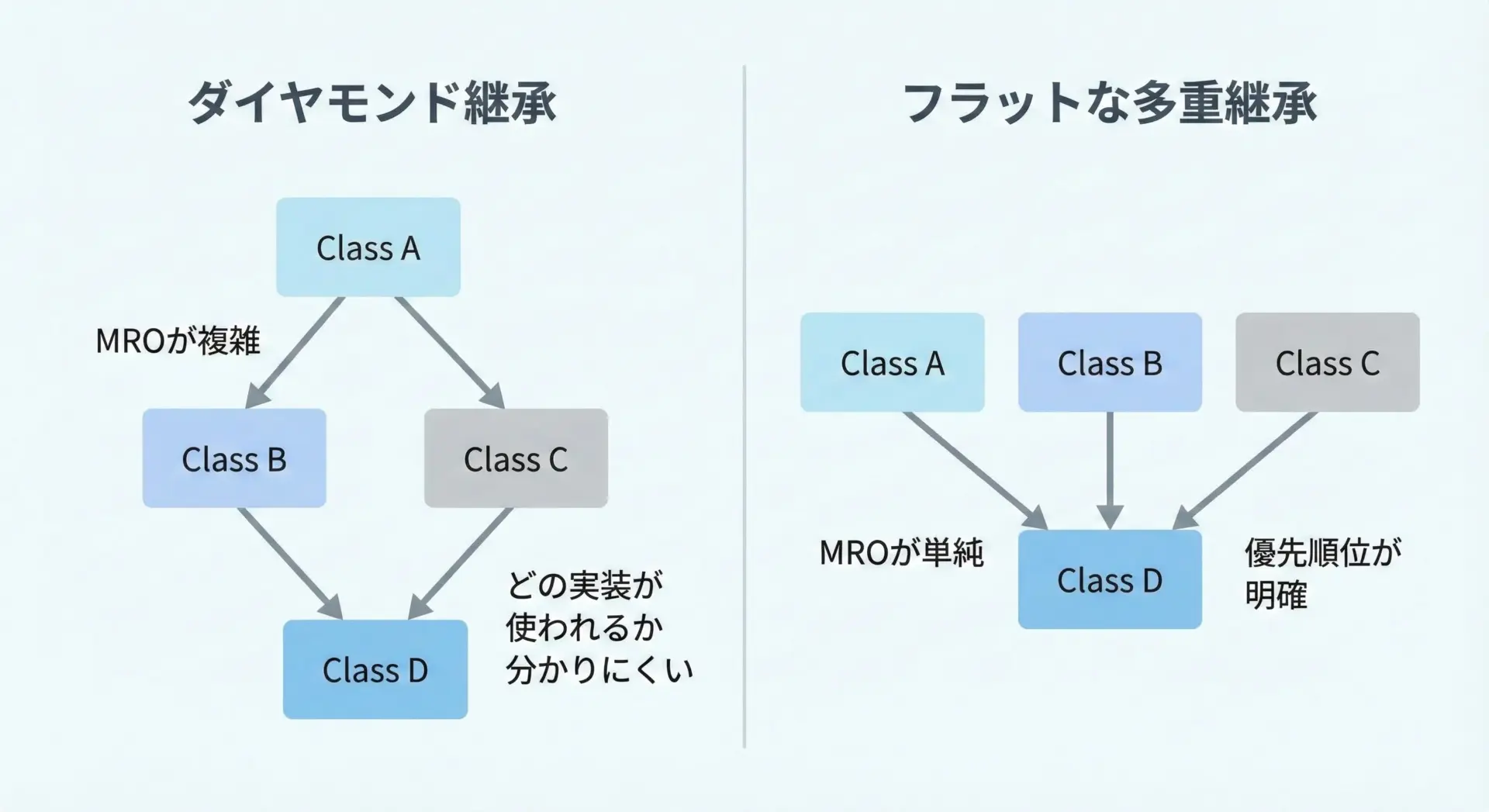
ダイヤモンド継承とは、同じ基底クラスを複数経路から継承する構造を指します。
PythonのMROはダイヤモンド継承にも対応していますが、設計としてはできるだけ避けるのが無難です。
class A:
def hello(self) -> None:
print("A")
class B(A):
def hello(self) -> None:
print("B")
super().hello()
class C(A):
def hello(self) -> None:
print("C")
super().hello()
class D(B, C):
pass
d = D()
d.hello()
print(D.mro())B
C
A
[<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]このような構造は、ちょっとした変更でMROが変わり、実行結果も変化しやすくなります。
Mixinを利用する際は、横に薄く並べる(水平な多重継承)構造を意識し、深さを増やさないことが重要です。
ベストプラクティス6: super()とMROを前提にメソッドチェーンを設計する
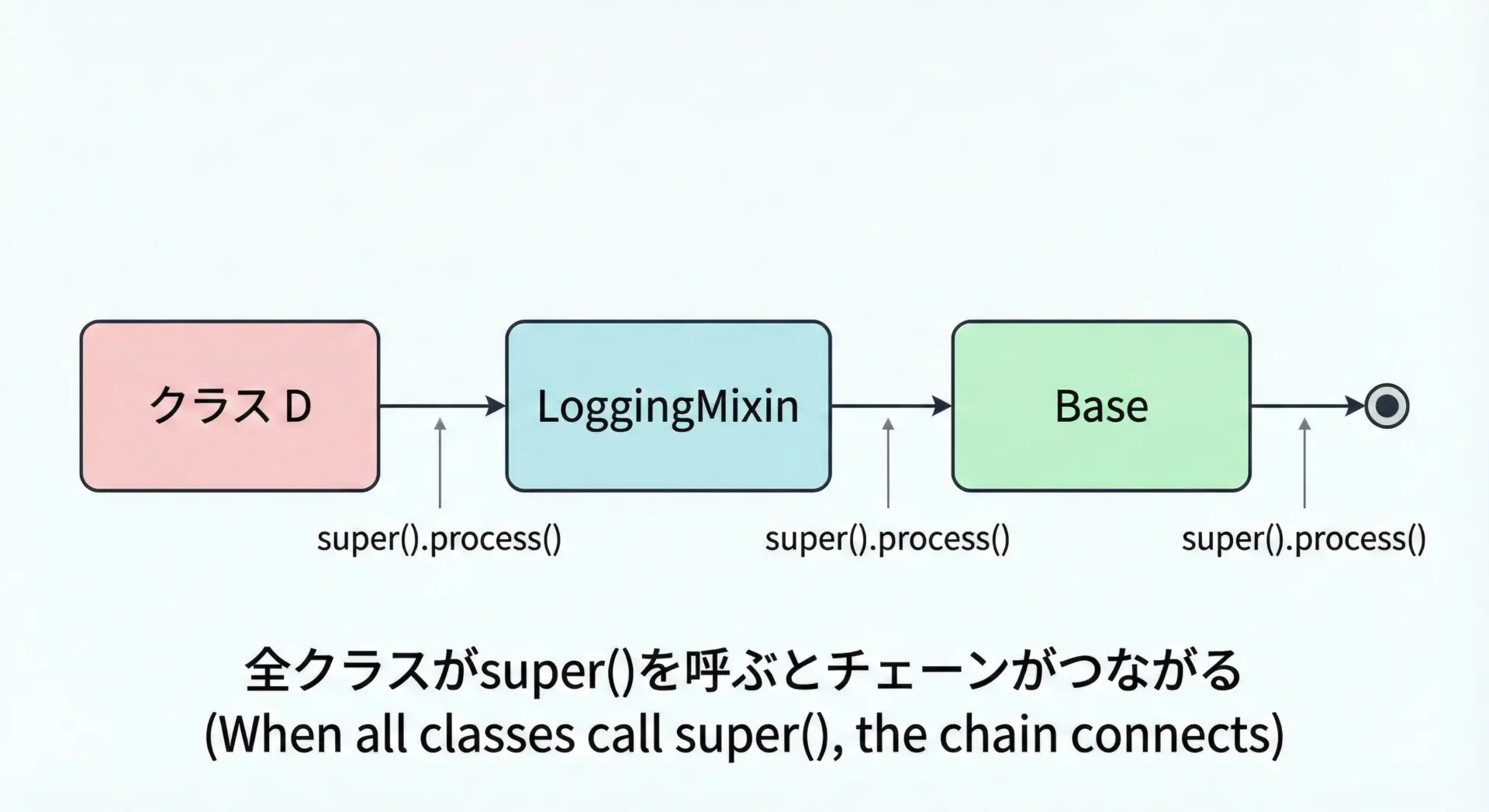
多重継承とMixinを正しく機能させるには、super()を一貫して使うことが重要です。
特に、同名のメソッドを複数のMixinでオーバーライドする場合、各メソッドがsuper()を呼ぶことで、MROに沿ってメソッドチェーンがつながります。
super()を正しく用いたチェーンの例
class Base:
def process(self) -> None:
print("Base.process")
class LoggingMixin(Base):
def process(self) -> None:
print("LoggingMixin.before")
super().process()
print("LoggingMixin.after")
class ValidationMixin(Base):
def process(self) -> None:
print("ValidationMixin.before")
super().process()
print("ValidationMixin.after")
class Service(ValidationMixin, LoggingMixin, Base):
pass
s = Service()
s.process()
print(Service.mro())ValidationMixin.before
LoggingMixin.before
Base.process
LoggingMixin.after
ValidationMixin.after
[<class '__main__.Service'>, <class '__main__.ValidationMixin'>, <class '__main__.LoggingMixin'>, <class '__main__.Base'>, <class 'object'>]この例では、すべてのprocessメソッドがsuper().process()を呼び出しているため、MROに沿って処理が流れています。
どこか1つでもsuper()呼び出しを忘れると、その先のチェーンは途切れます。
ベストプラクティス7: ABC(抽象基底クラス)とMixinを組み合わせて使う
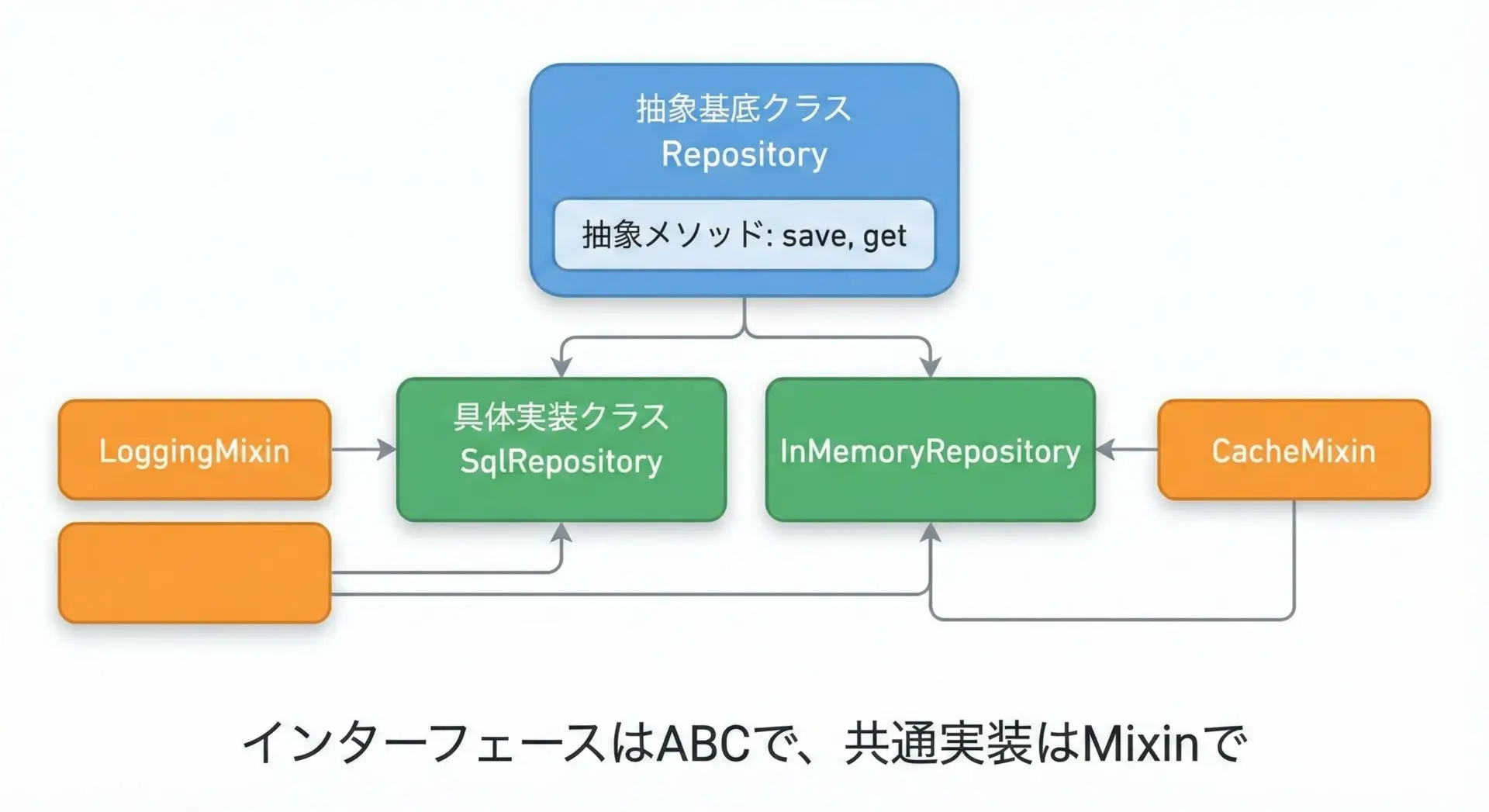
抽象基底クラス(ABC)は、インターフェース(契約)を定義するために、Mixinは共通実装を横断的に提供するために使うと整理がしやすくなります。
ABC + Mixinの組み合わせ例
from abc import ABC, abstractmethod
class Repository(ABC):
"""データ保存のインターフェースを定義するABC"""
@abstractmethod
def save(self, data: dict) -> None:
...
@abstractmethod
def get(self, key: str) -> dict | None:
...
class LoggingMixin:
"""保存・取得処理にログを追加するMixin"""
def save(self, data: dict) -> None: # type: ignore[override]
print(f"[LOG] Saving: {data}")
# super()で次の実装へ委譲
super().save(data)
def get(self, key: str) -> dict | None: # type: ignore[override]
print(f"[LOG] Getting key: {key}")
return super().get(key)
class InMemoryRepository(LoggingMixin, Repository):
def __init__(self) -> None:
self._store: dict[str, dict] = {}
def save(self, data: dict) -> None:
key = data["id"]
self._store[key] = data
def get(self, key: str) -> dict | None:
return self._store.get(key)
repo: Repository = InMemoryRepository()
repo.save({"id": "1", "name": "Alice"})
print(repo.get("1"))[LOG] Saving: {'id': '1', 'name': 'Alice'}
[LOG] Getting key: 1
{'id': '1', 'name': 'Alice'}インターフェースをABCで保証しつつ、ログという横断的な関心事をMixinで注入する形にすると、役割分担が明確になります。
ベストプラクティス8: Mixinをユーティリティ関数と比較して選択する

Mixinは便利ですが、常に最適解とは限りません。
「本当に継承にする必要があるのか」を、ユーティリティ関数との比較で検討することが大切です。
例えば、単にデータ構造をJSONに変換するだけなら、Mixinではなくモジュールレベルの関数の方がシンプルかもしれません。
# util_json.py
import json
from typing import Any
def to_json(data: Any) -> str:
return json.dumps(data, ensure_ascii=False)一方、特定のインターフェースと密接に結びついた共通処理(例: Djangoモデルのsave()処理にログを埋め込むなど)はMixinとして実装した方が自然な場面もあります。
判断基準としては、次のように考えると整理しやすくなります。
| 観点 | Mixinが向いている場合 | ユーティリティ関数が向いている場合 |
|---|---|---|
| 機能の性質 | クラスのインターフェースに深く関係する | データ変換など独立性が高い |
| 再利用方法 | 継承で複数クラスに共通実装を持たせたい | 単発で処理を呼び出したい |
| テスト | クラス単位でテストしたい | 関数単位でテストしたい |
ベストプラクティス9: DjangoやFlaskのMixinパターンから学ぶ
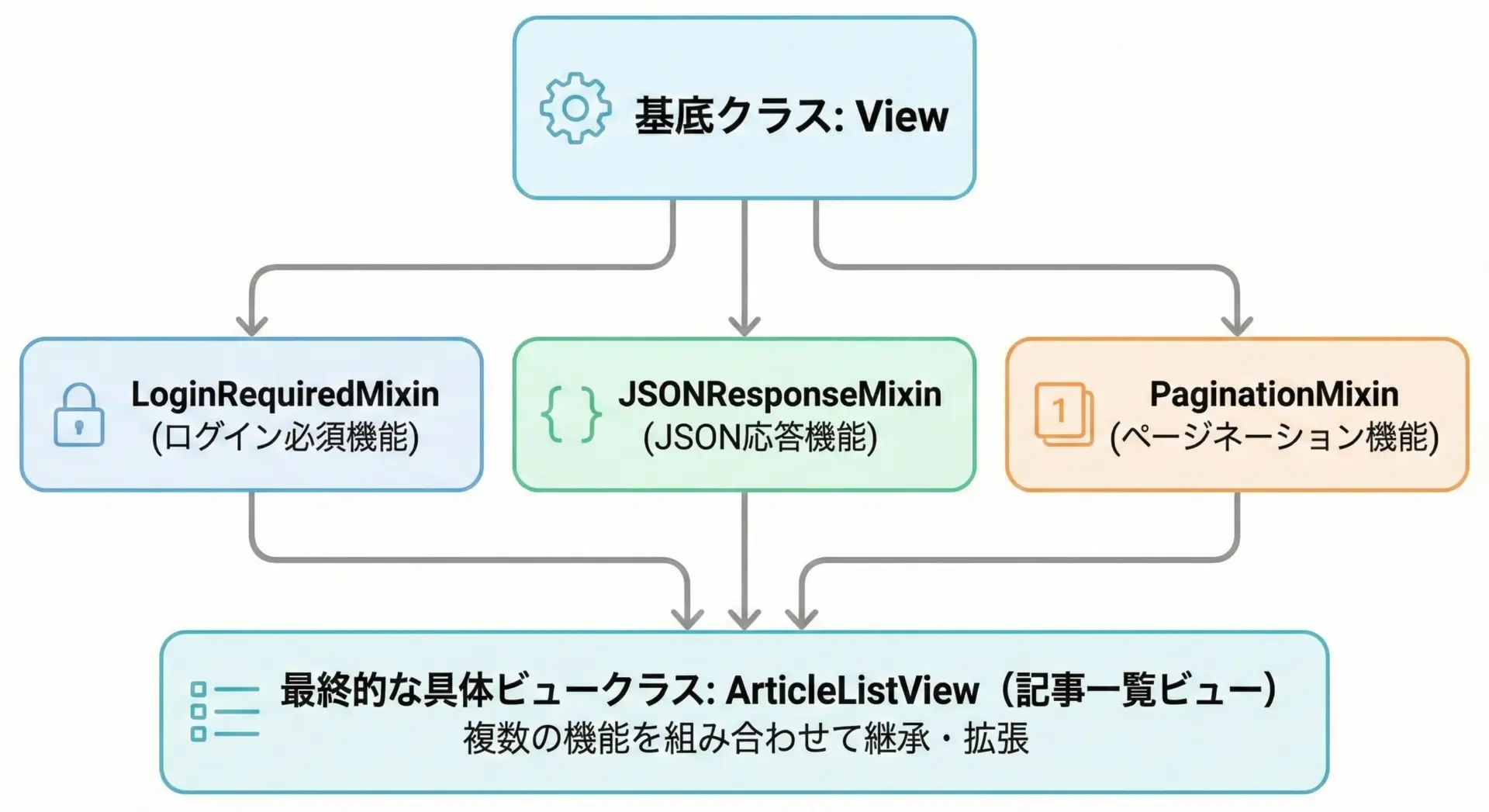
DjangoやFlaskなどのWebフレームワークは、Mixinを非常にうまく活用しています。
実務でよく見るパターンを観察することで、Mixin設計の勘所がつかめます。
代表的なパターンは次のようなものです。
- Djangoの
LoginRequiredMixin: 認証されていないユーザをログインページにリダイレクトする - Djangoの
MultipleObjectMixin: ページネーションなどリスト表示用の共通処理 - Flask拡張の各種Mixin: JSONレスポンス、セッション管理などを注入
これらに共通する特徴は、次の通りです。
- クラス名とドキュメントから役割が明確に読み取れる
- 1つのMixinが1つ(かごく近い範囲)の責務に限定されている
- Viewやモデルという「メインの概念」に対して、認証やレスポンス形式といった横断的な機能を追加している
実務で独自Mixinを設計する際は、DjangoなどのパブリックAPIの設計を真似ると失敗が減ります。
ベストプラクティス10: 型ヒントとmypyで多重継承の安全性を高める

多重継承を使うと、どのクラスにどのメソッドがあるのかが見えにくくなります。
型ヒントとmypyなどの静的型チェッカーを併用すると、インターフェースの不整合を早期に発見できます。
from typing import Protocol
class CanLog(Protocol):
def log(self, message: str) -> None:
...
class LoggingMixin:
def log(self, message: str) -> None:
print(f"[LOG] {message}")
class Service(LoggingMixin):
def do(self) -> None:
self.log("doing something")
def run(service: CanLog) -> None:
service.log("start")
s = Service()
run(s)上記のようにProtocol(構造的サブタイピング)を使うと、「logメソッドを持つならOK」というインターフェースだけを定義でき、多重継承と相性が良くなります。
mypyを導入すれば、super()の呼び出しやオーバーライドの誤りも検出しやすくなります。
実務で使えるPython Mixinサンプル集
ログ出力を共通化するLoggingMixinの例
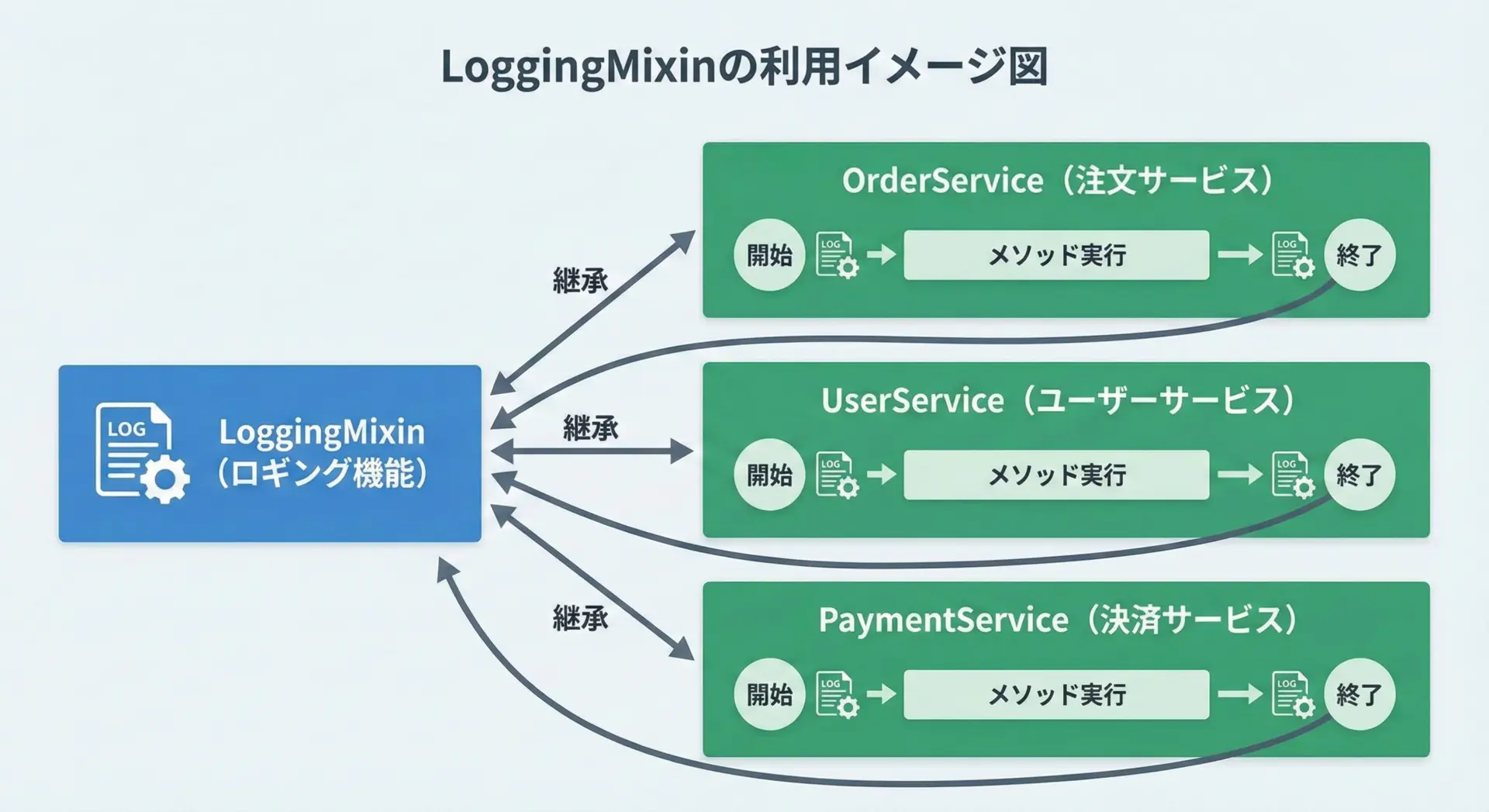
実務では、APIコールやバッチ処理など、あらゆる箇所でログ出力が必要になります。
LoggingMixinを用意しておくと、ログのフォーマットや出力先を一元管理しやすくなります。
import datetime as _dt
from typing import Any
class LoggingMixin:
"""簡易的なログ出力を提供するMixin"""
def log(self, level: str, message: str, **context: Any) -> None:
timestamp = _dt.datetime.now().isoformat(timespec="seconds")
ctx = " ".join(f"{k}={v}" for k, v in context.items())
print(f"{timestamp} [{level}] {self.__class__.__name__}: {message} {ctx}")
def log_info(self, message: str, **context: Any) -> None:
self.log("INFO", message, **context)
def log_error(self, message: str, **context: Any) -> None:
self.log("ERROR", message, **context)
class OrderService(LoggingMixin):
def create_order(self, user_id: str, amount: int) -> None:
self.log_info("Creating order", user_id=user_id, amount=amount)
# ここで注文作成処理を行う
self.log_info("Order created", user_id=user_id, amount=amount)
service = OrderService()
service.create_order("u-123", 5000)2025-12-17T10:00:00 [INFO] OrderService: Creating order user_id=u-123 amount=5000
2025-12-17T10:00:00 [INFO] OrderService: Order created user_id=u-123 amount=5000キャッシュ機能を追加するCacheMixinの例
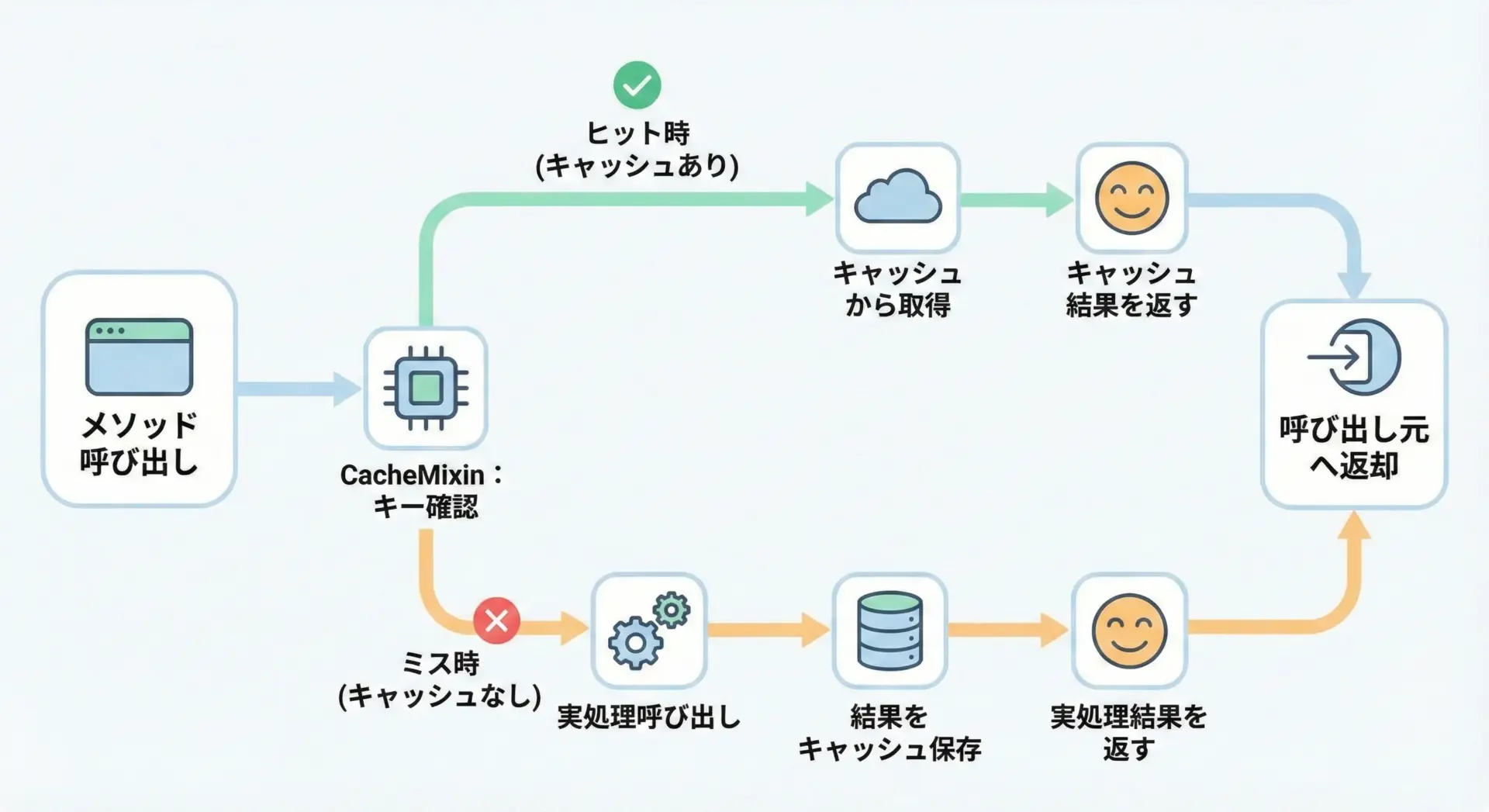
キャッシュは、外部APIコールや重い計算処理を高速化するのに有効です。
簡易的なインメモリキャッシュMixinを作ってみます。
from collections.abc import Callable
from functools import wraps
from typing import ParamSpec, TypeVar
P = ParamSpec("P")
R = TypeVar("R")
class CacheMixin:
"""簡易インメモリキャッシュを提供するMixin"""
def __init__(self) -> None:
# Mixinで状態を持つ例だが、__init__とsuper()をきちんと扱う前提
self._cache: dict[str, object] = {} # key -> value
def cached(self, key_func: Callable[P, str]) -> Callable[[Callable[P, R]], Callable[P, R]]:
"""デコレータとして使用し、結果をキャッシュする"""
def decorator(func: Callable[P, R]) -> Callable[P, R]:
@wraps(func)
def wrapper(*args: P.args, **kwargs: P.kwargs) -> R:
key = key_func(*args, **kwargs)
if key in self._cache:
# キャッシュヒット
return self._cache[key] # type: ignore[return-value]
result = func(*args, **kwargs)
self._cache[key] = result # type: ignore[assignment]
return result
return wrapper
return decorator
class PriceService(CacheMixin):
def __init__(self) -> None:
super().__init__()
# デコレータをインスタンスメソッドに適用
self.get_price = self.cached(lambda product_id: product_id)(self.get_price) # type: ignore[method-assign]
def get_price(self, product_id: str) -> int:
print(f"Fetching price for {product_id} from external API...")
return 100 # 擬似的な価格
svc = PriceService()
print(svc.get_price("p-001"))
print(svc.get_price("p-001")) # 2回目はキャッシュヒットFetching price for p-001 from external API...
100
100この例では、Mixin内で初期化処理を行っているため、super().__init__()の呼び出し順序に注意が必要です。
権限チェックに使えるPermissionMixinの例
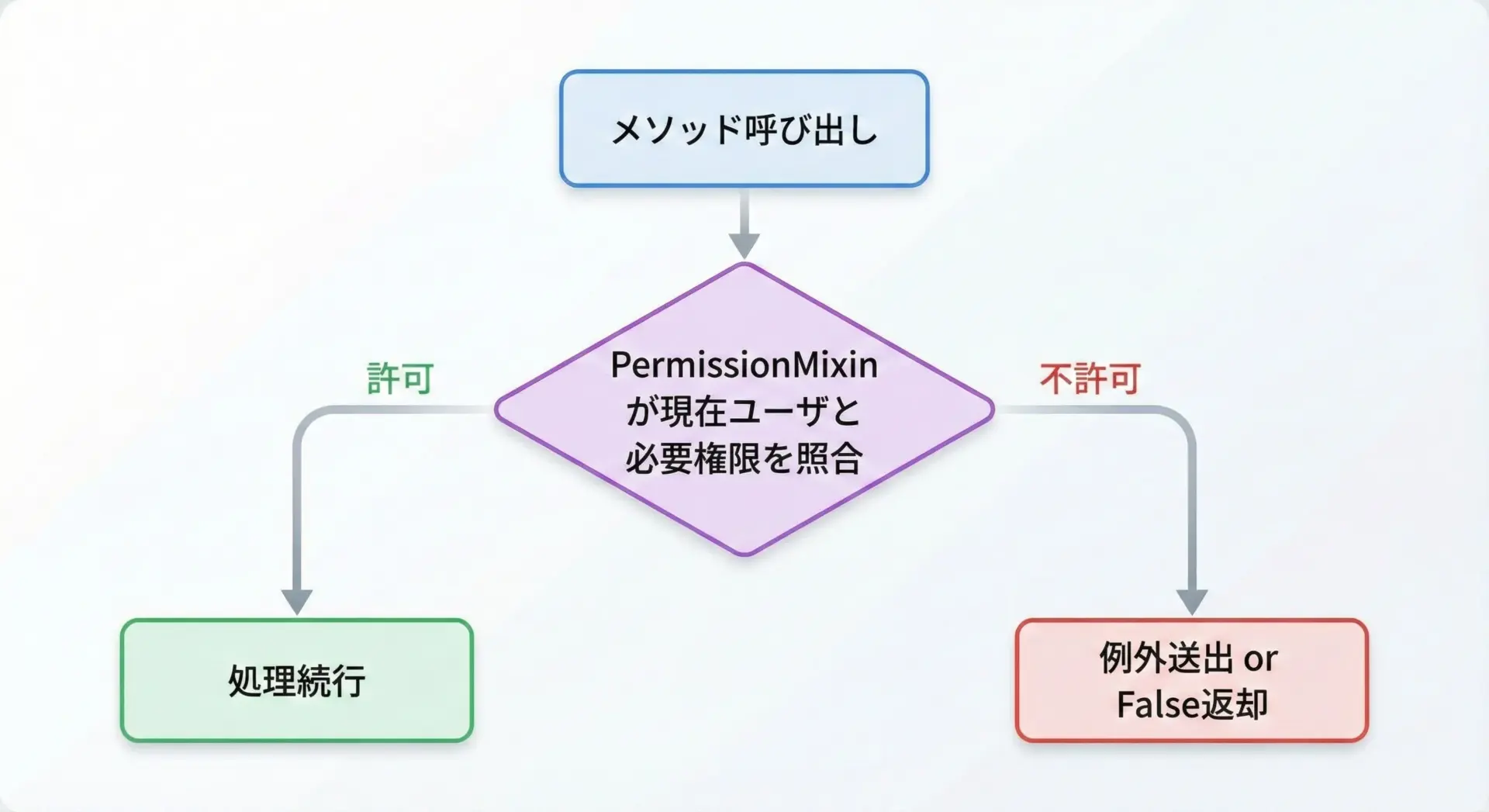
認可(Authorization)は、多くの業務システムで共通する関心事です。
権限チェックをMixinで共通化してみます。
class PermissionError(Exception):
"""権限不足を表す例外"""
pass
class PermissionMixin:
"""簡易的な権限チェックを提供するMixin"""
def check_permission(self, user_roles: list[str], required_role: str) -> None:
if required_role not in user_roles:
raise PermissionError(f"Required role '{required_role}' is missing")
class ReportService(PermissionMixin):
def generate_report(self, user_roles: list[str]) -> str:
# 管理者権限が必要
self.check_permission(user_roles, "admin")
return "report-content"
service = ReportService()
try:
print(service.generate_report(["user"]))
except PermissionError as e:
print("Error:", e)
print(service.generate_report(["user", "admin"]))Error: Required role 'admin' is missing
report-contentPermissionMixin自体は、ユーザの実体や保存方法には依存しておらず、役割リストだけを前提としているため、さまざまなシステムで再利用しやすい構造になっています。
シリアライズ処理の共通化SerializerMixinの例
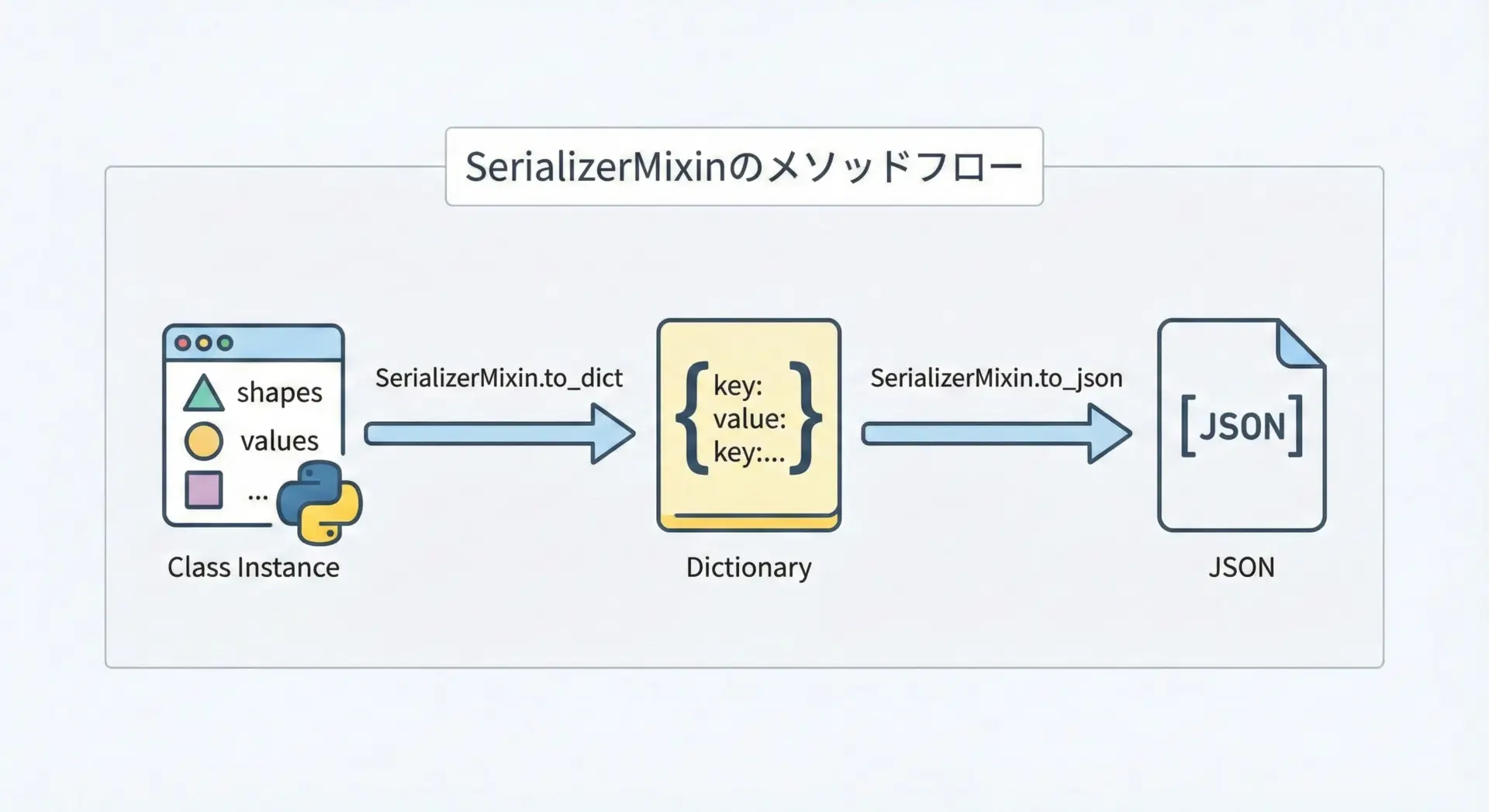
オブジェクトをJSONや辞書に変換する処理も、多くのクラスで共通します。
SerializerMixinを使って、シリアライズ処理を統一できます。
import json
from typing import Any
class SerializerMixin:
"""オブジェクトを辞書およびJSONへシリアライズするMixin"""
def to_dict(self) -> dict[str, Any]:
# __dict__をベースに、先頭が_の属性は除外する
return {
k: v
for k, v in self.__dict__.items()
if not k.startswith("_")
}
def to_json(self, **json_kwargs: Any) -> str:
return json.dumps(self.to_dict(), ensure_ascii=False, **json_kwargs)
class User(SerializerMixin):
def __init__(self, user_id: str, name: str, password_hash: str) -> None:
self.user_id = user_id
self.name = name
self._password_hash = password_hash # シリアライズ対象外
u = User("u-1", "Alice", "xxx123")
print(u.to_dict())
print(u.to_json()){'user_id': 'u-1', 'name': 'Alice'}
{"user_id": "u-1", "name": "Alice"}SerializerMixinは状態を持たず、公開属性から辞書を生成するだけなので、さまざまなモデルクラスに簡単に適用できます。
非同期処理に対応するAsyncMixinの例
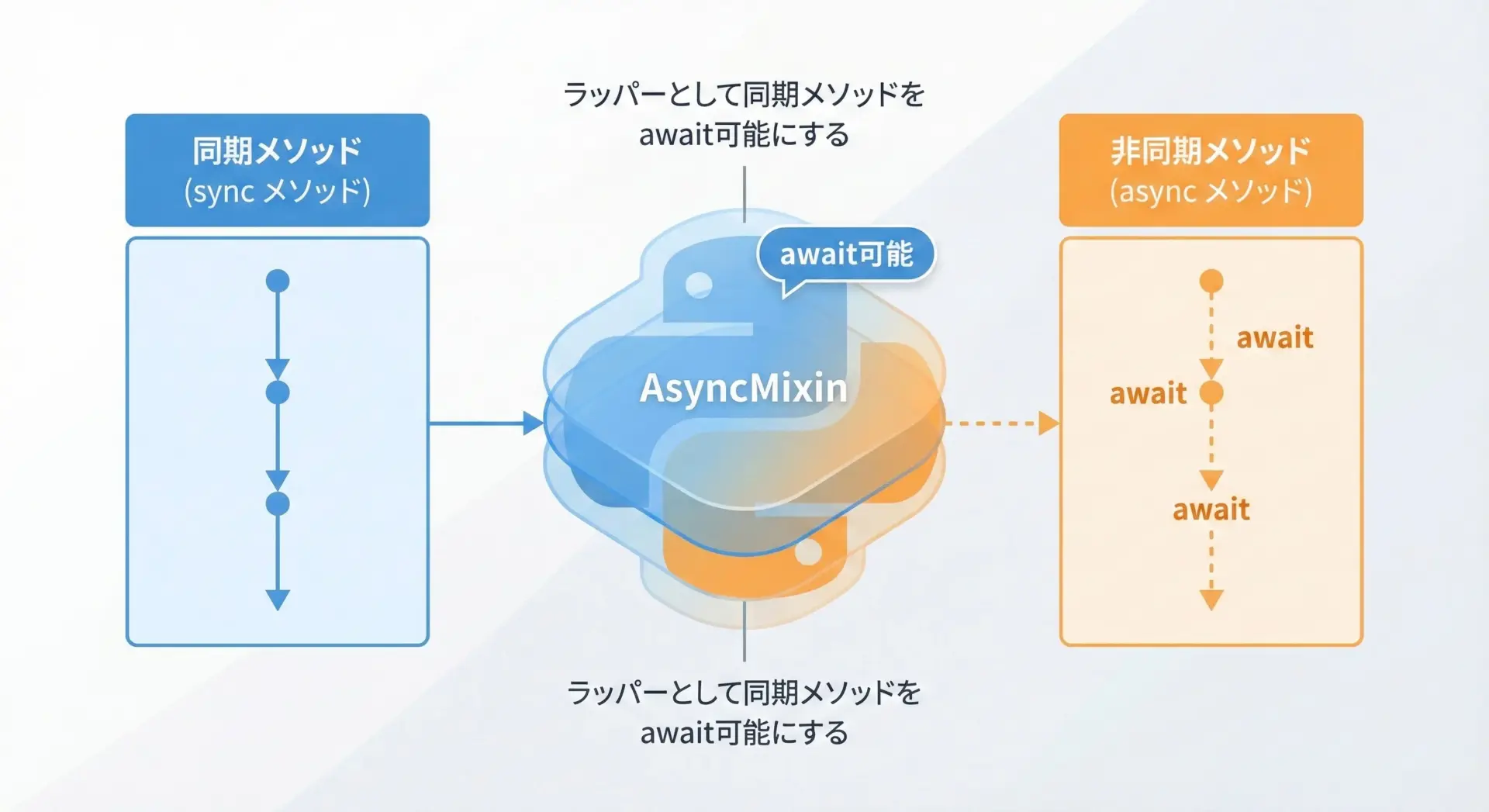
Pythonのasyncio環境では、CPUバウンドな処理や同期I/Oを非同期インターフェースで扱いたい場面があります。
簡単なAsyncMixinを作り、同期メソッドを非同期でラップしてみます。
import asyncio
from concurrent.futures import ThreadPoolExecutor
from typing import Callable, TypeVar
T = TypeVar("T")
class AsyncMixin:
"""同期関数を別スレッドで実行し、asyncメソッドとして扱うMixin"""
_executor: ThreadPoolExecutor | None = None
@classmethod
def _get_executor(cls) -> ThreadPoolExecutor:
if cls._executor is None:
cls._executor = ThreadPoolExecutor(max_workers=4)
return cls._executor
async def run_in_thread(self, func: Callable[[], T]) -> T:
loop = asyncio.get_running_loop()
return await loop.run_in_executor(self._get_executor(), func)
class ReportGenerator(AsyncMixin):
def generate_sync(self) -> str:
# 時間のかかる処理をシミュレート
import time
time.sleep(1)
return "sync-report"
async def generate_async(self) -> str:
# generate_syncを別スレッドで実行
return await self.run_in_thread(self.generate_sync)
async def main() -> None:
gen = ReportGenerator()
print(await gen.generate_async())
if __name__ == "__main__":
asyncio.run(main())sync-reportこのように、AsyncMixinを使うことで、既存の同期メソッドを大きく書き換えずに非同期インターフェースを提供できます。
Python多重継承・Mixin導入時のアンチパターンと注意点
継承の深さが増えすぎるクラス階層は避ける
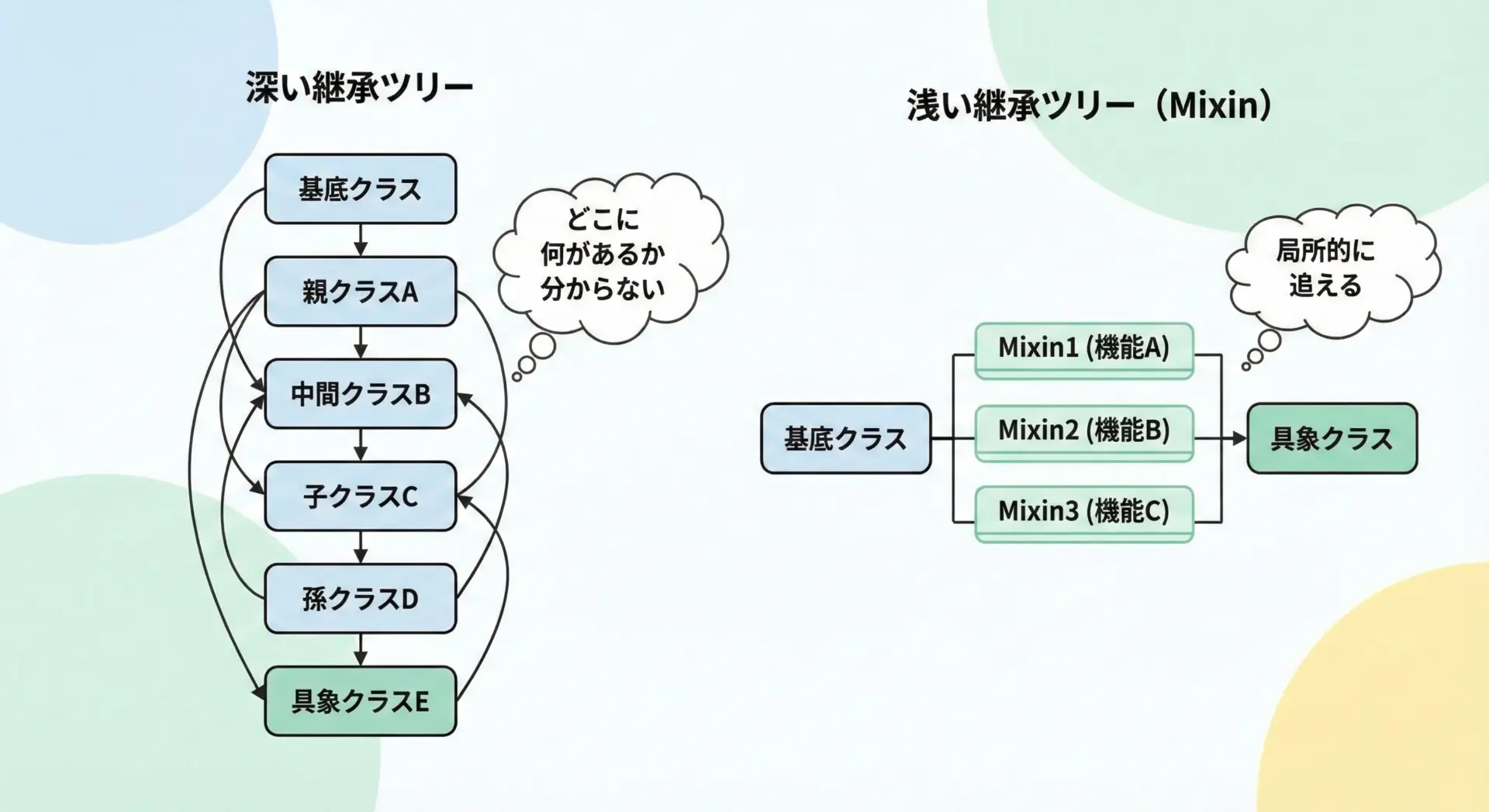
多重継承を乱用すると、「継承地獄」と呼ばれるような、深く複雑な階層構造が生まれます。
これは理解と保守を極端に難しくします。
継承の段数は、業務システムでは3〜4段を超えない程度に抑えるのが現実的な目安です。
Mixinを使う場合でも、横方向への拡張(Mixinの数)は多少増えても、縦方向(継承の深さ)は抑えるべきです。
initの競合と引数不一致を防ぐポイント
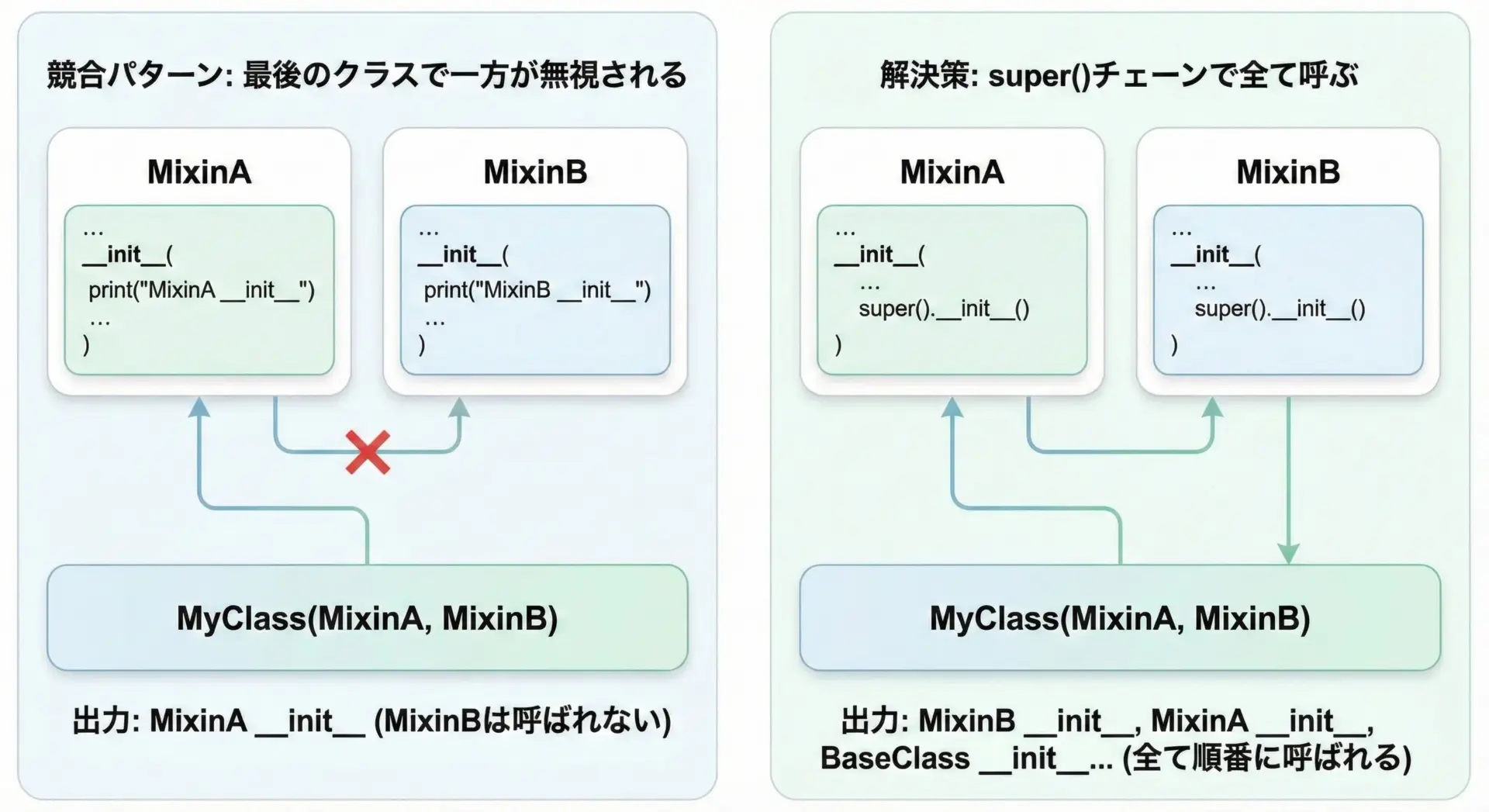
複数のMixinや基底クラスが__init__を実装していると、初期化処理が一部しか呼ばれないといった問題が起きやすくなります。
これを防ぐには、次のポイントを押さえることが重要です。
- すべての
__init__でsuper().__init__(*args, **kwargs)を呼び出す - 引数は
*argsと**kwargsで受け取り、不要なものは捨てる - なるべくMixin側では
__init__を定義せず、初期化メソッドを別名にする
super()を使った__init__チェーンの例
class A:
def __init__(self, *args, **kwargs) -> None:
print("A.__init__")
super().__init__(*args, **kwargs)
class B:
def __init__(self, *args, **kwargs) -> None:
print("B.__init__")
super().__init__(*args, **kwargs)
class C(A, B):
def __init__(self, *args, **kwargs) -> None:
print("C.__init__")
super().__init__(*args, **kwargs)
c = C()
print(C.mro())C.__init__
A.__init__
B.__init__
[<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>, <class 'object'>]このように、__init__もメソッドチェーンの一部として捉え、全クラスでsuper()を呼ぶことが重要です。
ダックタイピングとMixinのバランスを取る
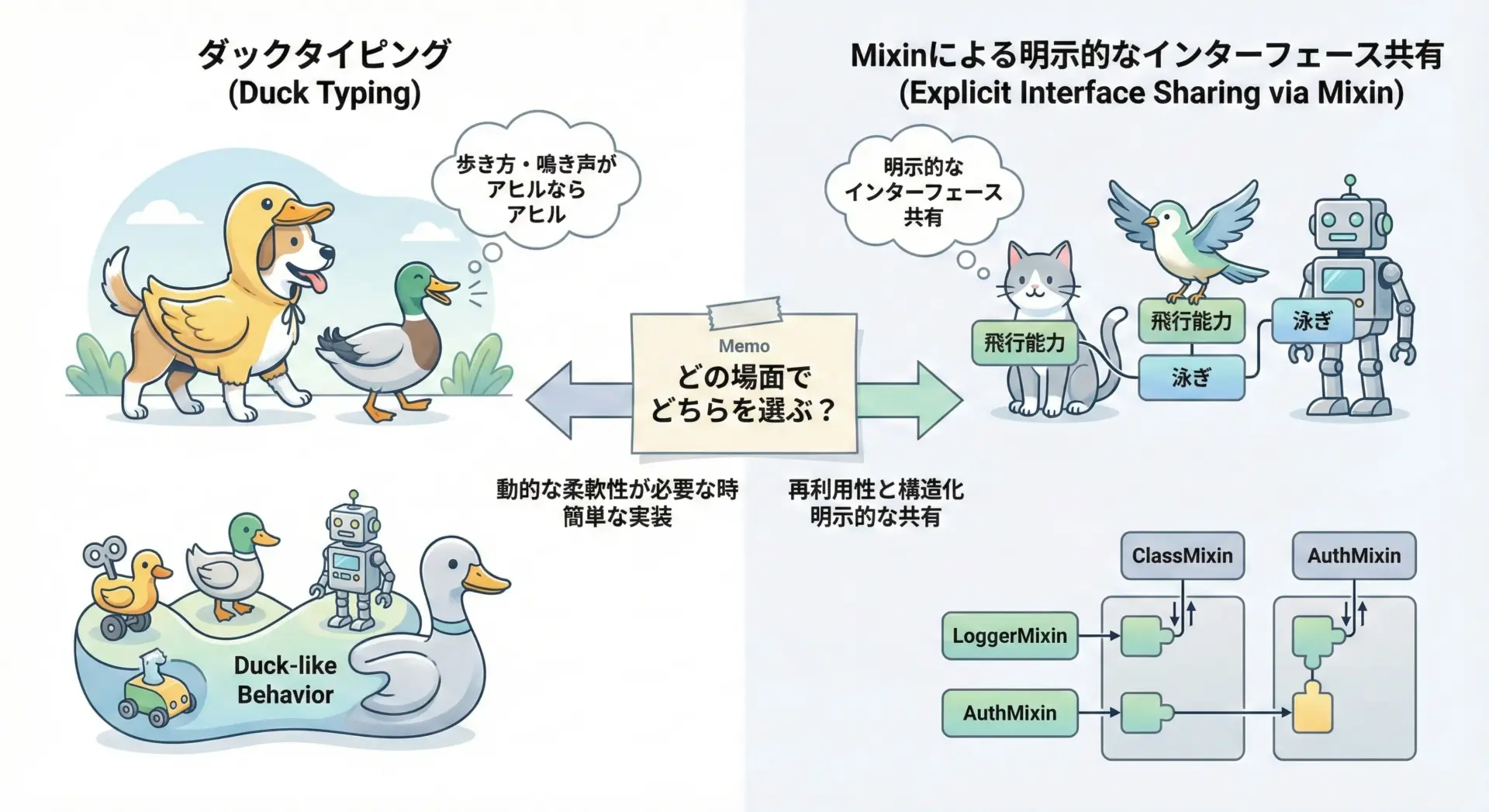
Pythonはダックタイピングを前提とした動的言語です。
「同じメソッドを持っていれば同じように扱える」という文化があるため、必ずしもMixinやABCを使わなくても共通インターフェースを構成できます。
しかし、大規模プロジェクトやチーム開発では、明示的なインターフェースがあった方が安全です。
MixinやABCを併用することで、「このクラスはsaveとgetを必ず持つ」といった契約をコードで表現できます。
バランスの取り方としては次のように考えるとよいです。
- 小規模・スクリプト的なコード: ダックタイピングで十分
- 中〜大規模・フレームワーク的なコード: ABC + Mixin + 型ヒントを積極的に活用
既存コードへの段階的なMixin導入戦略
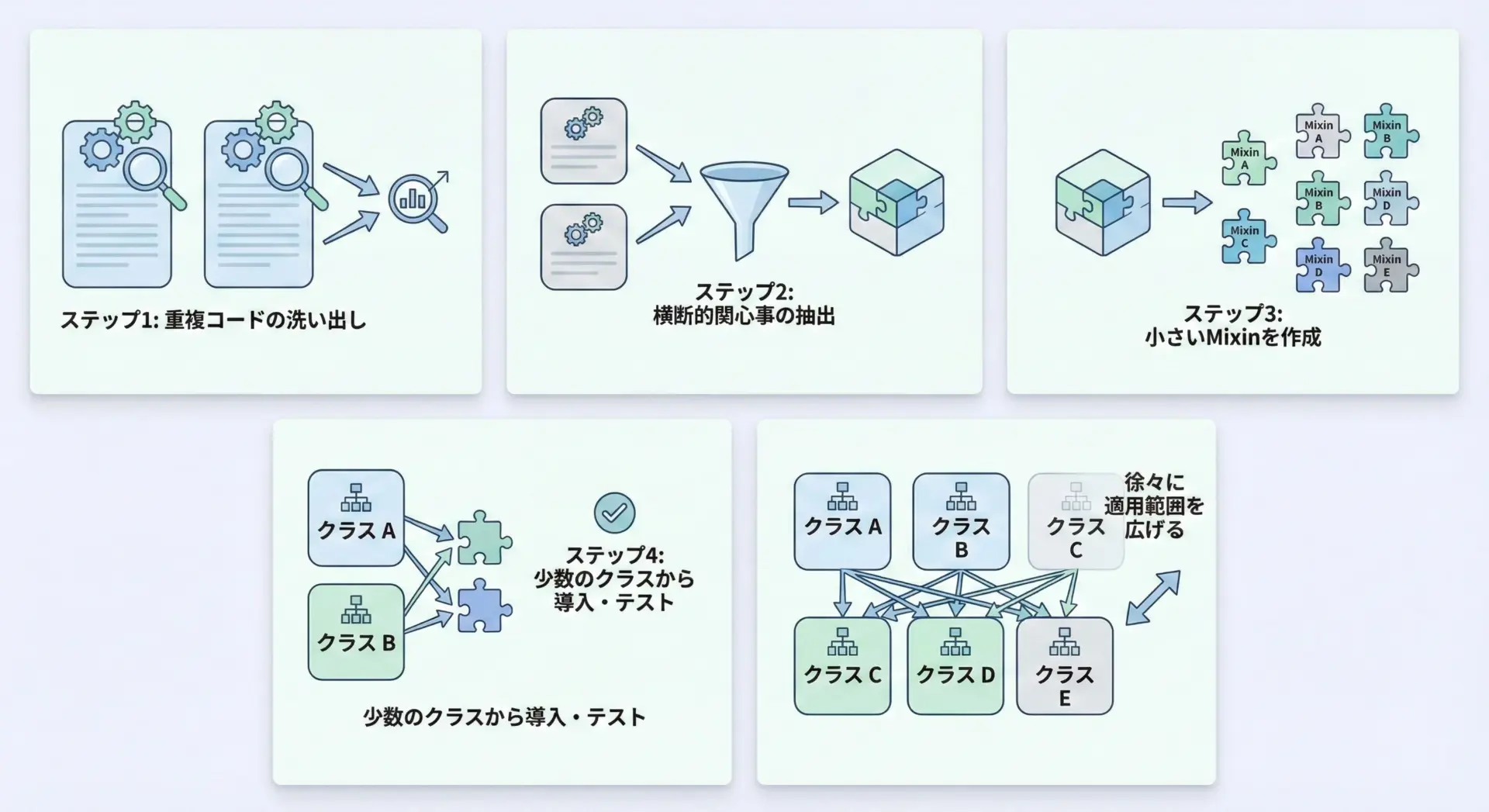
既存プロジェクトにいきなり大量のMixinを導入すると、バグや混乱を招きます。
段階的に安全に導入する戦略を取ることが重要です。
基本的な流れは次の通りです。
- まず重複している処理を洗い出し、ログ・権限・キャッシュなどの横断的関心事を特定する
- ごく小さな単一責務のMixinを1つだけ作る(例: LoggingMixin)
- 影響範囲の小さいクラスから導入し、テストを整備する
- 問題がなければ、徐々に他のクラスにも適用する
- その後、必要に応じて新しいMixin(例: PermissionMixin)を追加し、同様に段階的に展開する
一度に多くのMixinを導入しすぎると、バグ発生時に原因の切り分けが難しくなります。
導入のたびにテストを厚くし、MROやsuper()の挙動を確認しながら進めることが大切です。
まとめ
Pythonの多重継承とMixinは、ログや権限、キャッシュ、シリアライズなど横断的な関心事を再利用可能な形でまとめる強力な仕組みです。
一方で、MROやsuper()の理解が不十分なまま乱用すると、継承ツリーが複雑化し、保守性が急激に低下します。
本記事で紹介した「単一責務・明確な命名・ステートレス志向・super()チェーン・ABCとの併用・型チェック活用」といったベストプラクティスを意識することで、実務でも安全にMixinを取り入れられます。
まずは小さなLoggingMixinやSerializerMixinから試し、テストを整えつつ段階的に適用範囲を広げていくことをおすすめします。
