
Pythonでの開発では、設定ファイル、Web API、ログなど、さまざまな場面でJSONを扱います。
本記事では、Python標準ライブラリだけでJSONの読み込み(パース)・書き込み・整形を一通り使いこなせることを目標に、実用例とサンプルコードを交えながら丁寧に解説します。
JSON初心者の方でも、最後まで読めば業務で困らないレベルの基礎が身につく内容です。
PythonでJSONを扱う基本
JSONとは
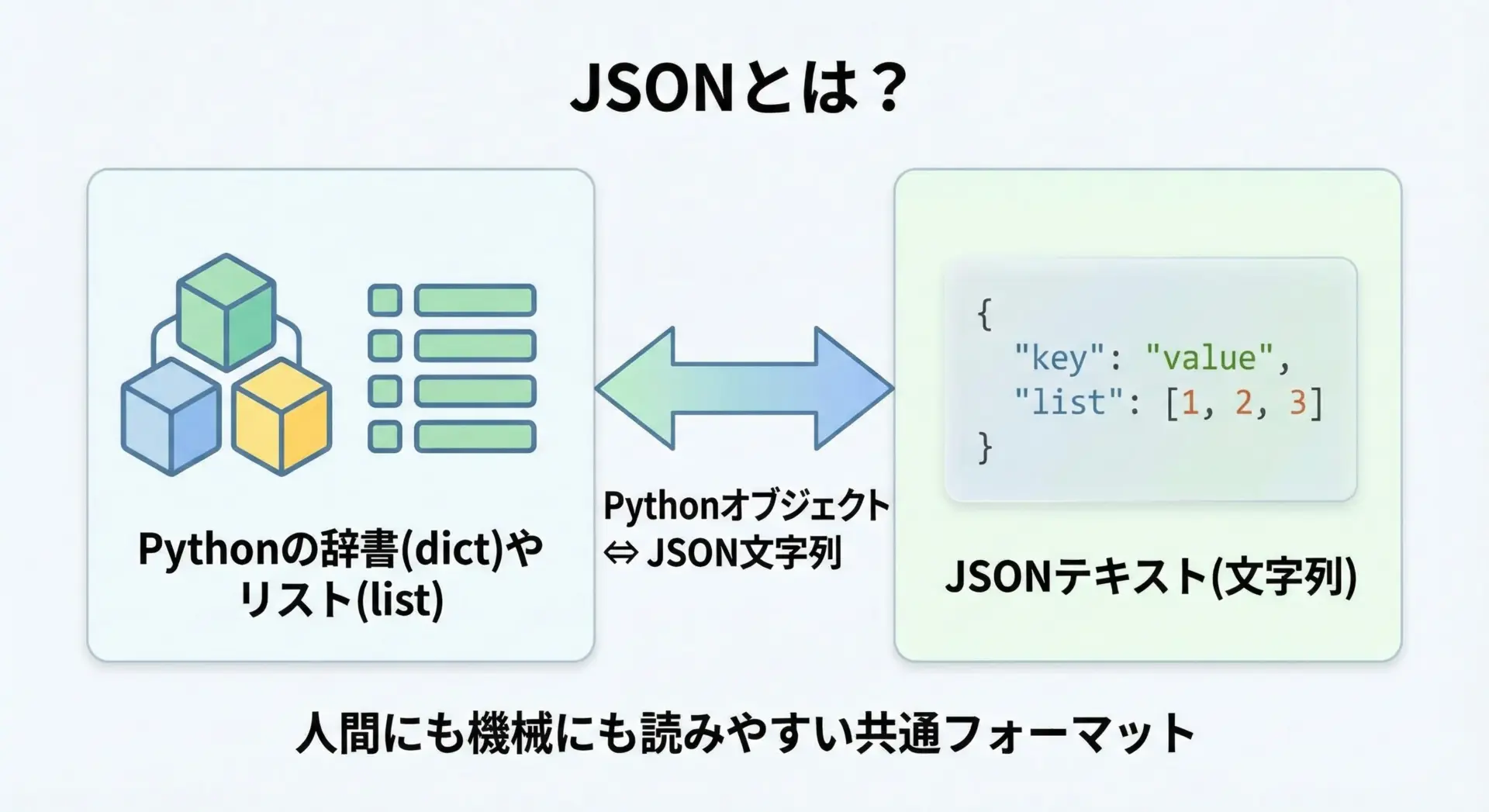
JSONとは、JavaScript Object Notationの略で、データをテキストで表現するためのシンプルなフォーマットです。
現在ではJavaScriptに限らず、さまざまな言語やサービスで採用されています。
Pythonで言えば、JSONは「辞書(dict)やリスト(list)などの構造を、文字列として表現したもの」とイメージすると理解しやすくなります。
人間にも読みやすく、かつ機械でのパース(解析)もしやすいことから、Web APIや設定ファイルの形式として広く利用されています。
JSONの特徴として、次のような点が挙げられます。
形式自体がシンプルで、ネストしたオブジェクトや配列を自然に表現できるため、階層構造を持つデータのやり取りに適しています。
PythonでJSONを扱う代表的な場面
PythonでJSONを扱う場面は非常に多く、代表的なものだけでもいくつかのパターンがあります。
APIクライアントを作成する場合、REST APIやGraphQL APIなどのレスポンスは、多くの場合JSON形式です。
PythonのrequestsライブラリなどでHTTPリクエストを送り、返ってきたJSONをパースして必要な情報を取り出します。
アプリケーションの設定ファイルとしてもJSONはよく使われます。
たとえばWebアプリのポート番号やデータベース接続設定、フラグなどをconfig.jsonにまとめておき、起動時に読み込むといった使い方です。
その他にも、ログファイルをJSON形式で吐き出して後で解析しやすくしたり、他言語で書かれたシステムとのデータ受け渡しフォーマットとしてJSONを使うケースも多く見られます。
JSONとPythonのデータ型の対応表
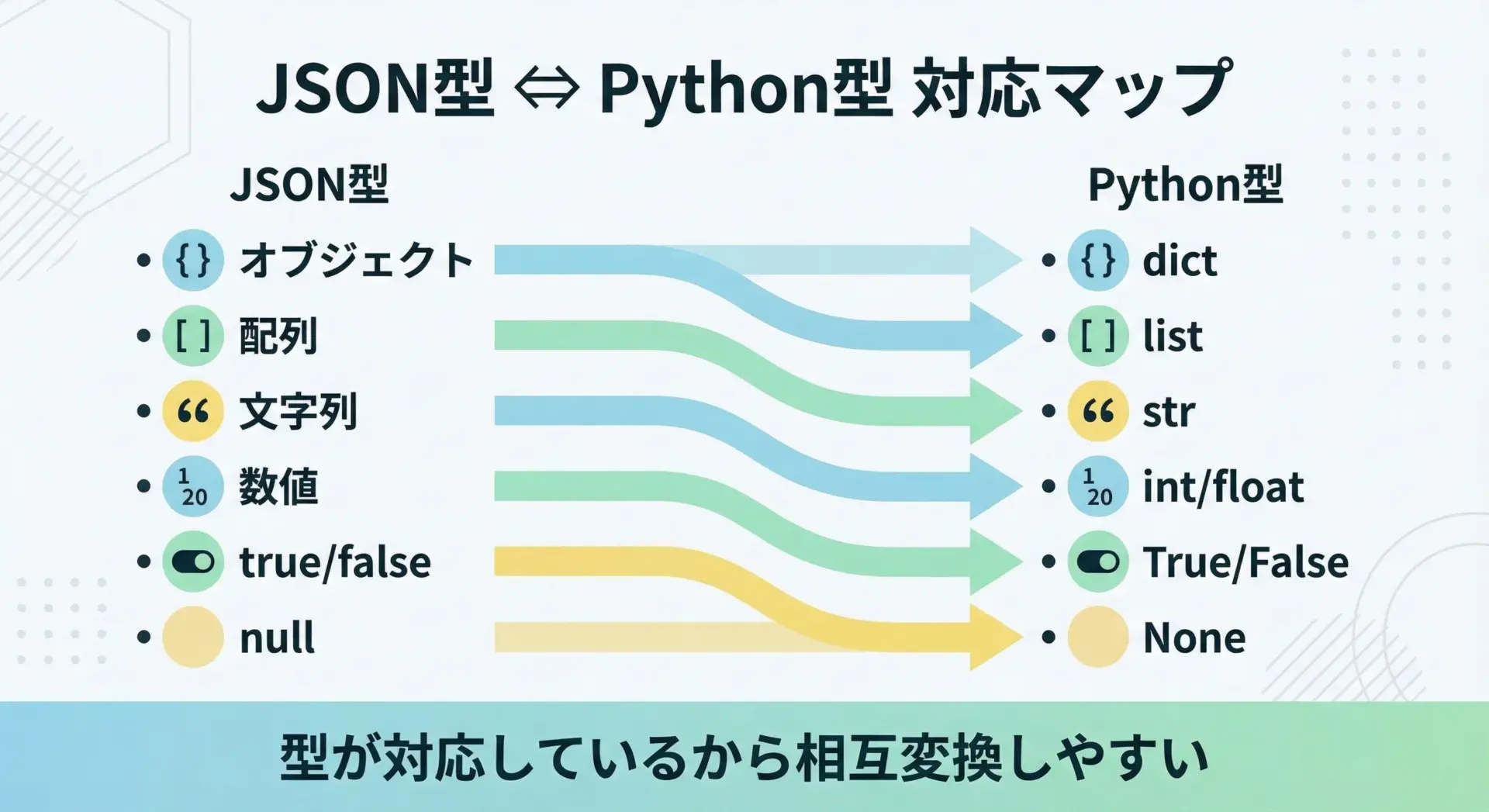
PythonでJSONを扱う際に重要なのは、JSONのデータ型とPythonのデータ型がどのように対応しているかを理解することです。
この対応を知っておくと、パース結果の型を予測しやすくなり、コードが書きやすくなります。
以下に、代表的な型の対応表を示します。
| JSONの型 | 表現例 | Pythonの型 | 説明 |
|---|---|---|---|
| object | {"a": 1} | dict | キーと値のペアの集合 |
| array | [1, 2, 3] | list | 順序付きの要素のリスト |
| string | "text" | str | 文字列 |
| number(int) | 10 | int | 整数 |
| number(float) | 3.14 | float | 浮動小数点数 |
| true / false | true | bool | PythonのTrue/Falseに対応 |
| null | null | NoneType | PythonのNoneに対応 |
この対応により、Pythonでは標準ライブラリのjsonモジュールだけで、PythonオブジェクトとJSON文字列との間を簡単に変換できるようになっています。
JSON読み込み(read)とパース
jsonモジュールの基本
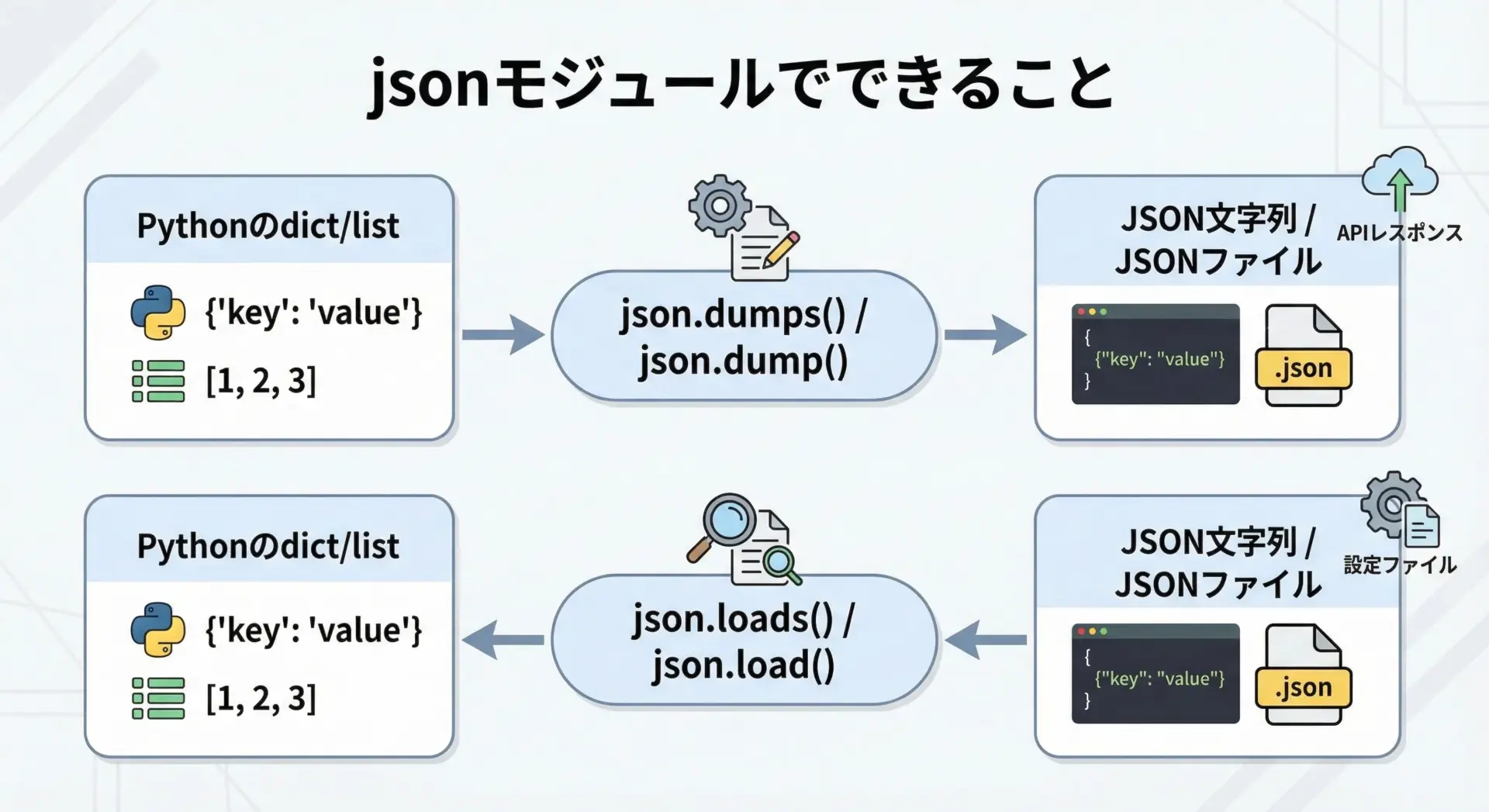
PythonでJSONを扱う場合、標準ライブラリのjsonモジュールを使います。
追加インストールは不要で、Pythonをインストールした時点で利用可能です。
jsonモジュールでよく使う関数は次の4つです。
json.loads(): JSON文字列をPythonオブジェクトに変換する(パースする)json.load(): ファイルからJSONを読み込み、Pythonオブジェクトに変換するjson.dumps(): PythonオブジェクトをJSON文字列に変換するjson.dump(): PythonオブジェクトをJSONとしてファイルに書き出す
これらを組み合わせることで、文字列・ファイル・Pythonオブジェクトの間を自由に行き来できるようになります。
文字列からJSONをパースする
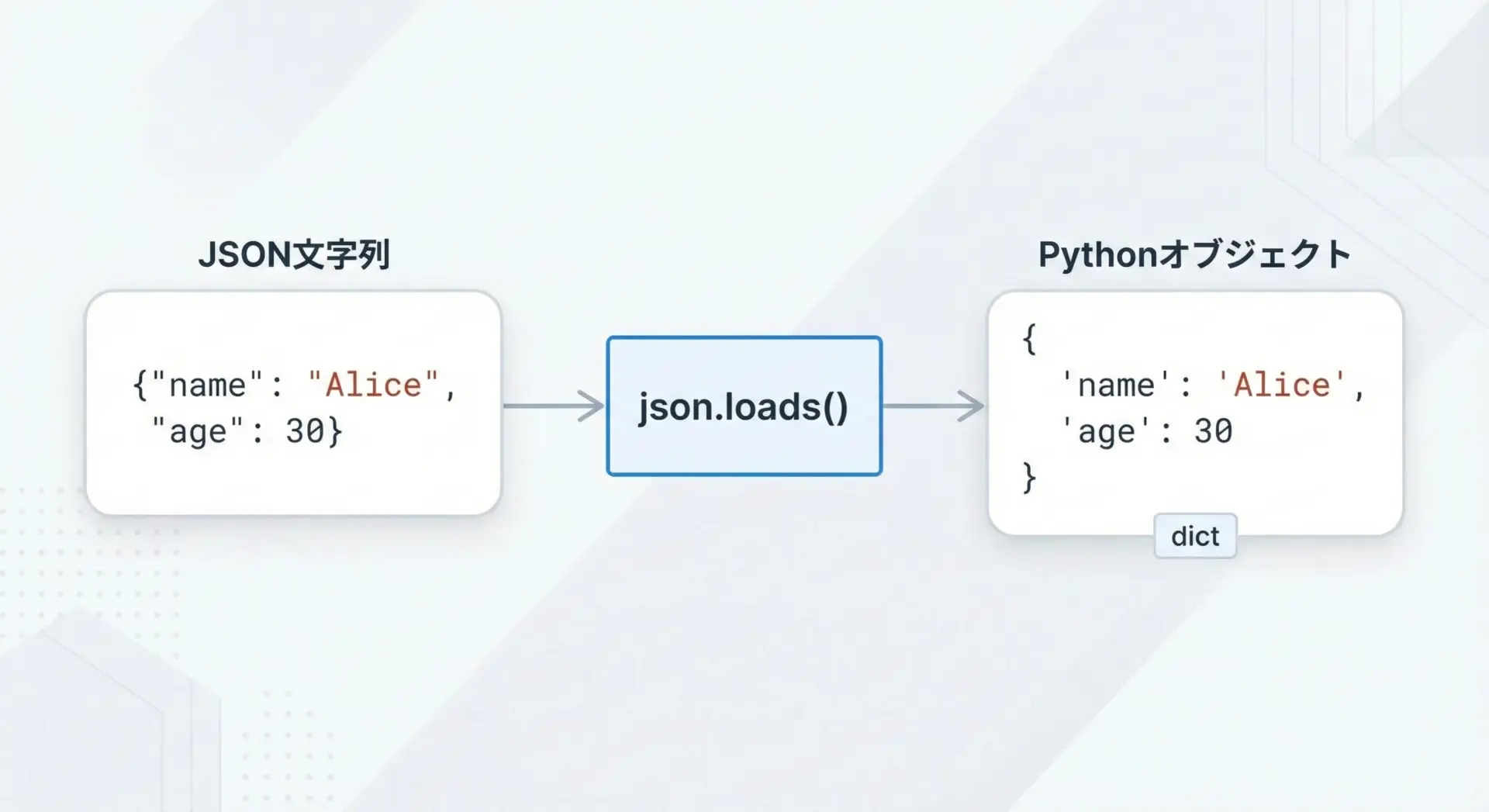
まずは、もっとも基本的な「JSON文字列をPythonオブジェクトに変換する」例を見てみます。
import json
# JSON形式の文字列を用意する
json_str = '{"name": "Alice", "age": 30, "languages": ["Python", "JavaScript"]}'
# json.loads() で文字列をパースして Pythonオブジェクト(dict)に変換する
data = json.loads(json_str)
# 型を確認する
print(type(data))
print(data)
# 個別の要素にアクセスする
print("name:", data["name"])
print("1つ目の言語:", data["languages"][0])<class 'dict'>
{'name': 'Alice', 'age': 30, 'languages': ['Python', 'JavaScript']}
name: Alice
1つ目の言語: Pythonjson.loads()は文字列を引数に取り、その中身が正しいJSONであれば対応するPythonオブジェクトを返します。
この例ではJSONオブジェクトがPythonのdictとしてパースされ、配列はlistとして扱えるようになります。
ファイルからJSONを読み込む
実務では、JSONは文字列よりもファイルとして扱うことのほうが多くなります。
Pythonではjson.load()を使って、ファイルから直接パースすることができます。
import json
# 例として読み込む JSON ファイル名
filename = "config.json"
# with 文を使うことで、ファイルを自動的にクローズできます
with open(filename, "r", encoding="utf-8") as f:
config = json.load(f)
# 読み込んだ内容を確認する
print(type(config))
print(config)<class 'dict'>
{'debug': True, 'port': 8080, 'database': {'host': 'localhost', 'user': 'app', 'password': 'secret'}}ファイルからの読み込みではjson.load()を使い、文字列からのパースではjson.loads()を使うという違いを整理しておくと混乱しにくくなります。
ネストしたJSONオブジェクトのアクセス方法
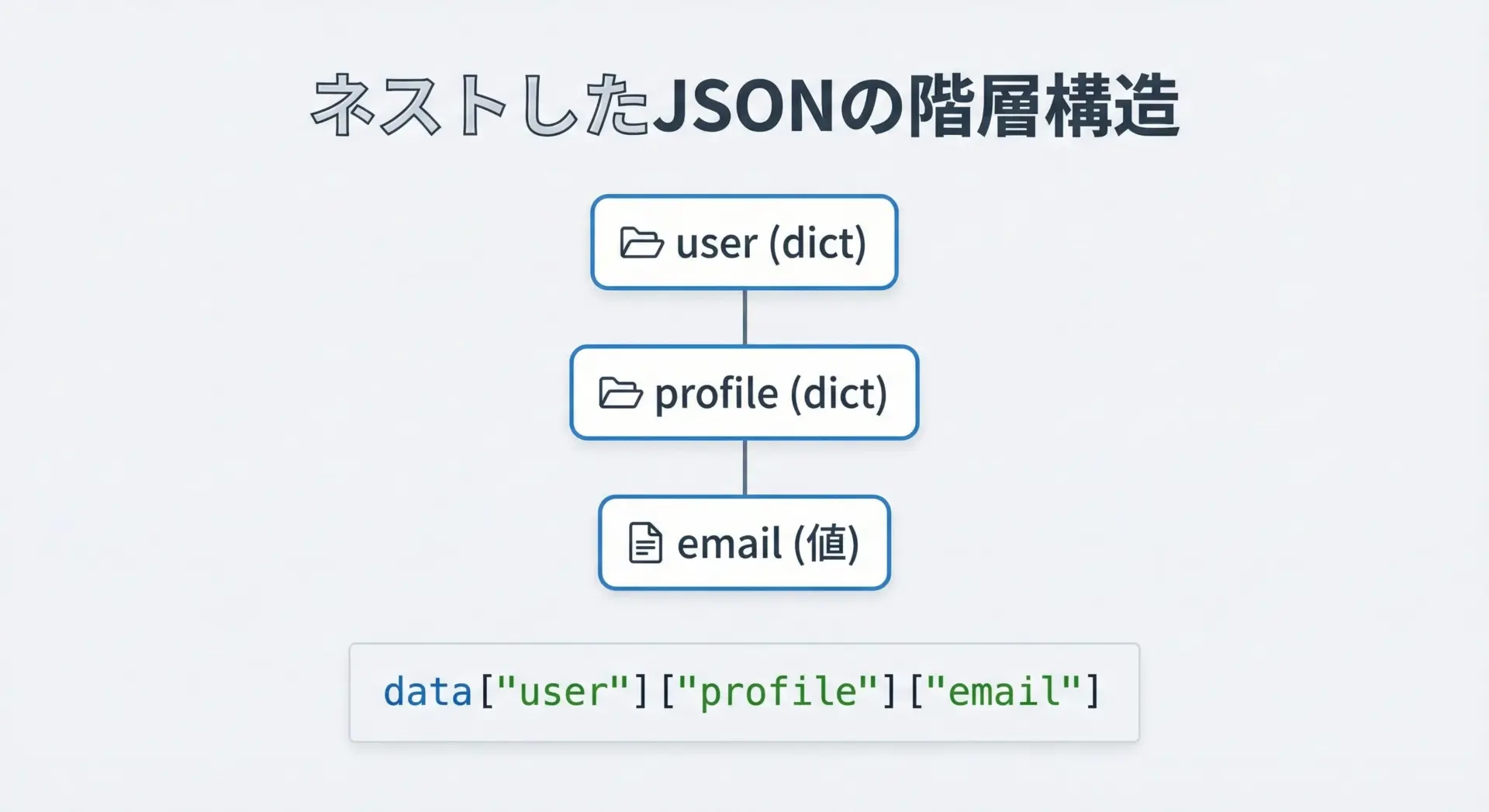
JSONでは、オブジェクトの中にオブジェクトや配列が入るなど、ネストした構造になることが一般的です。
Pythonでパースすると、これらはdictやlistが入れ子になった形になります。
import json
json_str = """
{
"user": {
"id": 123,
"name": "Bob",
"profile": {
"email": "bob@example.com",
"age": 25
}
}
}
"""
data = json.loads(json_str)
# ネストした値にアクセスする
user_id = data["user"]["id"]
email = data["user"]["profile"]["email"]
print("user_id:", user_id)
print("email:", email)user_id: 123
email: bob@example.comこのように、ネストしたJSONにアクセスする時も、dictとlistの通常のアクセス方法(角括弧とキー/インデックス)を組み合わせていくだけです。
ただし、存在しないキーにアクセスするとKeyErrorになるため、dict.get()を利用して安全にアクセスすることもよく行われます。
# get() を使って安全にアクセスする (存在しない場合は None を返す)
age = data.get("user", {}).get("profile", {}).get("age")
print("age:", age)age: 25パース時のエラー(JSONDecodeError)と対処法
JSONが正しくない形式だった場合、json.loads()やjson.load()はjson.JSONDecodeErrorを送出します。
実運用では外部からの入力に不備があることも多いため、エラーハンドリングは重要です。
import json
# カンマの位置が不正な壊れた JSON 文字列
broken_json = '{"name": "Alice", "age": 30,}'
try:
data = json.loads(broken_json)
except json.JSONDecodeError as e:
print("JSON のパースに失敗しました")
print("エラー内容:", e)JSON のパースに失敗しました
エラー内容: Expecting property name enclosed in double quotes: line 1 column 31 (char 30)このように、パース時にはtry-exceptでJSONDecodeErrorを捕捉し、ログに残す・ユーザーにメッセージを返す・デフォルト値を使うといった対処を行うのが一般的です。
JSON書き込み(write)と整形
PythonのdictをJSON文字列に変換する
PythonオブジェクトをJSON文字列に変換するときはjson.dumps()を使います。
ここで生成した文字列は、そのままAPIレスポンスとして返したり、ファイルに書き込んだりすることができます。
import json
data = {
"name": "Alice",
"age": 30,
"languages": ["Python", "JavaScript"],
"is_active": True
}
# Pythonオブジェクト(dict)を JSON 文字列に変換する
json_str = json.dumps(data)
print(type(json_str))
print(json_str)<class 'str'>
{"name": "Alice", "age": 30, "languages": ["Python", "JavaScript"], "is_active": true}ポイントは、PythonのTrue/FalseやNoneが、それぞれtrue/false/nullとして変換されることです。
自分で文字列連結してJSONを組み立てるのではなく、必ずjson.dumps()を使うほうが安全で確実です。
JSONをファイルに書き込む
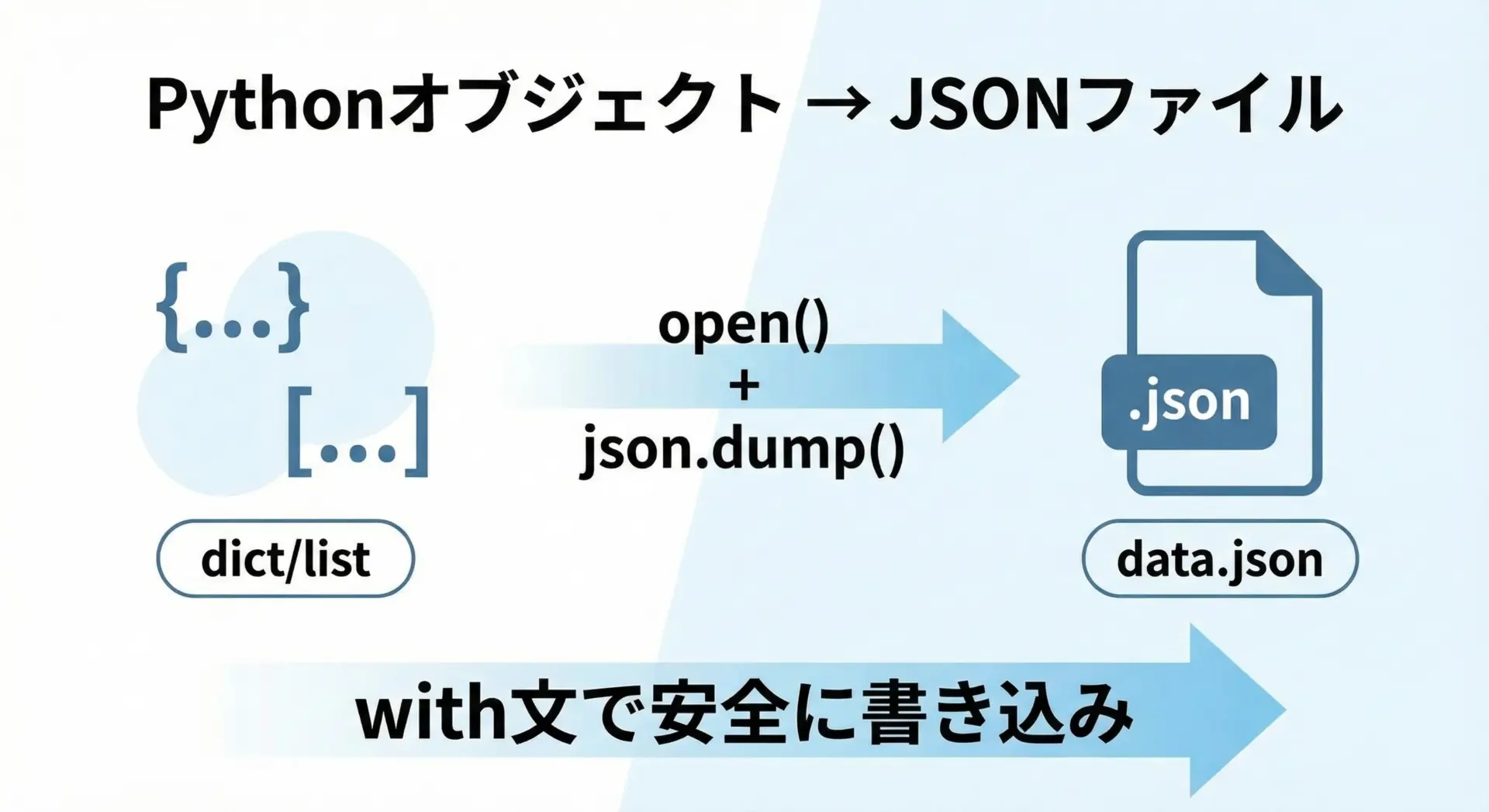
JSONファイルとして保存したい場合はjson.dump()を利用します。
import json
data = {
"debug": True,
"port": 8080,
"database": {
"host": "localhost",
"user": "app",
"password": "secret"
}
}
filename = "config.json"
# ファイルに JSON として書き込む
with open(filename, "w", encoding="utf-8") as f:
json.dump(data, f)
print("書き込みが完了しました:", filename)書き込みが完了しました: config.json文字列を自分で生成してwrite()するのではなく、json.dump()を使うことで、正しいJSONとして出力されるため、改行やカンマの付け忘れなどによる不正なJSONを防ぎやすくなります。
pretty print(indent)で読みやすく整形する

デフォルトでは、json.dumps()やjson.dump()は1行のコンパクトなJSONを生成します。
しかし、人間が読む設定ファイルなどでは、インデント付きの整形JSON(pretty print)のほうが便利です。
import json
data = {
"name": "Alice",
"age": 30,
"skills": ["Python", "Docker"],
"profile": {
"email": "alice@example.com",
"twitter": "@alice"
}
}
# インデントを付けて JSON 文字列に変換する
json_str = json.dumps(data, indent=2)
print(json_str){
"name": "Alice",
"age": 30,
"skills": [
"Python",
"Docker"
],
"profile": {
"email": "alice@example.com",
"twitter": "@alice"
}
}indent引数にはスペースの数を整数で指定します。
ファイル出力時も同様にjson.dump(data, f, indent=2)のように指定できます。
ensure_asciiと文字化け対策
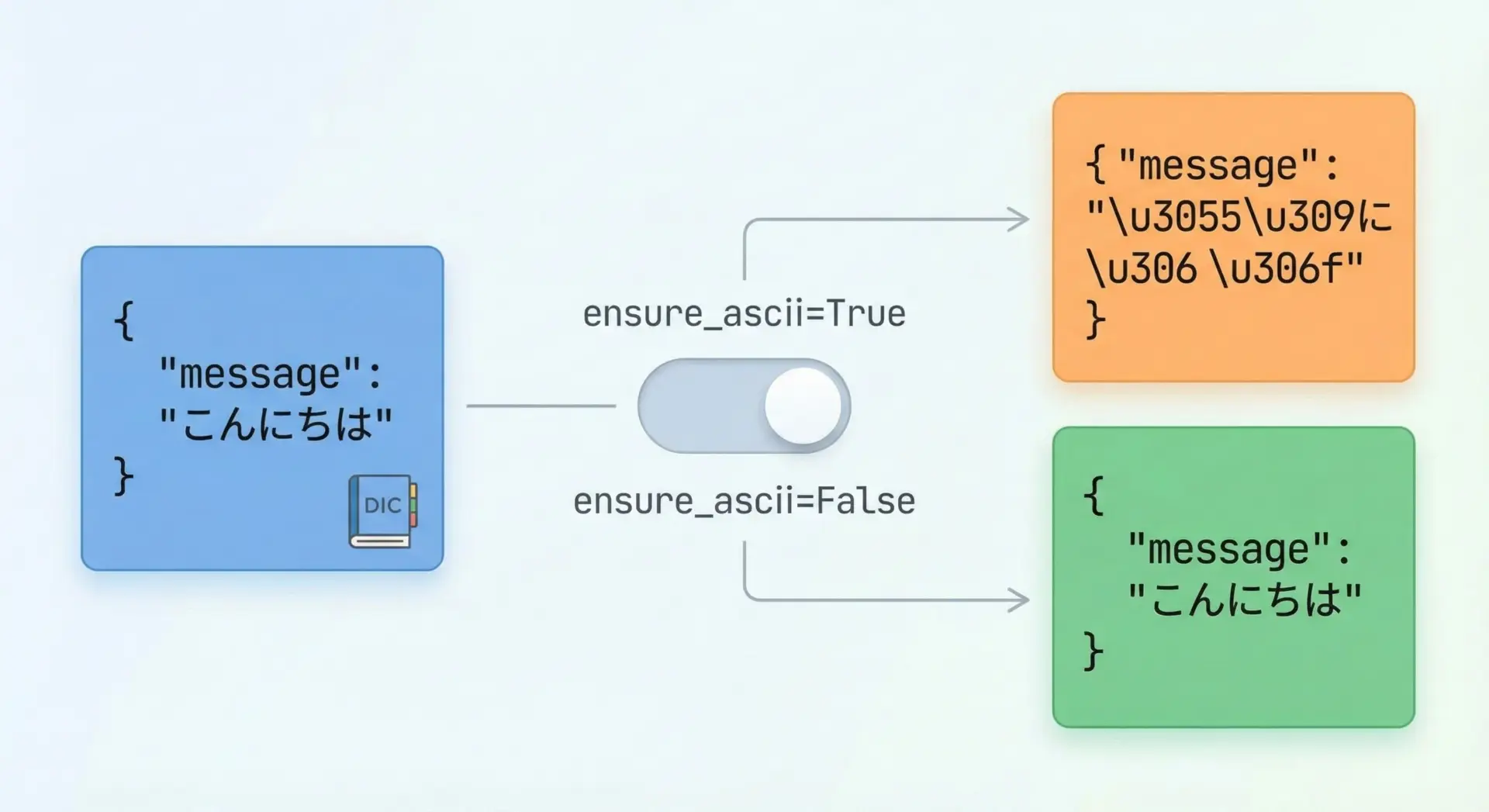
日本語など非ASCII文字を含む場合、json.dumps()のデフォルトではUnicodeエスケープ形式に変換されます。
人間が読むファイルでは、これが「文字化けしているように見える」原因になります。
import json
data = {"message": "こんにちは"}
# デフォルト (ensure_ascii=True)
json_default = json.dumps(data)
print("デフォルト:", json_default)
# ensure_ascii=False で日本語をそのまま出力
json_utf8 = json.dumps(data, ensure_ascii=False)
print("ensure_ascii=False:", json_utf8)デフォルト: {"message": "\u3053\u3093\u306b\u3061\u306f"}
ensure_ascii=False: {"message": "こんにちは"}日本語を含むJSONを人間が読む目的で保存する場合は、ensure_ascii=Falseを指定し、ファイルのエンコーディングをutf-8にするのが定番です。
# ファイルに日本語を含む JSON を書き込む例
with open("message.json", "w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False, indent=2)sort_keysでキーをソートして出力する
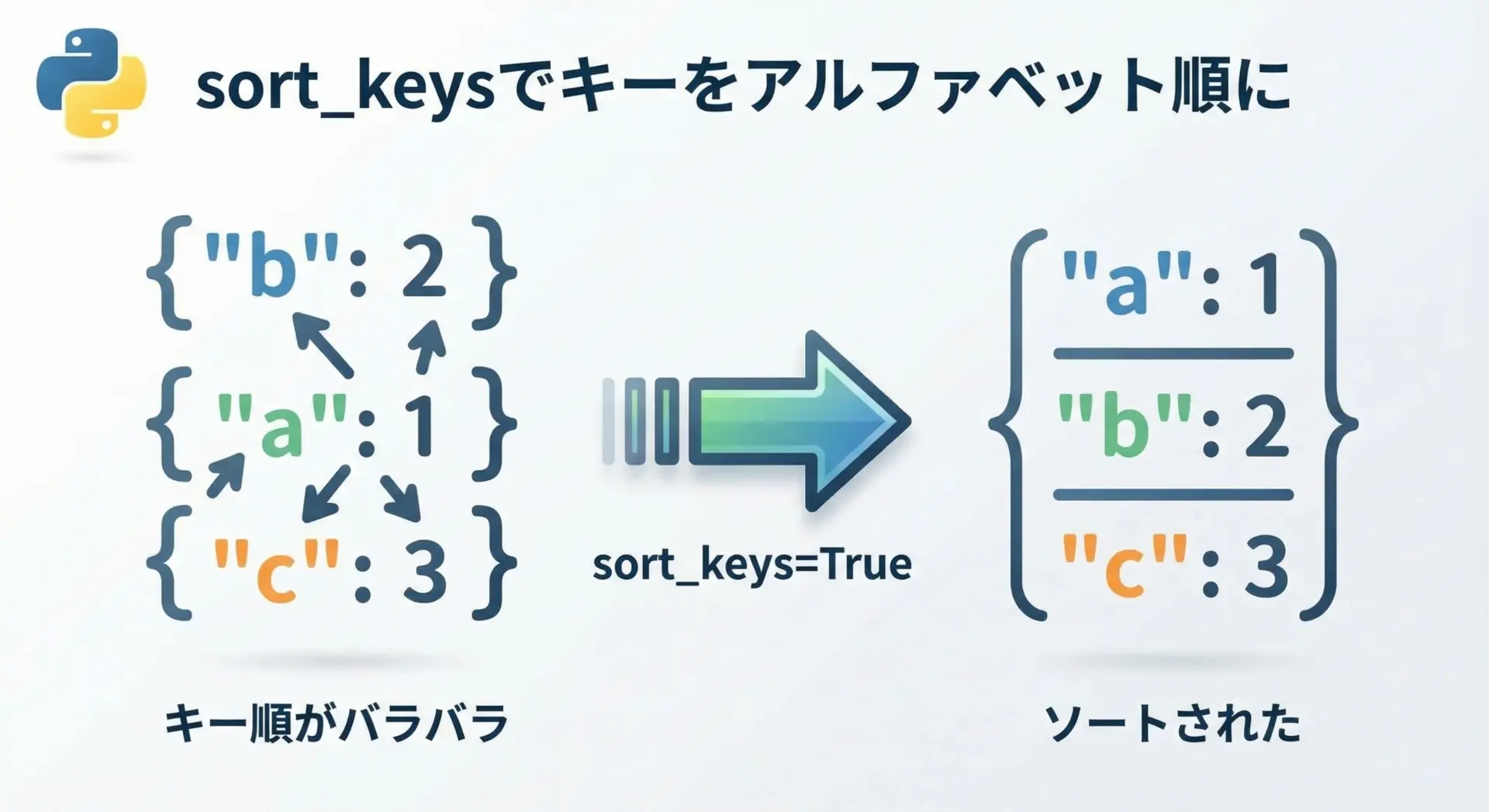
JSONは本来、オブジェクト内のキー順序を保証しませんが、見やすさや差分管理のしやすさのために、キーをソートして出力したい場面があります。
そんなときはsort_keys=Trueを指定します。
import json
data = {"b": 2, "c": 3, "a": 1}
print("そのまま:")
print(json.dumps(data))
print("\nsort_keys=True:")
print(json.dumps(data, sort_keys=True))そのまま:
{"b": 2, "c": 3, "a": 1}
sort_keys=True:
{"a": 1, "b": 2, "c": 3}設定ファイルや定義ファイルなどでGitの差分を見やすくしたいケースでも、ソートされた出力は役立ちます。
実用的なPython×JSON活用パターン
APIレスポンス(JSON)をPythonで処理する例
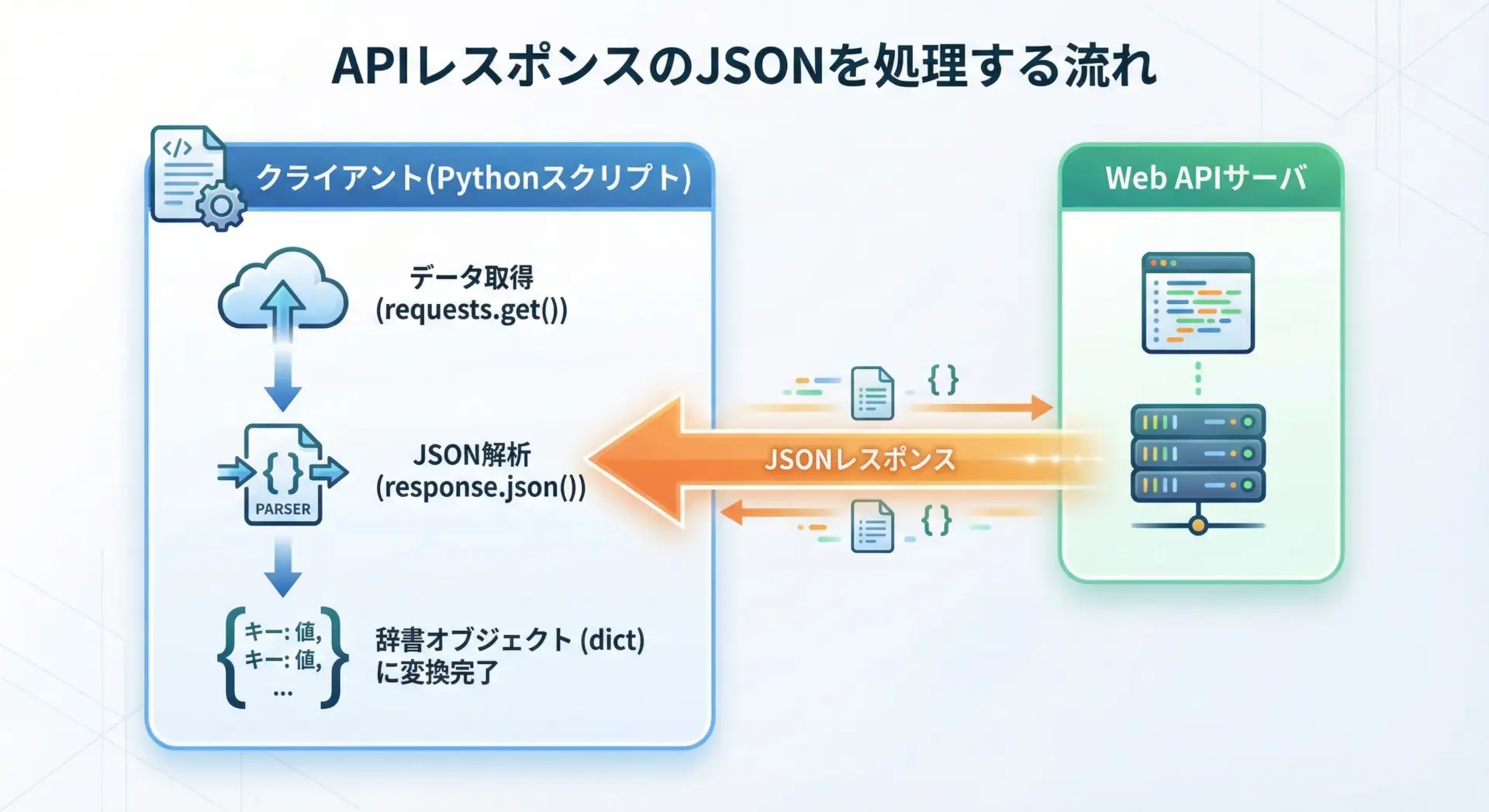
Web APIの多くはJSONを返します。
Pythonではrequestsライブラリを使うと、JSONレスポンスを簡単にdictとして扱えます。
import requests
# ダミーの公開APIを例にします (実在するエンドポイントに置き換えてもよい)
url = "https://jsonplaceholder.typicode.com/posts/1"
response = requests.get(url)
# レスポンスボディを JSON としてパース
data = response.json()
# 必要なフィールドを取り出す
print("ID:", data["id"])
print("タイトル:", data["title"])
print("本文:", data["body"])ID: 1
タイトル: sunt aut facere repellat provident occaecati excepturi optio reprehenderit
本文: quia et suscipit
suscipit recusandae consequuntur expedita et cum
...APIによっては、レスポンスが配列の形になっていることもあります。
その場合も、listとしてパースされるので、ループで処理できます。
# 複数の投稿を取得する例
url = "https://jsonplaceholder.typicode.com/posts"
response = requests.get(url)
posts = response.json() # list としてパースされる
# 最初の3件だけタイトルを表示
for post in posts[:3]:
print(post["id"], post["title"])設定ファイル(config)としてJSONを読み書きする
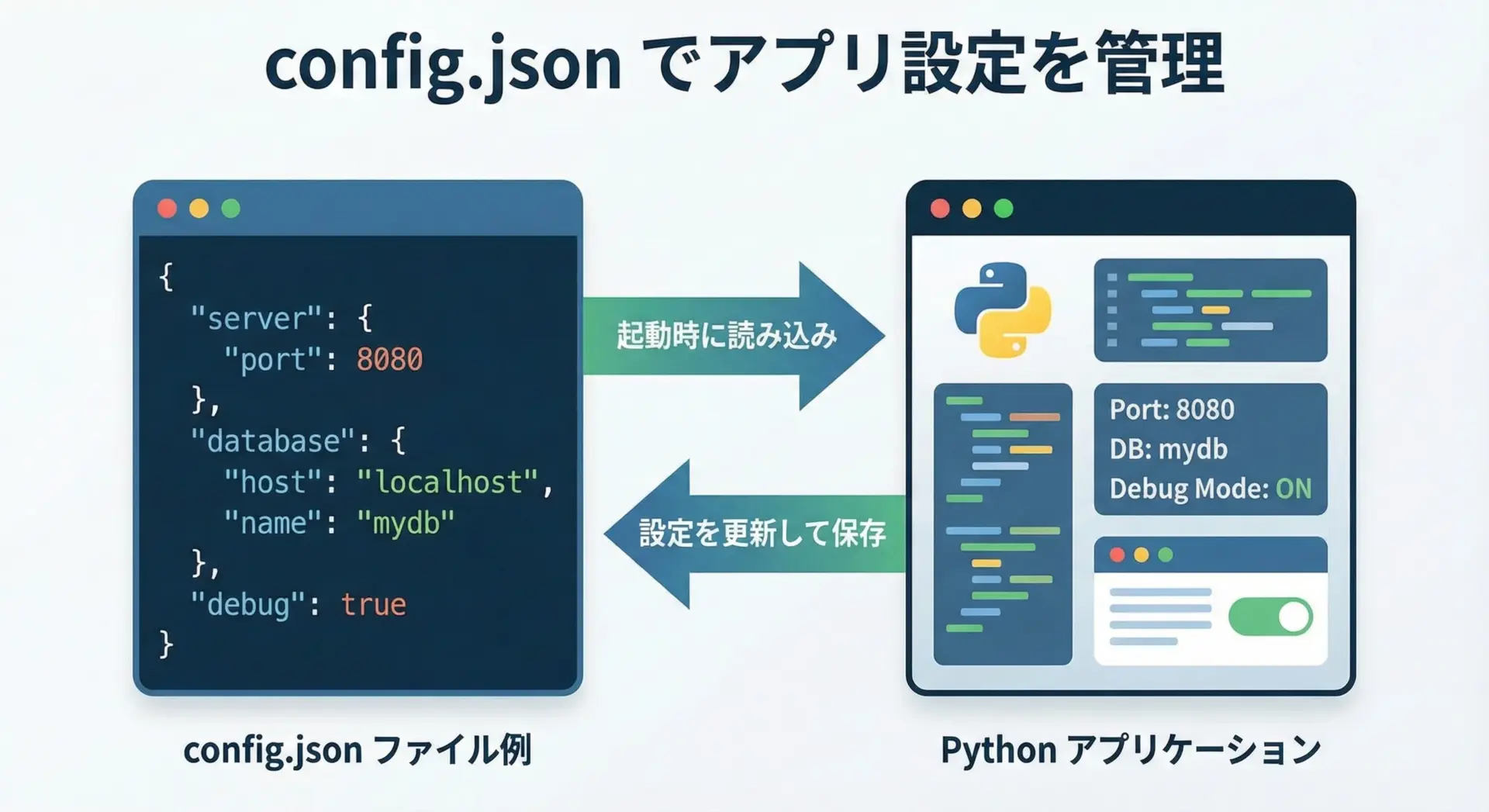
アプリケーションの設定をコードにベタ書きするのではなく、JSONの設定ファイルとして外出ししておくと、環境ごとの切り替えや運用時の変更が容易になります。
{
"debug": true,
"port": 5000,
"database": {
"host": "localhost",
"user": "app",
"password": "secret"
}
}上記のようなconfig.jsonを想定し、Pythonで読み込んで利用するコード例を示します。
import json
def load_config(path: str) -> dict:
"""JSON形式の設定ファイルを読み込む関数"""
with open(path, "r", encoding="utf-8") as f:
return json.load(f)
config = load_config("config.json")
print("デバッグモード:", config.get("debug"))
print("ポート番号:", config.get("port"))
print("DBホスト:", config["database"]["host"])デバッグモード: True
ポート番号: 5000
DBホスト: localhost設定を更新してファイルに書き戻すことも簡単です。
# 設定値を変更して保存し直す
config["debug"] = False
with open("config.json", "w", encoding="utf-8") as f:
json.dump(config, f, ensure_ascii=False, indent=2)このようにしておくと、本番環境と開発環境で異なる設定ファイルを用意するだけで挙動を切り替えられるため、柔軟な運用が可能になります。
大きなJSONファイルを段階的に読むテクニック
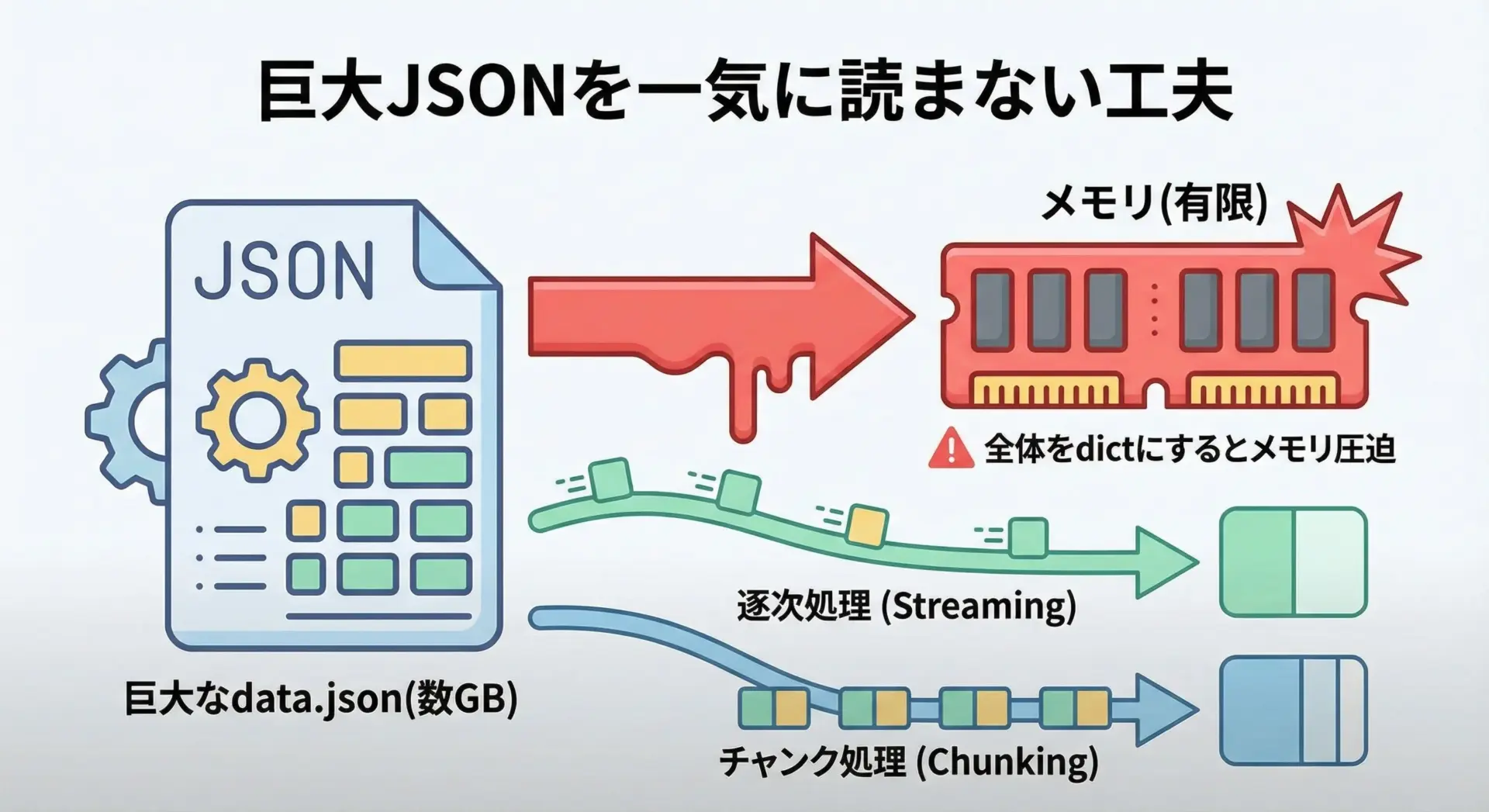
非常に大きなJSONファイル(数百MB〜数GB)を扱う場合、json.load()で全てを一度にメモリに読み込むと、メモリ不足を引き起こす可能性があります。
こうしたケースでは、ファイル構造に応じた工夫が必要です。
もっとも扱いやすいのは、1行に1レコードのJSON(JSON Lines形式)になっている場合です。
この場合、行ごとにjson.loads()でパースして処理し、不要になったデータは捨てていくことで、メモリ使用量を抑えられます。
import json
# 1行1JSONレコードのファイルを逐次処理する例
with open("large.jsonl", "r", encoding="utf-8") as f:
for line in f:
if not line.strip():
continue # 空行をスキップ
record = json.loads(line)
# 各レコードを都度処理する
print(record.get("id"), record.get("name"))1 Alice
2 Bob
3 Carol
...巨大な1つの配列になっているJSON([{...}, {...}, ...])の場合は、標準ライブラリだけでストリーミングパースするのは難しく、専用ライブラリ(例: ijsonなど)の導入を検討したほうが現実的です。
JSONとCSV/他形式との変換の考え方

JSONは階層構造を扱うのが得意ですが、CSVは2次元の表形式です。
そのため、JSONをCSVに変換する際は「どのようにフラットな表に落とし込むか」を設計する必要があります。
例えば、次のようなJSONの配列を考えます。
import json
json_str = """
[
{"id": 1, "name": "Alice", "age": 30},
{"id": 2, "name": "Bob", "age": 25}
]
"""
data = json.loads(json_str)これをCSVに変換する単純な例を示します。
import csv
import json
json_str = """
[
{"id": 1, "name": "Alice", "age": 30},
{"id": 2, "name": "Bob", "age": 25}
]
"""
records = json.loads(json_str)
# CSVに書き出す
with open("users.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=["id", "name", "age"])
writer.writeheader()
for row in records:
writer.writerow(row)
print("CSVに書き出しました")CSVに書き出しました生成されるusers.csvの中身は次のようになります。
id,name,age
1,Alice,30
2,Bob,25ネストしたJSONをCSVにする場合、「親子関係をどう表現するか」「配列要素をどう扱うか」など、構造設計が必要になります。
その際は、1対多の関係を複数のCSVに分ける、JSONの一部だけをCSVにする、といった方針を取ることが多いです。
まとめ
PythonでJSONを扱う際には、標準のjsonモジュールを使って「読み込み(パース)」「書き込み」「整形」を正しく使い分けることが重要です。
文字列ならloads/dumps、ファイルならload/dumpを使い、indentやensure_ascii、sort_keysなどのオプションで人間にとっても扱いやすいJSONを出力できます。
また、APIレスポンス処理や設定ファイル、大規模データの逐次処理、CSVなど他形式との変換など、実用的なパターンを押さえておくことで、さまざまな場面でJSONを活用できるようになります。
今回の内容を土台に、実プロジェクトのコードで実際に試しながら理解を深めてみてください。
