
PythonはWeb APIとJSONとの相性がとても良く、少ないコードで外部サービスからデータを取得し、解析し、保存することができます。
本記事ではPython初心者でも理解しやすいように、Web APIとは何かから始めて、requestsライブラリでのJSON取得、jsonモジュールによる解析、ファイル保存やCSV変換までを一通り解説します。
サンプルコードも豊富に掲載しますので、実際に手を動かしながら学んでみてください。
PythonでWeb APIとJSONを扱う基本
Web APIとは
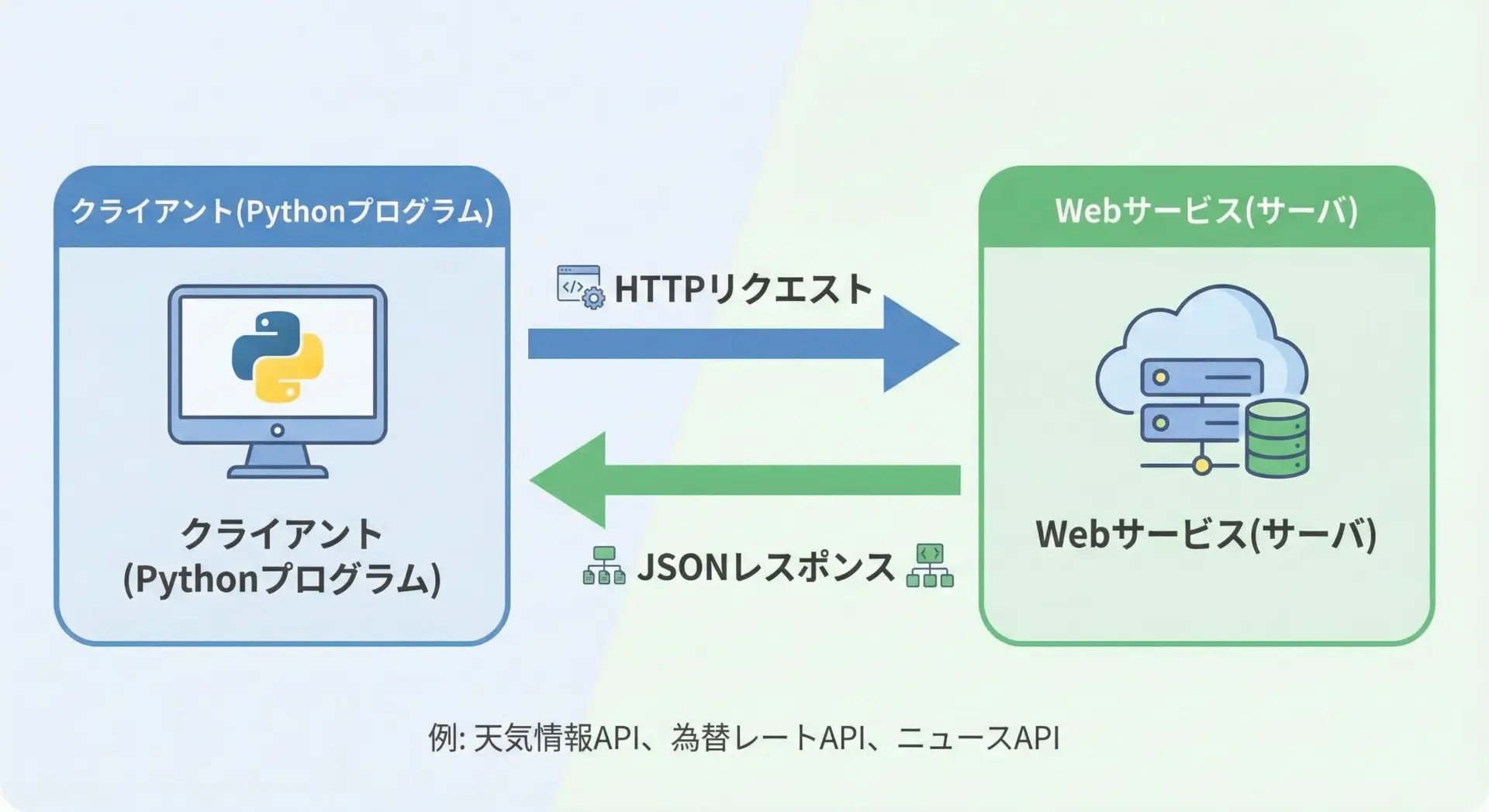
Web APIとは、インターネット経由で機能やデータを提供する仕組みのことです。
PythonプログラムはHTTP通信を使ってこのWeb APIにアクセスし、JSONなどの形式でデータを受け取ります。
Web APIでは、一般的に次のような流れでデータをやりとりします。
Pythonから特定のURLにHTTPリクエスト(多くはGETリクエスト)を送信すると、サーバ側が処理を行い、結果をJSON形式のレスポンスとして返してくれます。
プログラマはこのレスポンスを適切に解析し、アプリケーションの中で利用することになります。
REST APIとHTTPメソッドの概要
Web APIの多くはREST APIという設計方針に基づいて作られており、HTTPメソッドを使って操作の種類を表現します。
よく出てくるメソッドとしては次のようなものがあります。
- GET: データを取得するときに使用します。
- POST: データを新規作成するときに使用します。
- PUT/PATCH: 既存データを更新するときに使用します。
- DELETE: データを削除するときに使用します。
本記事では、まず最も基本的なGETメソッドを中心に説明します。
JSON形式の特徴とPythonでの扱い方
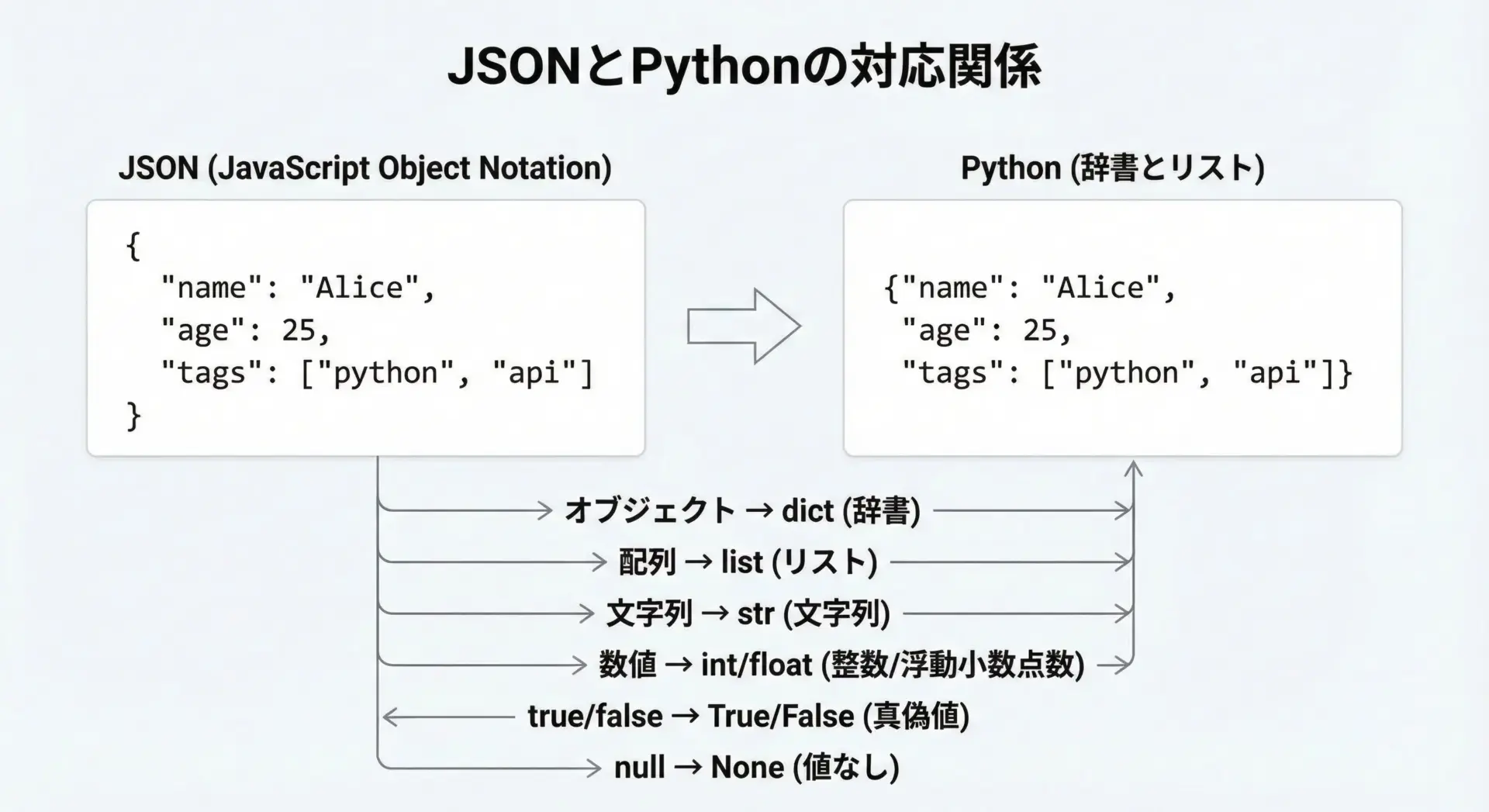
Web APIのレスポンスで最もよく使われるデータ形式がJSON(JavaScript Object Notation)です。
JSONは人間が読んでも理解しやすく、コンピュータも扱いやすい構造化データのフォーマットです。
JSONの主な特徴は次のようなものです。
- キーと値の組み合わせ(オブジェクト)が書きやすい
- 配列(リスト)を簡潔に表現できる
- 文字コードは基本的にUTF-8
- 多くのプログラミング言語で標準対応している
PythonではJSONは辞書(dict)やリスト(list)として扱われるのがポイントです。
例えば、次のようなJSONは:
{
"name": "Alice",
"age": 25,
"tags": ["python", "api"]
}Pythonの中では次のようなオブジェクトとして扱われます。
data = {
"name": "Alice", # str
"age": 25, # int
"tags": ["python", "api"] # list of str
}このように、JSONのオブジェクトはPythonのdict、JSONの配列はPythonのlistに対応しているため、Pythonでの処理が非常に自然になります。
PythonでWeb APIを使うメリット
PythonでWeb APIを扱うメリットは多数ありますが、ここでは特に重要な点を整理します。
まずPythonは標準ライブラリだけでもHTTP通信やJSON処理が行えるうえ、さらにrequestsという非常に使いやすい外部ライブラリが広く利用されています。
requestsを使うことで、数行のコードでWeb APIからデータを取得し、jsonモジュールを使えばそのデータを簡単にPythonオブジェクトに変換できます。
また、Pythonはデータ分析や機械学習のライブラリ(NumPy、pandas、matplotlibなど)が充実しているため、APIから取得したデータをそのまま加工・分析・可視化まで一気通貫で行える点も大きな利点です。
スクリプトとして自動実行するのも容易なので、定期的なデータ収集やバッチ処理にも適しています。
requestsでWeb APIからJSONを取得する
requestsの基本構文

PythonでHTTPリクエストを送る際に最もよく使われるライブラリの1つがrequestsです。
まずは基本的な使い方を確認します。
requestsは標準ライブラリではないため、事前にインストールが必要です。
pip install requestsインストールが完了したら、次のような基本構文でGETリクエストを送ります。
import requests # requestsライブラリをインポート
# アクセスしたいURLを指定
url = "https://api.example.com/data"
# GETリクエストを送信し、レスポンスオブジェクトを取得
response = requests.get(url)
# レスポンスのステータスコード(200なら成功)を確認
print("ステータスコード:", response.status_code)
# レスポンスボディ(中身のテキスト)を表示
print("レスポンス本文:")
print(response.text)上記はあくまで雰囲気をつかむための例です。
実際には、APIごとにURLやパラメータの指定方法が異なります。
requestsではrequests.get()のほかにpost()、put()、delete()なども提供されていますが、本記事ではGETを中心に解説します。
クエリパラメータとヘッダーの指定方法
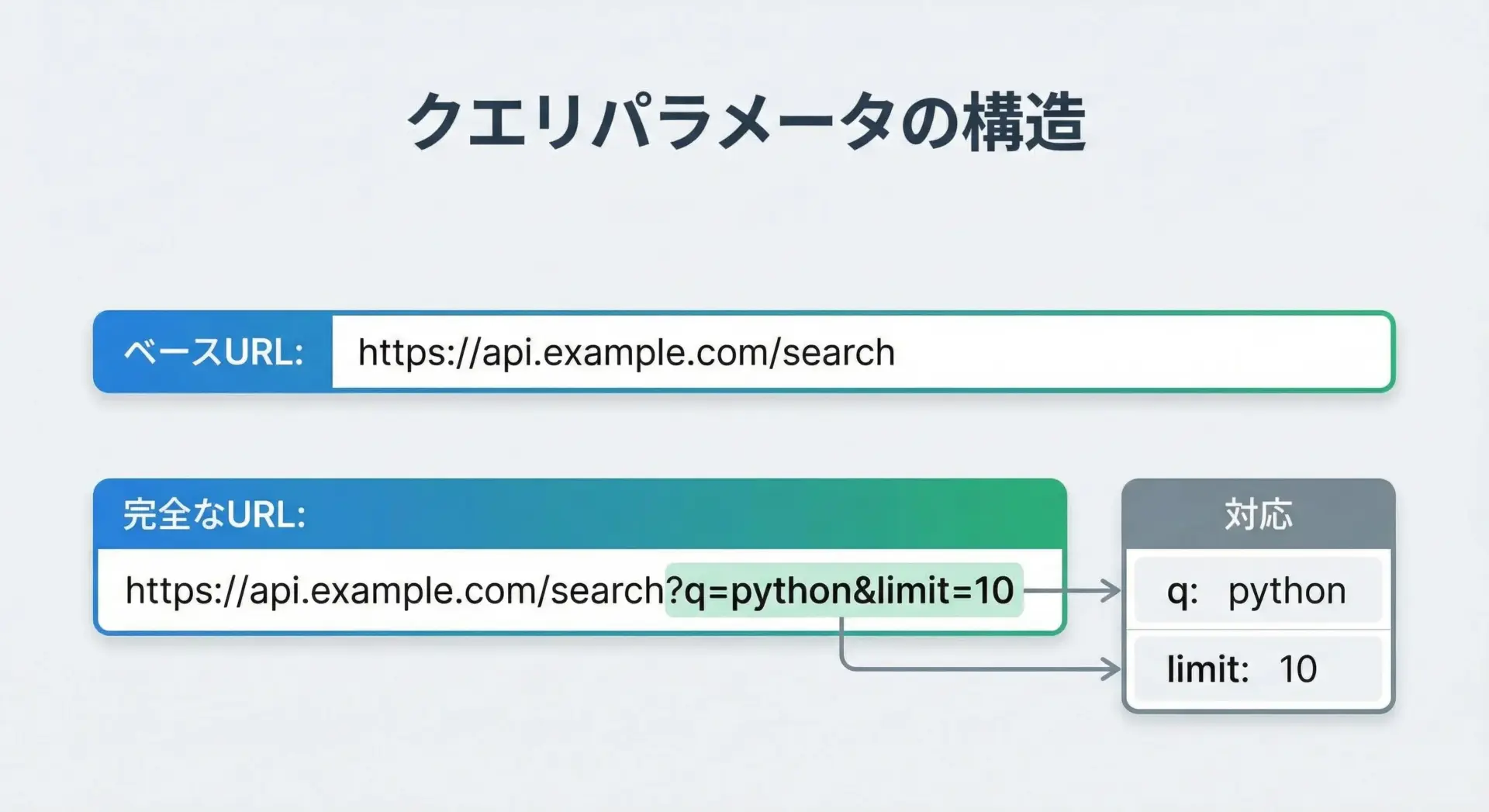
Web APIでは、URLに追加の情報(クエリパラメータ)を付けて送信したり、HTTPヘッダーで認証トークンなどを渡したりする必要があります。
requestsでは、これらをPythonのdictを使って簡単に指定できます。
クエリパラメータの指定
import requests
url = "https://api.example.com/search"
# クエリパラメータをdictで指定
params = {
"q": "python", # 検索キーワード
"limit": 10 # 取得件数
}
# params引数で渡すと、自動的にURLに付与される
response = requests.get(url, params=params)
print("最終的にアクセスしたURL:", response.url)このように、params引数にdictを渡すと、requestsが自動的にURLエンコードしてクエリ文字列を組み立ててくれます。
ヘッダーの指定
APIキーなどをHTTPヘッダーで送る必要がある場合は、headers引数を使います。
import requests
url = "https://api.example.com/data"
# APIキーやユーザーエージェントなどをヘッダーに設定
headers = {
"Authorization": "Bearer YOUR_API_TOKEN_HERE",
"User-Agent": "MyPythonApp/1.0"
}
response = requests.get(url, headers=headers)多くの有料APIや認証が必要なAPIでは、このようにヘッダーにトークンを入れてリクエストを送る形が一般的です。
ステータスコードとエラーハンドリング
HTTP通信では、リクエストが成功したかどうかをステータスコードで判断します。
代表的なコードを簡単に整理すると次のようになります。
| ステータスコード | 意味 | 例 |
|---|---|---|
| 200 | 成功 | 正常にデータ取得 |
| 400 | クライアントエラー | パラメータ不正など |
| 401 | 認証エラー | APIキー不正、トークン期限切れなど |
| 404 | 見つからない | URL間違い、リソース不存在 |
| 500 | サーバエラー | サーバ側での予期せぬエラー |
requestsでは、レスポンスオブジェクトのstatus_code属性で確認ができます。
import requests
url = "https://api.example.com/data"
response = requests.get(url)
if response.status_code == 200:
print("成功しました")
else:
print("失敗しました。ステータスコード:", response.status_code)
print("レスポンス本文:", response.text)よりPythonicな方法として、raise_for_status()メソッドを使うと、ステータスコードがエラーの場合に例外を発生させることができます。
import requests
url = "https://api.example.com/data"
try:
response = requests.get(url, timeout=10) # タイムアウトも設定
# エラーコード(4xx/5xx)ならHTTPError例外を発生させる
response.raise_for_status()
print("通信成功")
except requests.exceptions.HTTPError as e:
print("HTTPエラーが発生しました:", e)
except requests.exceptions.Timeout:
print("タイムアウトしました")
except requests.exceptions.RequestException as e:
# その他の通信エラーの総称
print("リクエストエラーが発生しました:", e)ネットワークエラーやAPI側の障害は必ず起こり得るため、このような例外処理をしっかり書くことが実運用では重要です。
サンプルAPIでのJSON取得例
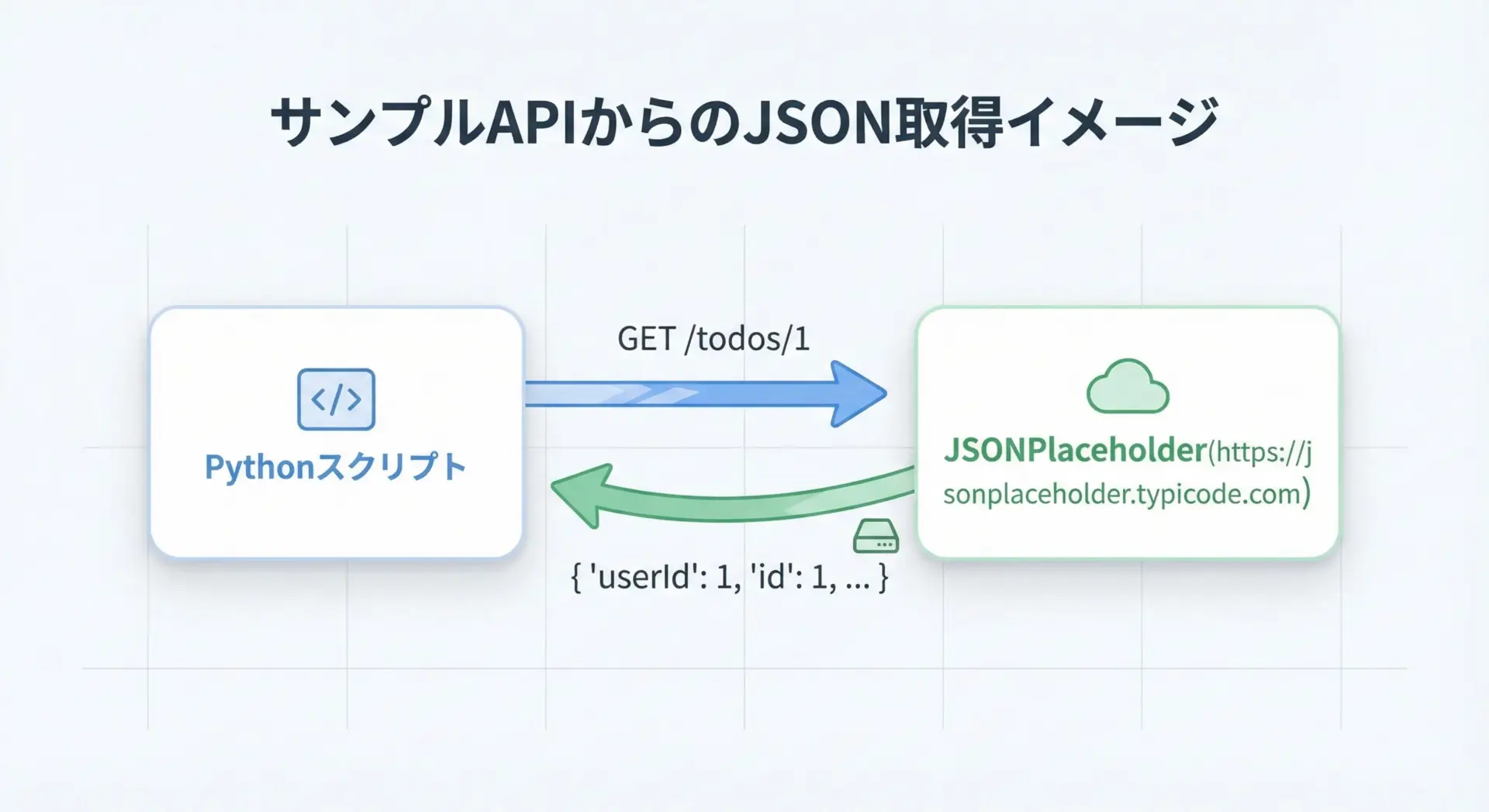
ここでは、無料で使えるサンプルAPIを用いて、実際にJSONを取得するコードを示します。
例えば、テスト用のJSONを返してくれる「JSONPlaceholder」というAPIがあります。
import requests
def fetch_todo(todo_id: int) -> None:
"""
指定したIDのToDoデータをJSONPlaceholderから取得して表示する関数です。
"""
url = f"https://jsonplaceholder.typicode.com/todos/{todo_id}"
try:
# GETリクエストを送信
response = requests.get(url, timeout=5)
# エラーコードなら例外を発生させる
response.raise_for_status()
# レスポンスをJSONとしてパース
todo = response.json() # dictとして取得される
# 結果を整形して表示
print("取得したToDoデータ:")
print("ID :", todo.get("id"))
print("ユーザーID:", todo.get("userId"))
print("タイトル :", todo.get("title"))
print("完了済み :", todo.get("completed"))
except requests.exceptions.RequestException as e:
# 通信に関するあらゆる例外を一括で捕捉
print("APIへのアクセス中にエラーが発生しました:", e)
if __name__ == "__main__":
# ID=1のToDoデータを取得
fetch_todo(1)上記プログラムを実行すると、次のような結果が得られます。
取得したToDoデータ:
ID : 1
ユーザーID: 1
タイトル : delectus aut autem
完了済み : Falseこのように、requestsでJSONを取得し、そのままPythonのdictとして扱えることがわかります。
JSONレスポンスを解析する
jsonモジュールでのロードとダンプ
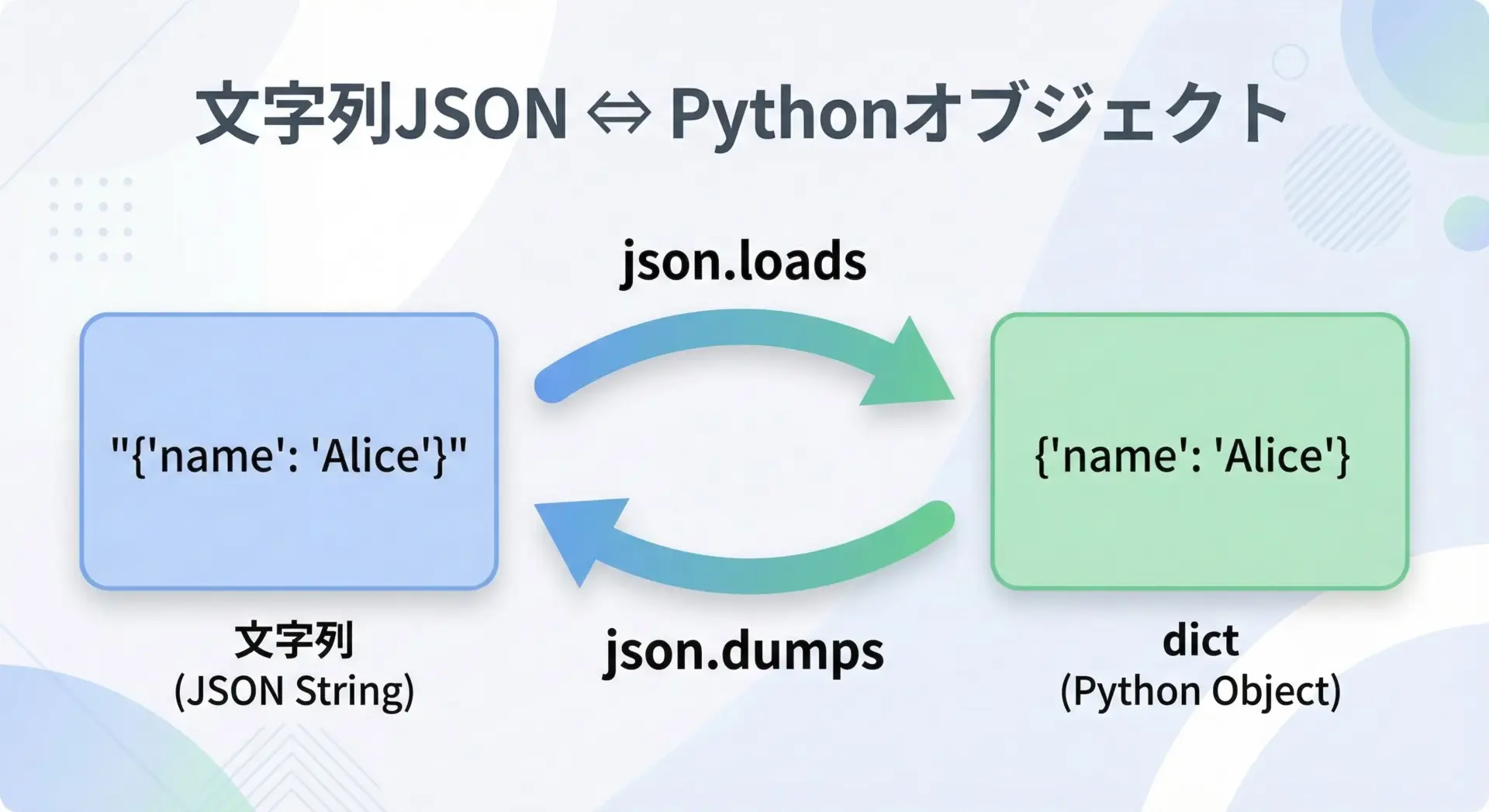
Python標準ライブラリのjsonモジュールを使うと、JSON文字列とPythonオブジェクトを相互に変換できます。
requestsのresponse.json()は内部的にこのjsonモジュールを利用しています。
文字列からPythonオブジェクトへ(ロード)
import json
# JSON形式の文字列
json_str = '{"name": "Alice", "age": 25, "is_active": true}'
# json.loadsでPythonオブジェクト(dict)に変換
data = json.loads(json_str)
print(type(data)) # <class 'dict'>
print(data["name"], data["age"], data["is_active"])PythonオブジェクトからJSON文字列へ(ダンプ)
import json
# Pythonのdict
data = {
"name": "Bob",
"age": 30,
"is_active": False,
"tags": ["python", "api"]
}
# json.dumpsでJSON文字列に変換
json_str = json.dumps(data, ensure_ascii=False, indent=2)
print(json_str)上記コードの実行結果のイメージは次の通りです。
{
"name": "Bob",
"age": 30,
"is_active": false,
"tags": [
"python",
"api"
]
}ensure_ascii=Falseを指定することで、日本語などもそのままの文字で出力できます。
indent=2は読みやすく整形してくれるオプションです。
dict・listとしてのJSONデータの扱い方
Web APIから取得したJSONは、よく「オブジェクト」形式(dict)か「配列」形式(list)かのいずれか、またはその組み合わせになっています。
オブジェクト(JSONオブジェクト ⇔ dict)の例
{
"id": 1,
"title": "sample",
"completed": false
}これはPythonでは次のように扱われます。
todo = {
"id": 1,
"title": "sample",
"completed": False
}
print(todo["title"]) # キーでアクセス
print(todo.get("title")) # getでアクセス(存在しない場合None)配列(JSON配列 ⇔ list)の例
[
{"id": 1, "title": "sample1"},
{"id": 2, "title": "sample2"}
]Pythonではリストと辞書の組み合わせになります。
todos = [
{"id": 1, "title": "sample1"},
{"id": 2, "title": "sample2"}
]
# 先頭要素のtitle
print(todos[0]["title"])
# すべてのtitleをfor文で表示
for todo in todos:
print(todo["id"], todo["title"])このように、配列はlist、オブジェクトはdictとしてアクセスするという基本さえ押さえておけば、多くのケースに対応できます。
ネストしたJSONから必要な値を取り出す
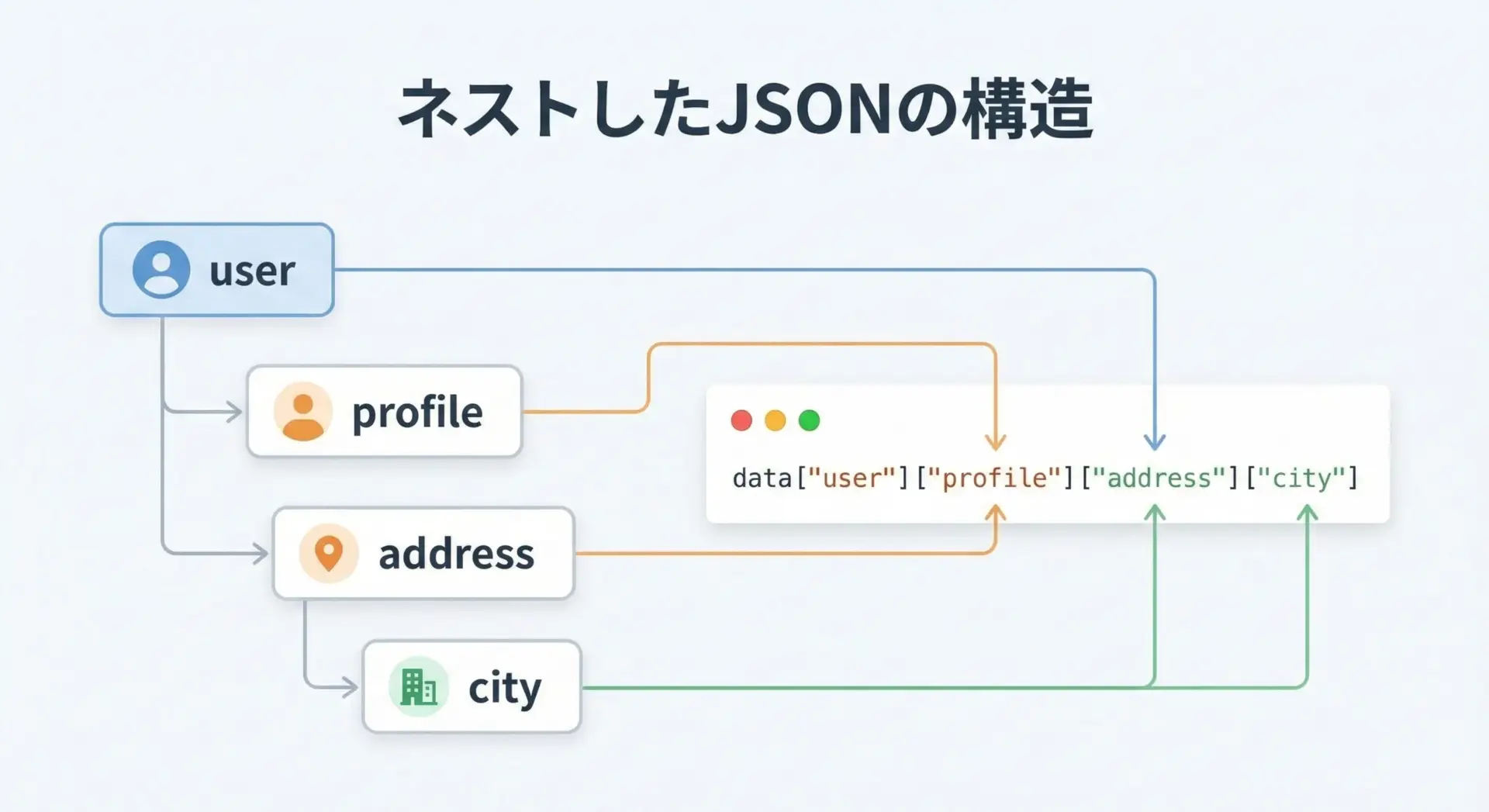
実際のWeb APIでは、JSONが入れ子(ネスト)構造になっていることがほとんどです。
ここではネストしたJSONから値を取り出す具体例を見てみます。
サンプルJSON
{
"user": {
"id": 123,
"name": "Alice",
"profile": {
"email": "alice@example.com",
"address": {
"city": "Tokyo",
"zip": "100-0001"
}
}
}
}このJSONをPythonのdictとして受け取ったとしましょう。
例えば都市名(city)を取り出したい場合は、次のようにアクセスします。
data = {
"user": {
"id": 123,
"name": "Alice",
"profile": {
"email": "alice@example.com",
"address": {
"city": "Tokyo",
"zip": "100-0001"
}
}
}
}
# 直接インデックスで辿る場合
city = data["user"]["profile"]["address"]["city"]
print("city:", city)
# getを使って安全に辿る例(途中が存在しない場合Noneを返す)
user = data.get("user", {})
profile = user.get("profile", {})
address = profile.get("address", {})
city_safe = address.get("city")
print("安全に取得したcity:", city_safe)ネストの深いJSONでは、キーの綴りを一文字間違えるだけでKeyErrorが発生するため、getメソッドで安全にアクセスするか、例外処理を組み合わせるのが実践的です。
例外処理(パースエラー・キー欠如)の書き方
JSONの解析では、思わぬ形式のデータが返ってくることがあり、そのたびにプログラムが落ちると困ります。
ここでは、JSONパース時のエラーとキーが存在しない場合のエラーに対する例外処理の基本形を示します。
JSONパースエラーへの対処
import json
def parse_json_safely(json_str: str) -> dict:
"""
JSON文字列をdictに変換します。
パースに失敗した場合は空のdictを返します。
"""
try:
data = json.loads(json_str)
return data
except json.JSONDecodeError as e:
print("JSONのパースに失敗しました:", e)
return {}
# 正しいJSON
valid_json = '{"name": "Alice"}'
print(parse_json_safely(valid_json))
# 間違ったJSON(末尾のカンマが余分)
invalid_json = '{"name": "Alice",}'
print(parse_json_safely(invalid_json))キー欠如(KeyError)への対処
def get_user_name(user_data: dict) -> str:
"""
user_dataからnameキーを取り出します。
存在しない場合は'不明'を返します。
"""
try:
return user_data["name"]
except KeyError:
print("nameキーが存在しませんでした")
return "不明"
user1 = {"name": "Alice", "age": 25}
user2 = {"age": 30}
print(get_user_name(user1)) # 'Alice'
print(get_user_name(user2)) # '不明'例外処理は「起こりうるエラーを想定しておく」ことが重要です。
Web API利用では、仕様書通りでないデータや一時的な不正レスポンスに備えて、パースとアクセスの両方でエラーハンドリングを入れておくと堅牢なコードになります。
JSONデータの保存と活用
JSONファイルへの保存と読み込み
Web APIから取得したJSONデータは、その場で使い捨てにするのではなくファイルに保存しておくことで、後から再利用したり、他のツールに渡したりできます。
JSONファイルへの保存
import json
import requests
def fetch_and_save_json(url: str, filepath: str) -> None:
"""
指定されたURLからJSONデータを取得し、ファイルに保存する関数です。
"""
response = requests.get(url, timeout=10)
response.raise_for_status()
# レスポンスボディをJSONとして取得(dictまたはlist)
data = response.json()
# ファイルに保存(UTF-8、整形付き)
with open(filepath, "w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False, indent=2)
print(f"JSONデータを{filepath}に保存しました")
if __name__ == "__main__":
url = "https://jsonplaceholder.typicode.com/todos"
fetch_and_save_json(url, "todos.json")JSONファイルの読み込み
import json
def load_json(filepath: str):
"""
JSONファイルを読み込んでPythonオブジェクトとして返す関数です。
"""
with open(filepath, "r", encoding="utf-8") as f:
data = json.load(f)
return data
if __name__ == "__main__":
todos = load_json("todos.json")
print("読み込んだ件数:", len(todos))
print("先頭要素:", todos[0])JSONファイルを介すことで、APIに毎回アクセスしなくてもローカル環境で何度でも解析やテストができるようになります。
CSVなど別形式への変換方法
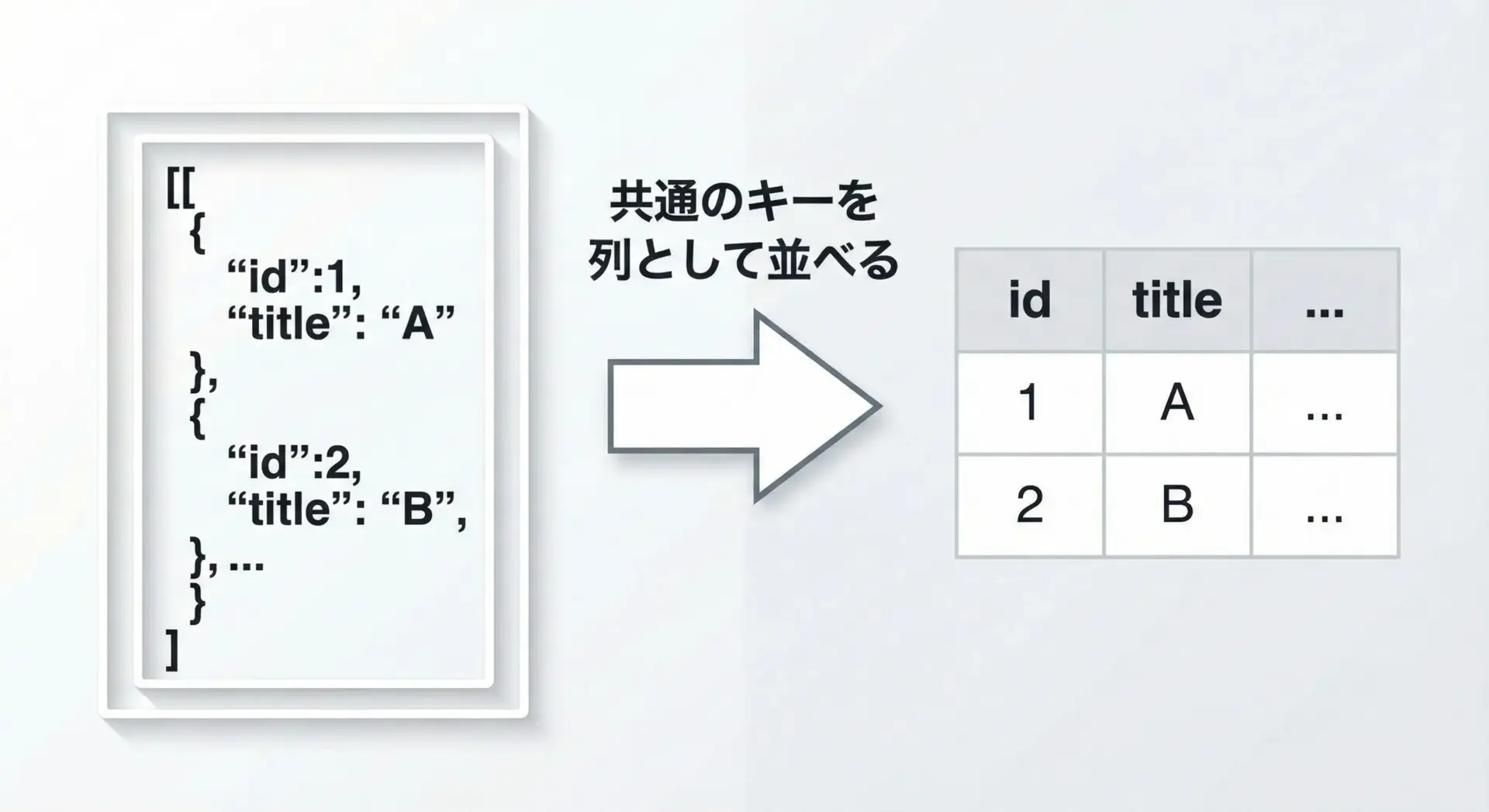
多くのビジネスツール(Excelなど)はCSV形式に対応しているため、APIから取得したJSONをCSVに変換して渡すケースがよくあります。
ここでは、JSONの配列をCSVに変換する簡単な例を紹介します。
import json
import csv
def json_to_csv(json_filepath: str, csv_filepath: str) -> None:
"""
JSONファイル(配列形式)を読み込み、CSVに変換して保存する関数です。
"""
# JSONファイルを読み込む
with open(json_filepath, "r", encoding="utf-8") as f:
data = json.load(f)
# dataはlist[dict]であることを想定
if not data:
print("データが空のため、CSVを作成しませんでした")
return
# 1件目のキー一覧をCSVのヘッダーとする
fieldnames = list(data[0].keys())
# CSVファイルに書き出す
with open(csv_filepath, "w", encoding="utf-8", newline="") as f:
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader() # ヘッダー行を書き込む
writer.writerows(data) # 各行を書き込む
print(f"JSONをCSVに変換しました: {csv_filepath}")
if __name__ == "__main__":
json_to_csv("todos.json", "todos.csv")このコードでは、各要素が同じキーを持つdictのリストであることを前提としています。
より複雑なネスト構造のJSONでは、あらかじめ必要なカラムだけを抽出し、フラットなdictに整形してからCSVに書き出すことが多いです。
データ加工と簡単な可視化への応用

JSONデータをPythonで扱う最大の強みは、そのままデータ分析・可視化に活用できる点です。
ここでは、簡単な集計と棒グラフ表示の例を示します。
pandasとmatplotlibを利用します。
事前にライブラリをインストールしておきます。
pip install pandas matplotlibサンプル: ユーザーごとのToDo完了件数を集計して可視化
import json
from collections import Counter
import matplotlib.pyplot as plt
import pandas as pd
def analyze_todos(json_filepath: str) -> None:
"""
ToDoリストのJSONからユーザーごとの完了件数を集計し、棒グラフで表示する関数です。
"""
# JSONファイルを読み込み
with open(json_filepath, "r", encoding="utf-8") as f:
todos = json.load(f)
# 完了済み(completed=True)のタスクだけを抽出
completed_todos = [t for t in todos if t.get("completed")]
# ユーザーIDごとに件数をカウント
user_ids = [t.get("userId") for t in completed_todos]
counts = Counter(user_ids)
# pandasのDataFrameに変換
df = pd.DataFrame(
{"userId": list(counts.keys()), "completed_count": list(counts.values())}
).sort_values("userId")
print("ユーザーごとの完了件数:")
print(df)
# 棒グラフで可視化
plt.figure(figsize=(8, 4))
plt.bar(df["userId"].astype(str), df["completed_count"])
plt.xlabel("ユーザーID")
plt.ylabel("完了済みToDo件数")
plt.title("ユーザーごとの完了済みToDo件数")
plt.tight_layout()
plt.show()
if __name__ == "__main__":
analyze_todos("todos.json")このスクリプトを実行すると、コンソールには集計結果の表が表示され、さらにユーザーIDごとの完了件数を表す棒グラフが表示されます。
出力例(コンソール部分)は次のようになります。
ユーザーごとの完了件数:
userId completed_count
0 1 11
1 2 8
2 3 7
...このようにAPI → JSON → Python(dict/list) → pandas/DataFrame → グラフという流れを身につけることで、さまざまなWebサービスのデータを自分の分析に取り込めるようになります。
まとめ
本記事では、PythonでWeb APIからJSONデータを取得し、解析・保存・活用する一連の流れを解説しました。
requestsによるHTTPアクセス、jsonモジュールによるパース、dict/listとしてのデータ操作、ファイルへの保存とCSV変換、さらに簡単な集計と可視化までをカバーしました。
まずはサンプルAPIで動作を確認し、慣れてきたら実際に使いたいAPIのドキュメントを読みながら、自分の用途に合わせたスクリプトへ発展させてみてください。
