
Pythonの標準ライブラリcollectionsに含まれるCounterは、データの頻度集計やランキング作成をとてもシンプルにしてくれる強力な機能です。
本記事では、基本的な使い方から、ランキング作成、ゼロ件の扱い、さらに差分計算や集合演算まで、実務でよく使うテクニックを一気に解説します。
Counterとは
Counterとは
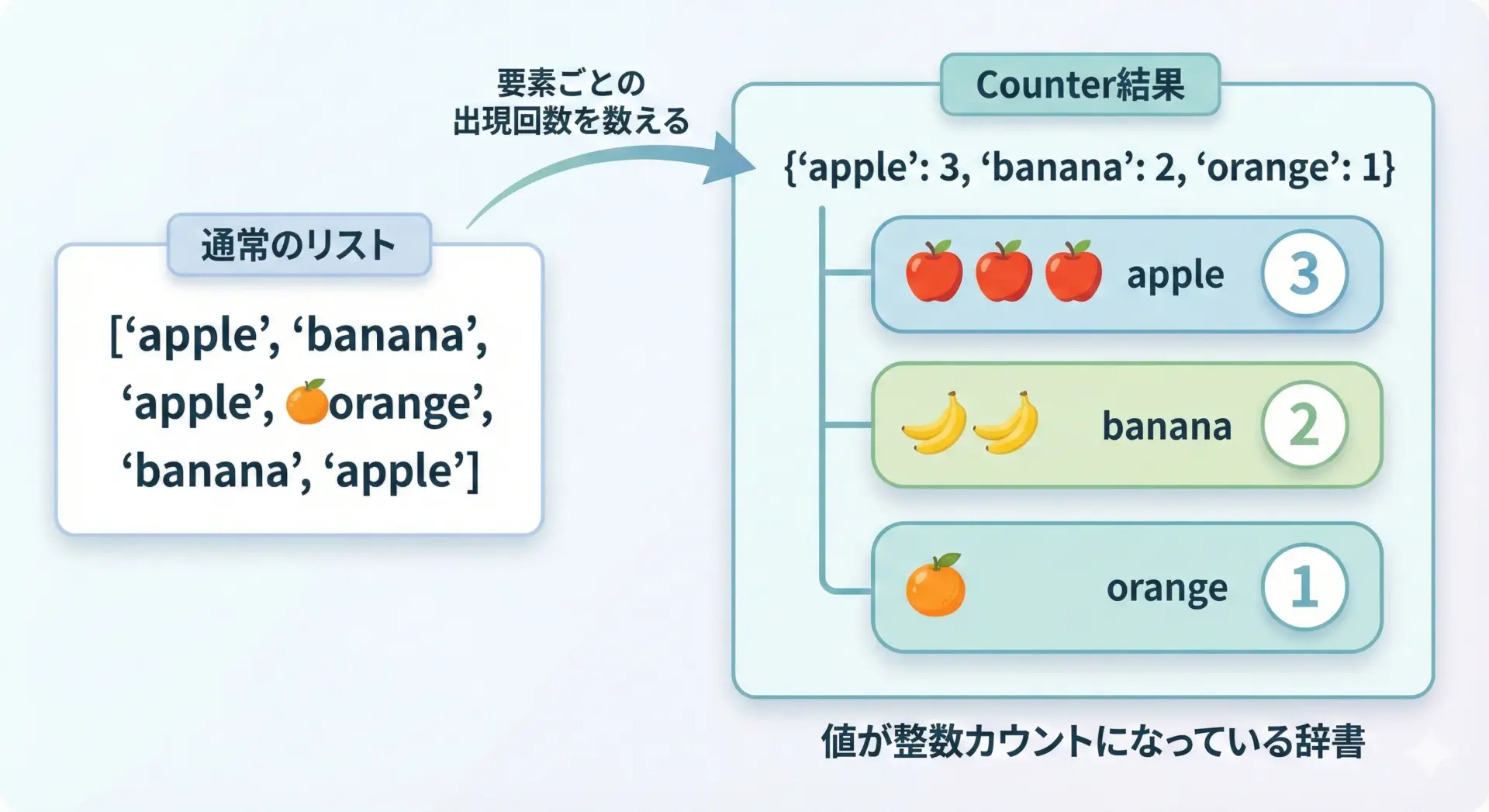
Counterとは、ハッシュ可能なオブジェクトの「出現回数」を数えるために設計された、辞書(dict)のサブクラスです。
主に次のような場面で活躍します。
文章中の単語出現回数を数えるときや、ログ中のステータスコード頻度を数えるとき、アンケートの回答選択肢の集計をするときなど、要素の「頻度」を扱いたいときに非常に便利です。
Counterは、キーに「要素」、値に「出現回数(整数)」を持つ点で辞書とよく似ていますが、頻度集計に特化した追加メソッドや演算子が用意されていることが特徴です。
通常のdictとの違い
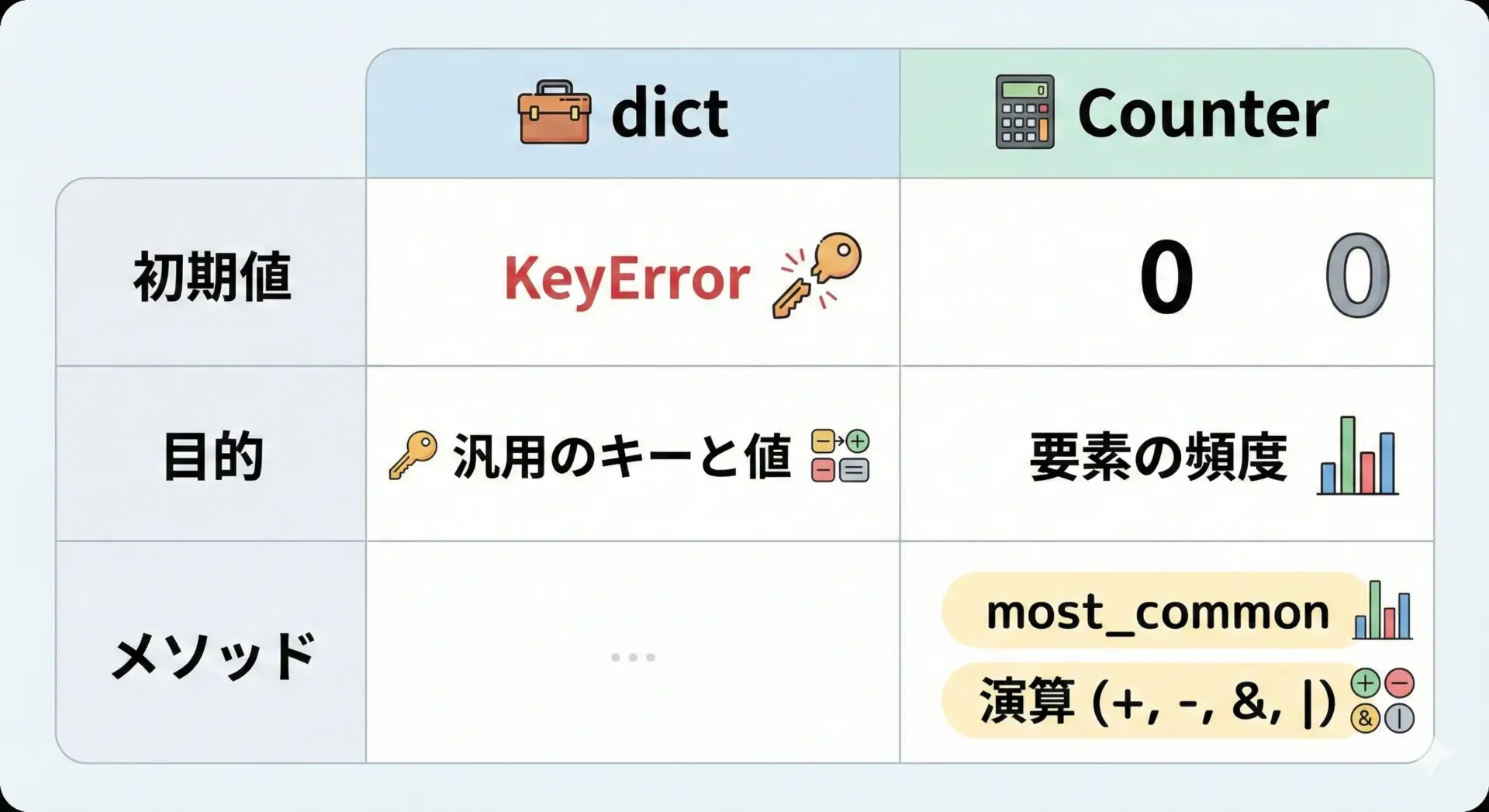
通常のdictとCounterの主な違いを文章で整理します。
通常の辞書では、例えば「まだ登録されていないキー」の値を参照しようとするとKeyErrorが発生します。
そのため、カウント用途では以下のように初期値を気にしながら実装する必要があります。
counts = {}
for item in items:
if item in counts:
counts[item] += 1
else:
counts[item] = 1一方でCounterは、存在しないキーのカウントを自動的に0として扱うため、次のようにシンプルに書けます。
from collections import Counter
counts = Counter()
for item in items:
counts[item] += 1さらに、通常の辞書にはない頻度集計用の便利メソッドとして、次のようなものがあります。
most_common()によるランキング取得- Counter同士の加算・減算・最大/最小の集合演算
- 要素の削除やゼロ・負数の扱いに関する明確なルール
Counterを使うメリット
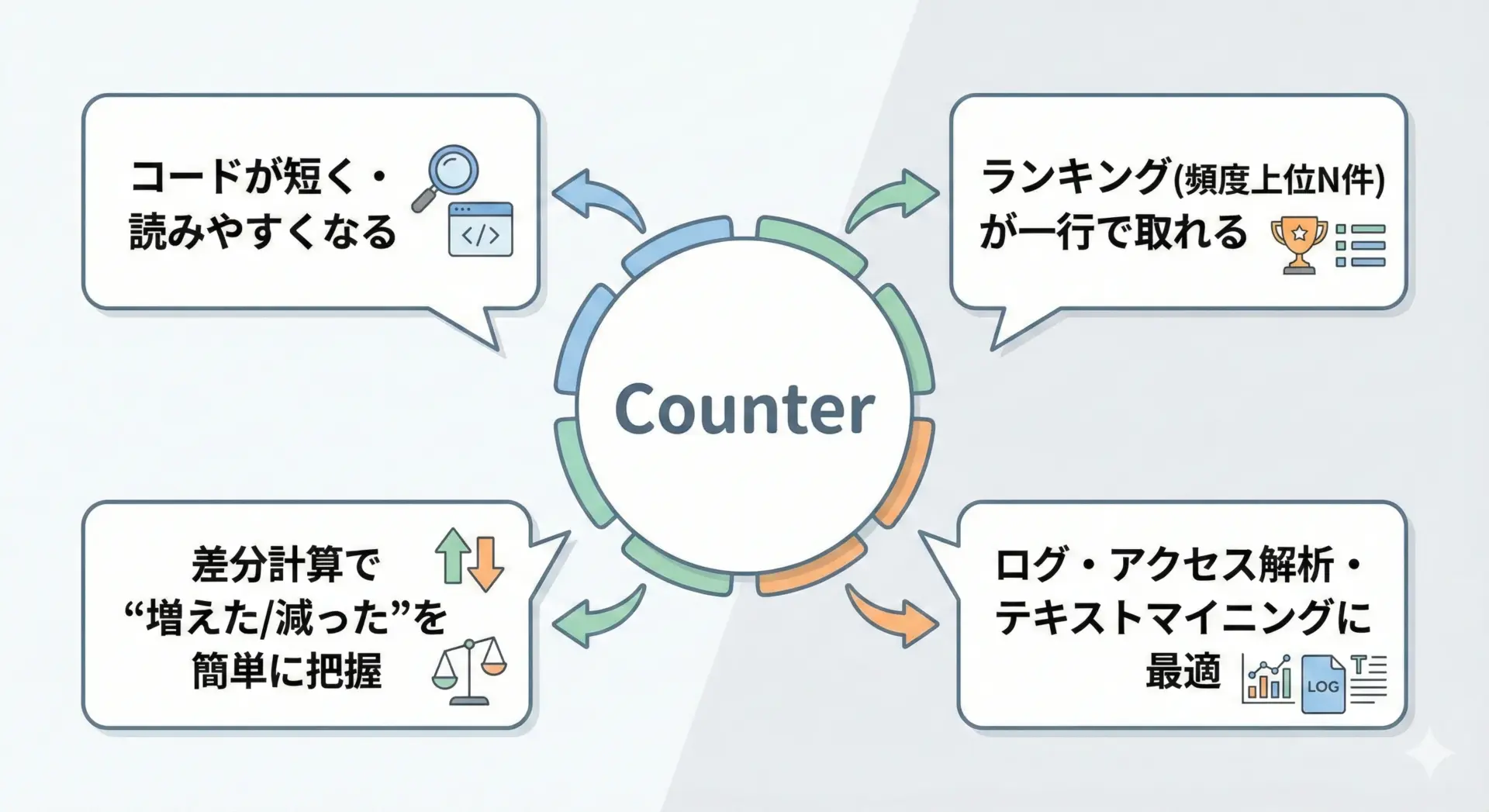
Counterを使う主なメリットを整理します。
まず、カウント処理のコード量が大きく減ることです。
前述の通り、存在チェックと初期化を書かなくてよくなるため、バグが入り込む余地も減ります。
次に、ランキングや上位N件抽出がワンライナーで書ける点です。
従来であればsorted()と自作のキー関数を組み合わせる必要がありましたが、Counterならmost_common()だけで済みます。
さらに、差分計算や集合演算が直感的に書けるため、ログ解析やアクセス解析など「ある時点と別の時点の違い」を知りたい場面に非常に向いています。
このように、Counterは単なる辞書の代わりではなく、頻度を扱うための「専用ツール」として用いることで、コードの見通しと保守性を高めてくれます。
Counterの基本的な使い方
Counterのインポート方法
Counterは標準ライブラリcollectionsモジュールの一部ですので、追加インストールは不要です。
インポートは1行で行えます。
from collections import Counter一度インポートしてしまえば、ファイル内でCounterクラスをそのまま使うことができます。
リストから要素の出現回数を数える
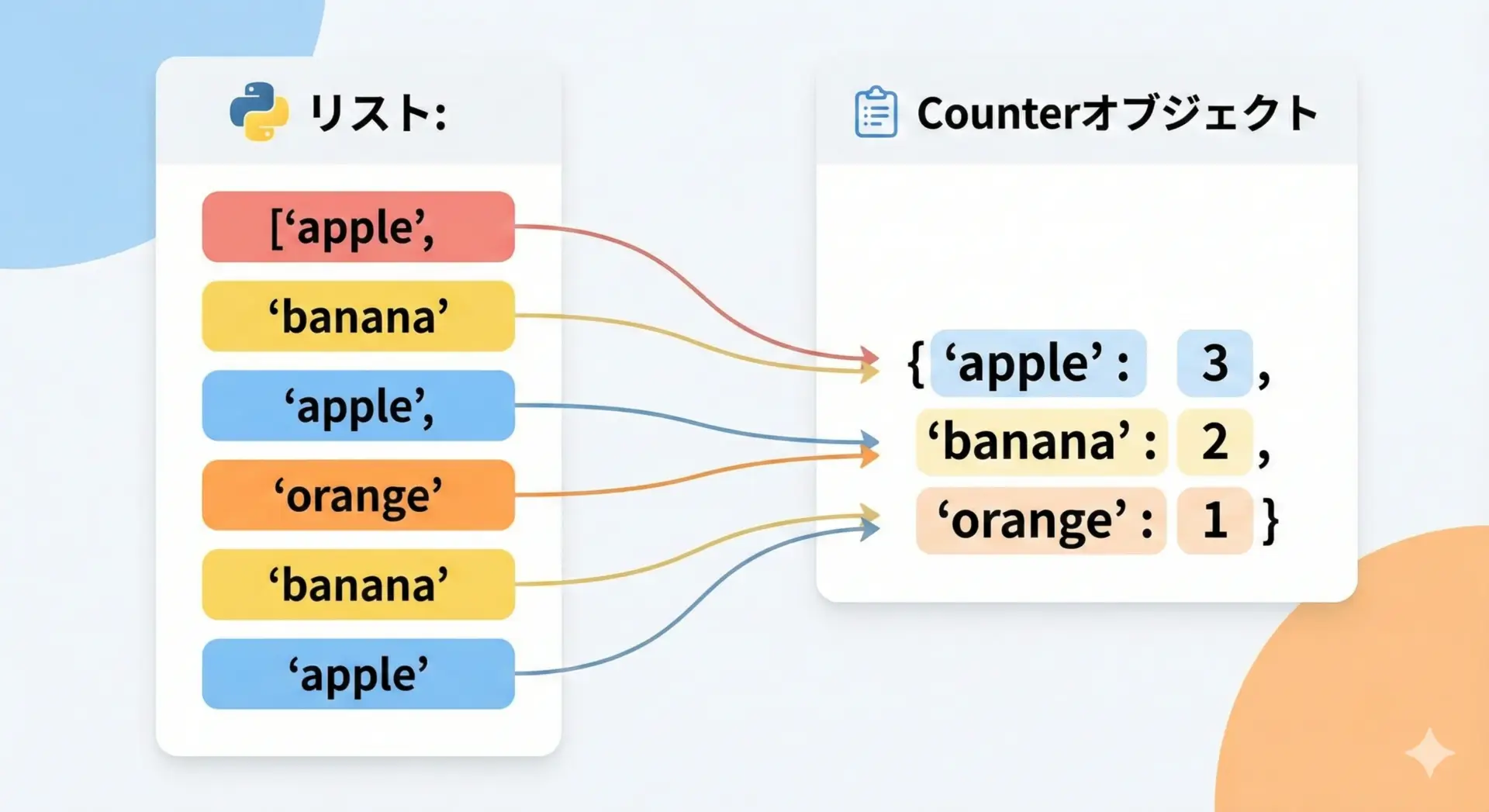
最も基本的な使い方は、リストに含まれる要素の出現回数を数える方法です。
from collections import Counter
fruits = ["apple", "banana", "apple", "orange", "banana", "apple"]
# リストからCounterを生成
fruit_counter = Counter(fruits)
print(fruit_counter)
print("appleの個数:", fruit_counter["apple"])
print("grapeの個数(存在しない要素):", fruit_counter["grape"])Counter({'apple': 3, 'banana': 2, 'orange': 1})
appleの個数: 3
grapeの個数(存在しない要素): 0存在しないキー"grape"の値が0として返ってくる点が、通常の辞書との違いをよく表しています。
文字列から文字の頻度を数える

Counterは、文字列(イテラブル)を渡すだけで、各文字の頻度を簡単に集計できます。
from collections import Counter
text = "hello world"
char_counter = Counter(text)
print(char_counter)
print("l の出現回数:", char_counter["l"])
print("スペースの出現回数:", char_counter[" "])Counter({'l': 3, 'o': 2, 'h': 1, 'e': 1, ' ': 1, 'w': 1, 'r': 1, 'd': 1})
l の出現回数: 3
スペースの出現回数: 1このように、文字列をそのまま渡すと1文字単位でカウントされます。
単語単位で数えたい場合は、先にsplit()などで分割してからCounterに渡します。
from collections import Counter
sentence = "apple banana apple orange banana apple"
# 単語ごとに分割してからカウント
word_list = sentence.split()
word_counter = Counter(word_list)
print(word_counter)Counter({'apple': 3, 'banana': 2, 'orange': 1})dictやタプルからCounterを作成する
Counterは、すでに辞書で管理されているカウント情報から作り直すこともできます。
また、タプルや他のイテラブルからも柔軟に生成できます。
from collections import Counter
# 既存のdictからCounterを作る
data_dict = {"apple": 3, "banana": 2, "orange": 1}
c_from_dict = Counter(data_dict)
# タプルからCounterを作る
data_tuple = ("apple", "banana", "apple")
c_from_tuple = Counter(data_tuple)
print("dictから:", c_from_dict)
print("タプルから:", c_from_tuple)dictから: Counter({'apple': 3, 'banana': 2, 'orange': 1})
タプルから: Counter({'apple': 2, 'banana': 1})このように、「イテラブル」か「マッピング(dictのようなオブジェクト)」なら、そのままCounterのコンストラクタに渡せると覚えておくと便利です。
頻度集計とランキングの実用テクニック
most_commonで頻度ランキングを作成する
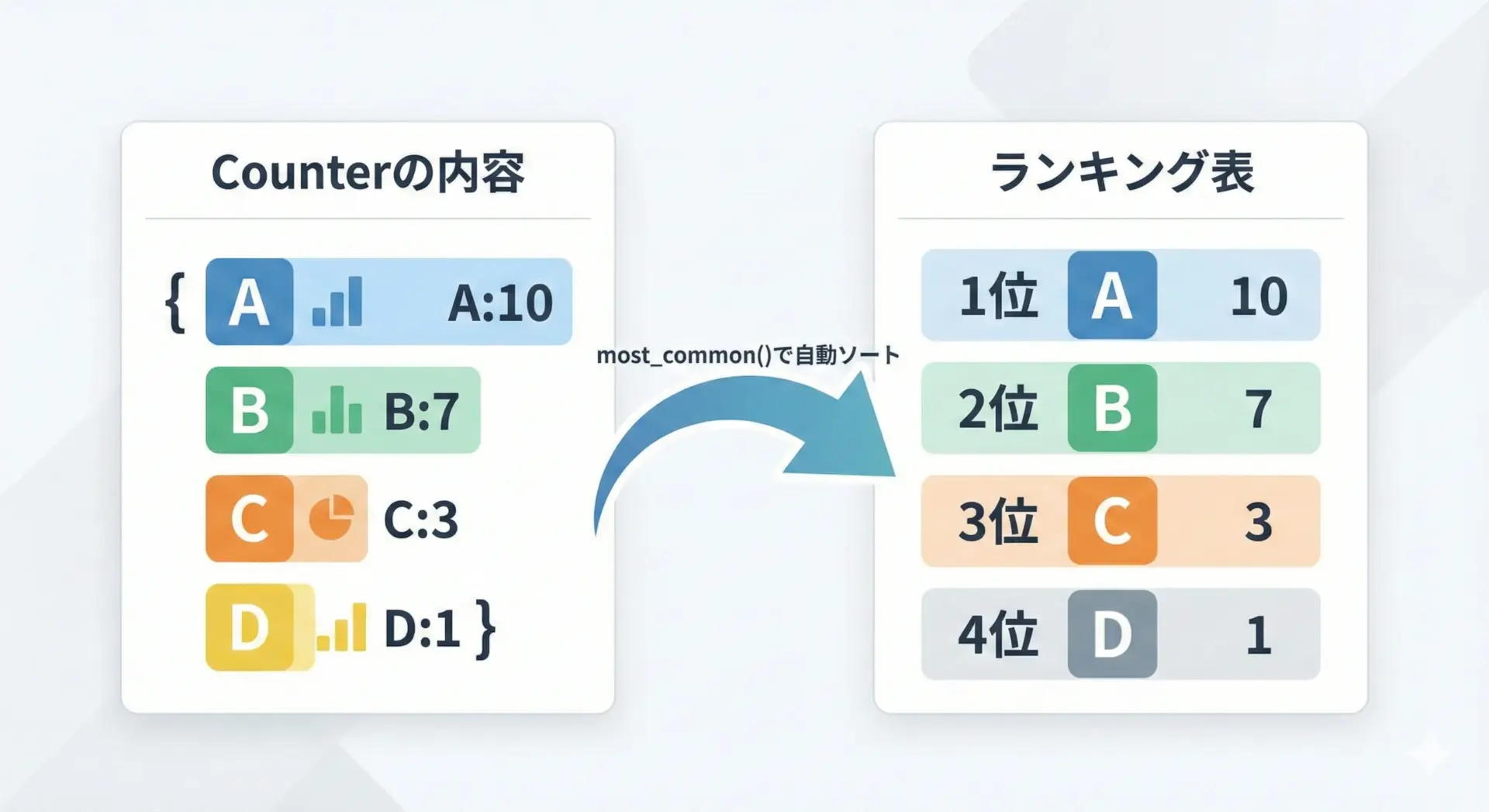
Counterの代表的なメソッドがmost_common()です。
これは「出現回数の多い順」にソートされたリストを返してくれます。
from collections import Counter
fruits = ["apple", "banana", "apple", "orange", "banana", "apple"]
counter = Counter(fruits)
# 頻度の高い順にすべて取得
ranking = counter.most_common()
print(ranking)[('apple', 3), ('banana', 2), ('orange', 1)]戻り値は(要素, カウント)のタプルを要素とするリストです。
これをそのままランキング表示などに利用できます。
頻度上位N件を取得する方法

most_common()は、引数に整数Nを渡すことで、頻度上位N件だけを取得することができます。
from collections import Counter
fruits = ["apple", "banana", "apple", "orange", "banana", "apple"]
counter = Counter(fruits)
top2 = counter.most_common(2) # 上位2件
print("上位2件:", top2)
top1 = counter.most_common(1) # 上位1件(最頻値)
print("最頻値:", top1)上位2件: [('apple', 3), ('banana', 2)]
最頻値: [('apple', 3)]「最頻値だけ欲しい」場合はmost_common(1)[0]のようにアクセスすることが多いです。
most_frequent, count = counter.most_common(1)[0]
print(most_frequent, count)apple 3出現回数が0の要素を扱うには
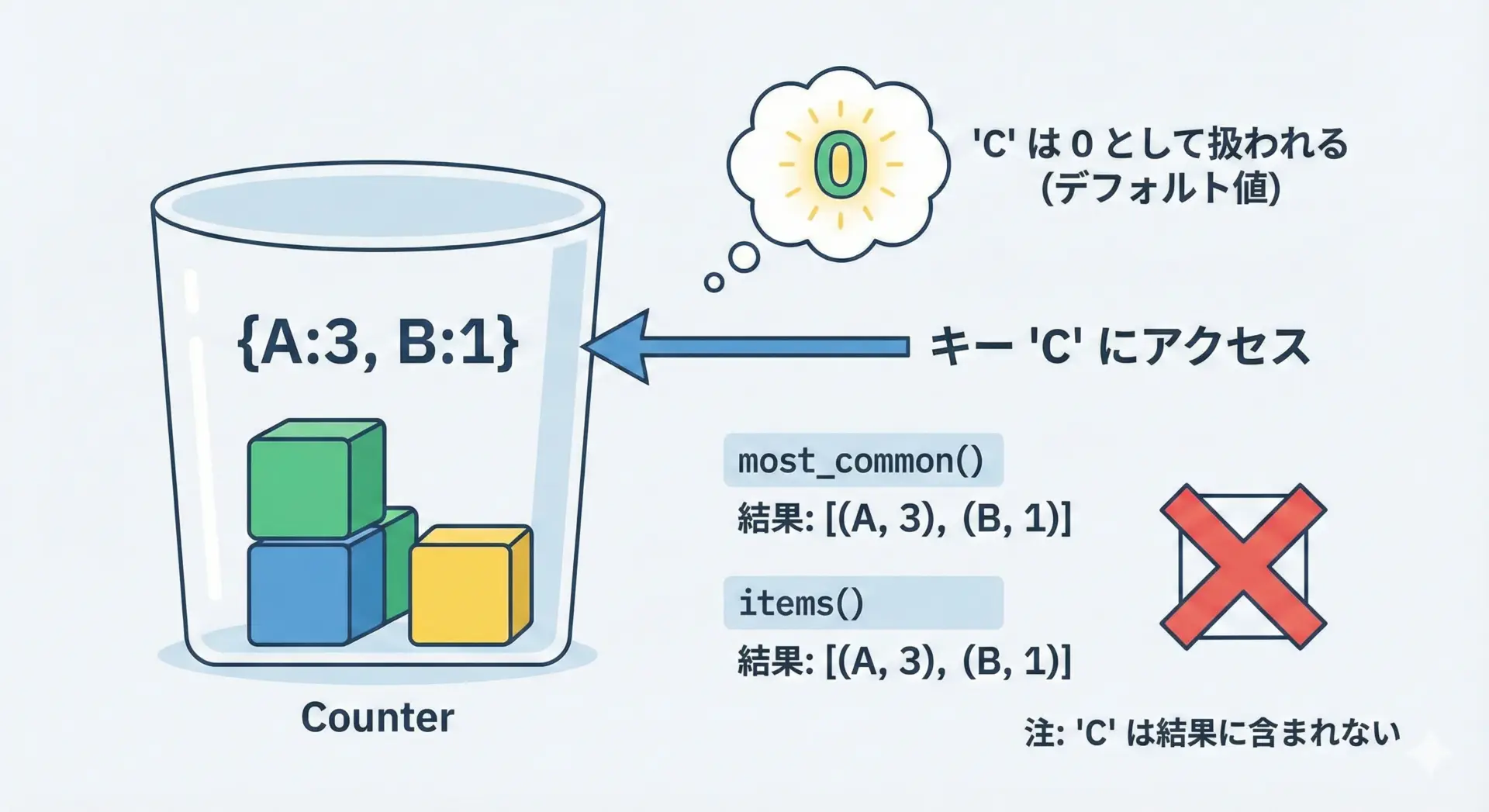
Counterでは、存在しないキーにアクセスしたときの値は常に0です。
一方で、「カウントが0以下の要素」は、基本的に内部表現からは取り除かれる、という特徴があります。
from collections import Counter
counter = Counter({"apple": 3, "banana": 1})
print(counter["grape"]) # 存在しないキー
counter["banana"] -= 1 # bananaを1つ減らして0に
print(counter)
print(list(counter.items()))0
Counter({'apple': 3, 'banana': 0})
[('apple', 3), ('banana', 0)]実際には、0の要素は計算の過程では残る場合もありますが、most_common()や集合演算などを行うと、0以下の要素は削除されることが多いと理解しておくのが安全です。
たとえば、あらかじめ「全候補の一覧」があり、その中で「出現回数0もきちんと表示したい」といった場合は、次のように対応します。
from collections import Counter
all_fruits = ["apple", "banana", "orange", "grape"]
observed = ["apple", "banana", "apple"]
counter = Counter(observed)
for fruit in all_fruits:
print(fruit, "=>", counter[fruit])apple => 2
banana => 1
orange => 0
grape => 0このように、「候補リストをループしながらCounterで頻度を問い合わせる」ことで、0件も含めて出力できます。
集計結果をソートして出力する方法
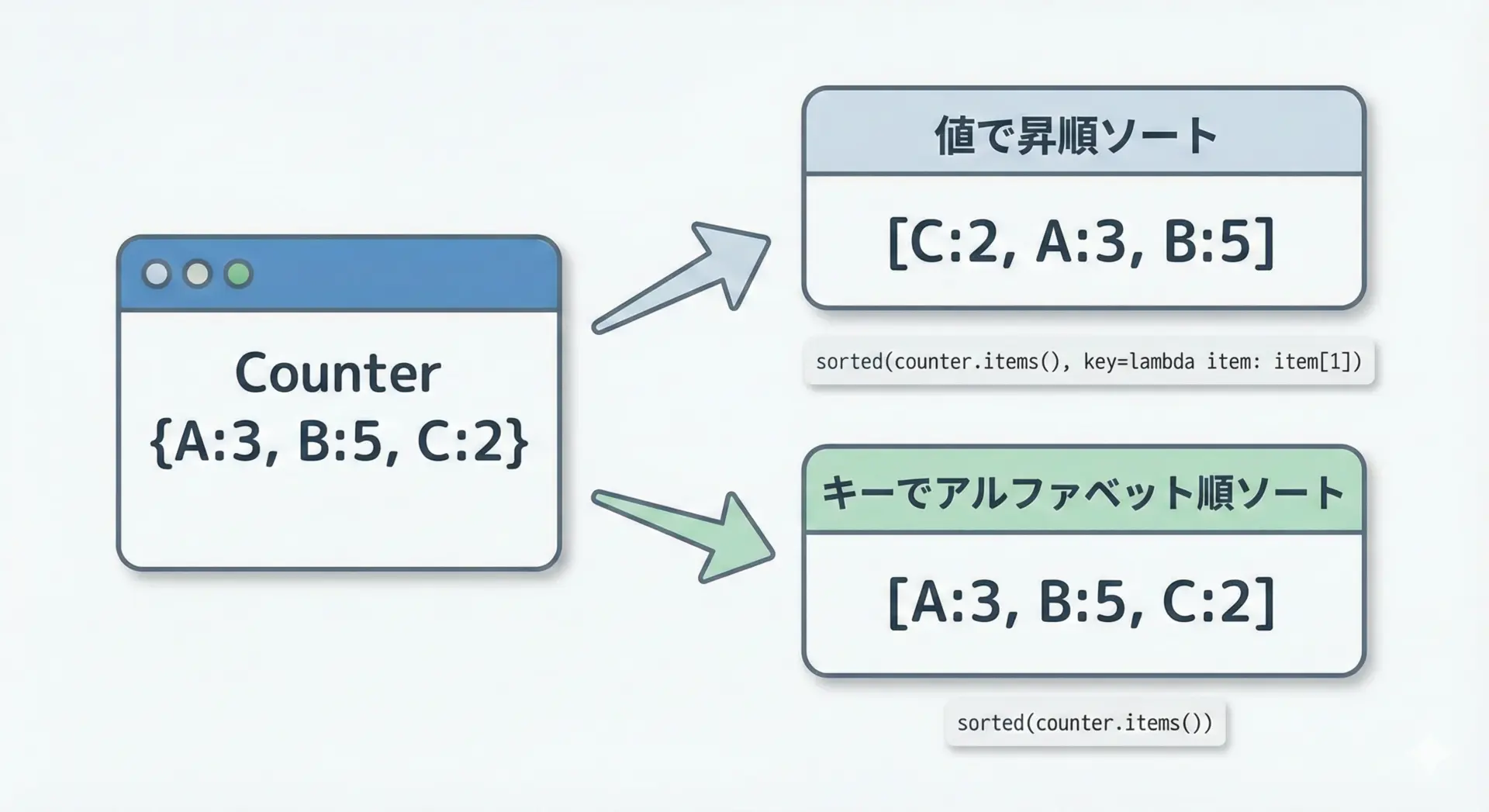
most_common()は「頻度の多い順(降順)」でしか並び替えできません。
もし、昇順で並べたい、キー順で並べたいといった場合は、通常のsorted()と組み合わせます。
from collections import Counter
counter = Counter({"apple": 3, "banana": 5, "orange": 2})
# カウントの昇順でソート
sorted_by_count_asc = sorted(counter.items(), key=lambda x: x[1])
print("カウント昇順:", sorted_by_count_asc)
# カウントの降順(=most_commonと同じ並び)
sorted_by_count_desc = sorted(counter.items(), key=lambda x: x[1], reverse=True)
print("カウント降順:", sorted_by_count_desc)
# キー(名前)のアルファベット順でソート
sorted_by_key = sorted(counter.items(), key=lambda x: x[0])
print("キー昇順:", sorted_by_key)カウント昇順: [('orange', 2), ('apple', 3), ('banana', 5)]
カウント降順: [('banana', 5), ('apple', 3), ('orange', 2)]
キー昇順: [('apple', 3), ('banana', 5), ('orange', 2)]「並び替えの基準を自由に変えたいときはsorted(counter.items(), key=...)を使う」と覚えておくと応用が利きます。
Counterで差分計算・集合演算を行う
カウントの加算と減算
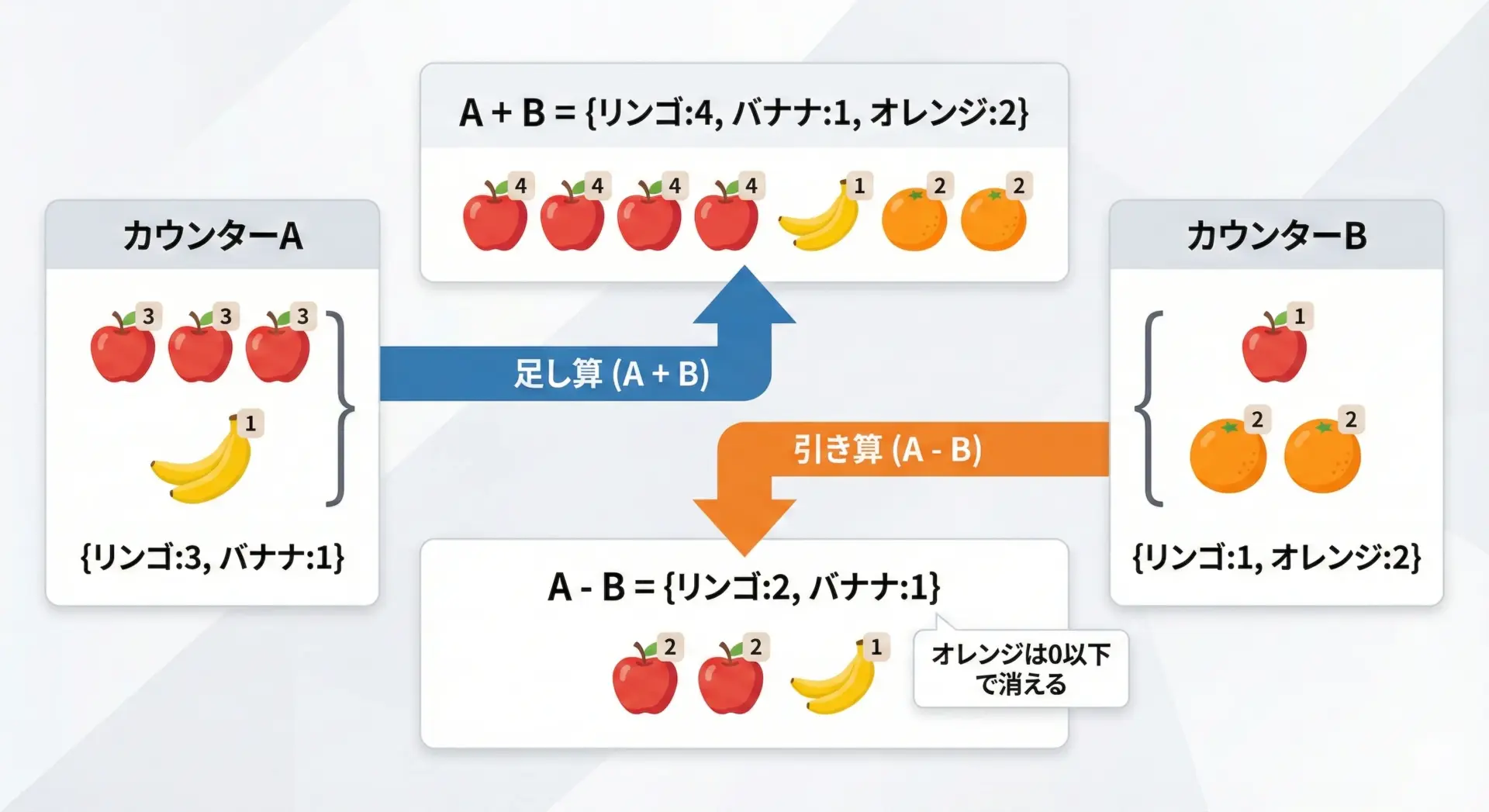
Counterの大きな特徴の1つが、Counter同士に対して四則演算のような操作ができることです。
特に加算と減算は実務でよく使います。
from collections import Counter
c1 = Counter(apple=3, banana=1)
c2 = Counter(apple=1, orange=2)
# 加算
added = c1 + c2
print("加算結果:", added)
# 減算
subtracted = c1 - c2
print("減算結果:", subtracted)加算結果: Counter({'apple': 4, 'orange': 2, 'banana': 1})
減算結果: Counter({'apple': 2, 'banana': 1})ここで重要なのは、減算では「カウントが0以下の要素は結果から除外される」点です。
この性質により、「前日から増えた分だけ」「エラーを除いた成功数だけ」といった差分集計が直感的に書けます。
また、update()とsubtract()というメソッドを使うと、元のCounterを破壊的に更新できます。
from collections import Counter
counter = Counter(apple=3)
counter.update({"apple": 2, "banana": 1}) # カウントを加算
print("update後:", counter)
counter.subtract({"apple": 4, "banana": 1}) # カウントを減算
print("subtract後:", counter)update後: Counter({'apple': 5, 'banana': 1})
subtract後: Counter({'apple': 1})要素ごとの最大値・最小値をとる
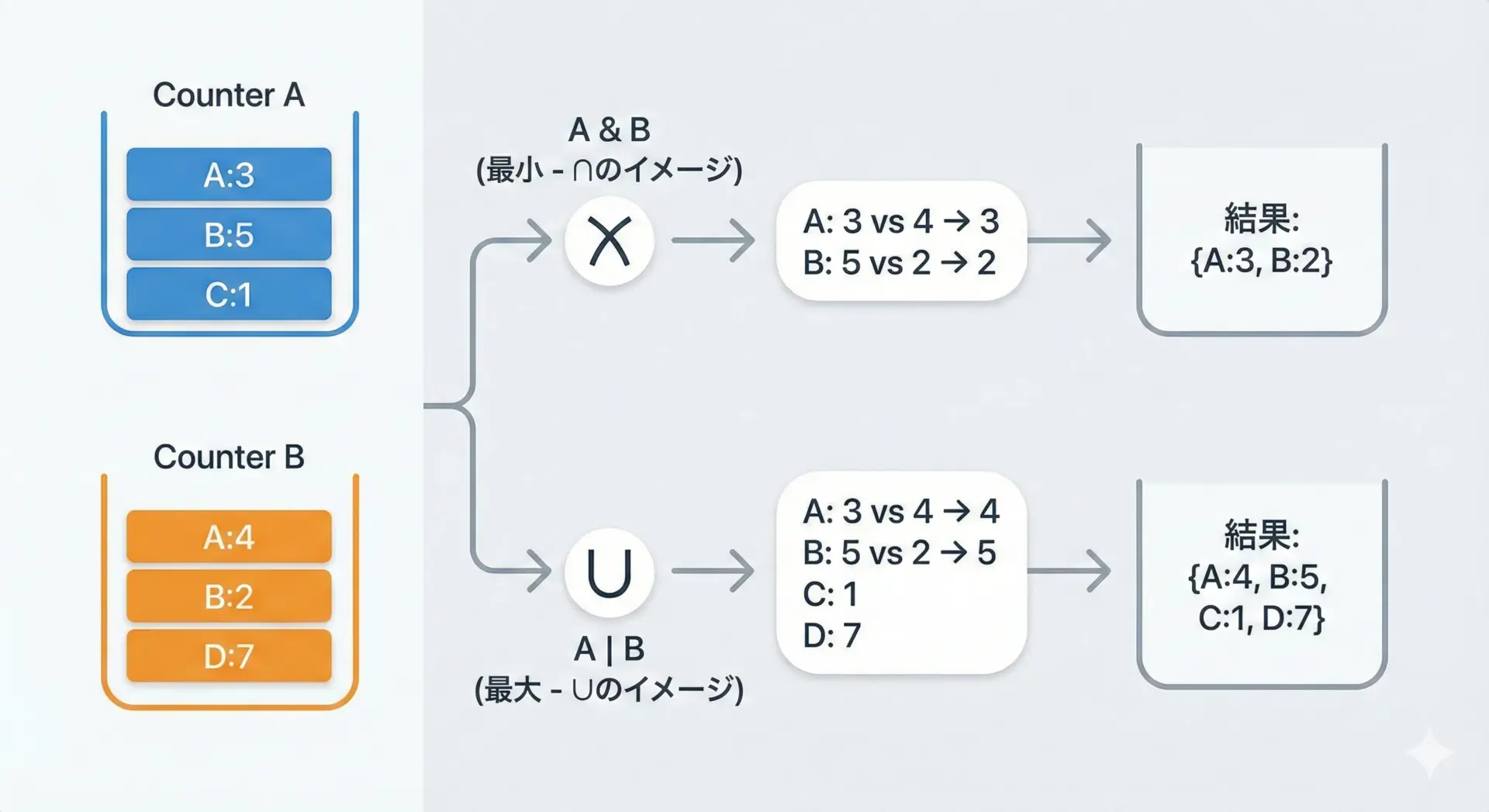
Counter同士には、&(AND) と |(OR) による「要素ごとの最小値・最大値」をとる演算も用意されています。
from collections import Counter
c1 = Counter(A=3, B=5, C=1)
c2 = Counter(A=4, B=2, D=7)
# 要素ごとの最小値(AND)
c_min = c1 & c2
print("要素ごとの最小値:", c_min)
# 要素ごとの最大値(OR)
c_max = c1 | c2
print("要素ごとの最大値:", c_max)要素ごとの最小値: Counter({'B': 2, 'A': 3})
要素ごとの最大値: Counter({'D': 7, 'B': 5, 'A': 4, 'C': 1})AND(&)は「両方に含まれる要素のみを取り、カウントは小さい方」、
OR(|)は「どちらか一方に含まれる要素をすべて取り、カウントは大きい方」、と理解すると直感的です。
ログ比較やA/Bテストで「共通に発生しているイベント」だけを取りたいときなどに重宝します。
複数Counterのマージと分割
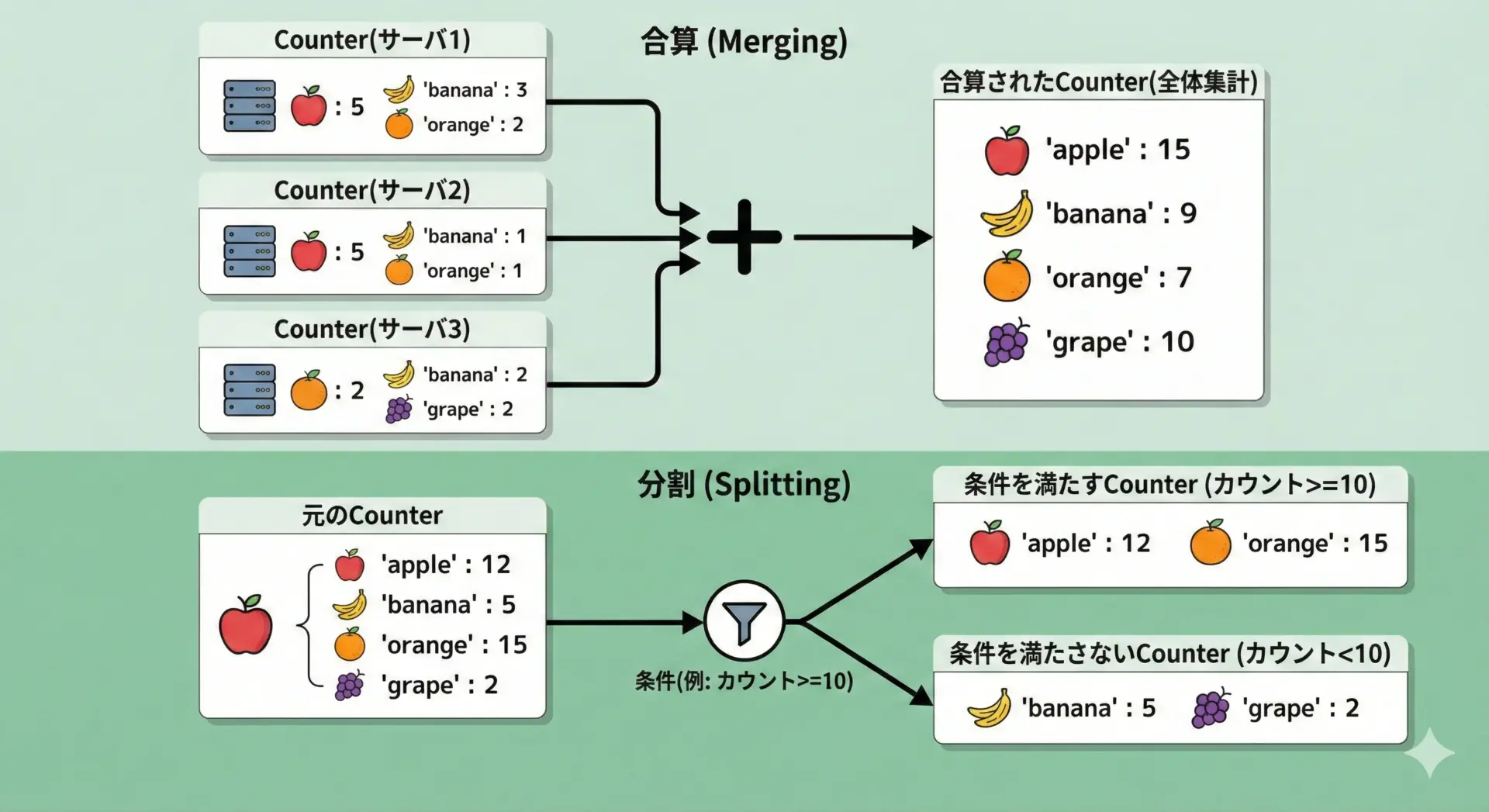
複数のCounterをまとめて合算したい場合、単純に足し算を繰り返すか、sum()を使う方法があります。
from collections import Counter
server1 = Counter(success=100, error=5)
server2 = Counter(success=80, error=2)
server3 = Counter(success=120, error=10)
# 足し算の連鎖
total1 = server1 + server2 + server3
# sumを使った書き方
total2 = sum([server1, server2, server3], Counter())
print("total1:", total1)
print("total2:", total2)total1: Counter({'success': 300, 'error': 17})
total2: Counter({'success': 300, 'error': 17})初期値にCounter()を渡してsum()を使うと、複数のCounterを一気に畳み込むことができます。
逆に、1つのCounterから条件に応じて分割したい場合は、辞書内包表記などを併用します。
from collections import Counter
counter = Counter({"apple": 10, "banana": 3, "orange": 7, "grape": 1})
# カウント5以上と未満で分割
high = Counter({k: v for k, v in counter.items() if v >= 5})
low = Counter({k: v for k, v in counter.items() if v < 5})
print("5以上:", high)
print("5未満:", low)5以上: Counter({'apple': 10, 'orange': 7})
5未満: Counter({'banana': 3, 'grape': 1})このように、「集計 → フィルタ条件で分割」というパターンを押さえておくと、さまざまな分析ロジックに応用できます。
差分計算でログやアクセス解析に活用する
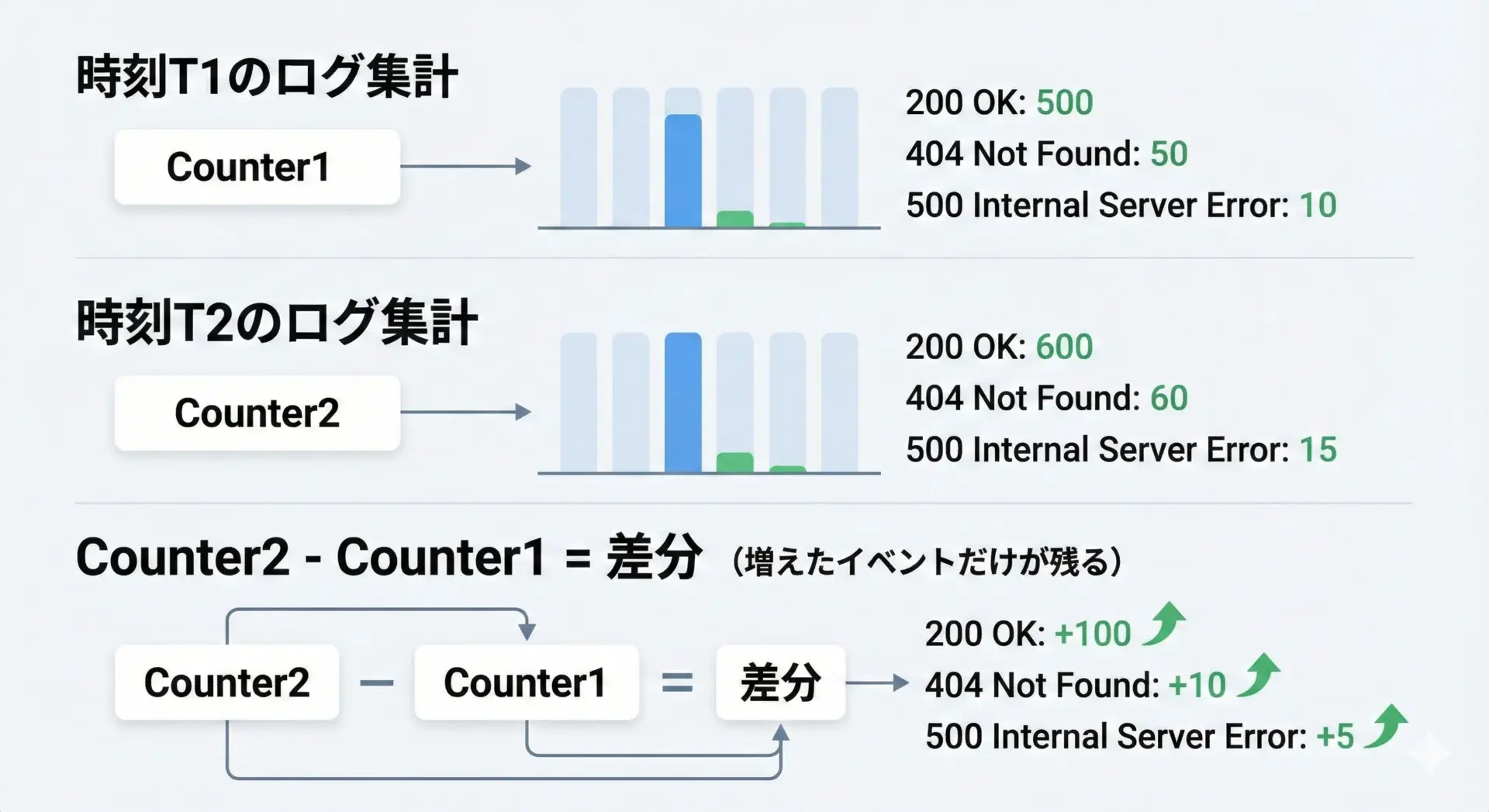
最後に、Counterの差分計算を使った、やや実務寄りの活用例を見てみます。
ここでは、ある時間帯ごとのHTTPステータスコードの発生回数を集計し、「前の時間帯からどのエラーがどれだけ増えたか」を把握するケースを考えます。
from collections import Counter
# 1時間目の集計結果
hour1 = Counter({
200: 950,
404: 10,
500: 3,
})
# 2時間目の集計結果
hour2 = Counter({
200: 1900,
404: 25,
500: 8,
})
# 累積集計から、1時間あたりの増分を計算
diff = hour2 - hour1
print("1時間あたりの増分:", diff)
# 差分が発生した(増えた)ステータスコードを多い順に表示
for status, count in diff.most_common():
print(f"status {status}: +{count}")1時間あたりの増分: Counter({200: 950, 404: 15, 500: 5})
status 200: +950
status 404: +15
status 500: +5この例では、2時間目までの累積値から1時間目までの累積値を引くことで、「直近1時間分だけの増分」を求めています。
実際のログ処理では、次のようなパターンで活用されることが多いです。
- 一定間隔ごとの累積メトリクスから、差分を取って「その間隔での増分」を算出する
- 前日と本日の集計結果の差分から、新たに発生したエラー種別だけを洗い出す
- バージョンリリース前後で、特定イベントの増減を確認する
減算時に0以下の要素が自動的に除外されるため、「増えていないもの・減ってしまったもの」を自然にフィルタできる点が、Counterの差分計算の大きな魅力です。
まとめ
Counterは、辞書に似た使い勝手を保ちながら、頻度集計やランキング、差分計算といった分析作業を驚くほど簡潔にしてくれる強力なツールです。
リストや文字列からのカウント、most_common()によるランキング、加算・減算・集合演算を組み合わせることで、ログ解析やアクセス解析、テキストマイニングなど幅広い用途に活用できます。
日常的な「数える処理」を見つけたら、まずCounterで書けないか考えてみることで、コードの見通しと保守性を大きく向上させられます。
