Pythonでは辞書(dict)を使う場面が多いですが、「キー順に並べ替えたい」「値順にランキングしたい」と感じることがよくあります。
本記事では、辞書をキー順・値順に昇順・降順でソートする方法から、複数条件での並び替えまで、実用的なパターンをサンプルコード付きで丁寧に解説します。
この記事を読み終える頃には、辞書の並び替えで迷うことはほとんどなくなるはずです。
辞書の並び替えの基本
dictは順序保持だが自動ソートはしない
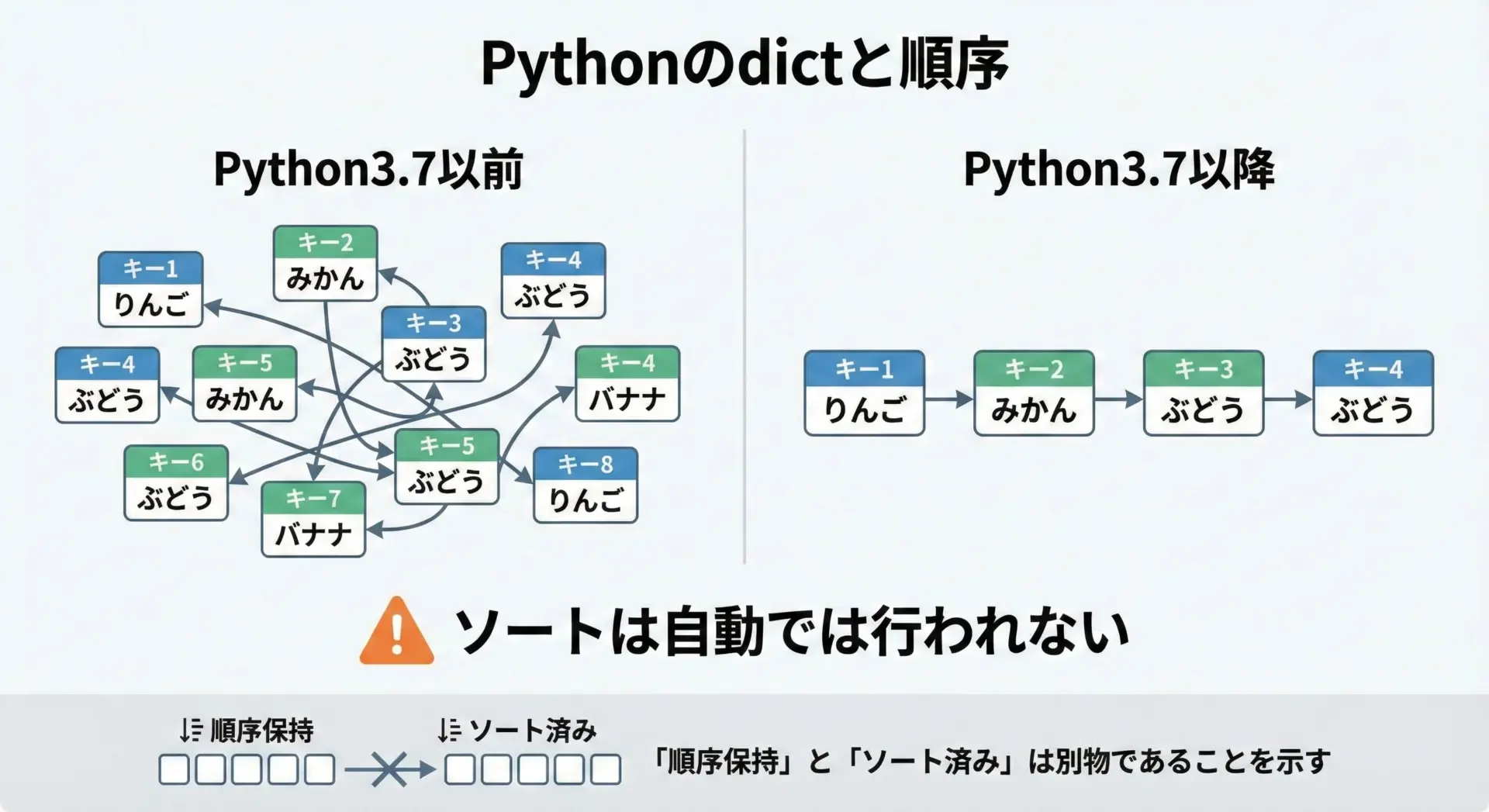
Python3.7以降では、辞書は挿入順を保持する仕様になっています。
つまり、次のようにキーを追加した順番は維持されますが、自動的にキーや値でソートされるわけではありません。
# 挿入順を確認する例
scores = {}
scores["alice"] = 80
scores["bob"] = 70
scores["charlie"] = 90
print(scores) # Python3.7以降では {'alice': 80, 'bob': 70, 'charlie': 90}この挿入順保持は便利ですが、「キーをアルファベット順にしたい」「点数の高い順に並べたい」といった場合には、自分で並び替え処理を書く必要があります。
並び替えにはsorted関数とラムダ式を使う
辞書の並び替えには、組み込み関数sortedを使うのが基本です。
sortedは「並び替え可能なオブジェクト(イテラブル)」を受け取り、ソート済みのリストを返します。
よく使う形は次のようになります。
sorted(並び替えたいもの, key=並び順を決める関数, reverse=降順にするかどうか)並び順を自分で決めたいときには、ラムダ式lambdaで「どの値を比較に使うか」を指定します。
# ラムダ式の簡単な例
nums = [3, 1, 10, 2]
# そのまま昇順
print(sorted(nums)) # [1, 2, 3, 10]
# 絶対値で比較する(ラムダ式を使用)
nums2 = [3, -5, 1, -2]
print(sorted(nums2, key=lambda x: abs(x))) # [1, -2, 3, -5]辞書のソートも、dict.keys()やdict.items()などをsortedに渡し、必要ならkey=にラムダ式を指定する、という形が基本パターンになります。
昇順・降順ソートの基本パターン
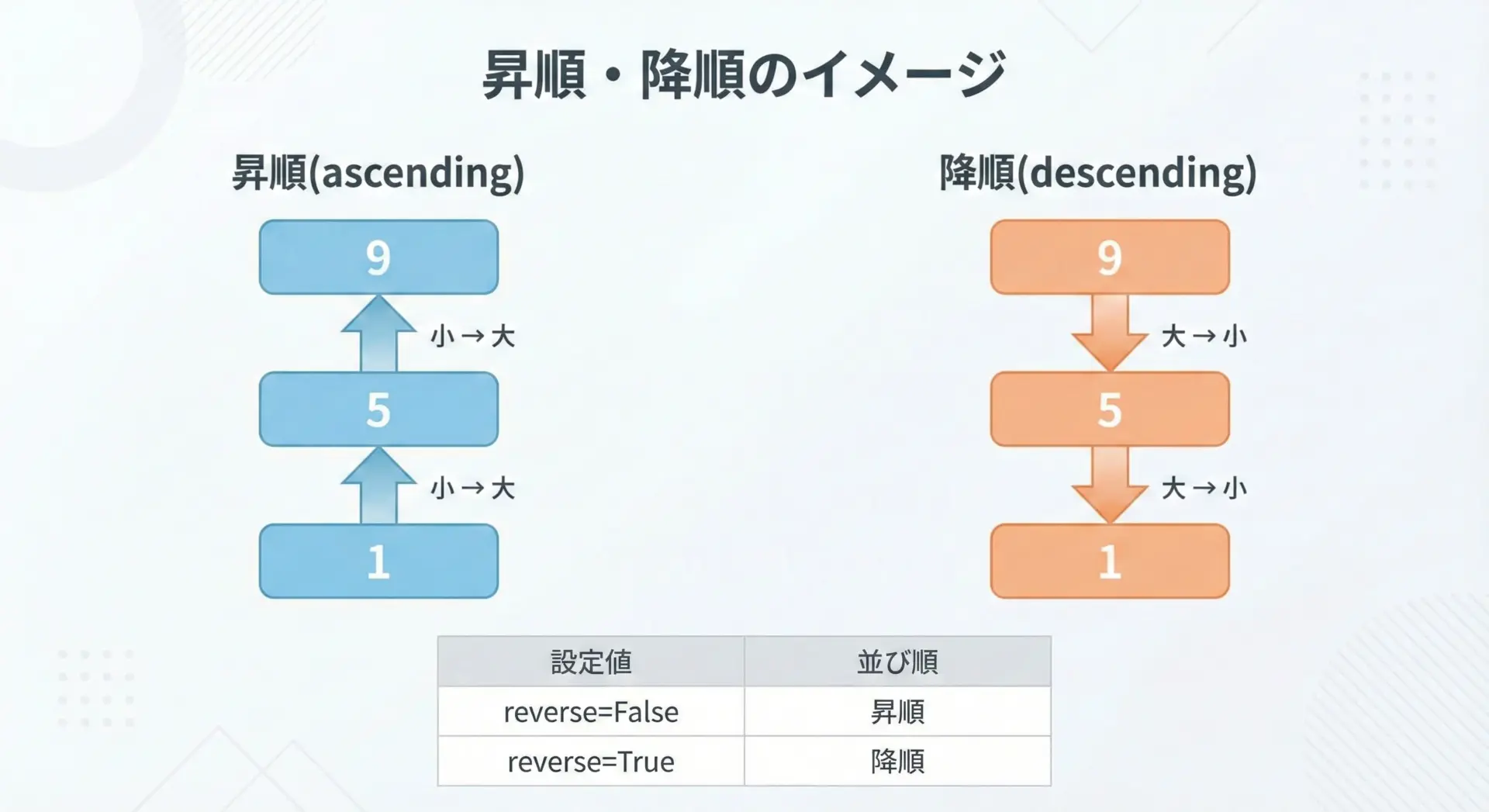
sortedは、デフォルトでは昇順で並び替えを行います。
降順にしたい場合はreverse=Trueを指定します。
nums = [5, 1, 9, 3]
# 昇順(小さい順)
asc = sorted(nums)
print(asc) # [1, 3, 5, 9]
# 降順(大きい順)
desc = sorted(nums, reverse=True)
print(desc) # [9, 5, 3, 1]辞書のキーや値をソートするときも、このreverseパラメータを組み合わせることで、昇順・降順を切り替えられます。
辞書をキー順に並び替える方法
ここからは、辞書のキーを基準に並び替える方法を順番に見ていきます。
キーはふつう文字列や数値が多く、ソートのルールがシンプルで分かりやすいため、最初に押さえておくと応用もしやすくなります。
キーを昇順にソート(sorted(dict.keys()))
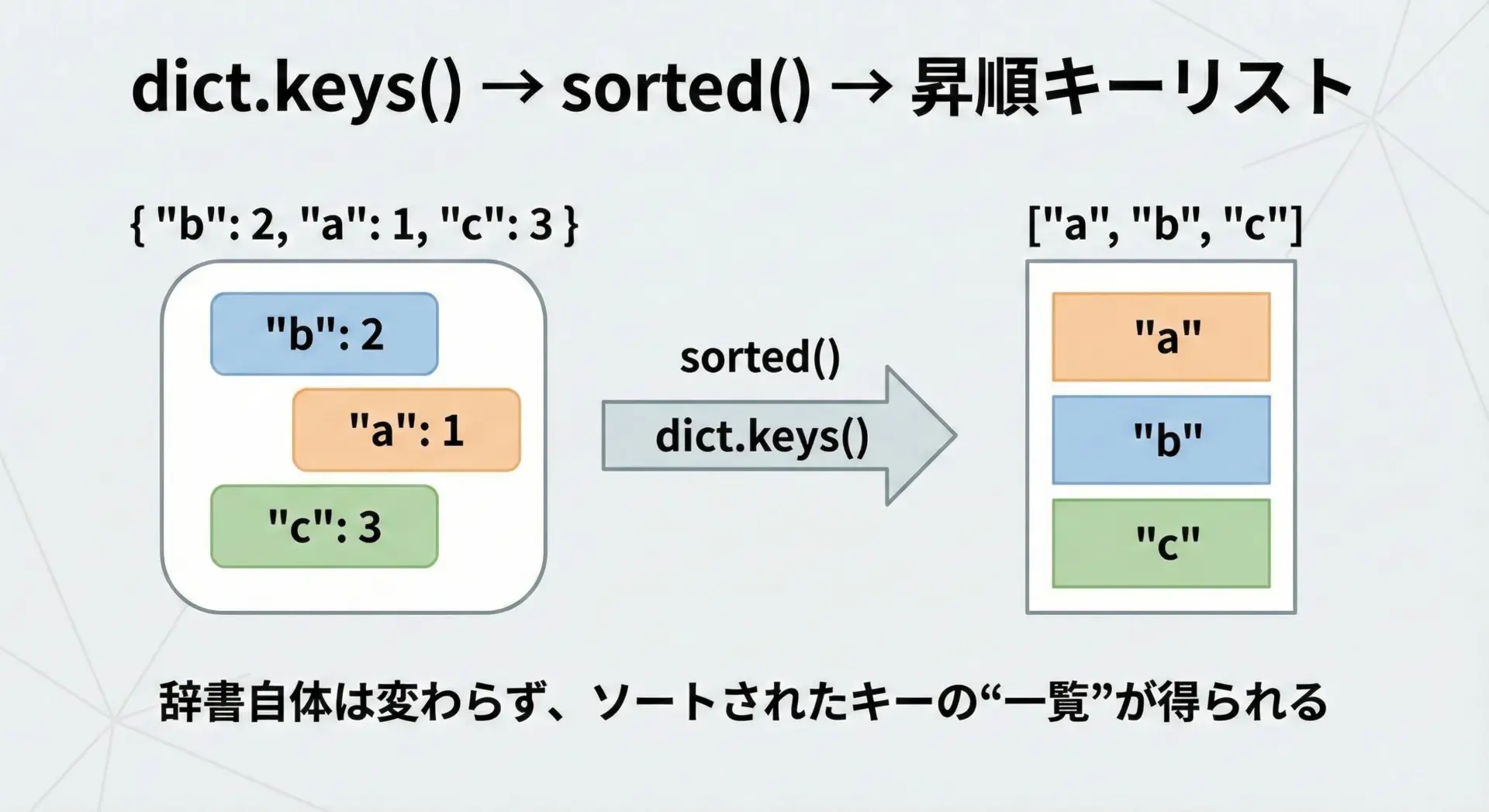
キーを昇順に並べたリストだけ欲しい場合は、dict.keys()をsortedに渡します。
scores = {"bob": 70, "alice": 80, "charlie": 90}
# キーを昇順(アルファベット順)に並べたリストを取得
sorted_keys = sorted(scores.keys())
print(sorted_keys)['alice', 'bob', 'charlie']このとき、元の辞書scoresの順序は変わりません。
あくまで「ソート済みのキーのリスト」が新しく返されるだけです。
キーを降順にソート
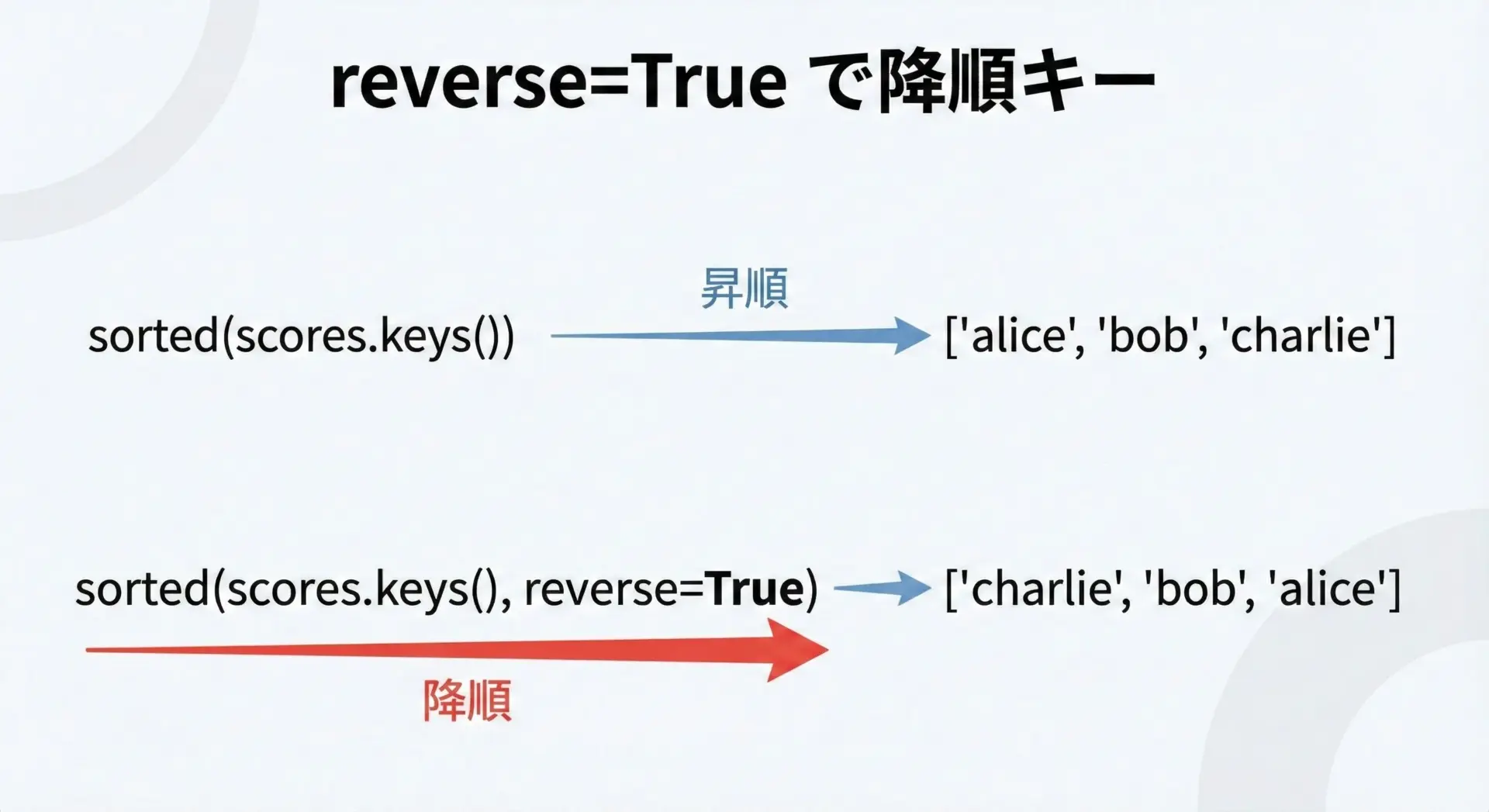
降順(逆順)にしたい場合は、reverse=Trueを付けるだけです。
scores = {"bob": 70, "alice": 80, "charlie": 90}
# キーを降順にソート
sorted_keys_desc = sorted(scores.keys(), reverse=True)
print(sorted_keys_desc)['charlie', 'bob', 'alice']このように昇順・降順はreverseの有無だけで切り替えられるため、キーソートではとてもよく使う書き方です。
辞書をキー順のリスト(タプル)として扱う方法
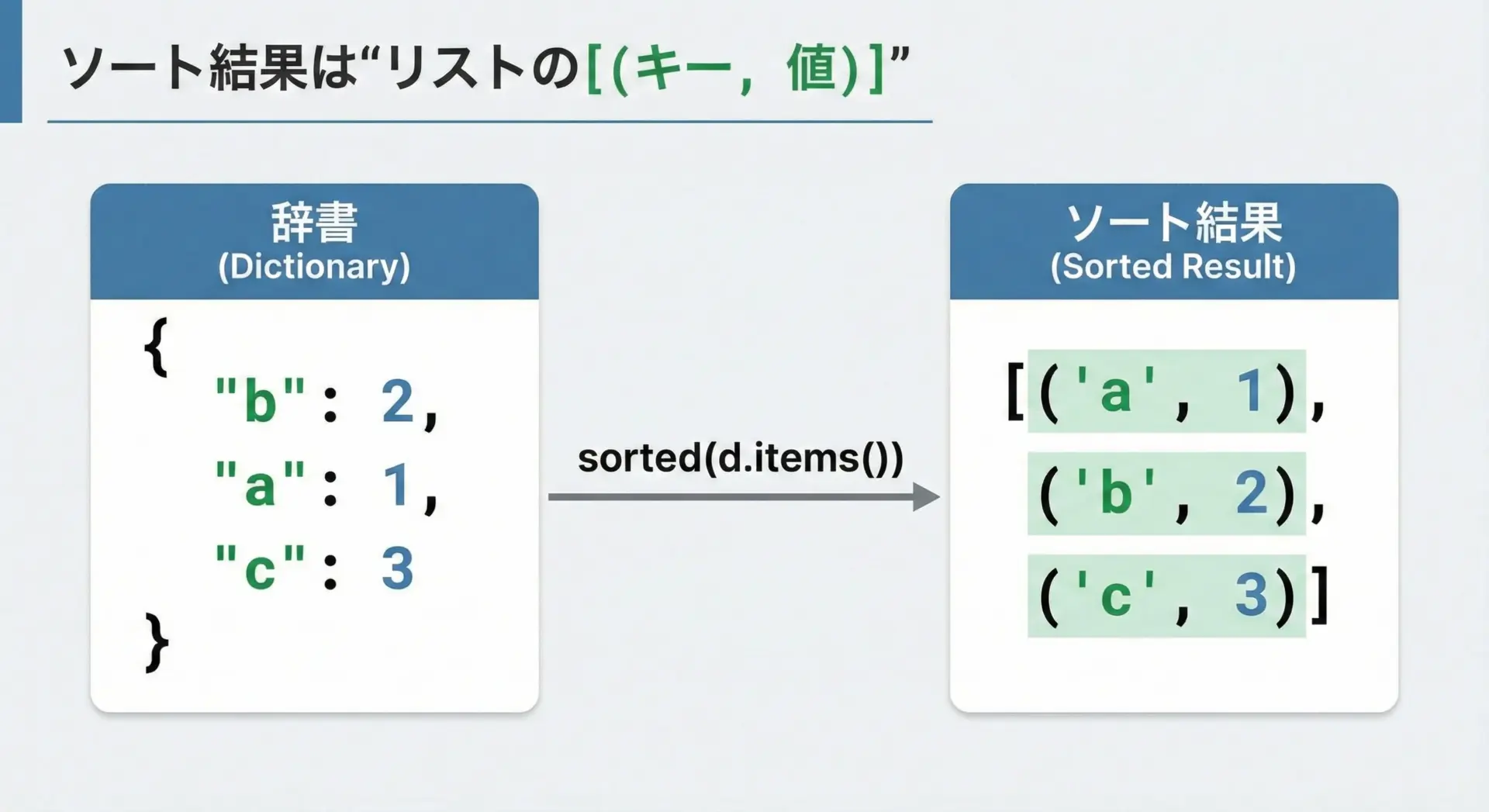
キー順に並べ替えた状態で「(キー, 値)のペア列」として扱いたい場合は、dict.items()をsortedに渡します。
scores = {"bob": 70, "alice": 80, "charlie": 90}
# items() は (キー, 値) のタプルの集合を返す
sorted_items = sorted(scores.items()) # デフォルトではキーで昇順ソート
print(sorted_items)[('alice', 80), ('bob', 70), ('charlie', 90)]ポイントとして、sorted(scores.items())はリストを返し、その各要素は('キー', 値)というタプルになっています。
辞書そのものではないため、インデックスでアクセスしたり、ループで順番に処理したりするときに向いています。
for name, score in sorted(scores.items()):
# キー昇順に処理される
print(name, score)alice 80
bob 70
charlie 90キー順に並んだ新しい辞書の作り方
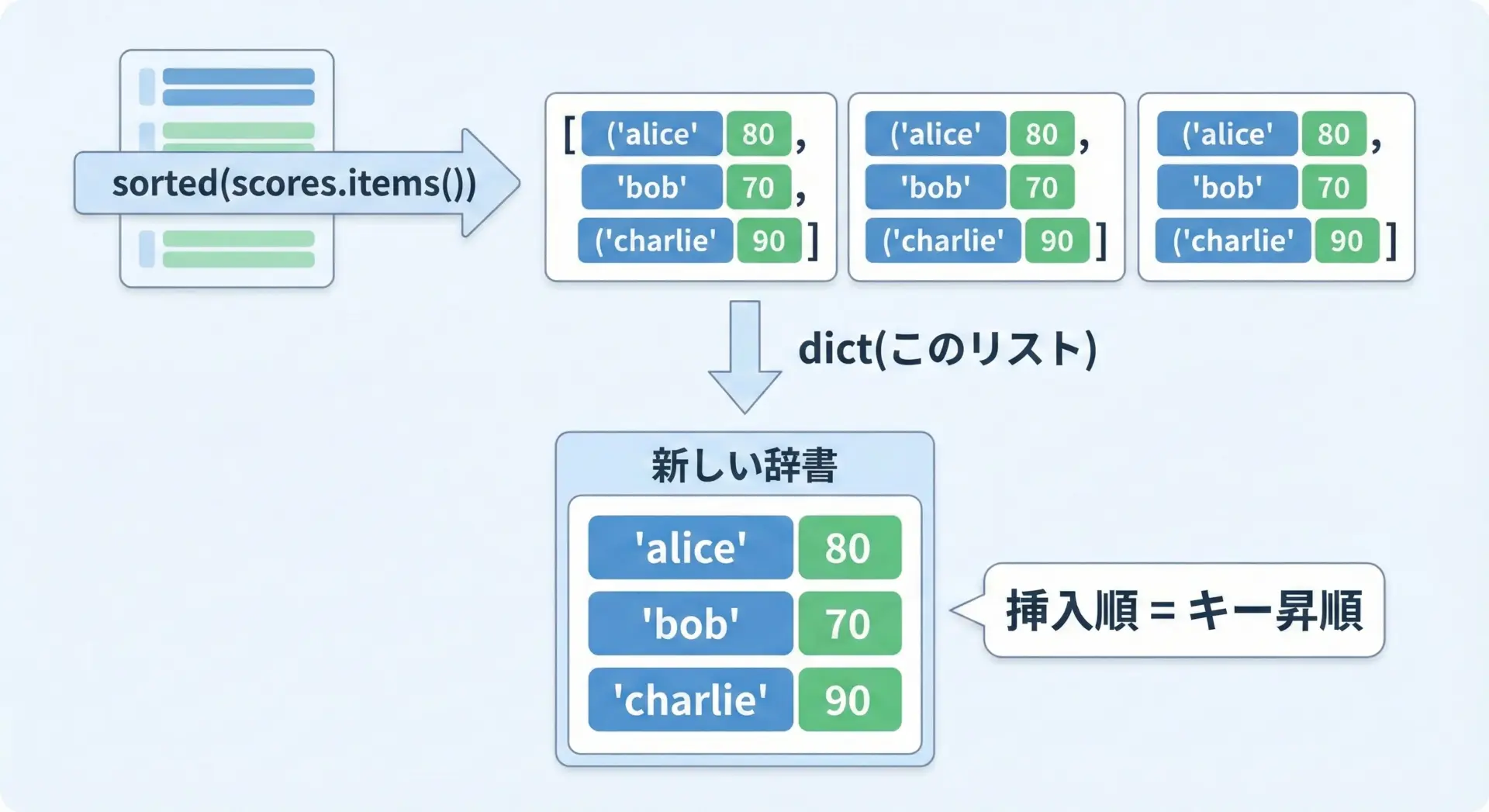
ソート済みの順番を持った辞書オブジェクトが欲しい場合は、sorted(...)の結果からdict()を作り直します。
scores = {"bob": 70, "alice": 80, "charlie": 90}
# キーで昇順に並び替えてから、新しい辞書を作る
sorted_scores = dict(sorted(scores.items()))
print(sorted_scores){'alice': 80, 'bob': 70, 'charlie': 90}Python3.7以降では、この新しい辞書sorted_scoresは「キー昇順の挿入順」を保持します。
そのため、後からループを回すときにも、キー昇順の順序で処理できます。
降順にしたい場合は、sorted側でreverse=Trueを指定します。
sorted_scores_desc = dict(sorted(scores.items(), reverse=True))
print(sorted_scores_desc){'charlie': 90, 'bob': 70, 'alice': 80}辞書を値順に並び替える方法
キーではなく、値(スコアや価格など)を基準に並び替えたいこともよくあります。
ここでは、key=引数にラムダ式を使うのが重要なポイントになります。
値を昇順にソート

辞書の値を昇順にソートするには、まずdict.items()で(キー, 値)のペアを取り出し、それをsortedに渡します。
その際、key=lambda x: x[1]と指定して、比較対象を「値」にするのがポイントです。
scores = {"alice": 80, "bob": 70, "charlie": 90}
# 値(スコア)を昇順に並び替え
sorted_by_value = sorted(scores.items(), key=lambda x: x[1])
print(sorted_by_value)[('bob', 70), ('alice', 80), ('charlie', 90)]ここでのxは('alice', 80)のようなタプルで、x[0]がキー、x[1]が値を表します。
このように、「どの部分を基準にソートするか」をラムダ式で指定すると、自由度の高い並び替えが可能になります。
値を降順にソート
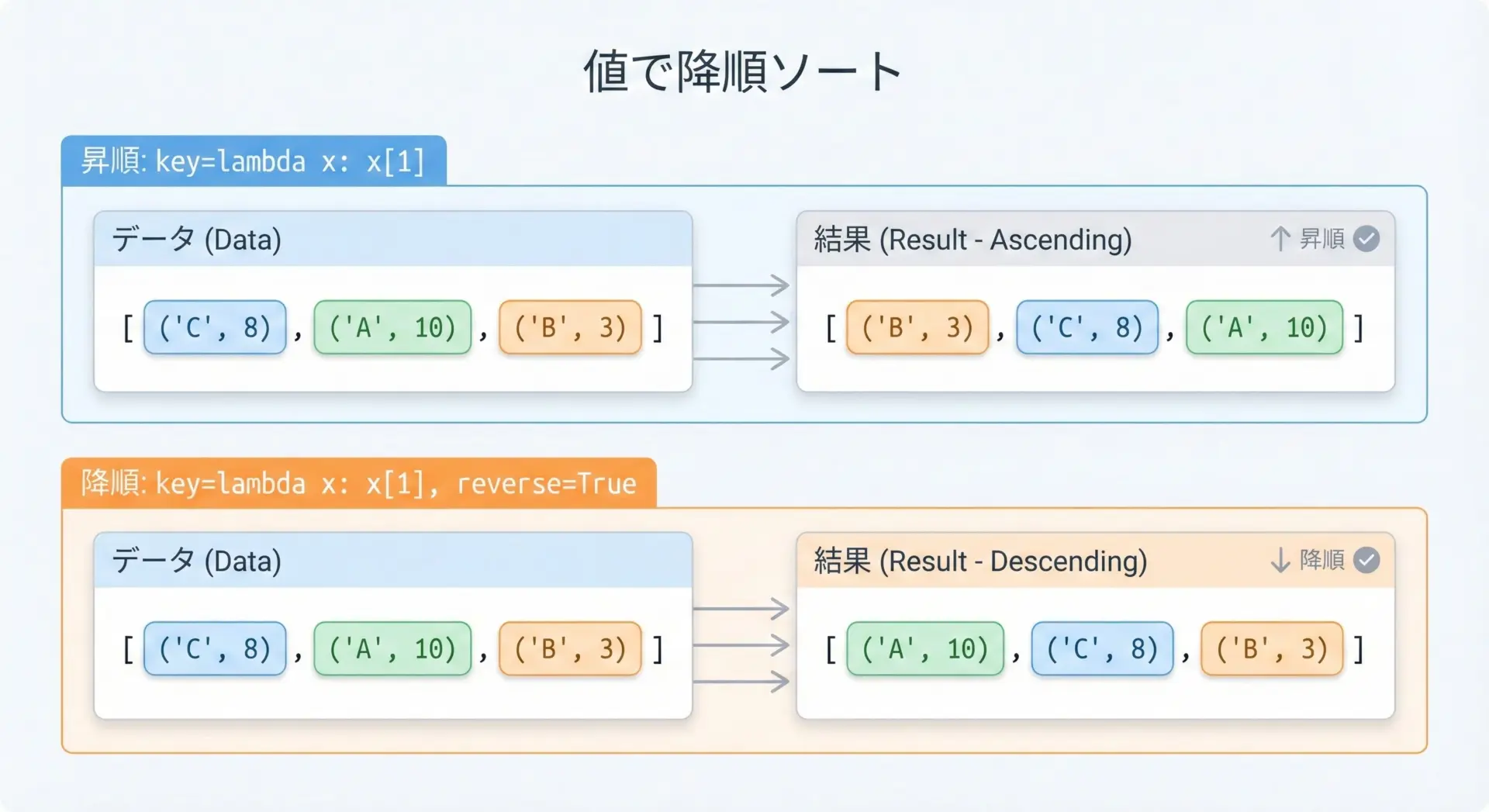
値を降順(大きい順)にしたい場合も、reverse=Trueを組み合わせて指定します。
scores = {"alice": 80, "bob": 70, "charlie": 90}
# 値(スコア)を降順に並び替え
sorted_by_value_desc = sorted(scores.items(), key=lambda x: x[1], reverse=True)
print(sorted_by_value_desc)[('charlie', 90), ('alice', 80), ('bob', 70)]「ランキングを作りたい」「スコアの高い人から順に表示したい」といった場面では、このパターンが非常によく使われます。
同じ値がある場合の並び
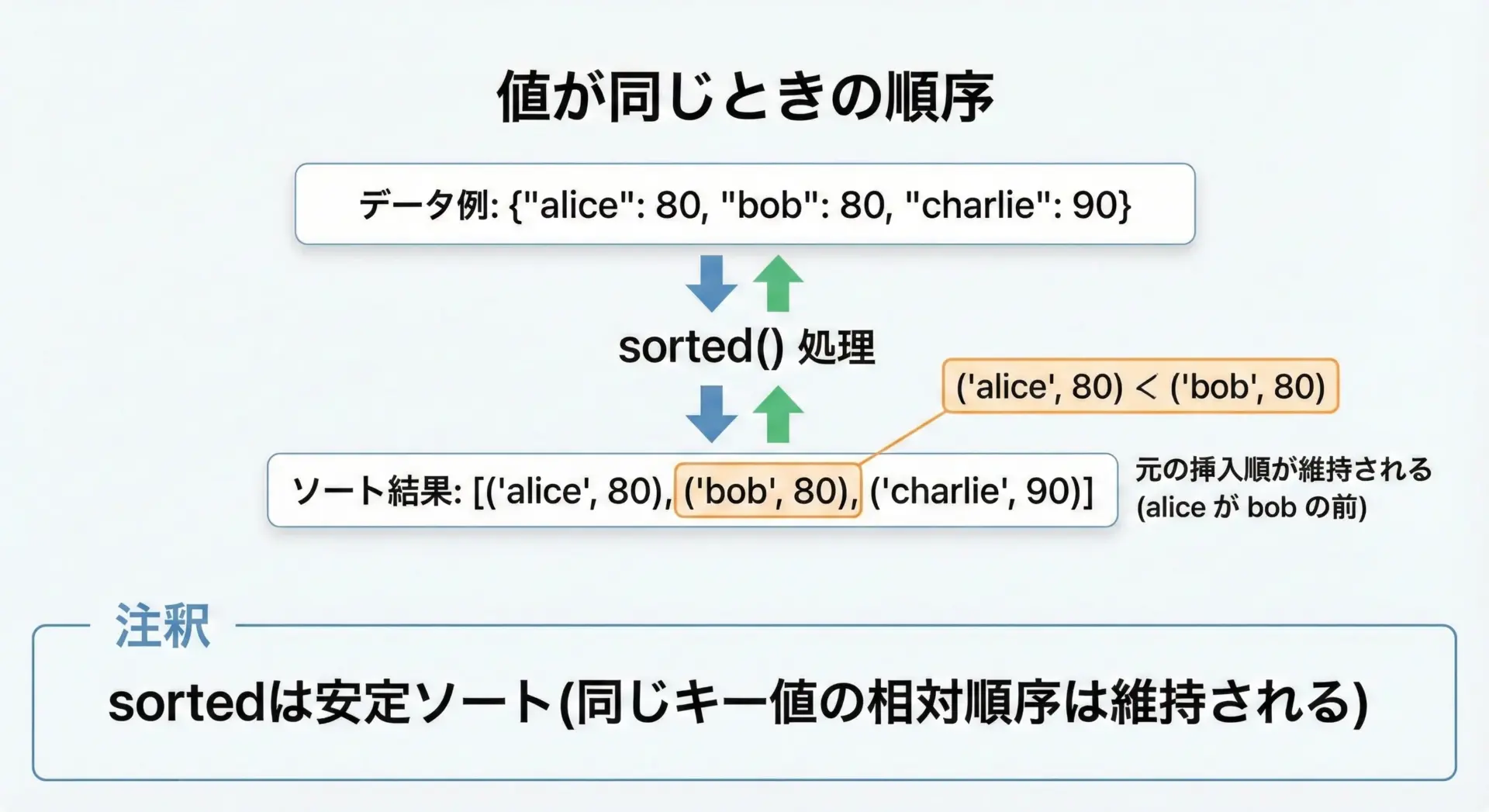
値でソートしたときに同じ値が複数ある場合、Pythonのsortedは「安定ソート」なので、同じ値同士の相対的な順番は、元の順番が維持されます。
scores = {"alice": 80, "bob": 80, "charlie": 90}
sorted_by_value = sorted(scores.items(), key=lambda x: x[1])
print(sorted_by_value)[('alice', 80), ('bob', 80), ('charlie', 90)]この例では、aliceとbobのスコアはどちらも80ですが、scoresに挿入した順番がalice→bobであるため、その順番が維持されています。
もし「同じ値のときはキーのアルファベット順にしたい」といった要件がある場合は、後述する複数条件ソートを使います。
値順ソートから辞書を再構築する方法
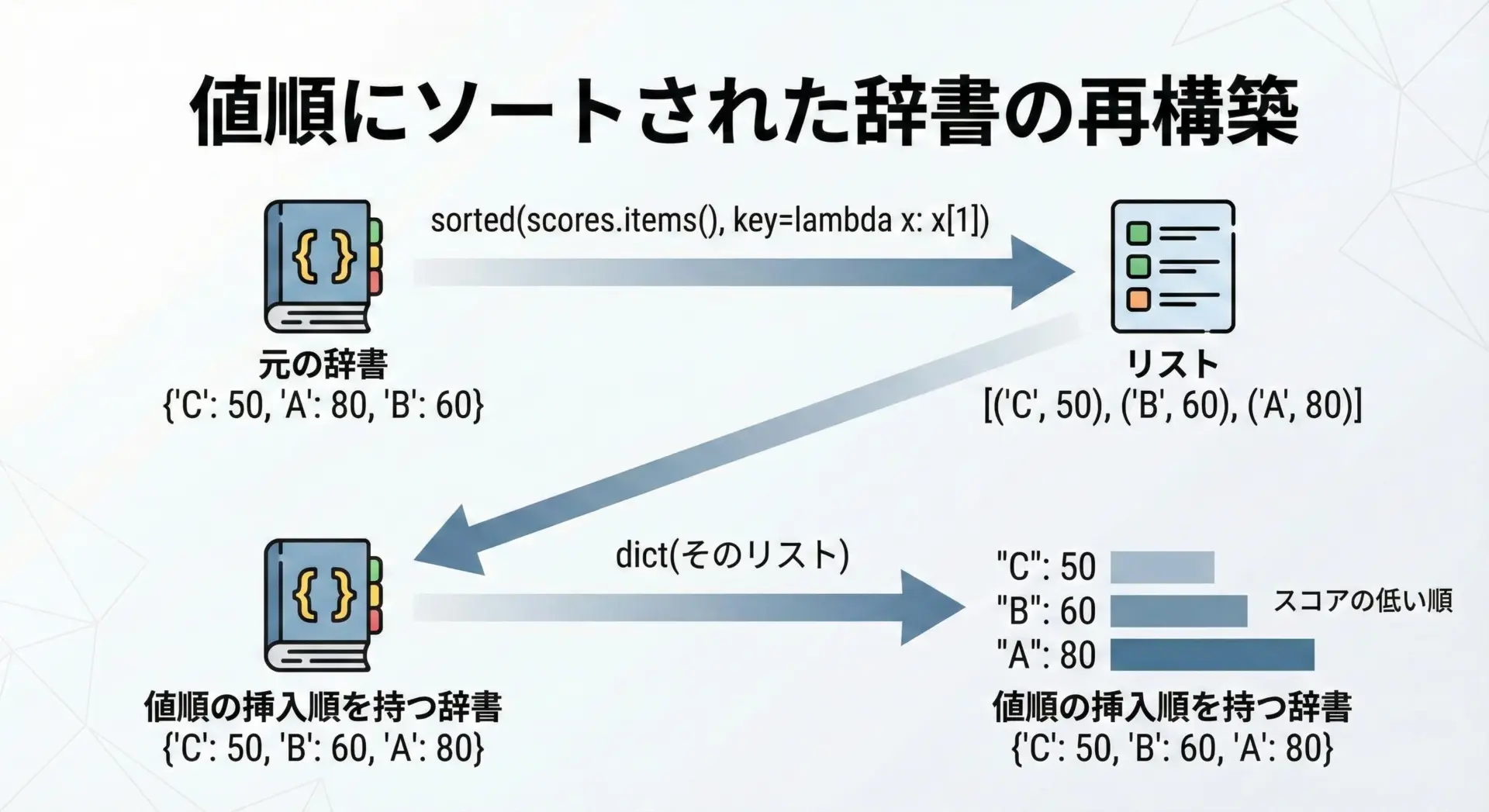
値順でソートした結果を「順序付き辞書」として扱いたいときには、キーソートと同じようにdict()で再構築します。
scores = {"alice": 80, "bob": 70, "charlie": 90}
# 値(スコア)の昇順でソートした辞書を作る
sorted_scores_by_value = dict(
sorted(scores.items(), key=lambda x: x[1])
)
print(sorted_scores_by_value){'bob': 70, 'alice': 80, 'charlie': 90}このsorted_scores_by_valueは、「スコアの低い順」に挿入された辞書になっているため、後からループで回してもこの順序が保持されます。
辞書の複数条件ソート
ここまでで「キーだけ」「値だけ」でのソートを見てきました。
しかし実際には、「まず値の昇順、その中でキーの昇順」といった複数条件で並び替えたいことも多くあります。
Pythonのsortedでは、比較に使う値としてタプルを返すことで、簡単に複数条件ソートを実現できます。
値→キーの優先順位で複数条件ソートする
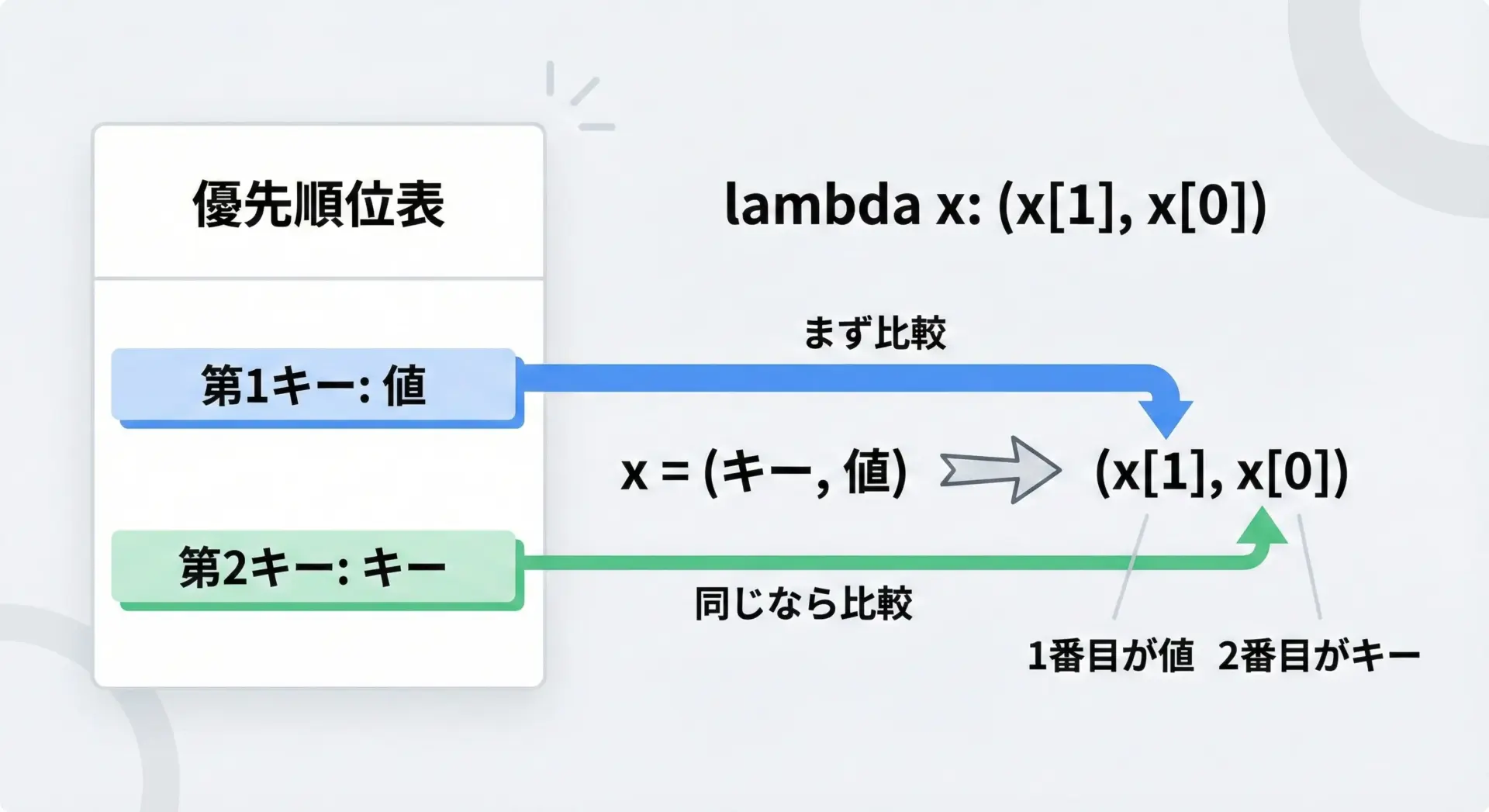
例えば、次のように「スコアが同じ場合は名前のアルファベット順で並べたい」ケースを考えます。
scores = {
"bob": 80,
"alice": 80,
"david": 70,
"charlie": 90,
}ここで、「スコア昇順 → 名前昇順」の優先順位で並び替えるときには、keyに「(値, キー)のタプル」を返すラムダ式を指定します。
scores = {
"bob": 80,
"alice": 80,
"david": 70,
"charlie": 90,
}
# まずスコア(値)の昇順、スコアが同じ場合は名前(キー)の昇順
sorted_multi = sorted(
scores.items(),
key=lambda x: (x[1], x[0]) # (値, キー) の順で比較
)
print(sorted_multi)[('david', 70), ('alice', 80), ('bob', 80), ('charlie', 90)]タプルで指定した順番が、ソートの優先順位になります。
この例では、まずx[1](スコア)で比較し、スコアが同じ場合だけx[0](名前)の比較になります。
複数条件をタプル(key=lambda x: (x[1], x[0]))で指定
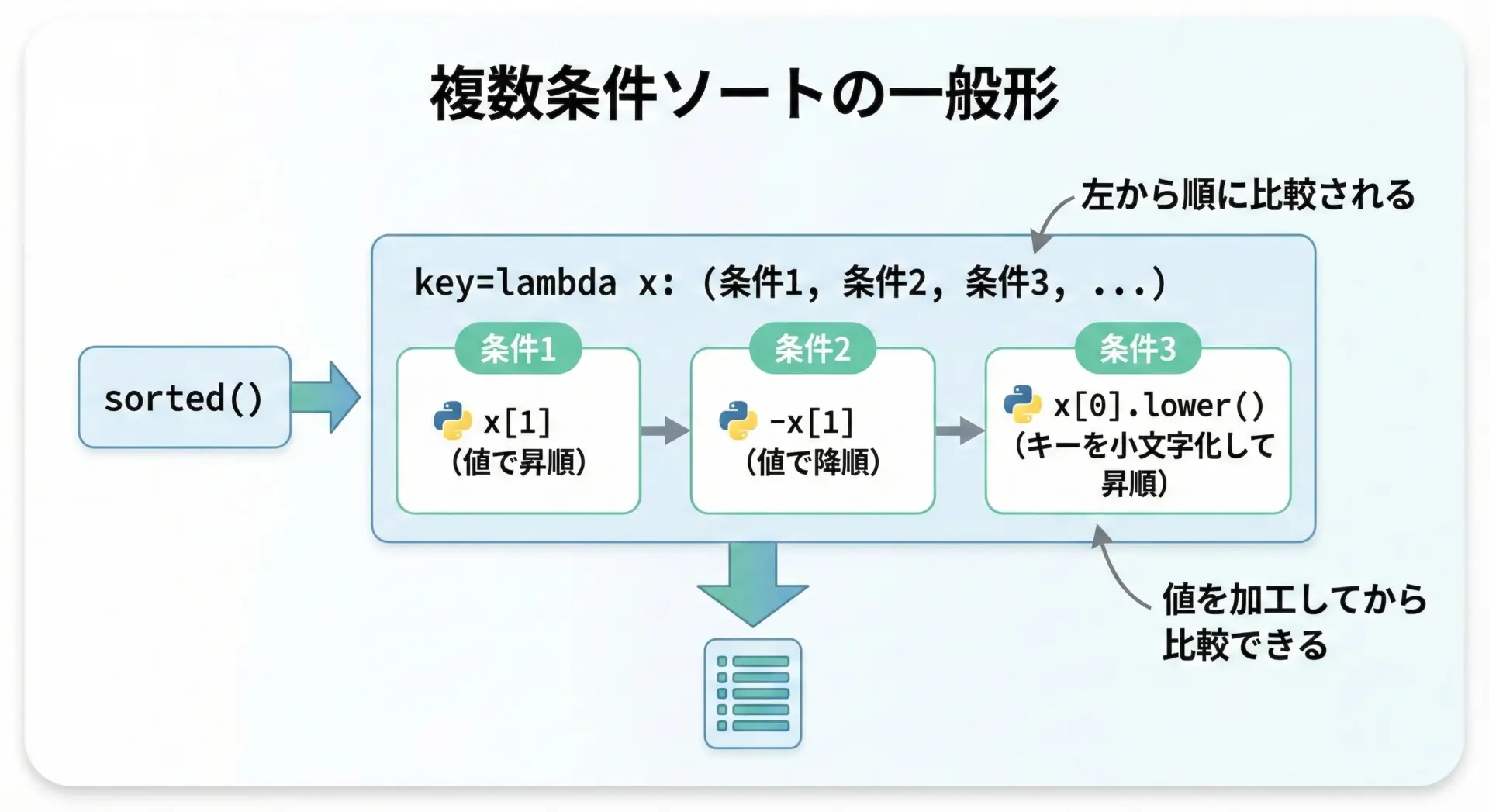
複数条件ソートでは、タプルの中にいくつでも条件を入れることができます。
例えば次のようなバリエーションが考えられます。
scores = {
"Bob": 80,
"alice": 80,
"david": 70,
"Charlie": 90,
}
# 1. スコア昇順 → 名前(小文字として)の昇順
sorted_case_insensitive = sorted(
scores.items(),
key=lambda x: (x[1], x[0].lower())
)
# 2. スコア“降順” → 名前昇順
# 降順にしたい部分はマイナスを付けて「疑似的に逆順」にする方法もある
sorted_score_desc_name_asc = sorted(
scores.items(),
key=lambda x: (-x[1], x[0]) # スコアはマイナスをかけて降順に
)
print("1:", sorted_case_insensitive)
print("2:", sorted_score_desc_name_asc)1: [('david', 70), ('alice', 80), ('Bob', 80), ('Charlie', 90)]
2: [('Charlie', 90), ('Bob', 80), ('alice', 80), ('david', 70)]ここでは、key=lambda x: (x[1], x[0].lower())のように、比較に使う値をその場で加工してからタプルにまとめている点が重要です。
これにより、単純な昇順・降順だけでなく、細かいルールを組み合わせたソートが可能になります。
文字列・数値を混在させたソートの注意点
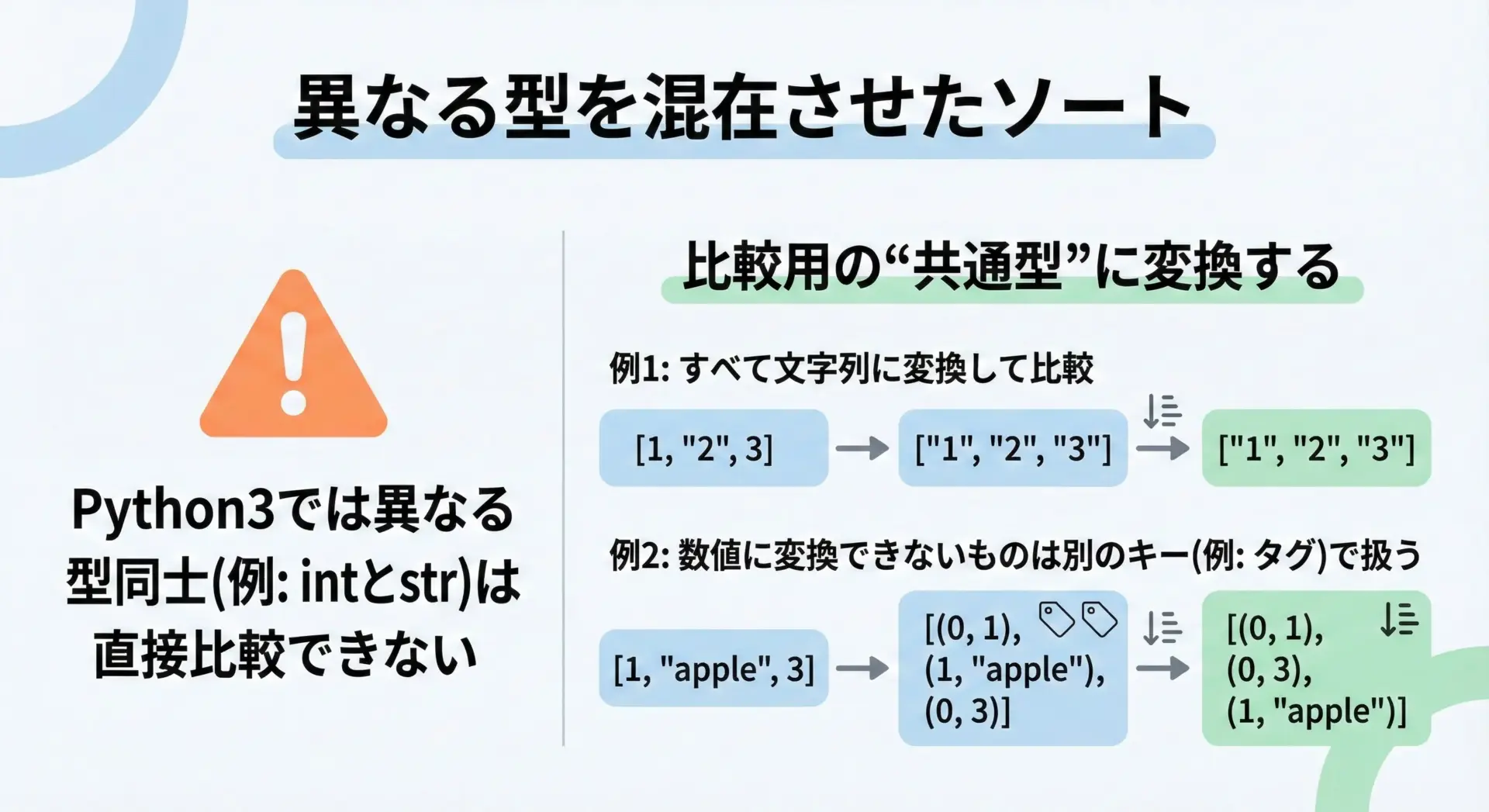
Python3では、異なる型どうしを直接比較してソートしようとするとエラーになります。
特に、値に数値と文字列が混ざっている辞書を、そのままsorted(..., key=lambda x: x[1])とすると失敗することがあります。
data = {"a": 10, "b": "20", "c": 5}
# これは TypeError になる可能性が高い
# sorted(data.items(), key=lambda x: x[1])このような場合は、比較に使う型をそろえる必要があります。
たとえば、「値をすべて文字列として扱ってソートする」などのルールを決めます。
data = {"a": 10, "b": "20", "c": 5}
# すべて文字列に変換してから比較(辞書の値そのものは変更しない)
sorted_mixed = sorted(
data.items(),
key=lambda x: str(x[1]) # 比較用に文字列へ変換
)
print(sorted_mixed)[('a', 10), ('c', 5), ('b', '20')]あるいは、「数値だけでソートし、数値でないものは最後に回す」といった、条件分岐を含むラムダ式を書くこともできます。
data = {"a": 10, "b": "20", "c": 5}
def safe_key(x):
value = x[1]
# 数値なら(0, 数値)、それ以外は(1, 文字列) というタプルにする
if isinstance(value, (int, float)):
return (0, value)
else:
return (1, str(value))
sorted_safe = sorted(data.items(), key=safe_key)
print(sorted_safe)[('c', 5), ('a', 10), ('b', '20')]ここでは、第1要素で「数値かどうか」を区別し、第2要素で実際の値を比較しています。
このように、異なる型が混在する場面では、そのまま比較しようとせず、「比較に使うための一貫した型」を設計することが重要です。
itemsメソッドを使った柔軟なソートパターン
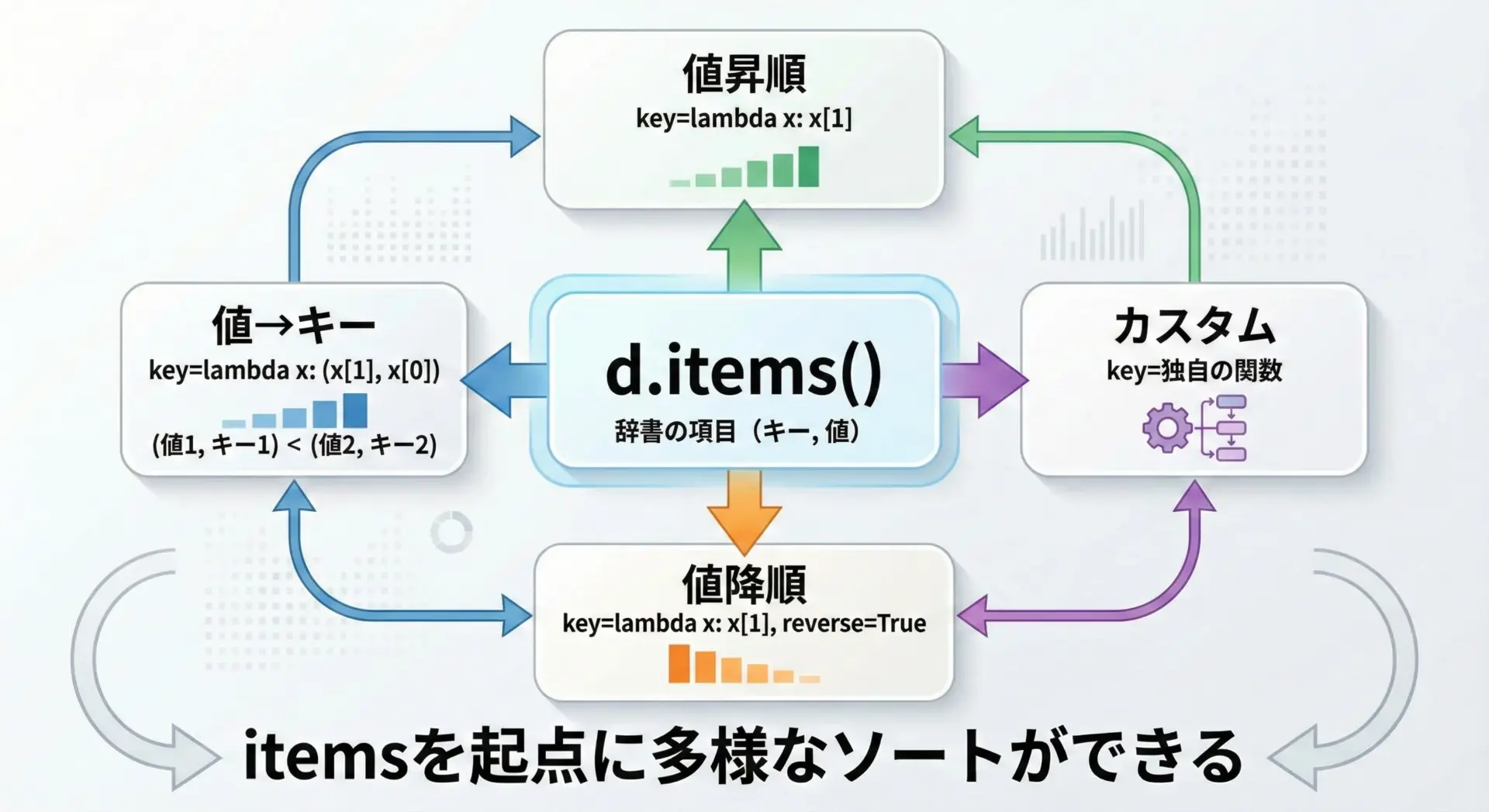
ここまでの例からも分かるように、dict.items()を起点にソートすると、非常に柔軟な並び替えが可能になります。
典型的なパターンをまとめると、次のようになります。
data = {
"alice": 3,
"bob": 1,
"charlie": 2,
}
# 1. キー昇順
sorted_by_key = sorted(data.items(), key=lambda x: x[0])
# 2. 値昇順
sorted_by_value = sorted(data.items(), key=lambda x: x[1])
# 3. 値降順 → キー昇順
sorted_by_value_desc_key = sorted(
data.items(),
key=lambda x: (-x[1], x[0])
)
# 4. 独自ルール: 「名前の長さ」→「名前の昇順」
sorted_custom = sorted(
data.items(),
key=lambda x: (len(x[0]), x[0])
)
print("1:", sorted_by_key)
print("2:", sorted_by_value)
print("3:", sorted_by_value_desc_key)
print("4:", sorted_custom)1: [('alice', 3), ('bob', 1), ('charlie', 2)]
2: [('bob', 1), ('charlie', 2), ('alice', 3)]
3: [('alice', 3), ('charlie', 2), ('bob', 1)]
4: [('bob', 1), ('alice', 3), ('charlie', 2)]まずitems()で(キー, 値)タプルを取り出す、次にsorted(..., key=...)にラムダ式で基準を渡す、必要に応じてdict()で再構築するという3ステップを押さえておけば、多くのパターンに対応できます。
まとめ
Pythonの辞書は挿入順を保持しますが、自動的にキー順・値順にソートされるわけではありません。
そのため、並び替えが必要なときはsortedとラムダ式を組み合わせて、自分で順序を定義することが重要です。
キー順に並べたいときはsorted(d.keys())やsorted(d.items())、値順に並べたいときはkey=lambda x: x[1]という書き方を基本形として覚えておくとよいでしょう。
さらに、タプルを使った複数条件ソートを身につければ、「値→キー」などの複雑な並び替えにも柔軟に対応できます。
