Pythonの辞書(dict)では、データをキーと値のペアで扱います。
その中でもkeysとvaluesは、キー一覧・値一覧を効率よく取得するための中核的な仕組みです。
本記事では、基本から実践的なテクニック、パフォーマンスまで丁寧に解説します。
図解を交えながら、初心者でも理解しやすい形で整理していきます。
辞書のkeysとvaluesとは
keysとvaluesの基本と役割
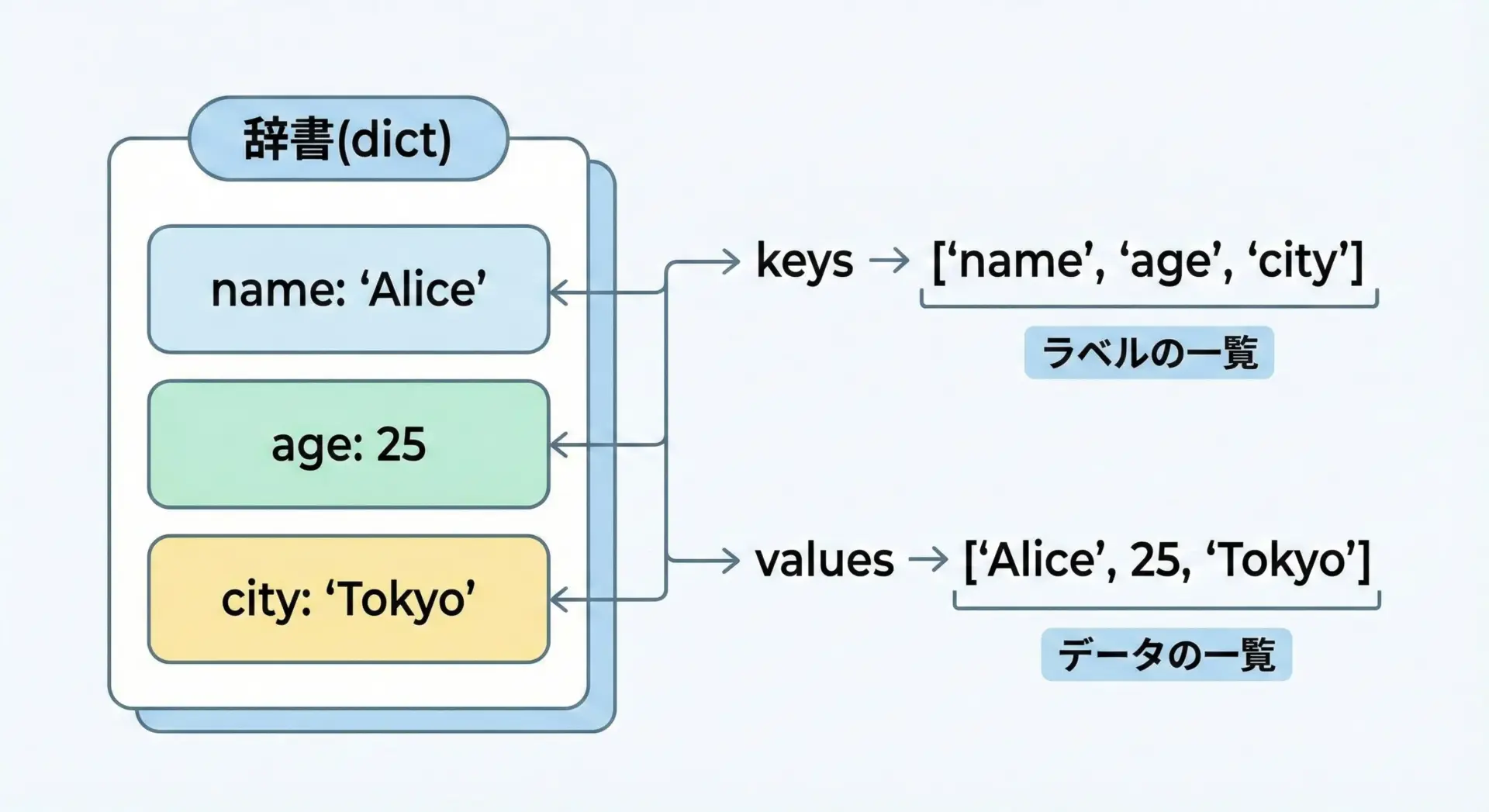
Pythonの辞書は、キーと値のペアをまとめて管理するためのデータ構造です。
例えば、ユーザー情報を表す辞書は次のようになります。
user = {
"name": "Alice",
"age": 25,
"city": "Tokyo"
}このとき、辞書には3つのペアが格納されています。
- キー(name, age, city)
- 値(“Alice”, 25, “Tokyo”)
dict.keysは、辞書に存在するキーの一覧を取り出すための機能です。
dict.valuesは、辞書に存在する値の一覧を取り出すための機能です。
どちらもメソッドとして提供されており、次のように使います。
user = {"name": "Alice", "age": 25, "city": "Tokyo"}
keys_view = user.keys()
values_view = user.values()
print(keys_view)
print(values_view)dict_keys(['name', 'age', 'city'])
dict_values(['Alice', 25, 'Tokyo'])ここで返ってくるのはリストではなくビューオブジェクトです。
ビューオブジェクトは、元の辞書を参照する「窓」のようなもので、元の辞書が変化するとビュー側も自動的に内容が変わるという特徴があります。
itemsとの違いと使い分け
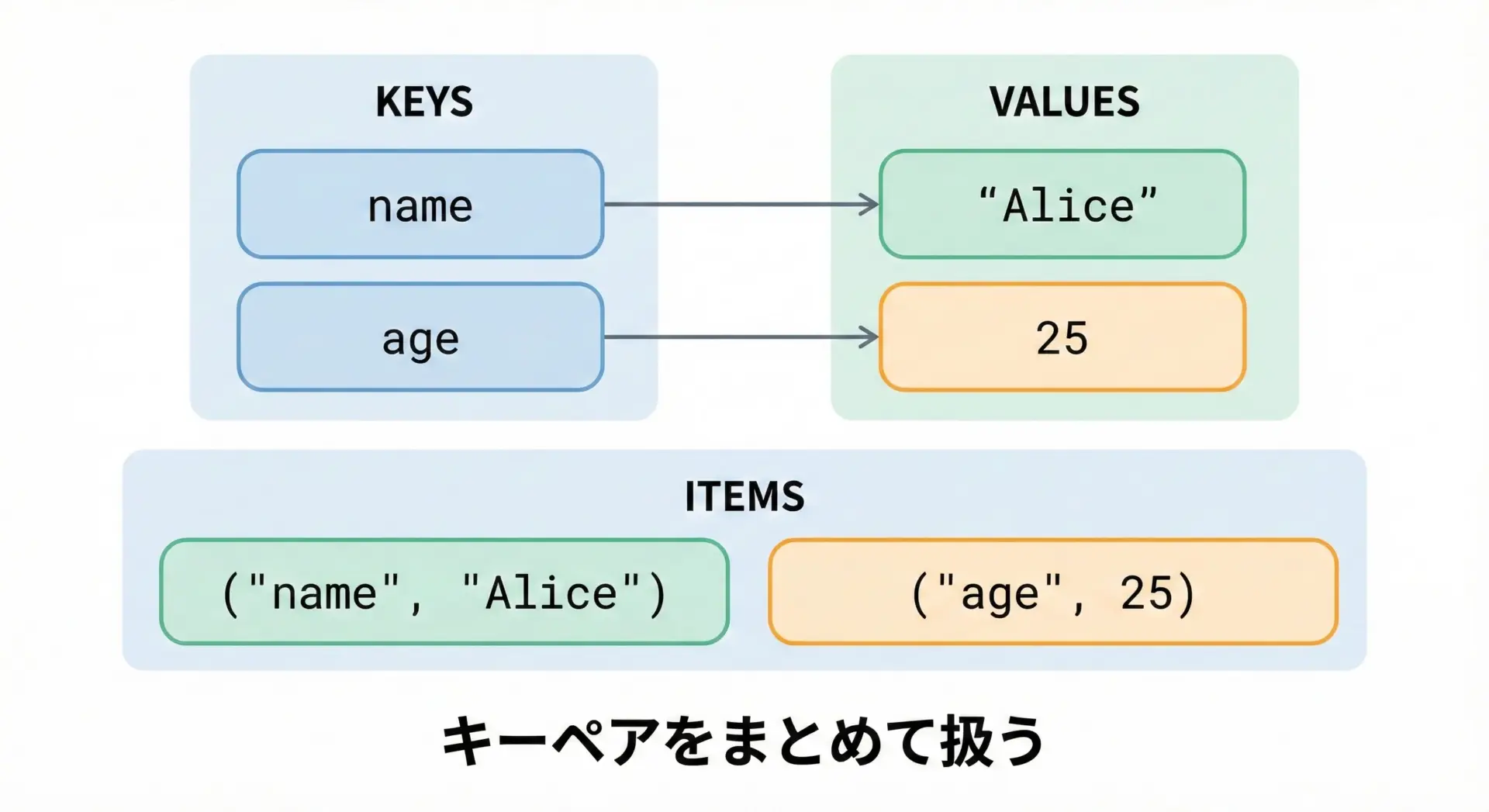
辞書にはitemsというメソッドもあります。
user = {"name": "Alice", "age": 25}
print(user.items())dict_items([('name', 'Alice'), ('age', 25)])itemsは「(キー, 値)のペア」を一覧として扱うためのビューです。
それぞれの特徴を整理すると、次のようになります。
| メソッド | 返り値の型(ビュー) | 何が欲しいとき向きか |
|---|---|---|
| keys() | dict_keys | キーだけを一覧で処理したいとき |
| values() | dict_values | 値だけを集計・検索したいとき |
| items() | dict_items | キーと値をセットでループ処理したいとき |
使い分けの目安としては、次のように考えると分かりやすいです。
- 条件分岐や存在確認など、キー中心の処理 →
keys() - 合計・最大値など、値に対する集計や分析 →
values() - キーから値を同時に参照しながら処理する →
items()が基本
実務では、ループ処理はほとんどitems()で書くと言ってよいほど、itemsの出番が多くなります。
dict.keysでキー一覧を取得する方法
keysメソッドの基本的な使い方
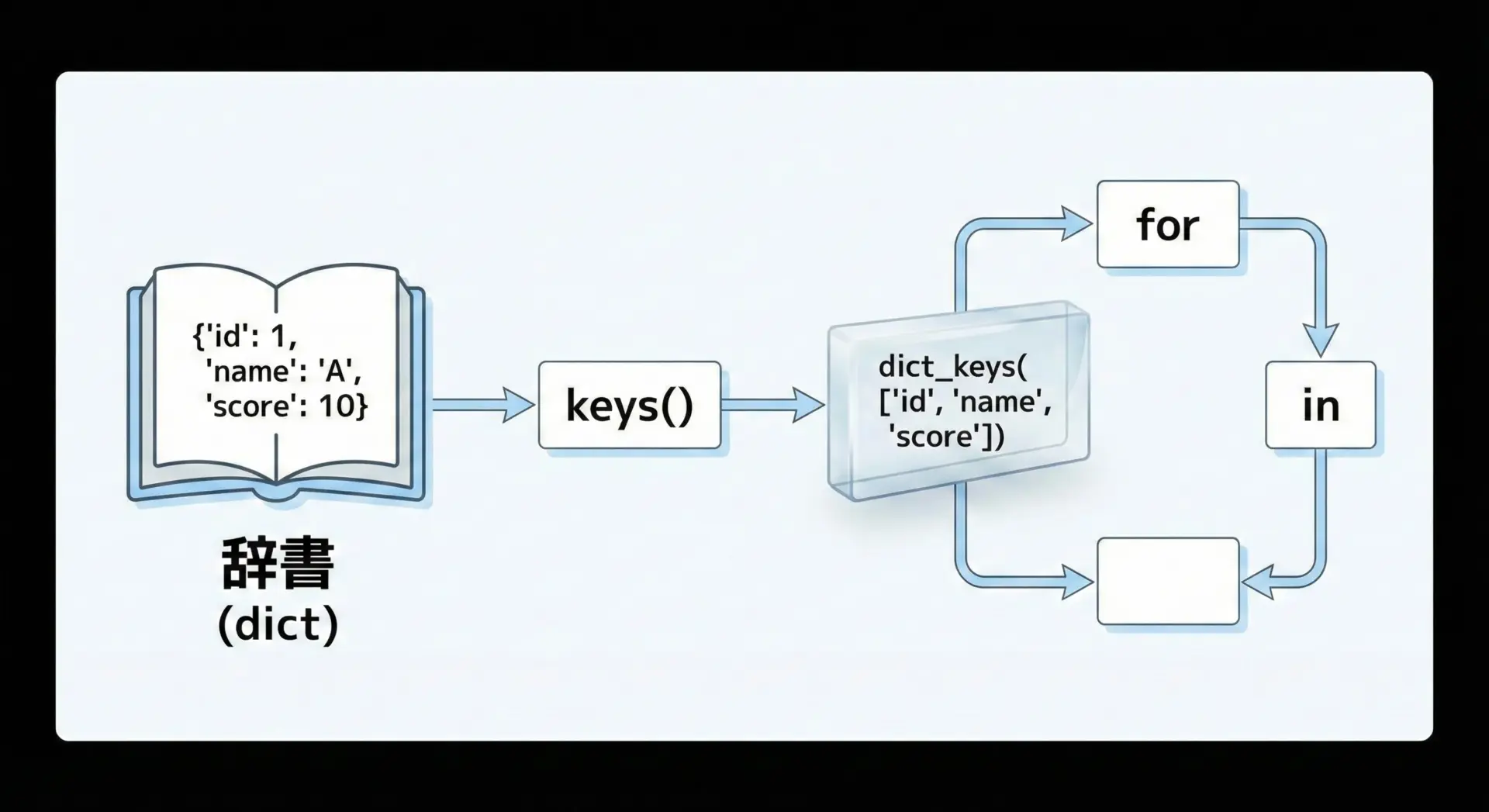
keysメソッドは、辞書に登録されているキーをまとめて参照したいときに使います。
基本形は次の通りです。
scores = {"Alice": 80, "Bob": 75, "Charlie": 90}
# キーのビューオブジェクトを取得
keys_view = scores.keys()
print(keys_view)
print(type(keys_view))dict_keys(['Alice', 'Bob', 'Charlie'])
<class 'dict_keys'>ここで大事なのはdict_keysはリストではないという点です。
そのため、インデックスでのアクセスはできません。
scores = {"Alice": 80, "Bob": 75}
keys_view = scores.keys()
# 次はエラーになります
# print(keys_view[0]) # TypeErrorビューオブジェクトはイテラブル(iterable)なので、for文でのループや、in演算子での存在確認にはそのまま使うことができます。
scores = {"Alice": 80, "Bob": 75, "Charlie": 90}
# for文でそのままループ
for name in scores.keys():
print(name)Alice
Bob
Charlielistやfor文でのkeysの活用例
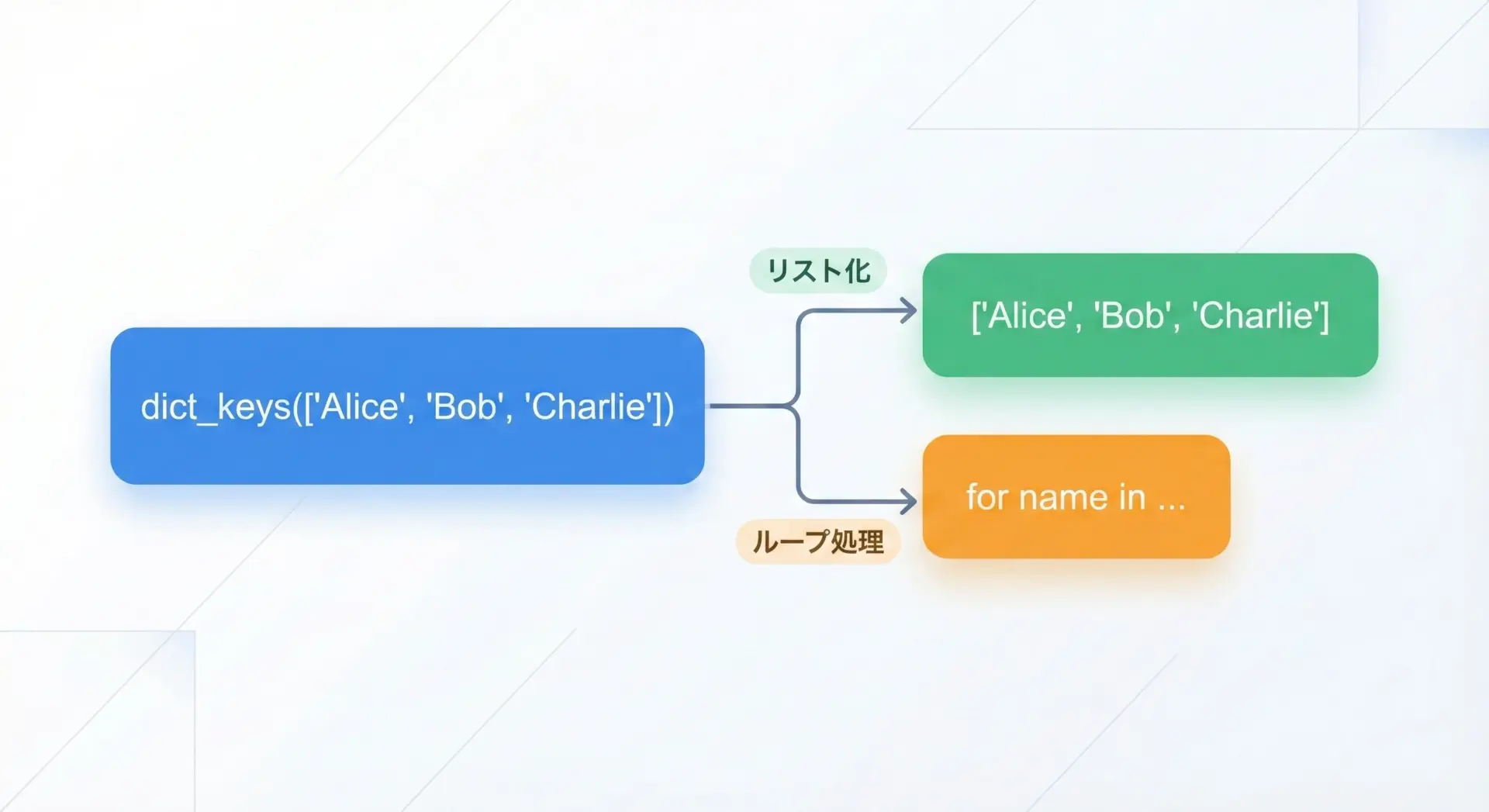
ビューオブジェクトを明示的にリストに変換したい場合は、list()を使います。
scores = {"Alice": 80, "Bob": 75, "Charlie": 90}
keys_list = list(scores.keys())
print(keys_list)
print(type(keys_list))['Alice', 'Bob', 'Charlie']
<class 'list'>キー一覧をリストにしておくと、インデックスアクセスやソートなど、リスト独自の操作が行えます。
scores = {"Alice": 80, "Bob": 75, "Charlie": 90}
keys_list = list(scores.keys())
keys_list.sort() # アルファベット順にソート
print(keys_list)['Alice', 'Bob', 'Charlie']一方で、単にループで全てのキーを処理したいだけであれば、リストに変換せず、そのままfor文に渡す方が効率的です。
scores = {"Alice": 80, "Bob": 75, "Charlie": 90}
# keys()を明示してもよいし、省略してもよい
for name in scores.keys():
print(name, scores[name])
print("----省略記法----")
# 省略記法(デフォルトでキーをループ)
for name in scores:
print(name, scores[name])Alice 80
Bob 75
Charlie 90
----省略記法----
Alice 80
Bob 75
Charlie 90Pythonではfor文で辞書をループすると、デフォルトでキーが取り出されるという仕様になっています。
そのため、for key in my_dict:という書き方が広く使われています。
メモリ効率を意識したkeysの扱い方
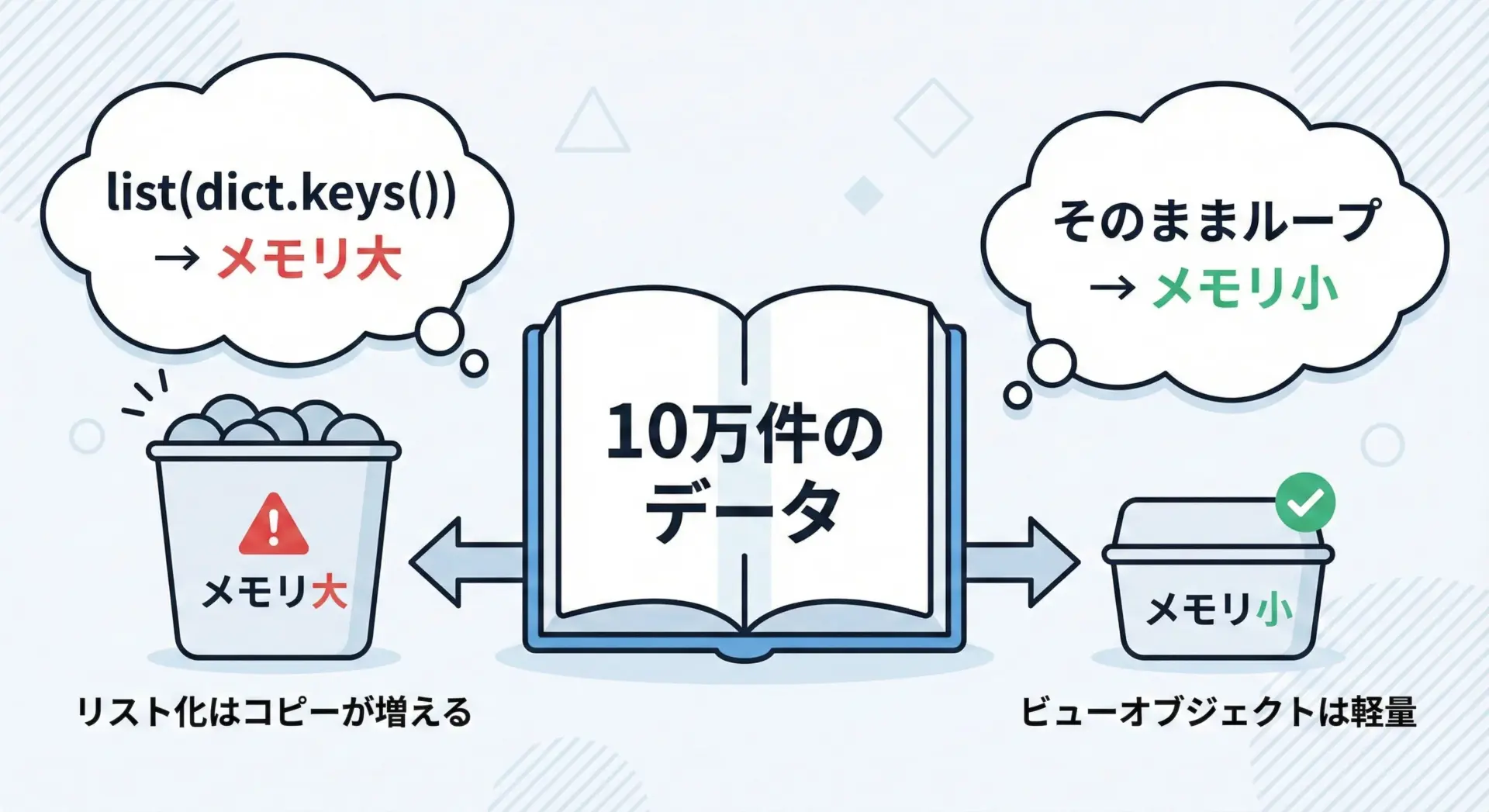
キーの数が少ない場合は、リストに変換しても問題になりにくいですが、何万件・何十万件といった大規模データではメモリ消費が無視できなくなります。
例えば、次の2パターンを比較してみます。
# ダミーの大きな辞書を用意
large_dict = {f"key_{i}": i for i in range(100_000)}
# パターン1: リストにしてからループ
for key in list(large_dict.keys()):
pass # ここでは何もしない
# パターン2: ビューのままループ
for key in large_dict.keys():
pass両者は見た目こそ似ていますが、内部で行っていることは大きく異なります。
- パターン1は、まずキーをすべてコピーしてリストを作成してからループします。
- パターン2は、コピーを作らず、ビューを通じて元の辞書を順番に参照します。
メモリ効率・速度の両面で、不要なリスト化は避けるのがベストプラクティスです。
特にループ用途なら、for key in dict_obj:またはfor key in dict_obj.keys():で十分です。
dict.valuesで値一覧を取得する方法
valuesメソッドの基本的な使い方
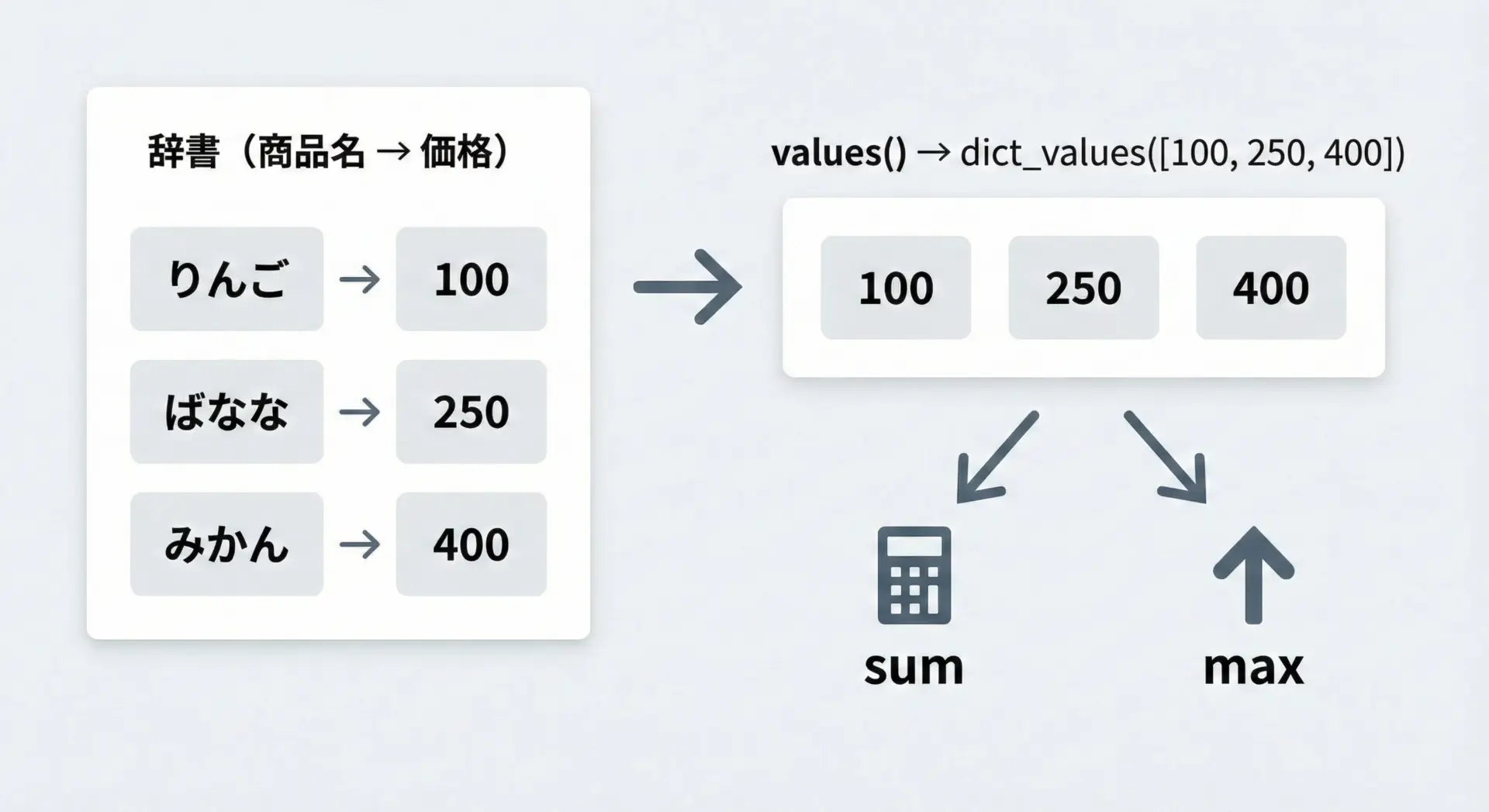
valuesメソッドは、辞書に登録されている値だけを一覧で取り出したいときに使います。
prices = {"apple": 100, "banana": 80, "orange": 120}
values_view = prices.values()
print(values_view)
print(type(values_view))dict_values([100, 80, 120])
<class 'dict_values'>dict_valuesもkeysと同様のビューオブジェクトであり、リストではありません。
そのため、必要に応じてリストへ変換して利用します。
prices = {"apple": 100, "banana": 80, "orange": 120}
values_list = list(prices.values())
print(values_list)[100, 80, 120]ビューオブジェクトは、そのままfor文でループするのに向いています。
prices = {"apple": 100, "banana": 80, "orange": 120}
for price in prices.values():
print(price)100
80
120重複値への注意点と対処法
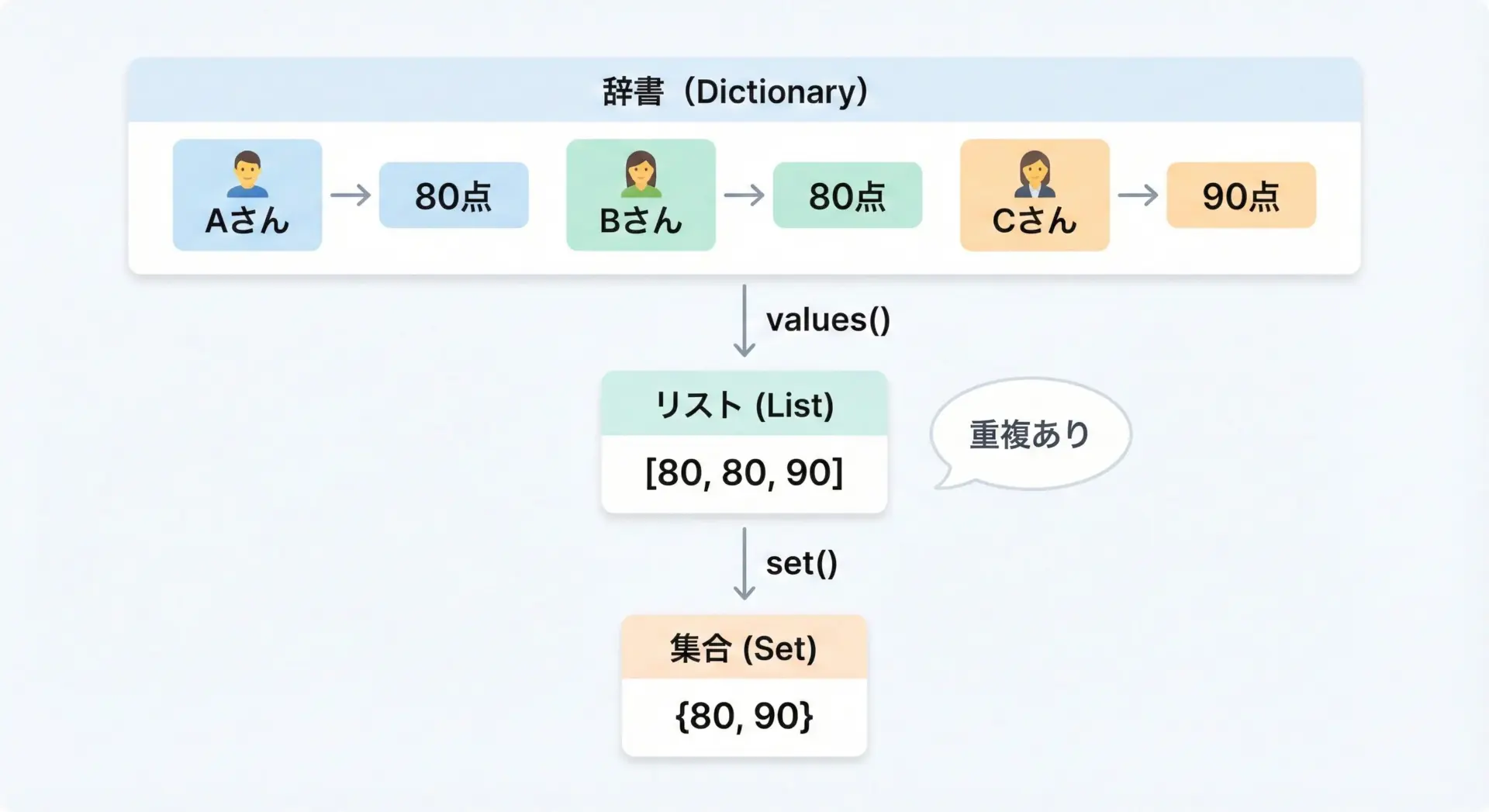
valuesメソッドは、あくまで「辞書に格納された値をそのまま返す」だけなので、値が重複していてもそのまま重複した状態で一覧になります。
scores = {"Alice": 80, "Bob": 80, "Charlie": 90}
values_list = list(scores.values())
print(values_list)[80, 80, 90]もし重複を排除した値の一覧が欲しい場合は、集合型のsetに変換するのが定番です。
scores = {"Alice": 80, "Bob": 80, "Charlie": 90}
unique_scores = set(scores.values())
print(unique_scores){80, 90}ただし、setは順序を保証しない点に注意が必要です。
重複を除きつつ、元の順序を保ちたい場合には、次のように工夫します。
scores = {"Alice": 80, "Bob": 80, "Charlie": 90}
seen = set()
unique_in_order = []
for v in scores.values():
if v not in seen:
seen.add(v)
unique_in_order.append(v)
print(unique_in_order)[80, 90]このように、重複をどう扱いたいかによって、valuesの後処理を工夫することが大切です。
合計・最大値など集計でのvalues活用
valuesメソッドは、数値を集計するときに特に威力を発揮します。
Pythonの組み込み関数と組み合わせれば、少ないコードで集計処理を記述できます。
prices = {"apple": 100, "banana": 80, "orange": 120}
total = sum(prices.values())
maximum = max(prices.values())
minimum = min(prices.values())
average = total / len(prices)
print("合計:", total)
print("最大値:", maximum)
print("最小値:", minimum)
print("平均:", average)合計: 300
最大値: 120
最小値: 80
平均: 100.0また、anyやallと組み合わせることで、条件を満たすかどうかをまとめて判定することもできます。
stocks = {"apple": 10, "banana": 0, "orange": 5}
# 在庫がすべて10以上あるか?
all_enough = all(stock >= 10 for stock in stocks.values())
# どれか1つでも在庫が0か?
any_zero = any(stock == 0 for stock in stocks.values())
print("在庫すべて10以上:", all_enough)
print("どれか在庫0:", any_zero)在庫すべて10以上: False
どれか在庫0: Trueこのように、valuesは「数値の集まり」として扱うことを前提に設計されていると考えると、さまざまな集計アイデアが浮かびやすくなります。
keysとvaluesを効率的に扱うテクニック
keysとvaluesを同時に扱う場合のベストプラクティス
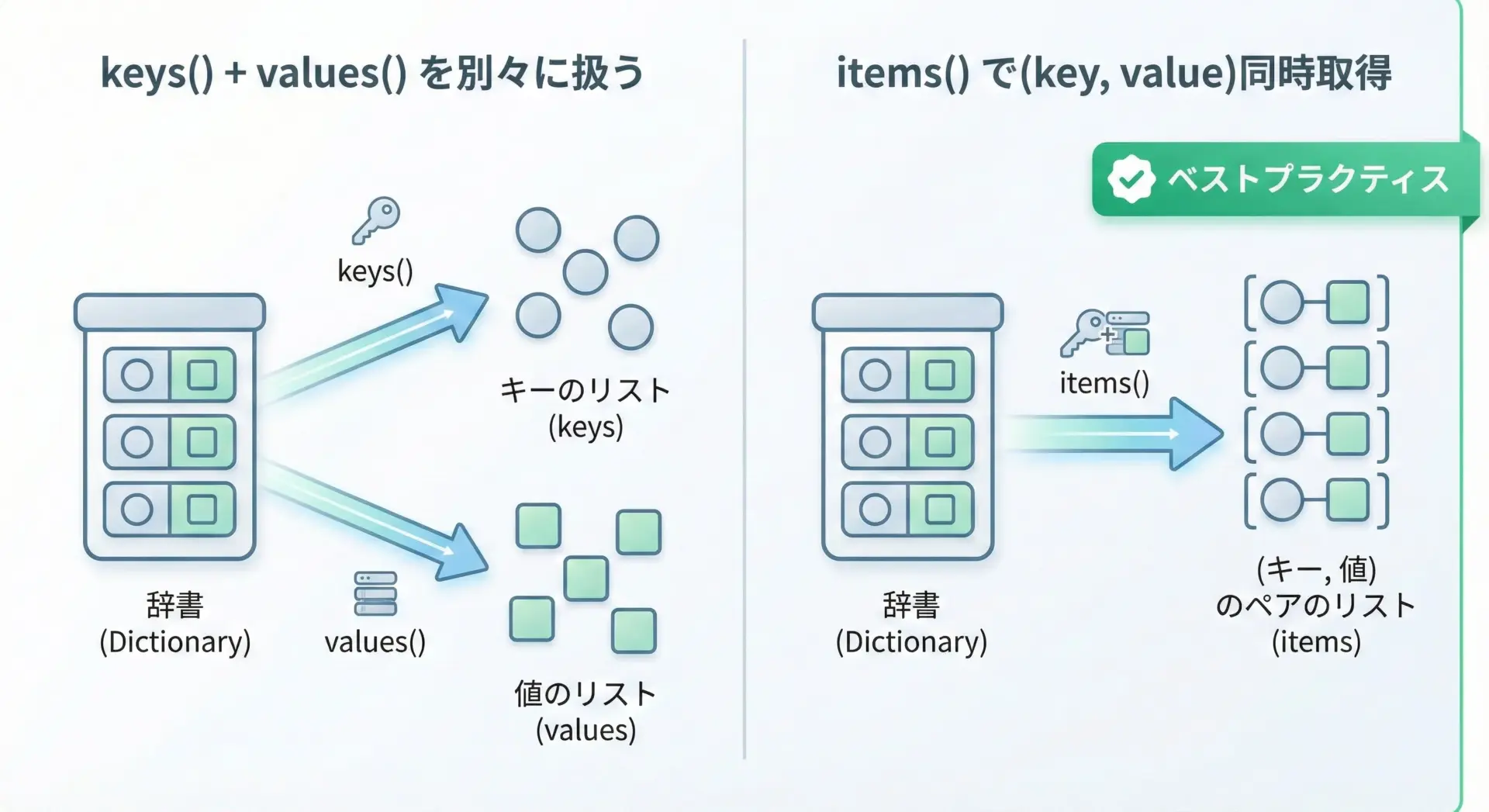
キーと値を同時に扱いたい場合、keysとvaluesを別々にループするのは非推奨です。
例えば次のようなコードはアンチパターンです。
scores = {"Alice": 80, "Bob": 75, "Charlie": 90}
# 悪い例: keysとvaluesを別のループで処理してしまう
for name in scores.keys():
print("名前:", name)
for score in scores.values():
print("点数:", score)この書き方だとキーと値の対応関係がコード上で見えにくく、ミスの原因になります。
代わりに、itemsを使って1回のループでキーと値を同時に取り出すのがベストプラクティスです。
scores = {"Alice": 80, "Bob": 75, "Charlie": 90}
for name, score in scores.items():
# nameとscoreがペアで処理できる
print(f"{name} さんは {score} 点です")Alice さんは 80 点です
Bob さんは 75 点です
Charlie さんは 90 点ですまた、キーと値の両方を加工した新しい辞書を作りたいときにも、itemsを使うと分かりやすく書けます。
scores = {"Alice": 80, "Bob": 75, "Charlie": 90}
# 全員の点数を10点加算した新しい辞書を作る
new_scores = {name: score + 10 for name, score in scores.items()}
print(new_scores){'Alice': 90, 'Bob': 85, 'Charlie': 100}「キーだけ」「値だけ」が欲しいときはkeys・values、「セットで関係を保ったまま処理したい」ときはitemsと覚えておくと実装が安定します。
パフォーマンス比較
keys・values・itemsのどれを使っても、通常規模の辞書であれば速度差はほとんど気になりません。
しかし、規模が大きくなってくると、細かな違いが積み重なることがあります。
以下は、非常に簡単なベンチマークの例です。
import time
data = {f"key_{i}": i for i in range(100_000)}
def loop_keys_direct(d):
# 直接dictをループ(キーを取り出す)
for k in d:
_ = d[k]
def loop_keys_method(d):
# keys()を使ってループ
for k in d.keys():
_ = d[k]
def loop_items(d):
# items()を使ってループ
for k, v in d.items():
_ = v
for func in (loop_keys_direct, loop_keys_method, loop_items):
start = time.time()
func(data)
elapsed = time.time() - start
print(func.__name__, ":", elapsed)loop_keys_direct : 0.0XXX
loop_keys_method : 0.0XXX
loop_items : 0.0XXX※実際の数値は実行環境に依存します。
目安としては次のように考えるとよいです。
- for key in dict: → もっともシンプルで、高速なことが多い
- for key in dict.keys(): → 可読性も高く、速度もほぼ同じ
- for key, value in dict.items(): → キーと値が同時に必要なときの定番
逆に、list(dict.keys())やlist(dict.values())でわざわざリスト化してからループするのは、基本的に不要なコストです。
メモリと時間の両面で損をしやすいため、特別な理由がない限り避けるべきです。
典型的な落とし穴とアンチパターン
辞書のkeys・valuesを使う際に、よくある落とし穴とその解決策をまとめます。
不要なlist変換
次のようなコードはよく見かけますが、ほとんどのケースで不要です。
data = {"a": 1, "b": 2, "c": 3}
# 悪い例: わざわざリストにしてからループ
for key in list(data.keys()):
print(key, data[key])改善案はシンプルで、そのまま辞書をループすることです。
data = {"a": 1, "b": 2, "c": 3}
# 良い例
for key in data:
print(key, data[key])キーをソートしたいなど、リストにしかない操作をする場合だけ、明示的なリスト変換を使うようにしましょう。
ビューをインデックスアクセスしようとする
dict_keysやdict_valuesはリストではないため、次のようなコードはエラーになります。
data = {"a": 1, "b": 2, "c": 3}
keys_view = data.keys()
# エラーになる書き方
# first_key = keys_view[0]インデックスで要素を取りたい場合は、リストに変換する必要があります。
data = {"a": 1, "b": 2, "c": 3}
keys_list = list(data.keys())
first_key = keys_list[0]
print(first_key)aただし、「最初の1件だけ欲しい」といった用途なら、next(iter(...))を使うやり方もあります。
data = {"a": 1, "b": 2, "c": 3}
first_key = next(iter(data.keys()))
print(first_key)aこの方法はリストを作らず、1件だけを取り出せるので効率的です。
ループ中に辞書のサイズを変更する
keys・valuesに限らず、辞書をループしている最中に、その辞書に要素を追加・削除するとエラーになります。
data = {"a": 1, "b": 2, "c": 3}
# 悪い例: 走査中に削除
for key in data.keys():
if key == "b":
# ここで辞書を書き換えるとRuntimeError
# del data[key]
passこの場合は「削除するキーを先にリストアップしておき、ループが終わった後で削除する」パターンが定番です。
data = {"a": 1, "b": 2, "c": 3}
# 削除対象のキーを先に集める
to_delete = [key for key in data if key == "b"]
# ループが終わってから削除
for key in to_delete:
del data[key]
print(data){'a': 1, 'c': 3}このように、走査用のビューと編集用の辞書を同時にいじらないことが、安定したコードを書くためのポイントです。
まとめ
辞書のkeysとvaluesは、キー一覧・値一覧を効率よく扱うための基本機能です。
keysは存在確認やループ処理、valuesは集計や分析で特に力を発揮し、キーと値をセットで扱いたいときにはitemsが最適です。
ビューオブジェクトは軽量で、元の辞書の変更を自動で反映する一方、不要なlist変換やループ中のサイズ変更といったアンチパターンには注意が必要です。
用途に応じてkeys・values・itemsを使い分けることで、読みやすく効率的なPythonコードを書くことができます。
