
Pythonの辞書(dict)を扱うとき、キーの存在確認はとてもよく登場します。
シンプルなin演算子からgetメソッド、そしてKeyErrorを使った例外処理まで、状況に応じた「正しい選び方」ができると、コードは読みやすく安全になります。
本記事では、初心者の方にも分かりやすいように、図解とサンプルコードを交えながら詳しく解説します。
辞書のキー存在確認の基本
dictにキーが存在するか確認する理由
Pythonの辞書でキーの存在確認をする最大の理由は「エラーを防ぎ、安全に値を取り出すため」です。
辞書は「キー」から「値」を取り出すデータ構造です。
例えばユーザー情報を辞書で持っている場合を考えます。
user = {
"name": "Taro",
"age": 20
}
print(user["name"]) # "name"キーの値を取得このとき、存在しないキーを指定するとKeyErrorが発生します。
user = {
"name": "Taro",
"age": 20
}
print(user["email"]) # "email"キーは存在しないTraceback (most recent call last):
File "sample.py", line 6, in <module>
print(user["email"])
KeyError: 'email'このように、辞書から値を取り出す前にキーの存在を確認しておくと、不要なエラーを防ぎ、プログラムを安全に動かすことができます。
また、キーの存在確認は次のような場面でも重要です。
- オプション項目(例: プロフィールの自己紹介文)があるかどうかをチェックしたいとき
- 設定ファイルで、指定されたキーがあるかどうかを検証したいとき
- APIレスポンス(JSON)で、特定のフィールドが送られているかどうか確認したいとき
このように、辞書のキー存在確認は、日常的なPythonプログラミングの中で頻繁に登場します。
Pythonの辞書(dict)でキーを扱う際の注意点
辞書のキーは「存在するかどうか」だけでなく、「どのような型をキーにしているか」「値がNoneのときどう扱うか」も意識する必要があります。
辞書のキーを扱うときに注意したいポイントを、いくつか整理します。
キーと値の「存在」と「中身」を混同しない
キーが存在するかどうかと、値が空かどうかは別問題です。
data = {
"name": "Taro",
"nickname": None,
}
print("nickname" in data) # True
print(data["nickname"]) # NoneTrue
Noneキー"nickname"は存在しているが、その値がNoneである、という状態です。
そのため、「値がNoneだからキーが存在しない」と判断してしまうと、バグの原因になります。
値を見て存在確認しない
次のような書き方は、意図しない動作を生みがちです。
data = {
"count": 0
}
if data.get("count"):
print("countがあります")
else:
print("countがありません")countがありませんこれは0が「偽」と判定されるためです。
「キーが存在するか」を知りたいときはin、値の有無(空文字や0など)を判定したいときは別途条件を書くように意識するとよいです。
ハッシュ可能なオブジェクトしかキーにできない
辞書のキーにできるのは、ハッシュ可能(immutable)なオブジェクトに限られます。
代表的なものは次の通りです。
- 利用できる:
str、int、float、tuple(要素もハッシュ可能な場合) など - 利用できない:
list、dict、setなど
誤ってリストなどをキーにしようとすると、エラーになります。
d = {}
d[[1, 2, 3]] = "NG"TypeError: unhashable type: 'list'辞書でキーを扱うときは、「存在確認」「値の中身」「キーの型」を明確に区別して考えることが大切です。
in演算子を使ったキー存在確認
in演算子によるキー存在確認の書き方
辞書のキー存在確認の最も基本的な方法がin演算子です。
構文はとてもシンプルで、キー in 辞書と書くだけで、そのキーが存在するかTrue/Falseで返ってきます。
user = {
"name": "Taro",
"age": 20
}
print("name" in user) # True
print("email" in user) # FalseTrue
False図解: in演算子によるキー存在確認のイメージ
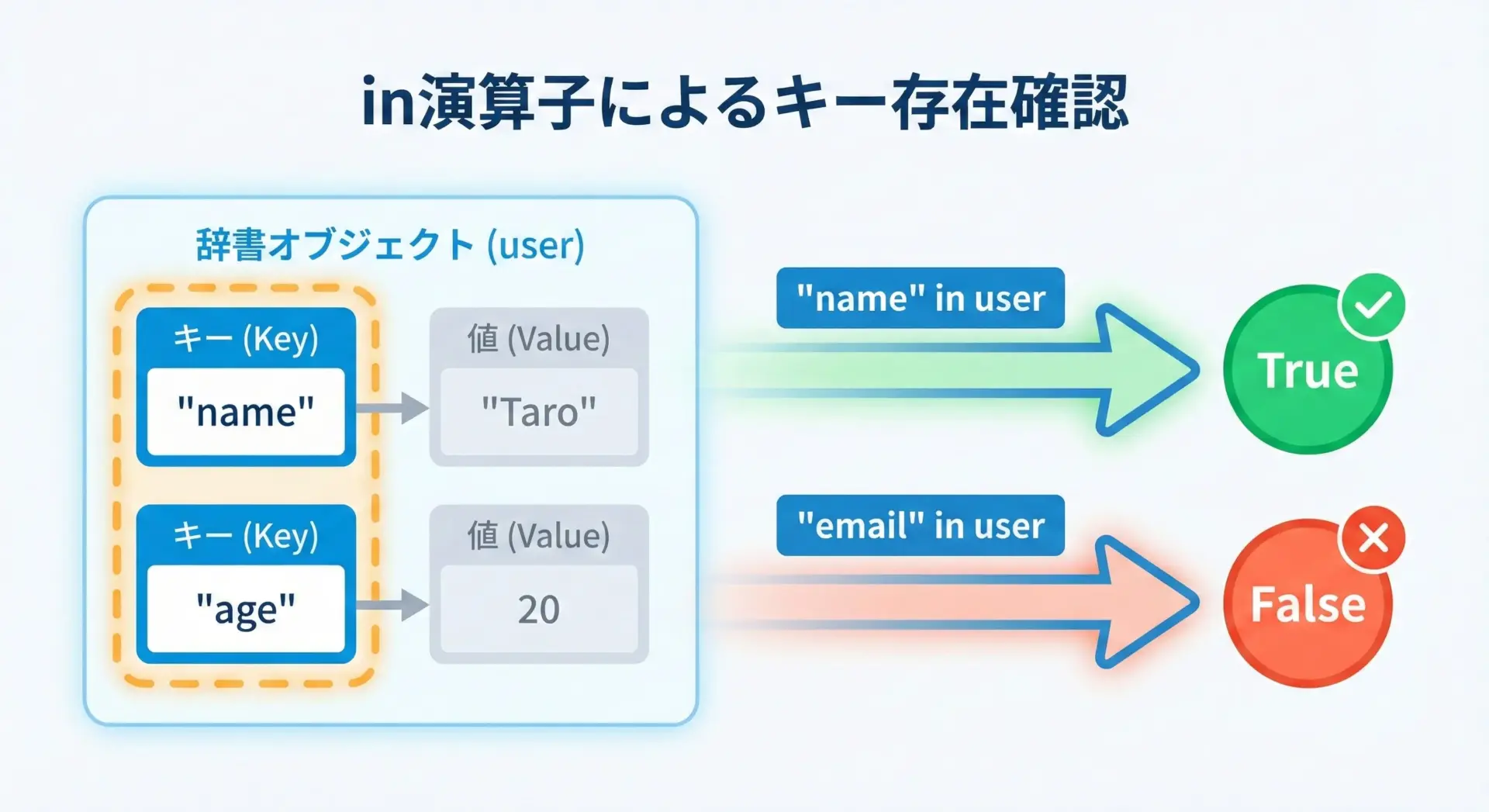
図の通り、in演算子は辞書の「キー」だけを見て存在確認を行います。
値は確認していない点に注意してください。
if文とinを使った典型的なコード例
辞書のキー存在確認は、実際のコードではif文と組み合わせて使うことがほとんどです。
user = {
"name": "Taro",
"age": 20
}
# "email"キーがあるかチェックしてから値を取り出す例
if "email" in user:
# キーが存在するときだけ値を使う
print("メールアドレス:", user["email"])
else:
print("メールアドレスは登録されていません")メールアドレスは登録されていませんこのようにif キー in 辞書という形で、安全に値を取り出せます。
少し応用した例も見てみます。
config = {
"timeout": 10,
"retries": 3,
}
# オプション設定をキー存在で分岐させる例
if "timeout" in config:
print("タイムアウト:", config["timeout"], "秒")
else:
print("デフォルトのタイムアウト値を使います")
if "log_level" in config:
print("ログレベル:", config["log_level"])
else:
print("ログレベルはINFOを使用します")タイムアウト: 10 秒
ログレベルはINFOを使用します値を取り出すときはif キー in dictとdict[キー]をセットで使う、というパターンは非常に頻出です。
in演算子のメリット・デメリット
メリット
1. シンプルで読みやすい
"key" in dという形は直感的で、Pythonに慣れていない人にも意味が伝わりやすいです。
2. 値を見ないので誤判定が少ない
inはあくまで「キーの有無」だけを判定するため、0や""やNoneなど、値が「偽」になるケースに影響されません。
3. パフォーマンスが良い(平均O(1)) 辞書のキー検索はハッシュテーブルを使っているため、平均して非常に高速です。
多くの場面でinはパフォーマンス面でも有利です。
デメリット
1. 存在確認と値取得が分かれる
if "key" in d:で存在を確認し、その後でd["key"]で値を取り出す必要があります。
「存在確認+値取得」を1行で済ませたい場合はgetの方が向いています。
2. デフォルト値を返す処理が書きにくい
「キーがなければこの値を使う」というロジックを書くとき、inだけだと若干まわりくどくなります。
if "timeout" in config:
timeout = config["timeout"]
else:
timeout = 10このような場合、getを使うとすっきり書けます。
詳しくは次の章で説明します。
getメソッドでのキー存在確認とデフォルト値
dict.getでキー存在確認と値取得を同時に行う方法
dict.get()は、キーの存在確認と値の取得を同時に行える便利なメソッドです。
基本の構文は次の通りです。
dict.get(key)dict.get(key, default)
キーが存在する場合は、その値を返します。
存在しない場合は、第二引数で指定したdefaultを返します(省略したときはNoneを返します)。
user = {
"name": "Taro",
"age": 20
}
print(user.get("name")) # "Taro"
print(user.get("email")) # None (デフォルト)Taro
None図解: getメソッドの動き
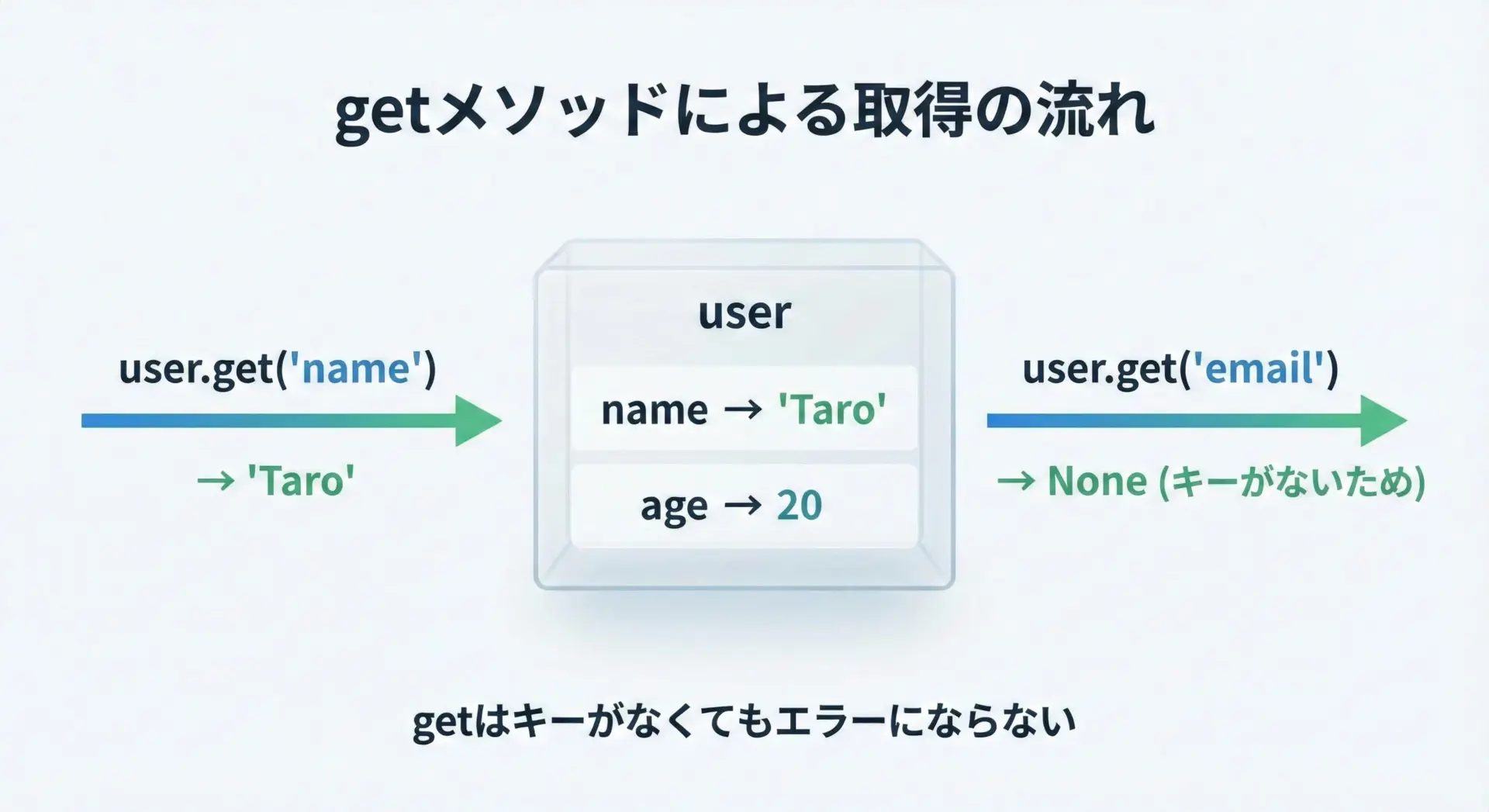
この図のように、getはキーがなくてもKeyErrorを発生させず、安全にNoneやデフォルト値を返してくれます。
getメソッドでデフォルト値を返すパターン
第二引数にデフォルト値を指定することで、「キーがないときの値」を簡単に設定できます。
config = {
"timeout": 10
}
timeout = config.get("timeout", 30) # あればその値、なければ30
mode = config.get("mode", "debug") # あればその値、なければ"debug"
print("timeout:", timeout)
print("mode:", mode)timeout: 10
mode: debugもしキー"mode"が存在しない場合でも、"debug"が返されます。
この書き方は、「存在すればその値、なければこの値」という処理を1行で書けるため、設定値やオプション値を扱う場面でとてもよく使われます。
dict.getとif文を組み合わせる例
getで取得した値を、そのままif文で判定するパターンもよくあります。
params = {
"q": "python dict",
# "page" は省略されることがある
}
page = params.get("page", 1) # ページ番号、省略時は1ページ目
if page == 1:
print("最初のページです")
else:
print(page, "ページ目です")最初のページですこのように、「なければ1を使う」「なければ空文字を使う」「なければ空リストを使う」などを簡潔に書けるのがgetの大きな魅力です。
inとgetの使い分けのポイント
「キーの存在そのものを知りたいのか」「値が欲しいのか」で使い分けると考えると分かりやすくなります。
代表的な使い分けを表にまとめます。
| 目的 | 推奨方法 | 説明 |
|---|---|---|
| キーが存在するかどうかだけ知りたい | "key" in d | 真偽値だけ分かればよい場合。 |
| キーがあれば値を使い、なければ別の値を使いたい | d.get("key", default) | 設定値やオプション処理に最適。 |
| キーがなければエラーにしたい(必須項目など) | d["key"]または例外処理 | 強制的にKeyErrorを発生させて不正データを検出する。 |
具体的な判断基準
- 存在フラグが欲しいだけ
→if "email" in user:のようにinを使う - 「あれば使う、なければデフォルト」を1行で書きたい
→timeout = config.get("timeout", 30)のようにgetを使う - キーがなければ「それはエラーにすべき」仕様
→ わざとd["key"]でKeyErrorを起こすか、後述する例外処理を使う
inは「存在チェック専用」、getは「値取得とデフォルト適用」、角括弧[]は「必須キー」を表す、と覚えておくと使い分けやすくなります。
例外処理(KeyError)を使ったキー存在確認
try-exceptでKeyErrorを捕捉する方法
「キーがなければエラーにしたいが、エラーを自分でハンドリングしたい」という場合に使うのが、try-exceptによるKeyErrorの捕捉です。
基本形は次のようになります。
user = {
"name": "Taro",
"age": 20
}
try:
# 必須とみなすキーを角括弧で取得
email = user["email"]
print("メールアドレス:", email)
except KeyError:
# キーが存在しない場合の処理
print("メールアドレスが設定されていません")メールアドレスが設定されていませんこのように、存在しないキーを角括弧[]でアクセスしたときに発生するKeyErrorを、自分でキャッチして分岐処理を書くことができます。
例: 必須キーと任意キーを分ける
user = {
"name": "Taro",
# "email" は任意
}
try:
# nameは必須項目なので、なければエラーとみなす
name = user["name"]
print("ユーザー名:", name)
except KeyError:
raise ValueError("ユーザー名(name)は必須です")
# emailは任意項目として扱う
email = user.get("email", "(未登録)")
print("メールアドレス:", email)ユーザー名: Taro
メールアドレス: (未登録)この例では、必須キーは角括弧アクセス+KeyErrorで厳しくチェックし、任意キーはgetでゆるく扱う、という使い分けをしています。
例外処理を使ったパフォーマンスと注意点
パフォーマンスの観点
Pythonでは「例外は通常のフローとして多用しない」のが一般的なスタイルです。
理由の1つは、例外処理は通常の処理よりコストが高いからです。
大量ループの中で、キーが存在しないことが頻繁に起こる場合にtry-exceptでKeyErrorを連発させると、パフォーマンスに悪影響が出る可能性があります。
そのため通常は次のような方針がおすすめです。
- 「キーがあることがほぼ確実」なとき:
→ 角括弧[]で直接アクセスし、万が一のために外側で1回だけ例外処理をする - 「キーがないこともよくある」場合:
→inやgetで事前に確認し、例外を乱発させない
可読性の観点
例外処理は強力な仕組みですが、多用するとコードの流れが追いにくくなります。
例として、次の2つの書き方を比べてみます。
# 例1: inでチェックするパターン
if "timeout" in config:
timeout = config["timeout"]
else:
timeout = 30# 例2: 例外処理でチェックするパターン
try:
timeout = config["timeout"]
except KeyError:
timeout = 30どちらも同じ意味ですが、「ただ存在チェックしたいだけ」であれば、例外処理を使わずinやgetで書く方が読みやすいことが多いです。
in・get・例外処理の使い分けまとめ
ここまで紹介した3つの方法を、「意図」と「コード量」「エラー処理の方針」という観点から整理します。
| 方法 | 向いている場面 | 特徴 |
|---|---|---|
in | 「キーの有無」だけを知りたいとき | 真偽値でシンプルに判定。値取得は別途角括弧[]で行う。 |
get | 「存在すればその値、なければデフォルト」を使いたいとき | 1行で書けて読みやすい。KeyErrorを発生させない。 |
try-except KeyError | 「必須キーがなければエラー」という仕様を明示したいとき | エラー処理を細かく制御できるが、多用すると読みにくくなる。 |
簡易的な指針
- 存在チェックだけなら
in
例: 「このオプションが指定されているか?」 - 値+デフォルトが欲しいなら
get
例: 「指定されていなければ10秒にする」 - 必須項目で、なければ例外にしたいなら
[]+例外処理
例: 「ユーザーIDがないレスポンスは不正として扱う」
この3つを場面ごとに正しく使い分けられると、辞書まわりのコードは一気に読みやすく、安全になります。
まとめ
本記事では、Pythonの辞書におけるキーの存在確認について、in演算子、getメソッド、KeyErrorを用いた例外処理の3つの方法を解説しました。
「キーの有無だけを知りたいならin」「値とデフォルトをまとめて扱うならget」「必須項目を厳格に扱うなら例外処理」という使い分けを意識すると、実務でも迷いにくくなります。
辞書のキー存在確認はあらゆるPythonコードで登場する基礎ですので、今回の内容を土台に、実際のプロジェクトでも積極的に活用してみてください。
