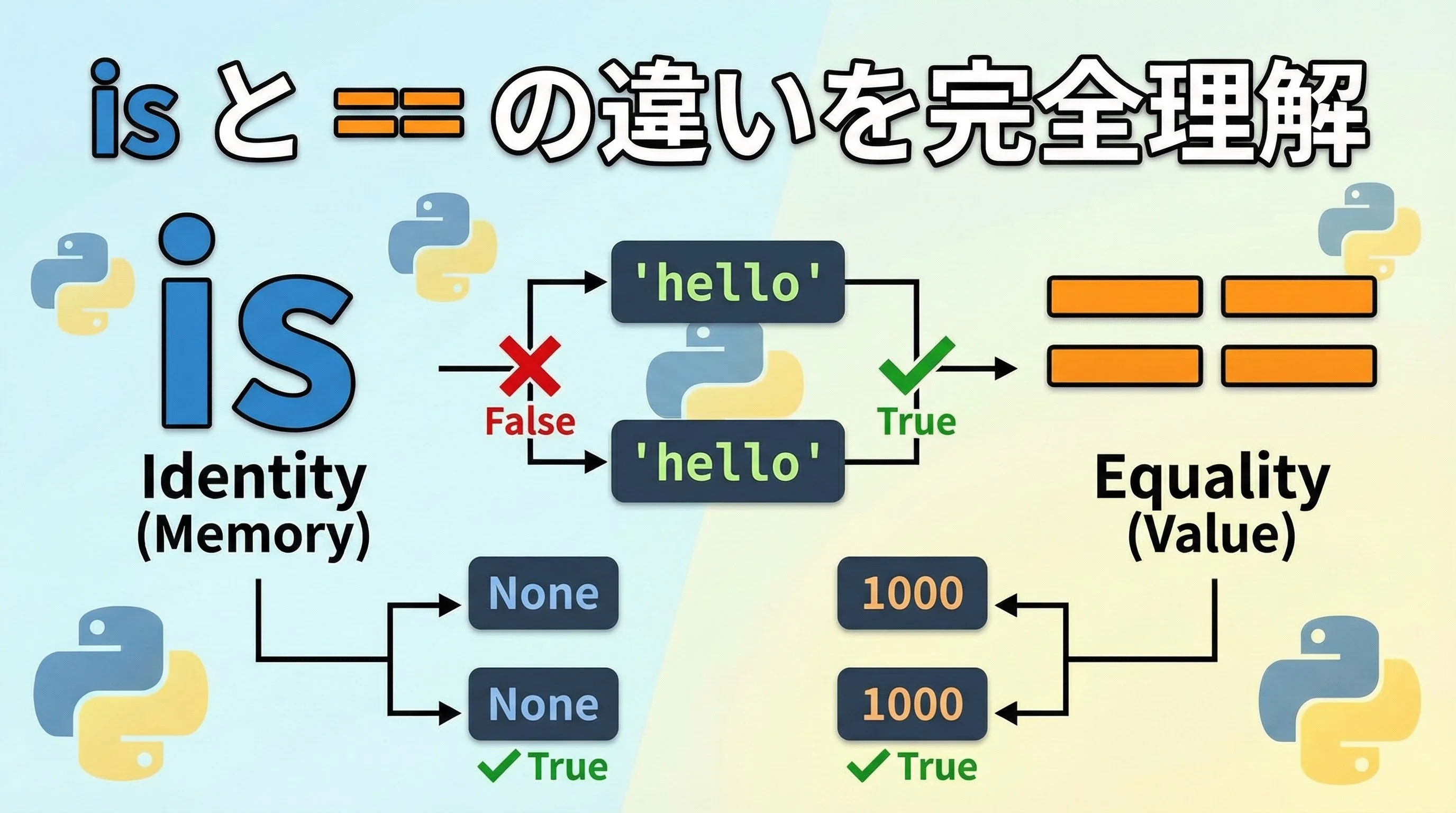
Pythonで値を比較するとき、多くの方がisと==の違いでつまずきます。
特にNoneや文字列、数値などでは、たまたま同じように動いてしまうケースもあり、バグに気づきにくくなります。
本記事では、Pythonの内部的な仕組みもイメージしながら、None・文字列・数値・リスト・独自クラスといった具体例を通して、isと==の正しい使い分けをじっくり解説していきます。
Pythonのisと==の基本的な違い
isは「同一オブジェクトか」を比較する演算子
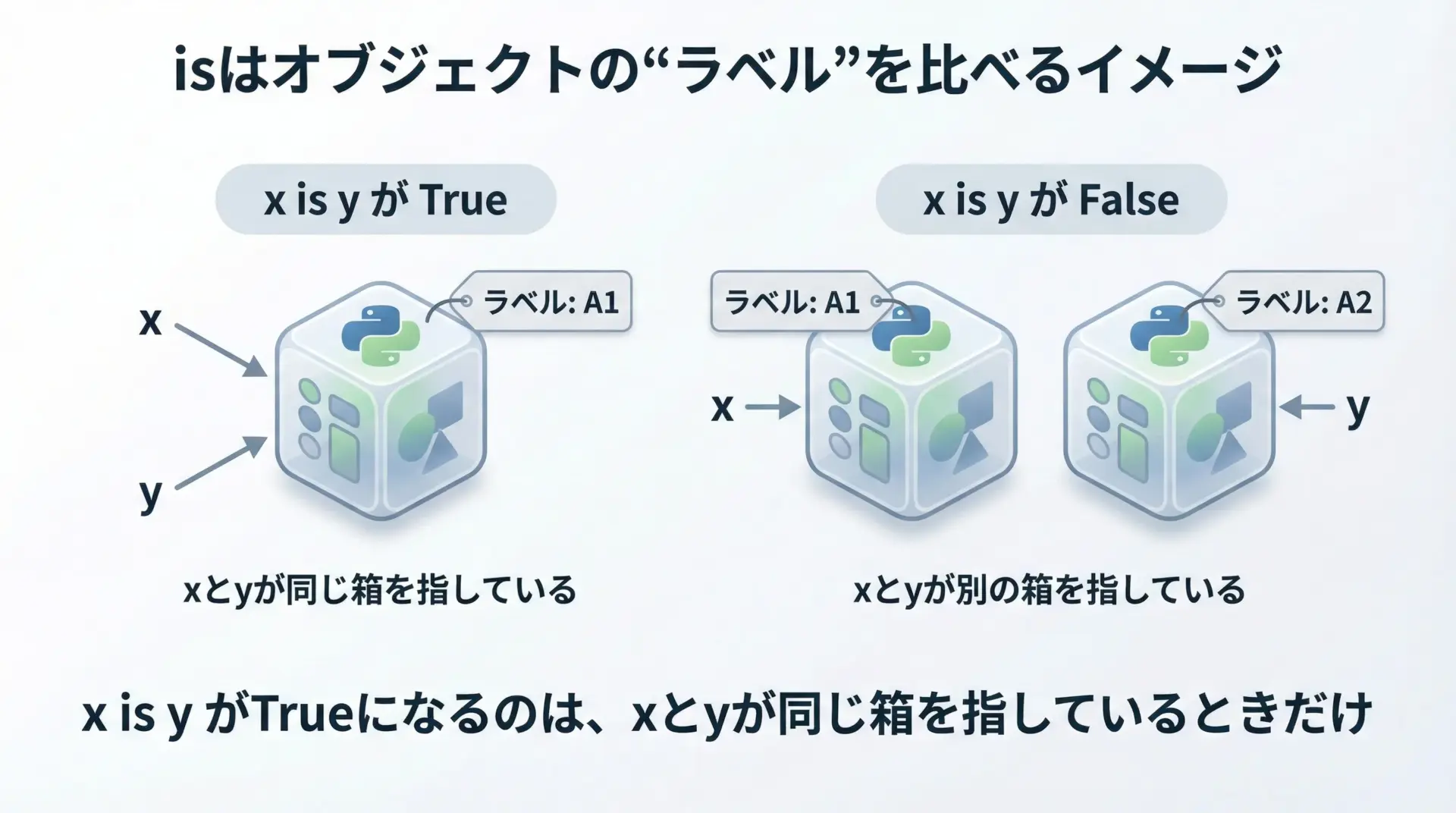
Pythonでは、変数は「値そのもの」ではなくオブジェクトへの参照を持っています。
演算子isは、2つの変数が「まったく同じオブジェクト」を指しているかどうかを調べるための演算子です。
もう少し日常的なイメージにすると、「同じ人を指しているか」を比べるのがisということになります。
同姓同名の別人ではなく、物理的に同じ人かどうかを比べているイメージです。
実際の挙動を簡単なコードで確認してみます。
# is の基本的な挙動を確認するサンプル
a = [1, 2, 3]
b = a # bはaと同じリストオブジェクトを参照
c = [1, 2, 3] # cは同じ内容だが、別に作られたリストオブジェクト
print(a is b) # 同じオブジェクトを指しているか
print(a is c) # 見た目が同じでも、オブジェクトとして同じかTrue
Falseaとbは同じリストオブジェクトを共有しているためa is bはTrueになります。
一方で、aとcは内容は同じでも別々に作られたリストなのでa is cはFalseになります。
==は「値が等しいか」を比較する演算子
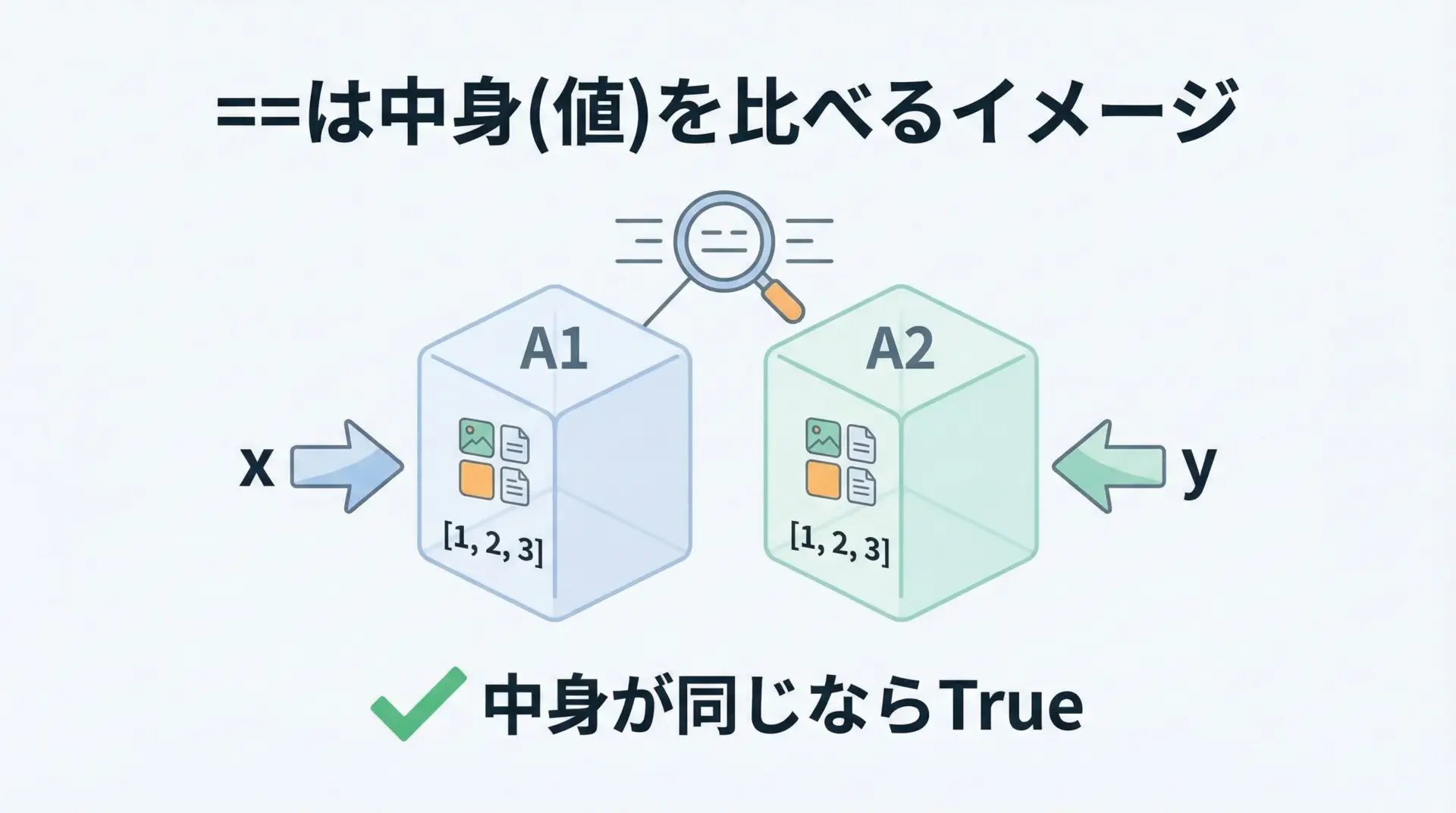
演算子==は、オブジェクトの「値(中身)が等しいか」を比べるための演算子です。
つまり、別のオブジェクトであっても、中身が同じならTrueになります。
先ほどと同じ例で、今度は==の結果を見てみます。
# == の基本的な挙動を確認するサンプル
a = [1, 2, 3]
b = a
c = [1, 2, 3]
print(a == b) # 値(中身)が等しいか
print(a == c) # 別オブジェクトだが中身は同じTrue
Truea, b, cはすべて「[1, 2, 3]」という同じ内容を持つリストなので、==で比較するとどちらもTrueになります。
ただし、先ほど見たようにa is cはFalseのままです。
このように、isは「同一性(identity)」、==は「等価性(equality)」を調べる、と整理すると覚えやすくなります。
isと==が混同されやすい典型例とは
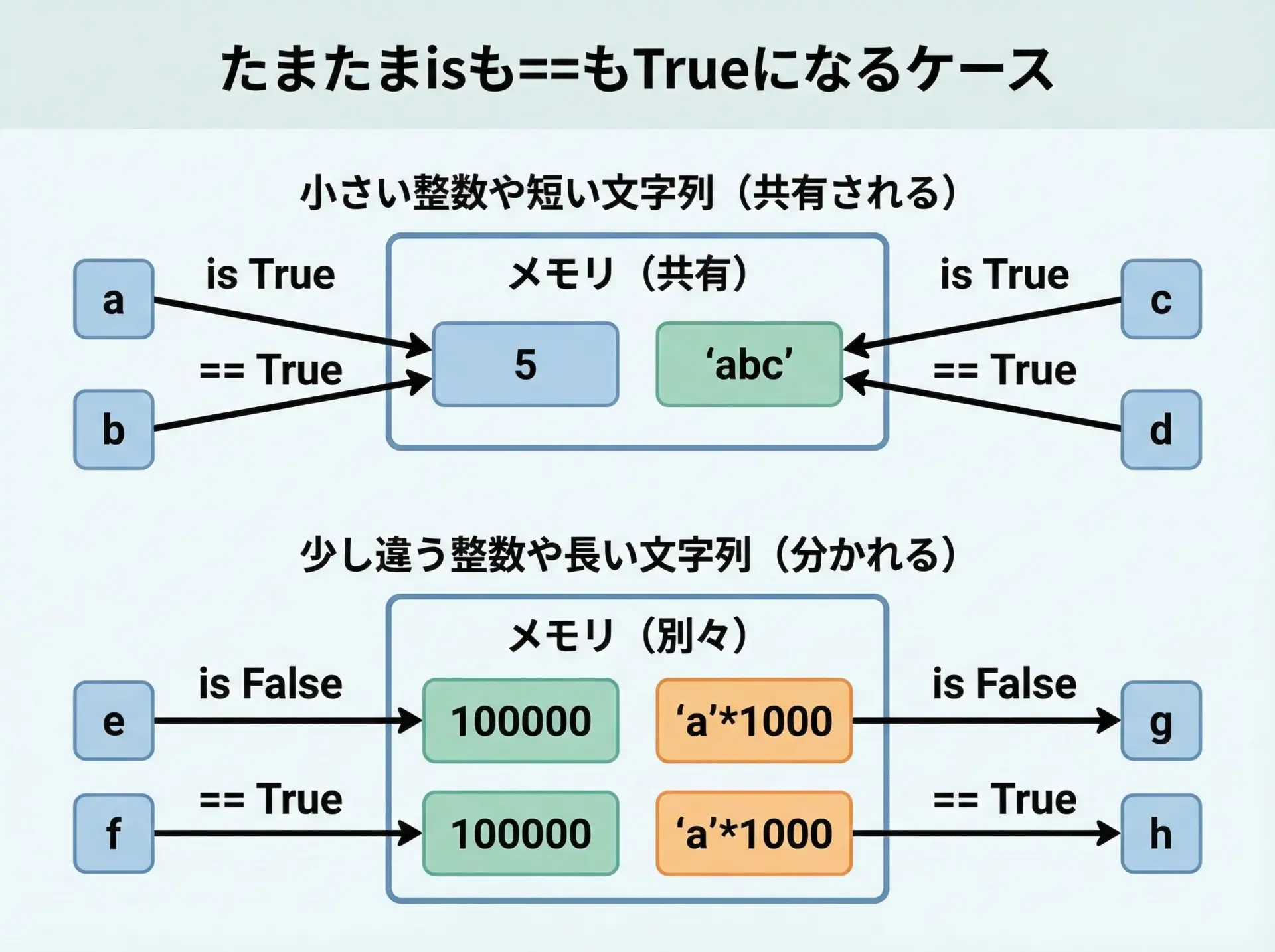
Pythonでは、一部の値は内部的な最適化(インターンやキャッシュ)により、同じ値を1つのオブジェクトとして共有することがあります。
その代表例が次の2つです。
- 小さい整数(たとえば-5~256程度)
- 一部の短い文字列や識別子風の文字列
これらは、同じ値を使い回すため、たまたまisでもTrueになることがあります。
これが「isでも==でも同じ結果になるから違いがわからない」という混乱の原因です。
# is と == がたまたま両方 True になる典型的なパターン
x = 10
y = 10
print(x == y) # 値として等しい
print(x is y) # CPythonなどではたまたま同じオブジェクトを共有している場合が多いTrue
Trueこのような例を見ると、「整数同士ならisを使ってもよいのでは?」と誤解しやすくなります。
しかし、これはあくまで実装依存の最適化による「たまたまの結果」であり、意図して使うべきものではありません。
NoneとPythonのis・==の使い分け
None比較でisが推奨される理由
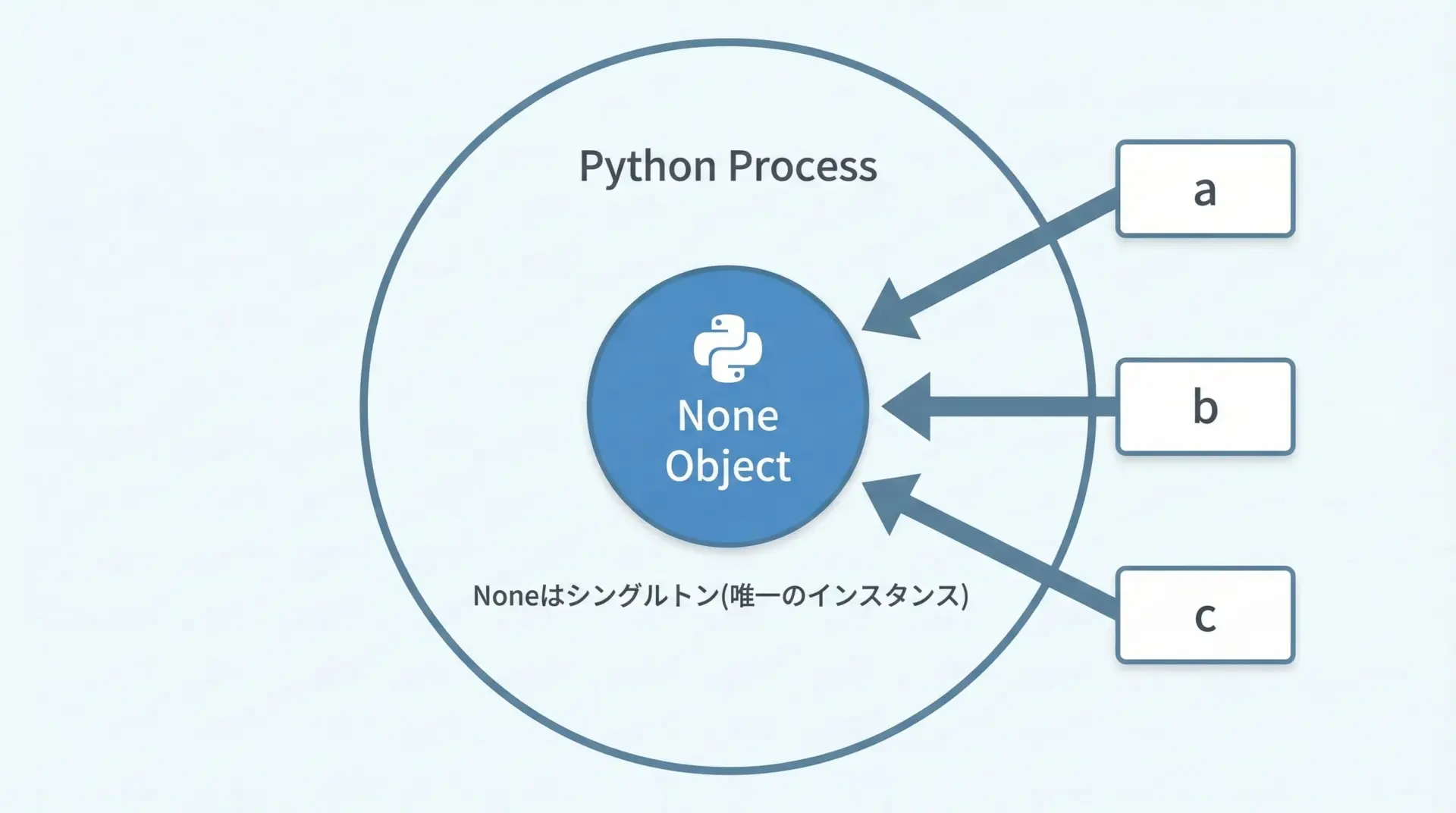
PythonのNoneは、プログラム全体でただ1つだけ存在する特別なオブジェクトです。
これをシングルトン(singleton)と呼びます。
シングルトンであるということは、「Noneかどうか」は「その変数が唯一のNoneオブジェクトを指しているかどうか」で判定できるということです。
したがって、Noneの判定ではisを使うのがPythonの慣習であり、スタイルガイド(PEP 8)でもif x is Noneの形が推奨されています。
# None の比較には is を使うのが定石
x = None
if x is None:
print("x は None です")x は None ですこのように「None判定にはis」と覚えておくとよいです。
if x is Noneとif x == Noneの違い
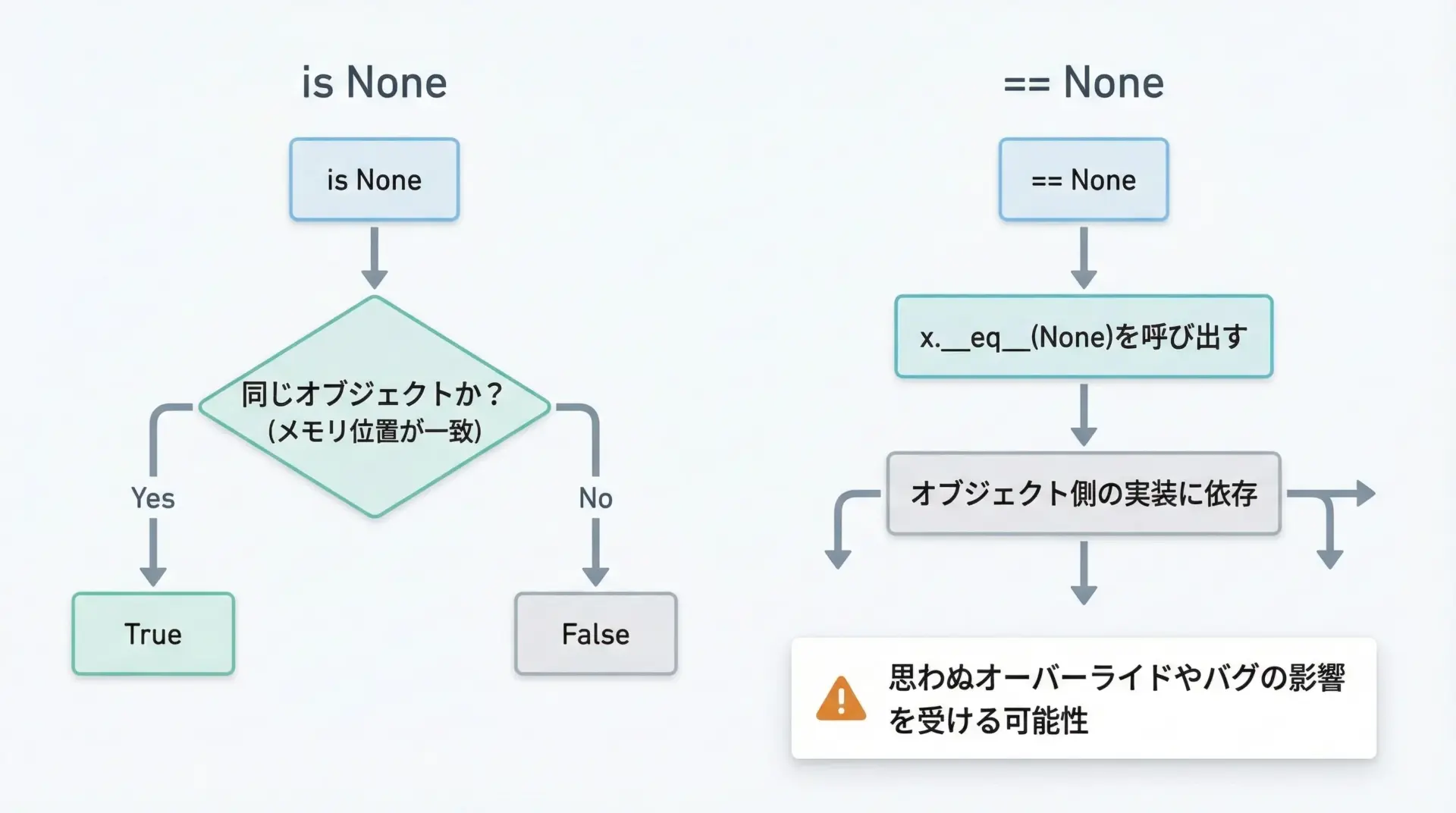
if x is Noneとif x == Noneは、多くのケースでは同じ結果になります。
しかし、内部的にはまったく違う処理をしています。
x is None
変数xがNoneオブジェクトそのものを指しているかを、単純に「参照の一致」でチェックします。クラス側の実装は一切関係ありません。x == None
実際にはx.__eq__(None)が呼び出され、オブジェクト側の等価比較の実装に依存します。クラスによっては不適切な__eq__が定義されている場合があり、思わぬ挙動になることがあります。
この違いは、独自クラスの例を使うとわかりやすくなります。
# __eq__ を変な実装にしてしまったクラスの例
class Weird:
def __eq__(self, other):
# 何と比べても必ず True を返してしまう
return True
x = Weird()
print(x == None) # 等価比較 (__eq__) の結果
print(x is None) # オブジェクトの同一性の比較True
Falseこのように、== はオブジェクトが用意した「等価性のルール」に従うのに対し、is は常に「同じオブジェクトかどうか」だけを見ていることがわかります。
None判定では、クラスの実装に左右されないisを使う方が安全です。
None・空文字・0の判定で気をつけるポイント

Pythonでは、「何もない」と見なされるものがいくつかありますが、それぞれ意味や用途が異なります。
代表的なものを表にまとめると次のようになります。
| 値 | 意味のイメージ | 真偽値として |
|---|---|---|
| None | 値が存在しない / 未設定である | False |
| “” | 文字列だが、中身が空 | False |
| 0 | 数値だが、大きさがゼロ | False |
| [] | リストだが、要素が1つも無い | False |
| {} | 辞書だが、キーが1つも無い | False |
特に混同しやすいのはNoneと空文字と0です。
これらは、どれもif x:のように真偽値コンテキストで評価するとFalseになりますが、意味はまったく違います。
None
「そもそも値が設定されていない」「まだ決まっていない」という状態を表します。""
「文字列としては存在しているが、文字数が0」という状態です。0
数値としては成り立っているが、その大きさがゼロという状態です。
この違いを無視して、if not x:のように雑に判定してしまうと、「空文字や0も未設定扱いになってしまう」というバグにつながります。
# 「値が未設定(None)か」を厳密に判定したい場合の例
def show_length(text):
# text が None かどうかは is で判定
if text is None:
print("テキストはまだ設定されていません")
return
# ここに来る時点で text は None ではないので、len が呼べる前提
if text == "":
print("テキストは空文字です")
else:
print(f"テキストの長さは {len(text)} です")
show_length(None)
show_length("")
show_length("abc")テキストはまだ設定されていません
テキストは空文字です
テキストの長さは 3 ですこのように、「未設定(None)かどうか」と「空であるかどうか」は別々に判定することが、安全で意図が明確なコードにつながります。
文字列におけるisと==の挙動
文字列比較でisを使うと危険な理由
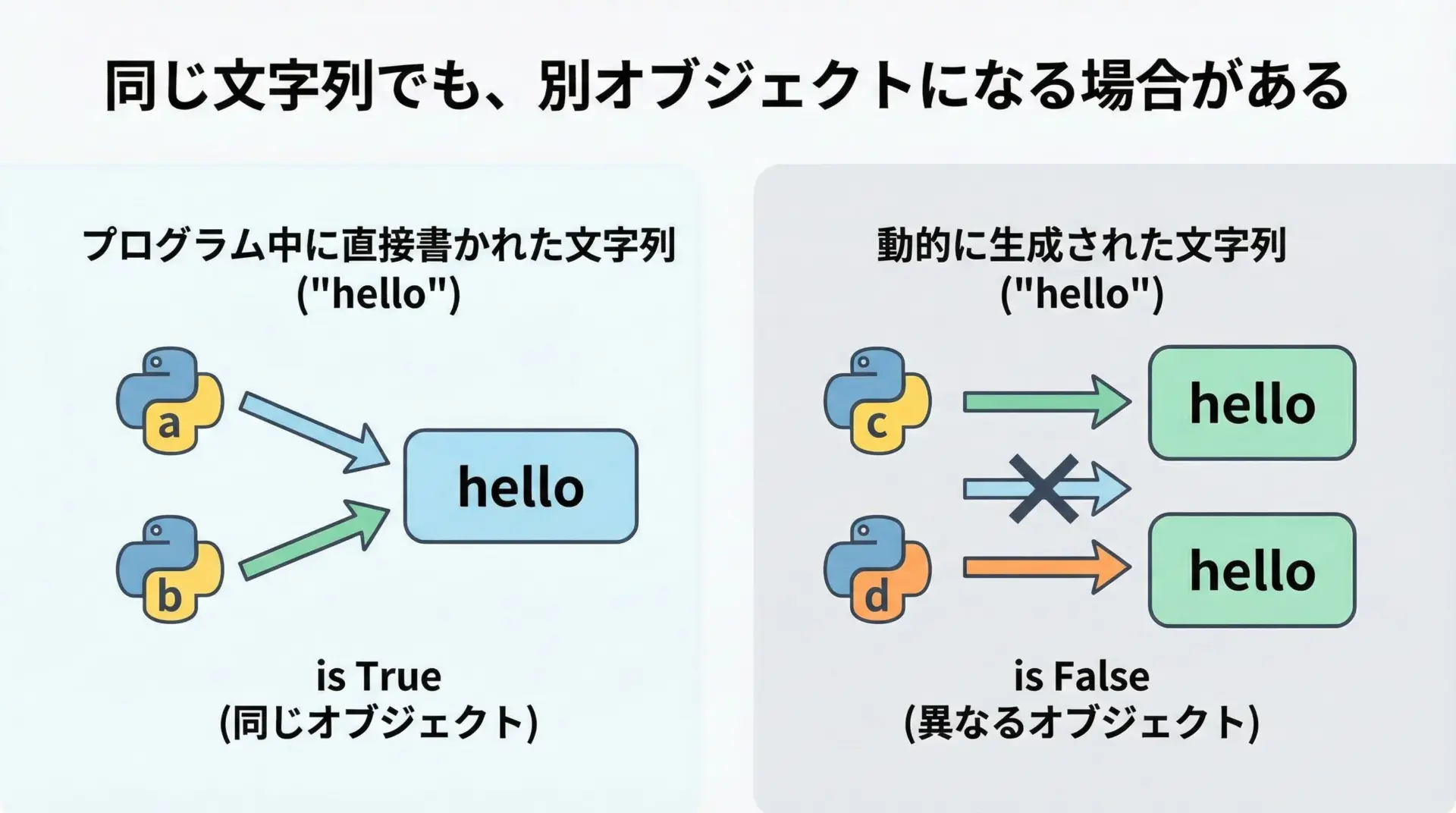
文字列は値として比較する場面が多く、== で比較するのが正しい方法です。
一方で、isで比較してしまうと、たまたま動いたり、突然動かなくなったりする危険があります。
理由は、文字列が同じでも、別オブジェクトとして存在することが普通にあるからです。
たとえば次のようなケースを考えます。
# 文字列比較で is を使うと危険な例
s1 = "python"
s2 = "python"
print(s1 == s2) # 中身は同じ
print(s1 is s2) # 環境によっては True になることもあるが、保証はないTrue
Trueこのコードだけを見ると、「文字列でもisで比較してよさそう」と思ってしまうかもしれません。
しかし、生成方法を変えると結果が変わります。
# 別の方法で同じ文字列を作る
s1 = "py" + "thon"
s2 = "".join(["py", "thon"])
print(s1 == s2) # 中身は依然として同じ
print(s1 is s2) # 多くの場合 False になるTrue
Falseこのように、文字列比較にisを使うことは仕様上も意味的にも誤りです。
isを使うべき場面は、Noneなど「特定の唯一のオブジェクト」を判定するときに限られると考えてください。
文字列のインターン(最適化)がisを紛らわしくする
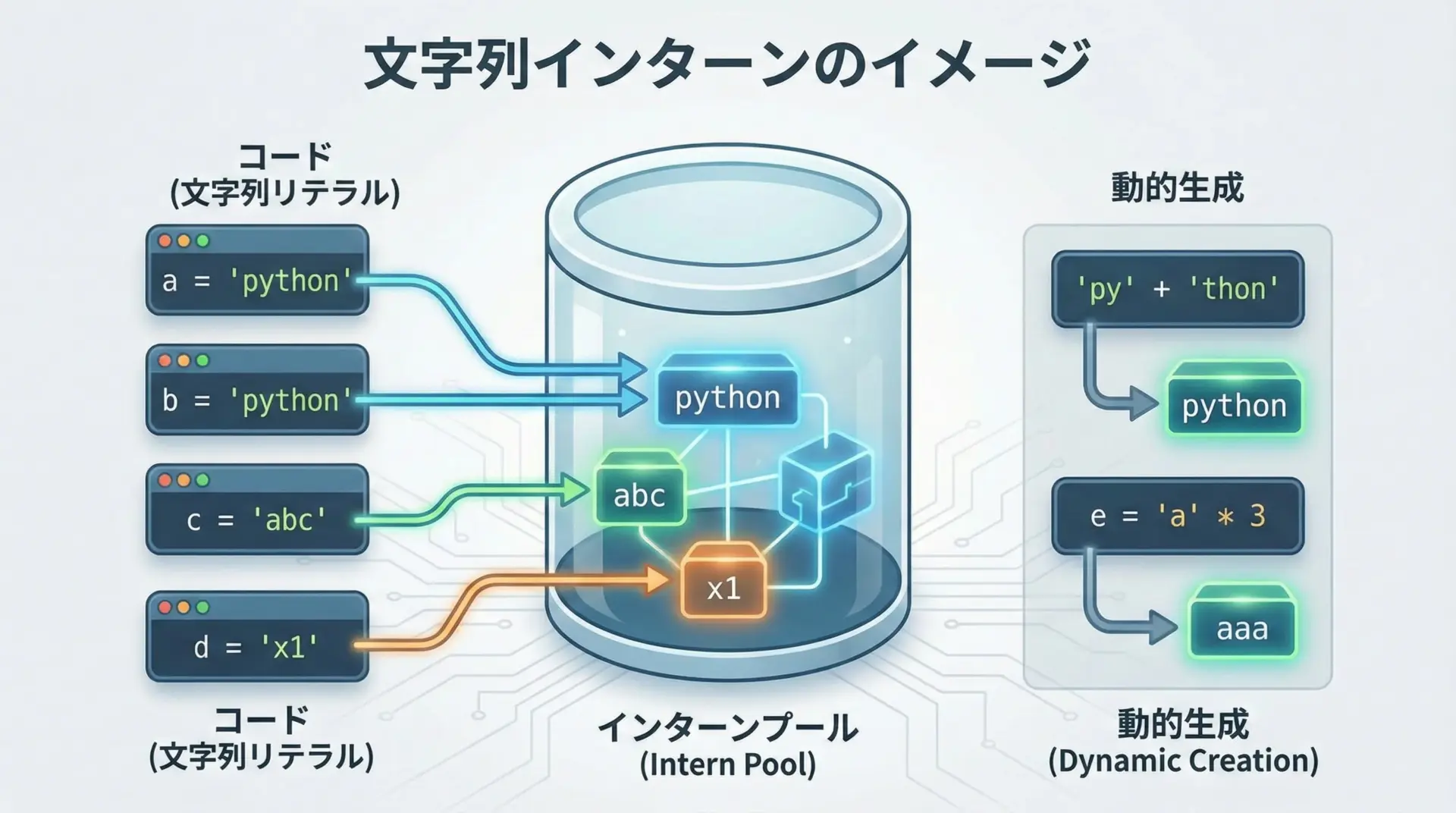
Pythonは内部的な最適化として、一部の文字列を「インターン」(共有)する仕組みを持っています。
インターンされた文字列は、同じ値であれば同一オブジェクトを再利用するため、isで比較してもTrueになります。
しかし、インターンされるかどうかは、次のような条件や実装の細部に依存します。
- 文字列がソースコード中のリテラルかどうか
- その文字列が識別子として有効な形かどうか(英数字とアンダースコアなど)
- 実行環境やPythonのバージョン
など
この不確実さが、「ある環境ではisがTrue、別の環境ではFalse」という再現しにくいバグを生み出します。
# インターンされやすい文字列とそうでない文字列の例
a = "hello_world"
b = "hello_world"
c = "hello world!" # 空白や記号を含む
d = "hello world!"
print(a is b) # True になる可能性が高い(インターンされやすい)
print(c is d) # False になる可能性が高いTrue
Falseこのような背景からも、「文字列の比較でisを使うのは絶対に避ける」べきであり、常に==で比較するというルールにしておくのが安全です。
実例で見る文字列のis比較の落とし穴
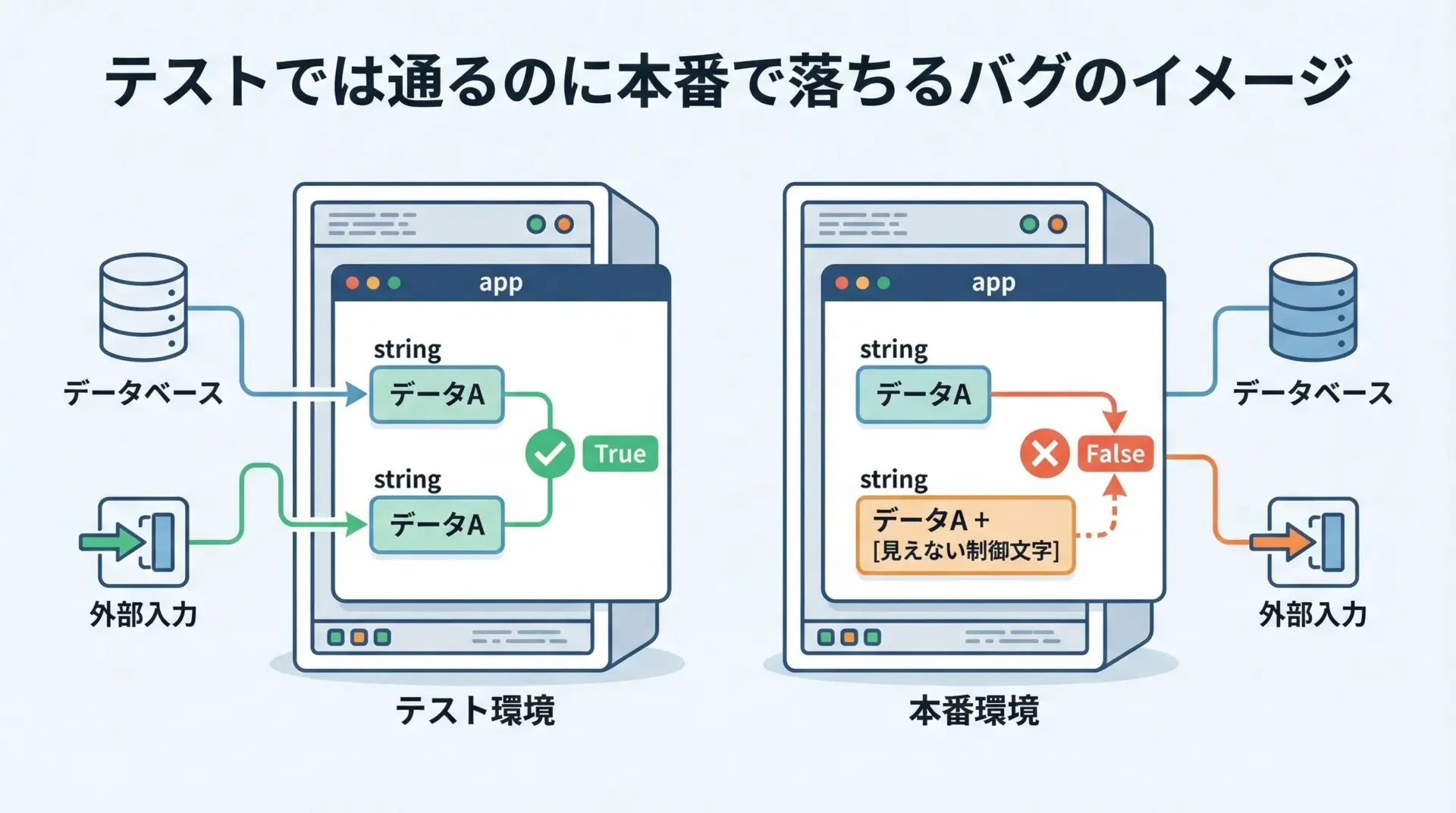
実務で起こりやすい落とし穴として、テストデータではうまく動いていたのに、本番データでは突然壊れるというパターンがあります。
次のようなコードを想像してみてください。
# 良くないコード例: 文字列比較に is を使ってしまっている
def is_status_ok(status):
# 本来は status == "OK" とすべきところを、誤って is を使っている
return status is "OK"
# テストコード
print(is_status_ok("OK")) # たまたま True になることがあるTrueテストでは「OK」というリテラルをそのまま渡しているため、インターンによって"OK"が共有され、isでもたまたまTrueになることがあります。
しかし、本番ではステータス文字列が次のように生成されているかもしれません。
# 本番での利用イメージ(外部から受け取った文字列)
import os
status = os.getenv("SERVICE_STATUS") # 例: 環境変数から取得
print(status) # "OK" と表示される
print(status == "OK") # True
print(status is "OK") # False になる可能性が高いOK
True
Falseこのようなコードは、テストでは問題なく通るのに、本番環境や将来のPythonバージョンで突然動かなくなる典型的な「地雷」です。
文字列に限らず、値を比べたいときには必ず==を使うという原則を徹底することで、この種のバグを未然に防ぐことができます。
数値・リスト・オブジェクトでのisと==
小さい整数でisがたまたまTrueになる理由
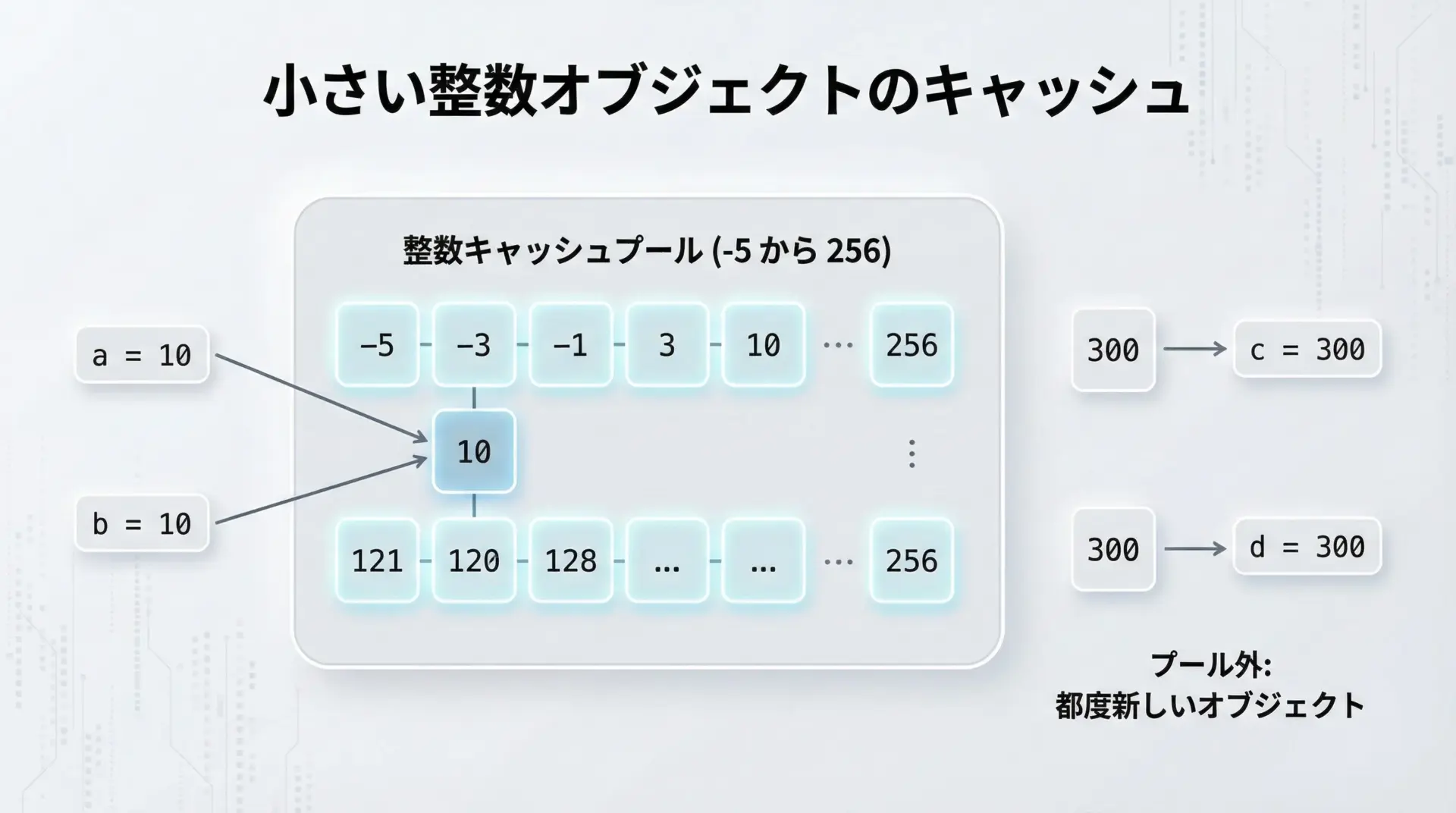
Python(CPython実装など)では、一部の小さい整数をあらかじめ作っておき、使い回す最適化が行われています。
典型的には-5から256までの範囲がキャッシュされます。
そのため、次のようなコードではisでもTrueになることがよくあります。
# 小さい整数では is が True になることが多い例
a = 10
b = 10
print(a == b) # 値が等しい
print(a is b) # キャッシュのため、同じオブジェクトを指しているTrue
Trueしかし、これは実装の最適化に過ぎず、仕様として保証されているわけではありません。
さらに、範囲外の整数ではあっさりFalseになります。
# 少し大きな整数だと is が False になる例
x = 1000
y = 1000
print(x == y) # 値は同じ
print(x is y) # 多くの場合 FalseTrue
Falseこのように、整数値の比較にisを使うのは完全に誤りです。
数値の比較では必ず==を使うことを徹底しましょう。
リストや辞書でisと==がどう違うか
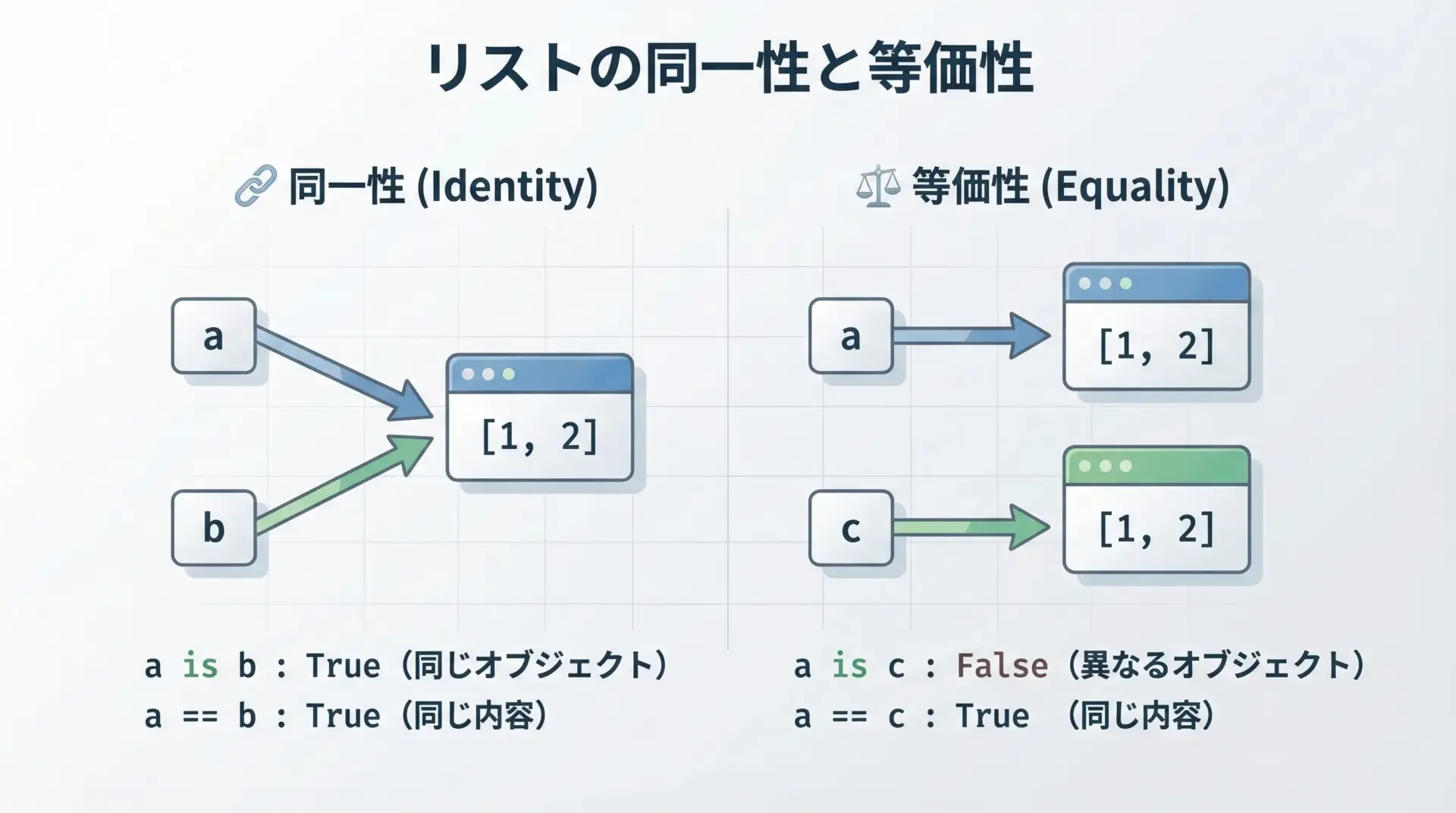
リストや辞書といった可変オブジェクトでは、isと==の違いが特にはっきり現れます。
# リストで is と == の違いを確認
a = [1, 2]
b = a # 同じリストを共有
c = [1, 2] # 別のリストだが中身は同じ
print(a is b) # True: 同じオブジェクト
print(a == b) # True: 中身も同じ
print(a is c) # False: 別オブジェクト
print(a == c) # True: 中身は同じTrue
True
False
Trueここからわかる重要なポイントは次の通りです。
- isがTrueなら、==もほぼ必ずTrueです。
(同じオブジェクトなので、中身も一致しているケースが普通です。) - しかし、==がTrueでも、isはTrueとは限らないということです。
(別オブジェクトだが、たまたま中身が同じ場合です。)
リストや辞書でisを使うべき場面は、「本当に同じインスタンスを共有していること」自体を確認したいときに限られます。
たとえば、キャッシュされているオブジェクトかどうかを調べたいときなどです。
# キャッシュされたリストかどうかを確認するイメージ例
_cache = []
def get_cache():
return _cache
x = get_cache()
y = get_cache()
print(x is y) # キャッシュが同じインスタンスかどうかTrueこのように、通常の「中身が同じかどうか」の比較には必ず==を使い、isは「同じインスタンスか」を確認するときだけに限定するのがよい設計です。
ユーザー定義クラスでの同一性と等価性の設計ポイント
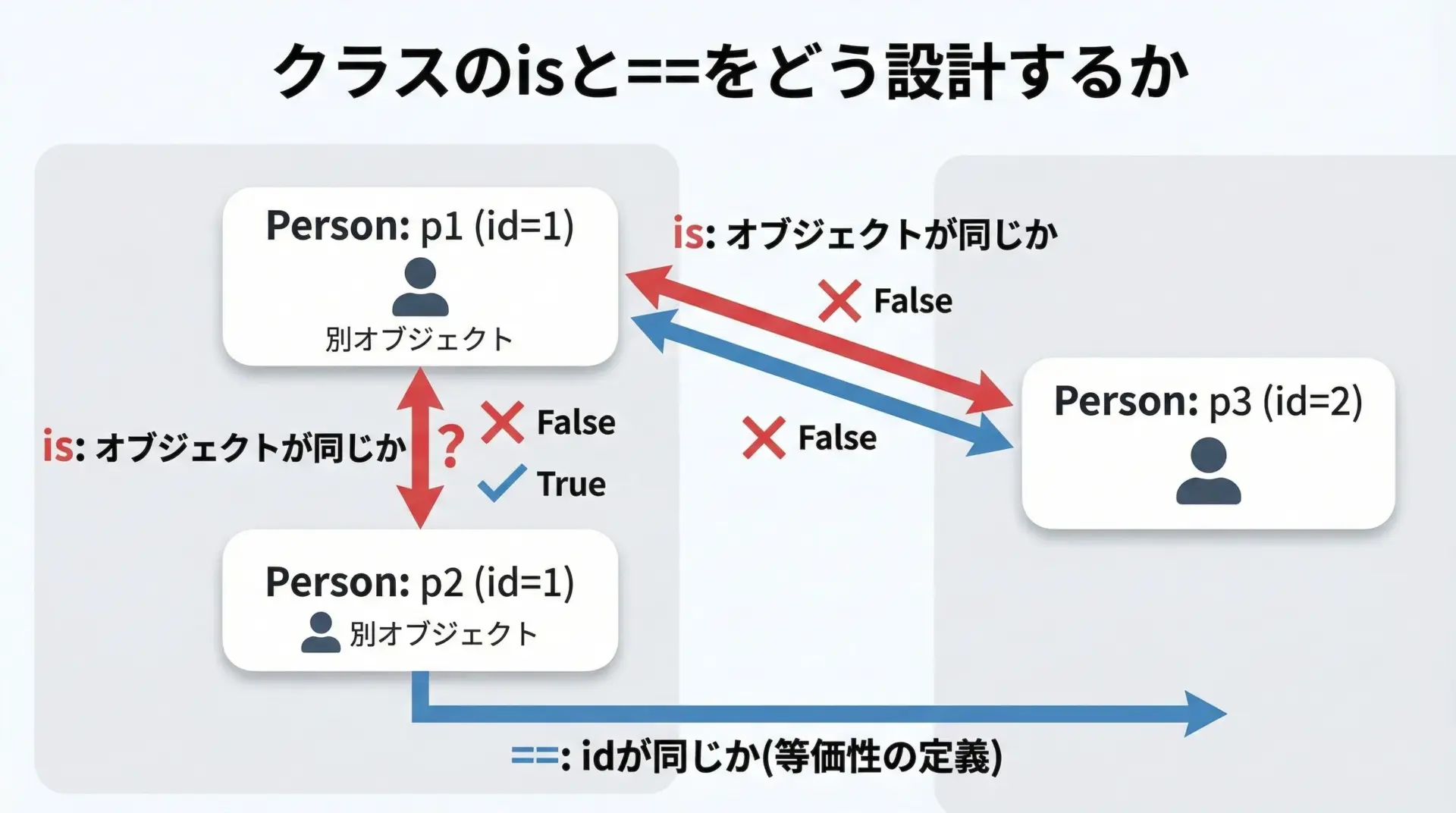
自分でクラスを定義する場合、isと==をどう扱うかは設計上の重要なポイントです。
is
これは常にオブジェクトの同一性を比べます。クラス側で制御することはできません。どのクラスであってもisの意味は変わりません。==
こちらはクラス側で__eq__メソッドを定義することで、「等価」と見なす条件を自分で決めることができます。
例えば、ユーザーIDが同じなら同じユーザーとみなしたいUserクラスを考えてみましょう。
# ユーザー定義クラスで等価性(__eq__)を設計する例
class User:
def __init__(self, user_id, name):
self.user_id = user_id
self.name = name
def __eq__(self, other):
# User同士を比較するときだけ user_id で等価性を判断する
if isinstance(other, User):
return self.user_id == other.user_id
return NotImplemented # 他の型との比較は Python に任せる
u1 = User(1, "Alice")
u2 = User(1, "Alice")
u3 = User(2, "Bob")
print(u1 is u2) # 別々に作られたオブジェクトなので False
print(u1 == u2) # user_id が同じなので True
print(u1 == u3) # user_id が違うので FalseFalse
True
Falseこの例では、「同一人物かどうか」を==で表現し、「同じインスタンスかどうか」をisで表現しています。
設計上のポイントを整理すると次のようになります。
| 比較方法 | 意味 | 制御可能か | 典型的な使い方 |
|---|---|---|---|
| is | 同一インスタンスかどうか | 制御不可 | シングルトン判定、キャッシュ確認など |
| == | クラスが定めた等価性かどうか | __eq__で定義可能 | IDや値など、ビジネス上の「同一性」判定 |
isをオーバーライドしたり、意味を変えることはできないため、クラス設計では「==の意味」だけを明確に定義し、isは常に「物理的な同一オブジェクトか」の確認に使う、と割り切るのがよいです。
まとめ
Pythonのisと==は見た目が似ていますが、意味も使いどころもまったく異なる演算子です。
isは同一オブジェクトかどうかを、==は値(等価性)が同じかどうかを確認します。
特にNone判定ではis Noneが推奨され、文字列や数値、リストなどの値比較には==を使うのが正しい書き方です。
文字列インターンや整数キャッシュの最適化により、isがたまたまTrueになるケースもありますが、それに依存すると環境差や将来の変更で簡単に壊れます。
「None判定だけis、それ以外の値比較は==」というシンプルなルールを守れば、紛らわしいバグを避け、安全で読みやすいPythonコードを書けるようになります。
