
Pythonで複数のリストを同時に処理したいとき、zip関数を使うとコードが驚くほどスッキリします。
この記事では、zip関数の基本から複数リストを一気にループ処理する実践テクニックまで、図解を交えながら丁寧に解説します。
for文との組み合わせ方や、長さの違うリストを扱うときの注意点、辞書生成やリスト内包表記との連携など、実務ですぐ使えるノウハウを整理して学んでいきます。
Pythonのzip関数とは
zip関数の基本構文と動作イメージ
まずはzip関数の基本から確認します。
zipは、複数のイテラブル(リストやタプルなど)を「横に並べて」束ねる関数です。
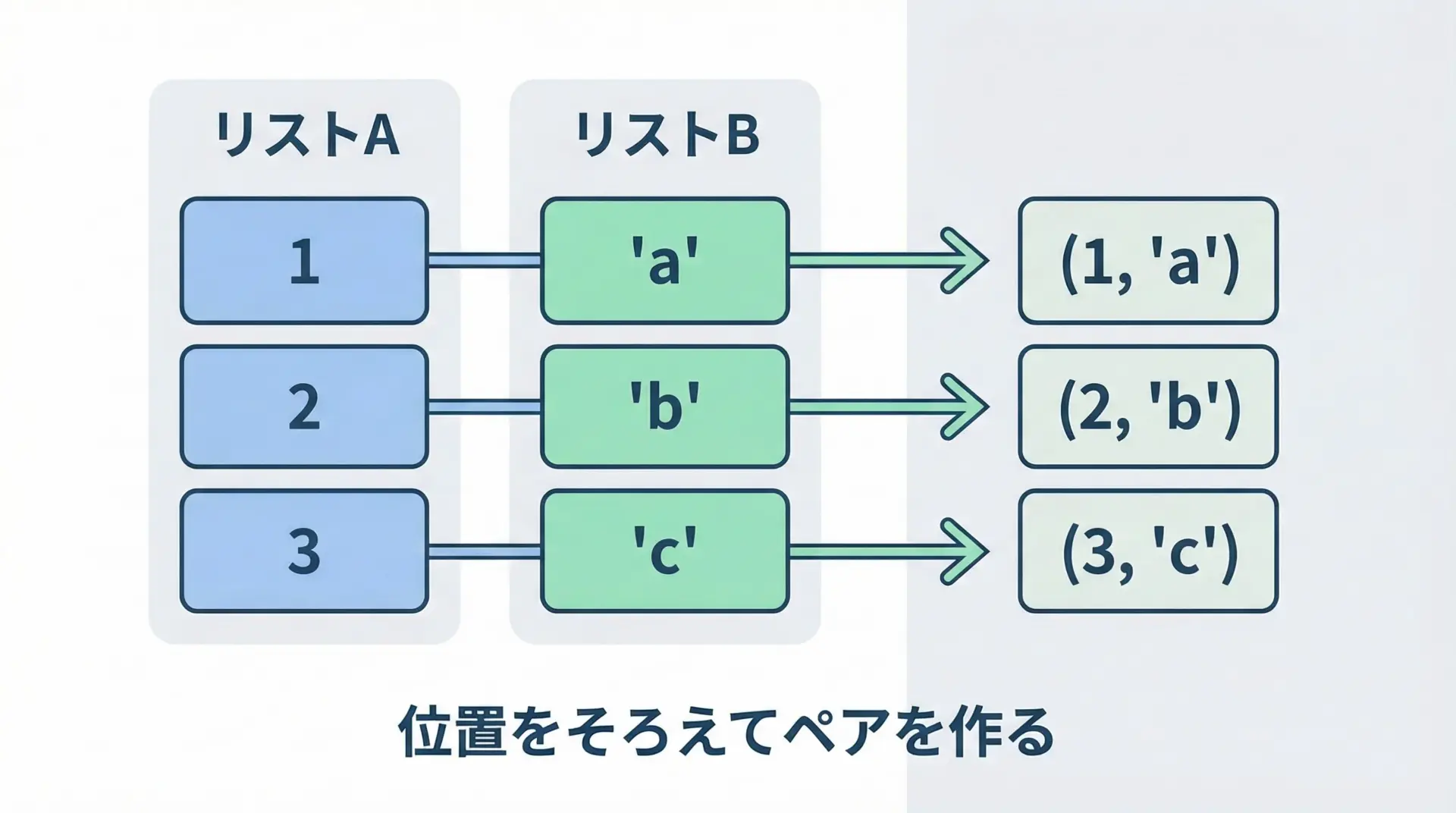
zip関数の基本構文はとてもシンプルです。
zip(イテラブル1, イテラブル2, ...)例えば、2つのリストをzipに渡すと、対応する位置の要素同士をペアにしたタプルの列が得られます。
numbers = [1, 2, 3]
letters = ["a", "b", "c"]
# zipオブジェクトを生成
paired = zip(numbers, letters)
# 実体を見るためにlistに変換
print(list(paired))[(1, 'a'), (2, 'b'), (3, 'c')]ここで重要なのは、zipが返すのはリストではなくイテレータ(反復可能オブジェクト)だという点です。
listに変換したときに初めて「中身をすべて取り出して表示」しているイメージになります。
複数リストを同時にループ処理する仕組み
zipの真価は、for文との組み合わせで発揮されます。
zipは、各リストの同じインデックス位置の要素を1組ずつ取り出すので、for文でループすると、自然に「同時ループ」になります。
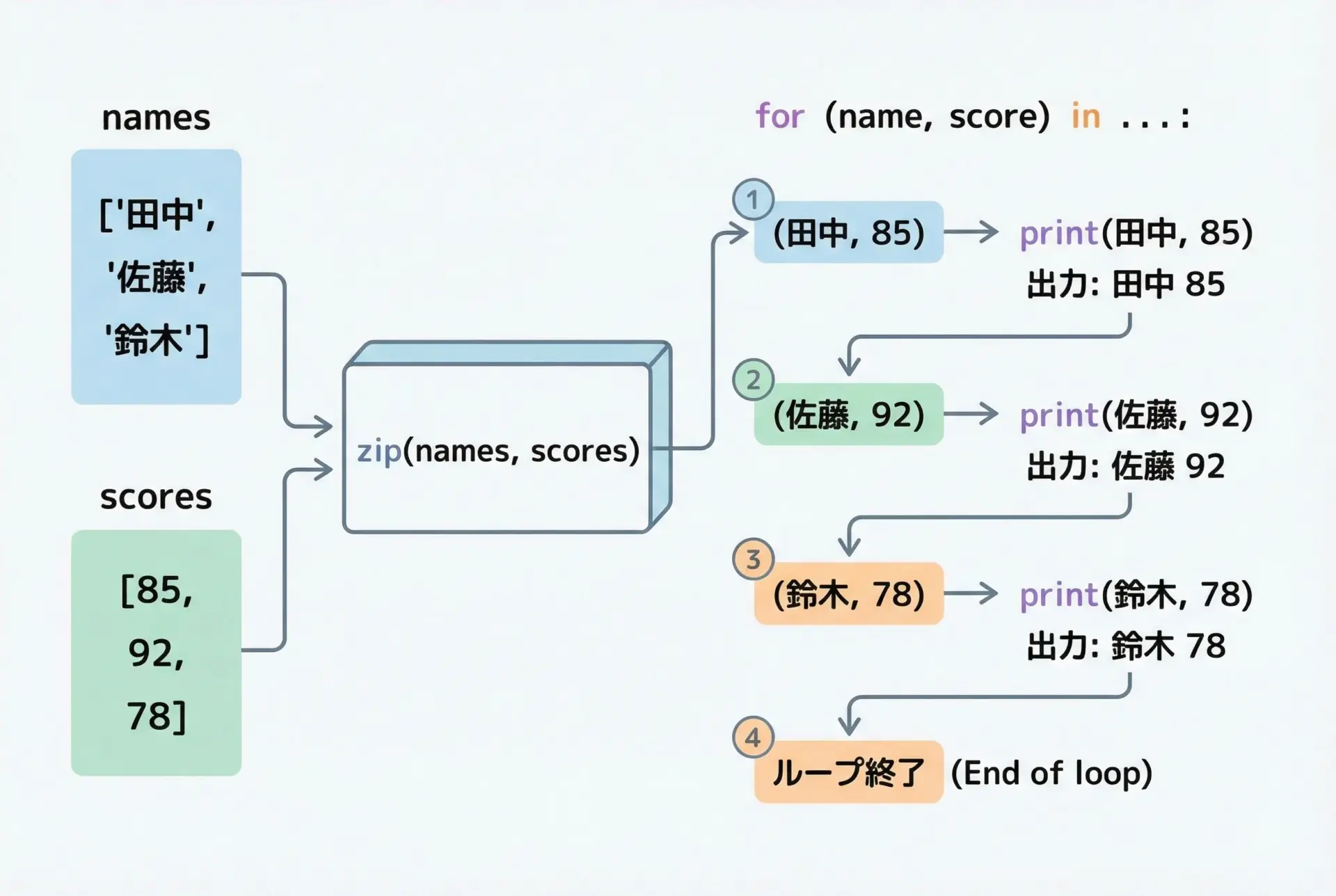
たとえば、名前とスコアの2つのリストを同時にループする場合は次のようになります。
names = ["Alice", "Bob", "Charlie"]
scores = [85, 92, 78]
for name, score in zip(names, scores):
# nameとscoreが対応する位置でペアになっている
print(f"{name} さんの点数: {score}")Alice さんの点数: 85
Bob さんの点数: 92
Charlie さんの点数: 78zipが内部でやっていることは、インデックス0の要素同士をペアにする、次に1の要素同士をペアにする、というシンプルな動作です。
zipとfor文の組み合わせの基本パターン
zipとfor文の組み合わせ方には、いくつかの定番パターンがあります。
代表的なものを整理しておきます。
1つ目は、タプルを2つ以上の変数にアンパックして受け取るパターンです。
xs = [1, 2, 3]
ys = [10, 20, 30]
for x, y in zip(xs, ys):
print(x, y)2つ目は、タプルのまま1つの変数で受け取るパターンです。
for pair in zip(xs, ys):
# pairは(1, 10)のようなタプル
print(pair)どちらも意味は同じですが、後で要素にアクセスする方法と可読性が変わります。
基本的にはアンパックして複数変数で受け取るほうが読みやすいことが多いです。
zip関数で複数リストを一気にループ処理する
2つのリストを同時ループして要素を組み合わせる
最もよくあるケースが、2つのリストを同時にループしながら、要素を使って処理を行うパターンです。
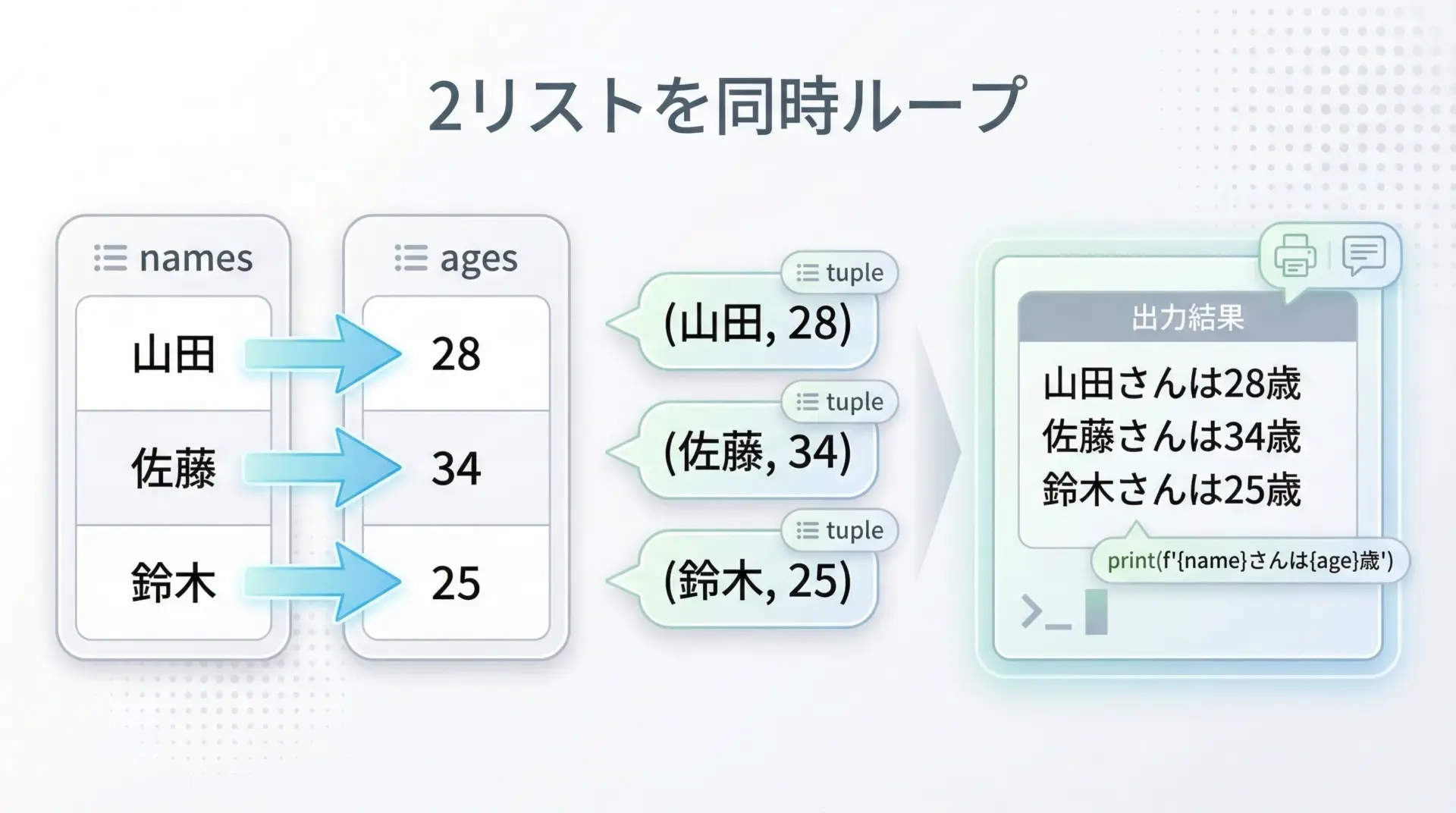
具体例として、名前と年齢をセットで表示してみます。
names = ["山田", "佐藤", "鈴木"]
ages = [28, 34, 25]
for name, age in zip(names, ages):
# nameとageは同じインデックスの要素
print(f"{name}さんは{age}歳です")山田さんは28歳です
佐藤さんは34歳です
鈴木さんは25歳ですこの書き方のメリットは、インデックスを意識せずに意味のある名前の変数だけで処理を書けることです。
インデックスミスも起きにくくなります。
3つ以上のリストをzipでまとめて処理する
zipは2つに限らず、3つ以上のリストもまとめて扱えます。
要素数が増えても考え方は同じで、同じインデックスの要素が1つのタプルにまとめられます。
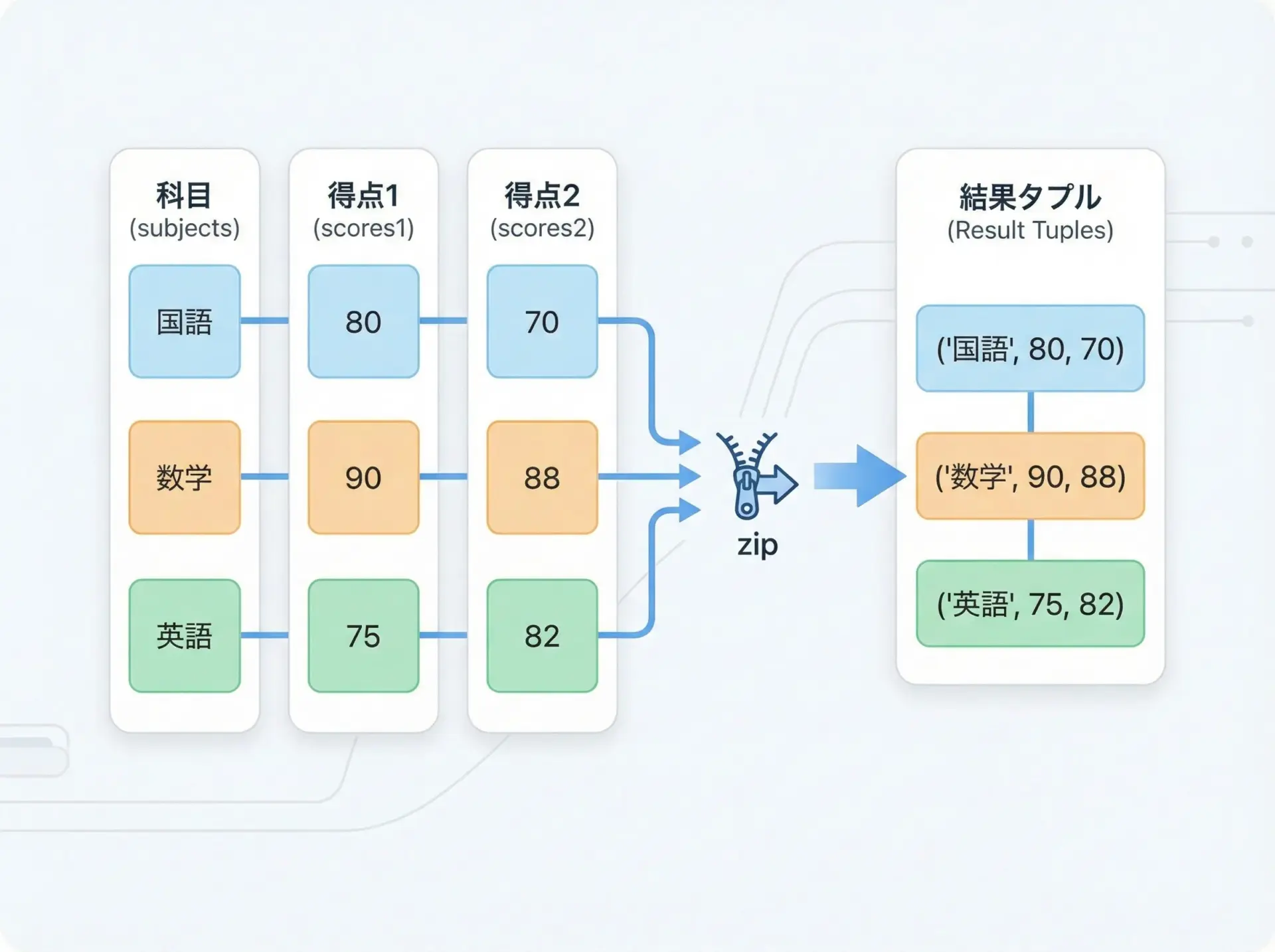
例として、科目名と2回分のテスト結果を同時に処理してみます。
subjects = ["国語", "数学", "英語"]
scores_mid = [80, 90, 75] # 中間テスト
scores_final = [70, 88, 82] # 期末テスト
for subject, mid, final in zip(subjects, scores_mid, scores_final):
avg = (mid + final) / 2
print(f"{subject}の平均点: {avg}")国語の平均点: 75.0
数学の平均点: 89.0
英語の平均点: 78.5変数が増えるときは、引数とfor側の変数名の順序をそろえることが重要です。
順序がズレると、思わぬバグにつながります。
インデックスループ(range)との書き方の違いと比較
同じことをインデックスループ(range(len(...)))で書くとどうなるかを比較してみます。
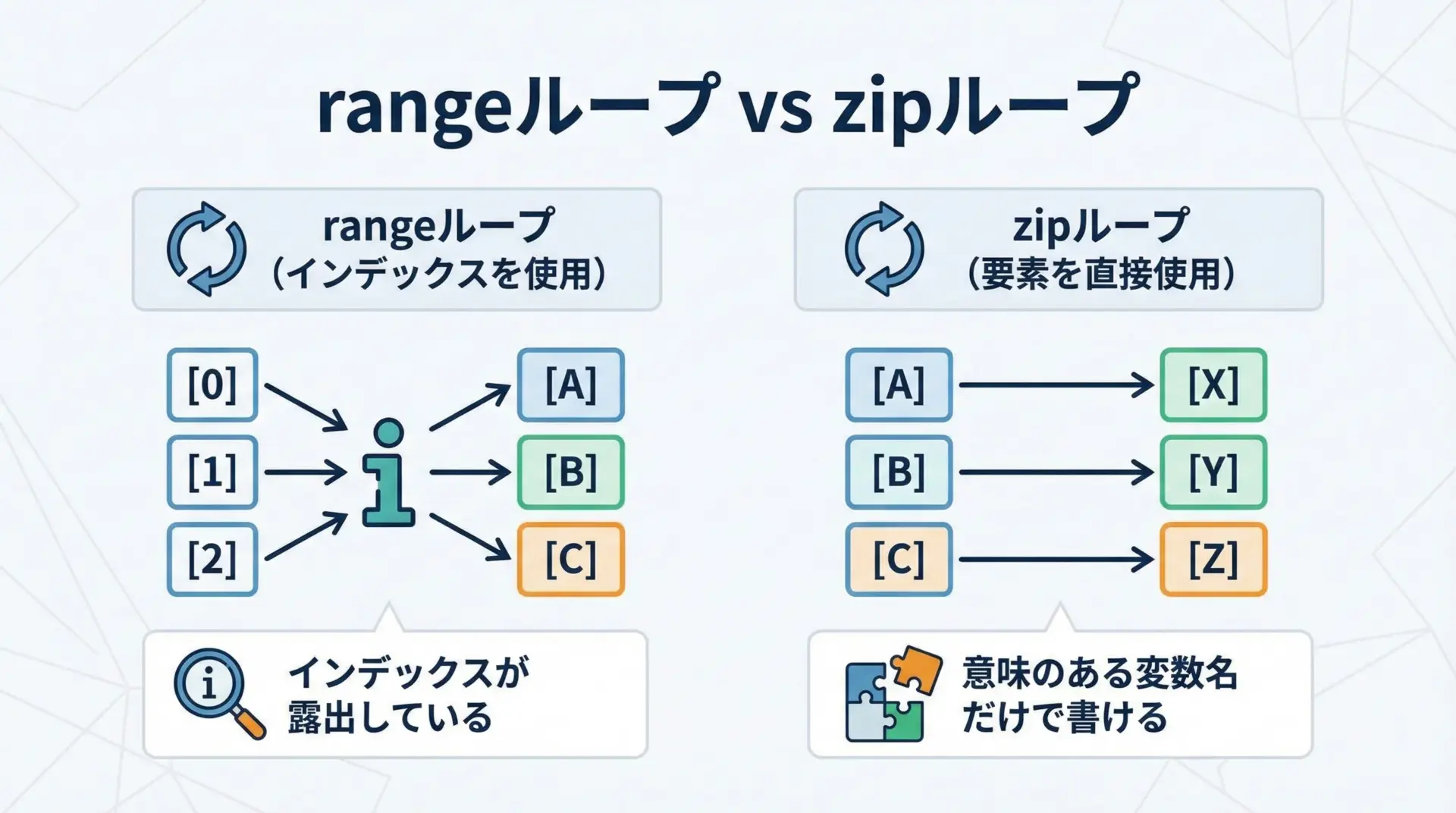
インデックスループのパターンは次のようになります。
names = ["山田", "佐藤", "鈴木"]
ages = [28, 34, 25]
# rangeとインデックスを使う場合
for i in range(len(names)):
name = names[i]
age = ages[i]
print(f"{name}さんは{age}歳です")これをzipで書き換えると、次のようにシンプルになります。
# zipを使う場合
for name, age in zip(names, ages):
print(f"{name}さんは{age}歳です")zipの方が行数が減るだけでなく、インデックスの存在を意識しなくてよくなり、バグの温床が1つ減ります。
特に、複数リストの長さが異なってしまった場合に、rangeとの組み合わせではIndexErrorを起こしやすいですが、zipなら後述の仕様により安全側に倒れます。
実践テクニックと注意点
zipで長さの異なるリストを扱うときの挙動
zipでよくハマるポイントが、長さの異なるリストを渡した場合の挙動です。
Pythonの組み込みzipは、最も短いシーケンスの長さに合わせてループを終了します。
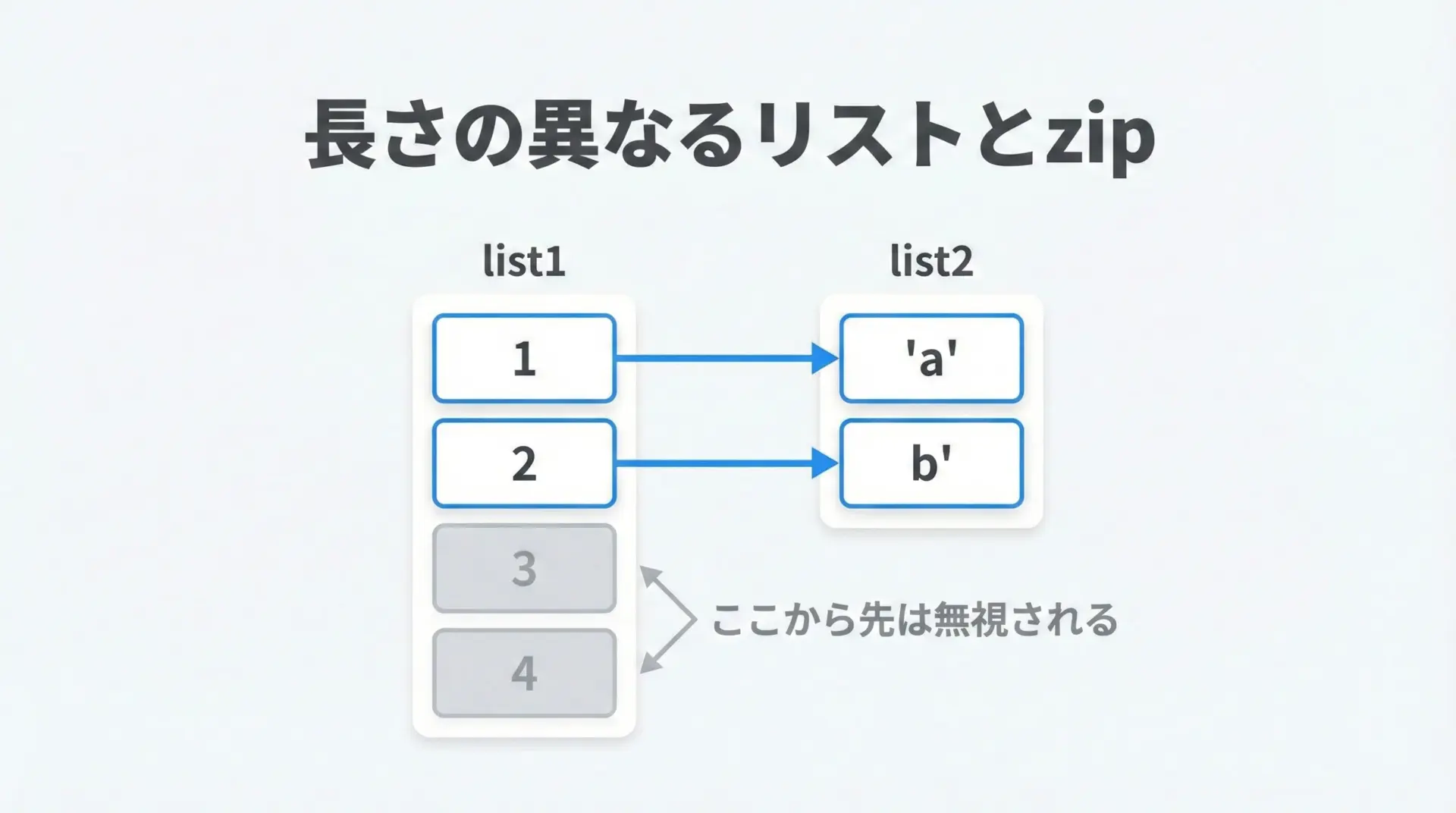
コードで確認してみます。
nums = [1, 2, 3, 4]
letters = ["a", "b"]
for n, s in zip(nums, letters):
print(n, s)1 a
2 b3と4は無視されてしまいます。
この仕様は、安全側(短い方に合わせる)に倒れる一方で、思ったより少ない回数しかループされないというバグを生みやすいので注意が必要です。
「必ず両方のリストを最後まで処理したい」場合は、後述するitertools.zip_longestを使うべきです。
zip_longest(itertools)で不足分を補いながらループする
不足分を補いながら最後までループしたいときは、標準ライブラリitertoolsモジュールのzip_longestを使います。
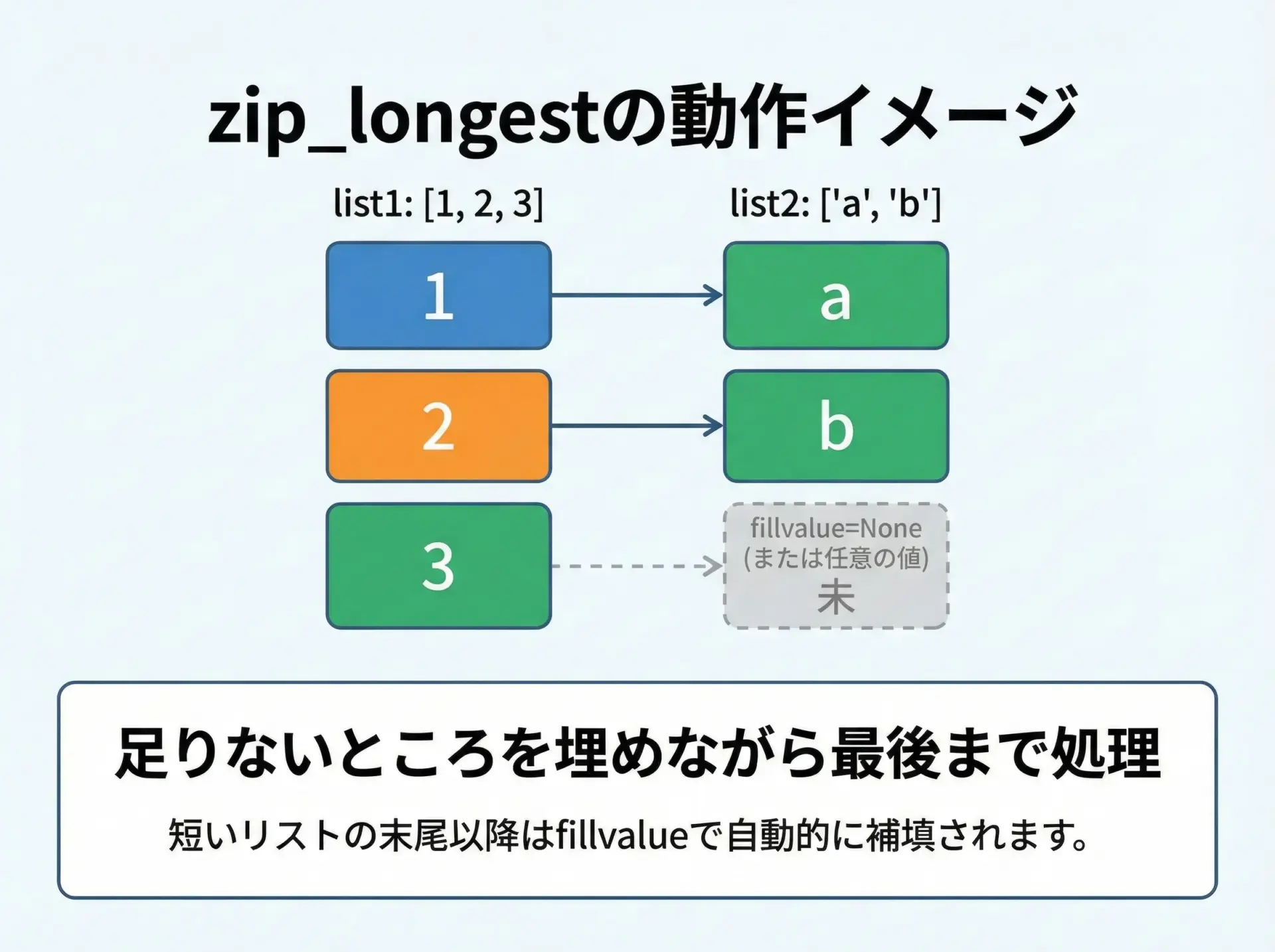
使い方はzipとほぼ同じですが、fillvalueキーワードで不足部分の埋め草を指定できます。
from itertools import zip_longest
nums = [1, 2, 3]
letters = ["a", "b"]
# 足りない部分をNoneで埋める
for n, s in zip_longest(nums, letters, fillvalue=None):
print(n, s)1 a
2 b
3 None任意の文字列や値で埋めることもできます。
for n, s in zip_longest(nums, letters, fillvalue="(なし)"):
print(n, s)1 a
2 b
3 (なし)ログの整形やCSV行の結合など、すべての要素を網羅的に処理したいケースで特に役立ちます。
アンパック(タプル展開)で可読性を高める書き方
zipで返されたタプルをどう受け取るかで、コードの読みやすさが変わります。
可読性を意識すると、for文のヘッダでアンパックしてしまうのが最もシンプルな書き方です。
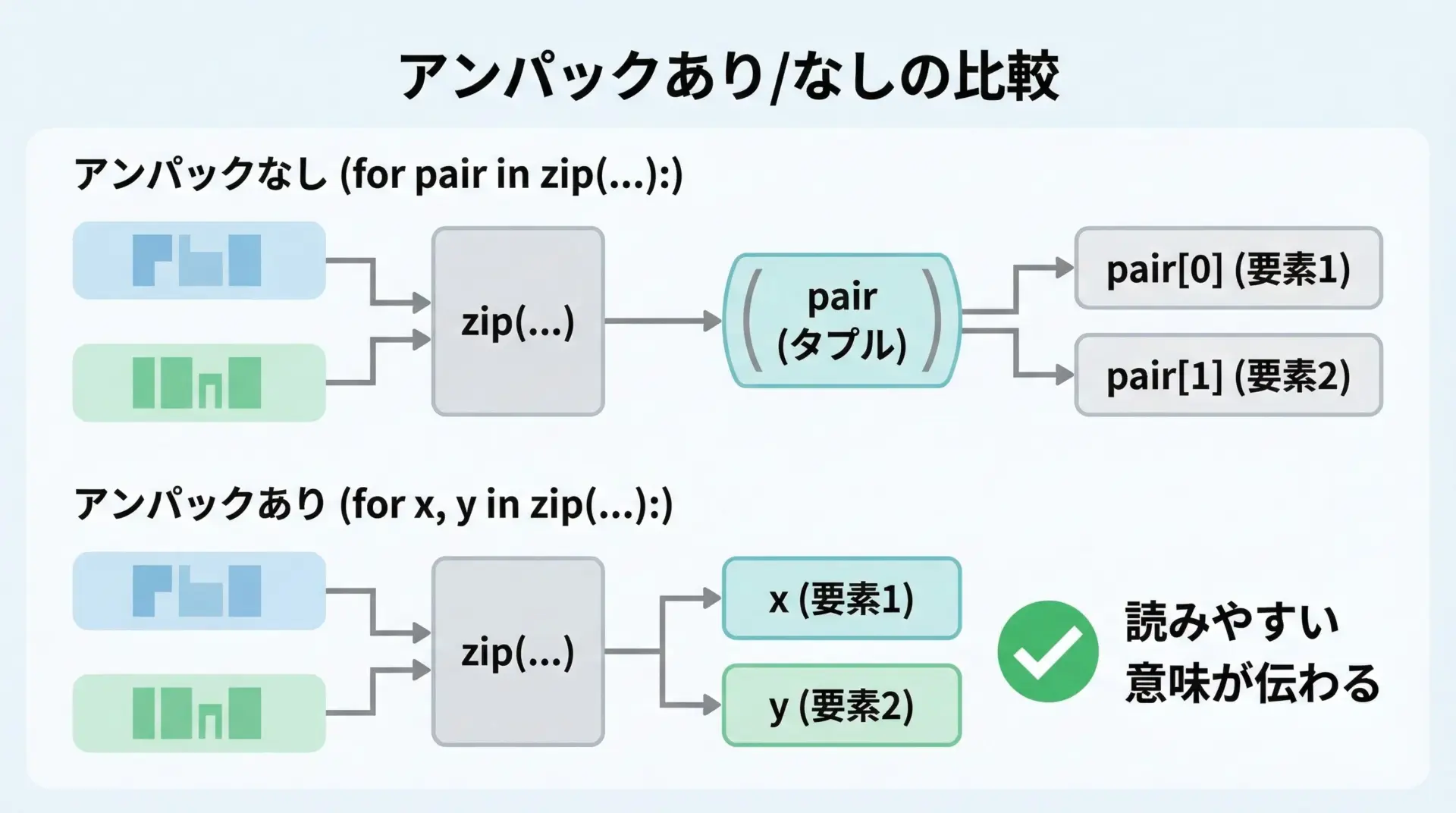
アンパックしない場合は次のようになります。
xs = [1, 2, 3]
ys = [10, 20, 30]
for pair in zip(xs, ys):
# pairは(1, 10)のようなタプル
x = pair[0]
y = pair[1]
print(x, y)アンパックする場合は、次のように一気に分解できます。
for x, y in zip(xs, ys):
# x, yとして直接扱えるので可読性が高い
print(x, y)タプルの要素数が3つ以上になっても同じ要領です。
for a, b, c in zip(list1, list2, list3):
...タプルの中身に明確な役割があるときは、必ず意味のある変数名にアンパックする習慣をつけると、後から読んだときにも理解しやすくなります。
zipとリスト内包表記で一行処理するテクニック
zipはリスト内包表記との相性も良く、「複数リストから新しいリストを組み立てる」処理を一行で書けるようになります。
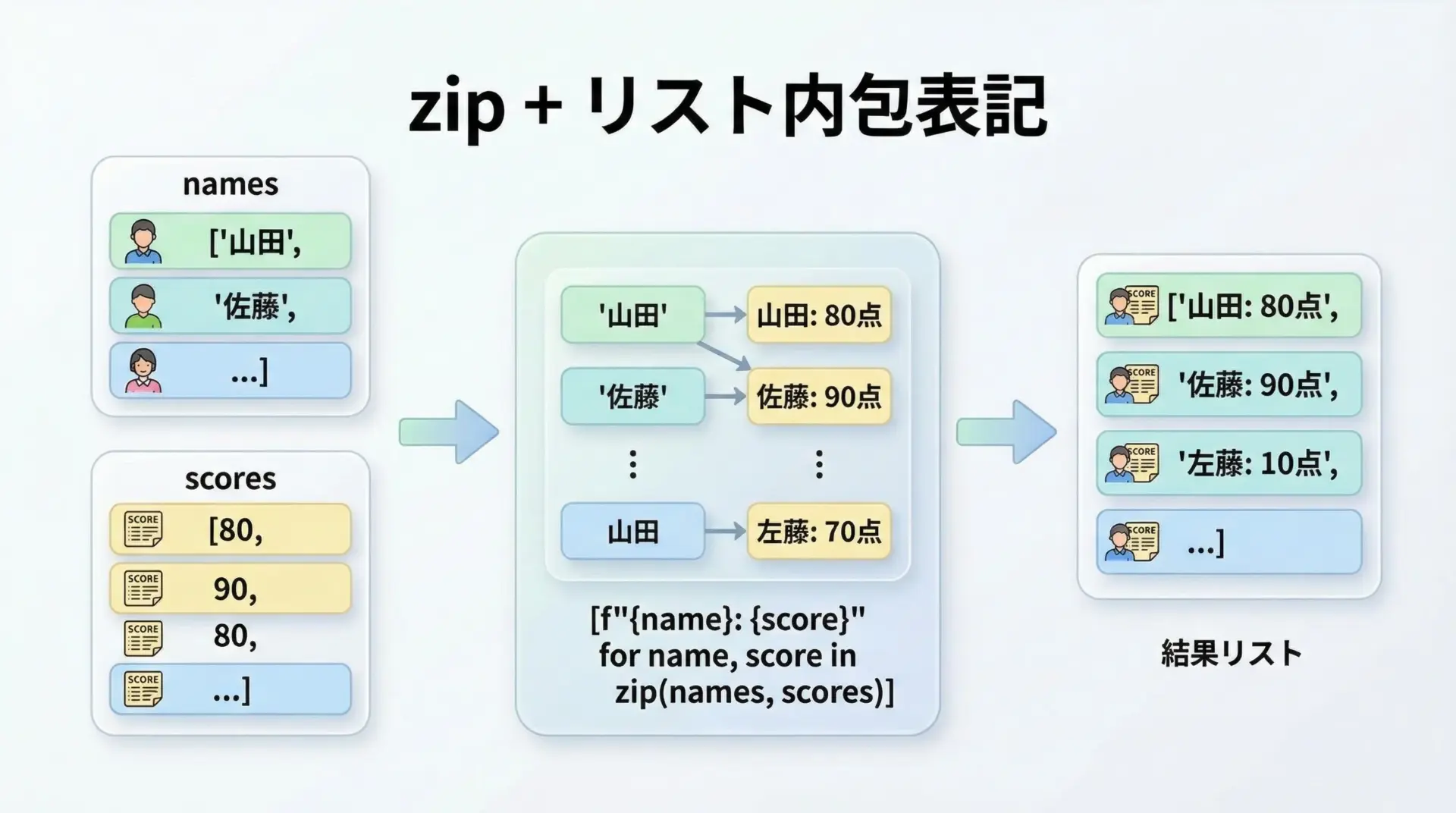
たとえば、名前と点数を"山田: 80点"のような文字列にしてリスト化するときは次のように書けます。
names = ["山田", "佐藤", "鈴木"]
scores = [80, 90, 75]
result = [f"{name}: {score}点" for name, score in zip(names, scores)]
print(result)['山田: 80点', '佐藤: 90点', '鈴木: 75点']数値の組み合わせにも簡単に応用できます。
xs = [1, 2, 3]
ys = [10, 20, 30]
# 対応する要素の和のリストを作る
sums = [x + y for x, y in zip(xs, ys)]
print(sums)[11, 22, 33]ループしながら新しいリストを作りたいときは、まず「zip + リスト内包表記で書けないか」を検討してみると、無駄なコードを省けることが多いです。
zipを使った辞書生成(dict)とキー・値の同時ループ
zipは辞書との連携でもよく使われます。
代表的なパターンは2つあり、1つは辞書の新規生成、もう1つは辞書のキーと値を同時にループするパターンです。
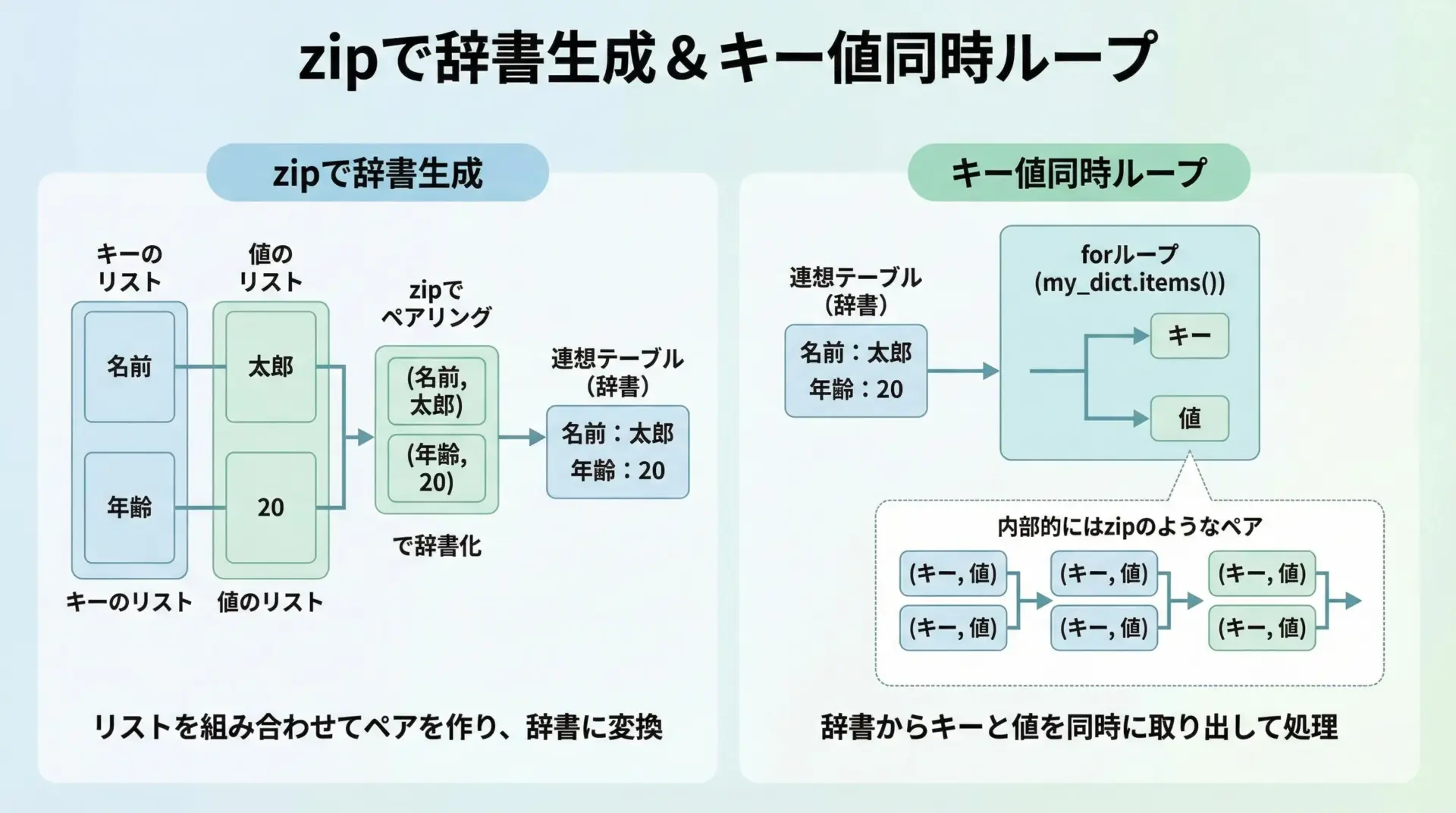
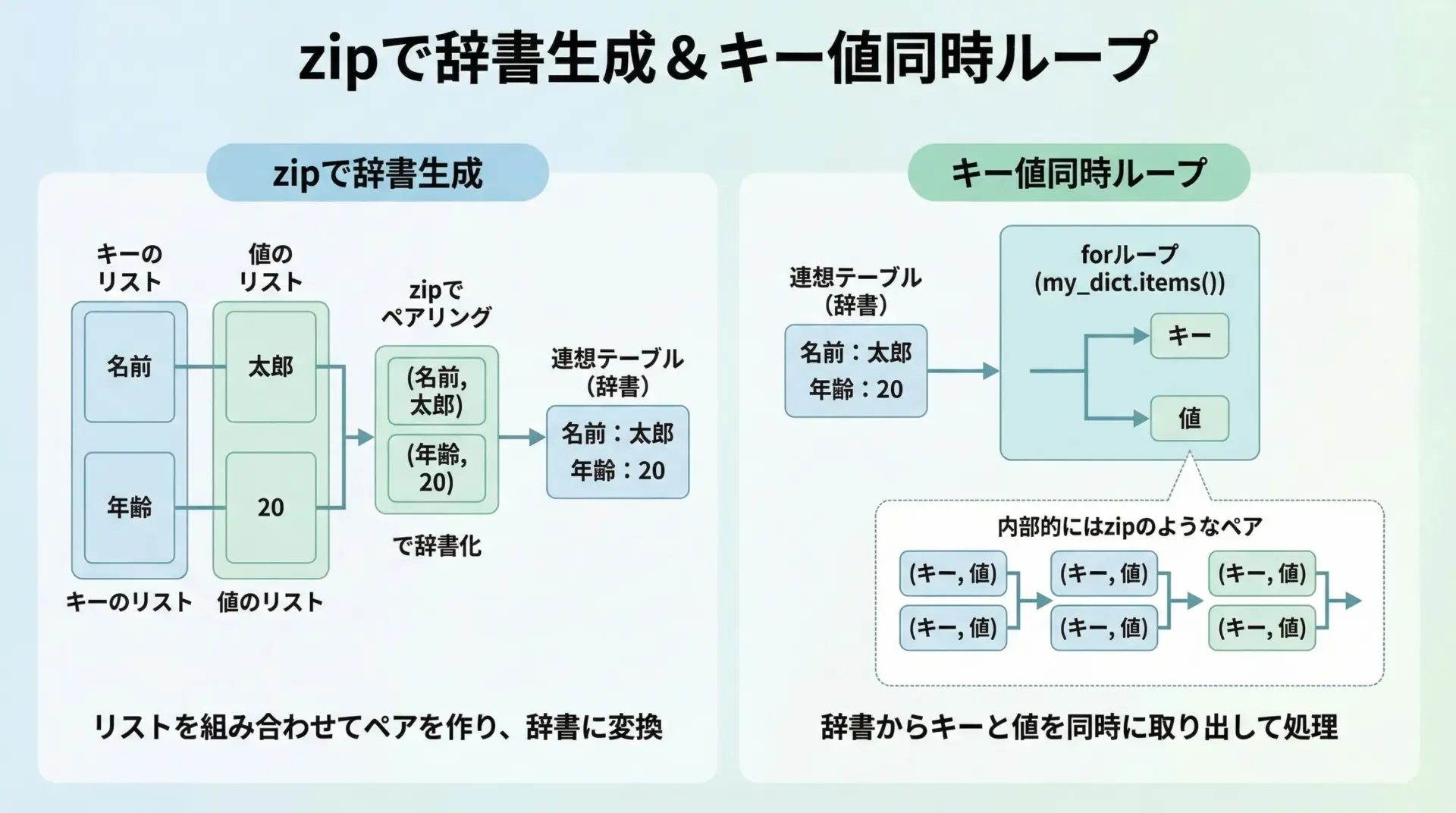
まず、2つのリストから辞書を作るには、dict(zip(keys, values))という書き方が定番です。
keys = ["apple", "banana", "orange"]
values = [120, 100, 150]
price_dict = dict(zip(keys, values))
print(price_dict){'apple': 120, 'banana': 100, 'orange': 150}この書き方は、設定値やマスタデータをコード内に持つときにとても便利です。
一方、既存の辞書を「キーと値を同時にループしたい」ときは、通常dict.items()を使います。
これは厳密にはzipではありませんが、「(キー, 値)のペアを順番に返す」という意味でzipと同じ発想です。
for fruit, price in price_dict.items():
print(f"{fruit}は{price}円です")appleは120円です
bananaは100円です
orangeは150円です2リスト → 辞書生成: dict(zip(…))、辞書 → ループ: dict.items()という対応をセットで覚えておくと、実務で非常によく役立ちます。
Pythonのzip関数を使いこなすコツ
ネストしたzipで二次元データを効率よく処理する
zipは、二次元のデータ構造(行列など)を扱うときにも威力を発揮します。
代表的な応用例が、行列の転置です。
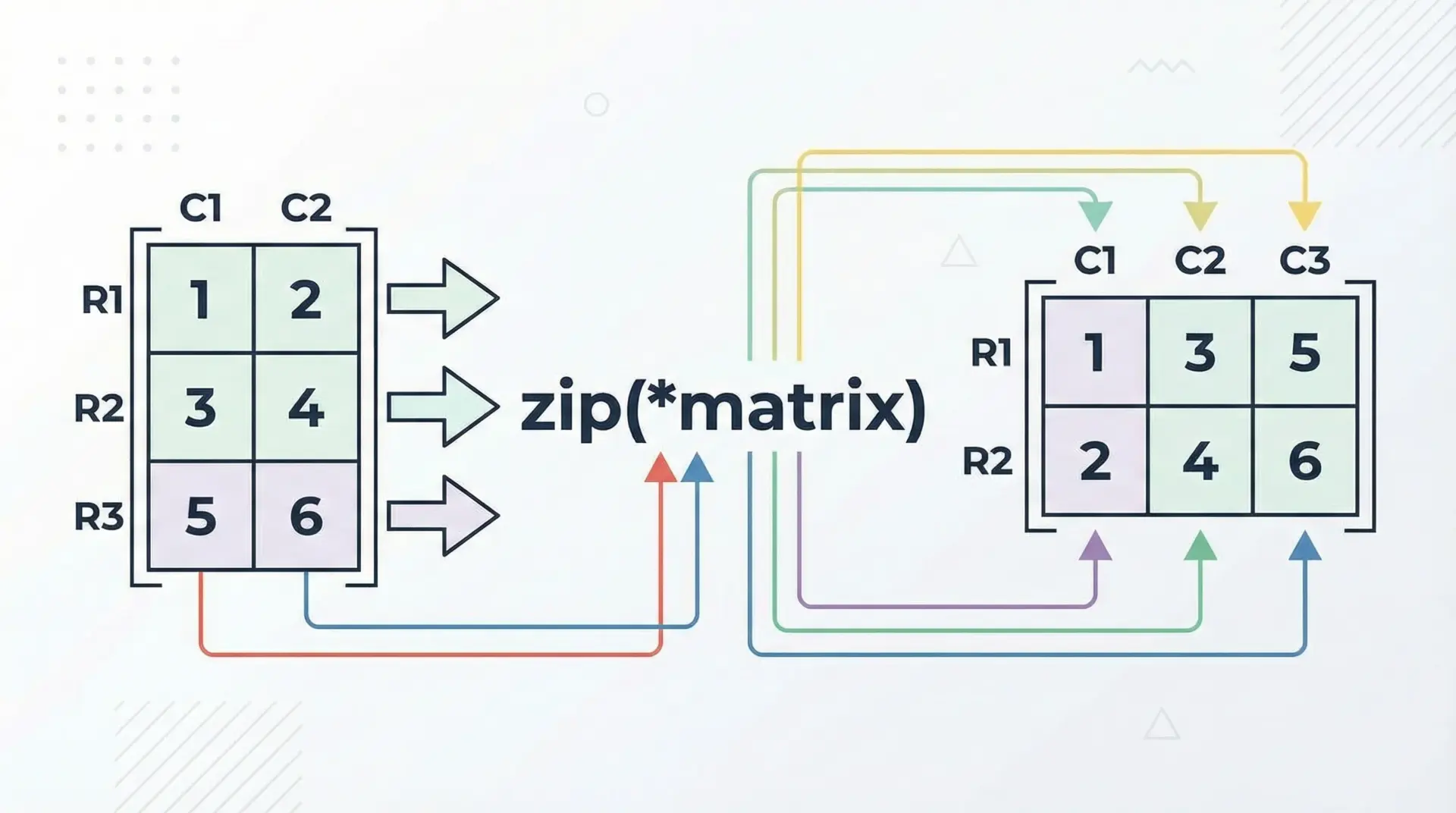
行列を行ごとのリストで表現しているとき、zip(*matrix)と書くことで列ごとのタプルに変換できます。
# 3行2列の行列を表す二次元リスト
matrix = [
[1, 2],
[3, 4],
[5, 6],
]
# *により各行が個別の引数としてzipに渡される
transposed = list(zip(*matrix))
print(transposed)[(1, 3, 5), (2, 4, 6)]*演算子は「アンパック」を意味し、リストやタプルを個別の引数として展開します。
つまり上記はzip([1, 2], [3, 4], [5, 6])と同じです。
二次元配列を行単位ではなく列単位で処理したいときや、CSVデータの列ごとの計算を行うときなどに非常に有用です。
zipで並列処理風のループを書いて処理を整理する
zipは内部的に並列処理をしているわけではありませんが、「複数の処理対象を横並びで同期して進める」という意味で、並列処理風のコードを簡潔に書くことができます。
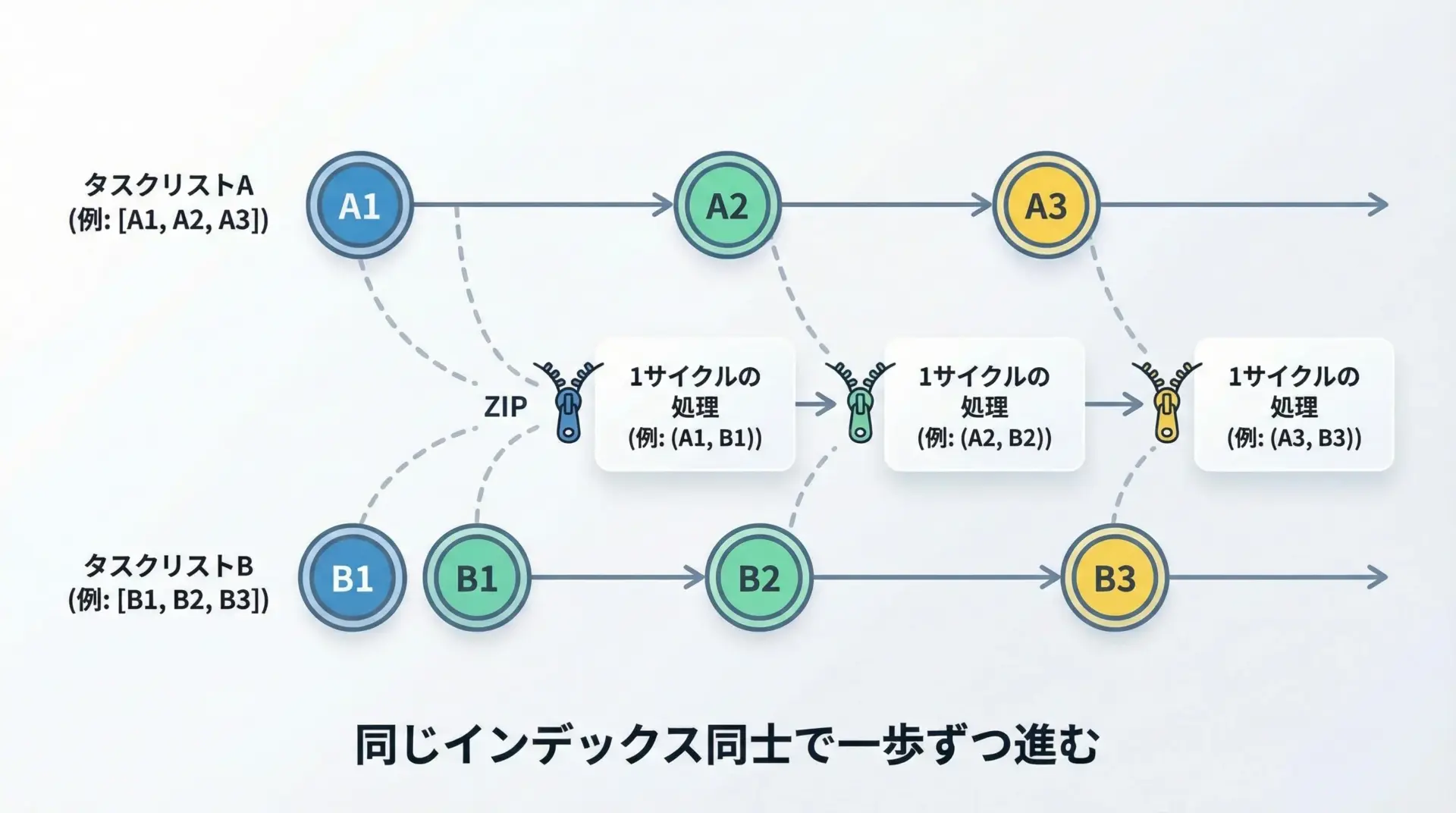
例えば、2つのログを日時順に揃えながら見ていくような処理を、シンプルなモデルで示します。
log_ids = [101, 102, 103]
statuses = ["OK", "WARN", "ERROR"]
for log_id, status in zip(log_ids, statuses):
# 各ログIDとステータスを同時に扱う
print(f"ログ{log_id}: 状態={status}")ログ101: 状態=OK
ログ102: 状態=WARN
ログ103: 状態=ERRORまた、enumerateと組み合わせることで、「位置情報 + 複数リスト」を同時に扱うこともできます。
names = ["山田", "佐藤", "鈴木"]
scores = [80, 90, 75]
for i, (name, score) in enumerate(zip(names, scores), start=1):
print(f"{i}位: {name}さん({score}点)")1位: 山田さん(80点)
2位: 佐藤さん(90点)
3位: 鈴木さん(75点)「複数の列がそろったテーブル状のデータ」を1行ずつ処理するような場面では、zipを使って並列進行のループを書いておくと、処理の構造が頭に入りやすくなります。
zip関数を使うべきケースと避けるべきケース
最後に、zipを使うべきケースと、あえて避けた方がよいケースを整理しておきます。
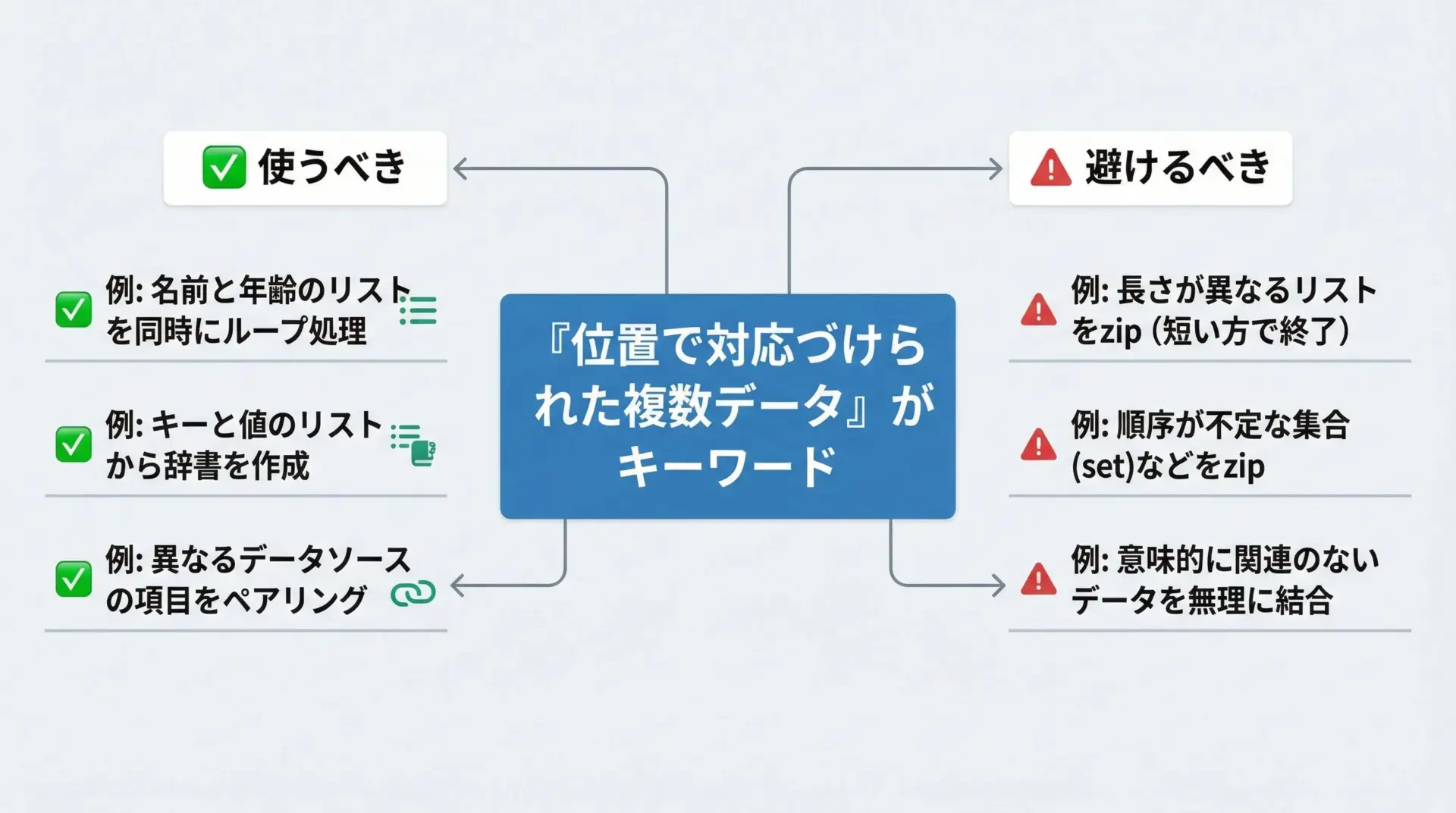
代表的な「使うべきケース」は次のような場面です。
| 使うべきケース | 理由 |
|---|---|
| 複数リストに「位置で対応づけられた」データが入っている | zipの設計と完全に一致するため、コードが素直になる |
| 複数列から新しいリスト・辞書・文字列を生成したい | リスト内包表記・dictとの連携が強力で、行数を減らせる |
| 行列やCSVなどの二次元データを列単位で処理したい | zip(*data)で転置し、列を一括処理できる |
逆に、避けた方がよいのは次のようなケースです。
| 避けるべきケース | 理由 |
|---|---|
| 各リストの長さがそろっている保証がないのに、zipでそのままループする | 長い側の末尾要素が静かに無視され、バグを見逃しやすい |
| 片方のリストだけを実際には使っておらず、他方はインデックス目的だけ | 不要なデータをzipに渡しており、意図が見えにくい |
| 1タプルの要素数が多く、for文のヘッダが長くなりすぎる | アンパックする変数が多すぎると読みづらくなる。構造の見直しを検討 |
特に「長さがそろっているか」問題は重要です。
場合によっては、zipでループしながらassertやチェックを挟み、前提条件を検証することも考えられます。
長さの違いを許容する場合は、zip_longestを使うことを積極的に検討してください。
まとめ
zip関数は、「位置で対応づけられた複数のデータ」を同時に処理するための標準的な道具です。
for文との組み合わせで、2つ以上のリストを一気にループ処理でき、インデックス管理の煩雑さやバグを大幅に減らせます。
さらに、zip_longestによる不足分の補完、アンパックによる可読性向上、リスト内包表記やdictとの連携、zip(*matrix)による二次元データの転置など、多くの場面で威力を発揮します。
日常的なコードの中でも、「インデックスで複数リストを触っているところはzipに書き換えられないか」を意識するだけで、Pythonらしく読みやすいコードに近づいていくはずです。
