
Pythonのlambda式は、短い処理をサッと書きたいときにとても便利な機能です。
しかし、書き方や使いどころを誤ると、コードが読みにくくなってしまいます。
本記事ではlambda式の基本構文から、sortedやpandas、GUIコールバックなど実務でよくある活用パターンまでを、サンプルコード付きでわかりやすく解説します。
Pythonのlambda式とは
lambda式の基本概要と特徴
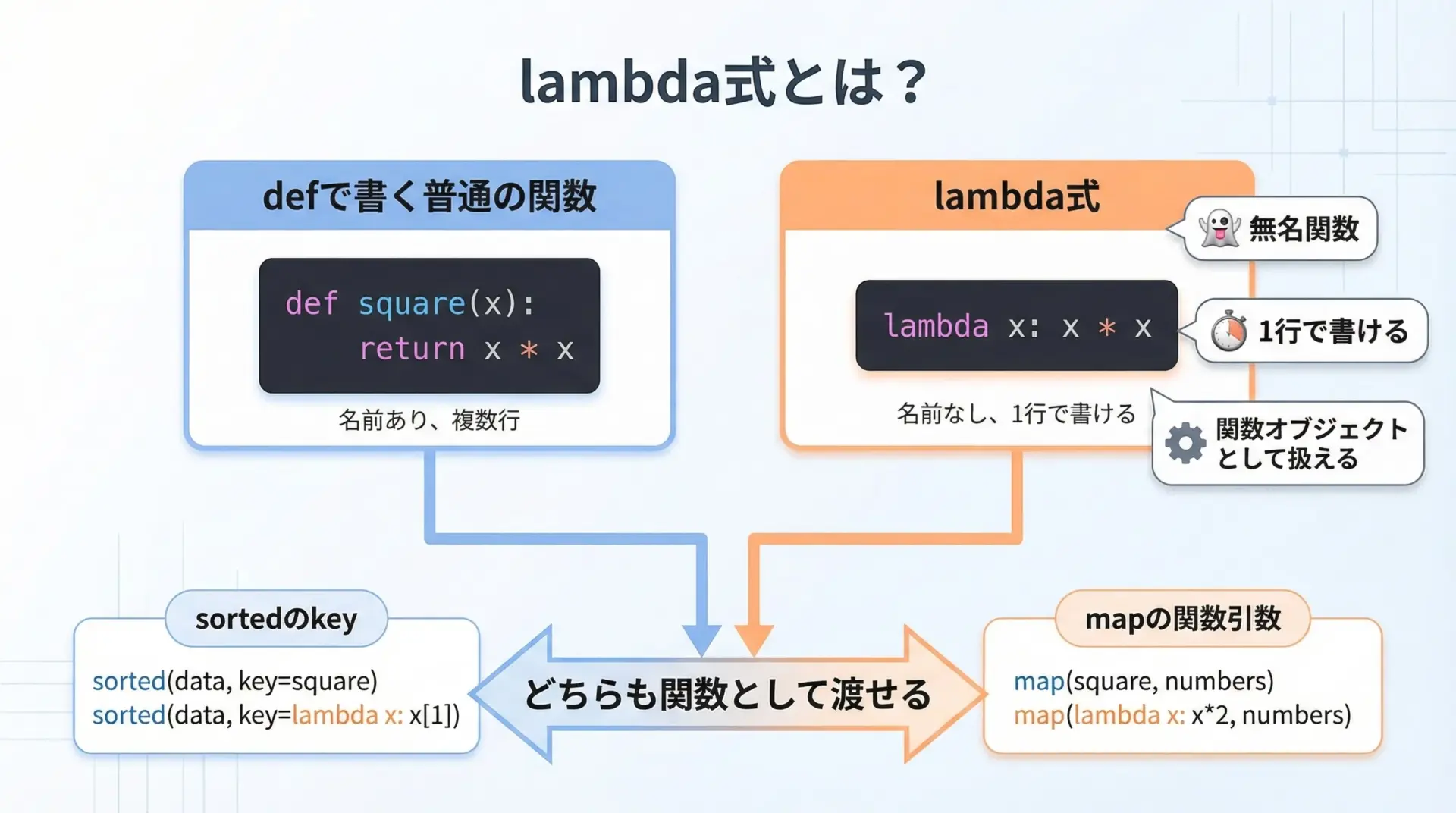
Pythonのlambda式とは、「その場かぎりの小さな関数」を1行で定義できる仕組みです。
無名関数(名前を持たない関数)とも呼ばれ、主に「関数を引数として渡す」場面で使われます。
通常の関数と同様に、引数を受け取り、処理を行い、値を返すことができますが、次のような特徴があります。
- 名前を付けなくても書ける(=無名関数)
- 1つの「式(expression)」だけを書ける
- その結果がそのまま戻り値になる
- defよりも短く書けるが、複雑な処理には不向き
無名関数と通常のdef関数の違い
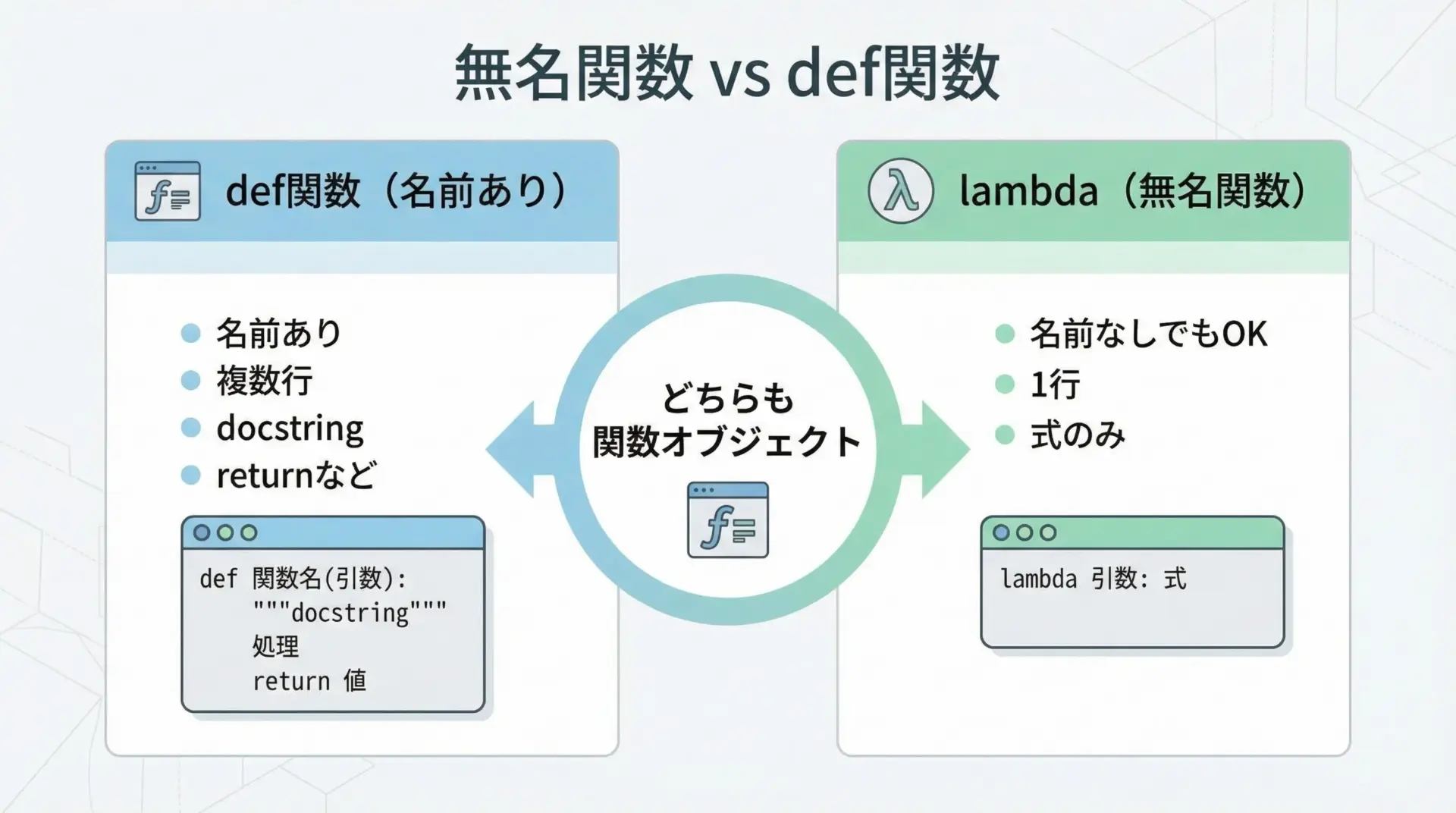
同じ処理を、通常のdef関数とlambda式で書き比べてみます。
# 通常のdef関数
def add_def(x, y):
"""xとyの合計を返す関数"""
return x + y
# lambda式を変数に代入して関数のように使う
add_lambda = lambda x, y: x + y # x + y の結果がそのまま戻り値になる
print(add_def(3, 4)) # 7
print(add_lambda(3, 4)) # 77
7どちらも「2つの引数を受け取り合計を返す関数」です。
違いは次の通りです。
| 項目 | def関数 | lambda式 |
|---|---|---|
| 名前 | 通常は付ける | 付けなくてもよい(無名) |
| 記述行数 | 複数行可 | 1行のみ |
| 本体 | 文(statement)も書ける | 式(expression)だけ |
| docstring | 書ける | 書けない |
| 用途 | 汎用的な処理、再利用 | その場限りの小さい処理 |
「読みやすさが必要な処理はdef」「その場だけの小さな変換ならlambda」と覚えておくと判断しやすくなります。
lambda式が役立つシーン
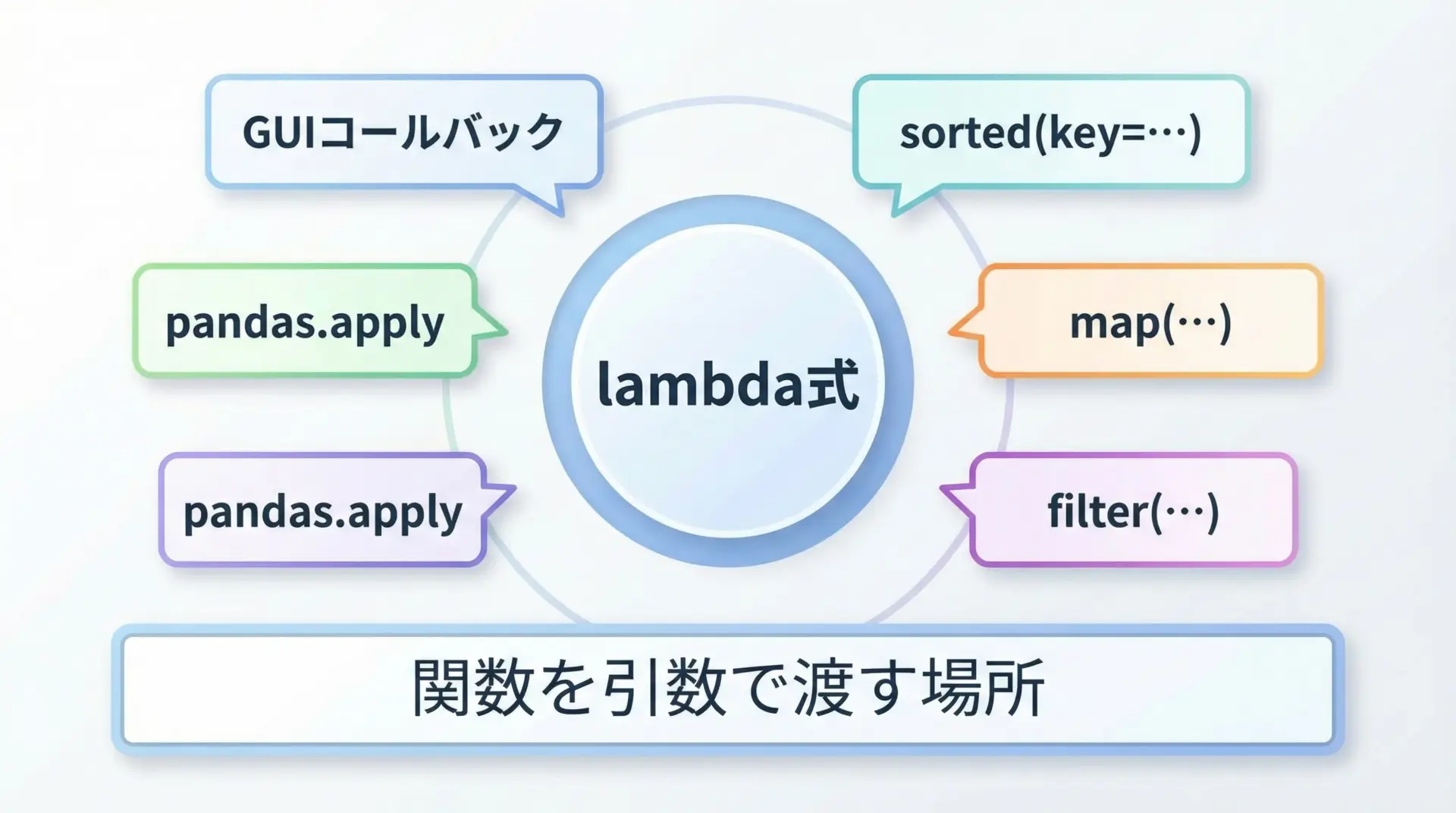
lambda式が特に役立つのは、「他の関数に、小さな処理を渡したいとき」です。
例えば次のような場面です。
- sortedで、ソートの並び順を決めるキー関数を指定するとき
- mapで、リストの各要素に1つの処理を一括適用するとき
- filterで、条件に合う要素だけを抽出するとき
- pandasで、シリーズや列に対して小さな処理を適用するとき
- GUIライブラリで、ボタンが押されたときの処理(コールバック)を短く書きたいとき
これらはいずれも「関数を引数として渡すAPI」であり、そこでlambda式の真価が発揮されます。
lambda式の基本構文
lambda式の書き方
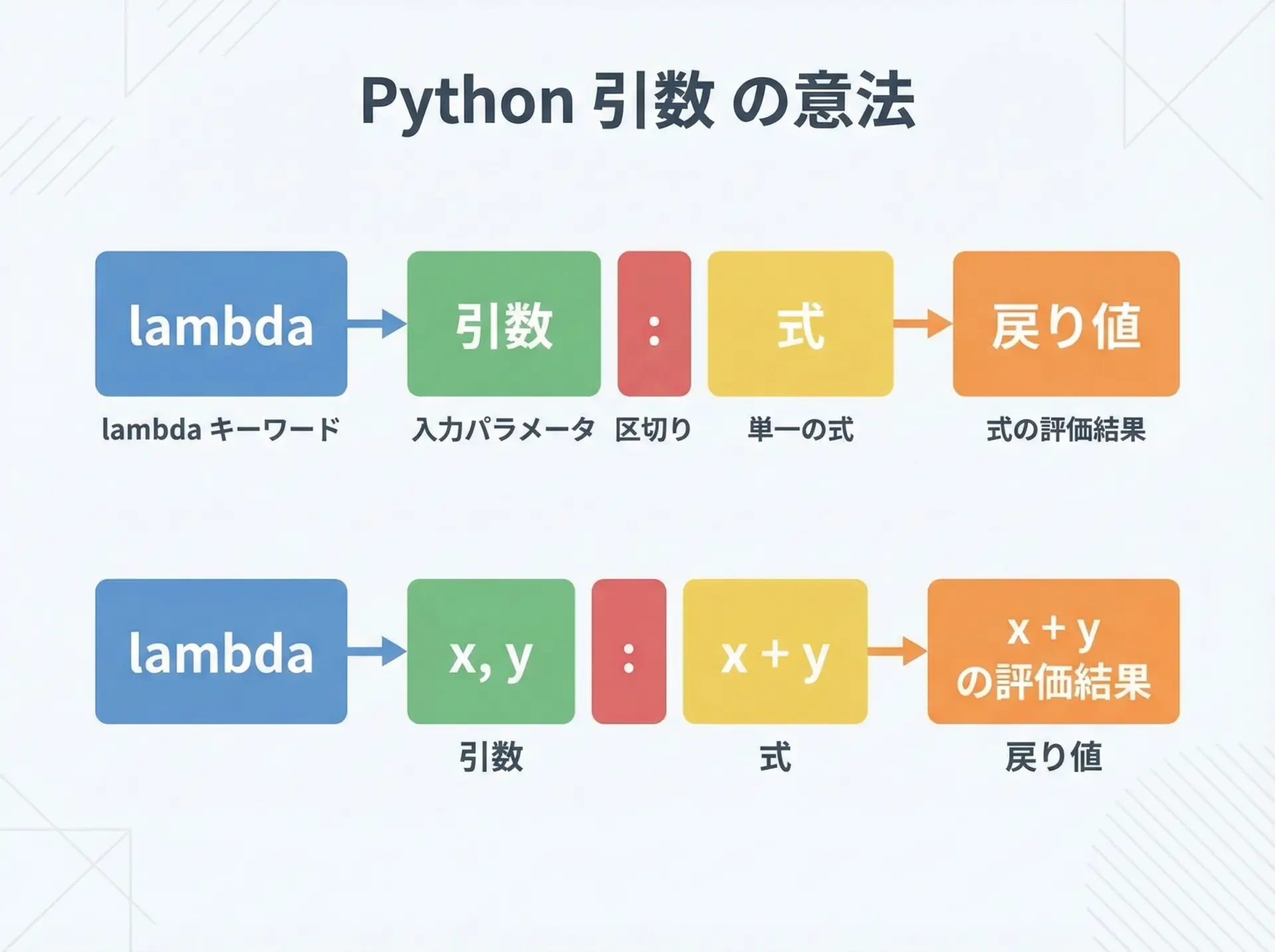
lambda式の基本構文はとてもシンプルです。
lambda 引数リスト: 式
ここでのポイントは次の通りです。
- lambda: キーワード
- 引数リスト:
xやx, yなど、関数の引数と同じ書き方 - : の右側: 「式(expression)」を1つだけ書く
- その式を評価した結果が、そのまま戻り値になる
簡単な例を見てみましょう。
# 1つの数を2倍にするlambda式
double = lambda x: x * 2
print(double(5)) # 1010単一引数のlambda式の例
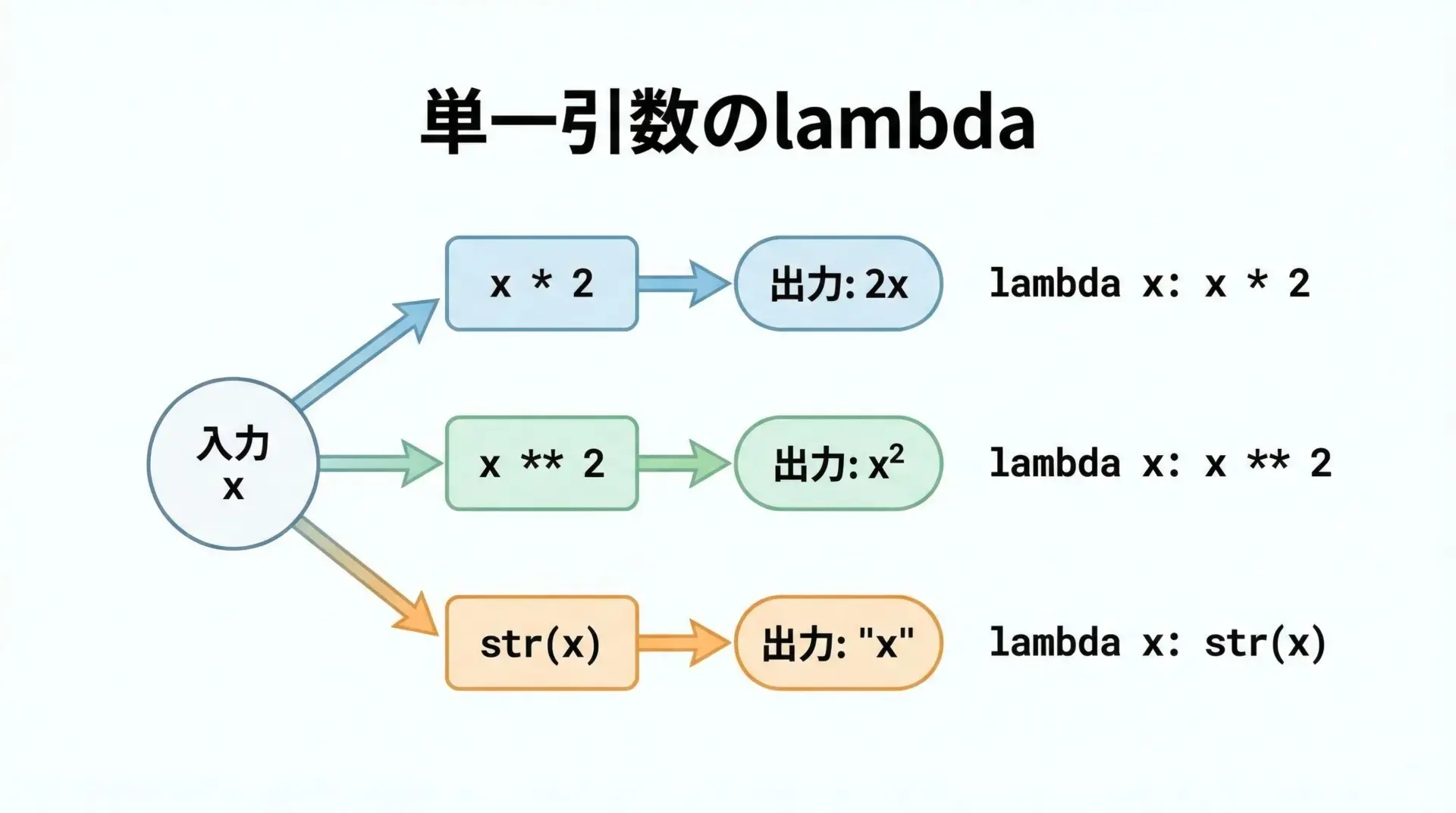
単一の引数を取るlambda式は最もよく使われます。
例えば、数値を加工したり、文字列を整形したりするケースです。
# xを2倍にする
double = lambda x: x * 2
# xを2乗する
square = lambda x: x ** 2
# xを文字列に変換して"様"を付ける
to_name = lambda x: str(x) + "様"
print(double(3)) # 6
print(square(4)) # 16
print(to_name("山田")) # 山田様6
16
山田様「引数が1つで、単純な変換をしたいとき」には、この形が最も自然です。
複数引数を取るlambda式の例
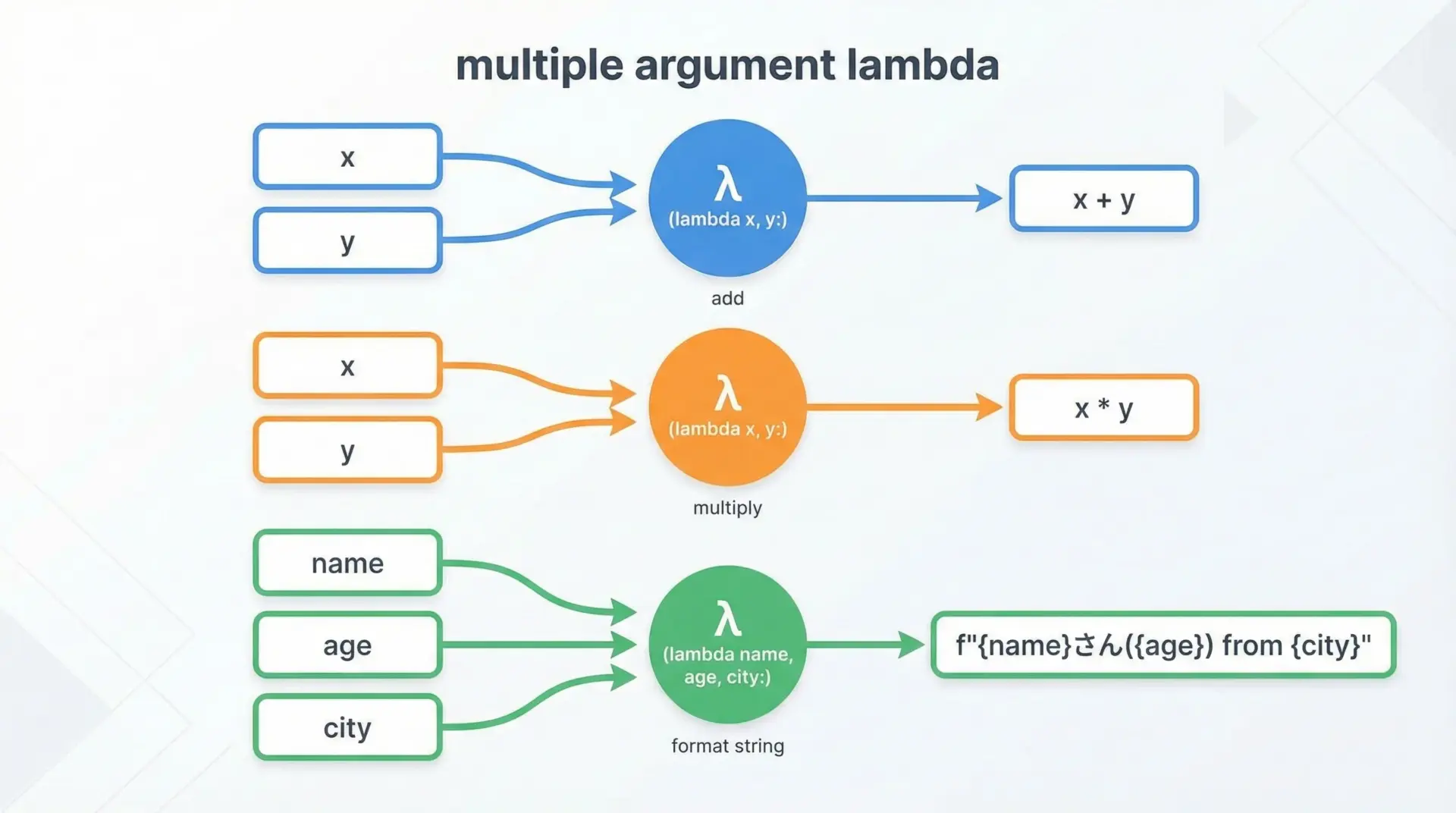
lambda式は、複数の引数も扱えます。
# 2つの数値の合計を返す
add = lambda x, y: x + y
# 2つの値を「大きい方」を返す
max_2 = lambda x, y: x if x > y else y
# 氏名と年齢から表示用の文字列を作る
format_user = lambda name, age: f"{name}さん({age}歳)"
print(add(3, 5)) # 8
print(max_2(10, 7)) # 10
print(format_user("佐藤", 29)) # 佐藤さん(29歳)8
10
佐藤さん(29歳)引数の書き方はdef関数と同じで、デフォルト値や可変長引数も利用できます。
ただし、複雑になりやすいので、実務ではあまり凝った引数構成はlambdaには持たせない方が無難です。
条件演算子を使ったlambda式

lambda式の中では条件演算子(三項演算子)を使うことで、簡単な条件分岐を1行で書けます。
# 偶数か奇数かを判定するlambda
odd_or_even = lambda x: "偶数" if x % 2 == 0 else "奇数"
# 年齢に応じて区分を返すlambda
age_group = lambda age: "成人" if age >= 20 else "未成年"
print(odd_or_even(3)) # 奇数
print(odd_or_even(10)) # 偶数
print(age_group(18)) # 未成年
print(age_group(22)) # 成人奇数
偶数
未成年
成人ただし、入れ子の条件(ネストしたif)をlambdaの中に書き始めると一気に読みにくくなります。
その場合は素直にdef関数に分ける方がよいです。
lambda式の実務での使い方
sortedでのキー指定にlambda式を使う
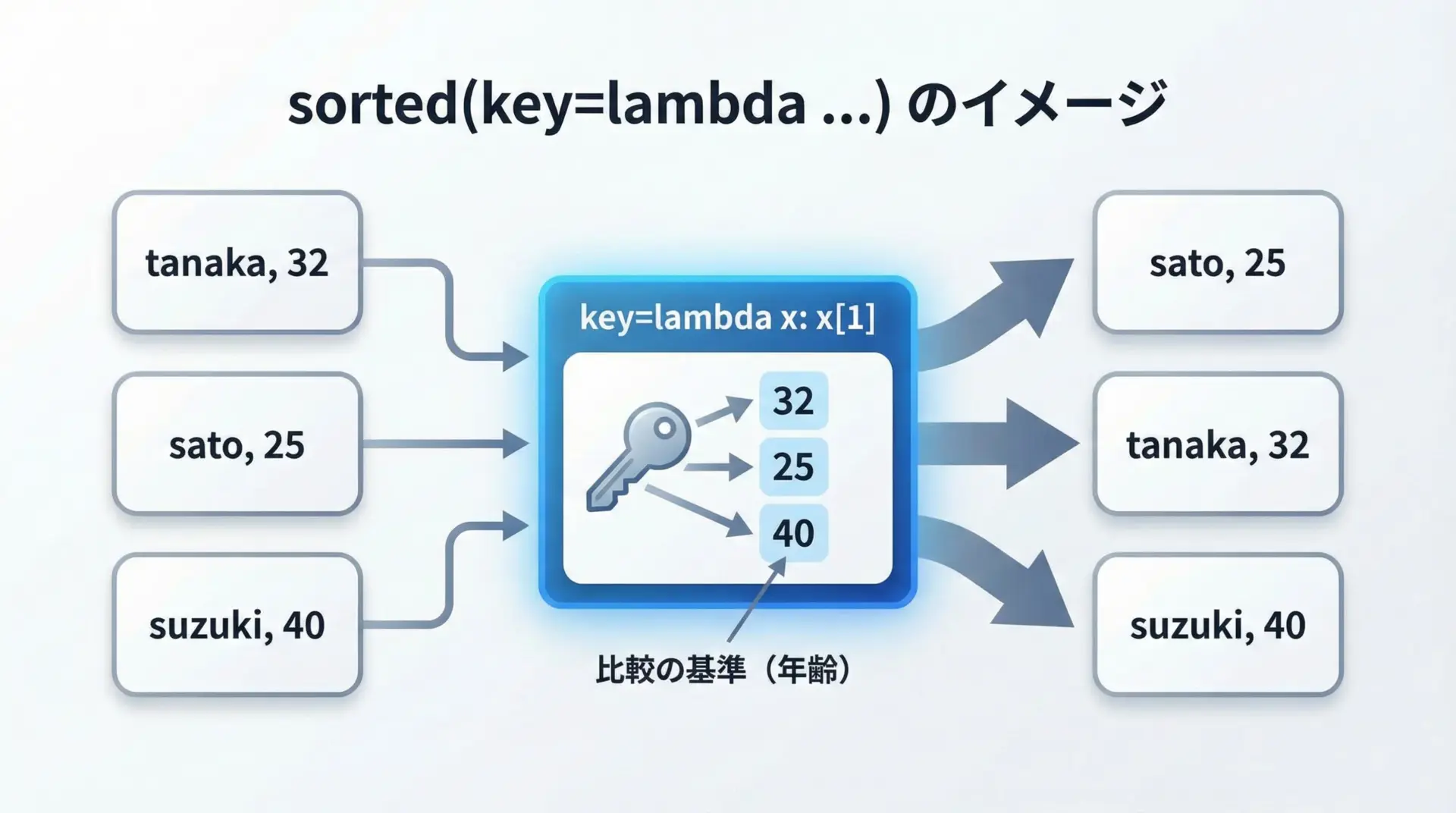
lambda式が最もよく使われる場所の1つがsortedのkey引数です。
ソートの「並び替え基準」を関数で指定できます。
# (名前, 年齢)のタプルのリスト
users = [
("tanaka", 32),
("sato", 25),
("suzuki", 40),
]
# 年齢(インデックス1)で昇順にソート
sorted_by_age = sorted(users, key=lambda user: user[1])
# 名前(インデックス0)でアルファベット順にソート
sorted_by_name = sorted(users, key=lambda user: user[0])
print("年齢順:", sorted_by_age)
print("名前順:", sorted_by_name)年齢順: [('sato', 25), ('tanaka', 32), ('suzuki', 40)]
名前順: [('sato', 25), ('suzuki', 40), ('tanaka', 32)]「オブジェクトのどの属性(どの要素)をソート基準にするか」を1行で指定できるため、辞書やクラスのリストをソートするときにも非常に便利です。
辞書の例も見てみます。
# ユーザー情報の辞書リスト
users = [
{"name": "tanaka", "age": 32},
{"name": "sato", "age": 25},
{"name": "suzuki", "age": 40},
]
# 年齢で昇順ソート
sorted_by_age = sorted(users, key=lambda u: u["age"])
# 年齢で降順ソート
sorted_by_age_desc = sorted(users, key=lambda u: u["age"], reverse=True)
print("年齢昇順:", sorted_by_age)
print("年齢降順:", sorted_by_age_desc)年齢昇順: [{'name': 'sato', 'age': 25}, {'name': 'tanaka', 'age': 32}, {'name': 'suzuki', 'age': 40}]
年齢降順: [{'name': 'suzuki', 'age': 40}, {'name': 'tanaka', 'age': 32}, {'name': 'sato', 'age': 25}]mapとlambda式でリストを一括変換
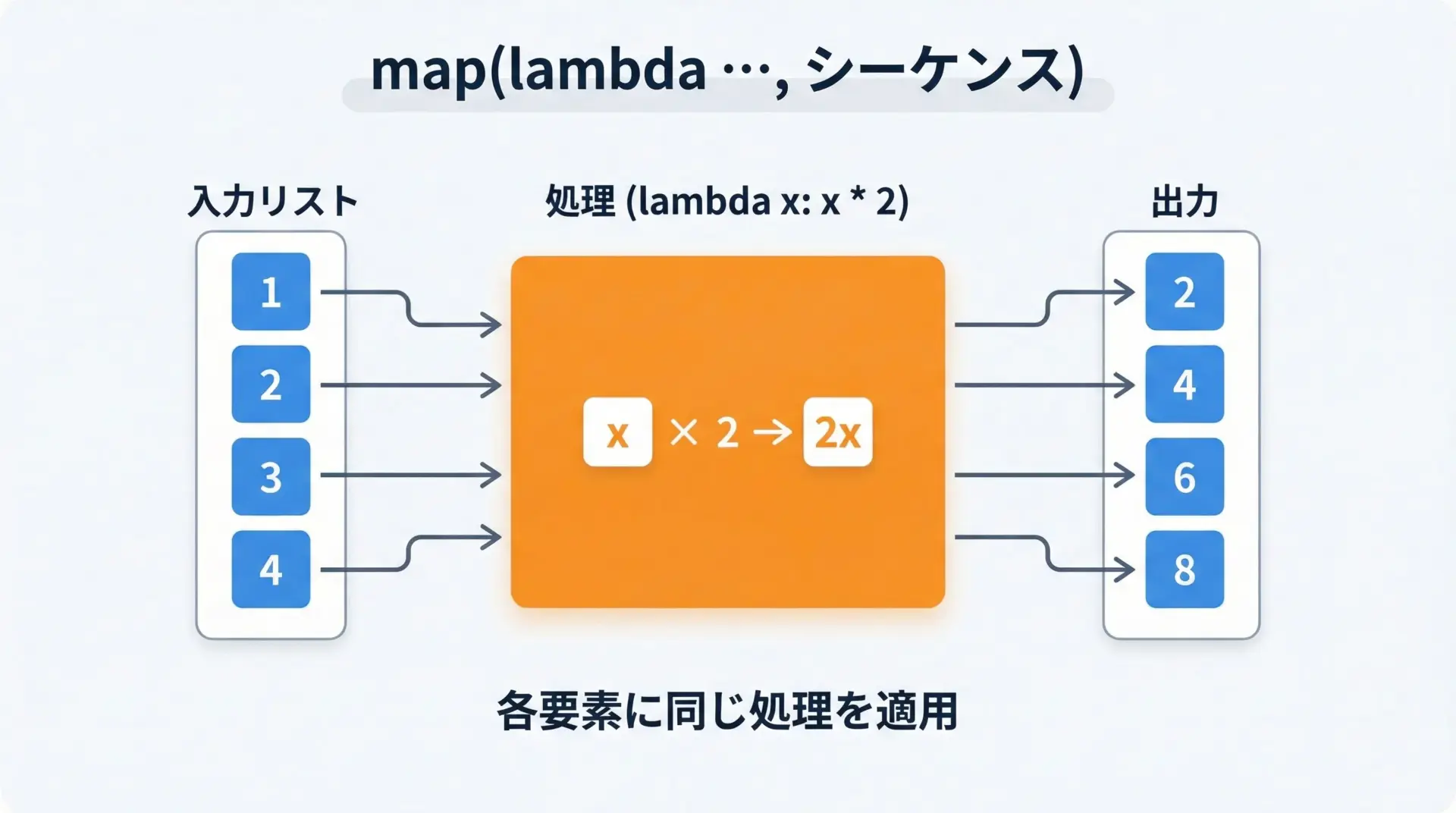
mapは、「シーケンスの各要素に同じ処理を適用する」関数です。
lambda式と組み合わせると、短く記述できます。
numbers = [1, 2, 3, 4, 5]
# それぞれ2倍にする
doubled = list(map(lambda x: x * 2, numbers))
# 文字列に変換して"点"を付ける
with_suffix = list(map(lambda x: str(x) + "点", numbers))
print(doubled) # [2, 4, 6, 8, 10]
print(with_suffix) # ['1点', '2点', '3点', '4点', '5点'][2, 4, 6, 8, 10]
['1点', '2点', '3点', '4点', '5点']ただしPythonらしさという観点では、同じ処理はリスト内包表記で書くことが推奨されるケースも多いです。
後ほど「リスト内包表記との使い分け」で詳しく説明します。
filterとlambda式でデータを抽出

filterは、「条件に合う要素だけを残す」ための関数です。
lambda式で条件を定義します。
numbers = [1, 2, 3, 4, 5, 6]
# 偶数だけを取り出す
evens = list(filter(lambda x: x % 2 == 0, numbers))
# 3以上の数だけを取り出す
ge_3 = list(filter(lambda x: x >= 3, numbers))
print(evens) # [2, 4, 6]
print(ge_3) # [3, 4, 5, 6][2, 4, 6]
[3, 4, 5, 6]こちらも、Pythonでは内包表記による条件付きループがよく使われます。
たとえば上記は次のようにも書けます。
evens = [x for x in numbers if x % 2 == 0]
ge_3 = [x for x in numbers if x >= 3]filterか内包表記かは、チームのコーディングスタイルや可読性を基準に選ぶとよいです。
list内包表記とlambda式の使い分け
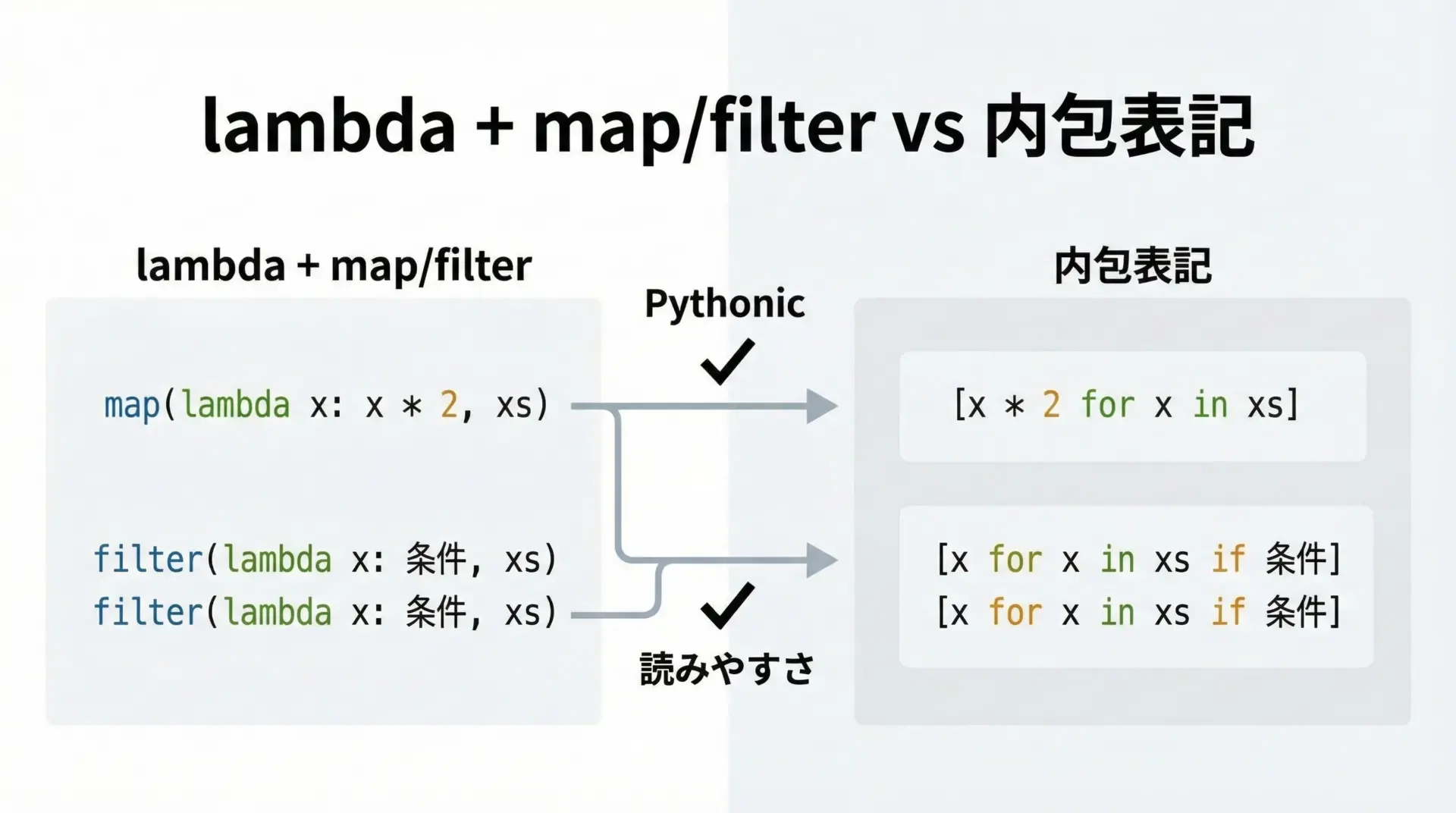
ここまで見てきた通り、map と filter はlambda式と相性が良い関数です。
しかし、Pythonコミュニティでは、読みやすさの観点から内包表記が好まれる傾向があります。
具体例で比較してみます。
numbers = [1, 2, 3, 4, 5]
# 例1: すべて2倍にする
# lambda + map
doubled_map = list(map(lambda x: x * 2, numbers))
# 内包表記
doubled_comp = [x * 2 for x in numbers]
# 例2: 偶数だけ2倍にして取り出す
# lambda + filter + map
even_doubled_map = list(map(lambda x: x * 2,
filter(lambda x: x % 2 == 0, numbers)))
# 内包表記
even_doubled_comp = [x * 2 for x in numbers if x % 2 == 0]
print(doubled_map)
print(doubled_comp)
print(even_doubled_map)
print(even_doubled_comp)[2, 4, 6, 8, 10]
[2, 4, 6, 8, 10]
[4, 8]
[4, 8]どちらも同じ結果になりますが、内包表記の方が処理の流れが直感的に読み取りやすいと感じる人が多いです。
目安としては次のように考えるとよいでしょう。
- 単純な変換・抽出: 内包表記を優先
- 関数を渡す必要があるAPI(map/filter以外): lambda式を利用
- 一連のデータパイプラインを関数で書きたい: lambda + map/filter も選択肢
pandasでのlambda式適用
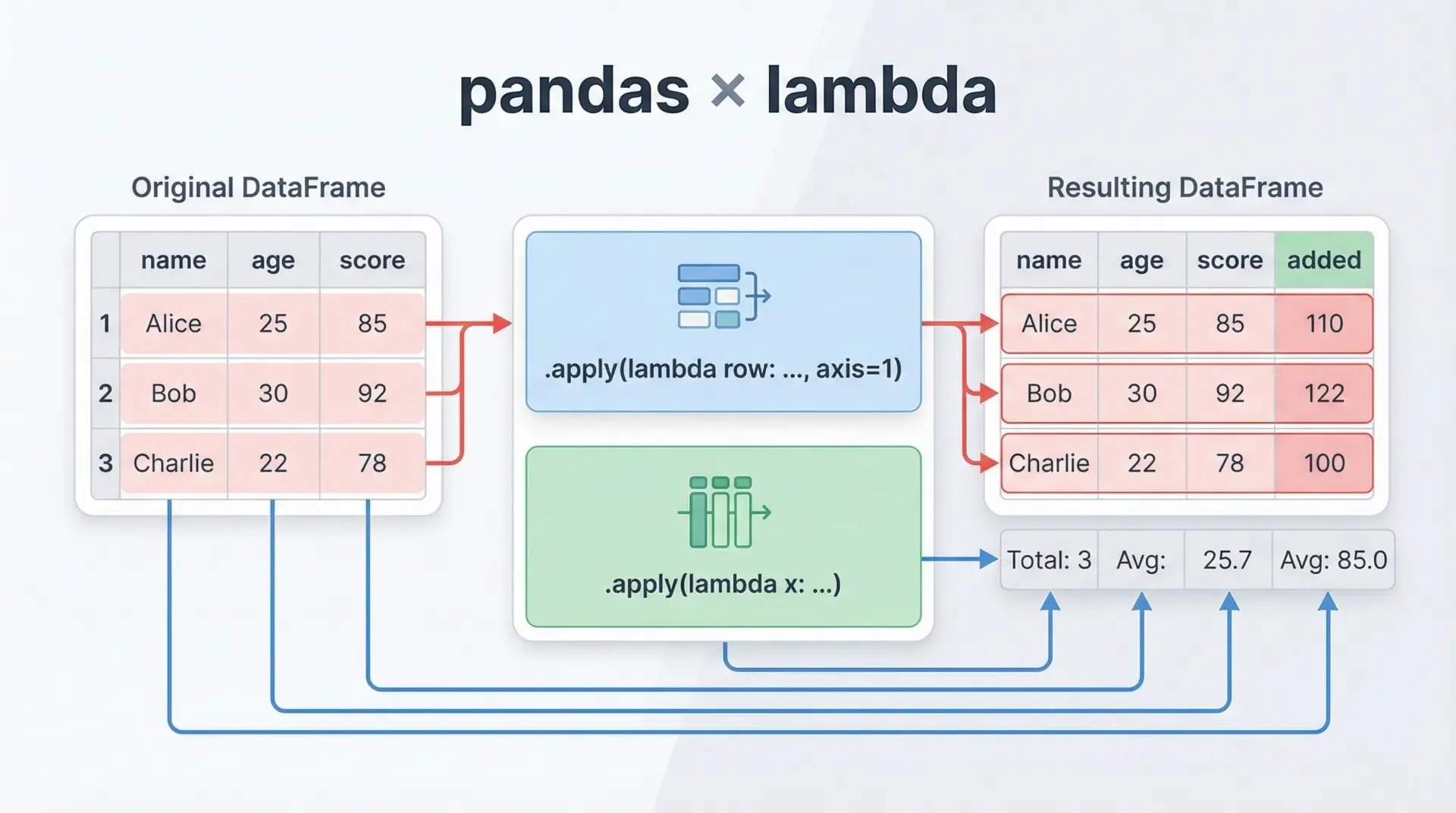
データ分析でよく使われるpandasでは、列または行ごとに処理を適用するためにlambda式が頻出します。
import pandas as pd
# サンプルデータの作成
df = pd.DataFrame({
"name": ["tanaka", "sato", "suzuki"],
"age": [32, 25, 40],
"score": [80, 90, 70],
})
# 1列に対してlambdaを適用(年齢 + 1)
df["age_next"] = df["age"].apply(lambda x: x + 1)
# 行全体に対してlambdaを適用(axis=1)
# 合格かどうかのフラグを追加
df["is_pass"] = df.apply(lambda row: row["score"] >= 80, axis=1)
print(df) name age score age_next is_pass
0 tanaka 32 80 33 True
1 sato 25 90 26 True
2 suzuki 40 70 41 Falseこのように列の変換・新しい列の作成・条件に基づくフラグ列の作成などでlambda式が活躍します。
ただし、pandasの場合はlambda + applyは柔軟ですが速度が遅くなりがちです。
可能であれば、ベクトル化された演算(列同士の計算やnp.whereなど)を優先した方がよいことも覚えておくと実務で役立ちます。
GUIやコールバック関数でのlambda式の活用
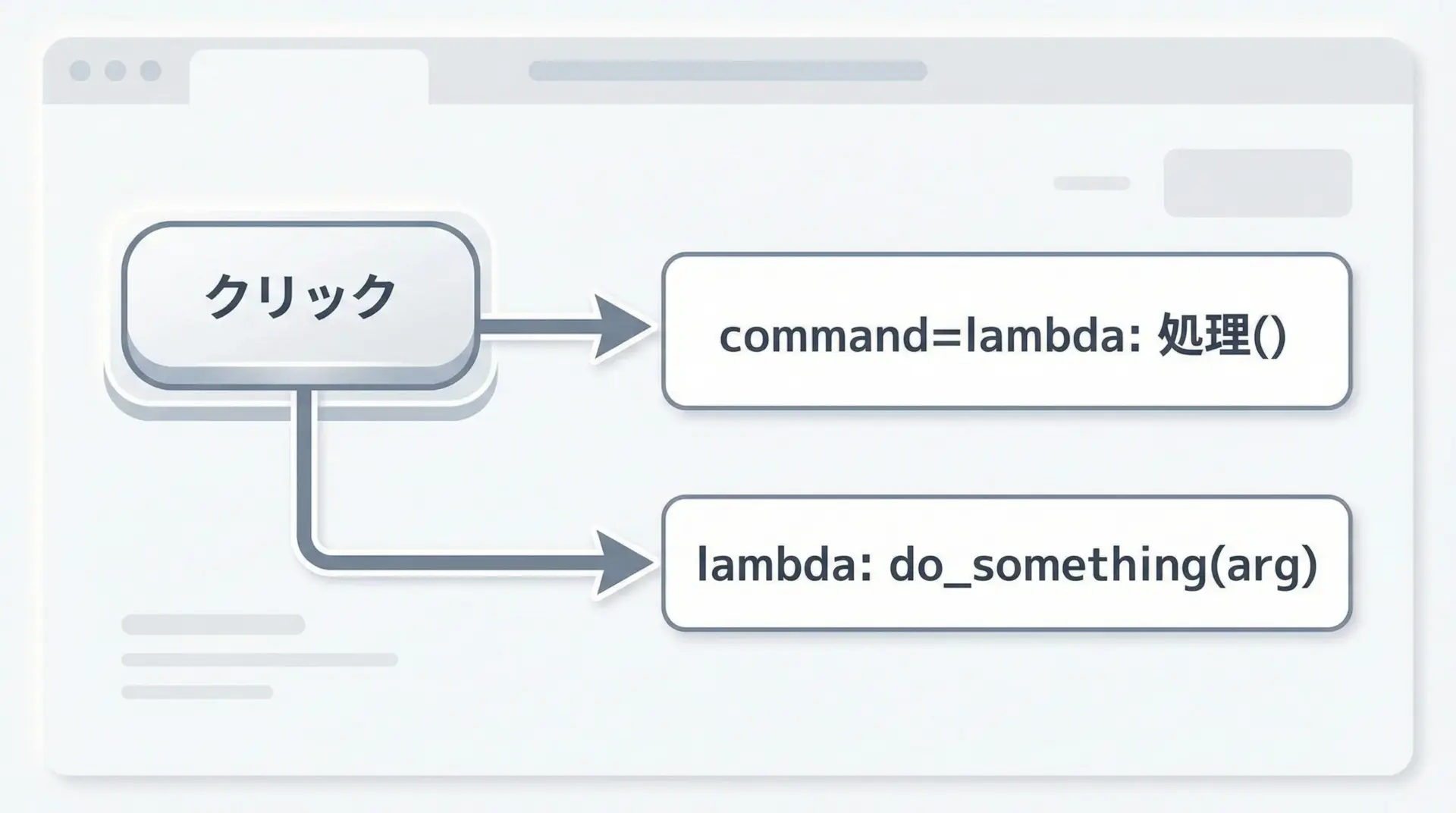
GUIライブラリ(Tkinterなど)や、非同期処理のコールバックでも、lambda式がよく使われます。
「イベントが起きたときに実行する関数」を、その場で短く書けるからです。
Tkinterの例を見てみます。
import tkinter as tk
root = tk.Tk()
root.title("lambdaサンプル")
def greet(name):
print(f"こんにちは、{name}さん")
# 引数なしのコールバック
button1 = tk.Button(root, text="挨拶(固定)",
command=lambda: greet("山田"))
button1.pack()
# 入力欄の内容を使うコールバック
entry = tk.Entry(root)
entry.pack()
button2 = tk.Button(
root,
text="入力名で挨拶",
command=lambda: greet(entry.get()) # entry.get() を実行するlambda
)
button2.pack()
root.mainloop()この例では、ボタンがクリックされたときに呼ばれる関数(command引数)としてlambda式を渡しています。
lambdaの中でgreet("山田")やgreet(entry.get())を呼び出すことで、「引数付きの関数呼び出し」をイベントに紐づけることができます。
lambda式を使うときの注意点とベストプラクティス
複雑すぎるlambda式は避けるべき理由

lambda式に慣れてくると、つい多くの処理を1行に詰め込みたくなります。
しかし、これは可読性を大きく損ないます。
例えば、次のようなlambdaは一見スマートに見えますが、読み解くのに時間がかかります。
# 悪い例: 条件が複雑で読みづらいlambda
judge = lambda x: "大" if x > 10 else ("中" if x > 5 else "小")同じ処理をdef関数で書くと、ずっと読みやすくなります。
def judge(x):
"""数値の大小を判定して '大', '中', '小' を返す"""
if x > 10:
return "大"
elif x > 5:
return "中"
else:
return "小"「1行で書けること」と「読みやすいこと」は別問題です。
特にチーム開発では、後から読む人の負担を考えて、lambdaの複雑さは意識的に抑えるべきです。
可読性を保つlambda式の書き方
lambda式を使うときは、次のようなルールを意識すると可読性を保ちやすくなります。
- 1行で視界に収まる長さにする
横に長くなりすぎるlambdaは、それだけで理解が難しくなります。 - 「シンプルな変換」「単純な条件」程度にとどめる
複数の条件分岐や、複雑な文字列操作などをlambdaに詰め込まないようにします。 - 必要なら変数に代入して意味を持たせる
匿名のままでは何をしているか伝わりにくいときは、適切な名前の変数に代入します。
# 匿名のlambdaをそのまま渡す(短いので許容)
sorted_users = sorted(users, key=lambda u: u["age"])
# 少し複雑になりそうなら、意味のある名前を付ける
get_age_group = lambda age: "adult" if age >= 20 else "child"
ages = [15, 20, 30]
groups = list(map(get_age_group, ages))
print(groups) # ['child', 'adult', 'adult']['child', 'adult', 'adult']「lambdaに名前を付けるならdefでいいのでは?」とも思えますが、処理が十分に短い場合はlambdaでも構いません。
チームのコーディング規約に従うのがベストです。
def関数に書き換えるべきケース

次のような場合は、迷わずdef関数に書き換えるべきです。
- 1行では収まらないロジックを実装したいとき
- 複数箇所で同じ処理を再利用したいとき
- 独立してテストを書きたい・デバッグしたいとき
- 処理の意図をdocstringで説明したいとき
例を見てみます。
# 悪い例: 長すぎるlambda
process_record = lambda r: (
r["name"].strip().title()
+ " (age: "
+ str(r["age"])
+ (", VIP" if r.get("vip") else "")
+ ")"
)
# 良い例: def関数に分離
def format_user_record(record):
"""ユーザー情報の辞書から表示用の文字列を生成する"""
name = record["name"].strip().title()
age = record["age"]
suffix = ", VIP" if record.get("vip") else ""
return f"{name} (age: {age}{suffix})"このように処理のステップを分解し、変数名やdocstringで意図を表現できるのがdef関数の大きな利点です。
実務で役立つlambda式の書き方まとめ
実務では、次のようなパターンを覚えておくとlambda式を効果的に活用できます。
# 1. sortedで特定の要素/属性をキーにソート
items = [("a", 3), ("b", 1), ("c", 2)]
sorted_items = sorted(items, key=lambda x: x[1])
# 2. 単純な変換をmapで一括適用(内包表記と比較して選ぶ)
numbers = [1, 2, 3]
doubled = list(map(lambda x: x * 2, numbers))
# or: doubled = [x * 2 for x in numbers]
# 3. filterで条件に合うデータだけ抽出(内包表記と比較して選ぶ)
evens = list(filter(lambda x: x % 2 == 0, numbers))
# or: evens = [x for x in numbers if x % 2 == 0]
# 4. pandasで列/行に処理を適用
# df["new"] = df["old"].apply(lambda x: x * 100)
# df["flag"] = df.apply(lambda row: 条件式, axis=1)
# 5. GUIコールバックで引数付き関数を紐づける
# button = Button(root, command=lambda: do_something(arg1, arg2))「1行で書けて、処理の意図がすぐに伝わる」場合にlambda式を使う、という判断基準を持っておくと、コードの質が安定します。
まとめ
lambda式は、Pythonで「小さな処理をその場で関数として渡す」ための強力な道具です。
sortedのkey指定、map・filter、pandasのapply、GUIコールバックなど、実務の多くの場面で活躍します。
一方で、複雑な処理までlambdaで書こうとすると一気に可読性が落ちることも押さえておきましょう。
基本は「短く」「単純に」「必要ならdefに逃がす」というスタンスで使い分けることで、読みやすくメンテナブルなPythonコードを書けるようになります。
