Pythonのジェネレータは、一度にすべての値を用意するのではなく、必要になったタイミングで値を1つずつ「生産」してくれる仕組みです。
特にyield文を使った関数は、大量データ処理やストリーミング処理で威力を発揮します。
本記事では、yieldの挙動やメリット、具体的な使い所までを図解たっぷりで丁寧に解説していきます。
Pythonジェネレータとは何か
ジェネレータとイテレータの違い
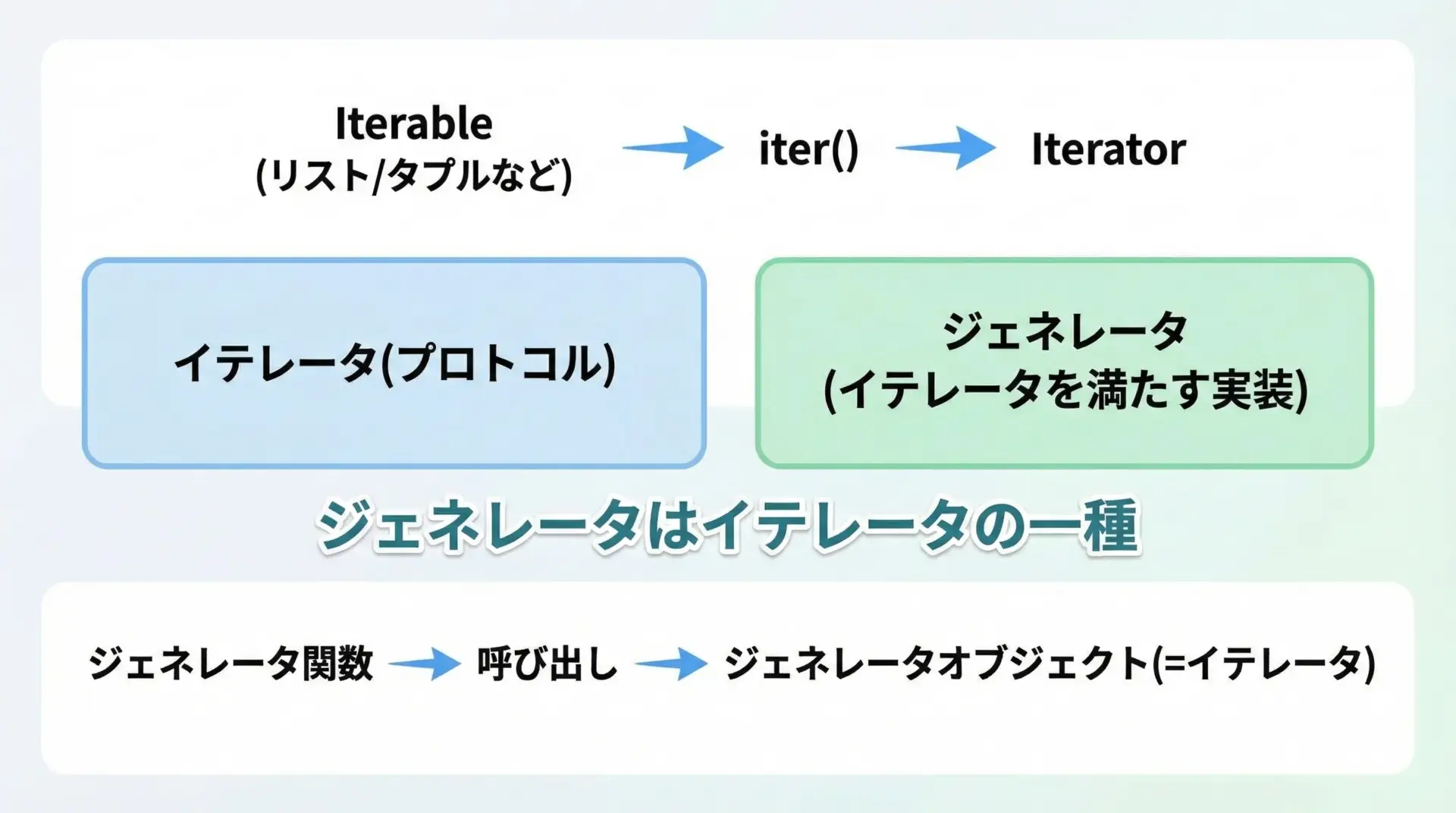
ジェネレータを理解するには、まずイテレータという概念を押さえておく必要があります。
Pythonでは、「次の値を順番に取り出せるオブジェクト」をイテレータと呼びます。
イテレータは次の2つの要件を満たします。
__iter__()メソッドを持ち、自分自身を返す__next__()メソッドを持ち、次の要素を返す(終わりではStopIterationを送出)
一方、ジェネレータは「イテレータを簡単に書くための仕組み」です。
yieldを含む関数を定義し、その関数を呼び出すと、イテレータとして振る舞う「ジェネレータオブジェクト」が返されます。
つまり関係としては、次のように整理できます。
- イテレータ … プロトコル(仕様)
- ジェネレータ … そのプロトコルを満たす具体的な実装方法の1つ
関数とジェネレータの違い
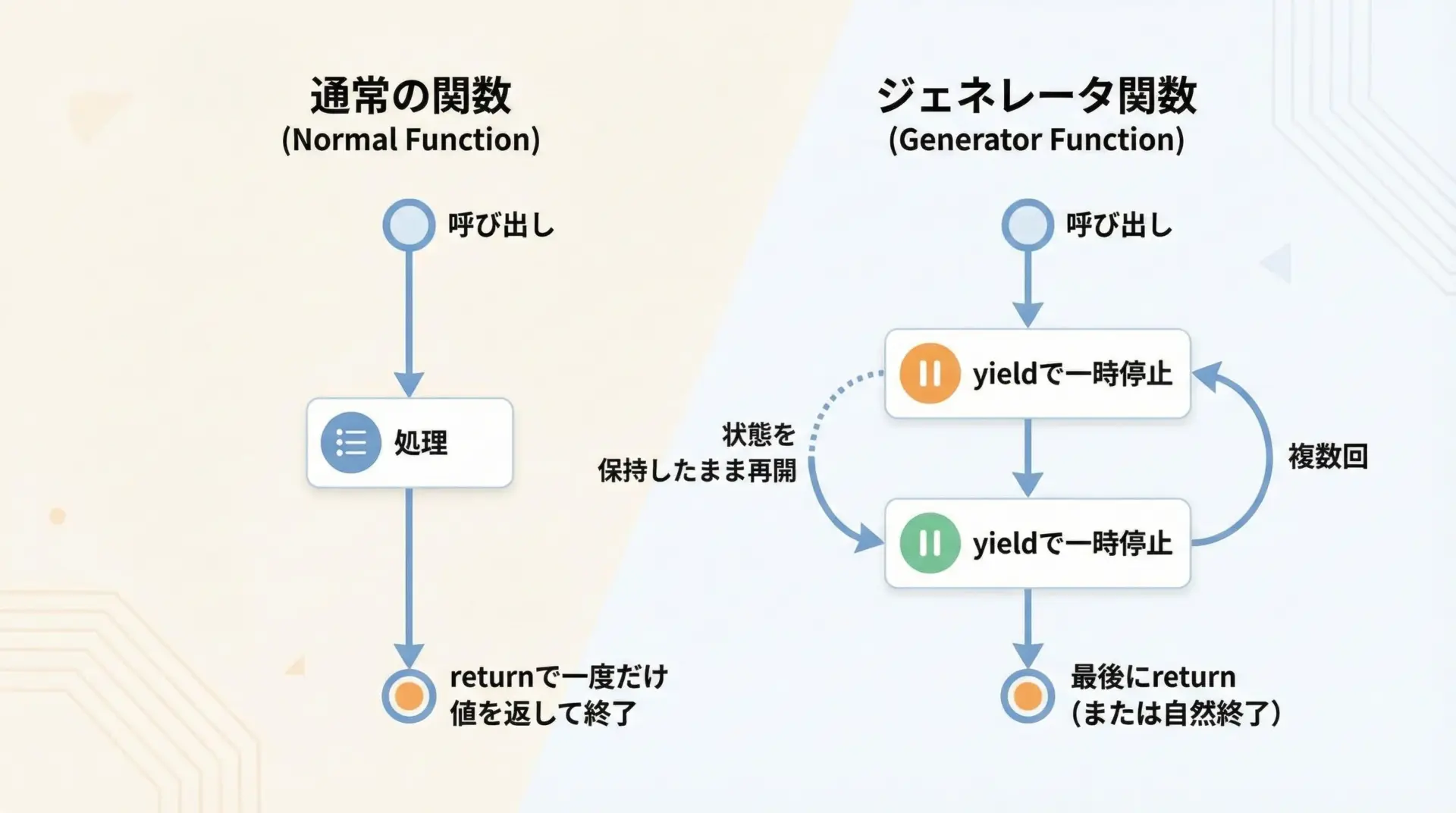
通常の関数とジェネレータ関数の最大の違いは、「いつ・何回、値を返すか」にあります。
- 通常の関数
呼び出すと一度だけ実行され、returnで値を返したら処理は完全に終了します。 - ジェネレータ関数
関数定義の中でyieldを使うと、その関数はジェネレータ関数になります。呼び出すとすぐには処理を実行せず、「再開可能な関数の状態」を持つジェネレータオブジェクトを返します。 : その後、next()やforループから呼び出されるたびに処理が進み、yieldの位置で値を返して一時停止します。
この「一時停止して、状態を保持したまま後から再開できる」という性質が、ジェネレータ最大の特徴です。
Pythonジェネレータが使われる典型シーン
ジェネレータは、次のような場面でよく使われます。
- 大量のデータを一度にメモリに載せたくない場合
- ファイルやネットワークからのストリーミングデータを、順次処理したい場合
- 複雑な処理を「ステップ」に分けて、パイプライン的に書きたい場合
- 再帰的な探索(ツリー探索、グラフ探索など)で、途中経過を逐次返したい場合
「全部まとめて処理する」のではなく「必要になった分だけ少しずつ処理する」イメージを持つと、ジェネレータの使い所が見えやすくなります。
yieldの基本的な挙動を図解で理解
yieldの実行タイミングと制御フロー
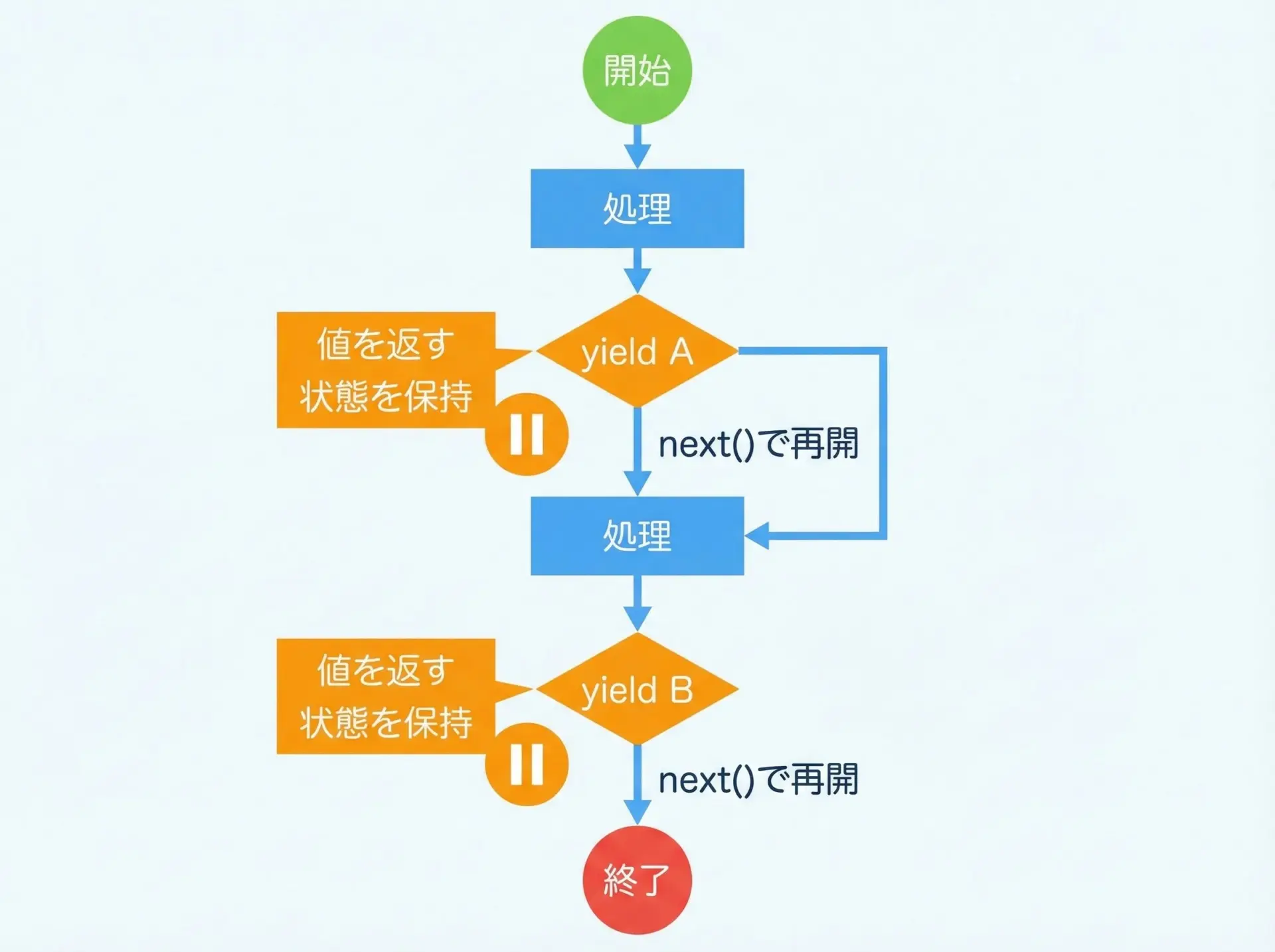
まずは、シンプルなジェネレータを見てみます。
def simple_generator():
print("start")
yield 1 # 1回目の値
print("between")
yield 2 # 2回目の値
print("end")このジェネレータの挙動を、next()で確認します。
gen = simple_generator() # まだ何も実行されていない
print(next(gen)) # ここで「start」が表示され、1が返る
print(next(gen)) # ここで「between」が表示され、2が返る
try:
print(next(gen)) # ここで「end」が表示され、その後StopIterationが送出される
except StopIteration:
print("finished")start
1
between
2
end
finishedこの例からわかるように、next()を呼ぶたびに、前回のyieldの直後から処理が再開し、次のyieldに到達したところで値を返して一時停止します。
next関数とforループによるジェネレータ実行
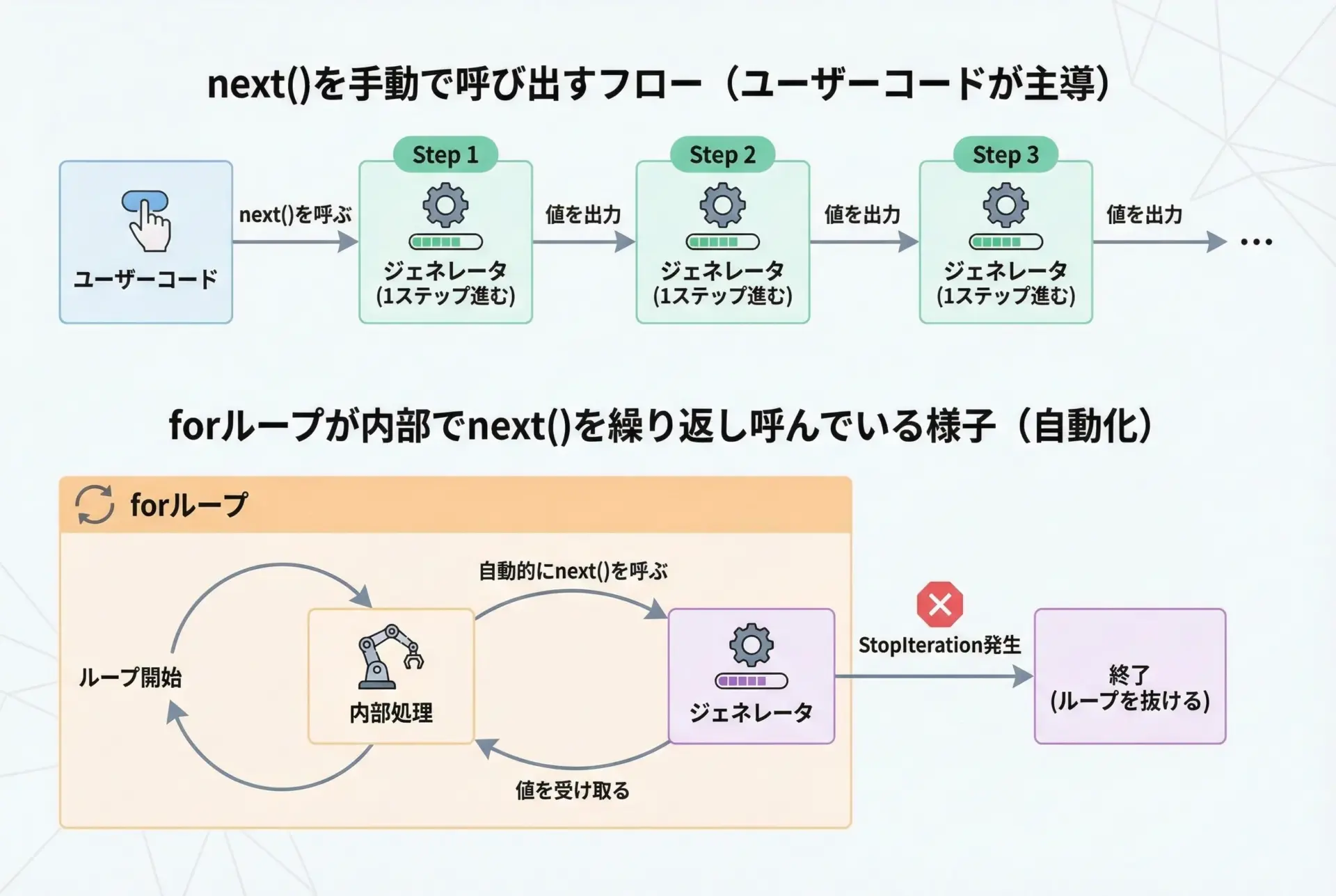
先ほどはnext()を手動で呼び出しましたが、実際にはforループが内部で自動的にnext()を呼び出してくれます。
そのため、多くの場合はforだけで十分です。
def counter(n):
print("generator started")
for i in range(n):
print(f"yielding {i}")
yield i
print("generator finished")
for value in counter(3):
print("got:", value)generator started
yielding 0
got: 0
yielding 1
got: 1
yielding 2
got: 2
generator finishedここでのポイントは、forループは内部で次の操作を繰り返しているということです。
- 最初に
iter()を呼んでイテレータ(ここではジェネレータオブジェクト)を取得 next()で値を1つ取得- 取得した値をループ変数に代入し、ループ本体を実行
StopIteration例外が出るまで2〜3を繰り返す
この仕組みを理解しておくと、ジェネレータのデバッグやカスタムイテレータの実装がしやすくなります。
yieldとreturnの組み合わせ方と注意点
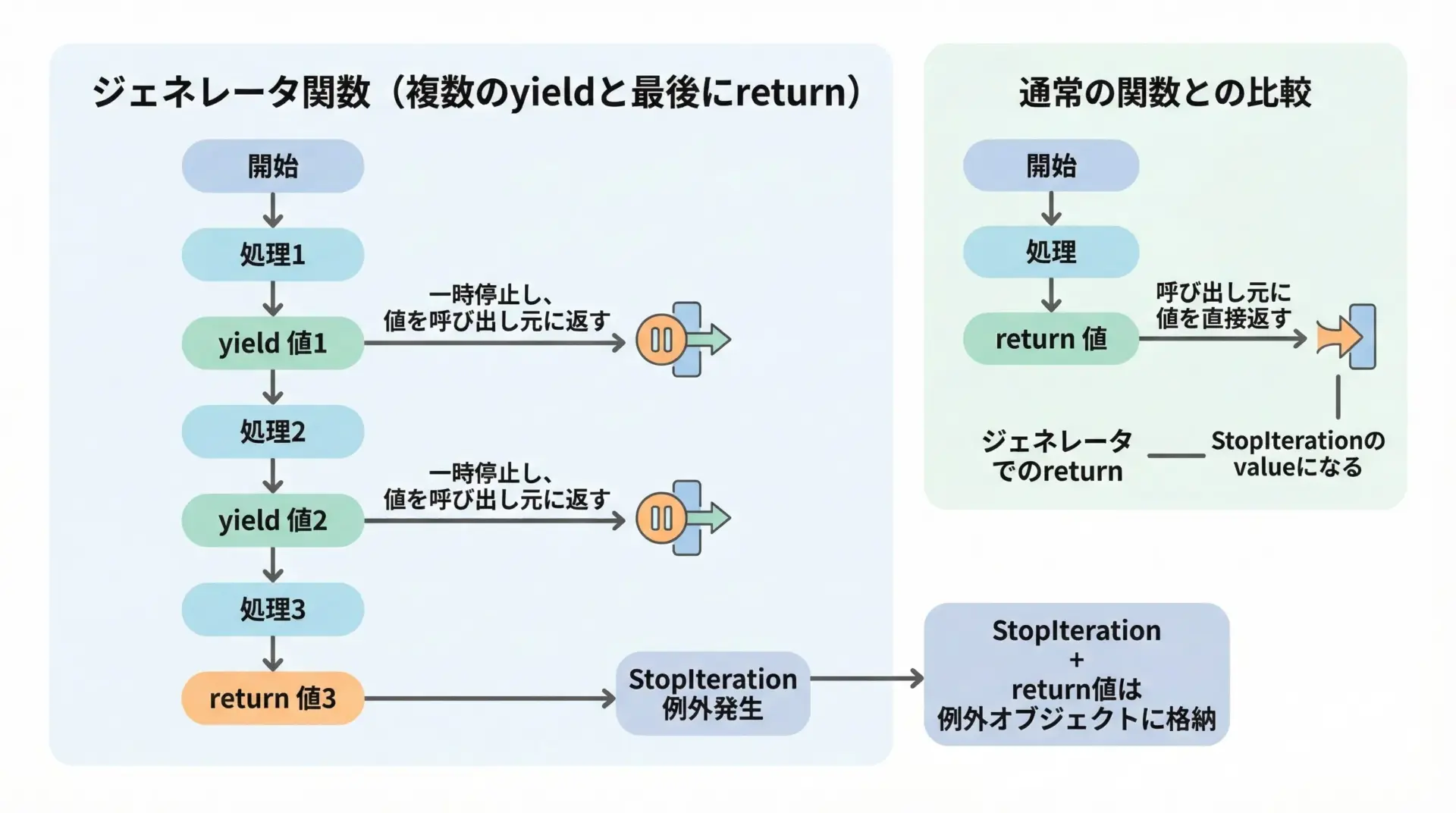
ジェネレータ関数内でもreturnを書けますが、挙動には注意が必要です。
def gen_with_return():
yield 1
yield 2
return 99 # ここでStopIteration(value=99)が送出される
g = gen_with_return()
print(next(g)) # 1
print(next(g)) # 2
try:
print(next(g)) # ここでStopIteration例外
except StopIteration as e:
print("stopped with value:", e.value)1
2
stopped with value: 99通常はforループを使うため、このreturnの値を直接扱うことはあまりありません。
forループはStopIterationを内部で処理してしまうからです。
そのため、「ジェネレータで複数の値を返したいときはyield、処理の終了だけを示したいときはreturn」という役割分担で覚えておくとよいです。
ジェネレータ式(generator expression)の挙動
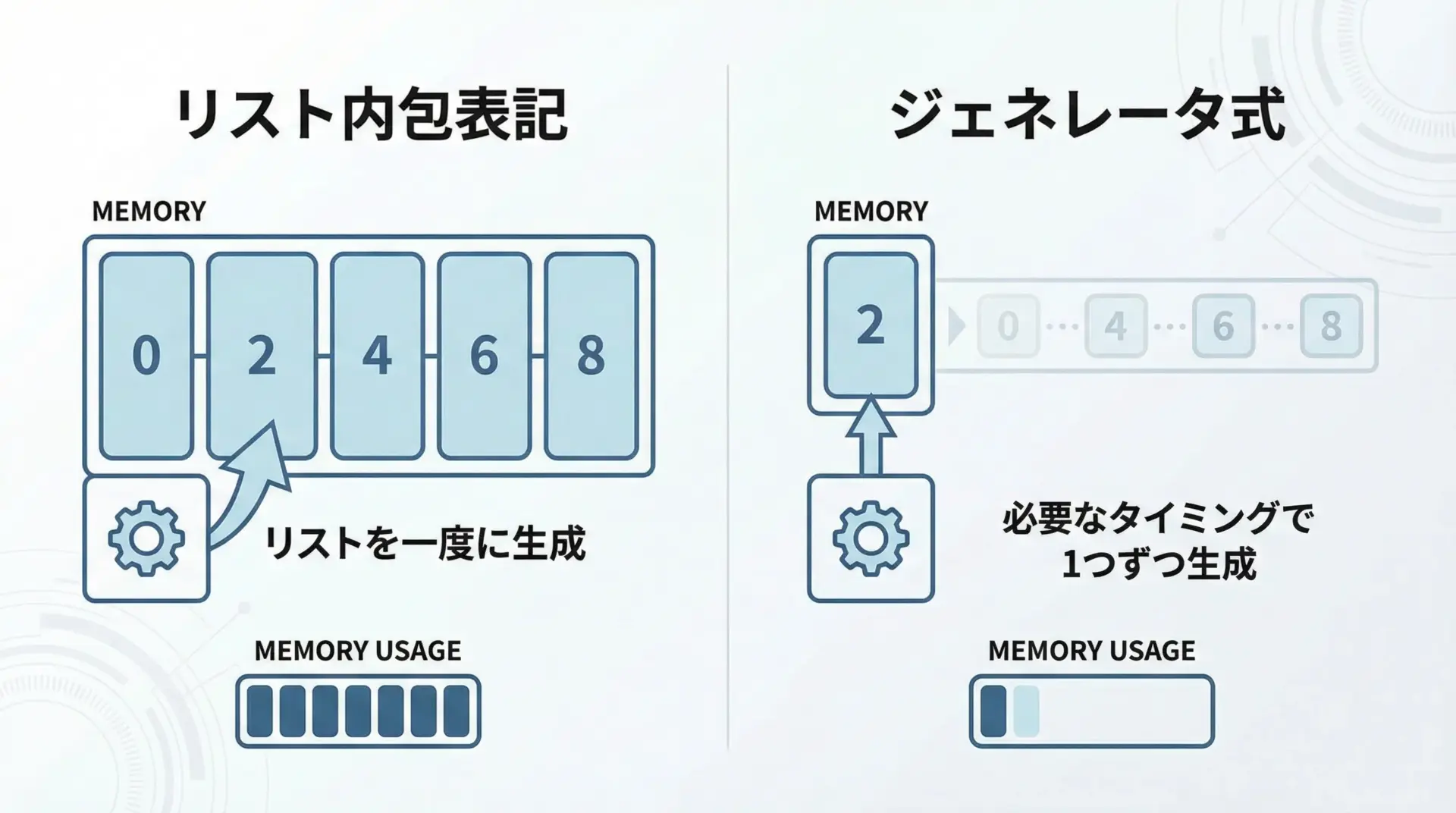
ジェネレータはyieldだけでなく、ジェネレータ式としても書けます。
これは、リスト内包表記に似た構文です。
# リスト内包表記(すべての値をリストとして生成)
lst = [x * 2 for x in range(5)]
print(lst)
# ジェネレータ式(値を1つずつ生成するジェネレータを返す)
gen = (x * 2 for x in range(5))
print(gen) # ジェネレータオブジェクトの表示
print(list(gen)) # ここで初めて値が生成される[0, 2, 4, 6, 8]
<generator object <genexpr> at 0x...>
[0, 2, 4, 6, 8]リスト内包表記との違いは、「すぐにリストを作るか」「後から必要に応じて生成するか」です。
大量データやストリーム処理では、ジェネレータ式を使うことでメモリ効率が良くなります。
ジェネレータのメリット
メモリ効率
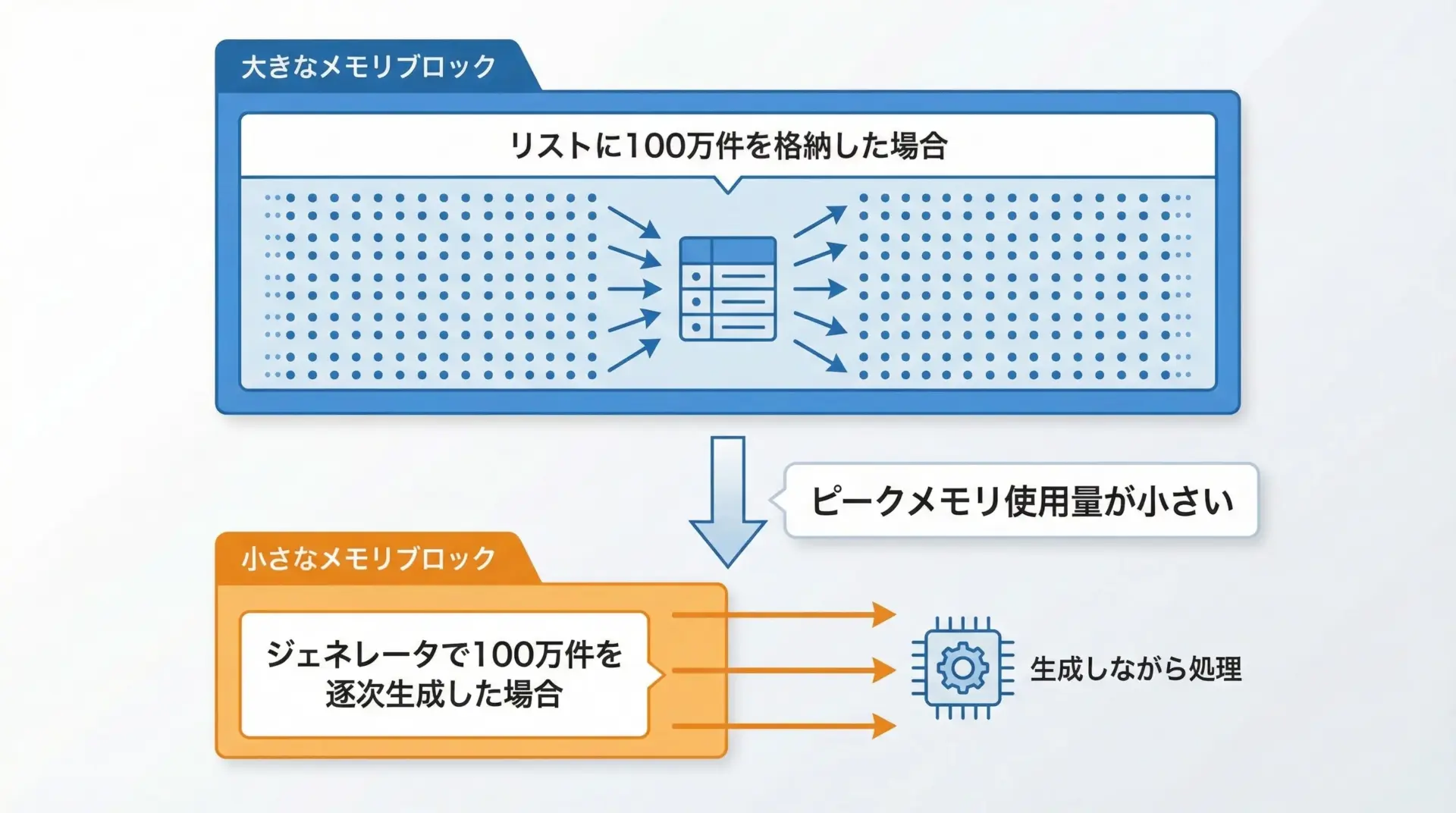
ジェネレータ最大のメリットはメモリ効率の良さです。
例として、100万件の整数を2乗する処理を考えてみます。
# リストで全件をメモリに載せる場合
def square_list(n):
result = []
for i in range(n):
result.append(i * i)
return result
# ジェネレータで1件ずつ返す場合
def square_generator(n):
for i in range(n):
yield i * i
N = 10**6
# リスト版
lst = square_list(N) # ここで100万件分のリストがメモリに載る
print("list length:", len(lst))
# ジェネレータ版
gen = square_generator(N)
count = 0
for _ in gen:
count += 1
print("generated count:", count)list length: 1000000
generated count: 1000000どちらも100万件処理できますが、リスト版はすべての値を保持するため、大きなメモリを必要とします。
一方、ジェネレータ版は「今必要な1件」だけをメモリに持てばよいので、ピークのメモリ使用量がはるかに少なくなります。
パフォーマンス向上
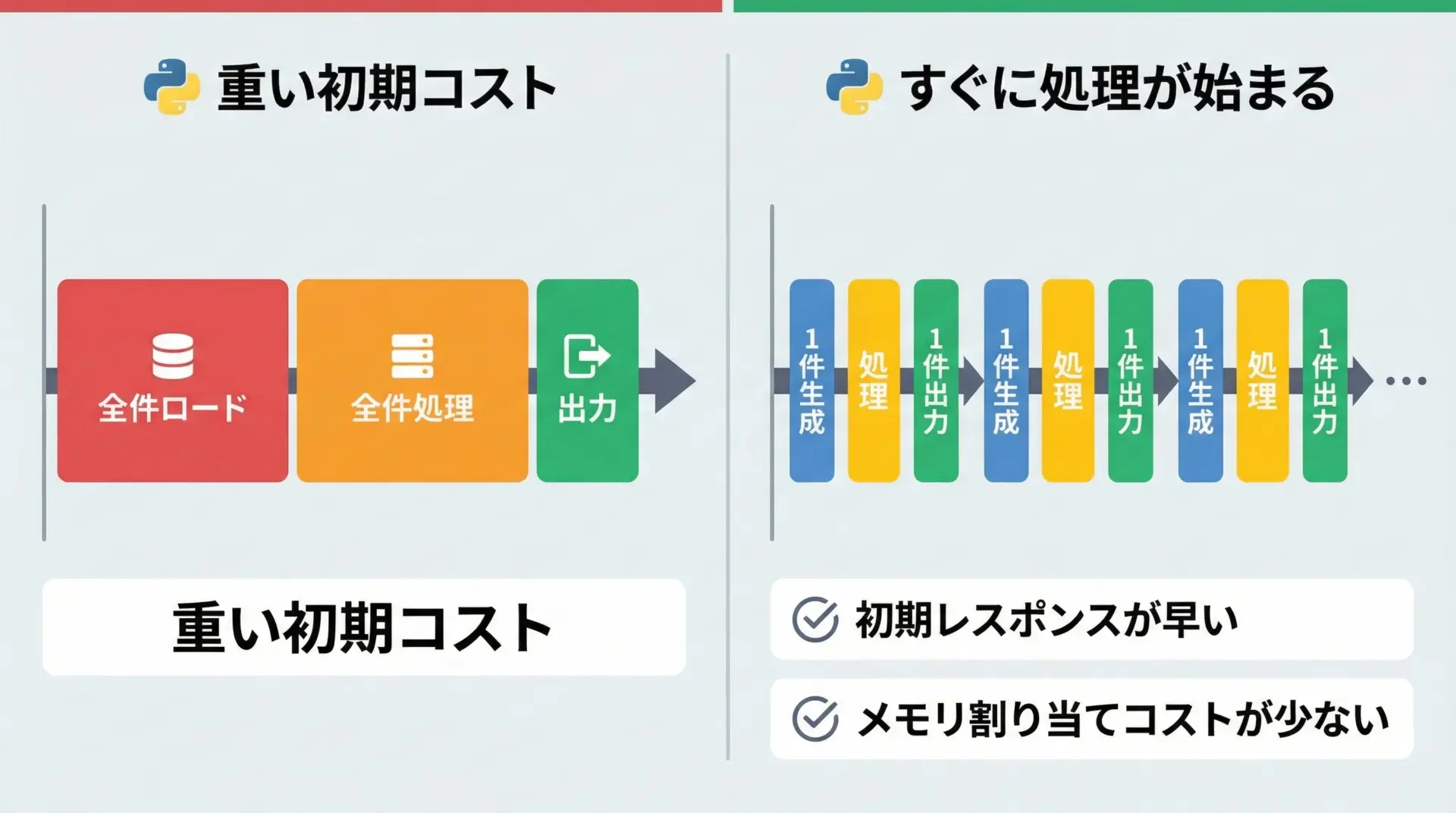
ジェネレータは必ずしも「すべての面で高速」というわけではありませんが、次のような観点でパフォーマンス向上に寄与しやすいです。
- 大量のオブジェクトを一度に作成しないため、メモリアロケーションのコストが減る
- 最初の結果がすぐに利用できるため、全体が終わる前に処理を進められる
- I/O待ちと計算を組み合わせたストリーム処理と相性が良い
特に、「最初の数件を先に返しつつ、裏で残りを処理したい」ようなケースでは、ジェネレータが有利になります。
コードの可読性と責務分離
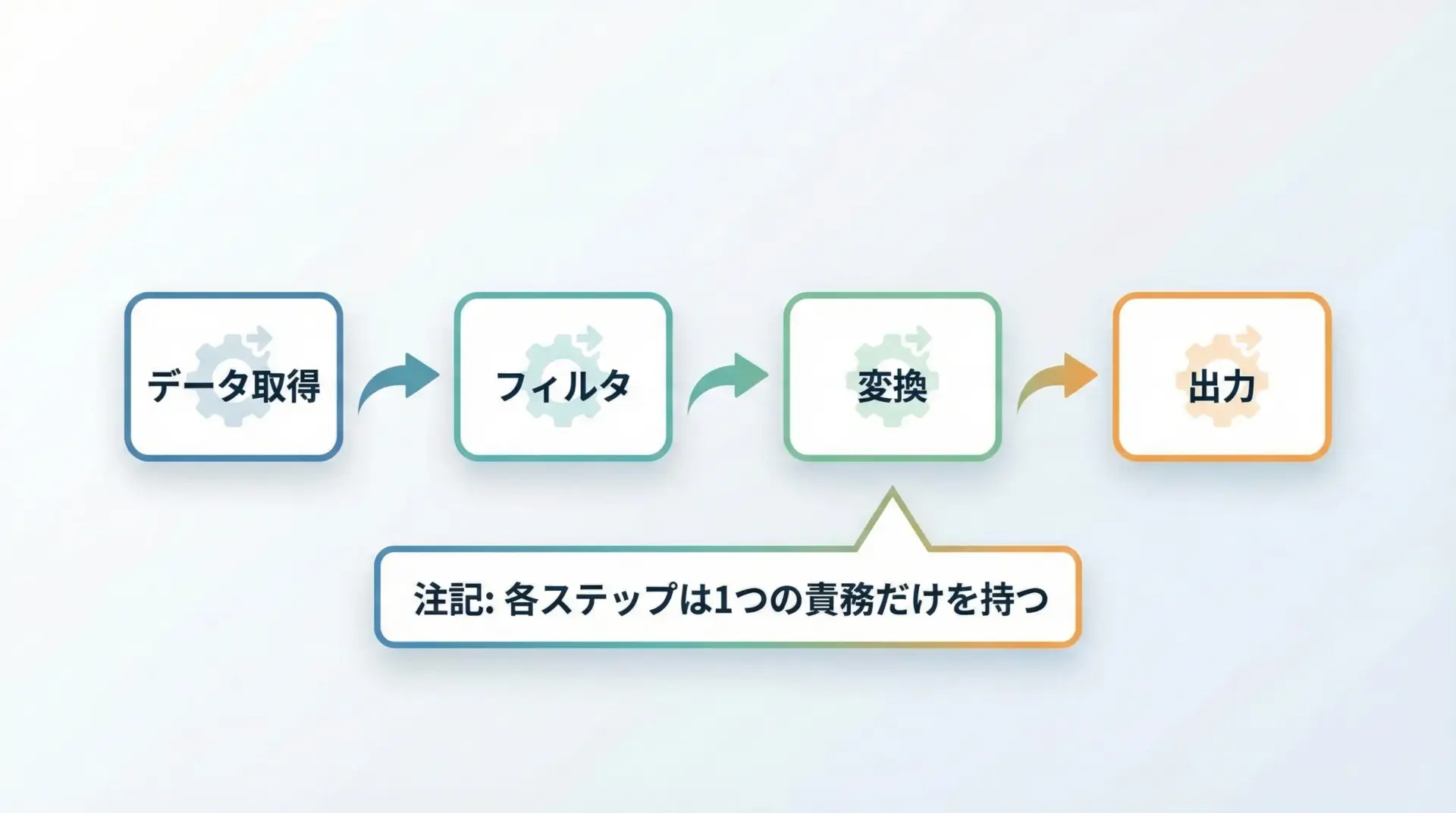
ジェネレータは「処理ステップを小さな関数に分けつつ、自然なforループの形でつなげる」ことができます。
def read_numbers(lines):
"""文字列行から整数を読み取るジェネレータ"""
for line in lines:
line = line.strip()
if not line:
continue
yield int(line)
def filter_even(numbers):
"""偶数だけを通すジェネレータ"""
for n in numbers:
if n % 2 == 0:
yield n
def square(numbers):
"""2乗に変換するジェネレータ"""
for n in numbers:
yield n * n
# パイプラインとしてつなげる
def process(lines):
nums = read_numbers(lines)
evens = filter_even(nums)
squared = square(evens)
return squared
data = ["1", "2", "3", "4", "", "5"]
for value in process(data):
print(value)4
16このように、各ジェネレータ関数は1つの責務だけを持ち、それらを組み合わせることで柔軟なパイプラインを構築できます。
結果として、コードの見通しがよくなり、テストもしやすくなります。
無限シーケンスやストリーミング処理との相性
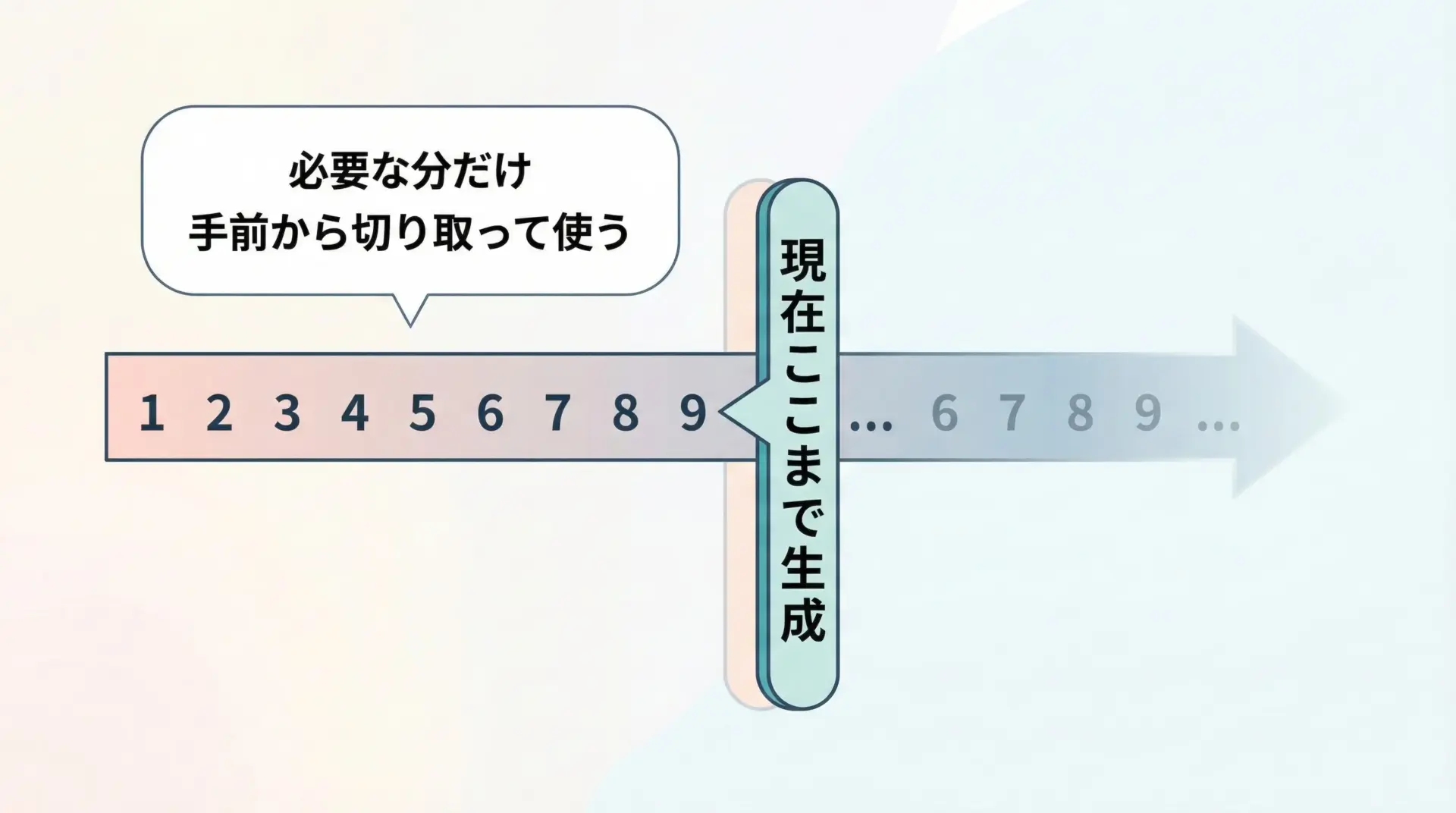
ジェネレータは無限シーケンスや終わりの見えないストリーミングデータと非常に相性が良いです。
例えば、自然数を無限に生成するジェネレータは次のように書けます。
def naturals():
n = 0
while True: # 無限ループ
yield n
n += 1
# 最初の5個だけ使う
gen = naturals()
for _ in range(5):
print(next(gen))0
1
2
3
4リストでは決して表現できない「終わりのない列」も、ジェネレータなら安全に扱えます。
ストリーミングAPIや無限に続くログ処理などにも応用しやすいです。
ジェネレータの実践的な使い所
大量データの逐次処理
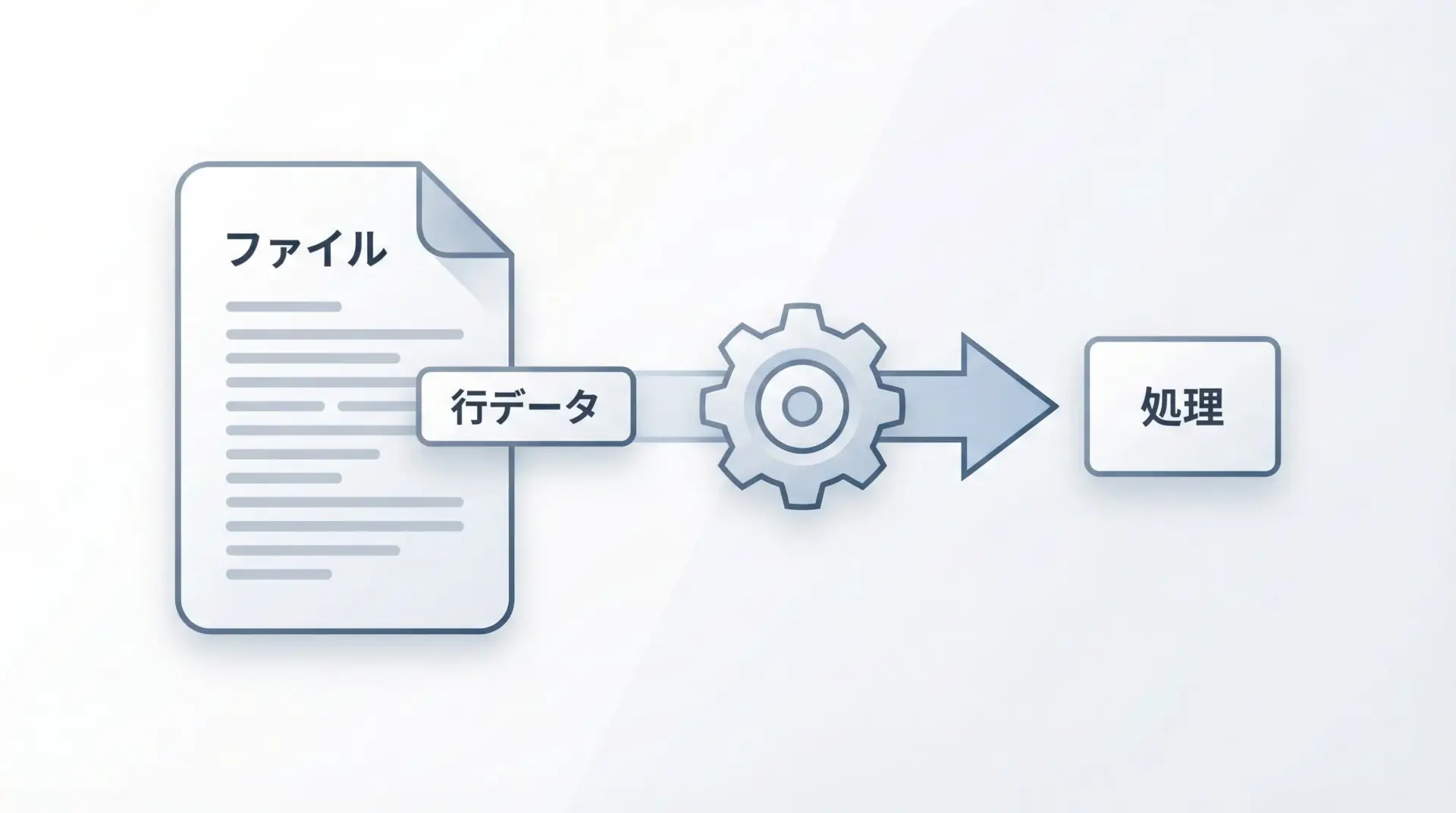
大量のデータ(例えば数GBのログファイル)を、一度にメモリに読み込むのは現実的ではありません。
ジェネレータを使えば、1行ずつ読み込んでは処理するといった逐次処理が簡単に書けます。
def read_large_file(path):
"""ファイルを1行ずつ読み込むジェネレータ"""
with open(path, "r", encoding="utf-8") as f:
for line in f:
yield line.rstrip("\n")
def search_keyword(lines, keyword):
"""特定のキーワードを含む行だけを返すジェネレータ"""
for line in lines:
if keyword in line:
yield line
def example():
logfile = "access.log"
lines = read_large_file(logfile)
error_lines = search_keyword(lines, "ERROR")
for line in error_lines:
print(line)
# example() を呼ぶと、巨大ファイルでも少ないメモリで検索できるこの構成だと、常に「1〜数行」程度だけがメモリに乗っている状態になり、ファイル全体のサイズに依存しないスケーラブルな処理が可能です。
APIレスポンスやストリームの段階的処理
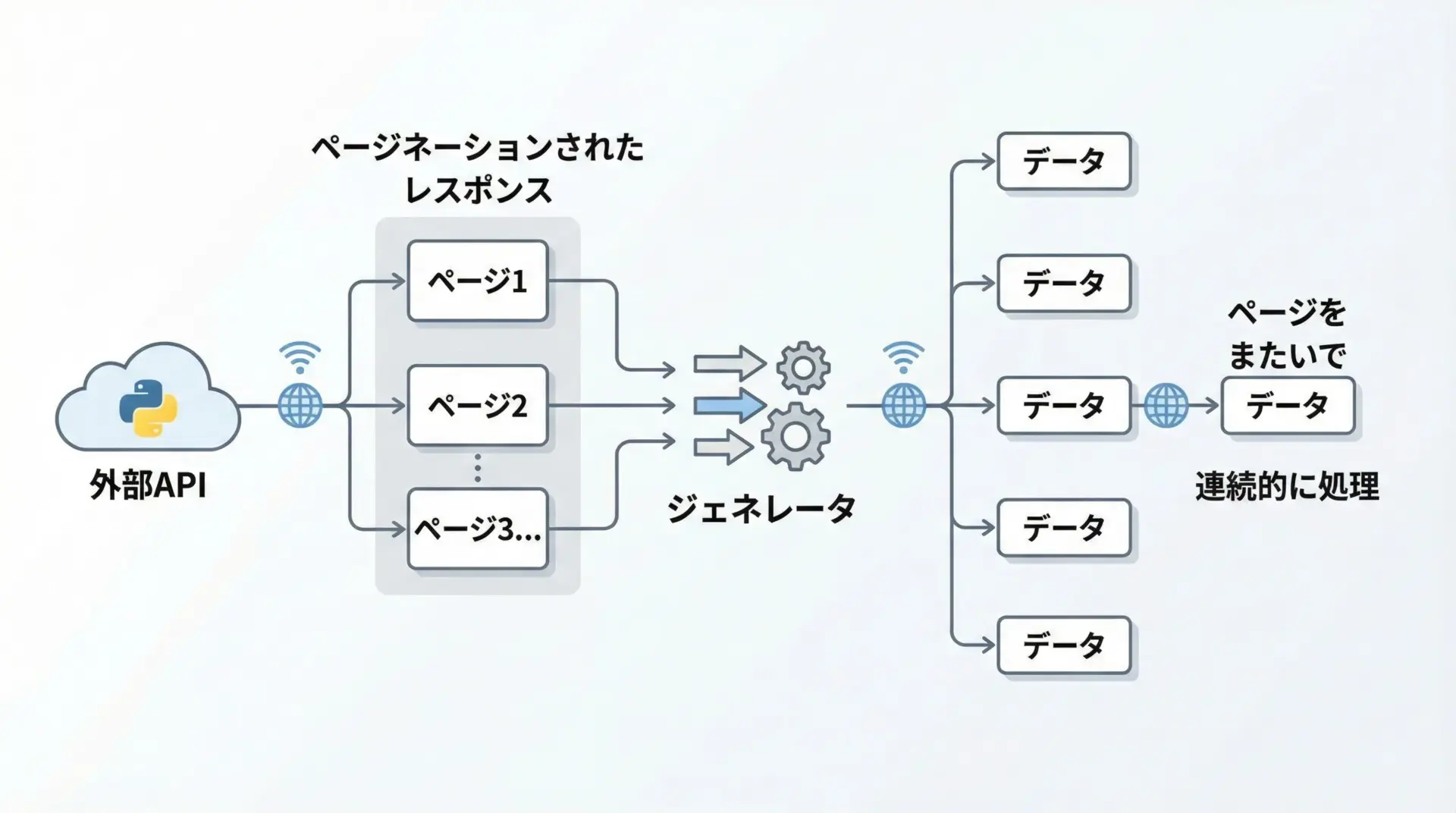
外部APIから大量のデータを取得する際、ページネーション(API側でページごとに分割されている)が行われていることが多いです。
ジェネレータを使うと、このページネーション処理を自然に隠蔽できます。
import requests
def fetch_items(api_url):
"""ページネーションされたAPIから、アイテムを逐次取得するジェネレータ"""
page = 1
while True:
params = {"page": page}
resp = requests.get(api_url, params=params)
resp.raise_for_status()
data = resp.json()
items = data["items"]
if not items:
# もうデータがなければ終了
return
for item in items:
yield item
page += 1
# 利用例
# for item in fetch_items("https://api.example.com/items"):
# print(item)このように書いておけば、呼び出し側は「単にforで回すだけ」で、裏でページネーションが行われているとは意識せずに済みます。
パイプライン処理と処理ステップの分割
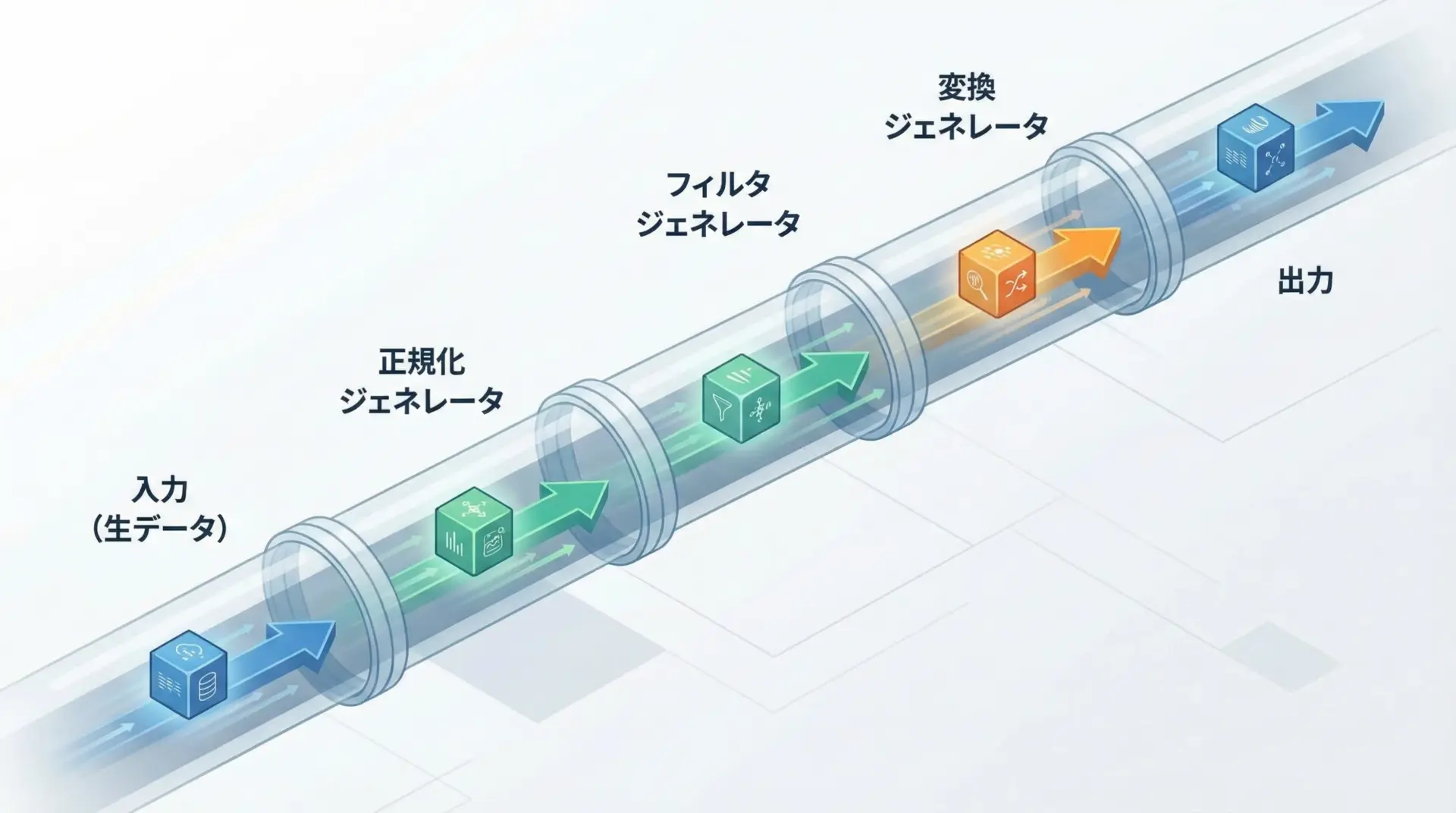
複数の処理を順番に適用する場合、ジェネレータをつなげることで、ストリーム指向のパイプラインを作れます。
def normalize(records):
"""レコードのフィールド名を小文字に揃える"""
for rec in records:
yield {k.lower(): v for k, v in rec.items()}
def filter_active(records):
"""status が active のものだけに絞り込む"""
for rec in records:
if rec.get("status") == "active":
yield rec
def project_fields(records, fields):
"""必要なフィールドだけを残す"""
for rec in records:
yield {k: rec.get(k) for k in fields}
def pipeline(records):
step1 = normalize(records)
step2 = filter_active(step1)
step3 = project_fields(step2, ["id", "name"])
return step3
def example():
raw = [
{"ID": 1, "Name": "Alice", "Status": "active"},
{"ID": 2, "Name": "Bob", "Status": "inactive"},
{"ID": 3, "Name": "Carol", "Status": "active"},
]
for rec in pipeline(raw):
print(rec)
# example() を呼び出した時の出力イメージ:
# {'id': 1, 'name': 'Alice'}
# {'id': 3, 'name': 'Carol'}このような構造にしておくと、途中のステップを差し替えたり、テストしたりするのが容易になります。
再帰処理や探索アルゴリズムでのジェネレータ活用
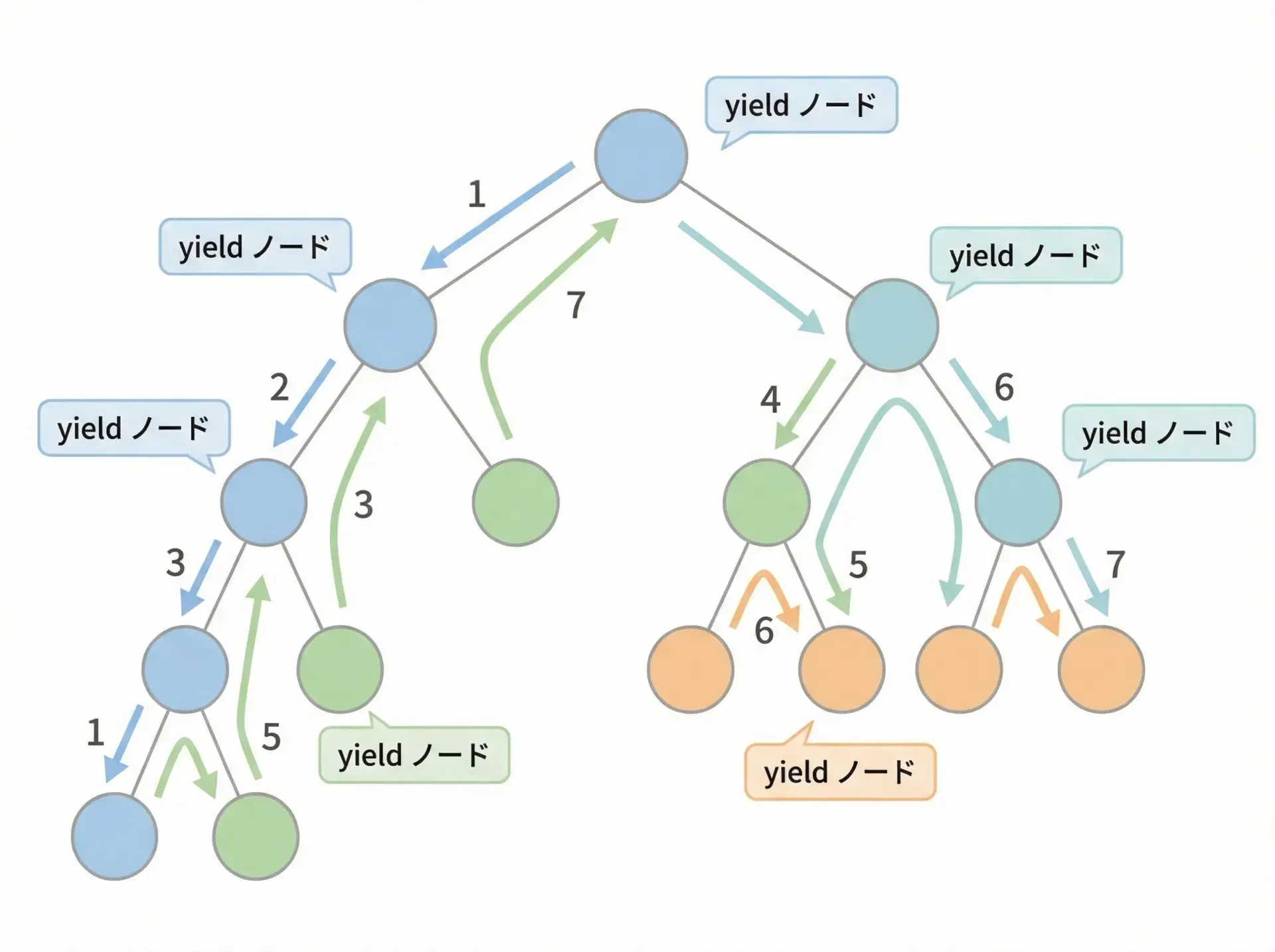
ツリー探索やグラフ探索などのアルゴリズムは、ジェネレータと相性が良いです。
結果をリストに全て溜めるのではなく、訪問したノードを順次yieldしていくことで、途中経過をそのまま利用できます。
class Node:
def __init__(self, value, children=None):
self.value = value
self.children = children or []
def dfs(node):
"""深さ優先探索でノードを順にyieldするジェネレータ"""
yield node
for child in node.children:
# 再帰ジェネレータからの値をまとめてyieldする
yield from dfs(child)
def example():
# ツリー構造を構築
# A
# / \
# B C
# / / \
# D E F
nD = Node("D")
nB = Node("B", [nD])
nE = Node("E")
nF = Node("F")
nC = Node("C", [nE, nF])
nA = Node("A", [nB, nC])
for node in dfs(nA):
print(node.value)
# example() の出力:
# A
# B
# D
# C
# E
# Fここではyield from dfs(child)という構文を使っています。
これは、別のジェネレータからの値を、そのまま外側のジェネレータとして流すための構文です。
再帰ジェネレータを書くときに非常に便利です。
既存コードをジェネレータにリファクタリングするポイント
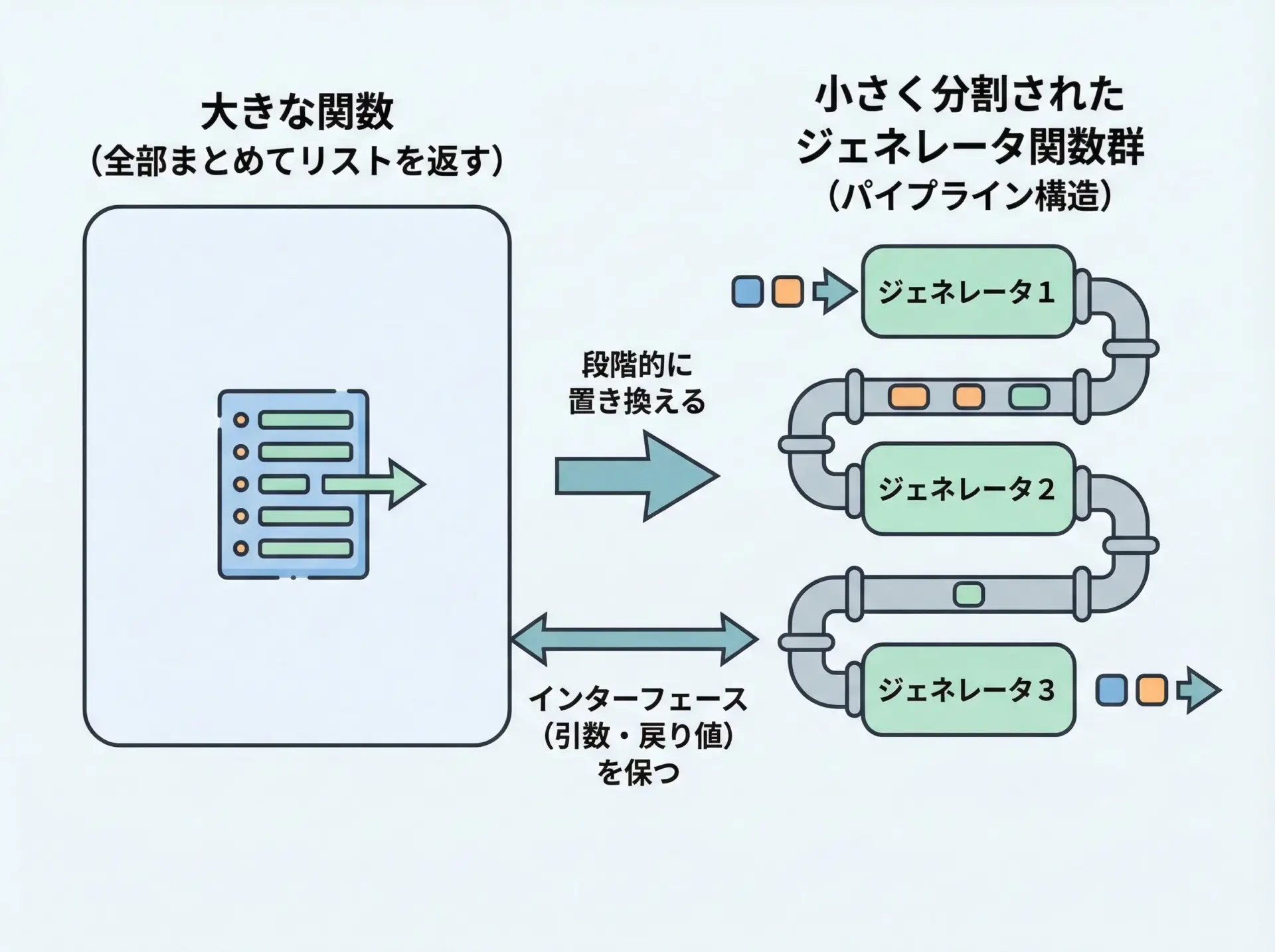
既存コードをジェネレータにリファクタリングする際は、次のようなステップを意識するとスムーズです。
- 「本当に全件を一度に必要としているのか」を確認する
もし呼び出し側が結局list()で全件をリストにしているだけなら、ジェネレータにしても大きな意味はない場合があります。
- 内部のループから、1件ずつyieldする形に書き換える
例えば、次のようなコードを考えます。
def collect_errors(lines):
errors = []
for line in lines:
if "ERROR" in line:
errors.append(line)
return errors
これをジェネレータ化すると次のようになります。def iter_errors(lines):
for line in lines:
if "ERROR" in line:
yield line
呼び出し側がリストを期待しているなら、当面はlist()で包んで互換性を保てます。# 既存インターフェースを一時的に維持
def collect_errors(lines):
return list(iter_errors(lines))- パイプラインを意識して関数を分割する
「読み込み」「フィルタリング」「変換」「集約」などのフェーズごとにジェネレータに切り出すと、テストしやすく、再利用も容易になります。
- 型ヒントやドキュメントで「ジェネレータを返す」ことを明示する
呼び出し側がジェネレータを意識できるようにしておくと、より効率的な使い方をしてもらいやすくなります。
このように、いきなり全てを書き換えるのではなく、小さなループから「1件ずつyieldする形」に直していくのがポイントです。
まとめ
Pythonのジェネレータは、「必要なときに、必要な分だけ値を生成する」仕組みとして、メモリ効率とコードの柔軟性を大きく高めてくれます。
yieldによる一時停止と再開の挙動を理解すれば、無限シーケンス、大量データ処理、ストリーミングAPI、探索アルゴリズムなど、さまざまな場面で自然に活用できます。
まずは既存の「リストを返す関数」を、1件ずつyieldするジェネレータに置き換えてみるところから始めてみてください。
