Pythonのprint関数は、プログラムの実行結果を画面に表示するための、最も基本的で重要な機能です。
コードの動きを確認したり、デバッグしたりするときにも頻繁に使われます。
本記事では、文字列・数値・変数の出力から、便利なオプションや整形方法まで、初心者の方にもわかりやすく丁寧に解説していきます。
Pythonのprint関数とは
print関数の基本構文と書き方
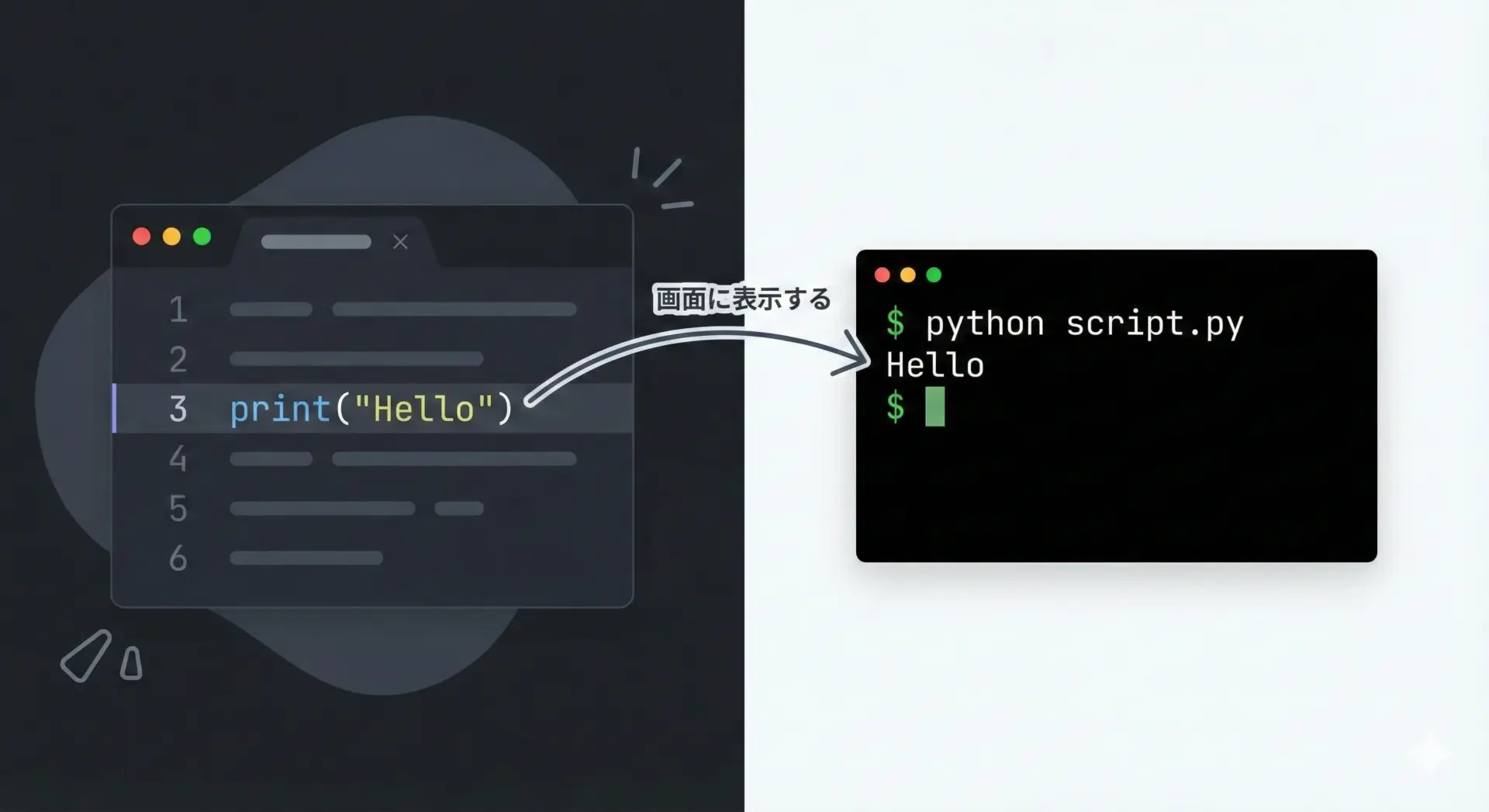
Pythonのprint関数は、引数として渡した値を、標準出力(通常は画面)に表示する関数です。
最も基本的な構文は次のようになります。
# print関数の基本構文
print(表示したい内容)具体的な例として、文字列を表示する最もシンプルなコードは次のとおりです。
# 文字列 "Hello, Python!" を画面に表示する
print("Hello, Python!")Hello, Python!Pythonのprint関数は、引数を1つだけ受け取る必要はなく、複数の値をカンマで区切って渡すこともできます。
この点は後ほど詳しく解説します。
print関数には、次のようなキーワード引数を指定できます。
| 引数名 | 役割 | 主な用途 |
|---|---|---|
end | 行末に付ける文字列 | 改行をしたくないときに変更する |
sep | 複数引数の区切り文字列 | カンマやタブなどを任意に指定 |
file | 出力先 | 標準出力以外のファイルなどに出力 |
flush | バッファの即時書き出し | リアルタイム性が必要なログなど |
本記事では、特によく使うendとsepを中心に解説します。
Python 2のprint文との違い

Python 3ではprintは「関数」ですが、Python 2では「文(print文)」でした。
この違いにより、書き方が少し変わります。
Python 2の例(参考):
# Python 2 の書き方(現在は非推奨・古いバージョン)
print "Hello" # カッコなしでもOK
print("Hello") # 実はこれもOKだが、意味合いが少し違う場合があるPython 3の例(現在主流):
# Python 3 の書き方
print("Hello") # 必ずカッコが必要Python 3では必ず関数呼び出しの形で、括弧を書かないとエラーになります。
現在学習する場合はPython 3だけを意識すれば十分ですので、以降はPython 3を前提に解説します。
print関数で文字列を出力する方法
文字列をそのままprintで表示する
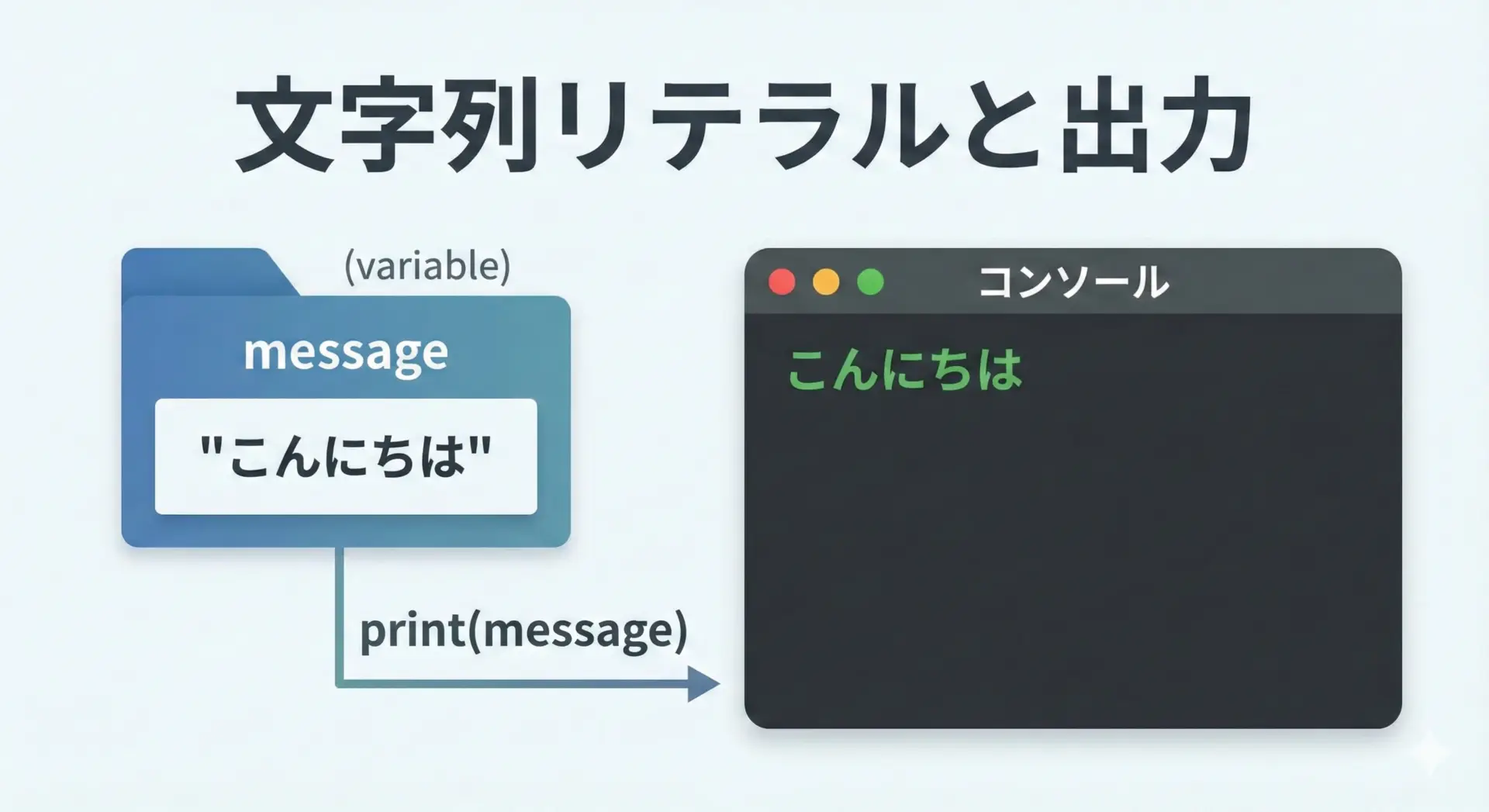
文字列を表示するときは、ダブルクォート(“)またはシングルクォート(‘)で囲んだ文字列リテラルを、そのままprint関数に渡します。
# 文字列を直接printする例
print("Hello, Python!")
print('Hello, World!')Hello, Python!
Hello, World!また、文字列を変数に代入してから表示することもよくあります。
# 文字列を変数に入れてから表示する例
greeting = "こんにちは、Python!"
print(greeting)こんにちは、Python!変数に入れてからprintすることで、値を何度も使い回したり、途中で書き換えたりしやすくなります。
シングルクォートとダブルクォートの違い

Pythonではシングルクォート(‘)とダブルクォート(“)は、どちらを使っても文字列として同じ意味になります。
基本的には好みで構いませんが、文字列の中に含めたいクォートの種類によって使い分けると便利です。
# ダブルクォートで囲んだ文字列
print("Pythonの世界へようこそ")
# シングルクォートで囲んだ文字列
print('Pythonの世界へようこそ')Pythonの世界へようこそ
Pythonの世界へようこそ例えば、文字列中に'を含めたいときは、外側を"で囲むとエスケープが不要になります。
# 文字列の中に ' を含めたい場合
print("Python's world") # 外側を " で囲むとそのまま書ける
# 文字列の中に " を含めたい場合
print('He said "Hello"') # 外側を ' で囲むPython's world
He said "Hello"もちろん、'や"を使ってエスケープすることも可能です。
# エスケープシーケンスを使う例
print('Python\'s world')
print("He said \"Hello\"")どちらを採用するかはコーディング規約やチームの方針にもよりますが、どちらでも意味は同じだと理解しておくとよいです。
複数の文字列をカンマ区切りでprintする
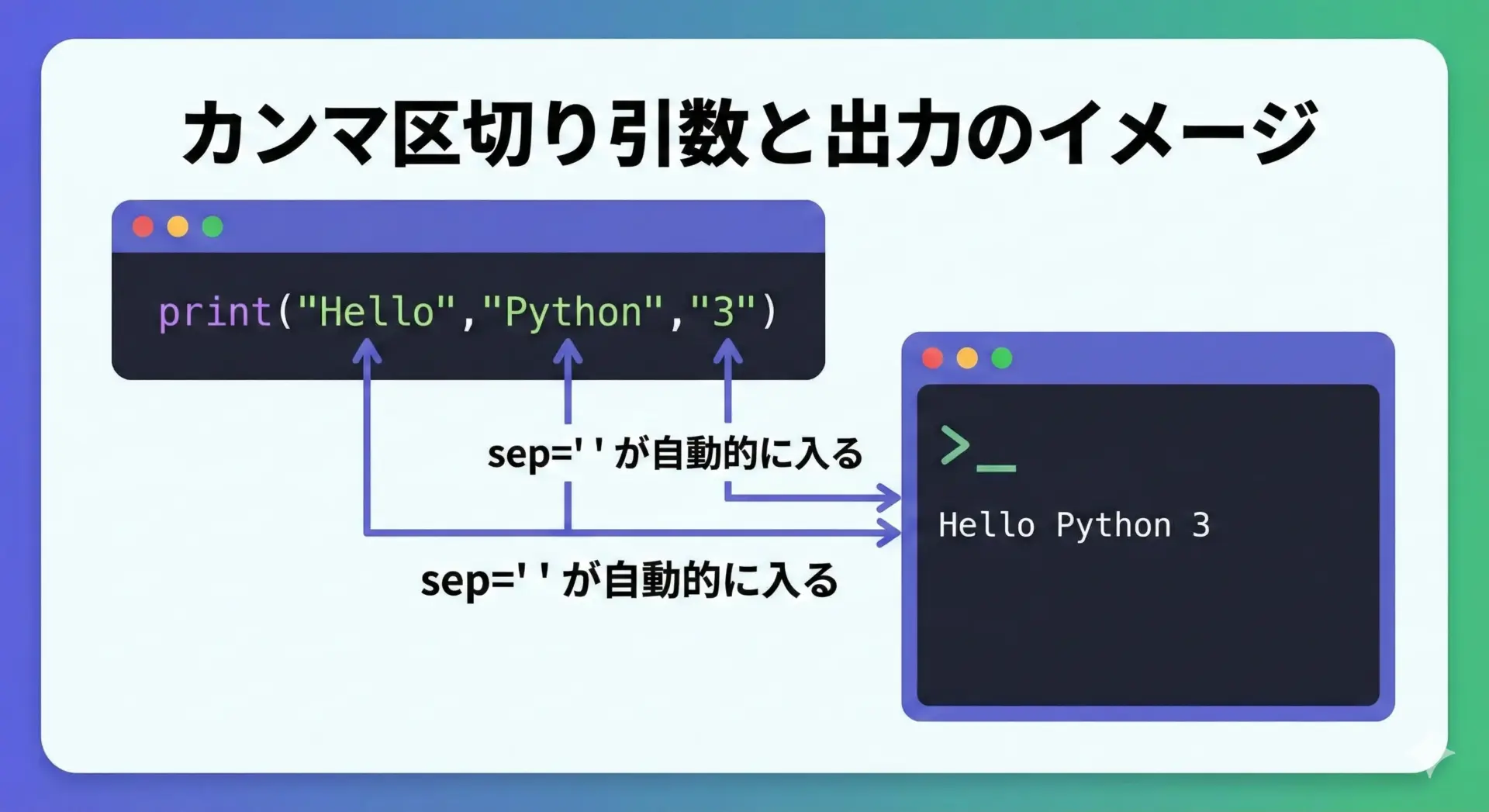
print関数は複数の値をカンマで区切って渡すことができます。
この場合、デフォルトでは半角スペースで区切って表示されます。
# 複数の文字列を一度に表示する例
print("Hello", "Python", "3")Hello Python 3この書き方は、文字列同士を+で結合するよりもシンプルで、数値を含む場合にも便利です。
区切り文字を変更したい場合は、後述のsep引数を使います。
日本語(マルチバイト文字)をprintするポイント

Python 3では、日本語などのマルチバイト文字も基本的にはそのままprintで表示できます。
例えば次のようなコードです。
# 日本語の表示
print("こんにちは")
print("Pythonで日本語を表示します")出力結果(正常な環境の場合):
こんにちは
Pythonで日本語を表示しますPython 3は標準で文字コードにUTF-8を使っているため、ソースコードファイルがUTF-8で保存されていれば、特別な設定をしなくても日本語を扱えます。
ただし、次のような点に注意が必要です。
- エディタ(IDE)の保存文字コードがUTF-8かどうかを確認すること。
- Windowsの古い環境などでは、コンソールの文字コード設定によっては文字化けする場合があること。
- その場合は、コンソール側の文字コード設定をUTF-8に変更したり、IDEの統合ターミナルを使用するなどの工夫が必要なこと。
一般的な最近の環境(PyCharm、VS Code、Google Colab、Jupyter Notebookなど)では、特別な設定なしで日本語をprintできることが多いです。
print関数で数値・変数を出力する方法
数値をprintする基本的な書き方
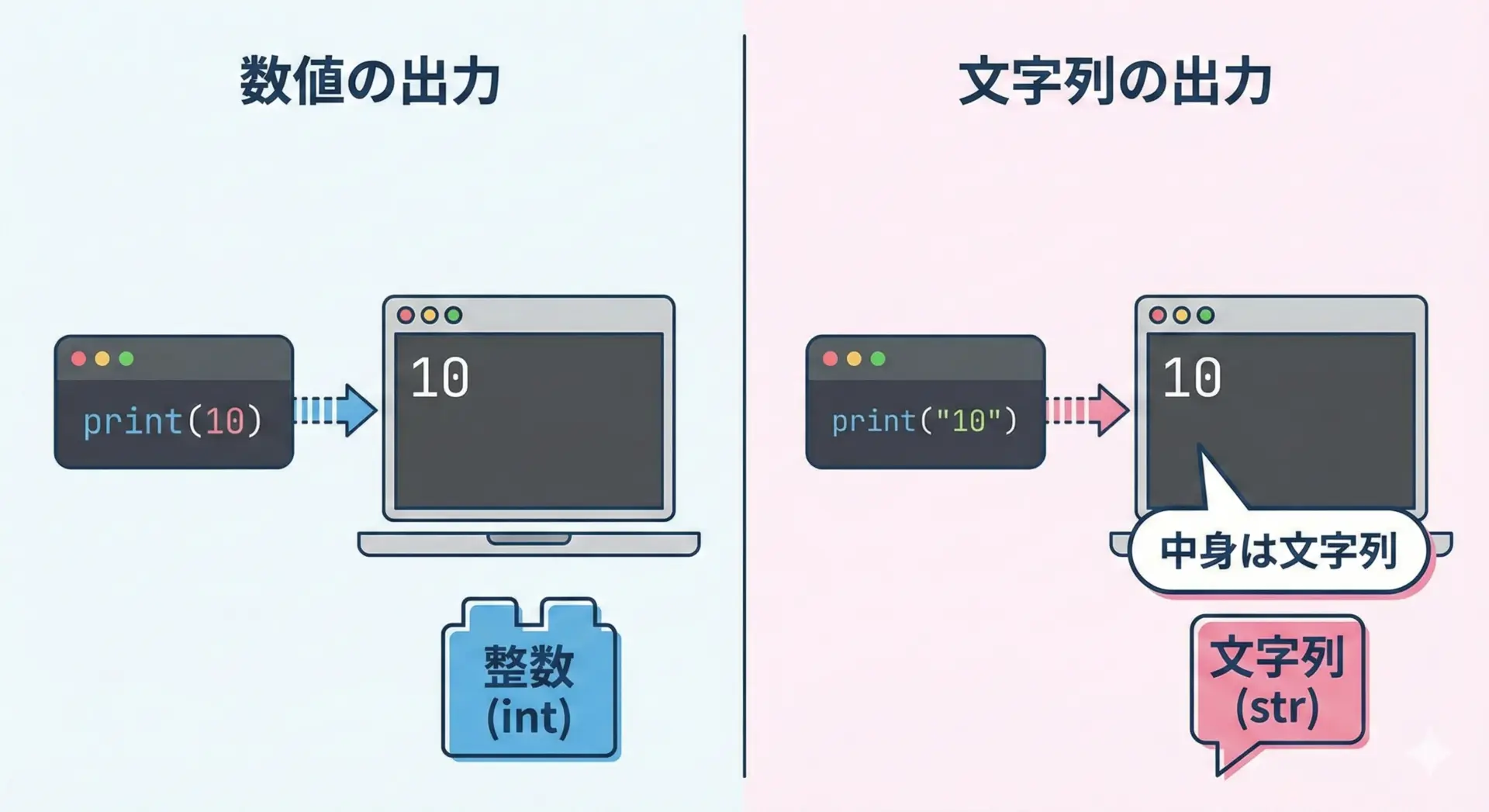
print関数は、数値もそのまま引数として渡すだけで表示できます。
文字列のときのようにクォートで囲む必要はありません。
# 数値の表示
print(10) # 整数
print(3.14) # 小数(浮動小数点数)10
3.14文字列として"10"と書いた場合と、数値として10と書いた場合は、見た目の出力は同じでも内部的な型が異なる点に注意してください。
# 型の違いを確認する例
print("10") # 文字列としての10
print(10) # 数値としての10変数の値をprintで確認する方法

プログラムを書くときには、変数の中身を確認する目的でprintを使うことがとても多いです。
# 変数の値をprintで確認する例
x = 10
y = 3.5
name = "Python"
print(x)
print(y)
print(name)10
3.5
Python複数の変数をまとめて表示することもできます。
x = 10
y = 20
print("xの値:", x)
print("yの値:", y)xの値: 10
yの値: 20このようにラベル文字列 + 変数という形で表示すると、あとから見返したときに何の値かわかりやすくなります。
文字列と数値を一緒にprintする方法

文字列と数値を同時に表示したい場面は非常に多いですが、書き方を間違えるとTypeErrorが発生します。
まず、カンマ区切りで渡す方法が最も簡単です。
result = 10
# カンマ区切りで渡す(おすすめ)
print("結果は", result, "です")結果は 10 です一方、+演算子で文字列と数値を結合する場合は、数値を文字列に変換する必要があります。
result = 10
# 数値を文字列に変換してから結合する
print("結果は" + str(result) + "です")結果は10ですこのように、+で結合する場合はstr()で数値を文字列化する必要があることを覚えておきましょう。
より便利な方法として後述するf文字列(f-string)もよく使われます。
型エラー(TypeError)を避ける書き方

Pythonでは異なる型同士を+で足し合わせると、TypeErrorが発生します。
特に、strとintの混在でよく起こります。
# よくあるエラー例
age = 20
print("年齢は" + age + "歳です") # これはエラーになるこのコードを実行すると、次のようなエラーメッセージが出ます。
TypeError: can only concatenate str (not "int") to strTypeErrorを避ける方法としては、次のいずれかを使います。
- カンマ区切りでprintする(一番簡単)
str()で数値を文字列に変換する- f文字列(f-string)を使う
age = 20
# 1. カンマ区切り
print("年齢は", age, "歳です")
# 2. str()で変換
print("年齢は" + str(age) + "歳です")
# 3. f文字列(f-string)
print(f"年齢は{age}歳です")どの方法でもエラーなく出力できますが、最近のPythonコードではf文字列が最もよく使われます。
この点は後ほど詳しく解説します。
print関数の便利な使い方
改行をしないprintの書き方
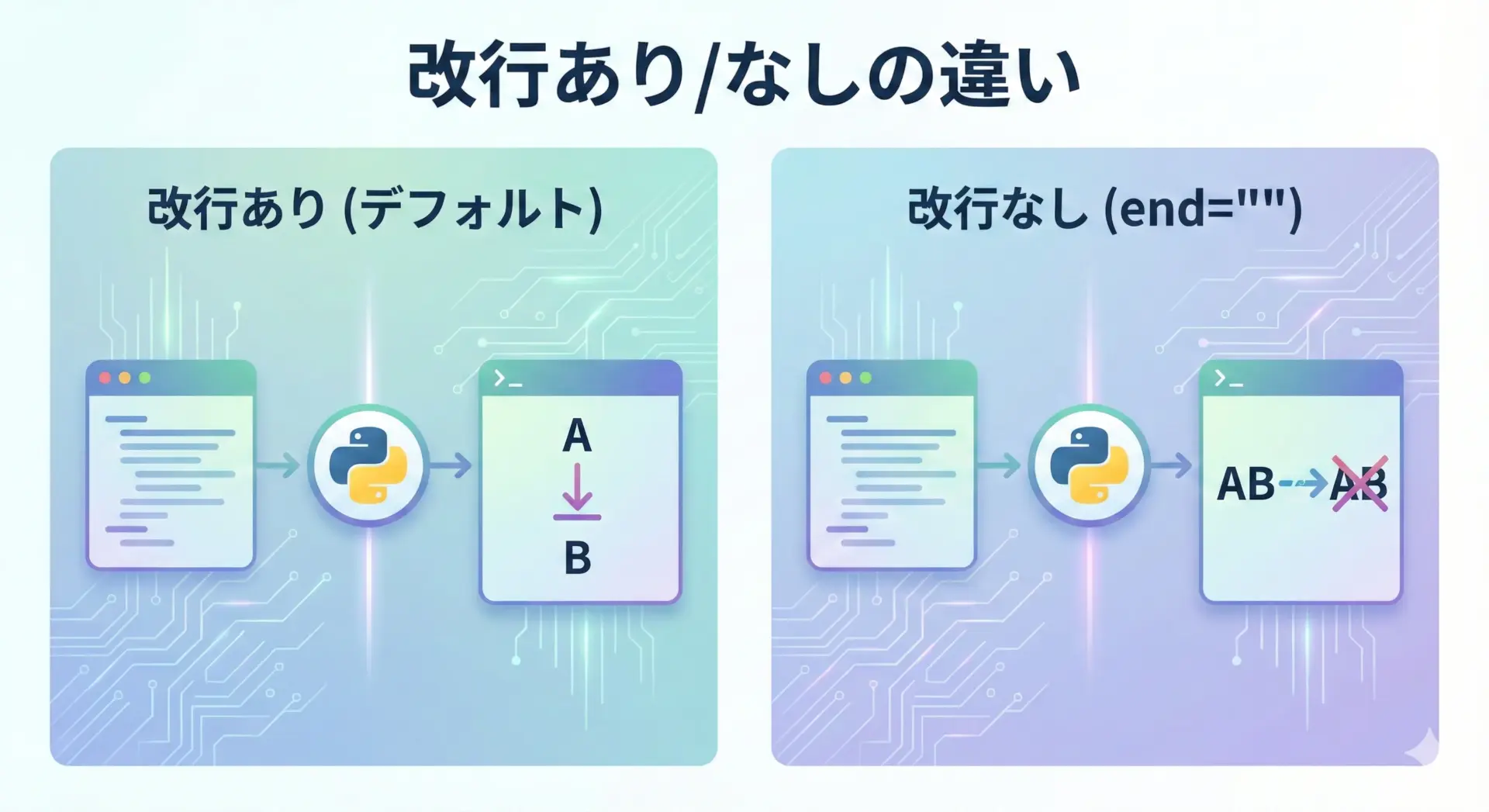
print関数は、デフォルトでは出力の最後に改行文字(\n)を付けます。
そのため、連続してprintすると行が分かれます。
print("A")
print("B")A
B改行をしたくない場合は、end引数を指定します。
endには、行末に追加したい文字列を指定します。
# 改行しないようにする例
print("A", end="") # 行末に何も追加しない
print("B") # ここで初めて改行されるABendにスペースを指定すると、スペース区切りの連続出力もできます。
for i in range(5):
print(i, end=" ") # 各数値の後ろにスペースを付ける
# 最後に改行だけ行いたければ以下のようにprint()
print()0 1 2 3 4このように進捗状況を横に並べて表示したいときなどに便利です。
区切り文字を変えるprintの書き方

複数の引数をprintで表示する場合、デフォルトの区切り文字は半角スペースです。
この区切り文字を変更したいときは、sep引数を使います。
# デフォルトの区切り文字(スペース)
print("A", "B", "C")A B C区切りをカンマにしたい場合は、次のようにします。
# sepで区切り文字を変更
print("A", "B", "C", sep=",")A,B,Cさらに、少し装飾した区切りも簡単に指定できます。
print("2025", "12", "13", sep="-") # 日付っぽく
print("A", "B", "C", sep=" - ") # 見た目を整える
print("apple", "banana", "orange", sep=" / ")2025-12-13
A - B - C
apple / banana / orangesepは「複数引数の間に挟まる文字列」だと理解しておくと、使い方がイメージしやすくなります。
f文字列(f-string)で変数を埋め込んでprintする
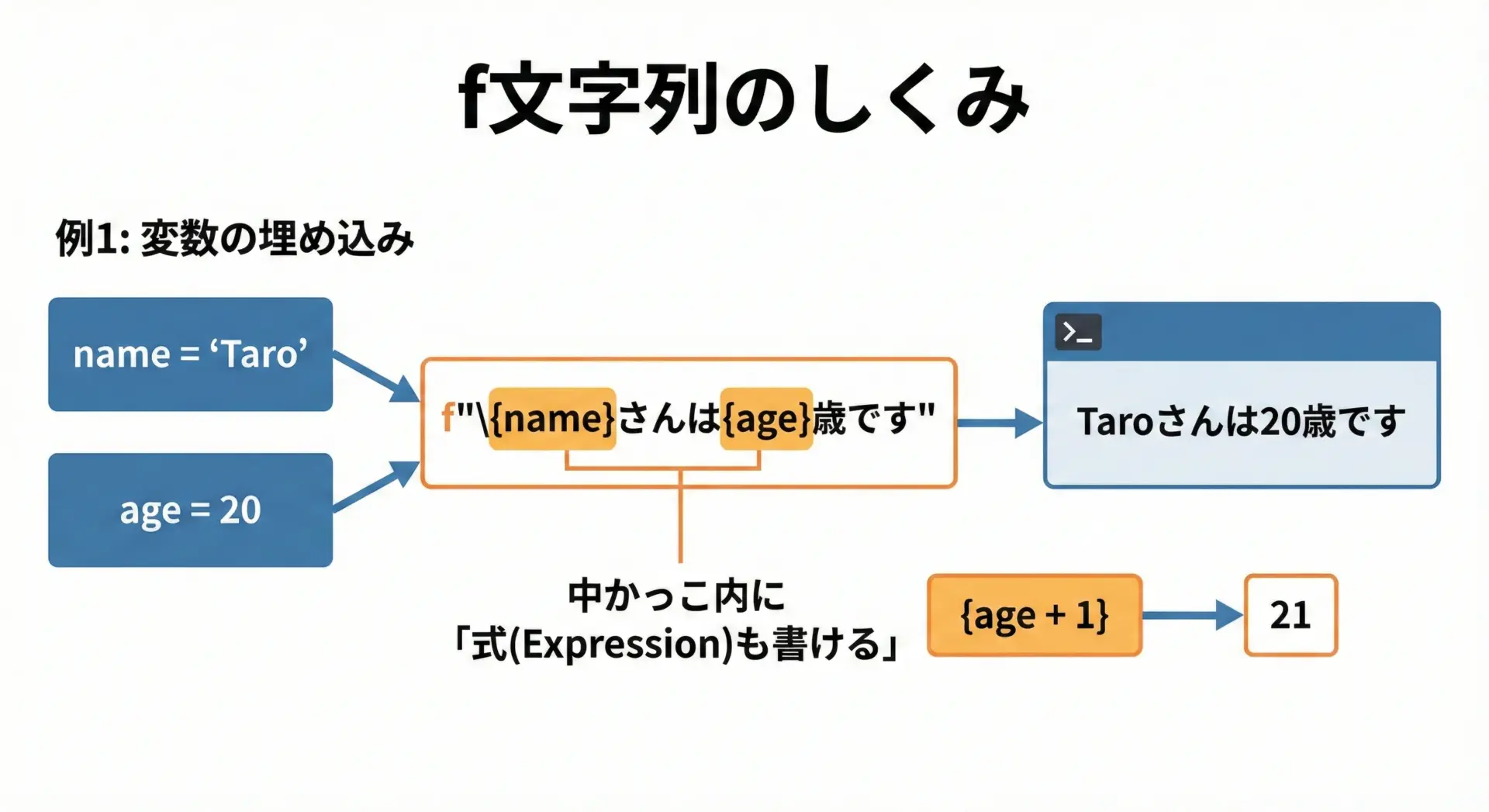
Python 3.6以降では、f文字列(f-string)という非常に便利な文字列整形の方法が使えます。
文字列リテラルの先頭にfを付け、{}の中に変数や式を書くだけで、その値が埋め込まれた文字列を作ることができます。
name = "Taro"
age = 20
# f文字列を使った出力
print(f"{name}さんは{age}歳です")Taroさんは20歳です中かっこの中には、変数だけでなく式も書けるため、計算結果を直接埋め込むこともできます。
price = 120
count = 3
print(f"単価: {price}円, 個数: {count}個, 合計: {price * count}円")単価: 120円, 個数: 3個, 合計: 360円数値のフォーマットもf文字列の中で指定できます。
例えば、小数点以下2桁まで表示したい場合は次のように書きます。
pi = 3.1415926535
# :.2f は「小数点以下2桁の浮動小数点数」という指定
print(f"円周率は約{pi:.2f}です")円周率は約3.14です可読性が高く、処理も高速なため、新しくPythonを書く場合はf文字列を第一候補に考えるとよいです。
format関数で整形してprintする方法

f文字列が登場する以前は、str.format()メソッドがよく使われていました。
現在でも、Python 3.5以前との互換性が必要な場合などに使われます。
name = "Hanako"
age = 18
# format関数を使った書き方
text = "{}さんは{}歳です".format(name, age)
print(text)Hanakoさんは18歳ですインデックスや名前付き引数を使うこともできます。
# インデックス指定
text = "{0}さんは{1}歳です。{0}さんは学生です。".format(name, age)
print(text)
# 名前付き引数
text = "{name}さんは{age}歳です".format(name="Jiro", age=25)
print(text)Hanakoさんは18歳です。Hanakoさんは学生です。
Jiroさんは25歳です数値の整形も可能です。
f文字列と同じように:.2fなどの指定が使えます。
pi = 3.1415926535
print("円周率は約{:.3f}です".format(pi))円周率は約3.142ですf文字列とformat()は、できることがほぼ同じですが、f文字列の方が読みやすく書きやすいため、特別な理由がなければf文字列を使うことをおすすめします。
デバッグでprintを活用するコツ

print関数は、「デバッグ(printデバッグ)」のためにも頻繁に使われます。
プログラムがどこまで実行されたかや、その時点で変数にどんな値が入っているかを確認するために、printを挟みます。
処理の流れを確認する
def process_data():
print("処理を開始します") # ここで開始を確認
# 何らかの処理
print("ステップ1完了") # ここまで実行されたか確認
# さらに処理
print("ステップ2完了")
print("処理を終了します")
process_data()処理を開始します
ステップ1完了
ステップ2完了
処理を終了しますこのように途中途中でメッセージを表示することで、どこまで処理が進んだかがわかります。
変数の値を確認する
x = 10
y = 0
print("割り算を行う前: x =", x, ", y =", y)
# ここでゼロ除算が起きるかもしれない
# printで値を確認しておけば原因を特定しやすい
result = x / y
print("結果:", result)このコードは実行するとエラーになりますが、エラーの直前に変数の値を表示しておくことで、原因を素早く特定できます。
printデバッグのちょっとしたコツ
printデバッグを行うときのコツとして、次のような工夫があります。
- どこからの出力かわかるように、ラベルを付ける
例:print("[DEBUG] xの値:", x) - 関数名や行番号などの情報を含める
例:print("[process_data] step1, value =", value) - デバッグが終わったら不要なprintは消すかコメントアウトする
本格的にはloggingモジュールを使う方法もありますが、最初はprintだけでも十分に役立ちます。
まとめ
Pythonのprint関数は、文字列や数値、変数の値を画面に表示するための、最も基本的かつ重要な機能です。
文字列の囲み方や、日本語(マルチバイト文字)の扱い、数値との組み合わせ方を理解することで、型エラー(TypeError)を避けつつ、分かりやすい出力が行えるようになります。
また、改行や区切り文字の制御、f文字列やformatによる整形表示を身につければ、実用的な出力が簡単に書けます。
さらに、printはデバッグの強力な味方でもありますので、本記事の内容を参考に、実際に手を動かしながら使いこなせるようになってください。
