Pythonでのコメントは、コードの読みやすさや保守性を大きく左右します。
この記事では、一行コメント・複数行コメント・docstringそれぞれの正しい書き方とルールを、実際のサンプルコードを交えながら丁寧に解説します。
Python初心者はもちろん、チーム開発でコメントスタイルを整えたい方にも役立つ内容を目指します。
Pythonコメントの基本ルール
Pythonコメントとは
Pythonにおけるコメントとは、インタプリタに無視され、人間のためだけに書かれる説明用のテキストのことです。
Pythonでは、主に次の3種類のコメントが使われます。
1つ目は一行コメントで、行頭や行中に#を置いて、その右側をコメントとする書き方です。
2つ目は複数行コメントで、複数行にわたる説明をブロックとしてまとめる形です。
3つ目はdocstring(ドックストリング)で、関数やクラス、モジュールの説明を行うための特別な文字列リテラルです。
Pythonのコメントは、「何をしているか」だけでなく「なぜそうしているのか」を伝えるために存在します。
ソースコードだけでは意図が伝わりにくい部分を補うことで、未来の自分やチームメンバーが安心してコードを読むことができるようになります。
一行コメントの書き方と注意点
一行コメントは、もっとも基本的で頻繁に使われるコメントの形式です。
Pythonでは#記号から行末までがコメントとして扱われます。
# ユーザーから名前を入力してもらう
name = input("名前を入力してください: ")
# あいさつメッセージを表示する
print(f"こんにちは、{name}さん!")このとき、コメントと#の間には半角スペースを1つ入れるのが一般的なスタイルです。
PEP 8(公式スタイルガイド)でも、インラインコメントでは#の前後にスペースを置くことが推奨されています。
一行コメントでは、次の点に注意すると読みやすくなります。
- コードの内容をそのまま繰り返さない
- 何をしているかだけでなく「なぜ」その処理が必要なのかを書く
- 簡潔で具体的な文章にする
コメントで避けるべきNG例

コメントにも書いてはいけないパターンがあります。
代表的なNG例を、よくあるコードとともに見てみましょう。
# 足し算している
result = a + bこのコメントは、コードをそのまま日本語で言い直しているだけで、情報としての価値がほとんどありません。
より良いコメントは次のようになります。
# 割引前と割引額から支払い金額を算出する
total_price = original_price - discountまた、コメントがコードと矛盾してしまうケースも避けるべきです。
# 10件だけデータを取得する
records = fetch_records(limit=100) # 実際には100件このようなコメントとコードが食い違っている状態は、バグの温床になります。
コメントは更新されずに放置されやすいため、「変更に弱いコメント」は書かないという意識も大切です。
一行コメントの書き方
ハッシュ(#)を使った基本的な書き方
Pythonでは、#を使って一行コメントを記述します。
#から行末までが丸ごとコメントとなり、インタプリタはその部分を無視します。
# 範囲を指定してforループを回す
for i in range(5):
print(i)コードの上に書くパターンのほか、同じ行の末尾にコメントを書く行末コメントも存在します。
count = 0 # カウンタの初期化基本ルールとして、日本語・英語どちらで書く場合でも、コメントは「完全な文」として書くと読みやすくなります。
日本語なら「〜します」で統一し、英語なら文頭を大文字で始め文末にピリオドを付けるなど、スタイルをそろえると良いでしょう。
コード行末コメントの使い分け
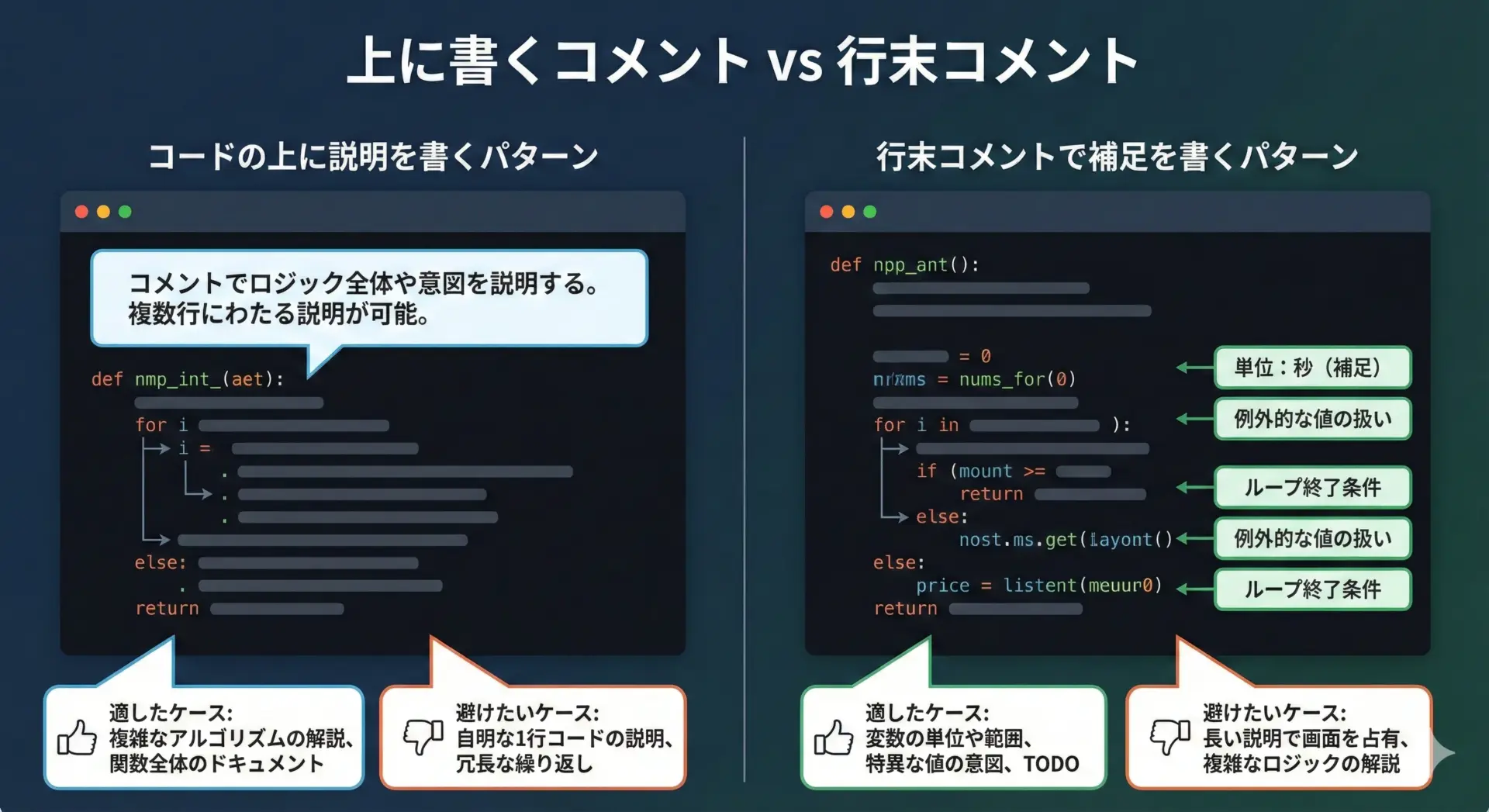
行末コメントは、コードのすぐ右側に説明を添えられる便利な形式ですが、使いすぎると行が横に長くなり、かえって読みにくくなります。
# 上に書くスタイル
max_connections = 10 # 同時接続の上限(ここでは意味がわかりやすい)一般的には、次のように使い分けるとバランスが良くなります。
- 変数の意味や単純な補足であれば行末コメント
- 処理の背景や「なぜ」が絡む説明は行の上に書く
たとえば、条件式の意図を説明したいときは、上部に書いた方が読みやすくなります。
# メンテナンスモード中は、一般ユーザーのアクセスを拒否する
if is_maintenance and not user.is_admin:
return "Service temporarily unavailable"行末コメントを使う場合は、コメントの前に2つ以上の半角スペースを空けると、コードとコメントの境界がはっきりし、視認性が高まります。
timeout = 30 # 秒単位のタイムアウト値読みやすいコメントの文体とトーン
コメントは、文章としての読みやすさも重要です。
Pythonコードは多くの場合、複数人で読むことを前提としています。
そのため、丁寧すぎず、くだけすぎない文体を意識するとよいでしょう。
日本語であれば、次のような決め方があります。
- 「〜します」「〜です」などの常体・敬体のどちらかに統一する
- 「〜する」「〜だ」といった常体で揃えるプロジェクトも多い
- 口語的な表現や感情表現は避ける
例えば、次のようなコメントは避けた方が良いです。
# とりあえずここで何かやってますw代わりに、具体的かつ中立的な表現にします。
# デバッグ用にリクエストパラメータをログ出力する英語コメントの場合も同様に、略語やスラングを避け、第三者から見ても意味が明確な文章を書くことを心がけます。
日本語コメントと英語コメントの使い分け
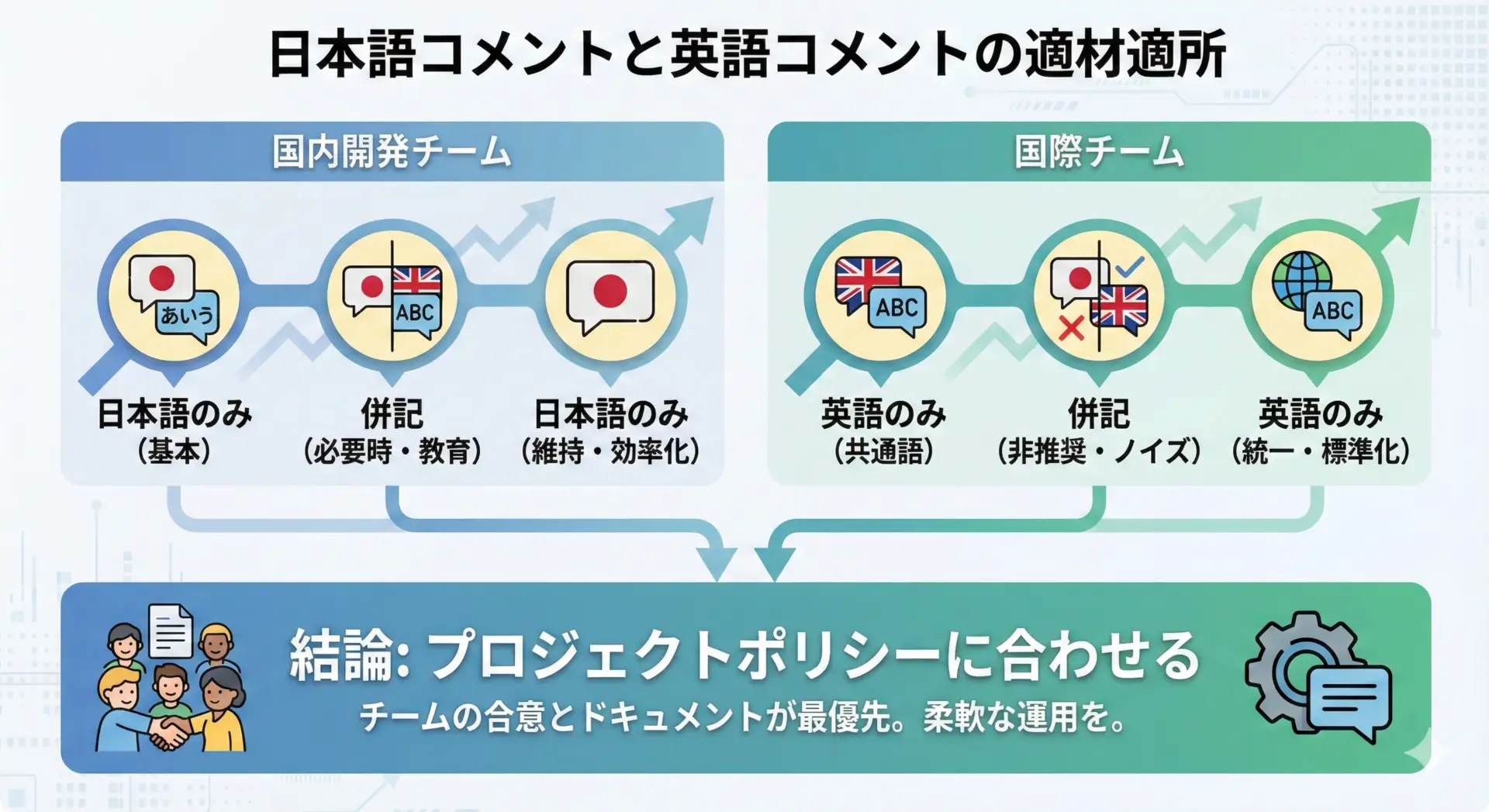
Pythonでコメントを書く際、日本語と英語のどちらを使うかは、プロジェクトの性質とチーム構成によって決めるのが基本です。
国内の少人数チームであれば、日本語コメントの方が素早く意図を共有しやすい場合が多いです。
一方、オープンソースプロジェクトや海外の開発者と協働するケースでは、英語コメントで統一する方が自然です。
混在させる場合は、同じファイル内でスタイルがバラバラになることを避けるため、次のようなルールを決めておくと良いでしょう。
- コード上のコメントは日本語、docstringは英語
- ログメッセージやエラーメッセージは英語、補足コメントは日本語
- ライブラリ部分は英語、アプリ固有部分は日本語
重要なのは、「なぜその言語を使うのか」をチームで共有し、一定の一貫性を保つことです。
複数行コメントの書き方
複数行コメントの基本パターン
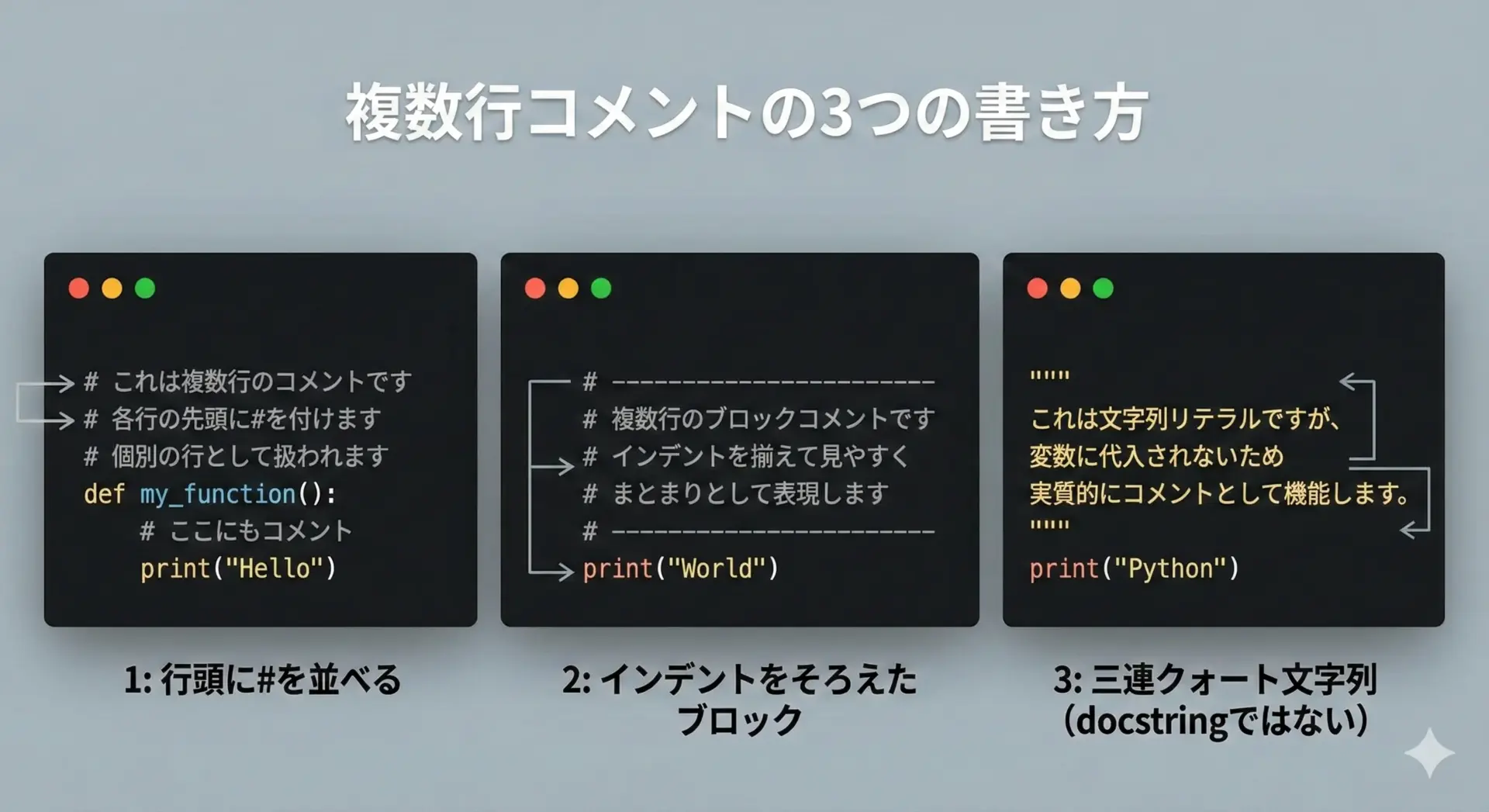
Pythonには、C言語の/* ... */のような明示的な複数行コメント構文はありません。
その代わりに、次のようなパターンがよく使われます。
1つ目は、行ごとに#を付ける方法です。
# ユーザー登録処理の概要
# 1. 入力値のバリデーション
# 2. 重複メールアドレスのチェック
# 3. ユーザー情報の保存
# 4. ウェルカムメールの送信この方法は、Pythonの公式スタイルガイドであるPEP 8でも推奨される、もっとも標準的な複数行コメントの書き方です。
2つ目は、いわゆる""" ... """や''' ... '''を使った三連クォートの文字列です。
ただし、これは厳密には「コメント」ではなく、評価されないだけの文字列リテラルという点に注意が必要です。
docstring以外で乱用するのは避けるのが無難です。
この点については後ほど詳しく解説します。
ブロックコメントの書き方とインデントルール
ブロックコメントとは、複数行にわたって、あるコードブロック全体の説明を書くコメントのことです。
特に関数の中などで、まとまった処理の意図を説明するときに便利です。
def process_order(order):
# 注文処理のメインロジック
# ここでは次のことを行う:
# - 在庫の確保
# - 決済の実行
# - 注文履歴の保存
# - 確定メールの送信
reserve_stock(order)
charge_payment(order)
save_order(order)
send_confirmation_mail(order)このように、コメントのインデントは、そのコメントが説明しているコードブロックに合わせるのが基本です。
関数の中であれば1段下げ、if文の中であればさらに1段下げる、といったルールでそろえると、コード構造とコメント構造が視覚的に一致して読みやすくなります。
コメントアウトによる一時的な無効化
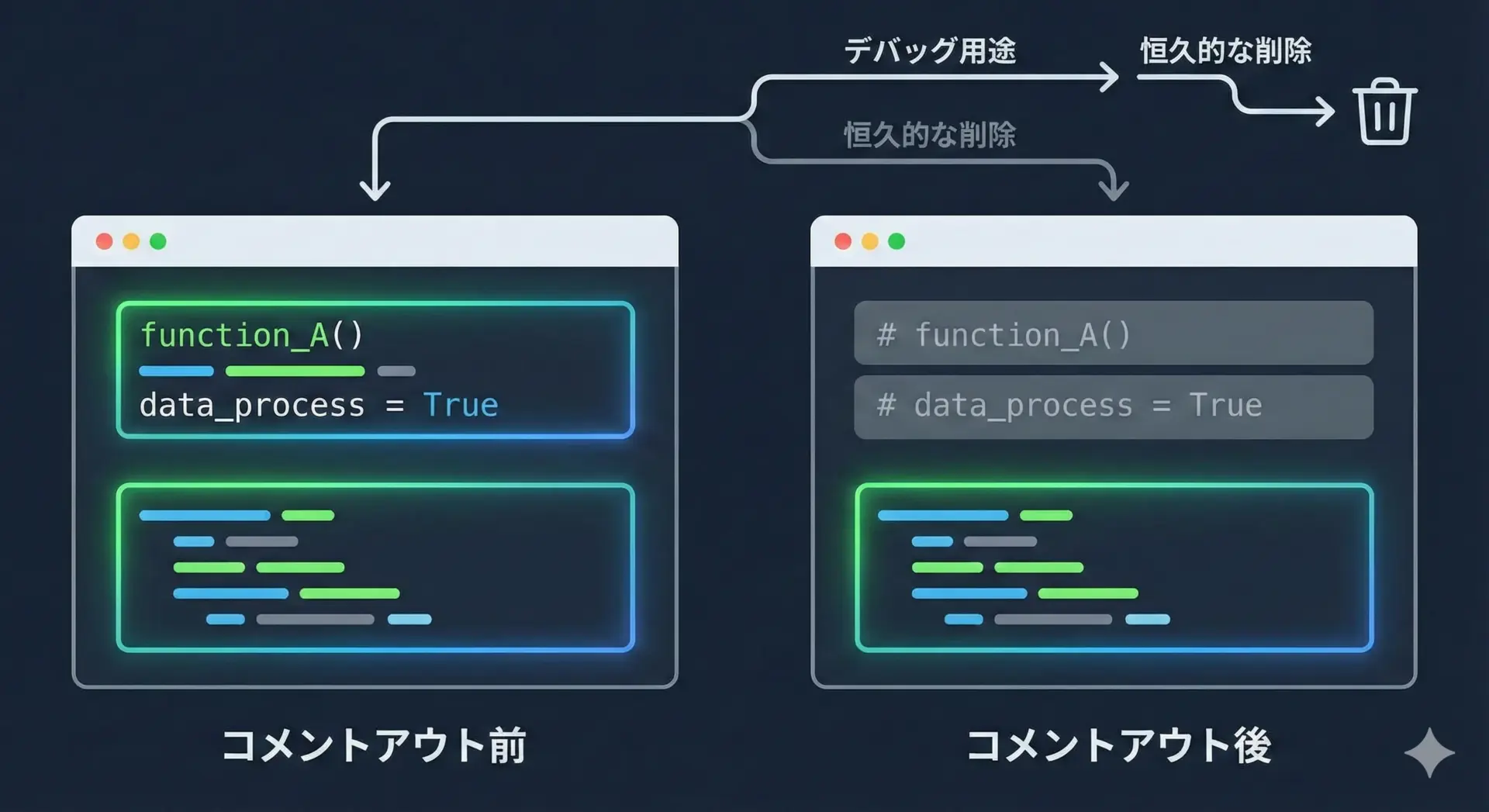
開発中に、特定の行やブロックを一時的に無効化したい場合、コメントアウトがよく使われます。
# 一時的にメール送信を止める(テスト用)
# send_confirmation_mail(order)複数行をまとめてコメントアウトしたい場合も、行ごとに#を付けるのが基本です。
多くのエディタやIDEには、選択範囲に一括で#を付け外しするショートカットが用意されています。
# デバッグ用に詳細ログを出力
# print("order =", order)
# print("stock =", stock)
# print("user =", user)ただし、コメントアウトしたコードを長期間放置するのは避けるべきです。
履歴を残したいだけならGitなどのバージョン管理システムに任せる方が適切です。
コメントアウトはあくまで、一時的なデバッグや検証のための手段と考えるとよいでしょう。
複数行コメントとdocstringの違い
複数行コメントとdocstringは、見た目が似ているものの、目的と扱われ方が大きく異なります。
Pythonインタプリタは、関数やクラス、モジュールの先頭に書かれた三連クォート文字列をdocstringとして認識します。
一方、それ以外の位置で書かれた三連クォート文字列は、評価はされるものの、特別な意味を持たない単なる文字列リテラルです。
def func():
"""これはdocstringとして扱われる。"""
pass
"""これはモジュールdocstring。
このファイル全体の説明として使われる。
"""これに対し、次のような書き方は、docstringではなく、値としてどこにも使われない文字列になります。
def func():
"""
これは関数本体の先頭にないので、
単なる評価されない文字列リテラルになる。
コメント代わりに使うのは推奨されない。
"""
do_something()PEP 8では、コメント代わりに三連クォート文字列を使うことは推奨されていません。
複数行コメントが必要な場合は、#を行ごとに付ける正攻法を選ぶようにしましょう。
docstringの書き方とルール
docstringとは
docstring(ドックストリング)とは、関数やクラス、モジュールの仕様や使い方を説明するための特別な文字列です。
Pythonでは、最初の文として定義本体の直後に三連クォート文字列を書くことで、そのオブジェクトの__doc__属性として扱われます。
docstringは、help()関数で表示されたり、IDEのツールチップに出てきたり、自動ドキュメント生成ツール(Sphinxなど)で利用されたりします。
そのため、外部から利用される関数やクラスにはdocstringを書くのが、Pythonにおける良い習慣です。
関数とメソッドのdocstring書き方
関数やメソッドのdocstringは、「何をする関数なのか」「引数・戻り値・例外」などを説明することが目的です。
最小限のdocstringは、次のように一行の説明文だけでも構いません。
def add(a: int, b: int) -> int:
"""2つの整数を足し合わせた結果を返します。"""
return a + b複雑な関数では、複数行のdocstringを用いて、引数や戻り値を詳しく説明します。
ここでは、Googleスタイルの簡易的な例を示します。
def divide(a: float, b: float) -> float:
"""2つの数値を割り算して結果を返します。
Args:
a: 被除数となる数値。
b: 除数となる数値。0は指定できません。
Returns:
割り算の結果となる数値。
Raises:
ValueError: bが0の場合に発生します。
"""
if b == 0:
raise ValueError("b must not be zero.")
return a / bこのように、先頭の一行で概要を簡潔に説明し、その後の空行を挟んで詳細を書くのが一般的なパターンです。
クラスとモジュールのdocstring書き方
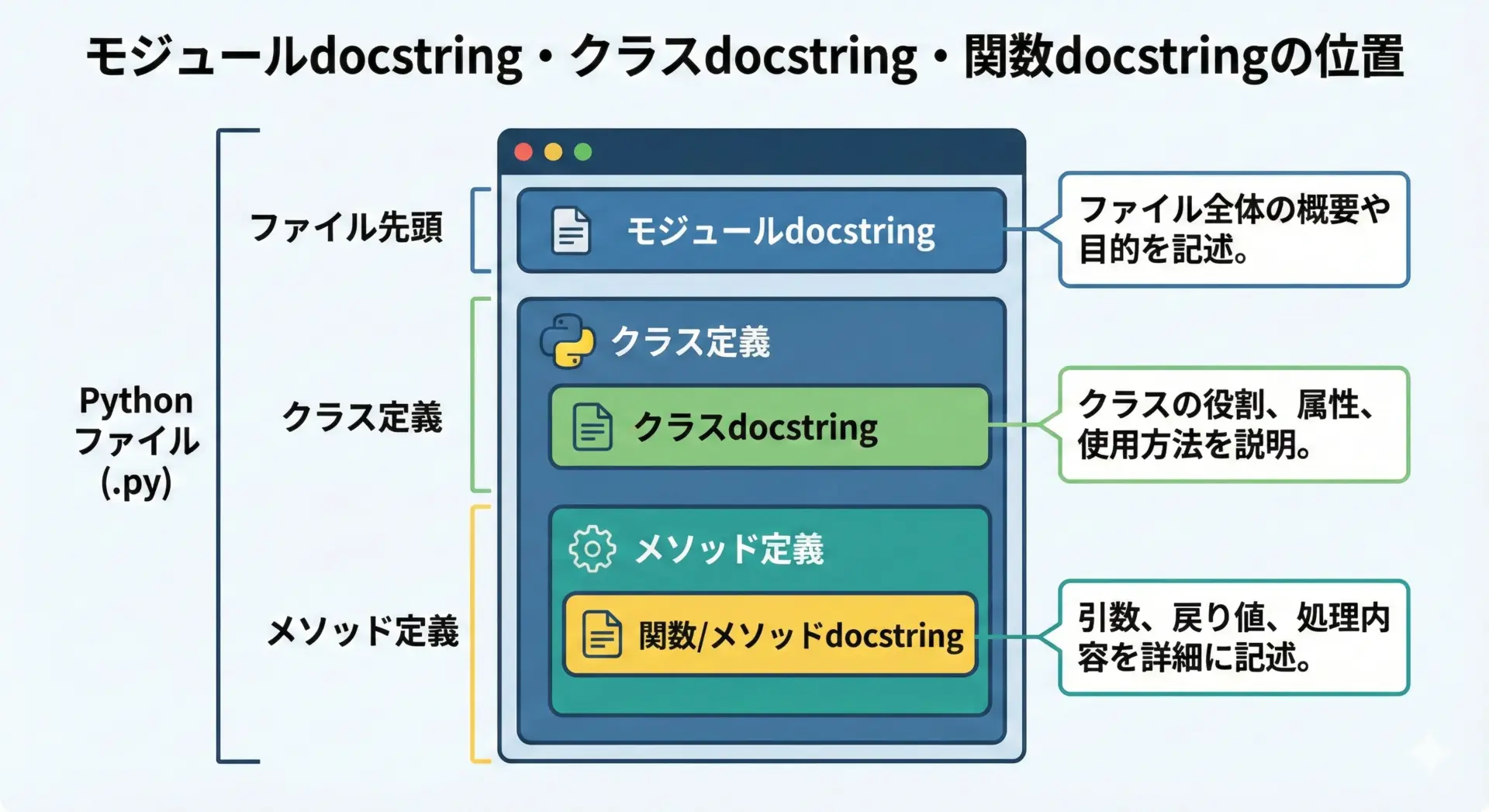
クラスやモジュールにもdocstringを書くことで、構造全体の理解が格段にしやすくなります。
モジュールdocstringは、ファイルの先頭に書くのがルールです。
"""ユーザー管理機能を提供するモジュール。
ユーザーの登録・認証・プロフィール更新などの処理をまとめています。
"""
import hashlib
from dataclasses import dataclassクラスのdocstringは、クラス定義直下に書きます。
class User:
"""アプリケーション内のユーザーを表すクラス。
ユーザー名とメールアドレス、パスワードハッシュを保持します。
"""
def __init__(self, name: str, email: str, password: str) -> None:
self.name = name
self.email = email
self.password_hash = self._hash_password(password)クラスdocstringでは、クラスが表す概念や責務に焦点を当て、個々のメソッドの詳細は各メソッドのdocstring側で説明する、という役割分担を意識するとよいでしょう。
一行docstringと複数行docstringの書き分け
docstringには、一行docstringと複数行docstringがあります。
PEP 257(docstringのスタイルガイド)では、それぞれ次のように書くことが推奨されています。
一行docstringは、1行で完結する短い説明に使います。
def is_even(n: int) -> bool:
"""引数が偶数かどうかを判定します。"""
return n % 2 == 0複数行docstringは、概要+詳細の構造にします。
def send_email(to: str, subject: str, body: str) -> None:
"""指定した宛先にメールを送信します。
SMTPサーバーの設定は環境変数から読み込みます。
HTMLメールには対応していません。
"""
...複数行docstringでは、最初の行は1文で要約し、その次の行は必ず空行にするのがPEP 257の推奨スタイルです。
その後に、詳細な説明やパラメータ情報を続けて書きます。
三連クォートの使い方と注意点
docstringでは、三連クォート(トリプルクォート)を使います。
Pythonでは"""と'''のどちらも利用できますが、多くのプロジェクトでは"""ダブルクォートを使用するスタイルで統一されています。
def func():
"""これはダブルクォートのdocstringです。"""
pass三連クォートの注意点として、次のことが挙げられます。
- 文字列の中に
"""を含めるときはエスケープや'''との使い分けが必要になる - docstring内でインデントを揃えすぎると、実際の文字列に不要な空白が含まれる
- 行頭や行末の空白は、ツールによってはそのまま出力される
Python標準ライブラリのtextwrap.dedentを使うと、docstring内の余分なインデントを取り除けますが、一般的なdocstringでは、最初の"""は行末に置き、2行目以降から本文を始める形がよく採用されます。
def func():
"""複数行docstringの例。
このように書くと、先頭行と本文の区切りが明確になります。
"""
passGoogleスタイル・NumPyスタイル・reSTの違い
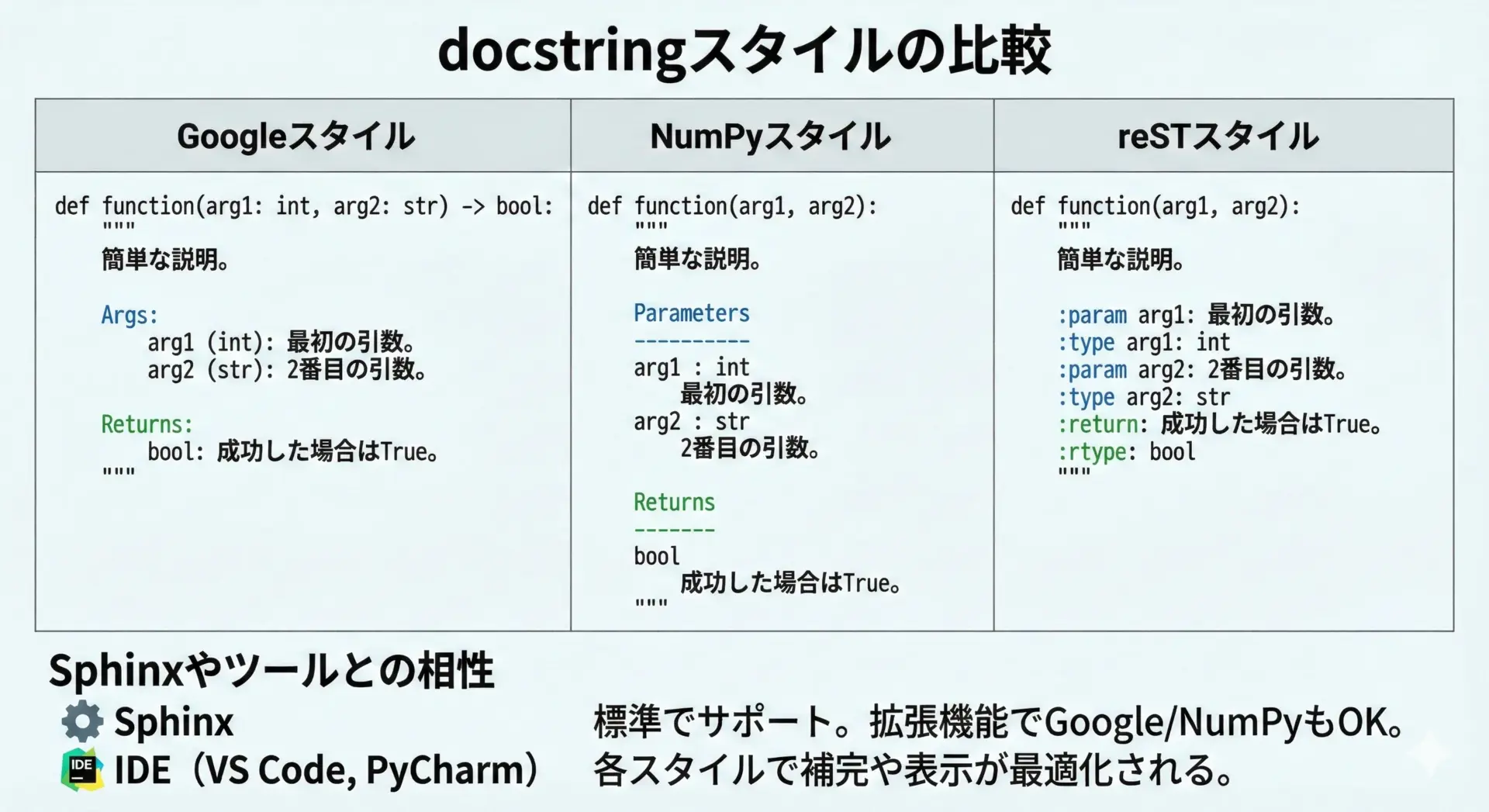
docstringにはいくつかの書式スタイルがあり、代表的なものとしてGoogleスタイル、NumPyスタイル、reST(reStructuredText)スタイルがあります。
どれを使うかはプロジェクトポリシーによりますが、Sphinxなどのドキュメントツールでの扱いやすさも大きく関わってきます。
代表的な違いを簡単な表にまとめます。
| スタイル | 特徴 | 例で使うセクション名 |
|---|---|---|
| シンプルで読みやすい箇条書き形式 | Args, Returns, Raises | |
| NumPy | 科学計算系でよく使われる、表形式に近い | Parameters, Returns, Notes |
| reST | Sphinx標準。マークアップがやや冗長 | :param:, :return:, :raises |
それぞれの簡単な例を見てみましょう。
Googleスタイルの例
def add(a: int, b: int) -> int:
"""Adds two integers.
Args:
a: First integer.
b: Second integer.
Returns:
Sum of a and b.
"""
return a + bNumPyスタイルの例
def add(a: int, b: int) -> int:
"""Add two integers.
Parameters
----------
a : int
First integer.
b : int
Second integer.
Returns
-------
int
Sum of a and b.
"""
return a + breSTスタイルの例
def add(a: int, b: int) -> int:
"""Add two integers.
:param a: First integer.
:type a: int
:param b: Second integer.
:type b: int
:returns: Sum of a and b.
:rtype: int
"""
return a + bどのスタイルにも一長一短がありますが、プロジェクト内でスタイルを統一することが何より重要です。
既存コードがある場合は、それに合わせるのが無難です。
型ヒントとdocstringの関係と書き方
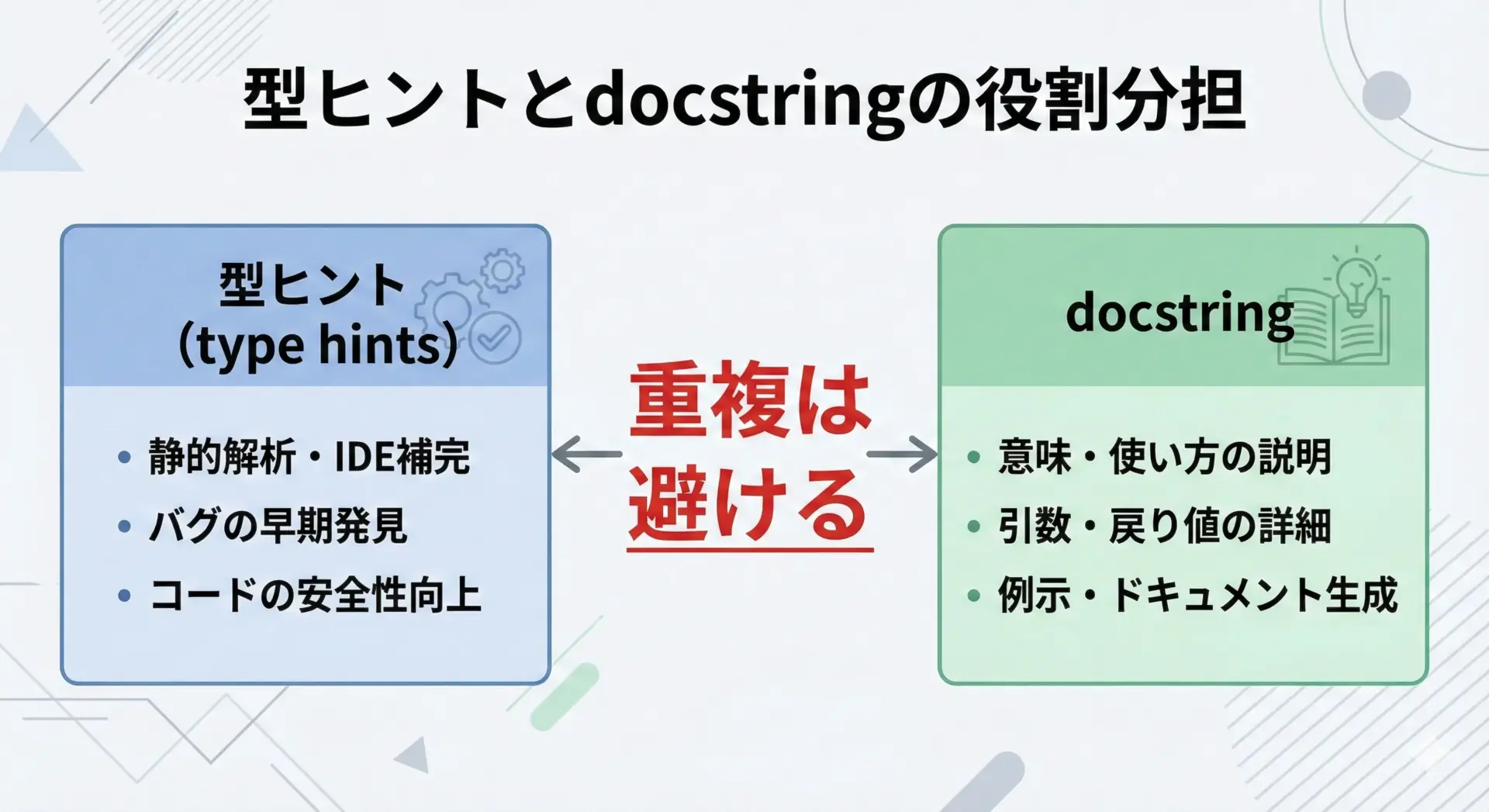
Python 3では、型ヒント(タイプヒント)を関数定義に直接書けるようになりました。
これにより、引数や戻り値の型情報をdocstringに重複して書く必要は基本的にありません。
def add(a: int, b: int) -> int:
"""2つの整数を足し合わせた結果を返します。"""
return a + b型ヒントがない場合は、docstringの方で型を説明することもあります。
def add(a, b):
"""2つの整数を足し合わせた結果を返します。
Args:
a (int): 1つ目の整数。
b (int): 2つ目の整数。
Returns:
int: 足し合わせた結果。
"""
return a + bしかし、型ヒントとdocstringの両方に同じ型情報を書いてしまうと、コード変更のたびに2箇所を更新しなければならず、食い違いのリスクが生じます。
そのため、可能な限り型ヒントに型情報を集約し、docstringでは「意味や制約条件」に集中するのがおすすめです。
例えば、次のように書き分けるとよいでしょう。
def get_users(limit: int | None = None) -> list[str]:
"""ユーザー名の一覧を取得します。
Args:
limit: 取得する最大件数。Noneの場合は全件を取得します。
Returns:
ユーザー名を表す文字列のリスト。
"""
...ここでは、型そのもの(整数・リスト・文字列など)は型ヒントで表現し、limitがNoneのときの意味や、戻り値の中身が何を表すのかといった「意味論的な情報」をdocstringで補っています。
まとめ
Pythonのコメントとdocstringは、コードの「読まれやすさ」と「保守のしやすさ」を大きく左右する要素です。
一行コメントでは#を正しく使い、複数行コメントではインデントと内容の粒度を意識し、docstringでは関数・クラス・モジュールの仕様を明確に記述します。
また、型ヒントとdocstringの役割分担を考え、情報の重複や矛盾を避けることも重要です。
プロジェクト内でスタイルを統一し、「未来の自分や他の開発者へのメッセージ」としてコメントを書いていくことで、長く信頼されるPythonコードへと育てていくことができます。
