
現代のプログラミングでは、文字コードの理解は避けて通れません。
特に日本語環境ではUnicode・UTF-8・Shift_JISの違いをきちんと押さえておかないと、原因不明の文字化けに悩まされることになります。
本記事では、抽象的な「文字」と具体的な「バイト列」を分けて説明しながら、これら3つの関係と違いを、プログラミングで実務的に使えるレベルまで整理していきます。
Unicode, UTF-8, Shift_JISとは何か
文字コードと文字化けとは
文字コードとは、コンピュータが文字を扱うために、文字に番号を割り当て、その番号を0と1のバイト列として表現する仕組みのことです。
人間は「A」「あ」「漢」などの文字そのものを認識しますが、コンピュータはそれを直接理解できないため、あらかじめ決めた対応表にしたがって番号に変換して扱います。
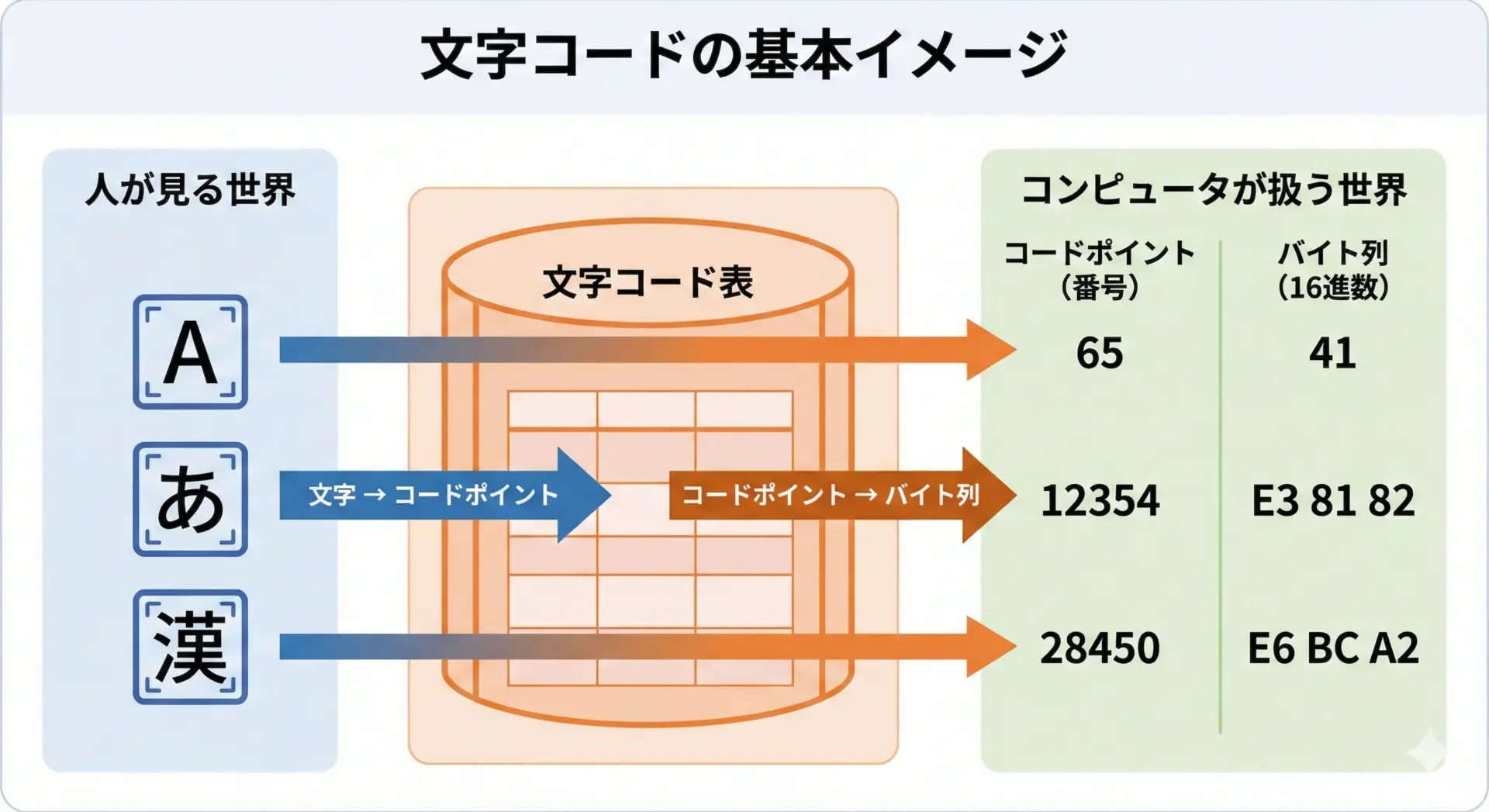
文字化けは、この「どの文字コード表で解釈するか」が食い違ったときに起こります。
たとえば、送信側はUTF-8としてバイト列を作っているのに、受信側がそれをShift_JISとして解釈しようとすると、「本来の文字」と「解釈された文字」がズレてしまい、意味不明な記号や文字列に見えてしまうのです。
Unicodeとは
Unicodeは、世界中の文字を統一的に扱うための文字集合(キャラクタセット)であり、抽象的な「文字」と「番号(コードポイント)」の対応を定めた規格です。
ここで重要なのは、Unicodeそのものは「バイト列の並べ方」までは決めていないという点です。
Unicodeは、次のような情報を定義しています。
- その文字がどのコードポイント(U+XXXX)を持つか
- 大文字・小文字の対応
- 結合文字、右から左に書く文字などの性質
たとえば、以下のように文字に一意な番号を割り当てます。
- 「A」 → U+0041
- 「あ」 → U+3042
- 「漢」 → U+6F22
この時点では、まだ「どのようなバイト列で保存するか」は決まっていません。
この「保存形式」を決めるのがUTF-8などのエンコーディング方式です。
UTF-8とは
UTF-8は、Unicodeのコードポイントを、実際にファイルや通信で扱えるバイト列として符号化(エンコード)する方式の1つです。
UTF-8は可変長の方式で、文字によって1〜4バイトを使い分けます。
UTF-8の大きな特徴は次の通りです。
- ASCIIの0x00〜0x7Fは、そのまま1バイトで表現される
- 英数字のみのテキストは、従来のASCIIと完全互換
- 日本語などの多バイト文字は、2〜3バイト以上で表現
- 世界中の多くの言語を1つの方式で表現可能
プログラミングやWebでは、事実上の標準エンコーディングになりつつあり、新規開発ではほぼUTF-8一択と言ってよい状況になっています。
Shift_JISとは
Shift_JISは、日本語を扱うために設計された古くからある文字コード方式です。
ASCIIとの互換性を保ちながら、日本語の漢字やかなを表現できるようにしたもので、Windowsや携帯電話、古いWebサイトなど、日本国内のさまざまな環境で長く使われてきました。
Shift_JISの主な特徴は次の通りです。
- 英数字や記号は1バイト
- 日本語の多くの文字は2バイト
- コードポイント体系はUnicodeとは別物
- ベンダーごとに独自拡張(機種依存文字)が存在
その結果、同じバイト列でも環境によって別の文字に見えるといった問題や、文字化けの原因になりやすい要素を多く含んでいます。
UnicodeとUTF-8の関係を理解する
抽象的な文字(文字集合)とバイト列
UnicodeとUTF-8の違いを理解するには、「文字集合」と「エンコーディング」を分けて考えることが重要です。
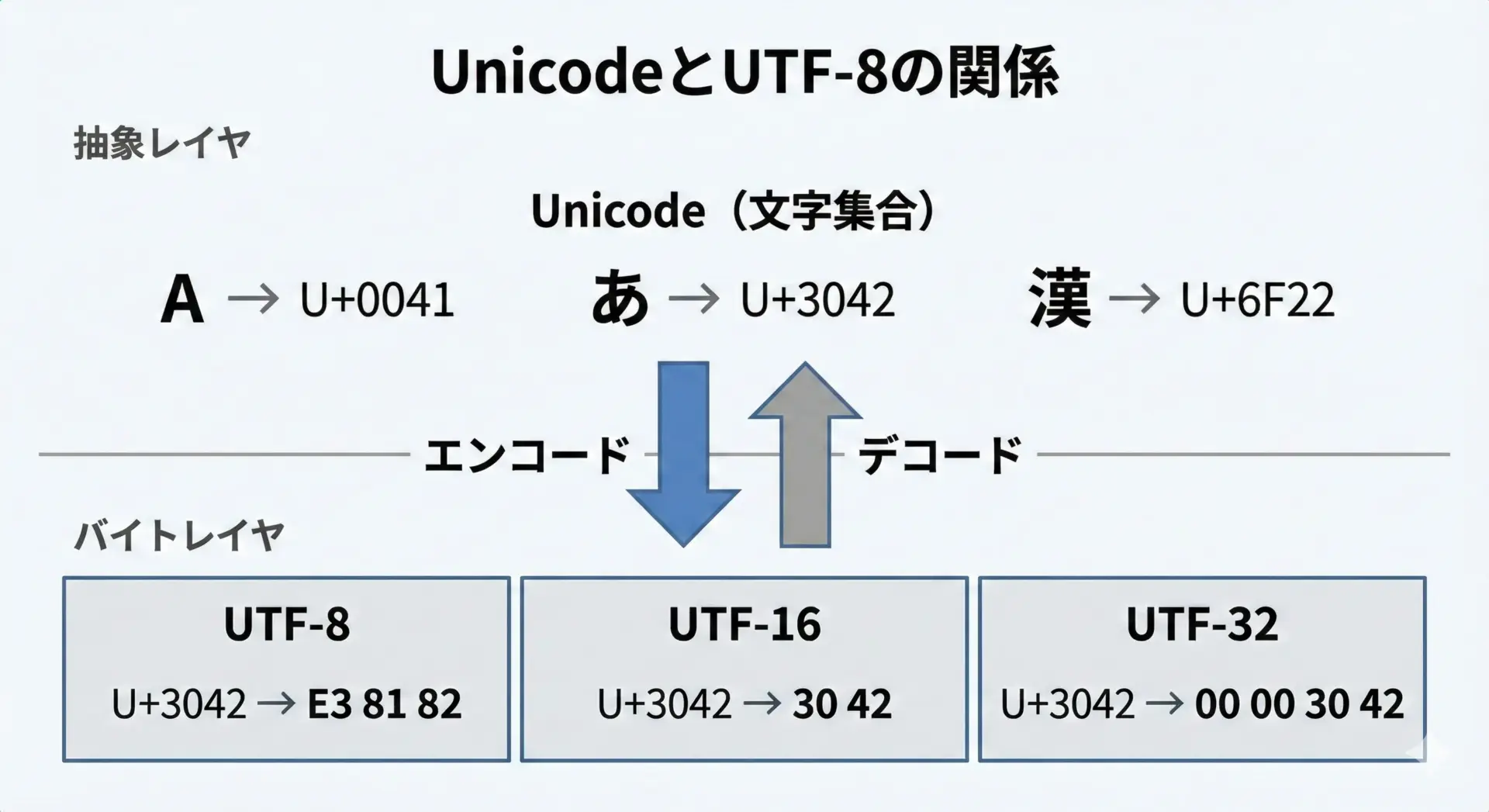
ポイントは次の2つです。
- Unicode = 文字集合とコードポイントのルール
- UTF-8 = Unicodeをバイト列にする具体的な方式
つまり、Unicodeは「世界中の文字に番号を振った辞書」であり、UTF-8は「その番号をファイルにどのように書き込むかのルール」と考えると理解しやすくなります。
Unicodeコードポイント(U+XXXX)とは
Unicodeでは、各文字に対してコードポイントと呼ばれる番号が割り振られています。
表記にはU+3042のように16進数で書くことが多いです。
いくつか具体例を挙げます。
- 「A」 →
U+0041 - 「0」 →
U+0030 - 「あ」 →
U+3042 - 「ア」 →
U+30A2 - 「漢」 →
U+6F22
このコードポイントは、UTF-8だけでなくUTF-16やUTF-32でも共通です。
「文字そのもののID」がコードポイントであり、「そのIDを何バイトでどう並べるか」が各エンコーディング方式ごとの役割です。
UTF-8の特徴
UTF-8には、プログラミング上とても扱いやすい特徴がいくつもあります。
1つ目はASCII互換であることです。
0x00〜0x7Fの文字は、UTF-8でもそのまま1バイトで表現されます。
そのため、英数字と基本的な記号のみのファイルは、ASCIIとしてもUTF-8としても同じように読めます。
2つ目は可変長エンコーディングであることです。
たとえば、以下のように文字種によってバイト数が変わります。
- ASCII文字(英数字など) → 1バイト
- 多くのヨーロッパ言語の文字 → 2バイト
- 日本語のひらがな・カタカナ・漢字の多く → 3バイト
3つ目は、バイト列から文字境界を判定しやすい構造を持っている点です。
先頭バイトと続くバイトでパターンが決まっており、不正なバイト列を検出しやすいため、セキュリティや信頼性の面でも有利です。
UTF-16やUTF-32との違いも簡単に整理
Unicodeを表現するエンコーディング方式には、UTF-8のほかにUTF-16やUTF-32などがあります。
それぞれの違いを簡潔に整理します。
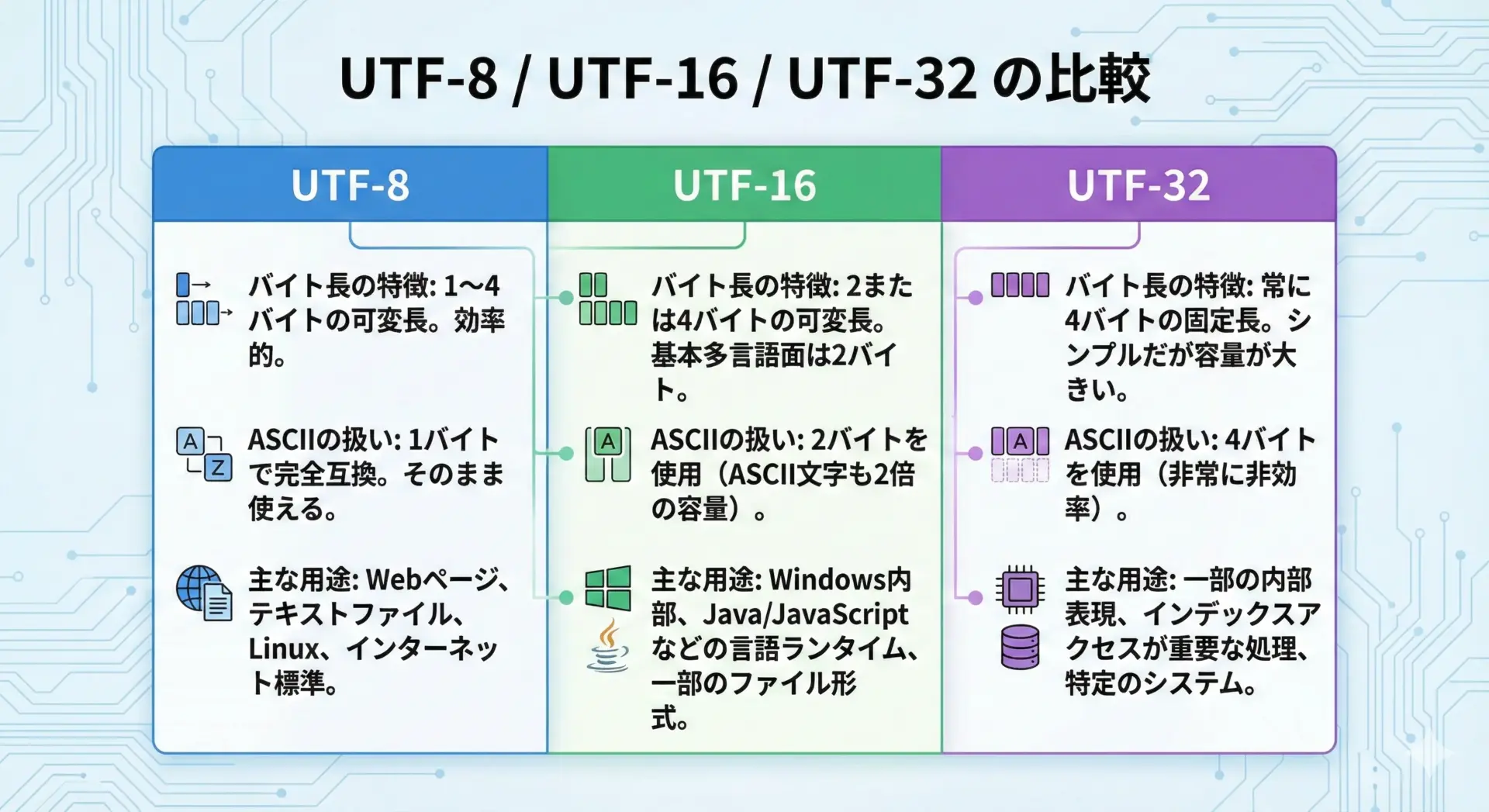
概要は次の通りです。
- UTF-8
- 1〜4バイトの可変長
- ASCIIは1バイトそのまま
- Web、テキストファイル、API、ログなどで広く利用
- UTF-16
- 基本2バイト(一部の文字は4バイト)
- ASCIIでも2バイトになることが多い
- Windows内部の文字列や、Java/C#/JavaScriptなどのランタイム内部表現でよく利用
- UTF-32
- 常に4バイト固定長
- どの文字も1コードポイント=4バイトで、インデックス計算が単純
- メモリ効率が悪いため、主に内部処理用のニッチな用途
プログラムを書く際には、「外部とのやりとり」にはUTF-8、「内部表現」は言語や環境が決めた形式に合わせる、という使い分けが一般的です。
Shift_JISとUTF-8の違い
Shift_JISの仕組みと歴史的背景
Shift_JISは、もともと日本語版のMS-DOSやWindowsのために設計された文字コードです。
ASCIIと互換性を保ちつつ、日本語の漢字やかなを扱えるようにした可変長の日本語専用コードと言えます。
Shift_JISの特徴的なポイントとして、次のようなものがあります。
- 1バイト文字
- ASCIIの英数字・記号など
- 2バイト文字
- 日本語の漢字や全角カナ
- 1バイト目、2バイト目ともに特定の範囲に収まるように設計
歴史的には、インターネットやUnicodeが普及する以前から、Windowsアプリケーション、メール、携帯電話、組み込み機器などで広く使われてきました。
そのため、長い互換性の積み重ねがあり、現在でも多くの資産がShift_JISで保存されています。
Shift_JISで起きやすい文字化けの原因
Shift_JISは実運用で広く使われた一方で、構造上文字化けが発生しやすいという問題を抱えています。
主な原因は次の通りです。
1つ目は可変長でありながら、バイトの範囲が他のコードと衝突しやすいことです。
たとえば、Shift_JISの2バイト目の値が、他の文字コードで有効な1バイト文字の範囲に重なってしまうケースがあります。
その結果、UTF-8のバイト列を誤ってShift_JISとして解釈すると、まったく別の文字の列になり、意味不明な文字列として表示されてしまいます。
2つ目はベンダーによる拡張やバリエーションの多さです。
同じ「Shift_JIS」と言っても、Windows Shift_JIS、JIS X 0208、JIS X 0213、携帯キャリアごとの拡張など、微妙に異なる定義が複数存在します。
そのため、ある環境では正しく表示される文字が、別の環境では文字化けや「□」に置き換わるといった問題が起こりやすくなります。
絵文字・漢字・機種依存文字の扱いの違い
UnicodeとShift_JISの違いは、絵文字や機種依存文字の扱いにも顕著に現れます。
Unicodeでは、スマートフォン絵文字を含め、世界中で使われる多種多様な絵文字に対して標準化されたコードポイントが割り振られています。
たとえば、「😀」にはU+1F600といったコードポイントが定義されており、UTF-8ではこのコードポイントを4バイトで表現します。
一方、従来のShift_JIS環境(特にガラケー時代)では、キャリアごとに独自の機種依存絵文字が定義されていました。
ソフトバンクの携帯で送った絵文字メールが、ドコモの携帯では別の絵文字や「〓」に見えるといった問題は、この独自拡張と互換性の欠如によるものです。
漢字についても、Shift_JISでは収録されていない漢字が少なからず存在します。
人名や地名などで使われる異体字や旧字は、Unicodeでは多数カバーされていますが、Shift_JISでは表現できず、やむを得ず似た字で代用しているケースもあります。
ファイルやWebでShift_JISが残っている理由
現在ではUTF-8が主流であるにもかかわらず、Shift_JISのデータやシステムが依然として残っているのには、いくつかの理由があります。
- 過去資産との互換性
古い業務システムや文書ファイルがShift_JIS前提で作られており、変更コストが高いことが多いです。 - Windowsの慣習
日本語Windowsではかつて、デフォルトの「ANSIコードページ」としてShift_JIS系が使われていたため、多くのデスクトップアプリがそれを前提に設計されてきました。 - 一部ツールやライブラリの制約
古いツールやライブラリがUTF-8に対応しておらず、Shift_JISで出力するようになっているケースがあります。
こうした背景から、既存データとのやりとりではShift_JIS対応が依然として必要であり、プログラマはUTF-8とShift_JISの相互変換や、文字コード判定ロジックを実装する場面にしばしば遭遇します。
プログラミングでの使い分けと実践ポイント
これからはUTF-8を選ぶべき理由
新規のシステムやサービスを設計する際は、原則としてUTF-8を選ぶことを強く推奨できます。
その理由は複数あります。
1つ目は国際化対応が容易であることです。
日本語だけでなく、英語、中国語、韓国語、その他の言語を同じ仕組みで扱えるため、将来の多言語化にもスムーズに対応できます。
2つ目はWeb標準との整合性です。
HTML5では、明示されない限りUTF-8が推奨されており、多くのWebフレームワークやAPIもUTF-8を前提に設計されています。
ブラウザやHTTPクライアントもUTF-8との相性が良く、実装・デバッグがシンプルになります。
3つ目はツールやライブラリのエコシステムです。
Git、Docker、クラウドサービス、各種CIツール、ログ収集基盤など、現代的な開発・運用環境はUTF-8前提で動作することが多く、UTF-8を選ぶことでトラブルの可能性を大きく減らせます。
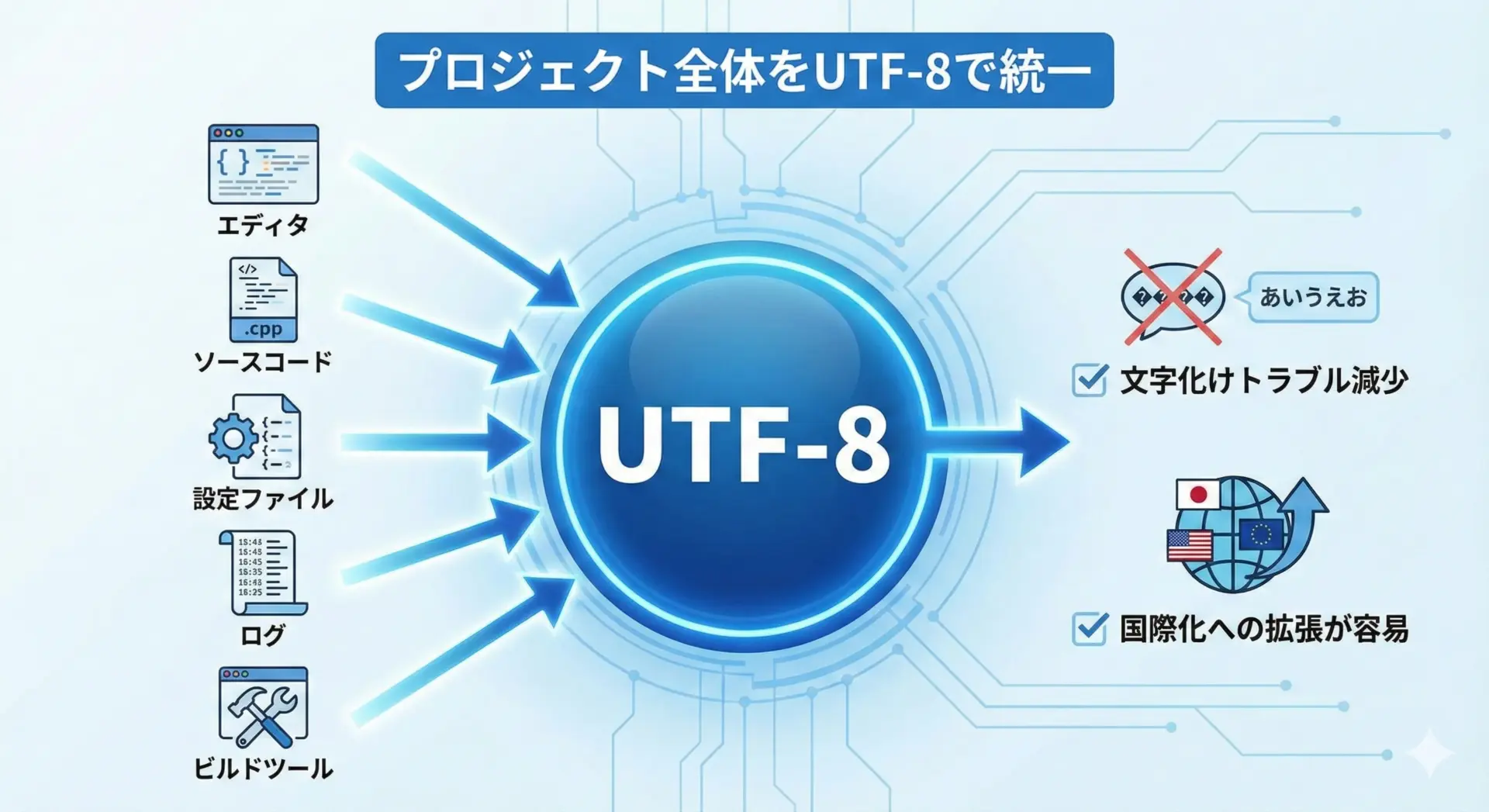
ソースコードとファイルをUTF-8に統一する
実務で文字化けトラブルを避けるためには、「プロジェクト内は原則すべてUTF-8」というルールを徹底することが非常に効果的です。
具体的には、次のような方針が考えられます。
- ソースコードファイル(.c, .java, .py, .rb, .js など)はすべてUTF-8で保存する
- テキスト設定ファイル(.ini, .yaml, .json, .env など)もUTF-8で統一する
- エディタやIDEのデフォルトエンコーディングをUTF-8に設定する
- コンパイラ・インタプリタに
-encoding UTF-8のようなオプションがあれば明示する
一方で、既存のShift_JIS資産にアクセスする場合は、「境界で変換する」という考え方が重要です。
たとえば、読み込んだ直後にUTF-8へ変換し、内部処理はすべてUTF-8で統一し、必要があれば書き出し時に再度Shift_JISへ変換する、という流れです。
文字コード判定と変換
現場では、「このファイルの文字コードが何かわからない」という状況も少なくありません。
このときに必要になるのが文字コードの判定と変換です。
プログラミング言語やOSには、次のような機能やツールがよく用意されています。
- 自動判定ライブラリ
例えばPythonのchardet、Rubyのnkf、Linuxのfileコマンドなど、バイト列から文字コードを推測するツールがあります。 - 変換ライブラリ
ICU、iconv、.NETのEncodingクラスなど、文字コードを明示して変換する機能が提供されています。
実務上は、判定結果をうのみにせず、仕様やメタデータで文字コードを明示することが重要です。
HTTPレスポンスヘッダのContent-Type、HTMLの<meta charset="utf-8">、CSV仕様書での文字コード指定など、「どのコードであるかを決め打ちできる情報」を必ず設計に含めるようにします。
データベース・Webアプリでの文字コード設定の注意点
データベースやWebアプリケーションでは、システムのさまざまな層で文字コードが関わるため、設定を統一しないと文字化けの原因になりやすくなります。
代表的な留意点を挙げます。
- データベースの文字セット
MySQLやPostgreSQLなどでは、データベース、テーブル、カラムごとに文字セットを設定できます。近年はutf8mb4のように、絵文字も含め完全なUTF-8を扱える設定を選ぶことが推奨されます。 - アプリケーションとDB間の接続設定
JDBCや各種ORMで、接続文字列にcharset=utf8mb4などを指定しないと、デフォルトのサーバ設定(場合によってはlatin1など)が使われ、文字化けにつながります。 - HTTPヘッダとHTMLの両方にcharsetを明示
Webアプリでは、レスポンスヘッダのContent-TypeとHTML内の<meta charset="utf-8">の両方をUTF-8で揃えておくことで、ブラウザの誤判定を防ぎます。
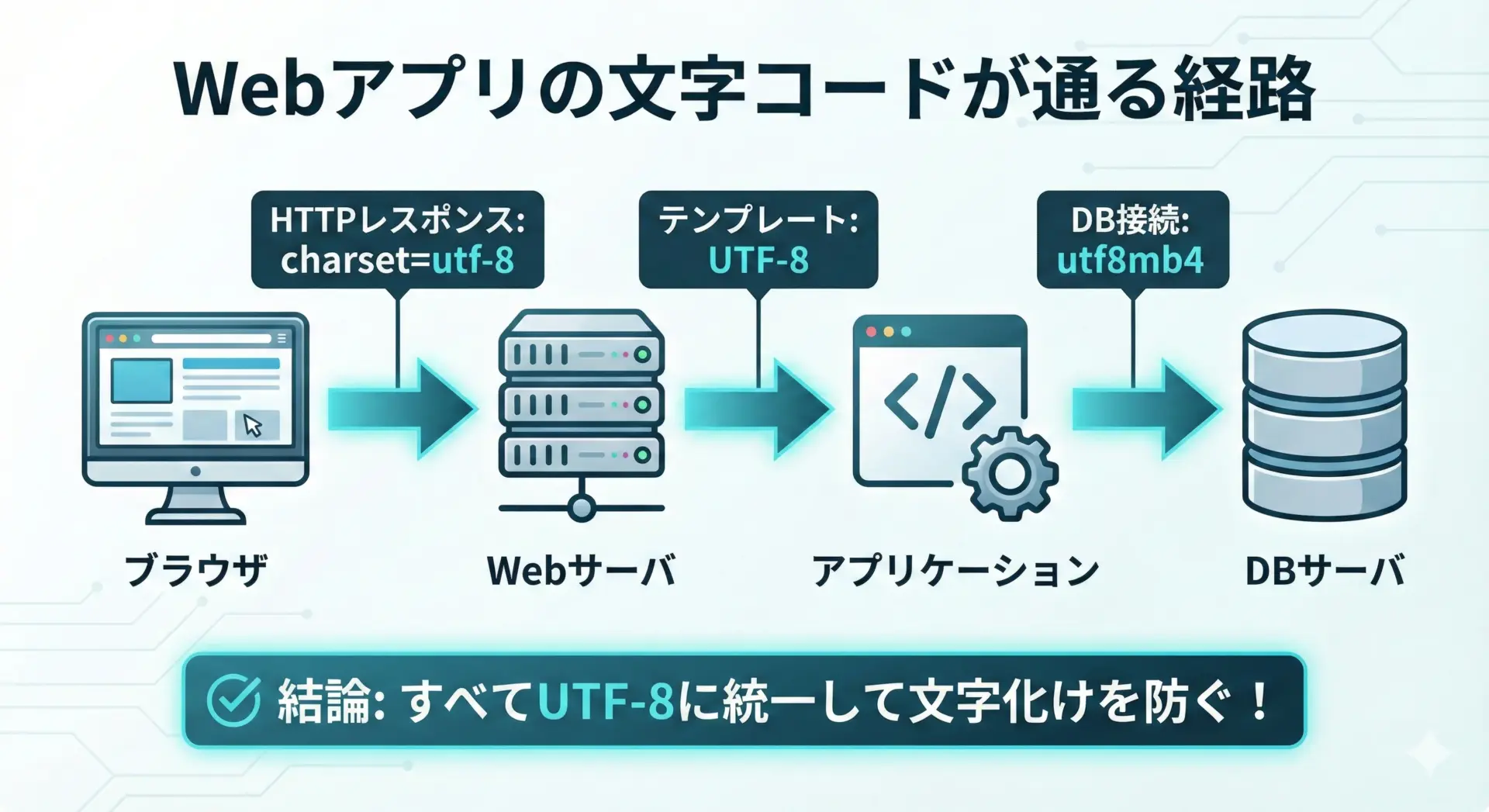
このように、「どの層もUTF-8に揃える」ことが、Webアプリケーションの文字コード設計の基本方針になります。
まとめ
Unicode・UTF-8・Shift_JISを整理すると、Unicodeは世界中の文字に番号を振った「文字集合」、UTF-8はそのUnicodeをバイト列として表現する「エンコーディング方式」、Shift_JISは日本語向けに歴史的に発展してきた別系統の文字コードだと言えます。
プログラミング実務においては、これから新しく作るシステムやファイルは原則としてUTF-8で統一し、既存のShift_JIS資産とは必要な箇所で明示的に変換する、という戦略が現実的です。
その際には、「境界で変換し、内部はUTF-8で揃える」ことを徹底することで、文字化けや互換性の問題を最小限に抑えることができます。
文字コードは一見とっつきにくいテーマですが、「文字集合」と「エンコーディング」を分けて考えるという視点を持てば、その構造は意外とシンプルです。
本記事の内容を押さえておけば、Unicode・UTF-8・Shift_JISの違いを踏まえた設計判断ができるようになり、日常的な文字化けトラブルにも落ち着いて対処できるようになるはずです。
