
Pythonでリストの操作をする際、長さを扱うことは避けて通れません。
len関数はとてもシンプルに見えますが、インデックスとの関係やネストしたリスト、他のデータ型との違いなど、意外とつまずきやすいポイントが潜んでいます。
この記事では、Pythonのlen関数でリストの長さを扱う基本から、実用的な使い方、そしてよくある落とし穴とベストプラクティスまでを、図解とコード例を交えながら丁寧に解説します。
リストの長さを取得するlen関数の基本
len関数とは
Pythonでシーケンスやコレクションの「要素数」を取得する標準関数がlenです。
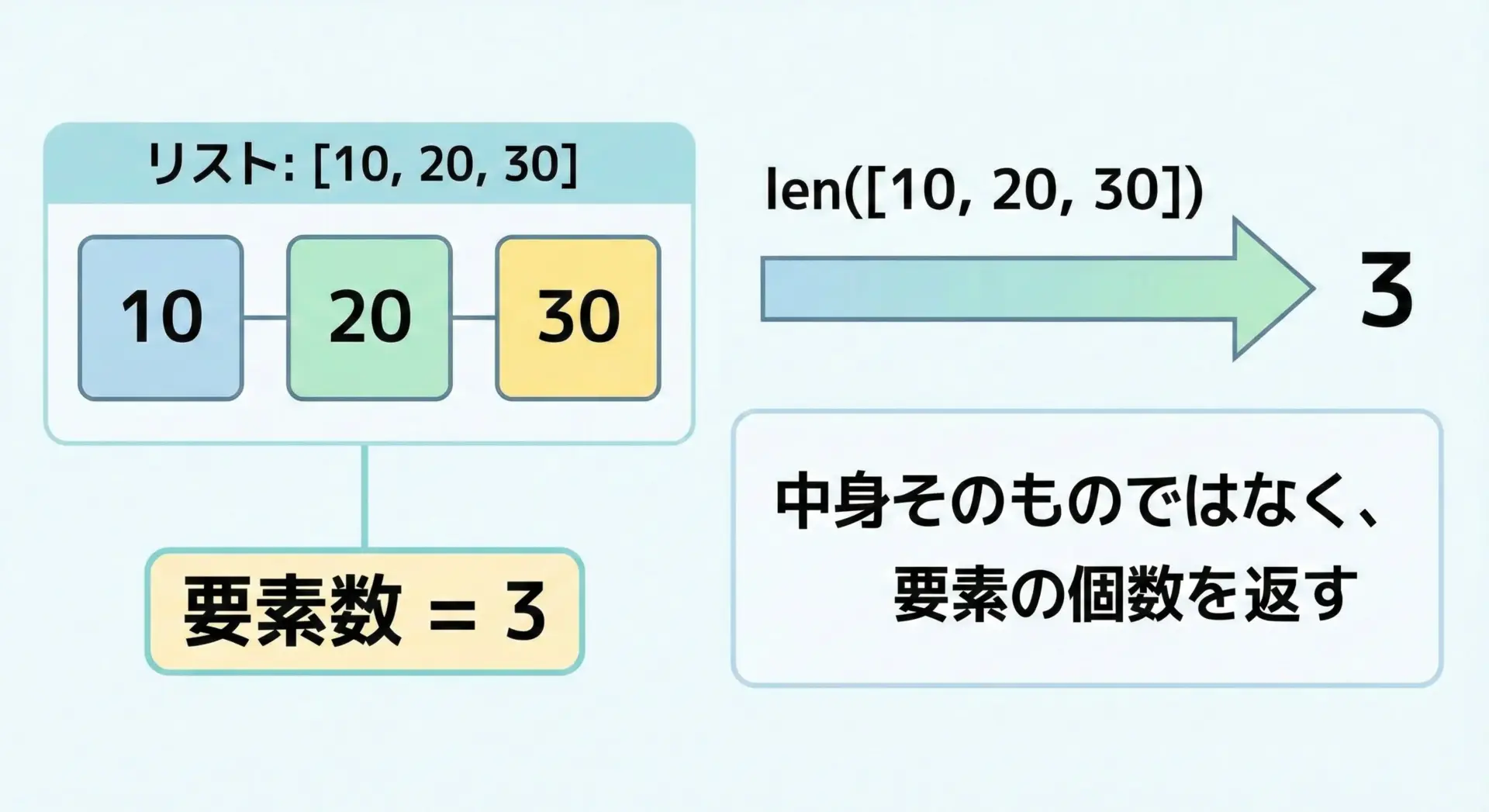
len関数は、リストの中身の合計値やインデックスを返すのではなく、あくまで要素数(何個入っているか)だけを返します。
Pythonのビルトイン関数なので、import不要でそのまま利用できます。
基本的な構文はとてもシンプルです。
- リストの長さを取得する:
len(リストオブジェクト)
たとえば、3つの要素を持つリストに対してlenを呼び出すと、整数値の3が返ります。
Pythonリストでlenを使う書き方の例
ここでは、基本的なlenの使い方を具体的なコードで確認します。
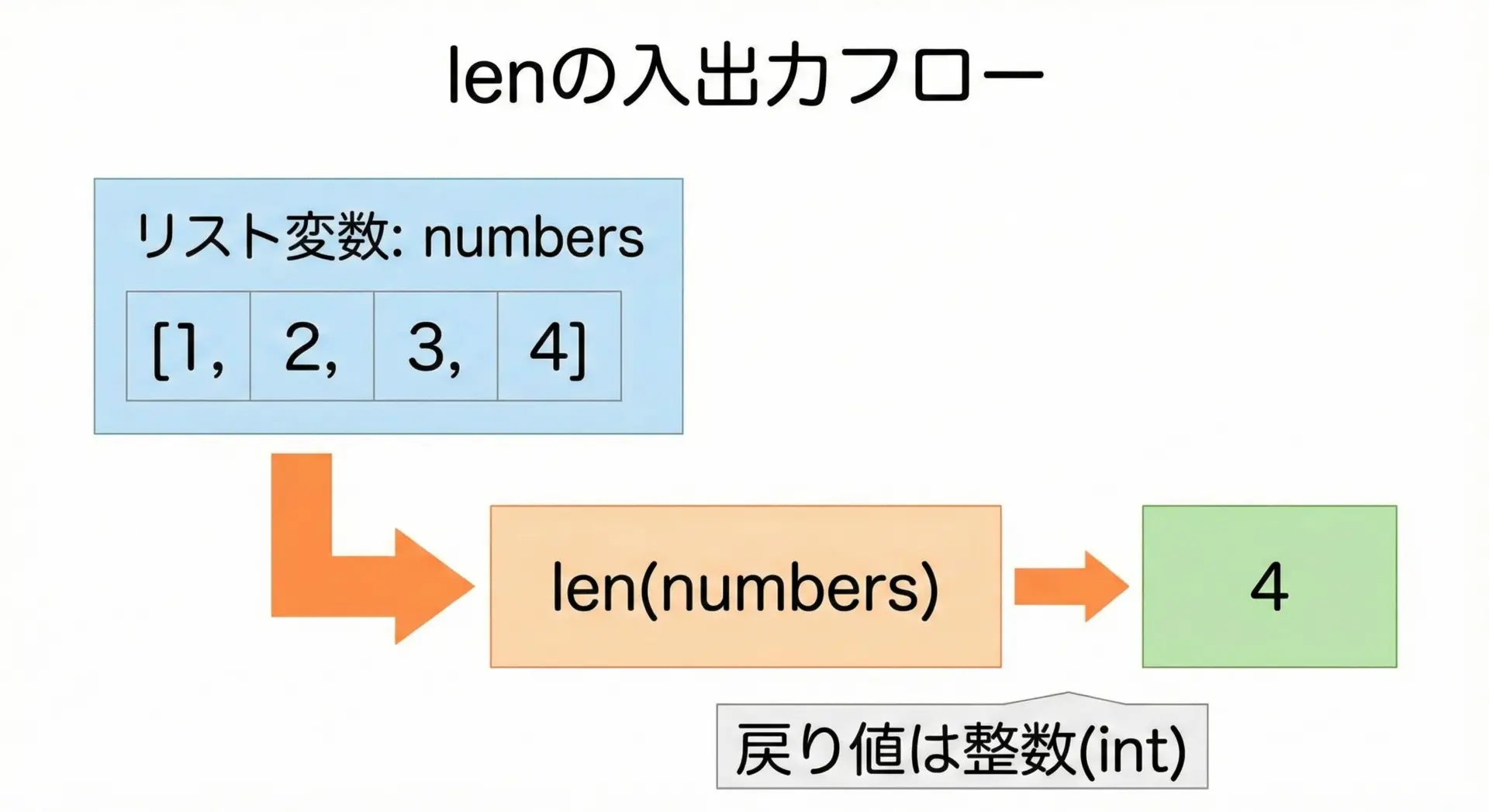
# リストを定義
numbers = [10, 20, 30, 40] # 4つの要素を持つリスト
# lenでリストの長さ(要素数)を取得
length = len(numbers)
# 結果を表示
print("numbers の中身:", numbers)
print("numbers の長さ:", length)
print("length の型:", type(length)) # 戻り値の型を確認numbers の中身: [10, 20, 30, 40]
numbers の長さ: 4
length の型: <class 'int'>この例からわかるように、len関数は常に整数(int)を返します。
また、リストそのものを変更するのではなく、長さの情報だけを別の値として返す点が重要です。
空リストと要素ありリストでのlenの違い
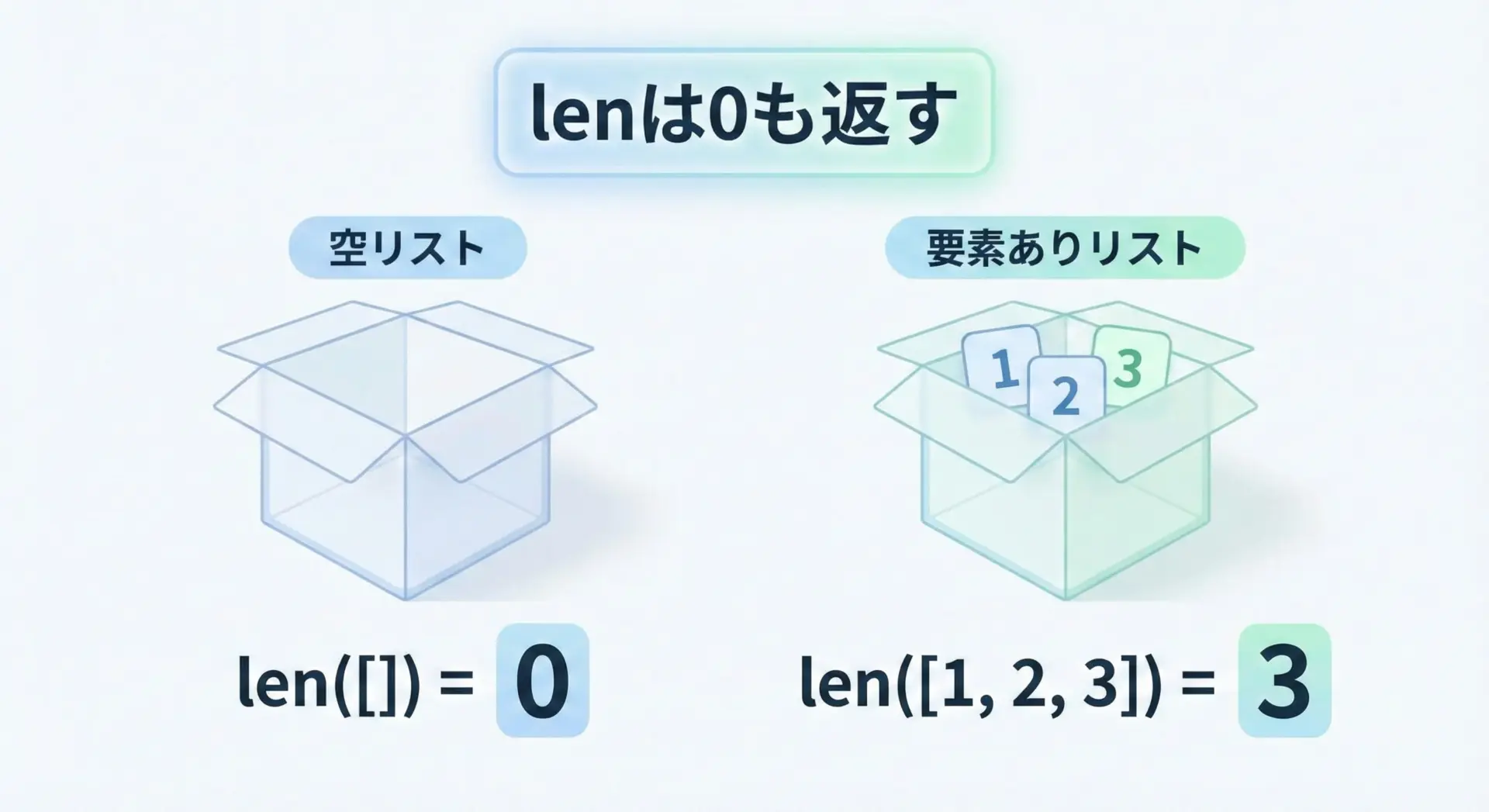
リストが空の場合と、要素を持っている場合でlenの結果はどのように変わるかを確認します。
# 空リスト
empty_list = []
# 要素ありリスト
items = ["apple", "banana", "orange"]
print("empty_list:", empty_list)
print("empty_list の長さ:", len(empty_list)) # 0 が返る
print("items:", items)
print("items の長さ:", len(items)) # 3 が返るempty_list: []
empty_list の長さ: 0
items: ['apple', 'banana', 'orange']
items の長さ: 3lenが0を返す場合、それはリストが空であることを意味します。
この性質は、後述する条件分岐(if文)などでリストが空かどうかを判定する際に非常に便利です。
lenで取得したリストの長さの実用的な使い方
lenは単に長さを表示するだけでなく、ループや条件分岐、スライスなど、実際のプログラム内で頻繁に活用されます。
for文とlenでインデックス付きループ
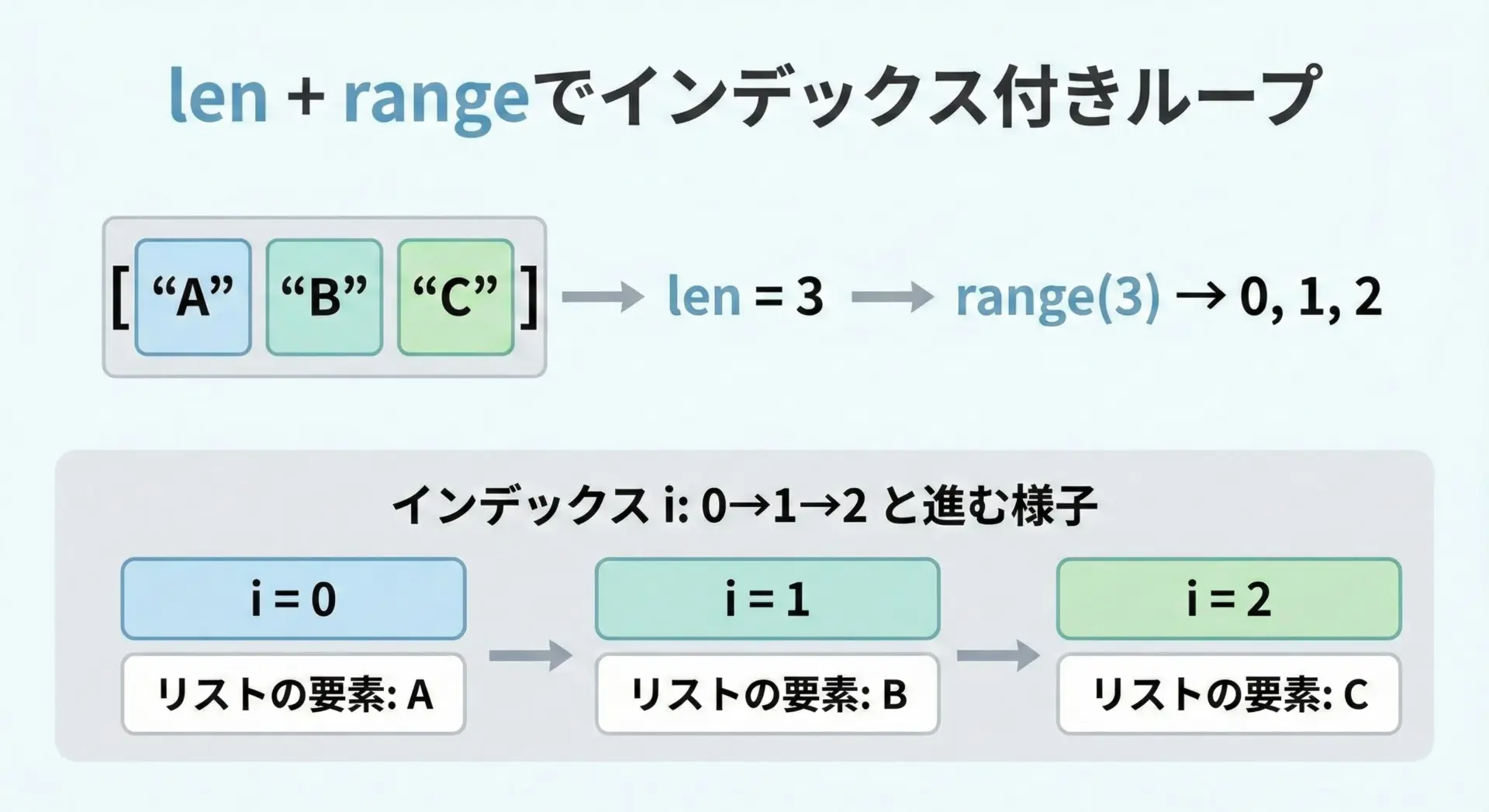
Pythonではfor 要素 in リストという書き方が基本ですが、インデックスも一緒に扱いたい場面ではlenとrangeを組み合わせたループが利用されます。
fruits = ["apple", "banana", "orange"]
# lenとrangeを使ってインデックス付きでループする例
for i in range(len(fruits)):
# i は 0, 1, 2 と変化する
print("インデックス:", i, "値:", fruits[i])インデックス: 0 値: apple
インデックス: 1 値: banana
インデックス: 2 値: orangeただし、PythonではよりPythonicな書き方としてenumerateを使うことが推奨されることが多いです。
fruits = ["apple", "banana", "orange"]
# enumerateを使ったよりPython的な書き方
for i, fruit in enumerate(fruits):
print("インデックス:", i, "値:", fruit)インデックス: 0 値: apple
インデックス: 1 値: banana
インデックス: 2 値: orangelen + rangeが悪いわけではありませんが、インデックスと値の両方が欲しいときにはenumerateの方が読みやすいことが多いです。
if文でリストの長さを条件分岐に使う
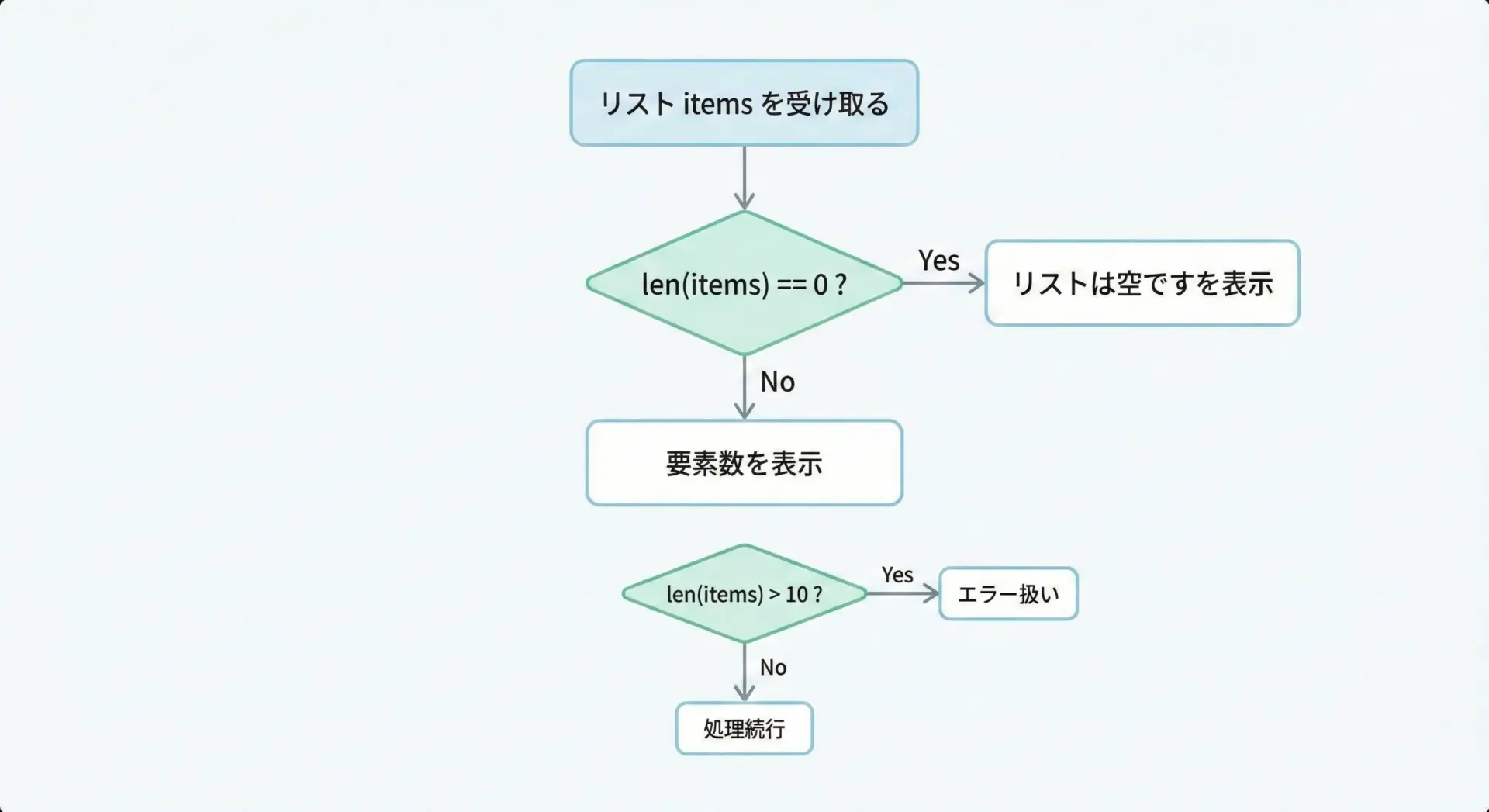
lenで取得した長さは、条件分岐にもよく使われます。
たとえば、ユーザー入力の数が一定以上かどうかを判断したり、結果リストが空かどうかをチェックしたりします。
items = ["task1", "task2"] # ここを [] に変えて実験してみても良い
if len(items) == 0:
print("リストは空です")
elif len(items) < 5:
print("リストの要素数は5未満です (要素数:", len(items), ")")
else:
print("リストの要素数は5以上です (要素数:", len(items), ")")リストの要素数は5未満です (要素数: 2 )ただし、「空かどうか」だけを知りたい場合は、後述する真偽値評価を使う方がPythonの慣習に沿っています。
この点については「リストの長さを扱う際のベストプラクティス」で詳しく説明します。
lenを使ったスライスや範囲指定のパターン

lenを使うと、リストを柔軟にスライス(部分取得)することができます。
特に、リストの半分に分割する、末尾からn個だけ取り出すなどの処理でよく使われます。
data = [10, 20, 30, 40, 50, 60]
# 全体の長さ
n = len(data)
# 前半(前半分)を取得
first_half = data[: n // 2] # 0 から n//2 - まで
# 後半(後半分)を取得
second_half = data[n // 2 :] # n//2 から最後まで
print("元データ:", data)
print("前半:", first_half)
print("後半:", second_half)
# 末尾から3個だけ取得する例
last_three = data[n - 3 :]
print("末尾3要素:", last_three)元データ: [10, 20, 30, 40, 50, 60]
前半: [10, 20, 30]
後半: [40, 50, 60]
末尾3要素: [40, 50, 60]このように、lenを使うことで「リストの長さに依存した柔軟な範囲指定」が可能になります。
固定のインデックスをハードコーディングするよりも、将来の変更に強いコードになります。
lenとリストでハマりやすい落とし穴
len自体は単純な関数ですが、インデックスとの関係やネスト構造などを理解していないと、思わぬバグにつながることがあります。
lenとインデックス最大値の違い

lenが返す値と、インデックスの最大値は1違うという点は、特に初心者がつまずきやすいポイントです。
nums = [100, 200, 300, 400]
print("len(nums):", len(nums)) # 4
print("nums[0]:", nums[0]) # OK
print("nums[3]:", nums[3]) # OK (最後の要素)
# print("nums[4]:", nums[4]) # これはエラー(IndexError)になるlen(nums): 4
nums[0]: 100
nums[3]: 400インデックスは0から始まるため、要素数が4つなら最大インデックスは3です。
len(list)と同じ値をインデックスとして使うとIndexErrorになります。
たとえば、for i in range(len(list))のループでは、iは常に0 〜 len(list) - 1の範囲になるため安全です。
ネストしたリストでのlenの結果に注意
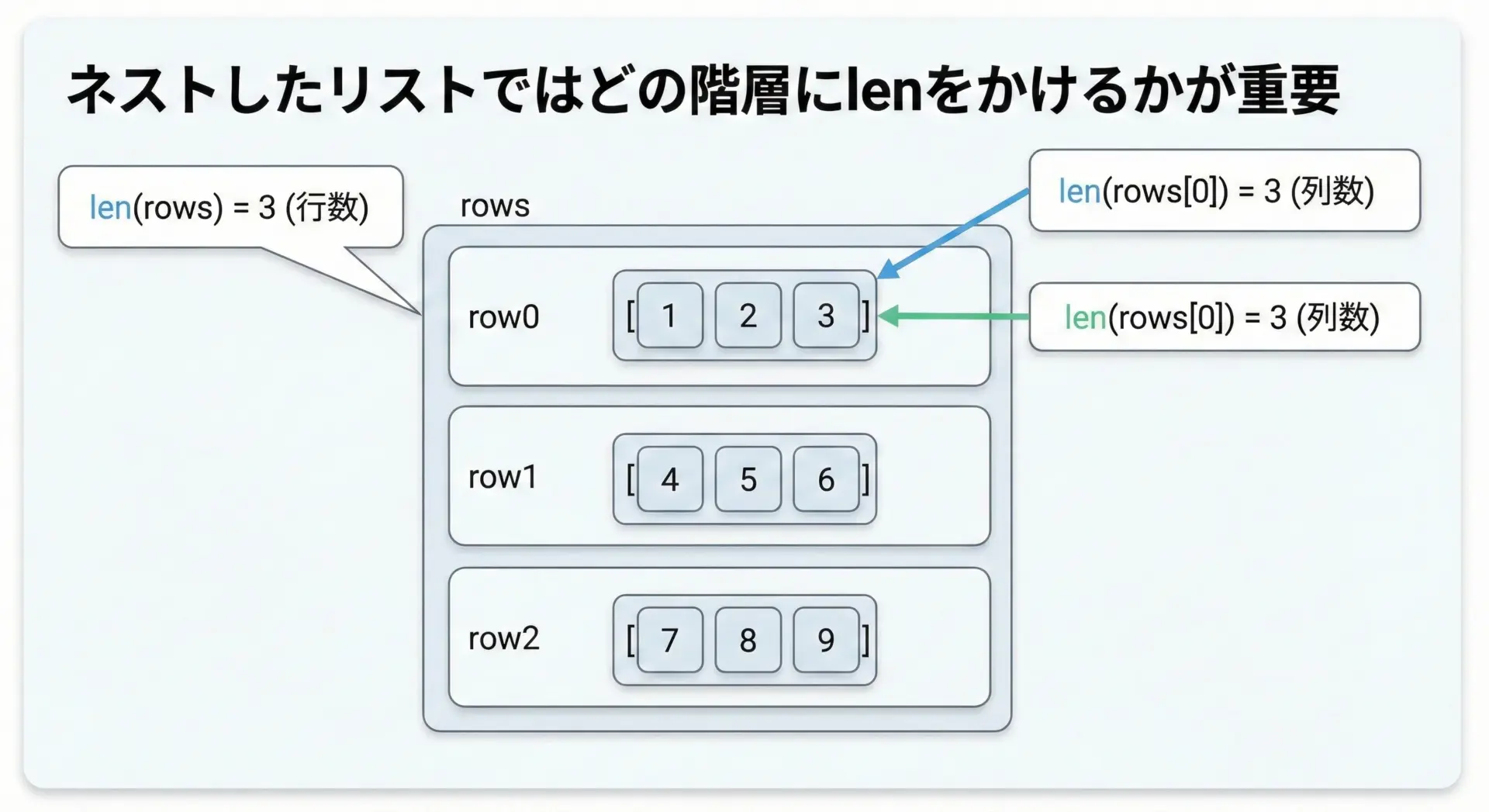
リストの中にリストが入っているネストしたリストでは、lenの結果がどの階層に対するものかを意識する必要があります。
matrix = [
[1, 2, 3], # 1行目
[4, 5, 6], # 2行目
[7, 8, 9], # 3行目
]
print("matrix 全体:", matrix)
# 外側リストの長さ(行数)
print("行数 len(matrix):", len(matrix))
# 各行の長さ(列数)
print("1行目の列数 len(matrix[0]):", len(matrix[0]))
print("2行目の列数 len(matrix[1]):", len(matrix[1]))
print("3行目の列数 len(matrix[2]):", len(matrix[2]))matrix 全体: [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
行数 len(matrix): 3
1行目の列数 len(matrix[0]): 3
2行目の列数 len(matrix[1]): 3
3行目の列数 len(matrix[2]): 3このように、外側のリストに対するlenは「行数」、内側のリストに対するlenは「列数」というイメージになります。
階層を勘違いすると、意図した数と違う長さを扱ってしまうので注意が必要です。
lenとlen()を付け忘れるミス
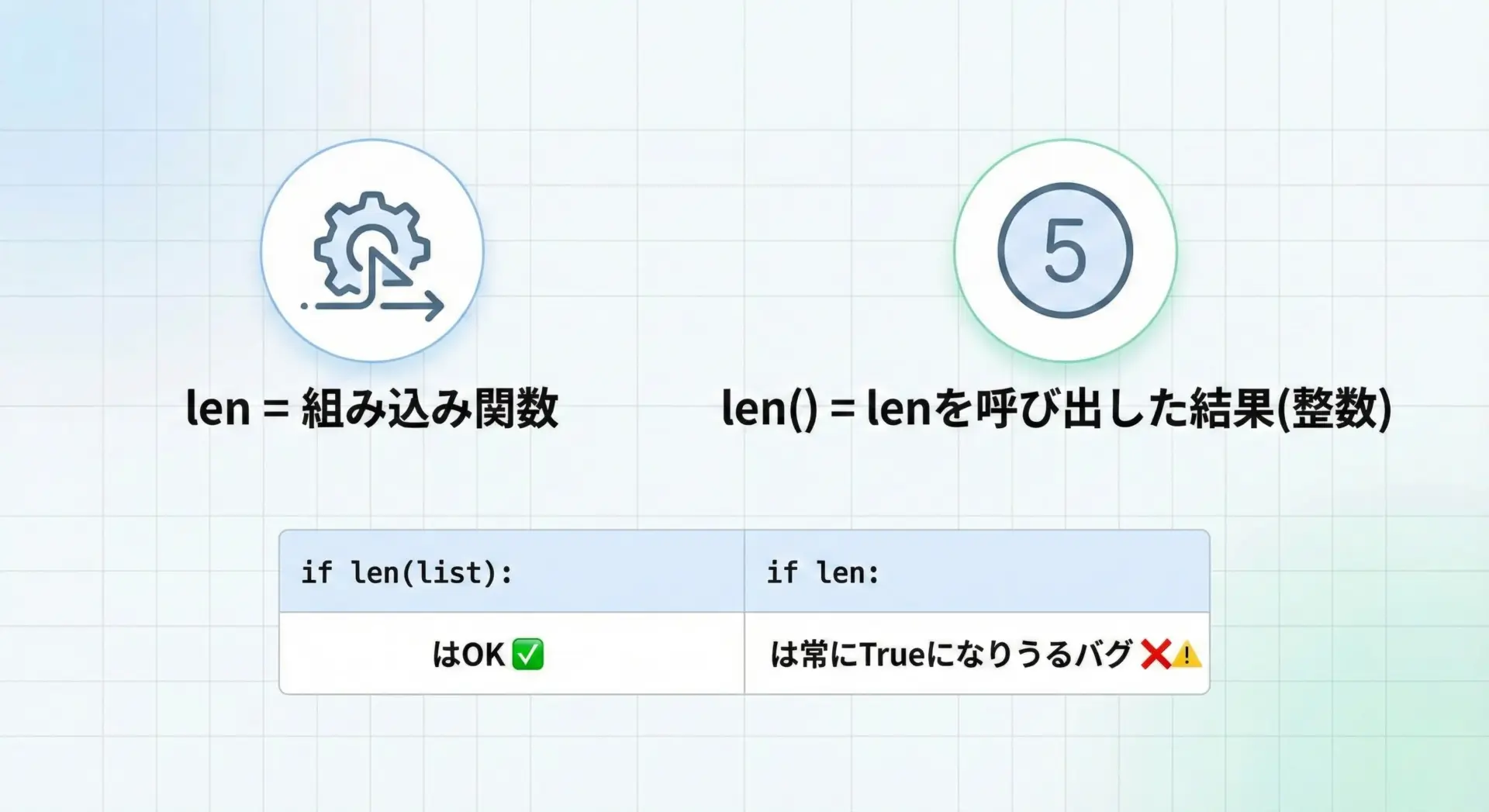
よくあるミスとして、lenという関数名そのものと、その呼び出し結果(len())を混同してしまうケースがあります。
items = [1, 2, 3]
# よくあるミスの例 (実行は非推奨)
if len: # これは「関数オブジェクト len が存在するか?」の判定になってしまう
print("len が True とみなされました(これは意図した条件ではありません)")
# 正しい書き方
if len(items): # len(items) が 0 なら False、それ以外なら True と判定される
print("items は空ではありません")len が True とみなされました(これは意図した条件ではありません)
items は空ではありません関数そのものは常に存在するオブジェクトなので、if文の条件に書くと基本的にはTrueと評価され、意図しない動作になります。
「長さ」を使いたいときは必ずlen(リスト)のように丸カッコを付けて呼び出す必要があります。
リスト以外(文字列・タプル・辞書・集合)でのlenの挙動の違い
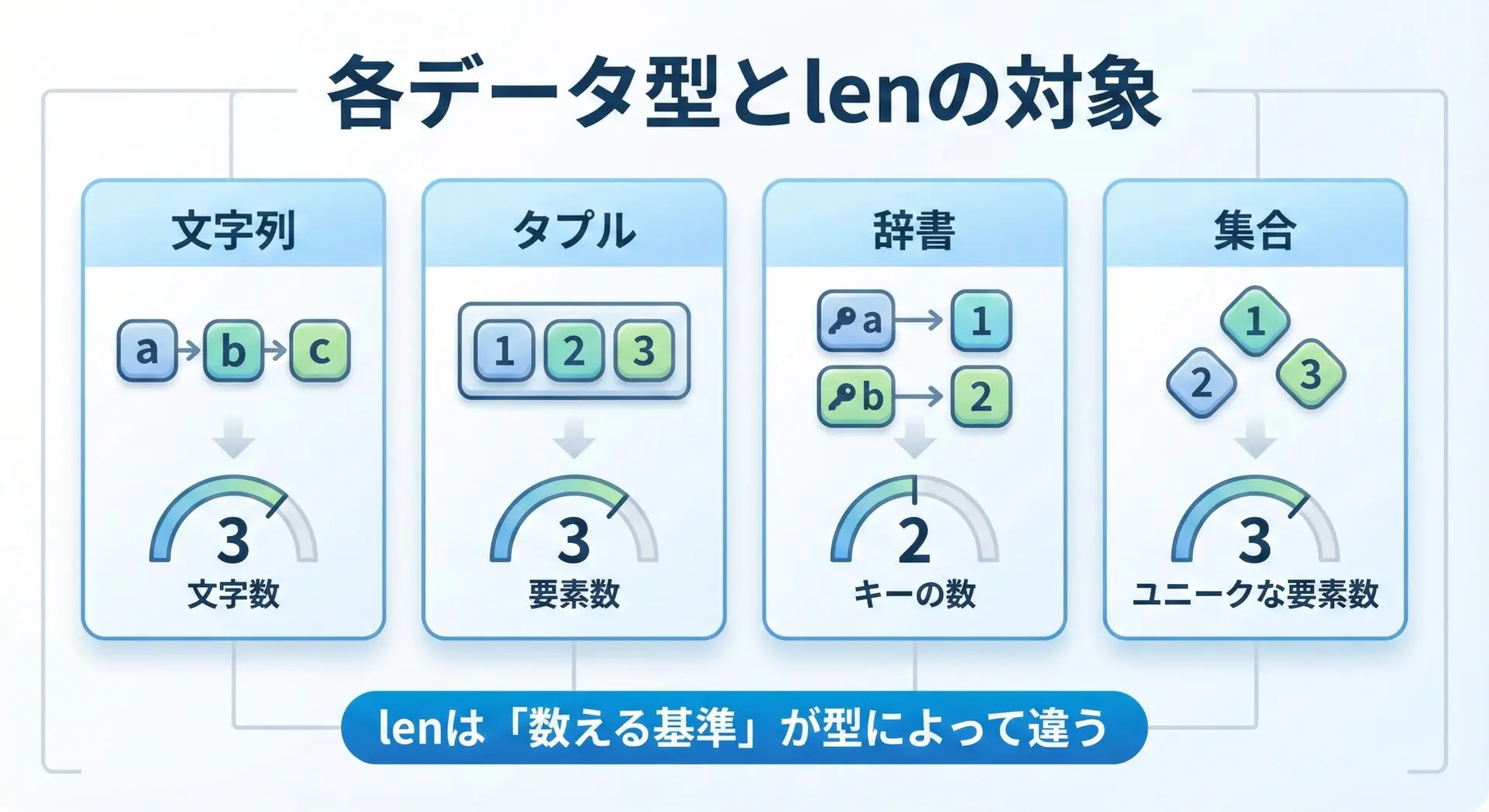
lenはリスト以外のオブジェクトにも使えますが、「何を数えているか」は型によって異なります。
代表的な例を表にまとめます。
| 型 | 例 | lenが返すもの |
|---|---|---|
| リスト | [1, 2, 3] | 要素の個数 |
| 文字列 | "hello" | 文字数 |
| タプル | (1, 2, 3) | 要素の個数 |
| 辞書(dict) | {"a": 1, "b": 2} | キーの個数 |
| 集合(set) | {1, 2, 3} | ユニークな要素の個数 |
s = "hello"
t = (1, 2, 3, 4)
d = {"a": 1, "b": 2}
st = {1, 2, 3, 3} # 重複3を含むが集合では1つにまとめられる
print("len(s):", len(s)) # 5 文字
print("len(t):", len(t)) # 4 要素
print("len(d):", len(d)) # 2 キー
print("len(st):", len(st)) # 3 要素(重複は除外される)len(s): 5
len(t): 4
len(d): 2
len(st): 3「lenは何でも同じ意味で数えているわけではない」ことを理解しておくと、辞書や集合を扱うときの混乱を防げます。
リストの長さを扱う際のベストプラクティス
ここからは、lenとリストを使う上で知っておくとよい実践的なコツや慣習を紹介します。
len(list)より暗黙真偽値(真偽評価)を使う場面

Pythonでは、リストが空かどうかを判定する場合に、lenよりもリスト自体の真偽値評価を使うことが多いです。
items = []
# 長さで判定する書き方
if len(items) == 0:
print("リストは空です(lenを使用)")
else:
print("リストには要素があります(lenを使用)")
# 真偽値評価で判定するPython的な書き方
if not items: # items が空なら False → not で True
print("リストは空です(真偽値評価)")
else:
print("リストには要素があります(真偽値評価)")リストは空です(lenを使用)
リストは空です(真偽値評価)空のリストはFalse、要素が1つ以上あるリストはTrueとして扱われるため、if items:やif not items:という書き方が自然です。
ただし、「要素数が0かどうか」ではなく「具体的な数値条件」を見たいときは、もちろんlen(list)を使うべきです。
頻繁に使う長さは変数に保持するべきか
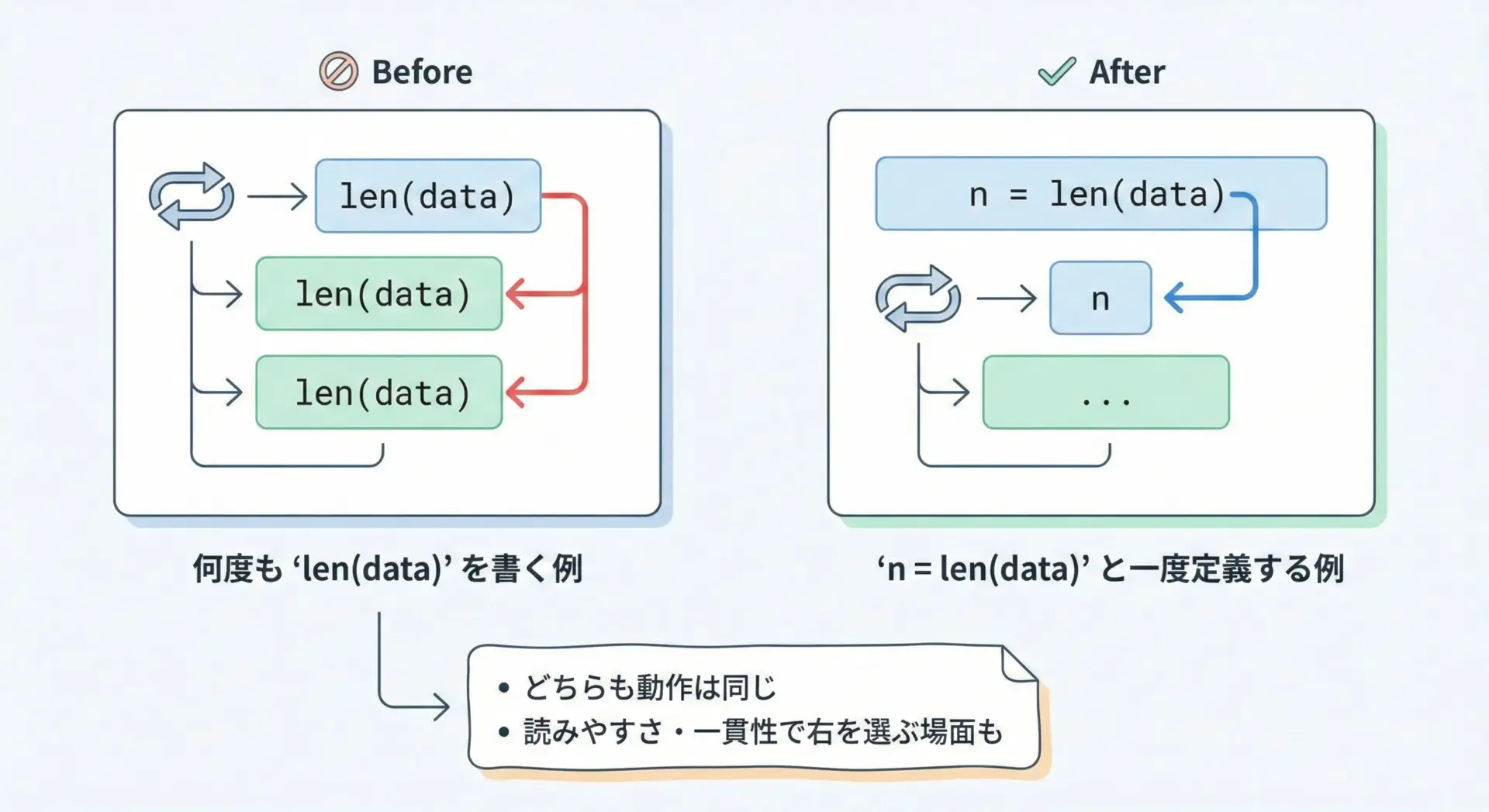
lenは多くの場合とても高速なので、リストに対して何度呼び出してもパフォーマンス問題になることはほぼありません。
しかし、コードの読みやすさという観点では、長さを変数に保持した方が良い場合があります。
data = [10, 20, 30, 40, 50]
# その1: 毎回 len(data) と書く
for i in range(len(data)):
print(i, data[i])
# その2: 先に長さを変数に入れて使う
n = len(data)
for i in range(n):
print(i, data[i])0 10
1 20
2 30
3 40
4 50
0 10
1 20
2 30
3 40
4 50どちらも結果は同じです。
ただし、同じ「長さ」を何度も使うような複雑な処理では、n = len(data)としてから使った方が、意図が明確で保守しやすいコードになることがあります。
大規模データでlenとパフォーマンスを意識するポイント
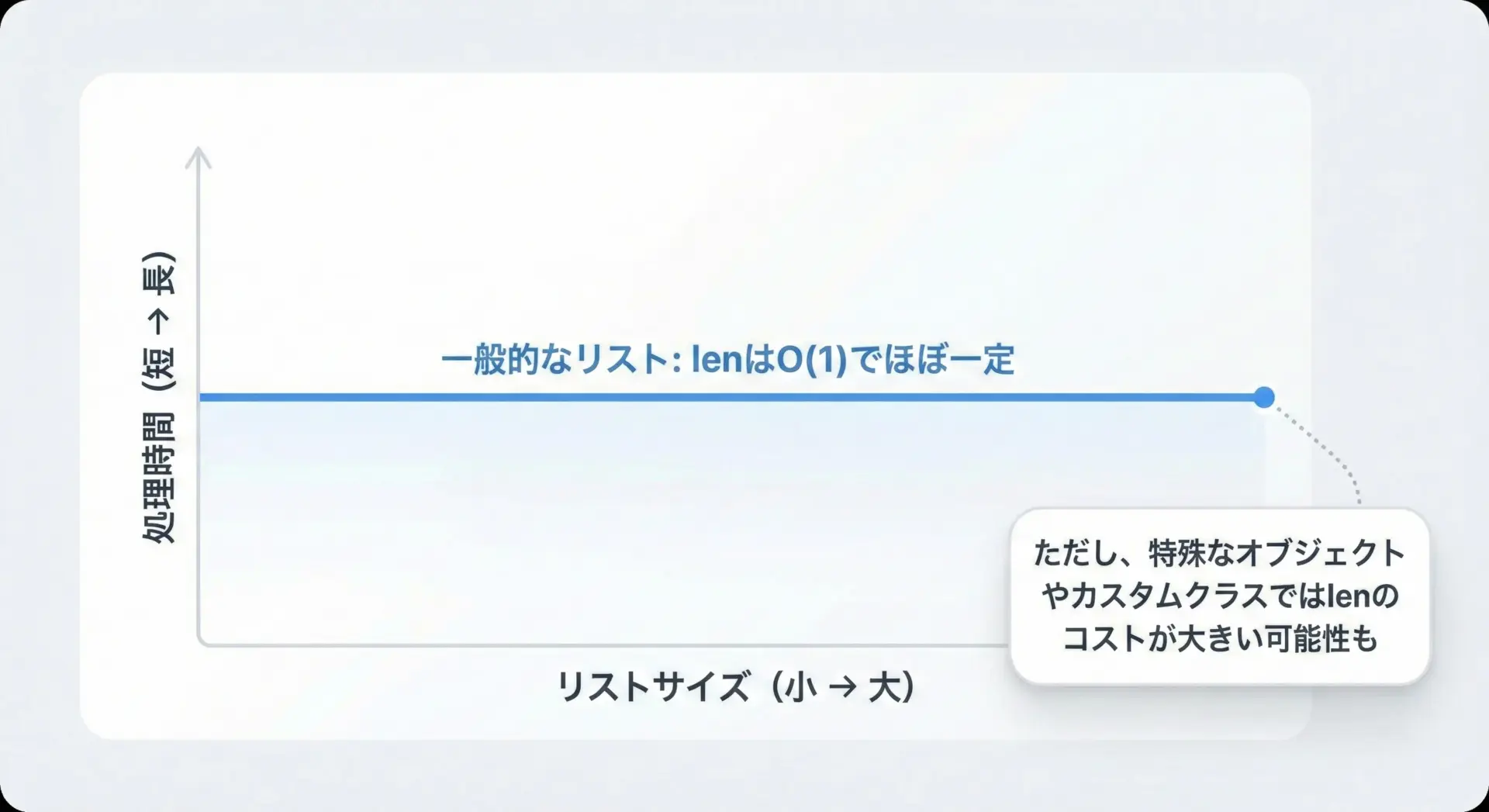
通常のPythonリストに対するlen(list)はO(1)(要素数に関わらない一定時間)で動作するため、数百万要素のリストでもlen自体がボトルネックになることはほとんどありません。
# 大きなリストに対しても len は一瞬で終わる例
big_list = list(range(1_000_000)) # 100万要素のリスト
print("big_list の長さ:", len(big_list))big_list の長さ: 1000000ただし、以下のようなケースでは注意が必要です。
- ジェネレータやイテレータのように、lenが定義されていないオブジェクト
- 自作クラスで
__len__メソッドを定義し、その中で重い計算をしている場合 - lenを呼ぶために、毎回巨大なリストを新しく生成しているような設計
一般的なリストであれば、パフォーマンスよりも「わかりやすいコード」になるかどうかを優先して問題ありません。
必要以上にlenの呼び出し回数を気にするより、無駄なリストコピーやネストの深いループの方を見直す方が効果的です。
まとめ
len関数は、Pythonでリストを扱ううえで欠かせない基本機能です。
lenは「要素数」を返し、リストではインデックスの最大値より1大きい値になること、ネストしたリストではどの階層に対してlenを使うかで意味が変わることを押さえておくと、バグを大きく減らせます。
また、空かどうかの判定ではlenではなくif items:のような真偽値評価を使うことがPython的な書き方です。
lenはリスト以外にも文字列や辞書などで利用できるため、各データ型で「何を数えているのか」を意識しながら、実用的なコードに活かしていきましょう。
