
Pythonでリストから値を検索してインデックスを取得する処理は、実務でも学習でも頻出です。
しかし、重複値がある場合や条件付きで探したい場合など、少し複雑になると書き方に迷いやすいところでもあります。
本記事では、「Pythonリストのインデックス取得」について基本から応用、パフォーマンスまで体系的に解説し、すぐに使えるサンプルコードを多数紹介します。
リストのインデックス取得の基本
まずは、Pythonに標準で用意されている機能を使って、シンプルなリストからインデックスを取得する基本を押さえます。
list.indexで最初のインデックスを取得する方法
Pythonのリストにはindexメソッドが用意されており、値からインデックスを取得するもっとも基本的な方法です。

list.indexは、指定した値が最初に現れる位置だけを返します。
基本的な使い方
# 基本的なlist.indexの使い方
numbers = [10, 20, 30, 20, 40]
# 値20が最初に現れる位置を取得
idx = numbers.index(20)
print("numbers:", numbers)
print("20 のインデックス:", idx)numbers: [10, 20, 30, 20, 40]
20 のインデックス: 1このようにnumbers.index(20)は1を返しますが、後ろにある20(インデックス3)は無視されます。
開始位置・終了位置を指定する
indexメソッドは、検索範囲を限定するためのstartとstop引数を指定することもできます。
これにより、リスト全体ではなく一部だけを検索できます。
# indexに開始位置と終了位置を指定する例
numbers = [10, 20, 30, 20, 40, 20]
# インデックス2以降で20を探す
idx_from_2 = numbers.index(20, 2)
# インデックス2〜4の範囲で20を探す(4は含まない)
idx_2_to_4 = numbers.index(20, 2, 5)
print("numbers:", numbers)
print("2番目以降で最初に見つかる20のインデックス:", idx_from_2)
print("インデックス2〜4で最初に見つかる20のインデックス:", idx_2_to_4)numbers: [10, 20, 30, 20, 40, 20]
2番目以降で最初に見つかる20のインデックス: 3
インデックス2〜4で最初に見つかる20のインデックス: 3検索を途中から再開したい場合や、部分リストだけを対象にしたい場合にstart/stopはよく使われます。
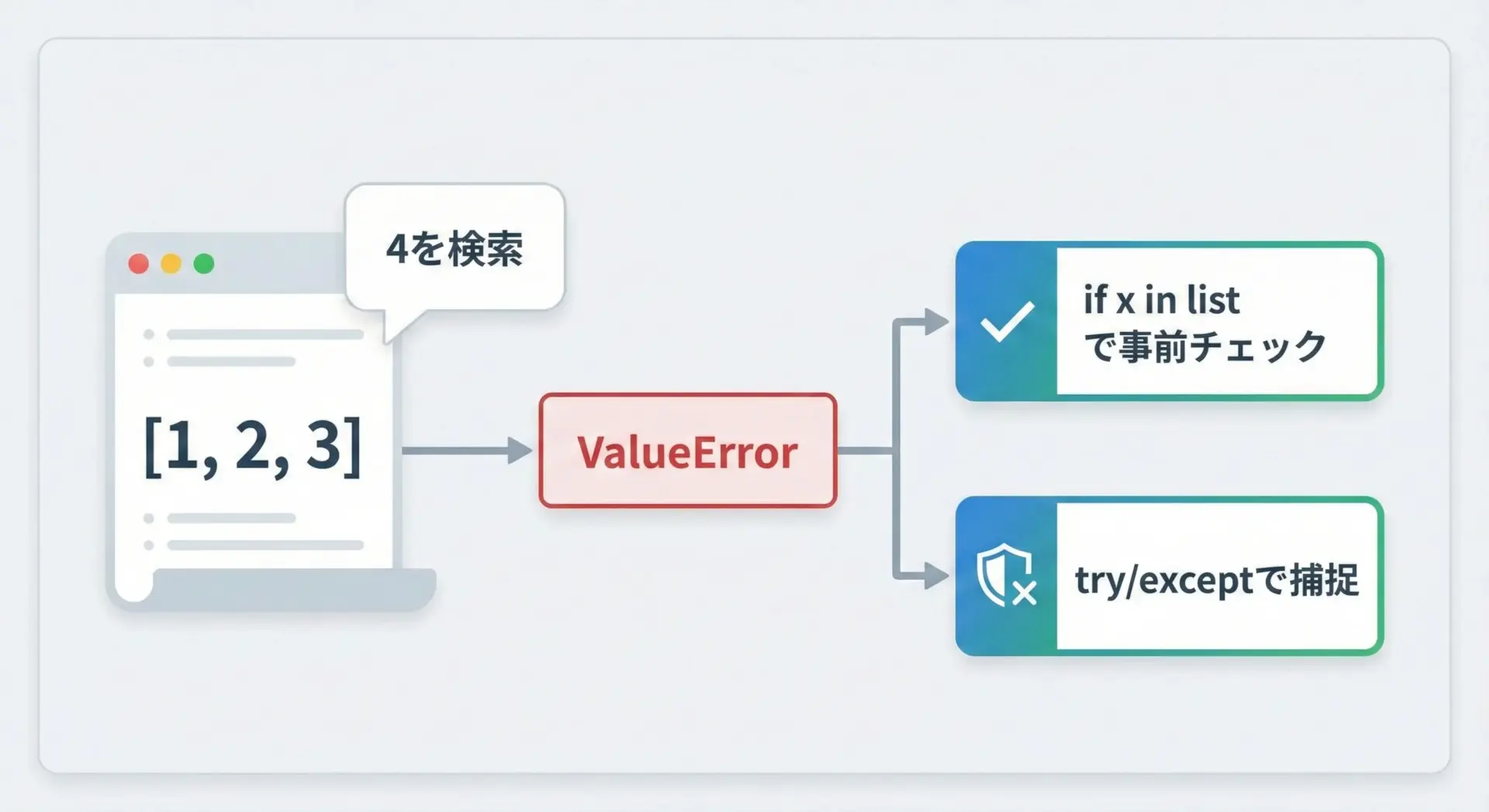
見つからない時のエラー(ValueError)対策と回避方法
list.indexは、値が見つからないとValueErrorが発生します。
初心者がハマりやすいポイントなので、対処方法を整理しておきます。
発生するエラーの例
numbers = [1, 2, 3]
# 4はリストに存在しないのでエラーになる
idx = numbers.index(4)Traceback (most recent call last):
File "example.py", line 4, in <module>
idx = numbers.index(4)
ValueError: 4 is not in listこのように、存在しない値を検索するとプログラムが止まってしまいます。
回避方法1: in演算子で事前に存在チェックする
もっとも分かりやすい方法は、in演算子で「含まれているか」を先に確認することです。
# in演算子で存在を確認してからindexを呼び出す
numbers = [1, 2, 3]
target = 4
if target in numbers:
idx = numbers.index(target)
print("見つかったインデックス:", idx)
else:
print("値", target, "はリストに存在しません")値 4 はリストに存在しませんこの書き方なら、存在しない場合でもエラーにはなりません。
回避方法2: try/exceptで例外を処理する
「見つからない場合はNoneを返す」など、関数として振る舞いを統一したい場合にはtry/exceptを使うのも有効です。
# ValueErrorをtry/exceptで捕捉する例
def safe_index(lst, value):
"""見つからないときはNoneを返すindex関数"""
try:
return lst.index(value)
except ValueError:
return None
numbers = [1, 2, 3]
print("2 のインデックス:", safe_index(numbers, 2))
print("4 のインデックス:", safe_index(numbers, 4))2 のインデックス: 1
4 のインデックス: Noneこのような安全版index関数を自作しておくと、実務コードでも扱いやすくなります。
インデックス取得の基本ループ(for)による実装
indexメソッドを使わず、自前のループでインデックスを探す方法も理解しておくと応用が効きます。
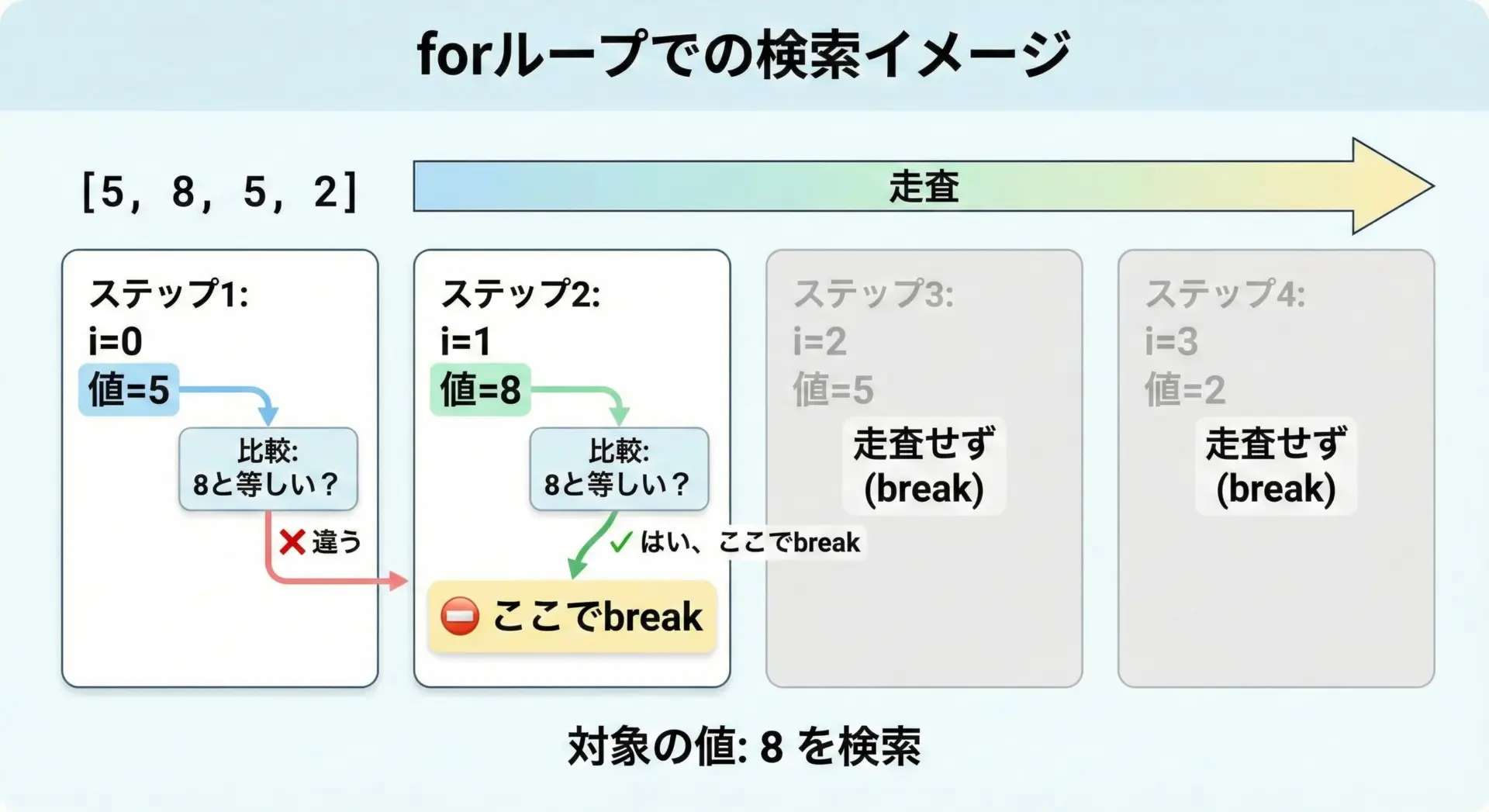
シンプルなforループによる検索
# forループで最初のインデックスを見つける
numbers = [5, 8, 5, 2]
target = 5
found_index = None
for i in range(len(numbers)):
if numbers[i] == target:
found_index = i
break # 最初に見つかったらループを抜ける
print("numbers:", numbers)
print("target:", target)
print("最初に見つかったインデックス:", found_index)numbers: [5, 8, 5, 2]
target: 5
最初に見つかったインデックス: 0この方法では、見つからなかった場合にfound_indexがNoneのままなので、後続処理で分岐しやすくなります。
重複値があるリストのインデックス取得
次に、同じ値が複数回登場するリストで、すべてのインデックスを取得する方法を整理します。
重複値のすべてのインデックスを取得する方法
list.indexは最初の1件しか返しませんが、実務では「すべての位置が欲しい」というケースも多くあります。
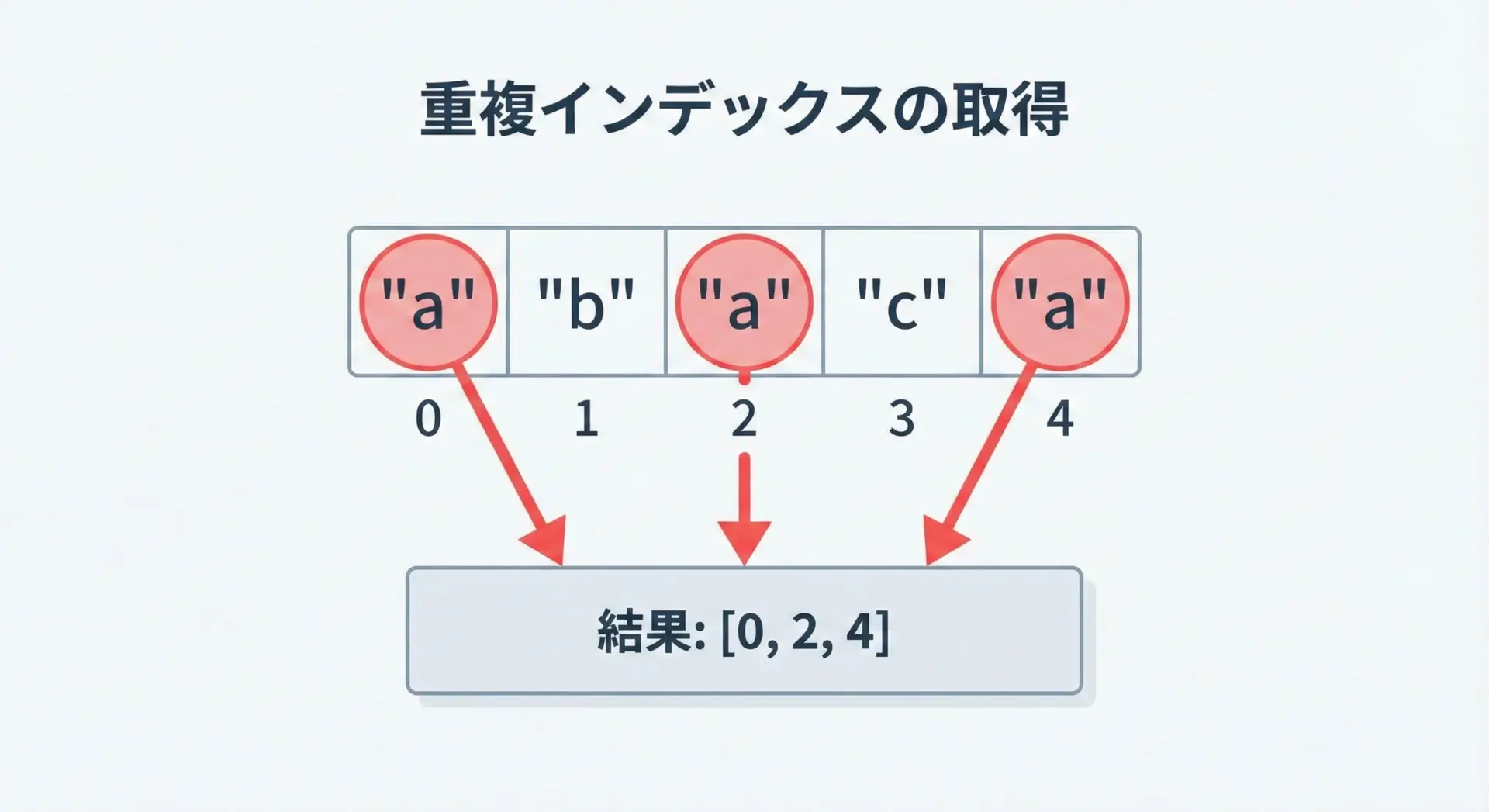
forループで全インデックスを取得
# forループで重複するすべてのインデックスを探す
letters = ["a", "b", "a", "c", "a"]
target = "a"
indices = []
for i, value in enumerate(letters):
if value == target:
indices.append(i)
print("letters:", letters)
print("target:", target)
print("すべてのインデックス:", indices)letters: ['a', 'b', 'a', 'c', 'a']
target: a
すべてのインデックス: [0, 2, 4]forループで条件に合うインデックスをリストに追加していくという基本パターンです。
ここで初めてenumerateも登場しました。
enumerateで値とインデックスを同時に扱うテクニック
enumerateは、リストをループしながら「インデックス」と「値」を同時に取り出せる便利な関数です。
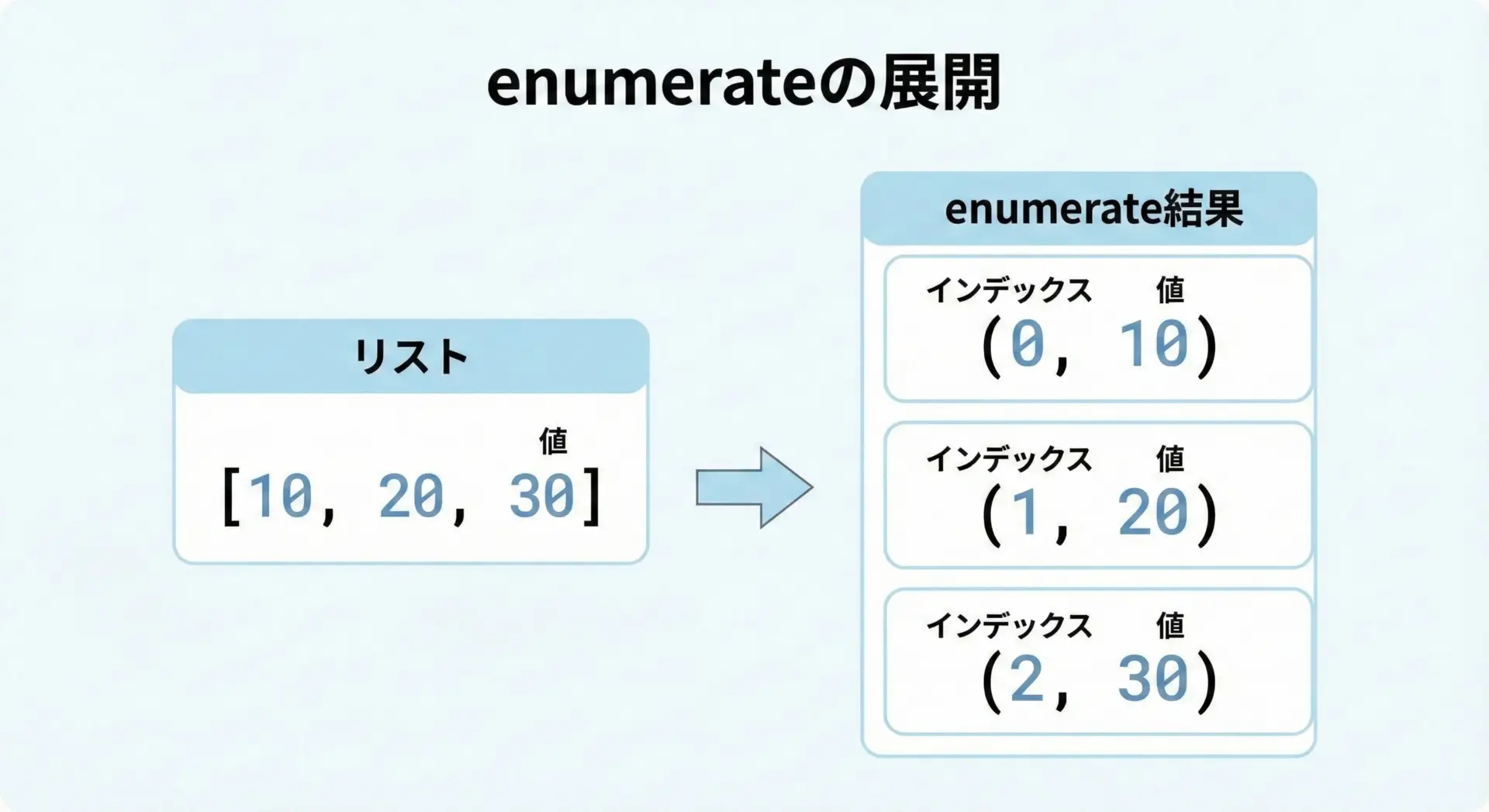
enumerateの基本
# enumerateの基本的な使い方
numbers = [10, 20, 30]
for i, value in enumerate(numbers):
print("インデックス:", i, "値:", value)インデックス: 0 値: 10
インデックス: 1 値: 20
インデックス: 2 値: 30enumerateを使った重複インデックス取得
すでに紹介した例を、enumerateの理解という観点からもう一度示します。
# enumerateで値とインデックスを同時に扱いながら検索
letters = ["x", "y", "x", "z"]
target = "x"
indices = [i for i, v in enumerate(letters) if v == target]
print("letters:", letters)
print("target:", target)
print("すべてのインデックス:", indices)letters: ['x', 'y', 'x', 'z']
target: x
すべてのインデックス: [0, 2]このコードでは、インデックスiと値vを同時に受け取り、条件に合うiだけを集めています。
リスト内包表記で重複インデックスを一括取得する方法
リスト内包表記を使うと、「検索して結果リストを作る」処理を1行で簡潔に書くことができます。
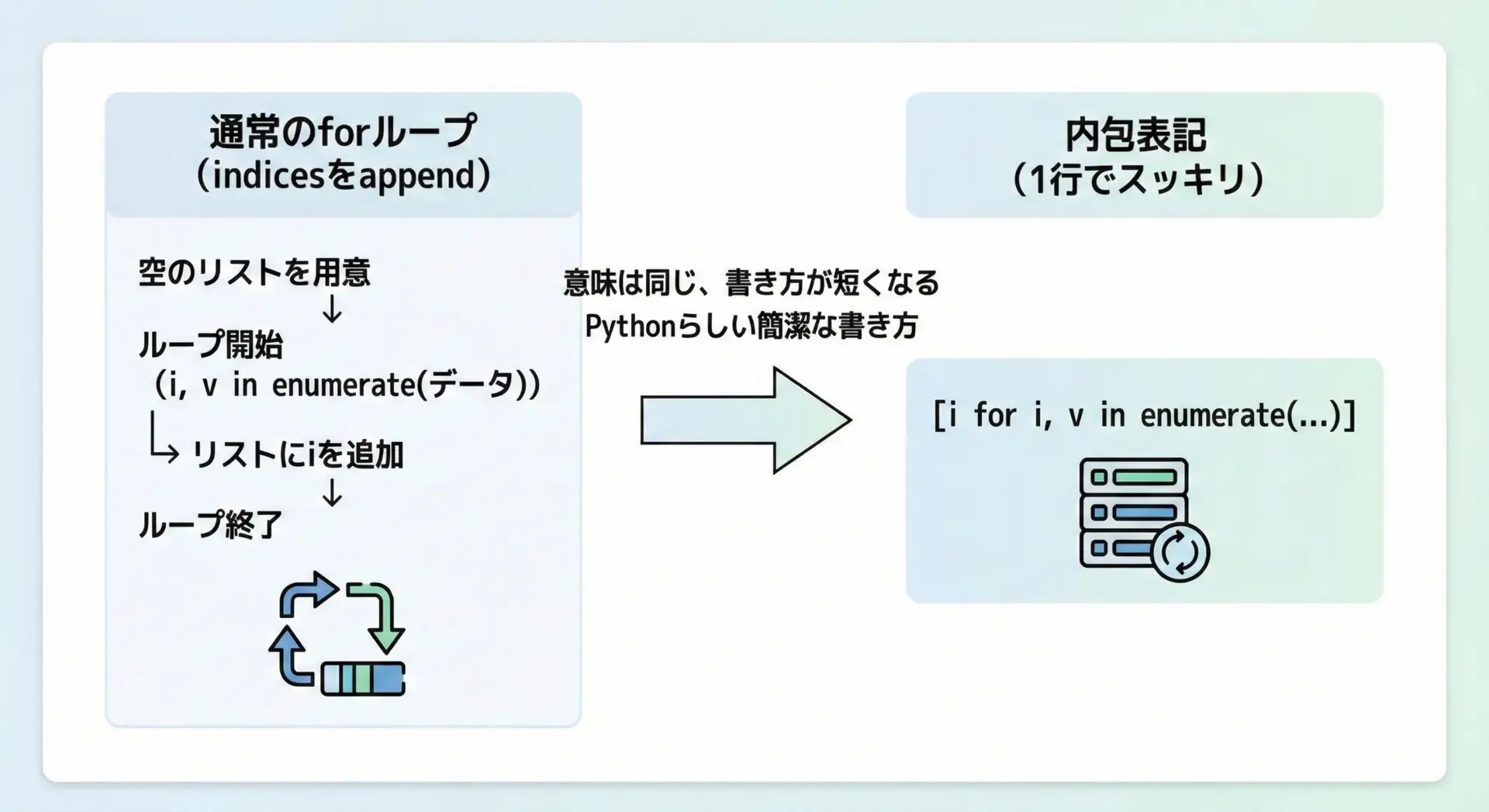
リスト内包表記による実装
# リスト内包表記で重複インデックスを取得
numbers = [1, 2, 3, 2, 4, 2]
target = 2
indices = [i for i, v in enumerate(numbers) if v == target]
print("numbers:", numbers)
print("target:", target)
print("すべてのインデックス:", indices)numbers: [1, 2, 3, 2, 4, 2]
target: 2
すべてのインデックス: [1, 3, 5]リスト内包表記は可読性とのバランスが重要です。
1行に詰めすぎると読みにくくなるため、条件が複雑な場合は次の章で解説するように、関数を分けたりコメントを追加したりする工夫が必要になります。
条件指定でインデックスを取得する方法
ここからは、単なる「値が等しい」だけでなく、さまざまな条件でインデックスを検索する方法を扱います。
条件に合う最初の要素のインデックスを取得する方法
たとえば「値が10以上の最初の要素」や「偶数の最初の要素」といった条件で検索したいケースです。
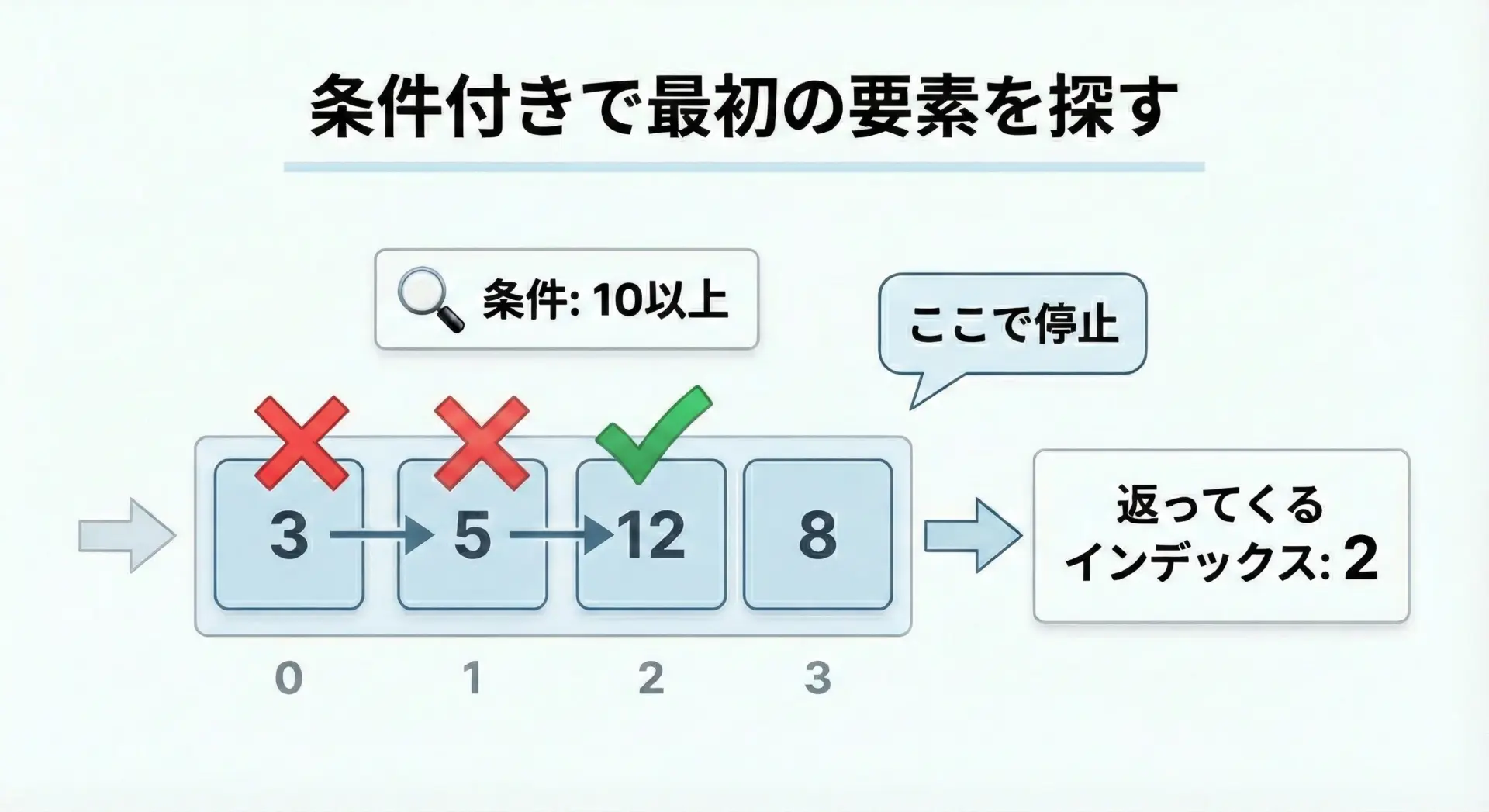
ループで条件付きの最初のインデックスを探す
# 条件(ここでは10以上)に合う最初の要素のインデックスを探す
numbers = [3, 5, 12, 8, 15]
def first_index_ge_10(lst):
"""10以上の要素が最初に現れるインデックスを返す(なければNone)"""
for i, v in enumerate(lst):
if v >= 10:
return i
return None # 見つからなかった場合
idx = first_index_ge_10(numbers)
print("numbers:", numbers)
print("10以上の最初のインデックス:", idx)numbers: [3, 5, 12, 8, 15]
10以上の最初のインデックス: 2このように、条件式を自由に書けることがループ検索の強みです。
条件に合うすべてのインデックスを取得するリスト内包表記
同じ発想を、「すべての要素」を対象に広げてリスト内包表記にすると、条件付きのインデックスリストが得られます。
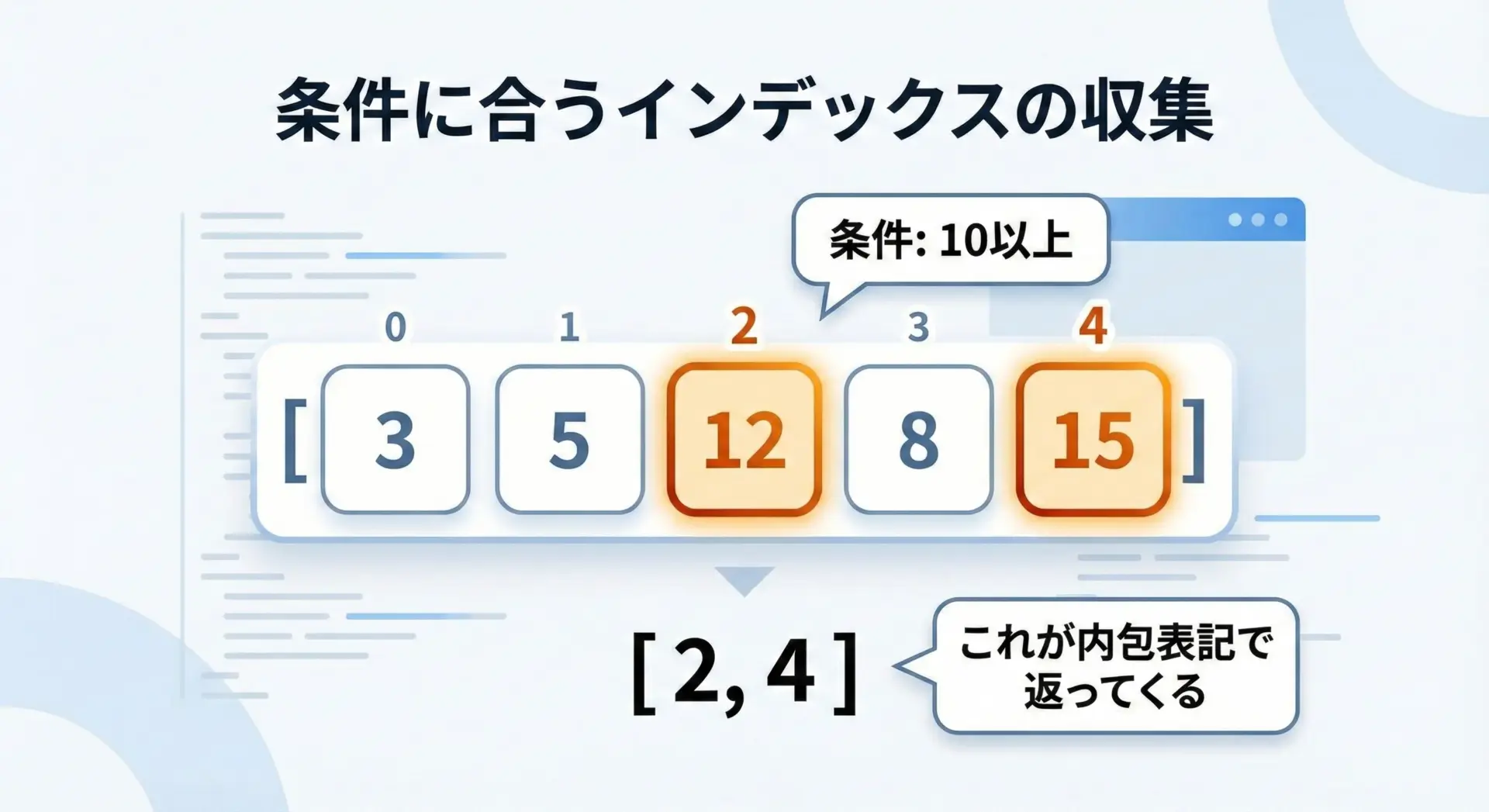
条件付きでインデックスを集める
# 条件に合うすべてのインデックスをリスト内包表記で取得
numbers = [3, 5, 12, 8, 15]
# 条件: 値が10以上
indices = [i for i, v in enumerate(numbers) if v >= 10]
print("numbers:", numbers)
print("10以上のインデックス:", indices)numbers: [3, 5, 12, 8, 15]
10以上のインデックス: [2, 4]「ifの条件部」を書き換えるだけで、さまざまな条件に対応できるのがポイントです。
複数条件(AND/OR)でインデックスを絞り込む書き方
条件が複数ある場合には、andやorなどの論理演算子が登場します。
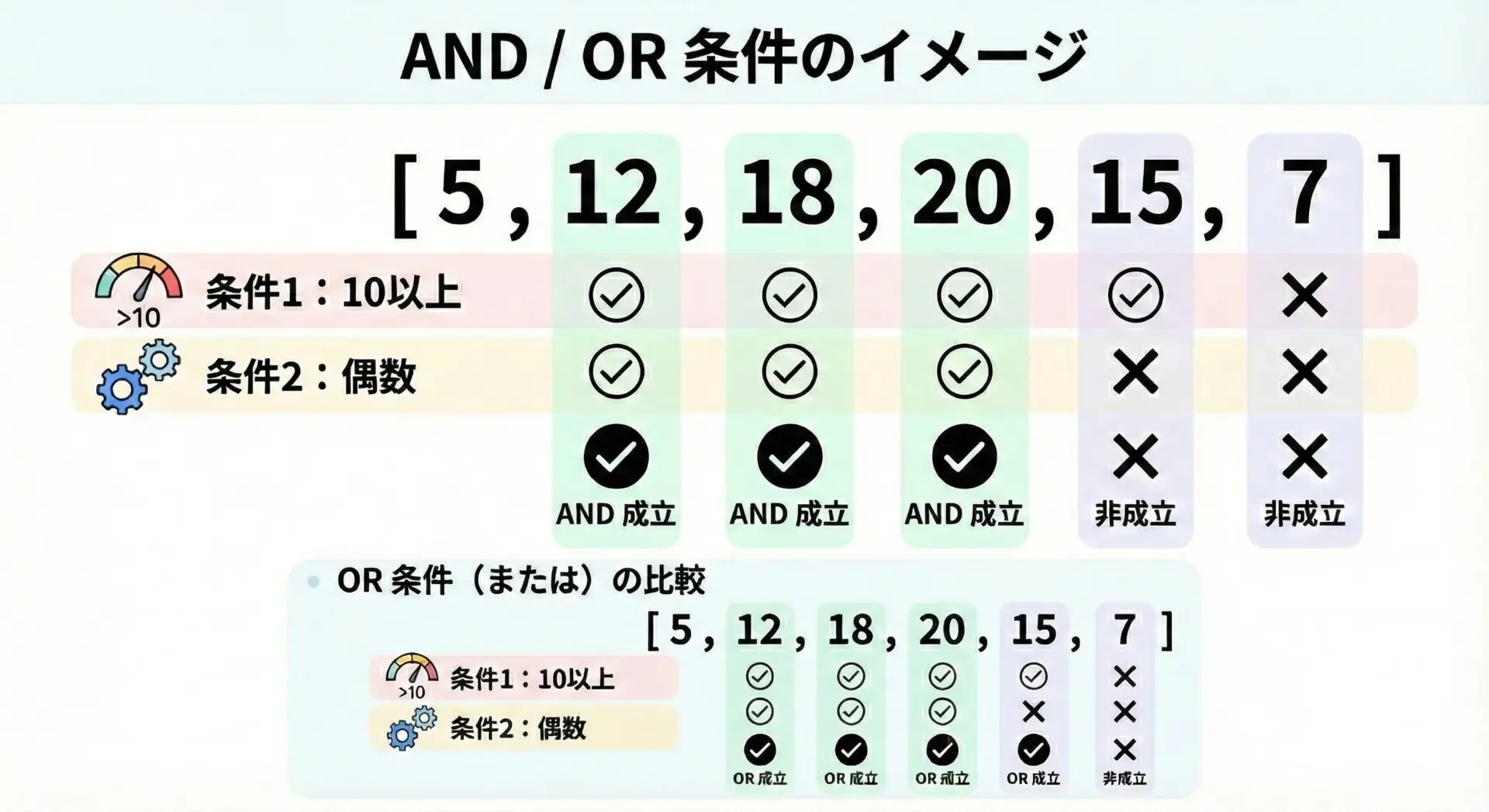
AND条件の例(10以上かつ偶数)
# 複数条件(AND)でインデックスを絞り込む
numbers = [5, 12, 18, 20, 7]
# 条件: 10以上「かつ」偶数
indices_and = [i for i, v in enumerate(numbers) if v >= 10 and v % 2 == 0]
print("numbers:", numbers)
print("10以上かつ偶数のインデックス:", indices_and)numbers: [5, 12, 18, 20, 7]
10以上かつ偶数のインデックス: [1, 2, 3]OR条件の例(10以上または偶数)
# 複数条件(OR)でインデックスを絞り込む
numbers = [5, 12, 18, 20, 7]
# 条件: 10以上「または」偶数
indices_or = [i for i, v in enumerate(numbers) if v >= 10 or v % 2 == 0]
print("numbers:", numbers)
print("10以上または偶数のインデックス:", indices_or)numbers: [5, 12, 18, 20, 7]
10以上または偶数のインデックス: [1, 2, 3]この例ではたまたま同じ結果になっていますが、ANDとORで意味はまったく異なります。
実務では条件が長くなりがちなので、適宜括弧()でグルーピングすると読みやすくなります。
文字列・辞書・オブジェクトを条件指定で検索する方法
リストの中身は数値だけとは限りません。
文字列や辞書、クラスインスタンスなどの「複雑な要素」に対して条件検索する場面がよくあります。
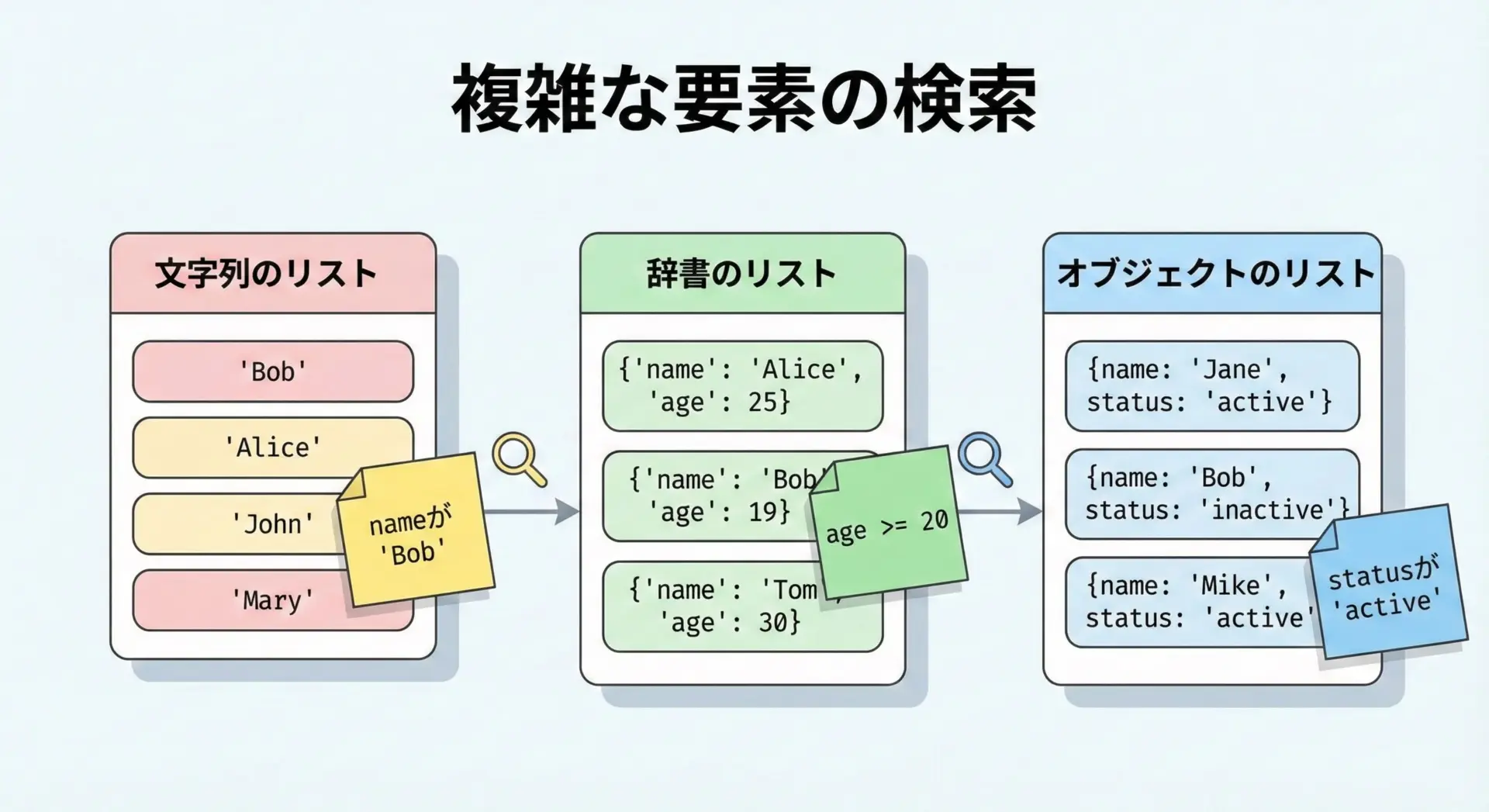
文字列のリスト: 部分一致で検索
# 文字列リストから「特定の文字列を含む要素」のインデックスを探す
fruits = ["apple", "banana", "pineapple", "grape"]
# 条件: "apple" を含む文字列
indices = [i for i, v in enumerate(fruits) if "apple" in v]
print("fruits:", fruits)
print('"apple" を含むインデックス:', indices)fruits: ['apple', 'banana', 'pineapple', 'grape']
"apple" を含むインデックス: [0, 2]辞書のリスト: 特定キーの値で検索
# 辞書のリストから特定のキーの値でインデックスを検索
users = [
{"id": 1, "name": "Alice", "age": 18},
{"id": 2, "name": "Bob", "age": 25},
{"id": 3, "name": "Bob", "age": 30},
]
# 条件: name が "Bob"
indices_name_bob = [i for i, u in enumerate(users) if u["name"] == "Bob"]
# 条件: age が20以上
indices_age_20up = [i for i, u in enumerate(users) if u["age"] >= 20]
print("users:", users)
print('nameが"Bob"のインデックス:', indices_name_bob)
print("ageが20以上のインデックス:", indices_age_20up)users: [{'id': 1, 'name': 'Alice', 'age': 18}, {'id': 2, 'name': 'Bob', 'age': 25}, {'id': 3, 'name': 'Bob', 'age': 30}]
nameが"Bob"のインデックス: [1, 2]
ageが20以上のインデックス: [1, 2]オブジェクトのリスト: 属性で検索
# クラスインスタンスのリストから属性で検索する例
class User:
def __init__(self, user_id, name, active):
self.user_id = user_id
self.name = name
self.active = active
users = [
User(1, "Alice", True),
User(2, "Bob", False),
User(3, "Charlie", True),
]
# 条件: active が True のユーザー
indices_active = [i for i, u in enumerate(users) if u.active]
print("activeなユーザーのインデックス:", indices_active)activeなユーザーのインデックス: [0, 2]このように、「値」「キー」「属性」など、対象に応じて条件部だけを書き換えれば同じパターンを使い回せます。
応用テクニックとパフォーマンス
最後に、大きなリストを扱う場合や、繰り返し検索する場合の工夫について解説します。
インデックスの逆引きに便利な辞書(dict)の活用方法
値からインデックスを高速に引きたい場合、辞書を使った「逆引きインデックス」を持っておくと効率的です。
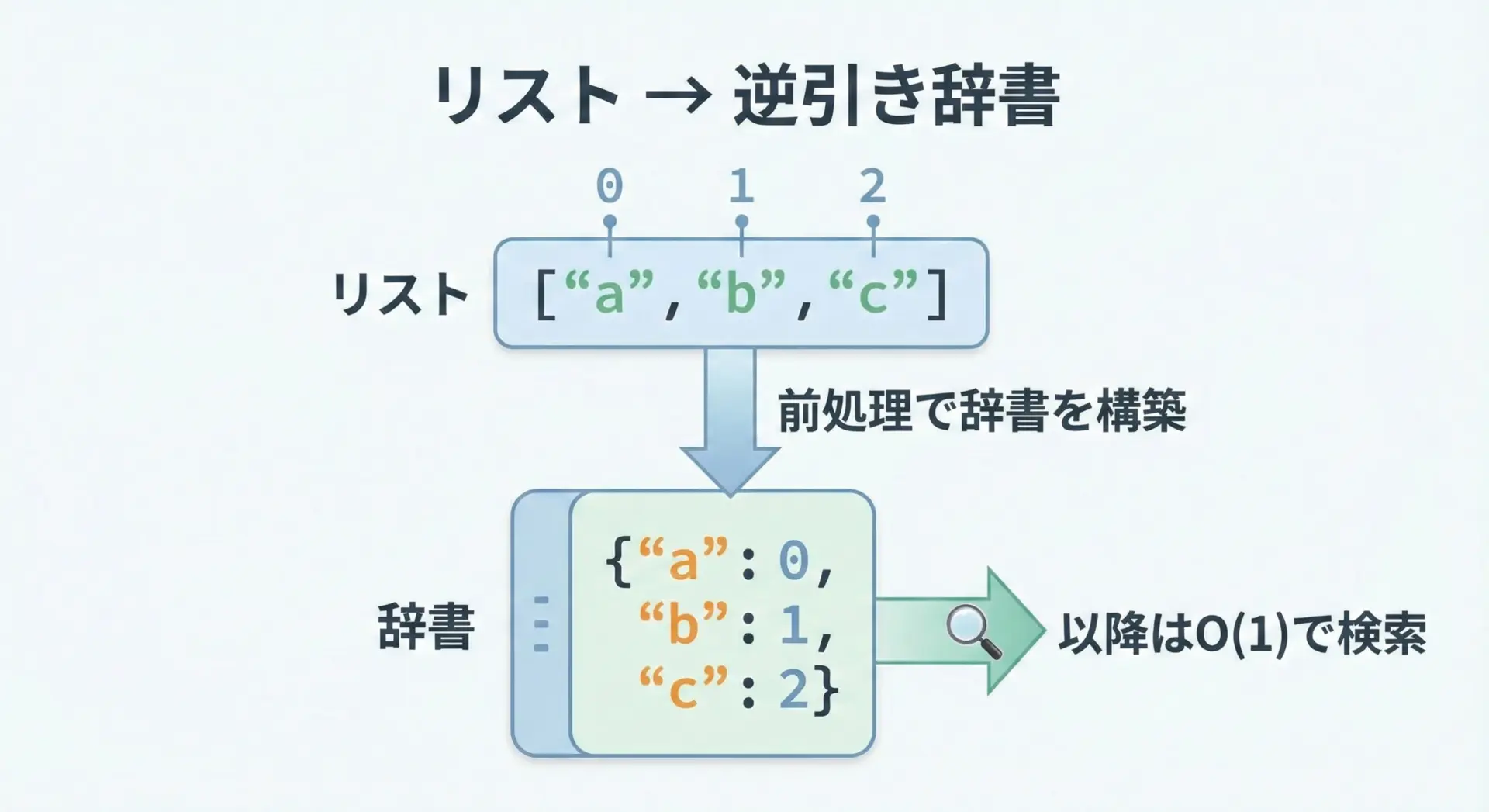
値→インデックスのマッピングを作る
# リストから値→インデックスへの辞書を作る
values = ["apple", "banana", "cherry"]
value_to_index = {v: i for i, v in enumerate(values)}
print("values:", values)
print("value_to_index:", value_to_index)
# 高速にインデックスを引ける
print('banana のインデックス:', value_to_index["banana"])values: ['apple', 'banana', 'cherry']
value_to_index: {'apple': 0, 'banana': 1, 'cherry': 2}
banana のインデックス: 1辞書の検索は平均してO(1)時間なので、同じリストに対して何度も検索する場合のパフォーマンス改善に役立ちます。
重複値がある場合の辞書
同じ値が複数のインデックスに現れる場合は、辞書の値を「インデックスのリスト」にするのが定番です。
# 重複値に対応した逆引き辞書
values = ["a", "b", "a", "c", "b"]
index_map = {}
for i, v in enumerate(values):
# setdefaultで初期リストを作ってからappend
index_map.setdefault(v, []).append(i)
print("values:", values)
print("index_map:", index_map)
print('"a" のインデックス一覧:', index_map["a"])
print('"b" のインデックス一覧:', index_map["b"])values: ['a', 'b', 'a', 'c', 'b']
index_map: {'a': [0, 2], 'b': [1, 4], 'c': [3]}
"a" のインデックス一覧: [0, 2]
"b" のインデックス一覧: [1, 4]このように前処理をしておけば、後続の検索はすべて辞書を引くだけで済みます。
大きなリストでのインデックス検索の速度と注意点
リストのindexやin、forループを使った検索は、「先頭から順に見ていく」線形探索です。
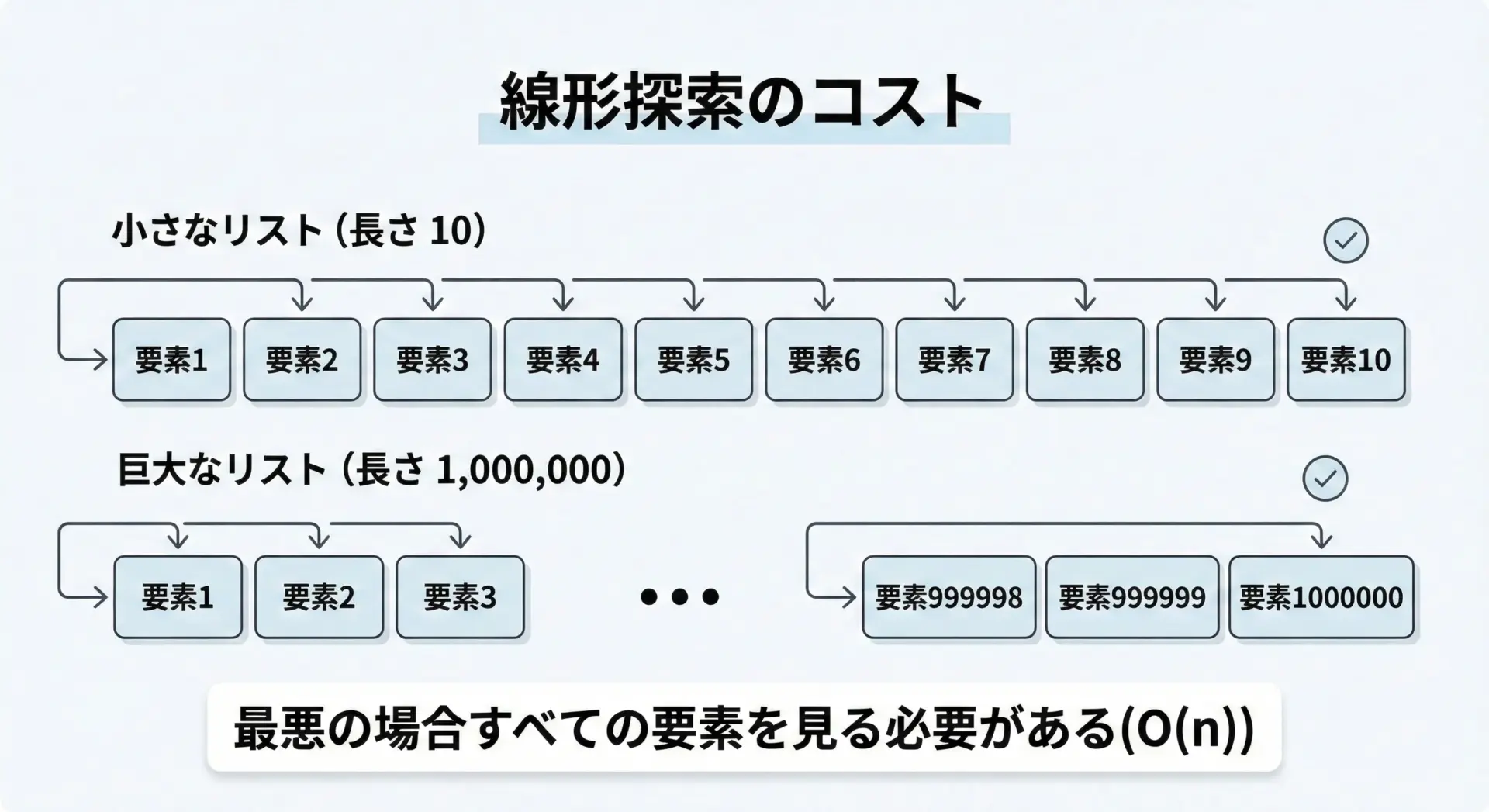
リストが小さいうちは問題ありませんが、要素数が数十万〜数百万を超えると、何度も線形探索をするのはコストが高くなります。
速度面での基本的な注意点
大きなリストでのインデックス検索では、次のような点に注意します。
- 同じリスト・同じ条件で何度も検索する場合は、逆引き辞書を事前に構築する
- リストを一度だけ走査するなら、1回のループの中で必要な情報をすべて集める
- 検索条件が単純であれば、リストよりもsetやdictに置き換えられないか検討する
このように設計段階でデータ構造を選び直すことで、後からパフォーマンスに悩まされるリスクを減らせます。
見やすいコードにするための関数化・ユーティリティ化のコツ
インデックス検索はコード中に何度も出てくる処理なので、小さな関数に切り出して「よく使うパターン」を部品化しておくと、可読性も保守性も上がります。
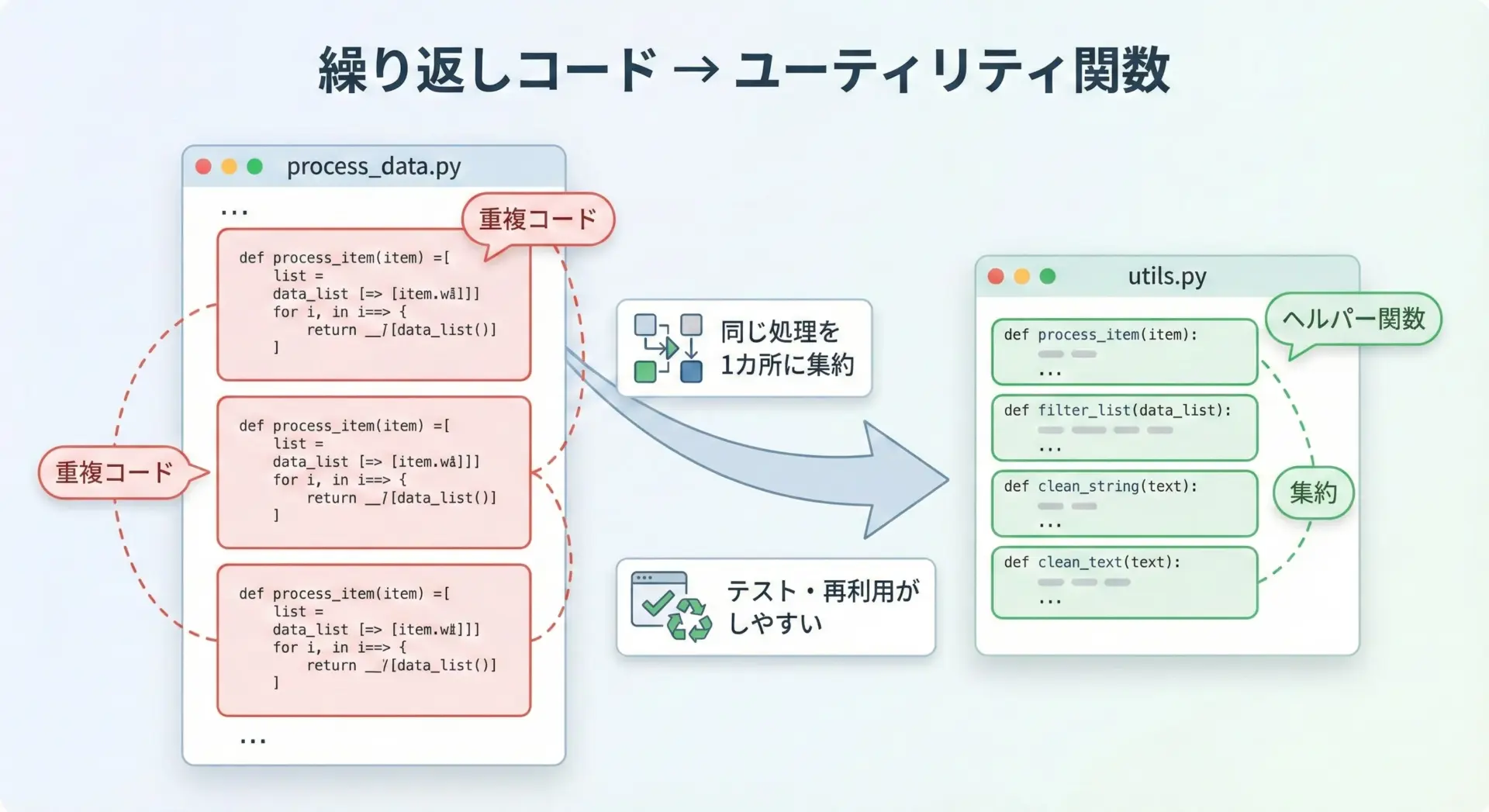
汎用的な検索ユーティリティ関数の例
# 汎用的な検索ユーティリティ関数の例
from typing import Iterable, Callable, TypeVar, List, Optional
T = TypeVar("T")
def find_first_index(iterable: Iterable[T], predicate: Callable[[T], bool]) -> Optional[int]:
"""
条件を満たす最初の要素のインデックスを返す。
見つからない場合はNoneを返す。
"""
for i, value in enumerate(iterable):
if predicate(value):
return i
return None
def find_all_indices(iterable: Iterable[T], predicate: Callable[[T], bool]) -> List[int]:
"""
条件を満たすすべての要素のインデックスをリストで返す。
"""
return [i for i, value in enumerate(iterable) if predicate(value)]
# --- 使い方の例 ---
numbers = [3, 5, 12, 8, 15]
# 10以上の最初のインデックス
idx = find_first_index(numbers, lambda x: x >= 10)
# 偶数すべてのインデックス
even_indices = find_all_indices(numbers, lambda x: x % 2 == 0)
print("numbers:", numbers)
print("10以上の最初のインデックス:", idx)
print("偶数のインデックス一覧:", even_indices)numbers: [3, 5, 12, 8, 15]
10以上の最初のインデックス: 2
偶数のインデックス一覧: [2, 3]このように「インデックス検索」を目的とした小さな関数を用意しておくと、呼び出し側のコードから条件式だけが浮き上がり、何をしているか理解しやすくなります。
まとめ
Pythonのリストからインデックスを取得する方法は、基本のlist.indexから始まり、forループ、enumerate、リスト内包表記、条件付き検索、逆引き辞書、ユーティリティ関数化まで幅広く存在します。
単一要素か重複要素か、1回だけの検索か繰り返しの検索か、といった状況に応じて最適な手法を選ぶことで、コードは短く分かりやすく、かつ効率的になります。
本記事のサンプルをベースに、自分のプロジェクト向けの検索ヘルパー関数や逆引きインデックスを整備しておくと、今後のPython開発がぐっと快適になります。
