Pythonのリストは、複数の値を1つにまとめて管理できる、とても重要なデータ構造です。
本記事では、リストの基本から、よく使うメソッド、さらに実務でも役立つ応用テクニックまでを一気に解説します。
これからPythonを本格的に学びたい人も、なんとなく使っている人も、この記事を読むことでリスト操作を体系的に理解できる内容になっています。
リストとは
リストとは何か
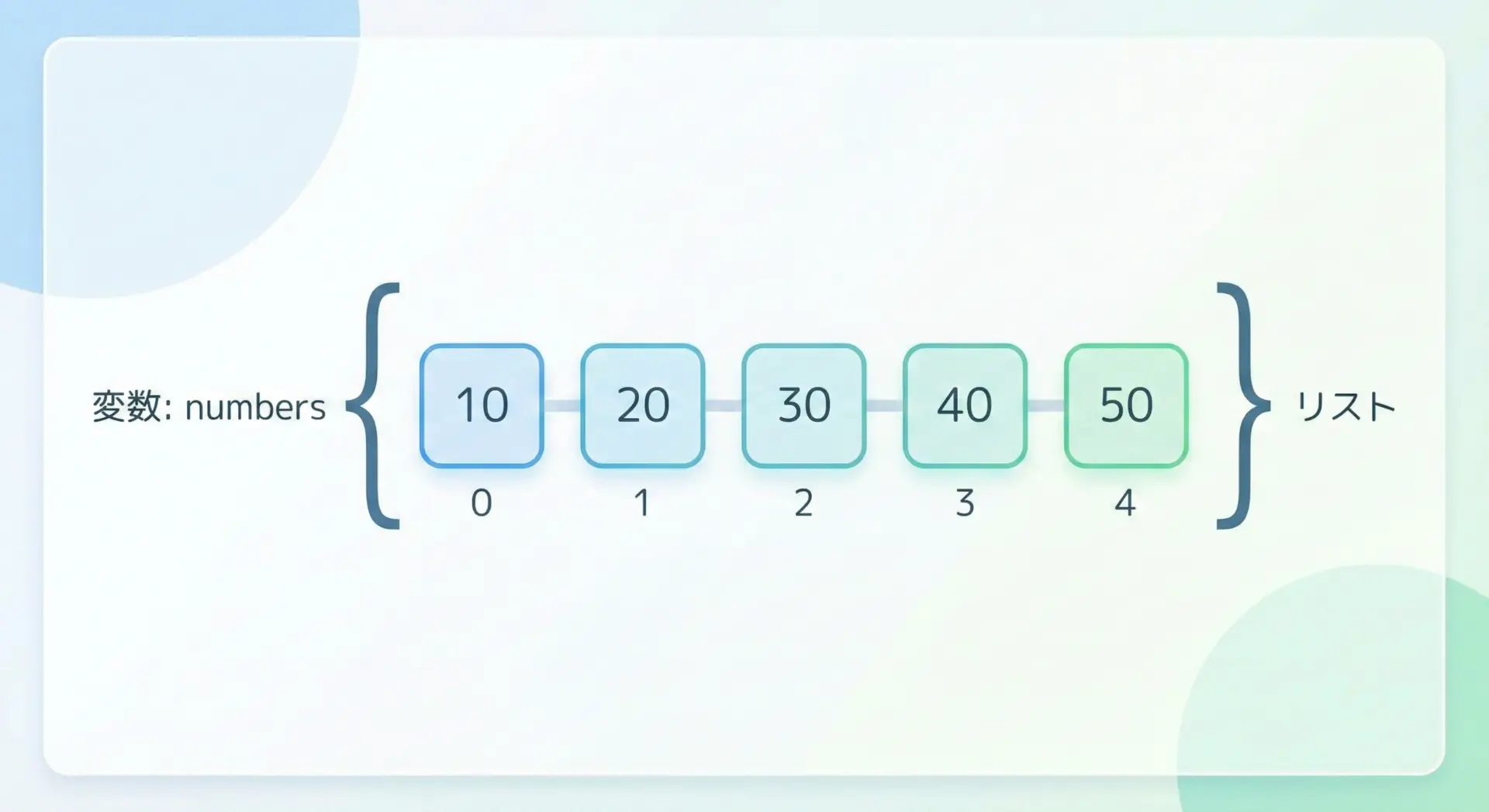
リスト(list)とは、複数の値を順番つきで並べて1つの変数に格納できるデータ構造です。
Pythonでは、角括弧の[]で囲んで表現します。
リストのイメージとしては、番号が振られた「箱」が横一列に並んでいて、それぞれの箱に好きな値を入れておける、という感じです。
番号(インデックス)を指定することで、好きな要素を取り出したり、書き換えたりできます。
リストは、次のような特徴を持っています。
文章で整理すると、リストは「順番がある」「変更できる」「重複を許す」データ構造です。
そのため、順序が大事なデータ(例: 並び順を保持したい商品リスト)や、あとから値を追加・削除したい場合にとても便利です。
Pythonリストの基本構文と書き方
Pythonのリストは、角括弧[]の中に値をカンマ,で区切って並べるだけで作成できます。
# 整数のリスト
numbers = [10, 20, 30]
# 文字列のリスト
fruits = ["apple", "banana", "orange"]
# 空のリスト
empty_list = []
# 混在したリスト(整数と文字列が混ざっている例)
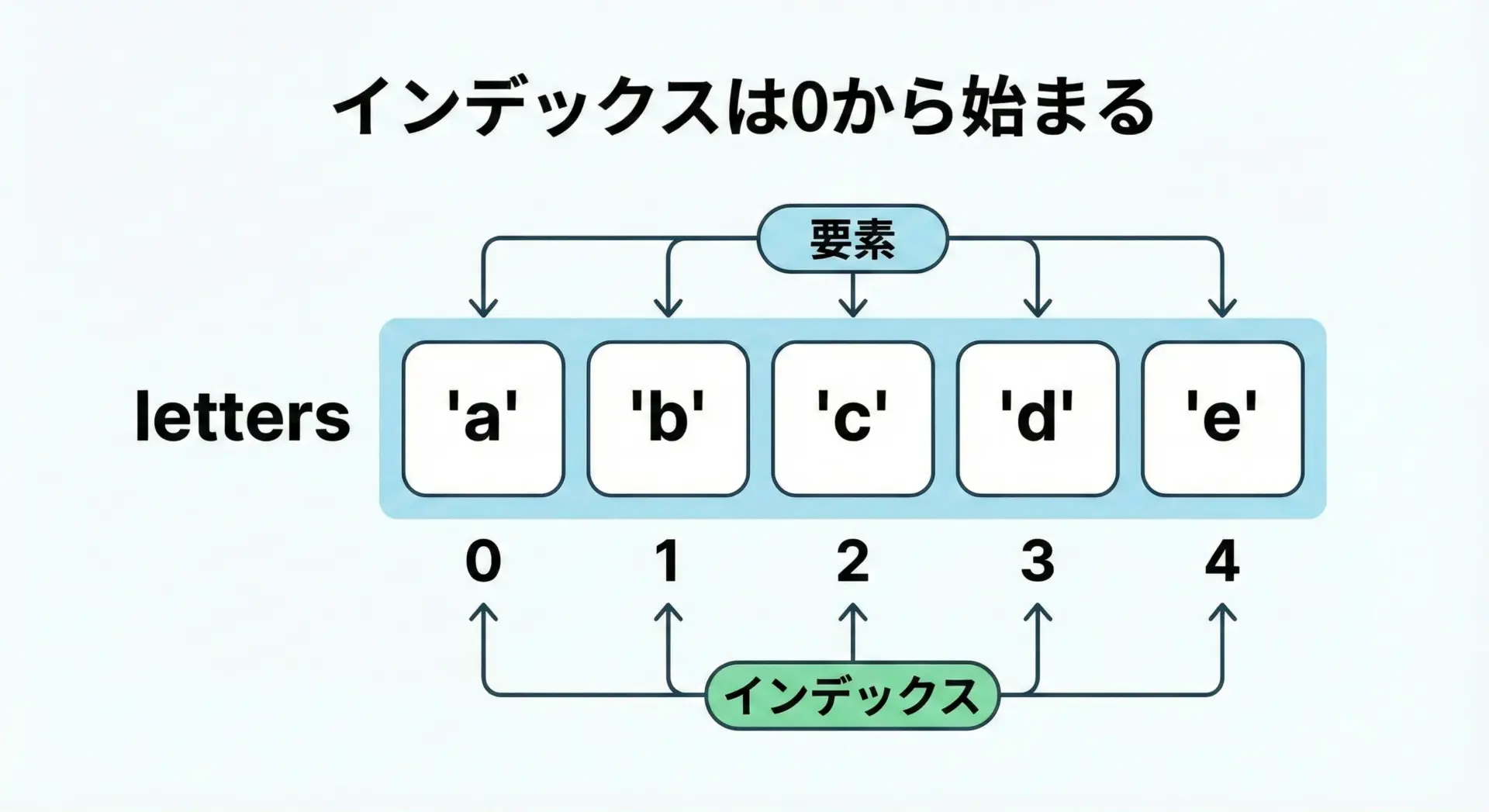
mixed = [1, "two", 3.0]Pythonでは、リストのインデックス(番号)は0から始まることに注意します。
最初の要素はインデックス0、2番目は1、というように数えます。
リストで扱えるデータ型の例
Pythonのリストはどんなデータ型でも格納できる柔軟な構造です。
さらに、同じリストの中に異なる型を混在させることもできます。
基本的なデータ型を格納した例
# さまざまな型を含むリスト
mixed_list = [
42, # 整数(int)
3.14, # 浮動小数点数(float)
"hello", # 文字列(str)
True, # 真偽値(bool)
]
print(mixed_list)[42, 3.14, 'hello', True]リストの中にリストを入れることも可能
リストの要素として、リスト自体を入れることもできます。
これをよくネストしたリストと呼びます。
matrix = [
[1, 2, 3], # 1行目
[4, 5, 6], # 2行目
[7, 8, 9], # 3行目
]
print(matrix)[[1, 2, 3], [4, 5, 6], [7, 8, 9]]このように、Pythonのリストは数字・文字列・真偽値だけでなく、他のリストやオブジェクトも自由に組み合わせて格納できる柔軟なコンテナです。
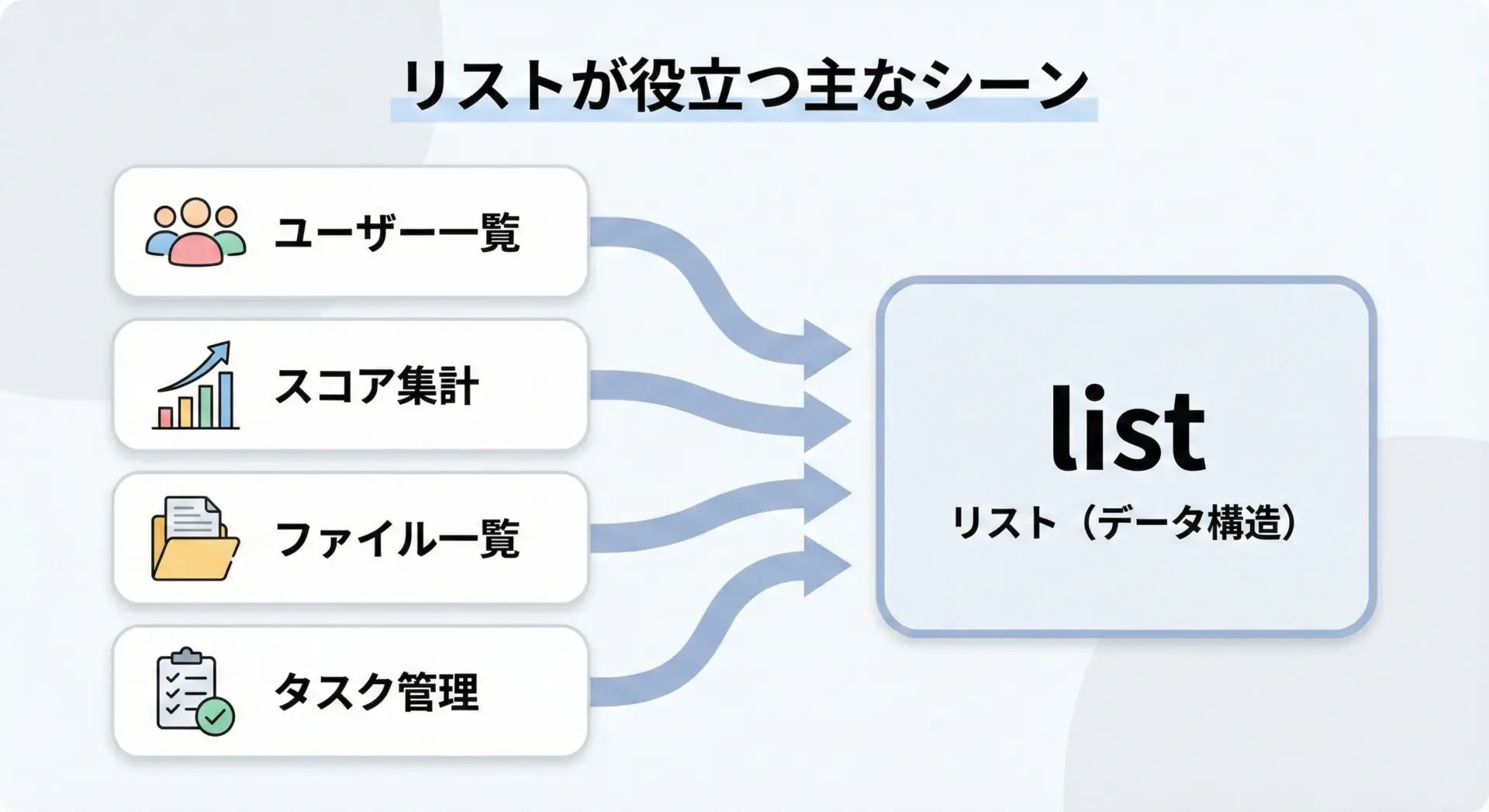
リストが便利なシーン
リストは日常的なプログラミングの多くの場面で使われます。
例えば次のようなケースです。
- ユーザー名や商品名など、複数の文字列を順番どおりに並べて管理したい
- 測定値やスコアなど、複数の数値をまとめて集計したい
- 複数のファイルパスをまとめて処理したい
- ループ処理で、同じ操作を複数の値に繰り返し適用したい
「同じ種類のデータを複数扱うときは、まずリストを検討する」という意識を持っておくとよいです。
リストの基本操作
リストの作成と初期化
リストを扱う最初のステップは作成と初期化です。
Pythonでは、とても簡単にリストを作ることができます。
値を直接書いて初期化
# 直接値を書いてリストを初期化
numbers = [1, 2, 3, 4, 5]
names = ["Alice", "Bob", "Charlie"]
print(numbers)
print(names)[1, 2, 3, 4, 5]
['Alice', 'Bob', 'Charlie']空のリストを作る
あとで要素を追加したい場合は、最初は空のリストとして作成します。
# 空のリストを2通りの方法で作成
data1 = [] # 一般的でよく使う書き方
data2 = list() # listコンストラクタを使う方法
print(data1)
print(data2)[]
[]同じ値を繰り返したリストを作る
同じ値を何回も繰り返したリストを作るには、掛け算演算子*が使えます。
# 0が5個並んだリストを作成
zeros = [0] * 5
print(zeros)[0, 0, 0, 0, 0]要素の取り出し
リストの要素は、インデックス(0から始まる番号)でアクセスします。
fruits = ["apple", "banana", "orange"]
# 先頭の要素(インデックス0)
first = fruits[0]
# 2番目の要素(インデックス1)
second = fruits[1]
# 3番目の要素(インデックス2)
third = fruits[2]
print(first, second, third)apple banana orange負のインデックスで末尾からアクセス
Pythonでは、負のインデックスを使うと、末尾側から数えることができます。
numbers = [10, 20, 30, 40, 50]
print(numbers[-1]) # 最後の要素(50)
print(numbers[-2]) # 最後から2番目(40)50
40
スライスで部分リストを取得する方法
スライス(slice)とは、リストの一部の範囲を取り出して新しいリストを作る機能です。
構文はlist[start:end]のように書きます。
基本的なスライス
numbers = [10, 20, 30, 40, 50]
# インデックス1以上、3未満を取り出す(20, 30)
sub1 = numbers[1:3]
# 先頭からインデックス3未満まで(10, 20, 30)
sub2 = numbers[:3]
# インデックス2以上、末尾まで(30, 40, 50)
sub3 = numbers[2:]
print(sub1)
print(sub2)
print(sub3)[20, 30]
[10, 20, 30]
[30, 40, 50]ステップ付きスライス
スライスには3番目の引数でステップも指定できます。
構文はlist[start:end:step]です。
numbers = [0, 1, 2, 3, 4, 5, 6]
# 1つおきに要素を取得(0, 2, 4, 6)
even_index = numbers[0::2]
# 逆順に取得
reversed_list = numbers[::-1]
print(even_index)
print(reversed_list)[0, 2, 4, 6]
[6, 5, 4, 3, 2, 1, 0]要素の変更・上書き
リストは変更可能(mutable)なデータ構造なので、後から要素を書き換えることができます。
scores = [50, 60, 70]
# 2番目の要素を80に変更(インデックス1)
scores[1] = 80
print(scores)[50, 80, 70]スライスを使って複数の要素を一度に変更
スライスを使うと、連続した複数要素を一度に置き換えることもできます。
numbers = [1, 2, 3, 4, 5]
# インデックス1〜3(2,3,4)を、10,20,30に置き換える
numbers[1:4] = [10, 20, 30]
print(numbers)[1, 10, 20, 30, 5]末尾への追加
リストの末尾に要素を追加するにはappendメソッドを使います。
これはリスト操作で最も頻繁に使われるメソッドの1つです。
fruits = ["apple", "banana"]
# 末尾に"orange"を追加
fruits.append("orange")
print(fruits)['apple', 'banana', 'orange']任意位置への挿入
任意の位置に要素を挿入したいときはinsertメソッドを使います。
numbers = [10, 30, 40]
# インデックス1の位置に20を挿入
numbers.insert(1, 20)
print(numbers)[10, 20, 30, 40]インデックス0に挿入すると先頭に追加され、インデックスがリストの長さ以上の場合は末尾に追加されます。
要素の削除
要素を削除する方法はいくつかあります。
目的によって使い分けます。
インデックスを指定して削除する(del, pop)
numbers = [10, 20, 30, 40]
# インデックス1の要素を削除(20が削除される)
del numbers[1]
print(numbers)
# popは削除した要素を返す
last = numbers.pop() # 末尾の要素(40)を削除
print(numbers)
print("popで取り出した値:", last)[10, 30, 40]
[10, 30]
popで取り出した値: 40値を指定して削除する(remove)
fruits = ["apple", "banana", "orange", "banana"]
# 最初に見つかった"banana"だけ削除
fruits.remove("banana")
print(fruits)['apple', 'orange', 'banana']removeは存在しない値を指定するとエラーになりますので、注意が必要です。
リストの長さを調べる
リストの要素数(長さ)は組み込み関数lenで取得します。
fruits = ["apple", "banana", "orange"]
length = len(fruits)
print("要素数:", length)要素数: 3in演算子で要素の存在チェック
in演算子を使うと、特定の値がリストに含まれているかどうかを簡単に調べられます。
fruits = ["apple", "banana", "orange"]
print("apple" in fruits) # "apple"が含まれているか?
print("grape" in fruits) # "grape"が含まれているか?True
Falseこの演算子は条件分岐(if文)と組み合わせて使う場面がとても多いです。
リストの代表的なメソッド
よく使うリストメソッド一覧
Pythonのリストには、多くの便利なメソッドが用意されています。
ここでは、よく使うものを表にまとめます。
| メソッド名 | 役割・概要 | 返り値 |
|---|---|---|
append(x) | 末尾に要素xを追加する | None |
insert(i, x) | 位置iに要素xを挿入 | None |
pop([i]) | 位置iの要素を取り出して削除(省略で末尾) | 削除した要素 |
remove(x) | 要素xを削除(最初に見つかった1つ) | None |
sort() | 自身を並び替える(破壊的) | None |
reverse() | 自身の順序を逆順にする(破壊的) | None |
extend(iter) | ほかのイテラブルの要素を末尾に追加 | None |
index(x) | 要素xが最初に見つかった位置を返す | インデックス |
count(x) | 要素xの出現回数を返す | 数(int) |
clear() | 全要素を削除して空にする | None |
copy() | 浅いコピーを返す | 新しいリスト |
これらのメソッドのうち、特にsort, reverse, extend, index, count, clear, copyについて詳しく見ていきます。
sortとsortedでリストを並び替え
リストの並び替えにはsortメソッドと組み込み関数sortedの2通りがあります。
sortメソッド(リスト自体を並び替える)
numbers = [5, 2, 9, 1]
# 昇順(小さい順)に並び替え
numbers.sort()
print("昇順:", numbers)
# 降順(大きい順)に並び替え
numbers.sort(reverse=True)
print("降順:", numbers)昇順: [1, 2, 5, 9]
降順: [9, 5, 2, 1]sortはリスト自体を書き換える(破壊的)ため、元の順序を残しておきたい場合には注意が必要です。
sorted関数(新しいリストを返す)
scores = [70, 90, 50]
# 元のリストはそのまま、新しい並び替え結果を得る
sorted_scores = sorted(scores)
print("元のリスト:", scores)
print("ソート結果:", sorted_scores)元のリスト: [70, 90, 50]
ソート結果: [50, 70, 90]元のリストは保持したいが、並び替えた結果も使いたいという場面ではsortedを使うと安全です。
reverseでリストを逆順にする
リストの順序をその場で逆転させるメソッドがreverseです。
letters = ["a", "b", "c", "d"]
letters.reverse()
print(letters)['d', 'c', 'b', 'a']なお、reversed()という組み込み関数もありますが、こちらは逆順に走査できるイテレータを返す点が異なります。
letters = ["a", "b", "c", "d"]
for ch in reversed(letters): # 逆順にループ
print(ch, end=" ")d c b aextendでリストを結合する
複数のリストを結合して、1つのリストにまとめたいケースは多くあります。
extendメソッドを使うと、別のリスト(またはイテラブル)の要素を、末尾にまとめて追加できます。
a = [1, 2, 3]
b = [4, 5]
# aの末尾にbの要素を追加
a.extend(b)
print(a)[1, 2, 3, 4, 5]+演算子との違いとして、a + bは新しいリストを返すのに対し、a.extend(b)はa自身を書き換える点に注意します。
a = [1, 2]
b = [3, 4]
c = a + b # 新しいリストを作る
print("a:", a)
print("b:", b)
print("c:", c)a: [1, 2]
b: [3, 4]
c: [1, 2, 3, 4]index・countで検索する
特定の値がリストのどこにあるか、また何回出現するかを調べたいときに使うのがindexとcountです。
indexで位置を調べる
fruits = ["apple", "banana", "orange", "banana"]
# 最初に見つかった"banana"の位置
pos = fruits.index("banana")
print("bananaの位置:", pos)bananaの位置: 1存在しない値を指定するとValueErrorが発生するため、事前にinでチェックするのが安全です。
fruits = ["apple", "banana"]
if "orange" in fruits:
print(fruits.index("orange"))
else:
print("orangeは含まれていません")orangeは含まれていませんcountで出現回数を調べる
numbers = [1, 2, 2, 3, 2, 4]
print("2の個数:", numbers.count(2))2の個数: 3clearで全要素を削除する
リストの中身をすべて消して、空にしたい場合はclearメソッドを使います。
data = [1, 2, 3]
data.clear()
print(data)[]リストオブジェクト自体は残したまま中身だけを空にするので、同じ変数をその後も使い続けられます。
copyでリストをコピーする
リストを別名ではなく別のオブジェクトとしてコピーしたい場合にはcopyメソッドを使います。
original = [1, 2, 3]
# 浅いコピーを作成
copied = original.copy()
copied[0] = 99 # コピー側だけ変更
print("original:", original)
print("copied :", copied)original: [1, 2, 3]
copied : [99, 2, 3]単にcopied = originalとすると同じリストを別名で参照しているだけになり、片方を変更するともう片方も変わってしまいます。
この点は非常に重要です。

リストの応用テクニック
リスト内包表記の基本と書き方
リスト内包表記(list comprehension)は、既存のリストや範囲から、新しいリストをコンパクトな記法で生成する方法です。
Pythonで非常によく使われるテクニックです。
基本構文は次のようになります。
[式 for 変数 in イテラブル]
例: 0〜4の2乗のリストを作る
# 通常のfor文で書く場合
squares = []
for x in range(5):
squares.append(x * x)
print(squares)[0, 1, 4, 9, 16]これをリスト内包表記で書くと、次のように1行で表現できます。
# リスト内包表記で同じ結果を得る
squares = [x * x for x in range(5)]
print(squares)[0, 1, 4, 9, 16]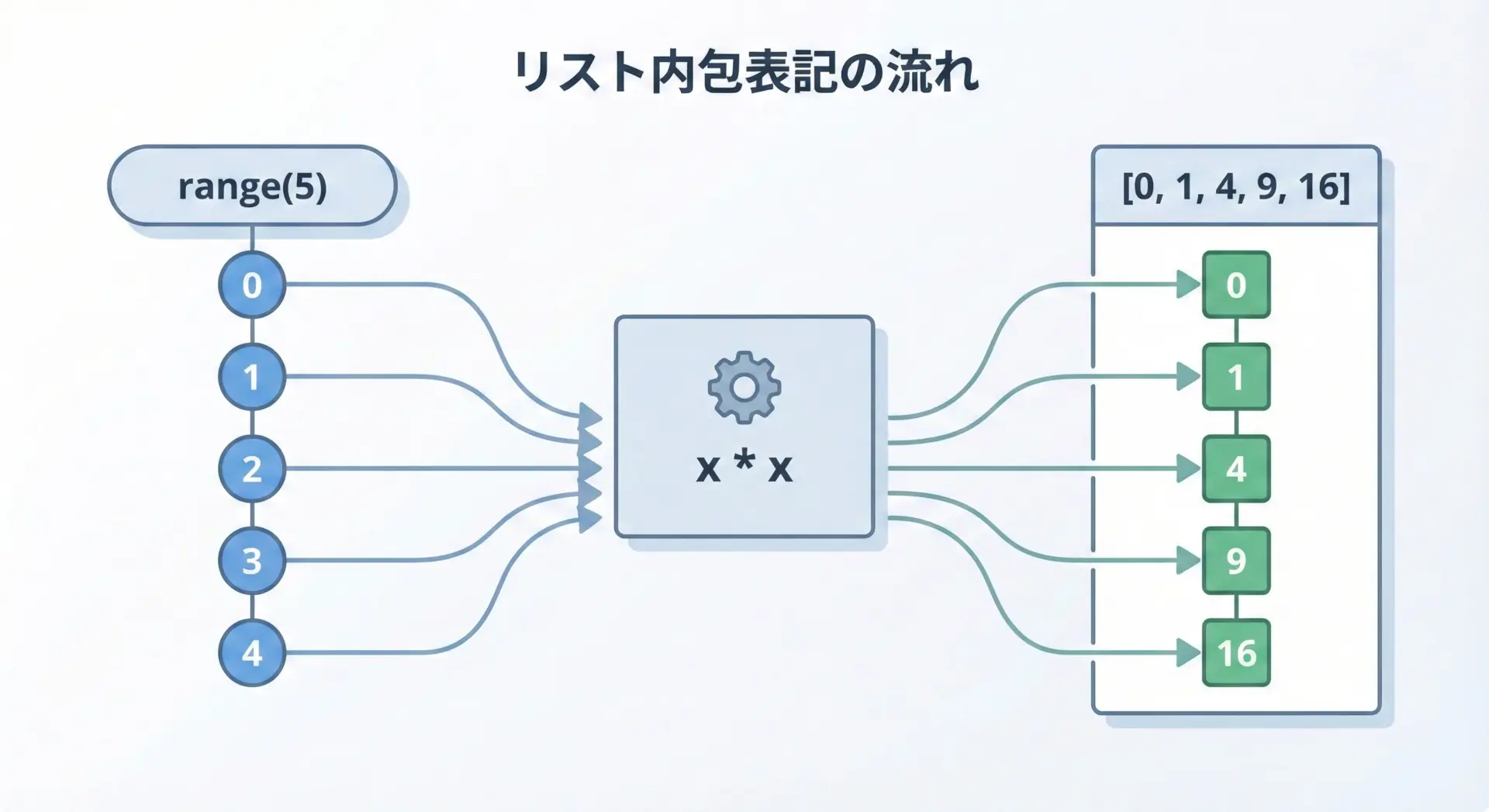
条件付きリスト内包表記
リスト内包表記は、条件をつけて要素をフィルタすることもできます。
基本構文は次の通りです。
[式 for 変数 in イテラブル if 条件]
例: 偶数だけを取り出す
numbers = list(range(10)) # 0〜9
# 偶数だけのリストを作る
evens = [x for x in numbers if x % 2 == 0]
print(evens)[0, 2, 4, 6, 8]このように、元のリストから条件に合うものだけを取り出した新しいリストを、短く書けるのが大きなメリットです。
ネストしたリスト(二次元リスト)の扱い方
ネストしたリスト(二次元リスト)は、「リストの中にリストが入っている」状態です。
表形式のデータや、行列などを表現するときによく使われます。

二次元リストの作成とアクセス
# 3行3列の行列を二次元リストで表現
matrix = [
[1, 2, 3], # 0行目
[4, 5, 6], # 1行目
[7, 8, 9], # 2行目
]
# 1行目(インデックス1)のリストを取得
row = matrix[1]
print("1行目:", row)
# 2行目(インデックス2)・3列目(インデックス2)の要素を取得
value = matrix[2][2]
print("2行目3列目の値:", value)1行目: [4, 5, 6]
2行目3列目の値: 9このように、行のインデックスと列のインデックスを二重の[]で指定してアクセスします。
for文と組み合わせたリスト処理
リストはfor文との相性が非常によいです。
リストの全要素に同じ処理をしたいときには必ずといってよいほど登場します。
リストの全要素を順に処理する
fruits = ["apple", "banana", "orange"]
for fruit in fruits:
# 各要素を大文字にして表示
print(fruit.upper())APPLE
BANANA
ORANGE二次元リストを二重ループで処理する
matrix = [
[1, 2, 3],
[4, 5, 6],
]
for row in matrix: # 各行を取り出す
for value in row: # 行の中の各値を取り出す
print(value, end=" ")
print() # 行ごとに改行1 2 3
4 5 6enumerateでインデックス付きループ
インデックスと要素を同時に使いたい場合は、組み込み関数enumerateが便利です。
fruits = ["apple", "banana", "orange"]
for i, fruit in enumerate(fruits):
print(i, ":", fruit)0 : apple
1 : banana
2 : orangeenumerate(fruits, start=1)のようにstart引数を指定すると、1から番号を振ることもできます。
for i, fruit in enumerate(fruits, start=1):
print(i, "位:", fruit)1 位: apple
2 位: banana
3 位: orange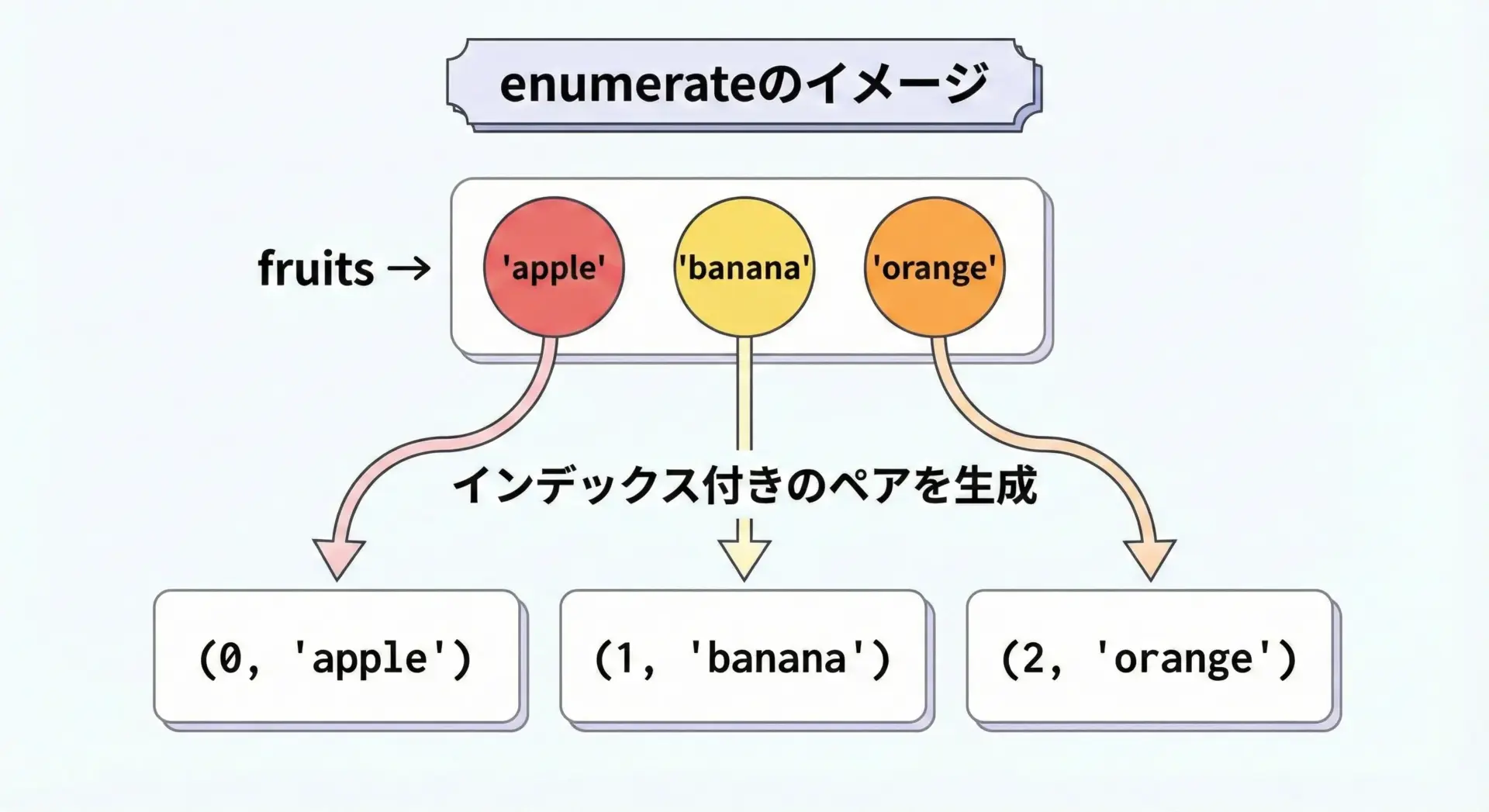
zipで複数リストを同時に処理
複数のリストを並行して処理したいときにはzip関数が役立ちます。
zipは、複数のイテラブルから同じ位置の要素を1組にして返してくれます。
names = ["Alice", "Bob", "Charlie"]
scores = [85, 92, 78]
for name, score in zip(names, scores):
print(name, "さんの点数は", score, "点です")Alice さんの点数は 85 点です
Bob さんの点数は 92 点です
Charlie さんの点数は 78 点です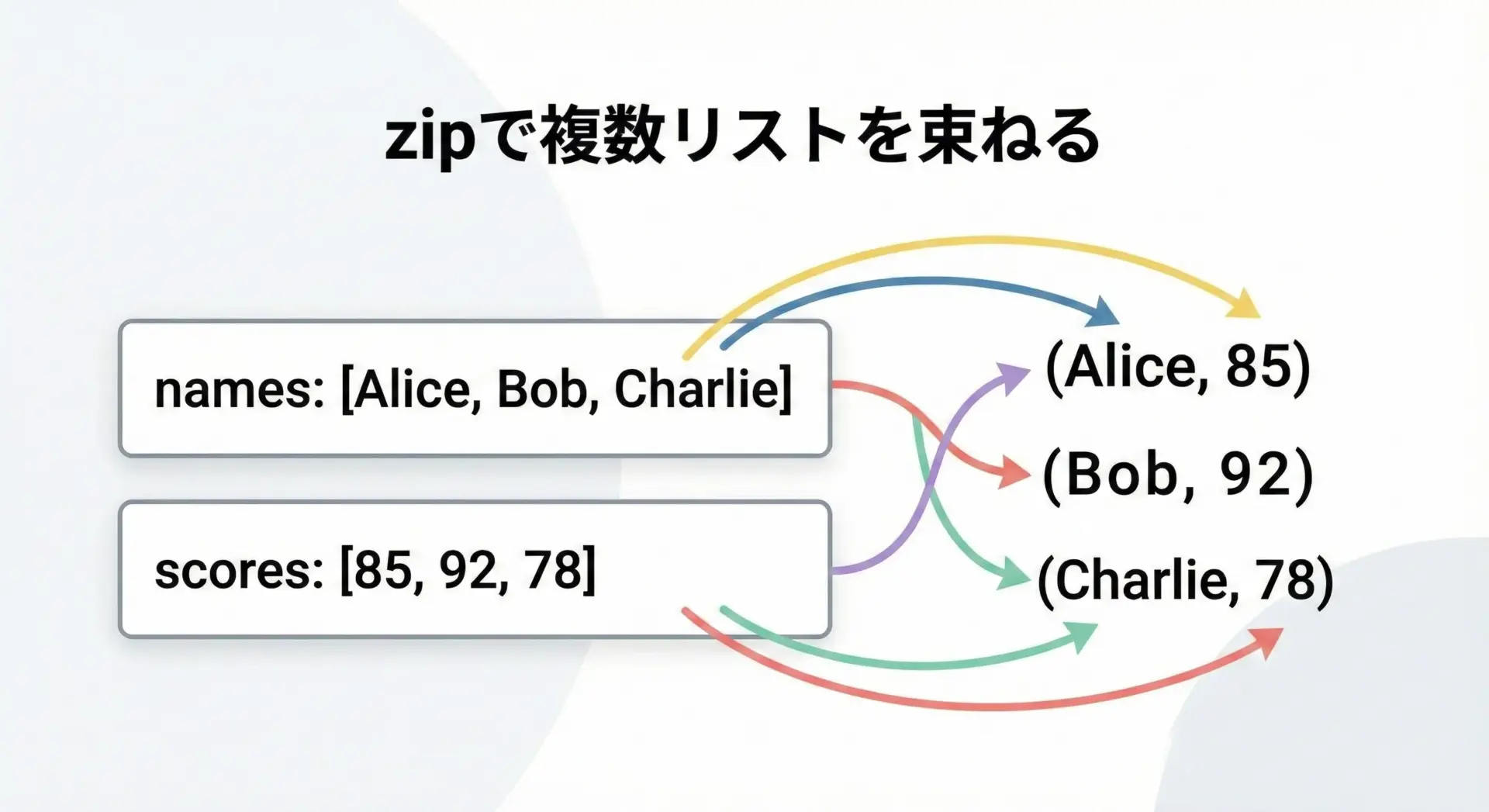
リストとタプル・辞書の使い分け
Pythonには、リストの他にもタプル(tuple)や辞書(dict)といったデータ構造があります。
これらの使い分けを理解しておくと、より適切な設計ができるようになります。
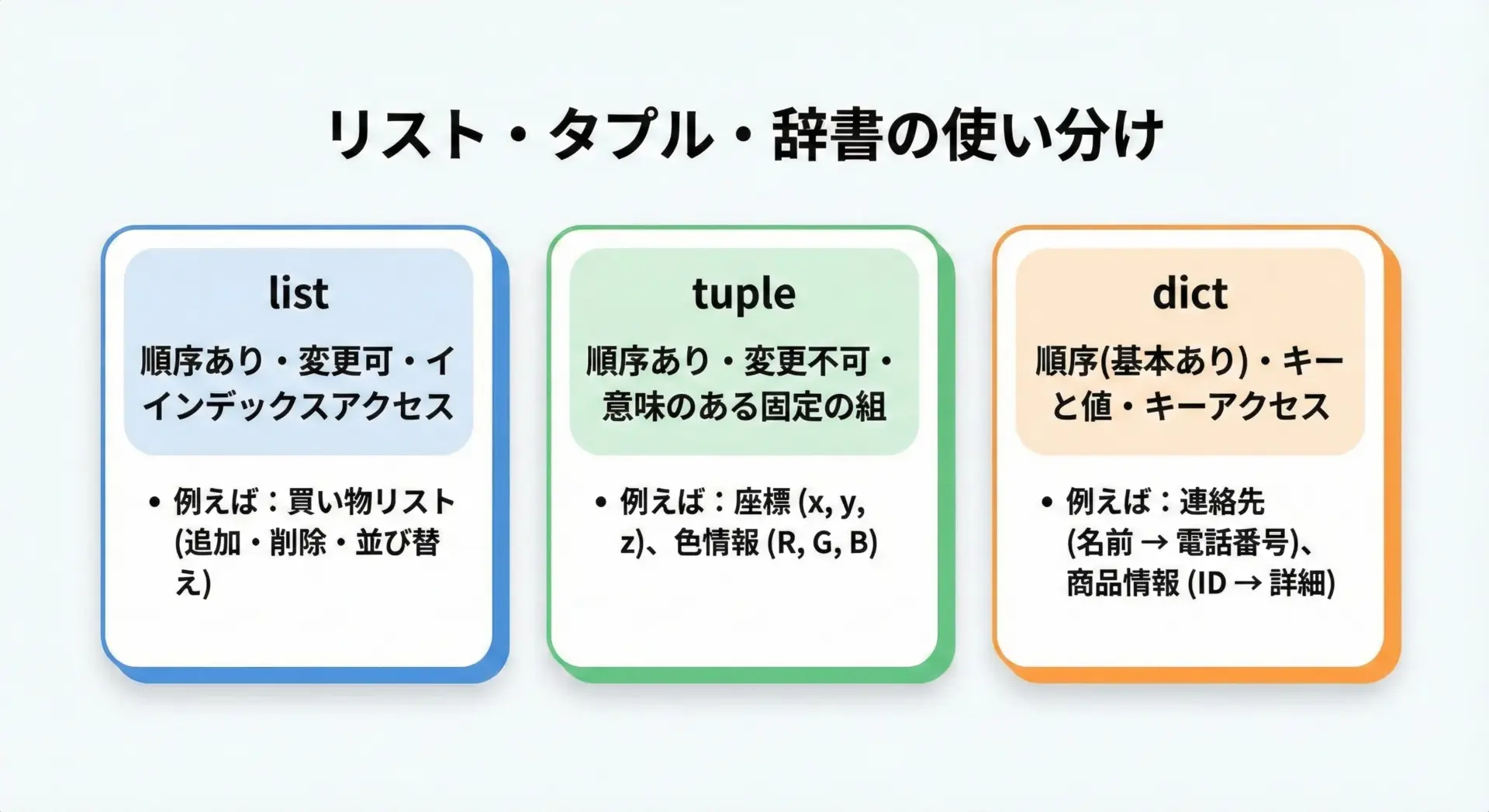
リストとタプルの違い
リストとタプルの主な違いは変更可能かどうかです。
| 種類 | 記法 | 変更可否 | 用途のイメージ |
|---|---|---|---|
| リスト | [] | 変更できる | あとで追加・削除・変更するデータの集合 |
| タプル | () | 変更できない | 変わらない前提のデータ、座標や設定の組など |
例えば、「x座標とy座標のペア」のように、意味が決まった固定の組み合わせはタプルで表現することが多いです。
point = (10, 20) # タプル一方、「ユーザーのリスト」「商品のリスト」のように、あとから増えたり減ったりする集合はリストで表現します。
users = ["Alice", "Bob"] # リスト
users.append("Charlie")リストと辞書の違い
辞書(dict)はキー(key)と値(value)のペアを扱うデータ構造です。
- リスト: インデックス(0,1,2,…)でアクセス
- 辞書: 任意のキー(“id”や”user1″など)でアクセス
# リストの例
scores_list = [85, 92, 78]
print(scores_list[0]) # 0番目のスコア
# 辞書の例
scores_dict = {"Alice": 85, "Bob": 92, "Charlie": 78}
print(scores_dict["Alice"]) # Aliceさんのスコア85
85「順番が大事で位置でアクセスしたい」ならリスト、「名前などのキーで直接アクセスしたい」なら辞書、というように使い分けると良いです。
まとめ
Pythonのリストは、複数の値を順序付きで扱える非常に強力なデータ構造です。
本記事では、リストの基本的な作り方や参照方法から、メソッドによる追加・削除・並び替え、リスト内包表記や二次元リスト、enumerateやzipとの組み合わせといった応用テクニックまで解説しました。
実務レベルのコードでも、リスト操作はあらゆる場面で登場します。
ここで紹介した考え方とパターンを押さえておけば、Pythonでのデータ処理やロジック構築がぐっと楽になりますので、ぜひ実際に手を動かして練習してみてください。
