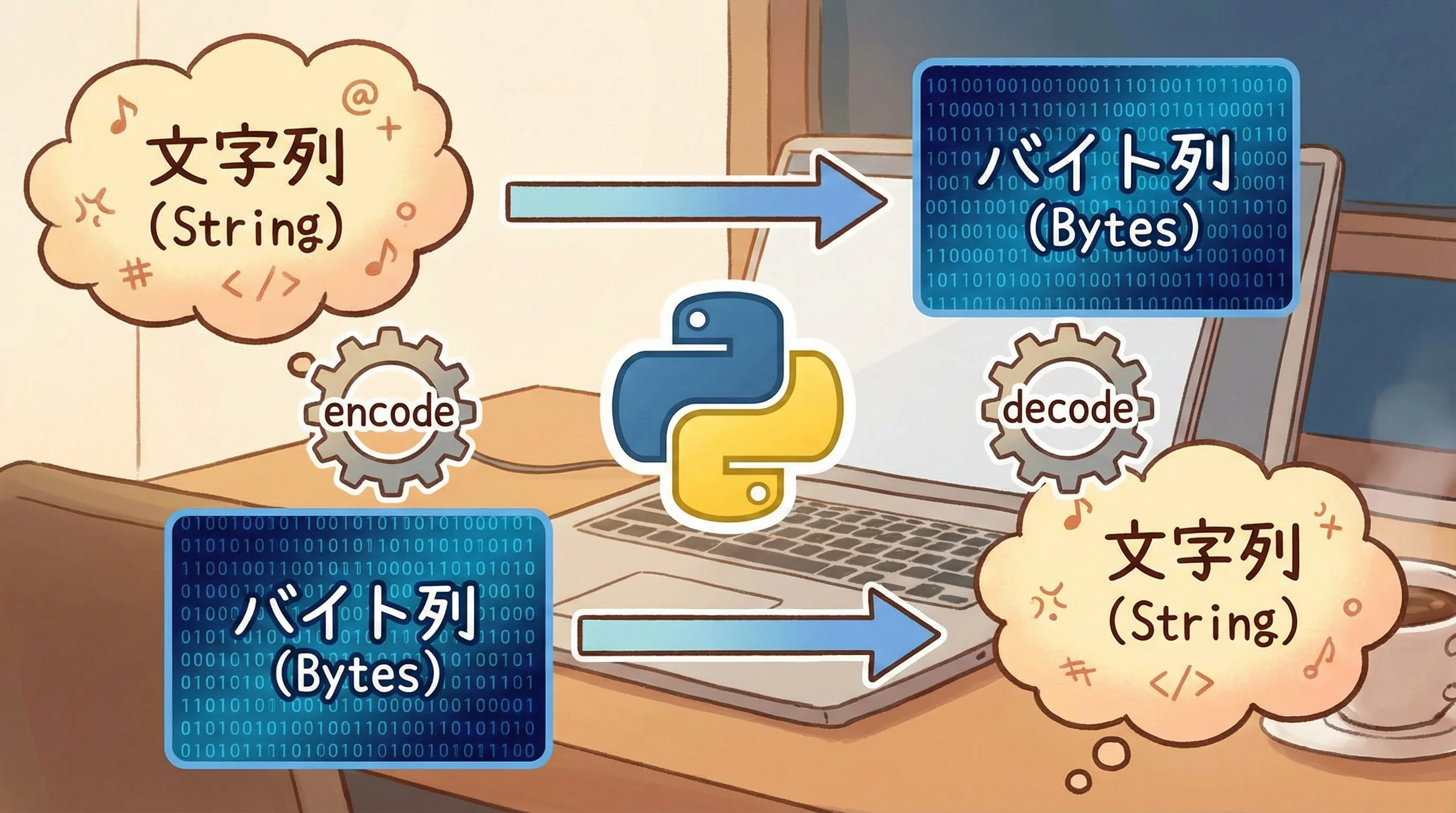
Pythonのencodeとdecodeは、文字列とバイト列を相互に変換するためのとても重要な機能です。
しかし、初心者の方は「どちらがどちら向きの変換なのか」「文字コードは何を指定すればよいのか」で混乱しがちです。
本記事では、文字列とバイト列の違いから、encode/decodeの使い方、よくあるエラーと対処法までを丁寧に解説します。
Pythonのencodeとdecodeとは
文字列とバイト列( bytes )の違い
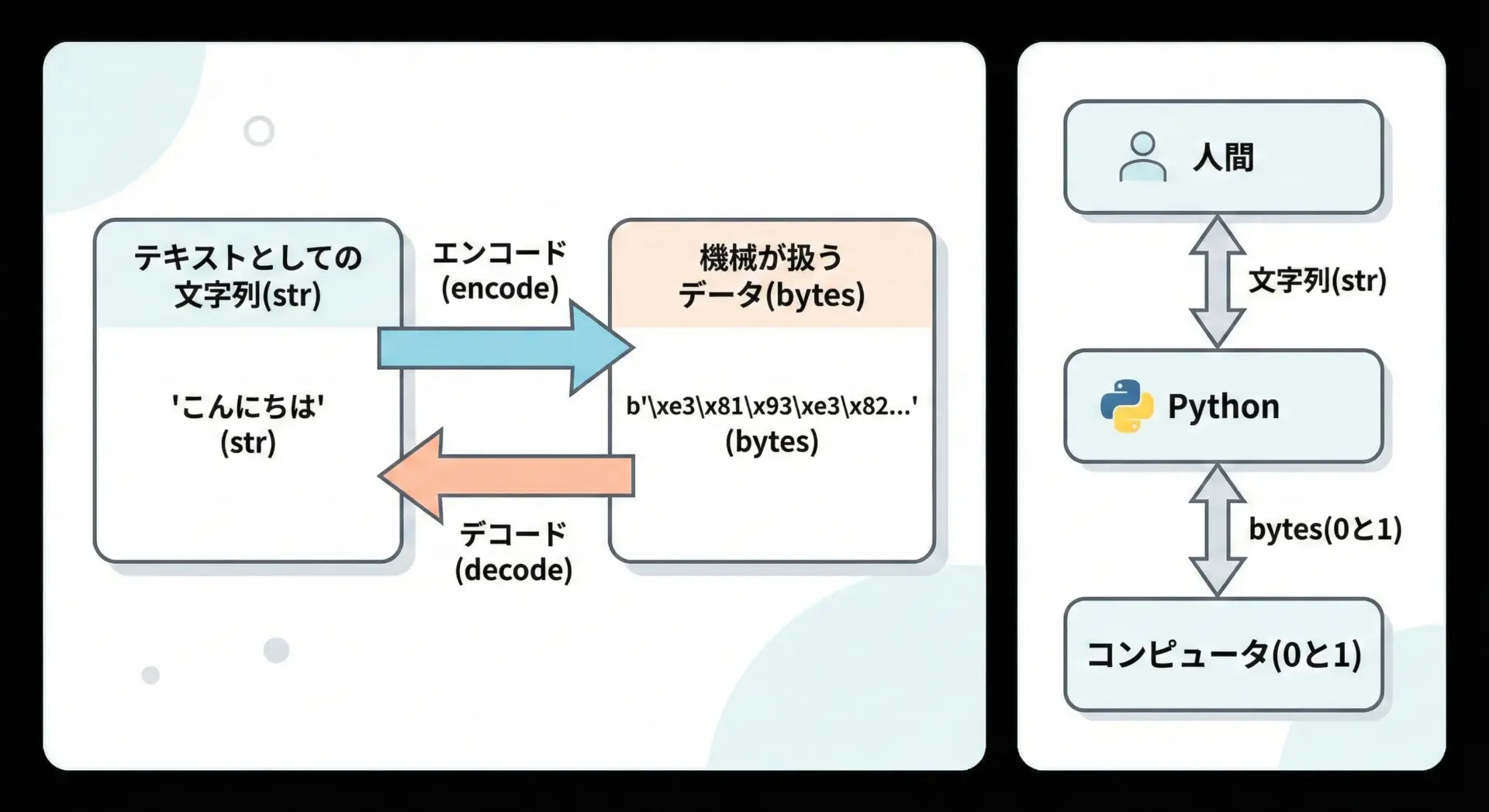
Pythonでは、文字を扱うときに大きく分けて2つのデータ型が登場します。
ひとつは文字列型(cst-code>str)、もうひとつはバイト列型(cst-code>bytes)です。
文字列型strは、人間にとって読みやすい「文字」として扱われます。
たとえば"こんにちは"や"ABC"などです。
これらは「文字の並び」という論理的な表現のため、内部的には何らかの文字コードで表現されていますが、普段はあまり意識しなくても使えます。
一方、バイト列型bytesは、コンピュータが直接扱う0と1の列を意識した形式です。
Pythonではb"ABC"やb"\xe3\x81\x93\xe3\x82\x93"のように表現されます。
見た目は少し難しく感じますが、これは「ある文字コードに基づいて数値(バイト)に変換された結果」です。
この2つの違いを簡単にまとめると次のようになります。
| 種類 | 型名 | 例 | 主な用途 |
|---|---|---|---|
| 文字列 | str | "こんにちは" | 画面表示、ロジック、文字操作など |
| バイト列 | bytes | b"\xe3\x81\x93…" | ファイル保存、ネット送受信、バイナリ処理など |
encodeとdecodeは、このstrとbytesを相互に変換するためのメソッドです。
- encode: str → bytes
- decode: bytes → str
この「どちらがどちら向きか」をまずはしっかり押さえておくことが重要です。
なぜエンコードとデコードが必要なのか
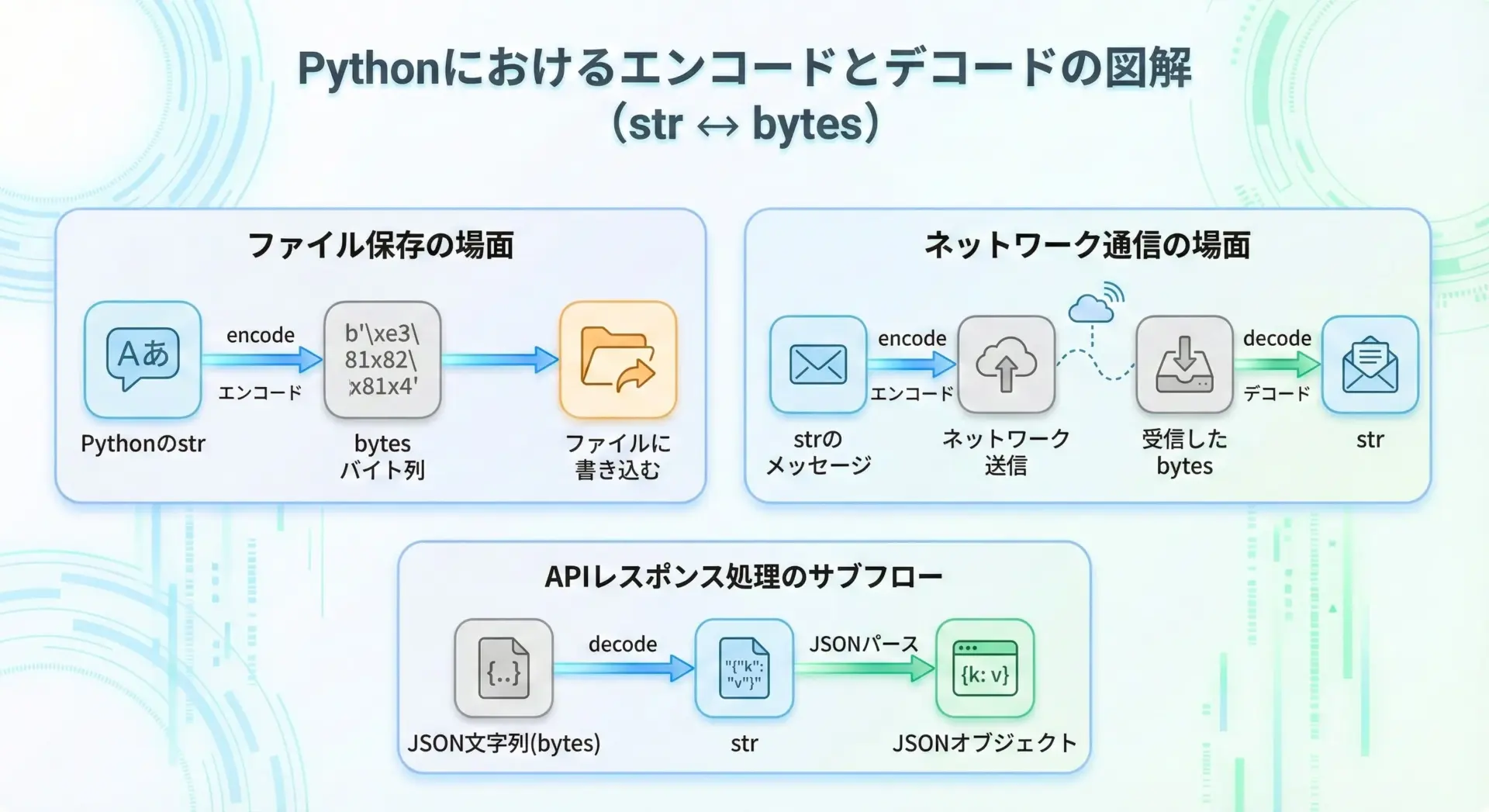
コンピュータは最終的にはすべてのデータを0と1(バイト列)として保存・通信します。
しかし、私たちは0と1の羅列を直接読み書きすることはできません。
そこで、人間が読める「文字列」と、コンピュータ向けの「バイト列」を橋渡しする作業が必要になります。
この橋渡しがencodeとdecodeです。
例えば、次のような場面では必ずエンコードやデコードが関係しています。
- テキストファイルに日本語を保存するとき
- ネットワーク経由でメッセージやJSONを送受信するとき
- Web APIのレスポンスを読み取るとき
- データベースに文字列を保存・取得するとき
Pythonでは内部的に多くの箇所で自動的にエンコード・デコードを行っていますが、ファイルやネットワークを自分で扱うときは、どこでエンコードするか、どこでデコードするかを意識する必要があります。
よく使う文字コード(UTF-8など)の基本
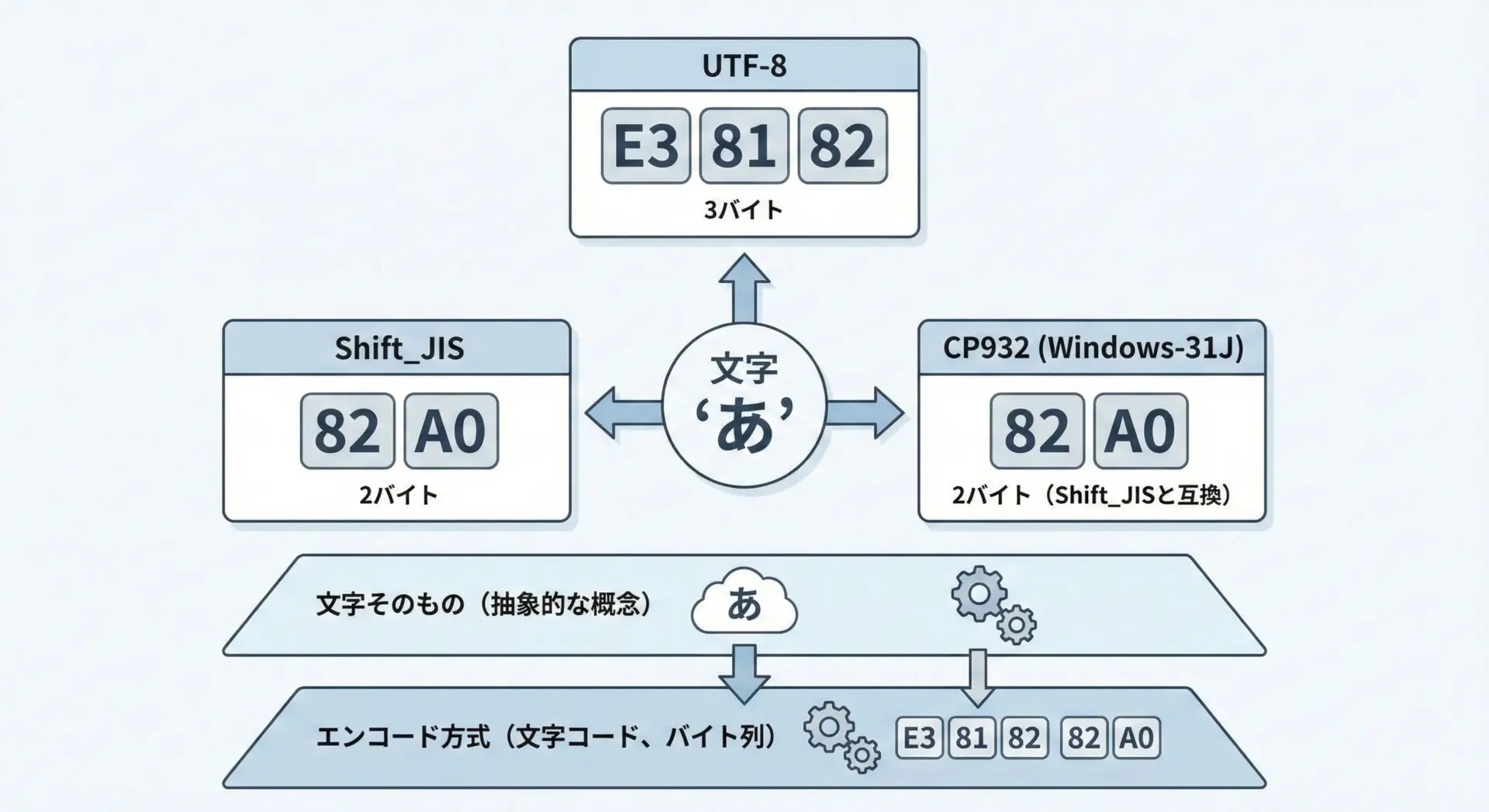
encodeやdecodeではencoding(文字コード)を必ず意識しなければなりません。
文字コードとは、「どの文字にどの数値(バイト列)を割り当てるか」という取り決めです。
代表的な文字コードには次のようなものがあります。
| 文字コード | 特徴 | Pythonでの指定名の例 |
|---|---|---|
| UTF-8 | 世界中の文字をほぼ網羅。現代の標準 | "utf-8" |
| Shift_JIS | 旧来の日本語環境でよく使われた文字コード | "shift_jis" |
| CP932 | Windows日本語向けのShift_JIS互換系 | "cp932" |
| EUC-JP | 一部Unix系で使われた日本語コード | "euc_jp" |
同じ「文字列」でも、文字コードが違うとバイト列の中身はまったく変わります。
そのため、encodeとdecodeでは「どの文字コードで変換するか」を正しく指定することが重要です。
とくに、ファイルやAPIの仕様で「UTF-8で送ります」「Shift_JISで保存します」と決められている場合は、その指定に合わせる必要があります。
encodeの使い方
str.encodeの基本的な書き方
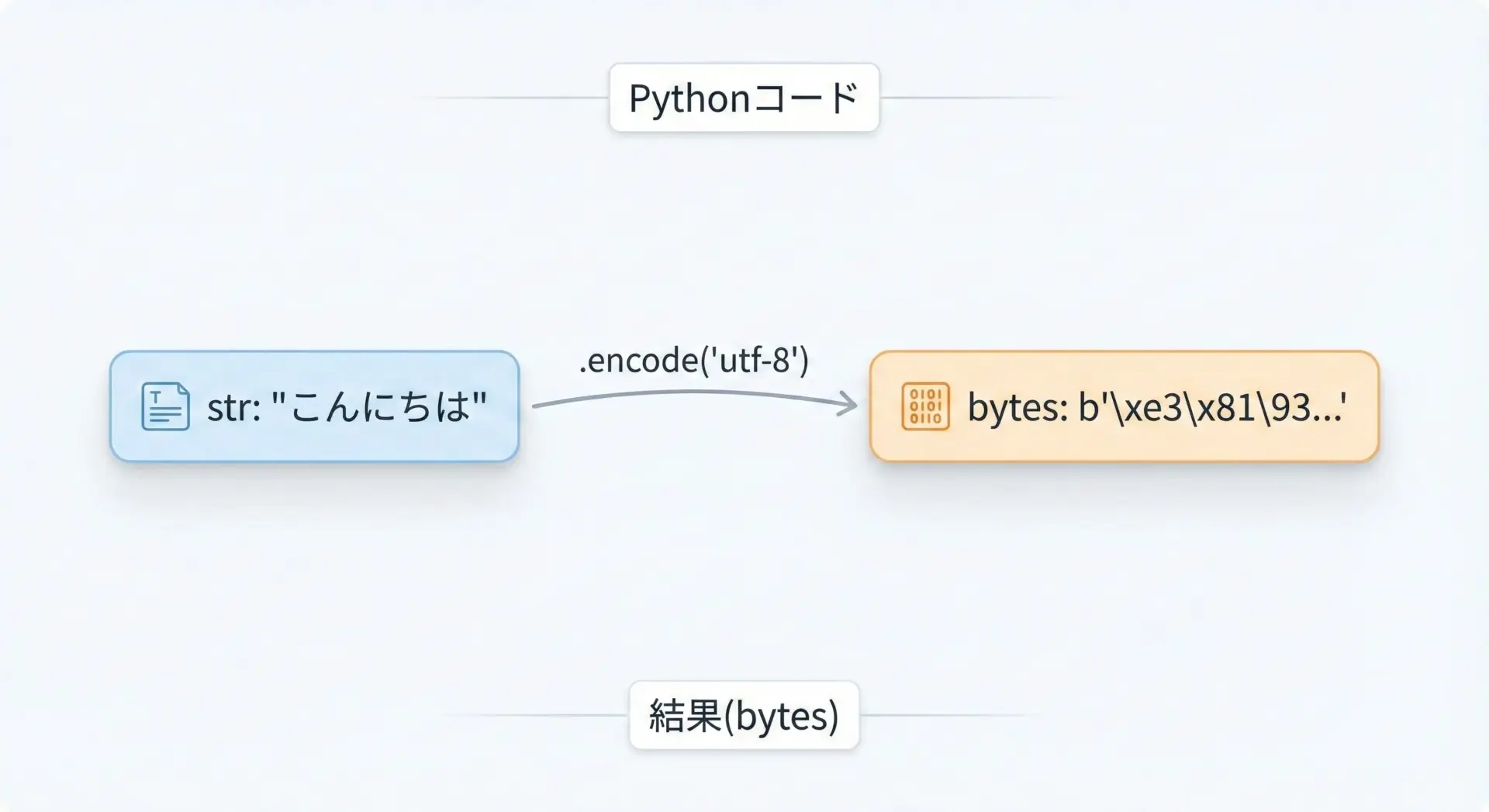
Pythonでエンコードを行うときは、文字列オブジェクトstrに対して.encode()メソッドを呼び出します。
基本的な書き方は次のようになります。
# 文字列からバイト列へ変換する基本形
text = "こんにちは" # str型
data = text.encode("utf-8") # bytes型に変換
print(text, type(text)) # 元はstr
print(data, type(data)) # 変換後はbytesこんにちは <class 'str'>
b'\xe3\x81\x93\xe3\x82\x93\xe3\x81\xab\xe3\x81\xa1\xe3\x81\xaf' <class 'bytes'>ここでは"utf-8"という文字コードを指定して、文字列をUTF-8のバイト列へ変換しています。
encodeは必ずstrに対して呼び出すという点を覚えておいてください。
encodeで指定するencodingとエラー処理
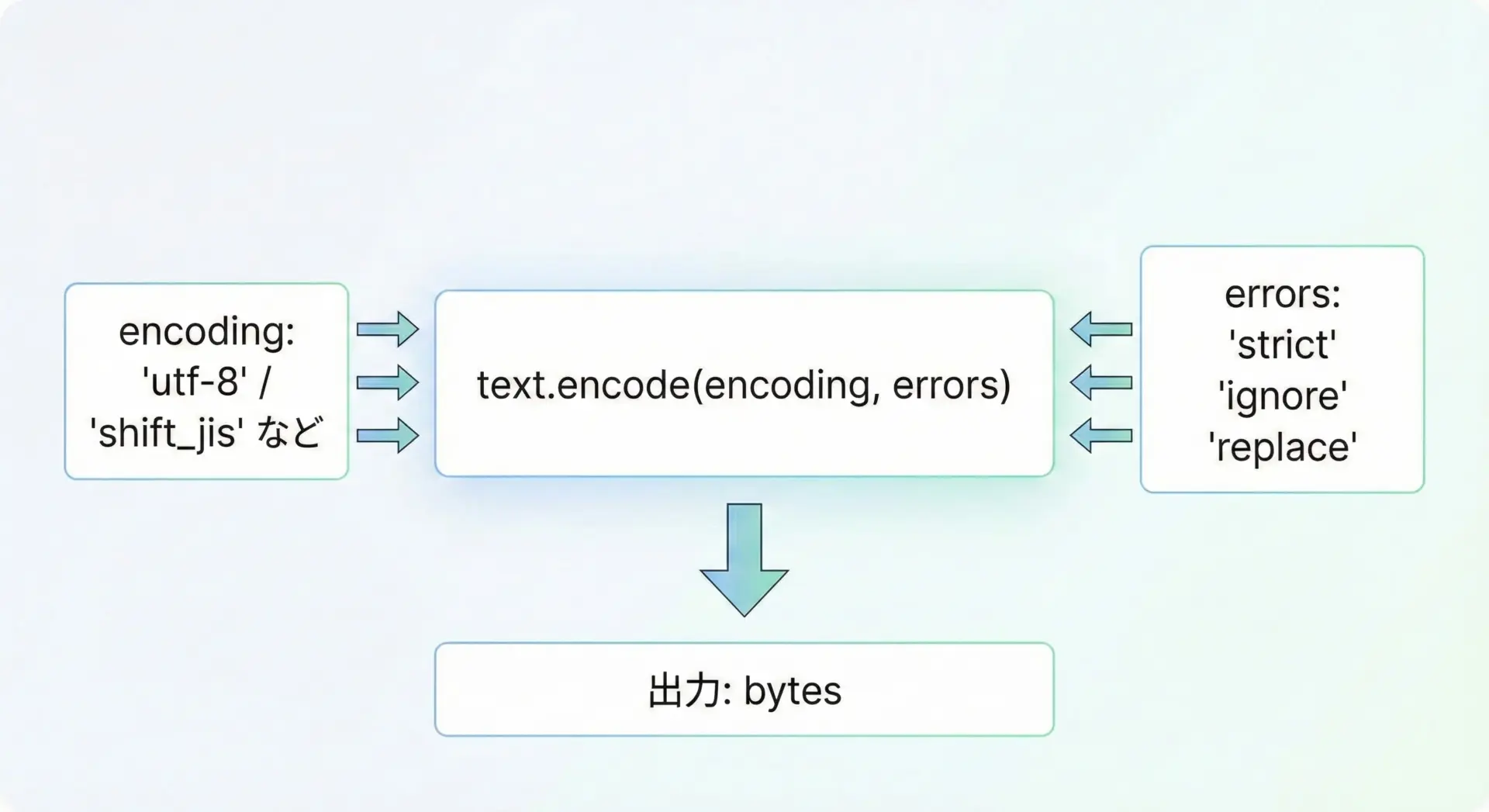
str.encodeには主に次のような引数があります。
encoding: 文字コード名(省略可能)errors: エラーが起きたときの扱い方(省略可能)
encoding(文字コード)の指定
encodingを省略すると、多くの環境では"utf-8"が使われます。
しかし、環境やバージョンによって異なる可能性もあり、またコードの意図も分かりづらくなるため、基本的には明示的に"utf-8"などを指定することをおすすめします。
text = "こんにちは"
# encoding省略(多くの環境でutf-8になるが、明示した方が安全)
data1 = text.encode()
# encodingを明示
data2 = text.encode("utf-8")
data3 = text.encode("shift_jis")
print(data1)
print(data2)
print(data3)b'\xe3\x81\x93\xe3\x82\x93\xe3\x81\xab\xe3\x81\xa1\xe3\x81\xaf'
b'\xe3\x81\x93\xe3\x82\x93\xe3\x81\xab\xe3\x81\xa1\xe3\x81\xaf'
b'\x82\xb1\x82\xf1\x82\xc9\x82\xbf\x82\xcd'同じ"こんにちは"でも、UTF-8とShift_JISでバイト列が異なることが分かります。
errors(エラー処理)の指定
エンコード時に、その文字コードでは表現できない文字が含まれているとUnicodeEncodeErrorが発生します。
そのときの挙動をerrorsで制御できます。
よく使う指定は次の通りです。
| errors | 挙動の概要 |
|---|---|
| strict | デフォルト。表現できない文字があれば例外を送出 |
| ignore | 表現できない文字を無視(削除)して続行 |
| replace | 表現できない文字を'?'などに置き換え |
具体例を見てみます。
text = "漢字と絵文字🙂を含むテキスト"
# Shift_JISで表現できない文字がある場合
try:
data_strict = text.encode("shift_jis", errors="strict")
except UnicodeEncodeError as e:
print("strict:", e)
# 無視する場合
data_ignore = text.encode("shift_jis", errors="ignore")
print("ignore:", data_ignore)
# 置き換える場合
data_replace = text.encode("shift_jis", errors="replace")
print("replace:", data_replace)strict: 'shift_jis' codec can't encode character '\U0001f642' in position 5: illegal multibyte sequence
ignore: b'\x8a\xbf\x8e\x9a\x82\xc6\x95F\x8a\x4a\x82\xf0\x8dO\x82\xe8\x83e\x83L\x83X\x83g'
replace: b'\x8a\xbf\x8e\x9a\x82\xc6? \x82\xf0\x8dO\x82\xe8\x83e\x83L\x83X\x83g'厳密に文字を保存したい場合はstrict、とにかく処理を止めたくない場合はignoreやreplaceを使う、という使い分けになります。
encodeの具体例
ここでは、実際にどのような場面でencodeを使うのか、簡単な例で確認します。
例1: 日本語をUTF-8でバイト列に変換
# 日本語文字列をUTF-8でエンコードする例
message = "Pythonで文字コードを学ぶ"
# UTF-8のバイト列に変換
data = message.encode("utf-8")
print("元の文字列:", message)
print("エンコード結果:", data)
print("バイト数:", len(data)) # 何バイトになったか確認元の文字列: Pythonで文字コードを学ぶ
エンコード結果: b'Python\xe3\x81\xa7\xe6\x96\x87\xe5\xad\x97\xe3\x82\xb3\xe3\x83\xbc\xe3\x83\x89\xe3\x82\x92\xe5\xad\xa6\xe3\x81\xb6'
バイト数: 34例2: 異なる文字コードでエンコードしてバイト数を比較
text = "あいうえお"
data_utf8 = text.encode("utf-8")
data_sjis = text.encode("shift_jis")
print("UTF-8:", data_utf8, "長さ:", len(data_utf8))
print("Shift_JIS:", data_sjis, "長さ:", len(data_sjis))UTF-8: b'\xe3\x81\x82\xe3\x81\x84\xe3\x81\x86\xe3\x81\x88\xe3\x81\x8a' 長さ: 15
Shift_JIS: b'\x82\xa0\x82\xa2\x82\xa4\x82\xa6\x82\xa8' 長さ: 10このように、同じ文字列でも文字コードによってバイト数や中身が変わることが分かります。
ファイル保存やネットワーク通信でのencodeの役割
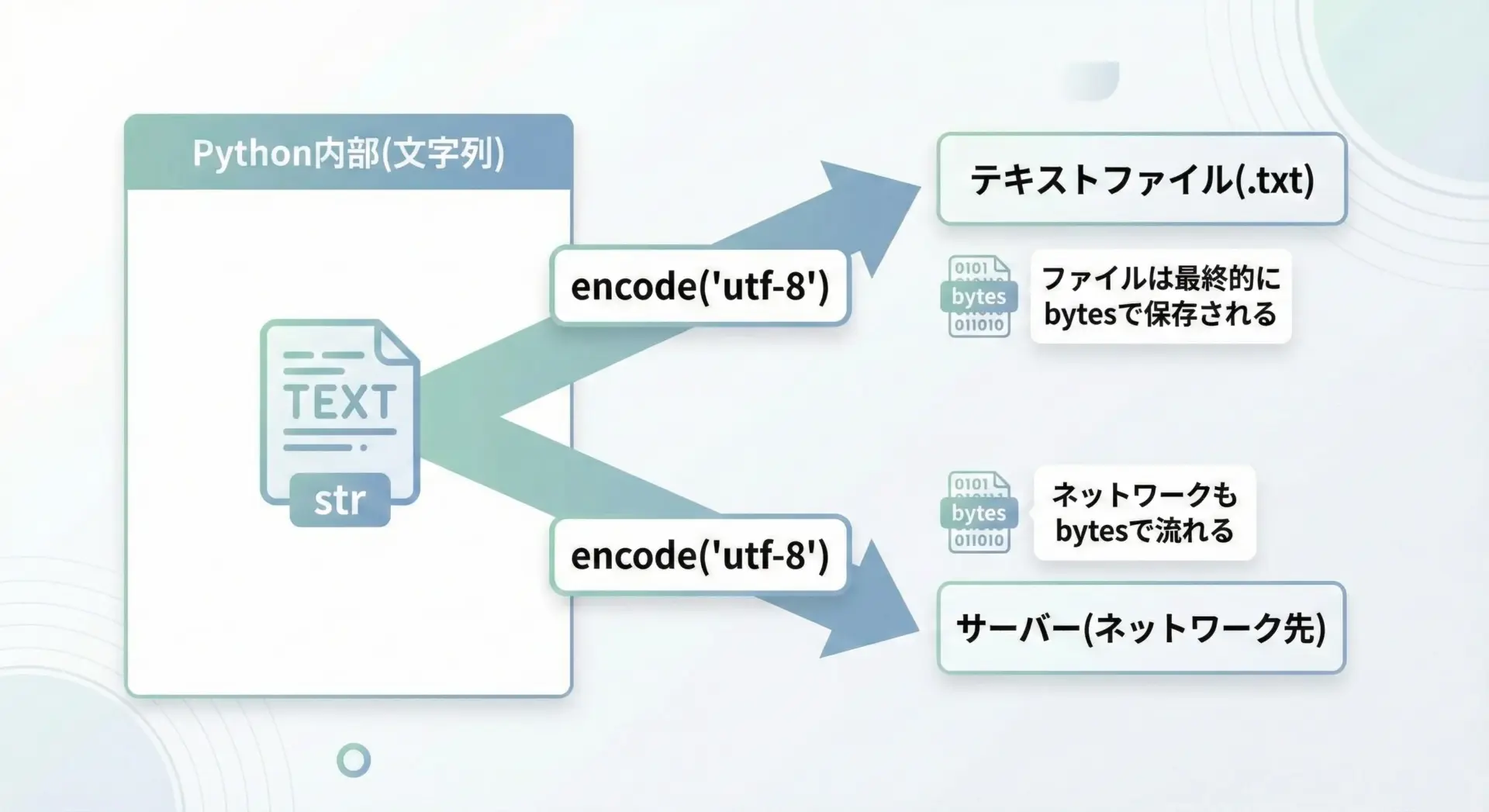
ファイルやネットワーク通信では、最終的には必ずバイト列がやり取りされます。
そのため、Pythonで文字列を扱っていても、保存や送信の直前でencodeが必要になります。
簡単な例として、openを使ったファイル保存を見てみます。
# テキストファイルにUTF-8で保存する例
text = "ファイルに保存するテキストです。"
# バイトモードで開き、手動でencodeして書き込む
with open("sample_bytes.txt", "wb") as f: # "wb" はバイナリ書き込みモード
data = text.encode("utf-8") # str → bytes
f.write(data) # bytesを書き込む(このコードを実行すると、カレントディレクトリに sample_bytes.txt が生成されます)実は、Pythonのopenで"w"モードとencodingを指定すれば、内部で自動的にencodeしてくれます。
# テキストモードで開くと自動的にエンコードされる
text = "自動的にUTF-8で保存されます。"
with open("sample_text.txt", "w", encoding="utf-8") as f:
f.write(text) # ここではstrを書いているが、内部でencodeされる(このコードを実行すると、sample_text.txt がUTF-8で保存されます)ネットワーク通信でも同様に、ソケットに送る前やHTTPリクエストボディを作るときにencodeすることが多いです。
例えば、HTTPライブラリの中でも、文字列を送信する際には内部でエンコードが行われています。
decodeの使い方
bytes.decodeの基本的な書き方
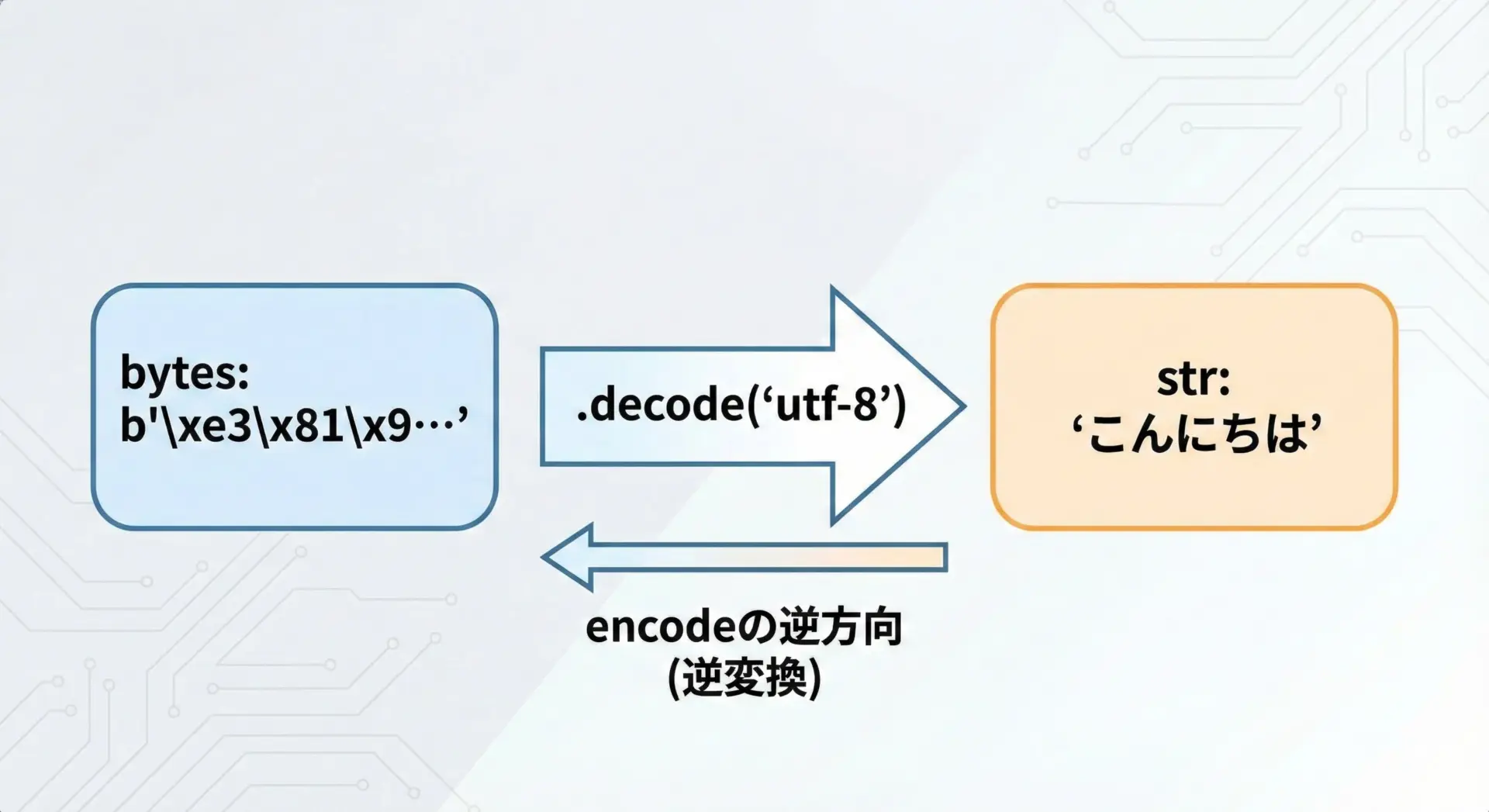
decodeはencodeの逆方向の操作です。
bytesからstrへ変換します。
基本的な書き方は次のようになります。
# バイト列から文字列へ変換する基本形
data = b'\xe3\x81\x93\xe3\x82\x93\xe3\x81\xab\xe3\x81\xa1\xe3\x81\xaf' # bytes型
text = data.decode("utf-8") # str型に変換
print(data, type(data)) # 元はbytes
print(text, type(text)) # 変換後はstrb'\xe3\x81\x93\xe3\x82\x93\xe3\x81\xab\xe3\x81\xa1\xe3\x81\xaf' <class 'bytes'>
こんにちは <class 'str'>.decode()はbytes型のオブジェクトに対して呼び出す点が重要です。
strに対して.decode()を呼ぶとエラーになります。
decodeで気をつける文字コードの指定
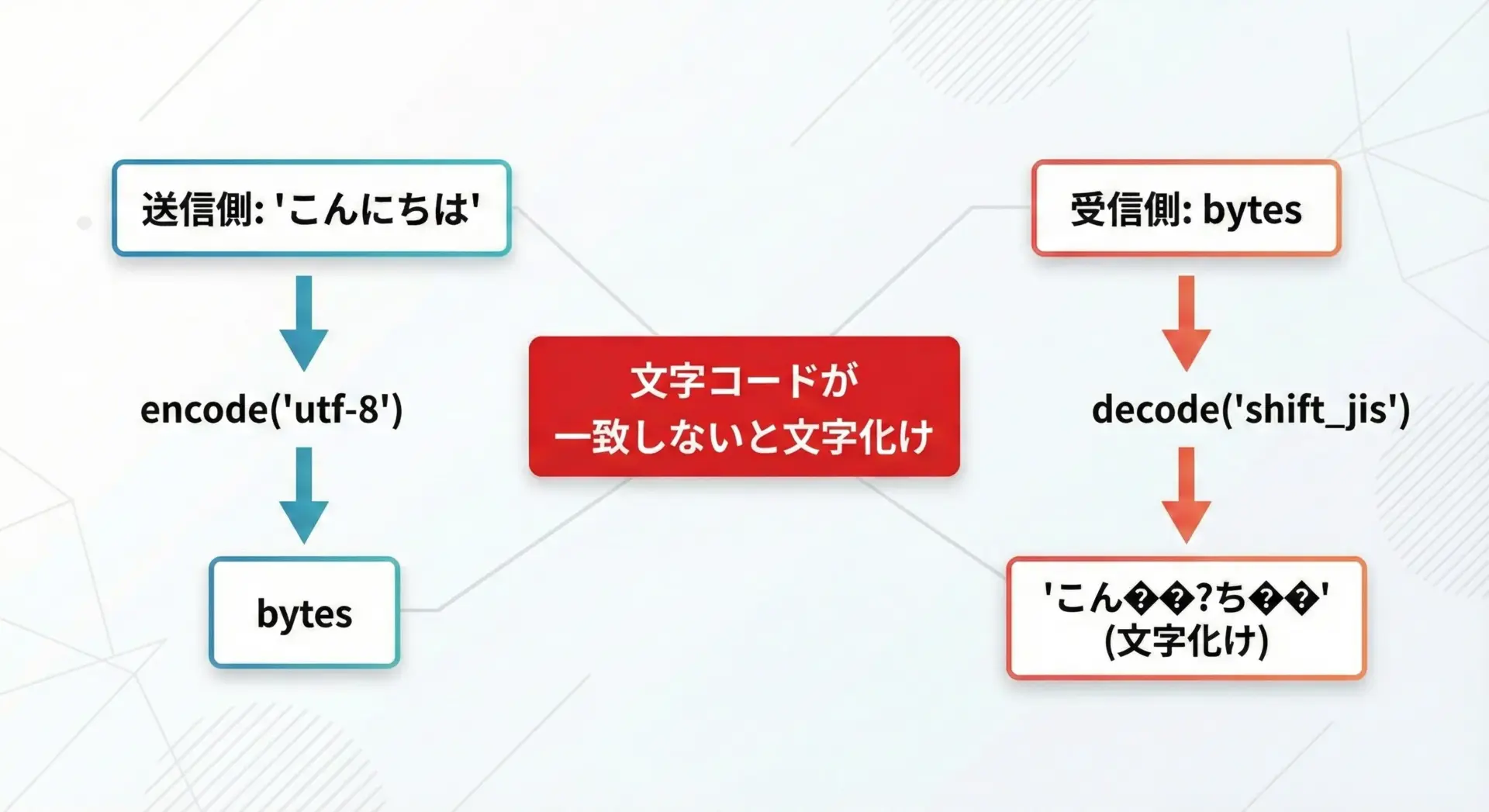
decodeでは「どの文字コードでエンコードされたbytesなのか」を正しく指定する必要があります。
ここを間違えると、いわゆる文字化けが発生します。
# UTF-8でエンコードされたバイト列
data_utf8 = "こんにちは".encode("utf-8")
# 正しくUTF-8としてデコード
text_ok = data_utf8.decode("utf-8")
print("正しいdecode:", text_ok)
# 間違ってShift_JISとしてデコードしようとする例
try:
text_ng = data_utf8.decode("shift_jis")
print("間違ったdecode:", text_ng) # 実行環境によっては例外・文字化けなど
except UnicodeDecodeError as e:
print("エラー発生:", e)正しいdecode: こんにちは
エラー発生: 'shift_jis' codec can't decode byte 0x83 in position 4: illegal multibyte sequence実際のアプリケーションでは、ファイルやAPIの仕様書を確認して「UTF-8なのか、Shift_JISなのか」を必ず合わせることが重要です。
送信側と受信側で文字コードが一致して初めて、正しくdecodeできます。
decodeの具体例
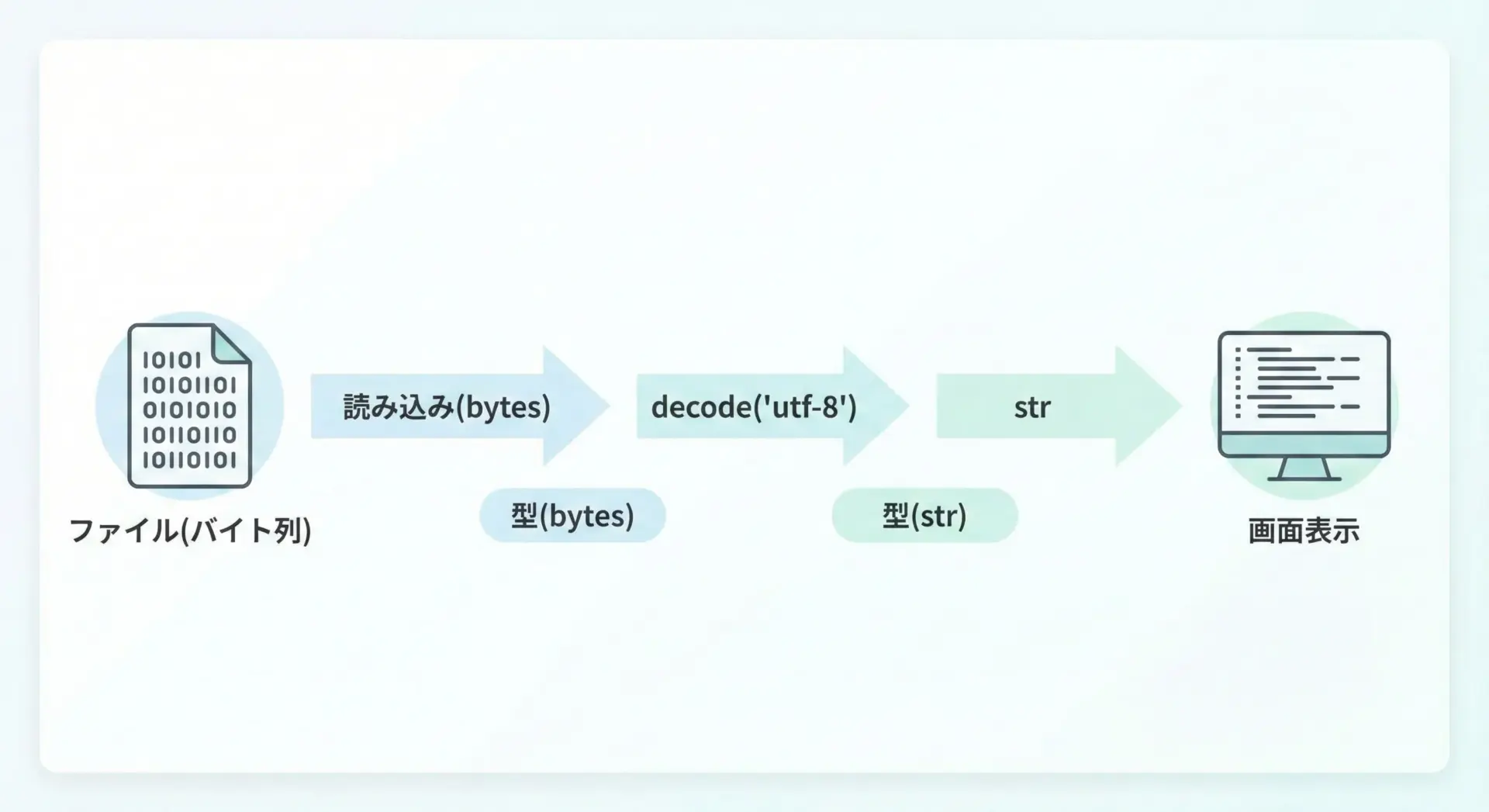
例1: 単純なバイト列のdecode
# bytesリテラルから文字列に戻す例
data = b'Python\xe3\x81\xa7\xe6\x96\x87\xe5\xad\x97\xe3\x82\xb3\xe3\x83\xbc\xe3\x83\x89'
text = data.decode("utf-8")
print("バイト列:", data)
print("デコード結果:", text)バイト列: b'Python\xe3\x81\xa7\xe6\x96\x87\xe5\xad\x97\xe3\x82\xb3\xe3\x83\xbc\xe3\x83\x89'
デコード結果: Pythonで文字コード例2: 異なる文字コードでエンコードされたバイト列のdecode
# 同じ日本語を異なる文字コードでエンコードして、正しくdecodeする例
text = "エンコードとデコード"
data_utf8 = text.encode("utf-8")
data_sjis = text.encode("shift_jis")
decoded_utf8 = data_utf8.decode("utf-8")
decoded_sjis = data_sjis.decode("shift_jis")
print("UTF-8からdecode:", decoded_utf8)
print("Shift_JISからdecode:", decoded_sjis)UTF-8からdecode: エンコードとデコード
Shift_JISからdecode: エンコードとデコードこのように、エンコード時と同じ文字コードを指定してdecodeすれば、必ず元の文字列に戻せます。
ファイル読み込みやAPIレスポンスでのdecodeの役割
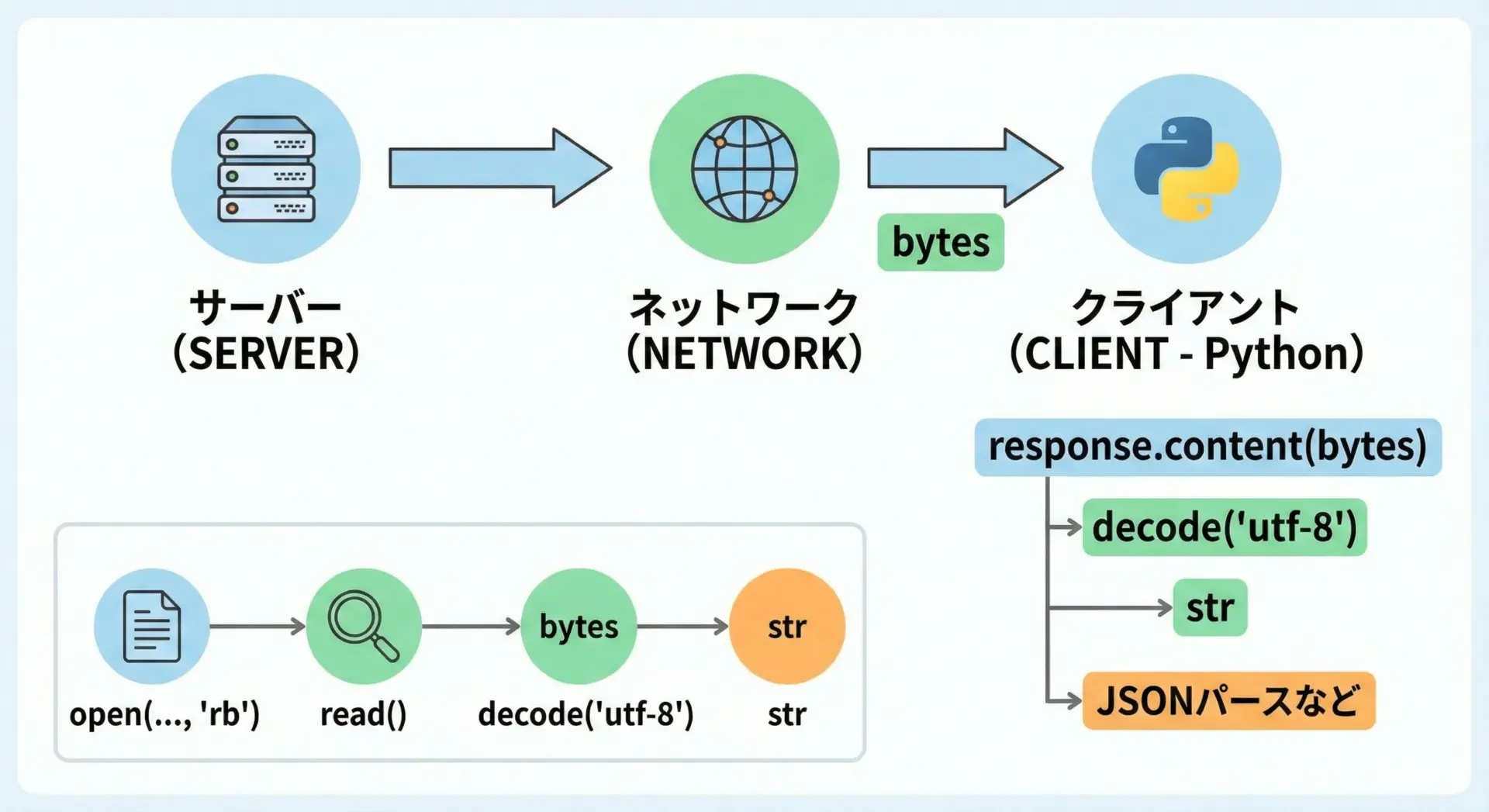
ファイル読み込みやWeb APIレスポンスでは、まずbytesとしてデータを受け取り、それをdecodeしてstrにします。
ファイル読み込みの例
# 事前にUTF-8で保存されたファイル sample_text.txt があるとする
with open("sample_text.txt", "rb") as f: # バイナリモードで読む
data = f.read() # bytesとして読み込み
text = data.decode("utf-8") # UTF-8でdecodeしてstrに
print("読み込んだバイト列:", data)
print("decode結果:", text)読み込んだバイト列: b'\xe8\x87\xaa\xe5\x8b\x95\xe7\x9a\x84\xe3\x81\xabUTF-8\xe3\x81\xa7\xe4\xbf\x9d\xe5\xad\x98\xe3\x81\x95\xe3\x82\x8c\xe3\x81\xbe\xe3\x81\x99\xe3\x80\x82'
decode結果: 自動的にUTF-8で保存されます。もちろん、openでencodingを指定すれば、自動的にdecodeしてくれます。
with open("sample_text.txt", "r", encoding="utf-8") as f:
text = f.read() # ここではすでにstrとして取得できる
print("テキストとして読み込み:", text)テキストとして読み込み: 自動的にUTF-8で保存されます。APIレスポンスでのdecode例(イメージ)
実際のHTTPクライアントライブラリでは、レスポンスボディをbytesで受け取り、それをdecodeしてからJSONパースなどを行います。
たとえばrequestsライブラリ(あくまでイメージ)の場合です。
import requests # 実際の実行には requests のインストールが必要です
response = requests.get("https://example.com/api")
# レスポンス本文を bytes で取得
content_bytes = response.content # type: bytes
# サーバーがUTF-8と明記している場合
text = content_bytes.decode("utf-8") # type: str
print("レスポンス文字列:", text[:100]) # 先頭100文字だけ表示レスポンス文字列: { "status": "ok", "data": ... (以下略)多くのライブラリではresponse.textのようにstrを直接返してくれるプロパティがありますが、その内部ではdecodeが必ず行われています。
encodeとdecodeの違いと初心者のつまずきポイント
encodeとdecodeの方向
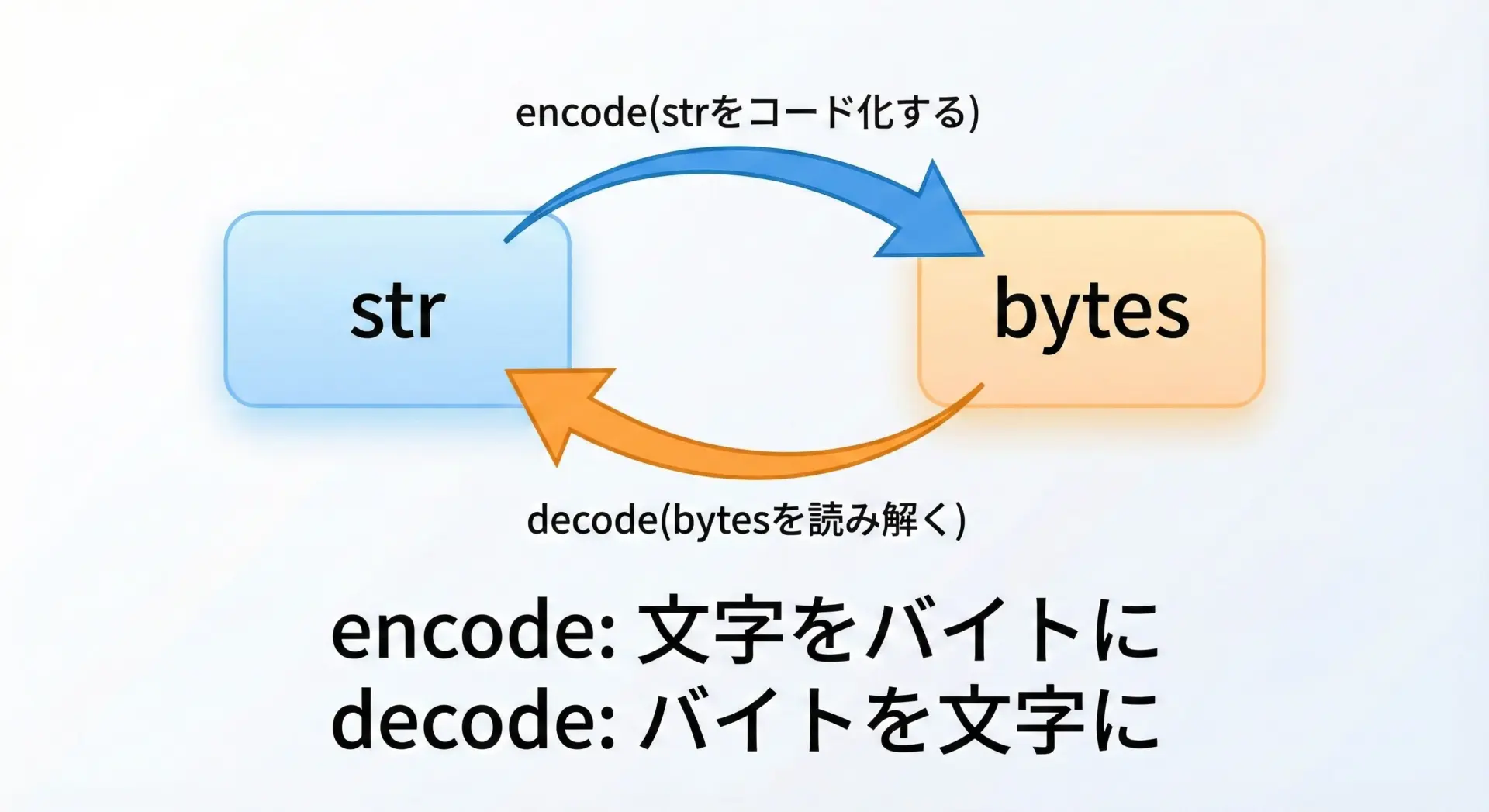
初心者が最初に混乱するのは、encodeとdecodeの「向き」です。
ここはシンプルに以下のように整理できます。
- encode: str → bytes
- decode: bytes → str
たとえば、次のように「どちらの型が元なのか」を意識すると覚えやすくなります。
- 文字列(str)を「エンコード」してbytesにする
- バイト列(bytes)を「デコード」してstrに戻す
この対応関係と、encodeはstrのメソッド、decodeはbytesのメソッドであることをセットで覚えておくと、混乱しづらくなります。
よくあるエラーと原因
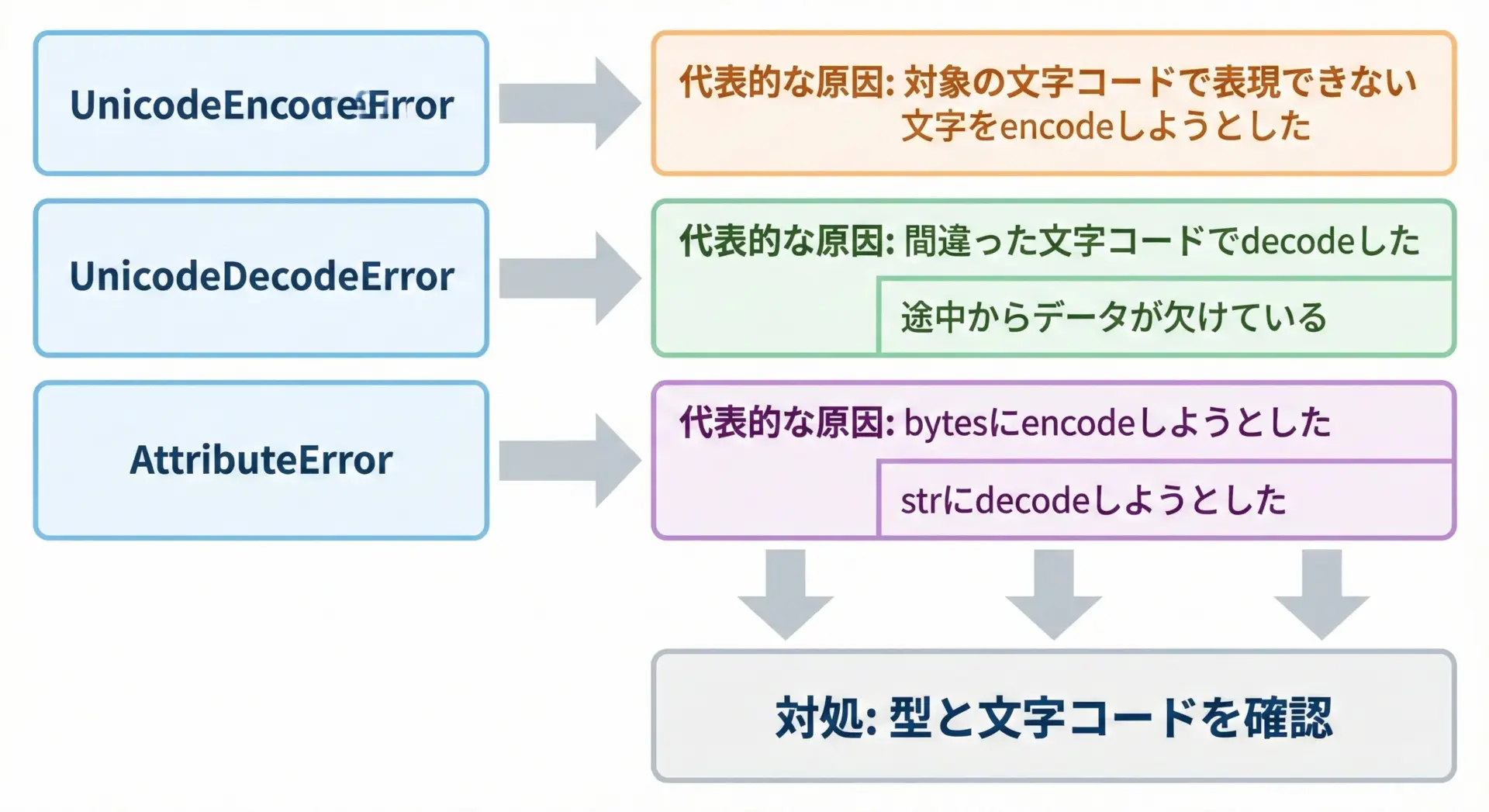
encode/decode周りでは、次のようなエラーがよく発生します。
1. UnicodeEncodeError
text = "絵文字🙂を含むテキスト"
# Shift_JISでは表現できない絵文字をエンコードしようとする
data = text.encode("shift_jis")UnicodeEncodeError: 'shift_jis' codec can't encode character '\U0001f642' in position 2: illegal multibyte sequence指定した文字コードで表現できない文字が含まれているのが原因です。
対処としては、UTF-8などより広い文字コードを使うか、errors="ignore"やerrors="replace"を指定します。
2. UnicodeDecodeError
# 本来はShift_JISでエンコードされたバイト列だが、UTF-8としてdecodeしようとする例
data_sjis = "テスト".encode("shift_jis")
text = data_sjis.decode("utf-8")UnicodeDecodeError: 'utf-8' codec can't decode byte 0x83 in position 0: invalid start byteエンコード時に使われた文字コードと、decode時に指定した文字コードが一致していないのが原因です。
送信元の仕様やファイルのエンコーディングを確認し、正しいencodingを指定する必要があります。
3. AttributeError(型を間違えた場合)
text = "こんにちは"
data = b"hello"
# strにdecodeしようとしてエラー
try:
text_decoded = text.decode("utf-8")
except AttributeError as e:
print("str.decode エラー:", e)
# bytesにencodeしようとしてエラー
try:
data_encoded = data.encode("utf-8")
except AttributeError as e:
print("bytes.encode エラー:", e)str.decode エラー: 'str' object has no attribute 'decode'
bytes.encode エラー: 'bytes' object has no attribute 'encode'正しくはencodeはstr側、decodeはbytes側に対して呼び出す必要があります。
Pythonのデフォルトエンコーディングの考え方
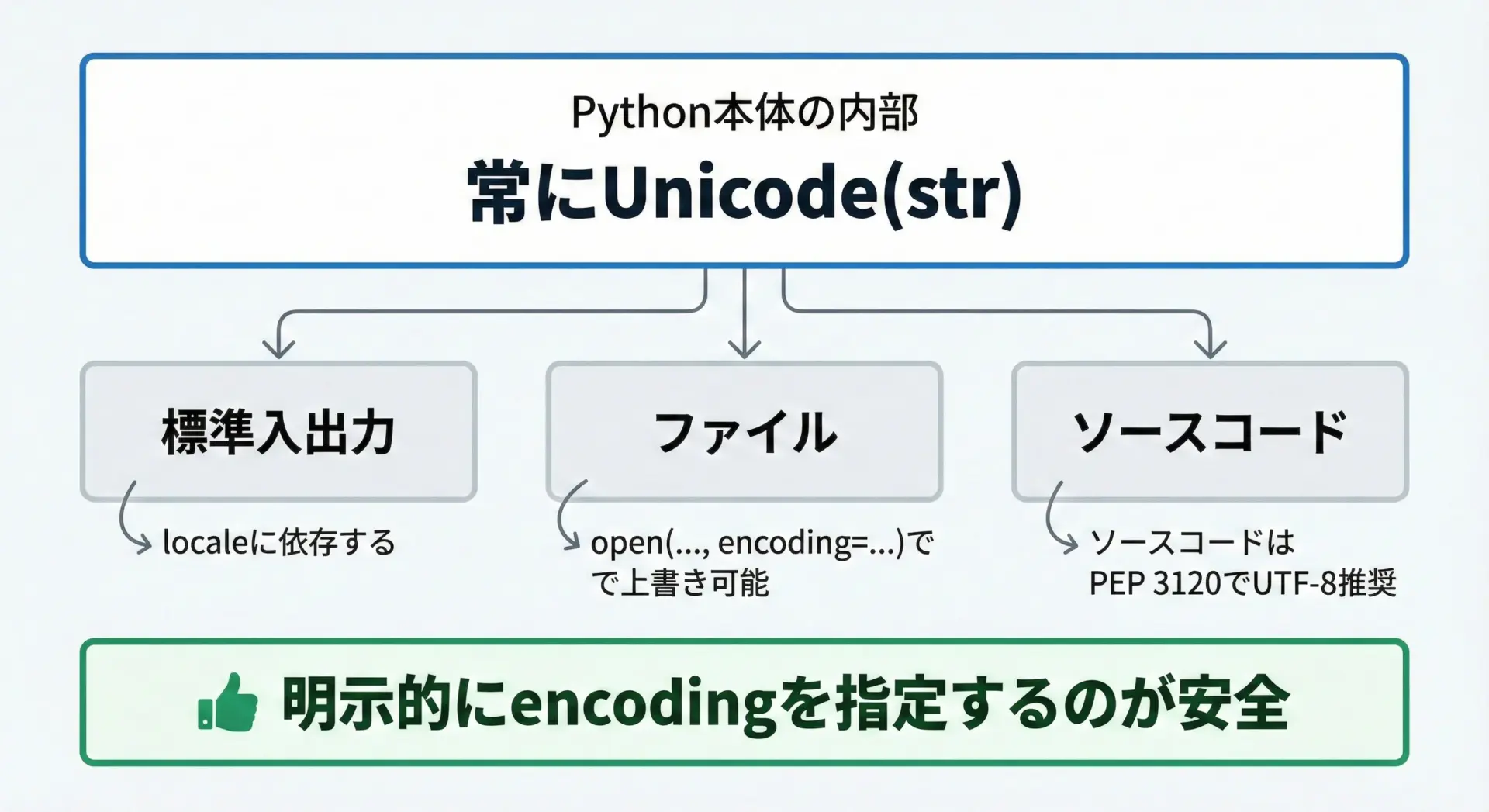
Pythonの内部では、文字列は基本的にUnicode(str)として管理されています。
そのうえで、外部とのやり取り(ファイル、コンソール、ネットワークなど)の際に文字コードが関係してきます。
初心者が混乱しやすいのは「デフォルトのエンコーディングが何か」です。
ポイントを整理すると次の通りです。
- Python 3系ではソースコードは原則UTF-8とみなされます
(特殊な指定をしない限り、ソースファイル内の日本語はUTF-8として解釈されます) str.encode()やbytes.decode()でencodingを省略した場合、多くの環境ではUTF-8が使われますが、環境依存する可能性もありますopen()でencodingを省略した場合、OSやロケールに依存することがあり、Windowsではcp932、Linuxではutf-8になるなどの違いがあります
そのため、実務や学習で混乱を避けたい場合は、基本的にencodingを明示することが重要です。
とくにファイルを扱うときは、次のように書くのが安全です。
# ファイル書き込み・読み込みではencodingを明示するのがおすすめ
with open("example.txt", "w", encoding="utf-8") as f:
f.write("こんにちは")
with open("example.txt", "r", encoding="utf-8") as f:
text = f.read()
print(text)こんにちは初心者が迷わないためのencode/decodeの覚え方
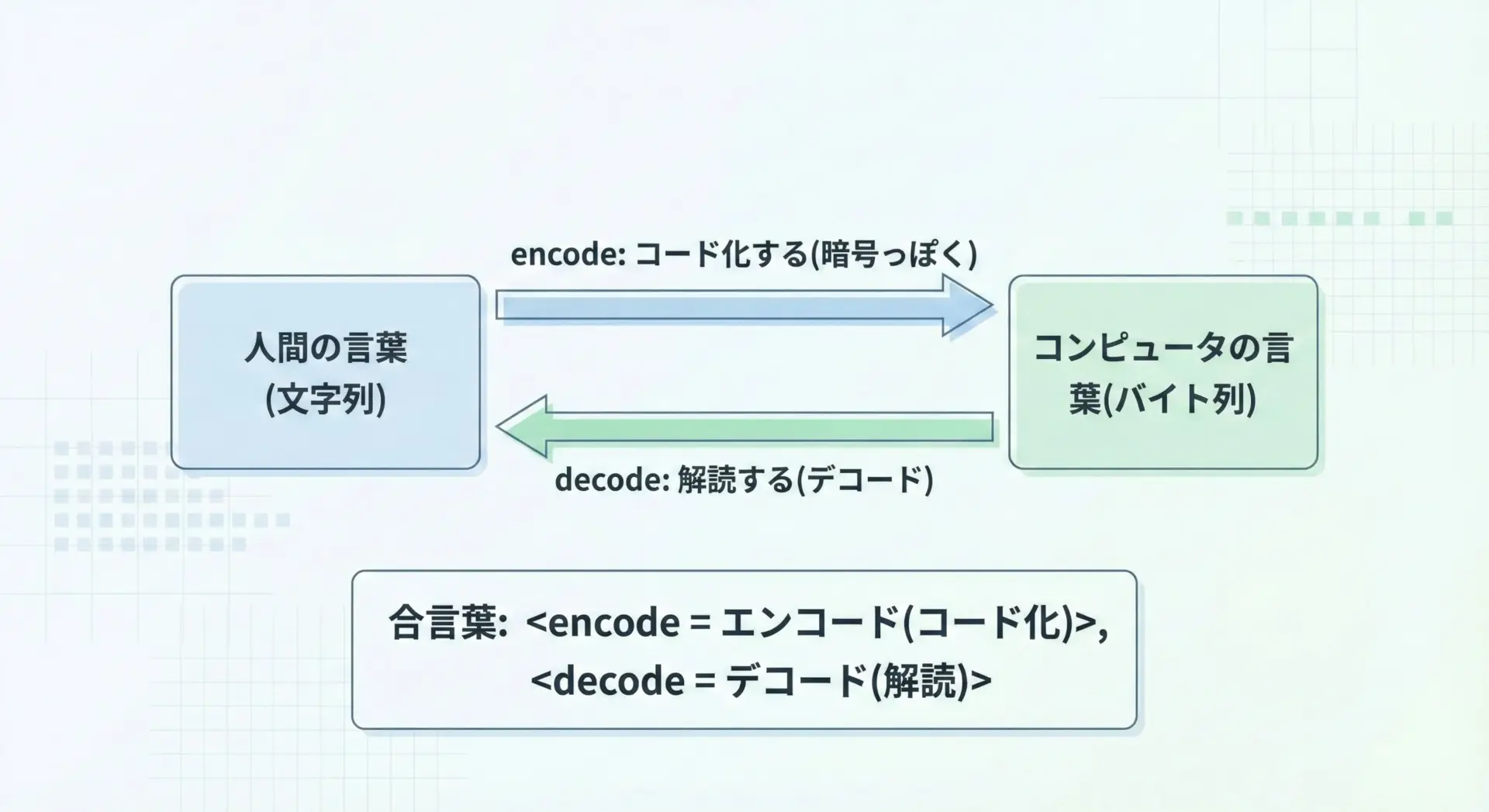
初心者が混乱しやすいポイントを整理しつつ、覚えやすいコツをまとめます。
1つ目のコツは、英単語の意味から覚えることです。
encode: 「コード化する」「暗号化する」に近いイメージ
→ 読みやすい文字(str)を、コンピュータ向けのコード(bytes)に変換decode: 「解読する」「コードを元に戻す」イメージ
→ コンピュータのコード(bytes)を、人間が読める文字(str)に戻す
2つ目のコツは型とメソッドの対応関係で覚えることです。
- str.encode() → 戻り値はbytes
- bytes.decode() → 戻り値はstr
3つ目のコツは、ペアで考えることです。
- 保存や送信:
str → encode → bytes - 読み込みや受信:
bytes → decode → str
これらをセットでイメージできるようになると、「今自分はどちら側にいるのか」「次にどちらの型が必要なのか」が分かりやすくなり、迷いにくくなります。
まとめ
Pythonのencodeとdecodeは、文字列(str)とバイト列(bytes)を相互に変換するための基本中の基本です。
encodeはstr → bytes、decodeはbytes → strであり、どちらもencoding(文字コード)を正しく指定することが重要です。
ファイル保存や読み込み、ネットワーク通信、APIレスポンスの処理など、外部とのやり取りでは必ずエンコードとデコードが関わります。
初心者の方は、str.encode()とbytes.decode()の型の対応と、UTF-8を基本とした文字コードの指定を意識することで、文字化けやエラーを大幅に減らすことができます。
