
Pythonで入力を扱うとき、文字列が数字なのか英字なのか、それとも英数字が混ざっているのかを判定したくなる場面はとても多いです。
本記事では、Pythonの組み込みメソッドと正規表現を使って「数字」「英字」「英数字」などを正確に判定する実践的な方法を、サンプルコードと図解を交えながら詳しく解説します。
Pythonでの文字列判定の基本
文字列が数字か英字か英数字かを判定したい場面
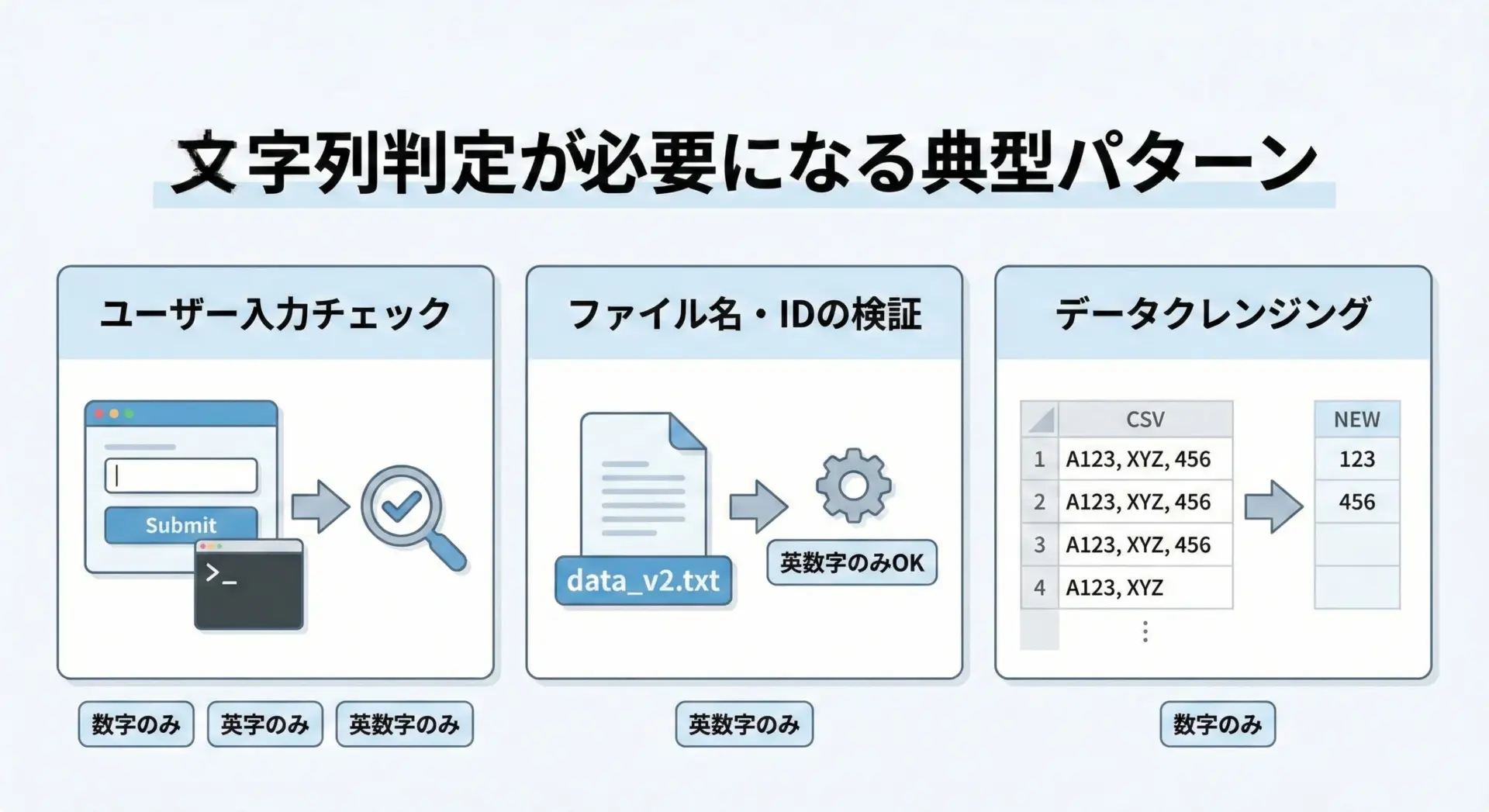
システム開発やデータ処理をしていると、文字列の内容をチェックしたい場面がよくあります。
例えば、ユーザーに会員IDを入力してもらう場合、仕様として「半角英数字のみ」「先頭は英字」「数字だけ」といった制約を付けることが多いです。
そのとき、プログラム側で「この文字列は本当に数字だけで構成されているのか」「英字だけか」「英数字だけか」を判定できる必要があります。
また、CSVやログファイルを解析するときに、数字だけの行を抽出したり、英字だけの列を検出したりするケースもあります。
このような処理は、Pythonが提供する文字列メソッドや正規表現を使うことで、短く読みやすいコードで実装できます。
Pythonの組み込みメソッドで簡単に判定できる理由
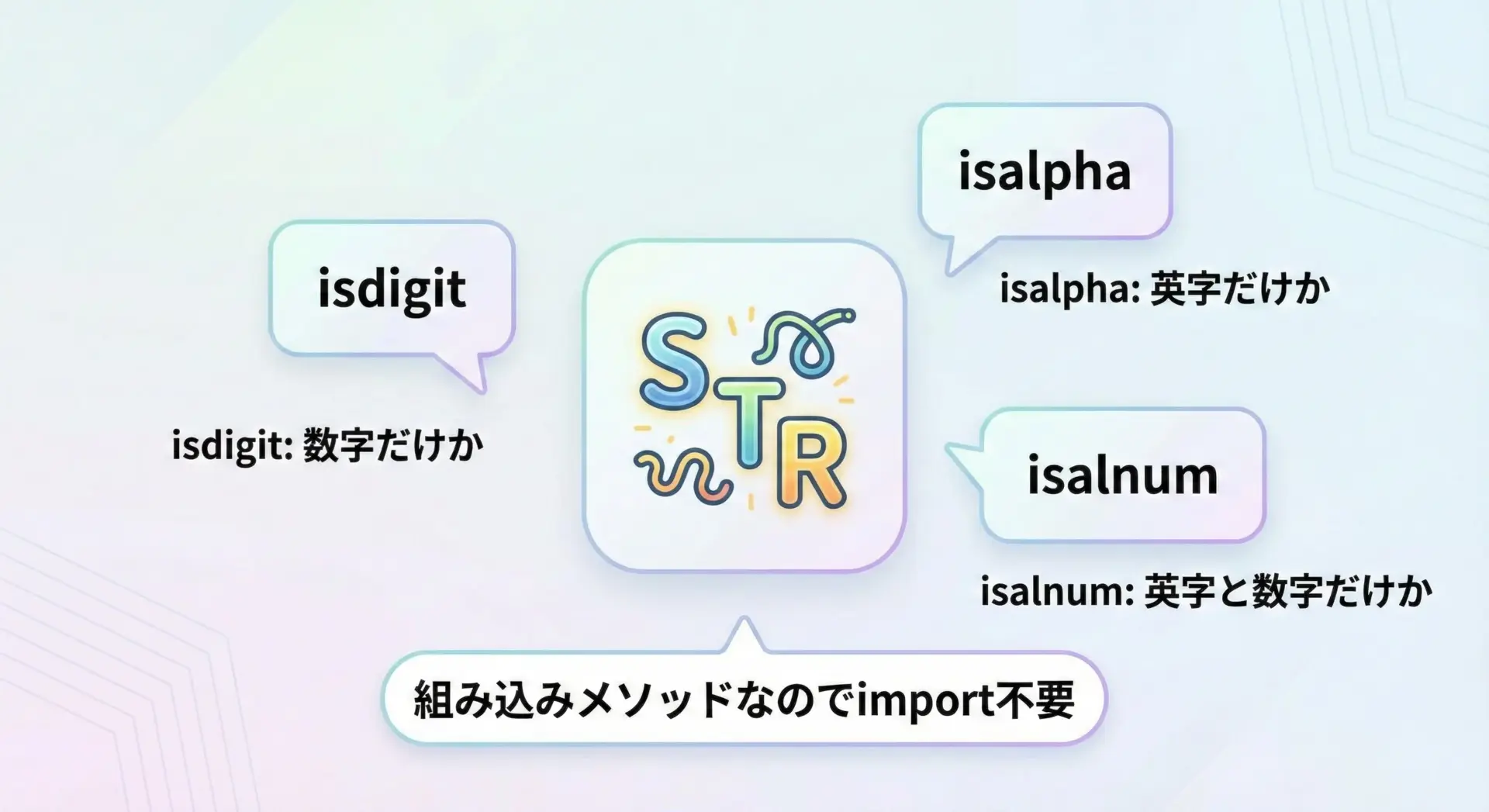
Pythonの文字列型strには、判定用のメソッドが標準で多数用意されています。
特に文字種の判定に関しては、次の3つが中心になります。
str.isdigit(): 文字列が「数字」だけで構成されているかどうかstr.isalpha(): 文字列が「文字(アルファベットなどの文字)」だけで構成されているかどうかstr.isalnum(): 文字列が「英字か数字」だけで構成されているかどうか
これらはPythonの組み込みメソッドなので、特別なモジュールをインポートする必要がなく、任意の文字列に対して直接利用できます。
ただし、「数字」「英字」の定義が、必ずしも「半角0〜9」「A〜Z、a〜z」に限定されていないという点が重要です。
Unicodeの観点で「数字」「文字」と認識される文字(全角数字、ローマ数字など)も含まれるため、要件によっては挙動を正しく理解しておく必要があります。
isdigitで数字かどうかを判定する方法
str.isdigitの基本的な使い方と注意点
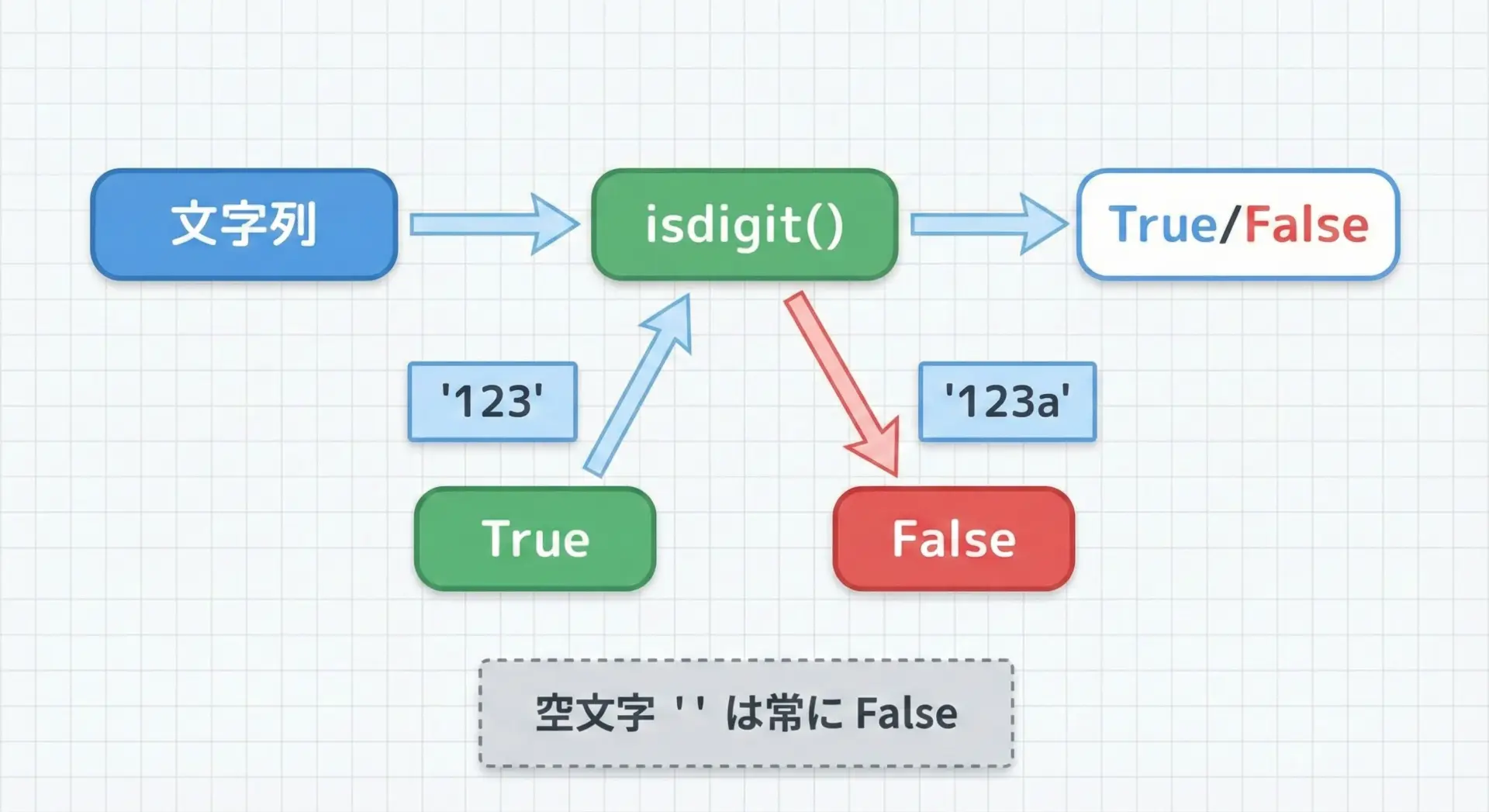
str.isdigit()は、文字列が「数字」だけで構成されているかどうかを判定するメソッドです。
使い方は非常にシンプルで、文字列オブジェクトに対してメソッドを呼び出すだけです。
# isdigit() の基本的な使い方
s1 = "123"
s2 = "123a"
s3 = ""
s4 = "0123" # 全角数字
print(s1.isdigit()) # "123" は数字だけ
print(s2.isdigit()) # "123a" は 'a' が含まれる
print(s3.isdigit()) # 空文字
print(s4.isdigit()) # 全角数字True
False
False
Trueポイントを整理すると、次のようになります。
空文字""に対してisdigit()を呼ぶと必ずFalseになることに注意してください。
また、後述しますが「数字」と判定されるのは半角0〜9に限らず、Unicode上で数字と定義されている文字も含まれます。
この性質は、国際化されたアプリケーションや、日本語環境での全角入力を扱うときに重要になります。
全角数字やローマ数字が含まれる場合の挙動

isdigit()は、Unicodeで「数字」として定義されている文字を広く受け付けます。
したがって、半角数字以外でもTrueになるケースがあります。
次のコードで挙動を確認してみます。
# 全角数字やローマ数字、丸数字などの isdigit() の挙動
samples = ["123", "123", "Ⅳ", "②", "2.5", "-123"]
for s in samples:
print(f"{repr(s):8} -> {s.isdigit()}")'123' -> True
'123' -> True
'Ⅳ' -> True
'②' -> True
'2.5' -> False
'-123' -> Falseここで注目すべき点は、全角数字"123"だけでなく、ローマ数字"Ⅳ"、丸数字"②"もTrueになることです。
これは、これらの文字がUnicode上で「数字(Character category: Nd, No など)」として扱われているためです。
一方、"-123"のようにマイナス記号が付いている場合や、"2.5"のように小数点が含まれている場合はFalseになります。
isdigit()は「数字だけで構成されているかどうか」を見るメソッドであり、「数値として解釈できるかどうか」を判定するメソッドではない点を意識しておくと混乱しにくくなります。
半角数字だけを判定したい場合の実装例
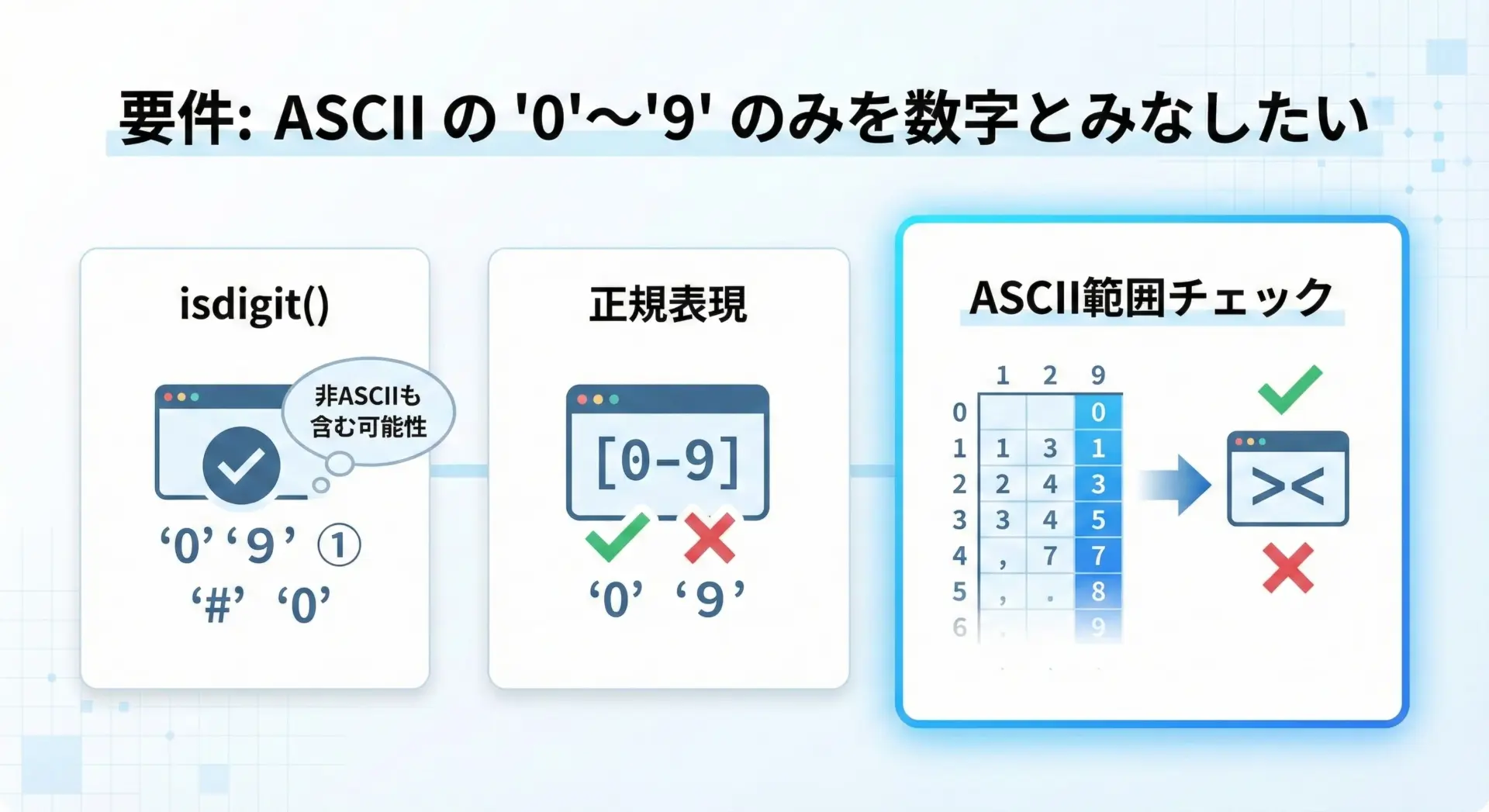
多くの日本語環境では、ユーザーが全角で数字を入力することがよくあります。
しかし、システムの仕様によっては「半角数字だけを許可したい」場合があります。
このようなとき、isdigit()だけでは判定が不十分です。
半角数字かどうかを判定する簡単な方法の1つは、str.isascii()と組み合わせる、あるいはstrの各文字が'0'から'9'の範囲にあるかをチェックする方法です。
# 半角数字だけを判定する関数の例 (ASCII '0'〜'9' のみを許可)
def is_ascii_digit(s: str) -> bool:
# 空文字は False
if not s:
return False
# すべての文字が '0'〜'9' の範囲に入っているかどうかをチェック
return all('0' <= ch <= '9' for ch in s)
# 動作確認
samples = ["123", "123", "Ⅳ", "②", "2.5", "-123", "00123"]
for s in samples:
print(f"{repr(s):8} -> {is_ascii_digit(s)}")'123' -> True
'123' -> False
'Ⅳ' -> False
'②' -> False
'2.5' -> False
'-123' -> False
'00123' -> Trueこのようにall('0' <= ch <= '9' for ch in s)のような判定を使うことで、「ASCIIの半角数字だけを厳格に受け付ける」ことができます。
要件次第では、後述する正規表現re.fullmatch(r"[0-9]+", s)を使う方法も有効です。
isalphaとisalnumで英字・英数字を判定する方法
str.isalphaで英字だけかどうかを判定する
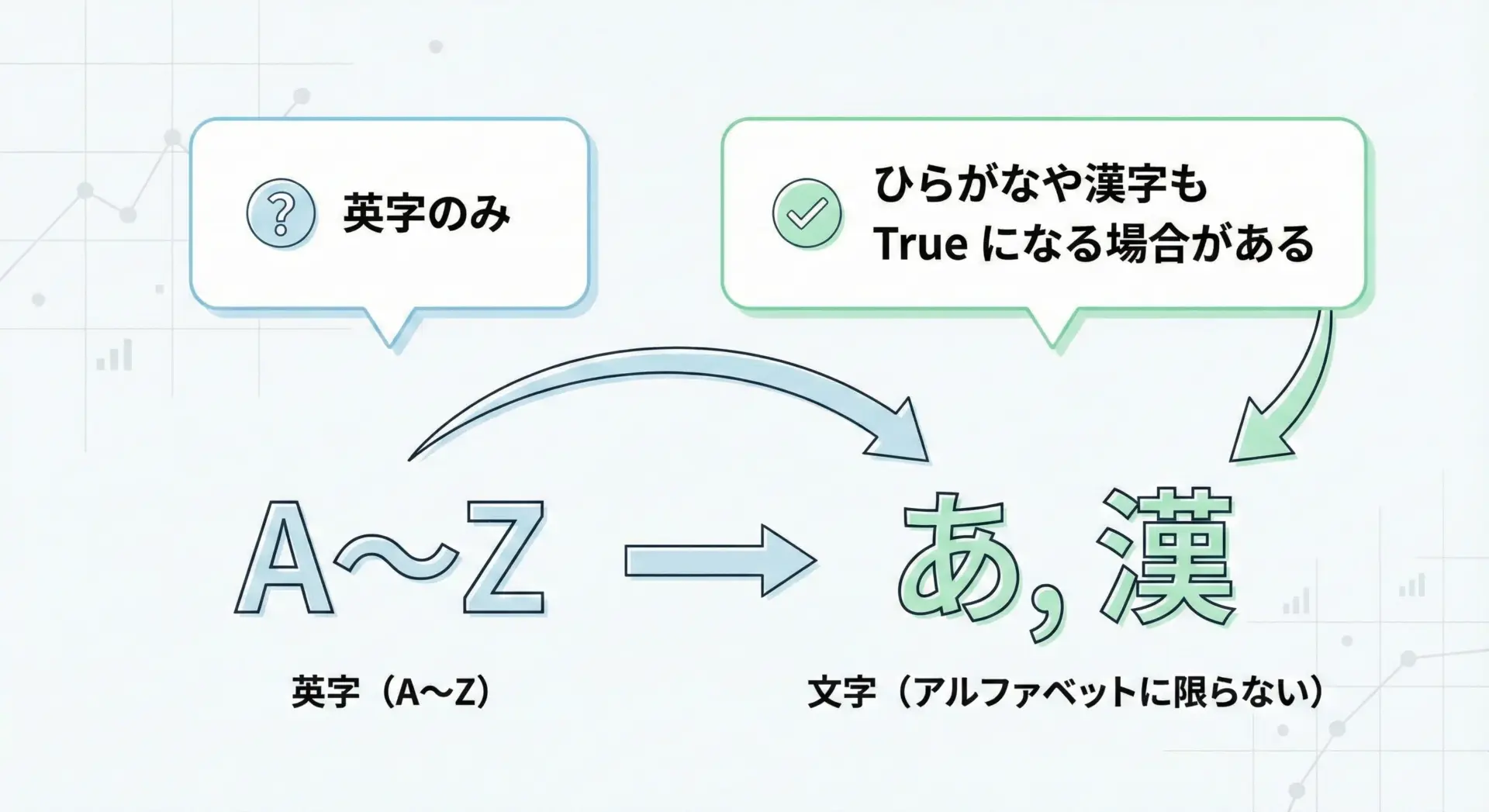
str.isalpha()は、文字列が「文字(アルファベットなどの文字)」だけで構成されているかどうかを判定します。
ここでの重要なポイントは、「英字だけ」でなく「ひらがな」「カタカナ」「漢字」など、Unicode上で「文字」と分類されるものも対象に含まれるという点です。
# isalpha() の基本的な挙動
samples = ["abc", "ABC", "あいう", "漢字", "abc123", "abc!", ""]
for s in samples:
print(f"{repr(s):8} -> {s.isalpha()}")'abc' -> True
'ABC' -> True
'あいう' -> True
'漢字' -> True
'abc123' -> False
'abc!' -> False
'' -> Falseこの結果から分かるように、日本語のひらがなや漢字もTrueになります。
そのため、「英字(A〜Z、a〜z)だけに限定したい」場合にisalpha()をそのまま使うのは不適切です。
そのような要件では、後のセクションで紹介する正規表現や、ASCII判定を加えた独自関数を使うことが推奨されます。
str.isalnumで英数字かどうかを判定する
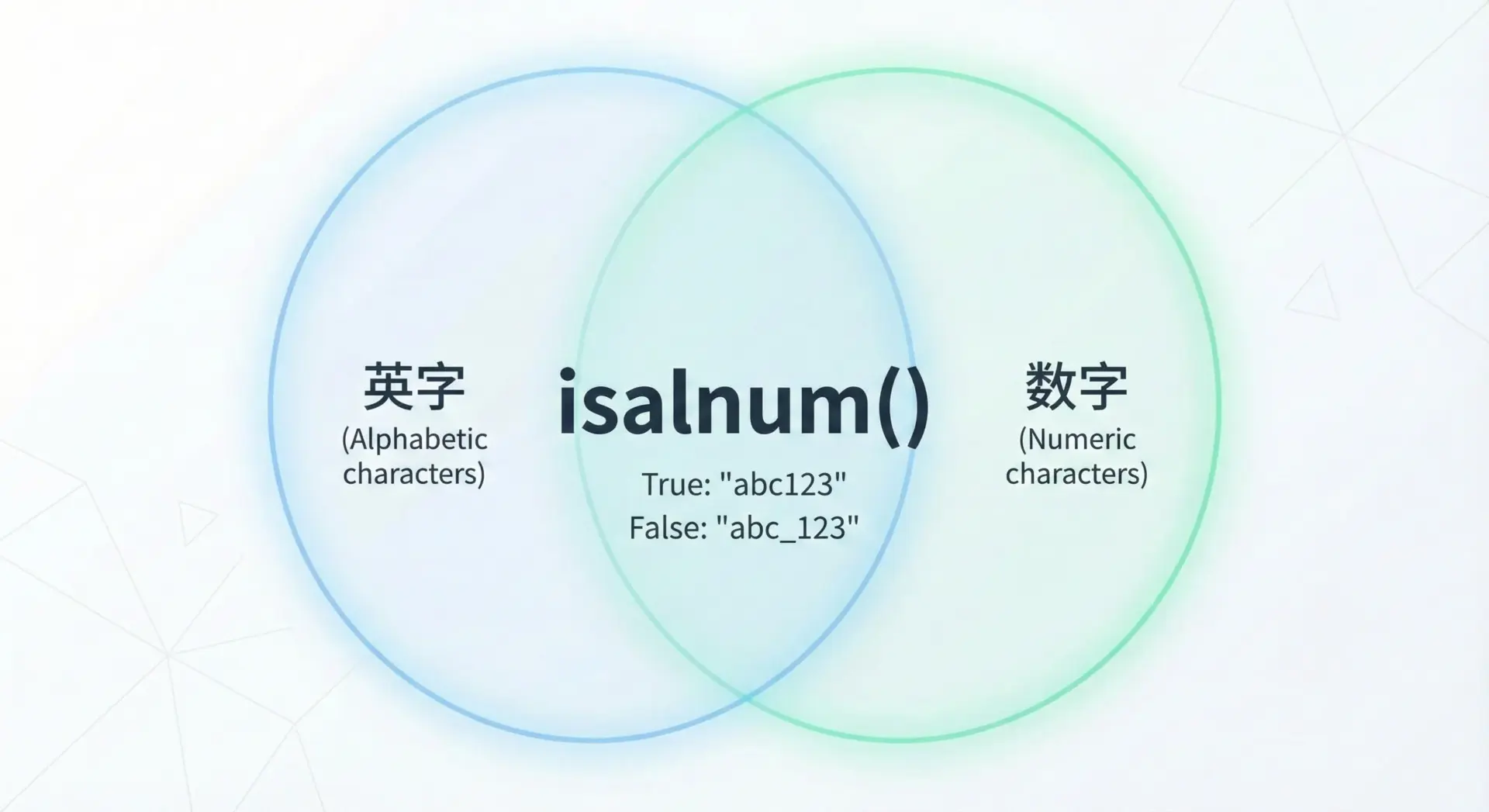
str.isalnum()は、文字列が「英字」と「数字」だけで構成されているかどうかを判定します。
英字と数字のどちらか一方だけでもよく、両方が混ざっていても問題ありません。
# isalnum() の基本的な挙動
samples = ["abc", "123", "abc123", "abc_123", "123!", "", "あ1い2"]
for s in samples:
print(f"{repr(s):10} -> {s.isalnum()}")'abc' -> True
'123' -> True
'abc123' -> True
'abc_123' -> False
'123!' -> False
'' -> False
'あ1い2' -> Trueここでも、日本語の「あ」「い」なども「文字」と見なされるため、"あ1い2"のような文字列もTrueになります。
つまり「英数字のみ」というより「文字と数字のみ」というイメージで捉えた方が実態に近いです。
アンダースコアや記号が含まれる場合の挙動
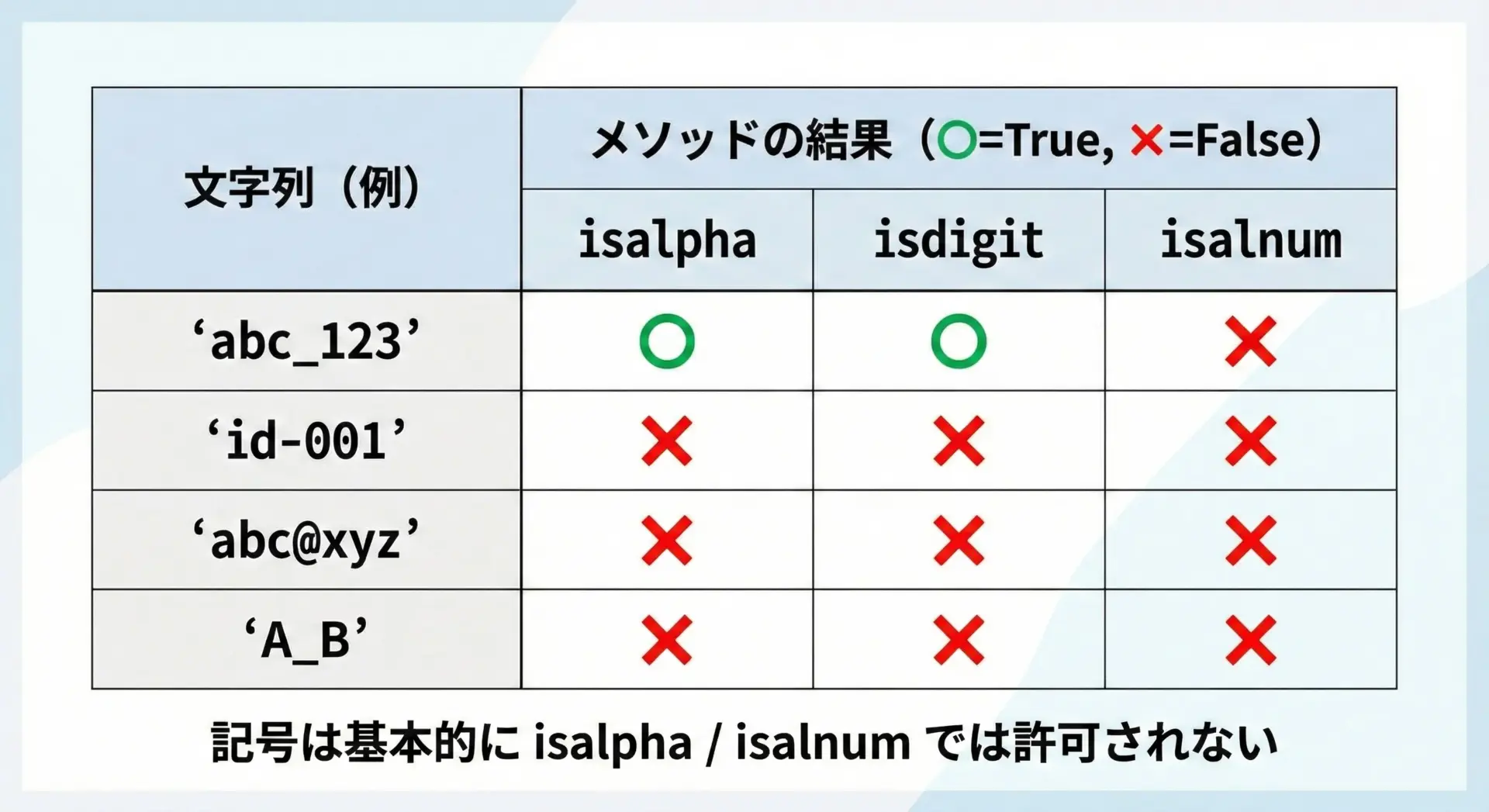
開発をしていると、IDや変数名などで"user_id"のようなアンダースコア付きの文字列を扱うことが多くあります。
このような記号を含む文字列は、isalpha()やisalnum()ではFalseになります。
# アンダースコアや記号が含まれる場合の挙動
samples = ["user_id", "id-001", "price$", "A_B", "123-456"]
for s in samples:
print(
f"{repr(s):10} -> "
f"isalpha: {s.isalpha():5} "
f"isdigit: {s.isdigit():5} "
f"isalnum: {s.isalnum():5}"
)'user_id' -> isalpha: False isdigit: False isalnum: False
'id-001' -> isalpha: False isdigit: False isalnum: False
'price$' -> isalpha: False isdigit: False isalnum: False
'A_B' -> isalpha: False isdigit: False isalnum: False
'123-456' -> isalpha: False isdigit: False isalnum: Falseこのように、アンダースコア"_"やハイフン"-"、ドル記号"$"などは「文字」でも「数字」でもないため、これらが1文字でも含まれているとisalpha()やisalnum()はFalseになります。
もし、「英数字とアンダースコアだけを許可したい」といった要件がある場合には、後述の正規表現で^[0-9A-Za-z_]+$のようなパターンを使うことが多いです。
英字と数字をそれぞれ分けて判定したい場合の書き方
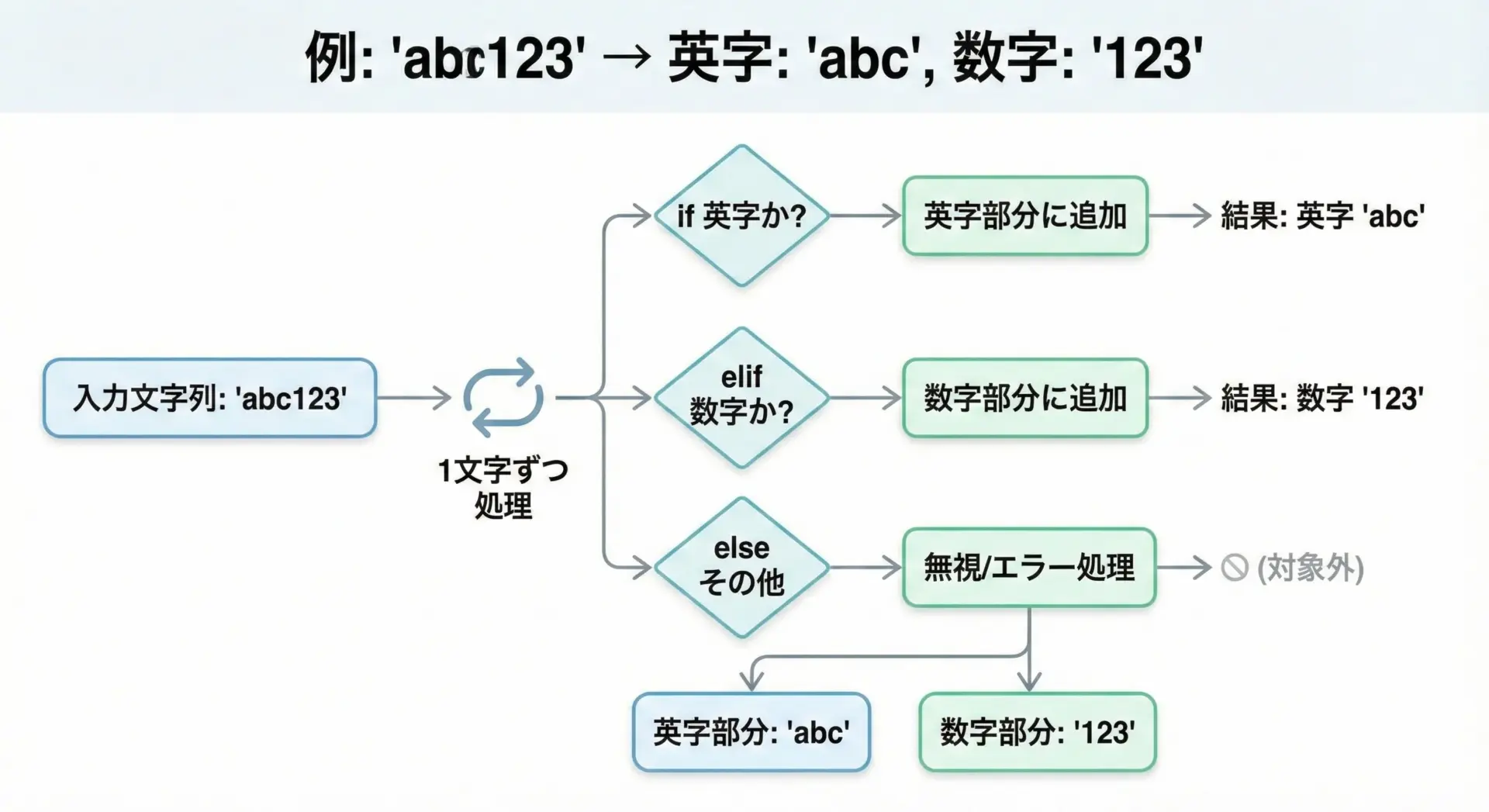
現実的な要件として、次のような判定を行いたい場合があります。
- 英字だけなら「英字だけです」
- 数字だけなら「数字だけです」
- 英数字が混在しているなら「英数字です」
- それ以外(記号などが含まれる)なら「対象外です」
このような判定は、isalpha()、isdigit()、isalnum()を組み合わせることで簡単に書けます。
# 英字のみ・数字のみ・英数字混在・その他 を判定する例
def classify_string(s: str) -> str:
if not s:
return "空文字です"
if s.isalpha():
return "英字だけの文字列です"
elif s.isdigit():
return "数字だけの文字列です"
elif s.isalnum():
# ここに来るのは「英字と数字のみ」かつ
# どちらか一方だけではないケース (混在) が主な想定
return "英字と数字からなる文字列です"
else:
return "英字・数字以外の文字が含まれています"
# 動作確認
samples = ["abc", "123", "abc123", "abc_123", "", "あい1"]
for s in samples:
print(f"{repr(s):10} -> {classify_string(s)}")'abc' -> 英字だけの文字列です
'123' -> 数字だけの文字列です
'abc123' -> 英字と数字からなる文字列です
'abc_123' -> 英字・数字以外の文字が含まれています
'' -> 空文字です
'あい1' -> 英字と数字からなる文字列ですここでは、isalpha()やisdigit()の判定が優先され、そのどちらでもないがisalnum()がTrueのときには「英字と数字からなる文字列」とみなしています。
ただし、最後の例"あい1"のように日本語もisalpha()でTrueになる点には注意が必要です。
もし「英字(A〜Z、a〜z)と数字だけを対象にしたい」のであれば、後の正規表現を用いた判定に切り替えることをおすすめします。
正規表現でより厳密に文字列を判定する方法
reモジュールで数字・英字・英数字を判定する
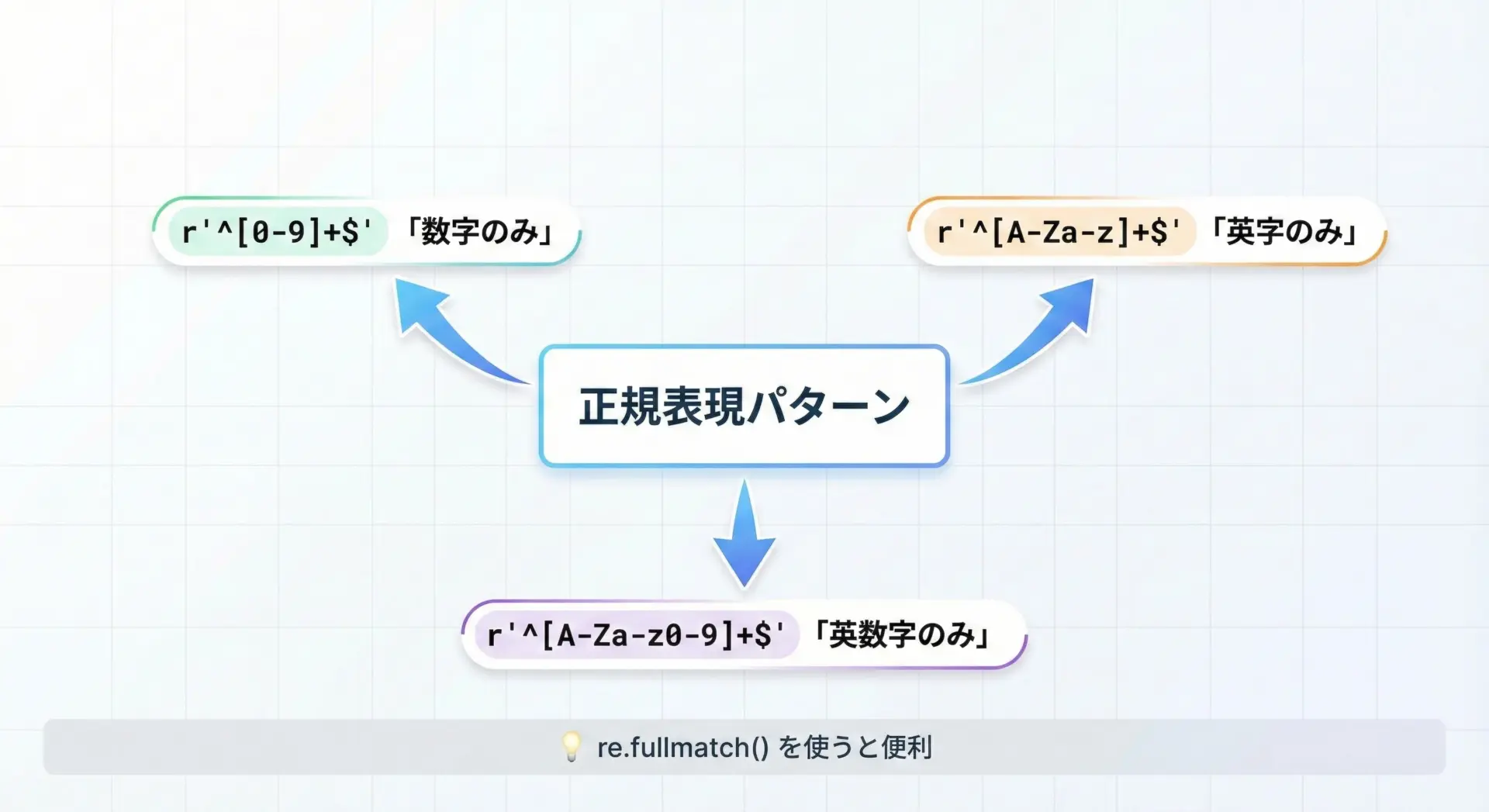
組み込みメソッドは手軽ですが、Unicodeの定義に依存しているため、「ASCIIの英数字だけ」「特定の文字だけ」などの厳密な制約を付けたいときには不向きな場合があります。
そういった場合には、reモジュールの正規表現を使うことで、判定条件を明確に指定できます。
Pythonでは、文字列全体が特定のパターンに一致するかを調べるときにre.fullmatch()を使うと分かりやすく書けます。
import re
# 正規表現で「数字のみ」「英字のみ」「英数字のみ」を判定する例
def is_ascii_digits(s: str) -> bool:
# 0〜9 の数字だけ
return re.fullmatch(r"[0-9]+", s) is not None
def is_ascii_alpha(s: str) -> bool:
# A〜Z, a〜z の英字だけ
return re.fullmatch(r"[A-Za-z]+", s) is not None
def is_ascii_alnum(s: str) -> bool:
# A〜Z, a〜z, 0〜9 の英数字だけ
return re.fullmatch(r"[A-Za-z0-9]+", s) is not None
samples = ["123", "123", "abc", "あbc", "abc123", "abc_123", ""]
for s in samples:
print(
f"{repr(s):10} -> "
f"digits: {is_ascii_digits(s):5} "
f"alpha: {is_ascii_alpha(s):5} "
f"alnum: {is_ascii_alnum(s):5}"
)'123' -> digits: True alpha: False alnum: True
'123' -> digits: False alpha: False alnum: False
'abc' -> digits: False alpha: True alnum: True
'あbc' -> digits: False alpha: False alnum: False
'abc123' -> digits: False alpha: False alnum: True
'abc_123' -> digits: False alpha: False alnum: False
'' -> digits: False alpha: False alnum: Falseこのように、正規表現を使うことで「ASCIIの英数字だけ」という要件を明確にコード化できます。
re.fullmatch()は、Noneではないときに「文字列全体がパターンにマッチした」と判断できます。
英小文字だけ・英大文字だけなど条件を絞る方法
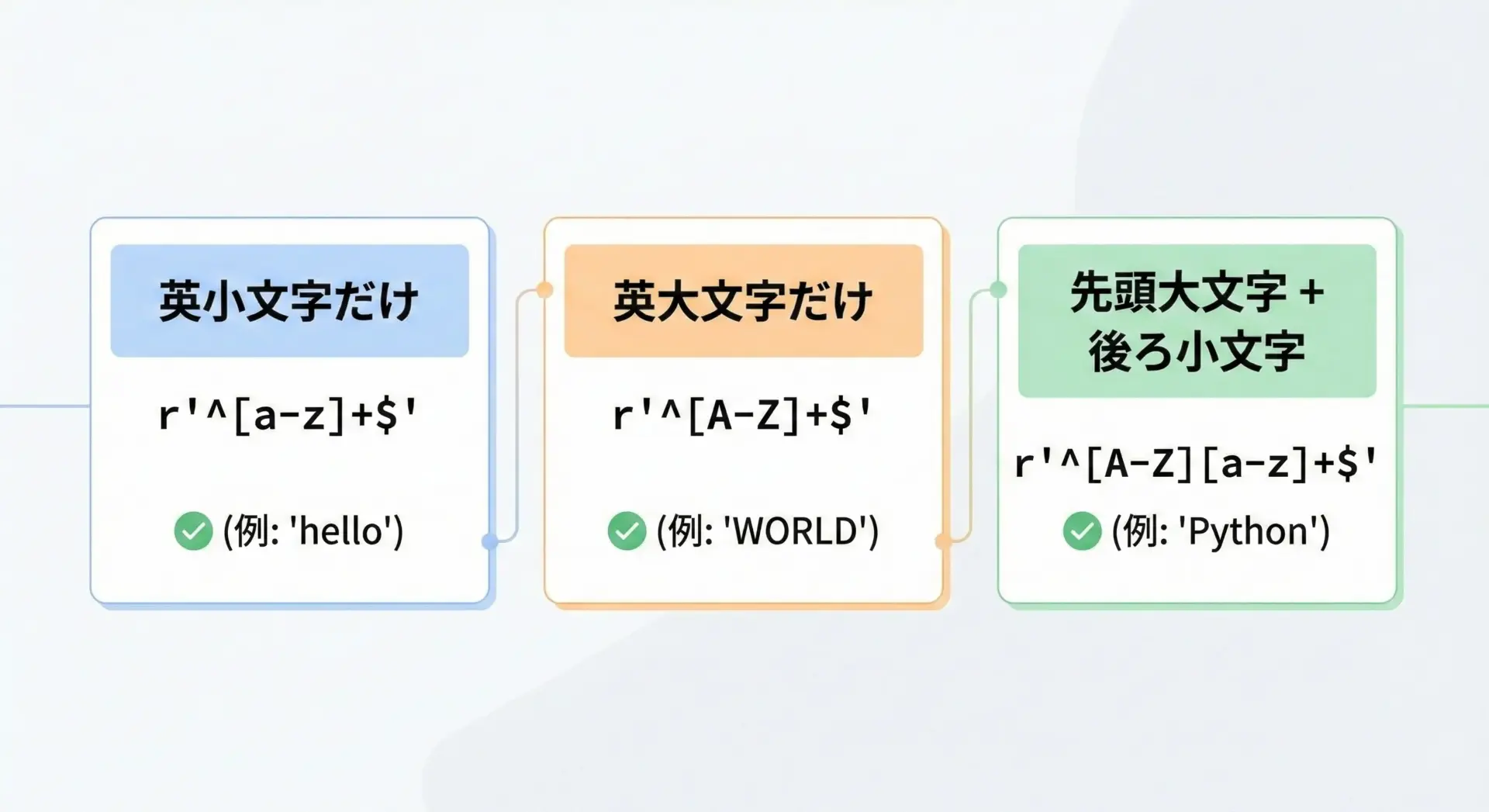
正規表現の利点は、英字の大文字・小文字を区別して細かく条件を指定できることです。
例えば、次のような判定が簡単に実現できます。
import re
def is_lower_alpha(s: str) -> bool:
# 英小文字だけ (a〜z)
return re.fullmatch(r"[a-z]+", s) is not None
def is_upper_alpha(s: str) -> bool:
# 英大文字だけ (A〜Z)
return re.fullmatch(r"[A-Z]+", s) is not None
def is_capitalized_word(s: str) -> bool:
# 先頭1文字が大文字、残りが小文字の英単語
return re.fullmatch(r"[A-Z][a-z]+", s) is not None
samples = ["hello", "WORLD", "Python", "python3", "PYthon"]
for s in samples:
print(
f"{repr(s):10} -> "
f"lower: {is_lower_alpha(s):5} "
f"upper: {is_upper_alpha(s):5} "
f"CapWord: {is_capitalized_word(s):5}"
)'hello' -> lower: True upper: False CapWord: False
'WORLD' -> lower: False upper: True CapWord: False
'Python' -> lower: False upper: False CapWord: True
'python3' -> lower: False upper: False CapWord: False
'PYthon' -> lower: False upper: False CapWord: Falseこのようなパターンは、例えばクラス名や定数名など、命名規則を自動チェックしたい場合に役立ちます。
マルチバイト文字や記号を含む文字列の扱い方

日本語や絵文字などのマルチバイト文字が混ざる場合、どのように扱うかを事前に決めておくことが重要です。
isalpha()やisalnum()はUnicode対応なので、日本語やその他の言語の文字にもTrueを返します。
一方で、ASCII英数字だけに限定したいなら、正規表現やisascii()と組み合わせるのが安全です。
次の例では、「英数字と日本語を含んだ文字列」から、ASCII英数字だけを取り出す例を示します。
import re
text = "商品ID: ABC123とXYZ999です😊"
# ASCII 英数字だけを抽出 (A〜Z, a〜z, 0〜9)
ascii_alnum_list = re.findall(r"[A-Za-z0-9]+", text)
print("元の文字列:", text)
print("抽出された ASCII 英数字:", ascii_alnum_list)元の文字列: 商品ID: ABC123とXYZ999です😊
抽出された ASCII 英数字: ['ABC123', 'XYZ']ここでは、re.findall()を使って、ASCII英数字の連続部分をすべて抽出しています。
全角数字"999"はパターン[0-9]にマッチしないため、結果には含まれません。
また、文字列が「ASCIIだけで構成されているか」を判定したい場合には、str.isascii()が便利です。
# isascii() で ASCII かどうかを判定する例 (Python 3.7以降)
samples = ["abc123", "123", "hello世界", "ASCII_only"]
for s in samples:
print(f"{repr(s):10} -> isascii: {s.isascii()}")'abc123' -> isascii: True
'123' -> isascii: False
'hello世界' -> isascii: False
'ASCII_only' -> isascii: True「まずASCIIかどうかをチェックし、そのうえで正規表現やisdigit()などを使う」という2段階の判定を行うことで、予期しない全角や他言語の文字が紛れ込むことを防ぎやすくなります。
まとめ
数字・英字・英数字の判定は、一見単純に見えて「Unicodeとしての定義」と「アプリの要件(ASCII限定など)」の差を理解しておくことが重要です。
Pythonではisdigit()・isalpha()・isalnum()で手軽に判定できますが、全角や他言語も含めた広い意味での「数字」「文字」として扱われます。
半角英数字に限定したい場合や、大文字・小文字の区別など細かい条件が必要な場合は、正規表現とre.fullmatch()を使ってルールを明示するのが良い設計です。
要件に応じて、組み込みメソッドと正規表現を適切に使い分けてください。
