
Pythonで文字列の先頭や末尾を判定するとき、正規表現を使わずにシンプルに書けるのがstartswithとendswithです。
ファイル名やURL、ログの解析など、実務での登場頻度もとても高いメソッドです。
この記事では、基礎から応用までを図解とサンプルコード付きで丁寧に解説し、実務でそのまま使える形で理解できるようにします。
Pythonのstartswithとendswithとは
文字列の先頭・末尾一致を判定するメソッド

Pythonのstartswithとendswithは、文字列の「先頭」または「末尾」が、指定した文字列(プレフィックスやサフィックス)と一致しているかどうかを調べるためのメソッドです。
どちらも、戻り値はTrueまたはFalseの論理値となり、条件分岐(if文)と一緒に使われることが多いです。
Pythonの組み込み文字列型strで利用でき、メソッド呼び出しの形式は次のようになります。
文字列.startswith(接頭辞[, start[, end]])文字列.endswith(接尾辞[, start[, end]])
どちらも、判定対象となる部分の開始位置(start)や終了位置(end)を、オプションで指定できるのが特徴です。
startswithとendswithの基本的な使い方
まずは、最もシンプルな使い方を見ておきます。
# 文字列の定義
text = "Python programming"
# 先頭が "Python" かどうか
print(text.startswith("Python")) # True
# 末尾が "ing" かどうか
print(text.endswith("ing")) # True
# 大文字・小文字は区別される
print(text.startswith("python")) # False
print(text.endswith("ING")) # FalseTrue
True
False
Falseこのように、startswithとendswithは「部分一致」ではなく、必ず先頭または末尾からの一致である点に注意が必要です。
文字列の途中に含まれているかどうかを調べたい場合は、in演算子やfindメソッドなどを使います。
startswithで先頭一致を判定する方法
単一の接頭辞でstartswithを使う
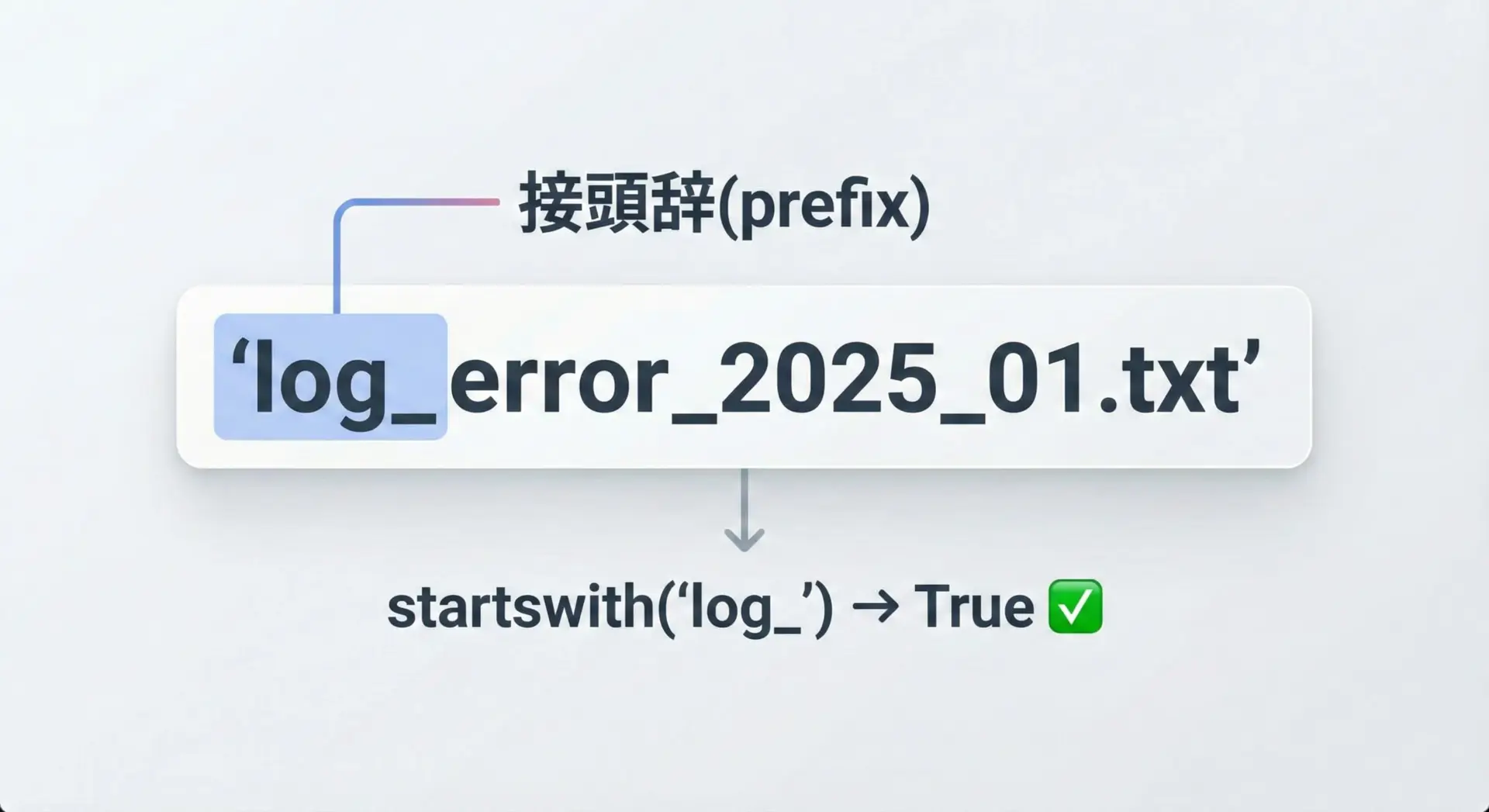
最も基本的なパターンは、1つの接頭辞(プレフィックス)を指定して判定する方法です。
filename = "log_error_2025_01.txt"
# "log_" から始まっているかどうか
if filename.startswith("log_"):
print("ログファイルです")
else:
print("ログファイルではありません")ログファイルですこのように、startswithはファイル種別やメッセージ種別などを簡単に判定するのに適しています。
大文字・小文字の扱い
startswithは大文字・小文字を区別します。
ケースインセンシティブに判定したい場合は、事前にlower()やupper()で揃える方法がよく使われます。
command = "START_SERVER"
# 小文字にそろえてから判定
if command.lower().startswith("start"):
print("起動コマンドです")起動コマンドです複数候補(タプル)でstartswithを使う
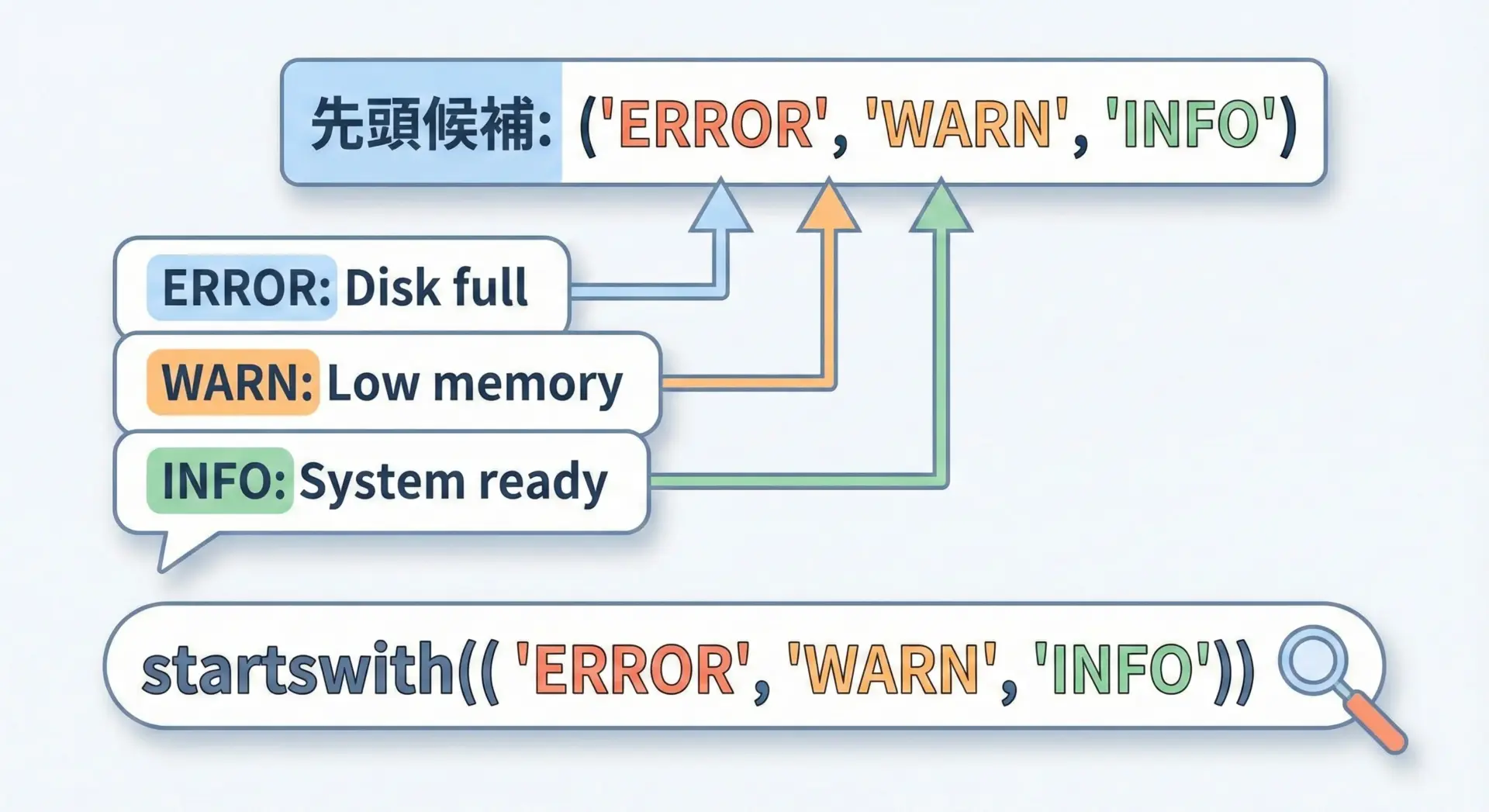
startswithは、接頭辞をタプルで複数指定することができます。
どれか1つでもマッチすればTrueになります。
log_line = "ERROR: Disk full"
# "ERROR", "WARN", "INFO" のいずれかで始まるか判定
if log_line.startswith(("ERROR", "WARN", "INFO")):
print("既知のログレベルです")
else:
print("未知の形式のメッセージです")既知のログレベルですこのようにタプルを使うと、複数の候補を「または(OR)」条件でまとめて書けるので、分岐の数を減らしてコードをすっきりさせることができます。
リストではなくタプルを使う理由
startswithに渡せるのはタプルだけで、リストはそのままでは使えません。
リストを使いたい場合は、次のようにタプルに変換します。
prefix_list = ["ERROR", "WARN", "INFO"]
text = "WARN: CPU high"
# タプルに変換してから渡す
if text.startswith(tuple(prefix_list)):
print("一致しました")一致しました位置を指定してstartswithで判定する
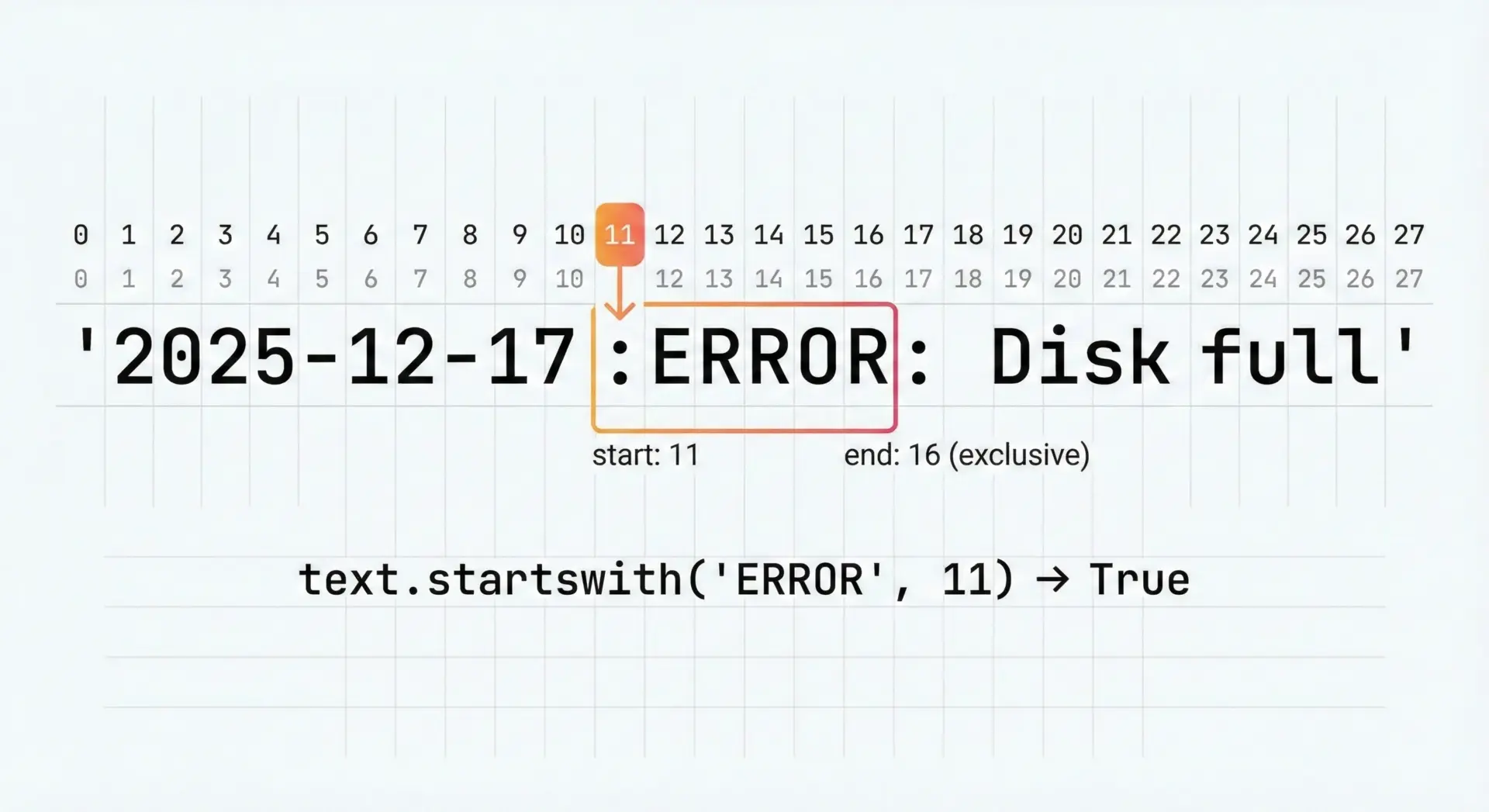
startswithは、第2引数と第3引数で判定を行う開始位置(start)と終了位置(end)を指定できます。
これは、文字列全体ではなく「一部の範囲」で先頭一致を調べたいときに便利です。
log_line = "2025-12-17: ERROR: Disk full"
# 先頭から 11 文字分は日付と区切りなので、その後から "ERROR" かどうかを判定
if log_line.startswith("ERROR", 12):
print("エラーログです")
else:
print("エラーではありません")出力結果(※インデックス位置により変わるので、実際に確認することを推奨):
エラーログです実際には、インデックスをfindやindexで取得してからstartswithを使うと、より柔軟な判定ができます。
log_line = "2025-12-17: ERROR: Disk full"
pos = log_line.find("ERROR")
if pos != -1 and log_line.startswith("ERROR", pos):
print("ERROR セクションを検出しました (位置:", pos, ")")ERROR セクションを検出しました (位置: 12 )startとendの両方を使う場合
startswith(prefix, start, end)と書いた場合、文字列の[start:end]スライスの「先頭」がprefixと一致するかどうかを判定します。
text = "ABCDE12345FGHIJ"
# インデックス 5〜10 の範囲は "12345"
print(text[5:10]) # 参考表示
# この範囲の先頭が "123" かどうかを判定
print(text.startswith("123", 5, 10))12345
Trueendswithで末尾一致を判定する方法
単一の接尾辞でendswithを使う

endswithは文字列の末尾が、指定した接尾辞(サフィックス)と一致するかどうかを判定します。
ファイル拡張子やURLの末尾などの判定に頻出です。
filename = "report_2025_01.csv"
if filename.endswith(".csv"):
print("CSVファイルです")
else:
print("CSVファイルではありません")CSVファイルです改行コードの除去と組み合わせる
ファイルから読み込んだ行末には、改行文字\nが含まれていることがあります。
その場合はrstrip()などと組み合わせて使うと安全です。
line = "OK\n"
# 改行を削ってから末尾判定
if line.rstrip().endswith("OK"):
print("ステータスOKです")ステータスOKです複数候補(タプル)でendswithを使う
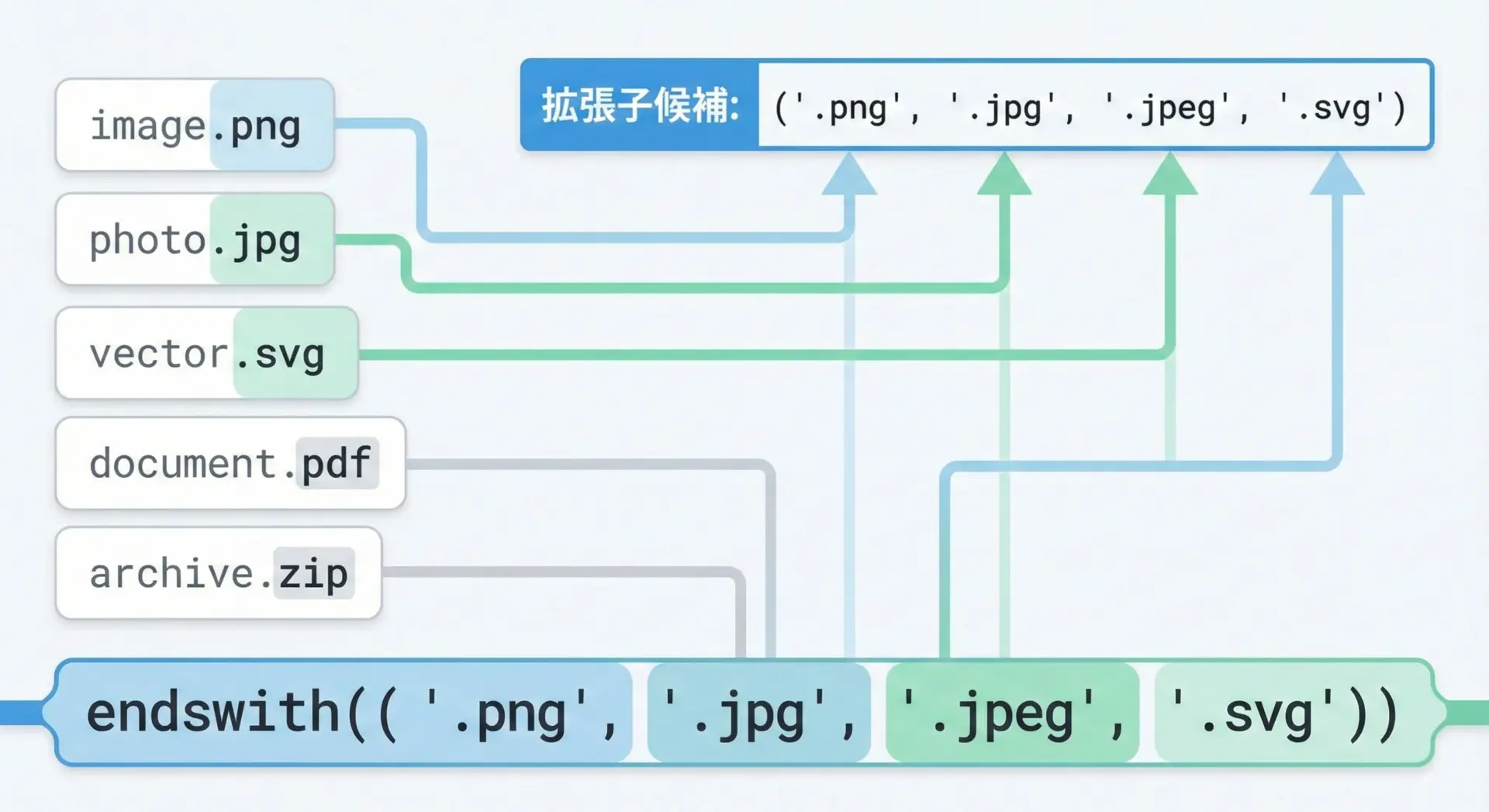
endswithもstartswithと同様に、タプルで複数の接尾辞を指定できます。
filename = "photo.jpg"
image_exts = (".png", ".jpg", ".jpeg", ".gif")
if filename.endswith(image_exts):
print("画像ファイルです")
else:
print("画像ファイルではありません")画像ファイルですこの構文は、ファイル拡張子のホワイトリストやブラックリストを作る際にとても便利です。
位置を指定してendswithで判定する

endswithも、第2引数と第3引数で判定範囲を限定できます。
文字列全体ではなく、一部の区間の末尾だけを見たい場合に利用します。
path = "path/to/file_backup_2025.log.tmp"
# 実際のログファイル名は ".log" までで、
# その後ろの ".tmp" は一時ファイルを示しているケースを想定
# まず ".log" の位置を探す
pos = path.find(".log")
if pos != -1 and path.endswith(".log", 0, pos + len(".log")):
print("拡張子 .log のファイルです (ただし .tmp が付いた一時ファイル)")
else:
print("拡張子 .log のファイルではありません")拡張子 .log のファイルです (ただし .tmp が付いた一時ファイル)ここでは、先頭からpos + len(".log")までの区間に対してendswithを適用しています。
「どこを評価範囲にするか」を柔軟に指定できる点が、start/end引数の強みです。
スライスとendswithの違い
スライスを使えば、末尾を切り出して比較することもできますが、endswithの方が読みやすくなります。
text = "example.txt"
# スライスで拡張子を取り出す方法
print(text[-4:] == ".txt") # True
# endswith を使う方法
print(text.endswith(".txt")) # TrueTrue
True「末尾が〜で終わるか」を表現する意図が明確なので、チーム開発ではendswithを使う方が好まれることが多いです。
startswithとendswithの応用例
ファイル拡張子での判定にendswithを使う
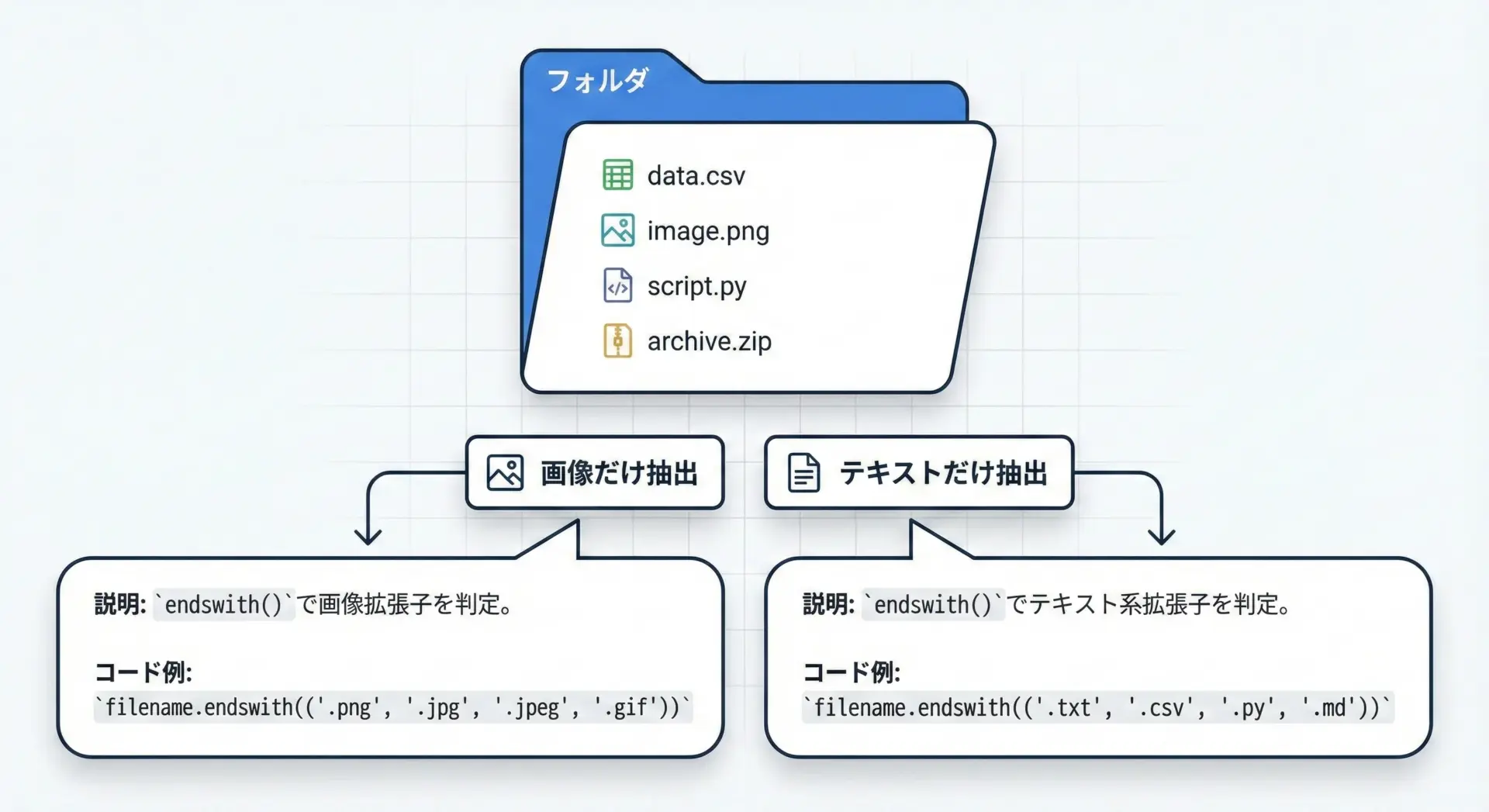
endswithは、ファイル拡張子ごとに処理を分けたいときに最もよく使われる用途の1つです。
次の例では、指定したフォルダ内から画像ファイルだけを抽出しています。
import os
# 画像拡張子のタプル
IMAGE_EXTS = (".png", ".jpg", ".jpeg", ".gif", ".bmp")
def list_image_files(directory: str) -> list[str]:
"""ディレクトリ内の画像ファイル名一覧を取得する関数"""
result = []
for name in os.listdir(directory):
# ディレクトリエントリが画像拡張子で終わるか判定
if name.lower().endswith(IMAGE_EXTS):
result.append(name)
return result
# サンプル: カレントディレクトリを対象に実行
if __name__ == "__main__":
images = list_image_files(".")
print("画像ファイル一覧:")
for img in images:
print(" -", img)出力例(環境により異なります):
画像ファイル一覧:
- logo.png
- banner.jpg
- icon.gifこのように、拡張子一覧をタプルでまとめておき、endswithで一括判定すると、拡張しやすく保守もしやすいコードになります。
拡張子だけを取り出したい場合との違い
os.path.splitextを使えば、拡張子を取り出して直接比較する方法もあります。
import os
filename = "report_2025_01.csv"
root, ext = os.path.splitext(filename)
print(root) # ファイル名本体
print(ext) # 拡張子 (例: ".csv")
if ext == ".csv":
print("CSVファイルです")report_2025_01
.csv
CSVファイルです「末尾が〜で終わるか」だけが知りたいならendswith、「拡張子そのものを後で再利用したい」ならsplitext、というように使い分けると便利です。
URLやコマンドの判定にstartswithを使う
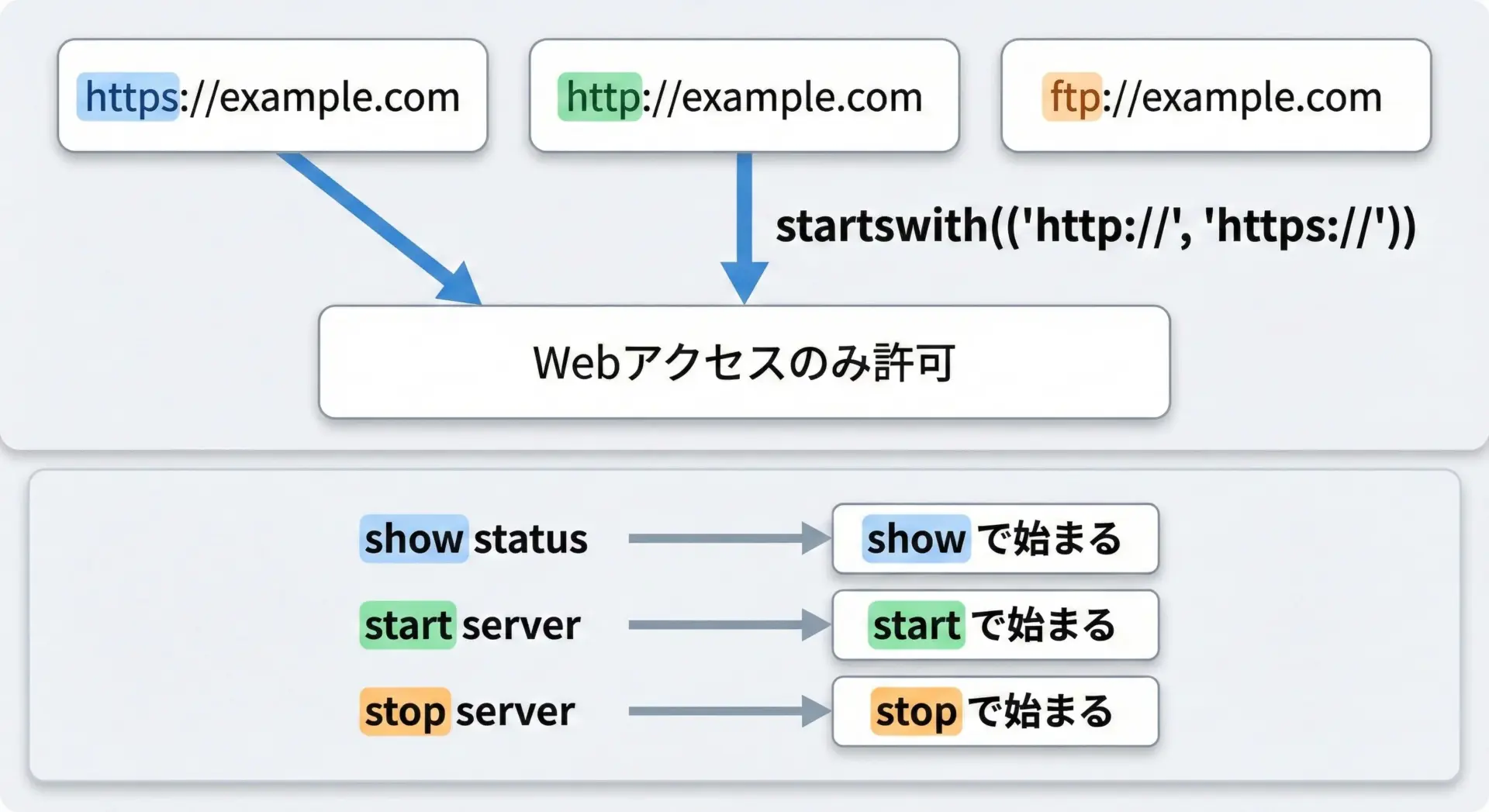
startswithは、URLスキームやコマンド種別の判定にもよく使われます。
url = "https://example.com"
if url.startswith(("http://", "https://")):
print("HTTP/HTTPS のURLです")
else:
print("その他のプロトコルです")HTTP/HTTPS のURLですCLI(コマンドラインインタフェース)のようなシンプルなコマンドパーサでも活躍します。
def handle_command(command: str) -> None:
"""簡易コマンドハンドラ"""
cmd = command.strip()
if cmd.startswith("show "):
# "show " の後ろの部分を取り出して処理
target = cmd[len("show "):]
print(f"情報を表示します: {target}")
elif cmd.startswith("start "):
service = cmd[len("start "):]
print(f"サービスを起動します: {service}")
elif cmd.startswith("stop "):
service = cmd[len("stop "):]
print(f"サービスを停止します: {service}")
else:
print("不明なコマンドです")
# 動作確認
handle_command("show status")
handle_command("start server")情報を表示します: status
サービスを起動します: server先頭の固定キーワードだけを頼りに処理を分けるようなシンプルなプロトコルやコマンド体系では、正規表現を使わなくてもstartswithだけで十分なことが多いです。
正規表現との違いと使い分け
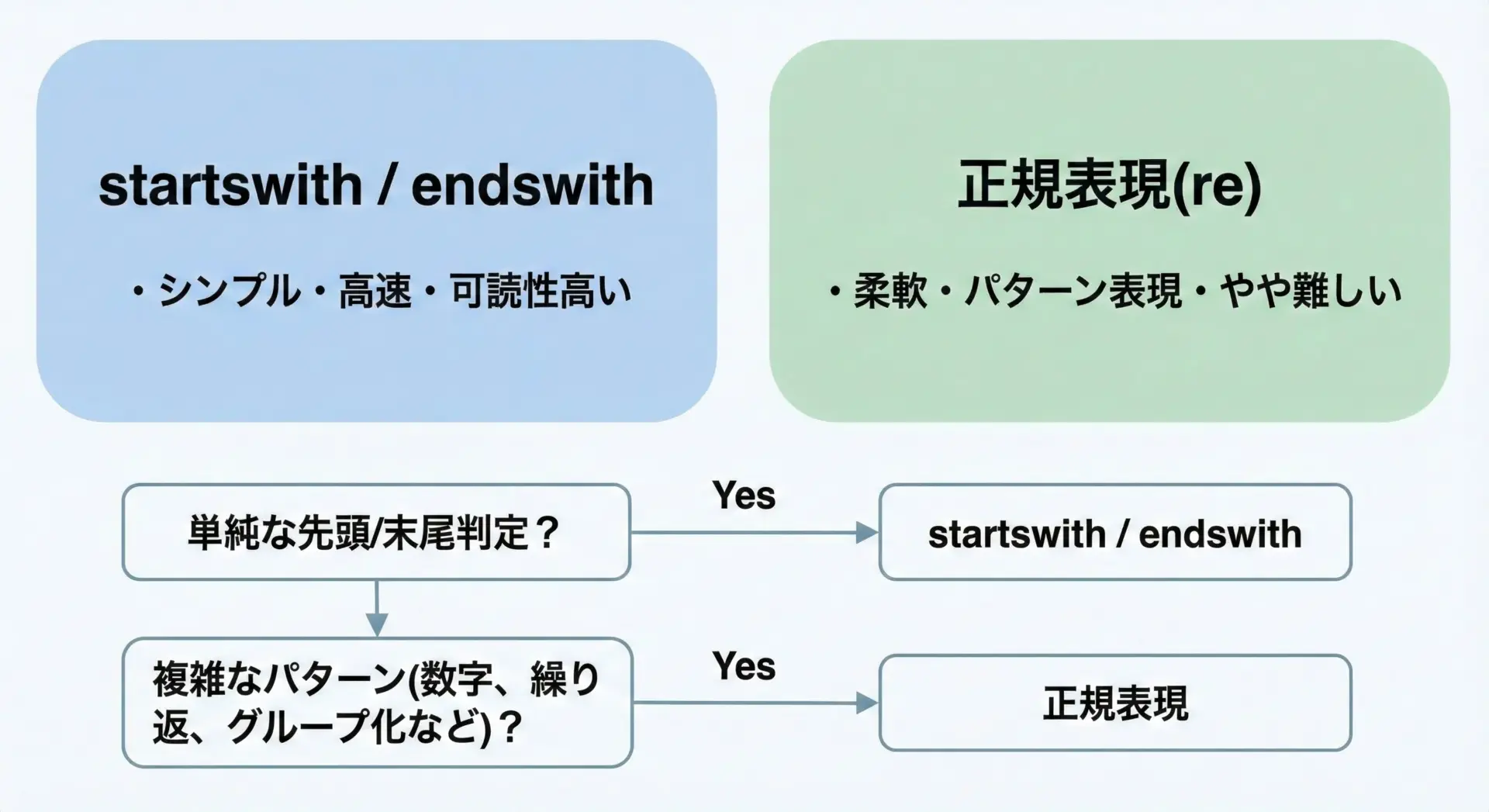
startswith / endswith と正規表現(reモジュール)は、どちらも文字列パターンの判定に使われますが、目的と得意分野が異なります。
startswith / endswith の特徴
- できること: 先頭一致・末尾一致のみ
- 長所: コードが短く、直感的で読みやすい
- 実装も軽く、だいたいの場合高速
text = "user_12345"
# 先頭が "user_" であるかどうかだけ知りたいなら十分
text.startswith("user_")正規表現(re)の特徴
- できること: 繰り返し、任意文字、数字だけ、桁数制限など、パターン表現が自由
- 短所: パターンの記法がやや難しく、可読性が落ちやすい
import re
text = "user_12345"
# "user_" に続いて 1〜5桁の数字、というパターン
pattern = r"^user_\d{1,5}$"
if re.match(pattern, text):
print("ユーザーID形式として正しいです")ユーザーID形式として正しいですどう使い分けるべきか
判断の目安として、次のように考えるとよいです。
- 単純に「この文字列で始まるか / 終わるか」を見たいだけ
→startswith / endswith を優先 - 「数字だけ」「アルファベットだけ」「桁数が決まっている」「複数パターンの組み合わせ」など、複雑な条件を付けたい
→正規表現を検討
実際のコードでも、まずはstartswithやendswithで書けないかを考え、それで難しい場合にだけ正規表現を使う方が、総合的な可読性と保守性が高くなりやすいです。
startswith / endswith と正規表現の比較例
同じ判定を、2通りの方法で書き比べてみます。
要件:「文字列が'http://'または'https://'で始まり、かつ'.jpg'または'.png'で終わっているか」
url = "https://example.com/image.png"
# 1. startswith / endswith で書く
if url.startswith(("http://", "https://")) and url.endswith((".jpg", ".png")):
print("HTTP(S)の画像URLです (startswith/endswith)")
# 2. 正規表現で書く
import re
pattern = r"^https?://.*\.(?:jpg|png)$"
if re.match(pattern, url):
print("HTTP(S)の画像URLです (正規表現)")HTTP(S)の画像URLです (startswith/endswith)
HTTP(S)の画像URLです (正規表現)要件が「先頭」と「末尾」に限定されているのであれば、前者のstartswith / endswithの方が読みやすいと感じる方が多いでしょう。
まとめ
Pythonのstartswithとendswithは、文字列の先頭・末尾判定をシンプルかつ高速に行える強力なメソッドです。
単一の接頭辞・接尾辞だけでなく、タプルで複数候補を指定したり、start/end引数で判定範囲を限定したりと、実務で使いやすい機能が揃っています。
ファイル拡張子やURL、ログ、コマンド解析などでは、まずこれらで書けないかを検討し、より複雑な条件が必要なときだけ正規表現を使う、という方針にするとコードの可読性と保守性が高まります。
