
Pythonで文字列を扱っていると、気付かないうちに入り込んだ空白のせいで、比較や検索がうまくいかないことがあります。
この記事では、Pythonで文字列の空白を削除する代表的な方法であるstrip、replace、正規表現(re)について、考え方から具体的なコード例まで詳しく解説します。
意図しないバグを防ぐための「使い分け」も丁寧に取り上げます。
Pythonで空白削除する基本の考え方
Pythonで扱う「空白文字」とは何か
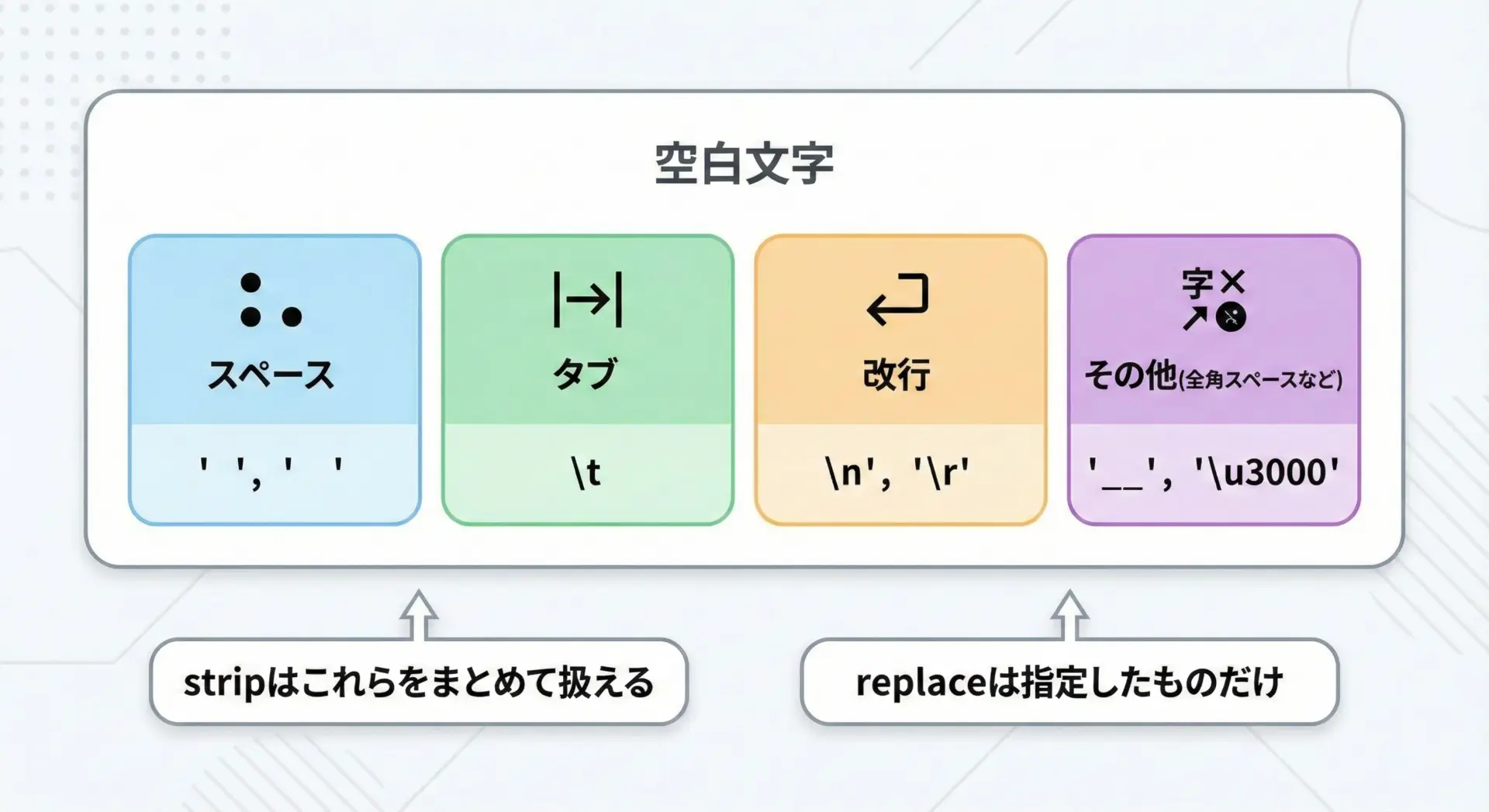
Pythonでいう「空白」は、単なる半角スペースだけではありません。
一般的に「空白文字」と呼ばれるのは、スペースやタブ、改行など、見た目には何も表示されない制御文字を含む広い概念です。
代表的な空白文字には次のようなものがあります。
- 半角スペース:
' ' - タブ:
'\t' - 改行:
'\n' - 復帰:
'\r' - 垂直タブ:
'\v' - フォームフィード:
'\f' - その他、Unicode上のさまざまな空白
Pythonのstr.strip()などのメソッドは、引数を省略すると、これらの典型的なホワイトスペースをまとめて対象にしてくれます。
つまり、単に「前後の空白を消したい」という用途であれば、スペースやタブ、改行を意識的に区別しなくても、stripに任せてしまえるということです。
半角スペースと全角スペースの違い
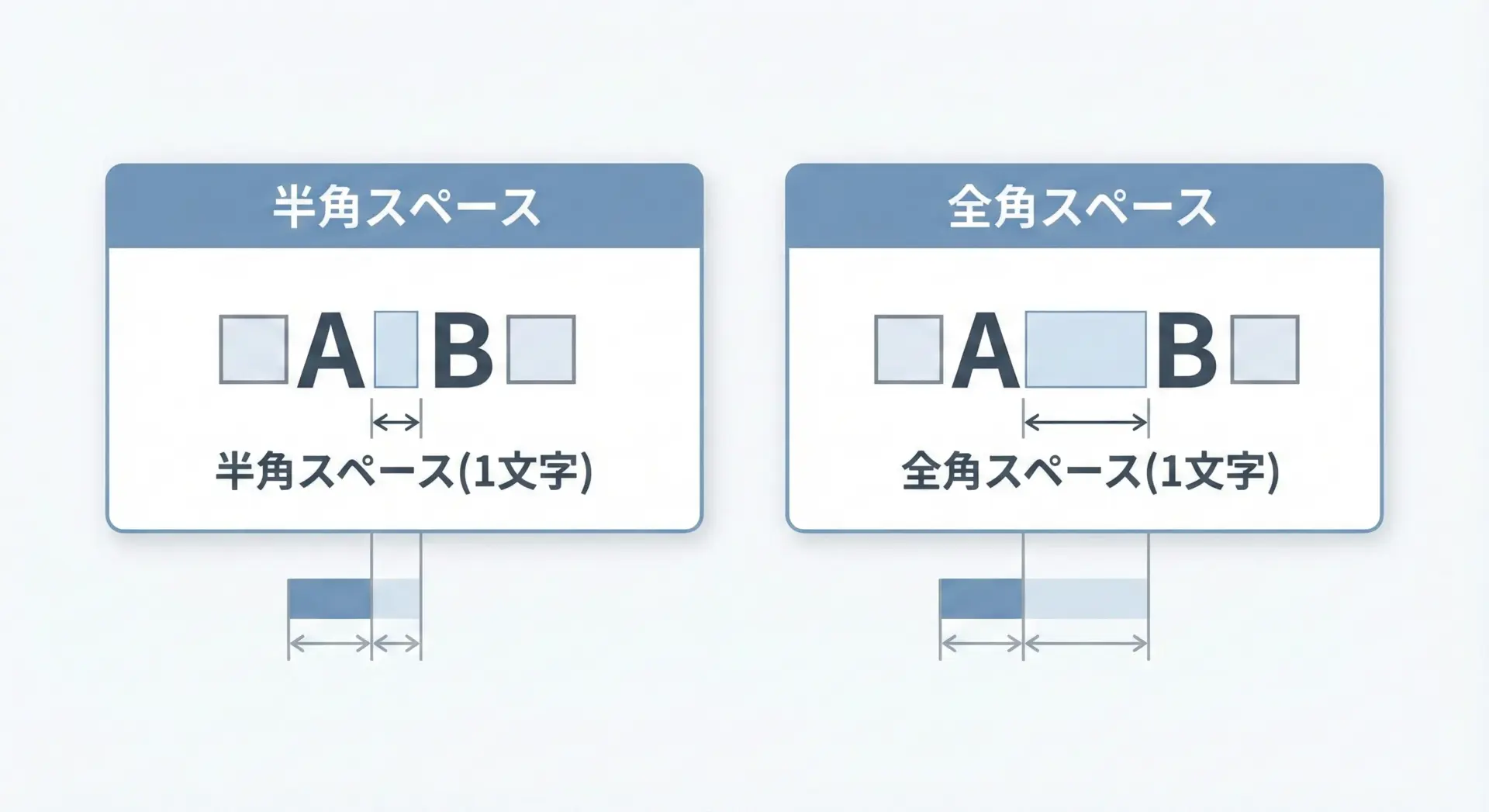
Pythonでよく混乱を招くのが半角スペースと全角スペースの違いです。
見た目は「空白」に見えても、Pythonからは全く別の文字として扱われます。
- 半角スペース:
' '(ASCIIのスペース) - 全角スペース:
' '(Unicodeの全角スペース、U+3000)
次の例を見ると、違いが分かりやすくなります。
text_half = "A B" # 半角スペース
text_full = "A B" # 全角スペース
print(text_half == text_full) # 比較
print(len(text_half), len(text_full)) # 長さを比較False
3 3両方とも長さは3文字ですが、真ん中の1文字は別のコードポイントなので文字列としては一致しません。
そのため、半角スペースだけを削除しても、全角スペースは残るという状況が簡単に起こります。
この違いはstripやreplaceの動作にも影響します。
例えばstrip()は全角スペースを「空白」として扱わないため、前後に全角スペースがある文字列を処理するときには注意が必要です。
前後の空白削除と文字列中の空白削除の使い分け

文字列の空白削除には、大きく分けて2つのパターンがあります。
1つ目は「前後の空白」だけを削除する場合です。
例えば、ユーザー入力の前後に紛れ込んだスペースや改行を取り除いて、純粋な値だけを取得したいケースです。
このときはstrip、lstrip、rstripが適しています。
2つ目は「文字列中の空白」を削除または整形する場合です。
例としては、郵便番号や電話番号の中に含まれるスペースを完全に取り除きたい場合や、単語間のスペースを「1つだけ」に正規化したい場合が挙げられます。
このときはreplaceや正規表現(re.sub)がよく使われます。
前後の空白処理をstrip、内部のパターン処理をreplaceや正規表現、と用途に応じて使い分けるのが基本的な戦略です。
stripで前後の空白を削除する方法
stripで前後の空白をまとめて削除する

strip()メソッドは、文字列の先頭と末尾にある空白文字をまとめて削除してくれます。
引数を指定しなければ、半角スペースだけでなくタブや改行などのホワイトスペース全般が対象になります。
text = " \n hello world \t "
# 前後の空白・改行・タブをまとめて削除
cleaned = text.strip()
print(repr(text))
print(repr(cleaned))' \n hello world \t '
'hello world'このように、内部のスペース(単語間のスペース)はそのまま残り、前後の余分な空白だけが削除されています。
ユーザー入力値や、ファイルから読み込んだ1行分の文字列をクリーンアップする際に非常に便利です。
lstripとrstripで左側・右側だけ空白削除

前後のどちらか片側だけを削除したい場合は、lstrip()とrstrip()を使います。
text = " hello world "
left_cleaned = text.lstrip() # 左側だけ空白削除
right_cleaned = text.rstrip() # 右側だけ空白削除
print(repr(left_cleaned))
print(repr(right_cleaned))'hello world '
' hello world'左側だけ、右側だけ、という細かい制御ができるため、レイアウト上、行末の空白だけは消したいが行頭のインデントは残したいといったケースで役立ちます。
stripで改行やタブも同時に削除する

strip()は、引数を省略すると空白だけでなくタブや改行もまとめて削除してくれます。
ファイルから1行ずつ読み込んだ文字列を扱うときに、末尾の改行を消したい場面は非常によくあります。
line = "\n\t sample data \n"
# デフォルトのstripは、改行・タブ・スペースなどをまとめて削除
cleaned = line.strip()
print(repr(line))
print(repr(cleaned))'\n\t sample data \n'
'sample data'テキストファイルなどを扱う場合、先にstrip()してからロジックを適用すると、余計な空白によるバグを防ぎやすくなります。
なお、改行だけを取りたい場合はrstrip("\n")やremovesuffix("\n")といったより限定的な方法もありますが、多くのケースではstrip()で十分です。
stripで特定の文字だけを削除する注意点
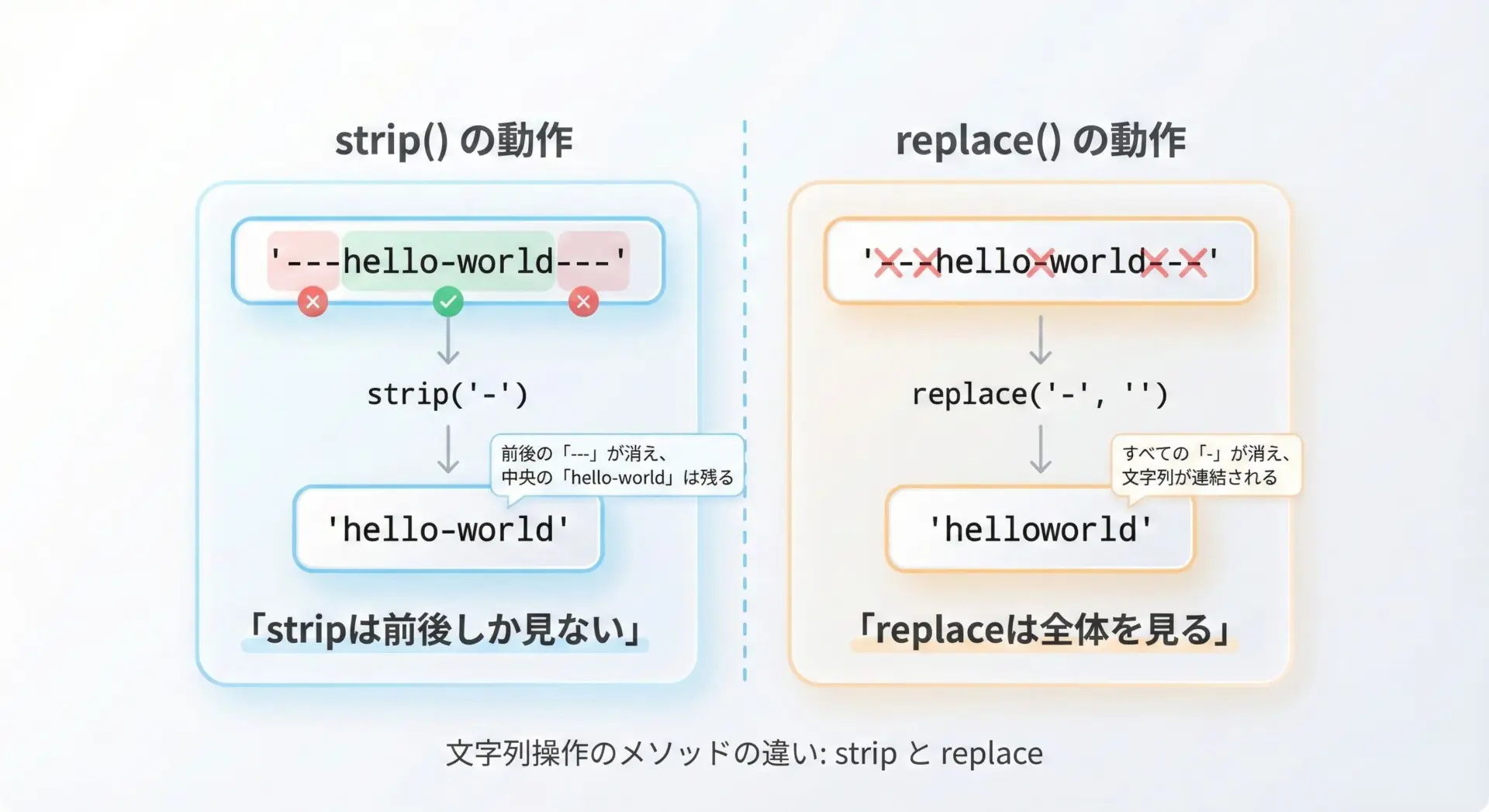
strip()には、引数として文字列を渡すことができます。
このとき、「その文字列全体」を削除するのではなく、「その文字列に含まれるいずれかの文字」を前後から削除するという挙動になります。
text = "---hello-world---"
# '-' を前後から削除
cleaned = text.strip("-")
print(repr(cleaned))'hello-world'ここでのポイントは次の通りです。
strip("-")は、“-“という1文字が連続している部分を前後から削るstrip("abc")とした場合、前後にある’a’、’b’、’c’のいずれかを削除できるだけであり、「abc」という文字列パターンを見ているわけではない
次の例で違いがよく分かります。
text = "abc123cba"
print(text.strip("abc")) # '123'
print(text.replace("abc", "")) # '123cba''123'
'123cba'stripは「前後から1文字ずつ、条件に合う限り削る」だけであり、途中の文字列には影響しません。
そのため、「全体から特定のパターンを削除したい」場合にはreplaceや正規表現を使う必要があります。
replaceで文字列中の空白を削除する方法
replaceで全ての半角スペースを削除する
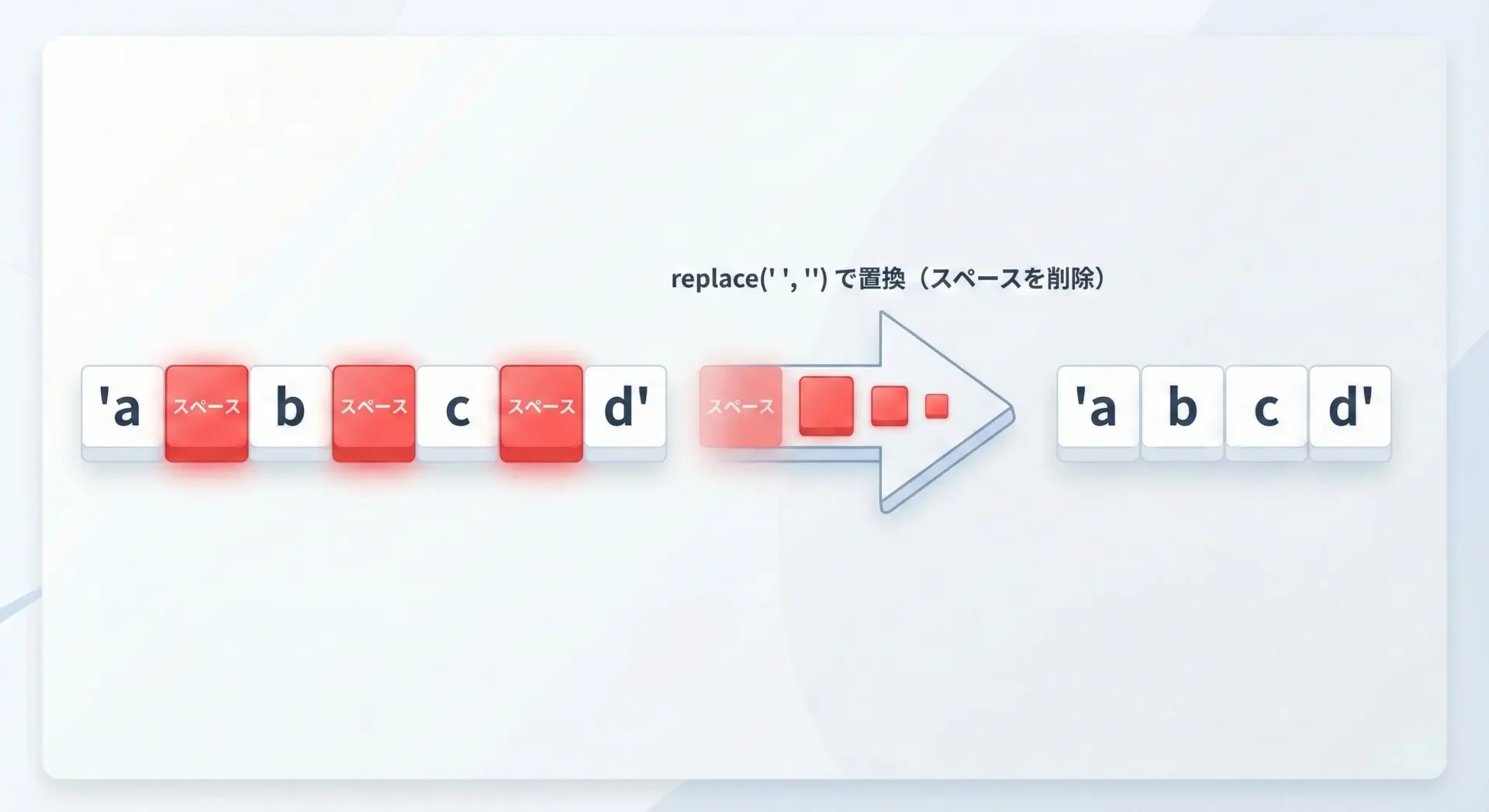
replace()は、文字列中の特定の部分文字列を別の文字列に一括置換するメソッドです。
すべての半角スペースを削除したい場合は、スペースを空文字列に置き換えます。
text = " a b c d "
# 半角スペースをすべて削除
no_space = text.replace(" ", "")
print(repr(text))
print(repr(no_space))' a b c d '
'abcd'stripは前後だけですが、replaceは文字列全体を対象にする点が大きな違いです。
例えば、電話番号、郵便番号、IDなど「スペースがすべて不要」なデータでは、replace(" ", "")がよく使われます。
単語間のスペースだけ1つにまとめる方法

連続するスペースを「1つのスペースにまとめたい」場合は、単純なreplace(" ", " ")でもある程度対応できますが、繰り返し適用が必要になるなど少し扱いにくいです。
Pythonでは、splitとjoinを組み合わせることで、単語間のスペースを1つに整理するのが定番のパターンです。
text = "Python string strip sample"
# 1. デフォルトのsplit()で分割すると、連続する空白をまとめて区切りとして扱う
# 2. ' 'でjoinし直せば、単語間スペースが1つに整形される
normalized = " ".join(text.split())
print(repr(text))
print(repr(normalized))'Python string strip sample'
'Python string strip sample'split()を引数なしで呼ぶと、スペースだけでなくタブや改行も「空白」とみなし、連続する空白は1つの区切りとして扱ってくれます。
これにより、「どんな空白で区切られていても、とりあえず単語リストに分解 → 1つのスペースでつなぎ直す」というシンプルな構成で、整形が実現できます。
全角スペースをreplaceで削除する
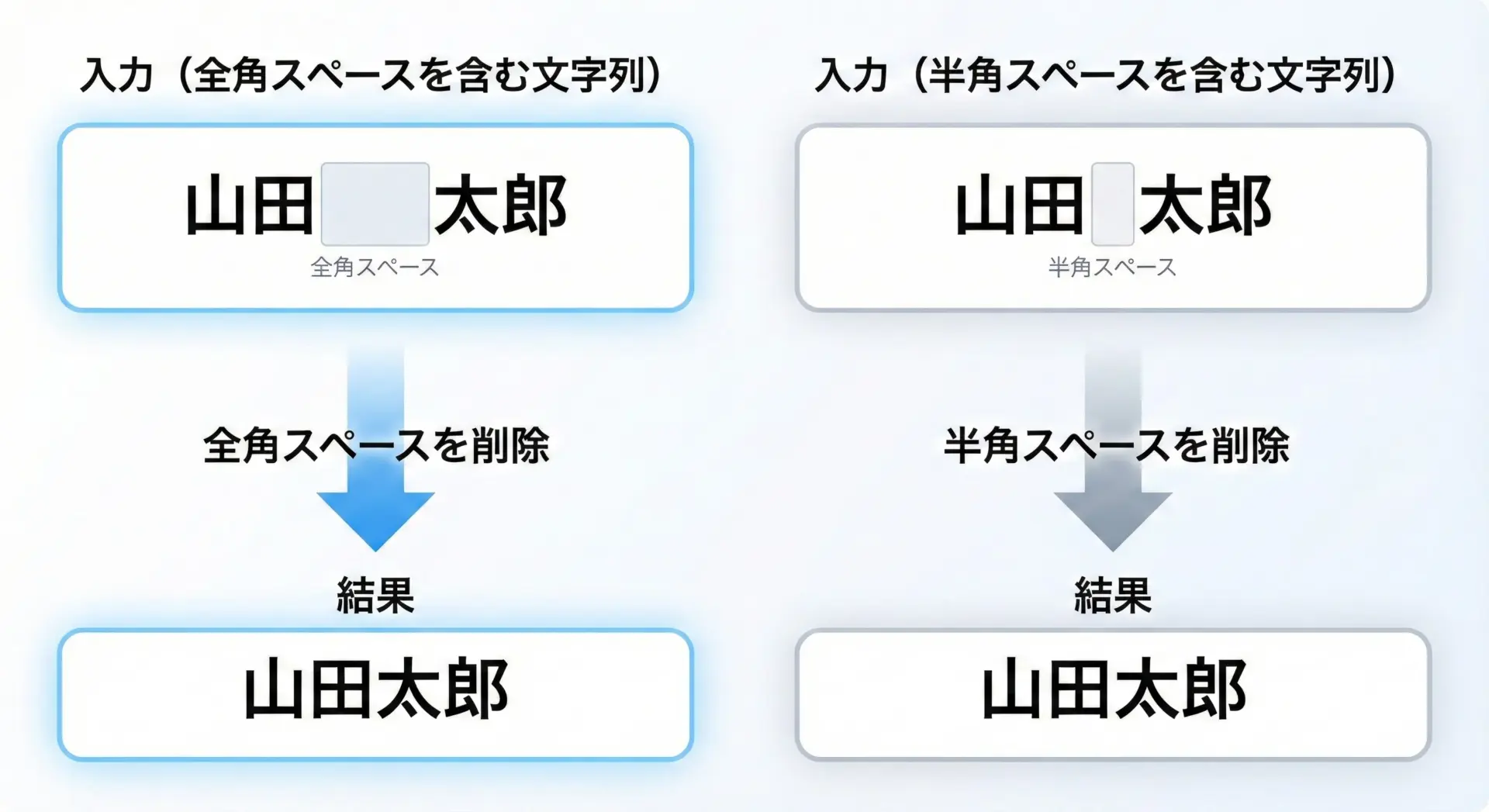
全角スペースは' 'という別の文字として扱う必要があります。
stripのデフォルト挙動では削除されないため、全角スペースを明示的にreplaceするケースが多くなります。
text = "山田 太郎" # 姓と名の間に全角スペース
# 全角スペースを削除
no_full_space = text.replace(" ", "")
print(repr(text))
print(repr(no_full_space))'山田 太郎'
'山田太郎'半角と全角が混在する可能性が高い入力を扱うときには、次のように両方を処理することもあります。
text = " 山田 太郎 " # 前後に半角、間に全角スペース
# 半角スペースと全角スペースを両方削除
no_space = text.replace(" ", "").replace(" ", "")
print(repr(no_space))'山田太郎'全角スペースはstripのデフォルト対象ではないという点を覚えておくと、意図しない空白が残る問題を避けやすくなります。
複数種類の空白を組み合わせて削除する
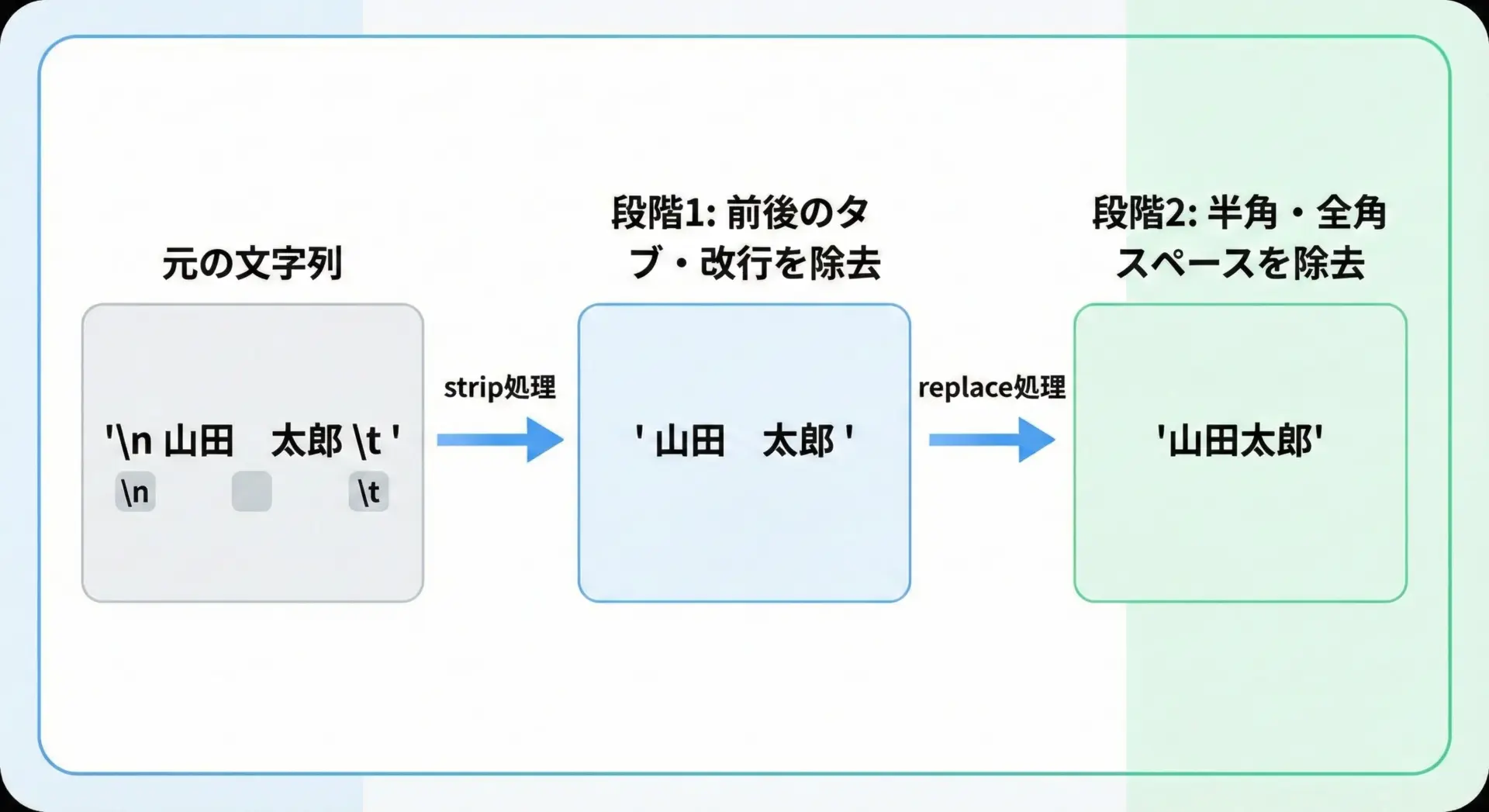
現実のデータでは、半角スペース、全角スペース、タブ、改行など複数種類の空白が混ざることが一般的です。
そのような場合は、stripとreplaceを組み合わせて段階的に処理する方法が分かりやすくて安全です。
text = "\n 山田 太郎 \t "
# 1. 前後の改行・タブ・スペースなどをまとめて削除
step1 = text.strip()
# 2. 中に残った半角・全角スペースを削除
step2 = step1.replace(" ", "").replace(" ", "")
print(repr(text))
print(repr(step1))
print(repr(step2))'\n 山田 太郎 \t '
'山田 太郎'
'山田太郎'このように、「前後の制御系空白」→「内部のスペース類」という順番で整理していくことで、予期せぬ空白が残りにくくなります。
要件次第では、「全角スペースは残す」「単語間のスペースは1つにするだけ」など、replaceの内容を調整して柔軟に対応できます。
正規表現(re)で柔軟に空白削除する方法
re.subで連続する空白を1つに置換する

正規表現を使うと、「空白が1つ以上続いている部分を1つのスペースにまとめる」といった柔軟な処理を簡潔に書けます。
import re
text = "Python\t string \n strip sample"
# 連続する空白文字(スペース・タブ・改行など)を1つの半角スペースに置換
normalized = re.sub(r"\s+", " ", text).strip()
print(repr(text))
print(repr(normalized))'Python\t string \n strip sample'
'Python string strip sample'ここで使っている\s+は、正規表現における「空白文字(スペース、タブ、改行など)が1回以上連続する部分」を意味します。
これにより、どんな種類の空白が何個続いていても、ひとまとめにして処理できる点がstripや単純なreplaceよりも強力です。
文字列中の全ての空白文字を削除する
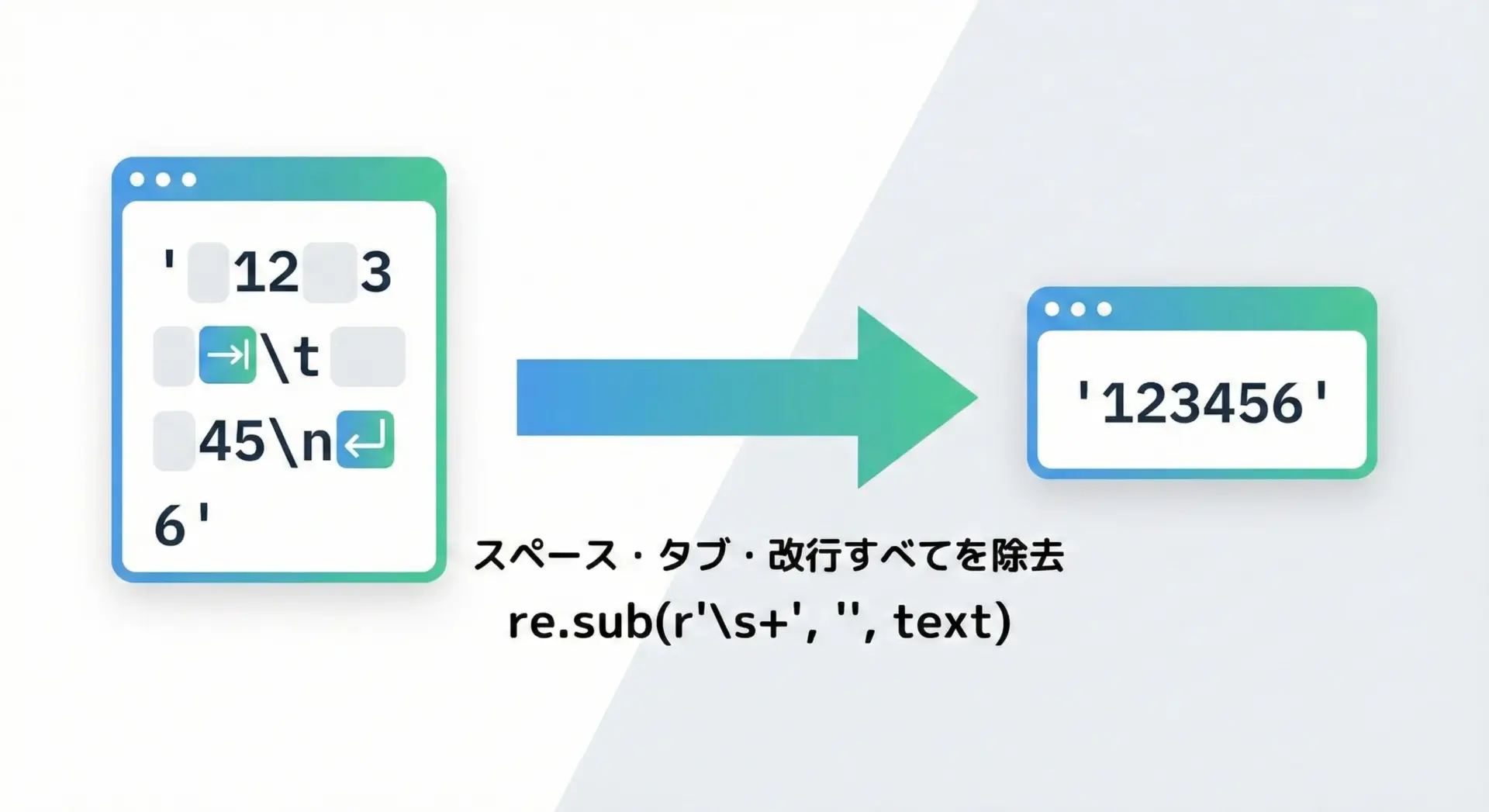
文字列中からすべての空白文字(スペース・タブ・改行など)を取り除きたい場合も、正規表現が簡潔です。
import re
text = " 12 3 \t 45\n6 "
# 空白文字(スペース・タブ・改行など)をすべて削除
no_whitespace = re.sub(r"\s+", "", text)
print(repr(text))
print(repr(no_whitespace))' 12 3 \t 45\n6 '
'123456'数字や英字、記号の間に入ったあらゆる空白を一掃したいときに非常に便利です。
ただし、言語として意味のあるスペース(単語区切りなど)も消えてしまうため、意図的にそうしたい場面かどうかをよく確認してから使う必要があります。
行頭・行末の空白だけ正規表現で削除する
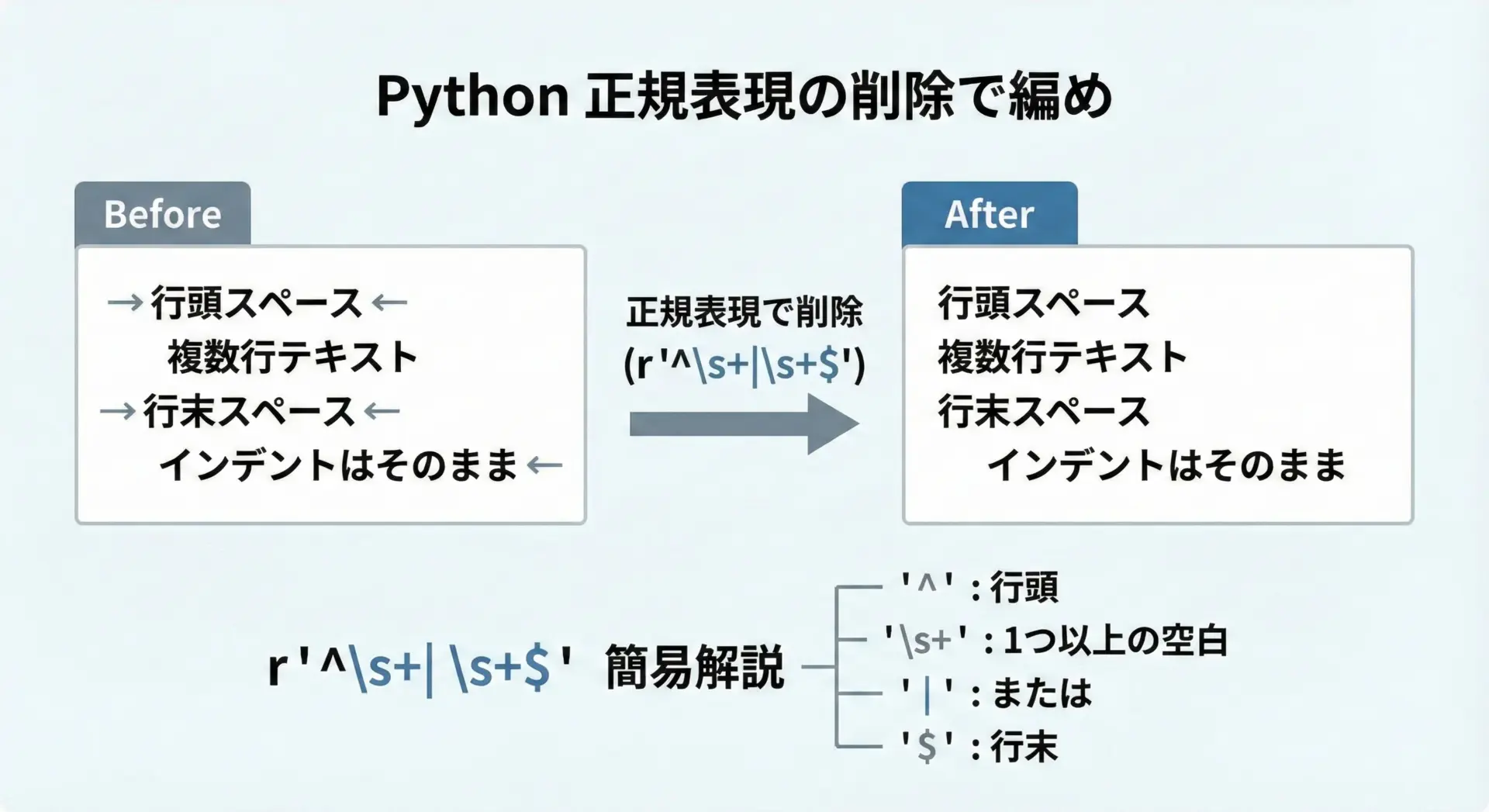
複数行テキストで、各行の先頭・末尾にある空白だけを削除したい場合があります。
例えば、行頭のインデントや中央のスペースは残したいが、余計な末尾スペースだけを落としたいケースです。
その際には、次のような正規表現パターンを使います。
import re
text = " line1 \n\tline2 \n line3\t "
# 各行の行頭(^)と行末($)にある空白(\s+)を削除
cleaned = re.sub(r"^\s+|\s+$", "", text, flags=re.MULTILINE)
print(repr(text))
print("---")
print(repr(cleaned))' line1 \n\tline2 \n line3\t '
---
'line1\nline2\nline3'ここでのポイントを整理します。
^: 行頭を意味する$: 行末を意味する\s+: 1文字以上の空白文字|: 「または」の意味で、^\s+または\s+$のどちらかにマッチre.MULTILINE: ^と$を「文字列全体」ではなく「各行の先頭・末尾」として扱うためのフラグ
stripだと文字列全体の前後しか見えませんが、正規表現なら各行単位で柔軟に前後の空白を調整できます。
タブや改行を含む空白を一括で扱うパターン
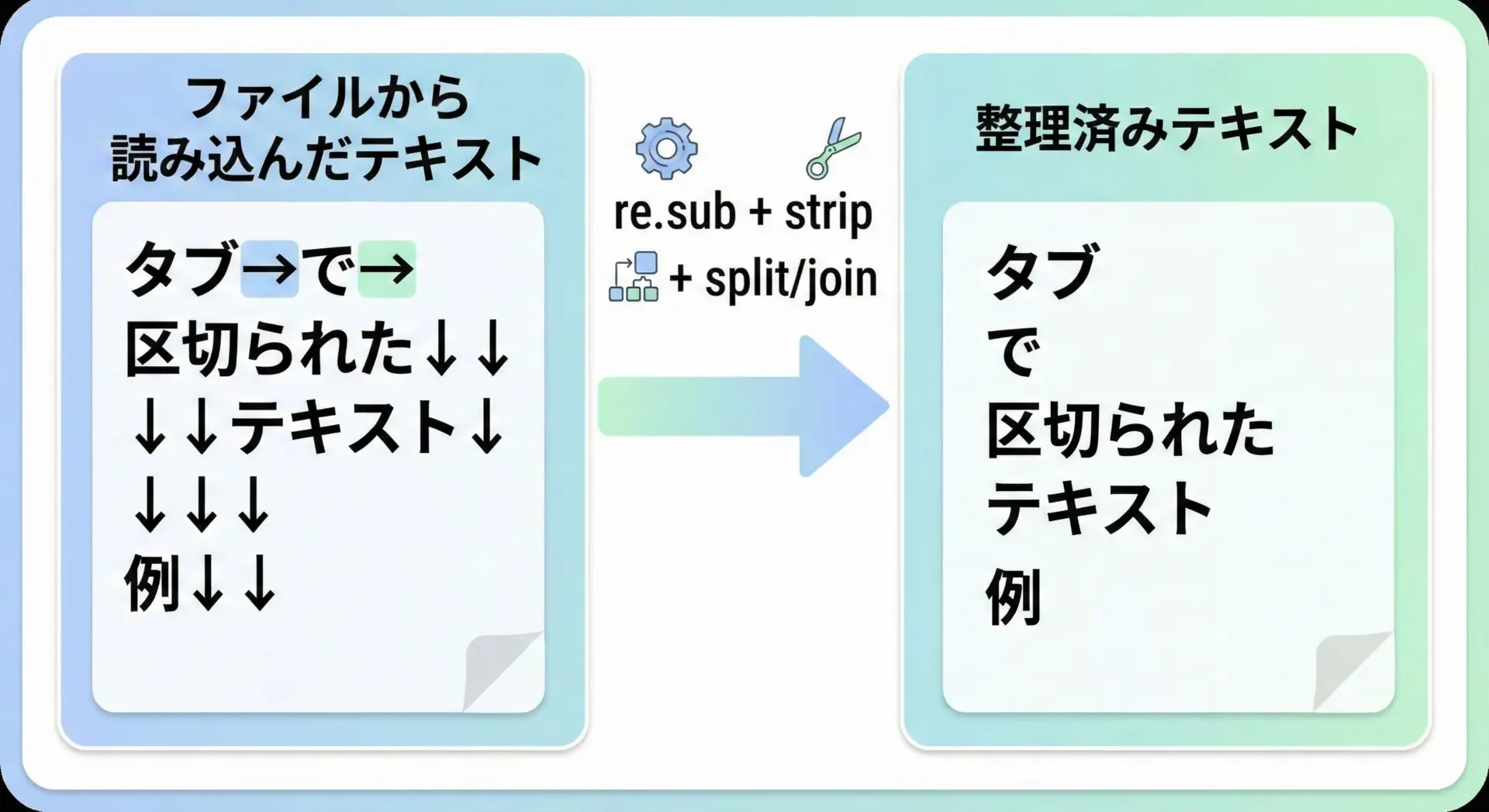
タブや改行を含む複雑な空白を一度に整理したい場合、re.subを複数回使う、またはsplitと組み合わせるというパターンがよく使われます。
import re
text = "Name:\tJohn Doe\n\nAddress:\t Tokyo Japan"
# 1. 連続する空白(スペース・タブ・改行など)を1つのスペースにまとめる
step1 = re.sub(r"\s+", " ", text)
# 2. 前後の空白をstripで削除
step2 = step1.strip()
print("元の文字列:")
print(repr(text))
print("\n整形後:")
print(repr(step2))元の文字列:
'Name:\tJohn Doe\n\nAddress:\t Tokyo Japan'
整形後:
'Name: John Doe Address: Tokyo Japan'この例では、\s+でタブ・改行・スペースをすべてまとめて「空白の連続」として扱い、それを1つのスペースに統一しています。
ログの整形やテキスト前処理など、「とにかく読みやすく整える」目的には非常に有効です。
より細かい要件(「改行は残したいが、タブだけスペースにしたい」など)がある場合は、次のように複数パターンを組み合わせることもできます。
import re
text = "Name:\tJohn Doe\n\nAddress:\t Tokyo Japan"
# タブをスペースに
step1 = text.replace("\t", " ")
# 行ごとに末尾スペースを削除
step2 = re.sub(r"[ ]+$", "", step1, flags=re.MULTILINE)
print(repr(step2))'Name: John Doe\n\nAddress: Tokyo Japan'このように、「どの種類の空白を」「どの範囲で」「どう変えたいか」を明確にし、それに合わせて正規表現パターンを設計することが重要です。
stripとreplaceと正規表現の使い分けまとめ
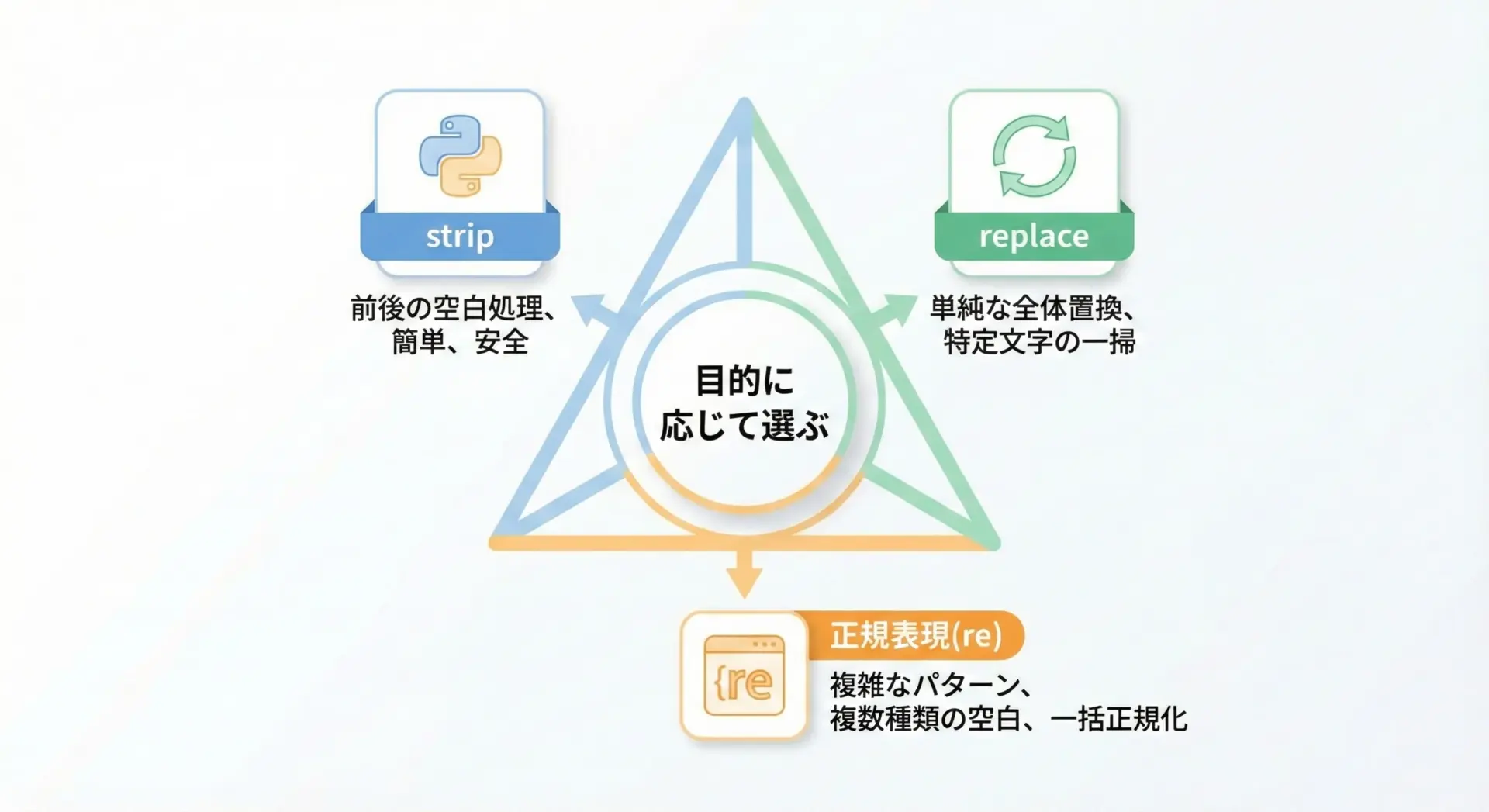
ここまで紹介した3つの手法の特徴と使い分けを整理しておきます。
空白削除の用途は、大きく分けて次の3タイプに分類できます。
- 前後の余計な空白を消したい
→strip / lstrip / rstripが最適です。引数なしで使えば、スペースやタブ、改行などをまとめて処理できます。 - 文字列の中にある特定の空白(半角・全角)を消したい
→replaceがシンプルで読みやすいです。.replace(" ", "")や.replace(" ", "")など、狙い撃ちで削除できます。 - 複数種類の空白をまとめて扱いたい / 複雑なルールで整形したい
→正規表現(re.sub)が強力です。\s+で「空白文字全般」を一度に扱ったり、行頭・行末だけを対象にしたりと柔軟な制御ができます。
「まずstripで前処理し、必要に応じてreplaceや正規表現で仕上げる」という2段構えの発想を持っておくと、多くの場面で安定した文字列処理が実現できます。
まとめ
Pythonで文字列の空白を削除するには、strip系・replace・正規表現(re)を目的に応じて使い分けることが重要です。
前後の余計な空白や改行を落としたいときはstrip、文字列全体から特定のスペースを消したいときはreplace、タブや改行を含む複雑な空白パターンを一括で整えたいときは正規表現を選びます。
特に半角スペースと全角スペースが別物である点を意識しつつ、ここで紹介したパターンを組み合わせれば、多くの「空白が原因のバグ」を未然に防ぐことができるはずです。
