Pythonで文字列を扱うとき、英字の大文字・小文字の変換は、入力の正規化や検索、ラベル生成などさまざまな場面で役立ちます。
本記事では、Pythonのlower・upper・swapcaseという3つのメソッドに焦点を当てて、それぞれの違いと使い方、注意点を詳しく解説します。
基本から実践的な活用例まで、順番に確認していきましょう。
Pythonの大文字・小文字変換の基本
Pythonで文字列の大文字・小文字を変換する方法
[cst-strongで囲むべき最重要テキスト]
Pythonでは、文字列の大文字・小文字変換は文字列メソッドlower・upper・swapcaseを呼び出すだけで簡単に行えます。
Pythonの文字列は不変(イミュータブル)なオブジェクトであり、lowerなどを呼び出しても元の文字列は書き換わらず、新しい文字列が返されます。
これは、どのメソッドでも共通の重要なポイントです。
代表的なメソッドは次の3つです。
str.lower()… 英字を小文字に変換するstr.upper()… 英字を大文字に変換するstr.swapcase()… 英字の大文字と小文字を反転する
[cst-boldで囲む少し重要なテキスト] 数字や記号はこれらのメソッドでは変化せず、そのまま維持されます。
lower・upper・swapcaseの違いと使い分け
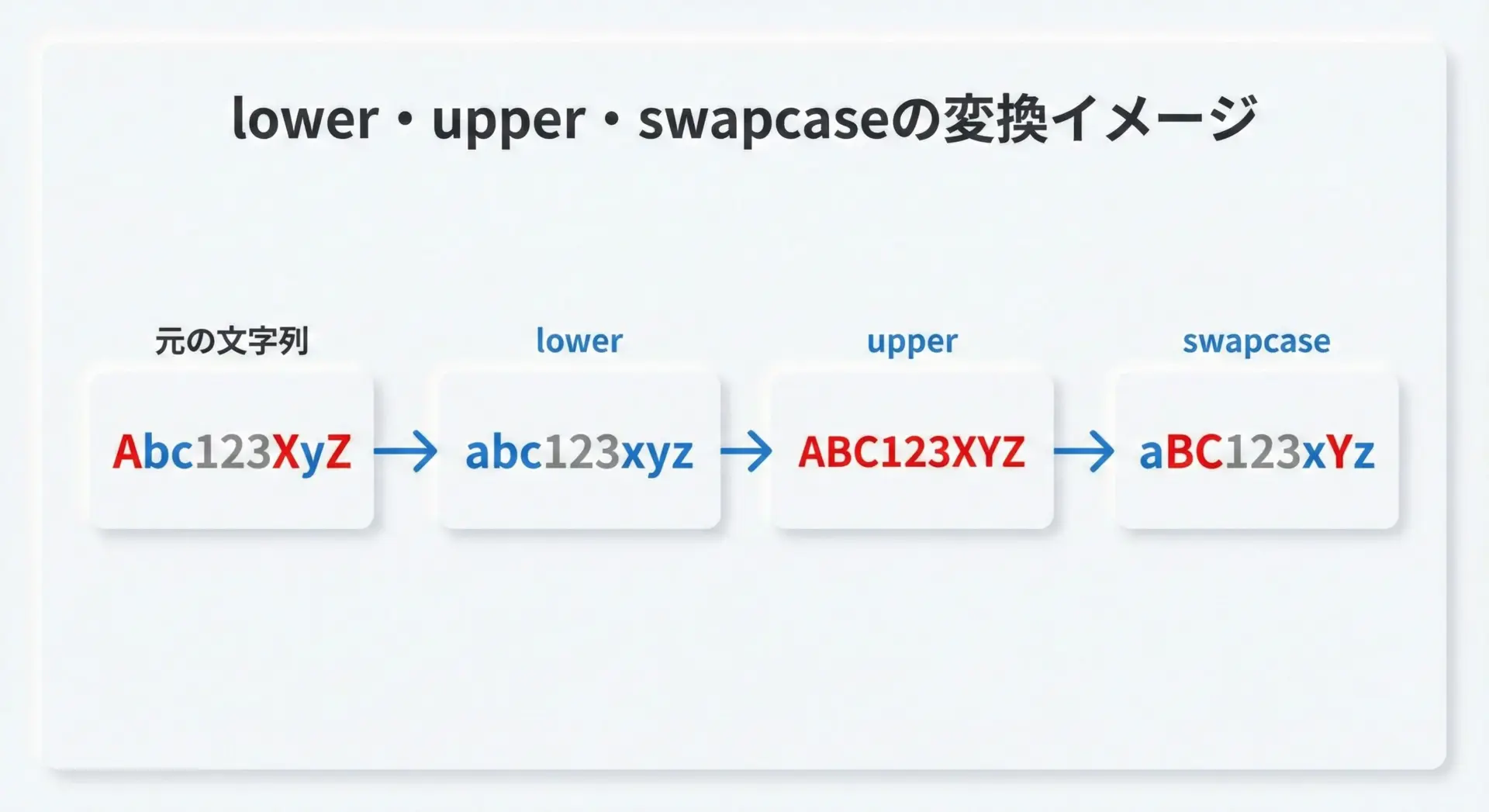
この3つのメソッドは、どれも「英字の大文字・小文字に関わる変換」という点では同じですが、動作ははっきりと異なります。
lowerは英字をすべて小文字に統一します。
逆にupperはすべて大文字に統一します。
swapcaseは、それぞれの文字の状態を「反転」するのが特徴で、大文字は小文字、小文字は大文字に変わります。
たとえば、文字列"AbC"に対してそれぞれのメソッドを適用すると、次のようになります。
| メソッド | 結果 |
|---|---|
| なし(元の文字列) | “AbC” |
lower() | “abc” |
upper() | “ABC” |
swapcase() | “aBc” |
文字列を比較したいときはlowerかupperで「揃える」、文字の状態を調べたり一時的に変えたりしたいときはswapcaseを使うと整理しておくと分かりやすくなります。
大文字・小文字変換が役立つ典型的な用途
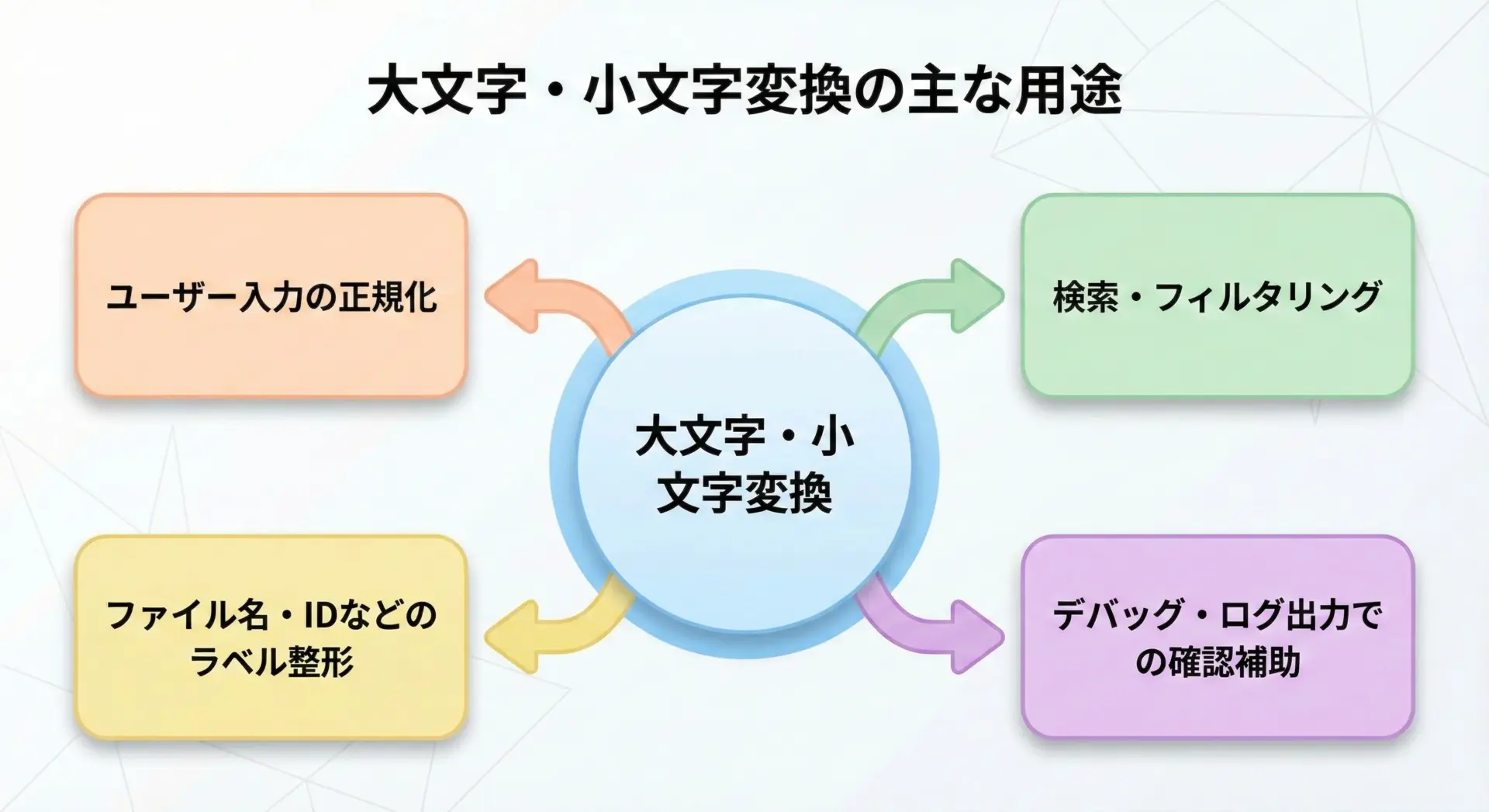
Pythonの大文字・小文字変換は、実用面でも多くの場面で活躍します。
典型的な用途としては、次のようなものが挙げられます。
まずユーザー入力の正規化です。
ログインIDやメールアドレス、検索キーワードなどは、人によって大文字・小文字の入力がばらばらになることがあります。
そこでlowerやupperを使って事前に変換しておくと、入力の揺れを吸収できます。
次に検索・フィルタリングの場面では、データ側と検索キーワード側の両方を小文字に変換してから比較することで、大文字・小文字を区別せずにマッチングできます。
また、ファイル名やログ用のラベルを一貫した形式にしたい場合にも、大文字・小文字変換が便利です。
すべて大文字のラベルに統一する、特定の部分だけ大文字にする、といった整形処理にupperがよく使われます。
さらに、swapcaseはデバッグの際に、ある部分の文字列がどのような大文字・小文字構成になっているかを把握したいときの一時的な変換として使われることがあります。
lowerメソッドで小文字に統一する
str.lowerの基本的な使い方と仕様
str.lower()は、文字列中の大文字アルファベットをすべて小文字に変換した新しい文字列を返すメソッドです。
元の文字列は変更されません。
基本形はとてもシンプルです。
text = "Hello, WORLD!"
lower_text = text.lower() # すべて小文字に変換このとき、text自体は変わらず、新しいlower_textが生成されます。
Pythonでは文字列はイミュータブルなため、lower()に限らずすべての文字列メソッドが同様の挙動をします。
英字以外の文字、たとえば数字や句読点、日本語などはlower()による変換の影響を受けません。
そのため、メールアドレスやURLなどの処理にも安心して利用できます。
lowerで英字を一括小文字化するサンプルコード
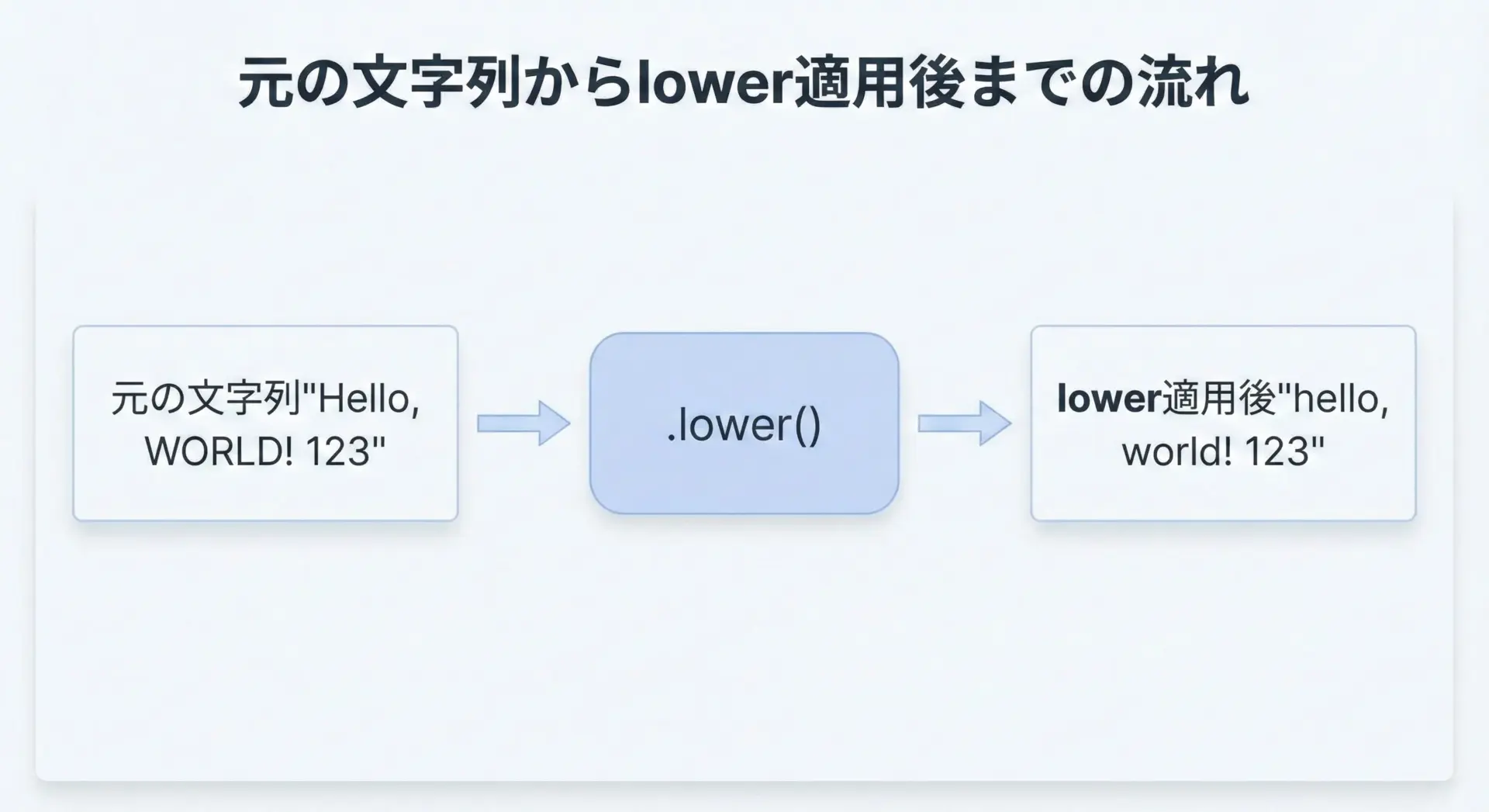
ここでは、いくつかの文字列にlower()を適用して、小文字化の挙動を確認してみます。
# 文字列を小文字に統一するサンプル
# 元の文字列
text1 = "Hello, WORLD!"
text2 = "Python3.11"
text3 = "メール: USER@Example.Com"
# lower()で小文字に変換
lower_text1 = text1.lower()
lower_text2 = text2.lower()
lower_text3 = text3.lower()
print("元の text1:", text1)
print("lower後 text1:", lower_text1)
print("元の text2:", text2)
print("lower後 text2:", lower_text2)
print("元の text3:", text3)
print("lower後 text3:", lower_text3)元の text1: Hello, WORLD!
lower後 text1: hello, world!
元の text2: Python3.11
lower後 text2: python3.11
元の text3: メール: USER@Example.Com
lower後 text3: メール: user@example.com出力結果を見て分かるとおり、英字だけが小文字化され、それ以外の文字はそのまま残っています。
メールアドレスのように、大文字・小文字を区別せず扱うべき文字列を正規化するのに適しています。
比較処理でlowerを使うときの注意点
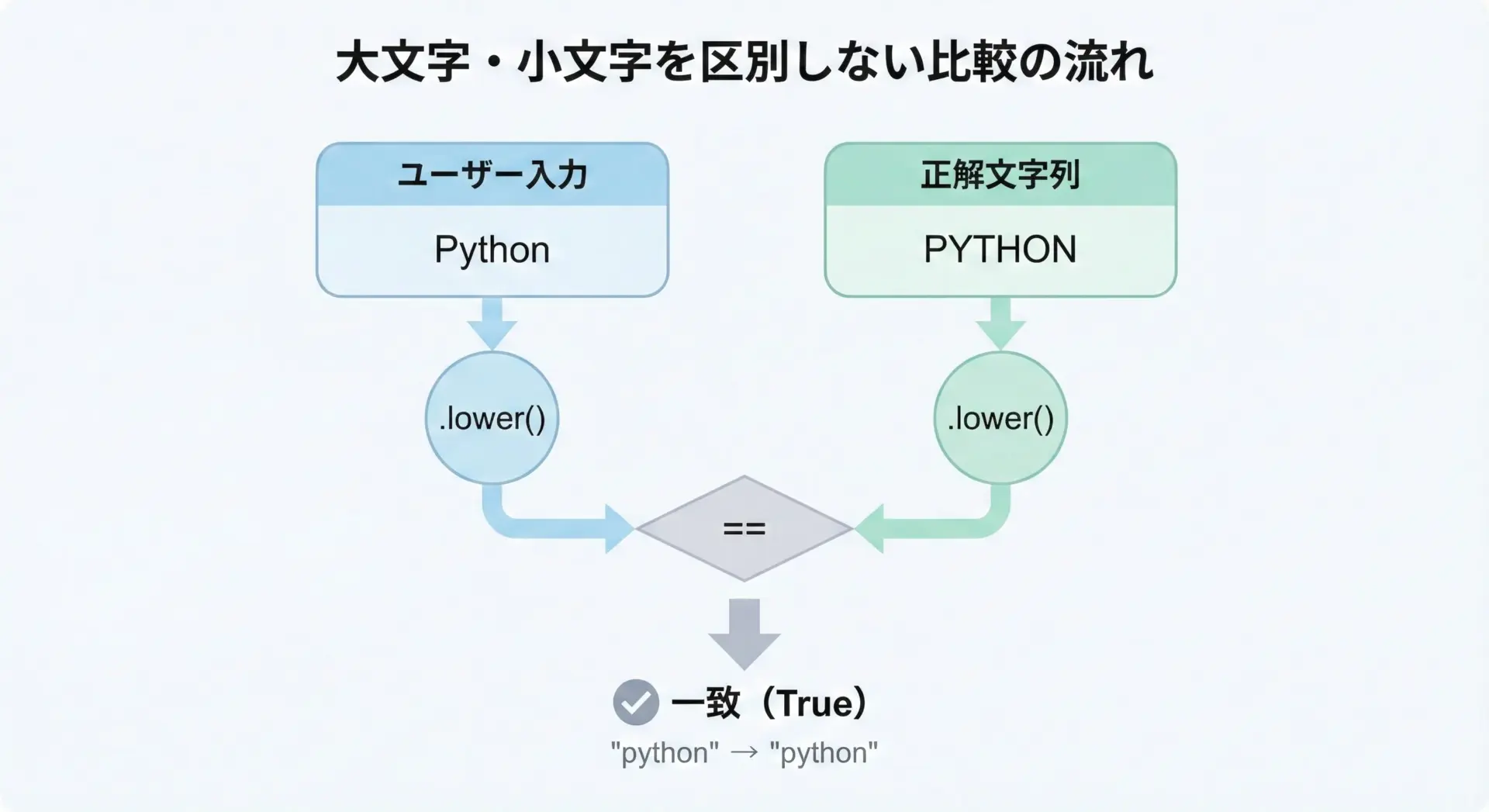
文字列の比較にlower()を使う場合、「どちら側にlower()を適用するのか」を必ず意識する必要があります。
片方だけを小文字化して比較すると、想定通りに一致判定ができないことがあります。
実装例を見てみましょう。
# ユーザー入力と正解文字列を比較する例
answer = "python"
user_input = input("好きな言語を入力してください: ")
# 1. 大文字・小文字を区別しない比較(推奨)
if user_input.lower() == answer.lower():
print("正解です!")
else:
print("違います。")
# 2. 片方だけlowerした比較(非推奨な例)
if user_input == answer.lower():
# ここは、大文字・小文字が違うと不正解扱いになる
print("これは、大文字・小文字を区別してしまう比較です。")この例では、上側の比較のように両方の文字列にlower()を適用してから比較することで、大文字・小文字の違いを無視した比較が可能になります。
一方で、メールアドレスなど本来は大文字・小文字の区別が仕様上既に定義されているケースでは、システムの要件に合わせて変換方法を検討する必要があります。
たとえば、ユーザー表示用には元の大文字・小文字を保持しつつ、検索用にはlower()で正規化した値を別に保持するといった設計が考えられます。
upperメソッドで大文字に統一する
str.upperの基本的な動作と特徴
str.upper()は、文字列中の小文字アルファベットをすべて大文字に変換した新しい文字列を返すメソッドです。
こちらも元の文字列は変わりません。
text = "Hello, world!"
upper_text = text.upper() # すべて大文字に変換upper()の挙動もlower()と同様で、英字だけが対象となり、数字や記号、日本語には影響を与えません。
「見出し」「タグ」「定数名」など、視覚的に強調したいテキスト表現に揃える目的で使われることが多いメソッドです。
upperで英字を一括大文字化するサンプルコード
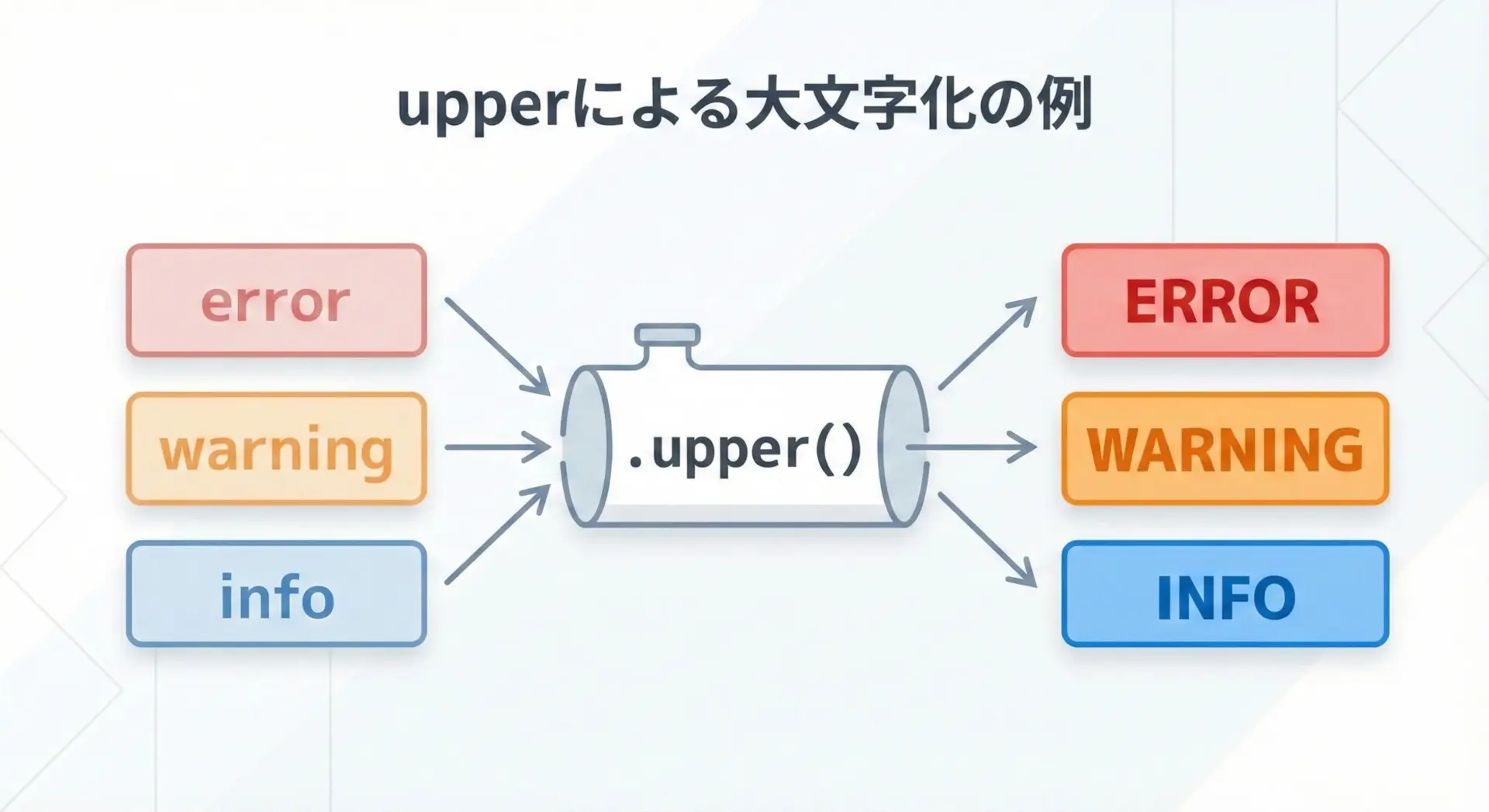
実際にいくつかの文字列をupper()で変換してみます。
# 文字列を大文字に統一するサンプル
labels = ["error", "Warning", "Info123", "ステータス: ok"]
for label in labels:
upper_label = label.upper() # ラベルを大文字に統一
print(f"元: {label} -> upper後: {upper_label}")元: error -> upper後: ERROR
元: Warning -> upper後: WARNING
元: Info123 -> upper後: INFO123
元: ステータス: ok -> upper後: ステータス: OKこのように、小文字の英字がすべて大文字に変換され、それ以外の部分はそのまま維持されます。
ログや画面表示で、エラー種別などを目立たせたいときに有用です。
見出し・ラベル生成でのupperの活用例
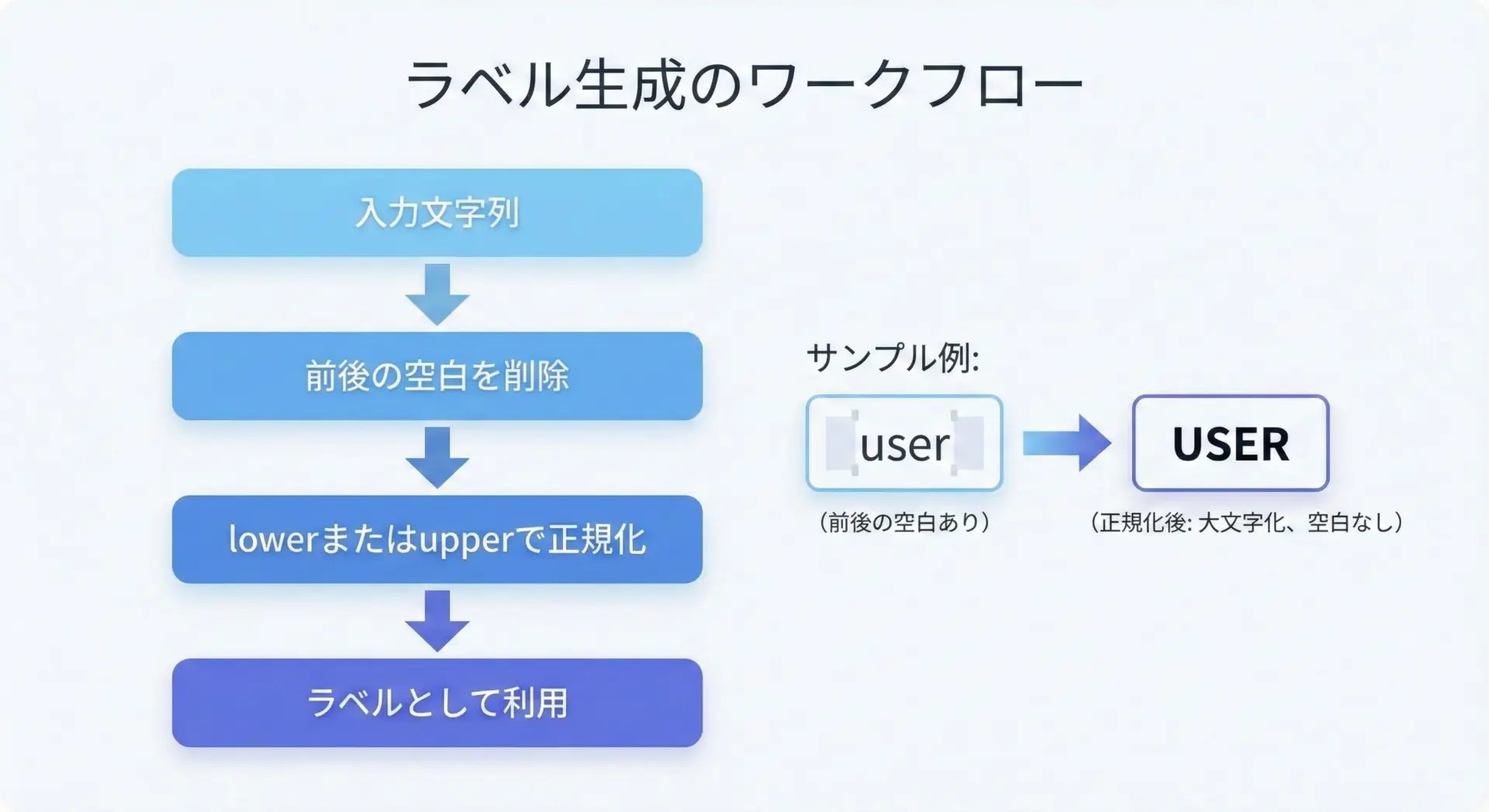
upper()は、プログラム内で扱う定数的なラベルや、UIに表示するカテゴリ名などを一貫したスタイルに整えるのに向いています。
代表的な活用パターンとして、ユーザー入力をラベルに変換する例を挙げます。
# ユーザー入力からラベルを生成する例
def normalize_label(raw: str) -> str:
"""
入力された文字列をラベル用に整形する関数。
- 前後の空白を削除
- 全角スペースも削除
- 大文字に統一
"""
# strip()で前後の半角・全角空白を削除
trimmed = raw.strip()
# ラベルとして扱いやすいように大文字に統一
label = trimmed.upper()
return label
# 使用例
inputs = [" user ", "Admin", " guest", "MOD "]
for s in inputs:
label = normalize_label(s)
print(f"入力: {repr(s)} -> ラベル: {label}")入力: ' user ' -> ラベル: USER
入力: 'Admin' -> ラベル: ADMIN
入力: ' guest' -> ラベル: GUEST
入力: 'MOD ' -> ラベル: MODこの例では、ラベルとして扱う文字列はupper()で大文字に統一することで、表示やログ出力の際に見た目を揃えています。
ただし、上記のように全角文字"MOD"などはupper()では変換されません。
全角の英字を半角に変換したい場合は、別途normalize関数(例: unicodedata.normalize)などを用いる必要があります。
swapcaseメソッドで大文字・小文字を反転する
str.swapcaseの基本と変換ルール
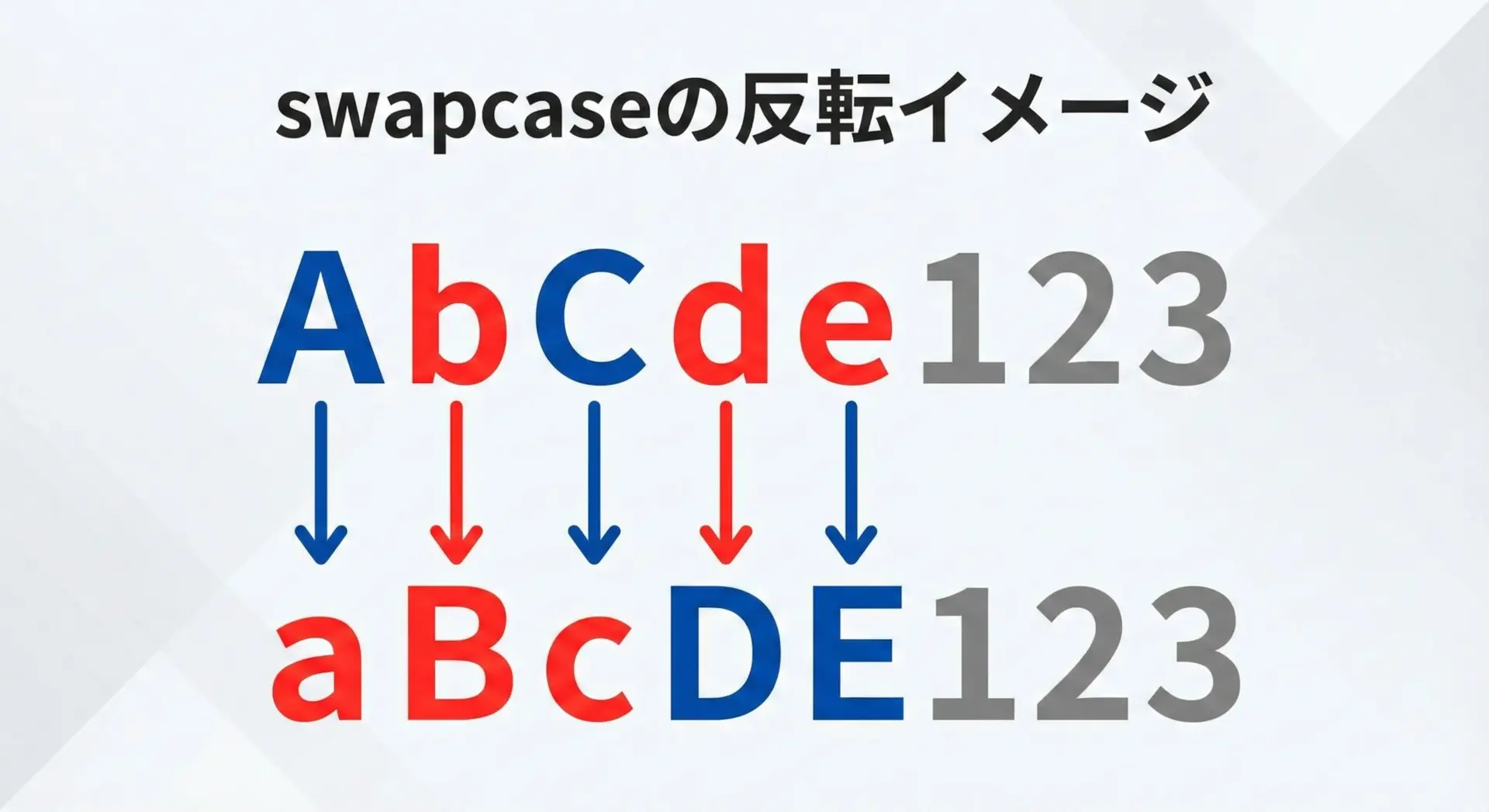
str.swapcase()は、その名の通り「ケース(大文字・小文字)を入れ替える」メソッドで、大文字は小文字に、小文字は大文字に変換されます。
text = "Hello, World!"
swapped = text.swapcase() # 大文字と小文字を反転このメソッドの変換ルールはシンプルです。
- 大文字の英字 → 小文字に変換
- 小文字の英字 → 大文字に変換
- それ以外の文字(数字・記号・日本語など) → 変化なし
lowerやupperと比べると、実務で使う機会は多くありませんが、デバッグやテキスト解析の補助、ちょっとした文字遊びなどに役立つメソッドです。
swapcaseで大文字・小文字を一括反転するサンプルコード
具体的な挙動を確認するため、さまざまな文字列にswapcase()を適用してみます。
# swapcase()で大文字・小文字を反転するサンプル
texts = [
"Hello, World!",
"python3.11",
"URL: HTTPS://Example.COM",
"タイトル:Python入門",
]
for t in texts:
swapped = t.swapcase() # 大文字・小文字を反転
print(f"元: {t}")
print(f"swapcase後: {swapped}")
print("-" * 30)元: Hello, World!
swapcase後: hELLO, wORLD!
------------------------------
元: python3.11
swapcase後: PYTHON3.11
------------------------------
元: URL: HTTPS://Example.COM
swapcase後: url: https://eXAMPLE.com
------------------------------
元: タイトル:Python入門
swapcase後: タイトル:pYTHON入門
------------------------------出力結果から、英字だけが反転していることが確認できます。
特に、URLやHTTPメソッドなど、部分的に大文字と小文字が混在した文字列の状態を一時的に変えたいときに挙動を確認しやすくなります。
データ整形・デバッグでのswapcaseの利用シーン
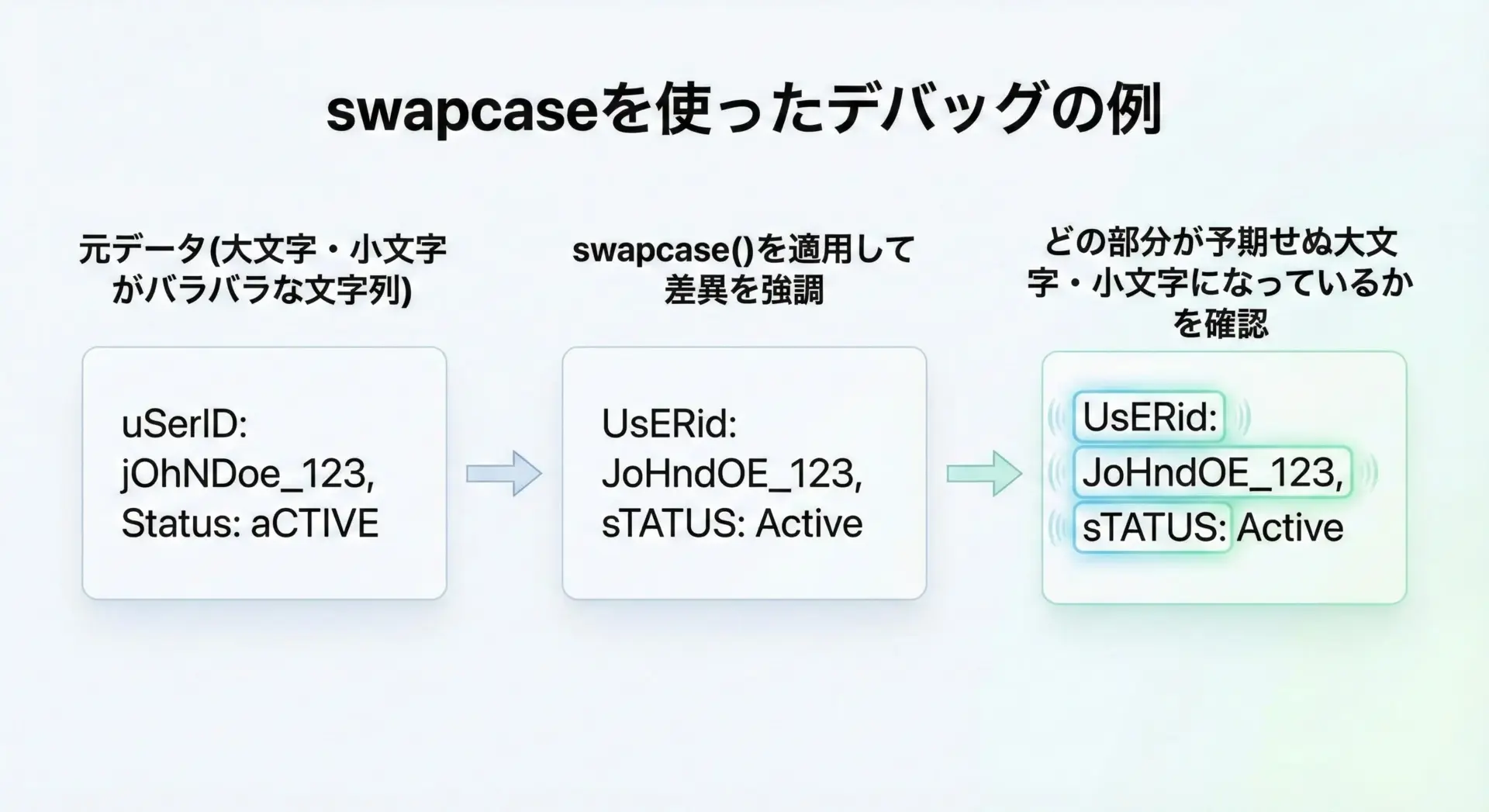
swapcase()は使いどころが少し特殊ですが、いくつか便利な場面があります。
1つめは、データ中の大文字・小文字の混在を目視で確認したいときです。
たとえば、すべて小文字であるはずのIDリストに紛れ込んだ大文字を検出したい場合、swapcase()を適用してから表示してみると、本来小文字であるべき位置が大文字になって強調されるため、違和感を見つけやすくなります。
簡単な例として、IDリストのチェックをしてみます。
# IDリストの大文字混在をswapcaseで「目立たせる」例
ids = ["user01", "User02", "admin", "GUEST01", "guest02"]
for user_id in ids:
swapped = user_id.swapcase()
print(f"元ID: {user_id} -> swapcase: {swapped}")元ID: user01 -> swapcase: USER01
元ID: User02 -> swapcase: uSER02
元ID: admin -> swapcase: ADMIN
元ID: GUEST01 -> swapcase: guest01
元ID: guest02 -> swapcase: GUEST02この結果を見ると、本来すべて小文字に統一したいIDなのに、大文字が含まれているものが一目で分かります。
たとえば"User02"のように、先頭だけ大文字になっているケースがかえって目立つようになります。
もう1つの利用シーンは、大文字・小文字のパターンを変えた複数のバリエーションを手軽に生成したいときです。
テストデータの作成や、文字遊び的なUIエフェクトなどで、元の文字列から別パターンを生成するための一手段として利用できます。
まとめ
本記事では、Pythonで大文字・小文字の変換を行うlower・upper・swapcaseの3つのメソッドについて、基本的な仕様からサンプルコード、実務での活用シーンまで詳しく解説しました。
比較や検索にはlowerやupperで文字列を正規化し、ラベルや見出しの整形にはupperを、デバッグや特殊なテキスト整形にはswapcaseを使うと整理しておくと、用途に応じた適切なメソッドを選択しやすくなります。
大文字・小文字変換はシンプルですが、文字列処理の品質と見通しを大きく高めてくれる重要なテクニックです。
