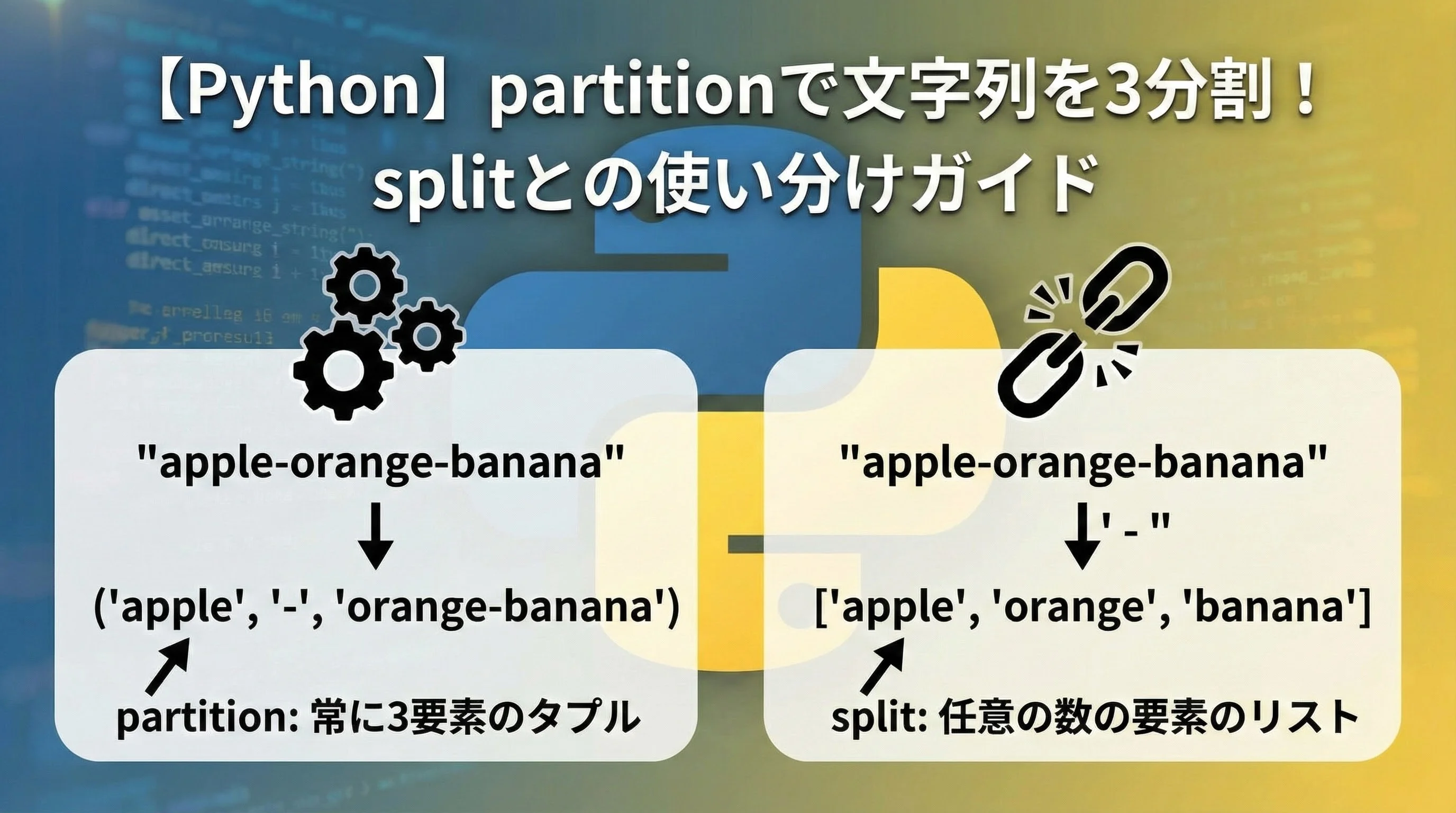
Pythonで文字列を分割するとき、多くの方はまずsplitを思い浮かべると思います。
しかし、Pythonには「3つにきっちり分ける」ことに特化したpartitionというメソッドがあります。
この記事では、partitionの基本からsplitとの違い、実務での使い分けパターンまで、図解とサンプルコードを交えながら丁寧に解説します。
Pythonのpartitionとは
partitionで文字列を3分割する基本

Pythonのstr.partition()メソッドは、「指定した区切り文字の最初の出現位置で、文字列を3つに分割する」ための機能です。
戻り値が3要素のタプルになることが最大の特徴です。
text = "user:password:extra"
# 最初の ":" で3分割する
left, sep, right = text.partition(":")
print("left :", left)
print("sep :", sep)
print("right:", right)left : user
sep : :
right: password:extraこのようにpartitionを使うと、「区切りの前」「区切りそのもの」「区切りの後ろ」を、一度にわかりやすく取り出せます。
戻り値(タプル)の構造と使いどころ
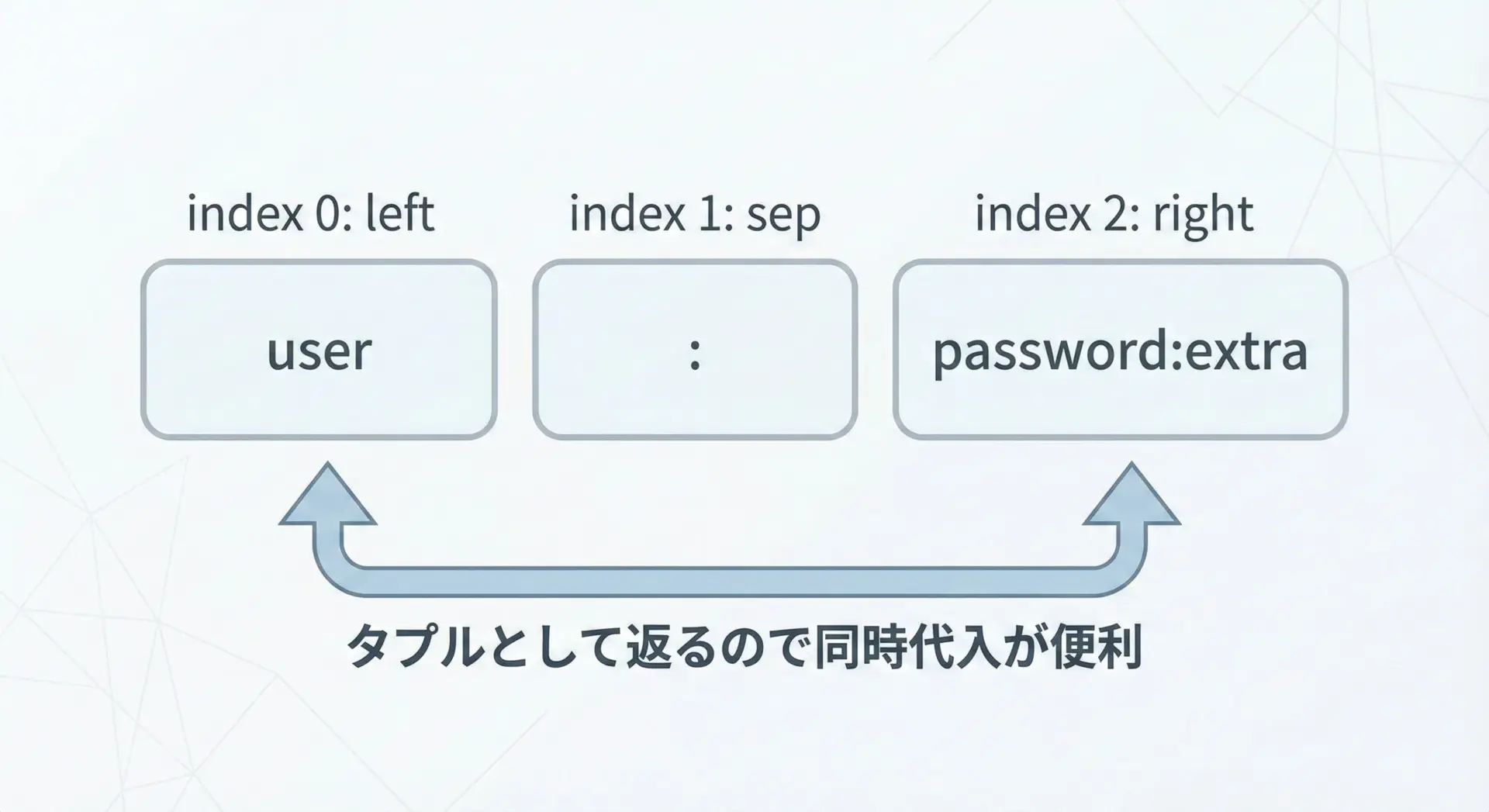
partitionは、つねに長さ3のタプルを返します。
構造は次の通りです。
- 0番目: 区切り文字より前の部分(
left) - 1番目: 区切り文字そのもの(
sep) - 2番目: 区切り文字より後ろの部分(
right)
このため、次のような「同時代入」がとても書きやすくなります。
config_line = "timeout=30"
key, sep, value = config_line.partition("=")
print("key :", key)
print("sep :", sep)
print("value:", value)key : timeout
sep : =
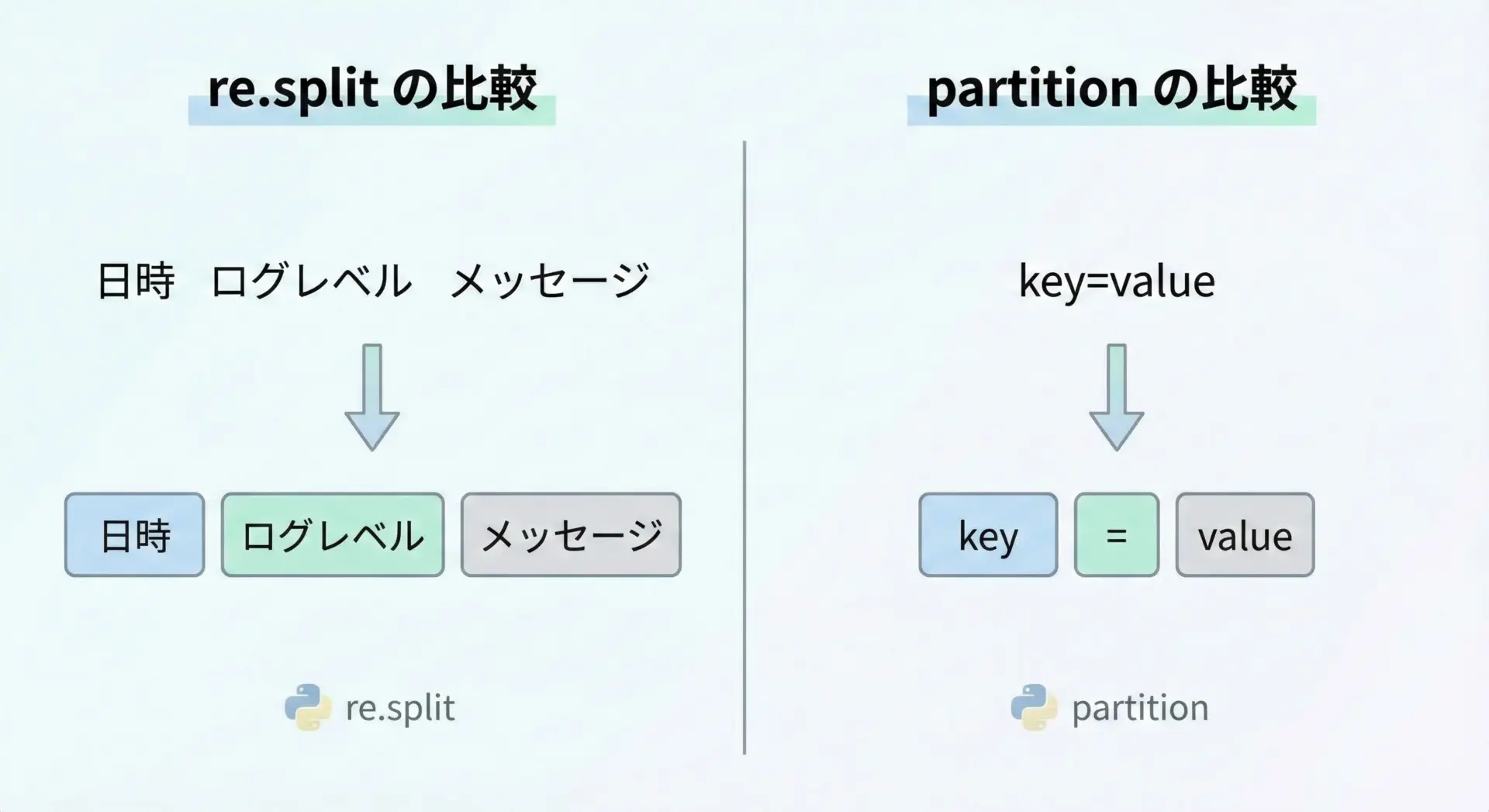
value: 30キーと値を一度の操作で安全に取り出せるので、設定ファイルやログの解析などで役立ちます。
また、1番目の要素が区切り文字そのものになるので、「本当に区切られたか」を簡単に判定できる点も大きなメリットです。
line = "invalid_line_without_equal"
key, sep, value = line.partition("=")
if sep == "":
print("区切り文字 '=' が見つかりませんでした")
else:
print("key:", key, "value:", value)区切り文字 '=' が見つかりませんでしたrpartitionとの違いと使い分け
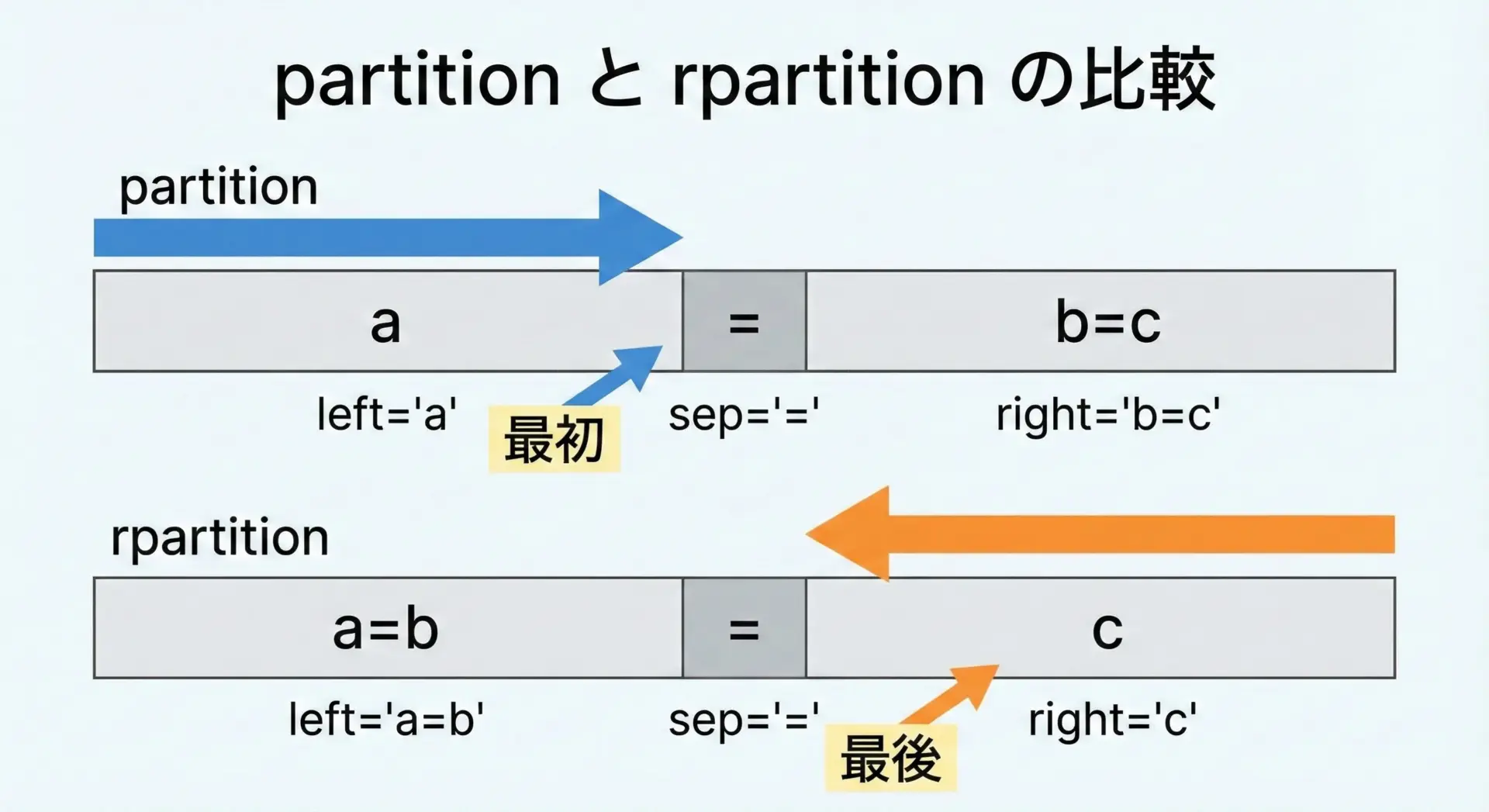
str.rpartition()はpartitionと非常によく似ていますが、「最後の」区切り文字で3分割する点が異なります。
s = "a=b=c"
print("partition :", s.partition("="))
print("rpartition:", s.rpartition("="))partition : ('a', '=', 'b=c')
rpartition: ('a=b', '=', 'c')使い分けとしては、次のように考えると整理しやすいです。
- 左側の最初の区切りで分割したいとき
→partition - 右側の最後の区切りで分割したいとき
→rpartition
例えば、拡張子付きファイル名をパスから分けたいときには、最後の"/"で分けるなどの用途にrpartitionが向いています。
partitionの具体的な使い方
先頭の区切り文字で3分割する例
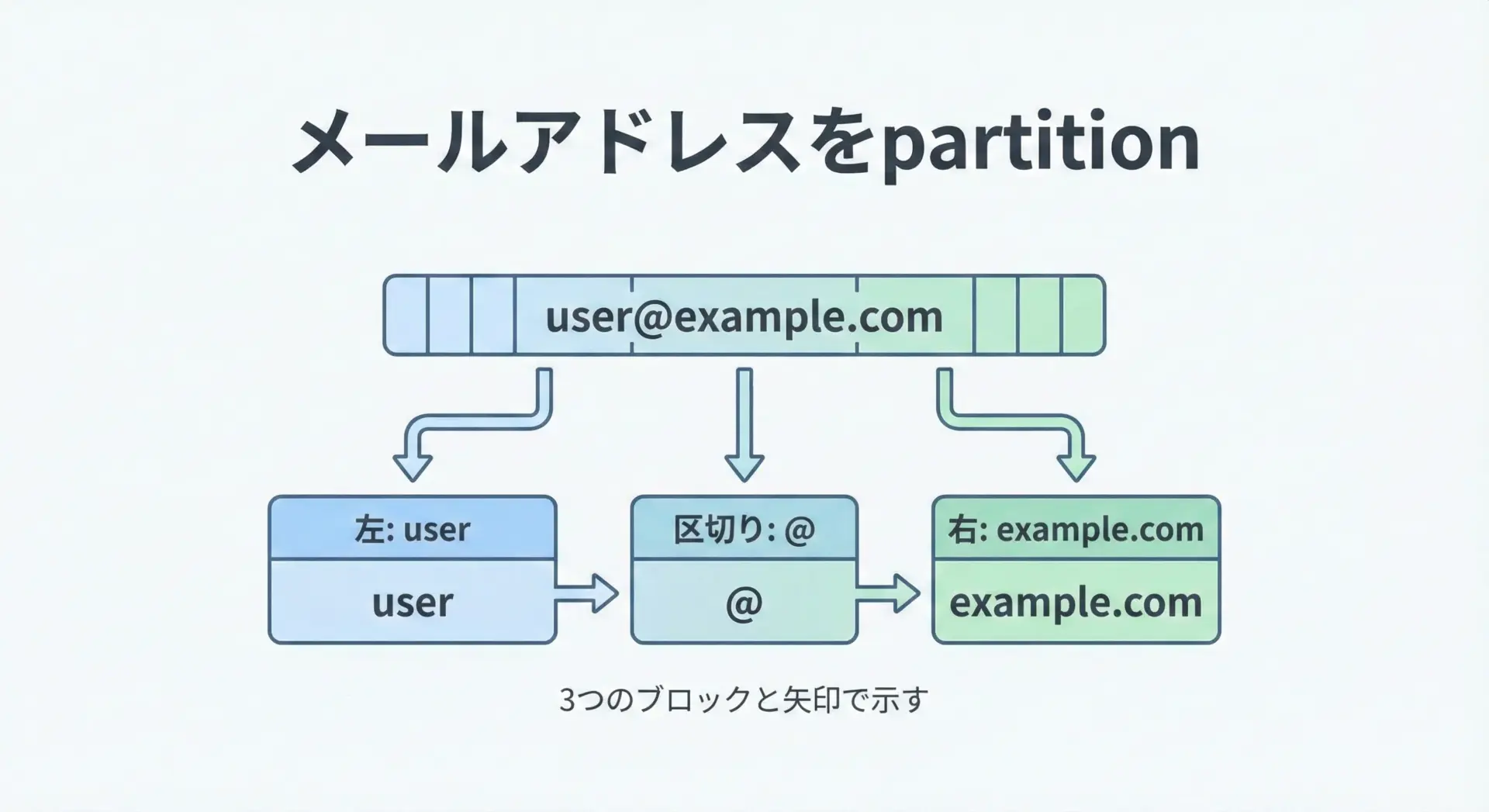
メールアドレスの"@"でユーザー名とドメインに分ける例です。
email = "user@example.com"
local, at, domain = email.partition("@")
print("local :", local)
print("at :", at)
print("domain:", domain)local : user
at : @
domain: example.comこのように「先頭の1回目の出現で必ず3つに分ける」、という挙動が一貫しているため、コードの挙動が読み取りやすくなります。
区切り文字が存在しない場合の挙動

partitionは、区切り文字が見つからなくてもエラーにはなりません。
代わりに、次のようなタプルを返します。
- 0番目: 元の文字列全体
- 1番目: 空文字
"" - 2番目: 空文字
""
s = "hello"
left, sep, right = s.partition(":")
print("left :", repr(left))
print("sep :", repr(sep))
print("right:", repr(right))
if sep == "":
print("区切り文字は見つかりませんでした")left : 'hello'
sep : ''
right: ''
区切り文字は見つかりませんでしたこの挙動により、例外処理をせずに「区切りがあるかどうか」を判定できるという利点があります。
先頭・末尾の空文字に注意するケース
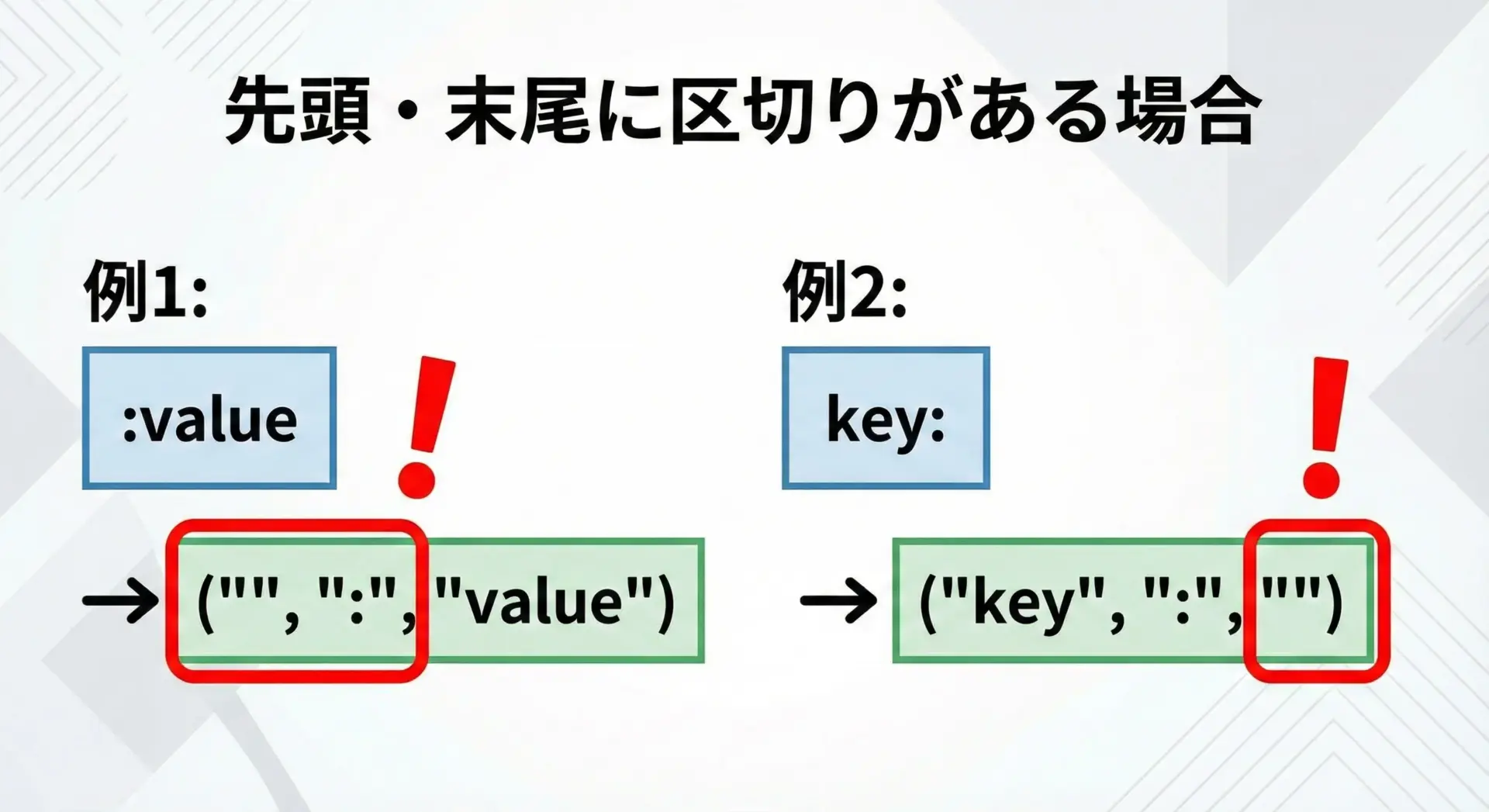
区切り文字が文字列の先頭や末尾にある場合、次のように空文字が含まれます。
print("':value' :", ":value".partition(":"))
print("'key:' :", "key:".partition(":"))
print("':' :", ":".partition(":"))
print("'::value' :", "::value".partition(":"))':value' : ('', ':', 'value')
'key:' : ('key', ':', '')
':' : ('', ':', '')
'::value' : ('', ':', ':value')このように、先頭や末尾に区切り文字があると左または右が空文字になるため、その後の処理で「最低1文字はあるはず」と決め打ちしてしまうとバグにつながります。
必要であれば、leftやrightが空文字でないかをチェックしてから処理を進めると安全です。
splitとの違いと使い分け
partitionとsplitの仕様の違い

まず、partitionとsplitの違いを表に整理します。
| 観点 | partition | split |
|---|---|---|
| 戻り値の型 | タプル(tuple) | リスト(list) |
| 要素数 | 常に3要素 | 1〜複数(可変) |
| 区切る位置 | 最初(または最後:rpartition)の1か所のみ | 該当するすべて、または最大maxsplit回 |
| 見つからないとき | (元文字列, “”, “”) を返す | 元文字列のみのリスト[s]] |
| 区切り文字を含めるか | タプルの2番目要素として返す | 通常は結果に含まれない |
例えば、同じ文字列に対して両者を使うと次のようになります。
s = "a=b=c"
print("partition:", s.partition("="))
print("split :", s.split("="))partition: ('a', '=', 'b=c')
split : ['a', 'b', 'c']partitionは「1回だけ3つに」、splitは「必要なだけ何個でも」というイメージを持つと理解しやすいです。
要素数が決まっているときはpartition
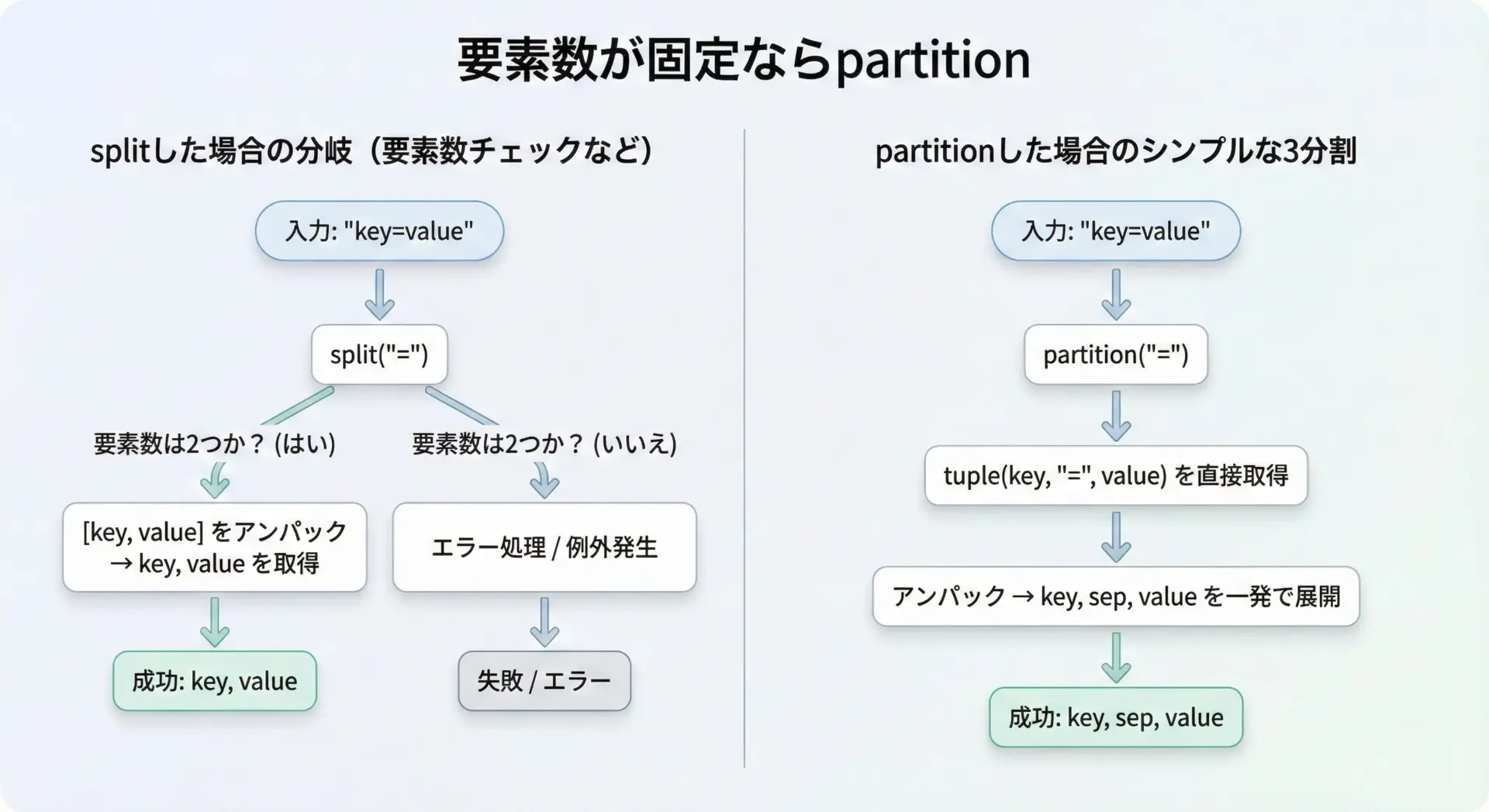
"key=value"のように、「区切りが1つだけ存在する前提」のデータではpartitionが非常に扱いやすいです。
line = "timeout=30"
# partition 版
key, sep, value = line.partition("=")
if sep == "":
print("不正な行です:", line)
else:
print("key:", key, "value:", value)
# split 版 (同じことをsplitでやると…)
parts = line.split("=")
if len(parts) != 2:
print("不正な行です:", line)
else:
key2, value2 = parts
print("key2:", key2, "value2:", value2)key: timeout value: 30
key2: timeout value2: 30どちらも同じ結果になりますが、partitionの方が要素数チェックがシンプルで、コードの意図も明確になります。
可変長の分割が必要なときはsplit
一方で、区切りの数が変わる可能性がある場合はsplitを使うべきです。
csv_line = "apple,banana,orange,grape"
fields = csv_line.split(",")
print(fields)
print("列数:", len(fields))['apple', 'banana', 'orange', 'grape']
列数: 4このようなケースでpartitionを使うと、right部分にカンマつきで残ってしまうため、さらに処理が必要になり非効率です。
「1回だけ切るならpartition、何回も切るならsplit」と覚えると実務で迷いにくくなります。
パフォーマンスとコードの可読性の観点
通常の規模の処理であれば、partitionとsplitのパフォーマンス差はほとんど気にしなくて構いません。
どちらもCで実装されており高速です。
ただし、コードの可読性の観点では次のような違いがあります。
- partition
- 「ここで1回だけ分けたい」という意図が明確
- 戻り値が3つで固定のため型や要素数がわかりやすい
- split
- 可変長のデータに柔軟に対応できる
- 要素数のチェックやアンパックがやや煩雑になる場合がある
そのため、「読みやすいコードを書きたい」「バグを減らしたい」という観点では、要素数が3つでよい場面では積極的にpartitionを選ぶのがおすすめです。
実践テクニックとパターン別ガイド
1行からキーと値をpartitionで取得
設定ファイルや環境変数など、「key=value」形式の行を処理するケースは非常に多いです。
このような場合、partitionはほぼ定番のテクニックとして使えます。
lines = [
"host=example.com",
"timeout=30",
"debug=true",
"invalid_line_without_equal"
]
config = {}
for line in lines:
# 行頭・行末の空白を除去
line = line.strip()
if not line:
continue # 空行はスキップ
key, sep, value = line.partition("=")
if sep == "":
# 不正な行としてログなどに出す
print("無視します(フォーマット不正):", line)
continue
config[key] = value
print("設定:", config)無視します(フォーマット不正): invalid_line_without_equal
設定: {'host': 'example.com', 'timeout': '30', 'debug': 'true'}partitionを使うことで、エラー処理と通常処理が明確に分かれ、読みやすいコードになります。
ファイルパスやURLをpartitionで分解

ファイルパスやURLなど、構造がある文字列を扱う際にもpartitionは便利です。
URLからスキームと残りを分ける
url = "https://example.com/path/to/resource"
scheme, sep, rest = url.partition("://")
print("scheme:", scheme)
print("sep :", sep)
print("rest :", rest)scheme: https
sep : ://
rest : example.com/path/to/resourceスキーム部分(http, https など)だけ知りたい場合、このように1行で簡単に取り出せます。
ファイルパスからディレクトリとファイル名を分ける(rpartition)
ファイルパスでは、最後の"/"でディレクトリとファイル名を分けたいケースが多いため、rpartitionを使うと便利です。
path = "/home/user/projects/app/main.py"
dir_path, sep, filename = path.rpartition("/")
print("dir_path:", dir_path)
print("sep :", sep)
print("filename:", filename)dir_path: /home/user/projects/app
sep : /
filename: main.pyもちろん、実務ではos.pathやpathlibといった専用モジュールを使うことも多いですが、軽量なスクリプトやちょっとした文字列処理ではpartition/rpartitionだけで十分なこともあります。
エラー文やログ文から必要な部分だけ抽出
ログファイルの1行から、ログレベルやメッセージ部分を切り出す例を考えます。
logs = [
"[INFO] Application started",
"[WARNING] Low disk space",
"[ERROR] Failed to connect to database",
]
for line in logs:
# 右側から "] " で1回だけ分割
level_part, sep, message = line.partition("] ")
if sep == "":
print("フォーマット不明:", line)
continue
# 左側 "[INFO" から "[", "]" を除いてレベルだけにする
level = level_part.strip("[] ")
print(f"level={level:<7} message={message}")level=INFO message=Application started
level=WARNING message=Low disk space
level=ERROR message=Failed to connect to databaseこのように、ログの形式が一定で、区切り文字が1つに決まっている場合は、partitionを使うことでとても見通しの良いコードになります。
正規表現(re)と組み合わせたsplitとの比較
複雑なパターンで文字列を分割したい場合、re.splitなどの正規表現を使うこともあります。
しかし、まずはpartitionで済むかを検討することをおすすめします。
単純なパターンであれば、その方が読みやすく高速です。
正規表現splitが必要なケースの例
例えば、空白が1個以上空いている位置で分割したい場合、partitionでは対応できません。
import re
line = "2025-01-01 ERROR Something bad happened"
date, level, message = re.split(r"\s+", line, maxsplit=2)
print("date :", date)
print("level :", level)
print("message:", message)date : 2025-01-01
level : ERROR
message: Something bad happenedこのように、区切りのパターンが「1文字」では表現しづらい場合にはre.splitが有効です。
partitionで代替できるなら積極的に使う
一方で、「最初の = で3つに分ける」「最後の / で3つに分ける」といった用途では、正規表現を使うよりpartitionの方が簡潔で明確です。
s = "user:password:extra"
# 正規表現で最初の ":" だけで分ける例(あまりおすすめしない)
import re
left, right = re.split(":", s, maxsplit=1)
print("re.split:", left, right)
# partition の方が意図も明確で安全
left2, sep2, right2 = s.partition(":")
print("partition:", left2, sep2, right2)re.split: user password:extra
partition: user : password:extra正規表現は強力ですが、そのぶん読み手の負担も大きくなります。
「1文字の区切りで1回だけ分ける」という要件であれば、まずpartitionを使い、どうしても足りない場合にのみre.splitを検討する、という順番がおすすめです。
まとめ
partitionは「文字列を3分割する」ことに特化した、シンプルで強力なメソッドです。
区切り文字の前後と区切りそのものを一度に扱えるため、キーと値の取得、URLやパスの分解、ログやエラー文の解析などで、わかりやすく安全なコードを書けます。
要素数が決まっているときはpartition(あるいはrpartition)、可変長の分割が必要なときはsplitやre.splitというように役割を整理しておくと、実務で迷わずに最適な手段を選べるようになります。
