
Pythonでテキストデータを扱うとき、文字列の分割と結合は必須テクニックです。
本記事では、基本のsplitとjoinから、CSVやログの処理、空白や改行の整形、正規表現による柔軟な分割まで、実務でよく使うパターンを図解とサンプルコード付きで詳しく解説します。
Pythonの文字列分割(split)の基本
splitの基本的な使い方と挙動
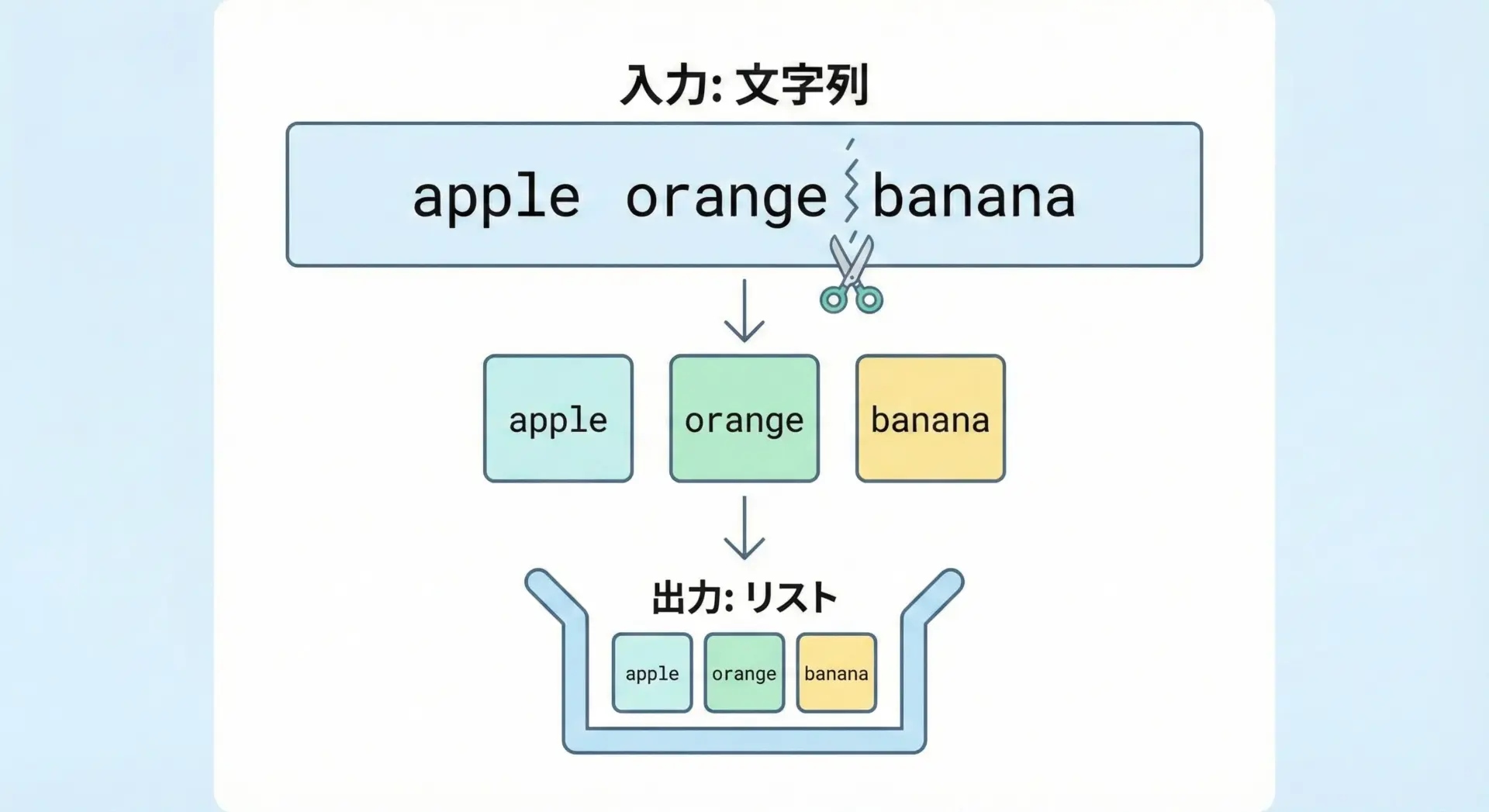
Pythonのsplitメソッドは、文字列を指定した区切りで分割して、リストとして返します。
まずは最も基本的な例を見てみます。
text = "apple orange banana"
# デフォルト(空白)で分割
fruits = text.split()
print(fruits) # 結果を確認
print(type(fruits)) # 型を確認['apple', 'orange', 'banana']
<class 'list'>このようにsplitは、もとの文字列はそのまま残しつつ、新しいリストを返します。
文字列自体は不変(immutable)なので、元の文字列が書き換えられることはありません。
デフォルト区切り(空白)でのsplitの動き
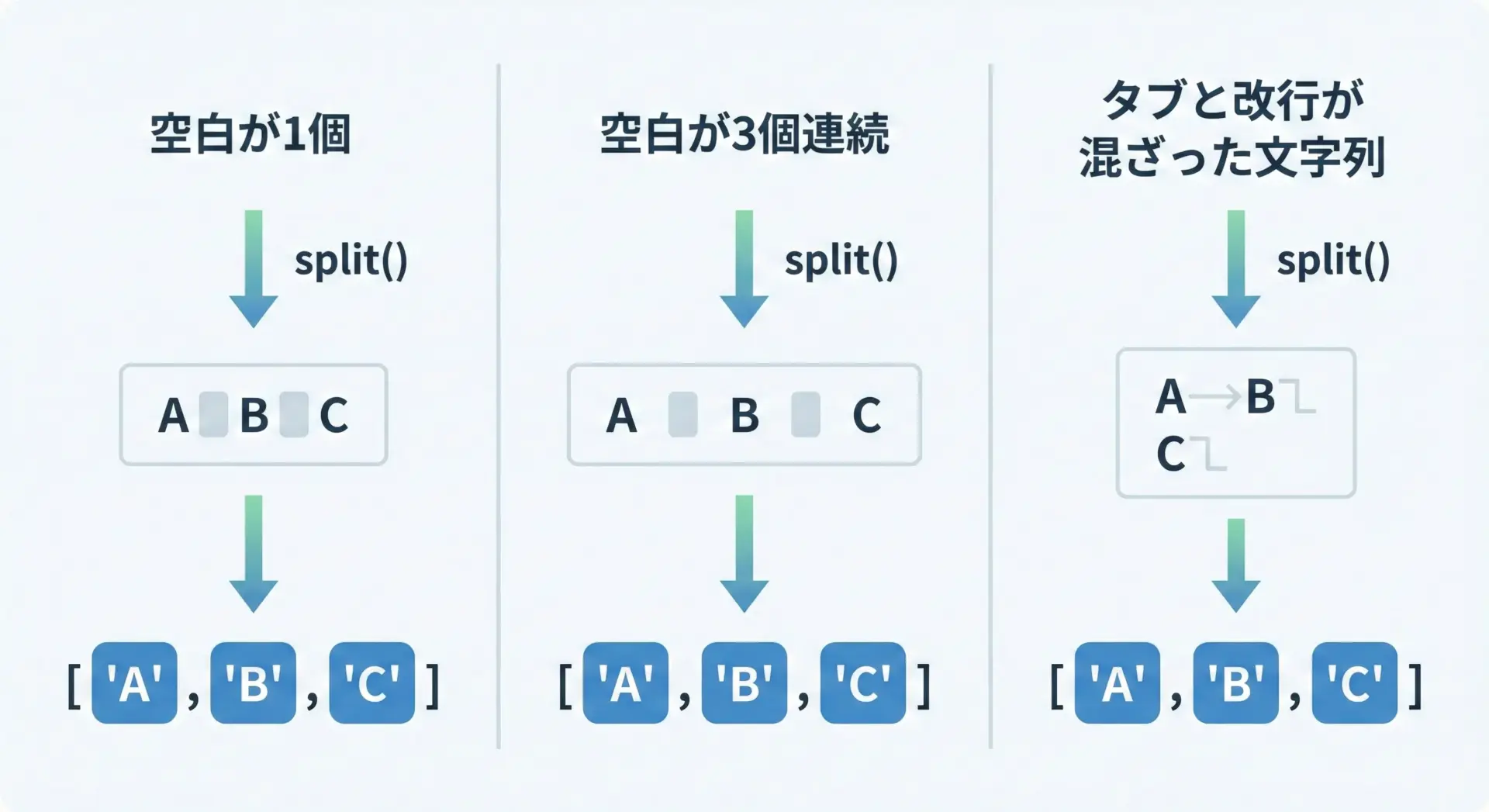
split()を引数なしで呼び出した場合、「連続する空白類(スペース、タブ、改行など)」をひとまとまりの区切りとして扱います。
また、文字列の前後にある空白は自動的に無視されます。
text1 = " apple orange\tbanana\n"
words1 = text1.split()
print(words1)['apple', 'orange', 'banana']ここでは、スペース、タブ(\t)、改行(\n)が混ざっていますが、split()は賢く処理して単語だけのリストを返しています。
この挙動は、「空白の数や種類がばらばらなテキスト」をきれいに分割したいときに非常に便利です。
区切り文字を指定したsplitの書き方
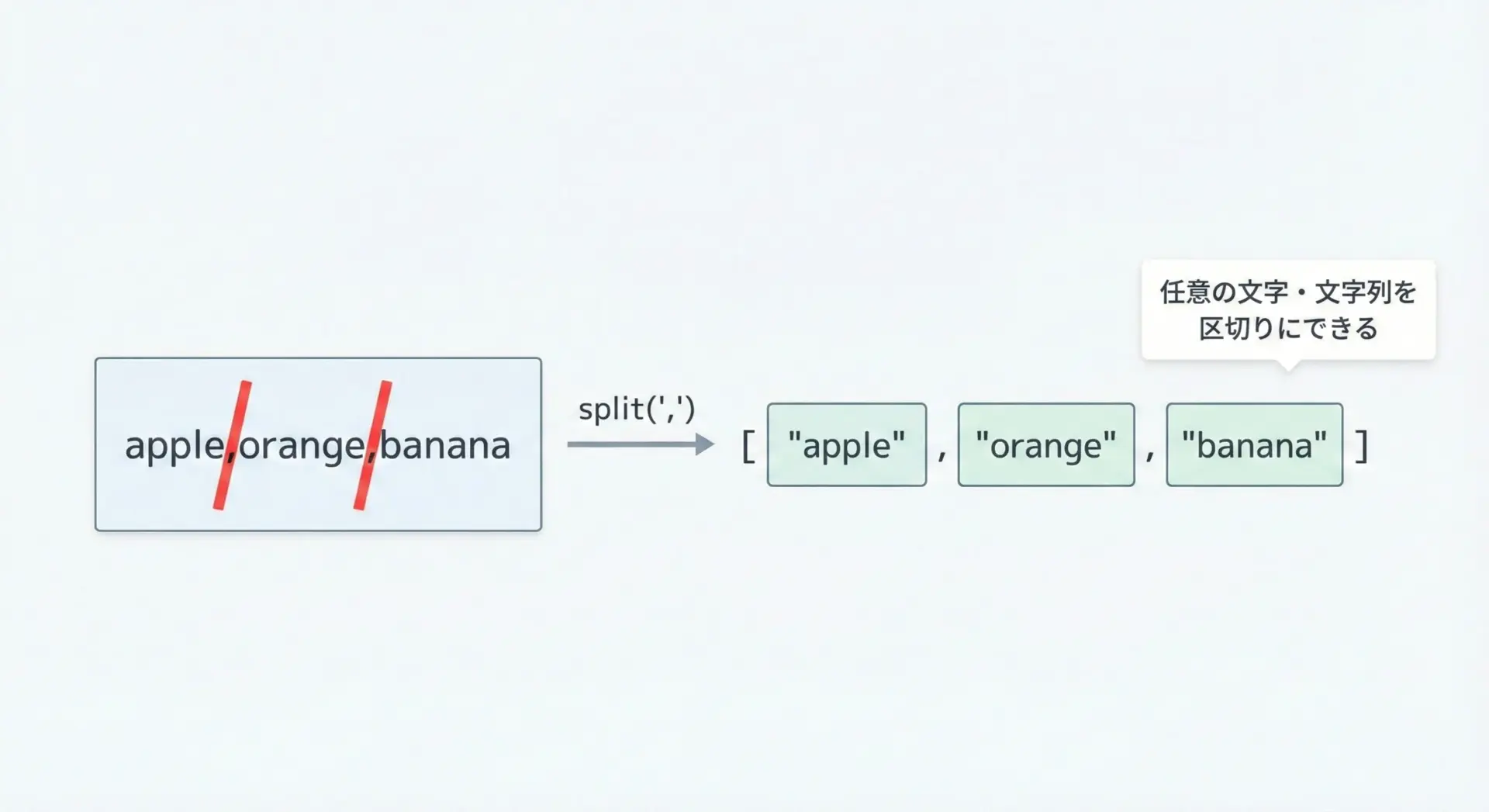
特定の文字や文字列で分割したい場合は、split(区切り文字)という形で引数を指定します。
text = "apple,orange,banana"
# カンマで分割
fruits = text.split(",")
print(fruits)['apple', 'orange', 'banana']区切り文字は1文字でなくてもかまいません。
例えば"::"のような文字列も使えます。
data = "id::name::email"
parts = data.split("::")
print(parts)['id', 'name', 'email']このように区切りとして使われている「文字列」そのものを指定できるので、独自フォーマットのログや設定ファイルなどにも柔軟に対応できます。
maxsplitで分割回数を制限する方法
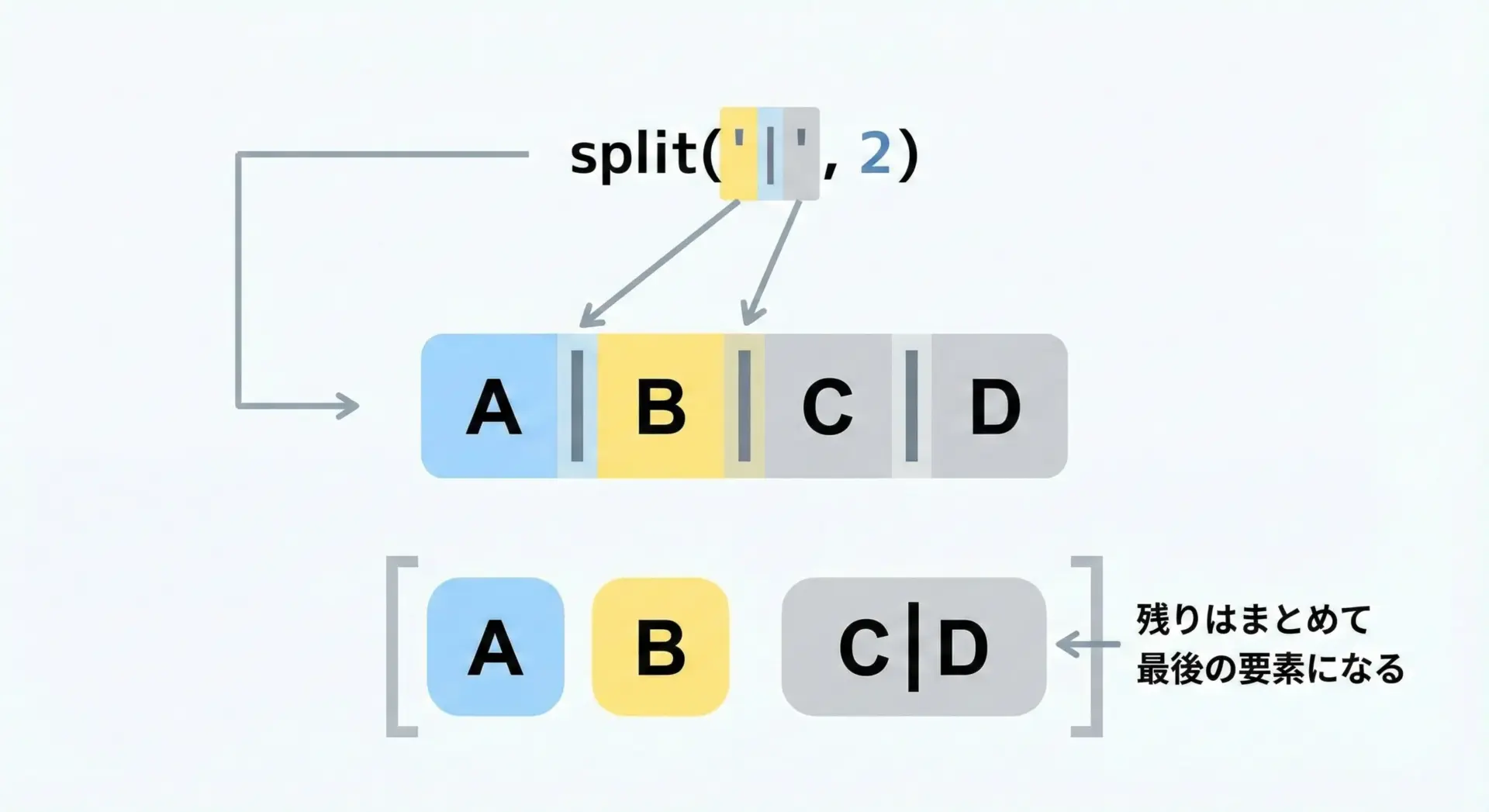
splitにはmaxsplitという第2引数があり、「最大何回まで分割するか」を指定できます。
text = "A|B|C|D"
# 最大2回まで分割
result = text.split("|", 2)
print(result)['A', 'B', 'C|D']この例では、区切り文字"|"は3つありますが、maxsplit=2なので2回だけ分割され、残りは最後の要素にまとめられます。
ログの先頭だけを区切り、残りを「メッセージ」としてひとまとめにしたい場合などに役立ちます。
改行コードでテキストをsplitする方法
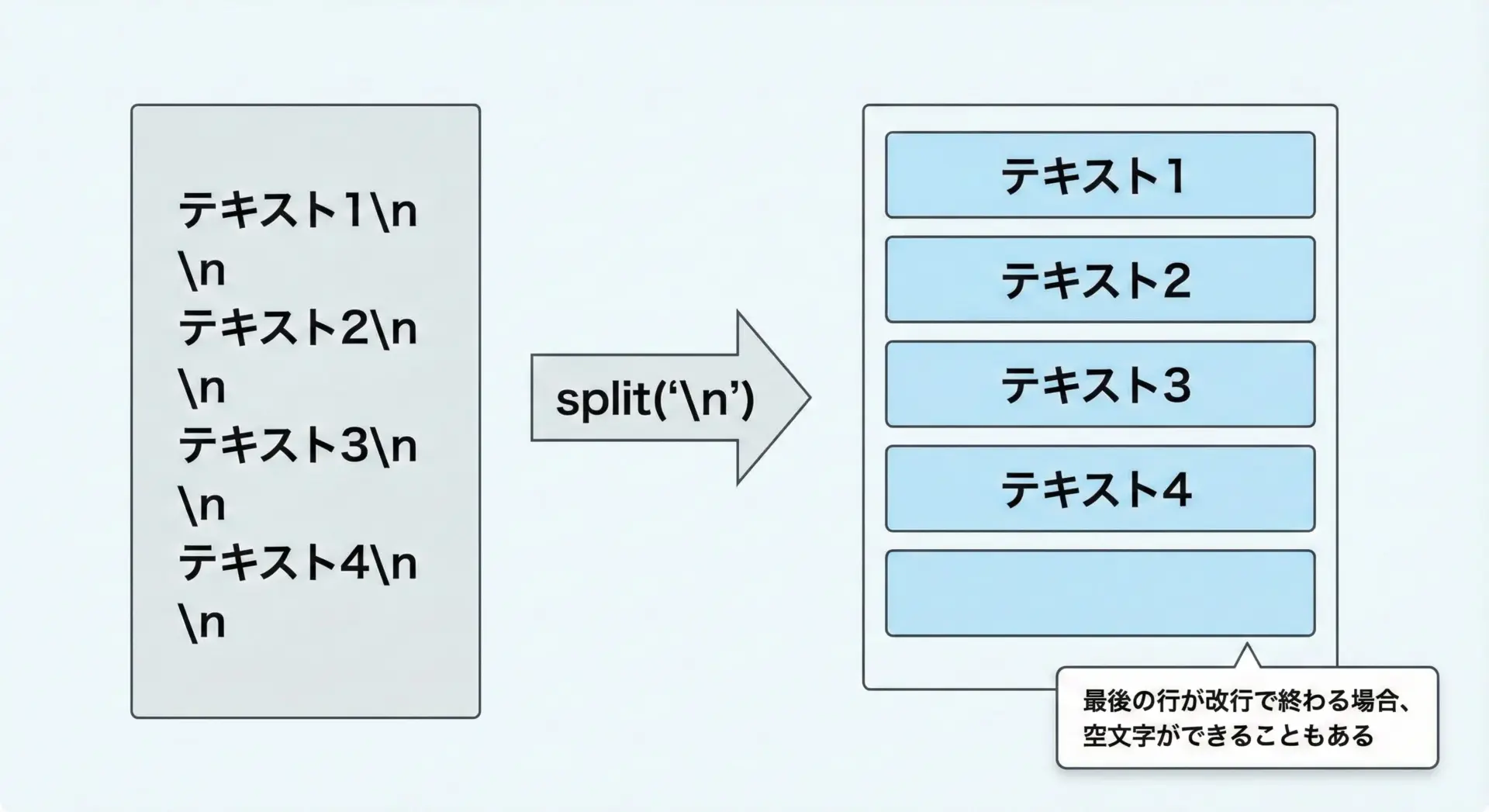
テキストファイルの内容を1つの文字列として読み込んだあと、行ごとに処理したい場合は、改行コード"\n"で分割します。
text = "1行目\n2行目\n3行目"
lines = text.split("\n")
print(lines)['1行目', '2行目', '3行目']ファイルによっては"\r\n"のような改行コードが使われていることもあります。
その場合はsplitlines()のほうが便利なので、後ほど詳しく解説します。
応用的なsplitテクニック集
カンマ区切りやタブ区切り(CSV/TSV)をsplitする

CSVやTSVのように決まった区切り文字で項目が並んでいるデータは、splitとの相性がとても良いです。
line_csv = "Alice,30,Tokyo"
line_tsv = "Bob\t25\tOsaka" # \t はタブ文字
# CSVをカンマで分割
csv_fields = line_csv.split(",")
# TSVをタブで分割
tsv_fields = line_tsv.split("\t")
print(csv_fields)
print(tsv_fields)['Alice', '30', 'Tokyo']
['Bob', '25', 'Osaka']実務ではcsv標準ライブラリを使うほうが安全な場面も多いですが、ざっくりログを解析したいときや簡易ツールを作るときなどにはsplitで十分なことも多いです。
連続した空白やタブをまとめてsplitするコツ
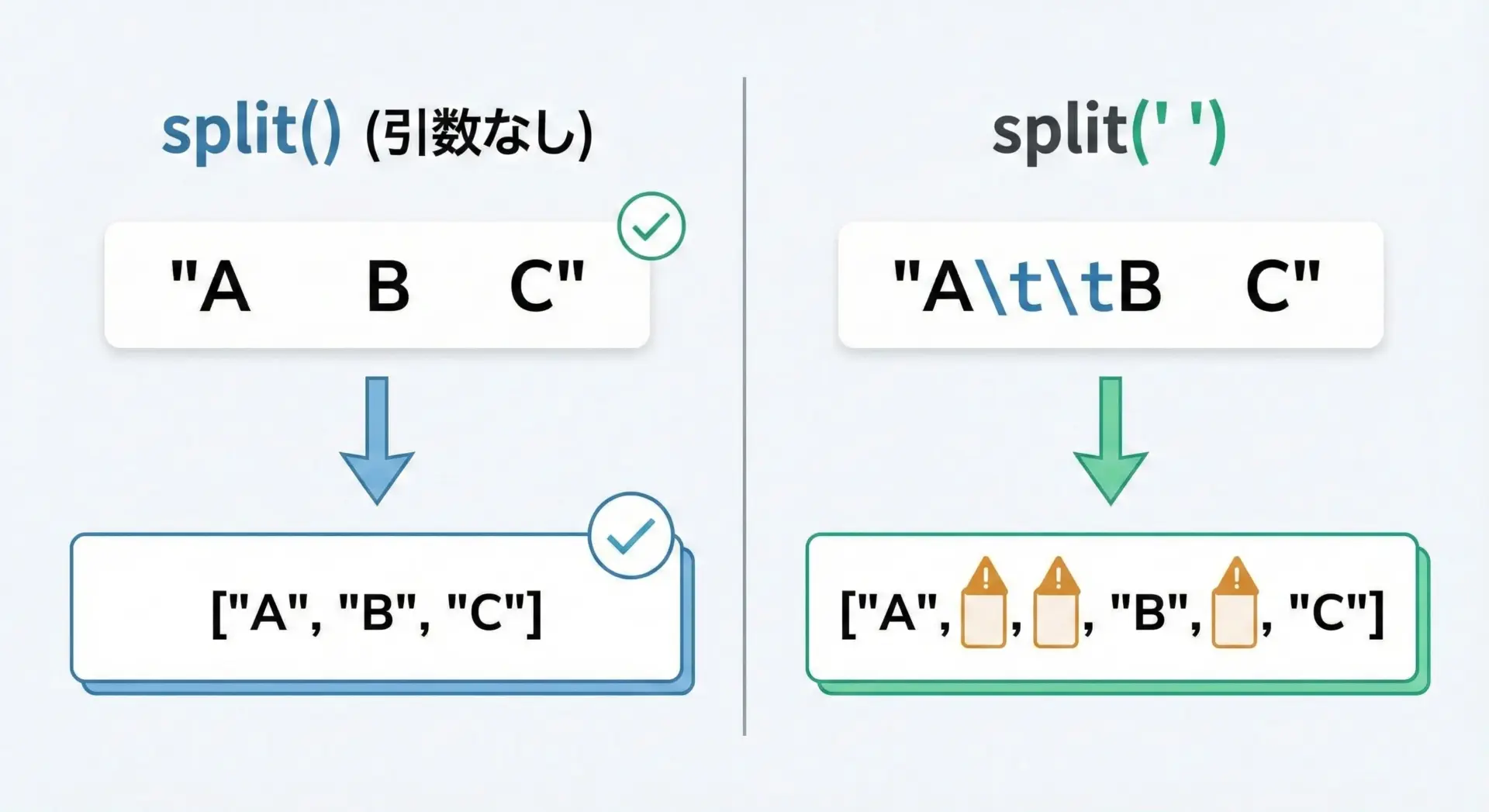
前半でも触れたとおり、引数なしのsplit()は連続する空白類を「1つの区切り」とみなすため、空白の数がバラバラでもきれいに単語を取り出せます。
text = "A B C"
print(text.split()) # 引数なし
print(text.split(" ")) # 半角スペースを明示['A', 'B', 'C']
['A', '', '', 'B', '', '', '', 'C']split(" ")のほうは、連続するスペースのぶんだけ空文字列が作られています。
これは空白の数そのものに意味があるレイアウトを扱うときには有利ですが、一般的なテキスト処理では邪魔になることが多いです。
そのため、「とにかく単語だけがほしい」場合はsplit()を使うのが基本のコツです。
正規表現で柔軟にsplitする方法
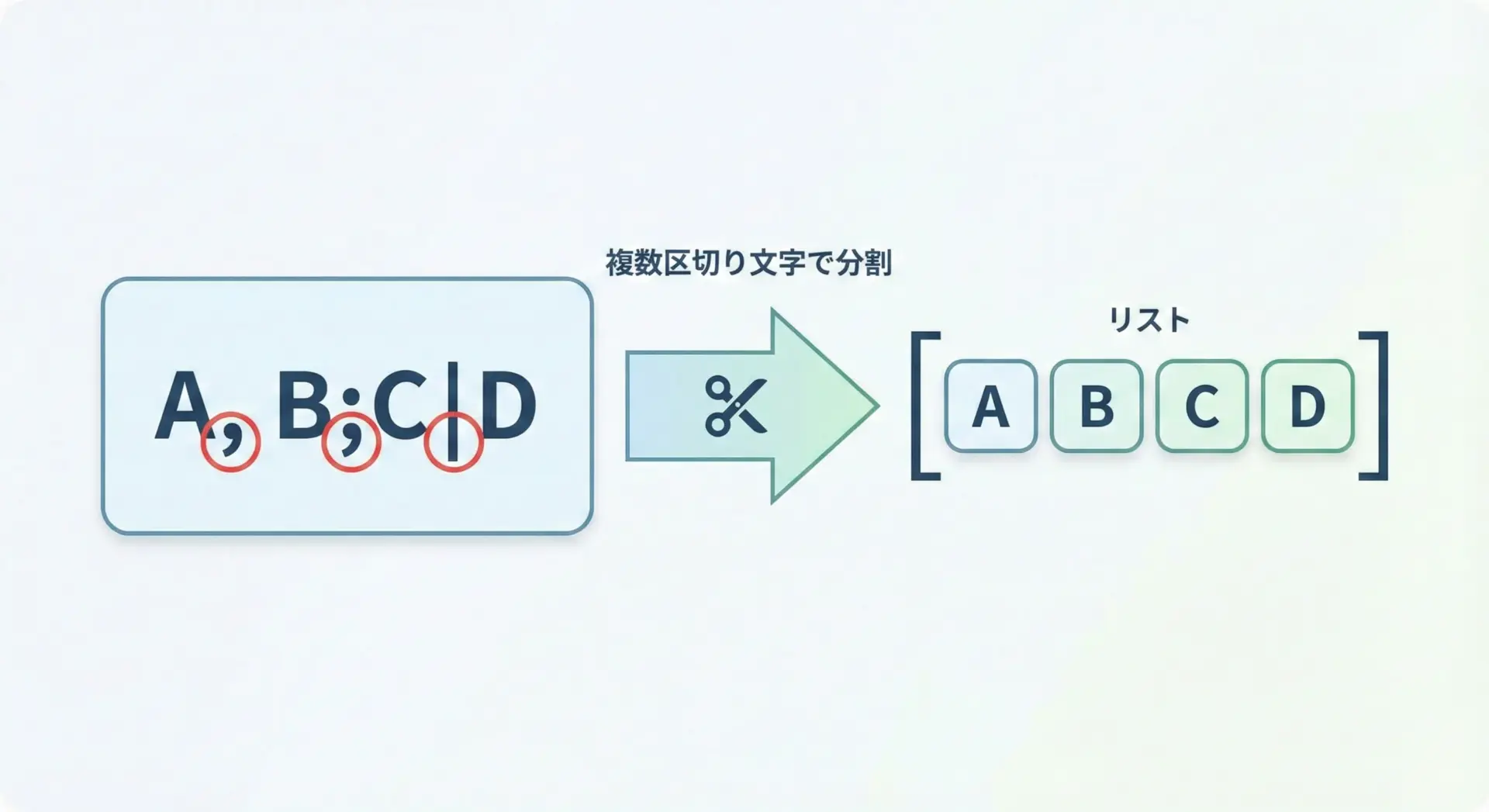
splitでは「1種類の区切り文字」しか指定できません。
複数の記号や空白をまとめて区切りとして扱いたいときは、reモジュールのre.splitが便利です。
import re
text = "A, B;C|D E"
# カンマ、セミコロン、パイプ、空白(1個以上)をすべて区切りにする
parts = re.split(r"[,;|\s]+", text)
print(parts)['A', 'B', 'C', 'D', 'E']正規表現では「何種類もの文字」「繰り返し」をまとめて表現できるため、ログ解析や自然言語処理の前処理などで大きな威力を発揮します。
数値文字列をsplitしてintやfloatに変換する
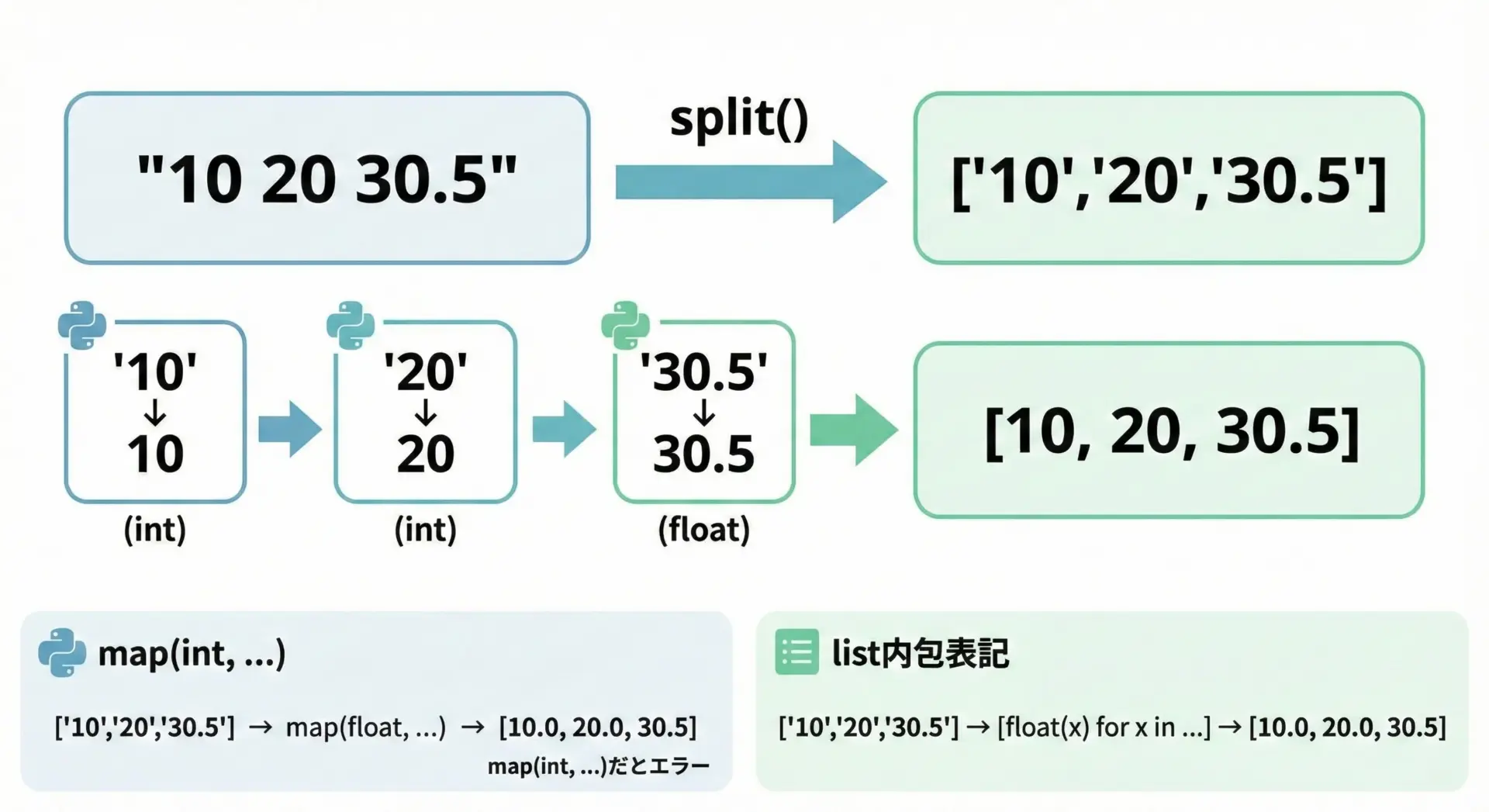
テキストとして書かれた数値を計算に使うには、分割してから数値型に変換する必要があります。
text = "10 20 30 40"
# 1. splitで文字列として分割
items = text.split()
# 2. intに変換(list内包表記)
numbers = [int(x) for x in items]
print(items)
print(numbers)
print(sum(numbers))['10', '20', '30', '40']
[10, 20, 30, 40]
100浮動小数点数が混ざる場合はfloatを使います。
text = "1.5 2.5 3.0"
numbers = [float(x) for x in text.split()]
print(numbers)[1.5, 2.5, 3.0]「split → 型変換」は、競技プログラミングや数値データ処理の定番パターンです。
splitlinesで複数行文字列を行単位に分割する
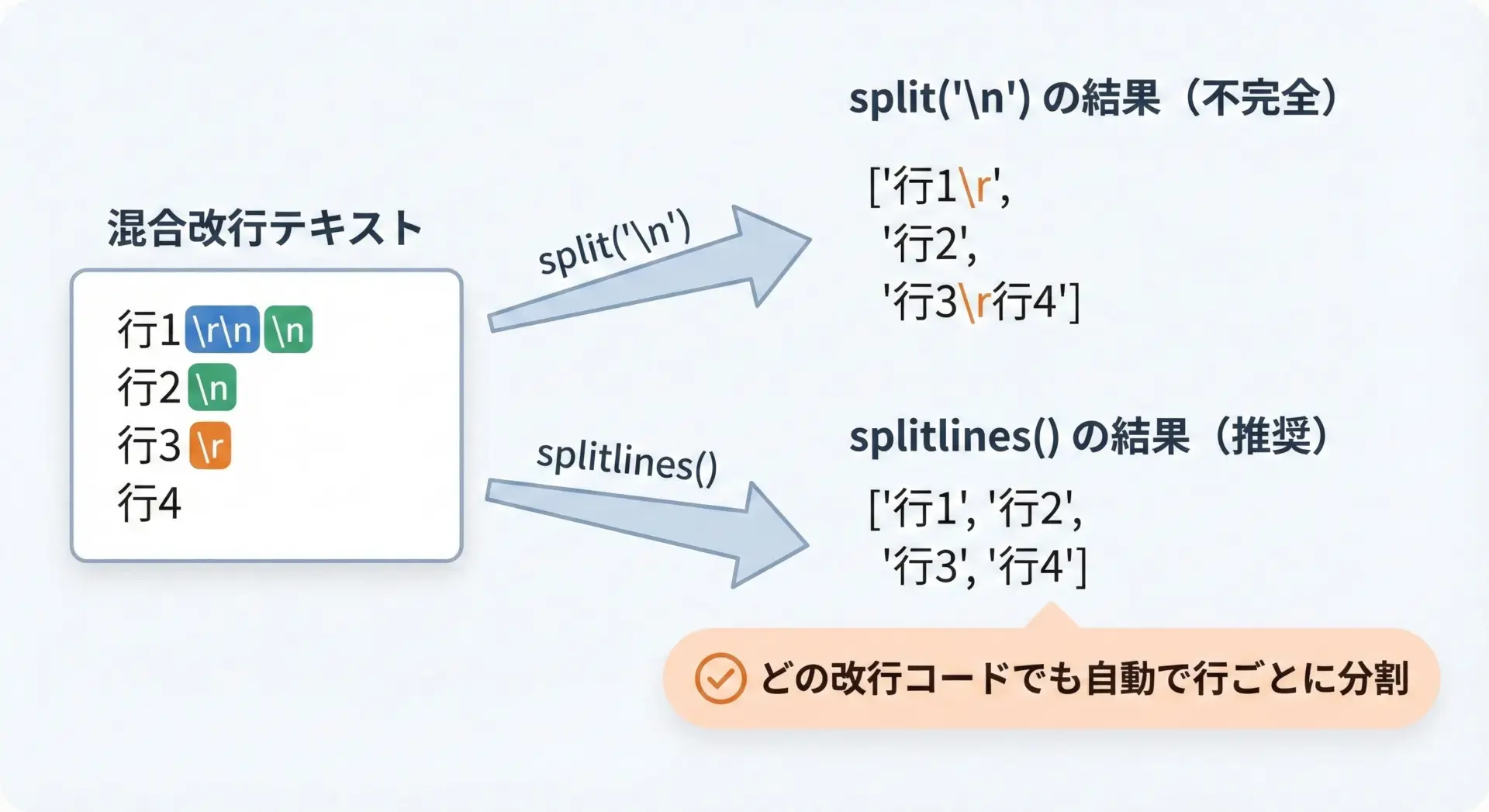
複数行のテキストを行ごとに扱いたい場合、split("\n")だけでは改行コードの違いに対応しきれないことがあります。
そこで役立つのがsplitlines()です。
text = "1行目\r\n2行目\n3行目\r4行目"
lines = text.splitlines()
print(lines)['1行目', '2行目', '3行目', '4行目']splitlines()は「\n」「\r\n」「\r」など、さまざまな改行コードを自動認識して行ごとに分割してくれます。
文字列結合(join)の基本
joinの基本構文とリスト結合の使い方
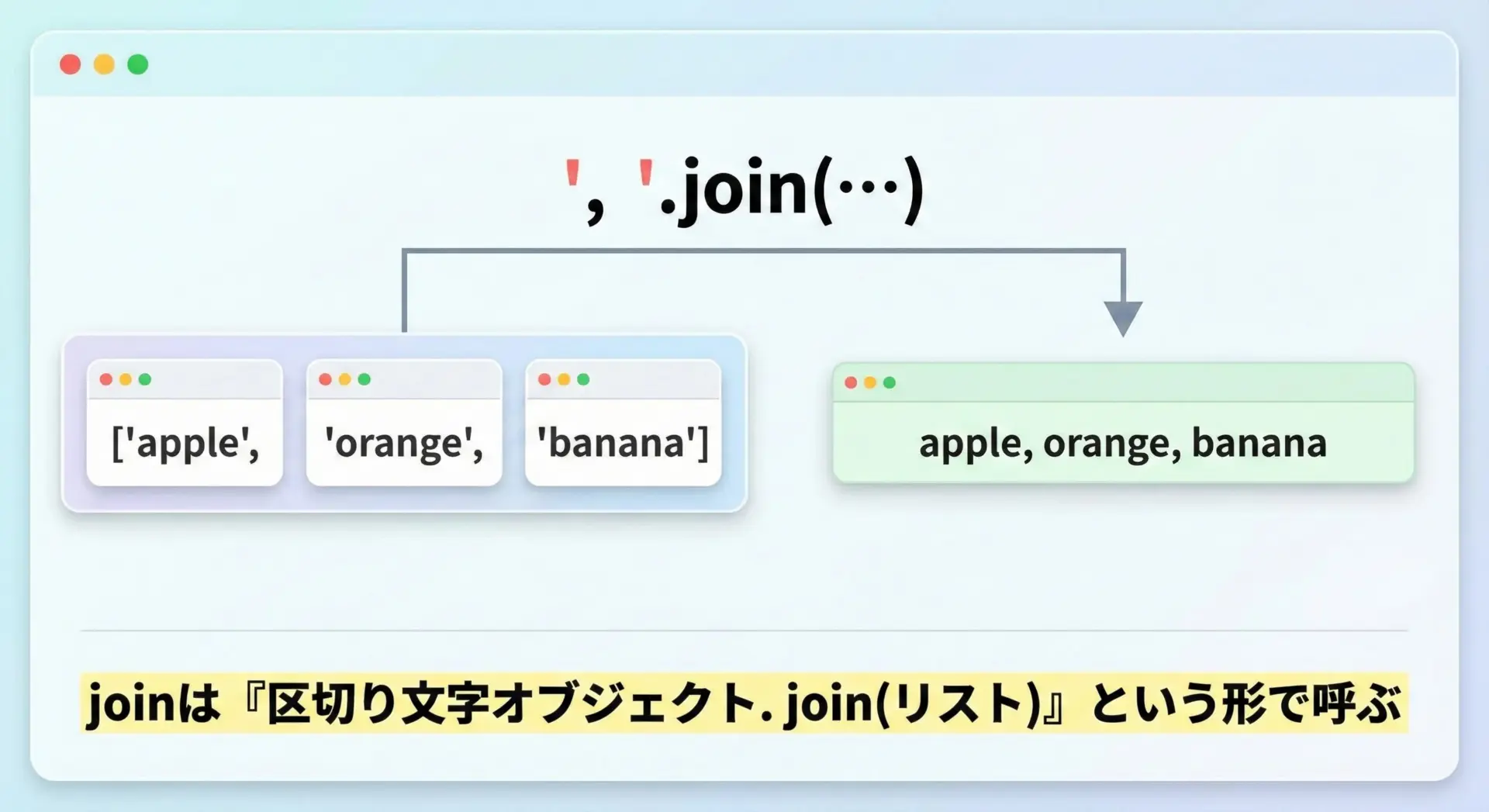
joinは、複数の文字列を1つに結合するためのメソッドです。
注意点は、リスト側ではなく「区切り文字側」で呼び出すことです。
fruits = ["apple", "orange", "banana"]
result = ", ".join(fruits)
print(result)
print(type(result))apple, orange, banana
<class 'str'>このように", "を「区切り」として使い、リスト内の要素をつないでいます。
joinの構文は
"区切り文字".join(文字列のリスト)
という形になります。
区切り文字を指定したjoinのパターン
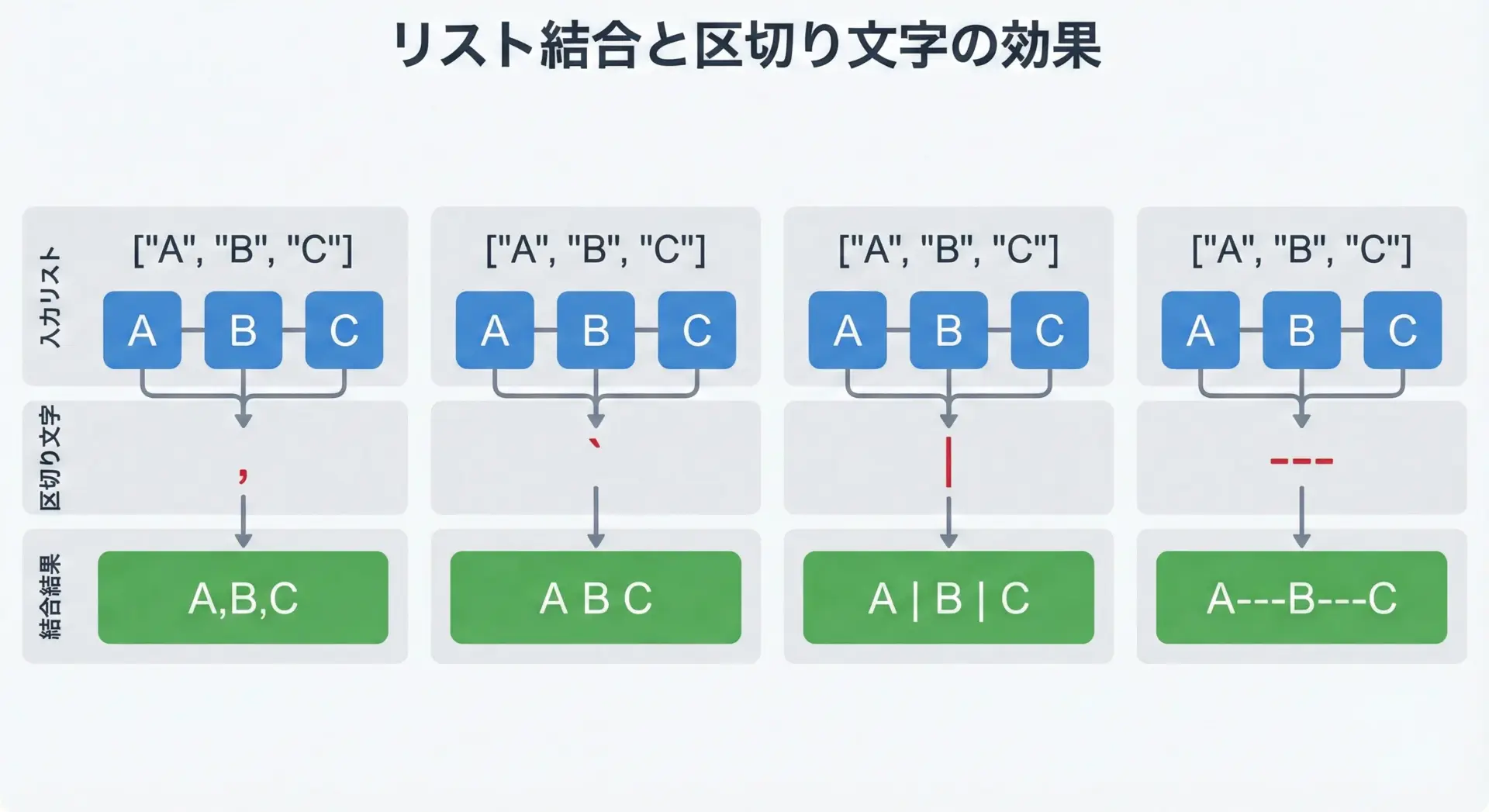
joinは、使う区切り文字しだいで印象も用途も大きく変わります。
いくつかの例をまとめて見てみます。
items = ["A", "B", "C"]
print(",".join(items)) # CSV風
print(" ".join(items)) # 単語の並び
print(" | ".join(items)) # 見やすいログ形式
print("---".join(items)) # 区切りを強調A,B,C
A B C
A | B | C
A---B---Cこのように「出力フォーマットを整える」用途でjoinは非常によく使われます。
空文字でjoinして文字列を連結する
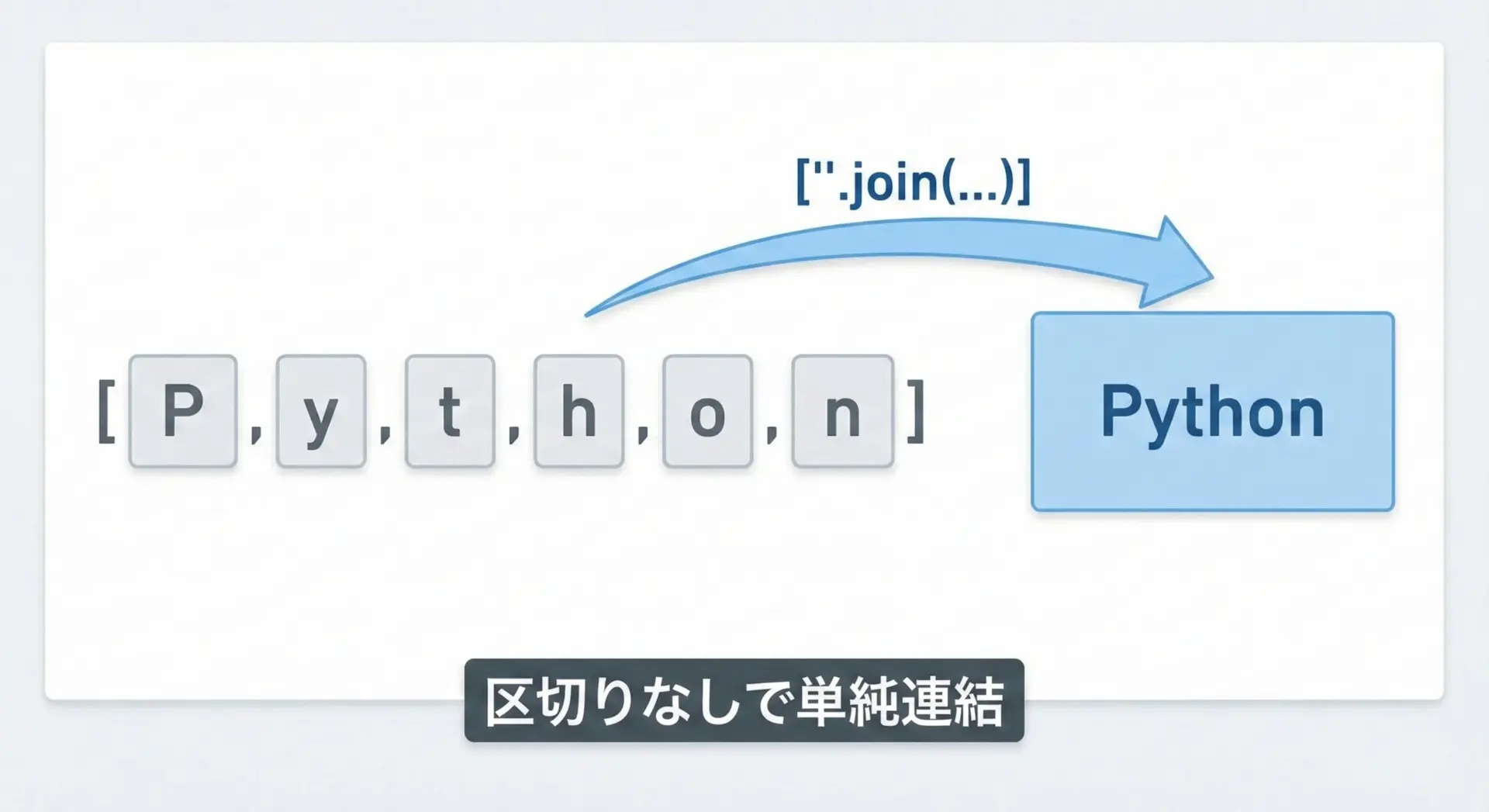
区切り文字に""(空文字)を指定すると、区切りなしで全要素をつなげることができます。
chars = ["P", "y", "t", "h", "o", "n"]
word = "".join(chars)
print(word)Python文字単位で処理したあとに元の文字列へ戻したいときなどに使います。
改行を挟んで複数行文字列をjoinで生成
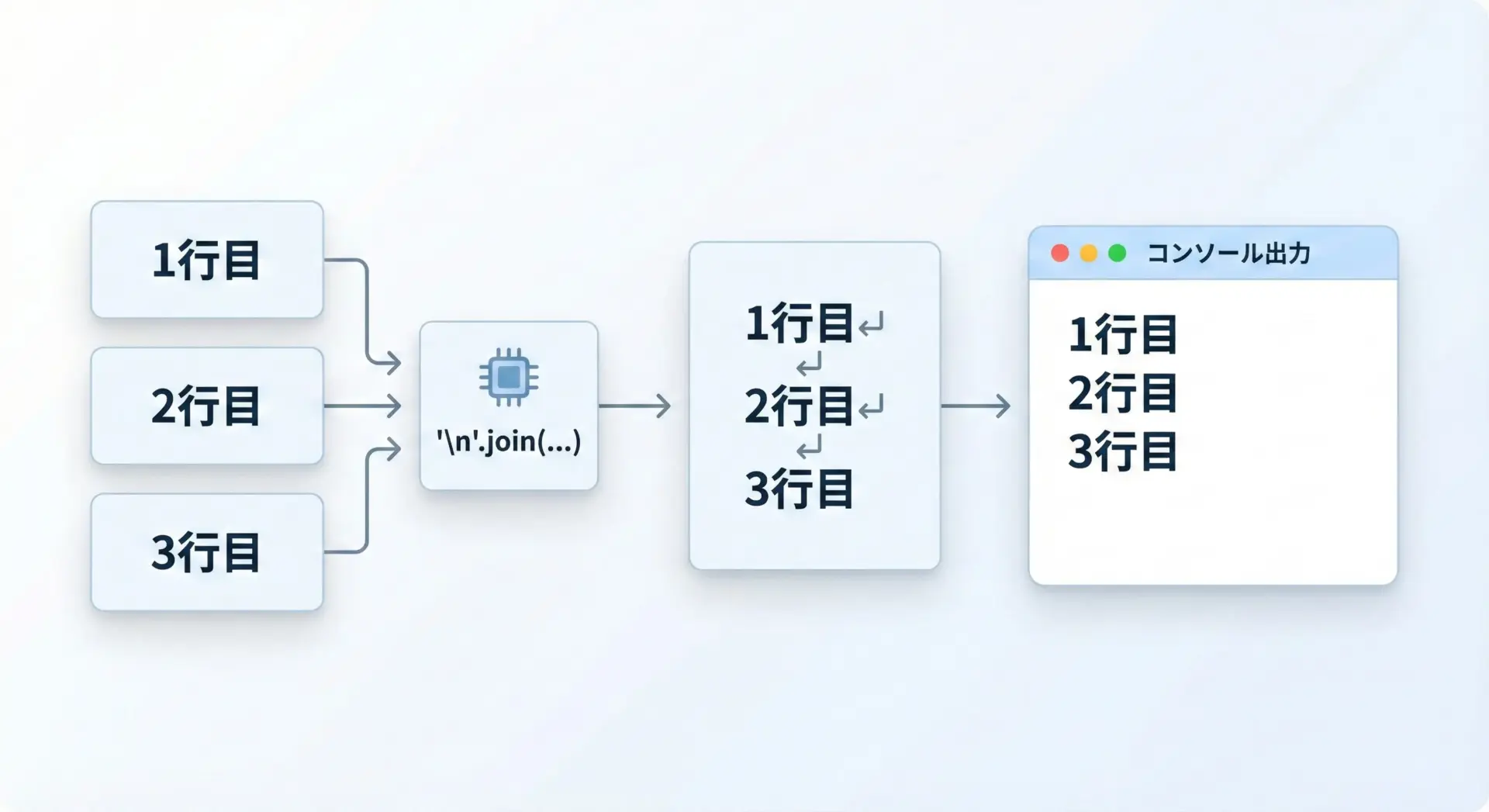
複数の行を持つテキストを作りたい場合は、"\n"を区切りに使うと便利です。
lines = ["1行目", "2行目", "3行目"]
text = "\n".join(lines)
print(text)1行目
2行目
3行目ファイルに書き出す前に行のリストから1本の文字列を組み立てるときなどに頻繁に使われます。
mapとjoinで数値リストを結合する方法
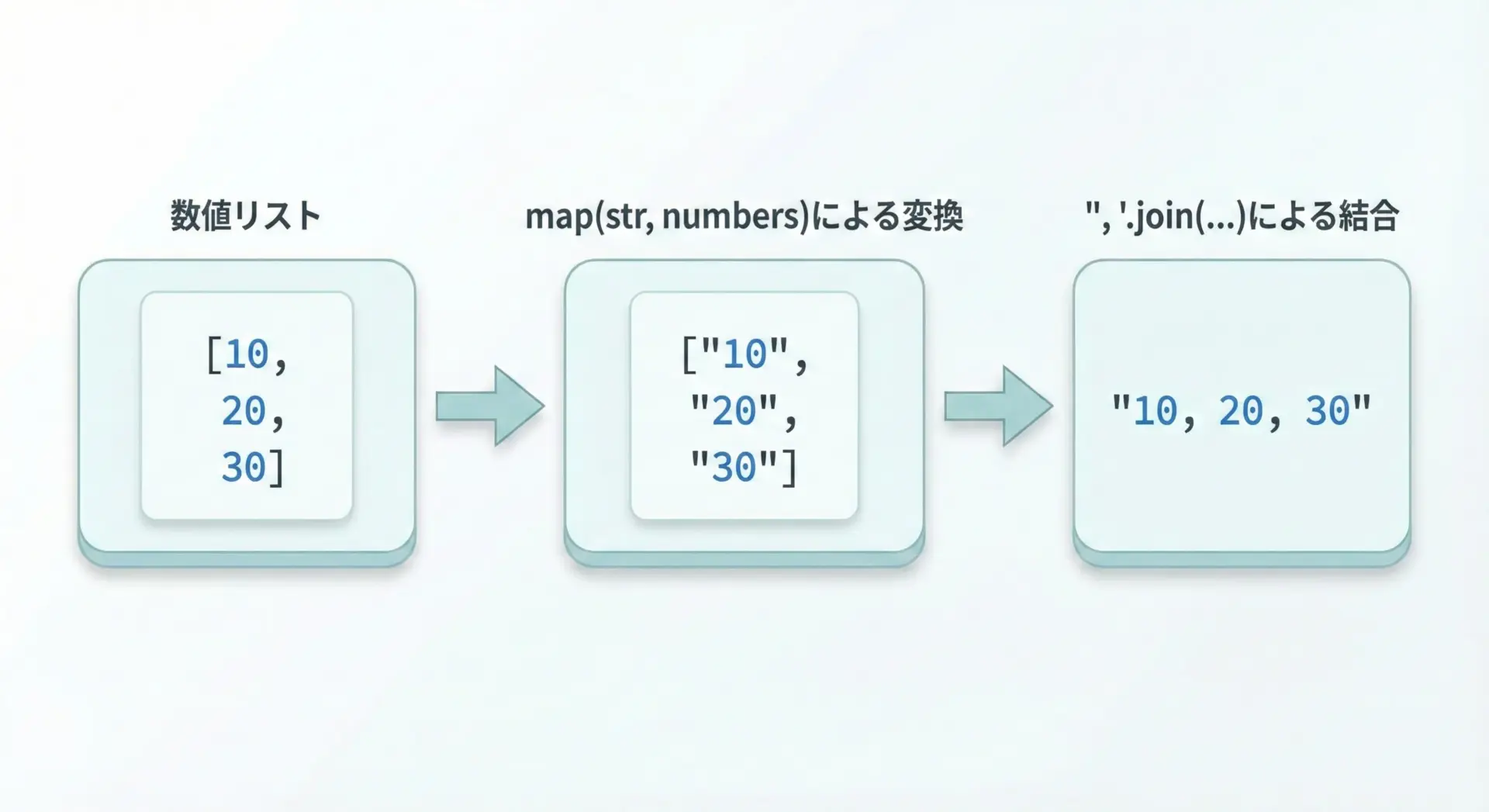
joinは文字列だけを結合できます。
そのため、数値リストを結合したい場合は、まず文字列に変換する必要があります。
numbers = [10, 20, 30]
# mapでstrに変換してからjoin
result = ", ".join(map(str, numbers))
print(result)10, 20, 30「mapでstrに変換 → joinで結合」は、デバッグ出力やログ出力などでとてもよく使うパターンです。
splitとjoinを組み合わせた便利ワザ
splitとjoinで空白や改行を整形する
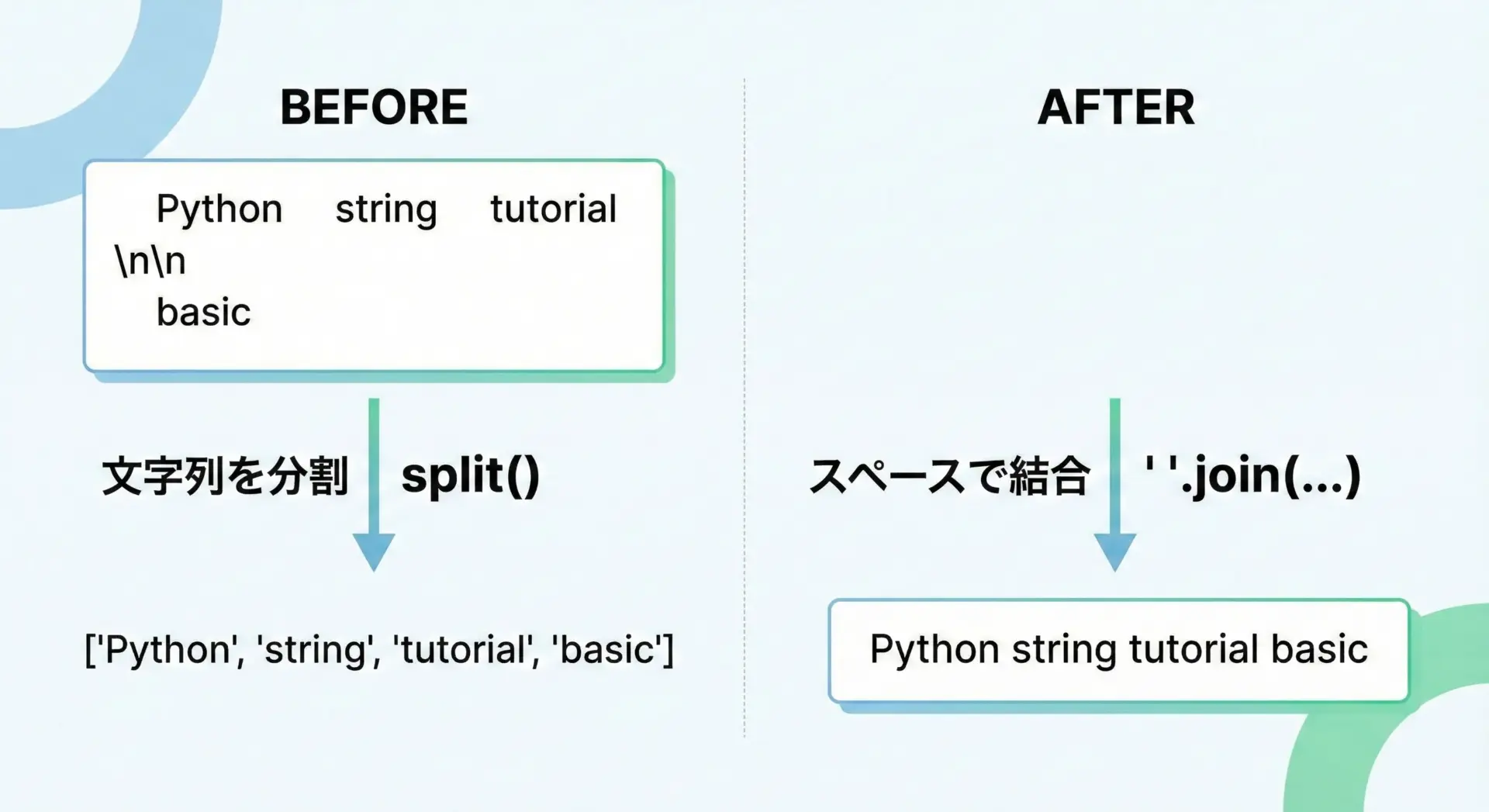
余分な空白や改行が混ざったテキストをきれいに整形するには、splitとjoinの組み合わせが有効です。
text = " Python string tutorial \n\n basic "
# 1. split() で単語だけ取り出す
words = text.split()
# 2. 半角スペースで連結して整形
clean = " ".join(words)
print(clean)Python string tutorial basicこのテクニックは、ユーザー入力やコピー&ペーストしたテキストの「余計な空白」を取り除くときに非常に便利です。
単語の並び替え・フィルタをしてからjoinする
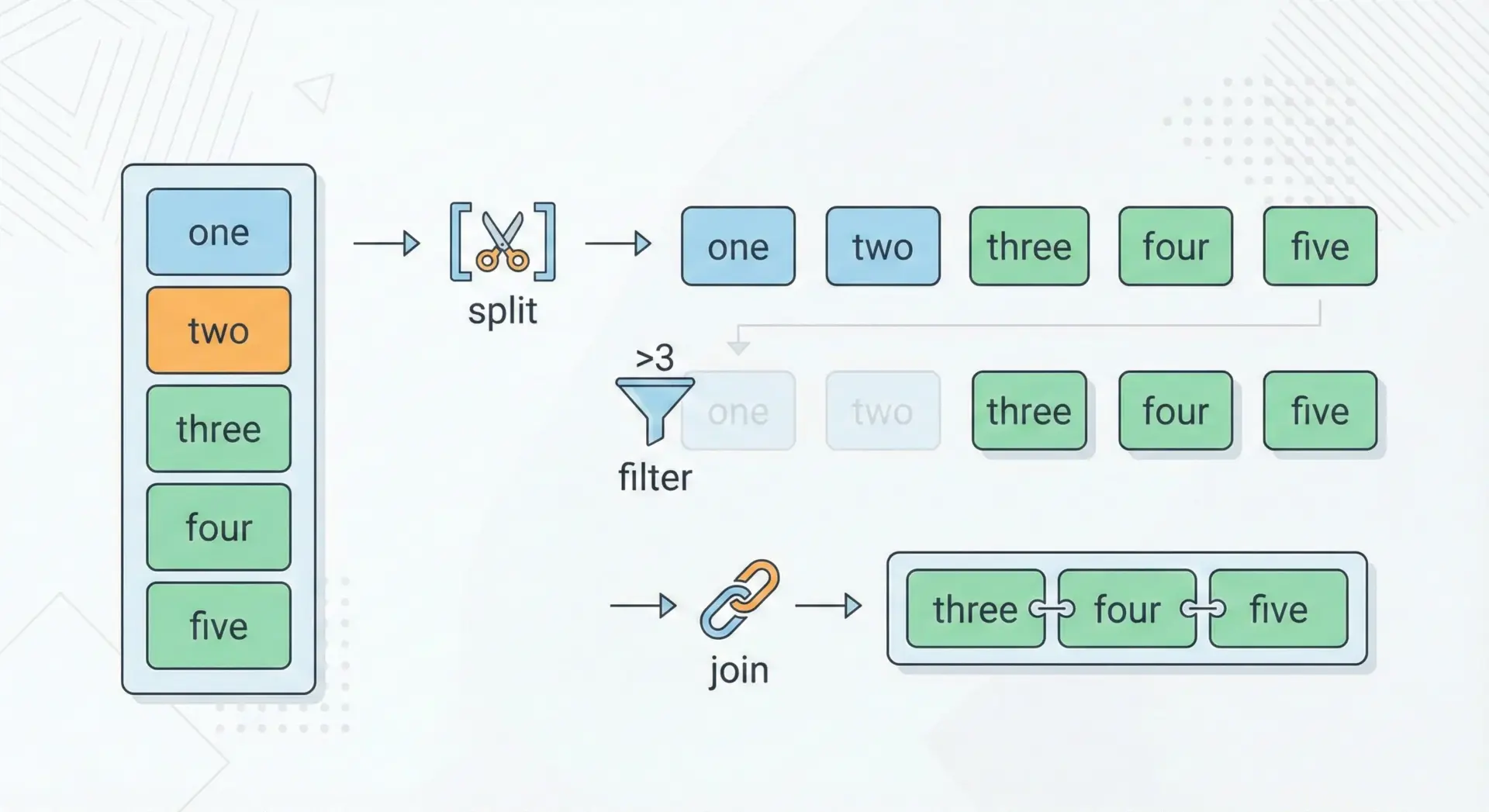
splitで単語リストにしてから並べ替えやフィルタを行い、最後にjoinで戻すという流れもよく使います。
text = "one two three four five"
# 単語に分割
words = text.split()
# 文字数が3以上の単語だけを残し、アルファベット順にソート
filtered_sorted = sorted(w for w in words if len(w) >= 3)
# 再度スペースで結合
result = " ".join(filtered_sorted)
print(result)five four one three twoこのように「split → 処理 → join」という3ステップで、テキストの再構成が柔軟に行えます。
CSV文字列をsplit・加工して再度joinする
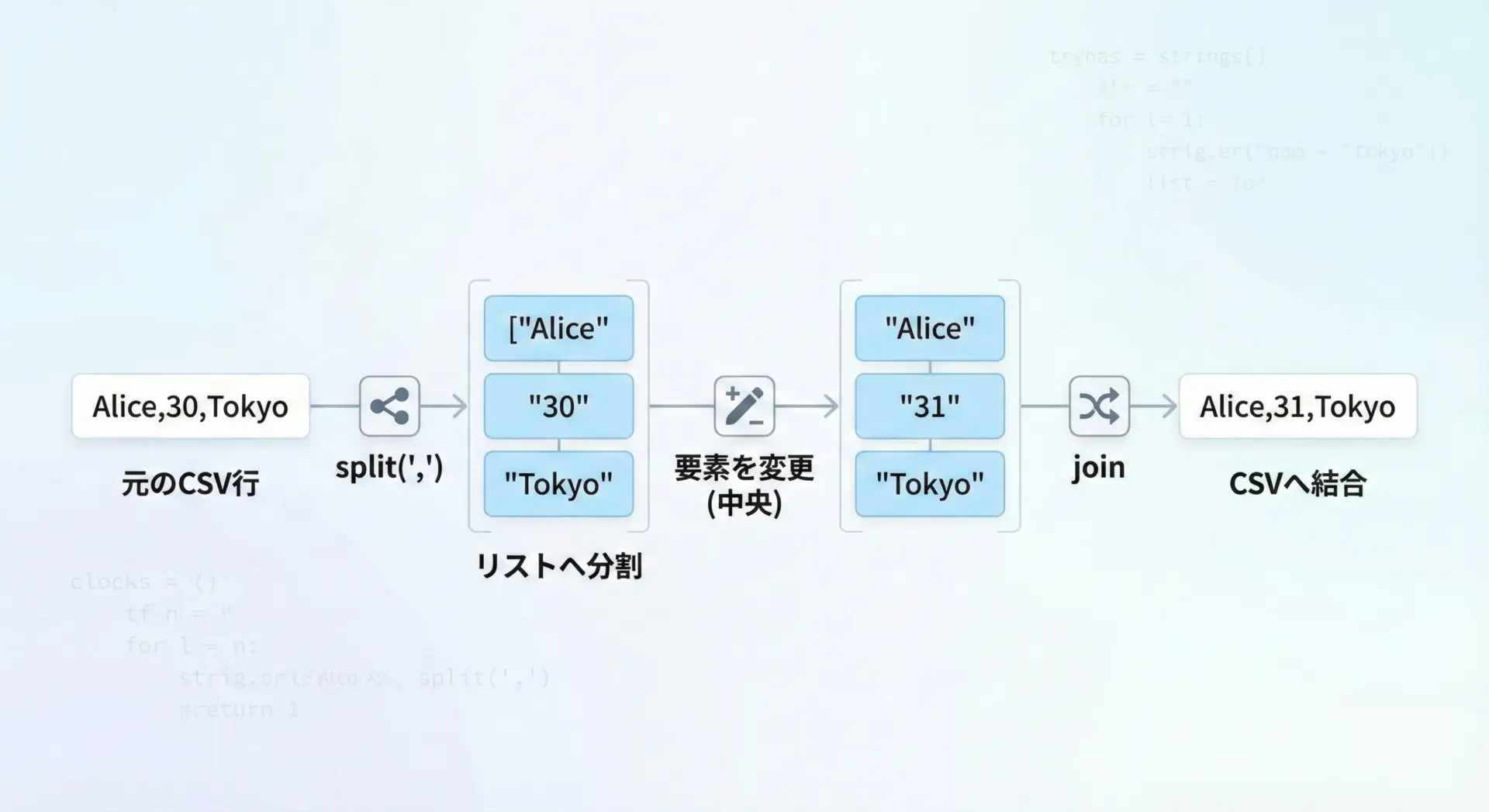
CSV形式の1行だけを手軽に加工したい場合も、splitとjoinが活躍します。
line = "Alice,30,Tokyo"
# CSVを分割
fields = line.split(",")
# 年齢(2番目の要素)を数値として1加算
age = int(fields[1])
fields[1] = str(age + 1)
# 再びCSV形式に結合
new_line = ",".join(fields)
print(new_line)Alice,31,Tokyo本格的なCSV処理ではcsvモジュールを使うべきですが、単純な1行加工ならこの方法が短く書けます。
文字列の前後・途中の不要文字を除去してjoinする
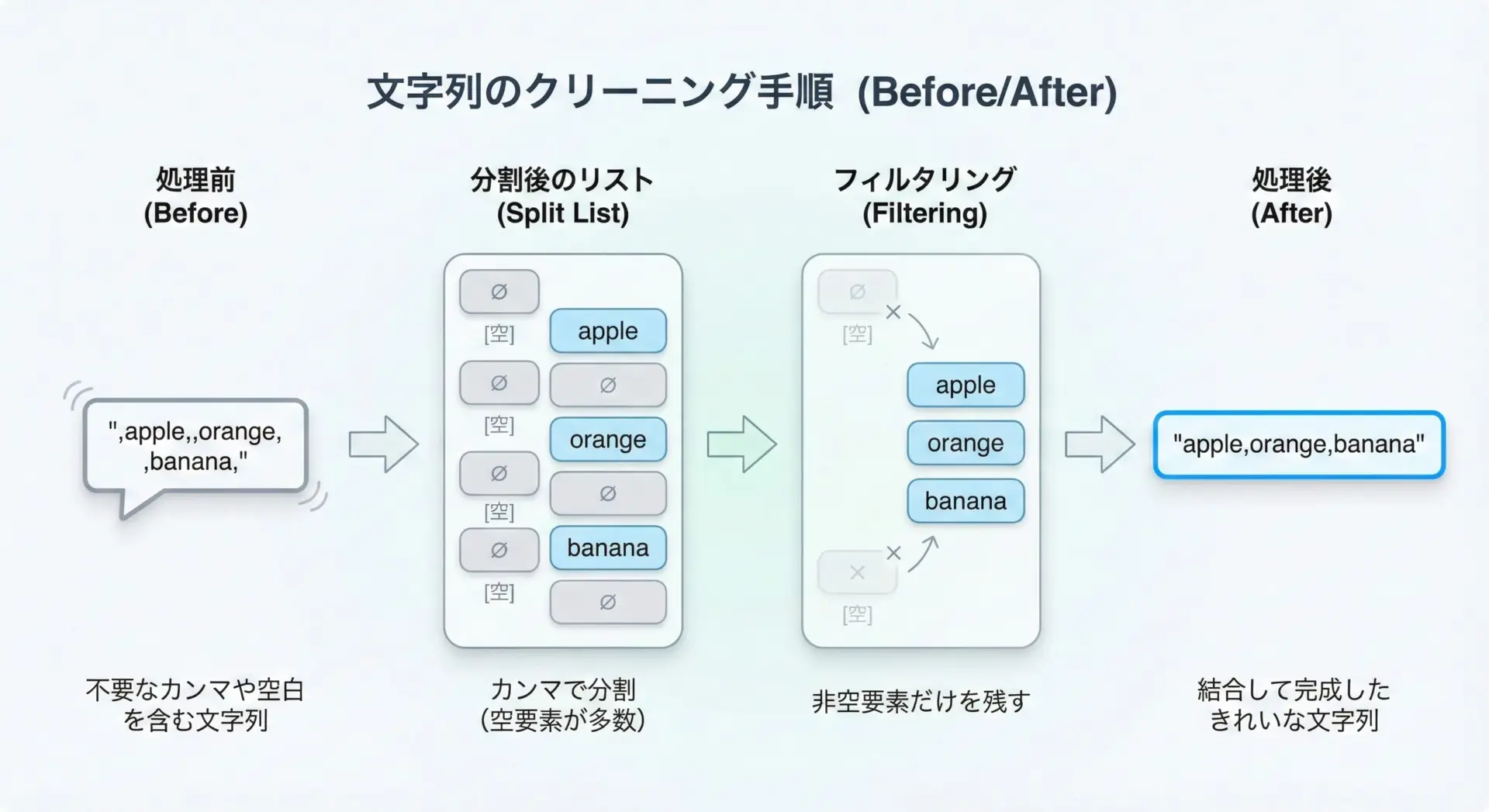
ログやユーザー入力には、余計な区切り文字が含まれていることがあります。
そうした場合も、分割してからフィルタして、再度結合するときれいに整えられます。
text = ",apple,,orange, ,banana,"
# 1. カンマで分割
parts = text.split(",")
# 2. 空文字や空白だけの要素を除外
clean_parts = [p.strip() for p in parts if p.strip()]
# 3. 余計な区切りのないCSVに整形
clean_text = ",".join(clean_parts)
print(clean_text)apple,orange,bananaここではstrip()で各要素の前後の空白を取り除き、空になったものを弾いてからjoinしています。
「split → strip / フィルタ → join」は、ノイズを含むデータの整形で頻出するパターンです。
まとめ
splitとjoinは、Pythonでのテキスト処理の基礎にして最重要テクニックです。
空白や任意の区切り文字での分割、maxsplitやsplitlinesによる制御、正規表現との連携、そしてjoinによる整った出力生成までを組み合わせれば、多くの文字列処理はシンプルなコードで実現できます。
日常的なログ解析やCSV加工などでも、まずは「split → 必要な処理 → join」という流れを意識すると、可読性と拡張性の高いコードを書けるようになります。
