C#を用いた開発において、文字列の解析やパターンマッチングは日常的に発生するタスクです。
その中でも正規表現(Regular Expression)は強力なツールですが、複雑なパターンを作成すると「どのカッコがどの値を抽出しているのか」がひと目で分からなくなるという課題があります。
そこで活用したいのが名前付きグループ(Named Groups)です。
名前付きグループを使用することで、抽出したデータに任意の名前を割り当てることができ、プログラムからの参照が圧倒的に分かりやすくなります。
本記事では、C#における名前付きグループの基本構文から、実戦的な抽出・置換方法、さらにはパフォーマンス最適化のコツまで、プロの視点で徹底的に解説します。
名前付きグループ(Named Groups)とは
正規表現におけるグループ化とは、パターンの一部を丸カッコ () で囲むことで、その部分にマッチした文字列を個別に抽出したり、繰り返しの単位として扱ったりする機能を指します。
通常、グループ化した値は「左から数えて何番目のカッコか」というインデックス番号(1, 2, 3…)で管理されます。
しかし、この方法には「パターンの修正でカッコが増減すると、インデックス番号がずれてバグの原因になる」という大きな欠点があります。

名前付きグループは、このインデックス番号の代わりに「名前」を用いてグループを管理する手法です。
C#の System.Text.RegularExpressions 名前空間はこの機能をフルサポートしており、可読性が高くメンテナンスしやすいコードを実現できます。
名前付きグループの基本構文
C#で名前付きグループを定義するには、特定のメタ文字をグループの開始カッコ内に記述します。
構文の書き方
C#(.NET)で一般的に使用される構文は以下の通りです。
(?<name>pattern): 最も一般的な形式(?'name'pattern): シングルクォートを使用する形式(動作は同じ)
例えば、日付文字列「2024-05-10」から年・月・日を抽出したい場合、名前付きグループを使用しないパターンと使用するパターンを比較してみましょう。
- インデックス指定(従来):
(\d{4})-(\d{2})-(\d{2}) - 名前付きグループ:
(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})
後者の書き方であれば、どの部分が「年(year)」で、どの部分が「月(month)」を指しているのかが正規表現パターン自体から明確に読み取れます。
インデックス指定との共存
名前付きグループを使用した場合でも、内部的にはインデックス番号が割り振られます。
ただし、.NETの仕様では「名前を持たないグループが先に番号付けされ、その後に名前付きグループが番号付けされる」というルールがある点に注意が必要です。
混乱を避けるため、一つのパターン内ではどちらかに統一するか、後述する ExplicitCapture オプションを使用するのが定石です。
C#での具体的な抽出方法
それでは、実際にC#のコードでどのように値を抽出するのか、具体的な手順を見ていきましょう。
Regex.Match を使った単一マッチの抽出
最も基本的な使い方は、Regex.Match メソッドで得られた Match オブジェクトから、名前を指定して Groups コレクションにアクセスする方法です。
using System;
using System.Text.RegularExpressions;
public class Program
{
public static void Main()
{
string input = "User: Tanaka, ID: 12345";
string pattern = @"User: (?<name>\w+), ID: (?<id>\d+)";
Match match = Regex.Match(input, pattern);
if (match.Success)
{
// 名前を指定して値を抽出
string userName = match.Groups["name"].Value;
string userId = match.Groups["id"].Value;
Console.WriteLine($"Name: {userName}");
Console.WriteLine($"ID: {userId}");
}
}
}このコードのポイントは、match.Groups["name"] のように、文字列のキーで値を取り出している点です。
これにより、パターンの途中に新しいカッコが追加されても、"name" というキーが変わらない限り、プログラム側の修正は不要になります。
複数のマッチを処理する Regex.Matches
複数の箇所にマッチする場合は、Regex.Matches を使用し、ループ内で各 Match オブジェクトに対して同様の処理を行います。
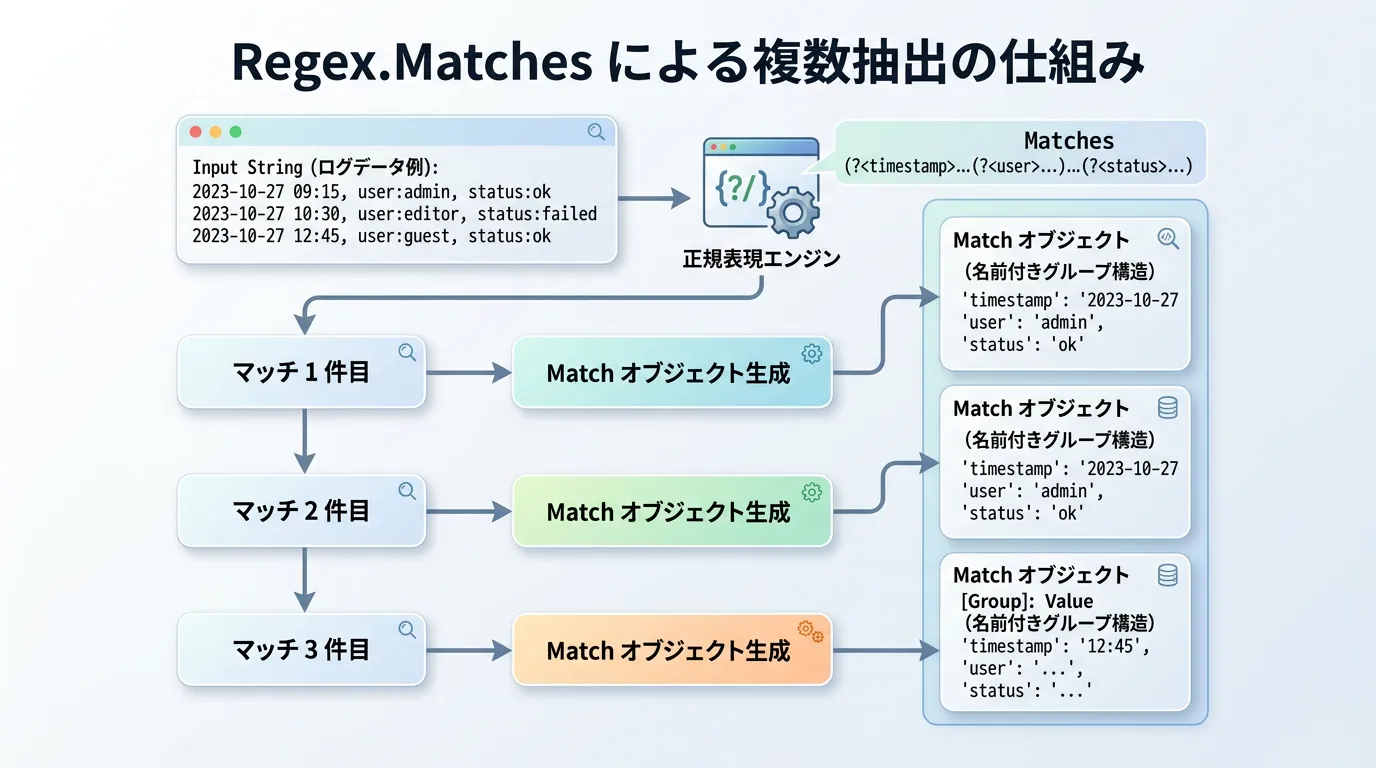
実践的な活用シーン
名前付きグループは、複雑な構造を持つデータの解析において真価を発揮します。
日付文字列のパース
システムのログファイルやユーザー入力など、様々なフォーマットの日付を解析する際に便利です。
string dateInput = "2026/01/16";
string datePattern = @"(?<year>\d{4})[/-](?<month>\d{1,2})[/-](?<day>\d{1,2})";
Match dateMatch = Regex.Match(dateInput, datePattern);
if (dateMatch.Success)
{
int year = int.Parse(dateMatch.Groups["year"].Value);
// 型変換などの処理も、名前がついているためミスが起きにくい
}ログファイルの解析
以下のような、特定の規則性を持つログメッセージから特定の情報を抜き出すケースです。
[2026-01-16 10:00:00] [INFO] Connection opened from 192.168.1.1
この場合、以下のようなパターンを構成できます。
^[(?<timestamp>.?)] [(?<level>.?)] (?<message>.*)$
このように、意味のある単位で名前を付けることで、ログ解析ロジックの可読性が劇的に向上します。
置換(Regex.Replace)での名前付きグループ利用
名前付きグループは、抽出だけでなく「置換」においても非常に強力です。
Regex.Replace メソッドを使用する際、置換後の文字列内で ${name} という形式でグループを参照できます。
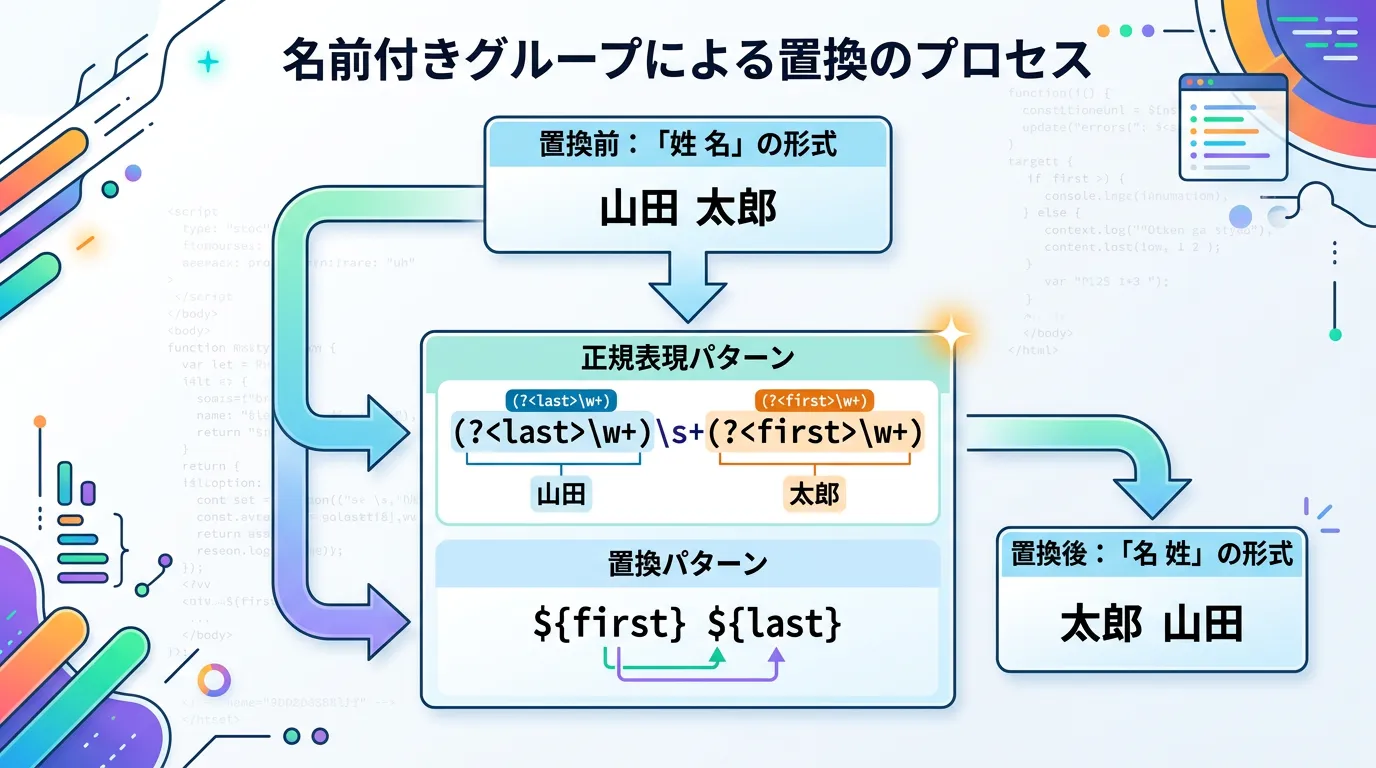
実装例:表示形式の変換
string inputName = "Yamada Taro";
string pattern = @"(?<last>\w+)\s+(?<first>\w+)";
string replacement = "${first} ${last}";
string result = Regex.Replace(inputName, pattern, replacement);
// 結果: Taro Yamadaインデックス指定の場合、置換文字列は $1 $2 のようになりますが、項目が増えると「$5 は何だったか?」と混乱します。
${first} のような記述であれば、置換処理の内容が一目瞭然です。
高度なテクニックと注意点
正規表現をよりプロフェッショナルに使いこなすための、一歩踏み込んだ知識を解説します。
RegexOptions.ExplicitCapture の活用
通常、名前を付けていない丸カッコ () も自動的にグループとしてキャプチャされます。
しかし、名前付きグループをメインで使う場合、意図しないキャプチャはメモリや計算資源の無駄になります。
そこで、RegexOptions.ExplicitCapture を指定します。
このオプションを有効にすると、(?<name>...) のように明示的に名前を付けたグループのみをキャプチャ対象とし、ただの () はグループ化(キャプチャ)を行わない単なる「グルーピング」として扱われます。
var options = RegexOptions.ExplicitCapture;
Regex regex = new Regex(@"(?<id>\d+) - (\w+)", options);
// (\w+) は名前がないため、Groups コレクションには含まれなくなる同名のグループ(.NET 5以降のサポート)
以前の正規表現エンジンでは、一つのパターン内で同じグループ名を重複させることはできませんでした。
しかし、最近の .NET(.NET 5 / .NET Core 3.1 以降など)では、条件分岐(OR条件)において同じ名前を使用することが可能になっています。
// 異なるフォーマットのどちらにマッチしても "code" という名前で取り出したい
string pattern = @"(ID:(?<code>\d+)|KEY:(?<code>[A-Z]+))";この機能により、入力ソースの揺れを吸収しつつ、抽出側のロジックを共通化できるというメリットがあります。
パフォーマンスへの影響
名前付きグループは、内部的にハッシュテーブルのような構造で名前とインデックスを紐付けているため、数値インデックスによるアクセスに比べるとごく僅かなオーバーヘッドが存在します。
しかし、通常のアプリケーション開発においてこれがボトルネックになることは稀です。
それよりも、コードの保守性とバグの抑制というメリットの方が遥かに大きいため、積極的に名前付きグループを使用することをお勧めします。
パフォーマンスが極めて重要な高負荷ループ内などで使用する場合は、Regex インスタンスを静的に保持(コンパイル済み正規表現の利用)するなどの対策を優先すべきです。
名前付きグループ活用のベストプラクティス
最後に、名前付きグループを効果的に運用するためのルールをまとめます。
| 項目 | ベストプラクティス | 理由 |
|---|---|---|
| 命名規則 | キャメルケース(userName)またはスネークケース(user_name)で統一する | 複数のグループがある場合の可読性を高めるため |
| オプション指定 | RegexOptions.ExplicitCapture を検討する | 不要なキャプチャを排除し、意図を明確にするため |
| 存在チェック | Groups["name"].Success を確認する | オプションのマッチング(?を使用した場合)で、値が存在するか安全に確認するため |
| 定数化 | グループ名を定数(const string)として定義する | マジックストリングを排除し、タイポによるバグを防ぐため |
特に、大規模な開発プロジェクトでは、正規表現パターンとグループ名を一箇所で管理することで、仕様変更に強い堅牢なコードを構築できます。
まとめ
C#の正規表現における名前付きグループは、単なる便利な機能に留まらず、「動くコード」を「保守可能なコード」へと昇華させるための必須テクニックです。
(?<name>pattern)で定義し、Groups["name"]で抽出する。- 数値インデックスに依存しないため、パターンの変更に強い。
- 置換処理でも
${name}を使って直感的に記述できる。 ExplicitCaptureを併用することで、よりクリーンな抽出が可能になる。
これまでインデックス番号で苦労していた方は、ぜひこの機会に名前付きグループを取り入れてみてください。
文字列処理のコードが驚くほどスッキリとし、チームメンバーにとっても理解しやすいプログラムになるはずです。
