
C#を利用したテキスト処理において、正規表現は非常に強力なツールです。
しかし、デフォルトの動作ではアルファベットの「大文字」と「小文字」を厳密に区別するため、ユーザー入力の検索やバリデーションを行う際に不都合が生じることが多々あります。
例えば、「Apple」という単語を探したい場合に「apple」や「APPLE」もヒットさせたいというケースは一般的です。
C#の正規表現(Regular Expressions)で大文字小文字を無視してマッチングさせる方法には、オプションフラグを指定する方法や、パターン内にインラインで記述する方法など、複数のアプローチが存在します。
この記事では、初心者から上級者まで役立つ、状況に応じた最適な実装方法を詳しく解説します。
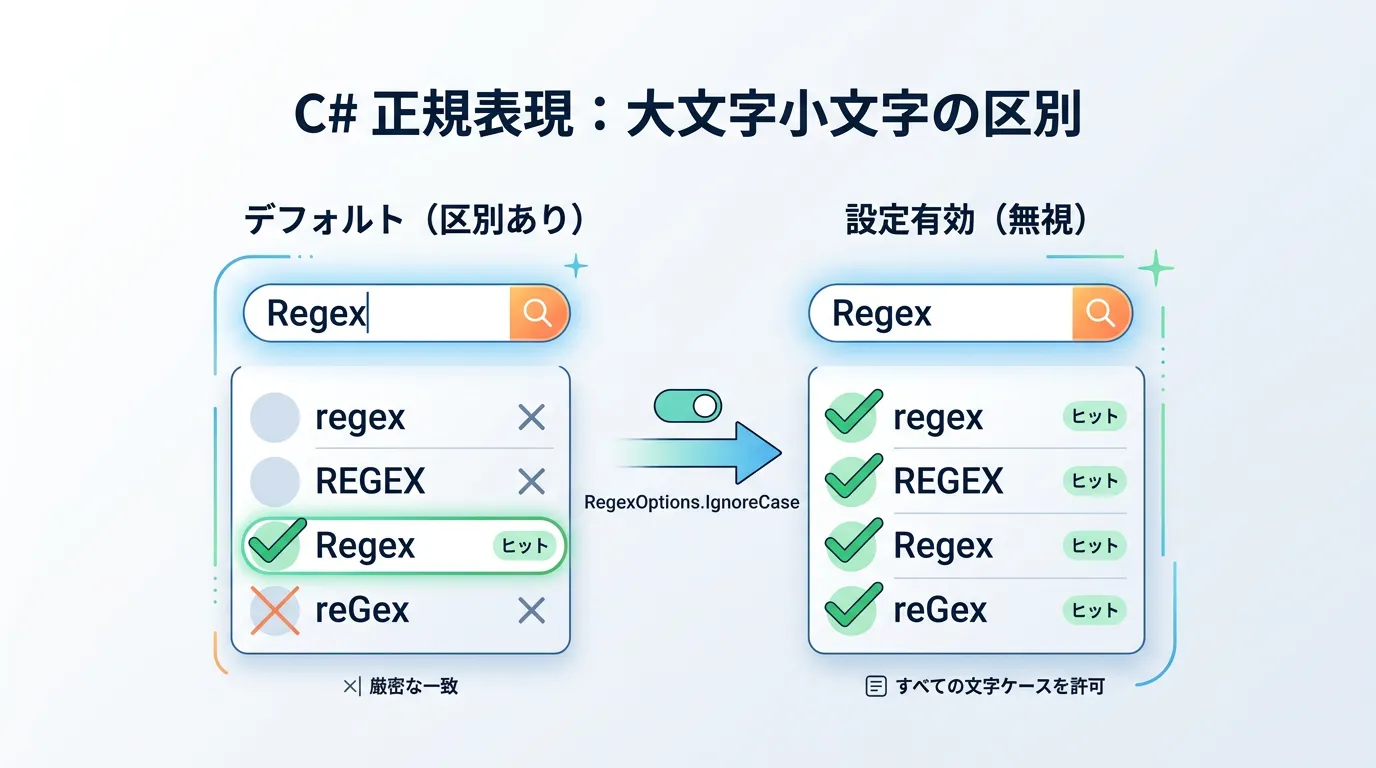
RegexOptions.IgnoreCase を使用する基本手法
C#で正規表現を扱う際、最も標準的かつ推奨される方法が RegexOptions.IgnoreCase 列挙型を使用する方法です。
これは、正規表現エンジンに対して「大文字と小文字の差異を無視して検索を実行せよ」と明示的に指示するオプションです。
静的メソッドでの利用例
もっとも手軽に利用できるのが、Regexクラスの静的メソッド(IsMatch, Match, Replaceなど)に引数として渡す方法です。
using System;
using System.Text.RegularExpressions;
string input = "Hello, C# World!";
string pattern = "hello";
// RegexOptions.IgnoreCase を第3引数に指定
if (Regex.IsMatch(input, pattern, RegexOptions.IgnoreCase))
{
Console.WriteLine("マッチしました!");
}このコードでは、検索対象の文字列が「Hello」でパターンが「hello」ですが、オプションが有効なため、問題なくマッチします。
インスタンス生成時の指定
同じパターンを繰り返し利用する場合は、Regex クラスのインスタンスを生成する際にオプションを渡す方がパフォーマンス面で有利です。
// コンストラクタでオプションを指定
var regex = new Regex("apple", RegexOptions.IgnoreCase);
string text = "I like Apple, apple, and APPLE.";
var matches = regex.Matches(text);
Console.WriteLine($"{matches.Count} 個のマッチが見つかりました。");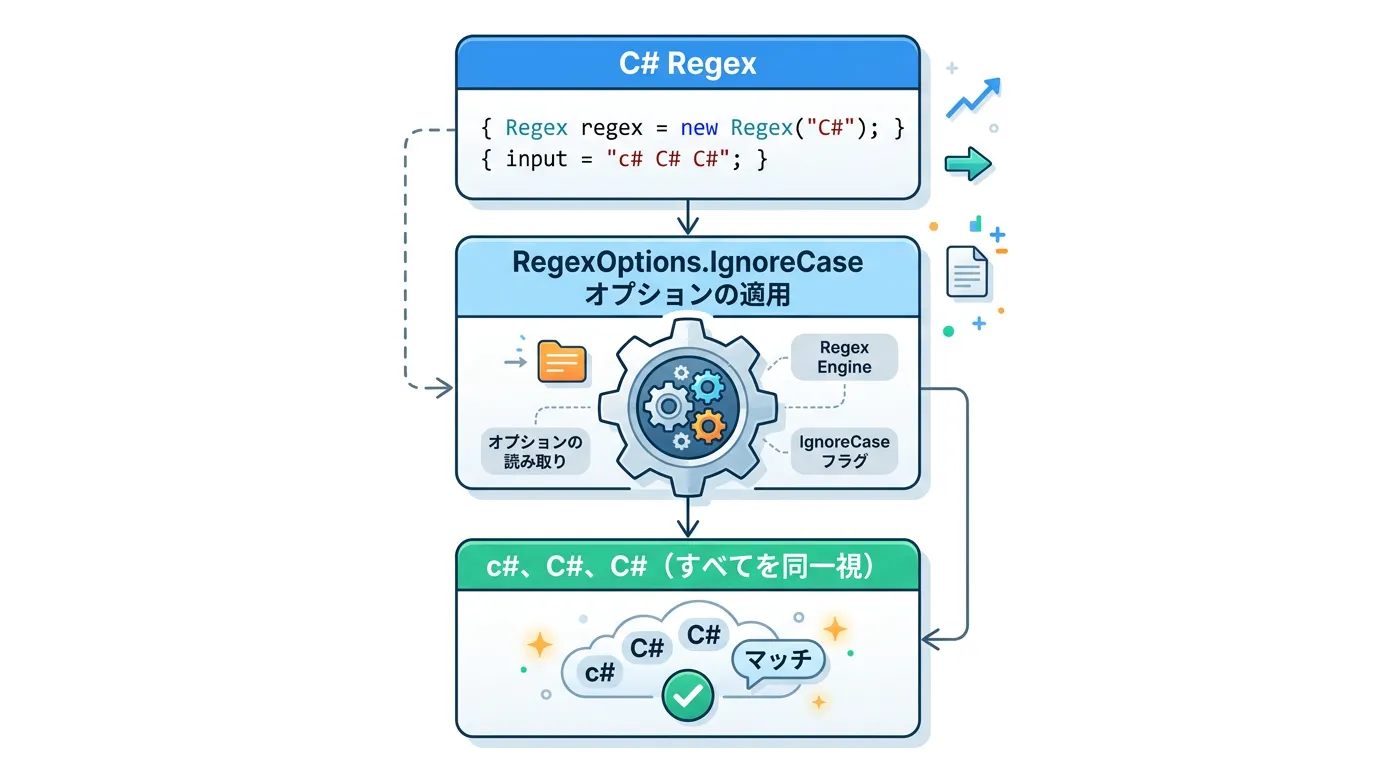
文字列の置換(Replace)における活用
大文字小文字を無視して特定の文字列を別の文字列に置き換えたい場合も、同様のオプションを使用します。
Regex.Replace での一括置換
以下の例では、文章中の「c#」という単語(大文字小文字不問)をすべて「C# 12」に置換します。
string original = "c# is great, C# is powerful, and C# is evolving.";
string pattern = "c#";
string replacement = "C# 12";
// 大文字小文字を無視して置換を実行
string result = Regex.Replace(original, pattern, replacement, RegexOptions.IgnoreCase);
Console.WriteLine(result);
// 出力: C# 12 is great, C# 12 is powerful, and C# 12 is evolving.このように、ユーザーがどのようなケースで入力しても、確実にターゲットを捉えて置換できるのが大きなメリットです。
インラインでの指定(正規表現パターン内での設定)
コードの引数としてオプションを渡すのではなく、正規表現パターンそのものに大文字小文字を無視する設定を埋め込むことも可能です。
これを「インラインオプション」と呼びます。
記法:(?i) の使用
パターンの先頭に (?i) を記述すると、それ以降のパターンは大文字小文字を無視するようになります。
| 記述方法 | 意味 |
|---|---|
(?i)abc | 「abc」「ABC」「Abc」などにマッチする |
abc(?i)def | 「abc」は厳密に区別し、「def」以降は無視する |
(?i)abc(?-i)def | 「abc」は無視し、「def」は厳密に区別する |
部分的な無視の適用
インライン指定の強力な点は、パターンの「一部だけ」に適用できることです。
// "Error" は大文字小文字を無視するが、"CODE" は大文字のみを対象とする
string pattern = @"(?i)error(?-i)CODE";
Console.WriteLine(Regex.IsMatch("ERRORCODE", pattern)); // True
Console.WriteLine(Regex.IsMatch("errorcode", pattern)); // False (CODE部分が小文字のため)特定のキーワードのみ柔軟に検索したい場合に非常に役立ちます。

最新の C# におけるソース生成(Source Generators)
現代的な .NET(.NET 7 以降)では、パフォーマンスを最大限に引き出すために「正規表現ソースジェネレーター」の使用が推奨されています。
これは、コンパイル時に正規表現の解析を行う仕組みです。
[GeneratedRegex] 属性での指定
ソースジェネレーターを使用する場合も、属性の引数としてオプションを指定できます。
using System.Text.RegularExpressions;
public partial class MyParser
{
// コンパイル時に正規表現コードを生成
[GeneratedRegex("search_term", RegexOptions.IgnoreCase)]
private static partial Regex SearchRegex();
public void Execute(string input)
{
if (SearchRegex().IsMatch(input))
{
// 処理
}
}
}この方法を採用すると、実行時のオーバーヘッドが削減され、モバイルアプリや高負荷なサーバーサイド処理において劇的なパフォーマンス向上が見込めます。
注意点とベストプラクティス
大文字小文字の無視は便利ですが、いくつか注意すべき点があります。
カルチャによる挙動の違い
言語によっては、大文字小文字の対応ルールが異なる場合があります(例:トルコ語の「i」と「I」)。
もし、特定の言語ルールに依存せず、数学的な文字コードの比較として処理したい場合は、RegexOptions.CultureInvariant を併用することを検討してください。
// 言語設定に左右されない比較
var options = RegexOptions.IgnoreCase | RegexOptions.CultureInvariant;
var regex = new Regex("file", options);パフォーマンスへの影響
単純な文字列の比較(string.Equals など)に比べると、正規表現は重い処理です。
正規表現が必要ない単純な「特定の単語が含まれているか」のチェックであれば、以下の方法の方が高速です。
// 正規表現を使わない高速な方法
bool contains = input.Contains("hello", StringComparison.OrdinalIgnoreCase);複雑なパターンマッチングが必要な場合のみ正規表現を選択するのが、エンジニアとしての賢明な判断です。
まとめ
C# で正規表現の大文字小文字を無視する方法は、大きく分けて以下の3つです。
- RegexOptions.IgnoreCase をメソッドの引数やコンストラクタに指定する(最も一般的)。
- パターン内に (?i) を記述する(部分的な制御に最適)。
- [GeneratedRegex] 属性でオプションを指定する(最新の .NET におけるパフォーマンス重視の選択)。
開発しているアプリケーションの規模や、要求されるパフォーマンス、パターンの複雑さに応じてこれらを使い分けてください。
特に大量のデータを処理するプログラムでは、インスタンスの再利用やソースジェネレーターの活用が鍵となります。
正規表現をマスターすることで、C# での文字列操作の幅は大きく広がります。
この記事で紹介したテクニックを駆使して、より堅牢でユーザーフレンドリーなコードを作成していきましょう。
