
C#を使用したアプリケーション開発において、文字列のバリデーションや検索、置換処理は避けて通れない要素です。
その中でも、強力な柔軟性を持つ正規表現 (Regular Expression)は、高度なテキスト処理を実現するための必須スキルと言えるでしょう。
C#では System.Text.RegularExpressions 名前空間に含まれる Regex クラスを利用することで、簡潔かつ高速に正規表現を扱うことが可能です。
本記事では、C#における正規表現の基礎から、特殊文字(メタ文字)や文字クラスの一覧、そして最新の .NET におけるパフォーマンス最適化までを網羅的に解説します。
C# 正規表現の基本概念
C#で正規表現を扱うための中心となるのが Regex クラスです。
このクラスは、不変 (immutable) であり、スレッドセーフな設計がなされています。
正規表現は特定の「パターン」を定義し、そのパターンに対して入力文字列が適合するかどうかを判定します。
C#で正規表現を利用する際、まず理解しておくべきは 逐次リテラル文字列 の活用です。
正規表現ではバックスラッシュ \ を多用しますが、C#の通常の文字列リテラルではバックスラッシュがエスケープ文字として扱われてしまいます。
そのため、文字列の先頭に @ を付与する ことで、バックスラッシュをそのまま記述できるようにするのが一般的です。
// 通常の文字列(バックスラッシュを2つ書く必要がある)
string pattern1 = "\\d{3}-\\d{4}";
// 逐次リテラル文字列(推奨される書き方)
string pattern2 = @"\d{3}-\d{4}";正規表現の特殊文字(メタ文字)一覧
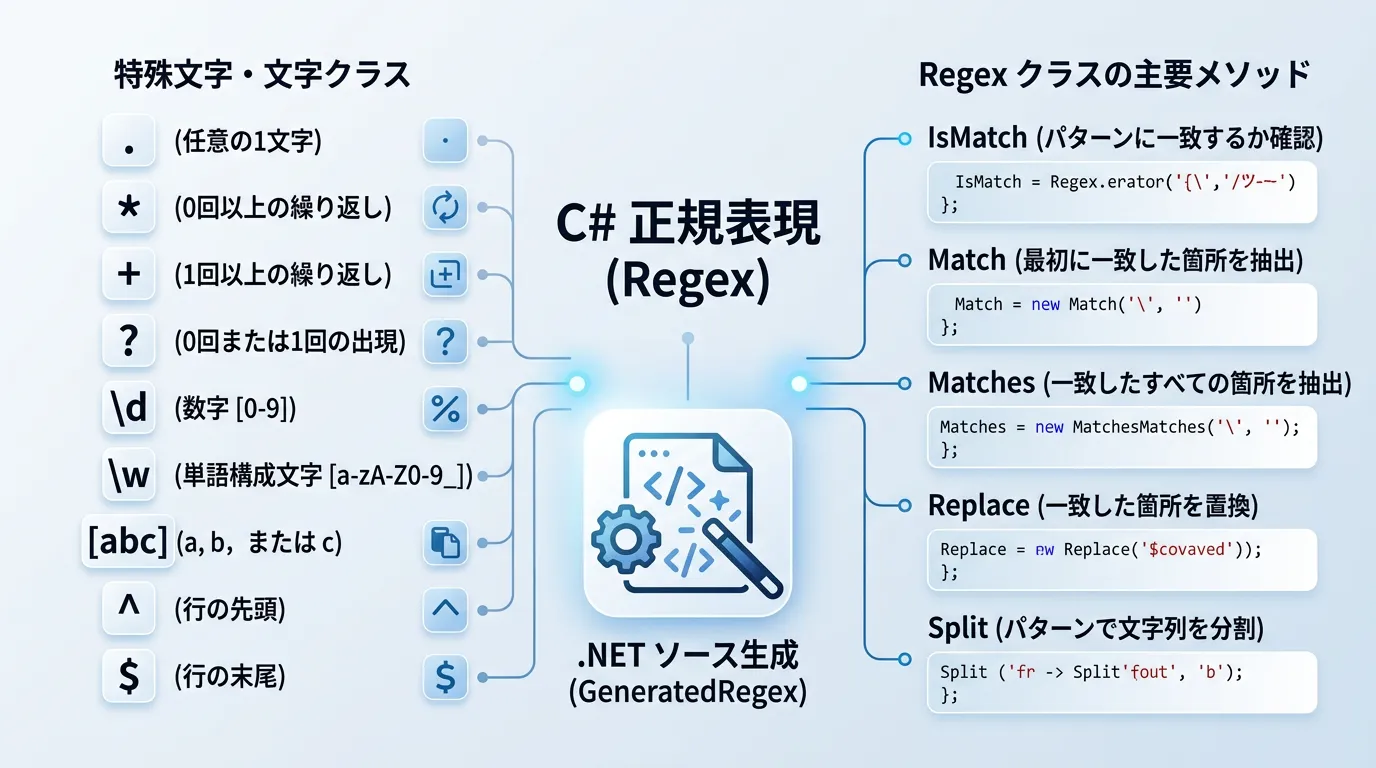
正規表現において、特別な意味を持つ文字を「特殊文字」または「メタ文字」と呼びます。
これらを組み合わせることで、複雑な文字列パターンを表現します。
基本的なメタ文字
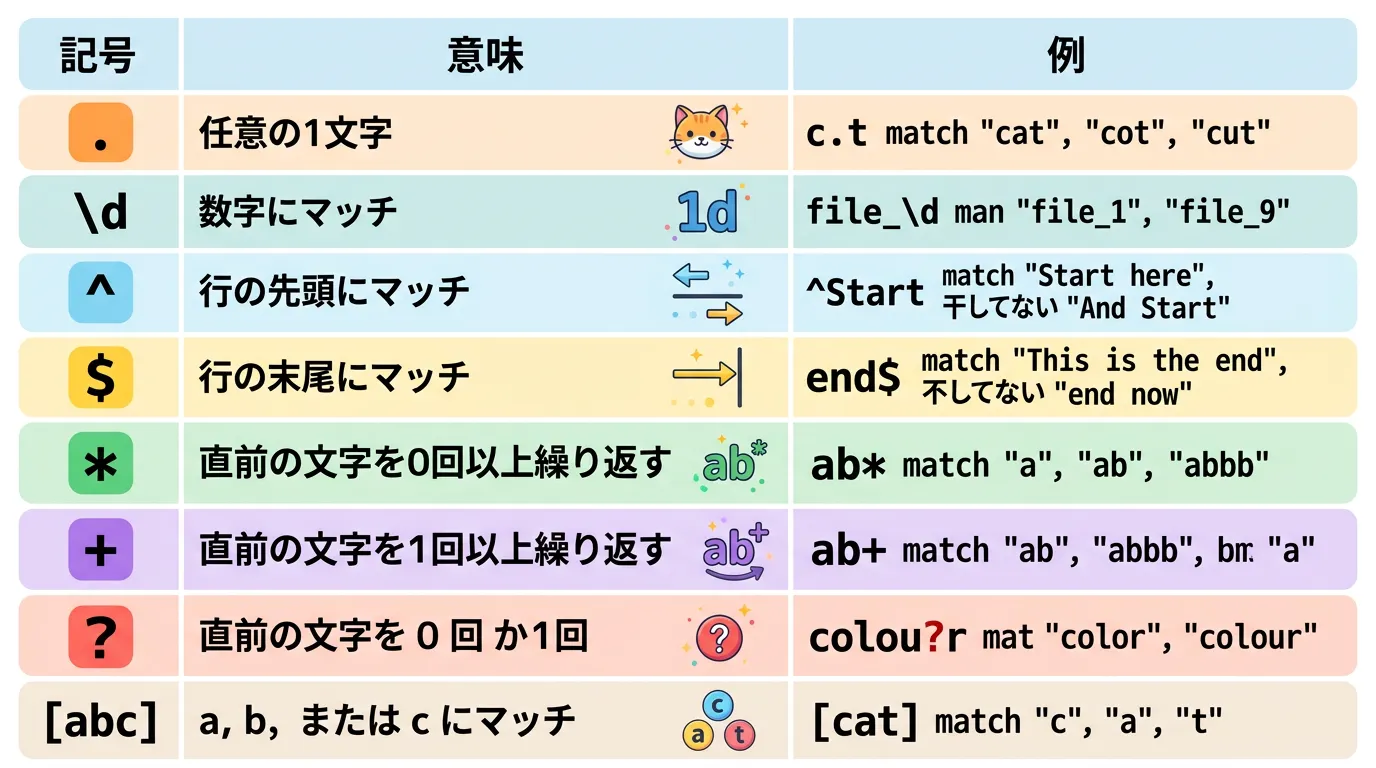
| 記号 | 意味 | 使用例 |
|---|---|---|
. | 改行を除く任意の1文字にマッチ | a.c → “abc”, “axc” など |
^ | 文字列の先頭にマッチ | ^abc → “abc” で始まる文字列 |
$ | 文字列の末尾にマッチ | xyz$ → “xyz” で終わる文字列 |
* | 直前の要素の0回以上の繰り返し | ab* → “a”, “ab”, “abbb” |
+ | 直前の要素の1回以上の繰り返し | ab+ → “ab”, “abbb”(”a”は不可) |
? | 直前の要素の0回または1回の出現 | ab? → “a”, “ab” |
| | いずれかの条件(OR)にマッチ | cat|dog → “cat” または “dog” |
() | グループ化 | (ab)+ → “ab”, “ababab” |
量指定子(繰り返し回数の指定)
特定の回数だけ繰り返したい場合は、波括弧 {} を使用します。
{n}: ちょうどn回繰り返す。{n,}:n回以上繰り返す。{n,m}:n回以上m回以下繰り返す。
例えば、郵便番号のように「数字3桁、ハイフン、数字4桁」を表現する場合は @"\d{3}-\d{4}" と記述します。
文字クラス(ワイルドカード)の解説
文字クラスは、特定の種類の文字セットにマッチさせるためのショートカットです。
C#の正規表現エンジンは Unicode に準拠しているため、非常に広範な文字をサポートしています。
主要な文字クラス一覧
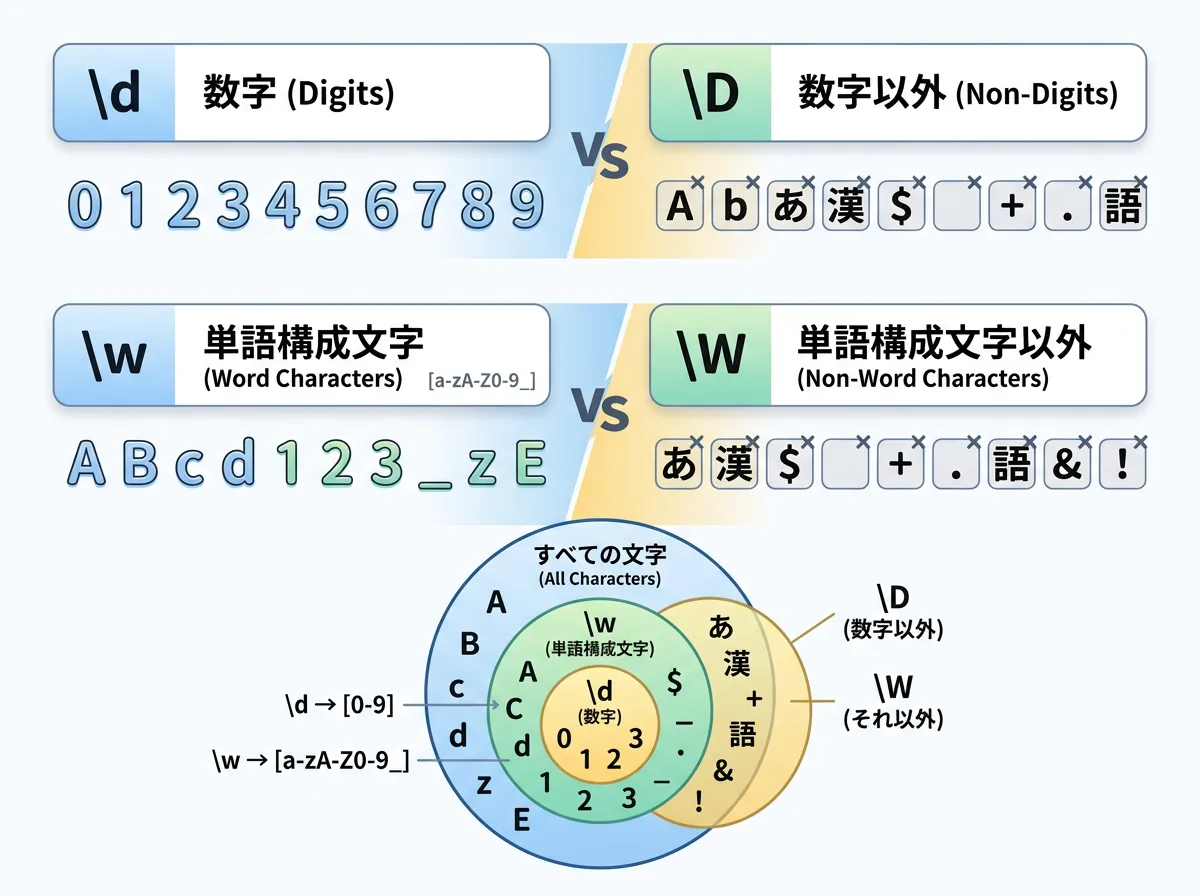
| クラス | 意味 | 補足説明 |
|---|---|---|
\d | 任意の数字 | [0-9] と同等(Unicodeの数字含む) |
\D | 数字以外の文字 | [^0-9] と同等 |
\w | 単語構成文字 | 英数字およびアンダースコア [a-zA-Z0-9_] |
\W | 単語構成文字以外 | 記号や空白など |
\s | 空白文字 | スペース、タブ、改行など |
\S | 空白以外の文字 | 可視文字すべて |
[abc] | 指定した文字のいずれか | ‘a’ または ‘b’ または ‘c’ |
[a-z] | 範囲指定 | aからzまでの小文字英字 |
[^abc] | 指定した文字以外 | ‘a’, ‘b’, ‘c’ 以外の任意の文字 |
C#のデフォルト設定では、\d は全角数字や他言語の数字にもマッチする場合があります。
純粋に半角の 0-9 だけを対象にしたい場合は、RegexOptions.ECMAScript を指定するか、明示的に [0-9] と記述するのが確実です。
Regex クラスの主要メソッドと使い方
C#で正規表現を実行するには、System.Text.RegularExpressions.Regex クラスのメソッドを使用します。
主に「判定」「抽出」「置換」「分割」の4つの用途があります。
1. 文字列の妥当性を確認する (IsMatch)
入力された文字列が特定のパターンに一致するかどうかを bool 値で返します。
フォームのバリデーションなどで最も頻繁に利用されます。
using System;
using System.Text.RegularExpressions;
string input = "090-1234-5678";
string pattern = @"^\d{2,4}-\d{2,4}-\d{4}$";
if (Regex.IsMatch(input, pattern))
{
Console.WriteLine("有効な電話番号形式です。");
}2. 一致した部分を抽出する (Match / Matches)
文字列の中からパターンに一致する箇所を抽出します。
Match は最初に見つかった1件、Matches は一致するすべての箇所をコレクションとして取得します。
string text = "価格は 1500円 と 2300円 です。";
string pattern = @"\d+";
// すべての数字を抽出
MatchCollection matches = Regex.Matches(text, pattern);
foreach (Match match in matches)
{
Console.WriteLine($"見つかった数値: {match.Value}");
}3. 文字列を置換する (Replace)
一致した部分を別の文字列に置き換えます。
string input = "apple, orange, banana";
string pattern = @",\s*";
string result = Regex.Replace(input, pattern, " | ");
// 結果: "apple | orange | banana"
Console.WriteLine(result);4. 文字列を分割する (Split)
正規表現を区切り文字として文字列を分割します。
string input = "2024/10/25 15:30:00";
string pattern = @"[/ : ]"; // スラッシュ、スペース、コロンのいずれか
string[] elements = Regex.Split(input, pattern);
foreach (var item in elements)
{
Console.WriteLine(item);
}正規表現のオプション (RegexOptions)
Regex クラスの挙動をカスタマイズするために、RegexOptions 列挙型を指定できます。
- IgnoreCase: 大文字と小文字を区別せずに検索します。
- Multiline:
^と$の意味を変更し、各行の先頭と末尾にマッチさせます。 - Singleline: ドット
.が改行文字\nにもマッチするようになります。 - Compiled: 正規表現を MSIL にコンパイルします。起動時間は長くなりますが、実行速度が向上します。同じパターンを大量に繰り返す場合に有効です。
.NET 7 以降の新機能:GeneratedRegex
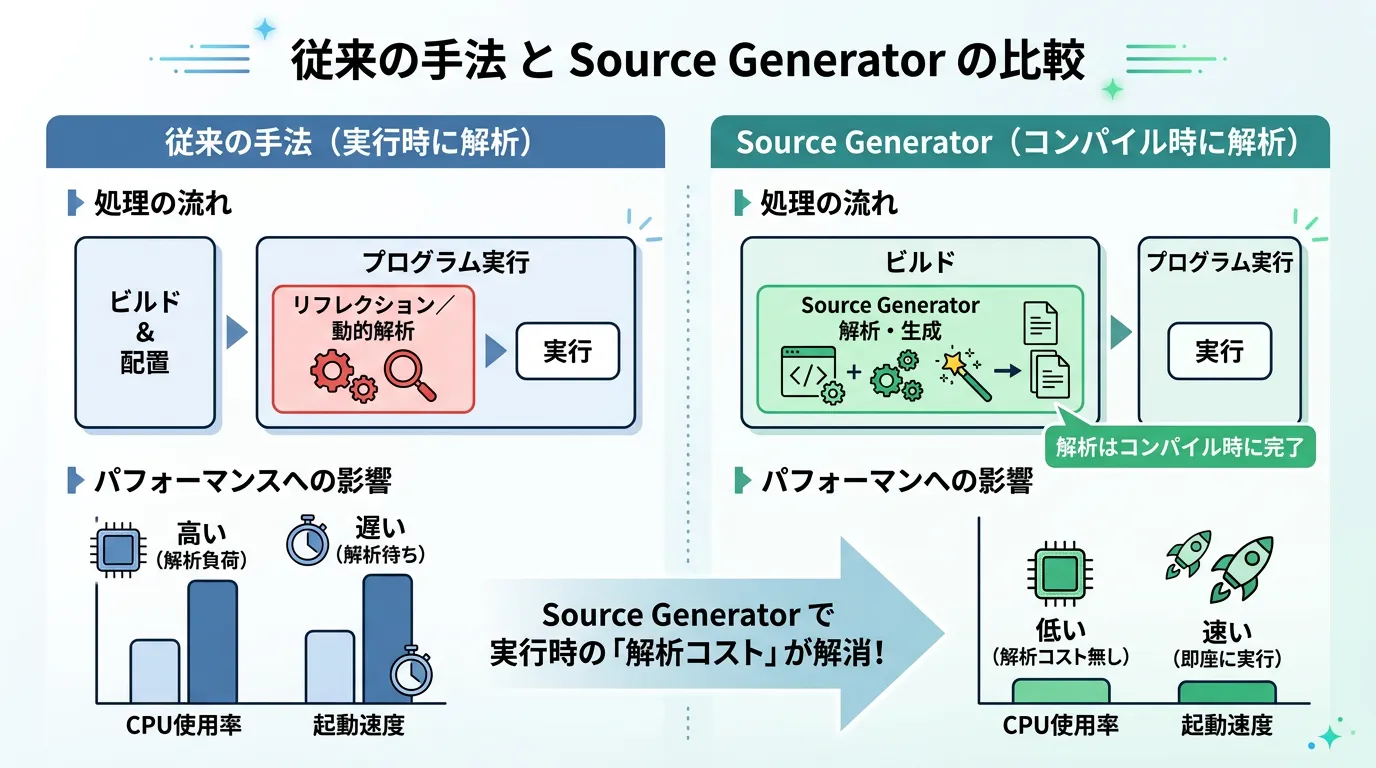
モダンな C# 開発(.NET 7 以降)において、パフォーマンスを追求するなら Source Generator を利用した正規表現が推奨されます。
これまでは実行時に正規表現を解析していましたが、[GeneratedRegex] 属性を使用すると、コンパイル時に正規表現を解析するコードを自動生成します。
これにより、実行時のオーバーヘッドがほぼゼロになり、パフォーマンスが劇的に向上します。
// パーシャルクラスにする必要がある
public partial class MyValidator
{
// コンパイル時に正規表現エンジンを生成
[GeneratedRegex(@"^\d{3}-\d{4}$", RegexOptions.IgnoreCase)]
private static partial Regex ZipCodeRegex();
public bool Validate(string zipCode)
{
return ZipCodeRegex().IsMatch(zipCode);
}
}この手法は、AOT (Ahead-Of-Time) コンパイル環境(クラウドネイティブなアプリやモバイルアプリなど)でも非常に有利に働きます。
パフォーマンスを最大化するためのヒント
正規表現は便利ですが、使い方を誤ると「バックトラッキング」という現象が発生し、CPUリソースを過剰に消費する原因(ReDoS攻撃の脆弱性など)になります。
1. タイムアウトを設定する
無限ループに近い状態を防ぐため、TimeSpan を指定してタイムアウトを設定することを強く推奨します。
var regex = new Regex(pattern, RegexOptions.None, TimeSpan.FromMilliseconds(100));2. 静的メソッド vs インスタンス
同じパターンを何度も使い回す場合は、インスタンスをキャッシュするか、前述の GeneratedRegex を使用してください。
単発の実行であれば、静的メソッド Regex.IsMatch() の方が内部キャッシュを利用するため効率的な場合があります。
3. 欲張りなマッチ (Greedy) と控えめなマッチ (Lazy)
デフォルトでは、量指定子( や +)は可能な限り長い文字列にマッチしようとします。
これを「欲張りなマッチ」と呼びます。
必要最小限の範囲にマッチさせたい場合は、? や +? のように、後ろに ? を付けることで「控えめなマッチ」に変更できます。
実践的なサンプル集
最後に、開発現場でよく使われる正規表現パターンの例を紹介します。
メールアドレスの簡易チェック
string emailPattern = @"^[^@\s]+@[^@\s]+\.[^@\s]+$";※完全な RFC 準拠の正規表現は非常に複雑になるため、実務ではこの程度の簡易チェックにとどめるか、専用のライブラリを使用するのが一般的です。
日付 (YYYY/MM/DD) の抽出
string datePattern = @"\b\d{4}/\d{1,2}/\d{1,2}\b";HTMLタグの除去
string html = "<p>Hello <b>World</b></p>";
string cleanText = Regex.Replace(html, "<.*?>", string.Empty);
// 結果: "Hello World"まとめ
C#の正規表現は、Regex クラスを中心に非常に強力な機能を備えています。
基本的な特殊文字や文字クラスをマスターするだけで、複雑な文字列操作を驚くほどシンプルに記述できるようになります。
重要なポイントを振り返りましょう。
- 特殊文字(メタ文字)を使いこなして柔軟なパターンを作る。
- 文字クラス(
\d,\wなど)で記述を簡略化する。 RegexOptionsやGeneratedRegexを活用してパフォーマンスを最適化する。- セキュリティと負荷対策のために、必ずタイムアウトを設定する。
正規表現は一度覚えると、C#に限らず多くのプログラミング言語やテキストエディタでも応用が効く「一生モノのスキル」です。
本記事を参考に、ぜひ日々のコーディングに取り入れてみてください。
