
C#を使用したテキスト処理において、正規表現は避けては通れない強力なツールです。
単に「特定の文字列が含まれているか」を判定するだけでなく、複雑なパターンから特定の情報を抜き出す際に真価を発揮するのが「グループ化」と「キャプチャ」の機能です。
正規表現を使いこなす上で、グループ化は最も重要なステップの一つと言えます。
本記事では、C#の System.Text.RegularExpressions 名前空間におけるグループ化の基本から、コードの可読性を飛躍的に高める「名前付きグループ」、そして最新のC#におけるパフォーマンス最適化までを徹底的に解説します。
正規表現におけるグループ化の基本概念
正規表現におけるグループ化とは、複数の文字やパターンを丸カッコ () で囲むことで、それらを一つの単位として扱う仕組みのことです。
これにより、繰り返し記号(量指定子)を適用したり、マッチした特定の部分だけを後から取り出したりすることが可能になります。
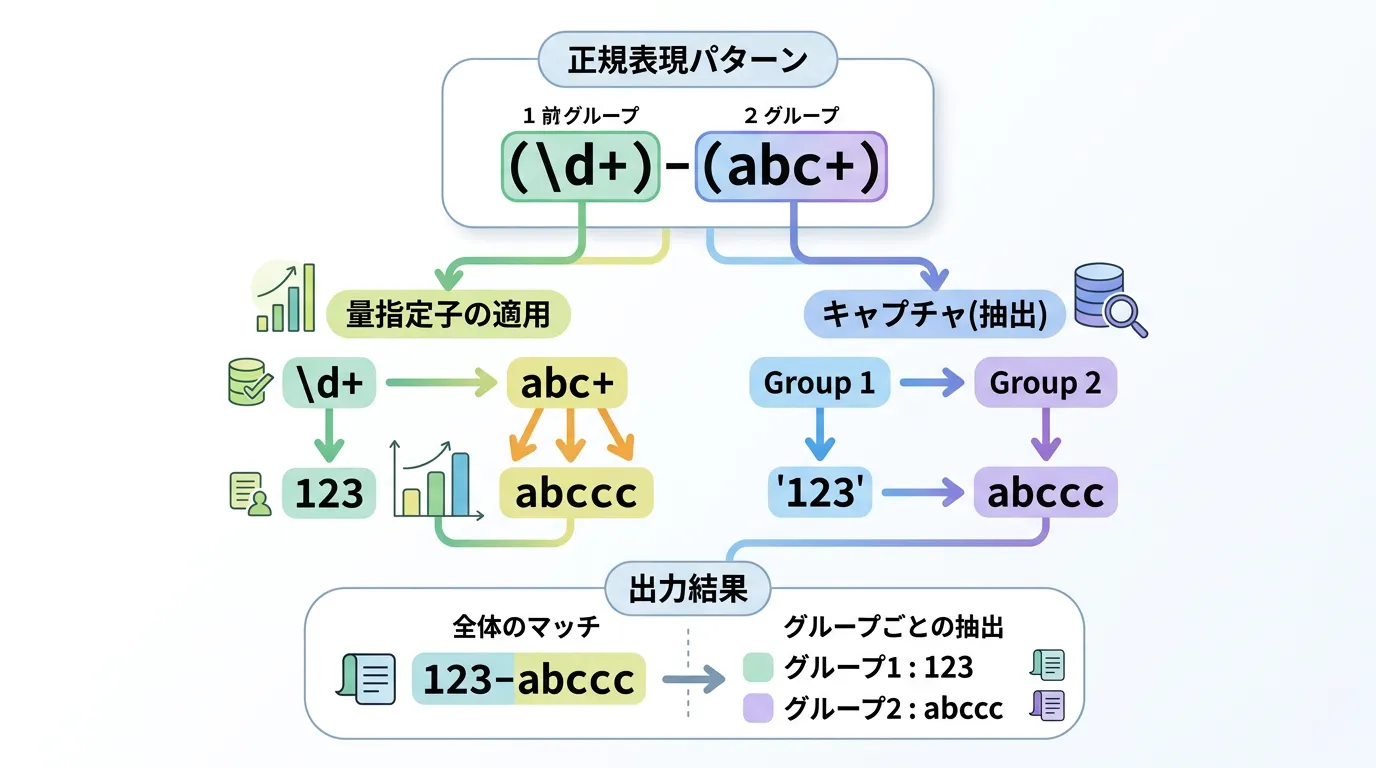
グループ化には主に2つの役割があります。
一つは、「パターンの構造化」です。
例えば (abc)+ と書けば、abc という文字列全体の繰り返しを表現できます。
もう一つは、本記事のメインテーマである「キャプチャ」です。
キャプチャとは、グループの中にマッチした文字列をメモリに保存し、後でプログラムから参照できるようにする機能を指します。
番号によるキャプチャの仕組み
C#で丸カッコ () を使用すると、自動的に「番号」が割り振られたグループとしてキャプチャされます。
これを番号付きグループと呼びます。
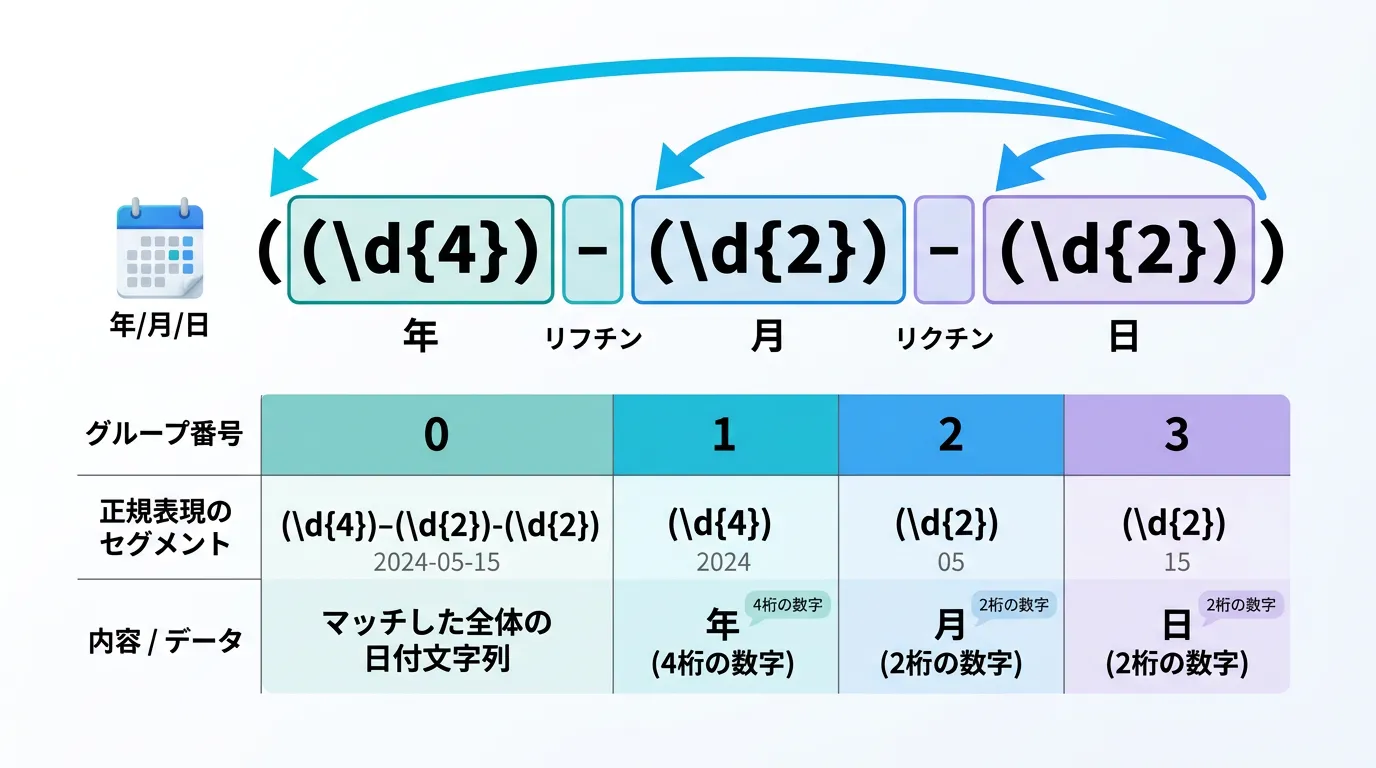
デフォルトでは、左側の開きカッコが現れる順番に従って、1, 2, 3… とインデックスが割り当てられます。
なお、0 番目のグループは常に「マッチした文字列全体」を指します。
番号付きグループを使用したコード例
以下は、日付の形式から年・月・日を抽出する基本的なコードです。
using System;
using System.Text.RegularExpressions;
public class Example
{
public static void Main()
{
string input = "本日の日付は 2026-01-16 です。";
string pattern = @"(\d{4})-(\d{2})-(\d{2})";
Match match = Regex.Match(input, pattern);
if (match.Success)
{
// Groups[0] はマッチした全体 ("2026-01-16")
// Groups[1] は第1グループ ("2026")
string year = match.Groups[1].Value;
string month = match.Groups[2].Value;
string day = match.Groups[3].Value;
Console.WriteLine($"年: {year}");
Console.WriteLine($"月: {month}");
Console.WriteLine($"日: {day}");
}
}
}この方法は手軽ですが、正規表現が複雑になりグループの数が増えると、「どの番号がどの項目を指しているのか」が分かりにくくなるという欠点があります。
また、パターンの途中に新しいグループを追加すると、それ以降のインデックス番号がずれてしまうため、メンテナンス性が低下します。
名前付きグループ(Named Captures)による可読性の向上
前述の番号による管理の問題を解決するのが、名前付きグループです。
グループに固有の名前を付けることで、コードからインデックス番号ではなく、名前(文字列)でキャプチャ内容にアクセスできるようになります。
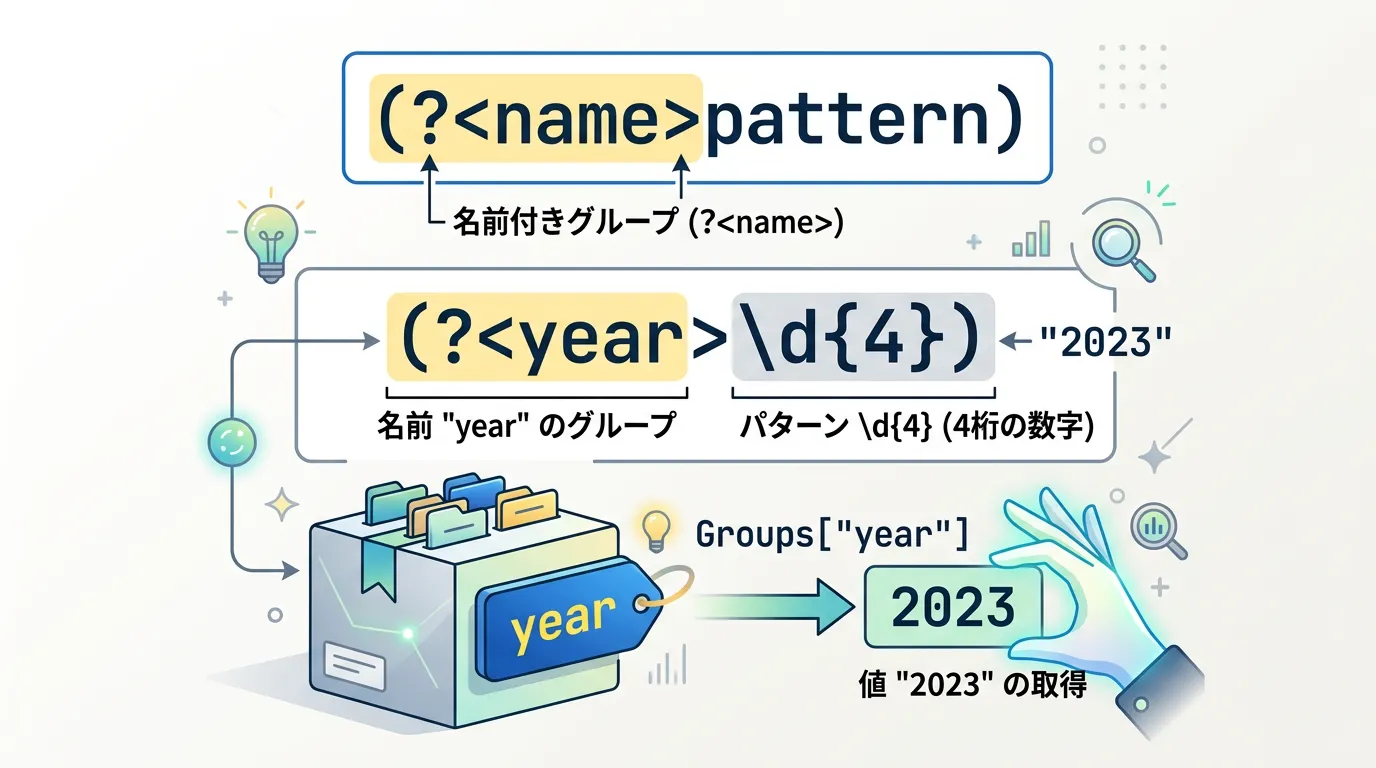
C#における名前付きグループの構文は (?<name>pattern) です。
名前付きグループの実装例
名前付きグループを使用すると、プログラムの意図が非常に明確になります。
using System;
using System.Text.RegularExpressions;
public class NamedGroupExample
{
public static void Main()
{
string input = "User: Tanaka, ID: 98765";
// 名前付きグループを使用して定義
string pattern = @"User: (?<userName>\w+), ID: (?<userId>\d+)";
Match match = Regex.Match(input, pattern);
if (match.Success)
{
// 名前でアクセスできるため、コードの意味が分かりやすい
string name = match.Groups["userName"].Value;
string id = match.Groups["userId"].Value;
Console.WriteLine($"ユーザー名: {name}");
Console.WriteLine($"ユーザーID: {id}");
}
}
}名前付きグループを利用するメリットは、単に読みやすいだけではありません。
正規表現のパターンを修正してグループの順番が変わったとしても、アクセスする際の名前が変わらなければC#側のコードを修正する必要がないという、保守上の大きな利点があります。
非キャプチャグループによる最適化
すべてのグループ化が「値の抽出」を目的としているわけではありません。
単に繰り返し単位を指定したいだけで、その内容を保存する必要がない場合は、非キャプチャグループを使用します。
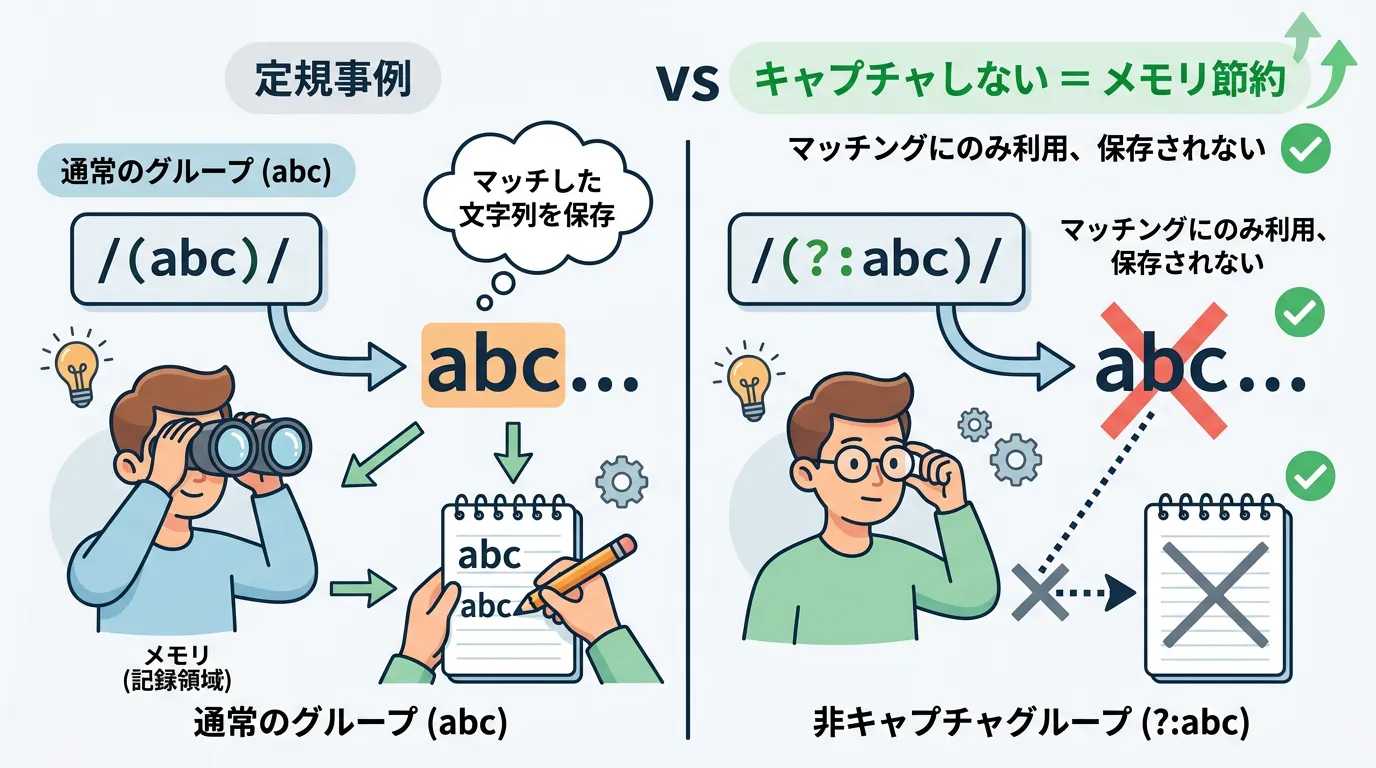
非キャプチャグループの構文は (?:pattern) です。
これを使用することで、正規表現エンジンはマッチした文字列を保持する手間を省けるため、実行速度の向上とメモリ消費の削減が期待できます。
非キャプチャグループの使いどころ
例えば、「http」または「https」のどちらかにはマッチさせたいが、その文字列自体を後で取り出す必要がない場合は、次のように記述します。
// (?: ) を使うことで、プロトコル部分はキャプチャされない
string pattern = @"(?:https?|ftp)://(?<domain>[a-zA-Z0-9.-]+)";大量のテキストを処理するアプリケーションや、高頻度で呼ばれるロジックでは、このわずかな差が累積的なパフォーマンスの差となります。
グループ化を利用した置換(Replacement)
キャプチャした内容は、Regex.Replace メソッド内でも活用できます。
これを利用すると、特定のパターンにマッチした文字列の構成を動的に入れ替えることが可能です。
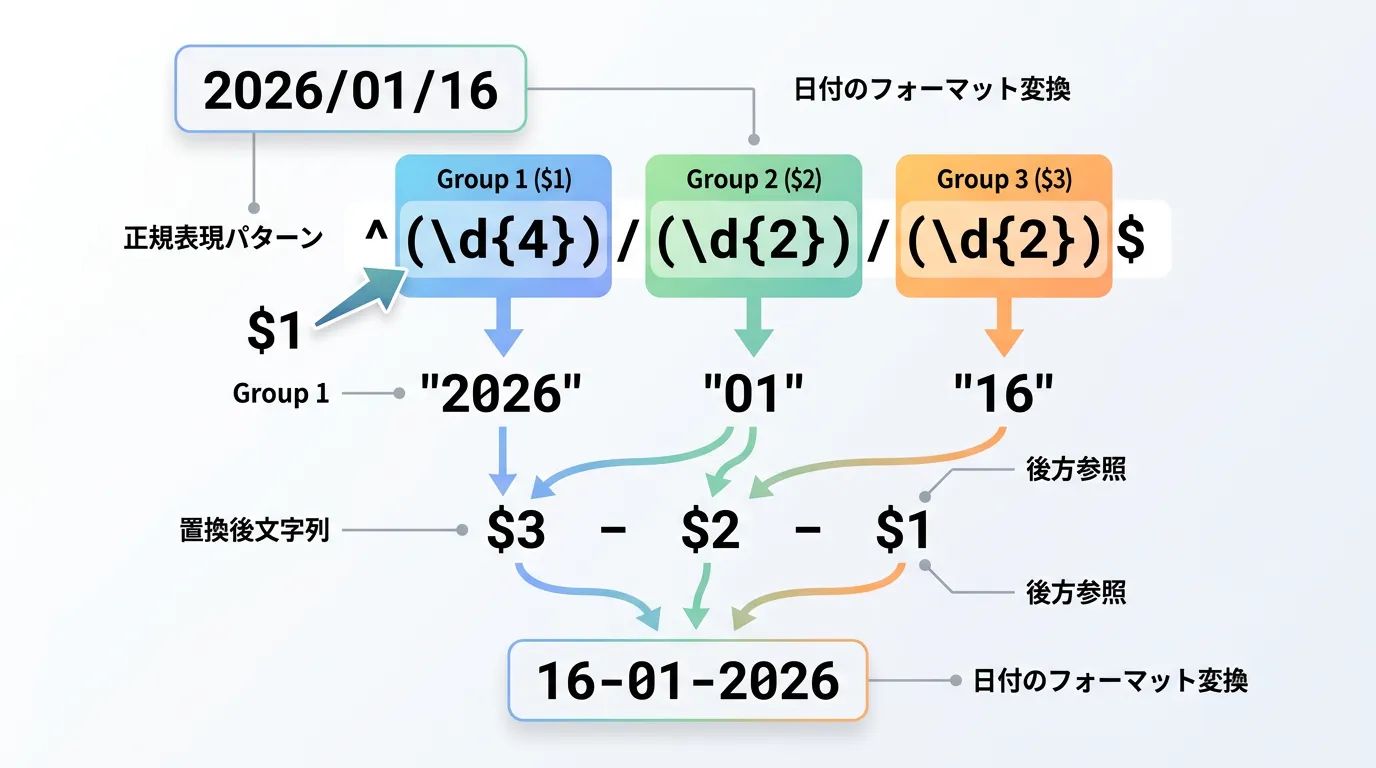
置換文字列内では、$1, $2 といった記法で番号付きグループを、${name} という記法で名前付きグループを参照できます。
string input = "2026/01/16";
// YYYY/MM/DD を DD-MM-YYYY に変換
string pattern = @"(?<year>\d{4})/(?<month>\d{2})/(?<day>\d{2})";
string replacement = "${day}-${month}-${year}";
string result = Regex.Replace(input, pattern, replacement);
Console.WriteLine(result); // 出力: 16-01-2026C# 独自の高度なグループ化機能
C#の正規表現エンジンは、他の言語と比較しても非常に高機能です。
その中でも、複雑なパターンの解析に役立つ特殊なグループ化機能を紹介します。
入れ子になったグループの解析
グループの中にさらにグループを作る「ネスト(入れ子)」も可能です。
この場合、番号は外側の左カッコから順番に割り振られます。
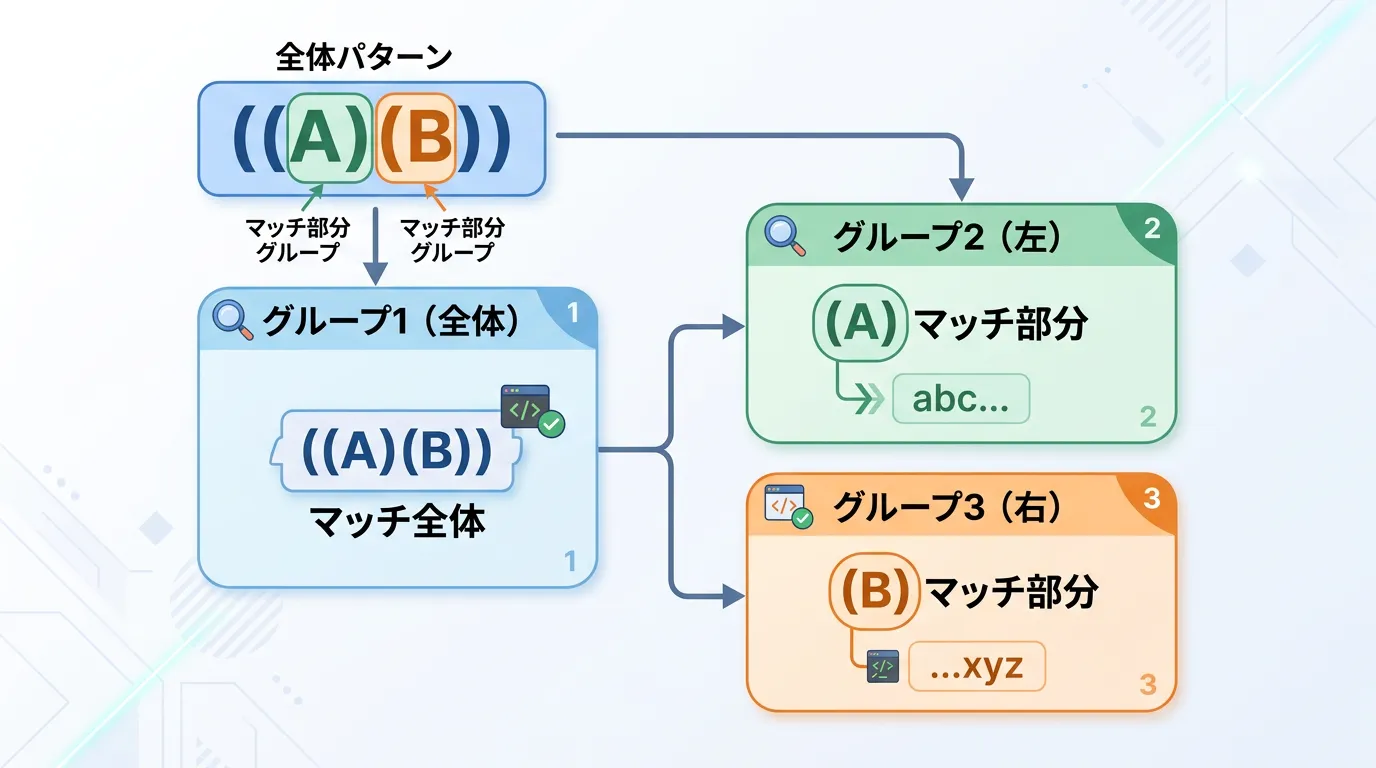
string input = "ABC";
string pattern = @"(A(B(C)))";
Match m = Regex.Match(input, pattern);
// Groups[1]: "ABC"
// Groups[2]: "BC"
// Groups[3]: "C"1つのグループに対する複数のキャプチャ
通常、1つのグループには1つの値が紐付くイメージですが、同じグループが量指定子によって複数回マッチした場合、その履歴がすべて保存されています。
これを取得するには match.Groups[n].Captures コレクションを参照します。
string input = "ID:10,ID:20,ID:30";
string pattern = @"(ID:(?<id>\d+),?)+";
Match match = Regex.Match(input, pattern);
foreach (Capture capture in match.Groups["id"].Captures)
{
Console.WriteLine($"抽出されたID: {capture.Value}");
}このように、Groups の下には Captures がぶら下がっており、マッチしたすべての履歴を遡れるのがC#の大きな特徴です。
パフォーマンスを最大化する:RegexSourceGenerator
現代のC#(特に .NET 7以降)では、正規表現のパフォーマンスを劇的に向上させる RegexSourceGenerator が導入されました。
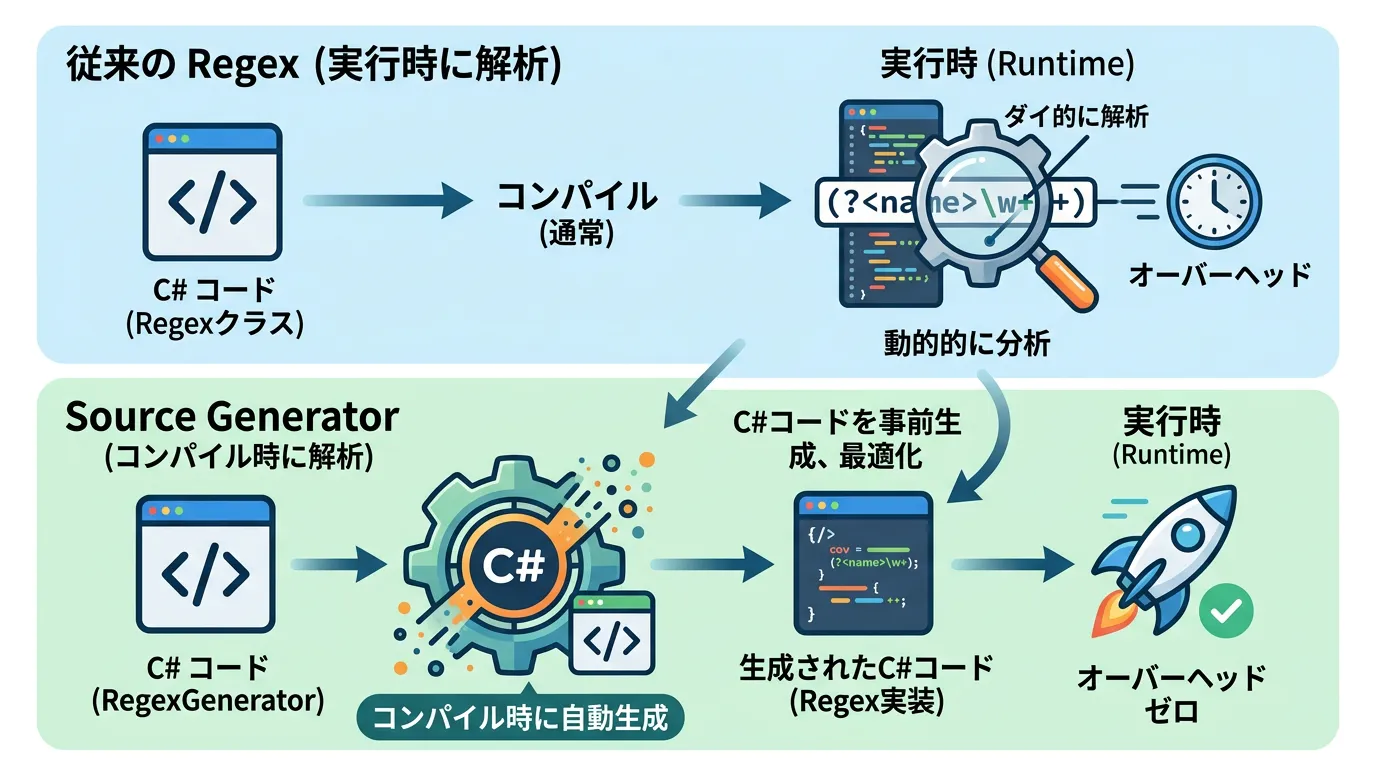
ソースジェネレーターを使用すると、実行時に正規表現のパターンを解析するのではなく、コンパイル時にそのパターン専用の高速な解析コードをC#として生成します。
// パーシャルメソッドに属性を付与する
[GeneratedRegex(@"(?<areaCode>\d{2,4})-(?<number>\d{4})")]
private static partial Regex PhoneNumberRegex();
public void Process(string input)
{
var match = PhoneNumberRegex().Match(input);
if (match.Success)
{
Console.WriteLine(match.Groups["areaCode"].Value);
}
}この方法を用いることで、グループ化やキャプチャを多用する複雑な正規表現であっても、ネイティブコードに近い速度で動作させることが可能になります。
正規表現グループ化のベストプラクティス
正規表現のグループ化を効果的に利用するためのポイントをまとめます。
| 項目 | 推奨されるアクション | 理由 |
|---|---|---|
| 名前付け | (?<name>...) を積極的に使う | コードの可読性と保守性が飛躍的に向上するため |
| 不要な保存の回避 | 抽出不要なグループには (?:...) を使う | メモリ消費を抑え、パフォーマンスを最適化するため |
| 事前コンパイル | GeneratedRegex または RegexOptions.Compiled を検討 | 繰り返し実行されるパターンの処理速度を上げるため |
| 範囲の明確化 | グループ内の境界を明確にする | 意図しない部分までキャプチャされる「欲張りなマッチ」を防ぐため |
特に、Webアプリケーションなどの高負荷な環境では、「キャプチャする必要がない場所で非キャプチャグループを使う」という習慣が、塵も積もれば山となる形でパフォーマンスに貢献します。
まとめ
C#における正規表現のグループ化とキャプチャは、単なる文字列検索を超えた「高度なデータ抽出」を可能にする強力な機能です。
丸カッコ () による基本的なグループ化から、コードの意図を明確にする名前付きグループ、そして効率的な実行を実現する非キャプチャグループまで、これらを適切に使い分けることで、より堅牢で効率的なプログラムを作成できます。
また、最新の .NET 環境では RegexSourceGenerator による最適化も利用可能です。
まずは身近な文字列処理から名前付きグループを取り入れ、保守性の高いきれいなコードを目指してみてください。
正規表現の真のパワーは、これらのグループ化をマスターした先にあります。
