
C#で正規表現を扱う際、検索したい文字列の中に * や ?、. といった記号が含まれていると、それらは「メタ文字」として解釈されてしまいます。
意図しないパターンマッチングを防ぎ、特定の文字列を 「リテラル(そのままの文字)」として安全に検索 するために不可欠なのが Regex.Escape メソッドです。
この記事では、Regex.Escapeの基本的な使い方から、実務で役立つ具体例、そしてセキュリティ対策としての側面までを詳しく解説します。
Regex.Escapeとは?
Regex.Escape は、System.Text.RegularExpressions 名前空間に属する静的メソッドです。
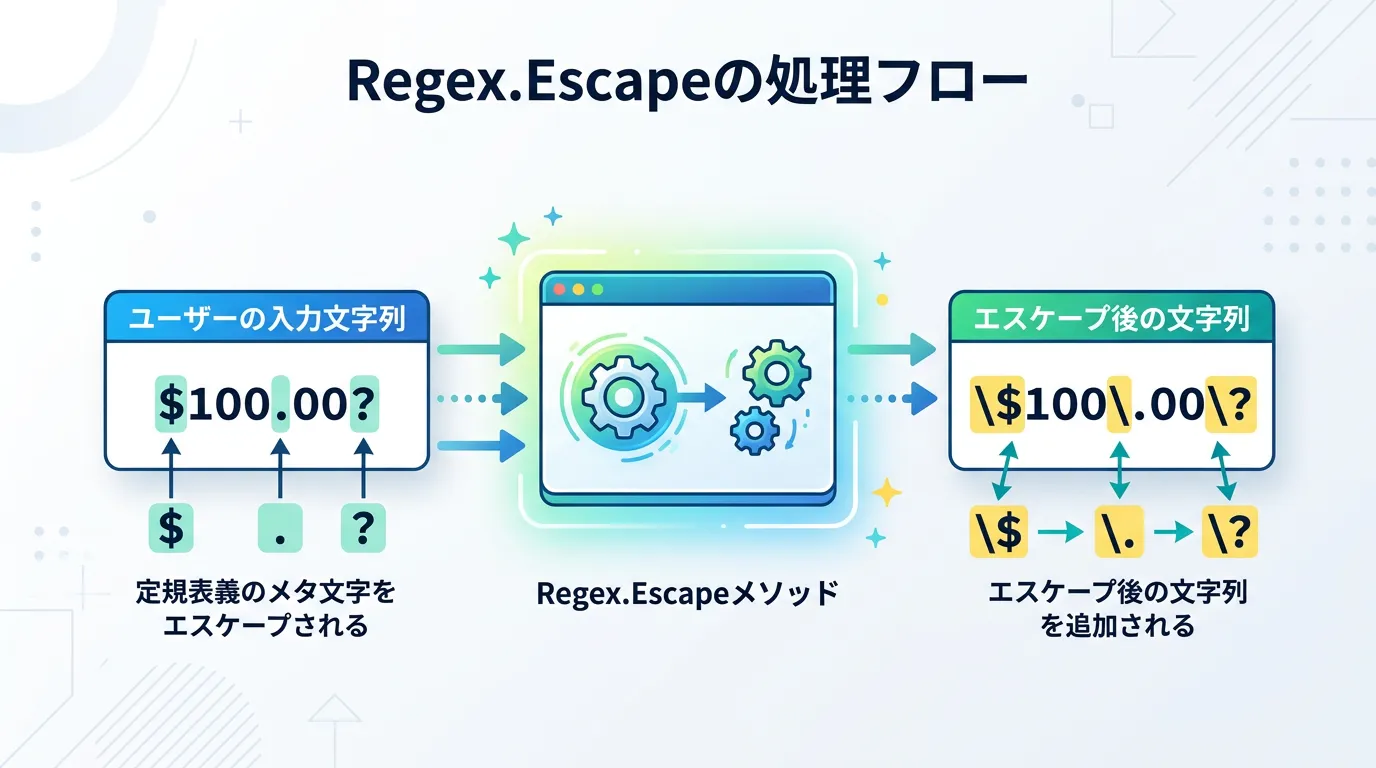
このメソッドの役割は非常にシンプルで、正規表現エンジンにおいて特別な意味を持つ文字を、その文字自体として解釈されるようにエスケープ処理すること です。
通常、正規表現で . は「任意の1文字」を意味しますが、Regex.Escape(".") を通すと . という文字列に変換されます。
これにより、正規表現エンジンはこれを「ただのドット」として認識するようになります。
なぜエスケープが必要なのか
プログラムの実行時にユーザーが入力したキーワードを検索条件にする場合、そのキーワードに何が含まれているかは予測できません。
例えば、ユーザーが C# (Basic) という文字列を検索しようとしたとき、そのまま正規表現のパターンに組み込むと、カッコ () が グループ化の記号 として扱われてしまい、構文エラーや意図しないマッチングを引き起こします。
このような 「動的に生成される検索パターン」の安全性を担保する ために、Regex.Escape が極めて重要な役割を果たします。
Regex.Escapeの基本的な使い方
Regex.Escape の使い方は非常に簡単です。
引数にエスケープしたい文字列を渡し、戻り値としてエスケープ済みの文字列を受け取ります。
サンプルコード:基本的な変換
using System;
using System.Text.RegularExpressions;
public class Program
{
public static void Main()
{
string original = "Hello. How much is (it)? $100*";
// 正規表現の特殊文字をエスケープ
string escaped = Regex.Escape(original);
Console.WriteLine("Original: " + original);
Console.WriteLine("Escaped: " + escaped);
}
}このコードを実行すると、出力は以下のようになります。
Original: Hello. How much is (it)? $100*
Escaped: Hello\. How much is \(it\)\? \$100\*ドット、カッコ、疑問符、ドル記号、アスタリスク の前にすべてバックスラッシュが挿入されていることがわかります。
これにより、この文字列をそのまま new Regex(escaped) のようにパターンとして使用しても、安全に完全一致検索を行うことができます。
エスケープ対象となる特殊文字一覧
Regex.Escape が変換対象とする文字は、正規表現エンジンで特別な意味を持つ文字群です。
具体的には以下の文字がエスケープされます。
| 文字 | 名称 | エスケープ後の例 |
|---|---|---|
\ | バックスラッシュ | \\ |
* | アスタリスク | \* |
+ | プラス | \+ |
? | クエスチョン | \? |
| | パイプ(垂直棒) | \| |
{ | 左中カッコ | \{ |
[ | 左大カッコ | \[ |
( | 左小カッコ | \( |
) | 右小カッコ | \) |
^ | キャレット | \^ |
$ | ドル | \$ |
. | ドット | \. |
# | シャープ | \# |
| (空白) | スペース | \ (特定の条件下) |
注意点として、Regex.Escape は すべての記号をエスケープするわけではありません。
例えば、シングルクォーテーションやダブルクォーテーション、カンマなどは、正規表現においてそれ自体が特別な意味を持たないため、エスケープされません。
実践的な活用シーン
ここでは、開発現場で Regex.Escape が実際にどのように使われるかを詳しく見ていきます。
1. ユーザー入力をキーワード検索に利用する
最も一般的なケースは、ユーザーがテキストボックスに入力した任意の文字列を、大きなテキストの中から検索する場合です。
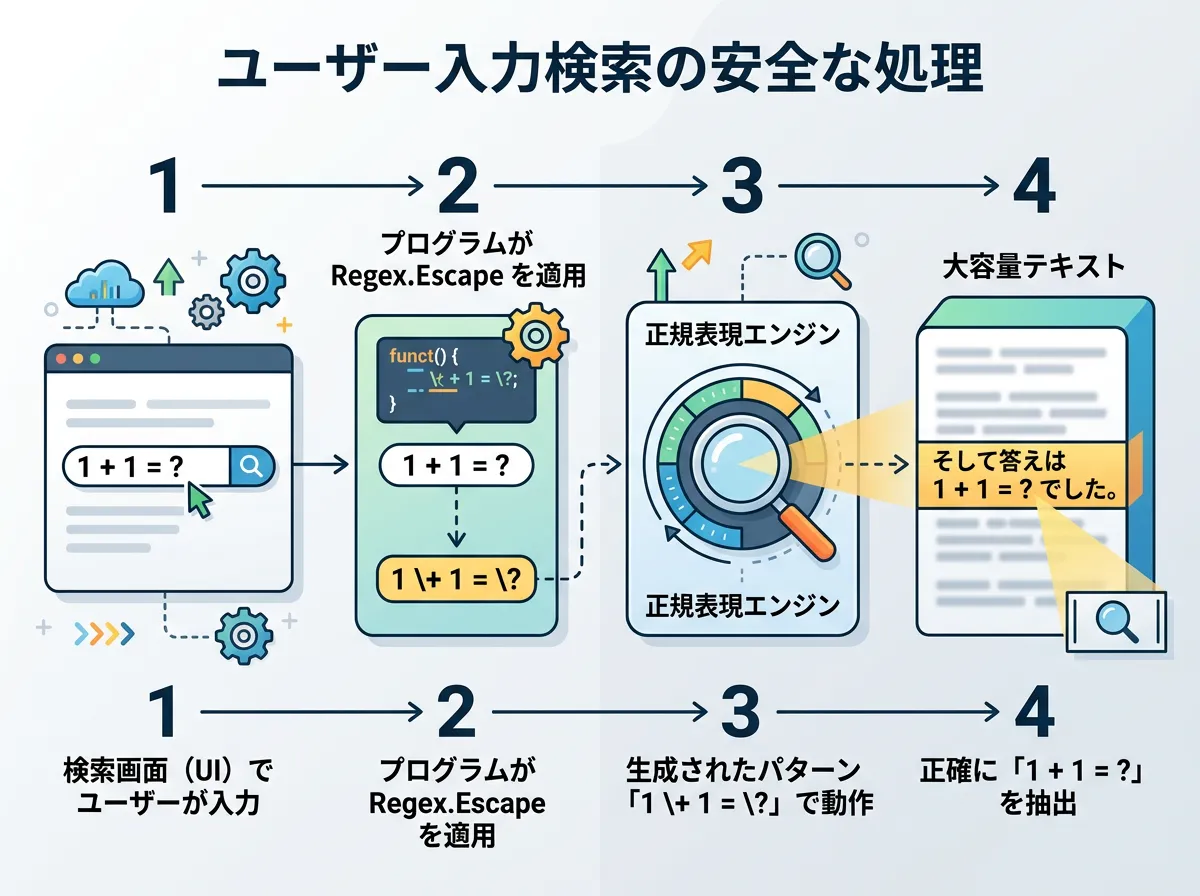
string userInput = "Contact (Support)?"; // ユーザーが入力したキーワード
string content = "Please Contact (Support)? or check the manual.";
// ユーザー入力をエスケープしてパターンを作成
string pattern = Regex.Escape(userInput);
// 検索実行
bool isMatch = Regex.IsMatch(content, pattern);
Console.WriteLine($"Pattern: {pattern}");
Console.WriteLine($"Is Match: {isMatch}");もし Regex.Escape を使わなかった場合、(Support)? の部分は「”Support” という文字列があってもなくても良い」というグループ化および量指定子として解釈されてしまい、期待した「カッコ付きの文字列」の検索ができなくなります。
2. ファイルパスやURLの動的なマッチング
ファイルパス(C:\Users\Documents)やURL(https://example.com/index.html?id=1)には、正規表現のメタ文字が多く含まれます。
これらを動的に組み合わせてパターンを作る際、手動でエスケープするのはミスのもとです。
string baseUrl = "https://example.com/search";
string query = "?q=c#&lang=jp";
// URL全体をリテラルとして扱いたい場合
string fullUrl = baseUrl + query;
string escapedPattern = "^" + Regex.Escape(fullUrl) + "$";
// ... ログデータなどの突き合わせに使用 ...3. 正規表現インジェクション攻撃の防止
セキュリティの観点からも Regex.Escape は重要です。
正規表現インジェクションとは、ユーザー入力をそのまま正規表現パターンとして使用することで、意図的に非常に重い処理(ReDoS: Regular Expression Denial of Service)を実行させたり、本来アクセスできない情報を抽出させたりする攻撃 です。
例えば、ユーザーが入力した文字列が .......*.* のようなものだった場合、これをそのまま正規表現エンジンに渡すと CPU 使用率が 100% に張り付いてしまう可能性があります。
Regex.Escape を通すことで、これらのメタ文字はすべて無効化され、安全な単なる文字列として処理されます。
逆操作:Regex.Unescapeについて
Regex.Escape と対になるメソッドに Regex.Unescape があります。
これは、エスケープされた文字列を元の形に戻すためのものです。
Unescapeの使用例
string escaped = @"\(Hello\)\?";
string unescaped = Regex.Unescape(escaped);
Console.WriteLine(unescaped); // 出力: (Hello)?Regex.Unescape は、単にバックスラッシュを取り除くだけでなく、\n (改行) や \t (タブ) といった エスケープシーケンスを実際の制御文字に変換する 機能も持っています。
設定ファイルや外部のテキストから正規表現パターンを読み込む際に、バックスラッシュが含まれている場合に重宝します。
パフォーマンスと注意点
Regex.Escape を使用する際のパフォーマンス面での留意点についても触れておきます。
高頻度な呼び出しへの対策
非常に大量のループ内で Regex.Escape を呼び出し、その結果を元に毎回 new Regex(pattern) を行うと、正規表現パターンの解析コストが積み重なり、パフォーマンスが低下します。
対策として、以下の検討を推奨します。
- パターンの再利用
同じキーワードを何度も検索する場合は、エスケープ済みのパターンを一度だけ作成し、
Regexインスタンスをキャッシュする。- 静的メソッドの利用
Regex.IsMatchなどの静的メソッドは、内部でパターンのキャッシュを保持しているため、単純な用途ではこちらの方が効率的な場合があります。
ソース生成正規表現(Source Generator)との関係
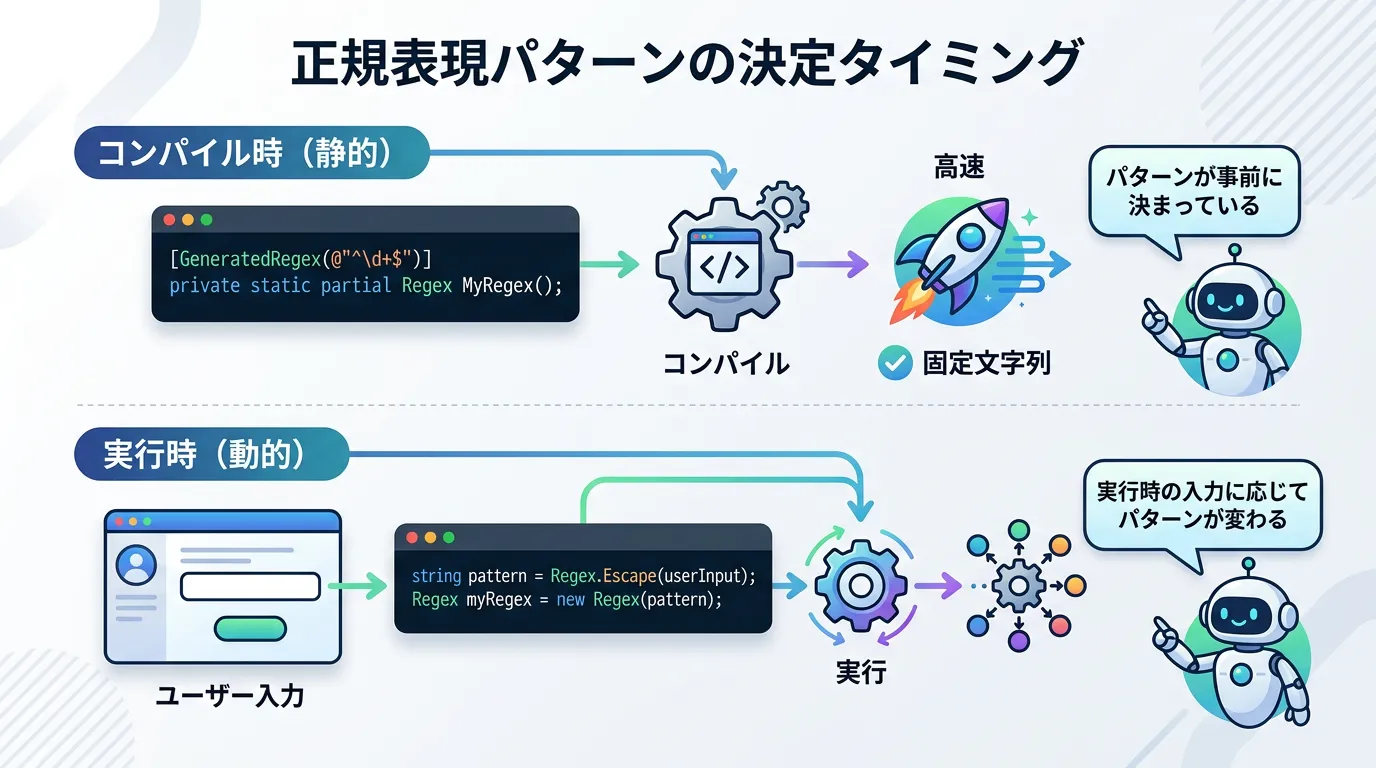
.NET 7 以降では、コンパイル時に正規表現を解析してコードを自動生成する GeneratedRegex が導入されました。
しかし、GeneratedRegex は コンパイル時にパターンが確定している必要がある ため、実行時にユーザー入力を Regex.Escape して作るパターンには適用できません。
実行時に決まるパターンについては、引き続き従来の Regex クラスと Regex.Escape を組み合わせて使用します。
まとめ
C# で正規表現を扱う際、Regex.Escape は「文字列の安全性を守るガードマン」のような存在です。
- ユーザー入力を正規表現パターンに組み込むときは、必ず Regex.Escape を使用する。
- メタ文字をリテラルとして扱うことで、意図しない挙動や例外を防ぐことができる。
- 正規表現インジェクション(ReDoS)などのセキュリティリスクを低減できる。
- 逆の操作が必要な場合は Regex.Unescape を利用する。
正規表現は非常に強力なツールですが、そのパワーゆえに扱いを誤るとバグの温床になります。
Regex.Escape を適切に活用して、堅牢で安全な C# プログラミングを実践しましょう。
