
C#を用いたアプリケーション開発において、特定の文字列パターンを検索し、その中から必要な部分だけを取り出す「文字列抽出」は非常に頻繁に発生するタスクです。
ログファイルの解析、ユーザー入力のバリデーション、スクレイピングデータの整形など、その用途は多岐にわたります。
こうした処理を効率的かつ正確に行うための強力なツールが、System.Text.RegularExpressions 名前空間に用意されている Regex クラスです。
特に Regex.Match メソッドは、文字列の中から特定のパターンに一致する最初の箇所を特定し、詳細な情報を取得するために欠かせません。
本記事では、C#における正規表現の基本から、Regex.Match を使った具体的な抽出手法、さらにはグループ化(Grouping)を活用した高度なテクニックまで、エンジニアが実務で即座に活用できる知識を網羅的に解説します。
Regex.Match の基本概念と使い方
C#で正規表現を扱う際、最も基本的なメソッドの一つが Regex.Match です。
このメソッドは、指定した入力文字列の中から正規表現パターンに一致する 最初の箇所 を探し出し、その結果を Match オブジェクトとして返します。
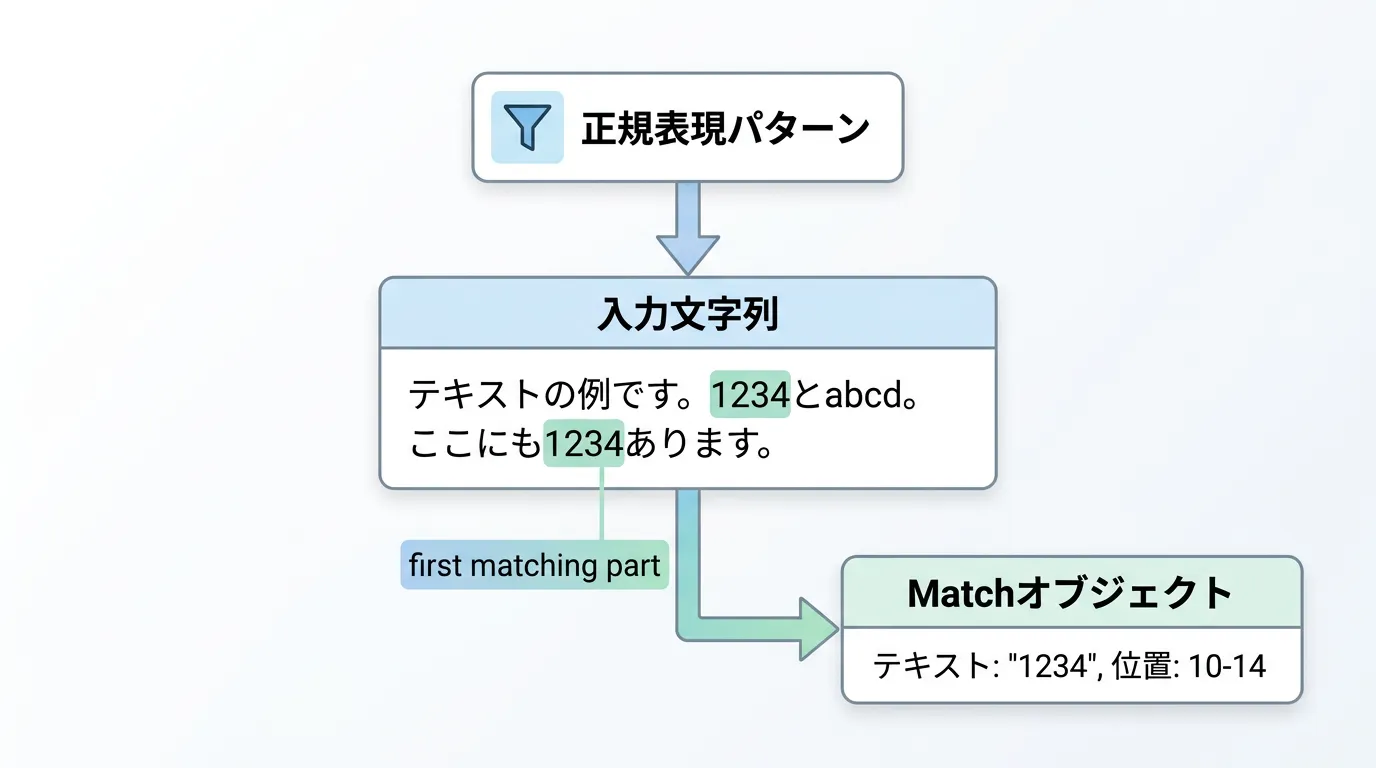
Regex.Match には、静的メソッドとして呼び出す方法と、Regex クラスのインスタンスを生成して呼び出す方法の2種類があります。
静的メソッドによる実行
静的メソッドは、特定のパターンを一度だけ使用する場合に便利です。
using System;
using System.Text.RegularExpressions;
string input = "今日の気温は25度です。";
string pattern = @"\d+"; // 1個以上の数字にマッチ
Match match = Regex.Match(input, pattern);
if (match.Success)
{
Console.WriteLine($"抽出結果: {match.Value}"); // 出力: 25
}インスタンスメソッドによる実行
同じパターンを繰り返し利用する場合は、Regex オブジェクトをインスタンス化することで、内部的なパターンのコンパイルが最適化され、パフォーマンスが向上します。
var regex = new Regex(@"\d+");
Match match = regex.Match("価格は1280円です。");
if (match.Success)
{
Console.WriteLine(match.Value); // 出力: 1280
}Match オブジェクトの主要なプロパティ
Regex.Match の戻り値である Match オブジェクトには、抽出した文字列以外にも多くの有益な情報が含まれています。
| プロパティ名 | 型 | 説明 |
|---|---|---|
Success | bool | パターンに一致した箇所が見つかったかどうかを返します。 |
Value | string | 一致した文字列そのものを返します。 |
Index | int | 元の文字列内における一致箇所の開始位置 (0から開始) を返します。 |
Length | int | 一致した文字列の長さを返します。 |
Groups | GroupCollection | グループ化によって分割された要素のコレクションを返します。 |
一致しなかった場合、match.Success は false になり、match.Value は空文字列を返します。
そのため、必ず Success プロパティでチェックを行うのが安全なコーディングの鉄則です。
グループ化(Groups)による特定箇所の抽出
正規表現の真価は、単にパターン全体にマッチさせるだけでなく、「パターンの一部だけを取り出す」ことにあります。
これを実現するのが「グループ化(Capturing Groups)」です。
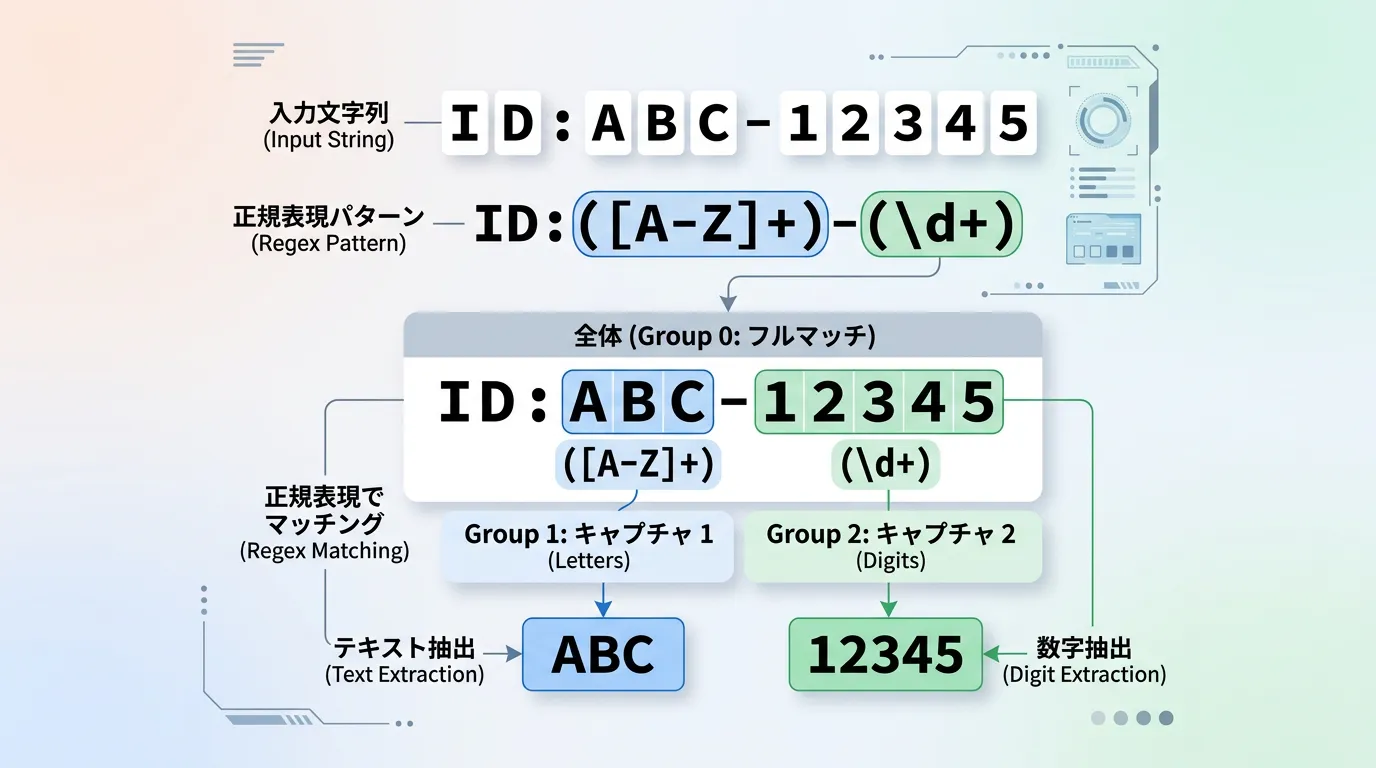
正規表現内で () を使用すると、その部分はグループとしてキャプチャされます。
インデックスによるグループ参照
デフォルトでは、グループには左から順に 1, 2, 3… とインデックスが割り振られます。
なお、Groups[0] には常にマッチした全体文字列が格納されます。
string input = "2024-05-20";
string pattern = @"(\d{4})-(\d{2})-(\d{2})";
Match match = Regex.Match(input, pattern);
if (match.Success)
{
string year = match.Groups[1].Value; // 2024
string month = match.Groups[2].Value; // 05
string day = match.Groups[3].Value; // 20
Console.WriteLine($"{year}年{month}月{day}日");
}名前付きグループ(Named Groups)
インデックスによる参照は、正規表現が複雑になると「何番目がどのデータか」が分かりにくくなり、保守性が低下します。
そこで推奨されるのが、名前付きグループです。
構文: (?<name>pattern)
string input = "ユーザー名: taro_tanaka, 年齢: 28";
string pattern = @"ユーザー名: (?<userName>\w+), 年齢: (?<age>\d+)";
Match match = Regex.Match(input, pattern);
if (match.Success)
{
// 名前でアクセスできるため可読性が高い
string name = match.Groups["userName"].Value;
string age = match.Groups["age"].Value;
Console.WriteLine($"Name: {name}, Age: {age}");
}Regex.Match と Regex.Matches の違い
「文字列の中に該当箇所が複数ある場合」の挙動に注意が必要です。
Regex.Match は最初に見つかった1件しか返しません。
すべての該当箇所を抽出したい場合は、Regex.Matches メソッドを使用します。
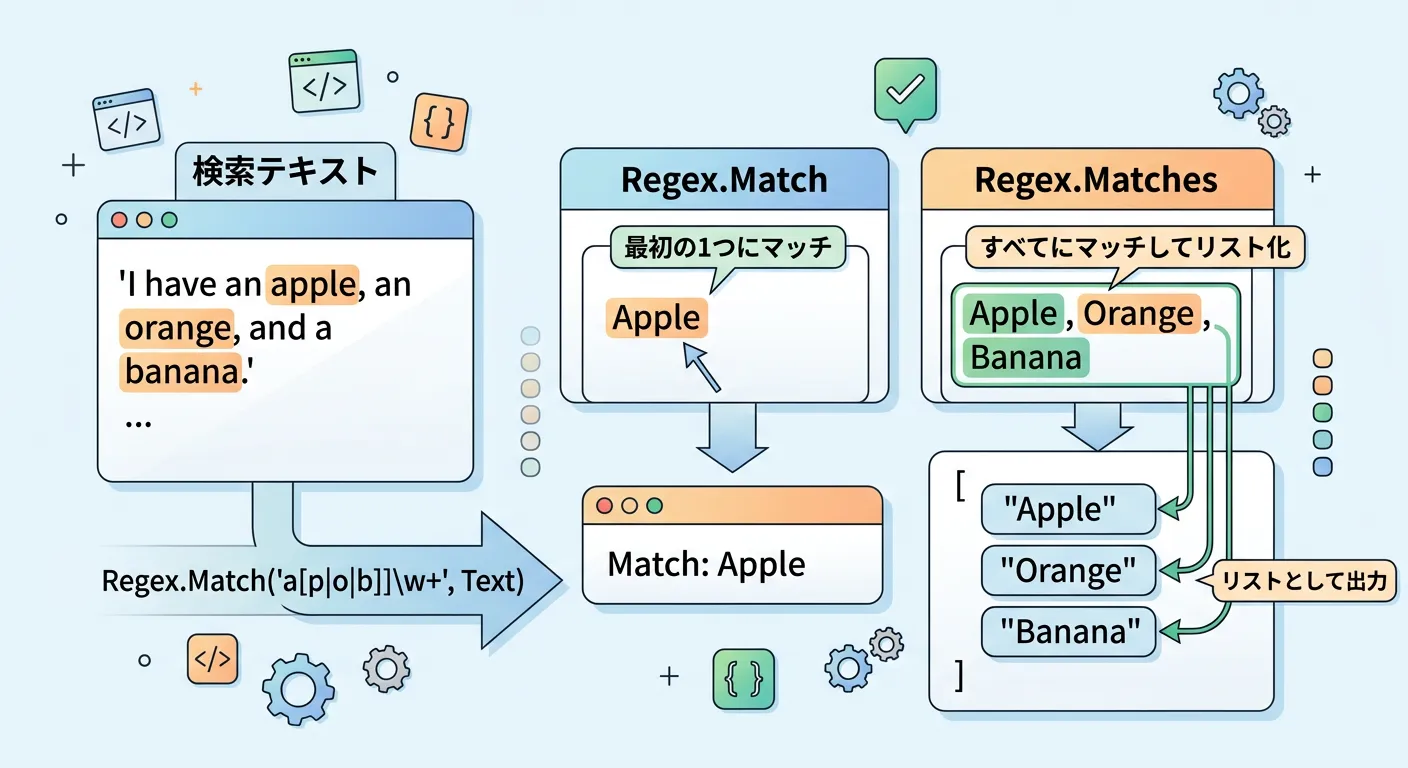
string input = "apple, orange, banana, apple";
string pattern = "apple";
// Matchの場合:最初の1つだけ
Match singleMatch = Regex.Match(input, pattern);
// Matchesの場合:すべて取得
MatchCollection matches = Regex.Matches(input, pattern);
foreach (Match m in matches)
{
Console.WriteLine($"見つかった項目: {m.Value} (位置: {m.Index})");
}大量のデータを扱う場合、MatchCollection をループで回す処理は非常によく使われるパターンです。
実践的な抽出シナリオ
ここでは、実務でよく遭遇する具体的な抽出パターンをいくつか紹介します。
URLからドメイン名を抽出する
複雑なURLの中から特定のホスト名だけを取り出します。
string url = "https://example.com/products/index.html";
string pattern = @"https?://(?<domain>[^/]+)";
Match match = Regex.Match(url, pattern);
if (match.Success)
{
Console.WriteLine($"ドメイン: {match.Groups["domain"].Value}");
}HTMLタグ内のテキストを抽出する
特定のタグに囲まれた中身だけを抽出します。
string html = "<h1>タイトルはこちら</h1>";
string pattern = @"<h1>(?<content>.*?)</h1>";
Match match = Regex.Match(html, pattern);
if (match.Success)
{
Console.WriteLine($"コンテンツ: {match.Groups["content"].Value}");
}※ HTMLの解析には本来 HtmlAgilityPack などの専用ライブラリが推奨されますが、単純な構造であれば正規表現でも対応可能です。
パフォーマンスを最大化する「Source Generator」
最新の C# (.NET 7以降) では、正規表現のパフォーマンスを劇的に向上させる Regex Source Generator が導入されています。
従来の実行時コンパイルではなく、コンパイル時に正規表現の解析コードを生成するため、実行時の負荷が大幅に軽減されます。
using System.Text.RegularExpressions;
public partial class DataParser
{
// 生成用の属性を付与したパーシャルメソッドを定義
[GeneratedRegex(@"\d{3}-\d{4}")]
private static partial Regex ZipCodeRegex();
public void Parse(string input)
{
Match match = ZipCodeRegex().Match(input);
if (match.Success)
{
Console.WriteLine($"郵便番号: {match.Value}");
}
}
}大規模なアプリケーションや、高頻度で実行されるループ内での正規表現処理には、この [GeneratedRegex] の使用を強く検討すべきです。
注意点とベストプラクティス
正規表現は強力ですが、誤った使い方をするとバグやパフォーマンス劣化の原因となります。
以下のポイントに注意しましょう。
- Success プロパティの確認
マッチしなかった場合に Groups[1].Value などにアクセスしても例外は発生しませんが、意図しない空文字処理が進んでしまうのを防ぐため、必ず if (match.Success) で囲みます。
- タイムアウトの設定
悪意のある入力(ReDoS攻撃)によって正規表現の処理が無限ループに近い状態になるのを防ぐため、MatchTimeout を設定することが推奨されます。
- 非キャプチャグループの使用
グループ化はしたいが抽出(保持)する必要がない場合は、(?:pattern) を使用することでメモリ消費を抑えられます。
- コンパイルオプション
Source Generator を使わない古い環境では、頻繁に使う Regex インスタンスに RegexOptions.Compiled を指定することを検討してください。
まとめ
C# の Regex.Match は、文字列抽出における中心的な役割を担うメソッドです。
単にパターンに一致するかを調べるだけでなく、グループ化(Groups)や名前付きグループを駆使することで、複雑なデータ構造から必要な情報だけをスマートに取り出すことができます。
また、最新の .NET 環境では GeneratedRegex による高速化も可能になっており、正規表現の柔軟性とパフォーマンスを両立させることが容易になりました。
文字列操作は、コードの品質と保守性に直結する部分です。
今回解説したテクニックを活用し、正規表現を「単なる文字列検索」から「高度なデータ抽出ツール」へと昇華させていきましょう。
さらに詳しく学びたい場合は、Microsoft Learn の正規表現ガイド を参照することをお勧めします。
