
C#を用いたアプリケーション開発において、文字列の検索や抽出、バリデーション(妥当性確認)は避けては通れないタスクです。
その中でも「正規表現(Regular Expression)」は、特定のパターンを持つ文字列を効率的に扱うための非常に強力なツールです。
C#では「Regex」クラスを中心に正規表現が実装されており、単純な文字列一致だけでなく、複雑な条件指定や置換処理を驚くほど簡潔に記述できます。
本記事では、C#における正規表現の基礎から、実戦で役立つ便利な使い方、そして最新の.NET環境におけるパフォーマンス最適化までを徹底的に解説します。
正規表現の基本概念とメタ文字の役割
正規表現とは、文字列の集合を一つのパターンで表現する記法のことです。
例えば「数字3桁-数字4桁」というパターンを定義することで、電話番号や郵便番号などの特定の形式を瞬時に見つけ出すことができます。
C#で正規表現を使いこなす第一歩は、「メタ文字」と呼ばれる特殊な記号の役割を理解することにあります。
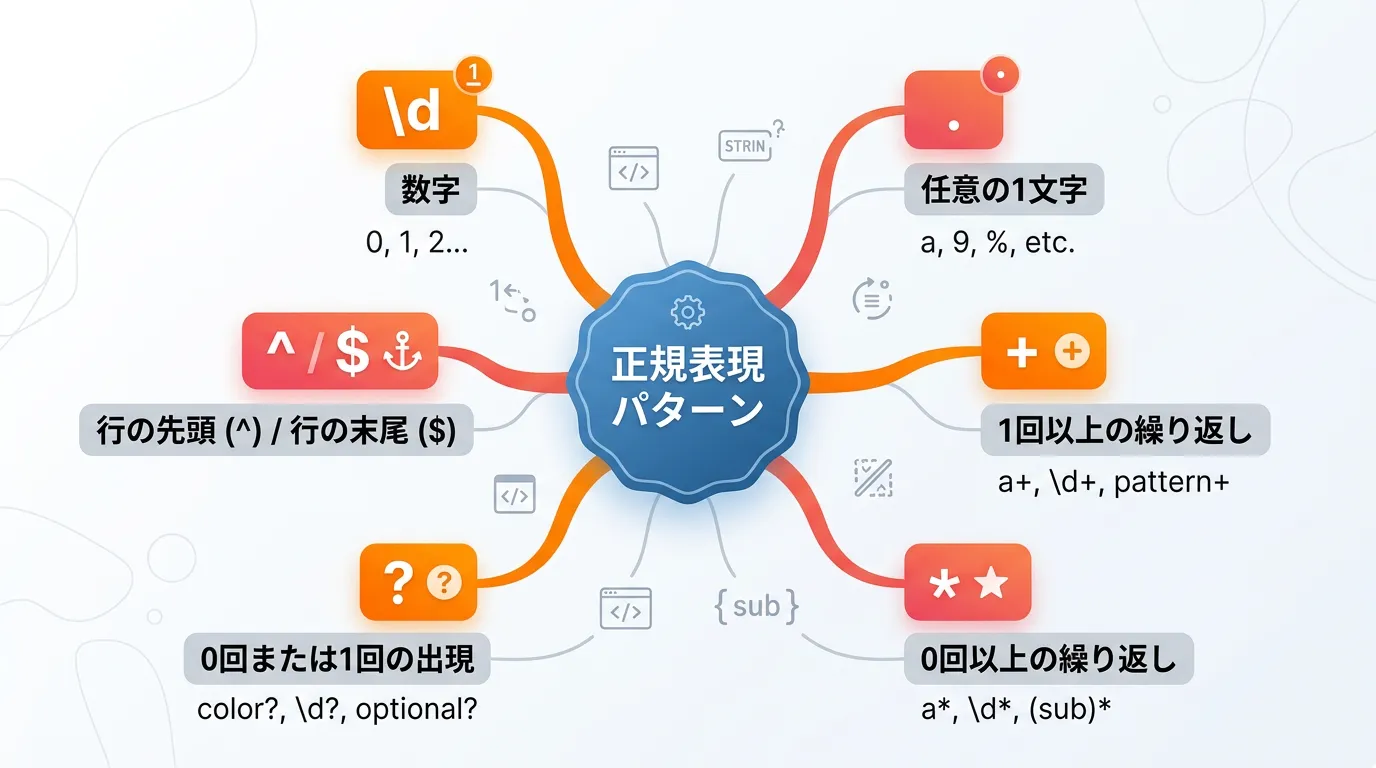
メタ文字は、正規表現において「文字そのもの」ではなく「特定の意味を持つ記号」として機能します。
C#の System.Text.RegularExpressions 名前空間で利用される主なメタ文字を以下の表にまとめました。
| メタ文字 | 意味 | 使用例 |
|---|---|---|
. | 任意の1文字(改行を除く) | a.c は “abc”, “axc” などに一致 |
\d | 任意の数字(0-9) | \d{3} は “123”, “999” などに一致 |
\w | 英数字およびアンダースコア | \w+ は単語全体に一致 |
\s | 空白文字(スペース、タブ、改行) | \s+ は連続する空白に一致 |
^ | 行の先頭 | ^Hello は “Hello world” に一致 |
$ | 行の末尾 | End$ は “The End” に一致 |
* | 直前の文字の0回以上の繰り返し | ab* は “a”, “ab”, “abbb” に一致 |
+ | 直前の文字の1回以上の繰り返し | ab+ は “ab”, “abbb” に一致(”a”は不可) |
? | 直前の文字の0回または1回のみ出現 | ab? は “a”, “ab” に一致 |
[ ] | カッコ内のいずれかの文字 | [aeiou] は母音のいずれかに一致 |
これらのメタ文字を組み合わせることで、複雑な条件を作成します。
例えば、日本の郵便番号(3桁の数字、ハイフン、4桁の数字)を表現する場合、^\d{3}-\d{4}$ というパターンになります。
ここで、C#特有の注意点として、文字列リテラル内でバックスラッシュ(\)を使用する際は、逐語的文字列リテラル(@””)を使用するのが一般的です。
例えば @"\d{3}" と書くことで、エスケープシーケンスの重複を避けることができます。
C# Regexクラスの主要メソッドと使い方
C#で正規表現を扱う中心的な存在が System.Text.RegularExpressions.Regex クラスです。
このクラスには、用途に応じた複数の静的メソッドおよびインスタンスメソッドが用意されています。
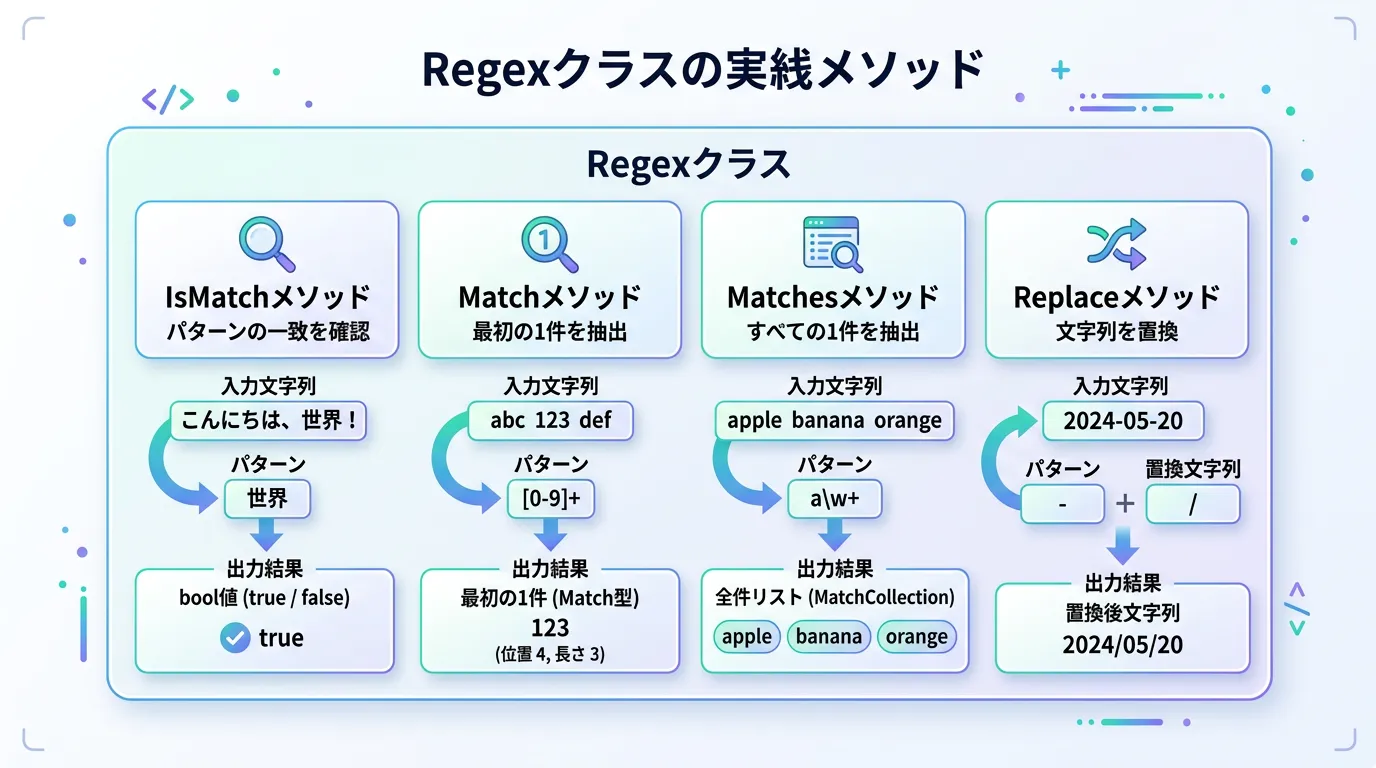
1. 文字列のパターン検証:IsMatch
最も頻繁に使われるのが、入力された文字列が特定のパターンに一致するかどうかを判定する IsMatch メソッドです。
ユーザー登録フォームでのメールアドレス形式チェックや、パスワードの強度チェックなどに利用されます。
using System.Text.RegularExpressions;
string input = "sample@example.com";
string pattern = @"^[^@\s]+@[^@\s]+\.[^@\s]+$";
if (Regex.IsMatch(input, pattern))
{
Console.WriteLine("有効なメールアドレス形式です。");
}IsMatchメソッドは真偽値(bool)を返すため、if文の条件式に直接組み込むことができ、コードの可読性を高めます。
2. 特定の部分を抽出する:Match と Matches
文字列の中から特定のパターンに一致する箇所を取り出したい場合は、Match または Matches を使用します。
- Match:最初に見つかった1件のみを返します。
- Matches:一致するすべての箇所をコレクションとして返します。
string text = "価格は 1500円、送料は 500円です。";
string pattern = @"\d+";
// 最初の数字だけを取得
Match match = Regex.Match(text, pattern);
if (match.Success)
{
Console.WriteLine($"最初の数字: {match.Value}"); // 1500
}
// すべての数字を取得
MatchCollection matches = Regex.Matches(text, pattern);
foreach (Match m in matches)
{
Console.WriteLine($"見つかった数字: {m.Value}");
}3. 文字列を置換・整形する:Replace
特定のパターンに合致する部分を別の文字列に置き換えるには Replace メソッドが適しています。
例えば、電話番号のハイフンを取り除いたり、ログファイル内の機密情報をマスクしたりする際に重宝します。
string phoneNumber = "090-1234-5678";
string pattern = @"-";
string result = Regex.Replace(phoneNumber, pattern, "");
Console.WriteLine(result); // 09012345678パフォーマンスを最大化する:静的メソッド・インスタンス・ソース生成
C#で正規表現を使用する際、開発者が直面する課題の一つが「実行速度」です。
正規表現のパターン解析はコストが高い処理であるため、呼び出し方によってアプリケーションのパフォーマンスに大きな差が出ます。
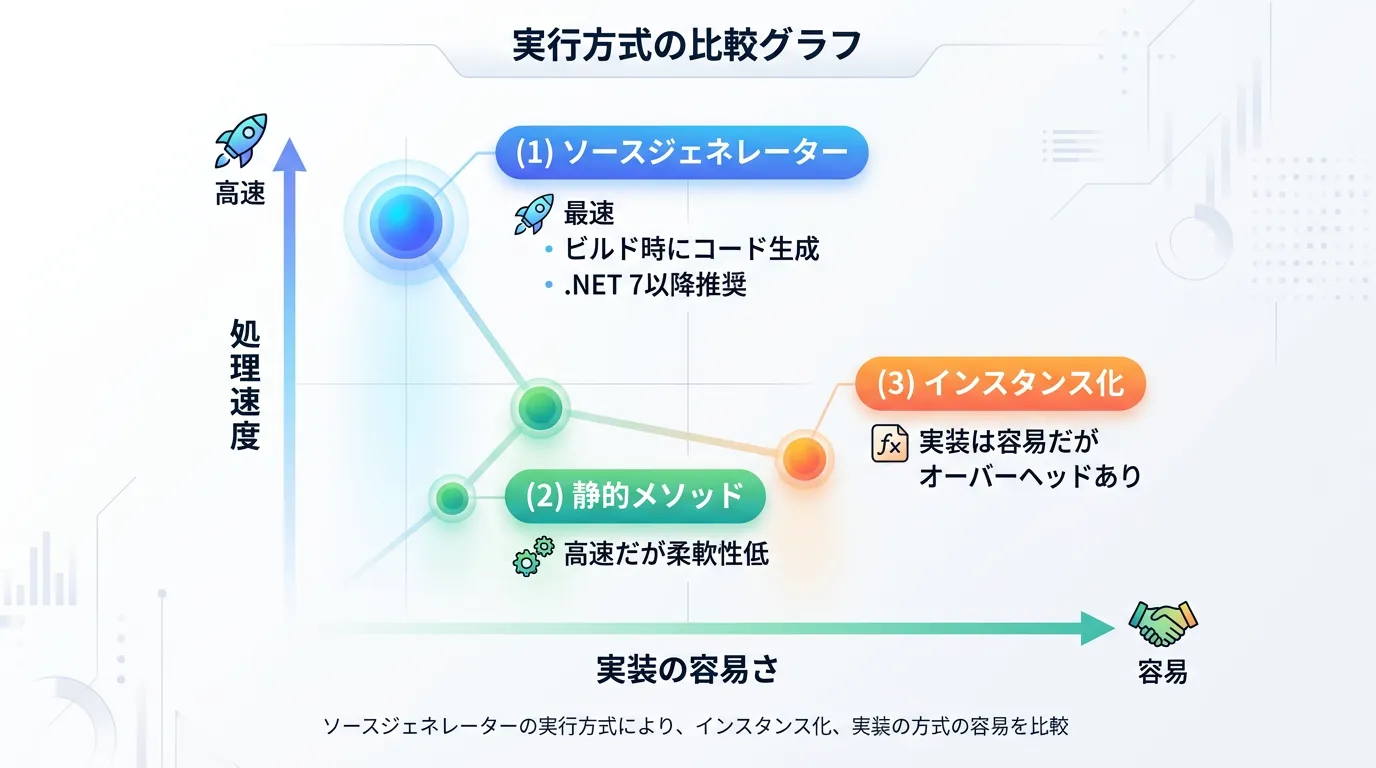
静的メソッド vs インスタンス化
最も手軽なのは Regex.IsMatch(input, pattern) のような静的メソッドの呼び出しです。
これは内部的に最近使用されたパターンをキャッシュしますが、頻繁に異なるパターンを呼び出す場合はオーバーヘッドが発生します。
一方、同じパターンを繰り返し使用する場合は、Regex クラスをインスタンス化(new Regex(pattern))して使い回す方が効率的です。
.NET 7以降の最強の選択肢:RegexSourceGenerator
最新のC#開発(.NET 7 / .NET 8 / .NET 9など)において、最も推奨されるのが「正規表現ソースジェネレーター」です。
これはコンパイル時に正規表現の解析を済ませ、最適化されたC#コードを自動生成する仕組みです。
// 部分クラス(partial)として定義
public partial class MyValidator
{
// 属性を付与してパターンを指定
[GeneratedRegex(@"^\d{3}-\d{4}$")]
private static partial Regex ZipCodeRegex();
public bool Validate(string code) => ZipCodeRegex().IsMatch(code);
}この方法を用いると、実行時の解析コストがゼロになり、アプリケーションの起動速度やメモリ効率が大幅に向上します。
大規模な文字列処理を行うバックエンドサービスや、リソースが限られたモバイルアプリでは必須のテクニックと言えるでしょう。
実践で役立つ!便利な正規表現パターン集
ここでは、実際の開発現場でそのままコピー&ペーストして使える便利なパターンをいくつか紹介します。
名前付きグループによる高度な抽出
正規表現では、一致した部分に名前を付けて管理することができます。
これにより、match.Groups[1] のようなインデックス指定ではなく、意味のある名前でデータを取り出せます。
string input = "2024-05-20";
string pattern = @"(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})";
Match m = Regex.Match(input, pattern);
if (m.Success)
{
string year = m.Groups["year"].Value;
string month = m.Groups["month"].Value;
Console.WriteLine($"{year}年の{month}月ですね。");
}よく使われるバリデーションパターン
以下は、Webアプリケーションなどで頻繁に利用されるパターンの例です。
| 対象 | 正規表現パターン | 解説 |
|---|---|---|
| 半角英数字のみ | ^[a-zA-Z0-9]+$ | IDやユーザー名のチェックに利用 |
| 郵便番号 | ^\d{3}-\d{4}$ | 日本の標準的な形式 |
| URL | https?://[\w/:%#$&?()~.=+-]+ | httpおよびhttpsから始まるURL |
| 日付 (YYYY/MM/DD) | ^\d{4}/\d{2}/\d{2}$ | 区切り文字をスラッシュにした日付 |
正規表現使用時の注意点とアンチパターン
正規表現は非常に強力ですが、使い方を誤るとシステムの停止を招く「正規表現の脆弱性(ReDoS)」や、メンテナンス性の低下を引き起こします。
1. カタストロフィック・バックトラッキング
複雑すぎるパターンや、入れ子になった繰り返し(例:(a+)+$)に対して特定の入力を与えると、解析に膨大な時間がかかり、CPU使用率が100%に張り付く現象が発生します。
これを防ぐためには、必ず「タイムアウト」を設定する習慣をつけましょう。
// 2秒でタイムアウトするように設定
var options = RegexOptions.None;
var timeout = TimeSpan.FromSeconds(2);
Regex.IsMatch(input, pattern, options, timeout);2. 読みやすさの維持
正規表現は「書いた本人にしか読めない」状態に陥りやすいコードの筆頭です。
C#では RegexOptions.IgnorePatternWhitespace を指定することで、パターン内にスペースやコメントを挿入できるようになります。
string complexPattern = @"
^ # 行頭
\d{3} # 市外局番
# ハイフン
\d{4} # 市内局番
$ # 行末";
Regex regex = new Regex(complexPattern, RegexOptions.IgnorePatternWhitespace);このように記述することで、後からコードをレビューするエンジニア(あるいは数ヶ月後の自分)の負担を劇的に減らすことができます。
まとめ
C#における正規表現は、単なる文字列検索の道具を超え、データの整合性を守り、複雑なテキスト解析をシンプルにするための不可欠な技術です。
Regex クラスの基本メソッドをマスターし、さらに .NET 7以降で導入された ソースジェネレーター を活用することで、高い生産性と圧倒的なパフォーマンスを両立させることができます。
最後に、正規表現を扱う上でのポイントを振り返りましょう。
- メタ文字を理解し、逐語的文字列リテラル(
@"")を活用する。 - 用途に合わせて
IsMatch,Match,Replaceを使い分ける。 - パフォーマンスが重要な箇所では
[GeneratedRegex]を使用する。 - タイムアウト設定を行い、ReDoS攻撃や無限ループのリスクを回避する。
- コメントや
IgnorePatternWhitespaceを使い、可読性の高いパターンを書く。
これらの知識を武器に、ぜひ日々のC#開発において正規表現を効果的に取り入れてみてください。
より高度なパターン設計が必要な場合は、Microsoft Learnの正規表現ガイド を参照しながら、試行錯誤を繰り返すことが上達への近道です。
