
C#の開発において、文字列操作は避けて通れない要素の一つです。
長らく.NETの世界では、文字列は UTF-16 形式として扱われてきました。
しかし、現代のWeb開発やネットワーク通信の主流は UTF-8 です。
このギャップを埋めるために、C# 11で導入された画期的な新機能が 「u8リテラル(UTF-8文字列リテラル)」 です。
これまでのC#では、UTF-8のバイト配列を作成するために、実行時の変換処理や冗長なコードが必要でしたが、u8リテラルの登場により、非常にシンプルかつ高速な記述が可能になりました。
本記事では、C# 11の新機能であるu8リテラルの基本から、その内部構造、パフォーマンス上のメリット、そして実戦での活用シーンまでを徹底的に解説します。
UTF-8文字列リテラル(u8)とは何か
C# 11で導入されたu8リテラルは、文字列リテラルの末尾に u8 サフィックスを付与することで、その文字列を UTF-8エンコードされたReadOnlySpan<byte> として扱う機能です。
従来のC#において、二重引用符で囲まれた通常の文字列(例: "Hello")は、内部的にUTF-16としてメモリ上に保持される System.String オブジェクトでした。
しかし、u8リテラルを使用すると、コンパイル時にUTF-8形式のバイト列に変換され、実行時のオーバーヘッドなしに利用できるようになります。
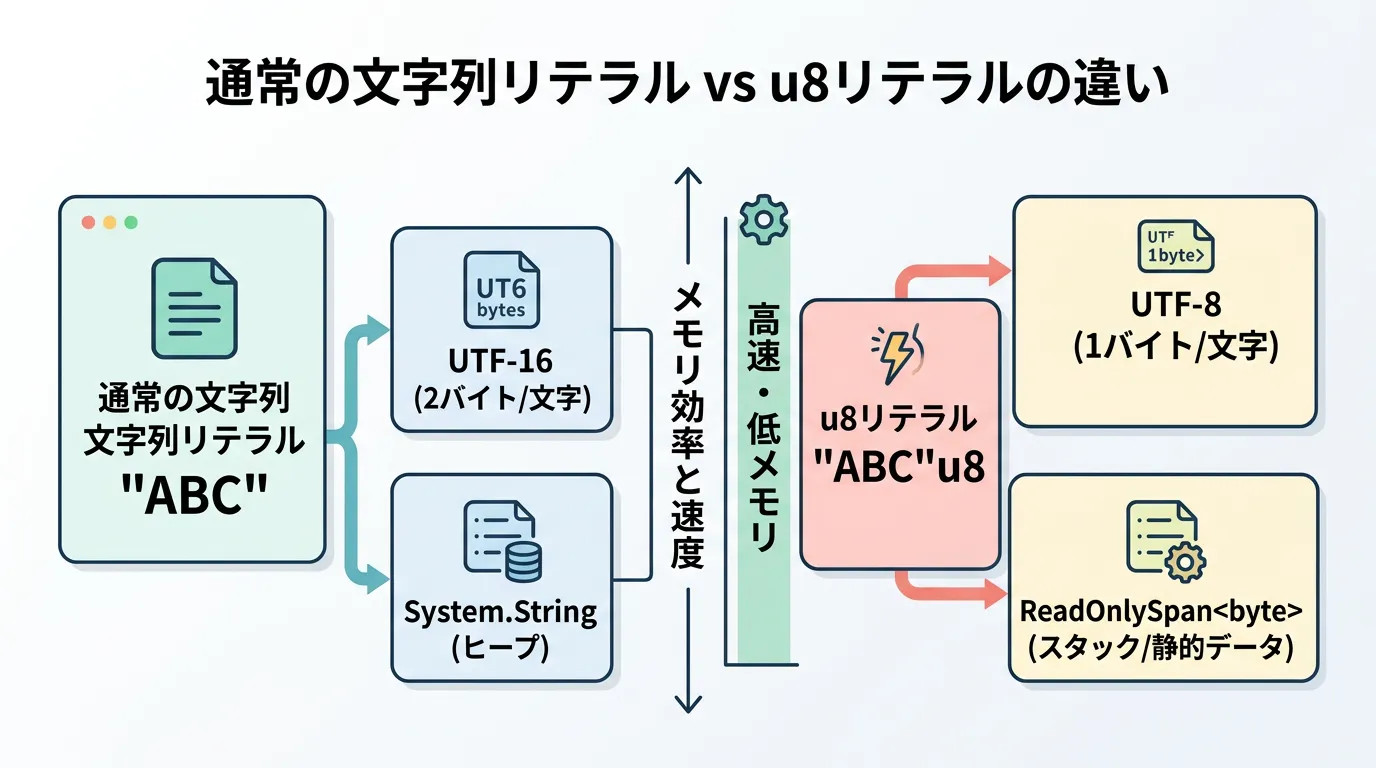
この機能の最大の特徴は、単なるシンタックスシュガー(書き方の簡略化)にとどまらず、実行時のパフォーマンスを極限まで高める設計になっている点にあります。
具体的には、文字列がプログラムの実行ファイル(バイナリ)の静的データセクションに埋め込まれるため、実行時に新しいメモリを割り当てる(アロケーション)必要がありません。
基本的な書き方
u8リテラルの使い方は非常に簡単です。
以下のように、文字列の末尾に u8 を付けるだけです。
// 従来の文字列(UTF-16)
string normalString = "Hello, C# 11";
// C# 11のu8リテラル(UTF-8)
ReadOnlySpan<byte> utf8String = "Hello, C# 11"u8;このコードにおいて、utf8String は ReadOnlySpan<byte> 型として推論されます。
これは、変更不可能なバイトの範囲を指す「ビュー」のようなものであり、ヒープメモリを消費せずに効率的にデータを参照できます。
なぜu8リテラルが必要だったのか
C# 11より前の時代、UTF-8のデータを扱うにはいくつかの課題がありました。
なぜマイクロソフトがこの機能を導入したのか、その背景にある「UTF-16とUTF-8の乖離」を理解することが重要です。
.NETとWebの「エンコードのねじれ」
.NET Frameworkの誕生以来、C#の string 型は一貫してUTF-16を採用してきました。
これは当時のWindows OSとの親和性を考慮した結果です。
しかし、現代のコンピューティング環境では状況が異なります。
- Web通信(HTTP/JSON):ほぼ100%がUTF-8。
- データベース:多くのシステムでUTF-8が標準。
- クラウドネイティブ:Linuxコンテナ上での動作が一般的になり、UTF-8がデフォルト。
このため、従来のC#プログラムでは、Web APIからデータを受け取ったり、JSONを書き出したりするたびに、「UTF-16 ⇔ UTF-8」の相互変換が発生していました。
この変換処理はCPUのリソースを消費し、さらに変換後のバイト配列を生成するためにメモリ(ヒープ)を割り当てる必要がありました。
これは高トラフィックなサーバーアプリケーションにおいて、無視できないパフォーマンスのボトルネックとなっていたのです。
従来の書き方とその限界
C# 11以前にUTF-8のバイト列を用意しようとすると、主に以下の2つの方法が取られていました。
Encoding.UTF8.GetBytes("...")を呼び出す。new byte[] { 0x48, 0x65, ... }のように手動でバイト配列を定義する。
前者はコードが読みやすいものの、実行時に毎回変換処理が走り、新しい配列オブジェクトが作成されるため非効率です。
後者は実行効率は高いものの、人間にとっては何が書かれているのか判読不能であり、メンテナンス性が極めて低いという問題がありました。
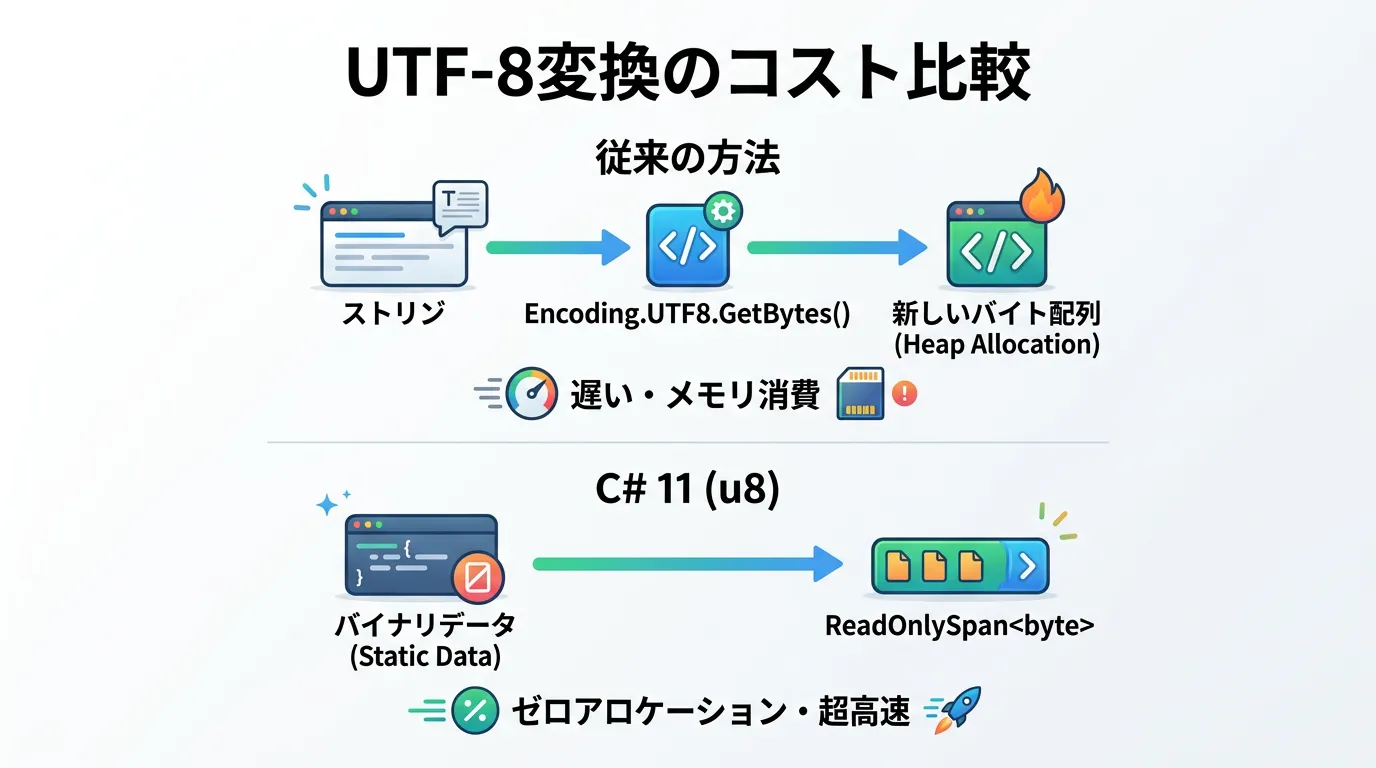
u8リテラルは、この 「コードの読みやすさ」と「実行時のパフォーマンス」という二律背反の課題を同時に解決する ために導入されました。
u8リテラルの動作原理とメモリ効率
u8リテラルがなぜ「効率的」と言われるのか、その技術的な裏側を詳しく見ていきましょう。
ReadOnlySpan<byte> による最適化
u8リテラルによって生成される値は、原則として ReadOnlySpan<byte> です。
この型は、Span<T> の読み取り専用版であり、スタック有効期間を持つ型(ref struct)です。
特筆すべきは、コンパイラがこのバイト列を 「アセンブリ(DLL/EXEファイル)内の静的データ」 として埋め込む点です。
プログラムが実行される際、このデータはメモリの特定の場所にロードされます。
ReadOnlySpan<byte> はその場所を直接指し示すだけで済むため、GC(ガベージコレクション)の管理対象となるヒープ領域へのメモリ割り当てが一切発生しません。
これを ゼロアロケーション と呼びます。
具体的なコンパイル結果のイメージ
例えば、以下のコードを記述したとします。
public void SendResponse()
{
var response = "OK"u8;
Process(response);
}このとき、コンパイラは内部的に以下のような処理と同等の最適化を行います(概念的な表現です)。
- 文字列 “OK” を UTF-8 バイト列
{ 0x4F, 0x4B }に変換する。 - そのバイト列をバイナリのデータ領域に静的に配置する。
response変数には、そのデータ領域の先頭アドレスと長さを保持させる。
このように、実行時に文字列を解析したり、変換したりするステップが完全に排除されているため、マイクロベンチマークレベルでも圧倒的な速度差が出ます。
実戦的な活用シーン
u8リテラルは、特に「低レイテンシ」や「高スループット」が求められるシステムで真価を発揮します。
具体的な活用例を紹介します。
1. HTTPヘッダーやプロトコルの実装
Webサーバーやカスタムプロトコルを実装する場合、固定の文字列をバイト列として送信する機会が多くあります。
// HTTPレスポンスの一部を効率的に記述
ReadOnlySpan<byte> header = "Content-Type: application/json\r\n"u8;
stream.Write(header);従来の Encoding.UTF8.GetBytes() では、リクエストが来るたびに配列を作成していましたが、u8リテラルならそのコストをゼロに抑えられます。
2. Utf8JsonWriter での利用
.NETの高機能なJSONシリアライザである System.Text.Json は、UTF-8を直接扱うことで高速化を実現しています。
Utf8JsonWriter クラスを使用する際、プロパティ名などをu8リテラルで渡すと非常に効率的です。
using var stream = new MemoryStream();
using var writer = new Utf8JsonWriter(stream);
writer.WriteStartObject();
// 文字列型ではなくUTF-8バイト列を直接渡す
writer.WriteString("message"u8, "Hello, World!"u8);
writer.WriteEndObject();
writer.Flush();これにより、ライブラリ内部でのUTF-16からUTF-8への再変換をバイパスでき、アプリケーション全体のパフォーマンスが向上します。
3. ロギングやデバッグ出力の最適化
大量のログを出力するシステムにおいて、ログのプレフィックスや固定メッセージをu8リテラルで定義しておくことで、GCへの負荷を軽減できます。
クラウド環境ではGCの頻度がパフォーマンスやコスト(CPU使用率)に直結するため、非常に有効なテクニックです。
従来のバイト配列との比較表
u8リテラルを使用する場合と、従来の手法を比較した表を以下に示します。
| 比較項目 | Encoding.UTF8.GetBytes() | 手動 byte[] 配列 | u8リテラル |
|---|---|---|---|
| 可読性 | 高い | 極めて低い | 極めて高い |
| 実行速度 | 低い(変換コストあり) | 高い | 最高(コンパイル時変換) |
| メモリ消費 | あり(ヒープ割り当て) | あり(配列オブジェクト) | なし(ゼロアロケーション) |
| 型 | byte[] | byte[] | ReadOnlySpan<byte> |
| メンテナンス | 容易 | 困難 | 容易 |
この表からもわかる通り、u8リテラルは「使いやすさ」を維持したまま、「最高性能」を手に入れられる手法であることがわかります。
注意点と制約事項
非常に便利なu8リテラルですが、使用にあたっていくつか知っておくべき制限事項があります。
1. 戻り値の型について
u8リテラルは通常 ReadOnlySpan<byte> を返しますが、代入先の型によっては byte[](配列)として扱うことも可能です。
// ReadOnlySpan<byte> として扱う(最も効率的)
ReadOnlySpan<byte> span = "Hello"u8;
// byte[] として扱う(配列のインスタンスが作成されるため、わずかにコストがかかる)
byte[] array = "Hello"u8.ToArray();基本的には ReadOnlySpan<byte> のまま扱うのがベストプラクティスです。
2. 定数(const)としての利用
現在のC#の仕様では、u8リテラルを const フィールドに直接割り当てることはできません。
なぜなら、ReadOnlySpan<byte> は ref struct であり、メタデータとしての定数にはなれないからです。
代わりに static readonly プロパティを使用するか、メソッド内で直接記述するのが一般的です。
// これはエラーになる
// private const ReadOnlySpan<byte> Prefix = "Log:"u8;
// 代わりの書き方
private static ReadOnlySpan<byte> Prefix => "Log:"u8;3. 文字列補間($””)の制約
C# 11のリリース当初、u8リテラルは文字列補間($"Hello, {name}"u8)を直接サポートしていませんでした。
しかし、その後の C# 12 において、特定の条件下でのUTF-8補間が改善されています。
C# 11をターゲットにしている場合は、固定の文字列リテラルに対してのみ u8 が使用できる点に注意してください。
u8リテラルを使いこなすためのTips
さらに一歩進んだ使い方として、以下のポイントを押さえておくと開発がよりスムーズになります。
ASCII文字以外を含む場合
u8リテラルは、当然ながら日本語などのマルチバイト文字も正しく扱えます。
var japanese = "こんにちは"u8;
Console.WriteLine(japanese.Length); // 出力: 15 (5文字 * 3バイト)内部的にはコンパイル時にUTF-8エンコードされるため、実行環境のエンコーディング設定に左右されることなく、常に正しいUTF-8バイト列が得られます。
文字列の結合について
複数のu8リテラルを + 演算子で結合することはできません。
結合が必要な場合は、ArrayBufferWriter<byte> や StackOverflow を避けるための Span 操作、あるいは C# 12 以降の機能を検討してください。
基本的には「固定の定数的な文字列」をバイト列として定義する用途に最も適しています。
まとめ
C# 11で導入された u8リテラル は、現代のソフトウェア開発において不可欠なUTF-8文字列を、最も効率的かつ直感的に扱うための強力なツールです。
- 実行時の変換コストがゼロ であり、パフォーマンスを劇的に向上させる。
- ReadOnlySpan<byte> を通じて、ヒープを汚さないクリーンなメモリ管理が可能。
- Web API、JSON処理、通信プロトコル など、現代的な開発シーンで幅広く活用できる。
これまでの Encoding.UTF8.GetBytes() を多用していたコードをu8リテラルに置き換えるだけで、アプリケーションのフットプリントを削減し、スケーラビリティを高めることができます。
最新のC#機能を積極的に取り入れ、より高速でモダンな .NET アプリケーションを構築していきましょう。
